
Rice Seed Purity Identification Technology Using Hyperspectral Image with LASSO Logistic Regression Model


Abstract
:1. Introduction
2. Materials and Methods
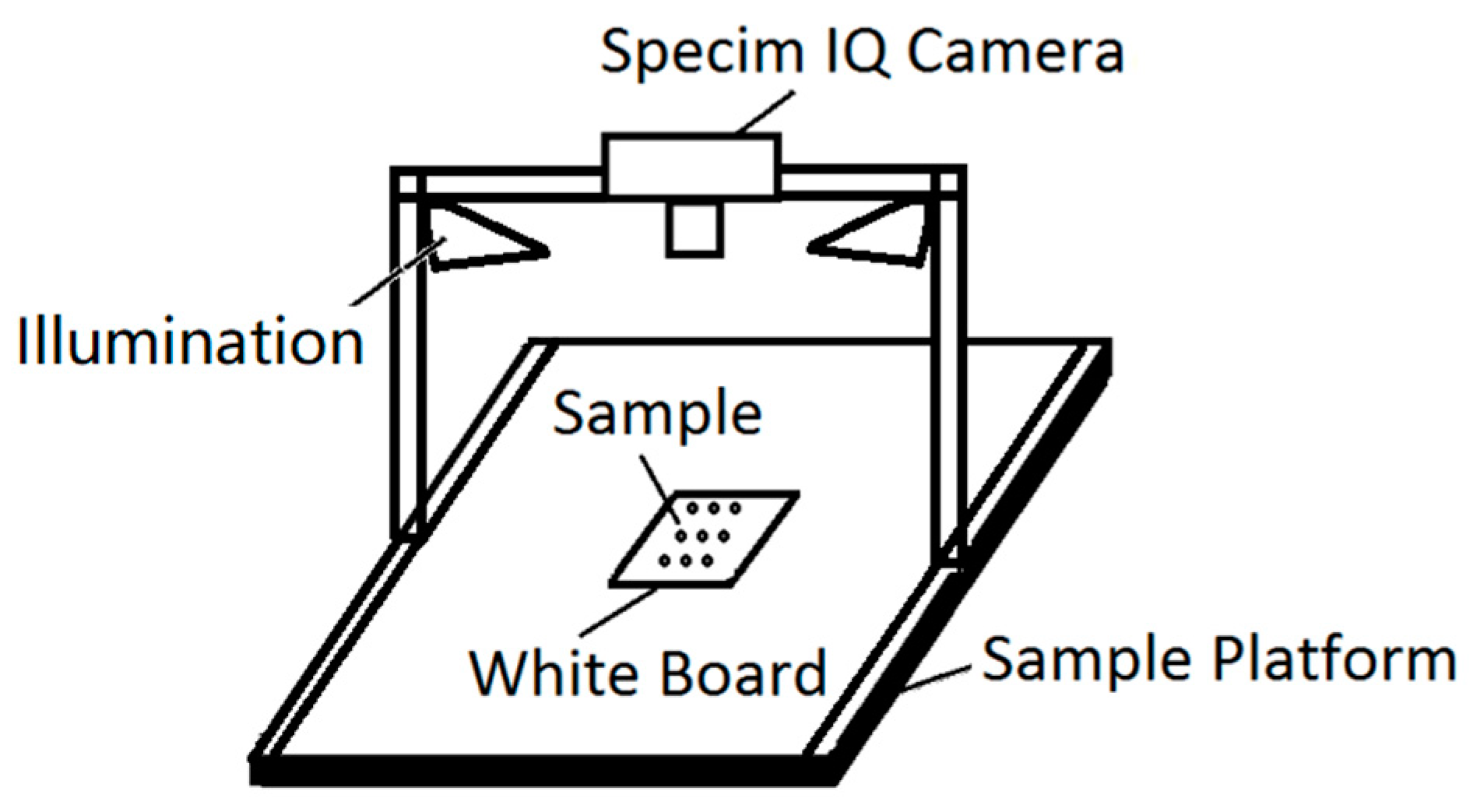
2.1. Sample Preparation and Data Acquisition
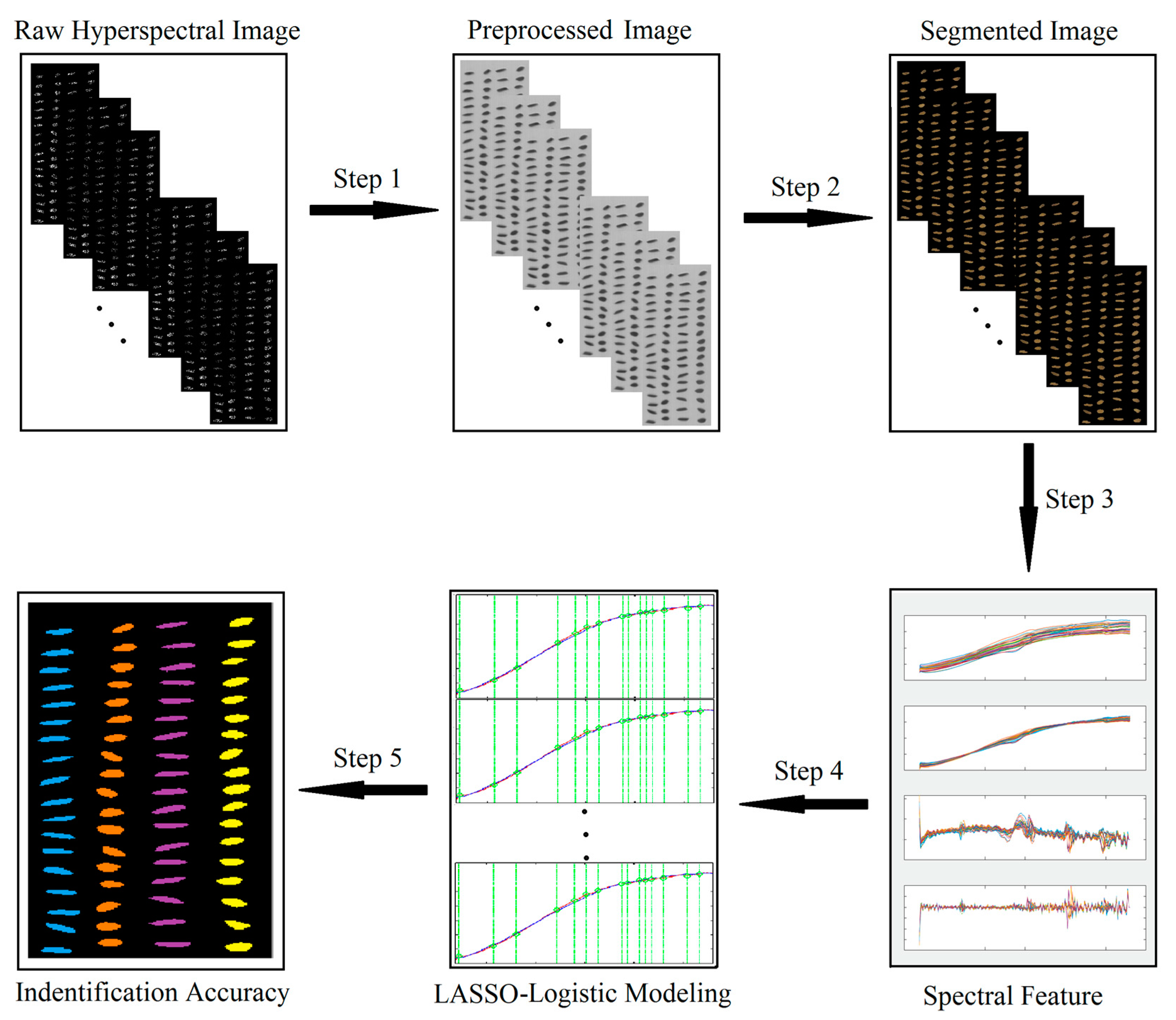
2.2. Data Processing Flow
2.3. Spectral Feature Extraction
2.3.1. Data Pre-Processing
2.3.2. Image Segmentation
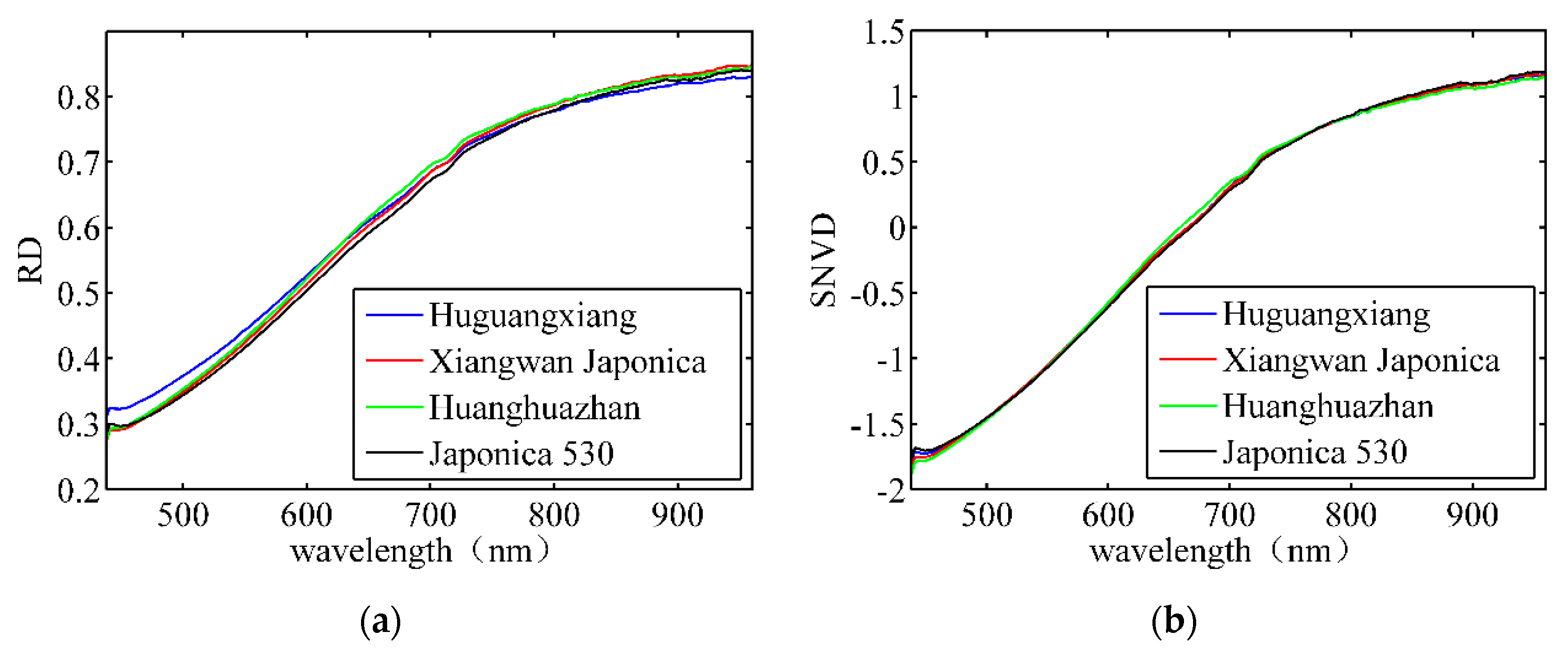
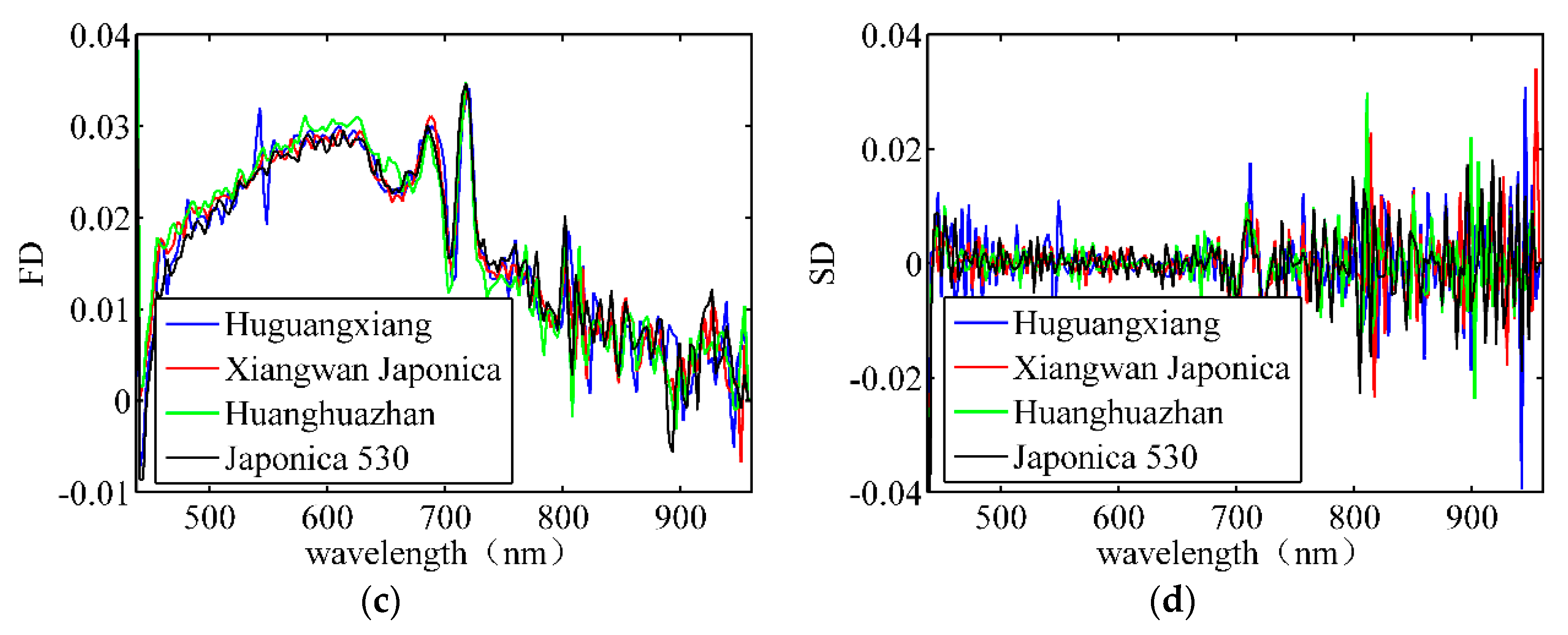
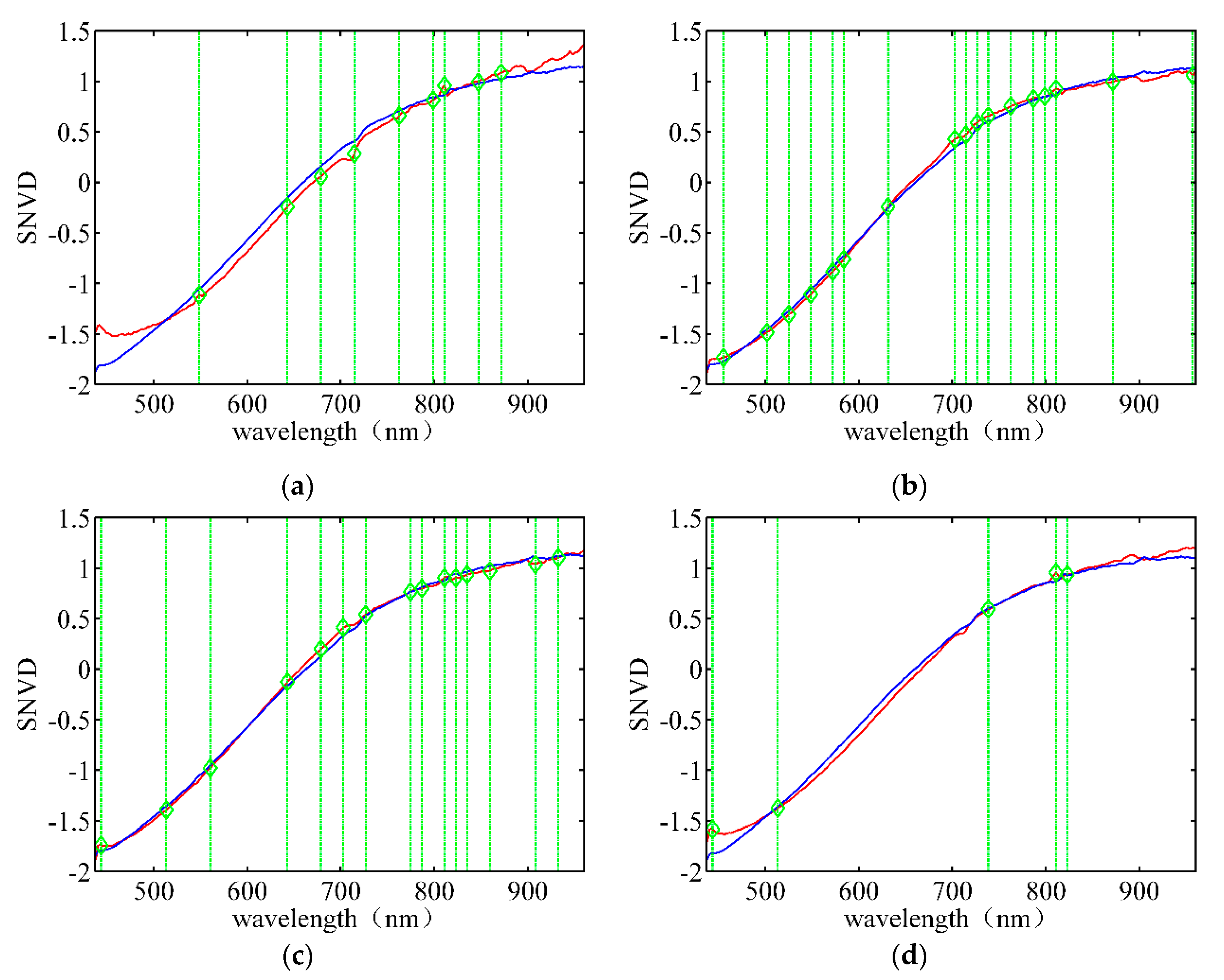
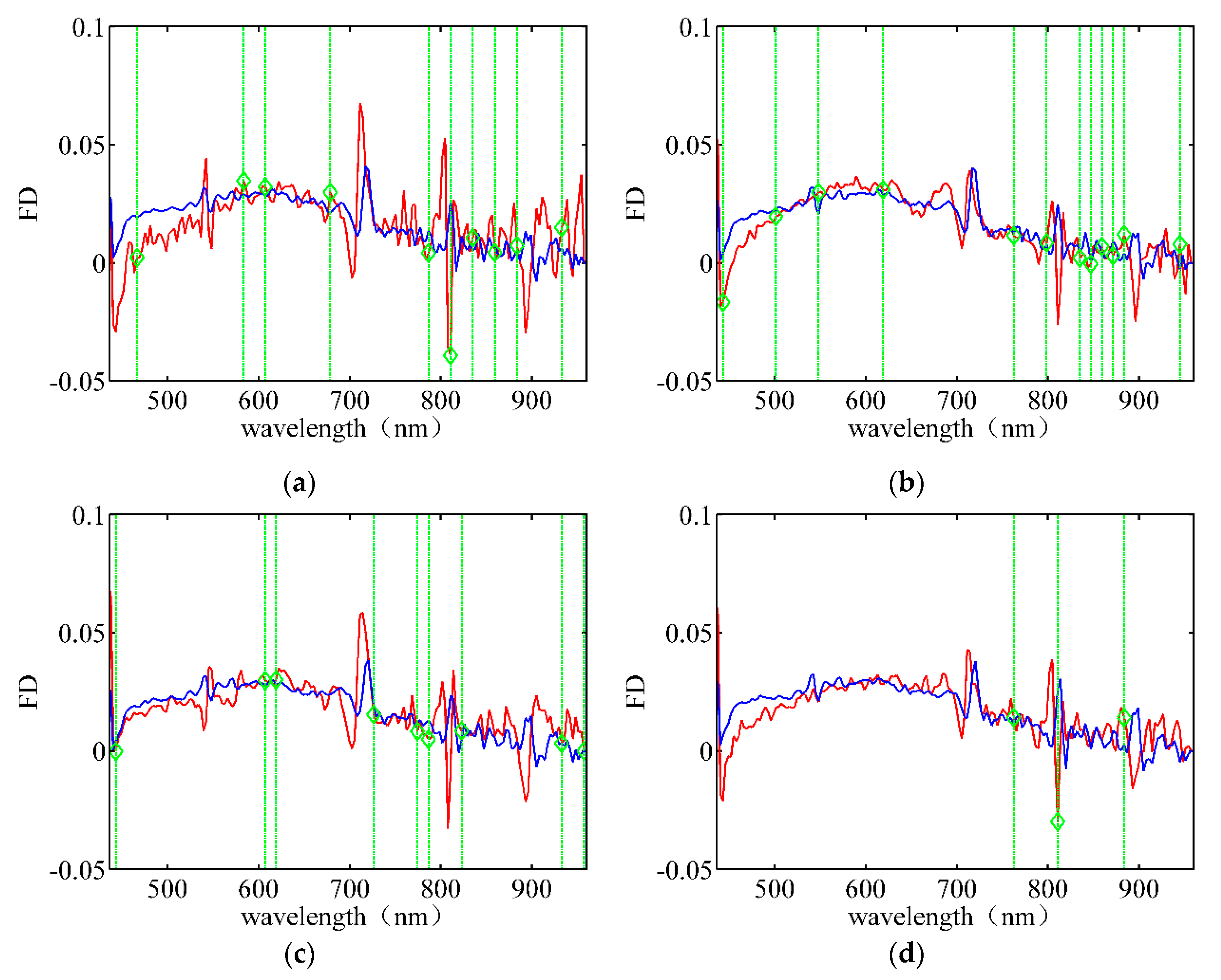
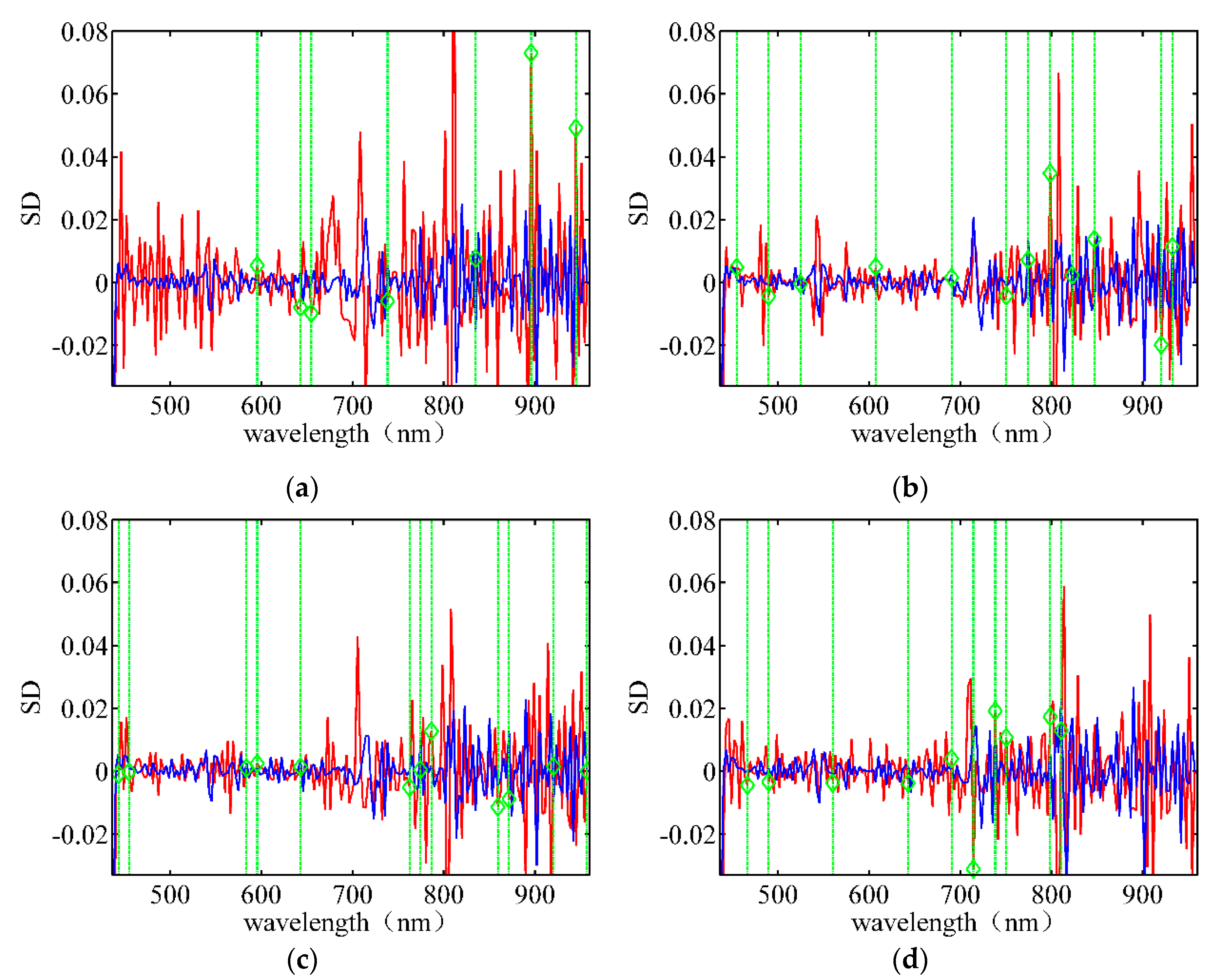
2.3.3. Spectral Feature
2.4. LLRM Foundation and Optimisation
2.4.1. Data Grouping
2.4.2. Partition of Sample Sets
2.4.3. LLRM
- (1)
- Data pre-processing: The data collected by hyperspectral technology were pre-processed. Then, they were grouped, as presented in Table 1.
- (2)
- Dividing the training and test sets: The SPXY algorithm was used to randomly divide the data into training and test sets with a 1:1 ratio.
- (3)
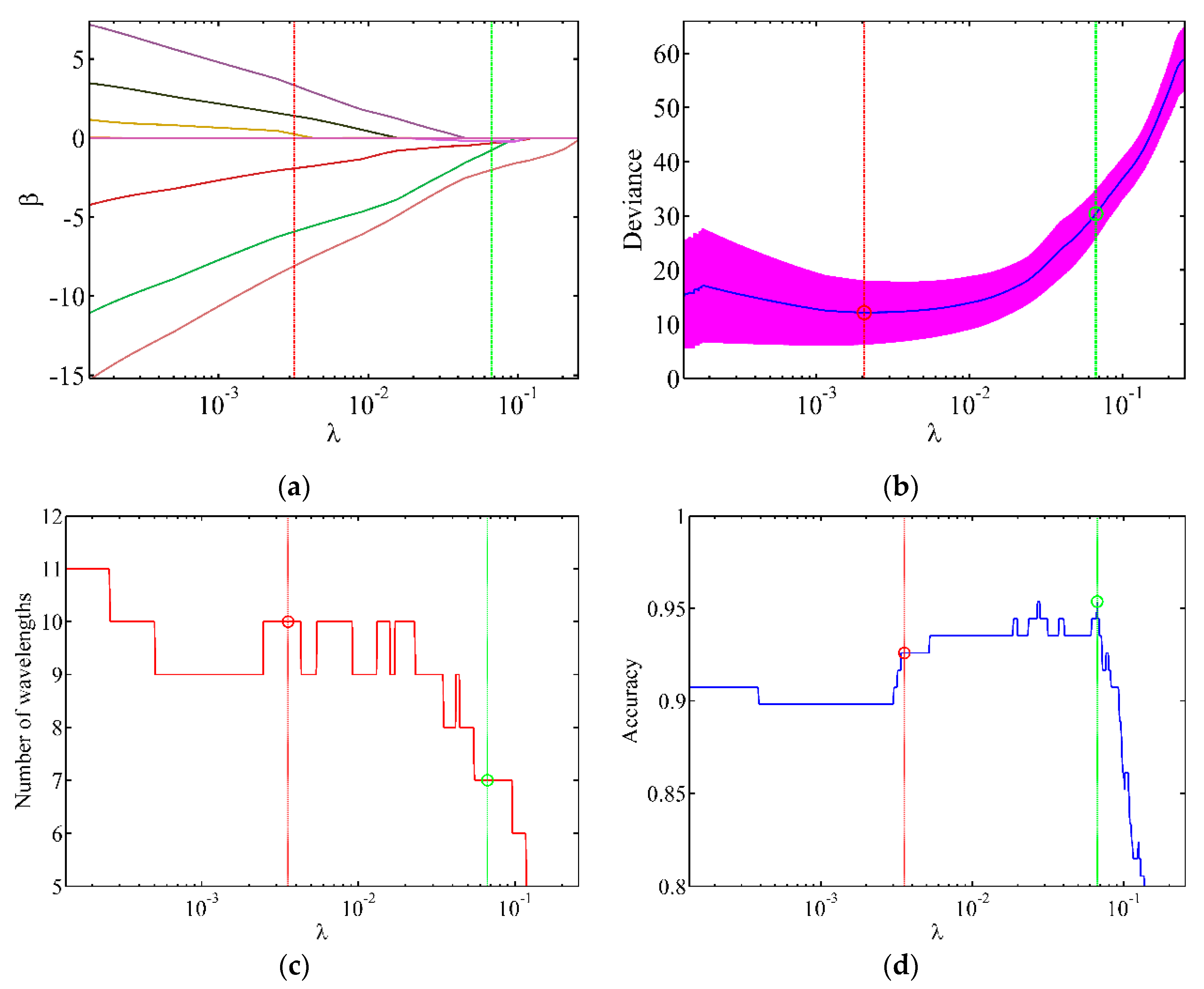
- Selecting the regularisation parameter: The training samples were divided into 10 parts using the cross-validation method, taking turns using 9 of their train, and then calculating the error of fitting the other one. The mean square error of the 10 prediction results was used to estimate the accuracy of the algorithm. Moreover, the optimal value of was selected based on the accuracy of the model prediction and by combining the number of feature bands.
- (4)
- Selecting the feature wavelength bands: The coordinate descent method was used to calculate the regression coefficient at an optimal value of . Then, the feature band was selected based on the regression coefficient.
- (5)
- Modelling: The feature wavelength bands from the test set were selected. Moreover, the regression model was considered the foundation.
- (6)
- Calculation of classification accuracy: The function is calculated as follows:
2.4.4. Optimum Selection
3. Results
3.1. Results of Wavelength Bands Selection
3.2. Band Selection
3.3. Comparison of Model Accuracy
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, J.; Sun, J.; Du, L.; Chen, B.; Zhang, Z.; Shi, S.; Gong, W. Monitoring of Paddy Rice Varieties Based on the Combination of the Laser-Induced Fluorescence and Multivariate Analysis. Food Anal. Methods 2017, 10, 2398–2403. [Google Scholar] [CrossRef]
- Cui, S.; Ma, X.; Wang, X.; Zhang, T.-A.; Hu, J.; Tsang, Y.F.; Gao, M.-T. Phenolic acids derived from rice straw generate peroxides which reduce the viability of Staphylococcus aureus cells in biofilm. Ind. Crops Prod. 2019, 140, 111561. [Google Scholar] [CrossRef]
- Nethra, N.; Prasad, S.R.; Vishwanath, K.; Dhanraj, K.; Gowda, R. Identification of rice hybrids and their parental lines based on seed, seedling characters, chemical tests and gel electrophoresis of total soluble seed proteins. Seed Sci. Technol. 2007, 35, 176–186. [Google Scholar] [CrossRef]
- Ellepola, S.W.; Choi, S.M.; Ma, C.Y. Conformational study of globulin from rice (Oryza sativa) seeds by Fourier-transform infrared spectroscopy. Int. J. Biol. Macromol. 2005, 37, 12–20. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Li, M.; Pan, T.; Pang, L.; Yao, L.; Zhang, J. Rapid and non-destructive analysis for the identification of multi-grain rice seeds with near-infrared spectroscopy. Spectrochim. Acta Mol. Biomol. Spectrosc. 2019, 219, 179–185. [Google Scholar] [CrossRef]
- Aznan, A.A.; Rukunudin, I.H.; Shakaff, A.; Ruslan, R.; Saad, F. The use of machine vision technique to classify cultivated rice seed variety and weedy rice seed variants for the seed industry. Int. Food Res. J. 2016, 23, 31–35. [Google Scholar]
- Kiratiratanapruk, K.; Temniranrat, P.; Sinthupinyo, W.; Prempree, P.; Chaitavon, K.; Porntheeraphat, S.; Prasertsak, A. Development of Paddy Rice Seed Classification Process Using Machine Learning Techniques for Automatic Grading Machine. J. Sens. 2020, 2020, 7041310. [Google Scholar] [CrossRef]
- Liu, Z.-Y.; Cheng, F.; Ying, Y.-B.; Rao, X.-Q. Identification of rice seed varieties using neural network. J. Zhejiang Univ. Sci. B 2005, 6, 1095–1100. [Google Scholar] [CrossRef] [Green Version]
- Fotiadou, K.; Tsagkatakis, G.; Tsakalides, P. Deep Convolutional Neural Networks for the Classification of Snapshot Mosaic Hyperspectral Imagery. Electron. Imaging 2017, 2017, 185–190. [Google Scholar] [CrossRef] [Green Version]
- Fabiyi, S.D.; Vu, H.; Tachtatzis, C.; Murray, P.; Harle, D.; Dao, T.K.; Andonovic, I.; Ren, J.; Marshall, S. Varietal Classification of Rice Seeds Using RGB and Hyperspectral Images. IEEE Access 2020, 8, 22493–22505. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Hyperspectral imaging technology combined with deep forest model to identify frost-damaged rice seeds. Spectrochim. Acta Mol. Biomol. Spectrosc. 2020, 229, 117973. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, Y.; Feng, X.; Xu, H.; Chen, J.; He, Y. Identification of Bacterial Blight Resistant Rice Seeds Using Terahertz Imaging and Hyperspectral Imaging Combined with Convolutional Neural Network. Front. Plant Sci. 2020, 11, 821. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, J.; He, Y.; Liu, F.; Feng, X.; Zhang, J. Assessment of the vigor of rice seeds by near-infrared hyperspectral imaging combined with transfer learning. RSC Adv. 2020, 10, 44149–44158. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Taha, M.F.; Wei, X.; He, Y.; Qiu, Z.; Liu, Y. Wheat Kernel Variety Identification Based on a Large Near-Infrared Spectral Dataset and a Novel Deep Learning-Based Feature Selection Method. Front. Plant Sci. 2020, 11, 575810. [Google Scholar] [CrossRef] [PubMed]
- Kong, W.; Zhang, C.; Liu, F.; Nie, P.; He, Y. Rice Seed Cultivar Identification Using Near-Infrared Hyperspectral Imaging and Multivariate Data Analysis. Sensors 2013, 13, 8916–8927. [Google Scholar] [CrossRef] [Green Version]
- Kuo, T.-Y.; Chung, C.-L.; Chen, S.-Y.; Lin, H.-A.; Kuo, Y.-F. Identifying rice grains using image analysis and sparse-representation-based classification. Comput. Electron. Agric. 2016, 127, 716–725. [Google Scholar] [CrossRef]
- Anami, B.S.; Malvade, N.N.; Palaiah, S.; Naveen, N.; Surendra, P. Automated recognition and classification of adulteration levels from bulk paddy grain samples. Inf. Process. Agric. 2019, 6, 47–60. [Google Scholar] [CrossRef]
- Chaugule, A.; Mali, S.N. Evaluation of Texture and Shape Features for Classification of Four Paddy Varieties. J. Eng. 2014, 2014, 617263. [Google Scholar] [CrossRef] [Green Version]
- Chaugule, A.A.; Mali, S.N. Identification of paddy varieties based on novel seed angle features. Comput. Electron. Agric. 2016, 123, 415–422. [Google Scholar] [CrossRef]
- Huang, K.-Y.; Chien, M.-C. A Novel Method of Identifying Paddy Seed Varieties. Sensors 2017, 17, 809. [Google Scholar] [CrossRef]
- Ansari, N.; Ratri, S.S.; Jahan, A.; Ashik-E-Rabbani, M.; Rahman, A. Inspection of paddy seed varietal purity using machine vision and multivariate analysis. J. Agric. Food Res. 2021, 3, 100109. [Google Scholar] [CrossRef]
- Vithu, P.; Moses, J.A. Machine vision system for food grain quality evaluation: A review. Trends Food Sci. Technol. 2016, 56, 13–20. [Google Scholar] [CrossRef]
- Bai, Z.; Hu, X.; Tian, J.; Chen, P.; Luo, H.; Huang, D. Rapid and nondestructive detection of sorghum adulteration using optimization algorithms and hyperspectral imaging. Food Chem. 2020, 331, 127290. [Google Scholar] [CrossRef] [PubMed]
- Okada, N.; Maekawa, Y.; Owada, N.; Haga, K.; Shibayama, A.; Kawamura, Y. Automated Identification of Mineral Types and Grain Size Using Hyperspectral Imaging and Deep Learning for Mineral Processing. Minerals 2020, 10, 809. [Google Scholar] [CrossRef]
- Femenias, A.; Gatius, F.; Ramos, A.J.; Sanchis, V.; Marín, S. Use of hyperspectral imaging as a tool for Fusarium and deoxynivalenol risk management in cereals: A review. Food Control 2020, 108, 106819. [Google Scholar] [CrossRef]
- Serranti, S.; Cesare, D.; Marini, F.; Bonifazi, G. Classification of oat and groat kernels using NIR hyperspectral imaging. Talanta 2013, 103, 276–284. [Google Scholar] [CrossRef]
- Yang, X.; Hong, H.; You, Z.; Cheng, F. Spectral and Image Integrated Analysis of Hyperspectral Data for Waxy Corn Seed Variety Classification. Sensors 2015, 15, 15578–15594. [Google Scholar] [CrossRef] [Green Version]
- Zhu, S.; Zhang, J.; Chao, M.; Xu, X.; Song, P.; Zhang, J.; Huang, Z. A Rapid and Highly Efficient Method for the Identification of Soybean Seed Varieties: Hyperspectral Images Combined with Transfer Learning. Molecules 2020, 25, 152. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qiu, Z.; Chen, J.; Zhao, Y.; Zhu, S.; He, Y.; Zhang, C. Variety Identification of Single Rice Seed Using Hyperspectral Imaging Combined with Convolutional Neural Network. Appl. Sci. 2018, 8, 212. [Google Scholar] [CrossRef] [Green Version]
- Weng, S.; Tang, P.; Yuan, H.; Guo, B.; Yu, S.; Huang, L.; Xu, C. Hyperspectral imaging for accurate determination of rice variety using a deep learning network with multi-feature fusion. Spectrochim. Acta Mol. Biomol. Spectrosc. 2020, 234, 118237. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Lu, X.; Mao, H.; Jin, X.; Wu, X. A Method for Rapid Identification of Rice Origin by Hyperspectral Imaging Technology. J. Food Process Eng. 2017, 40, e12297. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Zeng, S.; Li, H.; Xiao, Z.; Huang, X.; Jiang, H. Paddy variety identification using hyperspectral imagery under non-ideal illumination conditions. Int. J. Wavelets Multiresolut. Inf. Process. 2020, 18, 2050036. [Google Scholar] [CrossRef]
- Chin, J.A.; Wang, E.C.; Kibbe, M.R. Evaluation of hyperspectral technology for assessing the presence and severity of peripheral artery disease. J. Vasc. Surg. 2011, 54, 1679–1688. [Google Scholar] [CrossRef] [Green Version]
- Dai, Q.; Cheng, J.-H.; Sun, D.-W.; Zeng, X.-A. Advances in Feature Selection Methods for Hyperspectral Image Processing in Food Industry Applications: A Review. Crit. Rev. Food Sci. Nutr. 2015, 55, 1368–1382. [Google Scholar] [CrossRef] [PubMed]
- Baek, I.; Kim, M.S.; Cho, B.-K.; Mo, C.; Barnaby, J.Y.; McClung, A.M.; Oh, M. Selection of Optimal Hyperspectral Wavebands for Detection of Discolored, Diseased Rice Seeds. Appl. Sci. 2019, 9, 1027. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Li, X.; Zhao, L. A Fast Hyperspectral Feature Selection Method Based on Band Correlation Analysis. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1750–1754. [Google Scholar] [CrossRef]
- Mehmood, T.; Liland, K.H.; Snipen, L.; Sæbø, S. A review of variable selection methods in Partial Least Squares Regression. Chemom. Intell. Lab. Syst. 2012, 118, 62–69. [Google Scholar] [CrossRef]
- Rodarmel, C.; Shan, J. Principal component analysis for hyperspectral image classification. Surv. Land Inf. Sci. 2002, 62, 115–122. [Google Scholar]
- Kang, X.; Duan, P.; Li, S. Hyperspectral image visualization with edge-preserving filtering and principal component analysis. Inf. Fusion 2020, 57, 130–143. [Google Scholar] [CrossRef]
- Uddin, M.P.; Mamun, M.A.; Afjal, M.I.; Hossain, M.A. Information-theoretic feature selection with segmentation-based folded principal component analysis (PCA) for hyperspectral image classification. Int. J. Remote Sens. 2021, 42, 286–321. [Google Scholar] [CrossRef]
- Machidon, A.L.; Del Frate, F.; Picchiani, M.; Machidon, O.M.; Ogrutan, P.L. Geometrical Approximated Principal Component Analysis for Hyperspectral Image Analysis. Remote Sens. 2020, 12, 1698. [Google Scholar] [CrossRef]
- Hashjin, S.S.; Khazai, S. A new method to detect targets in hyperspectral images based on principal component analysis. Geocarto Int. 2020, 1–19. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Uezato, T.; Fauvel, M.; Dobigeon, N. Hyperspectral Unmixing with Spectral Variability Using Adaptive Bundles and Double Sparsity. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3980–3992. [Google Scholar] [CrossRef] [Green Version]
- Salehani, Y.E.; Gazor, S.; Cheriet, M. A new weighted ℓp-norm for sparse hyperspectral unmixing. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing, Montreal, QC, Canada, 14–16 November 2017; pp. 1255–1259. [Google Scholar]
- Sun, L.; Ge, W.; Chen, Y.; Zhang, J.; Jeon, B. Hyperspectral unmixing employing l1–l2 sparsity and total variation regularization. Int. J. Remote Sens. 2018, 39, 6037–6060. [Google Scholar] [CrossRef]
- Yang, D.; Bao, W. Group Lasso-Based Band Selection for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2438–2442. [Google Scholar] [CrossRef]
- Dankmar, B. Multinomial logistic regression algorithm. Ann. Inst. Stat. Math. 1992, 44, 197–200. [Google Scholar]
- Krishnapuram, B.; Carin, L.; Figueiredo, M.A.T.; Hartemink, A.J. Sparse multinomial logistic regression: Fast algorithms and generalization bounds. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 957–968. [Google Scholar] [CrossRef] [Green Version]
- Haut, J.M.; Paoletti, M.E. Cloud Implementation of Multinomial Logistic Regression for UAV Hyperspectral Images. IEEE J. Miniat. Air Space Syst. 2020, 1, 163–171. [Google Scholar] [CrossRef]
- Mohammadi, A.; Shaverizade, A. Ensemble deep learning for aspect-based sentiment analysis. Int. J. Nonlinear Anal. Appl. 2021, 12, 29–38. [Google Scholar]
- Bayaga, A. Multinomial logistic regression: Usage and application in risk analysis. J. Appl. Quant. Methods 2010, 5, 288–297. [Google Scholar]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G.M. An Introduction to Logistic Regression Analysis and Reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Behmann, J.; Acebron, K.; Emin, D.; Bennertz, S.; Matsubara, S.; Thomas, S.; Bohnenkamp, D.; Kuska, M.T.; Jussila, J.; Salo, H.; et al. Specim IQ: Evaluation of a New, Miniaturized Handheld Hyperspectral Camera and Its Application for Plant Phenotyping and Disease Detection. Sensors 2018, 18, 441. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qian, Y.; Ye, M. Hyperspectral Imagery Restoration Using Nonlocal Spectral-Spatial Structured Sparse Representation with Noise Estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 6, 499–515. [Google Scholar] [CrossRef]
- Barnes, R.J.; Dhanoa, M.S.; Lister, S.J. Standard Normal Variate Transformation and De-Trending of Near-Infrared Diffuse Reflectance Spectra. Appl. Spectrosc. 1989, 43, 772–777. [Google Scholar] [CrossRef]
- Rinnan, Å.; van den Berg, F.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Luo, J.; Ying, K.; Bai, J. Savitzky-Golay smoothing and differentiation filter for even number data. Signal Process. 2005, 85, 1429–1434. [Google Scholar] [CrossRef]
- Xia, C.; Yang, S.; Huang, M.; Zhu, Q.; Guo, Y.; Qin, J. Maize seed classification using hyperspectral image coupled with multi-linear discriminant analysis. Infrared Phys. Technol. 2019, 103, 103077. [Google Scholar] [CrossRef]
- Galvão, R.K.H.; Araujo, M.C.U.; José, G.E.; Pontes, M.J.C.; Silva, E.C.; Saldanha, T.C.B. A method for calibration and validation subset partitioning. Talanta 2005, 67, 736–740. [Google Scholar] [CrossRef] [PubMed]
- Tian, H.; Zhang, L.; Li, M.; Wang, Y.; Sheng, D.; Liu, J.; Wang, C. Weighted SPXY method for calibration set selection for composition analysis based on near-infrared spectroscopy. Infrared Phys. Technol. 2018, 95, 88–92. [Google Scholar] [CrossRef]
- Takayama, T.; Iwasaki, A. Optimal wavelength selection on hyperspectral data with fused lasso for biomass estimation of tropical rain forest. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 101–108. [Google Scholar] [CrossRef] [Green Version]
- Sirimongkolkasem, T.; Drikvandi, R. On Regularisation Methods for Analysis of High Dimensional Data. Ann. Data Sci. 2019, 6, 737–763. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unit/Grain | Type 1 | Type 2 | Type 3 | Type 4 | Sum |
|---|---|---|---|---|---|
| Group 1 | 72 | 24 | 24 | 24 | 144 |
| Group 2 | 72 | 12 | 12 | 12 | 108 |
| Group 3 | 72 | 6 | 6 | 6 | 90 |
| Group 4 | 72 | 3 | 3 | 3 | 81 |
| Group 5 | 72 | 24 | 12 | 6 | 114 |
| Group 6 | 72 | 12 | 24 | 6 | 114 |
| Group 7 | 72 | 6 | 12 | 24 | 114 |
| Group 8 | 72 | 36 | 0 | 0 | 108 |
| Group 9 | 72 | 0 | 36 | 0 | 108 |
| Group 10 | 72 | 0 | 0 | 36 | 108 |
| Group 11 | 12 | 72 | 12 | 12 | 108 |
| Group 12 | 12 | 12 | 72 | 12 | 108 |
| Group 13 | 12 | 12 | 12 | 72 | 108 |
| Group | Feature Wavelength Bands [nm] | Number |
|---|---|---|
| Group 1 | 548.55, 572.07, 643.01, 678.71, 714.55, 762.57, 798.77, 810.86, 822.98, 847.25, 871.60, 896.01, 908.24, 920.48 | 14 |
| Group 2 | 548.55, 643.01, 678.71, 714.55, 762.57, 798.77, 810.86, 847.25, 871.60 | 9 |
| Group 3 | 548.55, 631.15, 643.01, 678.71, 762.57, 798.77, 810.86, 847.25, 871.60, 920.48 | 10 |
| Group 4 | 548.55, 619.30, 678.71, 714.55, 798.77, 810.86, 871.60 | 7 |
| Group 5 | 548.55, 572.07, 583.85, 643.01, 678.71, 714.55, 762.57, 786.68, 810.86, 822.98, 847.25, 871.60, 896.01, 920.48 | 14 |
| Group 6 | 536.82, 548.55, 619.30, 678.71, 714.55, 762.57, 798.77, 810.86, 847.25 871.60, 896.01 | 11 |
| Group 7 | 548.55, 643.01, 678.71, 714.55, 750.54, 762.57, 798.77, 810.86, 847.25, 871.60, 957.32 | 11 |
| Group 8 | 548.55, 560.30, 572.07, 631.15, 643.01, 678.71, 762.57, 810.86, 847.25, 871.60, 896.01, 908.24, 920.48 | 13 |
| Group 9 | 525.10, 536.82, 619.30, 678.71, 726.53, 786.68, 798.77, 810.86, 847.25, 871.60, 896.01 | 11 |
| Group 10 | 560.30, 643.01, 678.71, 714.55, 798.77, 810.86, 871.60, 908.24, 920.48, 957.32 | 10 |
| Group 11 | 455.16, 501.72, 525.10, 548.55, 572.07, 583.85, 631.15, 702.58, 714.55, 726.53, 738.53, 762.57, 786.68, 798.77, 810.86, 871.60, 957.32 | 17 |
| Group 12 | 443.56, 513.40, 560.30, 643.01, 678.71, 702.58, 726.53, 774.62, 786.68, 810.86, 822.98, 835.11, 859.42, 908.24, 932.74 | 15 |
| Group 13 | 443.56, 513.40, 738.53, 810.86, 822.98 | 5 |
| Group | Feature Wavelength Bands [nm] | Number |
|---|---|---|
| Group 1 | 466.77, 583.85, 607.46, 678.71, 750.54, 822.98, 835.11, 847.25, 859.42, 883.79, 932.74 | 11 |
| Group 2 | 466.77, 583.85, 607.46, 678.71, 786.68, 810.86, 835.11, 859.42, 883.79, 932.74 | 10 |
| Group 3 | 455.16, 583.85, 666.79, 678.71, 810.86, 835.11, 859.42, 871.60, 883.79, 932.74 | 10 |
| Group 4 | 466.77, 583.85, 678.71, 810.86, 835.11, 859.42, 883.79 | 7 |
| Group 5 | 466.77, 583.85, 678.71, 835.11, 859.42, 883.79 | 6 |
| Group 6 | 466.77, 654.89, 714.55, 822.98, 859.42, 883.79, 932.74 | 7 |
| Group 7 | 455.16, 466.77, 525.10, 548.55, 607.46, 678.71, 786.68, 835.11, 859.42, 883.79, 932.74 | 11 |
| Group 8 | 466.77, 583.85, 678.71, 835.11, 859.42, 883.79 | 6 |
| Group 9 | 466.77, 501.72, 619.30, 702.58, 714.55, 822.98, 835.11, 847.25, 859.42, 883.79 | 10 |
| Group 10 | 455.16, 525.10, 607.46, 786.68, 835.11, 847.25, 859.42, 883.79, 932.74 | 9 |
| Group 11 | 443.56, 501.72, 548.55, 619.30, 762.57, 798.77, 835.11, 847.25, 859.42, 871.60, 883.79, 945.02 | 12 |
| Group 12 | 443.56, 607.46, 619.30, 726.53, 774.62, 786.68, 822.98, 932.74, 957.32 | 9 |
| Group 13 | 762.57, 810.86, 883.79 | 3 |
| Group | Feature Wavelength Bands [nm] | Number |
|---|---|---|
| Group 1 | 478.41, 560.30, 619.30, 643.01, 654.89, 690.64, 726.53, 786.68, 822.98, 847.25, 896.01 | 11 |
| Group 2 | 595.65, 643.01, 654.89, 738.53, 835.11, 896.01, 945.02 | 7 |
| Group 3 | 595.65, 643.01, 654.89, 726.53, 738.53, 835.11, 859.42, 945.02 | 8 |
| Group 4 | 466.77, 643.01, 654.89, 726.53, 738.53, 774.62, 835.11, 847.25, 859.42, 945.02 | 10 |
| Group 5 | 631.35, 643.01, 654.89, 690.64, 726.53, 738.53, 786.68, 847.25, 896.01 | 9 |
| Group 6 | 643.01, 654.89, 690.64, 738.53, 786.68, 847.25, 896.01, 945.02 | 8 |
| Group 7 | 478.41, 560.30, 643.01, 654.89, 690.64, 702.58, 738.53, 786.68, 822.98, 847.25, 896.01, 945.02 | 12 |
| Group 8 | 643.01, 654.89, 690.64, 726.53, 738.53, 786.68, 822.98, 835.11, 847.25, 896.01 | 10 |
| Group 9 | 455.16, 560.30, 643.01, 654.89, 690.64, 786.68, 896.01, 945.02 | 8 |
| Group 10 | 654.89, 690.64, 702.58, 822.98, 883.79, 896.01 | 6 |
| Group 11 | 455.16, 490.06, 525.10, 607.46, 690.64, 750.54, 774.62, 798.77, 822.98, 847.25, 920.48, 932.74 | 12 |
| Group 12 | 443.56, 455.16, 583.85, 595.65, 643.01, 762.57, 774.62, 786.68, 859.42, 871.60, 920.48, 957.32 | 12 |
| Group 13 | 466.77, 490.06, 560.30, 643.01, 690.64, 714.55, 738.53, 750.54, 798.77, 810.86 | 10 |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Group 6 | Group 7 | |
| LLRM | 99.31% | 100% | 100% | 98.77% | 100% | 100% | 100% |
| LRM | 97.22% | 97.22% | 78.89% | 71.60% | 100% | 97.37% | 95.61% |
| Group 8 | Group 9 | Group 10 | Group 11 | Group 12 | Group 13 | Average | |
| LLRM | 99.07% | 100% | 100% | 99.07% | 99.07% | 100% | 99.64% |
| LRM | 96.30% | 96.30% | 100% | 94.44% | 97.22% | 95.37% | 93.66% |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Group 6 | Group 7 | |
| LLRM | 98.61% | 100% | 100% | 100% | 100% | 100% | 99.12% |
| LRM | 95.83% | 86.11% | 73.33% | 74.07% | 87.72% | 90.35% | 94.74% |
| Group 8 | Group 9 | Group 10 | Group 11 | Group 12 | Group 13 | Average | |
| LLRM | 100% | 100% | 99.07% | 95.37% | 97.22% | 100% | 99.18% |
| LRM | 92.59% | 87.96% | 97.22% | 88.89% | 84.26% | 99.07% | 88.63% |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Group 6 | Group 7 | |
| LLRM | 91.67% | 95.37% | 96.67% | 98.77% | 93.86% | 92.98% | 94.74% |
| LRM | 88.19% | 81.48% | 78.89% | 77.78% | 80.70% | 83.33% | 95.61% |
| Group 8 | Group 9 | Group 10 | Group 11 | Group 12 | Group 13 | Average | |
| LLRM | 100% | 97.22% | 100% | 98.15% | 96.30% | 100% | 96.59% |
| LRM | 86.11% | 87.96% | 94.40% | 91.67% | 84.26% | 95.37% | 86.60% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Zeng, S.; Wu, G.; Li, H.; Chen, F. Rice Seed Purity Identification Technology Using Hyperspectral Image with LASSO Logistic Regression Model. Sensors 2021, 21, 4384. https://doi.org/10.3390/s21134384
Liu W, Zeng S, Wu G, Li H, Chen F. Rice Seed Purity Identification Technology Using Hyperspectral Image with LASSO Logistic Regression Model. Sensors. 2021; 21(13):4384. https://doi.org/10.3390/s21134384
Chicago/Turabian StyleLiu, Weihua, Shan Zeng, Guiju Wu, Hao Li, and Feifei Chen. 2021. "Rice Seed Purity Identification Technology Using Hyperspectral Image with LASSO Logistic Regression Model" Sensors 21, no. 13: 4384. https://doi.org/10.3390/s21134384
APA StyleLiu, W., Zeng, S., Wu, G., Li, H., & Chen, F. (2021). Rice Seed Purity Identification Technology Using Hyperspectral Image with LASSO Logistic Regression Model. Sensors, 21(13), 4384. https://doi.org/10.3390/s21134384