CAFD: Context-Aware Fault Diagnostic Scheme towards Sensor Faults Utilizing Machine Learning




Abstract
:1. Introduction
Contributions
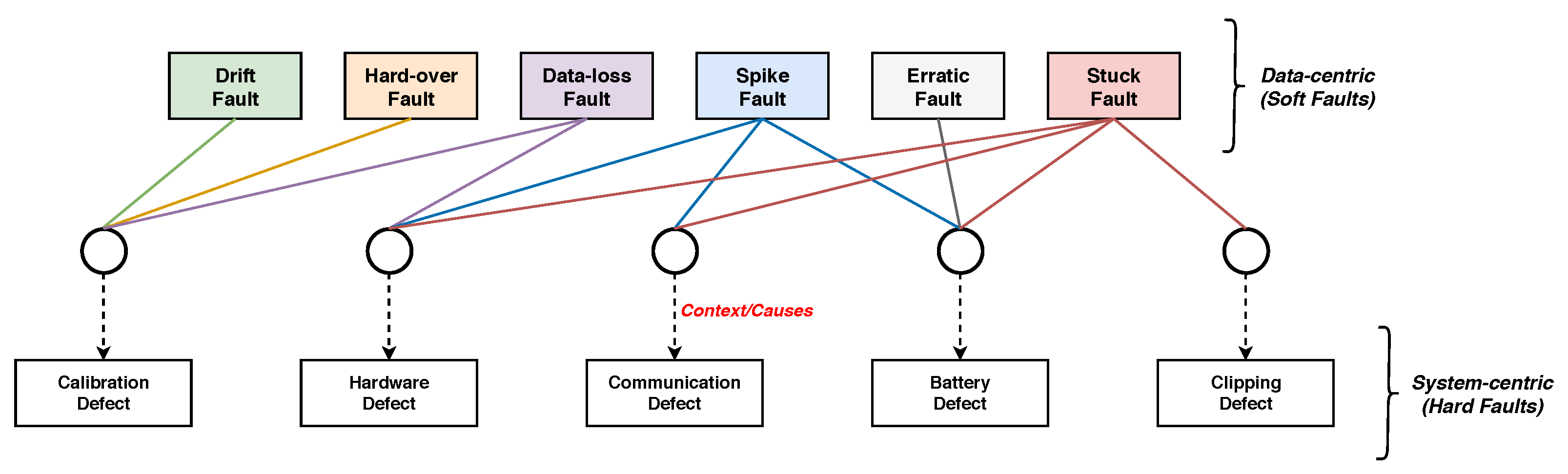
- All the commonly recognized sensor faults that occur in a WSN are considered: drift, hard-over/bias, erratic/precision degradation, spike, stuck, and data-loss.
- A realistic multi-hop WSN scenario composed of humidity and temperature sensor measurements is designed with extreme low-intensity faults.
- We presented the context-aware system based on multi-label classification as well as the multi-class classification for fault diagnosis, which, to our knowledge, has not been studied in earlier research.
- Following that, the lightweight CAFD scheme is developed based on the ensemble learning algorithm called Extra-Trees to detect and diagnose sensor faults in a timely fashion.
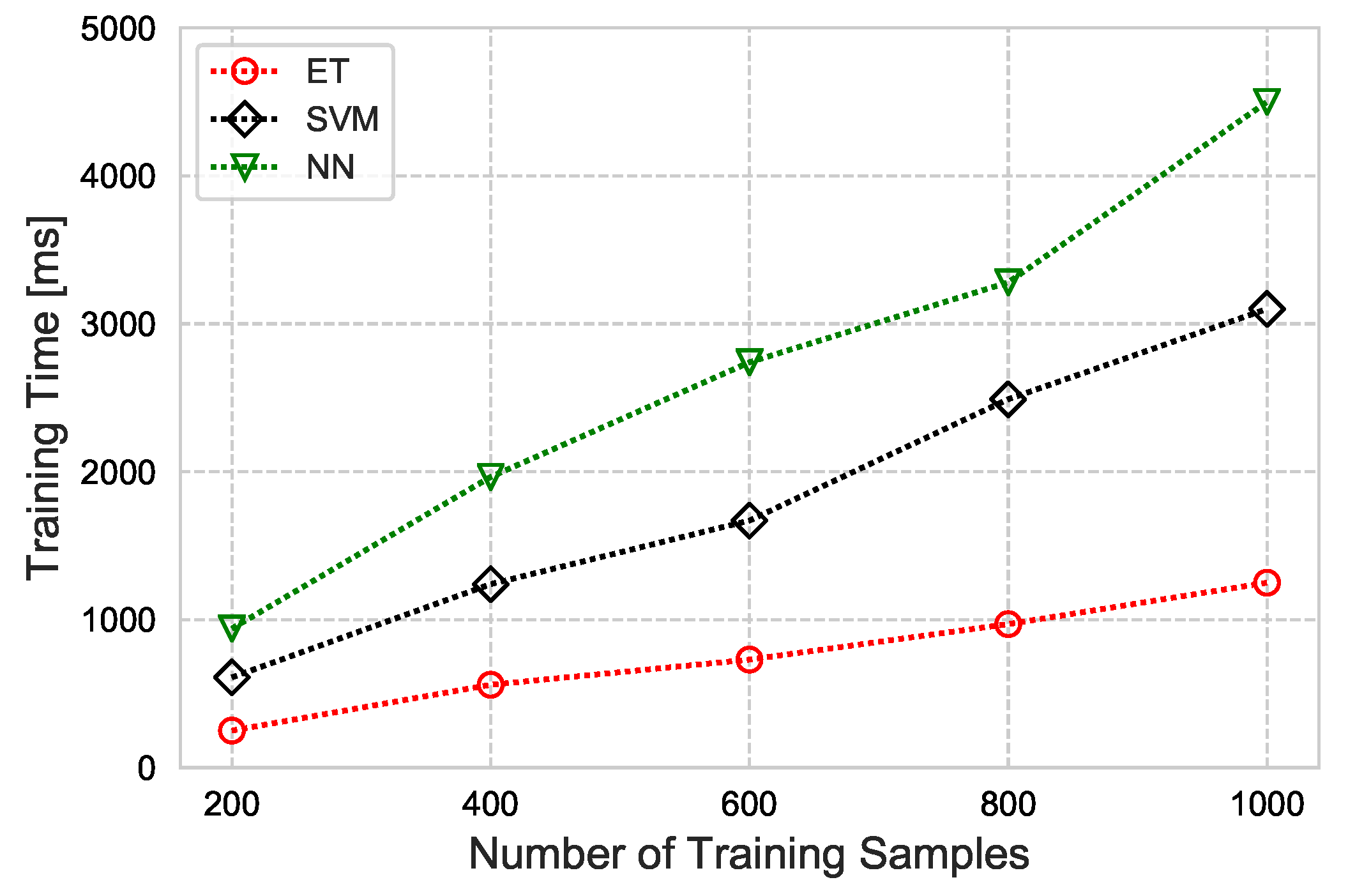
- Lastly, the proposed CAFD scheme’s effectiveness, along with that of the Extra-Trees algorithm, is revealed by comparison with a traditional approach and advanced ML classifiers (SVM and NN). Widely employed performance evaluation metrics—diagnostic accuracy, F1-score, ROC-AUC, and training time (as lightweight measure)—are used.
2. Related Work
3. Sensor Fault Taxonomy
3.1. Drift Fault
3.2. Hard-Over/Bias Fault
3.3. Spike Fault
3.4. Erratic/Precision Degradation Fault
3.5. Stuck Fault
3.6. Data-Loss Fault
4. The Proposed CAFD Scheme
4.1. Classification Techniques
- Binary Classification involves two classes. A set of data observations (or data samples) can only be assigned to one of the two classes. For instance, in sensor fault detection, data observations are categorized as either a normal class or an abnormal class.
- Multi-Class Classification deals with a single target variable of the individual class. In other words, this technique comprises more than two mutually exclusive classes. Data observations are categorized into multiple classes based on disparity. For instance, in sensor fault diagnosis, data observations of multiple classes are classified into any one of the target variables, such as a normal class, a drift fault class, a hard-over fault class, and so forth.
- Multi-Label Classification handles multiple target variables of the individual class. This technique is employed when data observations of a class concurrently belong to two or more target variables. For instance, in the stuck sensor fault class scenario, data observations simultaneously belong to multiple target variables, such as hardware, communication, battery, and clipping (as shown in Table 2).
4.2. Extra-Trees
4.3. System Model
5. Simulations and Results
5.1. Data Acquisition and Preparation
5.2. Results
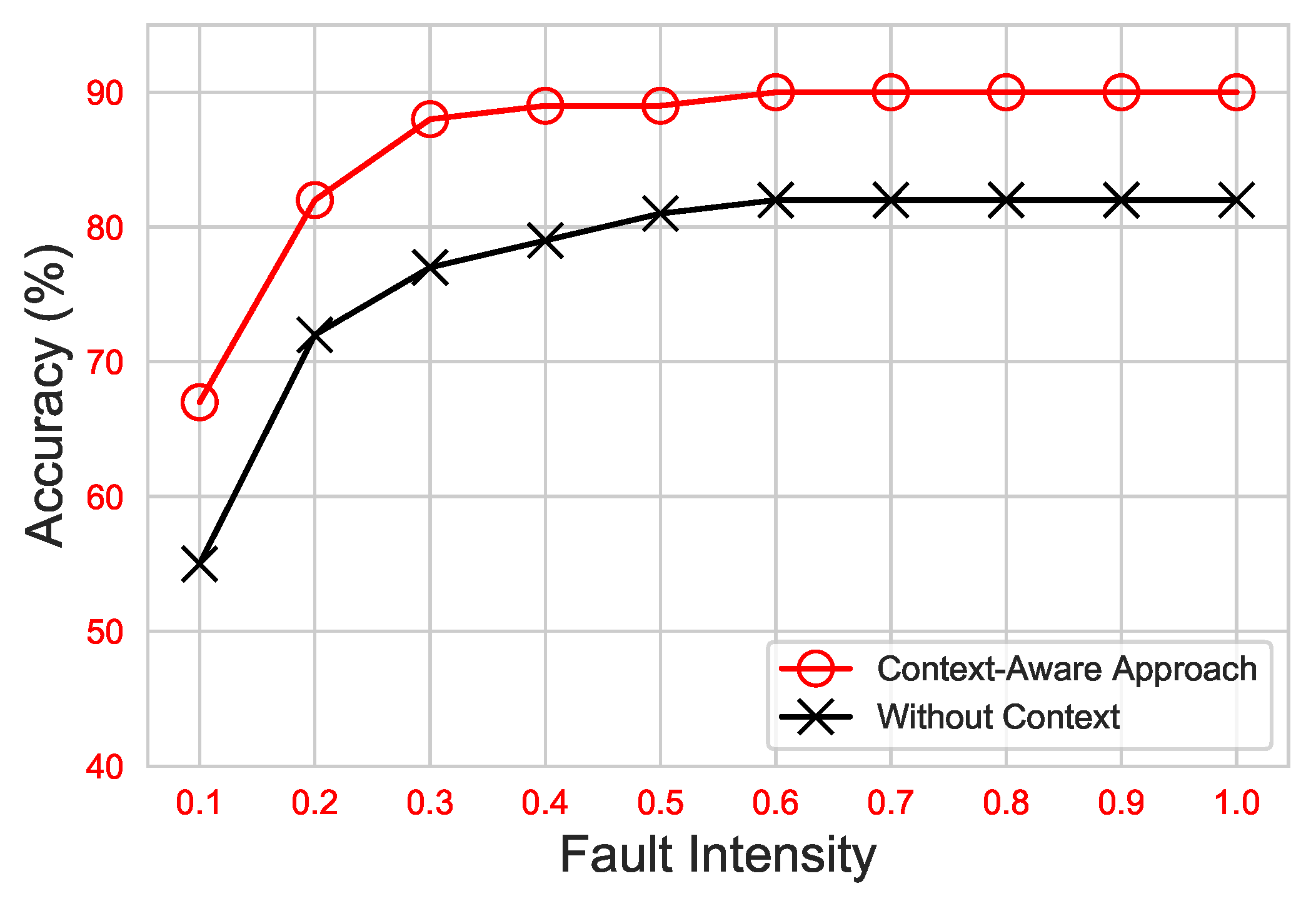
- Diagnostic Accuracy (DA) can be defined as the ratio of correctly diagnosed faulty or defective data samples to the total number of faulty samples.
- F1-score or F-measure is described as the weighted average of precision and recall. This weighted average is commonly used to assess the performance of ML classification models.where
- Area value under the ROC curve (ROC-AUC) is an evaluation metric that calculates a scalar value in the range . This measure determines how accurately the ML classifier can distinguish between faulty and non-faulty data observations. An accurate classifier can have an - value up to .
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ding, D.; Han, Q.L.; Wang, Z.; Ge, X. A survey on model-based distributed control and filtering for industrial cyber-physical systems. IEEE Trans. Indust. Inform. 2019, 15, 2483–2499. [Google Scholar] [CrossRef] [Green Version]
- Khaitan, S.K.; McCalley, J.D. Design techniques and applications of cyberphysical systems: A survey. IEEE Syst. J. 2014, 9, 350–365. [Google Scholar] [CrossRef]
- Fortino, G.; Fotia, L.; Messina, F.; Rosaci, D.; Sarné, G.M. Trust and Reputation in the Internet of Things: State-of-the-Art and Research Challenges. IEEE Access 2020, 8, 60117–60125. [Google Scholar] [CrossRef]
- Shah, S.A.; Ren, A.; Fan, D.; Zhang, Z.; Zhao, N.; Yang, X.; Luo, M.; Wang, W.; Hu, F.; Rehman, M.U.; et al. Internet of things for sensing: A case study in the healthcare system. Appl. Sci. 2018, 8, 508. [Google Scholar] [CrossRef] [Green Version]
- Kumar, D.P.; Amgoth, T.; Annavarapu, C.S.R. Machine learning algorithms for wireless sensor networks: A survey. Informat. Fusion 2019, 49, 1–25. [Google Scholar] [CrossRef]
- Ni, K.; Ramanathan, N.; Chehade, M.N.H.; Balzano, L.; Nair, S.; Zahedi, S.; Kohler, E.; Pottie, G.; Hansen, M.; Srivastava, M. Sensor network data fault types. ACM Trans. Sens. Netw. 2009, 5, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Zhao, S.; Liu, F. Sensor fault detection and diagnosis in the presence of outliers. Neurocomputing 2019, 349, 156–163. [Google Scholar] [CrossRef]
- Muhammed, T.; Shaikh, R.A. An analysis of fault detection strategies in wireless sensor networks. J. Netw. Comput. Appl. 2017, 78, 267–287. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part I: Fault diagnosis with model-based and signal-based approaches. IEEE Trans. Indust. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, W.; Khan, S.A.; Kim, J.M. A hybrid prognostics technique for rolling element bearings using adaptive predictive models. IEEE Trans. Indust. Electron. 2017, 65, 1577–1584. [Google Scholar] [CrossRef]
- Ahmad, Z.; Rai, A.; Maliuk, A.S.; Kim, J.M. Discriminant Feature Extraction for Centrifugal Pump Fault Diagnosis. IEEE Access 2020, 8, 165512–165528. [Google Scholar] [CrossRef]
- Beghi, A.; Brignoli, R.; Cecchinato, L.; Menegazzo, G.; Rampazzo, M.; Simmini, F. Data-driven fault detection and diagnosis for HVAC water chillers. Control Eng. Pract. 2016, 53, 79–91. [Google Scholar] [CrossRef]
- Park, S.T.; Li, G.; Hong, J.C. A study on smart factory-based ambient intelligence context-aware intrusion detection system using machine learning. J. Ambient Intell. Human. Comput. 2020, 11, 1405–1412. [Google Scholar] [CrossRef]
- Yin, H.; Jha, N.K. A health decision support system for disease diagnosis based on wearable medical sensors and machine learning ensembles. IEEE Trans. Multi-Scale Comput. Syst. 2017, 3, 228–241. [Google Scholar] [CrossRef]
- Mohapatra, D.; Subudhi, B.; Daniel, R. Real-time sensor fault detection in tokamak using different machine learning algorithms. Fusion Eng. Des. 2020, 151, 111401. [Google Scholar] [CrossRef]
- Jan, S.U.; Lee, Y.D.; Koo, I.S. A distributed sensor-fault detection and diagnosis framework using machine learning. Informat. Sci. 2021, 547, 777–796. [Google Scholar] [CrossRef]
- Jan, S.U.; Lee, Y.D.; Shin, J.; Koo, I. Sensor fault classification based on support vector machine and statistical time-domain features. IEEE Access 2017, 5, 8682–8690. [Google Scholar] [CrossRef]
- Zidi, S.; Moulahi, T.; Alaya, B. Fault detection in wireless sensor networks through SVM classifier. IEEE Sens. J. 2017, 18, 340–347. [Google Scholar] [CrossRef]
- Noshad, Z.; Javaid, N.; Saba, T.; Wadud, Z.; Saleem, M.Q.; Alzahrani, M.E.; Sheta, O.E. Fault detection in wireless sensor networks through the random forest classifier. Sensors 2019, 19, 1568. [Google Scholar] [CrossRef] [Green Version]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans. Indust. Electron. 2017, 65, 5990–5998. [Google Scholar] [CrossRef]
- Deng, Y.; Ren, Z.; Kong, Y.; Bao, F.; Dai, Q. A hierarchical fused fuzzy deep neural network for data classification. IEEE Trans. Fuzzy Syst. 2016, 25, 1006–1012. [Google Scholar] [CrossRef]
- Miao, X.; Liu, Y.; Zhao, H.; Li, C. Distributed online one-class support vector machine for anomaly detection over networks. IEEE Trans. Cybern. 2018, 49, 1475–1488. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Guo, Y.; Zhao, W. Long short-term memory neural network based fault detection and isolation for electro-mechanical actuators. Neurocomputing 2019, 360, 85–96. [Google Scholar] [CrossRef]
- Saeed, U.; Jan, S.U.; Lee, Y.D.; Koo, I. Fault diagnosis based on extremely randomized trees in wireless sensor networks. Reliab. Eng. Syst. Saf. 2021, 205, 107284. [Google Scholar] [CrossRef]
- Raposo, D.; Rodrigues, A.; Silva, J.S.; Boavida, F. A taxonomy of faults for wireless sensor networks. J. Netw. Syst. Manag. 2017, 25, 591–611. [Google Scholar] [CrossRef]
- Swain, R.R.; Khilar, P.M.; Bhoi, S.K. Heterogeneous fault diagnosis for wireless sensor networks. Ad Hoc Netw. 2018, 69, 15–37. [Google Scholar] [CrossRef]
- Zhang, Z.; Mehmood, A.; Shu, L.; Huo, Z.; Zhang, Y.; Mukherjee, M. A survey on fault diagnosis in wireless sensor networks. IEEE Access 2018, 6, 11349–11364. [Google Scholar] [CrossRef]
- Garcia, C.E.; Camana, M.R.; Koo, I. Machine learning-based Scheme for Fault Detection for Turbine Engine Disk. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 21–23 October 2020; pp. 11–16. [Google Scholar]
- Saeed, U.; Jan, S.U.; Lee, Y.D.; Koo, I. Machine Learning-based Real-Time Sensor Drift Fault Detection using Raspberry Pi. In Proceedings of the 2020 International Conference on Electronics, Information, and Communication (ICEIC), Barcelona, Spain, 19–21 January 2020; pp. 1–7. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Acosta, M.R.C.; Ahmed, S.; Garcia, C.E.; Koo, I. Extremely randomized trees-based scheme for stealthy cyber-attack detection in smart grid networks. IEEE Access 2020, 8, 19921–19933. [Google Scholar] [CrossRef]
- Suthaharan, S.; Alzahrani, M.; Rajasegarar, S.; Leckie, C.; Palaniswami, M. Labelled data collection for anomaly detection in wireless sensor networks. In Proceedings of the 2010 Sixth International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Brisbane, QLD, Australia, 7–10 December 2010; pp. 269–274. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AI | Artificial Intelligence |
| CAFD | Context-Aware Fault Diagnostic |
| CNN | Convolutional Neural Network |
| CPS | Cyber–Physical System |
| CV | Cross-Validation |
| DA | Diagnostic Accuracy |
| DL | Deep Learning |
| DT | Decision Tree |
| ET | Extra-Trees |
| FDNN | Fuzzy Deep Neural Network |
| IoT | Internet-of-Things |
| ML | Machine Learning |
| NN | Neural Network |
| ROC-AUC | Area under the ROC curve |
| RF | Random Forest |
| SVM | Support Vector Machine |
| WSN | Wireless Sensor Network |
| Label | Class | Calibration Defect | Hardware Defect | Communication Defect | Battery Defect | Clipping Defect |
|---|---|---|---|---|---|---|
| 1 | Normal/Legitimate | 0 | 0 | 0 | 0 | 0 |
| 2 | Hard-over Fault | 1 | 0 | 0 | 0 | 0 |
| 3 | Drift Fault | 1 | 0 | 0 | 0 | 0 |
| 4 | Spike Fault | 0 | 1 | 1 | 1 | 0 |
| 5 | Erratic Fault | 0 | 0 | 0 | 1 | 0 |
| 6 | Data-loss Fault | 1 | 1 | 0 | 0 | 0 |
| 7 | Stuck Fault | 0 | 1 | 1 | 1 | 1 |
| Algorithm | Parameters |
|---|---|
| Extra-Trees | n_estimators = 150 max_features = auto min_samples_split = 2 criterion = gini |
| Support Vector Machine | kernel = poly decision_function_shape = ovr gamma = auto C = 1.0 |
| Multi-Layer Perceptron | hidden_layer_sizes = 100 max_iter = 1000 solver = lbfgs activation = identity learning_rate = constant |
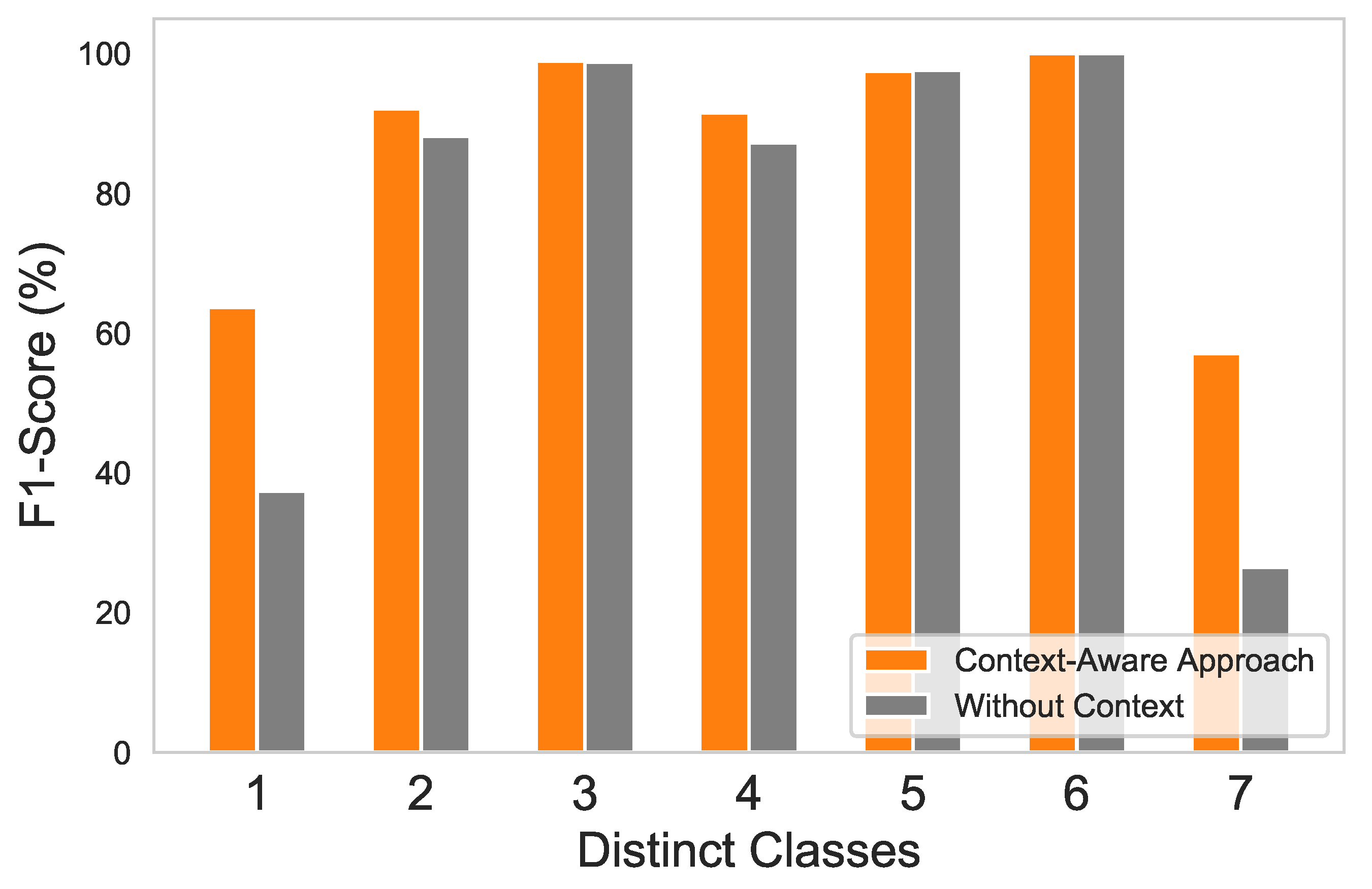
| Class | Context-Aware Approach | Without-Context Approach |
|---|---|---|
| F1-Score | F1-Score | |
| Normal/Legitimate | 63% | 37% |
| Hard-over Fault | 92% | 88% |
| Drift Fault | 98% | 98% |
| Spike Fault | 91% | 87% |
| Erratic Fault | 97% | 97% |
| Data-loss Fault | 100% | 100% |
| Stuck Fault | 57% | 26% |
| Average: 85.42% | Average: 76.14% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeed, U.; Lee, Y.-D.; Jan, S.U.; Koo, I. CAFD: Context-Aware Fault Diagnostic Scheme towards Sensor Faults Utilizing Machine Learning. Sensors 2021, 21, 617. https://doi.org/10.3390/s21020617
Saeed U, Lee Y-D, Jan SU, Koo I. CAFD: Context-Aware Fault Diagnostic Scheme towards Sensor Faults Utilizing Machine Learning. Sensors. 2021; 21(2):617. https://doi.org/10.3390/s21020617
Chicago/Turabian StyleSaeed, Umer, Young-Doo Lee, Sana Ullah Jan, and Insoo Koo. 2021. "CAFD: Context-Aware Fault Diagnostic Scheme towards Sensor Faults Utilizing Machine Learning" Sensors 21, no. 2: 617. https://doi.org/10.3390/s21020617
APA StyleSaeed, U., Lee, Y. -D., Jan, S. U., & Koo, I. (2021). CAFD: Context-Aware Fault Diagnostic Scheme towards Sensor Faults Utilizing Machine Learning. Sensors, 21(2), 617. https://doi.org/10.3390/s21020617