Figure 1.
A typical pictorial presentation of the skin lesion images with different challenging for segmentation.
Figure 1.
A typical pictorial presentation of the skin lesion images with different challenging for segmentation.
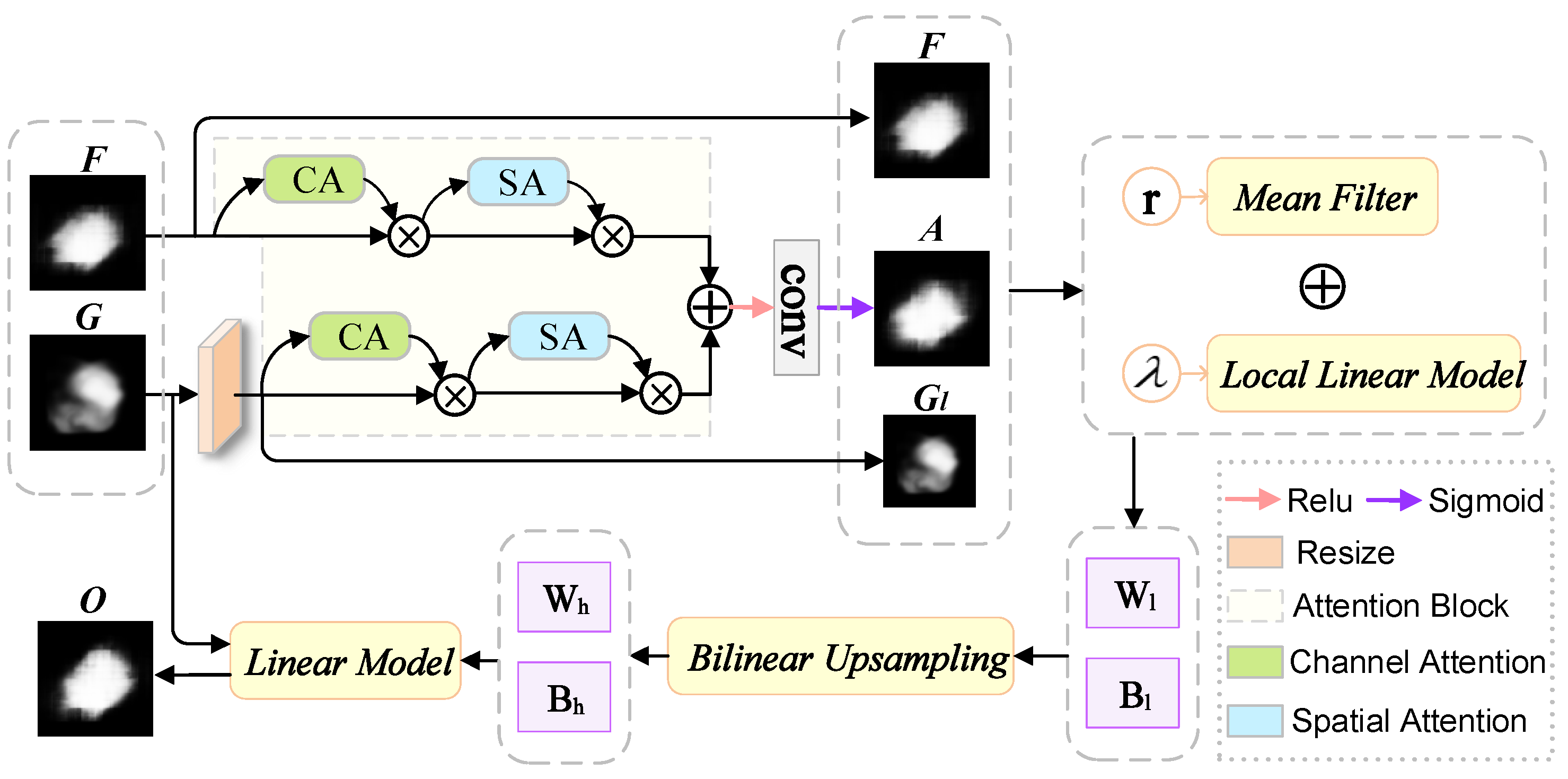
Figure 2.
CSAG and DCCNet model architecture.
Figure 2.
CSAG and DCCNet model architecture.
Figure 3.
CSFAG model architecture.
Figure 3.
CSFAG model architecture.
Figure 4.
Visual display of CSFAG module input and output (A dermoscopy image of melanoma is a case, the red line is ground truth).
Figure 4.
Visual display of CSFAG module input and output (A dermoscopy image of melanoma is a case, the red line is ground truth).
Figure 5.
Attention module; (a) channel attention submodule; (b) spatial attention submodule.
Figure 5.
Attention module; (a) channel attention submodule; (b) spatial attention submodule.
Figure 6.
Densely connected convolution module.
Figure 6.
Densely connected convolution module.
Figure 7.
Visual description of the input dermoscopy image in different color spaces.
Figure 7.
Visual description of the input dermoscopy image in different color spaces.
Figure 8.
Visualized results of structural ablation experiments. The first two lines are Benign Nevus, the middle two lines are Melanoma lesions, and the last two lines are Seborrheic Keratosis lesions. (a) Original image; (b) the ground truth; (c) U-Net; (d) 1. M-Net; (d) 2. M-Net+Dense Convolutions; (d) 3. M-Net+ CSFAG; (e) CSAG and DCCNet model; (f) ground truth (red) and U-Net+ (purple), MNet (green), M-Net+Dense Convolutions (yellow), M-Net+CSFAG (black) and ours (blue) segmentation results comparison chart. All pictures are preprocessed.
Figure 8.
Visualized results of structural ablation experiments. The first two lines are Benign Nevus, the middle two lines are Melanoma lesions, and the last two lines are Seborrheic Keratosis lesions. (a) Original image; (b) the ground truth; (c) U-Net; (d) 1. M-Net; (d) 2. M-Net+Dense Convolutions; (d) 3. M-Net+ CSFAG; (e) CSAG and DCCNet model; (f) ground truth (red) and U-Net+ (purple), MNet (green), M-Net+Dense Convolutions (yellow), M-Net+CSFAG (black) and ours (blue) segmentation results comparison chart. All pictures are preprocessed.
Figure 9.
Visualization results of the attention module ablation. The first two lines are Benign Nevus, the middle two lines are Melanoma lesions, and the last two lines are Seborrheic Keratosis lesions. (a) Original skin lesion image; (b) Ground truth corresponding to the lesion; (c) SE Block+Baseline model lesion segmentation results; (d) FPA+Baseline model lesion segmentation results; (e) CBAM+Baseline model lesion segmentation Results; (f) CSAG and DCCNet (ours) model lesion segmentation results; (g) ground truth (red) and SEnet+Baseline (purple), FPA+Baseline (green), CBAM+Baseline (yellow) and ours (blue) segmentation Results comparison chart. All pictures are preprocessed.
Figure 9.
Visualization results of the attention module ablation. The first two lines are Benign Nevus, the middle two lines are Melanoma lesions, and the last two lines are Seborrheic Keratosis lesions. (a) Original skin lesion image; (b) Ground truth corresponding to the lesion; (c) SE Block+Baseline model lesion segmentation results; (d) FPA+Baseline model lesion segmentation results; (e) CBAM+Baseline model lesion segmentation Results; (f) CSAG and DCCNet (ours) model lesion segmentation results; (g) ground truth (red) and SEnet+Baseline (purple), FPA+Baseline (green), CBAM+Baseline (yellow) and ours (blue) segmentation Results comparison chart. All pictures are preprocessed.
Figure 10.
Visualized results of ROC curve and PR curve.
Figure 10.
Visualized results of ROC curve and PR curve.
Figure 11.
Visualization results of the robustness test of the CSAG module on the ISIC 2017 data set. The first two lines are Benign Nevus, the middle two lines are Melanoma lesions, and the last two lines are Seborrheic Keratosis lesions. (a) Original image; (b) the ground truth; (c) 1. U-Net; (c) 2. U-Net+CSFAG; (c) 3. Comparison of segmentation results ground truth (red), U-Net (purple), U-Net+CSFAG (green) and ours (blue); (d) 1. SegNet; (d) 2. SegNet+CSFAG; (d) 3. Comparison of segmentation results of ground truth (red) and SegNet (white), SegNet+CSFAG (black) and ours (blue) (e) 1. M-Net; (e) 2. M-Net+CSFAG; (e) 3. Comparison of segmentation results of ground truth (red) and M-Net (yellow), M-Net+CSFAG (pink) and ours (blue) (f) CSAG and DCCNet (ours) model. All pictures are preprocessed.
Figure 11.
Visualization results of the robustness test of the CSAG module on the ISIC 2017 data set. The first two lines are Benign Nevus, the middle two lines are Melanoma lesions, and the last two lines are Seborrheic Keratosis lesions. (a) Original image; (b) the ground truth; (c) 1. U-Net; (c) 2. U-Net+CSFAG; (c) 3. Comparison of segmentation results ground truth (red), U-Net (purple), U-Net+CSFAG (green) and ours (blue); (d) 1. SegNet; (d) 2. SegNet+CSFAG; (d) 3. Comparison of segmentation results of ground truth (red) and SegNet (white), SegNet+CSFAG (black) and ours (blue) (e) 1. M-Net; (e) 2. M-Net+CSFAG; (e) 3. Comparison of segmentation results of ground truth (red) and M-Net (yellow), M-Net+CSFAG (pink) and ours (blue) (f) CSAG and DCCNet (ours) model. All pictures are preprocessed.
Figure 12.
Visualization results for the PH2 data set. (a) Original skin lesion image; (b) ground truth corresponding to the lesion. (c) CSARM-CNN model lesion segmentation results; (d) ground truth (red) and segmentation results (blue) comparison chart.
Figure 12.
Visualization results for the PH2 data set. (a) Original skin lesion image; (b) ground truth corresponding to the lesion. (c) CSARM-CNN model lesion segmentation results; (d) ground truth (red) and segmentation results (blue) comparison chart.
Table 1.
The distribution of The ISIC Challenge 2017 data set and PH2 datasets.
Table 1.
The distribution of The ISIC Challenge 2017 data set and PH2 datasets.
| Dataset | ISIC 2017 | PH2 |
|---|
| Me | SK | Ne | Total | Me | SK | Ne | Total |
|---|
| Training data | 404 | 296 | 1450 | 2150 | - | - | - | - |
| Test data | 117 | 90 | 393 | 600 | 40 | - | 160 | 200 |
Table 2.
Determination of the numberD of densely connected blocks on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
Table 2.
Determination of the numberD of densely connected blocks on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
| Method | Overall |
|---|
| ACC | SEN | SPE | DIC | JAC | MCC |
|---|
| D = 1 | 95.04 | 87.58 | 96.40 | 84.96 | 75.30 | 81.49 |
| D = 2 | 95.21 | 87.51 | 96.99 | 85.90 | 77.91 | 82.51 |
| D = 3 | 95.94 | 87.03 | 99.35 | 86.97 | 78.85 | 83.93 |
| D = 4 | 95.61 | 86.50 | 97.46 | 86.35 | 77.89 | 83.50 |
Table 3.
ISIC-2017 data set, performance comparison of U-Net, M-Net, M-Net+DC (Dense Convolutions), M-Net+CSFAG and CSAG and DCCNet (ours) in sensitivity, specificity and accuracy. Bold data indicates that the value is the maximum value in this indicator.
Table 3.
ISIC-2017 data set, performance comparison of U-Net, M-Net, M-Net+DC (Dense Convolutions), M-Net+CSFAG and CSAG and DCCNet (ours) in sensitivity, specificity and accuracy. Bold data indicates that the value is the maximum value in this indicator.
| Method | Params | Nevus Cases | Melanoma Cases | SK Cases | Overall |
|---|
| SEN | SPE | ACC | SEN | SPE | ACC | SEN | SPE | ACC | SEN | SPE | ACC |
|---|
| U-Net | 8.6M | 81.80 | 97.53 | 93.83 | 70.31 | 98.08 | 89.62 | 57.84 | 98.34 | 89.07 | 74.53 | 97.59 | 92.32 |
| M-Net | 10.92M | 85.96 | 97.31 | 96.05 | 78.60 | 97.58 | 92.17 | 72.60 | 98.32 | 91.69 | 83.22 | 98.32 | 94.58 |
| M-Net+DC | 13.79M | 87.63 | 97.98 | 96.13 | 79.62 | 97.97 | 93.34 | 68.80 | 99.60 | 92.89 | 84.46 | 99.15 | 95.10 |
| M-Net+CSFAG | 24.89M | 89.92 | 97.63 | 96.82 | 79.40 | 97.20 | 93.24 | 69.94 | 98.02 | 93.39 | 86.54 | 97.41 | 95.85 |
| Ours | 28.74M | 89.85 | 99.43 | 97.46 | 80.23 | 99.51 | 94.70 | 80.24 | 99.70 | 94.99 | 87.03 | 99.35 | 95.94 |
Table 4.
On the ISIC-2017 data set, performance comparison of U-Net, M-Net, M-Net+DC (Dense Convolutions), M-Net+CSFAG and CSAG and DCCNet (ours) in Jaccard coefficient, Dice coefficient and Matthew correlation coefficient. Bold data indicates that the value is the maximum value in this indicator.
Table 4.
On the ISIC-2017 data set, performance comparison of U-Net, M-Net, M-Net+DC (Dense Convolutions), M-Net+CSFAG and CSAG and DCCNet (ours) in Jaccard coefficient, Dice coefficient and Matthew correlation coefficient. Bold data indicates that the value is the maximum value in this indicator.
| Method | Params | Nevus Cases | Melanoma Cases | SK Cases | Overall |
|---|
| DIC | JAC | MCC | DIC | JAC | MCC | DIC | JAC | MCC | DIC | JAC | MCC |
|---|
| U-Net | 8.6M | 78.71 | 64.89 | 75.12 | 73.16 | 57.68 | 66.73 | 64.39 | 47.49 | 58.55 | 74.32 | 59.13 | 69.64 |
| M-Net | 10.92M | 86.89 | 77.34 | 84.80 | 81.72 | 69.20 | 78.36 | 74.32 | 59.13 | 71.56 | 83.68 | 74.08 | 81.30 |
| M-Net+DC | 13.79M | 87.14 | 78.16 | 85.56 | 83.31 | 72.13 | 77.11 | 78.19 | 62.80 | 73.85 | 84.74 | 76.65 | 81.78 |
| M-Net+CSFAG | 24.89M | 88.46 | 79.31 | 86.68 | 83.70 | 72.71 | 79.83 | 79.16 | 65.51 | 75.20 | 85.63 | 76.86 | 83.20 |
| Ours | 28.74M | 90.65 | 82.90 | 89.19 | 84.24 | 73.68 | 78.10 | 82.14 | 72.78 | 77.56 | 86.97 | 78.85 | 83.93 |
Table 5.
Performance evaluation of sensitivity, specificity, and accuracy performance of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
Table 5.
Performance evaluation of sensitivity, specificity, and accuracy performance of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
| Method | Params | Nevus Cases | Melanoma Cases | SK Cases | Overall |
|---|
| SEN | SPE | ACC | SEN | SPE | ACC | SEN | SPE | ACC | SEN | SPE | ACC |
|---|
| SE Block+Baseline | 26.62M | 90.25 | 97.05 | 96.89 | 78.77 | 98.68 | 93.41 | 78.23 | 98.04 | 94.01 | 85.91 | 97.97 | 95.44 |
| FPA+Baseline | 32.08M | 88.26 | 98.67 | 96.21 | 76.12 | 98.22 | 93.57 | 77.20 | 98.12 | 93.45 | 82.29 | 98.15 | 95.35 |
| CBAM+Baseline | 27.40M | 89.01 | 98.25 | 97.06 | 76.05 | 97.75 | 93.59 | 81.69 | 96.68 | 94.16 | 82.76 | 97.70 | 95.99 |
| Baseline | 13.79M | 87.63 | 97.98 | 96.13 | 79.62 | 97.97 | 93.34 | 68.80 | 99.60 | 92.89 | 84.46 | 99.15 | 95.10 |
| Ours | 28.74M | 89.85 | 99.43 | 97.46 | 80.23 | 99.51 | 94.70 | 80.24 | 99.70 | 94.99 | 87.03 | 99.35 | 95.94 |
Table 6.
Performance evaluation of Jaccard coefficient, Dice coefficient and Matthew correlation coefficient of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
Table 6.
Performance evaluation of Jaccard coefficient, Dice coefficient and Matthew correlation coefficient of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
| Method | Params | Nevus Cases | Melanoma Cases | SK Cases | Overall |
|---|
| DIC | JAC | MCC | DIC | JAC | MCC | DIC | JAC | MCC | DIC | JAC | MCC |
|---|
| SE Block+Baseline | 26.62M | 87.61 | 78.47 | 86.13 | 84.15 | 73.52 | 78.79 | 81.76 | 72.10 | 80.91 | 85.89 | 78.48 | 82.63 |
| FPA+Baseline | 32.08M | 87.36 | 77.89 | 85.90 | 83.99 | 73.64 | 77.20 | 81.36 | 70.34 | 76.83 | 85.09 | 77.05 | 82.89 |
| CBAM+Baseline | 27.40M | 88.55 | 79.45 | 86.74 | 84.92 | 72.91 | 77.90 | 82.47 | 71.17 | 78.98 | 85.16 | 77.15 | 82.38 |
| Baseline | 13.79M | 87.14 | 78.16 | 85.56 | 83.31 | 72.13 | 77.11 | 78.19 | 62.80 | 73.85 | 84.74 | 76.65 | 81.78 |
| Ours | 28.74M | 90.65 | 82.90 | 89.19 | 84.24 | 73.68 | 78.10 | 82.14 | 72.78 | 77.56 | 86.97 | 78.85 | 83.93 |
Table 7.
The performance comparison of sensitivity, specificity and accuracy of the three basic architecture networks and their new network structure with the CSAG and DCCNet (ours) model on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
Table 7.
The performance comparison of sensitivity, specificity and accuracy of the three basic architecture networks and their new network structure with the CSAG and DCCNet (ours) model on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
| Method | Params | Nevus Cases | Melanoma Cases | SK Cases | Overall |
|---|
| SEN | SPE | ACC | SEN | SPE | ACC | SEN | SPE | ACC | SEN | SPE | ACC |
|---|
| UNet | 8.60M | 81.80 | 97.53 | 93.83 | 70.31 | 98.08 | 89.62 | 57.84 | 98.34 | 89.07 | 74.53 | 97.59 | 92.32 |
| UNet+CSFAG | 23.15M | 87.35 | 99.31 | 96.00 | 73.89 | 97.68 | 90.16 | 82.98 | 98.87 | 91.49 | 85.67 | 98.45 | 94.34 |
| SegNet | 28.08M | 82.83 | 98.65 | 95.60 | 73.24 | 99.02 | 91.69 | 65.62 | 98.98 | 92.64 | 80.19 | 99.00 | 95.46 |
| SegNet+CSFAG | 42.78M | 85.51 | 98.99 | 96.31 | 74.47 | 99.14 | 93.29 | 82.69 | 98.10 | 91.82 | 82.41 | 98.99 | 95.34 |
| M-Net | 10.92M | 85.96 | 97.31 | 96.05 | 78.60 | 97.58 | 92.17 | 72.60 | 98.32 | 91.69 | 83.22 | 98.32 | 94.58 |
| M-Net+CSFAG | 24.89M | 88.82 | 97.63 | 96.82 | 79.40 | 97.20 | 93.24 | 69.94 | 98.02 | 93.39 | 86.54 | 97.41 | 95.85 |
| Ours | 28.74M | 89.85 | 99.43 | 97.46 | 80.23 | 99.51 | 94.70 | 80.24 | 99.70 | 94.99 | 87.03 | 99.35 | 95.94 |
Table 8.
The performance comparison of Jaccard coefficient, Dice coefficient and Matthew correlation coefficient of the three basic architecture networks and their new network structure with the CSAG and DCCNet (ours) model on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
Table 8.
The performance comparison of Jaccard coefficient, Dice coefficient and Matthew correlation coefficient of the three basic architecture networks and their new network structure with the CSAG and DCCNet (ours) model on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
| Method | Params | Nevus Cases | Melanoma Cases | SK Cases | Overall |
|---|
| DIC | JAC | MCC | DIC | JAC | MCC | DIC | JAC | MCC | DIC | JAC | MCC |
|---|
| UNet | 8.60M | 78.71 | 64.89 | 75.12 | 73.16 | 57.68 | 66.73 | 64.39 | 47.49 | 58.55 | 74.32 | 59.13 | 69.64 |
| UNet+CSFAG | 23.15M | 86.28 | 75.87 | 83.88 | 76.75 | 62.27 | 71.30 | 72.46 | 56.82 | 67.14 | 81.08 | 68.18 | 77.77 |
| SegNet | 28.08M | 83.66 | 71.91 | 81.28 | 77.84 | 63.73 | 73.28 | 73.67 | 58.31 | 70.15 | 83.07 | 71.05 | 80.70 |
| SegNet+CSFAG | 42.78M | 86.43 | 76.10 | 84.41 | 82.04 | 69.55 | 78.58 | 75.35 | 60.45 | 70.80 | 85.06 | 74.00 | 82.36 |
| M-Net | 10.92M | 86.89 | 77.34 | 84.80 | 81.72 | 69.20 | 78.36 | 74.32 | 59.13 | 71.56 | 83.68 | 74.08 | 81.30 |
| M-Net+CSFAG | 24.89M | 88.46 | 79.31 | 86.68 | 83.70 | 72.71 | 79.83 | 79.16 | 65.51 | 75.20 | 85.63 | 76.86 | 83.20 |
| Ours | 28.74M | 90.65 | 82.90 | 89.19 | 84.24 | 73.68 | 78.10 | 82.14 | 72.78 | 77.56 | 86.97 | 78.85 | 83.93 |
Table 9.
Performance evaluation of sensitivity, specificity, and accuracy performance of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
Table 9.
Performance evaluation of sensitivity, specificity, and accuracy performance of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
| Method | Nevus Cases | Melanoma Cases | SK Cases | Overall |
|---|
| SEN | SPE | ACC | SEN | SPE | ACC | SEN | SPE | ACC | SEN | SPE | ACC |
|---|
| U-Net [57] | 76.76 | 97.26 | 92.89 | 58.71 | 96.81 | 84.98 | 43.81 | 97.64 | 84.83 | 67.15 | 97.24 | 90.14 |
| FCN-AlexNet [58] | 82.44 | 97.58 | 94.84 | 72.35 | 96.23 | 87.82 | 71.70 | 97.92 | 89.35 | 78.86 | 97.37 | 92.65 |
| FCN-32s [58] | 83.67 | 96.69 | 94.59 | 74.36 | 96.32 | 88.94 | 75.80 | 96.41 | 89.45 | 80.67 | 96.72 | 92.72 |
| FCN-16s [58] | 84.23 | 96.91 | 94.67 | 75.14 | 96.27 | 89.94 | 75.48 | 96.25 | 88.83 | 81.14 | 96.68 | 92.74 |
| FCN-8s [58] | 83.91 | 97.22 | 94.55 | 78.37 | 95.96 | 89.63 | 69.85 | 96.57 | 87.40 | 80.72 | 96.87 | 92.52 |
| DeepLabV3+ [58] | 88.54 | 97.21 | 95.67 | 77.71 | 96.37 | 89.65 | 74.59 | 98.55 | 90.06 | 84.34 | 97.25 | 93.66 |
| Mask-RCNN [58] | 87.25 | 96.38 | 95.32 | 78.63 | 95.63 | 89.31 | 82.41 | 94.88 | 90.85 | 84.84 | 96.01 | 93.48 |
| SegNet [57] | 85.19 | 96.30 | 93.93 | 73.78 | 94.26 | 87.90 | 70.58 | 92.50 | 87.29 | 80.05 | 95.37 | 91.76 |
| FrCN [57] | 88.95 | 97.44 | 95.62 | 78.91 | 96.04 | 90.78 | 82.37 | 94.08 | 91.29 | 85.40 | 96.69 | 94.03 |
| Ensemble-A [58] | 92.08 | 95.37 | 95.59 | 84.62 | 94.20 | 90.85 | 87.49 | 94.41 | 91.72 | 89.93 | 95.00 | 94.04 |
| Ours | 89.85 | 99.43 | 97.46 | 80.23 | 99.51 | 94.70 | 80.24 | 99.70 | 94.99 | 87.03 | 99.35 | 95.94 |
Table 10.
Performance evaluation of Jaccard coefficient, Dice coefficient and Matthew correlation coefficient of different modules and CSFAG modules on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
Table 10.
Performance evaluation of Jaccard coefficient, Dice coefficient and Matthew correlation coefficient of different modules and CSFAG modules on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
| Method | Nevus Cases | Melanoma Cases | SK Cases | Overall |
|---|
| DIC | JAC | MCC | DIC | JAC | MCC | DIC | JAC | MCC | DIC | JAC | MCC |
|---|
| U-Net [57] | 82.16 | 69.71 | 78.05 | 70.82 | 54.83 | 63.71 | 57.88 | 40.73 | 63.89 | 76.27 | 61.64 | 71.23 |
| FCN-AlexNet [58] | 85.61 | 77.01 | 82.91 | 75.94 | 64.32 | 70.35 | 75.09 | 63.76 | 71.51 | 82.15 | 72.55 | 78.75 |
| FCN-32s [58] | 85.08 | 76.39 | 82.29 | 78.39 | 67.23 | 72.70 | 76.18 | 64.78 | 72.10 | 82.44 | 72.86 | 78.89 |
| FCN-16s [58] | 85.60 | 77.39 | 82.92 | 79.22 | 68.41 | 73.26 | 75.23 | 64.11 | 71.42 | 82.80 | 73.65 | 79.31 |
| FCN-8s [58] | 84.33 | 76.07 | 81.73 | 80.08 | 69.58 | 74.39 | 68.01 | 56.54 | 65.14 | 81.06 | 71.87 | 77.81 |
| DeepLabV3+ [58] | 88.29 | 81.09 | 85.90 | 80.86 | 71.30 | 76.01 | 77.05 | 67.55 | 74.62 | 85.16 | 77.15 | 82.28 |
| Mask-RCNN [58] | 88.83 | 80.91 | 85.38 | 80.28 | 70.69 | 74.95 | 80.48 | 70.74 | 76.31 | 85.58 | 77.39 | 81.99 |
| SegNet [57] | 85.69 | 74.97 | 81.84 | 79.11 | 65.45 | 71.03 | 72.54 | 56.91 | 64.32 | 82.09 | 69.63 | 76.79 |
| FrCN [57] | 89.68 | 81.28 | 86.90 | 84.02 | 72.44 | 77.90 | 81.83 | 69.25 | 76.11 | 87.08 | 77.11 | 83.22 |
| Ensemble-A [58] | 89.28 | 82.11 | 86.33 | 83.54 | 74.53 | 78.08 | 82.53 | 73.45 | 78.61 | 87.14 | 79.34 | 83.57 |
| Ours | 90.65 | 82.90 | 89.19 | 84.24 | 73.68 | 78.10 | 82.14 | 72.78 | 77.56 | 86.97 | 78.85 | 83.93 |
Table 11.
Performance evaluation of accuracy, Dice coefficient, Jaccard coefficient, sensitivity, specificity, and performance of different modules and CSFAG modules on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
Table 11.
Performance evaluation of accuracy, Dice coefficient, Jaccard coefficient, sensitivity, specificity, and performance of different modules and CSFAG modules on the ISIC-2017 data set. Bold data indicates that the value is the maximum value in this indicator.
| Model | Year | ACC | DIC | JAC | SEN | SPE |
|---|
| CDNN [59] | 2017 | 0.934 | 0.849 | 0.765 | 0.825 | 0.975 |
| SLSDeep [60] | 2018 | 0.936 | 0.878 | 0.782 | 0.816 | 0.983 |
| Jahanifar M et al. [61] | 2018 | 0.930 | 0.839 | 0.749 | 0.810 | 0.981 |
| Bi L et al. [62] | 2019 | 0.862 | 0.857 | 0.777 | 0.967 | 0.941 |
| Att-DenseUnet [63] | 2019 | 0.9329 | 0.8786 | 0.8035 | 0.8734 | 0.9314 |
| DAGAN [64] | 2020 | 0.935 | 0.859 | 0.771 | 0.835 | 0.976 |
| CSARM-CNN [65] | 2020 | 0.958 | 0.846 | 0.733 | 0.802 | 0.994 |
| DSC [66] | 2020 | 0.938 | 0.862 | 0.783 | 0.870 | 0.964 |
| Ours | | 0.959 | 0.869 | 0.788 | 0.870 | 0.993 |
Table 12.
Performance evaluation of sensitivity, specificity, and accuracy performance of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
Table 12.
Performance evaluation of sensitivity, specificity, and accuracy performance of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
| Method | Nevus Cases | Melanoma Cases | Overall |
|---|
| SEN | SPE | ACC | SEN | SPE | ACC | SEN | SPE | ACC |
|---|
| FCN [47] | 95.35 | 94.09 | 94.44 | 90.30 | 94.02 | 92.82 | 90.30 | 94.02 | 92.82 |
| SegNet [47] | 91.57 | 96.57 | 95.19 | 75.50 | 96.83 | 86.04 | 86.53 | 96.61 | 93.36 |
| U-Net [47] | 86.68 | 97.63 | 94.60 | 70.58 | 98.47 | 84.36 | 81.63 | 97.76 | 92.55 |
| FrCn [47] | 94.48 | 95.46 | 95.20 | 91.57 | 96.55 | 94.64 | 93.72 | 95.65 | 95.08 |
| Ours | 93.30 | 98.19 | 97.35 | 85.34 | 95.72 | 91.00 | 89.75 | 97.73 | 95.90 |
Table 13.
Performance evaluation of Jaccard coefficient, Dice coefficient and Matthew correlation coefficient of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
Table 13.
Performance evaluation of Jaccard coefficient, Dice coefficient and Matthew correlation coefficient of different attention modules and CSFAG modules on the ISIC-2017 data set using baseline as the basic structure. Bold data indicates that the value is the maximum value in this indicator.
| Method | Nevus Cases | Melanoma Cases | Overall |
|---|
| DIC | JAC | MCC | DIC | JAC | MCC | DIC | JAC | MCC |
|---|
| FCN [47] | 90.46 | 82.59 | 86.78 | 89.03 | 80.22 | 83.71 | 89.03 | 80.22 | 83.71 |
| SegNet [47] | 91.32 | 84.03 | 87.99 | 84.55 | 73.23 | 73.89 | 89.36 | 80.77 | 84.64 |
| U-Net [47] | 89.88 | 81.63 | 86.32 | 82.04 | 69.55 | 71.73 | 87.61 | 77.95 | 82.78 |
| FrCn [47] | 91.38 | 84.13 | 88.15 | 92.92 | 86.77 | 88.62 | 91.77 | 84.79 | 88.30 |
| Ours | 92.37 | 85.83 | 90.78 | 89.61 | 83.87 | 85.02 | 90.97 | 83.44 | 88.34 |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}