
Robot Transparency and Anthropomorphic Attribute Effects on Human–Robot Interactions

 ,
,
Abstract
:1. Introduction
2. Robot-to-Human Communication
2.1. Communication Transparency
2.2. Anthropomorphism
3. HRI Outcomes
3.1. Safety
3.2. Usability
3.3. Workload
3.4. Trust
3.5. Affect
3.6. Current Study
4. Methods
4.1. Participants
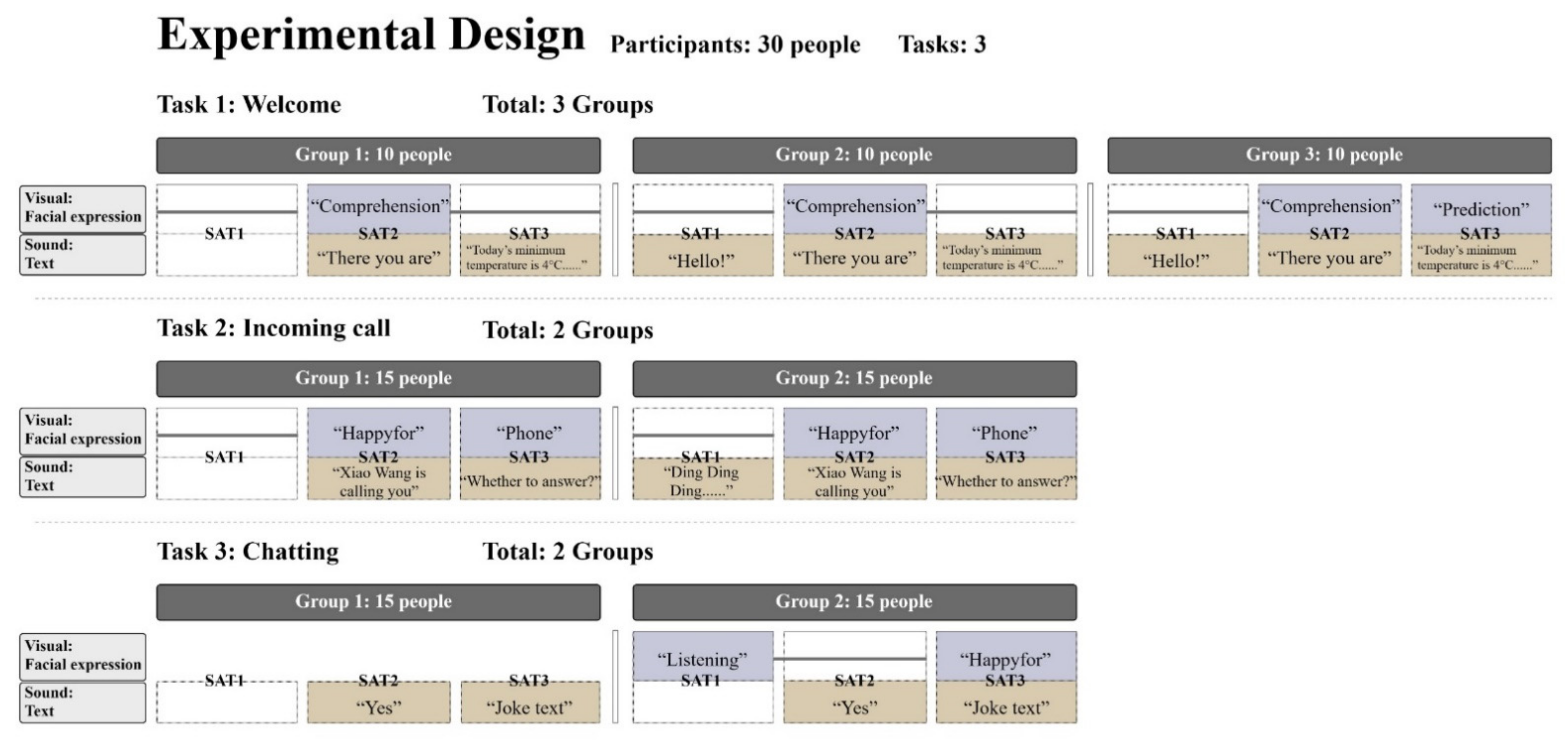
4.2. Design
4.3. Apparatus and Materials
4.3.1. Self-Report Metrics
4.3.2. Performance Metrics
4.4. Procedure
5. Results
5.1. Task One: Welcome
5.1.1. Sweep
5.1.2. Affect
5.2. Task Two: Incoming Call
5.2.1. Safety
5.2.2. Usability
5.2.3. Workload
5.2.4. Trust
5.2.5. Sweep
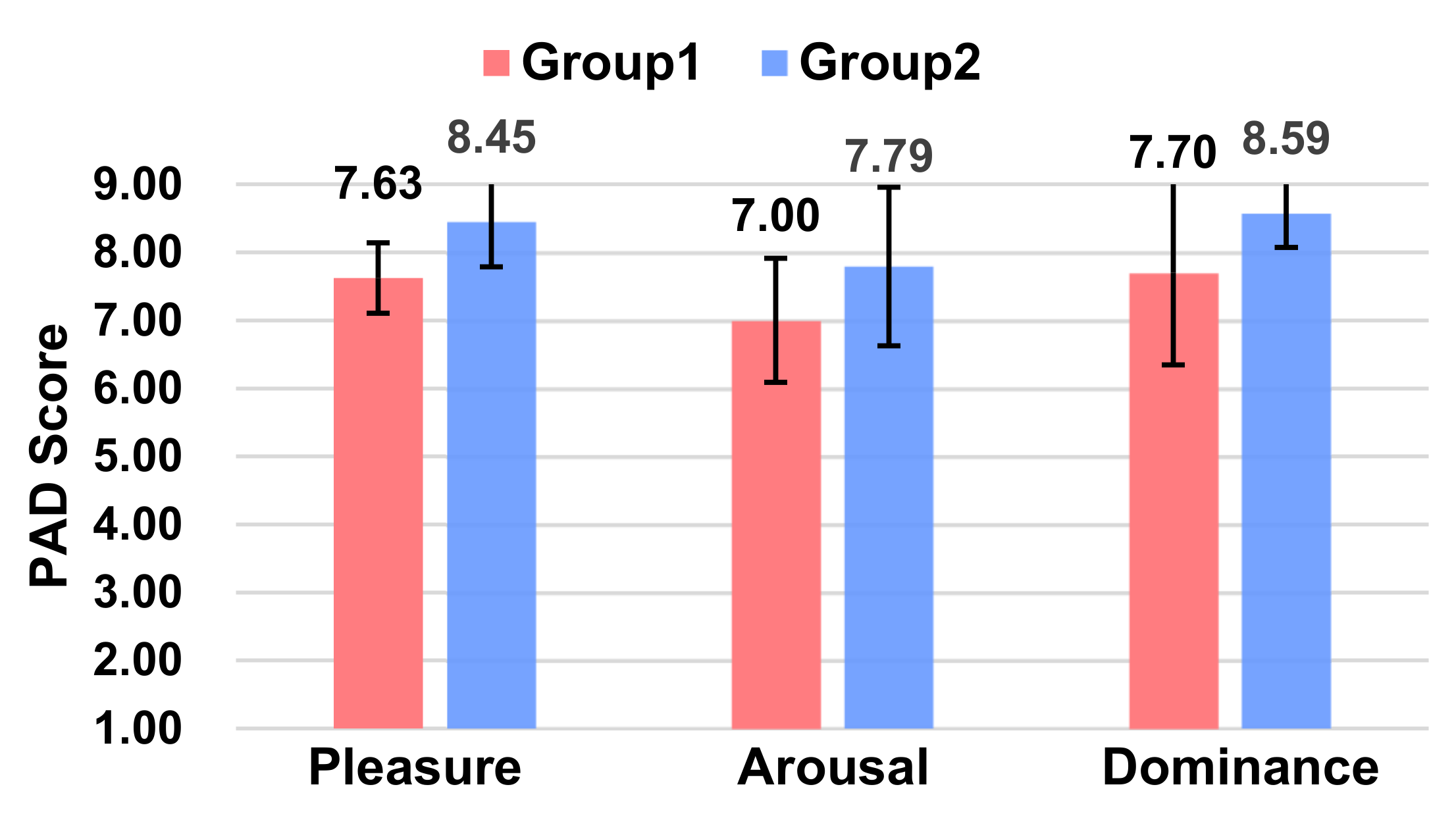
5.2.6. Affect
5.3. Task Three: Chatting
5.3.1. Safety
5.3.2. Usability
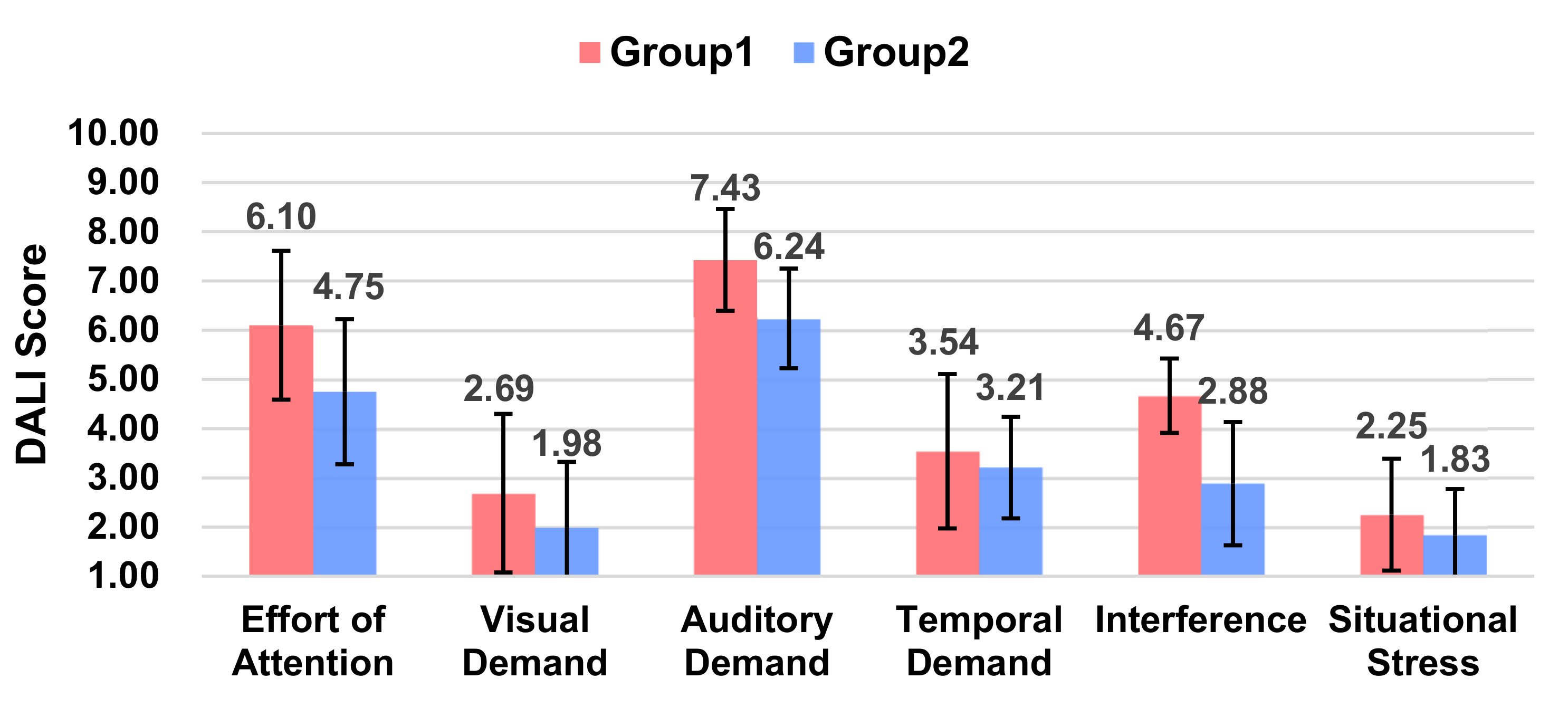
5.3.3. Workload
5.3.4. Trust
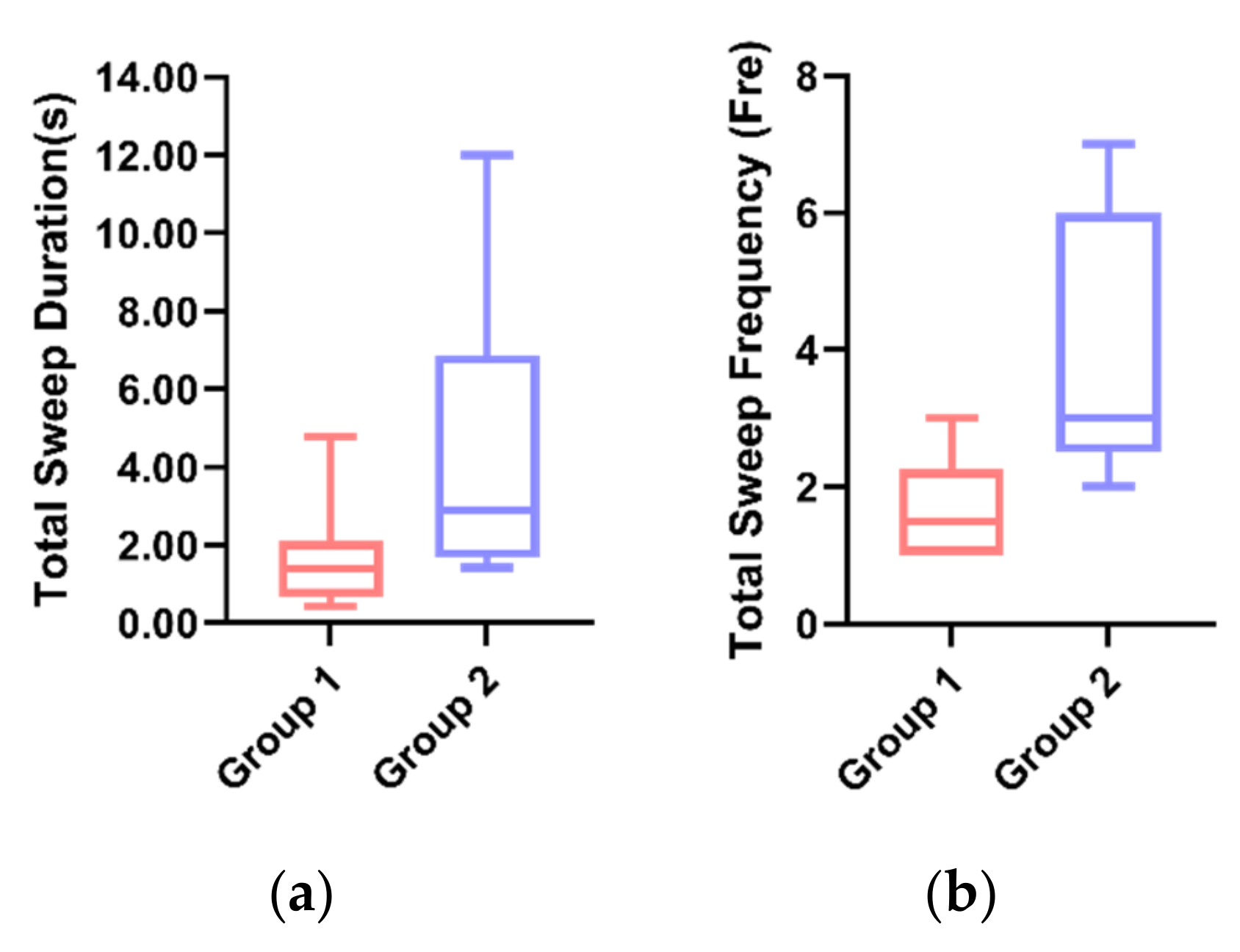
5.3.5. Sweep
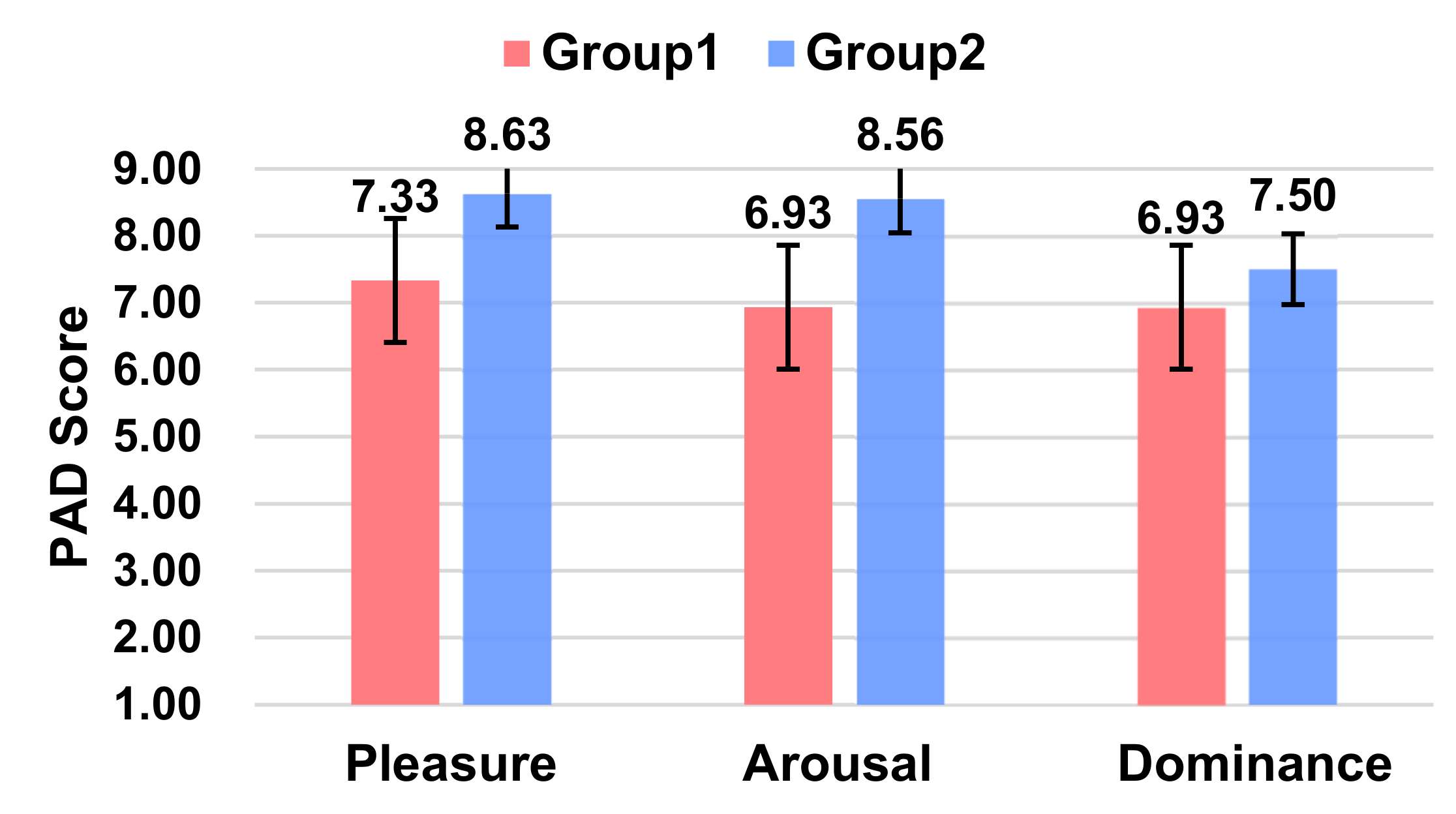
5.3.6. Affect
6. Discussion
6.1. Transparency
6.2. Anthropomorphism
6.3. HRI Variable Relationships
6.4. Implications for HRI Design
6.5. Limitations of the Current Study
7. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mavridis, N. A review of verbal and non-verbal human–robot interactive communication. Robot. Auton. Syst. 2015, 63, 22–35. [Google Scholar] [CrossRef] [Green Version]
- Muthugala, M.A.V.J.; Jayasekara, A.G.B.P. A Review of Service Robots Coping with Uncertain Information in Natural Language Instructions. IEEE Access 2018, 6, 12913–12928. [Google Scholar] [CrossRef]
- Williams, K.; Flores, J.A.; Peters, J. Affective Robot Influence on Driver Adherence to Safety, Cognitive Load Reduction and Sociability. In Proceedings of the 6th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Seattle, WA, USA, 17–19 September 2014; Association for Computing Machinery: Seattle, WA, USA, 2014; pp. 1–8. [Google Scholar]
- Williams, K.J.; Peters, J.C.; Breazeal, C.L. Towards leveraging the driver’s mobile device for an intelligent, sociable in-car robotic assistant. In 2013 IEEE Intelligent Vehicles Symposium (IV); IEEE: Piscataway, NJ, USA, 2013; pp. 369–376. [Google Scholar]
- Large, D.R.; Harrington, K.; Burnett, G.; Luton, J.; Thomas, P.; Bennett, P. To Please in a Pod: Employing an Anthropomorphic Agent-Interlocutor to Enhance Trust and User Experience in an Autonomous, Self-Driving Vehicle. In Proceedings of the 11th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Utrecht, The Netherlands, 21–25 September 2019; Association for Computing Machinery: Utrecht, The Netherlands, 2019; pp. 49–59. [Google Scholar]
- Kontogiorgos, D.; Pereira, A.; Andersson, O.; Andersson, M.; Rabal, E.G.; Vartiainen, V.; Gustafson, J. The Effects of Anthropomorphism and Non-verbal Social Behaviour in Virtual Assistants. In Proceedings of the 19th ACM International Conference on Intelligent Virtual Agents, Paris, France, 2–5 July 2019; Association for Computing Machinery: Paris, France, 2019; pp. 133–140. [Google Scholar]
- Chen, J.Y.C.; Barnes, M.J.; Harper-Sciarini, M. Supervisory Control of Multiple Robots: Human-Performance Issues and User-Interface Design. IEEE Trans. Syst. Man Cybern. Part C 2011, 41, 435–454. [Google Scholar] [CrossRef]
- Salas, E.; Sims, D.E.; Burke, S.C. Is there a “Big Five” in Teamwork? Small Group Res. 2005, 36, 555–599. [Google Scholar] [CrossRef]
- Lyons, J.B. Being transparent about transparency: A model for human-robot interaction. In Proceedings of the AAAI Spring Symposium on Trust in Autonomous Systems, Palo Alto, CA, USA, 25–27 March 2013; pp. 48–53. [Google Scholar]
- Chen, J.Y.C.; Barnes, M.J. Human–Agent Teaming for Multirobot Control: A Review of Human Factors Issues. IEEE Trans. Human-Machine Syst. 2014, 44, 13–29. [Google Scholar] [CrossRef]
- Chen, J.Y.C.; Lakhmani, S.G.; Stowers, K.; Selkowitz, A.R.; Wright, J.; Barnes, M. Situation awareness-based agent transparency and human-autonomy teaming effectiveness. Theor. Issues Ergon. Sci. 2018, 19, 259–282. [Google Scholar] [CrossRef]
- Duffy, B.R. Anthropomorphism and the social robot. Robot. Auton. Syst. 2003, 42, 177–190. [Google Scholar] [CrossRef]
- Guznov, S.; Lyons, J.; Pfahler, M.; Heironimus, A.; Woolley, M.; Friedman, J.; Neimeier, A. Robot Transparency and Team Orientation Effects on Human–Robot Teaming. Int. J. Human-Computer Interact. 2020, 36, 650–660. [Google Scholar] [CrossRef]
- Zlotowski, J.; Proudfoot, D.; Bartneck, C. More Human Than Human: Does the Uncanny Curve Really Matter? In Proceedings of the HRI2013 Workshop on Design of Human Likeness in HRI from Uncanny Valley to Minimal Design, Tokyo, Japan, 3 March 2013; pp. 7–13. [Google Scholar]
- Gray, H.M.; Gray, K.; Wegner, D.M. Dimensions of Mind Perception. Science 2007, 315, 619. [Google Scholar] [CrossRef] [Green Version]
- Waytz, A.; Heafner, J.; Epley, N. The Mind in the Machine: Anthropomorphism Increases Trust in an Autonomous Vehicle. J. Exp. Soc. Psychol. 2014, 52, 113–117. [Google Scholar] [CrossRef]
- Maddox, J. Visual-Manual NHTSA Driver Distraction Guidelines for In-Vehicle Electronic Devices; Federal Register: Washington, DC, USA, 2012.
- Brooke, J. SUS: A Quick and Dirty Usability Scale. Usability Eval. Ind. 1996, 189, 4–7. [Google Scholar]
- Wickens, C.D. Multiple resources and performance prediction. Theor. Issues Ergon. Sci. 2002, 3, 159–177. [Google Scholar] [CrossRef]
- Hoff, K.A.; Bashir, M. Trust in automation: Integrating empirical evidence on factors that influence trust. Hum. Factors 2015, 57, 407–434. [Google Scholar] [CrossRef]
- Mercado, J.E.; Rupp, M.A.; Chen, J.Y.C.; Barnes, M.J.; Barber, D.; Procci, K. Intelligent Agent Transparency in Human-Agent Teaming for Multi-UxV Management. Hum. Factors 2016, 58, 83–93. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Selkowitz, A.; Lakhmani, S.G.; Larios, C.N.; Chen, J.Y.C. Agent Transparency and the Autonomous Squad Member. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting; SAGE: Los Angeles, CA, USA, 2016; Volume 60, pp. 1319–1323. [Google Scholar]
- Lee, J.D.; See, K.A. Trust in automation: Designing for appropriate reliance. Hum. Factors 2004, 46, 50. [Google Scholar] [CrossRef] [PubMed]
- Rempel, J.K.; Holmes, J.G.; Zanna, M.D. Trust in close relationships. J. Personal. Soc. Psychol. 1985, 49, 95–112. [Google Scholar] [CrossRef]
- Muir, B.M.; Moray, N. Trust in automation. Part I. Theoretical Issues in trust and human intervention in automated systems. Ergonomics 1996, 37, 1905–1922. [Google Scholar] [CrossRef]
- Stedmon, A.W.; Sharples, S.; Littlewood, R.; Cox, G.; Patel, H.; Wilson, J.R. Datalink in air traffic management: Human factors issues in communications. Appl. Ergon. 2007, 38, 473–480. [Google Scholar] [CrossRef]
- Parasuraman, R.; Riley, V. Humans and Automation: Use, Misuse, Disuse, Abuse. Hum. Factors 1997, 39, 230–253. [Google Scholar] [CrossRef]
- Parasuraman, R.; Hancock, P.A.; Olofinboba, O. Alarm effectiveness in driver-centred collision-warning systems. Ergonomics 1997, 40, 390–399. [Google Scholar] [CrossRef]
- Sanders, T.L.; Wixon, T.; Schafer, K.E.; Chen, J.Y.C.; Hancock, P.A. The influence of modality and transparency on trust in human-robot interaction. In Proceedings of the IEEE International Inter-Disciplinary Conference on Cognitive Methods in Situation Awareness and Decision Support (CogSIMA), San Antonio, TX, USA, 3–6 March 2014. [Google Scholar]
- Nass, C.; Jonsson, I.-M.; Harris, H.; Reaves, B.; Endo, J.; Brave, S.; Takayama, L. Improving automotive safety by pairing driver emotion and car voice emotion. In CHI ‘05 Extended Abstracts on Human Factors in Computing Systems; Association for Computing Machinery: New York, NY, USA, 2005; pp. 1973–1976. [Google Scholar]
- Peter, C.; Urban, B. Emotion in Human-Computer Interaction. In Expanding the Frontiers of Visual Analytics and Visualization; Dill, J., Earnshaw, R., Kasik, D., Vince, J., Wong, P.C., Eds.; Springer: London, UK, 2012; pp. 239–262. [Google Scholar]
- Jeon, M. Chapter 1-Emotions and Affect in Human Factors and Human–Computer Interaction: Taxonomy, Theories, Approaches, and Methods. In Emotions and Affect in Human Factors and Human-Computer Interaction; Jeon, M., Ed.; Academic Press: San Diego, CA, USA, 2017; pp. 3–26. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Poitschke, T.; Schuller, B.; Blaschke, C.; Färber, B.; Nguyen-Thien, N. Emotion on the road: Necessity, acceptance, and feasibility of affective computing in the car. Adv. Human-Computer Interact. 2010, 2010, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Jeon, M.; Walker, B.N.; Yim, J.-B. Effects of specific emotions on subjective judgment, driving performance, and perceived workload. Transp. Res. Part F: Traffic Psychol. Behav. 2014, 24, 197–209. [Google Scholar] [CrossRef]
- Dula, C.S.; Geller, E. Geller, Risky, aggressive, or emotional driving: Addressing the need for consistent communication in research. J. Saf. Res. 2003, 34, 559–566. [Google Scholar] [CrossRef]
- Fischer, K. How People Talk with Robots: Designing Dialogue to Reduce User Uncertainty. AI Mag. 2011, 32, 31–38. [Google Scholar] [CrossRef] [Green Version]
- Ososky, S.; Schuster, D.; Phillips, E.; Jentsch, F.G. Building appropriate trust in human-robot teams. In 2013 AAAI Spring Symposium Series; AAAI: Menlo Park, CA, USA, 2013; pp. 60–65. [Google Scholar]
- Lewis, J.R. Psychometric evaluation of an after-scenario questionnaire for computer usability studies: The ASQ. SIGCHI Bull. 1991, 23, 78–81. [Google Scholar] [CrossRef]
- Pauzie, A. A method to assess the driver mental workload: The driving activity load index (DALI). Intell. Transp. Syst. IET 2009, 2, 315–322. [Google Scholar] [CrossRef]
- Bradley, M.M.; Lang, P.J. Measuring emotion: The self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef]
- Shneiderman, B. Designing the user interface strategies for effective human-computer interaction. SIGBIO Newsl. 1987, 9, 6. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task 1: Welcome | Task 2: Incoming Call | Task 3: Chatting | ||||||
|---|---|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 3 | Group 1 | Group 2 | Group 1 | Group 2 | ||
| Transparency information | L2: voice and vision; L3: voice | L1: voice; L2: voice and vision; L3: voice | L1: voice; L2: voice and vision; L3: voice and vision | L2: voice and vision; L3: voice and vision | L1: voice; L2: voice and vision; L3: voice and vision | L2: voice; L3: voice | L1: vision; L2: voice; L3: voice and vision | |
| ① Safety | Standard Deviation of Vehicle Speed | / | 0.42 | 0.27 | 1.14 | 0.90 | ||
| Standard Deviation of Left Lane Departure | 0.18 | 0.77 | 1.09 | 1.34 | ||||
| ② Usability | Total Means | / | 6.70 | 6.32 | 6.17 | 6.45 | ||
| Ease of Task Completion | 6.61 | 6.42 | 5.70 | 6.27 | ||||
| Time Required to Complete Tasks | 6.79 | 6.04 | 6.50 | 6.69 | ||||
| Satisfaction with Support Information | 6.71 | 6.50 | 6.80 | 6.40 | ||||
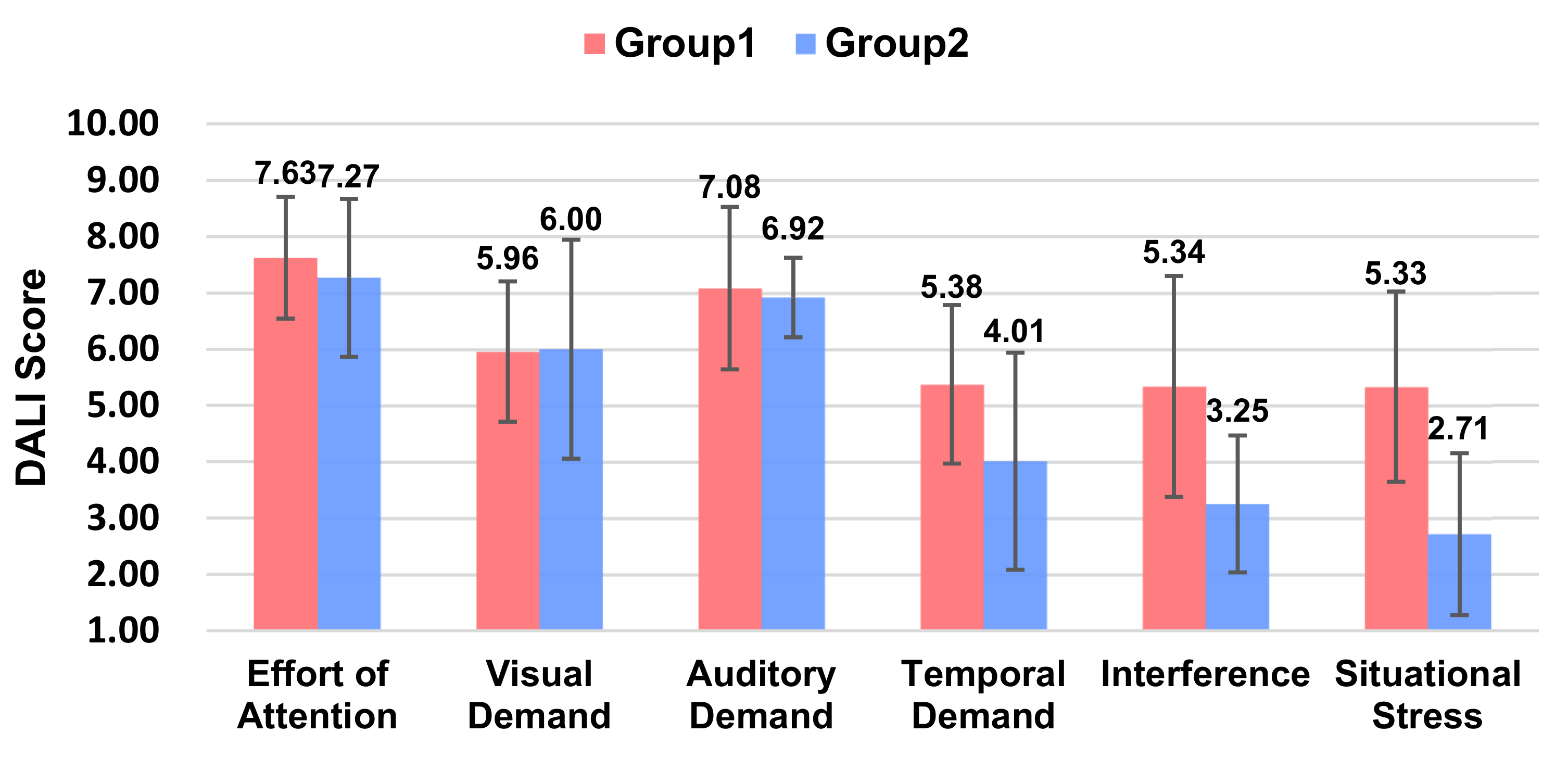
| ③ Workload | Total Means | / | 6.12 | 5.03 | 4.45 | 3.48 | ||
| Effort of Attention | 7.63 | 7.27 | 6.10 | 4.75 | ||||
| Visual Demand | 5.96 | 6.00 | 2.69 | 1.98 | ||||
| Auditory Demand | 7.08 | 6.92 | 7.43 | 6.24 | ||||
| Temporal Demand | 5.38 | 4.01 | 3.54 | 3.21 | ||||
| Interference | 5.34 | 3.25 | 4.67 | 2.88 | ||||
| Situational Stress | 5.33 | 2.71 | 2.25 | 1.83 | ||||
| ④ Trust | Total Means | / | 6.43 | 6.48 | 6.33 | 6.35 | ||
| Predictability | 6.13 | 6.36 | 6.08 | 6.39 | ||||
| Dependability | 6.59 | 6.57 | 6.36 | 6.30 | ||||
| Loyalty/Desire to continue using | 6.57 | 6.50 | 6.55 | 6.35 | ||||
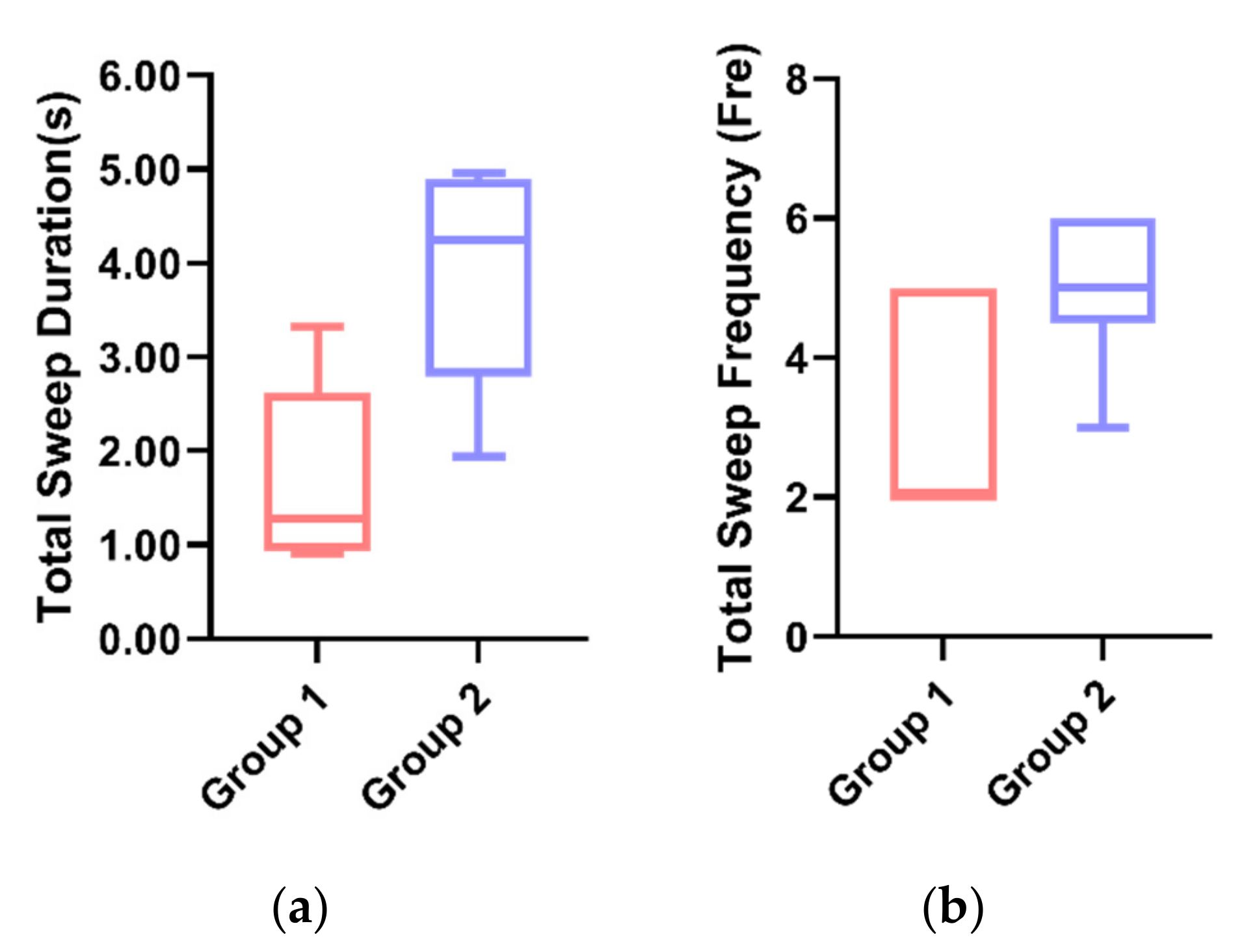
| ⑤ Sweep | Total Sweep Duration(s) | 1.973 | 4.648 | 4.015 | 1.671 | 3.893 | 1.695 | 4.439 |
| Total Sweep Frequency (Fre) | 2.50 | 2.50 | 2.67 | 3.00 | 5.00 | 1.67 | 4.00 | |
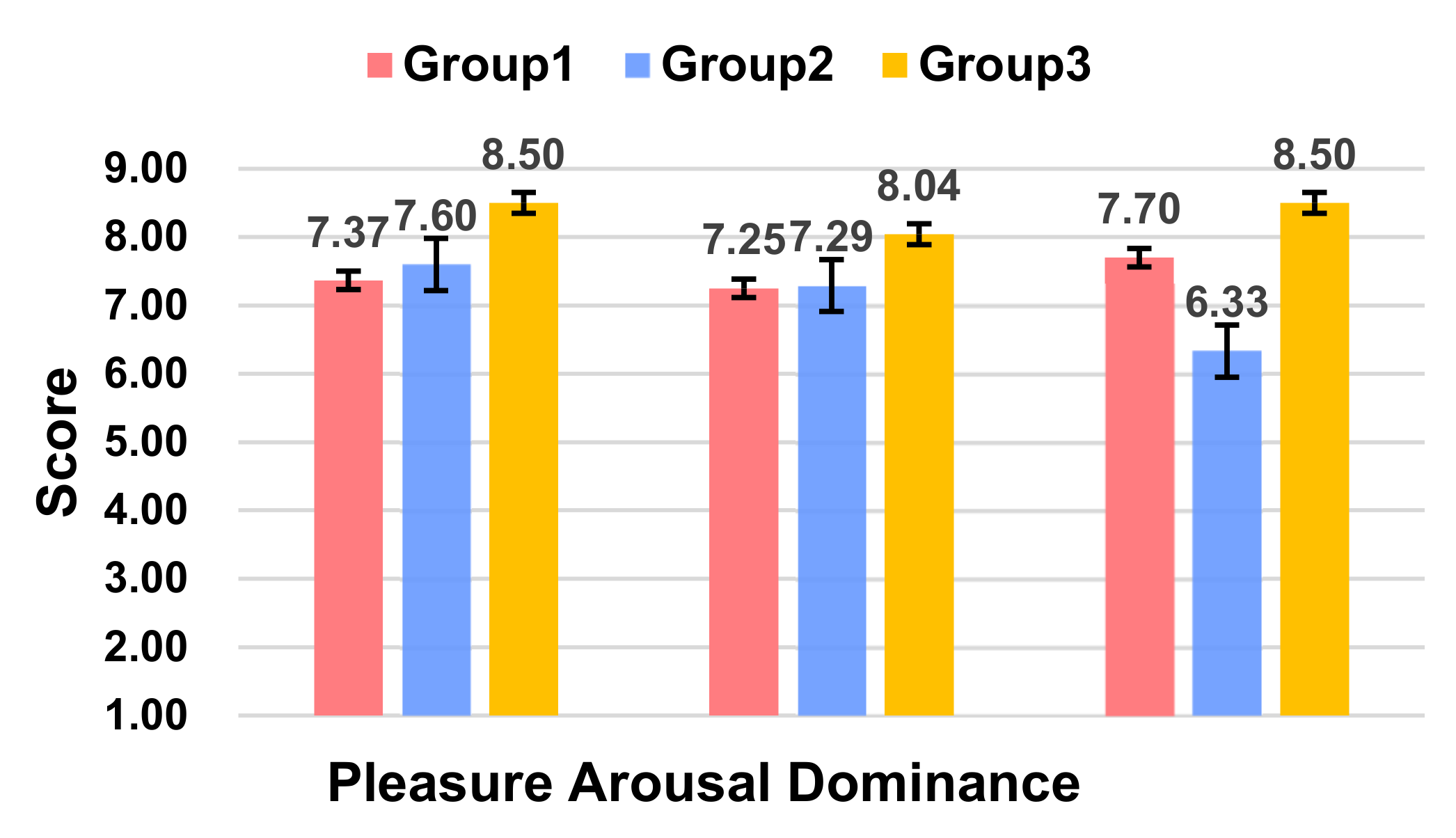
| ⑥ Affect | Pleasure Score | 7.37 | 7.25 | 7.70 | 7.83 | 8.63 | 7.63 | 8.45 |
| Arousal Score | 7.60 | 7.29 | 6.33 | 6.93 | 8.56 | 7.00 | 7.79 | |
| Dominance Score | 8.50 | 8.04 | 8.50 | 6.93 | 7.50 | 7.70 | 8.59 | |
| Conclusion | The better group: Group 3 Reason: L1 anthropomorphic voice information and L3 level visual information can get more attention from the participants and, at the same time, obtain a more positive emotional experience. | The better group: Group 1 Reason: Adding L1 level voice information (Ding Ding Ding), Group 2 can make the participants have more positive emotions and reduce the workload. However, the evaluation of the usability was lower, possibly because the voice of “Ding Ding Ding” made people feel uncomfortable. At the same time, the participants in Group 1 had significantly better vehicle lateral control levels and better safety. | The better group: Group 2 Reason: Compared with Group 1, Group 2 added visual information that can make the participants have more positive emotions. Group 1 communicated with the participants only through voice interactions, which caused the participants’ temporal loads to be significantly higher and caused certain interferences. Additionally, the ability of Group 1 to control the vehicle laterally was not as good as Group 2, so the robots with expressions were better than a pure voice robot. | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Liu, Y.; Yue, T.; Wang, C.; Mao, J.; Wang, Y.; You, F. Robot Transparency and Anthropomorphic Attribute Effects on Human–Robot Interactions. Sensors 2021, 21, 5722. https://doi.org/10.3390/s21175722
Wang J, Liu Y, Yue T, Wang C, Mao J, Wang Y, You F. Robot Transparency and Anthropomorphic Attribute Effects on Human–Robot Interactions. Sensors. 2021; 21(17):5722. https://doi.org/10.3390/s21175722
Chicago/Turabian StyleWang, Jianmin, Yujia Liu, Tianyang Yue, Chengji Wang, Jinjing Mao, Yuxi Wang, and Fang You. 2021. "Robot Transparency and Anthropomorphic Attribute Effects on Human–Robot Interactions" Sensors 21, no. 17: 5722. https://doi.org/10.3390/s21175722
APA StyleWang, J., Liu, Y., Yue, T., Wang, C., Mao, J., Wang, Y., & You, F. (2021). Robot Transparency and Anthropomorphic Attribute Effects on Human–Robot Interactions. Sensors, 21(17), 5722. https://doi.org/10.3390/s21175722