
A Variable-Length Chromosome Genetic Algorithm for Time-Based Sensor Network Schedule Optimization



Abstract
:1. Introduction
2. Sensor Network Schedule Optimization Problem
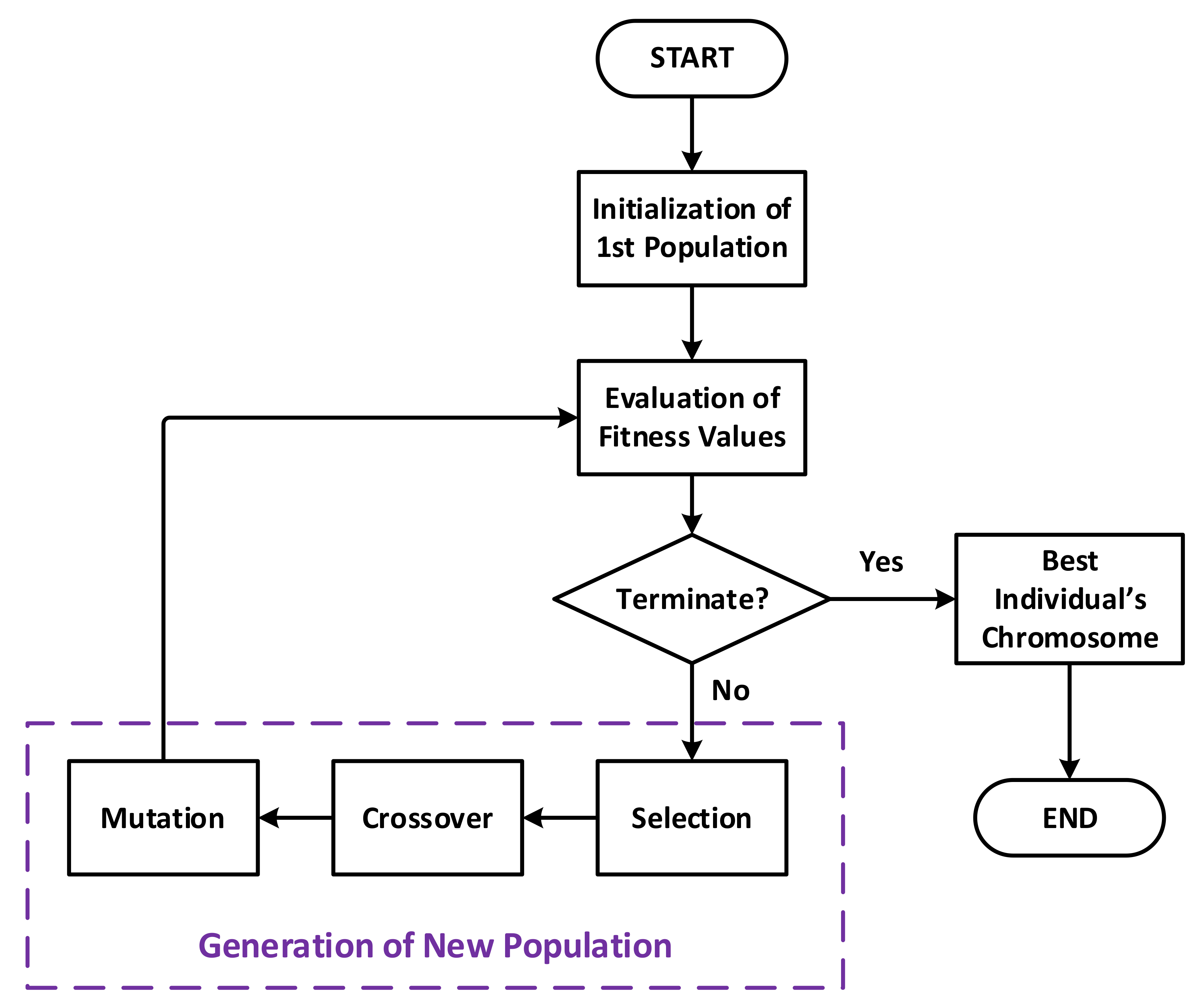
3. Overview of Genetic Algorithms
- Selection keeps the best individuals in the population based on their fitness values. The selected individuals survive and remain as they are to the next generation.
- Crossover takes pairs of parent individuals and randomly combines their genes to create children.
- Mutation takes a parent chromosome and introduces random changes to make children.
4. Variable-Length Chromosome Genetic Algorithm for Network Scheduling Problem
4.1. Formulation of Variable-Length Chromosome Genetic Algorithm
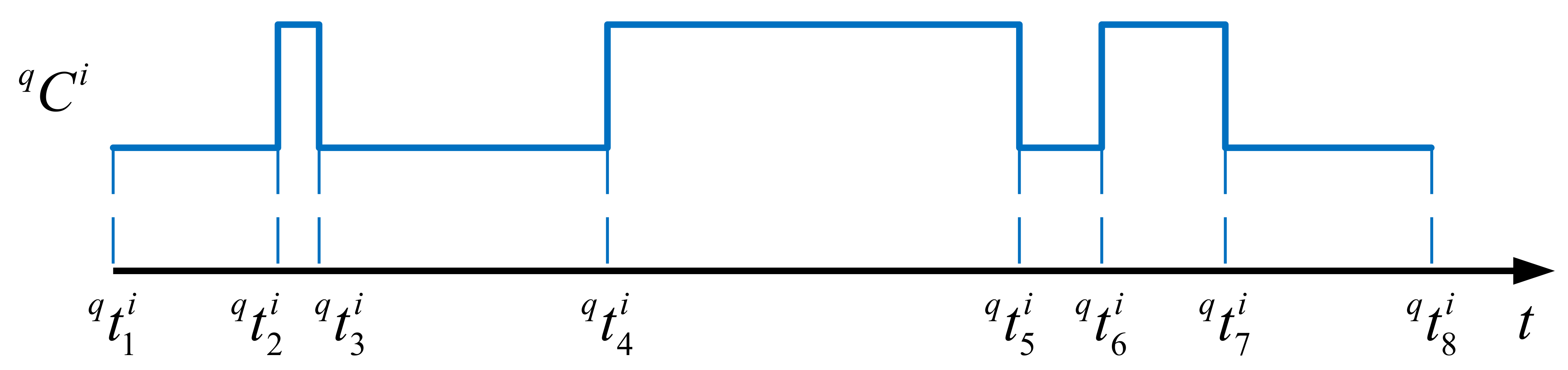
4.1.1. Chromosome Structure
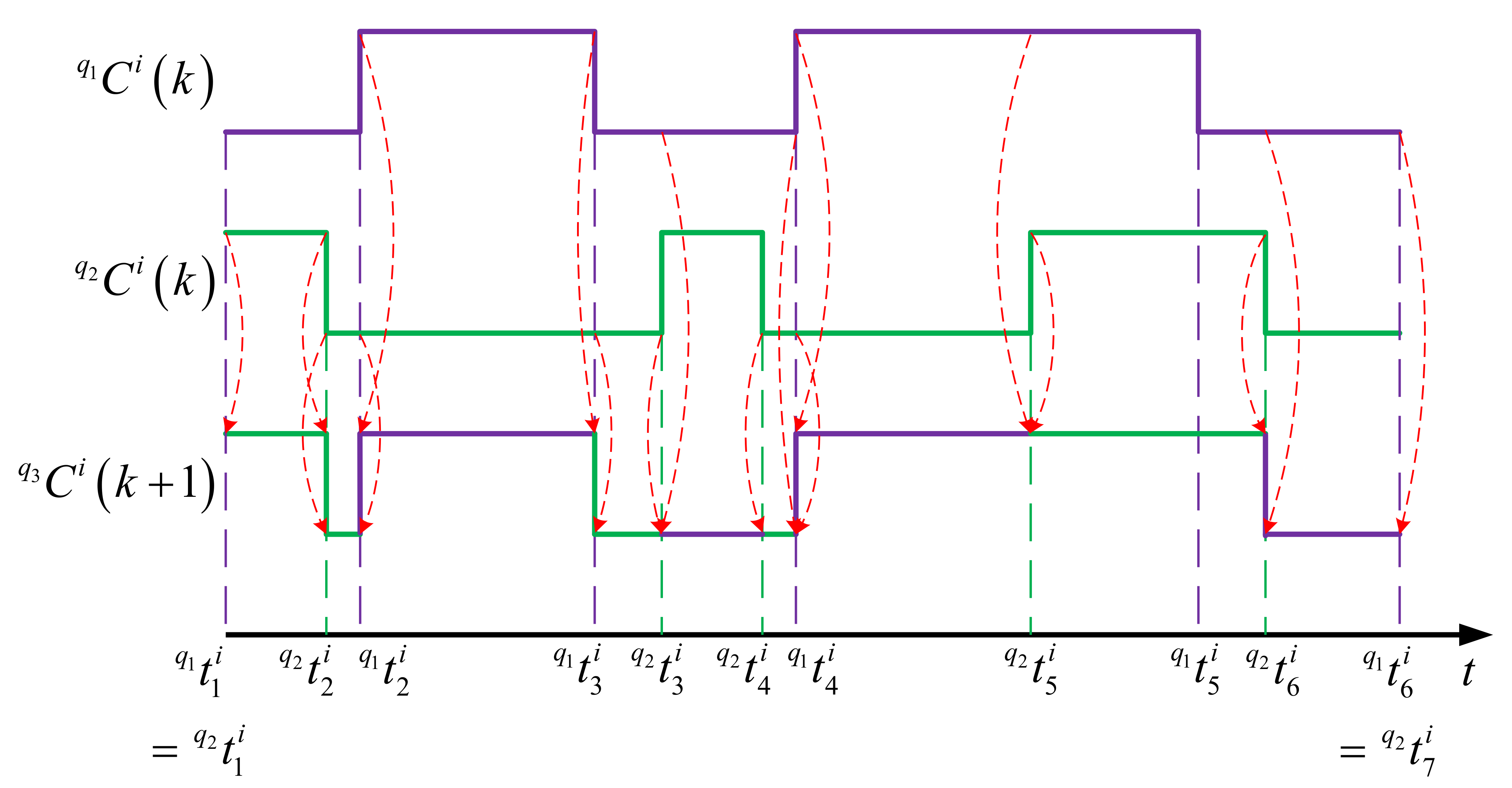
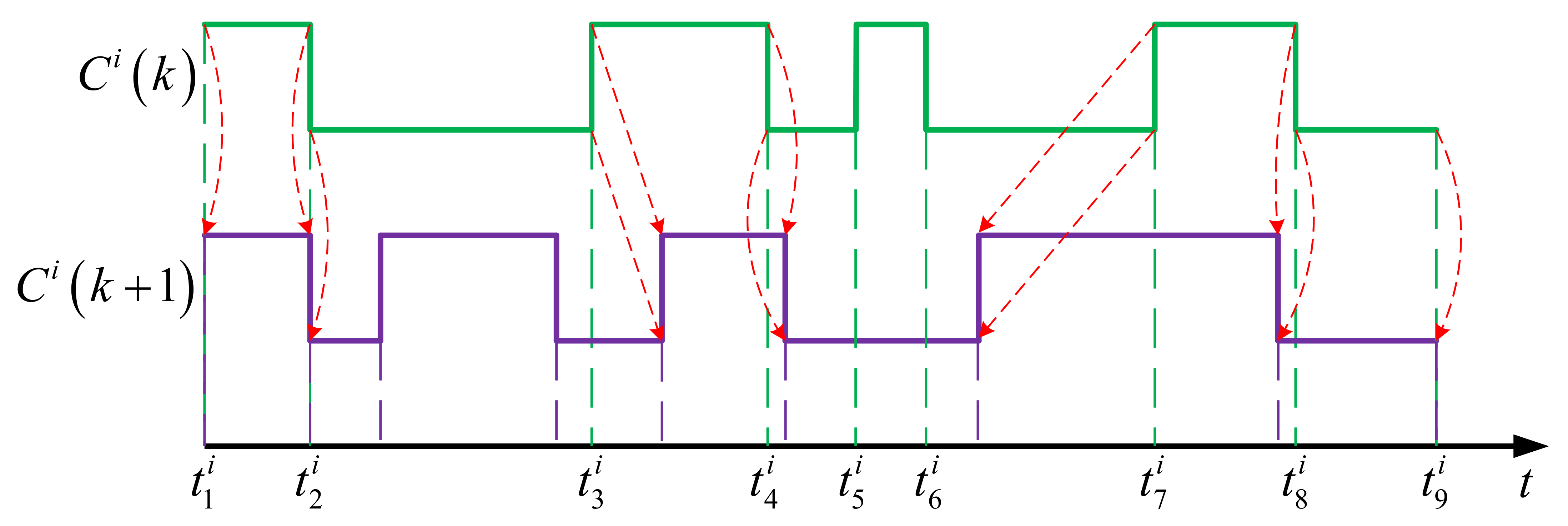
4.1.2. Crossover Operation
4.1.3. Mutation Operation
- Copy: The child interval is same as the parent interval, like the intervals and in the example.
- Insertion: A new interval with inverse mode is inserted in a manner that its start and end times are generated randomly but stay within the boundaries of the parent one, as in the case of the interval in the example.
- Removal: The parent interval is removed and not inherited by the child node, as in the case of the interval in the example.
- Shift: The boundaries of the child interval is made by moving those of the parent one backward or forward in the time axis, as in the case of the intervals and in the example.
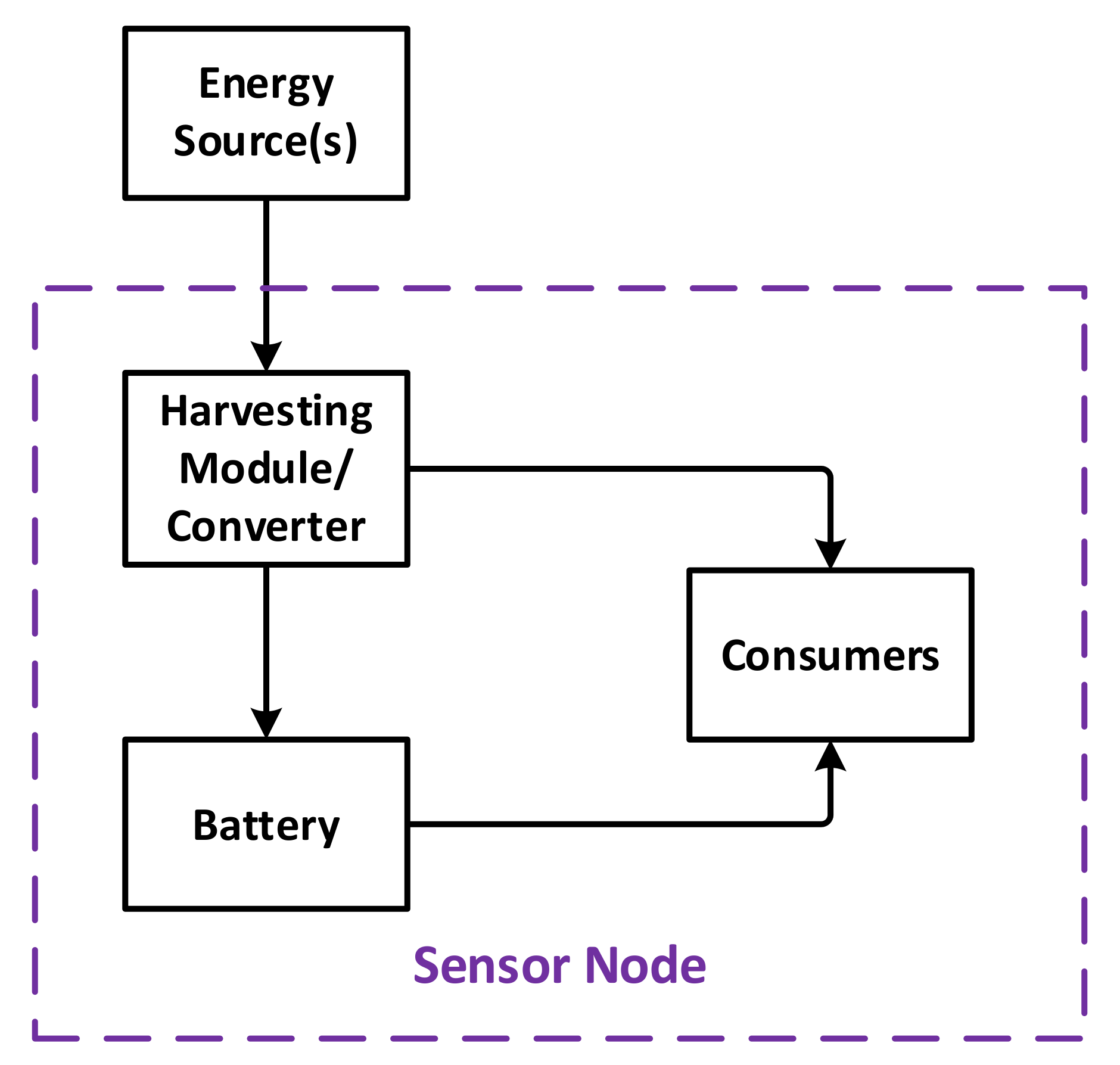
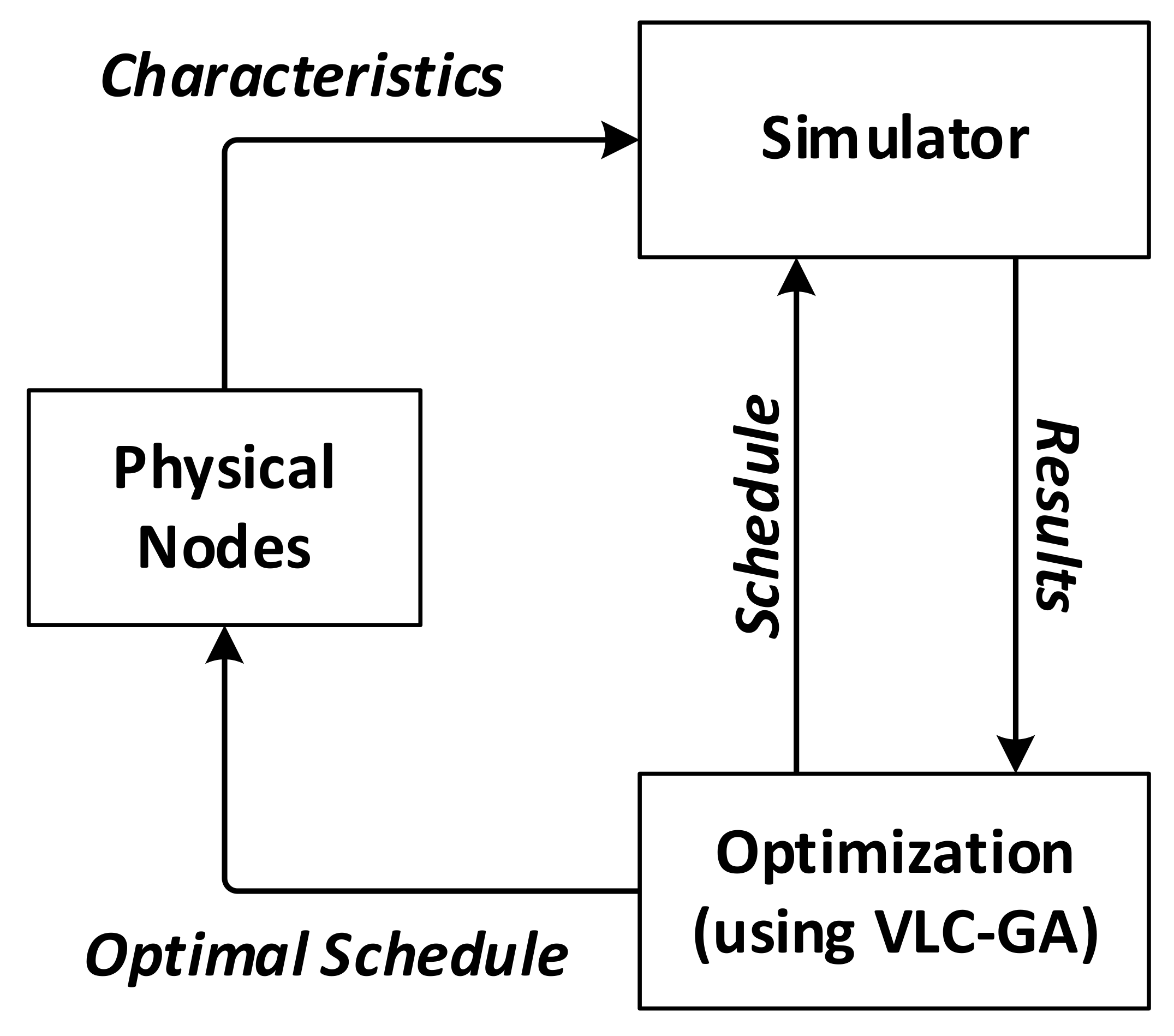
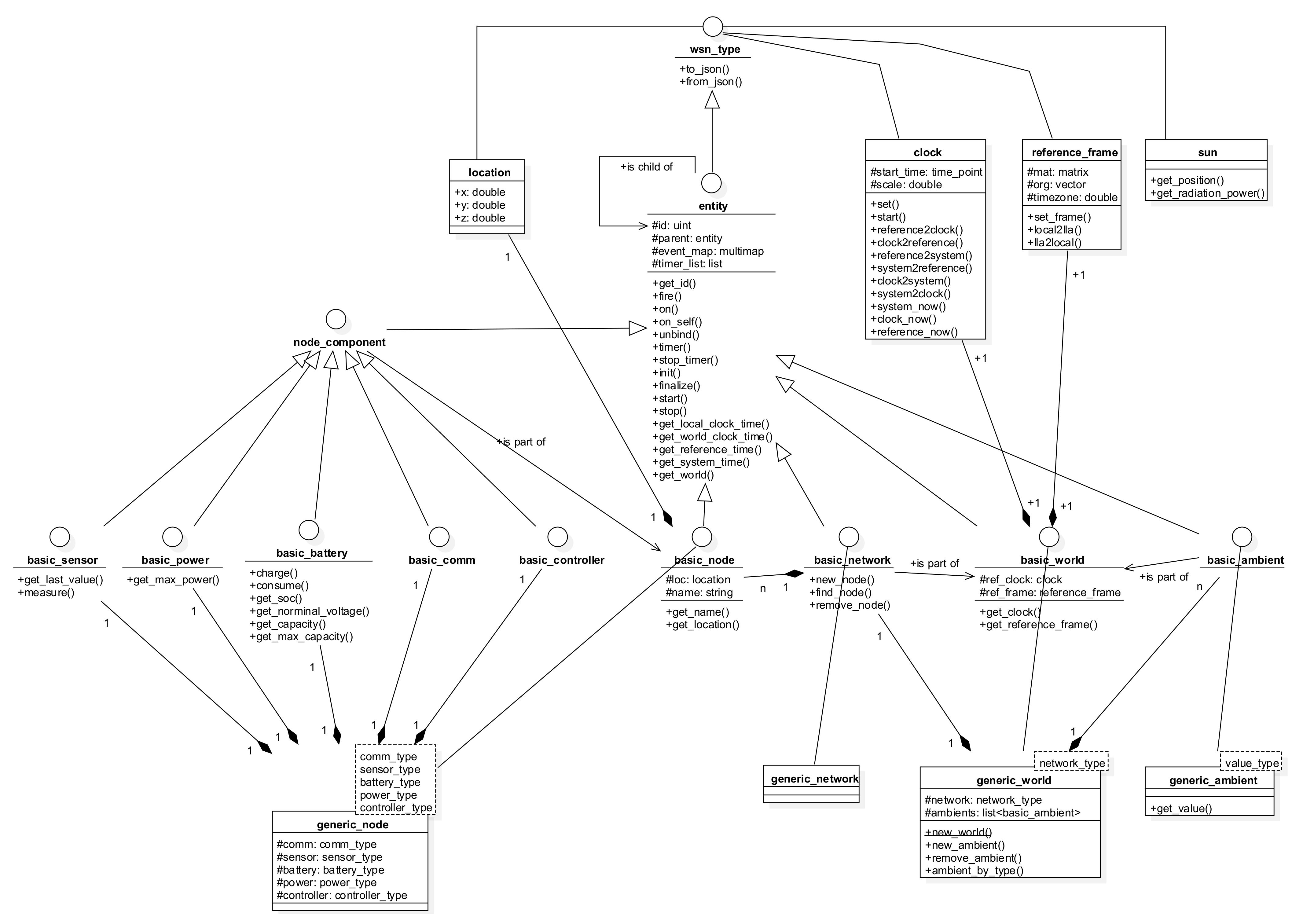
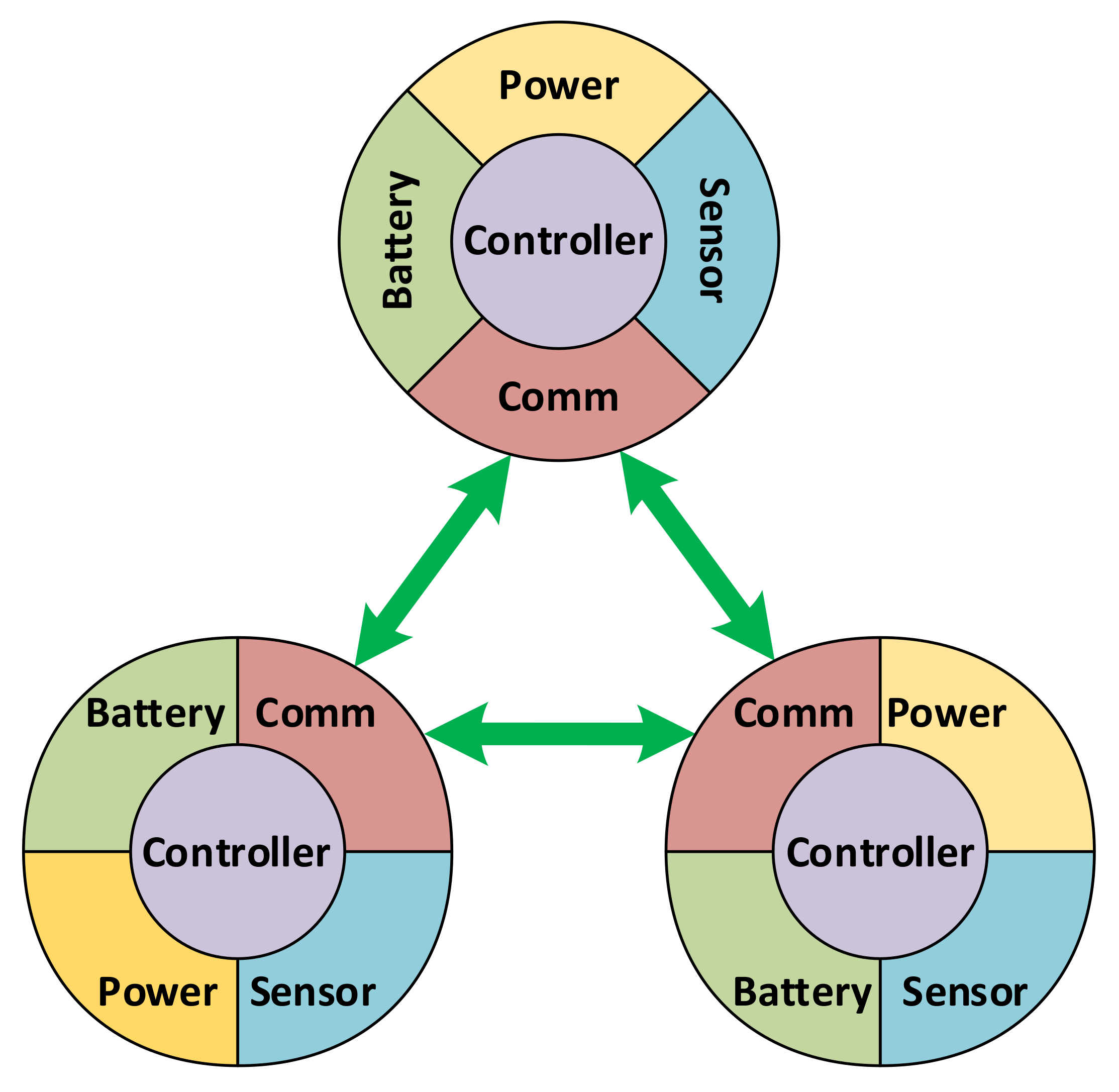
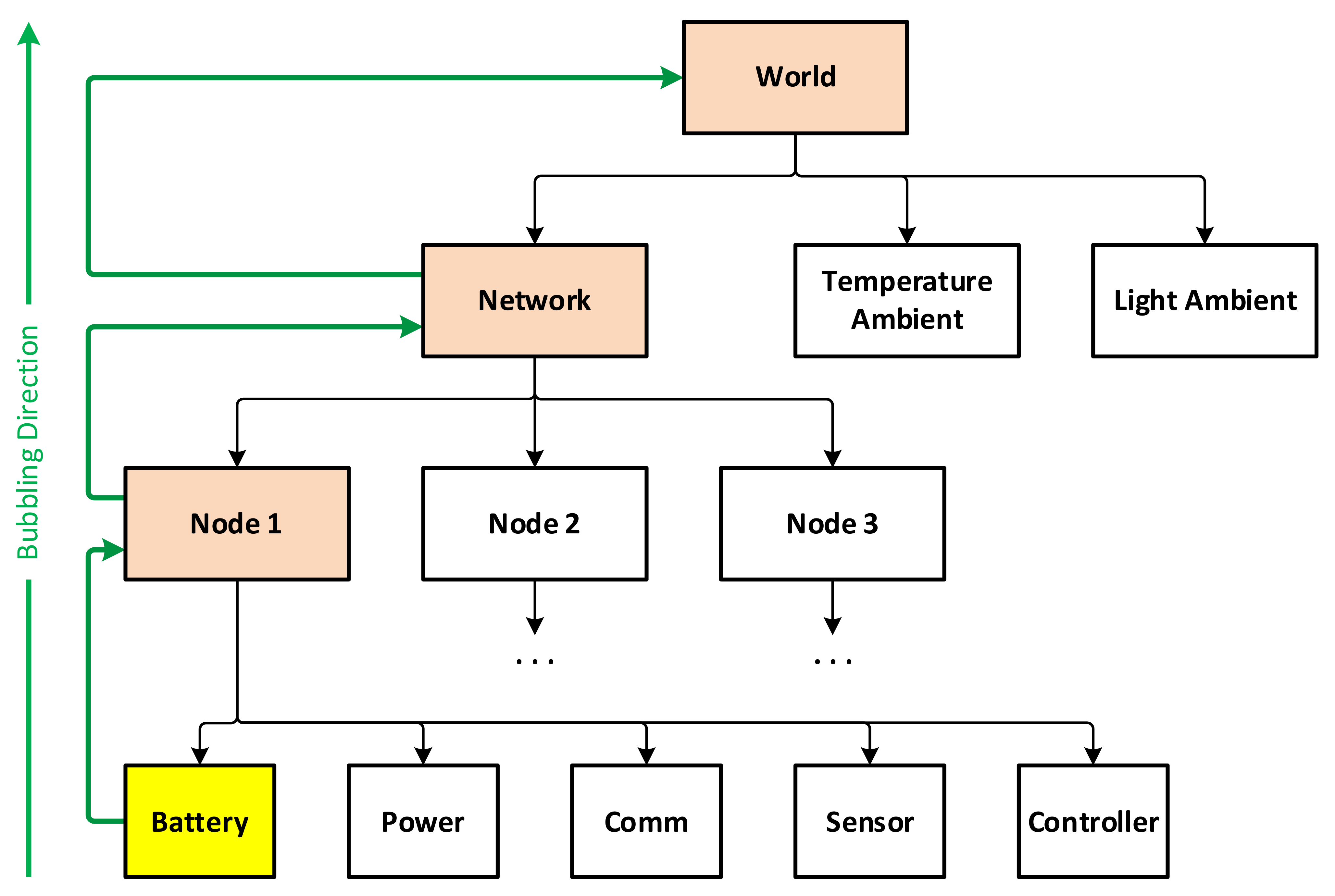
4.2. Energy-Aware Simulation of Sensor Networks
- Node components, whose base interface is node_component. A node component can be of one among five types, i.e., battery, power, sensor, communication, and controller, which are explained below.
- Sensor nodes, whose base interface is basic_node.
- Networks, whose base interface is basic_network.
- Working environments, whose base interface is basic_world.
- Ambient environmental elements, with basic_ambient. An ambient environmental element represents an external physical field, such as temperature, light, humidity, etc., that has impact on the functioning of the sensor network. Examples of possible impacts are energy source for the power components, or measurement values for the sensor components.
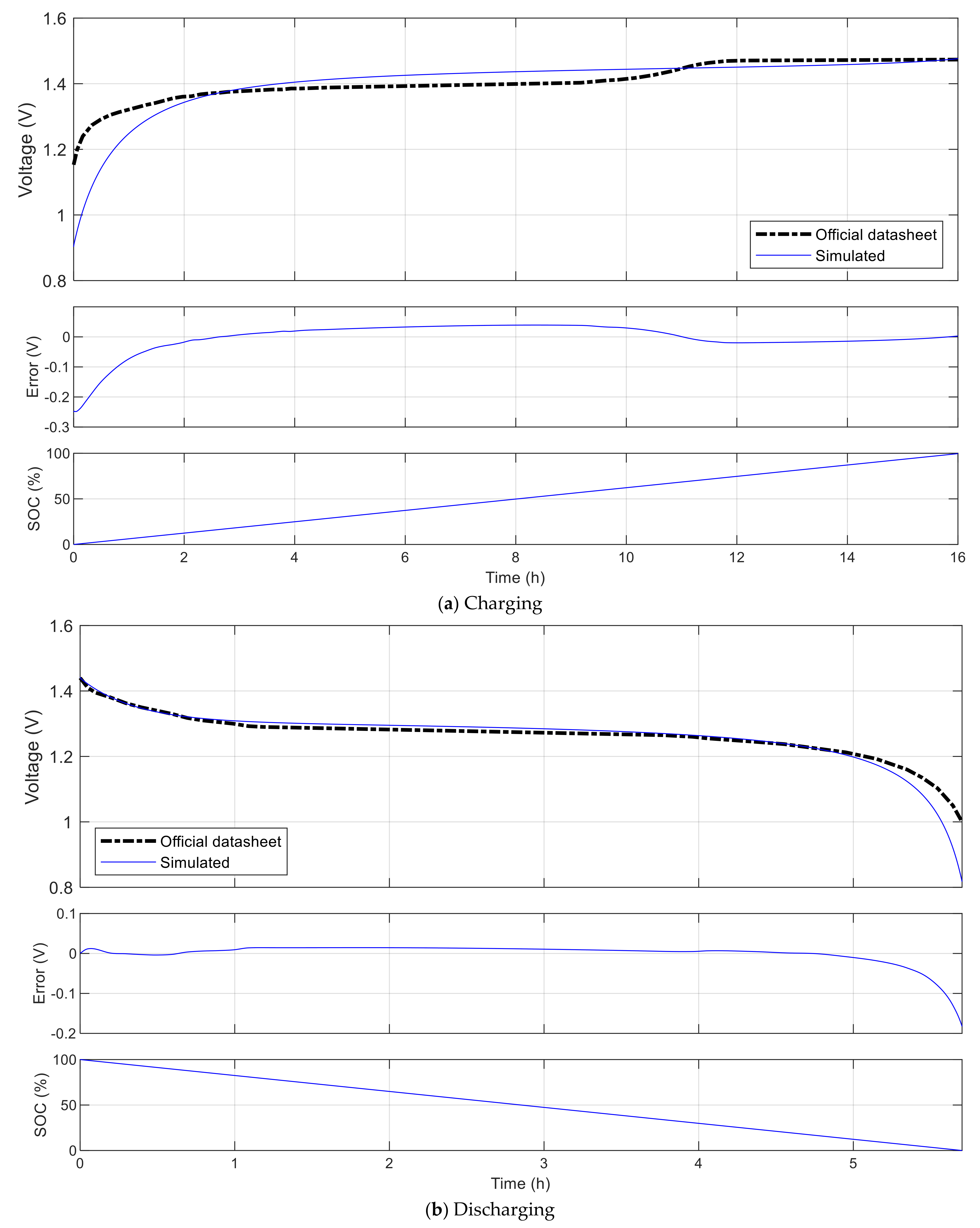
- Battery: used to simulate the energy storage behaviors. A library of common battery types, including lead acid, Li-ion, Ni-Cd and Ni-MH, is implemented as part of this platform, using the models given in [35].
- Power: responsible for collecting power from external sources, including ambient energy harvesting as well as wired or wireless sources feeding. Regarding the simulations in this work, a solar energy source is used to charge the batteries using the model given in [36].
- Sensor: used to simulate the sensing mechanism.
- Communication: implementing low- and high-level communication protocols. Note that the communication is for data routing required by other purposes, not for schedule cooperation, as earlier stated in this paper.
- Controller: implementing the functioning and incorporation of the four other components in the node.
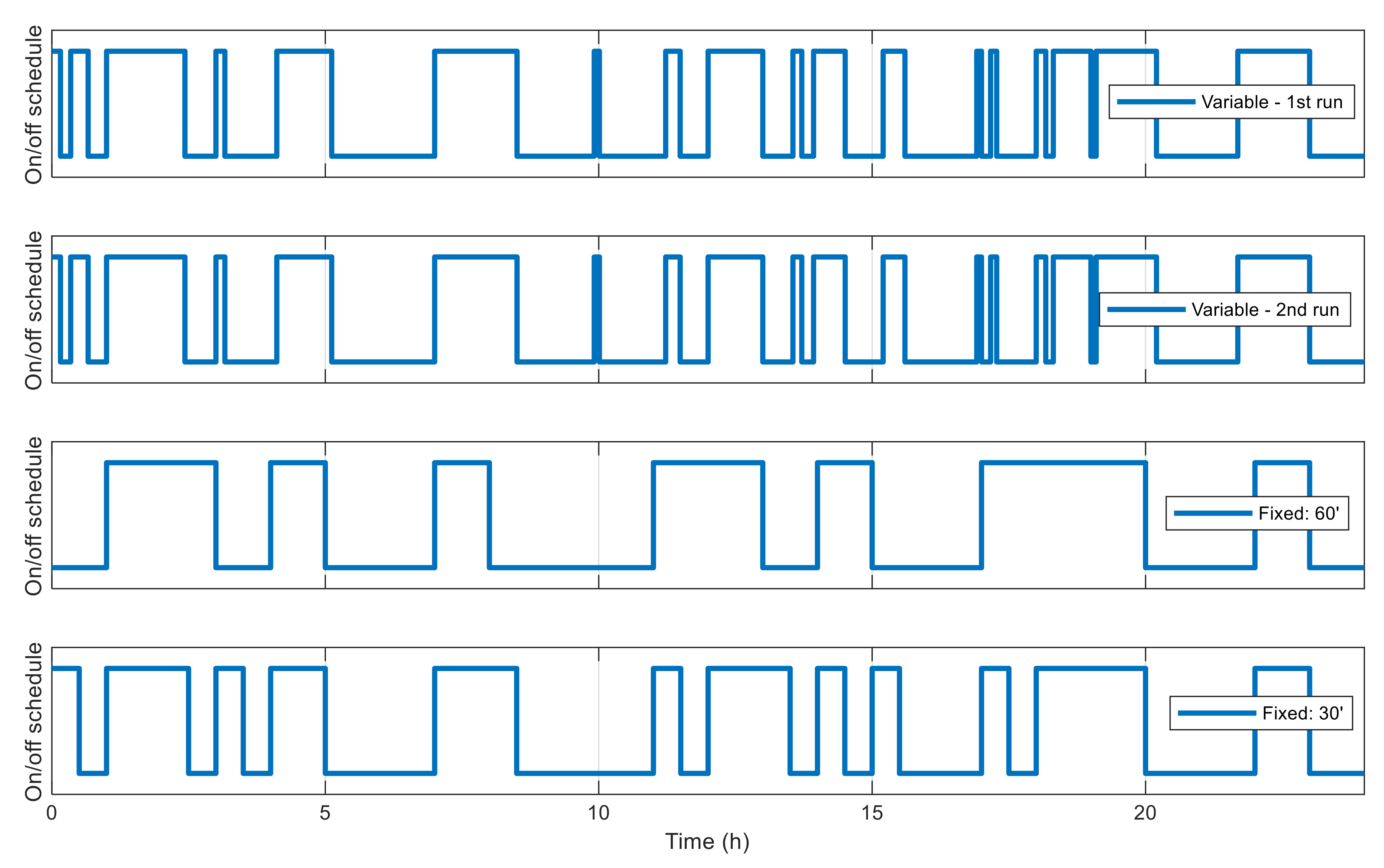
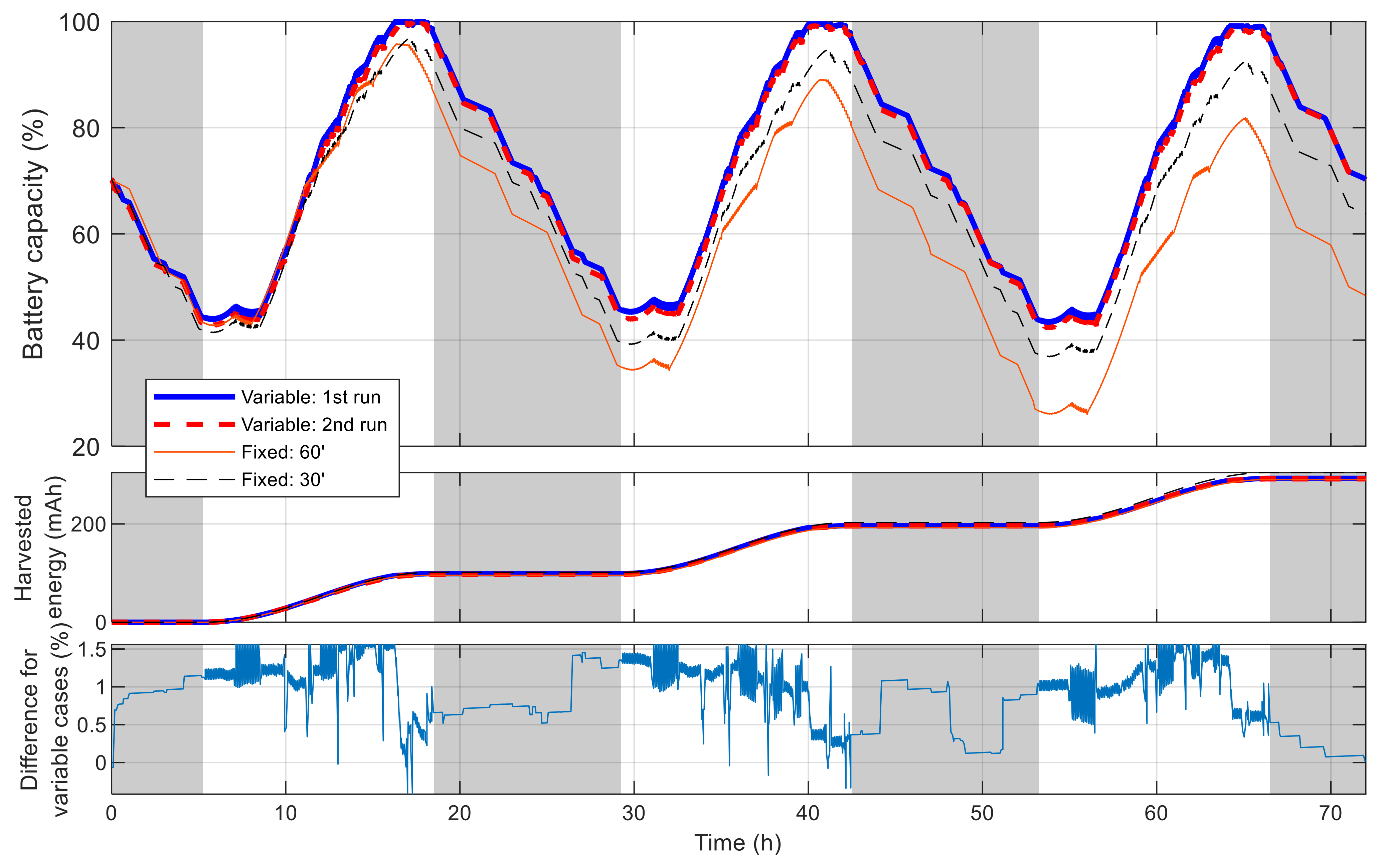
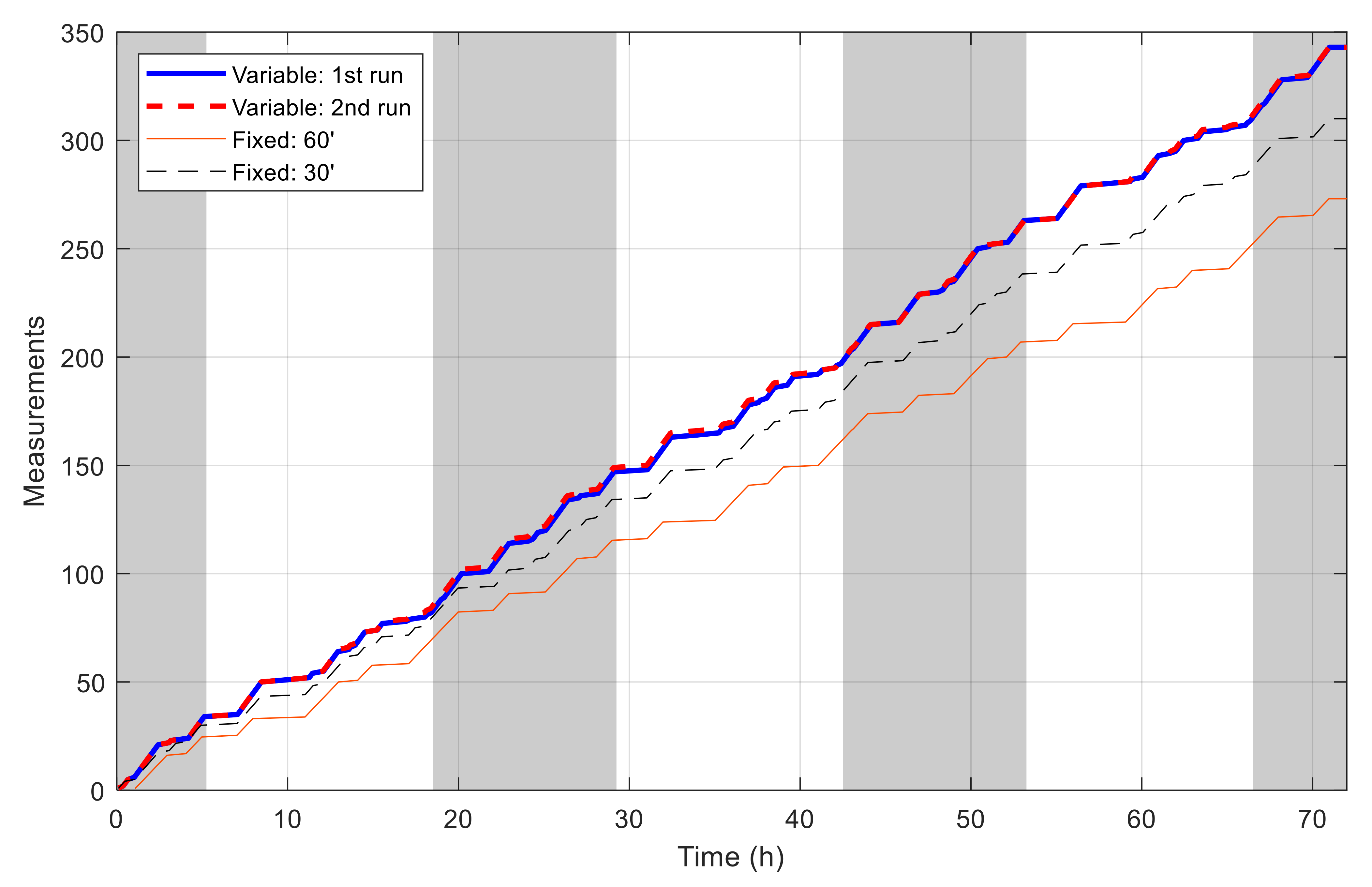
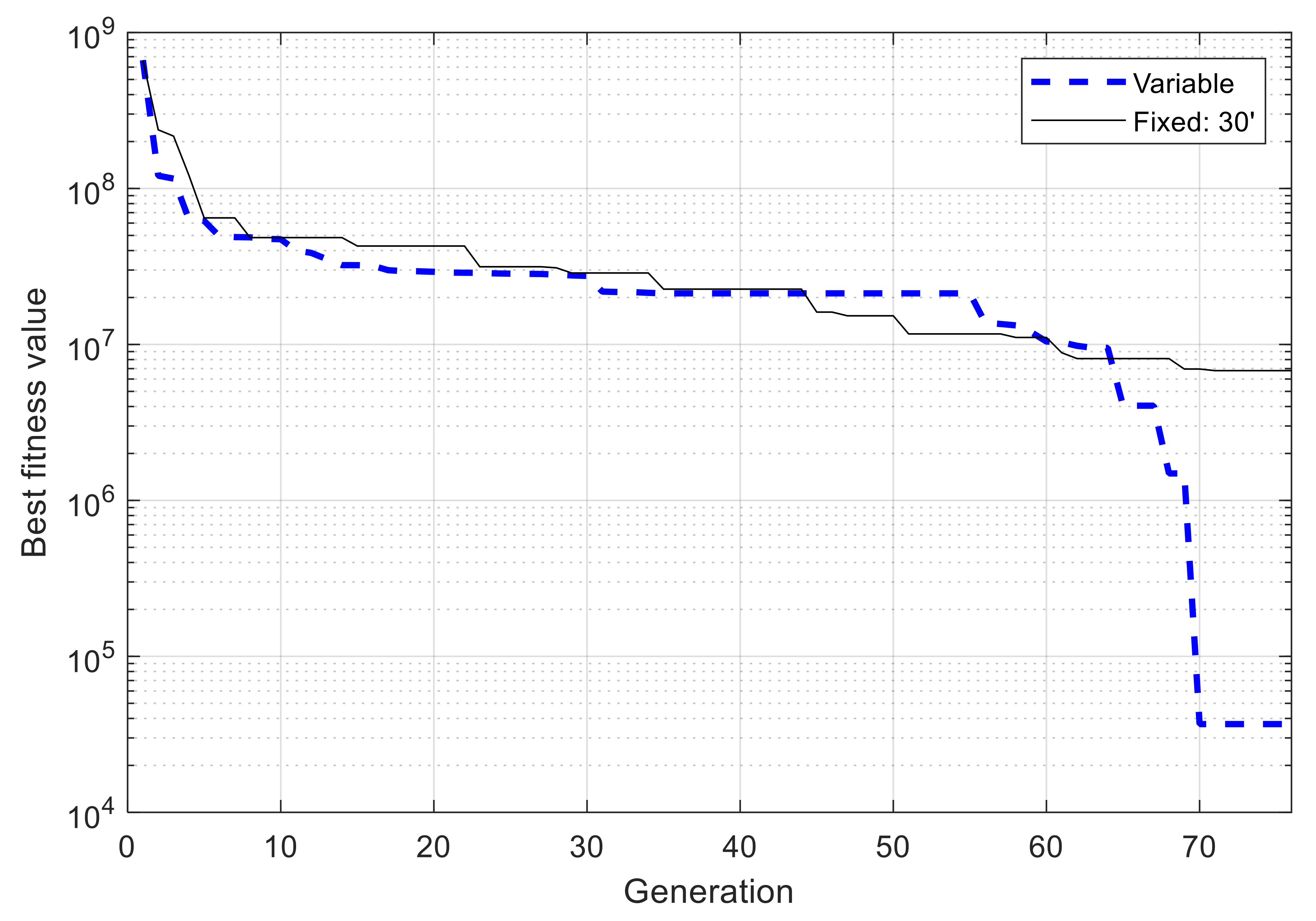
5. Case Studies and Simulation Results
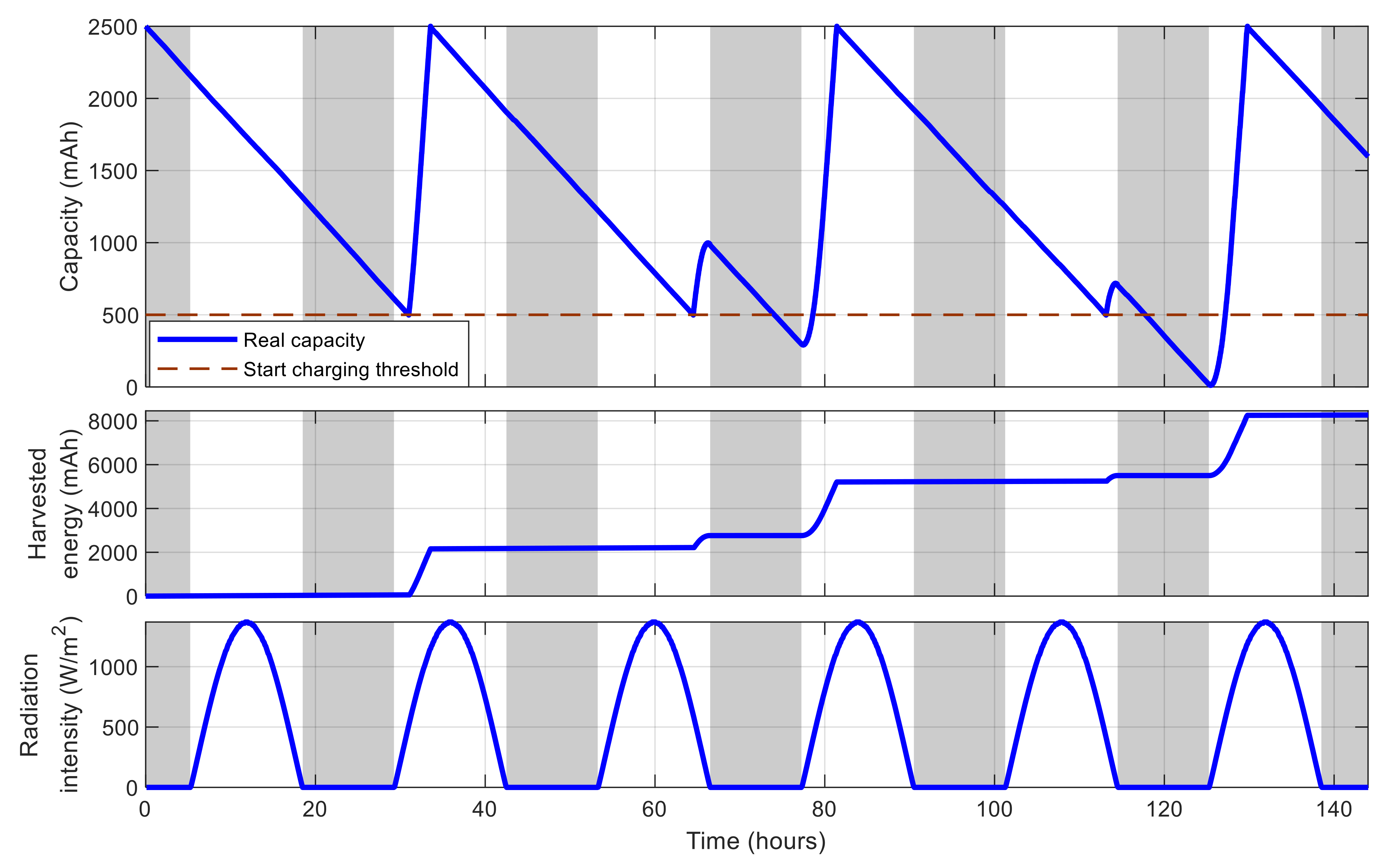
5.1. Single-Node Case
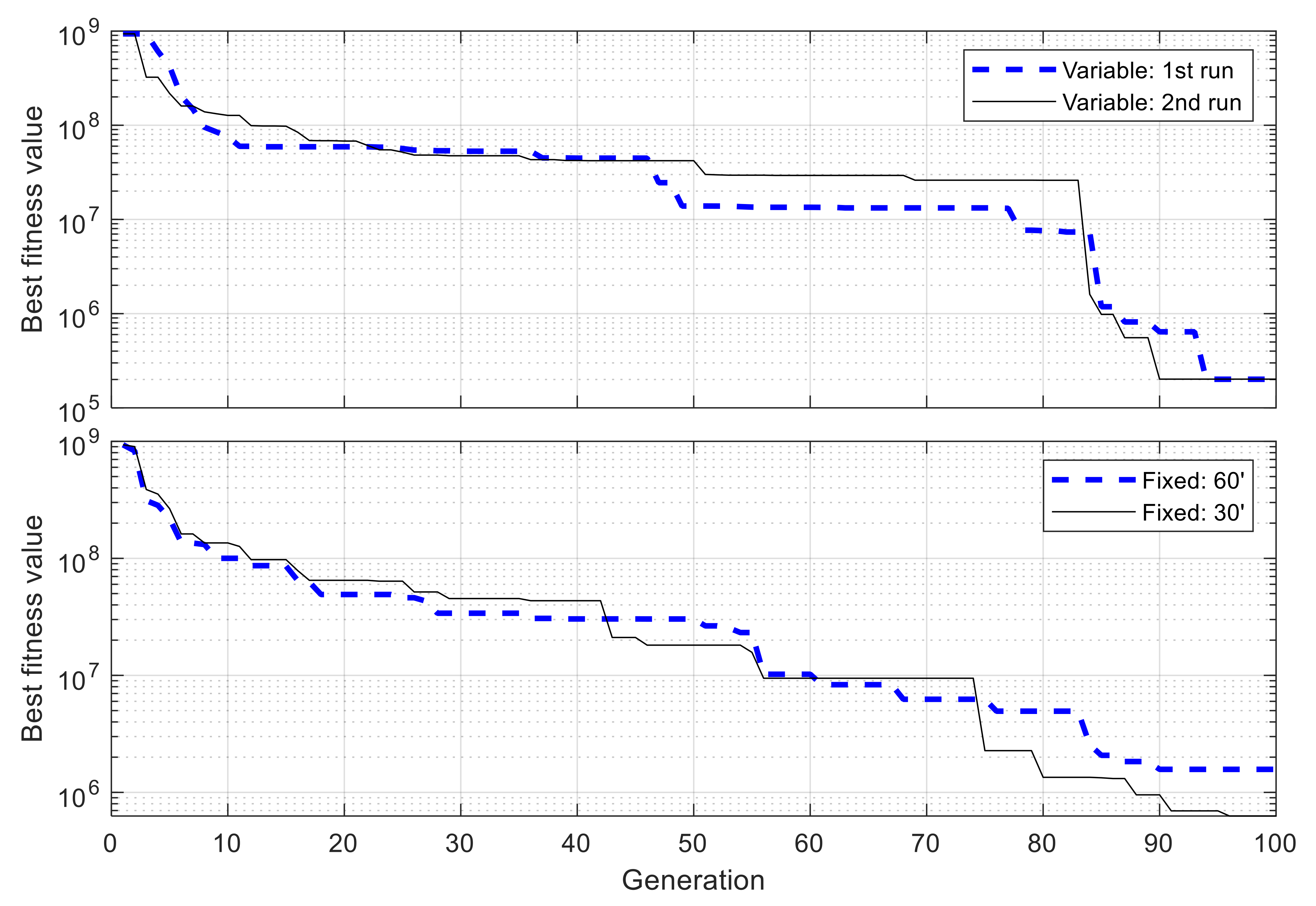
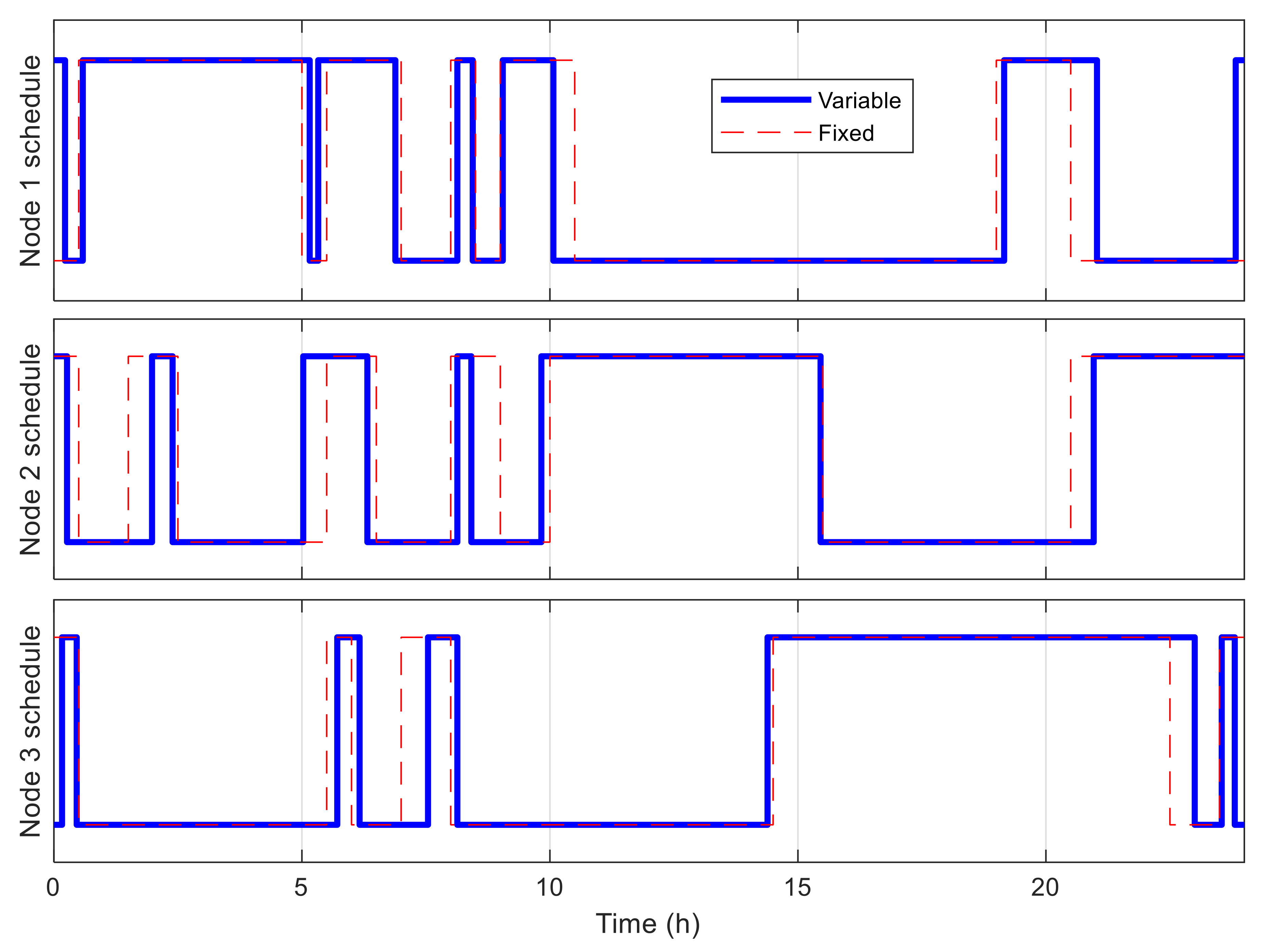
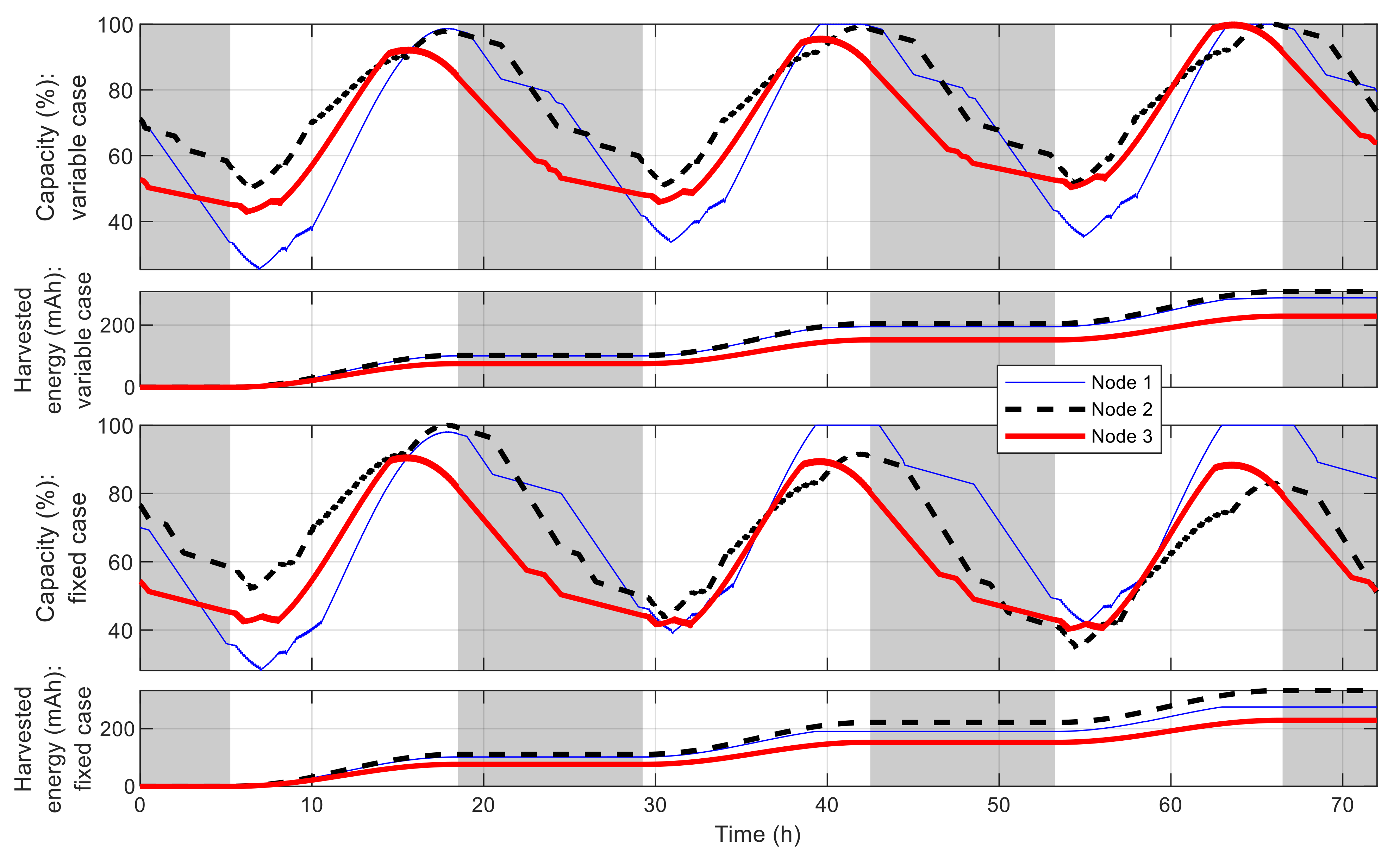
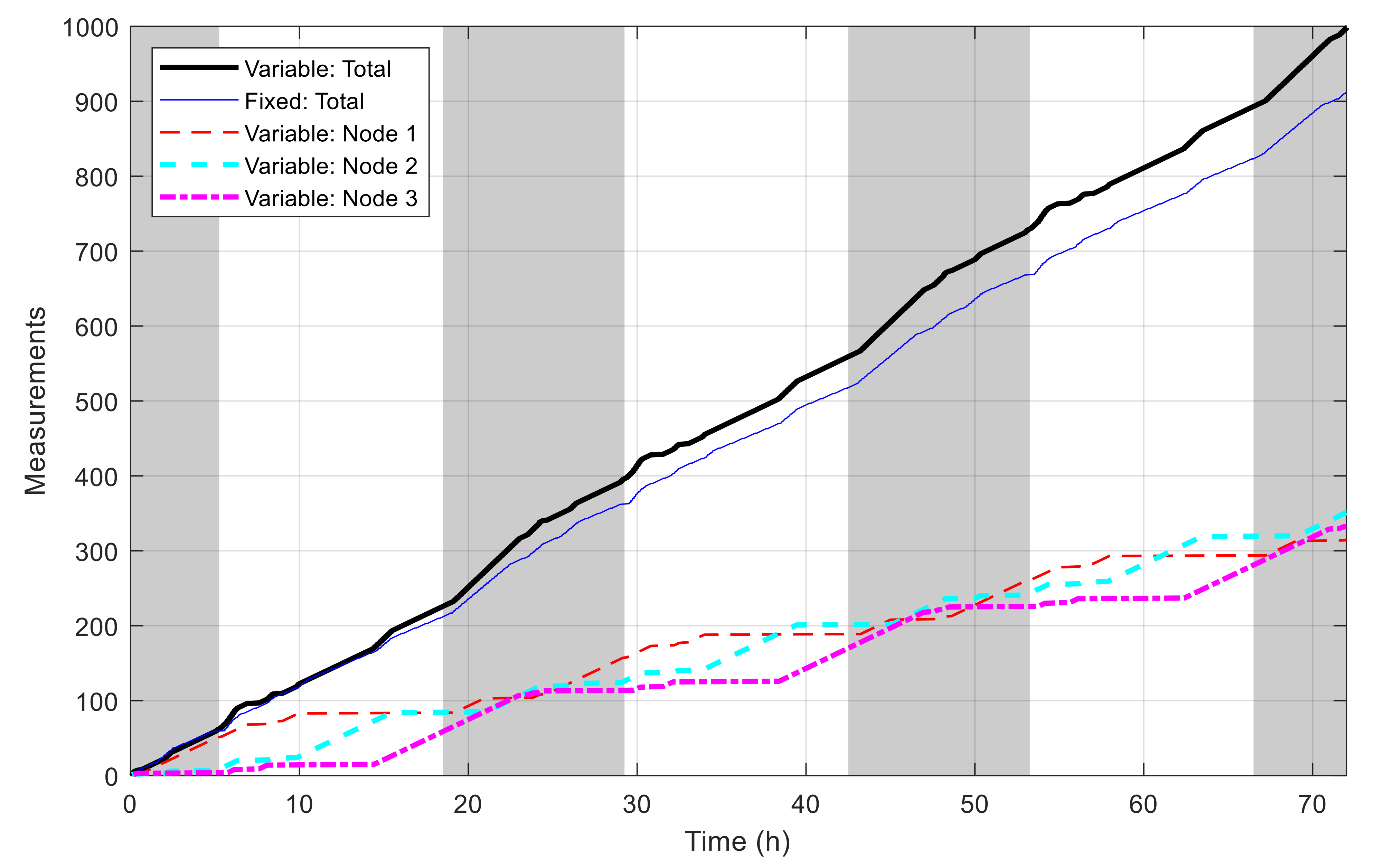
5.2. Multiple-Node Case
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ibrahiem, M.M.; El, E.; Ramakrishnan, S. Wireless Sensor Networks: From Theory to Applications; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Deng, J.; Han, Y.S.; Heinzelman, W.B.; Varshney, P.K. Scheduling sleeping nodes in high density cluster-based sensor networks. Mob. Netw. Appl. 2005, 10, 825–835. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Yang, X. A survey of energy-efficient scheduling mechanisms in sensor networks. Mob. Netw. Appl. 2006, 11, 723–740. [Google Scholar] [CrossRef]
- Miller, M.J.; Vaidya, N.H. A MAC protocol to reduce sensor network energy consumption using a wakeup radio. IEEE Trans. Mob. Comput. 2005, 4, 228–242. [Google Scholar] [CrossRef]
- Nawaz, F.; Hassan, S.A.; Hashmi, A.J.; Jung, H. A physical-layer scheduling approach in large-scale cooperative networks. IEEE Access 2019, 7, 134338–134347. [Google Scholar] [CrossRef]
- Nguyen, M.T.; Nguyen, T.T.K.; Keith, A.T. An energy-efficient combination of sleeping schedule and cognitive radio in wireless sensor networks utilizing compressed sensing. In Proceedings of the International Conference on Engineering Research and Applications, Thai Nguyen, Vietnam, 1–2 November 2020; pp. 154–160. [Google Scholar]
- Azimi, S.; Keyhan, K. The design a fuzzy system in order to schedule sleep and waking of sensors in wireless sensor networks. Int. J. Eng. Res. Appl. 2016, 6, 37–42. [Google Scholar]
- Daneshvaramoli, M.; Kiarostami, M.; Monfared, S.K.; Karisani, H.; Dehghannayeri, K.; Rahmati, D.; Gorgin, S. Decentralized communication-less multi-agent task assignment with cooperative Monte-Carlo tree search. In Proceedings of the 6th IEEE International Conference on Control, Automation and Robotics (ICCAR), Singapore, 4 April 2020; pp. 612–616. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; The University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Ant system: Optimization by a colony of cooperating agents. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1996, 26, 29–41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the Sixth International IEEE Symposium on Micro Machine and Human Science (MHS’95), Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Pan, W.T. A new fruit fly optimization algorithm: Taking the financial distress model as an example. Knowl. Based Syst. 2012, 26, 69–74. [Google Scholar] [CrossRef]
- Yang, X.S. Firefly algorithms for multimodal optimization. In International Symposium on Stochastic Algorithms; Springer: Berlin/Heidelberg, Germany, 2009; pp. 169–178. [Google Scholar]
- Passino, K.M. Biomimicry of bacterial foraging for distributed optimization and control. IEEE Control Syst. Mag. 2002, 22, 52–67. [Google Scholar]
- Wang, G.G.; Deb, S.; Cui, Z. Monarch butterfly optimization. Neural Comput. Appl. 2019, 31, 1995–2014. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.G.; Deb, S.; Coelho, L.D.S. Earthworm optimisation algorithm: A bio-inspired metaheuristic algorithm for global optimisation problems. Int. J. Bio-Inspired Comput. 2018, 12, 1–22. [Google Scholar] [CrossRef]
- Wang, G.G.; Deb, S.; Coelho, L.D.S. Elephant herding optimization. In Proceedings of the 3rd IEEE International Symposium on Computational and Business Intelligence (ISCBI), Bali, Indonesia, 7–9 December 2015. [Google Scholar]
- Wang, G.G. Moth search algorithm: A bio-inspired metaheuristic algorithm for global optimization problems. Memetic Comput. 2018, 10, 151–164. [Google Scholar] [CrossRef]
- Li, S.; Chen, H.; Wang, M.; Heidari, A.A.; Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 2020, 111, 300–323. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 2017, 105, 30–47. [Google Scholar] [CrossRef] [Green Version]
- Rahkar Farshi, T. Battle royale optimization algorithm. Neural Comput. Appl. 2021, 33, 1139–1157. [Google Scholar] [CrossRef]
- Wang, G.G.; Tan, Y. Improving metaheuristic algorithms with information feedback models. IEEE Trans. Cybern. 2017, 49, 542–555. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Yang, X.; Yin, K.; Zhang, S.; Cristoforo, J.A. Multi-path QoS-aware web service composition using variable length chromosome genetic algorithm. Inf. Technol. J. 2011, 10, 113–119. [Google Scholar] [CrossRef] [Green Version]
- Brie, A.H.; Morignot, P. Genetic planning using variable length chromosomes. In Proceedings of the 15th International Conference on Automated Planning and Scheduling (ICAPS), Berkeley, CA, USA, 11–15 June 2005; pp. 320–329. [Google Scholar]
- Cruz-Piris, L.; Marsa-Maestre, I.; Lopez-Carmona, K.A. A variable-length chromosome genetic algorithm to solve a road traffic coordination multipath problem. IEEE Access 2019, 7, 111968–111981. [Google Scholar] [CrossRef]
- Nordin, P.; Keller, R.E.; Francone, F.D. Genetic Programming; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Kaur, H.; Tejpal, G.; Sharma, S. A review article on genetic algorithm in wireless sensor network. In Proceedings of the 2nd IEEE International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 22 October 2017; pp. 246–250. [Google Scholar]
- Deif, D.S.; Gadallah, Y. Wireless sensor network deployment using a variable-length genetic algorithm. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Istanbul, Turkey, 6–9 April 2014; pp. 2450–2455. [Google Scholar]
- Anwit, R.; Jan, P.K. A variable length genetic algorithm approach to optimize data collection using mobile sink in wireless sensor networks. In Proceedings of the 5th International IEEE Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 22–23 February 2018; pp. 73–77. [Google Scholar]
- Naderi, M.Y.; Chowdhury, K.R.; Basagni, S.; Heinzelman, W.; De, S.; Jana, S. Experimental study of concurrent data and wireless energy transfer for sensor networks. In Proceedings of the IEEE Global Communications Conference (GLOBECOM’14), Austin, TX, USA, 8–12 December 2014; pp. 2543–2549. [Google Scholar]
- Du, R.; Fischione, C.; Xiao, M. Joint node deployment and wireless energy transfer scheduling for immortal sensor networks. In Proceedings of the 15th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Net-works (WiOpt’17), Paris, France, 15–19 May 2017; pp. 1–8. [Google Scholar]
- Soyata, T.; Copeland, L.; Heinzelman, W. RF energy harvesting for embedded systems: A survey of tradeoffs and methodology. IEEE Circuits Syst. Mag. 2016, 16, 22–57. [Google Scholar] [CrossRef]
- Shaikh, F.K.; Zeadally, S. Energy harvesting in wireless sensor networks: A comprehensive review. Renew. Sustain. Energy Rev. 2016, 55, 1041–1054. [Google Scholar] [CrossRef]
- Tremblay, O.; Dessaint, L.A. Experimental validation of a battery dynamic model for EV applications. World Electr. Veh. J. 2009, 3, 289–298. [Google Scholar] [CrossRef] [Green Version]
- Reda, I.; Andreas, A. Solar position algorithm for solar radiation applications. Solar Energy 2004, 76, 577–589. [Google Scholar] [CrossRef]
- Ha, V.P.; Dao, T.K.; Le, M.H.; Nguyen, T.H.; Nguyen, V.T. Design and implementation of an energy simulation platform for wireless sensor networks. In Proceedings of the IEEE International Conference on Multimedia Analysis and Pattern Recognition (MAPR), Hanoi, Vietnam, 8–9 October 2020. [Google Scholar]
- Panasonic Ni-MH Handbook: Industrial Batteries. Available online: https://eu.industrial.panasonic.com/sites/default/pidseu/files/downloads/files/ni-mh-handbook-2014_interactive.pdf (accessed on 6 June 2021).
- Michalsky, J.J. The astronomical almanac’s algorithm for approximate solar position (1950–2050). Sol. Energy 1988, 40, 227–235. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of nodes (n) | 1 |
| Maximal battery capacity | 3500 mAh |
| Battery charging rate | 0.8 W |
| Background power consumption rate in Sleep mode | 0.05 W |
| Average power consumption rate in Active mode | 0.17 W |
| Power consumption per measurement | 0.22 Ws |
| Power consumption per SMS transmission | 13.27 Ws |
| Installation location (latitude, longitude) | 21.004°, 105.846° |
| Measurement rate in Active mode | 5 min |
| Simulation time (T) | 3 days |
| Parameter | Value |
|---|---|
| Population size | 100 |
| Selection rate | 20% |
| Mutation rate | 30% |
| Crossover rate | 50% |
| Rates of mutation operations: Copy, Insertion, Removal, Shift | 90%, 3.33%, 3.33%, 3.33% |
| 1 | |
| 1 | |
| 10 | |
| 1 × 108 | |
| 1 × 108 | |
| 1 × 106 | |
| 1 × 106 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ha, V.-P.; Dao, T.-K.; Pham, N.-Y.; Le, M.-H. A Variable-Length Chromosome Genetic Algorithm for Time-Based Sensor Network Schedule Optimization. Sensors 2021, 21, 3990. https://doi.org/10.3390/s21123990
Ha V-P, Dao T-K, Pham N-Y, Le M-H. A Variable-Length Chromosome Genetic Algorithm for Time-Based Sensor Network Schedule Optimization. Sensors. 2021; 21(12):3990. https://doi.org/10.3390/s21123990
Chicago/Turabian StyleHa, Van-Phuong, Trung-Kien Dao, Ngoc-Yen Pham, and Minh-Hoang Le. 2021. "A Variable-Length Chromosome Genetic Algorithm for Time-Based Sensor Network Schedule Optimization" Sensors 21, no. 12: 3990. https://doi.org/10.3390/s21123990
APA StyleHa, V. -P., Dao, T. -K., Pham, N. -Y., & Le, M. -H. (2021). A Variable-Length Chromosome Genetic Algorithm for Time-Based Sensor Network Schedule Optimization. Sensors, 21(12), 3990. https://doi.org/10.3390/s21123990