Application of Hyperspectral Imaging and Deep Learning for Robust Prediction of Sugar and pH Levels in Wine Grape Berries


Abstract
:
1. Introduction
2. Material and Methods
2.1. Data Acquisition
2.2. Spectral Preprocessing
2.3. One-Dimensional Convolutional Neural Network Architecture
2.4. Hyperparameter Optimization
2.5. Model Training, Validation, and Test Methodology
3. Results
3.1. Sampling Characterization
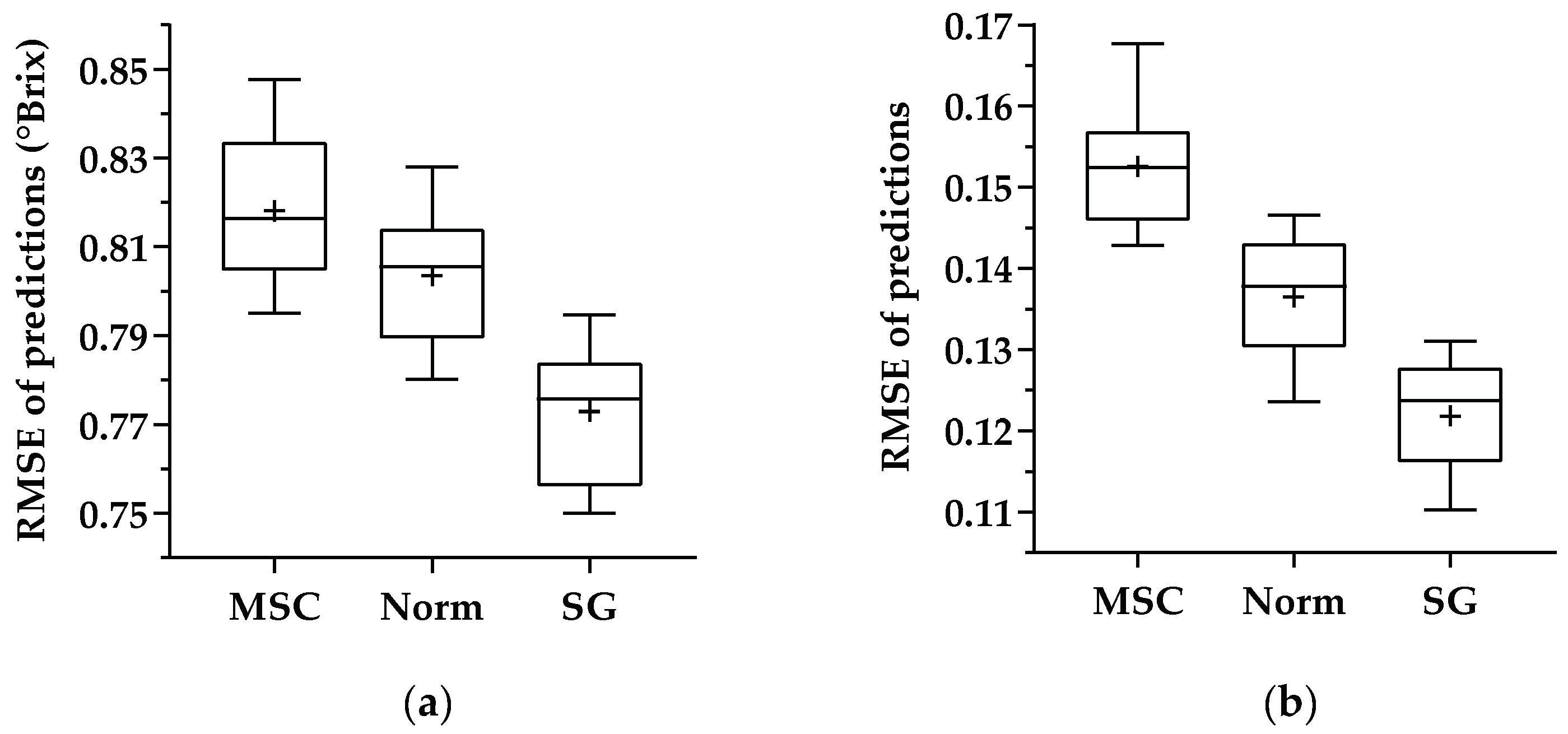
3.2. Effect of Spectral Preprocessing in 1D CNN Model
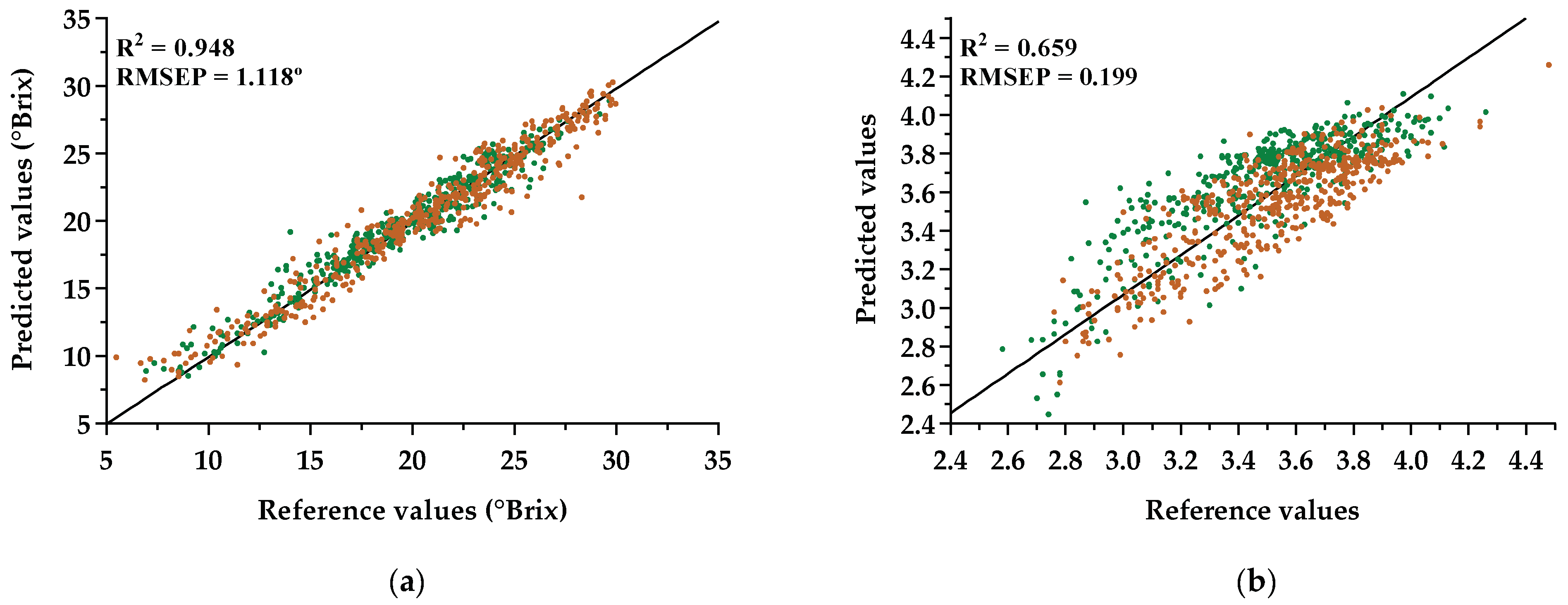
3.3. Generalization Ability: Testing with Different Varieties
3.4. Generalization Ability: Testing with a Different Vintage
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE | |||||
|---|---|---|---|---|---|
| Present Work Results: | Sugar (°Brix) | pH | |||
| Different vintages (six) | 0.755 | 0.110 | |||
| Testing with a different vintage | 1.085 | 0.183 | |||
| Testing with different varieties | 1.025/1.203 | 0.234/0.158 | |||
| Published works that | Algorithm | ||||
| Used a small number of berries per sample and (as in the present work) | Used more than two vintages | [8] | SVM | 1.411 worse than the present results | 0.144 worse than the present results |
| Tested with a different vintage | [3] | ANN | - | 0.191 similar to the present results | |
| [4] | PLS | 1.344 worse than the present results | - | ||
| ANN | 1.355 worse than the present results | - | |||
| Tested with different varieties | [3] | ANN | - | 0.170/0.176 similar to the present results | |
| [8] | SVM | 2.443/3.186 worse than the present results | 0.303/0.253 worse than the present results | ||
| Used one vintage | [1] | PLS | 1.270 worse than the present results | - | |
| [4] | PLS | 0.939 worse than the present results | |||
| ANN | 0.955 worse than the present results | ||||
| [11] | PLS | 1.150 worse than the present results | - | ||
| [15] | ANN | 0.950 worse than the present results | 0.180 worse than the present results | ||
| Used one vintage + blending varieties | [2] | LS-SVM * | 0.960 worse than the present results | Different range of pH values | |
| PLS | 0.930 worse than the present results | ||||
| Used homogenate samples and | Used more than two vintages | [5] | MPLS ** | 1.000 worse than the present results | 0.120 similar to the present results |
| Used one vintage | [7] | MPLS ** | 1.370 worse than the present results | 0.120 similar to the present results | |
| [10] | MPLS ** | - | 0.150 worse than the present results | ||
| Tested with a different vintage | [12,13] | PLS | 1.090 similar to the present results | 0.060 better than the present results | |
| Used one vintage + blending varieties | [12,13] | PLS | 0.650 similar to the present results | 0.050 better than the present results | |
References
- Arana, I.; Jarén, C.; Arazuri, S. Maturity, variety and origin determination in white grapes (Vitis vinifera L.) using near infrared reflectance technology. J. Near Infrared Spectrosc. 2005, 13, 349–357. [Google Scholar] [CrossRef]
- Cao, F.; Wu, D.; He, Y. Soluble solids content and pH prediction and varieties discrimination of grapes based on visible–near infrared spectroscopy. Comput. Electron. Agric. 2010, 71, S15–S18. [Google Scholar] [CrossRef]
- Gomes, V.; Fernandes, A.; Martins-Lopes, P.; Pereira, L.; Mendes Faia, A.; Melo-Pinto, P. Characterization of neural network generalization in the determination of pH and anthocyanin content of wine grape in new vintages and varieties. Food Chem. 2017, 218, 40–46. [Google Scholar] [CrossRef]
- Gomes, V.M.; Fernandes, A.M.; Faia, A.; Melo-Pinto, P. Comparison of different approaches for the prediction of sugar content in new vintages of whole Port wine grape berries using hyperspectral imaging. Comput. Electron. Agric. 2017, 140, 244–254. [Google Scholar] [CrossRef]
- González-Caballero, V.; Pérez-Marín, D.; López, M.-I.; Sánchez, M.-T. Optimization of NIR Spectral Data Management for Quality Control of Grape Bunches during On-Vine Ripening. Sensors 2011, 11, 6109–6124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hernández-Hierro, J.M.; Nogales-Bueno, J.; Rodríguez-Pulido, F.J.; Heredia, F.J. Feasibility Study on the Use of Near-Infrared Hyperspectral Imaging for the Screening of Anthocyanins in Intact Grapes during Ripening. J. Agric. Food Chem. 2013, 61, 9804–9809. [Google Scholar] [CrossRef] [PubMed]
- Nogales-Bueno, J.; Hernández-Hierro, J.M.; Rodríguez-Pulido, F.J.; Heredia, F.J. Determination of technological maturity of grapes and total phenolic compounds of grape skins in red and white cultivars during ripening by near infrared hyperspectral image: A preliminary approach. Food Chem. 2014, 152, 586–591. [Google Scholar] [CrossRef] [PubMed]
- Silva, R.; Gomes, V.; Mendes-Faia, A.; Melo-Pinto, P. Using support vector regression and hyperspectral imaging for the prediction of oenological parameters on different vintages and varieties ofwine grape berries. Remote Sens. 2018, 10, 312. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Zhang, F.; Ning, J.; Liu, X.; Zhang, Z.; Yang, S. Predicting the anthocyanin content of wine grapes by NIR hyperspectral imaging. Food Chem. 2015, 172, 788–793. [Google Scholar] [CrossRef]
- Cozzolino, D.; Cynkar, W.; Janik, L.; Dambergs, R.; Francis, L.; Gishen, M. Measurement of colour, total soluble solids and pH in whole red grapes using visible and near infrared spectroscopy. In Proceedings of the 12th Australian Wine Industry Technical Conference, Melbourne, Australia, 24–29 July 2004; pp. 334–335. [Google Scholar]
- dos Santos Costa, D.; Oliveros Mesa, N.F.; Santos Freire, M.; Pereira Ramos, R.; Teruel Mederos, B.J. Development of predictive models for quality and maturation stage attributes of wine grapes using vis-nir reflectance spectroscopy. Postharvest Biol. Technol. 2019, 150, 166–178. [Google Scholar] [CrossRef]
- Fadock, M. Non-Destructive VIS-NIR Reflectance Spectrometry for Red Wine Grape Analysis; The University of Guelph: Guelph, ON, Canada, 2011. [Google Scholar]
- Fadock, M.; Brown, R.B.; Reynolds, A.G. Visible-Near Infrared Reflectance Spectroscopy for Nondestructive Analysis of Red Wine Grapes. Am. J. Enol. Vitic. 2016, 67, 38–46. [Google Scholar] [CrossRef]
- Fernandes, A.; Oliveira, P.; Moura, J.; Oliveira, A.; Falco, V.; Correia, M.; Melo-Pinto, P. Determination of anthocyanin concentration in whole grape skins using hyperspectral imaging and adaptive boosting neural networks. J. Food Eng. 2011, 105, 216–226. [Google Scholar] [CrossRef]
- Fernandes, A.M.; Franco, C.; Mendes-Ferreira, A.; Mendes-Faia, A.; da Costa, P.L.; Melo-Pinto, P. Brix, pH and anthocyanin content determination in whole Port wine grape berries by hyperspectral imaging and neural networks. Comput. Electron. Agric. 2015, 115, 88–96. [Google Scholar] [CrossRef]
- Ferrer-Gallego, R.; Hernández-Hierro, J.M.; Rivas-Gonzalo, J.C.; Escribano-Bailón, M.T. Determination of phenolic compounds of grape skins during ripening by NIR spectroscopy. LWT Food Sci. Technol. 2011, 44, 847–853. [Google Scholar] [CrossRef] [Green Version]
- Gowen, A.A.; O’Donnell, C.P.; Cullen, P.J.; Downey, G.; Frias, J.M. Hyperspectral imaging—An emerging process analytical tool for food quality and safety control. Trends Food Sci. Technol. 2007, 18, 590–598. [Google Scholar] [CrossRef]
- Hall, A.; Lamb, D.W.; Holzapfel, B.; Louis, J. Optical remote sensing applications in viticulture—A review. Aust. J. Grape Wine Res. 2002, 8, 36–47. [Google Scholar] [CrossRef]
- Janik, L.J.; Cozzolino, D.; Dambergs, R.; Cynkar, W.; Gishen, M. The prediction of total anthocyanin concentration in red-grape homogenates using visible-near-infrared spectroscopy and artificial neural networks. Anal. Chim. Acta 2007, 594, 107–118. [Google Scholar] [CrossRef] [PubMed]
- Le Moigne, M.; Dufour, E.; Bertrand, D.; Maury, C.; Seraphin, D.; Jourjon, F. Front face fluorescence spectroscopy and visible spectroscopy coupled with chemometrics have the potential to characterise ripening of Cabernet Franc grapes. Anal. Chim. Acta 2008, 621, 8–18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gomes, V.; Fernandes, A.; Faia, A.; Melo-Pinto, P. Determination of sugar content in whole Port Wine grape berries combining hyperspectral imaging with neural networks methodologies. In Proceedings of the Computational Intelligence for Engineering Solutions (CIES), 2014 IEEE Symposium, Orlando, FL, USA, 9–12 December 2014; pp. 188–193. [Google Scholar]
- Gomes, V.; Fernandes, A.; Faia, A.; Pinto, P.M. A Comparison of Neural Networks and Partial Least Squares for Estimation of Sugar Content in Wine Grape Berries Using Hyperspectral Imaging. In Proceedings of the International Conference on Computer Science and Environmental Engineering (Csee 2015), Beijing, China, 17–18 May 2015. [Google Scholar]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Guidici, D.; Clark, M.L. One-Dimensional Convolutional Neural Network Land-Cover Classification of Multi-Seasonal Hyperspectral Imagery in the San Francisco Bay Area, California. Remote Sens. 2017, 9, 629. [Google Scholar] [CrossRef] [Green Version]
- Xie, B.; Zhang, H.K.; Xue, J. Deep Convolutional Neural Network for Mapping Smallholder Agriculture Using High Spatial Resolution Satellite Image. Sensors 2019, 19, 2398. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Han, F.; Ghazali, K.H.; Mohamed, I.I.; Zhao, Y. A review of convolutional neural networks in remote sensing image. In Proceedings of the 8th International Conference on Software and Computer Applications; Association for Computing Machinery: New York, NY, USA, 2019; pp. 263–267. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology, ICET 2017, Antalya, Turkey, 21–23 August 2017. [Google Scholar]
- Acquarelli, J.; van Laarhoven, T.; Gerretzen, J.; Tran, T.N.; Buydens, L.M.C.; Marchiori, E. Convolutional neural networks for vibrational spectroscopic data analysis. Anal. Chim. Acta 2017, 954, 22–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, J.; Osadchy, M.; Ashton, L.; Foster, M.; Solomon, C.J.; Gibson, S.J. Deep convolutional neural networks for Raman spectrum recognition: A unified solution. Analyst 2017, 142, 4067–4074. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Xu, J.; Lin, T.; Ying, Y. Convolutional neural network based classification analysis for near infrared spectroscopic sensing. In Proceedings of the 2018 ASABE Annual International Meeting; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2018; p. 1. [Google Scholar]
- Fernandes, A.M.; Utkin, A.B.; Eiras-Dias, J.; Cunha, J.; Silvestre, J.; Melo-Pinto, P. Grapevine variety identification using “Big Data” collected with miniaturized spectrometer combined with support vector machines and convolutional neural networks. Comput. Electron. Agric. 2019, 163. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, Y.; Yan, T.; Bai, X.; Xiao, Q.; Gao, P.; Li, M.; Huang, W.; Bao, Y.; He, Y.; et al. Application of near-infrared hyperspectral imaging for variety identification of coated maize kernels with deep learning. Infrared Phys. Technol. 2020, 111, 103550. [Google Scholar] [CrossRef]
- Cui, C.; Fearn, T. Modern practical convolutional neural networks for multivariate regression: Applications to NIR calibration. Chemom. Intell. Lab. Syst. 2018, 182, 9–20. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; McBratney, A.B. Using deep learning to predict soil properties from regional spectral data. Geoderma Reg. 2019, 16. [Google Scholar] [CrossRef]
- Xu, Z.; Zhao, X.; Guo, X.; Guo, J. Deep Learning Application for Predicting Soil Organic Matter Content by VIS-NIR Spectroscopy. Comput. Intell. Neurosci. 2019, 2019. [Google Scholar] [CrossRef]
- Malek, S.; Melgani, F.; Bazi, Y. One-dimensional convolutional neural networks for spectroscopic signal regression. J. Chemom. 2018, 32, e2977. [Google Scholar] [CrossRef]
- Ng, W.; Minasny, B.; Montazerolghaem, M.; Padarian, J.; Ferguson, R.; Bailey, S.; McBratney, A.B. Convolutional neural network for simultaneous prediction of several soil properties using visible/near-infrared, mid-infrared, and their combined spectra. Geoderma 2019, 352, 251–267. [Google Scholar] [CrossRef]
- Bjerrum, E.J.; Glahder, M.; Skov, T. Data augmentation of spectral data for convolutional neural network (CNN) based deep chemometrics. arXiv 2017, arXiv:1710.01927. [Google Scholar]
- Pang, L.; Men, S.; Yan, L.; Xiao, J. Rapid Vitality Estimation and Prediction of Corn Seeds Based on Spectra and Images Using Deep Learning and Hyperspectral Imaging Techniques. IEEE Access 2020, 8. [Google Scholar] [CrossRef]
- Singh, A.K.; Ganapathysubramanian, B.; Sarkar, S.; Singh, A. Deep Learning for Plant Stress Phenotyping: Trends and Future Perspectives. Trends Plant Sci. 2018, 23, 883–898. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- International Organisation of Vine and Wine. Organisation International de la Vigne e du Vin Recueil des Méthodes Internationales D’analyse des Vins et des Mouts; OIV: Paris, France, 2006. [Google Scholar]
- Maldonado, A.I.L.; Rodriguez-Fuentes, H.; Contreras, J.A.V. Hyperspectral Imaging in Agriculture, Food and Environment; IntechOpen: London, UK, 2018; ISBN 9781789232905. [Google Scholar]
- Rinnan, Å.; van den Berg, F.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Gautam, R.; Vanga, S.; Ariese, F.; Umapathy, S. Review of multidimensional data processing approaches for Raman and infrared spectroscopy. EPJ Tech. Instrum. 2015, 2, 8. [Google Scholar] [CrossRef] [Green Version]
- Zeaiter, M.; Rutledge, D. Preprocessing Methods. In Comprehensive Chemometrics: Chemical and Biochemical Data Analysis; Brown, S.D., Tauler, R., Walczak, B., Eds.; Elsevier: Amsterdam, The Netherlands, 2009; pp. 121–231. ISBN 978-0-444-52701-1. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning. PMLR, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; Volume 9, pp. 249–256. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter Optimization for Machine Learning Models Based on Bayesian Optimizationb. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian optimization of machine learning algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25, pp. 2951–2959. [Google Scholar]
- Victoria, A.H.; Maragatham, G. Automatic tuning of hyperparameters using Bayesian optimization. Evol. Syst. 2020. [Google Scholar] [CrossRef]
- Murugan, P. Hyperparameters Optimization in Deep Convolutional Neural Network/Bayesian Approach with Gaussian Process Prior. arXiv 2017, arXiv:1712.07233. [Google Scholar]
- Sameen, M.I.; Pradhan, B.; Lee, S. Application of convolutional neural networks featuring Bayesian optimization for landslide susceptibility assessment. CATENA 2020, 186, 104249. [Google Scholar] [CrossRef]
- Cho, H.; Kim, Y.; Lee, E.; Choi, D.; Lee, Y.; Rhee, W. Basic Enhancement Strategies When Using Bayesian Optimization for Hyperparameter Tuning of Deep Neural Networks. IEEE Access 2020, 8, 52588–52608. [Google Scholar] [CrossRef]
- Shi, D.; Ye, Y.; Gillwald, M.; Hecht, M. Designing a lightweight 1D convolutional neural network with Bayesian optimization for wheel flat detection using carbody accelerations. Int. J. Rail Transp. 2020, 1–31. [Google Scholar] [CrossRef]








| Vintage | Variety | No. of Samples |
|---|---|---|
| 2012 | Touriga Franca | 240 |
| 2013 | Touriga Franca | 81 |
| Touriga Nacional | 60 | |
| Tinta Barroca | 82 | |
| 2014 | Touriga Franca | 120 |
| Touriga Nacional | 118 | |
| Tinta Barroca | 120 | |
| 2016 | Touriga Franca | 407 |
| Touriga Nacional | 132 | |
| Tinta Barroca | 143 | |
| 2017 | Touriga Franca | 540 |
| Touriga Nacional | 144 | |
| Tinta Barroca | 118 | |
| 2018 | Touriga Franca | 360 |
| Hyperparameter | Range Values |
|---|---|
| Convolution layer 1—number of filters (#Filters 1) | 5–256 |
| Convolution layer 1—kernel size 1 | 3–100 |
| Convolution layer 2—number of Filters (#Filters 2) | 5–256 |
| Convolution layer 2—kernel size 2 | 3–100 |
| Dense No. of neurons (neurons) | 4–256 |
| Dropout rate (dropout 1/2) | 0.1–0.6 |
| Learning rate (LR) | 0.01–0.06 |
| Batch size | 8–260 |
| Preprocessing | #Filters 1 | Kernel Size 1 | #Filters 2 | Kernel Size 2 | Neurons | Dropout 1/2 | LR | Batch Size |
|---|---|---|---|---|---|---|---|---|
| MSC | 39 | 40 | 60 | 7 | 128 | 0.20/0.15 | 0.050 | 8 |
| Norm | 34 | 50 | 47 | 9 | 128 | 0.15/0.15 | 0.039 | 8 |
| SG | 60 | 50 | 60 | 3 | 128 | 0.40/0.20 | 0.033 | 8 |
| Parameter | Preprocessing | Validation Set | Test Set |
|---|---|---|---|
| RMSEV | RMSEP | ||
| Sugar | MSC | 0.765 °Brix | 0.806 °Brix |
| Norm | 0.743 °Brix | 0.791 °Brix | |
| SG | 0.726 °Brix | 0.755 °Brix | |
| pH | MSC | 0.150 | 0.146 |
| Norm | 0.127 | 0.124 | |
| SG | 0.119 | 0.110 |
| Parameter | TN | TB |
|---|---|---|
| RMSEP | RMSEP | |
| Sugar | 1.025 °Brix | 1.203 °Brix |
| pH | 0.234 | 0.158 |
| Preprocessing | #Filters 1 | Kernel Size 1 | #Filters 2 | Kernel Size 2 | Neurons | Dropout 1/2 | LR | Batch Size |
|---|---|---|---|---|---|---|---|---|
| SG | 15 | 32 | 29 | 19 | 90 | 0.41/0.20 | 0.043 | 8 |
| Parameter | RMSEV | RMSEP |
|---|---|---|
| Sugar | 1.227 °Brix | 1.396 °Brix |
| pH | 0.182 | 0.223 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomes, V.; Mendes-Ferreira, A.; Melo-Pinto, P. Application of Hyperspectral Imaging and Deep Learning for Robust Prediction of Sugar and pH Levels in Wine Grape Berries. Sensors 2021, 21, 3459. https://doi.org/10.3390/s21103459
Gomes V, Mendes-Ferreira A, Melo-Pinto P. Application of Hyperspectral Imaging and Deep Learning for Robust Prediction of Sugar and pH Levels in Wine Grape Berries. Sensors. 2021; 21(10):3459. https://doi.org/10.3390/s21103459
Chicago/Turabian StyleGomes, Véronique, Ana Mendes-Ferreira, and Pedro Melo-Pinto. 2021. "Application of Hyperspectral Imaging and Deep Learning for Robust Prediction of Sugar and pH Levels in Wine Grape Berries" Sensors 21, no. 10: 3459. https://doi.org/10.3390/s21103459
APA StyleGomes, V., Mendes-Ferreira, A., & Melo-Pinto, P. (2021). Application of Hyperspectral Imaging and Deep Learning for Robust Prediction of Sugar and pH Levels in Wine Grape Berries. Sensors, 21(10), 3459. https://doi.org/10.3390/s21103459