
Unsupervised Learning for Product Use Activity Recognition: An Exploratory Study of a “Chatty Device”

 ,
,  ,
,
Abstract
:1. Introduction
- the first approach to detect discrete product use activities in the wild (vibrations, being stationary, drops, and pickups), enhancing previous approaches that focus only on human activity (walking, standing, and sitting). Product behavior within each product use activity can then be studied by the design team for further investigation and possible modifications for the product;
- the use of the Fuzzy C-means algorithm to effectively and efficiently detect product use activities. The behavior of product associated with product activities would then be easy to study as, instead of dealing with large amount of data within each cluster, the center of cluster can be studied; and
- a novel (publicly available) curated and manually verified dataset consisting of actual product use activity allowing researchers to conduct further studies in this domain and compare machine learning results (Dataset is available at: https://doi.org/10.6084/m9.figshare.11475252.v1, accessed on 3 December 2020) curated and manually verified dataset consisting of actual product use activity (for further comparative studies) allowing researchers to conduct further studies in this domain and compare machine learning results).
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Activities | Application in Product-Use Activity Identification | |||||
|---|---|---|---|---|---|---|---|
| Drop & Pickup | Vibrations | Walking | Standing | Sitting | Stationary Position | ||
| [23,26,29,31,34,37,38,39,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72] | 0 | 0 | X | X | X | 0 | 0 |
| [27,73,74,75,76,77,78] | 0 | 0 | X | X | 0 | 0 | 0 |
| [23,79,80,81,82,83,84,85,86] | 0 | 0 | X | 0 | 0 | 0 | 0 |
| [33,87,88,89] | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| [90] | 0 | 0 | 0 | 0 | X | 0 | 0 |
| [35,91] | 0 | 0 | X | 0 | X | 0 | 0 |
| [30,92] | 0 | 0 | 0 | X | 0 | 0 | 0 |
| This Paper | X | X | X | X | X | X | X |
3. Materials
- Acceleration: 3-axes acceleration data,
- Orientation: Azimuth, Pitch, and Roll,
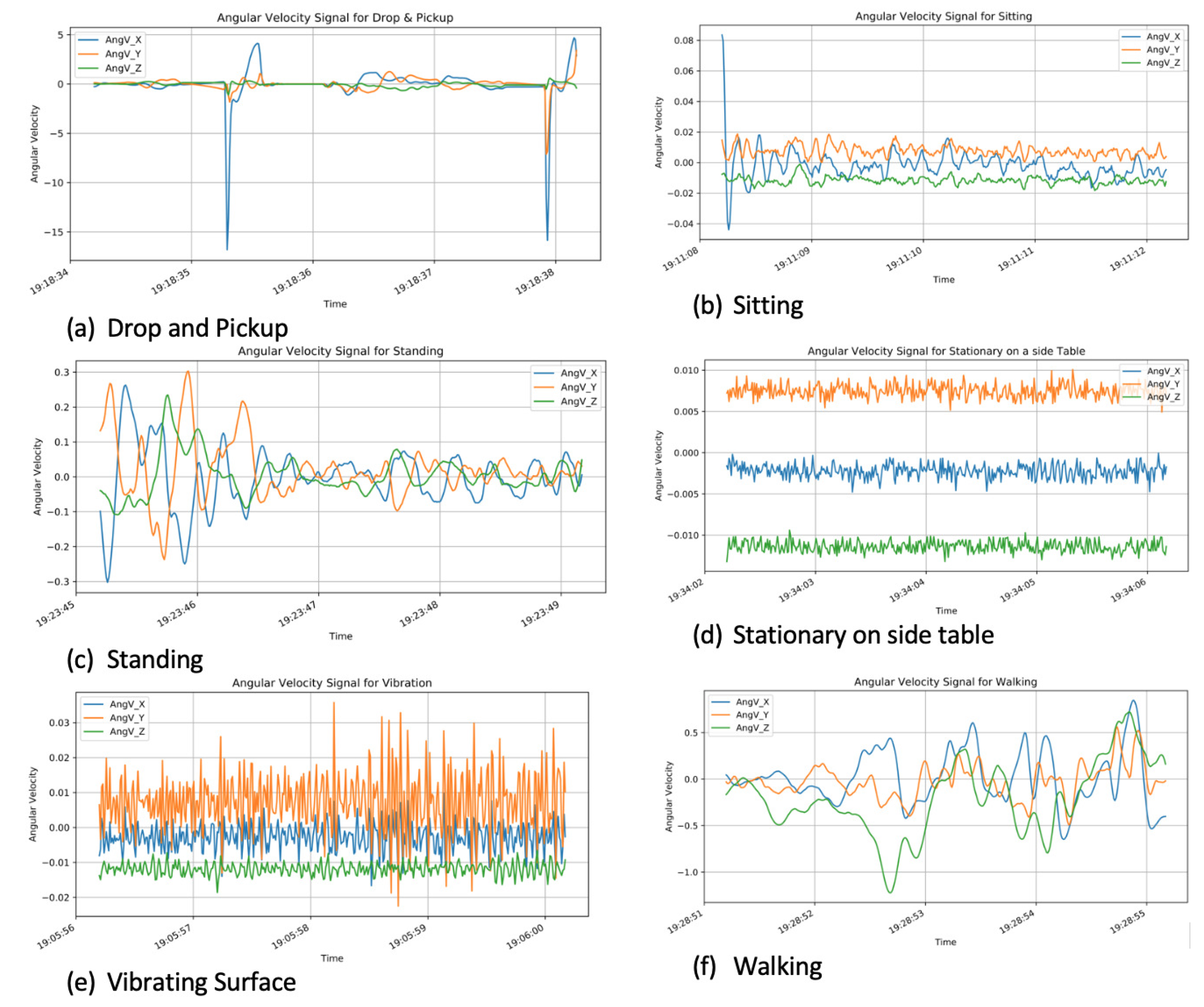
- Angular Velocity: 3-axes gyroscopes for rotational motion,
- Magnetic Field: 3-axes magnetic field.
4. Methodology
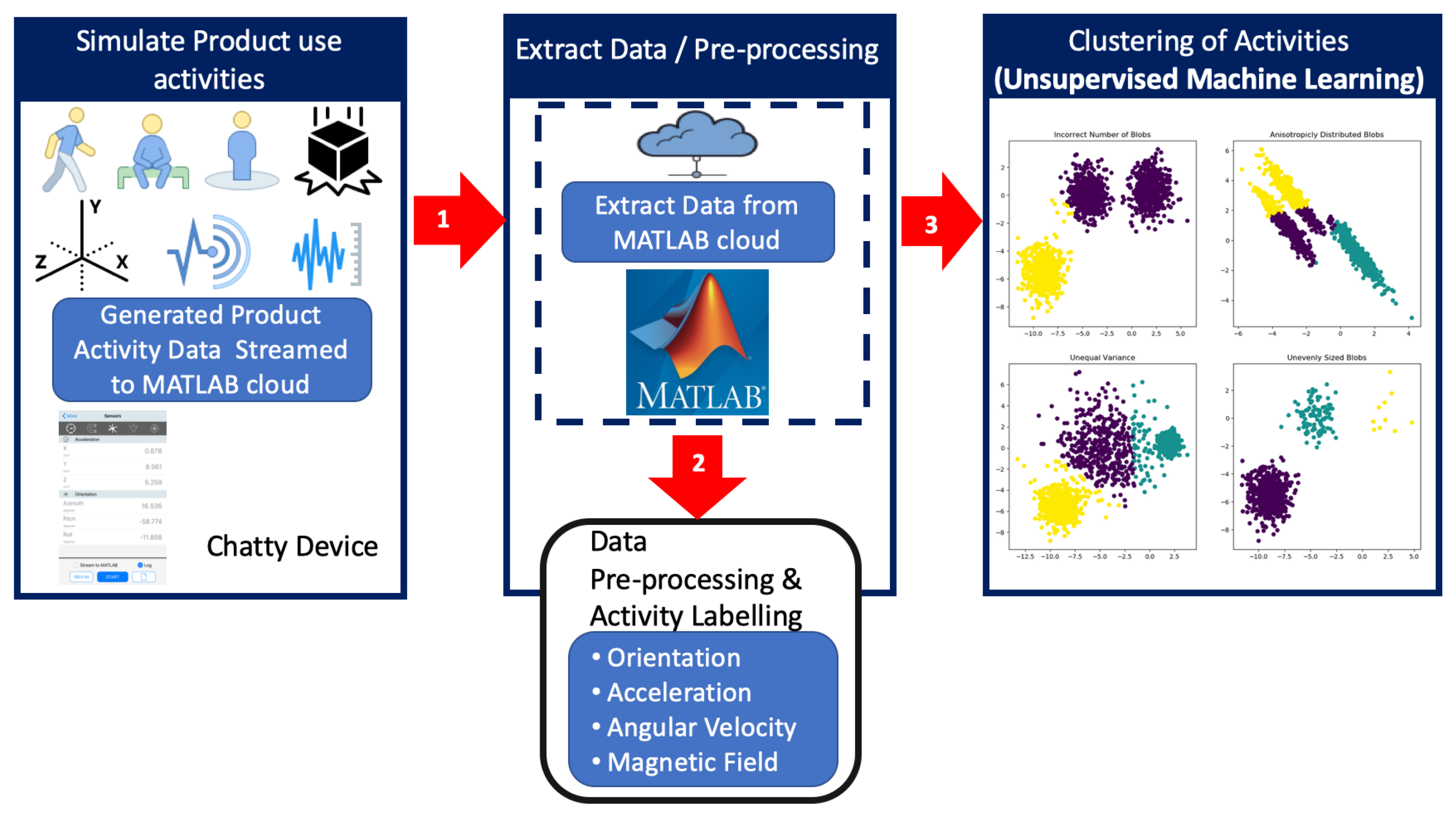
4.1. Data Acquisition
- The MATLAB mobile app was installed and configured on the Chatty device through the Apple App store.
- A registered user account was used, and the device was connected to MathWorks Cloud account.
- Using the MATLAB Mobile interface, the sensors were turned “on”.
- A sampling rate of 100Hz was selected, and the log button was used to initiate recording of the sensor data readings.
- After the expected duration, the logged results were saved to the Cloud and given file names which corresponded to the activities carried out.
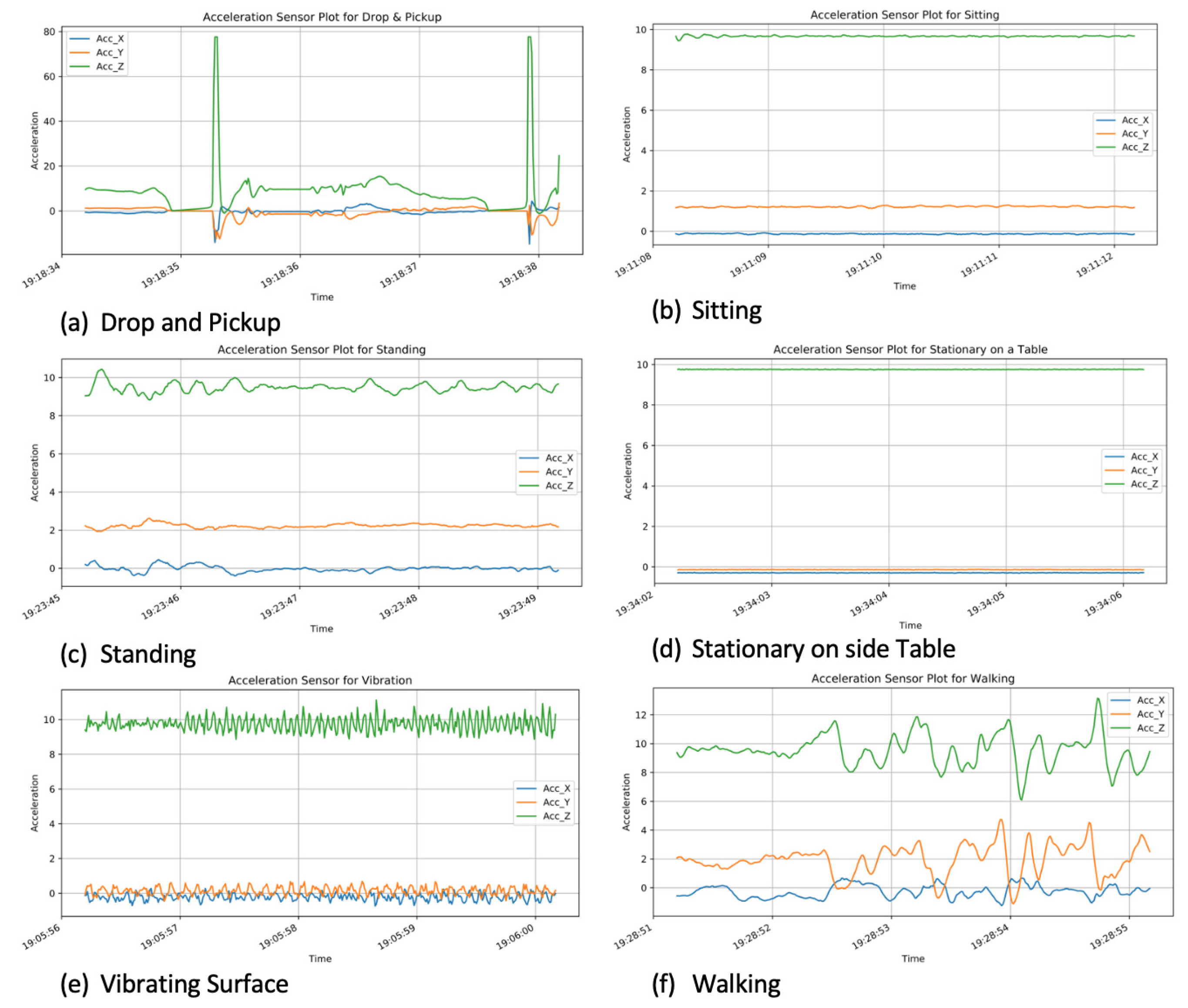
4.2. Data Pre-Processing and Feature Selection
- dropping and picking up,
- vibrating,
- non-vibrating stationary surface,
- standing,
- walking, and
- sitting.
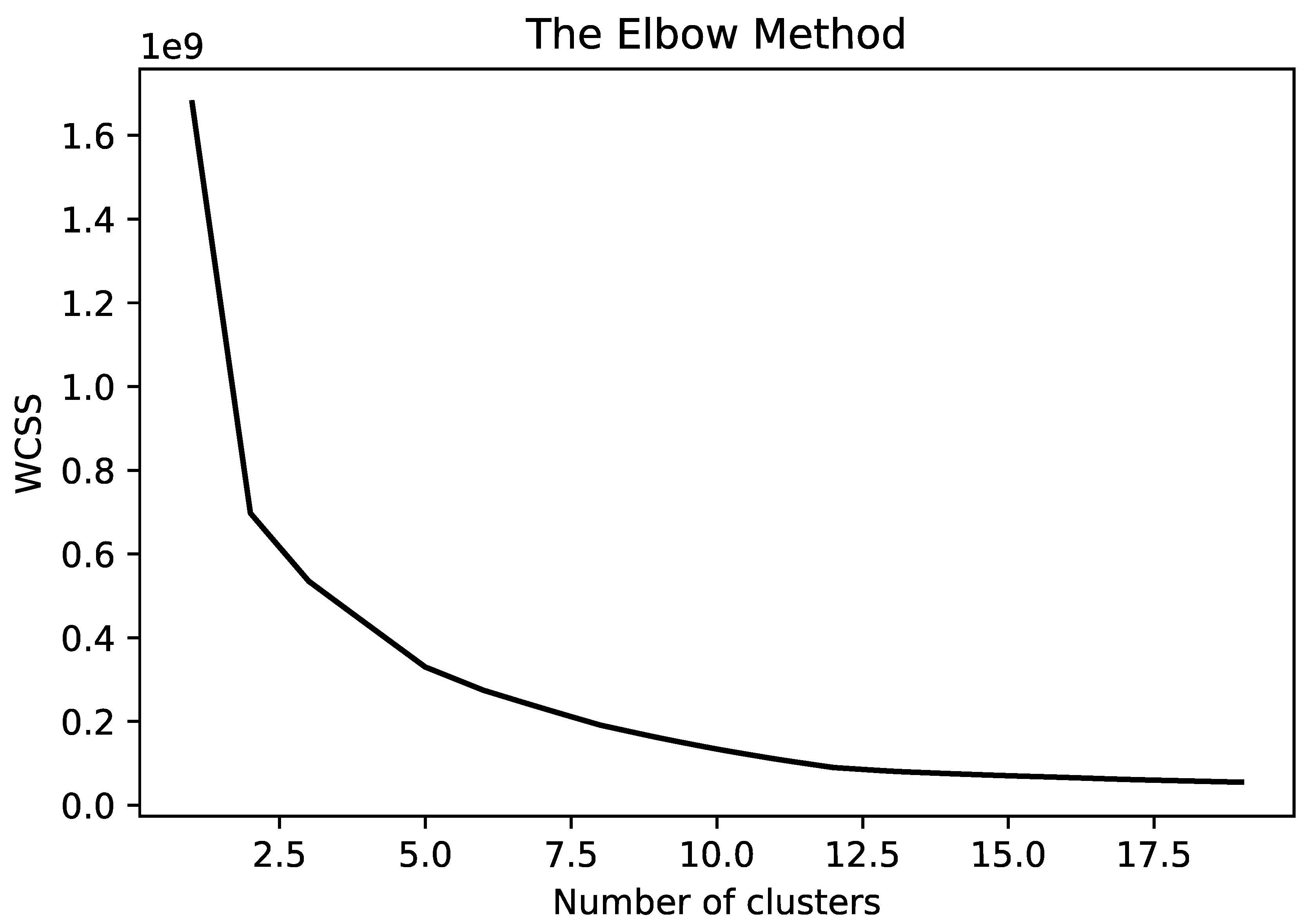
4.3. Finding an Optimal Number of Clusters
4.4. Experiments
4.4.1. WEKA
K-Means
Expectation-Maximization (EM)
Farthest First
4.4.2. Fuzzy C-Means
| Algorithm 1: Calculate fuzzy C-means. |
| Require: and k |
| return U and R |
| is randomly initialized |
| while do |
| Calculate as follows. |
| Update as follows. |
| end while |
| End |
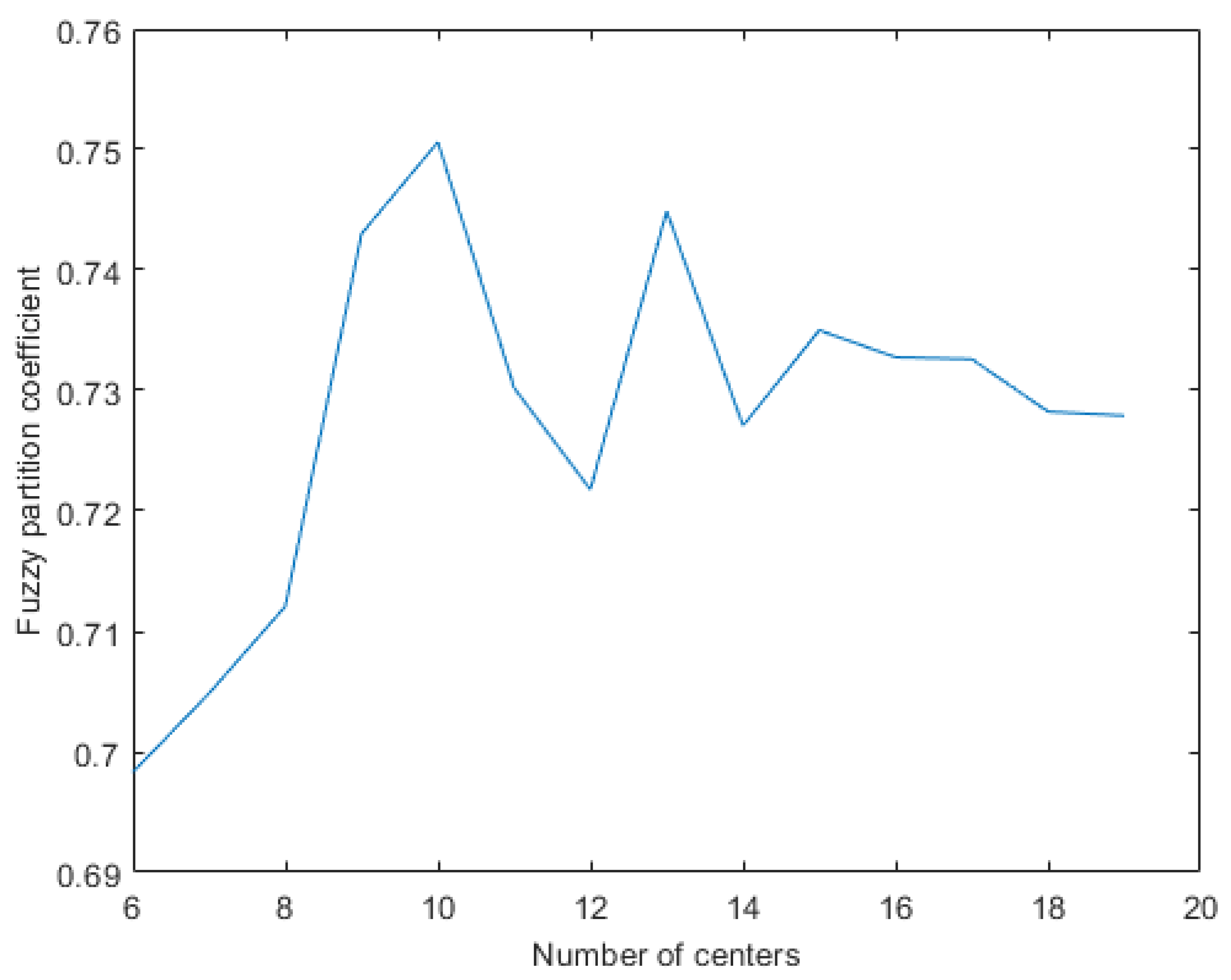
4.4.3. Fuzzy Partition Coefficient
4.4.4. Cluster Class Assignment
4.5. Evaluation Metrics
- F-measure: The F-measure performance metric uses recall and precision for performance measurement, and it is a harmonic mean between them. In practice, high F-measure value ensures that both recall and precision are reasonably high [120]. Precision is used to measure the exactness of the prediction set, as well as recall its completeness. These can be represented mathematically as:where: TP = True Positives; TN = True Negatives; FP = False Positives; FN = False Negatives.
- Matthews correlation coefficient (MCC): MCC is a correlation coefficient between the observed and predicted classifications. This measure takes into account TP, FP, TN, and FN values and is generally regarded as a balanced measure, which can be used even if the classes are unbalanced. This measure returns a value between and +1. A coefficient of +1 represents a perfect prediction, 0 means a random prediction, and indicates total disagreement between prediction and observations [121,122].The MCC is computed as follows:
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cordeiro, G.A.; Ordóñez, R.E.C.; Ferro, R. Theoretical proposal of steps for the implementation of the Industry 4.0 concept. Braz. J. Oper. Prod. Manag. 2019, 16, 166–179. [Google Scholar] [CrossRef]
- Popkova, E.G.; Ragulina, Y.V.; Bogoviz, A.V. Fundamental Differences of Transition to Industry 4.0 from Previous Industrial Revolutions; Springer: Cham, Switzerland, 2019; pp. 21–29. [Google Scholar] [CrossRef]
- Yin, Y.; Stecke, K.E.; Li, D. The evolution of production systems from Industry 2.0 through Industry 4.0. Int. J. Prod. Res. 2018, 56, 848–861. [Google Scholar] [CrossRef] [Green Version]
- Muhuri, P.K.; Shukla, A.K.; Abraham, A. Industry 4.0: A bibliometric analysis and detailed overview. Eng. Appl. Artif. Intell. 2019, 78, 218–235. [Google Scholar] [CrossRef]
- Lützenberger, J.; Klein, P.; Hribernik, K.; Thoben, K.D. Improving Product-Service Systems by Exploiting Information from the Usage Phase. A Case Study. Procedia CIRP 2016, 47, 376–381. [Google Scholar] [CrossRef] [Green Version]
- Kong, X.T.; Luo, H.; Huang, G.Q.; Yang, X. Industrial wearable system: The human-centric empowering technology in Industry 4.0. J. Intell. Manuf. 2019, 30, 2853–2869. [Google Scholar] [CrossRef]
- Thürer, M.; Pan, Y.H.; Qu, T.; Luo, H.; Li, C.D.; Huang, G.Q. Internet of Things (IoT) driven kanban system for reverse logistics: Solid waste collection. J. Intell. Manuf. 2019, 30, 2621–2630. [Google Scholar] [CrossRef]
- Opresnik, D.; Hirsch, M.; Zanetti, C.; Taisch, M. Information—The hidden value of servitization. In IFIP Advances in Information and Communication Technology; Springer: New York, NY, USA, 2013; Volume 415, pp. 49–56. [Google Scholar] [CrossRef] [Green Version]
- Hou, L.; Jiao, R.J. Data-informed inverse design by product usage information: A review, framework and outlook. J. Intell. Manuf. 2020, 31, 529–552. [Google Scholar] [CrossRef]
- Yannou, B.; Yvars, P.A.; Hoyle, C.; Chen, W. Set-based design by simulation of usage scenario coverage. J. Eng. Des. 2013, 24, 575–603. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Li, X.; Zhang, J.; Chen, S.; Zhou, M.; Farneth, R.A.; Marsic, I.; Burd, R.S. CAR—A deep learning structure for concurrent activity recognition. In Proceedings of the 2017 16th ACM/IEEE International Conference on Information Processing in Sensor Networks, IPSN 2017, Pittsburgh, PA, USA, 18–21 April 2017; pp. 299–300. [Google Scholar] [CrossRef]
- Zheng, P.; Xu, X.; Chen, C.H. A data-driven cyber-physical approach for personalised smart, connected product co-development in a cloud-based environment. J. Intell. Manuf. 2020, 31, 3–18. [Google Scholar] [CrossRef]
- Burnap, P.; Branson, D.; Murray-Rust, D.; Preston, J.; Richards, D.; Burnett, D.; Edwards, N.; Firth, R.; Gorkovenko, K.; Khanesar, M.; et al. Chatty factories: A vision for the future of product design and manufacture with IoT. In Proceedings of the Living in the Internet of Things (IoT 2019), London, UK, 1–2 May 2019; pp. 4–6. [Google Scholar] [CrossRef]
- Crabtree, A.; Chamberlain, A.; Grinter, R.E.; Jones, M.; Rodden, T.; Rogers, Y. Introduction to the Special Issue of “The Turn to The Wild”. ACM Trans. Comput. Hum. Interact. 2013, 20. [Google Scholar] [CrossRef]
- Voet, H.; Altenhof, M.; Ellerich, M.; Schmitt, R.H.; Linke, B. A Framework for the Capture and Analysis of Product Usage Data for Continuous Product Improvement. J. Manuf. Sci. Eng. Trans. ASME 2019, 141. [Google Scholar] [CrossRef]
- Moraes, M.M.; Mendes, T.T.; Arantes, R.M.E. Smart Wearables for Cardiac Autonomic Monitoring in Isolated, Confined and Extreme Environments: A Perspective from Field Research in Antarctica. Sensors 2021, 21, 1303. [Google Scholar] [CrossRef] [PubMed]
- Milwaukee-Tool. ONE-KEY Tool Tracking, Customization and Security Technology. Available online: https://onekey1.milwaukeetool.com/ (accessed on 24 May 2021).
- Swan, M. Sensor Mania! The Internet of Things, Wearable Computing, Objective Metrics, and the Quantified Self 2.0. J. Sens. Actuator Netw. 2012, 1, 217–253. [Google Scholar] [CrossRef] [Green Version]
- Schmitt, R.; IIF—Institut für Industriekommunikation und Fachmedien GmbH; Apprimus Verlag; Business Forum Qualität (20.:2016:Aachen) Herausgebendes Organ. Smart Quality—QM im Zeitalter von Industrie 4.0: 20. Business Forum Qualität; 12. und 13 September 2016, Aachen; Apprimus Verlag: Aachen, Germany, 2016. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Vepakomma, P.; De, D.; Das, S.K.; Bhansali, S. A-Wristocracy: Deep learning on wrist-worn sensing for recognition of user complex activities. In Proceedings of the 2015 IEEE 12th International Conference on Wearable and Implantable Body Sensor Networks, BSN 2015, Cambridge, MA, USA, 9–12 June 2015. [Google Scholar] [CrossRef]
- Kim, Y.; Toomajian, B. Hand Gesture Recognition Using Micro-Doppler Signatures with Convolutional Neural Network. IEEE Access 2016, 4, 7125–7130. [Google Scholar] [CrossRef]
- Hammerla, N.Y.; Halloran, S.; Ploetz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables. 2016. Available online: http://xxx.lanl.gov/abs/1604.08880 (accessed on 3 December 2020).
- Qin, J.; Liu, L.; Zhang, Z.; Wang, Y.; Shao, L. Compressive Sequential Learning for Action Similarity Labeling. IEEE Trans. Image Process. 2016, 25, 756–769. [Google Scholar] [CrossRef]
- Patel, A.A. Hands-On Unsupervised Learning Using Python: How to Build Applied Machine Learning Solutions from Unlabeled Data; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Rani, S.; Babbar, H.; Coleman, S.; Singh, A.; Aljahdali, H.M. An Efficient and Lightweight Deep Learning Model for Human Activity Recognition Using Smartphones. Sensors 2021, 21, 3845. [Google Scholar] [CrossRef]
- Russell, B.; McDaid, A.; Toscano, W.; Hume, P. Moving the Lab into the Mountains: A Pilot Study of Human Activity Recognition in Unstructured Environments. Sensors 2021, 21, 654. [Google Scholar] [CrossRef]
- Jun, K.; Choi, S. Unsupervised End-to-End Deep Model for Newborn and Infant Activity Recognition. Sensors 2020, 20, 6467. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Luo, H.; Wang, Q.; Zhao, F.; Ye, L.; Zhang, Y. A Human Activity Recognition Algorithm Based on Stacking Denoising Autoencoder and LightGBM. Sensors 2019, 19, 947. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wyatt, D.; Philipose, M.; Choudhury, T. Unsupervised Activity Recognition Using Automatically Mined Common Sense. AAAI 2005, 1, 21–27. [Google Scholar]
- Huynh, D.T.G. Human Activity Recognition with Wearable Sensors. Ph.D. Thesis, Technische Universität, Darmstadt, Germany, 2008. [Google Scholar]
- Li, F.; Dustdar, S. Incorporating Unsupervised Learning in Activity Recognition. In Proceedings of the AAAI Publications, Workshops at the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–8 August 2011; pp. 38–41. [Google Scholar]
- Vandewiele, F.; Motamed, C. An unsupervised learning method for human activity recognition based on a temporal qualitative model. In Proceedings of the International Workshop on Behaviour Analysis and Video Understanding, Antipolis, France, 23 September 2011; p. 9. [Google Scholar]
- Trabelsi, D.; Mohammed, S.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. An unsupervised approach for automatic activity recognition based on Hidden Markov Model regression. IEEE Trans. Autom. Sci. Eng. 2013, 10, 829–835. [Google Scholar] [CrossRef] [Green Version]
- Uddin, M.Z.; Thang, N.D.; Kim, J.T.; Kim, T. Human Activity Recognition Using Body Joint-Angle Features and Hidden Markov Model. ETRI J. 2011, 33, 569–579. [Google Scholar] [CrossRef] [Green Version]
- Mathie, M.J.; Coster, A.C.F.; Lovell, N.H.; Celler, B.G. Accelerometry: Providing an integrated, practical method for long-term, ambulatory monitoring of human movement. Physiol. Meas. 2004, 25, R1–R20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Veltink, P.; Bussmann, H.; de Vries, W.; Martens, W.L.J.; Van Lummel, R. Detection of static and dynamic activities using uniaxial accelerometers. IEEE Trans. Rehabil. Eng. 1996, 4, 375–385. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aminian, K.; Robert, P.; Buchser, E.E.; Rutschmann, B.; Hayoz, D.; Depairon, M. Physical activity monitoring based on accelerometry: Validation and comparison with video observation. Med. Biol. Eng. Comput. 1999, 37, 304–308. [Google Scholar] [CrossRef] [PubMed]
- Foerster, F.; Fahrenberg, J. Motion pattern and posture: Correctly assessed by calibrated accelerometers. Behav. Res. Methods Instrum. Comput. 2000, 32, 450–457. [Google Scholar] [CrossRef]
- Isaia, C.; McNally, D.S.; McMaster, S.A.; Branson, D.T. Effect of mechanical preconditioning on the electrical properties of knitted conductive textiles during cyclic loading. Text. Res. J. 2019, 89, 445–460. [Google Scholar] [CrossRef]
- Cappozzo, A.; Della Croce, U.; Leardini, A.; Chiari, L. Human movement analysis using stereophotogrammetry: Part 1: Theoretical background. Gait Posture 2005, 21, 186–196. [Google Scholar] [PubMed]
- Sutherland, D.H. The evolution of clinical gait analysis part l: Kinesiological EMG. Gait Posture 2001, 14, 61–70. [Google Scholar] [CrossRef]
- Yang, C.C.; Hsu, Y.L.; Shih, K.S.; Lu, J.M. Real-time gait cycle parameter recognition using a wearable accelerometry system. Sensors 2011, 11, 7314–7326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, H.; Black, N.D.; Harris, N.D. Position-sensing technologies for movement analysis in stroke rehabilitation. Med. Biol. Eng. Comput. 2005, 43, 413–420. [Google Scholar] [CrossRef] [PubMed]
- Chen, X. Modelling and Predicting Textile Behaviour; Elsevier: Amsterdam, The Netherlands, 2009. [Google Scholar]
- Almaslukh, B.; Almaslukh, B.; Almuhtadi, J.; Artoli, A. An Effective Deep Autoencoder Approach for Online Smartphone-Based Human Activity Recognition Online Smartphone-Based Human Activity Recognition View Project an Effective Deep Autoencoder Approach for Online Smartphone-Based Human Activity Recognition. Available online: https://www.semanticscholar.org/paper/An-effective-deep-autoencoder-approach-for-online-Almaslukh-Artoli/d77c62ee69df0bdbd0be2a95001e1a03f6228cc1 (accessed on 24 May 2021).
- Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep Activity Recognition Models with Triaxial Accelerometers. In Proceedings of the Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 8–13. [Google Scholar]
- LSTM Networks for Mobile Human Activity Recognition; Atlantis Press: Paris, France, 2016. [CrossRef] [Green Version]
- Guan, Y.; Ploetz, T. Ensembles of Deep LSTM Learners for Activity Recognition Using Wearables. 2017. Available online: http://xxx.lanl.gov/abs/1703.09370 (accessed on 5 January 2021). [CrossRef] [Green Version]
- Fang, H.; Hu, C. Recognizing human activity in smart home using deep learning algorithm. In Proceedings of the 33rd Chinese Control Conference, CCC 2014, Nanjing, China, 28–30 July 2014; pp. 4716–4720. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.Y. Deep Recurrent Neural Networks for Human Activity Recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gjoreski, H.; Bizjak, J.; Gjoreski, M.; Gams, M. Comparing Deep and Classical Machine Learning Methods for Human Activity Recognition using Wrist Accelerometer. In Proceedings of the IJCAI-16 Workshop on Deep Learning for Artificial Intelligence (DLAI), New York, NY, USA, 9–15 July 2016; pp. 1–7. [Google Scholar]
- Ha, S.; Choi, S. Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In Proceedings of the International Joint Conference on Neural Networks, Vancouver, BC, Canada, 24–29 July 2016; pp. 381–388. [Google Scholar] [CrossRef]
- Inoue, M.; Inoue, S.; Nishida, T. Deep recurrent neural network for mobile human activity recognition with high throughput. Artif. Life Robot. 2018, 23, 173–185. [Google Scholar] [CrossRef] [Green Version]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In Proceedings of the MM 2015—ACM Multimedia Conference, Brisbane, Australia, 26–30 October 2015; pp. 1307–1310. [Google Scholar] [CrossRef]
- Lane, N.D.; Georgiev, P. Can deep learning revolutionize mobile sensing? In Proceedings of the HotMobile 2015—16th International Workshop on Mobile Computing Systems and Applications, Santa Fe, NM, USA, 12–13 February 2015; pp. 117–122. [Google Scholar] [CrossRef] [Green Version]
- Ordóñez, F.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Radu, V.; Lane, N.D.; Bhattacharya, S.; Mascolo, C.; Marina, M.K.; Kawsar, F. Towards multimodal deep learning for activity recognition on mobile devices. In Proceedings of the UbiComp 2016 Adjunct—The 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 185–188. [Google Scholar] [CrossRef]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.Z. Deep learning for human activity recognition: A resource efficient implementation on low-power devices. In Proceedings of the BSN 2016—13th Annual Body Sensor Networks Conference, San Francisco, CA, USA, 14–17 June 2016; pp. 71–76. [Google Scholar] [CrossRef] [Green Version]
- Ronao, C.A.; Cho, S.B. Deep convolutional neural networks for human activity recognition with smartphone sensors. Proc. Kiise Korea Comput. Congr. 2015, 9492, 858–860. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Walse, K.H.; Dharaskar, R.V.; Thakare, V.M. PCA based optimal ANN classifiers for human activity recognition using mobile sensors data. In Smart Innovation, Systems and Technologies; Springer: Berlin/Heidelberg, Germany, 2016; Volume 50, pp. 429–436. [Google Scholar] [CrossRef]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. DeepSense: A unified deep learning framework for time-series mobile sensing data processing. In Proceedings of the 26th International World Wide Web Conference, WWW 2017, Perth, Australia, 3–7 April 2017; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2017; pp. 351–360. [Google Scholar] [CrossRef]
- Zebin, T.; Scully, P.J.; Ozanyan, K.B. Human activity recognition with inertial sensors using a deep learning approach. In Proceedings of the IEEE Sensors, Orlando, FL, USA, 30 October–3 November 2016. [Google Scholar] [CrossRef] [Green Version]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional Neural Networks for human activity recognition using mobile sensors. In Proceedings of the 2014 6th International Conference on Mobile Computing, Applications and Services, MobiCASE 2014, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Wu, X.; Luo, D. Real-time activity recognition on smartphones using deep neural networks. In Proceedings of the 2015 IEEE 12th Intl Conf on Ubiquitous Intelligence and Computing and 2015 IEEE 12th Intl Conf on Autonomic and Trusted Computing and 2015 IEEE 15th Intl Conf on Scalable Computing and Communications and Its Associated Workshops (UIC-ATC-ScalCom), Beijing, China, 10–14 August 2015; pp. 1236–1242. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X.; Luo, D. Recognizing human activities from raw accelerometer data using deep neural networks. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications, ICMLA 2015, Miami, FL, USA, 9–11 December 2015; pp. 865–870. [Google Scholar] [CrossRef]
- Krishnan, N.C.; Panchanathan, S. Analysis of low resolution accelerometer data for continuous human activity recognition. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 3337–3340. [Google Scholar] [CrossRef]
- Foerster, F.; Smeja, M.; Fahrenberg, J. Detection of posture and motion by accelerometry: A validation study in ambulatory monitoring. Comput. Hum. Behav. 1999, 15, 571–583. [Google Scholar] [CrossRef]
- Najafi, B.; Aminian, K.; Paraschiv-Ionescu, A.; Loew, F.; Büla, C.J.; Robert, P. Ambulatory system for human motion analysis using a kinematic sensor: Monitoring of daily physical activity in the elderly. IEEE Trans. Biomed. Eng. 2003, 50, 711–723. [Google Scholar] [CrossRef]
- Banos, O.; Damas, M.; Pomares, H.; Prieto, A.; Rojas, I. Daily living activity recognition based on statistical feature quality group selection. Expert Syst. Appl. 2012, 39, 8013–8021. [Google Scholar] [CrossRef]
- Cheng, W.Y.; Scotland, A.; Lipsmeier, F.; Kilchenmann, T.; Jin, L.; Schjodt-Eriksen, J.; Wolf, D.; Zhang-Schaerer, Y.P.; Garcia, I.F.; Siebourg-Polster, J.; et al. Human Activity Recognition from Sensor-Based Large-Scale Continuous Monitoring of Parkinson’s Disease Patients. In Proceedings of the 2017 IEEE 2nd International Conference on Connected Health: Applications, Systems and Engineering Technologies, CHASE 2017, Philadelphia, PA, USA, 17–19 July 2017; pp. 249–250. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Lane, N.D. From smart to deep: Robust activity recognition on smartwatches using deep learning. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communication Workshops, PerCom Workshops 2016, Sydney, NSW, Australia, 14–18 March 2016; Institute of Electrical and Electronics Engineers Inc.: Sydney, NSW, Australia, 2016. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing, BigComp 2017, Jeju, Korea, 13–16 February 2017; pp. 131–134. [Google Scholar] [CrossRef]
- Thomas Plötz, N.Y.H. Feature Learning for Activity Recognition in Ubiquitous Computing. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 1729–1734. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X.; Luo, D. Human activity recognition with HMM-DNN model. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics and Cognitive Computing, ICCI*CC 2015, Beijing, China, 6–8 July 2015; pp. 192–197. [Google Scholar] [CrossRef]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.Z. A Deep Learning Approach to on-Node Sensor Data Analytics for Mobile or Wearable Devices. IEEE J. Biomed. Health Inform. 2017, 21, 56–64. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Exploiting multi-channels deep convolutional neural networks for multivariate time series classification. Front. Comput. Sci. 2016, 10, 96–112. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, Y. A Deep Learning Approach to Human Activity Recognition Based on Single Accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2015, Hong Kong, China, 9–12 October 2015; Institute of Electrical and Electronics Engineers Inc.: Hong Kong, China, 2016; pp. 1488–1492. [Google Scholar] [CrossRef]
- Edel, M.; Köppe, E. Binarized-BLSTM-RNN based Human Activity Recognition. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation, IPIN 2016, Alcala de Henares, Spain, 4–7 October 2016. [Google Scholar] [CrossRef]
- Mohammed, S.; Tashev, I. Unsupervised deep representation learning to remove motion artifacts in free-mode body sensor networks. In Proceedings of the 2017 IEEE 14th International Conference on Wearable and Implantable Body Sensor Networks, BSN 2017, Eindhoven, The Netherlands, 9–12 May 2017; pp. 183–188. [Google Scholar] [CrossRef]
- Panwar, M.; Ram Dyuthi, S.; Chandra Prakash, K.; Biswas, D.; Acharyya, A.; Maharatna, K.; Gautam, A.; Naik, G.R. CNN based approach for activity recognition using a wrist-worn accelerometer. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, Jeju, Korea, 11–15 July 2017; pp. 2438–2441. [Google Scholar] [CrossRef]
- Mantyjarvi, J.; Himberg, J.; Seppanen, T. Recognizing human motion with multiple acceleration sensors. In Proceedings of the 2001 IEEE International Conference on Systems, Man and Cybernetics. e-Systems and e-Man for Cybernetics in Cyberspace (Cat.No.01CH37236), Tucson, AZ, USA, 7–10 October 2001; Volume 2, pp. 747–752. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–17. [Google Scholar] [CrossRef]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window Size Impact in Human Activity Recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hammerla, N.Y.; Fisher, J.M.; Andras, P.; Rochester, L.; Walker, R.; Plötz, T. PD disease state assessment in naturalistic environments using deep learning. Proc. Natl. Conf. Artif. Intell. 2015, 3, 1742–1748. [Google Scholar]
- Hayashi, T.; Nishida, M.; Kitaoka, N.; Takeda, K. Daily activity recognition based on DNN using environmental sound and acceleration signals. In Proceedings of the 2015 23rd European Signal Processing Conference, EUSIPCO 2015, Nice, France, 31 August–4 September 2015; pp. 2306–2310. [Google Scholar] [CrossRef] [Green Version]
- Lane, N.D.; Georgiev, P.; Qendro, L. DeepEar: Robust smartphone audio sensing in unconstrained acoustic environments using deep learning. In Proceedings of the UbiComp 2015—The 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 283–294. [Google Scholar] [CrossRef] [Green Version]
- Sathyanarayana, A.; Joty, S.; Fernandez-Luque, L.; Ofli, F.; Srivastava, J.; Elmagarmid, A.; Taheri, S.; Arora, T. Impact of Physical Activity on Sleep: A Deep Learning Based Exploration. arXiv 2016, arXiv:1607.07034. [Google Scholar]
- Kim, Y.; Li, Y. Human Activity Classification with Transmission and Reflection Coefficients of On-Body Antennas Through Deep Convolutional Neural Networks. IEEE Trans. Antennas Propag. 2017, 65, 2764–2768. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, L.; Liu, Z.; Liu, K.; Li, X.; Liu, Y. Lasagna: Towards deep hierarchical understanding and searching over mobile sensing data. In Proceedings of the Annual International Conference on Mobile Computing and Networking, MOBICOM, New York, NY, USA, 3–7 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 334–347. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zhang, X.; Gao, Q.; Yue, H.; Wang, H. Device-Free Wireless Localization and Activity Recognition: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2017, 66, 6258–6267. [Google Scholar] [CrossRef]
- Costello, S. The Sensors That Make the iPhone So Cool. Available online: https://www.lifewire.com/sensors-that-make-iphone-so-cool-2000370 (accessed on 4 February 2020).
- Allan, A. Basic Sensors in iOS; O’Reilly Media: Sebastopol, CA, USA, 2011; p. 89. [Google Scholar]
- MATLAB. 7 Reasons MATLAB Is the Easiest and Most Productive Environment for Engineers and Scientists. 2020. Available online: https://www.linkedin.com/pulse/7-reasons-matlab-easiest-most-productive-environment-engineers-tate?articleId=6228200317306044416 (accessed on 4 February 2020).
- Frank, E.; Hall, M.; Trigg, L.; Holmes, G.; Witten, I.H. Data mining in bioinformatics using Weka. Bioinformatics 2004, 20, 2479–2481. [Google Scholar] [CrossRef] [Green Version]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Bansal, A.; Sachan, A.; Kaur, M. Analyzing Machine Learning and Statistical Models for Software Change Prediction. Available online: https://www.krishisanskriti.org/vol_image/22Oct201506104627%20%20%20%20%20%20%20%20%20%20Ankita%20Bansal%20%20%20%20%20%20%20%20%20%20%2099-103.pdf (accessed on 4 February 2020).
- Malhotra, R.; Khanna, M. Examining the effectiveness of machine learning algorithms for prediction of change prone classes. In Proceedings of the 2014 International Conference on High Performance Computing & Simulation (HPCS), Bologna, Italy, 21–25 July 2014; pp. 635–642. [Google Scholar]
- Malhotra, R.; Khanna, M. Investigation of relationship between object-oriented metrics and change proneness. Int. J. Mach. Learn. Cybern. 2013, 4, 273–286. [Google Scholar] [CrossRef]
- Nizamani, S.; Memon, N.; Wiil, U.K.; Karampelas, P. Modeling suspicious email detection using enhanced feature selection. arXiv 2013, arXiv:1312.1971. [Google Scholar] [CrossRef] [Green Version]
- Kodinariya, T.M.; Makwana, P.R. Review on determining number of Cluster in K-Means Clustering. Int. J. 2013, 1, 90–95. [Google Scholar]
- Pollard, D. Strong consistency of k-means clustering. Ann. Stat. 1981, 9, 135–140. [Google Scholar] [CrossRef]
- Chakrabarty, N.; Rana, S.; Chowdhury, S.; Maitra, R. RBM Based Joke Recommendation System and Joke Reader Segmentation. In International Conference on Pattern Recognition and Machine Intelligence; Springer: Cham, Switzerland, 2019; pp. 229–239. [Google Scholar]
- Kuraria, A.; Jharbade, N.; Soni, M. Centroid Selection Process Using WCSS and Elbow Method for K-Mean Clustering Algorithm in Data Mining. Int. J. Sci. Res. Sci. Eng. Technol. 2018, 4, 190–195. [Google Scholar] [CrossRef]
- Shippey, T.; Bowes, D.; Hall, T. Automatically identifying code features for software defect prediction: Using AST N-grams. Inf. Softw. Technol. 2019, 106, 142–160. [Google Scholar] [CrossRef]
- Zang, H.; Zhang, S.; Hapeshi, K. A review of nature-inspired algorithms. J. Bionic Eng. 2010, 7, S232–S237. [Google Scholar] [CrossRef]
- Shrivastava, P.; Shukla, A.; Vepakomma, P.; Bhansali, N.; Verma, K. A survey of nature-inspired algorithms for feature selection to identify Parkinson’s disease. Comput. Methods Programs Biomed. 2017, 139, 171–179. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability; Univeraity of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Elsevier Inc.: Amsterdam, The Netherlands, 2016; pp. 1–621. [Google Scholar] [CrossRef] [Green Version]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The Global k-Means Clustering Algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data Via the EM Algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Krishnan, T. The EM Algorithm and Extensions, 2nd ed.; Wiley Blackwell: Hoboken, NJ, USA, 2007; pp. 1–369. [Google Scholar] [CrossRef]
- Sharmila, S.; Kumar, M. An optimized farthest first clustering algorithm. In Proceedings of the 2013 Nirma University International Conference on Engineering, NUiCONE 2013, Ahmedabad, India, 28–30 November 2013. [Google Scholar] [CrossRef]
- Miyamoto, S.; Ichihashi, H.; Honda, K. Algorithms for Fuzzy Clustering Methods in c-Means Clustering with Applications; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Stetco, A.; Zeng, X.J.; Keane, J. Fuzzy C-means++: Fuzzy C-means with effective seeding initialization. Expert Syst. Appl. 2015, 42, 7541–7548. [Google Scholar] [CrossRef]
- Döring, C.; Lesot, M.J.; Kruse, R. Data analysis with fuzzy clustering methods. Comput. Stat. Data Anal. 2006, 51, 192–214. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Maheshwari, S.; Agrawal, J.; Sharma, S. A new approach for Classification of Highly Imbalancade Datasets using Evolutionary Algorithms. Int. J. Sci. Eng. Res. 2011, 2, 1–5. [Google Scholar]
- Shepperd, M.; Bowes, D.; Hall, T. Researcher bias: The use of machine learning in software defect prediction. IEEE Trans. Softw. Eng. 2014, 40, 603–616. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Wursch, M.; Giger, E.; Gall, H.; Lu, J. A bayesian network based approach for change coupling prediction. In Proceedings of the 15th Working Conference on Reverse Engineering, WCRE’08, Antwerp, Belgium, 15–18 October 2008; pp. 27–36. [Google Scholar]






| Precision | Recall | F-Measure | MCC | Classes Mapped to Clusters | |
|---|---|---|---|---|---|
| K-means | 0.58 | 0.57 | 0.57 | 0.45 | All 6 |
| Expectation-maximization (EM) | 0.79 | 0.80 | 0.79 | 0.78 | All 6 |
| Farthest first | 0.57 | 0.67 | 0.61 | 0.31 | Only 3 |
| Fuzzy C-means | 0.87 | 0.87 | 0.87 | 0.84 | All 6 |
| Evaluation Metrics | Class #1 Dropping and Picking Up | Class #2 Sitting | Class #3 Standing | Class #4 Stationary on Side Table | Class #5 Vibrating Surface | Class #6 Walking |
|---|---|---|---|---|---|---|
| Precision | 0.94 | 0.82 | 0.84 | 0.76 | 0.99 | 0.94 |
| Recall | 1. | 1. | 0.69 | 0.99 | 0.53 | 1. |
| F-measure | 0.97 | 0.90 | 0.76 | 0.86 | 0.69 | 0.97 |
| MCC | 0.96 | 0.88 | 0.72 | 0.84 | 0.69 | 0.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lakoju, M.; Ajienka, N.; Khanesar, M.A.; Burnap, P.; Branson, D.T. Unsupervised Learning for Product Use Activity Recognition: An Exploratory Study of a “Chatty Device”. Sensors 2021, 21, 4991. https://doi.org/10.3390/s21154991
Lakoju M, Ajienka N, Khanesar MA, Burnap P, Branson DT. Unsupervised Learning for Product Use Activity Recognition: An Exploratory Study of a “Chatty Device”. Sensors. 2021; 21(15):4991. https://doi.org/10.3390/s21154991
Chicago/Turabian StyleLakoju, Mike, Nemitari Ajienka, M. Ahmadieh Khanesar, Pete Burnap, and David T. Branson. 2021. "Unsupervised Learning for Product Use Activity Recognition: An Exploratory Study of a “Chatty Device”" Sensors 21, no. 15: 4991. https://doi.org/10.3390/s21154991
APA StyleLakoju, M., Ajienka, N., Khanesar, M. A., Burnap, P., & Branson, D. T. (2021). Unsupervised Learning for Product Use Activity Recognition: An Exploratory Study of a “Chatty Device”. Sensors, 21(15), 4991. https://doi.org/10.3390/s21154991