
XCycles Backprojection Acoustic Super-Resolution

 , , ,
, , ,  , , ,
, , ,  and
and
Abstract
:1. Introduction
- A novel backprojection model architecture was proposed to improve the resolution of the acoustic images. The proposed XCycles BackProjection model (XCBP), in contrast to the feedforward model approach, fully uses the iterative correction procedure. It takes low- and high-resolution encoded features together to extract the necessary residual error correction for the encoded features in each cycle.
- The acoustic map imaging dataset (https://doi.org/10.5281/zenodo.4543786), provided simulated and real captured images with multiple scales factor (×2, ×4, ×8). Although these images shared similar technical characteristics, they lacked artificial artifacts caused by the conventional downsampling strategy. Instead, they had more natural artifacts simulating the real-world problem. The dataset consisted of low- and high-resolution images with double-precision fractional delays and sub-sampling phase delay error. To the best of the authors’ knowledge, this is the first work to provide such a large dataset with its specific characteristics for the SISR problem and the sub-sampling phase delay error problem;
- The proposed benchmark and the developed method outperformed the classical interpolation operators and the recent feedforward state-of-the-art models and drastically reduced the sub-sampling phase delay error estimation.
- The proposed model contributed to the Thermal Image Super-Resolution Challenge—PBVS 2021 [11] and won the first place with superior performance in the second evaluation when the LR image and HR image are captured with different cameras.
2. Related Work
3. Acoustic Beamforming
3.1. Delay and Sum Beamforming
3.2. Fractional Delays
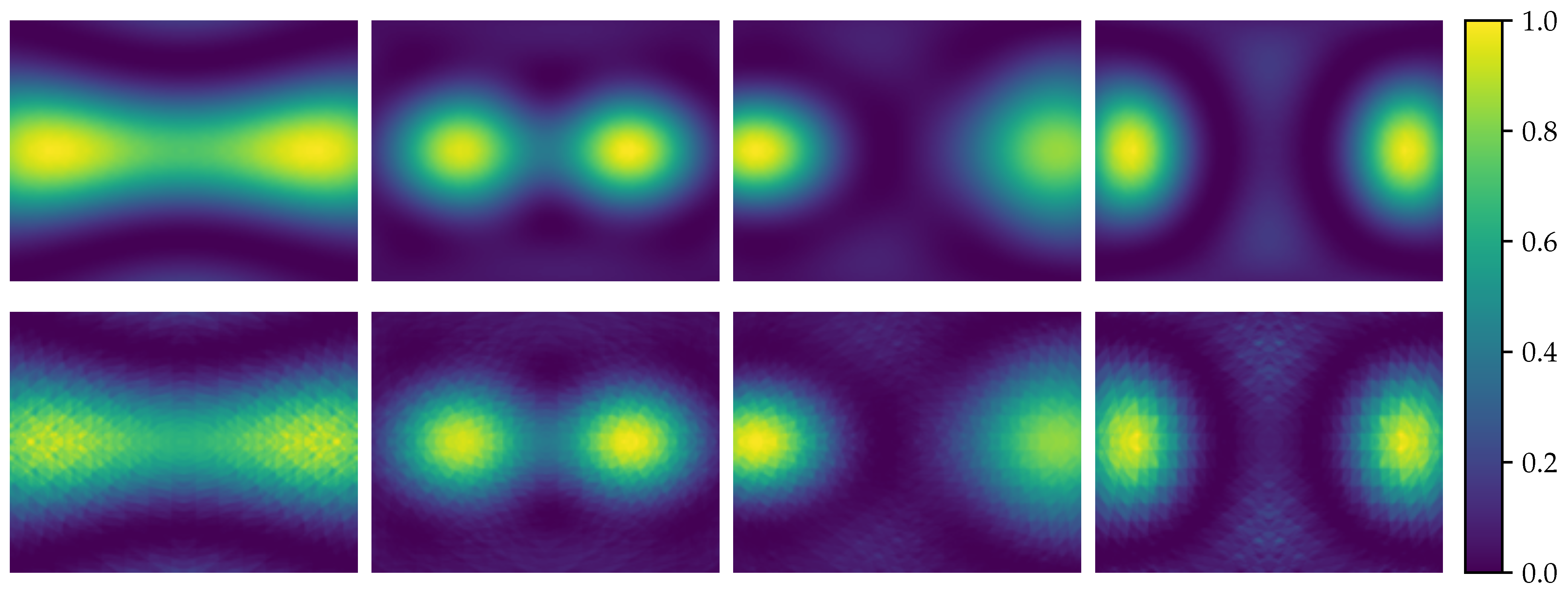
4. Acoustic Map Imaging Dataset
4.1. Acoustic Camera Characteristics
4.2. Generation of Acoustic Datasets
4.3. Dataset Properties
5. XCycles Backprojection Network
5.1. Network Architecture
5.2. Residual Features Extraction Module
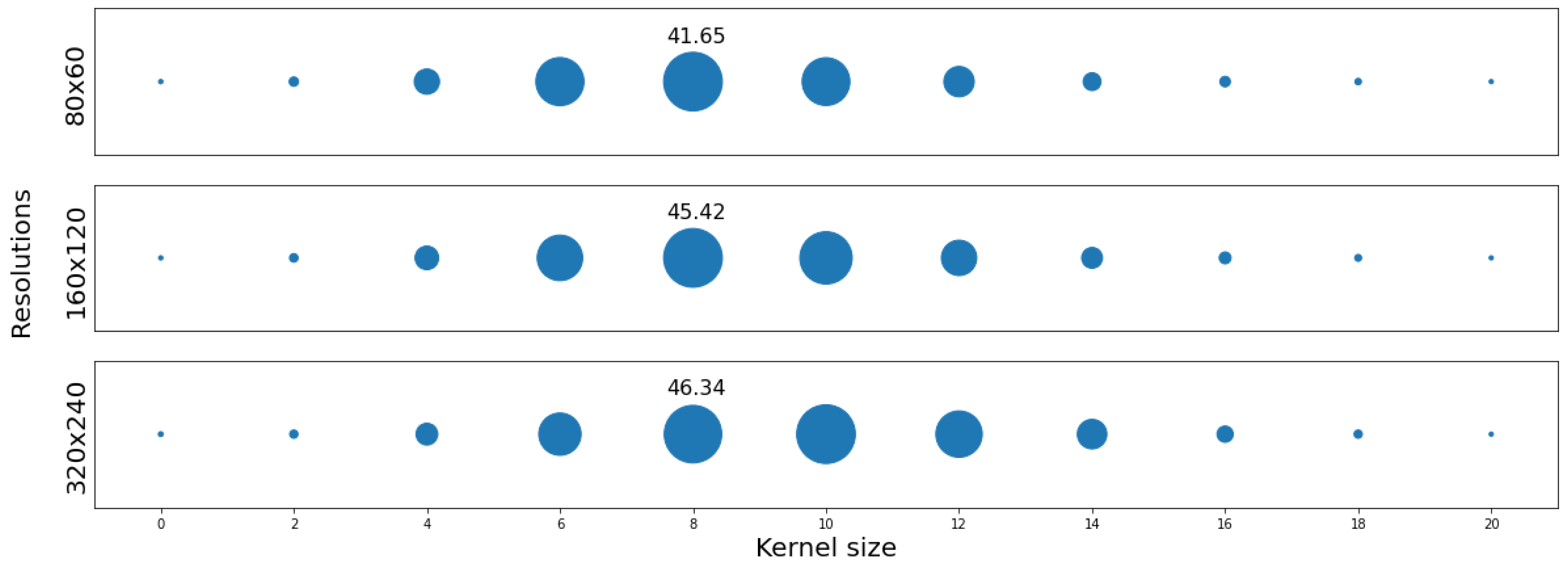
5.3. Implementation Details
6. Experiments
6.1. Training Settings
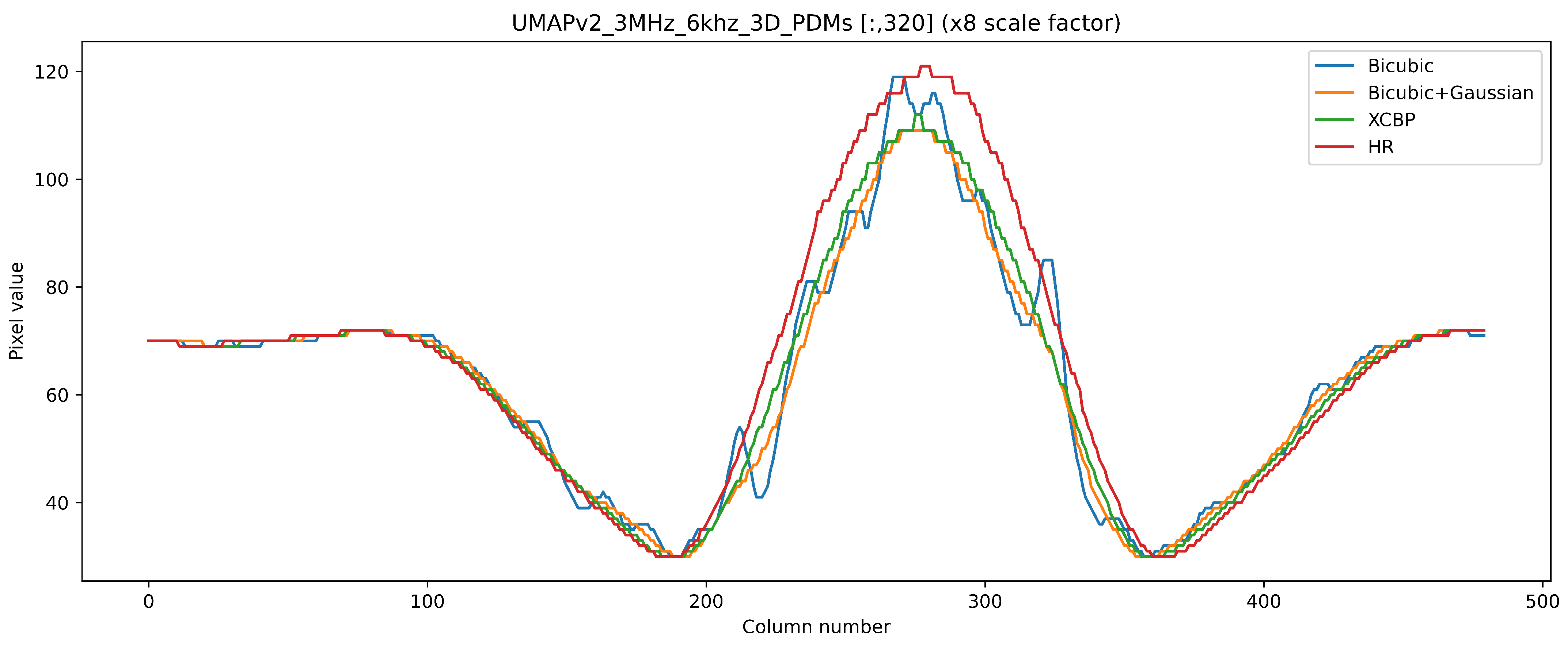
6.2. Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Almasri, F.; Debeir, O. Multimodal sensor fusion in single thermal image super-resolution. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 418–433. [Google Scholar]
- Fréchette-Viens, J.; Quaegebeur, N.; Atalla, N. A Low-Latency Acoustic camera for Transient Noise Source Localization. In Proceedings of the 8th Berlin Beamforming Conference, BeBeC-2020S01, Berlin, Germany, 2–3 March 2020. [Google Scholar]
- Da Silva, B.; Segers, L.; Rasschaert, Y.; Quevy, Q.; Braeken, A.; Touhafi, A. A Multimode SoC FPGA-Based Acoustic Camera for Wireless Sensor Networks. In Proceedings of the 2018 13th International Symposium on Reconfigurable Communication-Centric Systems-on-Chip (ReCoSoC), Lille, France, 9–11 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Vandendriessche, J.; da Silva, B.; Lhoest, L.; Braeken, A.; Touhafi, A. M3-AC: A Multi-Mode Multithread SoC FPGA Based Acoustic Camera. Electronics 2021, 10, 317. [Google Scholar] [CrossRef]
- Zimmermann, B.; Studer, C. FPGA-based real-time acoustic camera prototype. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems (ISCAS), Paris, France, 30 May–2 June 2010; p. 1419. [Google Scholar]
- Izquierdo, A.; Villacorta, J.J.; del Val Puente, L.; Suárez, L. Design and evaluation of a scalable and reconfigurable multi-platform system for acoustic imaging. Sensors 2016, 16, 1671. [Google Scholar] [CrossRef] [Green Version]
- Grondin, F.; Glass, J. SVD-PHAT: A fast sound source localization method. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 4140–4144. [Google Scholar]
- Zotkin, D.N.; Duraiswami, R. Accelerated speech source localization via a hierarchical search of steered response power. IEEE Trans. Speech Audio Process. 2004, 12, 499–508. [Google Scholar] [CrossRef]
- Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X.; Nathan, S.; Kansal, P.; Mehri, A.; Ardakani, P.; Dalal, A.; Akula, A.; Sharma, D.; et al. Thermal Image Super-Resolution Challenge—PBVS 2021. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Virtual, 19–25 June 2021. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2016; Volume 9906, pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Irani, M.; Peleg, S. Improving resolution by image registration. CVGIP Graph. Model. Image Process. 1991, 53, 231–239. [Google Scholar] [CrossRef]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1664–1673. [Google Scholar]
- Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X.; Guo, L.; Hou, J.; Mehri, A.; Behjati Ardakani, P.; Patel, H.; Chudasama, V.; Prajapati, K.; et al. Thermal Image Super-Resolution Challenge-PBVS 2020. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 96–97. [Google Scholar]
- Wei, P.; Lu, H.; Timofte, R.; Lin, L.; Zuo, W.; Pan, Z.; Li, B.; Xi, T.; Fan, Y.; Zhang, G.; et al. AIM 2020 challenge on real image super-resolution: Methods and results. arXiv 2020, arXiv:2009.12072. [Google Scholar]
- Tashev, I.; Malvar, H.S. A New Beamformer Design Algorithm for Microphone Arrays. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP’05), Philadelphia, PA, USA, 23 March 2005; Volume 3, pp. iii/101–iii/104. [Google Scholar] [CrossRef] [Green Version]
- Tiete, J.; Dominguez, F.; Silva, B.; Segers, L.; Steenhaut, K.; Touhafi, A. SoundCompass: A Distributed MEMS Microphone Array-Based Sensor for Sound Source Localization. Sensors 2014, 14, 1918–1949. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taghizadeh, M.J.; Garner, P.N.; Bourlard, H. Microphone Array Beampattern Characterization for Hands-Free Speech Applications. In Proceedings of the 2012 IEEE 7th Sensor Array and Multichannel Signal Processing Workshop (SAM), Hoboken, NJ, USA, 17–20 June 2012; pp. 465–468. [Google Scholar] [CrossRef] [Green Version]
- Herbordt, W.; Kellermann, W. Computationally Frequency-Domain Realization of Robust Generalized, Sidelobe Cancellers. In Proceedings of the 2001 IEEE Fourth Workshop on Multimedia Signal Processing (Cat. No.01TH8564), Cannes, France, 3–5 October 2001; pp. 51–55. [Google Scholar] [CrossRef]
- Lepauloux, L.; Scalart, P.; Marro, C. Computationally Efficient and Robust Frequency-Domain GSC. In Proceedings of the 12th IEEE International Workshop on Acoustic Echo and Noise Control, Tel-Aviv, Israel, 30 August–2 September 2010. [Google Scholar]
- Rombouts, G.; Spriet, A.; Moonen, M. Generalized Sidelobe Canceller Based Combined Acoustic Feedback-and Noise Cancellation. Signal Process. 2008, 88, 571–581. [Google Scholar] [CrossRef]
- Gao, S.; Huang, Y.; Zhang, T.; Wu, X.; Qu, T. A Modified Frequency Weighted MUSIC Algorithm for Multiple Sound Sources Localization. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Birnie, L.; Abhayapala, T.D.; Chen, H.; Samarasinghe, P.N. Sound Source Localization in a Reverberant Room Using Harmonic Based Music. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 651–655. [Google Scholar]
- Jo, B.; Choi, J.W. Direction of Arrival Estimation Using Nonsingular Spherical ESPRIT. J. Acoust. Soc. Am. 2018, 143, 181–187. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Huang, Q.; Zhang, L.; Fang, Y. Direction of Arrival Estimation Using Distributed Circular Microphone Arrays. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; pp. 182–185. [Google Scholar] [CrossRef]
- Maskell, D.L.; Woods, G.S. The estimation of subsample time delay of arrival in the discrete-time measurement of phase delay. IEEE Trans. Instrum. Meas. 1999, 48, 1227–1231. [Google Scholar] [CrossRef]
- Laakso, T.I.; Valimaki, V.; Karjalainen, M.; Laine, U.K. Splitting the unit delay [FIR/all pass filters design]. IEEE Signal Process. Mag. 1996, 13, 30–60. [Google Scholar] [CrossRef]
- Segers, L.; Vandendriessche, J.; Vandervelden, T.; Lapauw, B.J.; da Silva, B.; Braeken, A.; Touhafi, A. CABE: A Cloud-Based Acoustic Beamforming Emulator for FPGA-Based Sound Source Localization. Sensors 2019, 19, 3906. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hegde, N. Seamlessly Interfacing MEMs Microphones with Blackfin Processors. 2010. Available online: https://www.analog.com/media/en/technical-documentation/application-notes/EE-350rev1.pdf (accessed on 14 January 2019).
- Rivadeneira, R.; Sappa, A.; Vintimilla, B. Thermal Image Super-resolution: A Novel Architecture and Dataset. In Proceedings of the VISIGRAPP 2020—15th International Conference on Computer Vision Theory and Applications, Valletta, Malta, 27–29 February 2020; pp. 111–119. [Google Scholar] [CrossRef]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A learned representation for artistic style. arXiv 2016, arXiv:1610.07629. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Brandalero, M.; Ali, M.; Le Jeune, L.; Hernandez, H.G.M.; Veleski, M.; da Silva, B.; Lemeire, J.; Van Beeck, K.; Touhafi, A.; Goedemé, T.; et al. AITIA: Embedded AI Techniques for Embedded Industrial Applications. In Proceedings of the 2020 International Conference on Omni-Layer Intelligent Systems (COINS), Barcelona, Spain, 31 August–2 September 2020; pp. 1–7. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Microphone array | UMAP |
| Beamforming method | Filtering + delay and sum |
| Filtering method | 3125khz_cic24_fir1_ds4 |
| Sampling frequency () | 3125 kHz |
| Order CIC filter () | 4 |
| Decimation factor CIC filter () | 24 |
| Order FIR filter () | 23 |
| Decimation factor FIR filter () | 4 |
| SRP in block mode | yes |
| SRP length | 64 |
| Emulation start time | 50 ms |
| Emulation end time | 100 ms |
| Methods | Simulated | Real Captured | ||||
|---|---|---|---|---|---|---|
| Scale ×2 | Scale ×4 | Scale ×8 | Scale ×2 | Scale ×4 | Scale ×8 | |
| Bicubic | 38.00/0.9426 | 38.16/0.9548 | 37.81/0.9728 | 37.36/0.9513 | 37.31/0.9615 | 36.93/0.9764 |
| Bicubic-Gaussian | 46.34/0.9942 | 45.47/0.9943 | 41.48/0.9935 | 40.99/0.9954 | 40.46/0.9954 | 38.82/0.9946 |
| SRCNN | 47.00/0.9934 | 46.49/0.9941 | 44.87/0.9938 | 42.24/0.9940 | 42.25/0.9941 | 42.07/0.9943 |
| VDSR | 50.98/0.9963 | 50.89/0.9963 | 49.98/0.9954 | 44.23/0.9952 | 44.28/0.9950 | 43.47/0.9942 |
| RCAN | 54.65/0.9978 | 55.19/0.9980 | 54.63/0.9978 | 46.82/0.9971 | 46.57/0.9967 | 48.88/0.9962 |
| XCBP-AC | 54.83/0.9977 | 55.49/0.9979 | 55.77/0.9980 | 44.64/0.9970 | 46.66/0.9970 | 46.58/0.9968 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almasri, F.; Vandendriessche, J.; Segers, L.; da Silva, B.; Braeken, A.; Steenhaut, K.; Touhafi, A.; Debeir, O. XCycles Backprojection Acoustic Super-Resolution. Sensors 2021, 21, 3453. https://doi.org/10.3390/s21103453
Almasri F, Vandendriessche J, Segers L, da Silva B, Braeken A, Steenhaut K, Touhafi A, Debeir O. XCycles Backprojection Acoustic Super-Resolution. Sensors. 2021; 21(10):3453. https://doi.org/10.3390/s21103453
Chicago/Turabian StyleAlmasri, Feras, Jurgen Vandendriessche, Laurent Segers, Bruno da Silva, An Braeken, Kris Steenhaut, Abdellah Touhafi, and Olivier Debeir. 2021. "XCycles Backprojection Acoustic Super-Resolution" Sensors 21, no. 10: 3453. https://doi.org/10.3390/s21103453
APA StyleAlmasri, F., Vandendriessche, J., Segers, L., da Silva, B., Braeken, A., Steenhaut, K., Touhafi, A., & Debeir, O. (2021). XCycles Backprojection Acoustic Super-Resolution. Sensors, 21(10), 3453. https://doi.org/10.3390/s21103453