
Attention-Based Multi-Scale Convolutional Neural Network (A+MCNN) for Multi-Class Classification in Road Images

Abstract
:1. Introduction
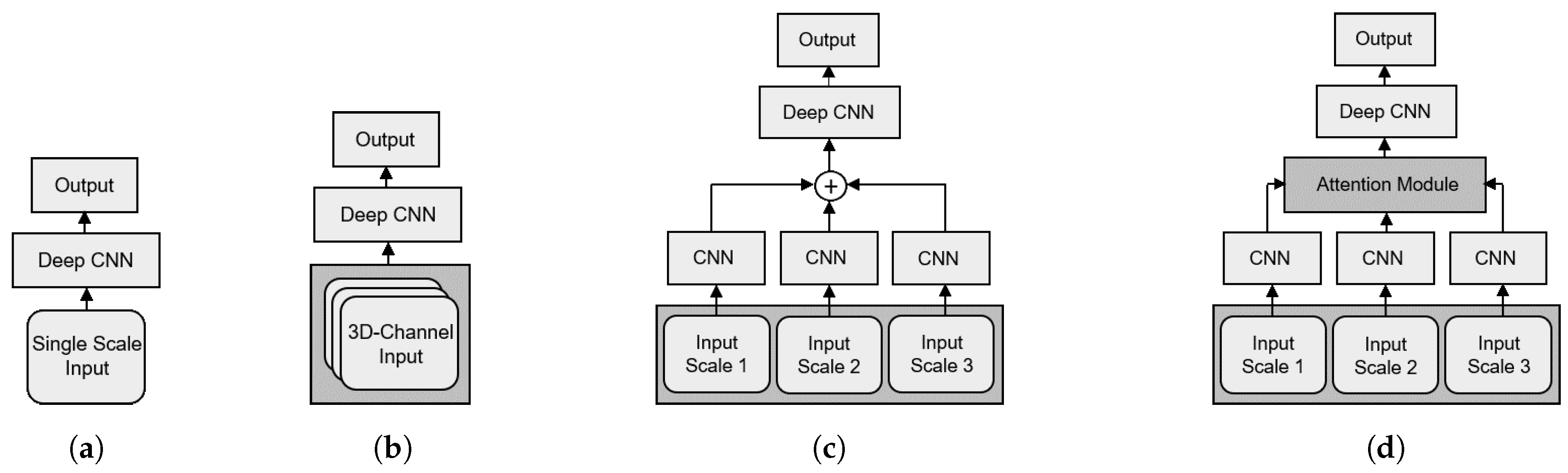
- We employ the A+MCNN with two unique features that are crucial for improving classification performance: (i) the extraction of multi-scale features using input tiles at three different scales, and (ii) an attention-module for the mid-fusion to produce score maps as weight matrices determining the degree to which feature maps at different scales should contribute to the final class label prediction.
- Using the UCF-PAVE 2017 dataset, the classification task is conducted for a wide range of objects in images collected from two types of pavement in various conditions. Furthermore, quantitative and qualitative comparisons of the state-of-the-art classifiers’ performance on pavement objects are provided.
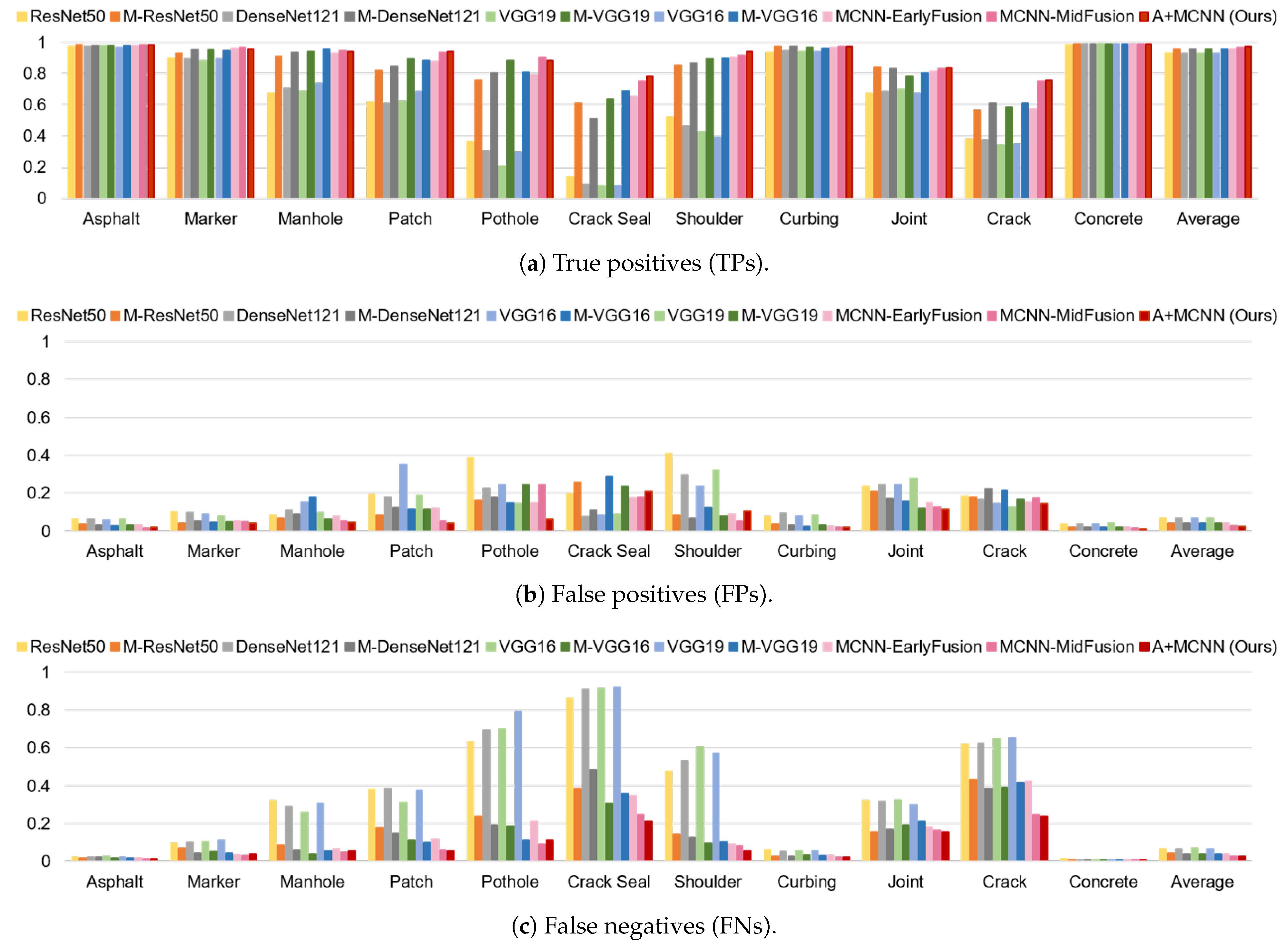
- The A+MCNN outperforms all compared classifiers by 1∼26% on average in terms of the F-score.
2. Related Works
2.1. Deep Learning in Pavement Image Analysis
2.2. Multi-Scale Features in Deep Learning
2.3. Attention Models in Deep Learning
3. Method
3.1. Network Architecture
3.2. Multi-Scale Inputs
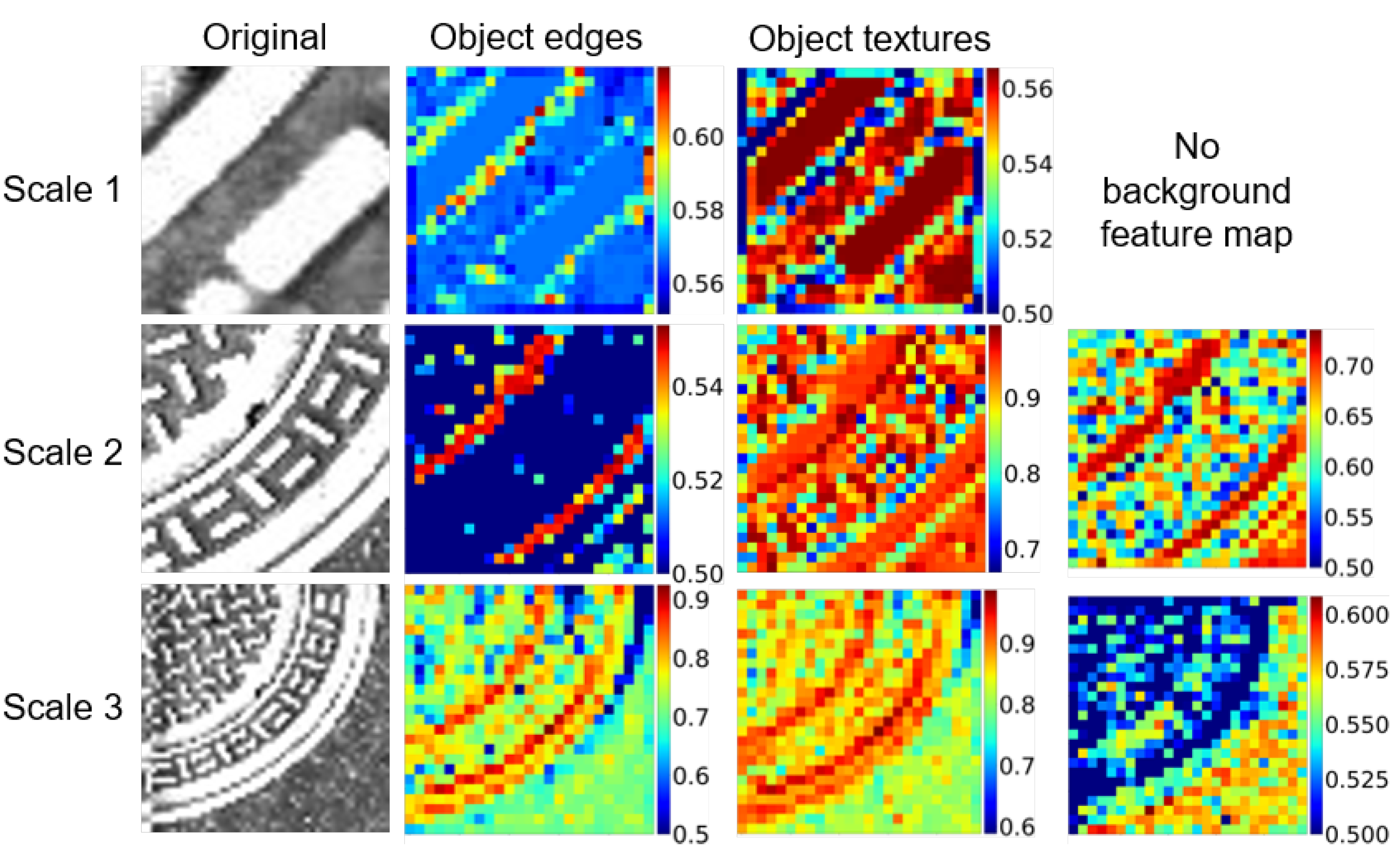
3.3. Mid-Level Fusion with an Attention Module
4. Data Preparation for Evaluation
5. Experiment Setup and Results
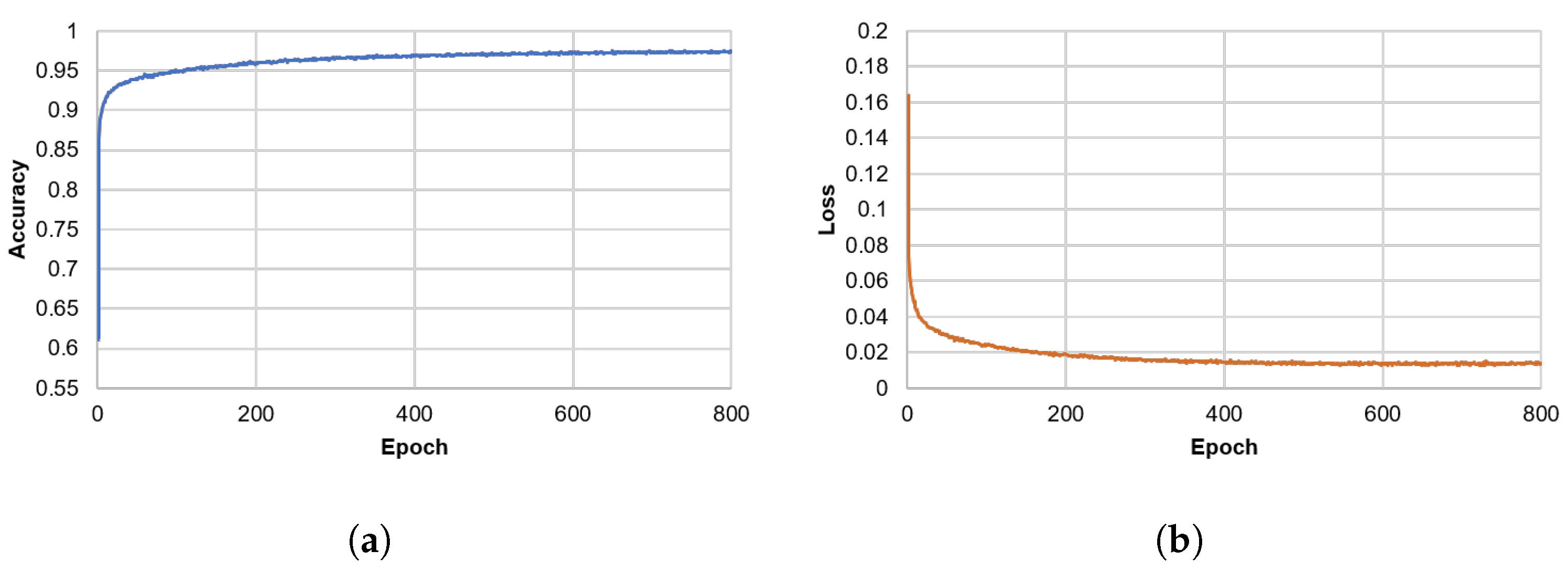
5.1. Training
5.2. Baseline Models for Performance Comparison
5.3. Experiment Results
6. Discussion
6.1. Effects of A+MCNN Parameters
6.2. Capability of Class Separation
6.3. Computational Costs
6.4. Comparison with a Pavement Classifier
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- ASCE’s Infrastructure Report Card|GPA: C-. In ASCE’s 2021 Infrastructure Report Card; American Society of Civil Engineers: Reston, VA, USA, 2021.
- Gopalakrishnan, K. Deep learning in data-driven pavement image analysis and automated distress detection: A review. Data 2018, 3, 28. [Google Scholar] [CrossRef] [Green Version]
- Zakeri, H.; Nejad, F.M.; Fahimifar, A. Image based techniques for crack detection, classification and quantification in asphalt pavement: A review. Arch. Comput. Methods Eng. 2017, 24, 935–977. [Google Scholar] [CrossRef]
- Ragnoli, A.; De Blasiis, M.R.; Di Benedetto, A. Pavement distress detection methods: A review. Infrastructures 2018, 3, 58. [Google Scholar] [CrossRef] [Green Version]
- Cao, W.; Liu, Q.; He, Z. Review of pavement defect detection methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder–Decoder network for pixel-level road crack detection in black-box images. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 713–727. [Google Scholar] [CrossRef]
- Song, W.; Jia, G.; Jia, D.; Zhu, H. Automatic Pavement Crack Detection and Classification Using Multiscale Feature Attention Network. IEEE Access 2019, 7, 171001–171012. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1525–1535. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Zong, J.; Nie, J.; Wu, Z.; Han, H. Pavement crack detection algorithm based on densely connected and deeply supervised network. IEEE Access 2021, 9, 11835–11842. [Google Scholar] [CrossRef]
- Hu, Y.; Zhao, C.X. A novel LBP based methods for pavement crack detection. J. Pattern Recognit. Res. 2010, 5, 140–147. [Google Scholar] [CrossRef]
- Yun, H.B.; Mokhtari, S.; Wu, L. Crack recognition and segmentation using morphological image-processing techniques for flexible pavements. Transp. Res. Rec. 2015, 2523, 115–124. [Google Scholar] [CrossRef]
- Chambon, S.; Subirats, P.; Dumoulin, J. Introduction of a wavelet transform based on 2D matched filter in a Markov Random Field for fine structure extraction: Application on road crack detection. In Image Processing: Machine Vision Applications II. International Society for Optics and Photonics; International Society for Optics and Photonics: Bellingham, WA, USA, 2009; Volume 7251, p. 72510A. [Google Scholar]
- Koch, C.; Brilakis, I. Pothole detection in asphalt pavement images. Adv. Eng. Inform. 2011, 25, 507–515. [Google Scholar] [CrossRef]
- Wu, L.; Mokhtari, S.; Nazef, A.; Nam, B.; Yun, H.B. Improvement of crack-detection accuracy using a novel crack defragmentation technique in image-based road assessment. J. Comput. Civ. Eng. 2016, 30, 04014118. [Google Scholar] [CrossRef]
- Sultani, W.; Mokhtari, S.; Yun, H.B. Automatic pavement object detection using superpixel segmentation combined with conditional random field. IEEE Trans. Intell. Transp. Syst. 2017, 19, 2076–2085. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inform. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, C.; Chen, L.C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Fei-Fei, L. Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 82–92. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE international Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Li, B.; Wang, K.C.; Zhang, A.; Yang, E.; Wang, G. Automatic classification of pavement crack using deep convolutional neural network. Int. J. Pavement Eng. 2020, 21, 457–463. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Fei, Y.; Liu, Y.; Tao, S.; Chen, C.; Li, J.Q.; Li, B. Deep learning–based fully automated pavement crack detection on 3D asphalt surfaces with an improved CrackNet. J. Comput. Civ. Eng. 2018, 32, 04018041. [Google Scholar] [CrossRef] [Green Version]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. Deepcrack: Learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 2018, 28, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Lau, S.L.; Chong, E.K.; Yang, X.; Wang, X. Automated pavement crack segmentation using u-net-based convolutional neural network. IEEE Access 2020, 8, 114892–114899. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Munich, Germany, 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Radopoulou, S.C.; Brilakis, I. Automated detection of multiple pavement defects. J. Comput. Civ. Eng. 2017, 31, 04016057. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhao, X.; Li, H. Method for detecting road pavement damage based on deep learning. In Health Monitoring of Structural and Biological Systems XIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10972, p. 109722D. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inform. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Anand, S.; Gupta, S.; Darbari, V.; Kohli, S. Crack-pot: Autonomous road crack and pothole detection. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–6. [Google Scholar]
- Yao, J.; Fidler, S.; Urtasun, R. Describing the scene as a whole: Joint object detection, scene classification and semantic segmentation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 702–709. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Convolutional feature masking for joint object and stuff segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3992–4000. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Lin, G.; Shen, C.; Van Den Hengel, A.; Reid, I. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3194–3203. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.C.; Tang, X. Semantic image segmentation via deep parsing network. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1377–1385. [Google Scholar]
- Chandra, S.; Usunier, N.; Kokkinos, I. Dense and low-rank gaussian crfs using deep embeddings. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5103–5112. [Google Scholar]
- Chandra, S.; Kokkinos, I. Fast, exact and multi-scale inference for semantic image segmentation with deep gaussian crfs. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 402–418. [Google Scholar]
- Pinheiro, P.; Collobert, R. Recurrent convolutional neural networks for scene labeling. Int. Conf. Mach. Learn. PMLR 2014, 32, 82–90. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Mostajabi, M.; Yadollahpour, P.; Shakhnarovich, G. Feedforward semantic segmentation with zoom-out features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3376–3385. [Google Scholar]
- Komori, T.; Matsushima, K.; Takahashi, O. Automatic Pavement Crack Detection using Multi-Scale Image & Neighborhoods Information. In Proceedings of the 2019 International Conference on Mechatronics, Robotics and Systems Engineering (MoRSE), Bali, Indonesia, 4–6 December 2019; pp. 227–232. [Google Scholar]
- Ai, D.; Jiang, G.; Kei, L.S.; Li, C. Automatic pixel-level pavement crack detection using information of multi-scale neighborhoods. IEEE Access 2018, 6, 24452–24463. [Google Scholar] [CrossRef]
- Sun, M.; Guo, R.; Zhu, J.; Fan, W. Roadway Crack Segmentation Based on an Encoder-decoder Deep Network with Multi-scale Convolutional Blocks. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 0869–0874. [Google Scholar]
- König, J.; Jenkins, M.D.; Barrie, P.; Mannion, M.; Morison, G. Segmentation of Surface Cracks Based on a Fully Convolutional Neural Network and Gated Scale Pooling. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Xiao, T.; Xu, Y.; Yang, K.; Zhang, J.; Peng, Y.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.J.; Wierstra, D. Draw: A recurrent neural network for image generation. arXiv 2015, arXiv:1502.04623. [Google Scholar]
- Cao, C.; Liu, X.; Yang, Y.; Yu, Y.; Wang, J.; Wang, Z.; Huang, Y.; Wang, L.; Huang, C.; Xu, W.; et al. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2956–2964. [Google Scholar]
- Yoo, D.; Park, S.; Lee, J.Y.; Paek, A.S.; So Kweon, I. Attentionnet: Aggregating weak directions for accurate object detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2659–2667. [Google Scholar]
- Caicedo, J.C.; Lazebnik, S. Active object localization with deep reinforcement learning. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2488–2496. [Google Scholar]
- Ba, J.; Mnih, V.; Kavukcuoglu, K. Multiple object recognition with visual attention. arXiv 2014, arXiv:1412.7755. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. Int. Conf. Mach. Learn. PMLR 2015, 37, 2048–2057. [Google Scholar]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked attention networks for image question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 21–29. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Zang, J.; Wang, L.; Liu, Z.; Zhang, Q.; Hua, G.; Zheng, N. Attention-based temporal weighted convolutional neural network for action recognition. In IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer: Rhodes, Greece, 2018; pp. 97–108. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Liu, M.Y.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2097–2104. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
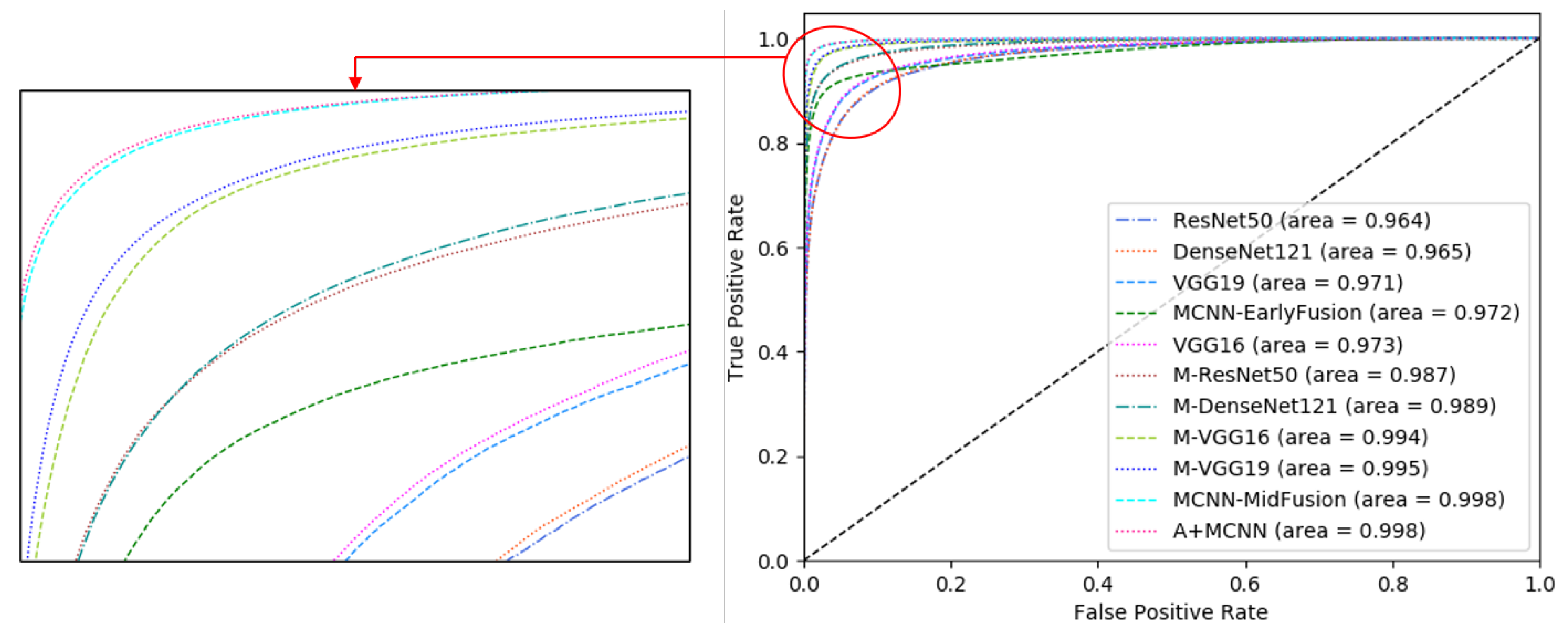{kind=link}
{kind=link}
| References | Methods | Tasks | Objects | Pavement Types |
|---|---|---|---|---|
| [10] | Local Binary Pattern (Non-DL) | Segmentation | Crack Only | Asphalt |
| [11,14] | MorphLink-C (Non-DL) | Segmentation | Crack Only | Asphalt |
| [12] | Wavelet Transform (Non-DL) | Segmentation | Crack Only | Not Specified |
| [32,33] | CNN (DL) | Segmentation | Crack Only | Asphalt |
| [34,35] | CNN (DL) | Segmentation | Crack Only | Not Specified |
| [15] | Superpixel (Non-DL) | Segmentation | Marker, Patch, Manhole, Crack seal | Asphalt |
| [29] | CNN (DL) | Classification | Crack Only | Not Specified |
| [30] | CNN (DL) | Classification | Crack Only | Asphalt+Concrete |
| [31] | CNN (DL) | Classification | Longitudinal Crack, Traverse Crack, Block Crack, Alligator Crack | Asphalt |
| [13] | Shape & Texture Features (Non-DL) | Detection | Pothole Only | Asphalt |
| [38] | CNN (DL) | Detection | Lateral Crack, Longitudinal Crack, Alligator Crack, Pothole, Well Cover | Asphalt |
| [39] | CNN (DL) | Detection | Crack, Pothole | Asphalt |
| [41] | CNN (DL) | Detection | Longitudinal Crack, Transverse Crack, Patch, Pothole | Asphalt |
| Types | Labels | Asphalt Pavement | Concrete Pavement | All Pavement | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of Tiles | Avg. Number of Tiles/img | Std. Number of Tiles/img | Number of Tiles | Avg. Number of Tiles/img | Std. Number of Tiles/img | Total Number of Tiles | Avg. Number of Tiles/img | Std. Number of Tiles/img | ||
| Distress objects | Crack (CRK) | 383,637 (5.4%) | 533 | 723 | 73,325 (2.3%) | 147 | 288 | 456,962 (4.5%) | 376 | 616 |
| Crack seal (CRS) | 18,797 (0.3%) | 26 | 213 | 4812 (0.2%) | 9 | 41 | 23,609 (0.2%) | 19 | 166 | |
| Patch (PAT) | 229,021 (3.2%) | 318 | 960 | 33,955 (1.1%) | 68 | 246 | 262,976 (2.6%) | 216 | 765 | |
| Pothole (POT) | 16,912 (0.2%) | 23 | 208 | 11 (0.0%) | 0 | 0 | 16,923 (0.2%) | 13 | 160 | |
| Non-distress objects | Joint (JNT) | 0 (0.0%) | 0 | 0 | 96,684 (3.1%) | 194 | 147 | 96,684 (0.9%) | 79 | 134 |
| Marker (MRK) | 276,903 (3.9%) | 385 | 635 | 23,432 (0.7%) | 47 | 212 | 300,335 (2.9%) | 247 | 533 | |
| Manhole cover (MAN) | 26,104 (0.4%) | 36 | 119 | 5186 (0.2%) | 10 | 36 | 31,290 (0.3%) | 25 | 95 | |
| Curbing (CUR) | 257,835 (3.7%) | 358 | 394 | 4284 (0.1%) | 8 | 67 | 262,119 (2.6%) | 215 | 351 | |
| Shoulder (SHO) | 19,593 (0.3%) | 27 | 136 | 3626 (0.1%) | 7 | 35 | 23,219 (0.2%) | 19 | 107 | |
| Backgrounds | Asphalt (ASP) | 5,820,803 (82.6%) | 8095 | 3791 | 0 (0.0%) | 0 | 0 | 5,820,803 (57.2%) | 4790 | 4933 |
| Concrete (CON) | 0 (0.0%) | 0 | 0 | 2,888,409 (92.2%) | 5823 | 414 | 2,888,409 (28.4%) | 2377 | 2874 | |
| All | 7,049,605 (100%) | 9,801 | - | 3,133,724 (100%) | 6,313 | - | 10,183,329 (100%) | 8,376 | - | |
| Metric | Method | Asphalt | Marker | Manhole | Patch | Pothole | Crack Seal | Shoulder | Curbing | Joint | Crack | Concrete | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | VGG16 | 0.941 | 0.91 | 0.828 | 0.66 | 0.547 | 0.501 | 0.623 | 0.92 | 0.733 | 0.709 | 0.963 | 0.758 |
| VGG19 | 0.938 | 0.917 | 0.878 | 0.765 | 0.587 | 0.474 | 0.571 | 0.916 | 0.713 | 0.726 | 0.96 | 0.768 | |
| ResNet50 | 0.94 | 0.897 | 0.887 | 0.76 | 0.487 | 0.412 | 0.562 | 0.923 | 0.741 | 0.67 | 0.964 | 0.749 | |
| DenseNet121 | 0.94 | 0.9 | 0.863 | 0.773 | 0.574 | 0.549 | 0.612 | 0.91 | 0.735 | 0.691 | 0.963 | 0.774 | |
| M-VGG16 | 0.969 | 0.953 | 0.841 | 0.885 | 0.844 | 0.707 | 0.88 | 0.975 | 0.837 | 0.742 | 0.98 | 0.874 | |
| M-VGG19 | 0.968 | 0.948 | 0.938 | 0.888 | 0.784 | 0.731 | 0.916 | 0.965 | 0.865 | 0.776 | 0.979 | 0.887 | |
| M-ResNet50 | 0.962 | 0.957 | 0.93 | 0.908 | 0.825 | 0.704 | 0.911 | 0.963 | 0.8 | 0.756 | 0.981 | 0.881 | |
| M-DenseNet121 | 0.967 | 0.947 | 0.911 | 0.874 | 0.818 | 0.823 | 0.926 | 0.965 | 0.829 | 0.733 | 0.98 | 0.889 | |
| MCNN-EarlyFusion | 0.966 | 0.945 | 0.924 | 0.882 | 0.842 | 0.788 | 0.91 | 0.974 | 0.845 | 0.786 | 0.98 | 0.895 | |
| MCNN-MidFusion | 0.982 | 0.948 | 0.944 | 0.945 | 0.788 | 0.808 | 0.944 | 0.978 | 0.867 | 0.812 | 0.983 | 0.909 | |
| A+MCNN (ours) | 0.983 | 0.959 | 0.954 | 0.956 | 0.934 | 0.789 | 0.929 | 0.979 | 0.879 | 0.839 | 0.987 | 0.926 | |
| Recall | VGG16 | 0.971 | 0.896 | 0.74 | 0.688 | 0.299 | 0.085 | 0.394 | 0.942 | 0.676 | 0.352 | 0.989 | 0.639 |
| VGG19 | 0.978 | 0.886 | 0.693 | 0.622 | 0.206 | 0.08 | 0.43 | 0.944 | 0.7 | 0.345 | 0.99 | 0.625 | |
| ResNet50 | 0.975 | 0.902 | 0.677 | 0.618 | 0.368 | 0.139 | 0.524 | 0.938 | 0.676 | 0.379 | 0.986 | 0.653 | |
| DenseNet121 | 0.976 | 0.898 | 0.709 | 0.615 | 0.305 | 0.092 | 0.466 | 0.948 | 0.684 | 0.376 | 0.988 | 0.642 | |
| M-VGG16 | 0.979 | 0.947 | 0.959 | 0.884 | 0.812 | 0.693 | 0.903 | 0.965 | 0.808 | 0.611 | 0.989 | 0.868 | |
| M-VGG19 | 0.981 | 0.953 | 0.941 | 0.898 | 0.884 | 0.64 | 0.895 | 0.969 | 0.785 | 0.586 | 0.991 | 0.866 | |
| M-ResNet50 | 0.983 | 0.931 | 0.911 | 0.822 | 0.76 | 0.612 | 0.856 | 0.972 | 0.841 | 0.567 | 0.988 | 0.84 | |
| M-DenseNet121 | 0.977 | 0.953 | 0.938 | 0.85 | 0.806 | 0.514 | 0.872 | 0.974 | 0.831 | 0.614 | 0.99 | 0.847 | |
| MCNN-EarlyFusion | 0.982 | 0.962 | 0.934 | 0.882 | 0.788 | 0.652 | 0.908 | 0.969 | 0.819 | 0.574 | 0.991 | 0.86 | |
| MCNN-MidFusion | 0.984 | 0.968 | 0.951 | 0.94 | 0.907 | 0.752 | 0.916 | 0.976 | 0.835 | 0.752 | 0.991 | 0.906 | |
| A+MCNN (ours) | 0.987 | 0.969 | 0.953 | 0.943 | 0.886 | 0.788 | 0.944 | 0.986 | 0.842 | 0.761 | 0.991 | 0.914 | |
| F-Score | VGG16 | 0.956 | 0.903 | 0.782 | 0.674 | 0.386 | 0.145 | 0.483 | 0.931 | 0.703 | 0.471 | 0.976 | 0.674 |
| VGG19 | 0.958 | 0.901 | 0.774 | 0.686 | 0.306 | 0.137 | 0.49 | 0.93 | 0.707 | 0.468 | 0.975 | 0.667 | |
| ResNet50 | 0.957 | 0.9 | 0.768 | 0.682 | 0.419 | 0.207 | 0.542 | 0.93 | 0.707 | 0.484 | 0.975 | 0.688 | |
| DenseNet121 | 0.958 | 0.899 | 0.778 | 0.685 | 0.399 | 0.158 | 0.53 | 0.928 | 0.709 | 0.487 | 0.975 | 0.682 | |
| M-VGG16 | 0.974 | 0.95 | 0.896 | 0.884 | 0.827 | 0.7 | 0.891 | 0.97 | 0.822 | 0.67 | 0.984 | 0.87 | |
| M-VGG19 | 0.974 | 0.95 | 0.939 | 0.893 | 0.831 | 0.682 | 0.906 | 0.967 | 0.823 | 0.667 | 0.985 | 0.874 | |
| M-ResNet50 | 0.972 | 0.943 | 0.92 | 0.863 | 0.791 | 0.655 | 0.883 | 0.968 | 0.82 | 0.648 | 0.984 | 0.859 | |
| M-DenseNet121 | 0.972 | 0.95 | 0.924 | 0.862 | 0.812 | 0.633 | 0.898 | 0.969 | 0.83 | 0.668 | 0.985 | 0.864 | |
| MCNN-EarlyFusion | 0.974 | 0.953 | 0.929 | 0.882 | 0.814 | 0.714 | 0.909 | 0.971 | 0.832 | 0.663 | 0.986 | 0.875 | |
| MCNN-MidFusion | 0.983 | 0.958 | 0.947 | 0.942 | 0.843 | 0.779 | 0.93 | 0.977 | 0.851 | 0.781 | 0.987 | 0.907 | |
| A+MCNN (ours) | 0.985 | 0.964 | 0.953 | 0.949 | 0.909 | 0.788 | 0.936 | 0.982 | 0.860 | 0.798 | 0.989 | 0.920 |
| Computational Costs | Single-Scale Baselines | Multi-Scale Baselines | MCNN-EarlyFusion | MCNN-MidFusion | A+MCNN |
|---|---|---|---|---|---|
| Number of parameters | 51 M | 51 M | 62 M | 88 M | 95 M |
| Training time/epoch | 107.9 s | 110 s | 96.6 s | 181.7 s | 199.4 s |
| Inference time/100 batches | 4.0 s | 4.2 s | 5.5 s | 8.0 s | 8.7 s |
| Metric | Method | Asphalt | Marker | Manhole | Patch | Pothole | Crack Seal | Shoulder | Curbing | Joint | Crack | Concrete | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | CNN | 0.921 | 0.893 | 0.823 | 0.790 | 0.427 | 0.305 | 0.514 | 0.925 | 0.709 | 0.664 | 0.945 | 0.675 |
| M-CNN | 0.942 | 0.918 | 0.881 | 0.773 | 0.576 | 0.572 | 0.740 | 0.939 | 0.734 | 0.648 | 0.955 | 0.756 | |
| Recall | CNN | 0.980 | 0.853 | 0.407 | 0.457 | 0.076 | 0.052 | 0.249 | 0.907 | 0.610 | 0.241 | 0.976 | 0.491 |
| M-CNN | 0.974 | 0.919 | 0.544 | 0.596 | 0.202 | 0.147 | 0.646 | 0.943 | 0.738 | 0.433 | 0.989 | 0.571 | |
| F-Score | CNN | 0.950 | 0.873 | 0.545 | 0.579 | 0.128 | 0.089 | 0.335 | 0.916 | 0.656 | 0.354 | 0.960 | 0.527 |
| M-CNN | 0.958 | 0.918 | 0.673 | 0.673 | 0.299 | 0.234 | 0.690 | 0.941 | 0.736 | 0.519 | 0.972 | 0.620 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eslami, E.; Yun, H.-B. Attention-Based Multi-Scale Convolutional Neural Network (A+MCNN) for Multi-Class Classification in Road Images. Sensors 2021, 21, 5137. https://doi.org/10.3390/s21155137
Eslami E, Yun H-B. Attention-Based Multi-Scale Convolutional Neural Network (A+MCNN) for Multi-Class Classification in Road Images. Sensors. 2021; 21(15):5137. https://doi.org/10.3390/s21155137
Chicago/Turabian StyleEslami, Elham, and Hae-Bum Yun. 2021. "Attention-Based Multi-Scale Convolutional Neural Network (A+MCNN) for Multi-Class Classification in Road Images" Sensors 21, no. 15: 5137. https://doi.org/10.3390/s21155137
APA StyleEslami, E., & Yun, H. -B. (2021). Attention-Based Multi-Scale Convolutional Neural Network (A+MCNN) for Multi-Class Classification in Road Images. Sensors, 21(15), 5137. https://doi.org/10.3390/s21155137