
Deep ConvNet: Non-Random Weight Initialization for Repeatable Determinism, Examined with FSGM †



Abstract
:1. Introduction
1.1. Related Work
1.2. Contribution and Novelty
- Arguably part of a new category of weight initialization type,
- Does not redefine limit values, as such is compatible to them,
- A replacement to random numbers, that is aligned to image classification,
- Is detached from the dataset used, without data sampling,
- Repeatable and deterministic that is aligned to safety critical applications,
- Higher retention of previous model content in transferred learning,
- Applicable to other methods in combination, (i.e., complementary).
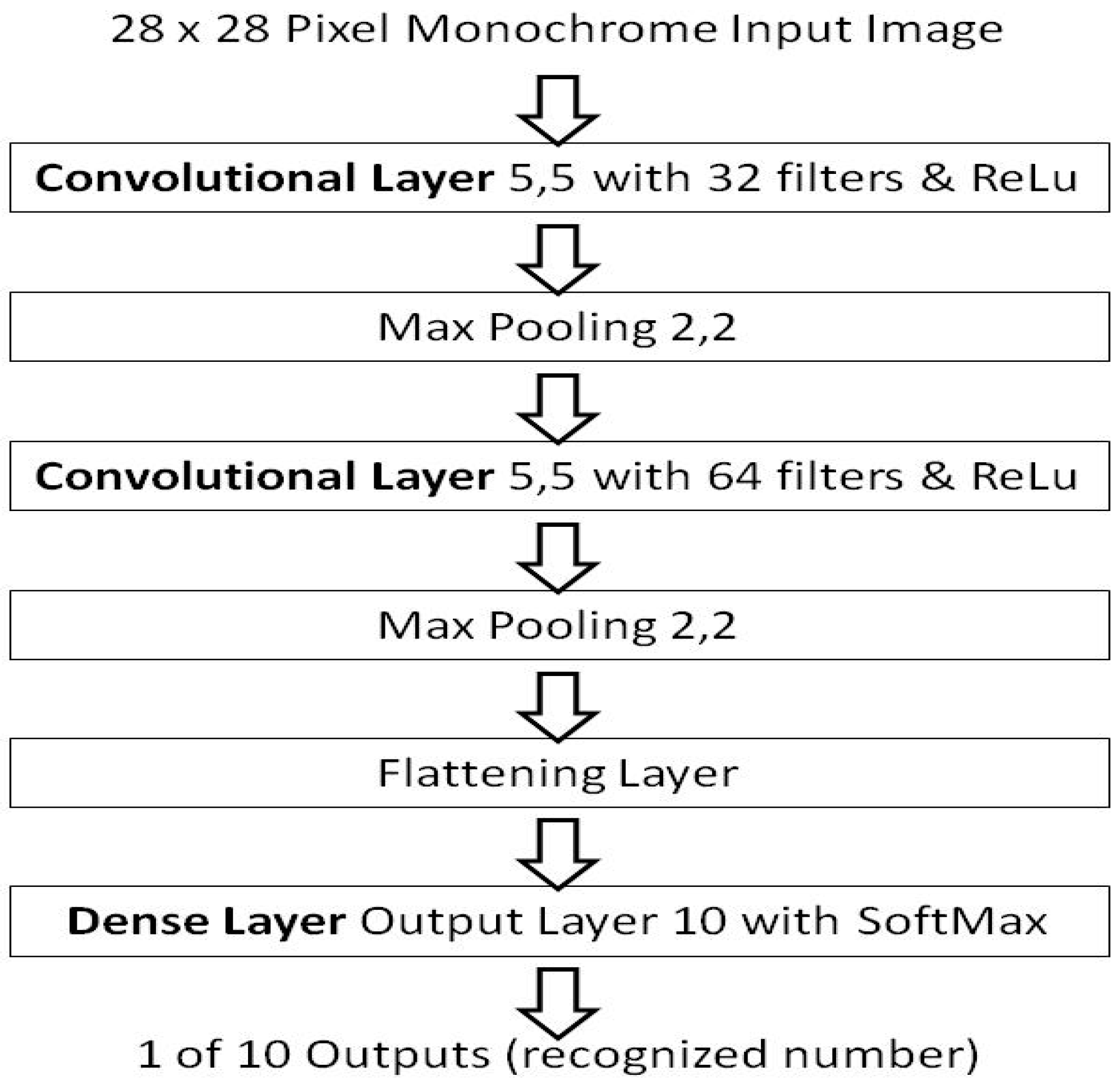
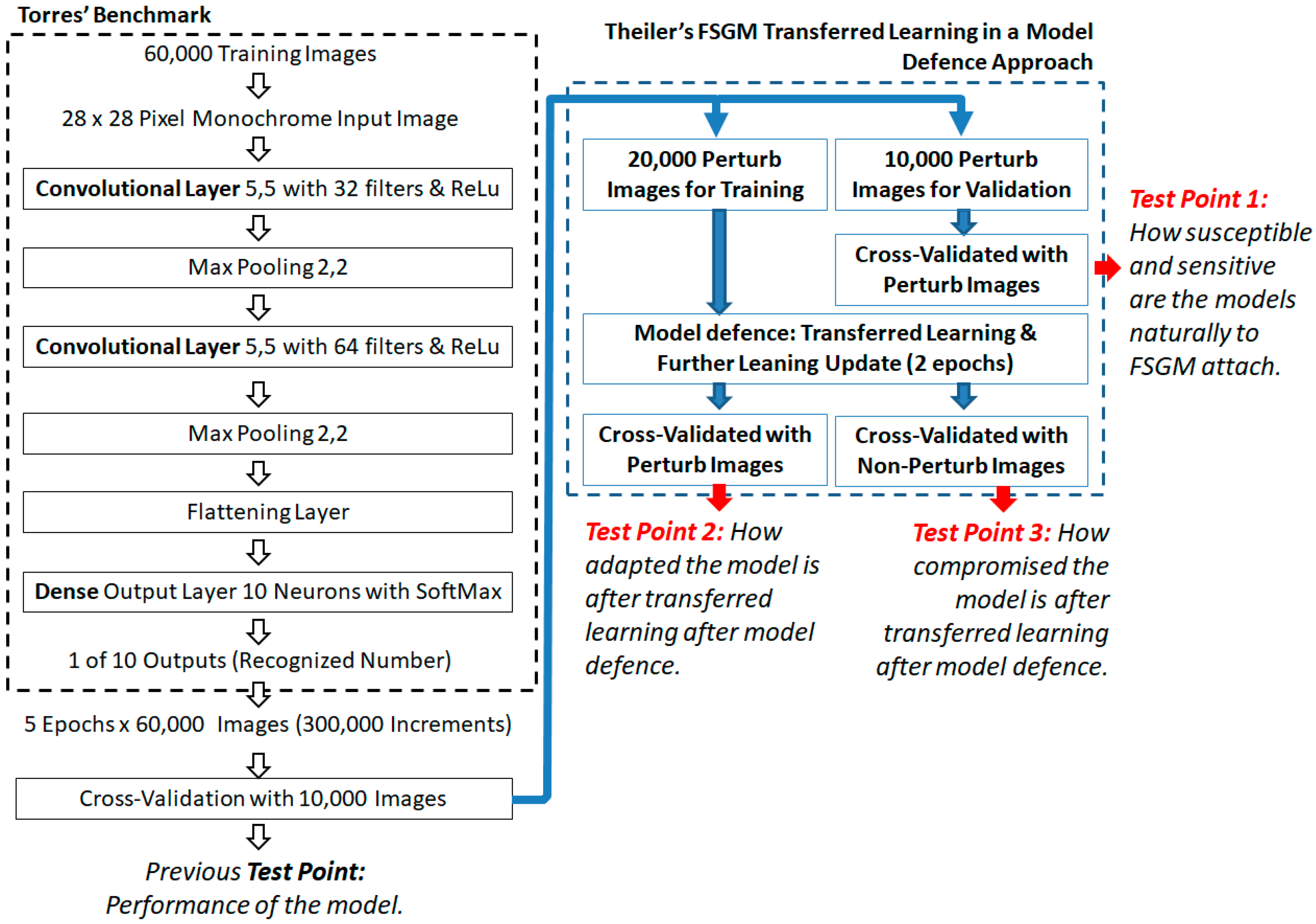
2. Experiment Benchmark Baseline Model
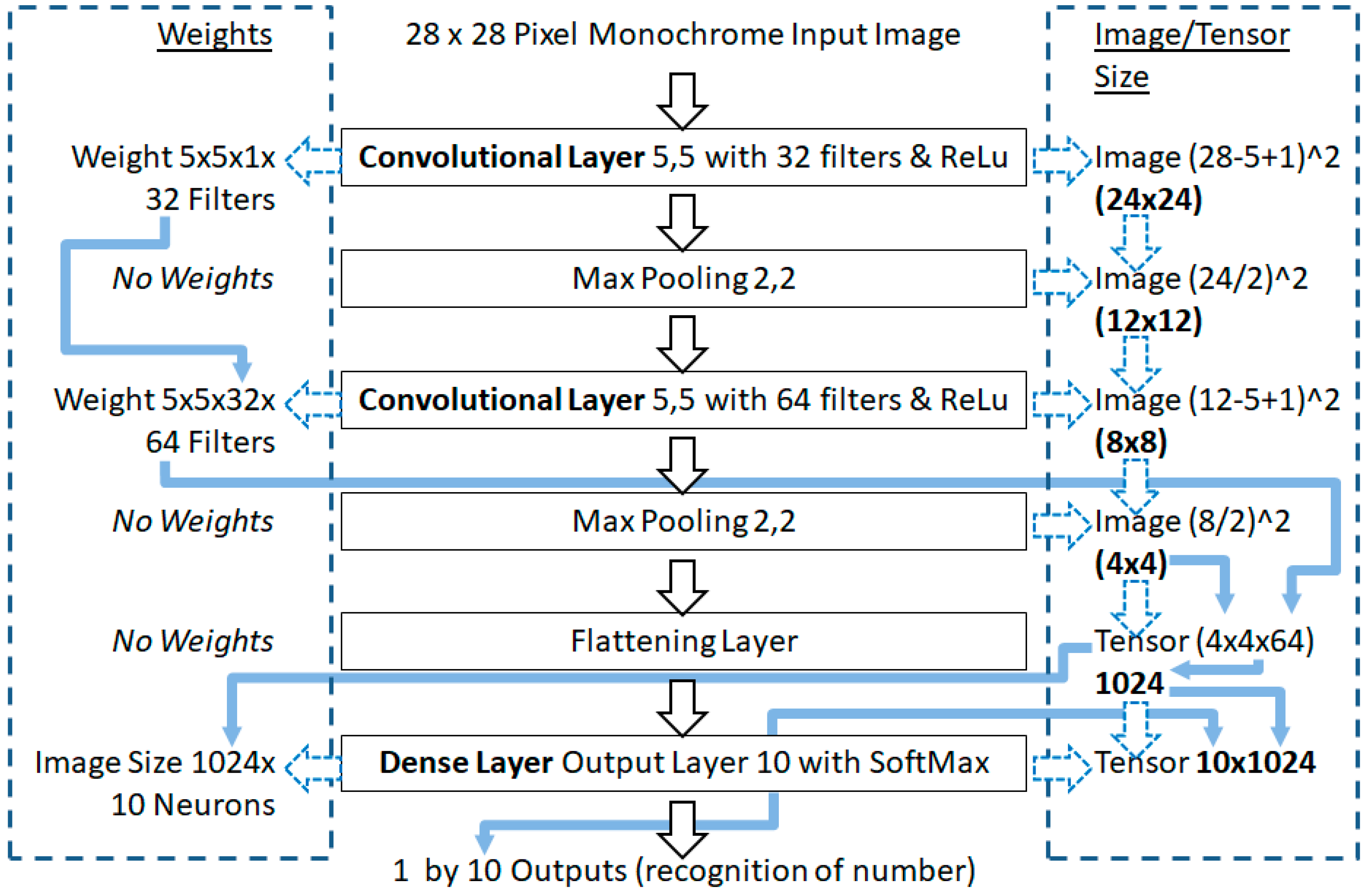
Understanding the Weights and Image Sizes
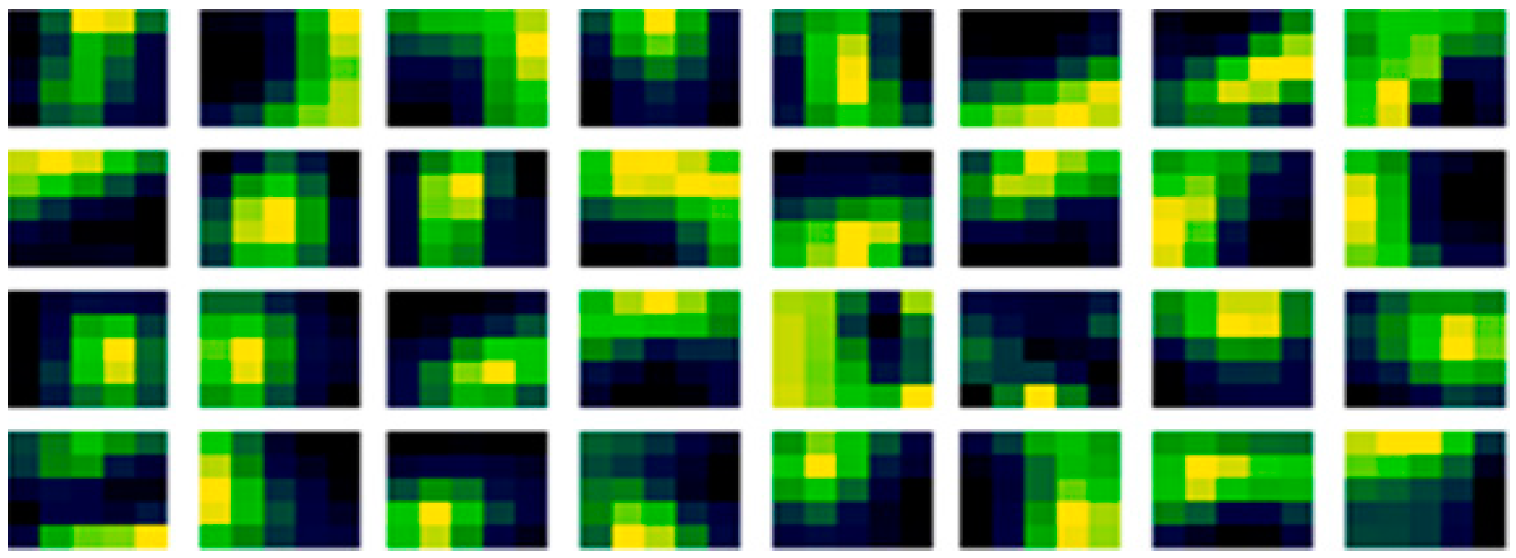
3. The Proposed (Non-Random) Method
4. Comparison of the Benchmark with the Proposed (Non-Random) Method
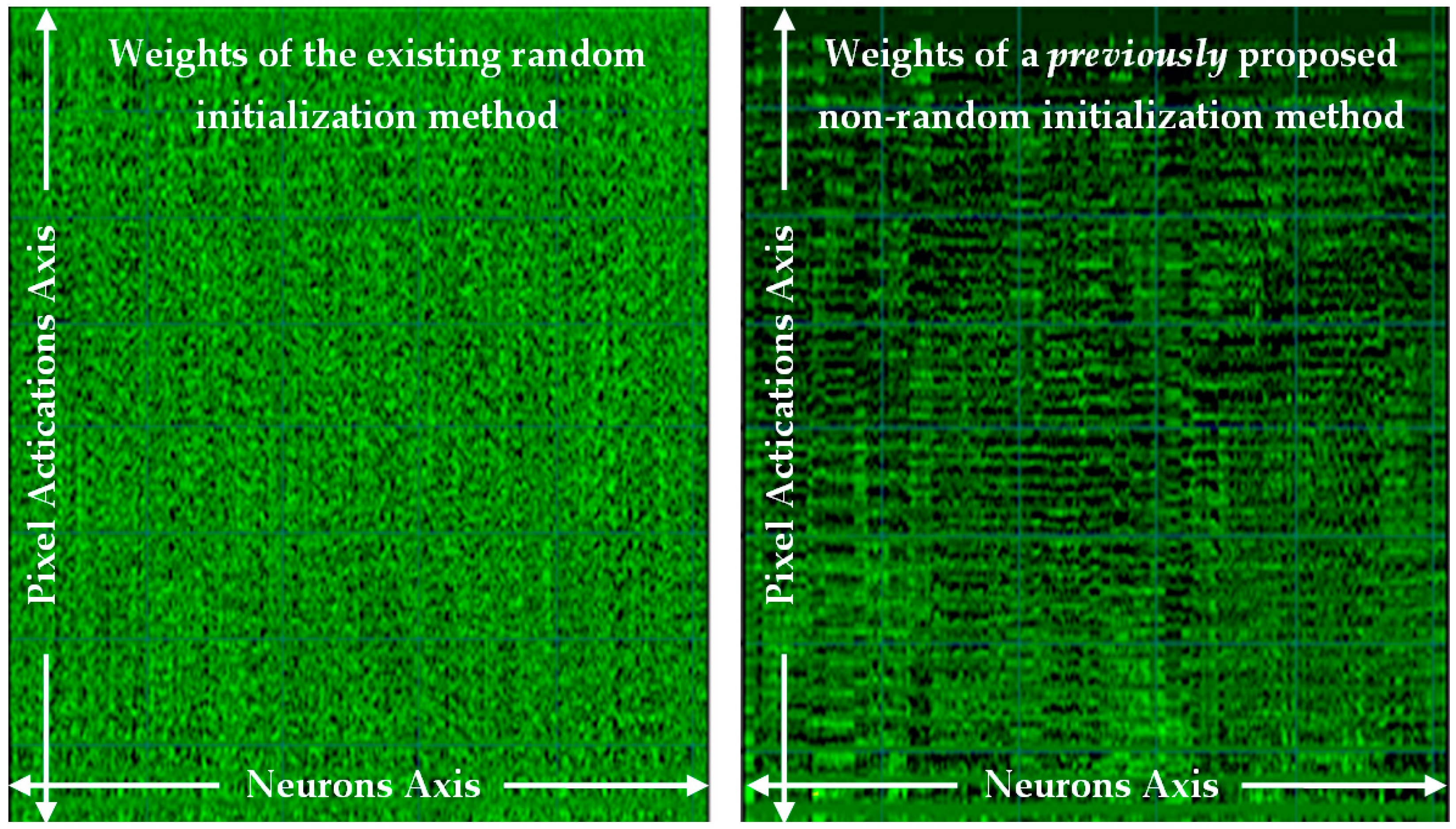
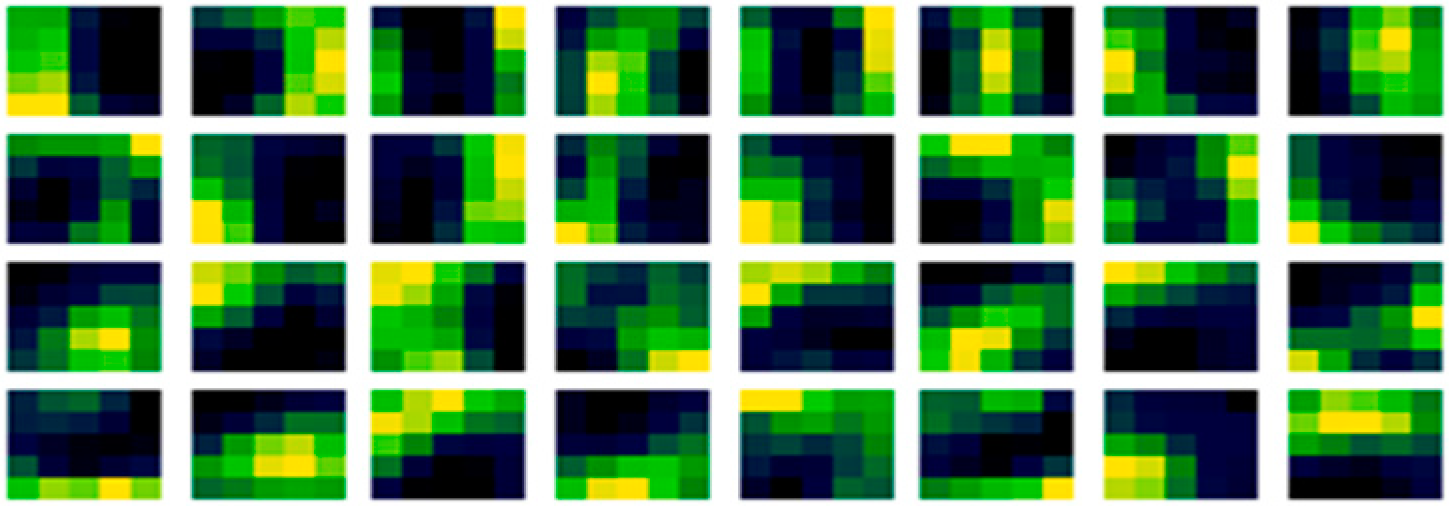
4.1. Comparison of the Weights before and after Learning
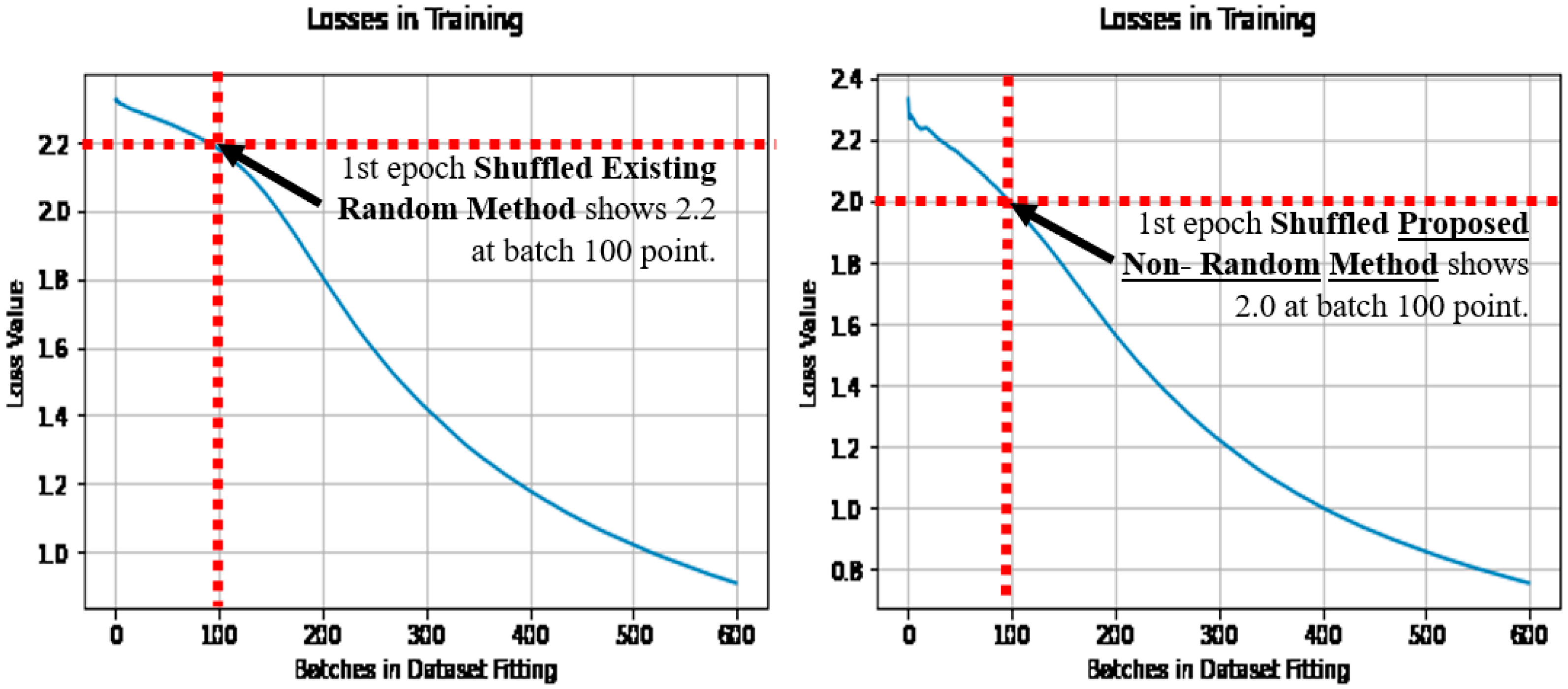
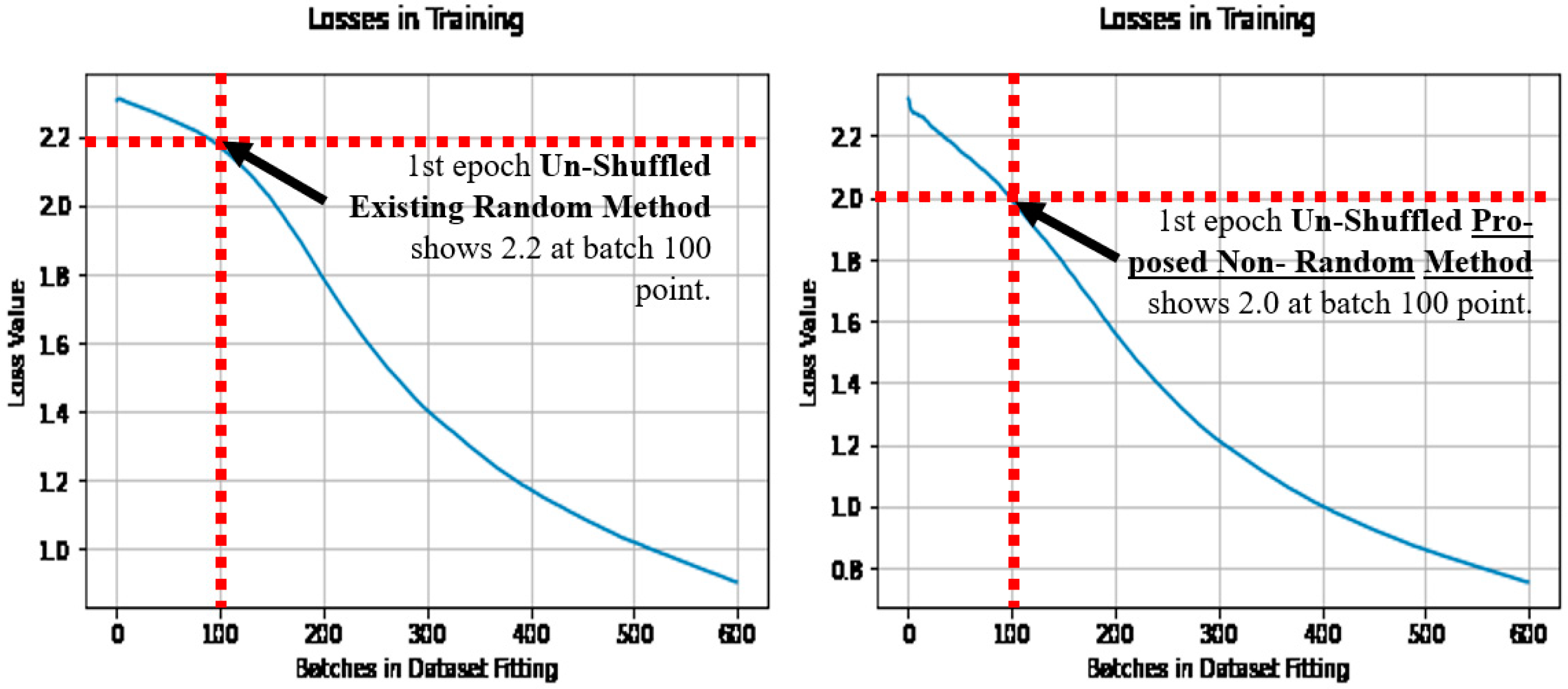
4.2. Comparison of the Optimization Objective (Loss) in Learning
4.3. Comparison to the State-of-the-Art (He et al. Initialization)
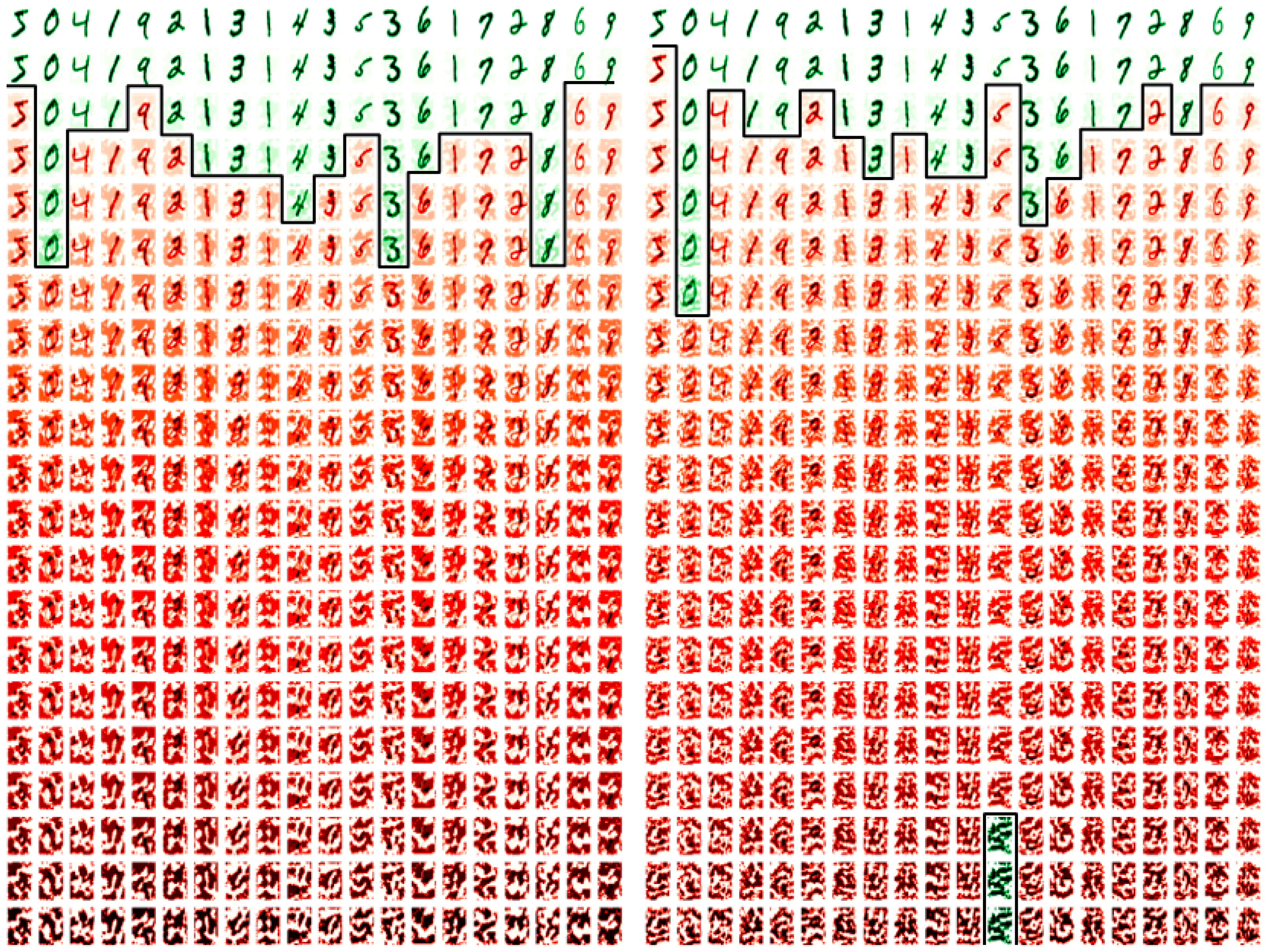
5. Fast Sign Gradient Method (FSGM) and Transferred Learning Approach
5.1. The FSGM Transferred Learning Approach
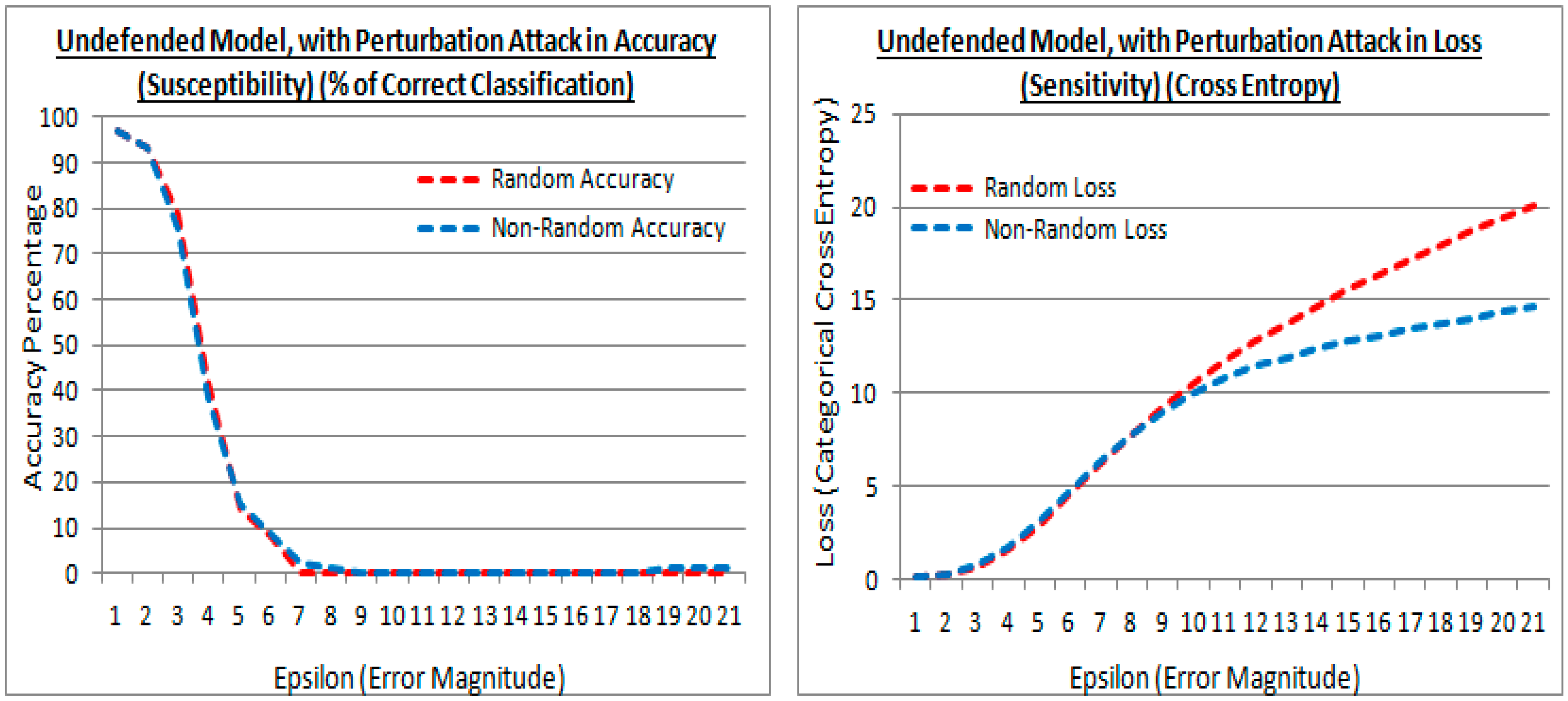
5.2. The Undefended Model, Attacked by FSGM
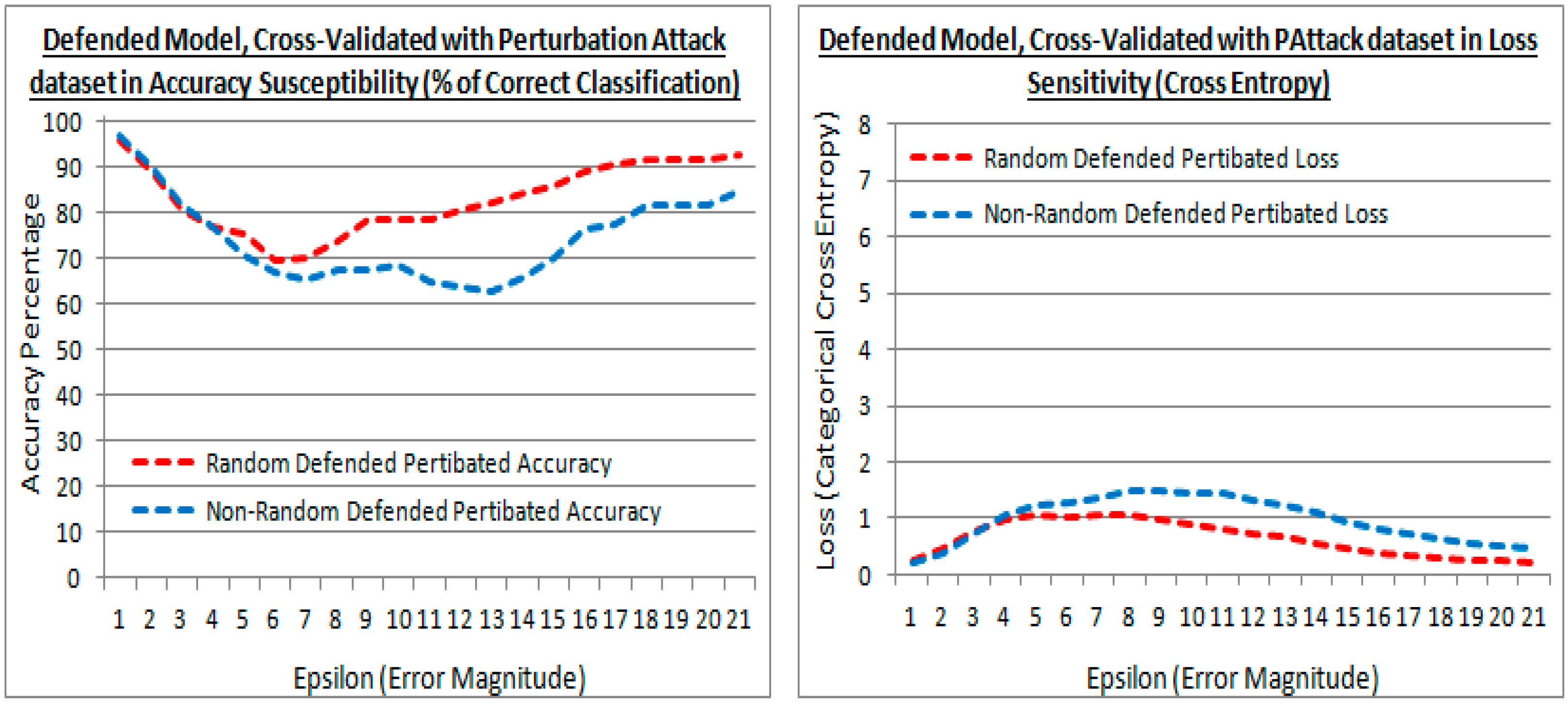
5.3. Defending a Model from FSGM
5.4. Examining the Transferred Learning Adaption
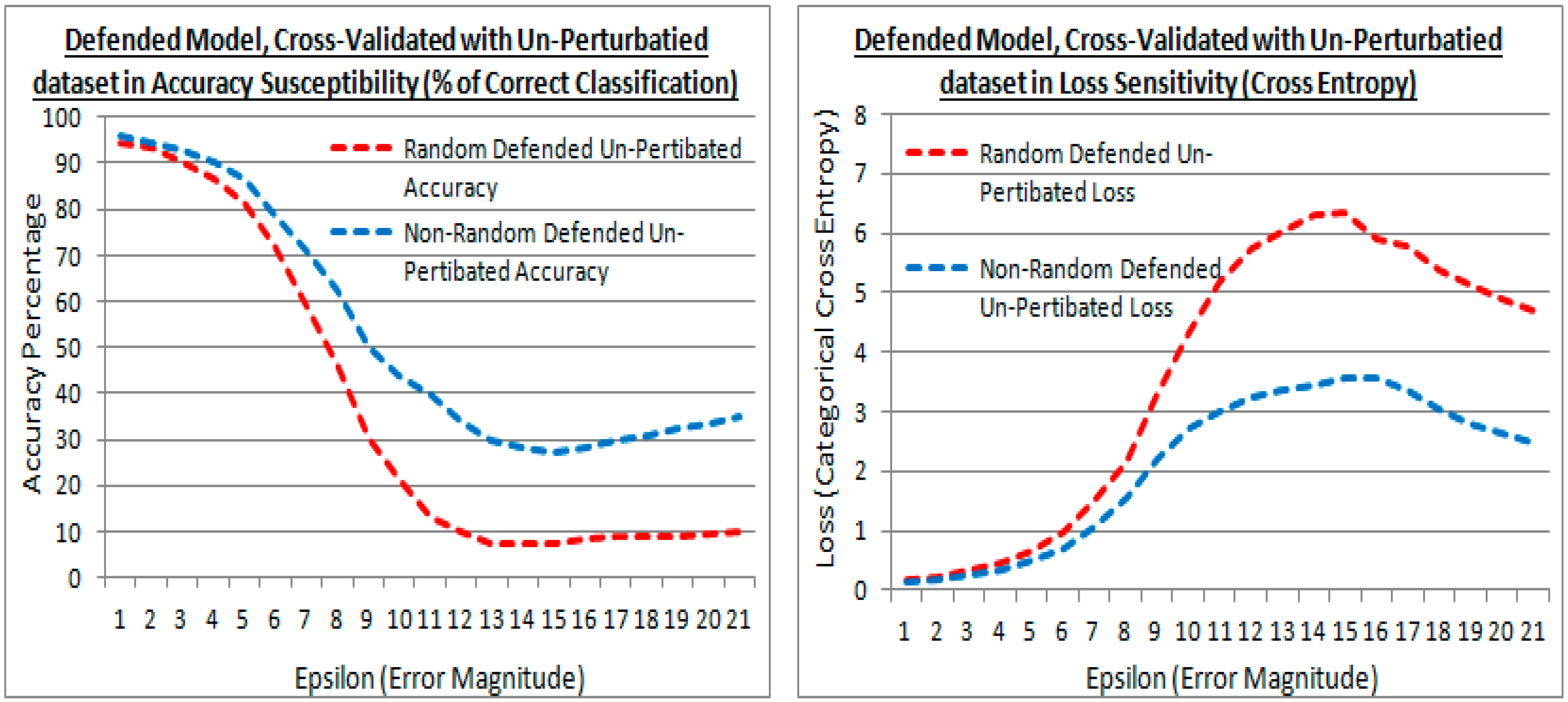
5.5. Examining the Model Compromise in Defense to the Original Cross-Validation Dataset
5.6. FSGM Attacks with Varying Epsilon Values
5.7. Color Images and Dissimilar Model Architectures
6. Discussion and Conclusions
6.1. Proposed Method in Neural Networks
6.2. Proposed Method in FSGM with Transferred Learning
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Pseudocode
| Layer_Type_Rand = 0 Layer_Type_CovNet = 1 Layer_Type_Dense = 2 |
| valset (n, m, Limit, LayerType) if (LayerType = Layer_Type_CovNet) return (cos (n/m*pi())*Limit) else if (LayerType = Layer_Type_Dense) return (n/m*(2*Limit)-Limit) end if end if return random_uniform(-limit, limit) |
| shuffle_data (VectorData) length = floor (Size (VectorData)) half_length = floor (length/2) Shuff_Data = zeros (length) if (mod (length, 2) ! = 0) Shuff_Data [length-1] = VectorData [half_length] end if for n is 0 to half_length-1 step 1 Shuff_Data [n*2] = VectorData [n] Shuff_Data [n*2 + 1] = VectorData [length-1-n] end loop return Shuff_Data |
| init_conv (Filters, Channels, Width, Height, Limit): InitVal = zeros ( [[[[0 … Filters-1)] 0…Channels-1] 0 … Width-1)] 0 … Height-1)]) m = Width * Height * Channels -1 for nFilter is 0 to Filters-1 step 1 cnt = 0 for nDepth is 0 to Channels-1 step 1 for nHeight is 0 to Height-1 step 1 for nWidth is 0 to Width-1 step 1 InitVal [nHeight][nWidth][nDepth][nFilter] = valset (cnt, m, Limit, Layer_Type_CovNet) cnt = cnt + 1 end loop end loop end loop initval_trans = transpose (InitVal) if (mod (nFilter + 1, 2) = 0) initval_transvect = reshape (initval_trans[nFilter], (1, Width * Height * Channels)) initval_transvect = flip (initval_transvect) initval_trans[nFilter] = reshape (initval_transvect, (Channels, Width, Height)) end if for iteration is 0 to floor (nFilter/2)-1 step 1 initval_transvect = reshape (initval_trans[nFilter], (Width * Height * Channels, 1)) initval_transvect = shuffle_data (initval_transvect) initval_trans[nFilter] = reshape (initval_transvect, (Channels, Width, Height)) end loop InitVal = transpose (initval_trans) end loop return InitVal |
References
- Hubel, D.H.; Wiesel, T.N. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1958, 195, 215–243. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Shape and arrangement of columns in cat’s striate context. J. Physiol. 1963, 165, 559–568. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 253–256. [Google Scholar]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber., J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction. In Artificial Neural Networks and Machine Learning—ICANN 2011. Lecture Notes in Computer Science; Honkela, T., Duch, W., Girolami, M., Kaski, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6791. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Srivastava, S.; Bisht, A.; Narayan, N. Safety and security in smart cities using artificial intelligence—A review. In Proceedings of the 2017 7th International Conference on Cloud Computing, Data Science & Engineering Confluence, Noida, India, 12–13 January 2017; pp. 130–133. [Google Scholar]
- Knight, J. Safety critical systems: Challenges and directions. In Proceedings of the 24th International Conference on Software Engineering, ICSE 2002, Orlando, FL, USA, 25 May 2002; pp. 547–550. [Google Scholar]
- Serban, A.C. Designing Safety Critical Software Systems to Manage Inherent Uncertainty. In Proceedings of the 2019 IEEE International Conference on Software Architecture Companion (ICSA-C), Hamburg, Germany, 25–26 March 2019; pp. 246–249. [Google Scholar]
- Carpenter, P. Verification of requirements for safety-critical software. In Proceedings of the 1999 annual ACM SIGAda International Conference on Ada, Redondo Beach, CA, USA, 17–21 October 1999; Volume XIX, pp. 23–29. [Google Scholar]
- Połap, D.; Włodarczyk-Sielicka, M.; Wawrzyniak, N. Automatic ship classification for a riverside monitoring system using a cascade of artificial intelligence techniques including penalties and rewards. ISA Trans. 2021. [Google Scholar] [CrossRef] [PubMed]
- Ali, F.; Ali, A.; Imran, M.; Naqvi, R.A.; Siddiqi, M.H.; Kwak, K.-S. Traffic accident detection and condition analysis based on social networking data. Accid. Anal. Prev. 2021, 151, 105973. [Google Scholar] [CrossRef] [PubMed]
- Holen, M.; Saha, R.; Goodwin, M.; Omlin, C.W.; Sandsmark, K.E. Road Detection for Reinforcement Learning Based Autonomous Car. In Proceedings of the the 3rd International Conference on Information Science and System (ICISS), Cambridge, UK, 19–22 March 2020; pp. 67–71. [Google Scholar]
- Fremont, D.J.; Chiu, J.; Margineantu, D.D.; Osipychev, D.; Seshia, S.A. Formal Analysis and Redesign of a Neural Network-Based Aircraft Taxiing System with VerifAI. In Transactions on Petri Nets and Other Models of Concurrency XV; Springer Science and Business Media LLC: Cham, Swizerland, 2020; Volume 12224, pp. 122–134. [Google Scholar]
- Thombre, S.; Zhao, Z.; Ramm-Schmidt, H.; Garcia, J.M.V.; Malkamaki, T.; Nikolskiy, S.; Hammarberg, T.; Nuortie, H.; Bhuiyan, M.Z.H.; Sarkka, S.; et al. Sensors and AI Techniques for Situational Awareness in Autonomous Ships: A Review. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Rudd-Orthner, R.N.M.; Mihaylova, L. Non-Random Weight Initialisation in Deep Learning Networks for Repeatable Determinism. In Proceedings of the 2019 10th International Conference on Dependable Systems, Services and Technologies (DESSERT), Leeds, UK, 5–7 June 2019; pp. 223–230. [Google Scholar]
- Rudd-Orthner, R.; Mihaylova, L. Repeatable determinism using non-random weight initialisations in smart city applications of deep learning. J. Reliab. Intell. Environ. 2020, 6, 31–49. [Google Scholar] [CrossRef]
- Blumenfeld, Y.; Gilboa, D.; Soudry, D. Beyond signal propagation: Is feature diversity necessary in deep neural network initialization? PMLR 2020, 119, 960–969. [Google Scholar]
- Seuret, M.; Alberti, M.; Liwicki, M.; Ingold, R. PCA-Initialized Deep Neural Networks Applied to Document Image Analysis. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 877–882. [Google Scholar]
- Seyfioğlu, M.S.; Gürbüz, S.Z. Deep neural network initialization methods for micro-doppler classification with low training sample support. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2462–2466. [Google Scholar] [CrossRef]
- Humbird, K.D.; Peterson, J.L.; Mcclarren, R.G. Deep neural network initialization with decision trees. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1286–1295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Dauphin, Y.N.; Ma, T. Fixup initialization: Residual learning without normalization. arXiv 2019, arXiv:2002.10097. [Google Scholar]
- Ding, W.; Sun, Y.; Ren, L.; Ju, H.; Feng, Z.; Li, M. Multiple Lesions Detection of Fundus Images Based on Convolution Neural Network Algorithm with Improved SFLA. IEEE Access 2020, 8, 97618–97631. [Google Scholar] [CrossRef]
- Wang, Y.; Rong, Y.; Pan, H.; Liu, K.; Hu, Y.; Wu, F.; Peng, W.; Xue, X.; Chen, J. PCA Based Kernel Initialization For Convolutional Neural Networks. In Data Mining and Big Data. DMBD 2020. Communications in Computer and Information Science; Tan, Y., Shi, Y., Tuba, M., Eds.; Springer: Singapore, 2020; Volume 1234. [Google Scholar]
- Ferreira, M.F.; Camacho, R.; Teixeira, L.F. Autoencoders as weight initialization of deep classification networks for cancer versus cancer studies. BMC Med. Inform. Decis. Mak. 2019, 20, 141. [Google Scholar]
- Lyu, Z.; ElSaid, A.A.; Karns, J.; Mkaouer, M.W.; Desell, T. An experimental study of weight initialization and Lamarckian inheritance on neuroevolution. EvoApplications 2021, 584–600. [Google Scholar]
- Rudd-Orthner, R.N.M.; Mihaylova, L. Non-random weight initialisation in deep convolutional networks applied to safety critical artificial intelligence. In Proceedings of the 2020 13th International Conference on Developments in eSystems Engineering (DeSE), Liverpool, UK, 14–17 December 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Arat, M.M. Weight Initialization Schemes—Xavier (Glorot) and He. Mustafa Murat ARAT, 2019. Available online: https://mmuratarat.github.io/2019-02-25/xavier-glorot-he-weight-init (accessed on 15 January 2021).
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 28 May 2021).
- Torres, J. Convolutional Neural Networks for Beginners using Keras & TensorFlow 2, Medium, 2020. Available online: https://towardsdatascience.com/convolutional-neural-networks-for-beginners-using-keras-and-tensorflow-2-c578f7b3bf25 (accessed on 12 July 2021).
- Kassem. MNIST: Simple CNN Keras (Accuracy: 0.99) => Top 1%. 2019. Available online: https://www.kaggle.com/elcaiseri/mnist-simple-cnn-keras-accuracy-0-99-top-1 (accessed on 16 January 2021).
- Kakaraparthi, V. Xavier and He Normal (he-et-al) Initialization, Medium 2018. Available online: https://medium.com/@prateekvishnu/xavier-and-he-normal-he-et-al-initialization-8e3d7a087528 (accessed on 7 May 2021).
- Hewlett-Packard. HP-UX Floating-Point Guide HP 9000 Computers Ed 4. 1997, p. 38. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.172.9291&rep=rep1&type=pdf (accessed on 7 May 2021).
- Rudd-Orthner, R.; Mihaylova, L. Numerical discrimination of the generalisation model from learnt weights in neural networks. In Proceedings of the International Conf. on Computing, Electronics & Communications Engineering (iCCECE), London, UK, 23–24 August 2019. [Google Scholar]
- Goodfellow, I..; McDaniel, P.; Papernot, N. Making machine learning robust against adversarial inputs. Commun. ACM 2018, 61, 56–66. [Google Scholar] [CrossRef]
- Molnar, C. 6.2 Adversarial Examples. Interpretable Machine Learning. 2021. Available online: https://christophm.github.io/interpretable-ml-book/adversarial.html (accessed on 7 May 2021).
- Theiler, S. Implementing Adversarial Attacks and Defenses in Keras & Tensorflow 2.0. Medium, 2019. Available online: https://medium.com/analytics-vidhya/implementing-adversarial-attacks-and-defenses-in-keras-tensorflow-2-0-cab6120c5715 (accessed on 7 May 2021).
- Schwinn, L.; Raab, R.; Eskofier, B. Towards rapid and robust adversarial training with one-step attacks. arXiv 2020, arXiv:2002.10097. [Google Scholar]
- Wu, Z. Muti-Type Aircraft of Remote Sensing Images: MTARSI. 2019. Available online: https://zenodo.org/record/3464319#.YNv5oOhKiUk (accessed on 30 June 2021).
- Rudd-Orthner, R.; Mihaylova, L. Multi-Type Aircraft of Remote Sensing Images: MTARSI 2. 2021. Available online: https://zenodo.org/record/5044950#.YNwn8uhKiUk (accessed on 30 June 2021).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
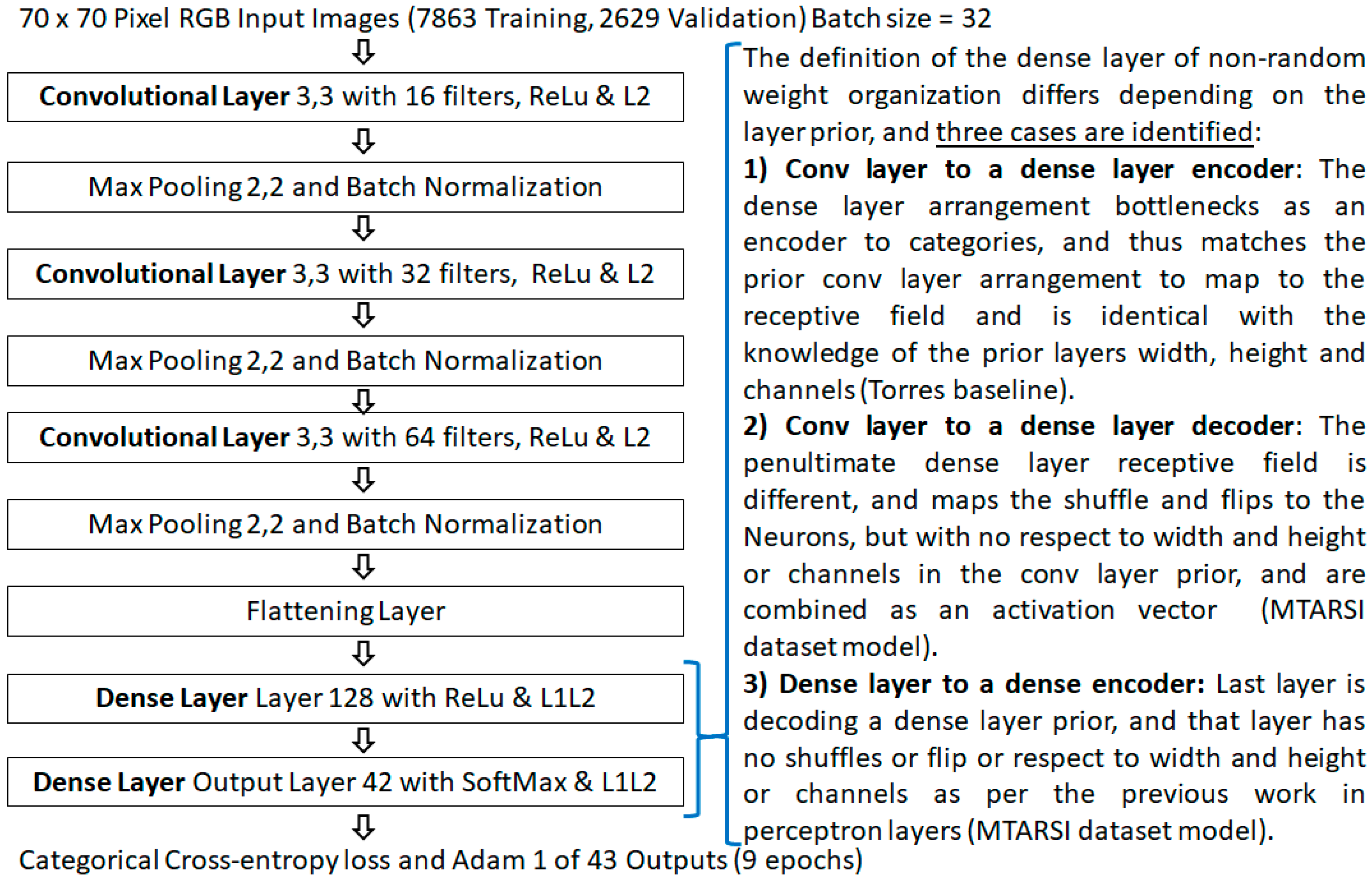{kind=link}
| Layer | Filter/Pool/Neurons | Depth | Image/Tensor Size | Weights |
|---|---|---|---|---|
| Input 28 × 28 × 1 | N/A | 1 (B/W image) | 28 × 28 (748) | N/A |
| Conv Layer 1 | 5 by 5 by 32 filters | 1 | 24 × 24 (576) | 800 |
| Max Pooling | 2 by 2 | 32 | 12 × 12 (144) | N/A |
| Conv Layer 2 | 5 by 5 by 64 filters | 32 | 8 × 8 (64) | 51200 |
| Max Pooling | 2 by 2 | 64 | 4 × 4 (16) | N/A |
| Flatten Layer | N/A | 1 | 1 × (4 × 4 × 64) 1024 | N/A |
| Dense Layer | 10 | 1 | 10 × 1024 (10,240) | 10240 |
| Epochs | Accuracy (Cross-val.) | Loss (Cross-val.) | Gains over Existing (Random) Method |
|---|---|---|---|
| 5 Shuffled | 97.5% | 0.085728347 | +0.599% (Cross-validation gain) |
| 4 Shuffled | 97.11% | 0.097854339 | N/A |
| 3 Shuffled | 96.85% | 0.114757389 | N/A |
| 2 Shuffled | 95.96% | 0.141269892 | N/A |
| 1 Shuffled | 93.77% | 0.230065033 | +2.642% (Cross-validation gain) |
| 1 No Shuffle | 93.28% | 0.230725348 | +3.705% (Cross-validation gain) |
| Epochs | He et al. (Non-Rnd) Measure | He with Proposed Method Gains Over: | ||
|---|---|---|---|---|
| Loss | Accuracy | Glorot (Non-Rand) [Table 2] | He (Rnd) | |
| 5 Shuffled | 0.082669578 | 97.55% | +0.05% | +0.7% |
| 4 Shuffled | 0.093996972 | 97.19% | +0.08% | +0.91% |
| 3 Shuffled | 0.10997723 | 96.97% | +0.12% | +1.49% |
| 2 Shuffled | 0.134461805 | 96.15% | +0.19% | +1.83% |
| 1 Shuffled | 0.214723364 | 94.11% | +0.34% | +5.13% |
| 1 No Shuffle | 0.217569217 | 93.57% | +0.29% | +4.27% |
| Initialization Method Used Prior to Model Defense via Transferred Learning | Non-Attack Cross-Validation Dataset | Attack Cross-Validation Dataset | ||
|---|---|---|---|---|
| Loss (Cross-Val) | Accuracy (Cross-Val) | Loss (Cross-Val) | Accuracy (Cross-Val) | |
| Proposed (Non-Random) Method | 0.9854 | 67.01% | 1.3331 | 61.82% |
| Existing (Random) Method | 1.2736 | 61.05% | 0.8366 | 78.41% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rudd-Orthner, R.N.M.; Mihaylova, L. Deep ConvNet: Non-Random Weight Initialization for Repeatable Determinism, Examined with FSGM. Sensors 2021, 21, 4772. https://doi.org/10.3390/s21144772
Rudd-Orthner RNM, Mihaylova L. Deep ConvNet: Non-Random Weight Initialization for Repeatable Determinism, Examined with FSGM. Sensors. 2021; 21(14):4772. https://doi.org/10.3390/s21144772
Chicago/Turabian StyleRudd-Orthner, Richard N. M., and Lyudmila Mihaylova. 2021. "Deep ConvNet: Non-Random Weight Initialization for Repeatable Determinism, Examined with FSGM" Sensors 21, no. 14: 4772. https://doi.org/10.3390/s21144772
APA StyleRudd-Orthner, R. N. M., & Mihaylova, L. (2021). Deep ConvNet: Non-Random Weight Initialization for Repeatable Determinism, Examined with FSGM. Sensors, 21(14), 4772. https://doi.org/10.3390/s21144772