
Deep Reinforcement Learning for UAV Trajectory Design Considering Mobile Ground Users



Abstract
:1. Introduction
- The proposed DQN model exploits an average channel power gain information rather than individual GU position information, which greatly reduces the size of input parameter and computational complexity.
- Reflecting the density of GUs, the adjustment of UAV-BS altitude is enabled. This leads to 3-D trajectory design according to diverse moving patterns of GUs.
- The proposed DQN model learns from a static GUs distribution, then the derived model can be applied to mobile GU scenarios in which the proposed model requires neither the user mobility information nor re-learning for the moving GUs.
- The accuracy of the proposed model is validated by comparing the result of the proposed model with a mathematical optimization solver [24].
2. System Model
2.1. Air to Ground Model
2.2. QoE Model
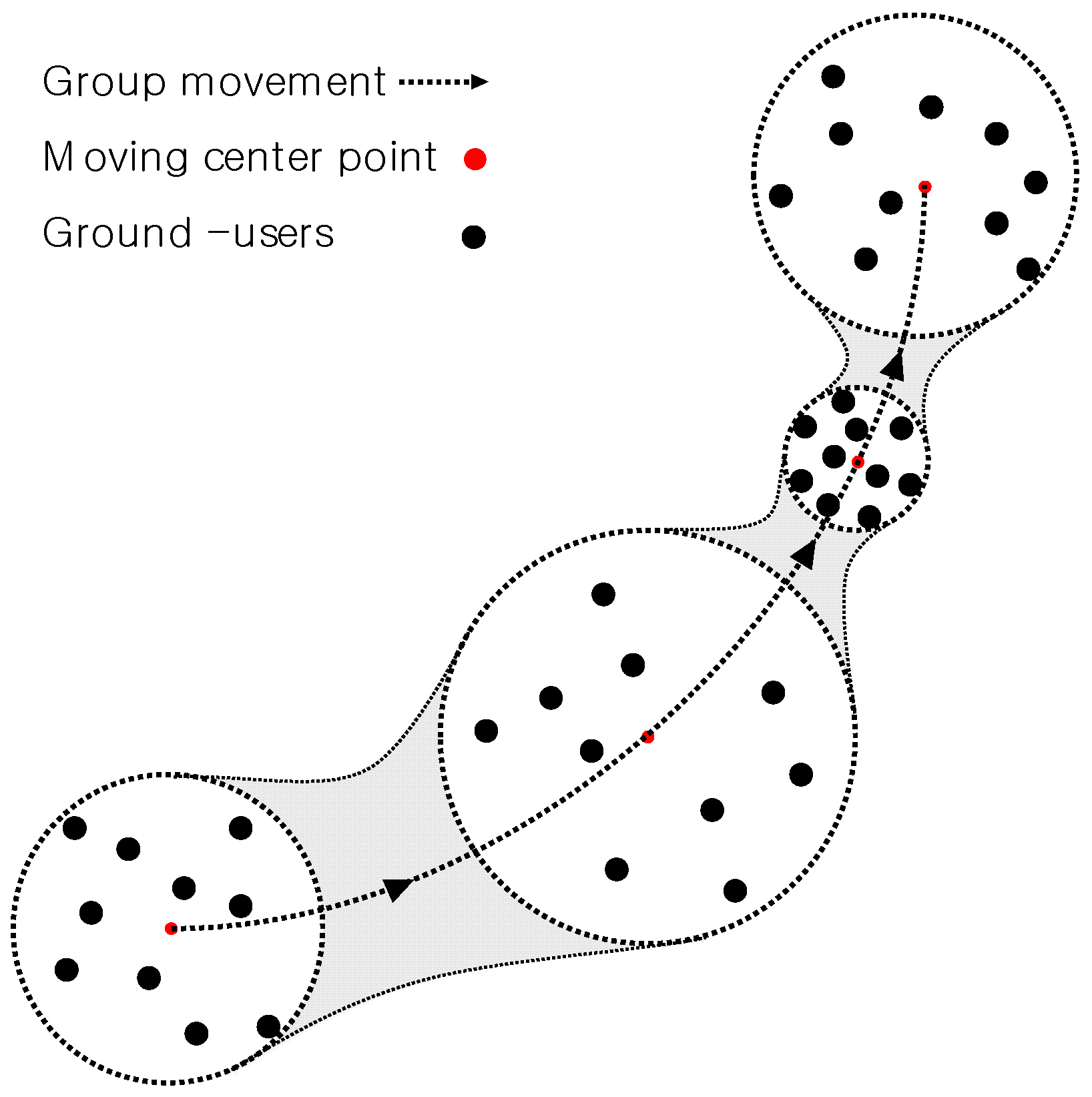
2.3. User Mobility Model
3. Proposed Algorithm
3.1. Problem Formulation
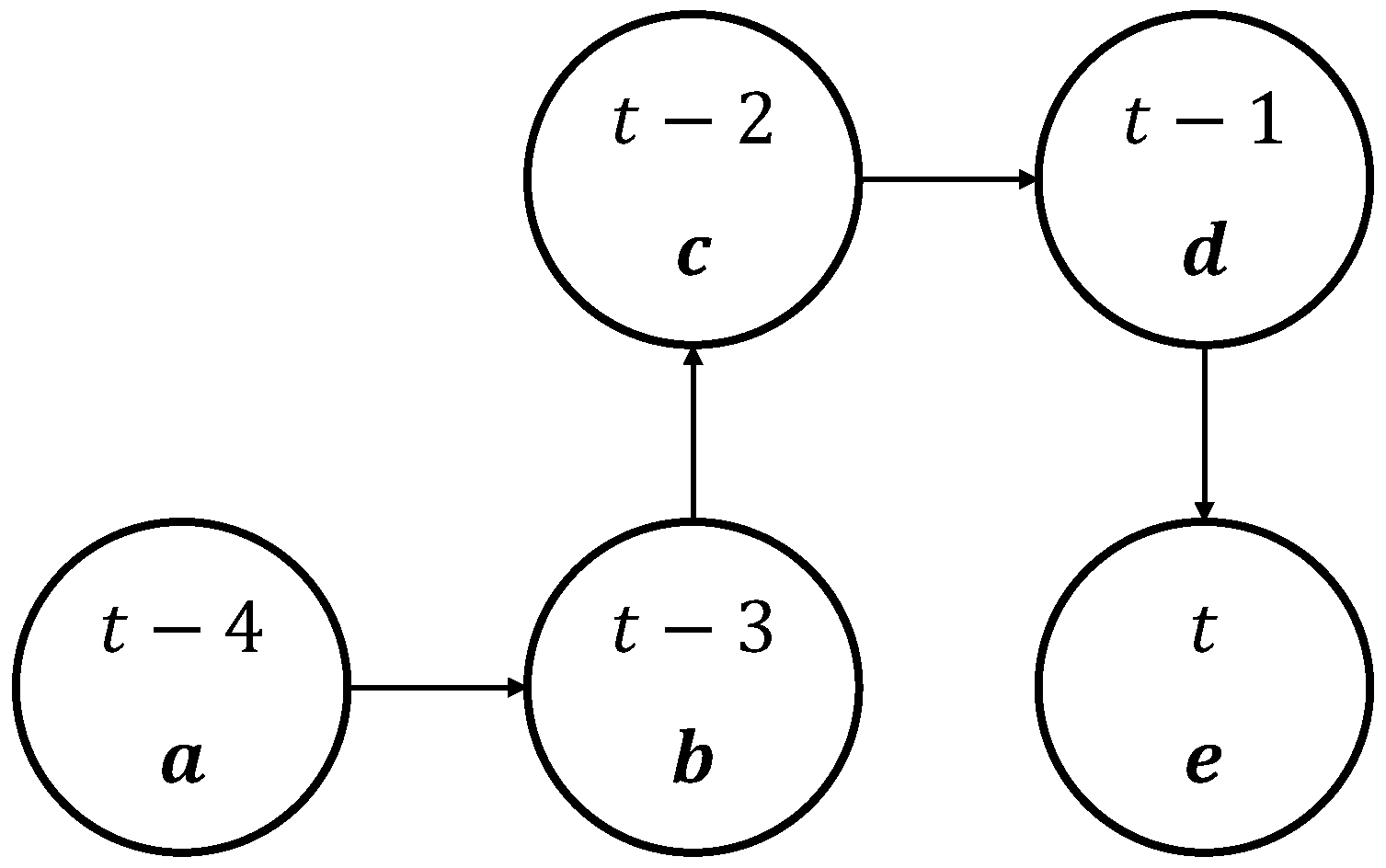
3.2. MDP
3.3. Deep Q-Network (DQN) Algorithm
| Algorithm 1. DQN algorithm for UAV-BS trajectory |
| • Initialize the replay memory D |
| • Initialize action-value function Q with random weights |
| • Initialize target-value function Q’ with random weights |
| • Initialize the position of GUs with radius. |
| • Set probability = 1, = 0.1, = 0.99997 |
| 1: for episode = do |
| 2: Initialize the position of the UAV-BS |
| 3: for do |
| 4: if |
| 5: |
| 6: end if |
| 7: Select a random action with probability |
| 8: while the UAV-BS position goes out of the grid |
| 9: Select other action except |
| 10: end while |
| 11: otherwise select |
| 12: Execute action and observe reward and state |
| 13: Store transition in D |
| 14: Sample random mini-batch of transitions from D |
| 15: Perform a gradient descent to update action-value function Q |
| 16: Every episode update target-value function Q’ |
| 17: end for |
| 18: end for |
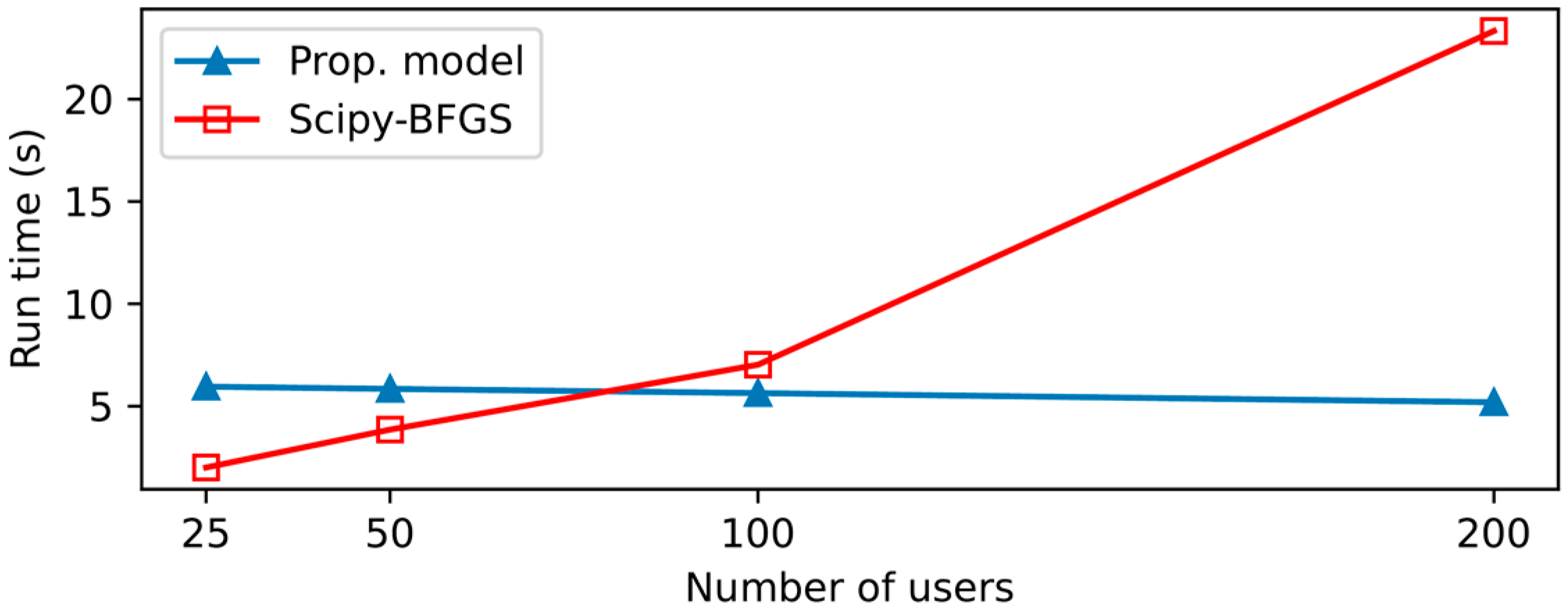
3.4. Algorithm Complexity
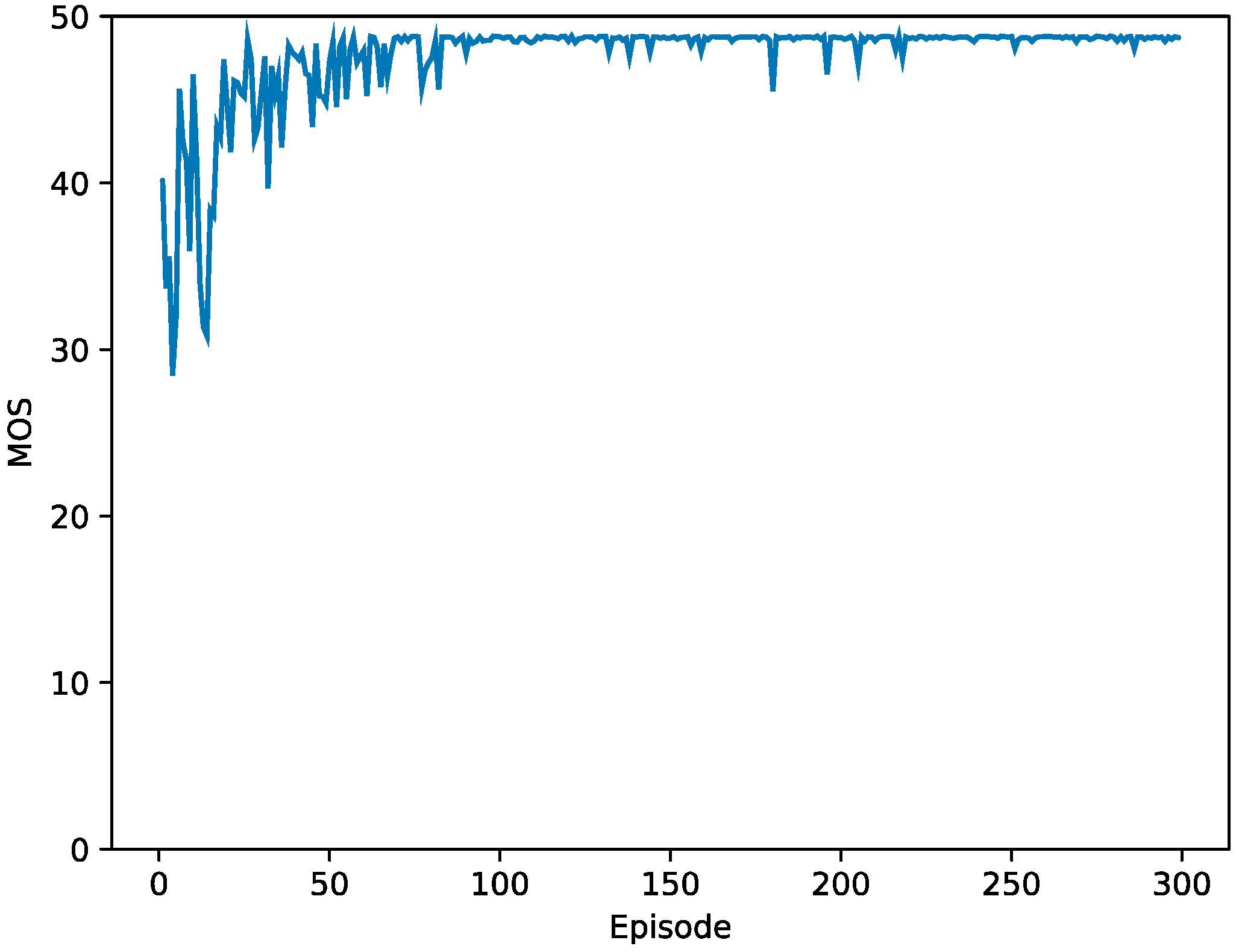
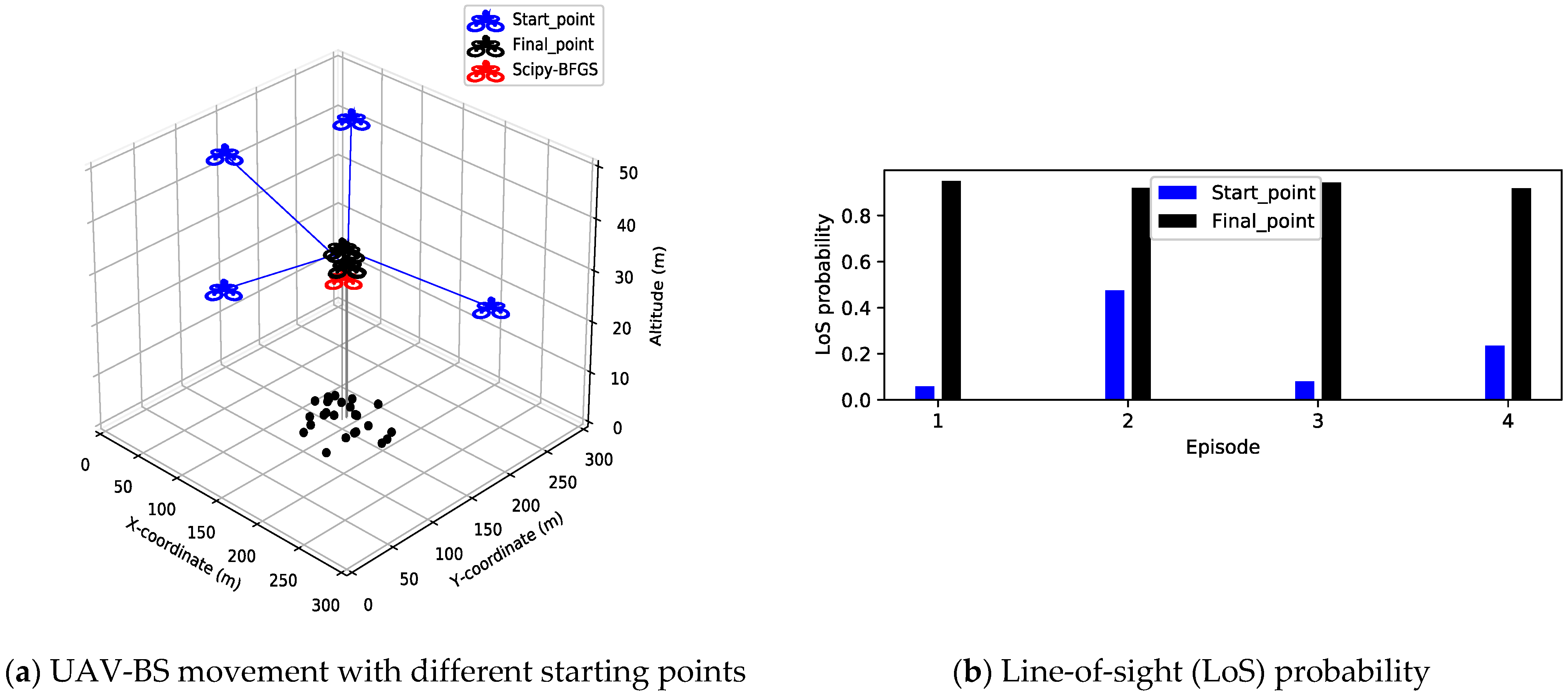
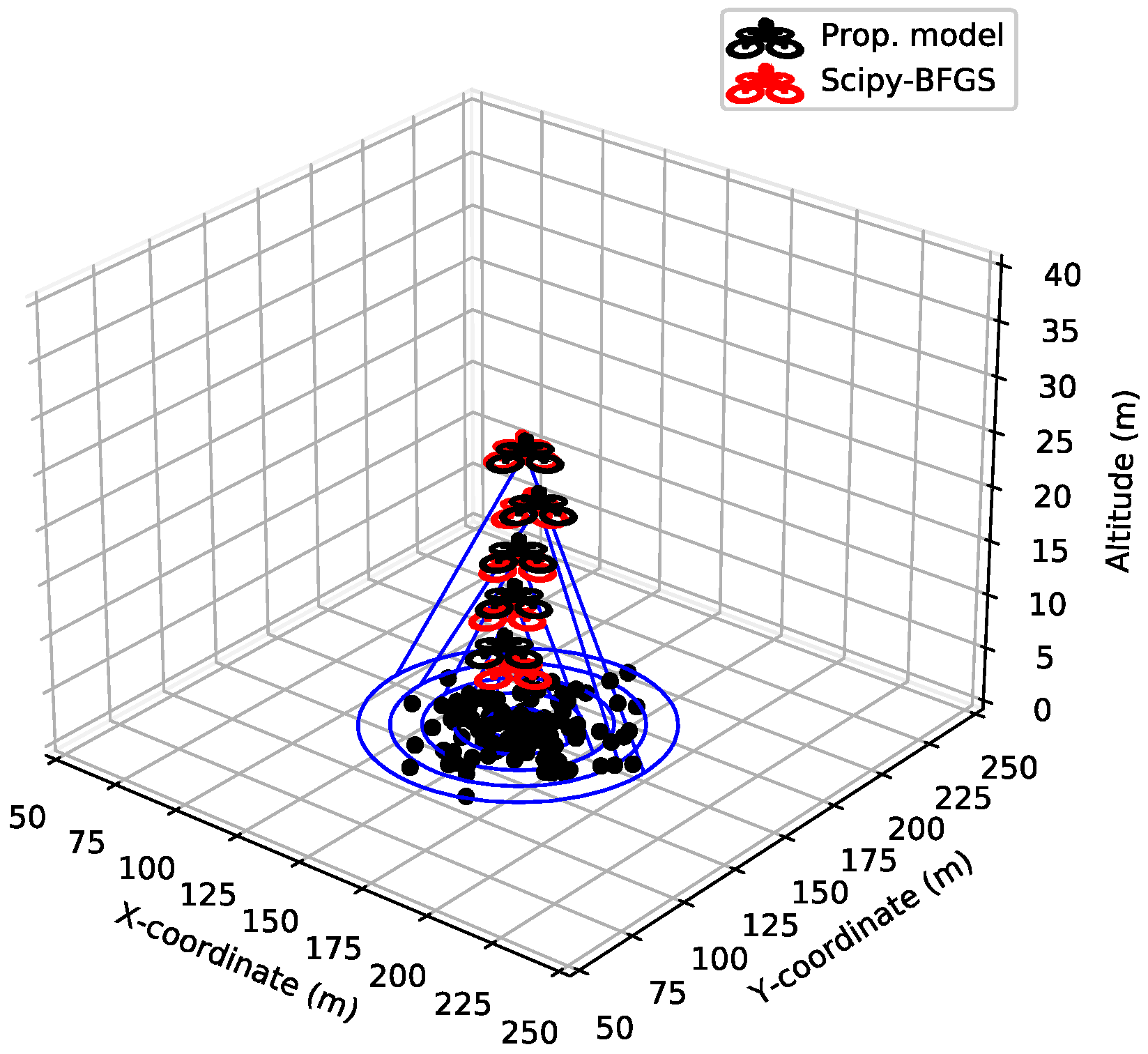
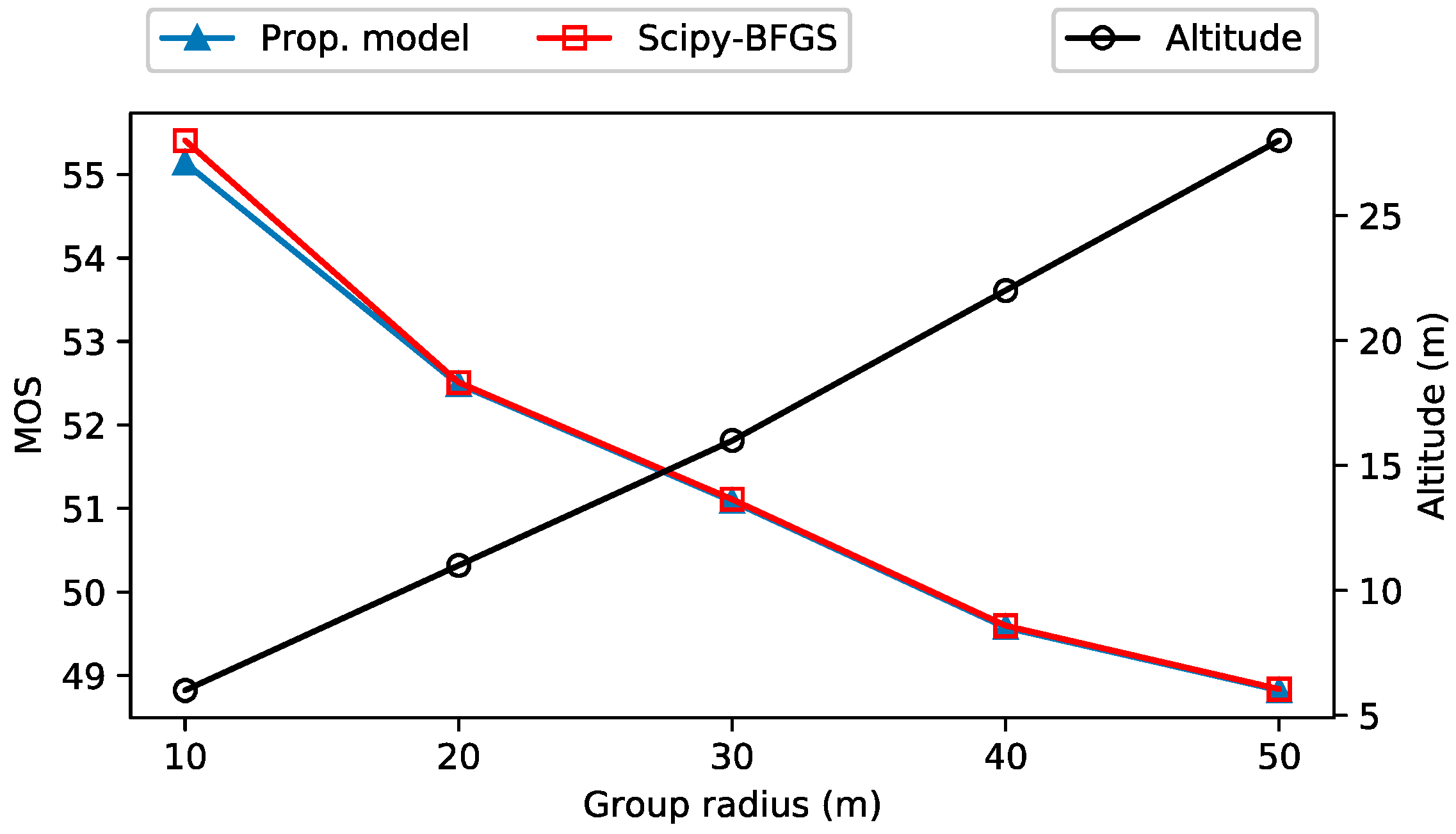
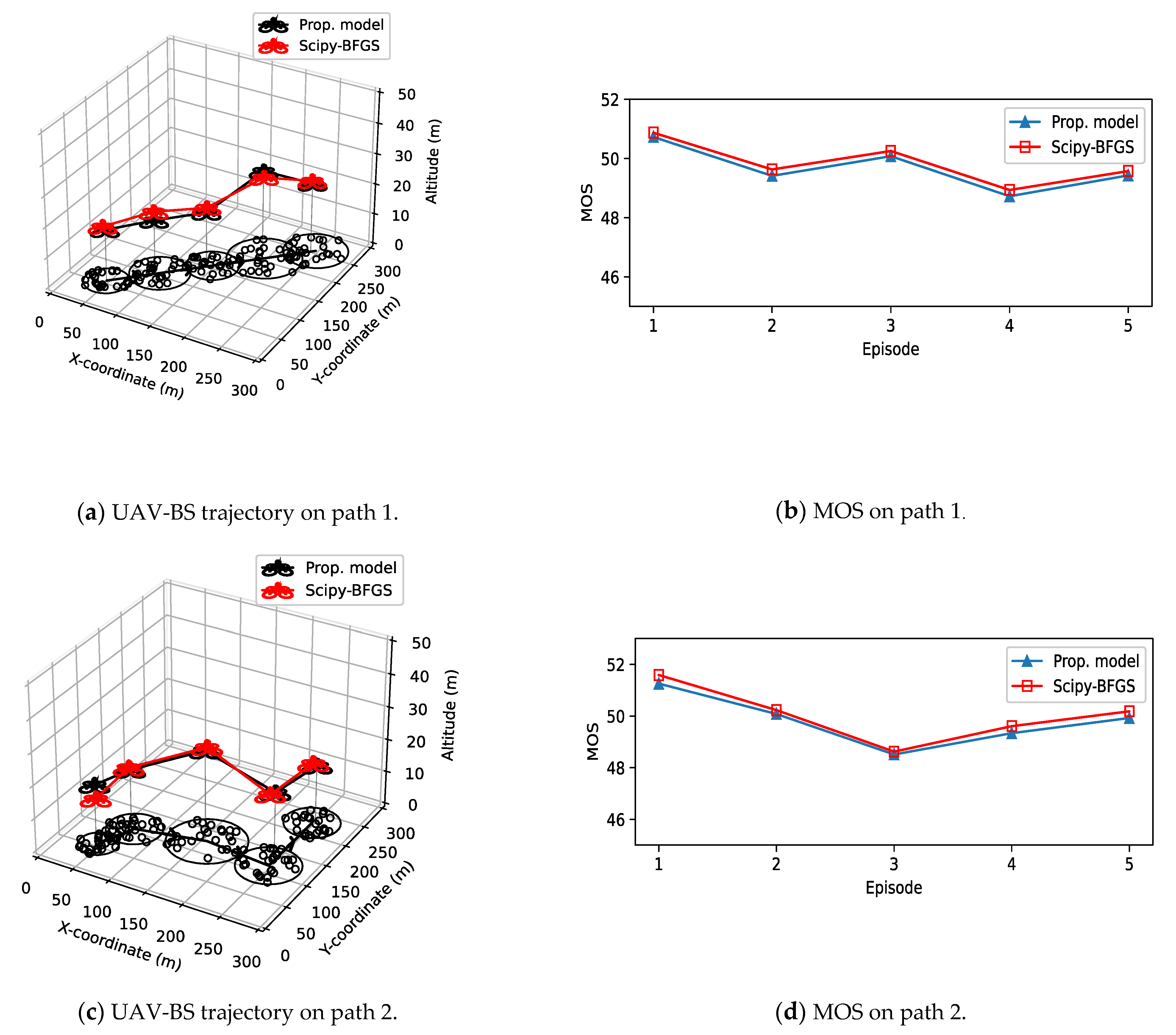
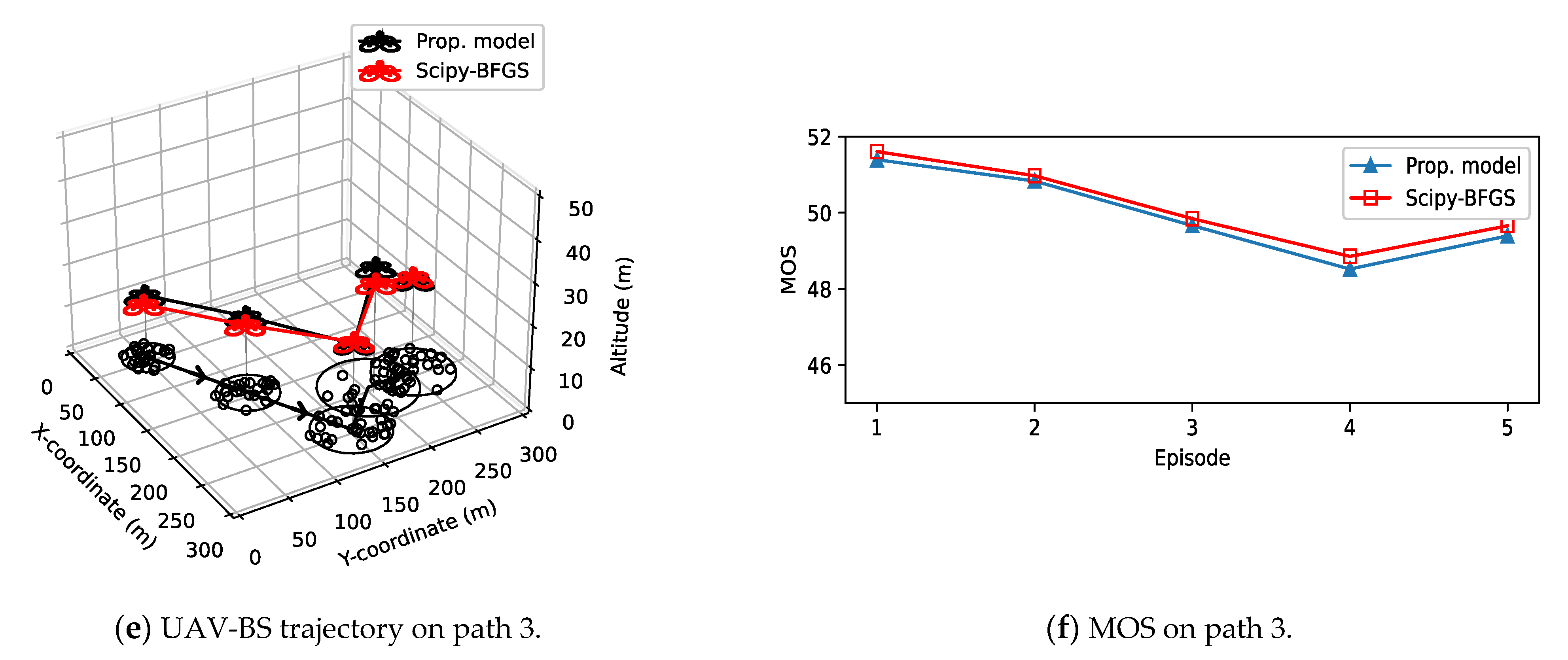
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Bacco, M.; Barsocchi, P.; Cassará, P.; Germanese, D.; Gotta, A.; Leone, G.-R.; Moroni, D.; Pascali, M.-A.; Tampucci, M. Monitoring ancient buildings: Real deployment of an IoT system enhanced by UAVs and virtual reality. IEEE Access 2020, 8, 50131–50148. [Google Scholar] [CrossRef]
- Wang, B.; Sun, Y.; Liu, D.; Nguyen, H.-M.; Duong, T.-Q. Social-aware UAV-assisted mobile crowd sensing in stochastic and dynamic environments for disaster relief networks. IEEE Trans. Veh. Technol. 2020, 69, 1070–1074. [Google Scholar] [CrossRef]
- Costa, F.-G.; Ueyama, J.; Braun, T.; Pessin, G.; Osorio, F.-S.; Vargas, P.-A. The use of unmanned aerial vehicles and wireless sensor network in agricultural applications. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 5045–5048. [Google Scholar]
- Hayat, S.; Yanmaz, E.; Brown, T.-X.; Bettstetter, C. Multi-objective UAV path planning for search and rescue. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5569–5574. [Google Scholar] [CrossRef]
- Kumar, K.; Kumar, S.; Kaiwartya, O.; Kashyap, P.K.; Lloret, J.; Song, H. Drone assisted Flying Ad-Hoc Networks: Mobility and Service oriented modeling using Neuro-fuzzy. Ad Hoc Netw. 2020, 106, 102242. [Google Scholar] [CrossRef]
- Kumar, K.; Kumar, S.; Kaiwartya, O.; Sikandar, A.; Kharel, R.; Mauri, J.L. Internet of Unmanned Aerial Vehicles: QoS Provisioning in Aerial Ad-Hoc Networks. Sensors 2020, 20, 3160. [Google Scholar] [CrossRef] [PubMed]
- Cicek, C.T.; Gultekin, H.; Tavli, B.; Yanikomeroglu, H. UAV Base Station Location Optimization for Next Generation Wireless Networks: Overview and Future Research Directions. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman (UVS) 2019, Muscat, Oman, 5–7 February 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Lai, C.; Chen, C.; Wang, L. On-Demand Density-Aware UAV Base Station 3D Placement for Arbitrarily Distributed Users With Guaranteed Data Rates. IEEE Wirel. Commun. Lett. 2019, 8, 913–916. [Google Scholar] [CrossRef] [Green Version]
- Cherif, N.; Jaafar, W.; Yanikomeroglu, H.; Yongacoglu, A. On the Optimal 3D Placement of a UAV Base Station for Maximal Coverage of UAV Users. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Alzenad, M.; El-Keyi, A.; Lagum, F.; Yanikomeroglu, H. 3-D Placement of an Unmanned Aerial Vehicle Base Station (UAV-BS) for Energy-Efficient Maximal Coverage. IEEE Wirel. Commun. Lett. 2017, 6, 434–437. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Wang, Q.; Liu, J.; Zhang, W. 3D Deployment with machine learning and system performance analysis of UAV-enabled networks. In Proceedings of the 2020 IEEE/CIC International Conference on Communications in China (ICCC), Chongqing, China, 9–11 August 2020; pp. 554–559. [Google Scholar] [CrossRef]
- Hou, M.-C.; Deng, D.-J.; Wu, C.-L. Optimum aerial base station deployment for UAV networks: A reinforcement learning approach. In Proceedings of the 019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Saxena, V.; Jaldén, J.; Klessig, H. Optimal UAV base station trajectories using flow-level models for reinforcement learning. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 1101–1112. [Google Scholar] [CrossRef]
- Hao, G.; Ni, W.; Tian, H.; Cao, L. Mobility-aware trajectory design for aerial base station using deep reinforcement learning. In Proceedings of the 2020 International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 21–23 October 2020; pp. 1131–1136. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Chen, Y. Reinforcement learning in multiple-UAV networks: Deployment and movement design. IEEE Trans. Veh. Technol. 2019, 68, 8036–8049. [Google Scholar] [CrossRef] [Green Version]
- Yin, S.; Zhao, S.; Zhao, Y.; Yu, F.-R. Intelligent trajectory design in UAV-aided communications with reinforcement learning. IEEE Trans. Veh. Technol. 2019, 68, 8227–8231. [Google Scholar] [CrossRef]
- Wu, J.; Yu, P.; Feng, L.; Zhou, F.; Li, W.; Qiu, X. 3D aerial base station position planning based on deep Q-network for capacity enhancement. In Proceedings of the 2019 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Washington, DC, USA, 8–12 April 2019; pp. 482–487. [Google Scholar]
- Watkins, J.-C.-H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Hassabis, D. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- McClelland, J.L.; Rumelhart, D.E.; Group, T.P.R. Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Bayerlein, H.; De Kerret, P.; Gesbert, D. Trajectory optimization for autonomous flying base station via reinforcement learning. In Proceedings of the IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Colonnese, S.; Cuomo, F.; Pagliari, G.; Chiaraviglio, L. Q-SQUARE: A Q-learning approach to provide a QoE aware UAV flight path in cellular networks. Ad Hoc Netw. 2019, 91, 101872. [Google Scholar] [CrossRef]
- Abeywickrama, H.V.; He, Y.; Dutkiewicz, E.; Jayawickrama, B.A.; Mueck, M. A Reinforcement Learning Approach for Fair User Coverage Using UAV Mounted Base Stations Under Energy Constraints. IEEE Open J. Veh. Technol. 2020, 1, 67–81. [Google Scholar] [CrossRef]
- Wright, S.; Nocedal, J. Numerical Optimization; Springer: New York, NY, USA, 1999. [Google Scholar]
- Rugelj, M.; Sedlar, U.; Volk, M.; Sterle, J.; Hajdinjak, M.; Kos, A. Novel cross-layer QoE-aware radio resource allocation algorithms in multiuser OFDMA systems. IEEE Commun. Mag. 2014, 62, 3196–3208. [Google Scholar] [CrossRef]
- Cui, J.; Liu, Y.; Ding, Z.; Fan, P.; Nallanathan, A. QoE-Based Resource Allocation for Multi-Cell NOMA Networks. IEEE Trans. Wirel. Commun. 2018, 17, 6160–6176. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| Environmental parameters | |
| Noise power spectral | |
| Path loss exponent | |
| Attenuation factors for line of sight (LoS) and non-LoS (NLoS) | |
| Traffic load |
| Time | State |
|---|---|
| Parameter | Value |
|---|---|
| Batch size | 64 |
| Learning rate | 0.001 |
| Size of replay memory | 5000 |
| Number of hidden layers | 2 |
| Number of neurons in each hidden layer | 48 |
| Type of activation function | Rectified linear unit (ReLU) |
| Time Parameter | Value |
|---|---|
| 25 | |
| 10–50 m | |
| 2 GHz | |
| Transmit power | 20 dBm |
| 1 MHz | |
| 8,000,000 bits | |
| 9.61, 0.16 | |
| 1.120, 4.6746 | |
| 2 | |
| 3 dB | |
| 23 dB | |
| 5, 10 m | |
| −100 dBm | |
| 10, 1 |
| BFGS | Proposed Algorithm | |
|---|---|---|
| Time complexity | ) | |
| Input | Exact positions of the UAV-BS and all the GUs | Differences of the average received channel power gain |
| Output | Optimal position(coordinate) | Optimal action(direction) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, W.; Jeon, Y.; Kim, T.; Kim, Y.-I. Deep Reinforcement Learning for UAV Trajectory Design Considering Mobile Ground Users. Sensors 2021, 21, 8239. https://doi.org/10.3390/s21248239
Lee W, Jeon Y, Kim T, Kim Y-I. Deep Reinforcement Learning for UAV Trajectory Design Considering Mobile Ground Users. Sensors. 2021; 21(24):8239. https://doi.org/10.3390/s21248239
Chicago/Turabian StyleLee, Wonseok, Young Jeon, Taejoon Kim, and Young-Il Kim. 2021. "Deep Reinforcement Learning for UAV Trajectory Design Considering Mobile Ground Users" Sensors 21, no. 24: 8239. https://doi.org/10.3390/s21248239
APA StyleLee, W., Jeon, Y., Kim, T., & Kim, Y. -I. (2021). Deep Reinforcement Learning for UAV Trajectory Design Considering Mobile Ground Users. Sensors, 21(24), 8239. https://doi.org/10.3390/s21248239