1. Introduction
An electronic nose (e-nose), which mimics biological olfaction, is an odor analysis device composed of a carefully selected sensor array and an appropriate pattern recognition algorithm [
1]. E-nose has the ability to detect and distinguishing characteristics such as the type and concentration of gas. E-nose has become more and more widely used in the world. Sigfredo et al. designed an array of gas sensor and five machine learning algorithms to detect and evaluate contamination in grapevine berries and taint in wines [
2]. Hao Wei et al. used PEN3 e-nose for data collection and designed a back-propagation neural network (BPNN) to detect brown core in the Chinese pear variety huangguan [
3]. Winston Li et al. used four classifiers—MLP, SVM, KNN, and Parzen—and fusion in Dempster–Shafer to improve the accuracy of odor classification [
4]. In addition, fluctuation enhanced sensing (FES) has been applied to the field of e-noses to detect gas-phase chemicals [
5,
6,
7]. In FES, noise is considered to carry much useful information, so it uses microfluctuations caused by the interaction between chemical sensors and gas molecules to improve sensitivity and selectivity [
8]. With the development of e-nose technology, e-nose has been designed and optimized many times and widely used in food testing [
9], environmental monitoring [
10,
11], medical diagnosis [
12,
13,
14], and the space shuttle [
15,
16,
17]. In particular, for a long time, Chinese herbal medicine has been classified based on traditional identifying methods such as human smell, taste, vision, and touch, while the human smell is the most common method to distinguish the variety and various herb-growing areas. However, human identification of Chinese herbal medicines is highly subjective and time-consuming because individual differences and external disturbances may easily influence humans distinguishing. In recent years, several new technologies have emerged to replace manual classification of Chinese medicinal materials, such as gas chromatography-mass spectrometry (GC–MS) [
18] and Electronic tongue (E-tongue) [
19]. They are challenging to be commonly used because of their high price or damage to the integrity of Chinese medicinal materials.
At present, many deep learning methods and applications have been proposed, and they were also applied to odor identifications. Danli Wu et al. used a convolutional neural network (CNN) to predict odor pleasantness [
20]. You Wang et al. designed an optimized deep convolutional neural network to classify dendrobium data collected by e-nose [
21]. Yan Shi et al. designed a CNN-SVM model to classify beer data collected by PEN3 e-nose [
22]. Deep learning algorithm can automatically extract and recognize odor features from odor data. Compared with traditional machine learning methods [
23,
24], the deep learning method has more advantages when applied in the field of odor recognition and achieved better performance.
An e-nose is usually operating in a separate way where the gas sensing hardware collects response data then transmits them to a computer for identification. Considering the feature of real-time data processing, some studies integrated odor identification function into automatic odor sampling hardware. Zhiyuan Wu et al. designed a low-cost e-nose system and identified cigarettes using random forest [
10]. A. Ali et al. proposed a hardware/software co-design approach using the Zynq platform based on principal component analysis [
25]. The integration of the e-nose system has several advantages. First of all, the integration makes the system less complicated and increase mobility because the identification algorithm runs locally and avoid using an additional computer. Furthermore, integration reduces data transmission, which makes it easier for real-time odor identification. It can be seen that the integrated e-nose design has become an important research direction. Although the integrated e-nose has many benefits, such as portability, low cost, and miniaturization, there are still some challenges in designing the integrated e-nose. The design of integrated e-nose is limited by chip performance, which leads to simple algorithms can be conducted. A simple algorithm may have a certain effect in some specific applications, but the effect may worsen in a complex odor recognition field. Complex algorithms are limited by the computational performance of simple chips, resulting in slow recognition speed, which leads to many excellent deep learning models that usually need to run on computers with GPUs. Therefore, it is vital to contrive this system capable of low-cost, fast identification, and maintaining the accuracy of identification, especially in the practical application of e-nose.
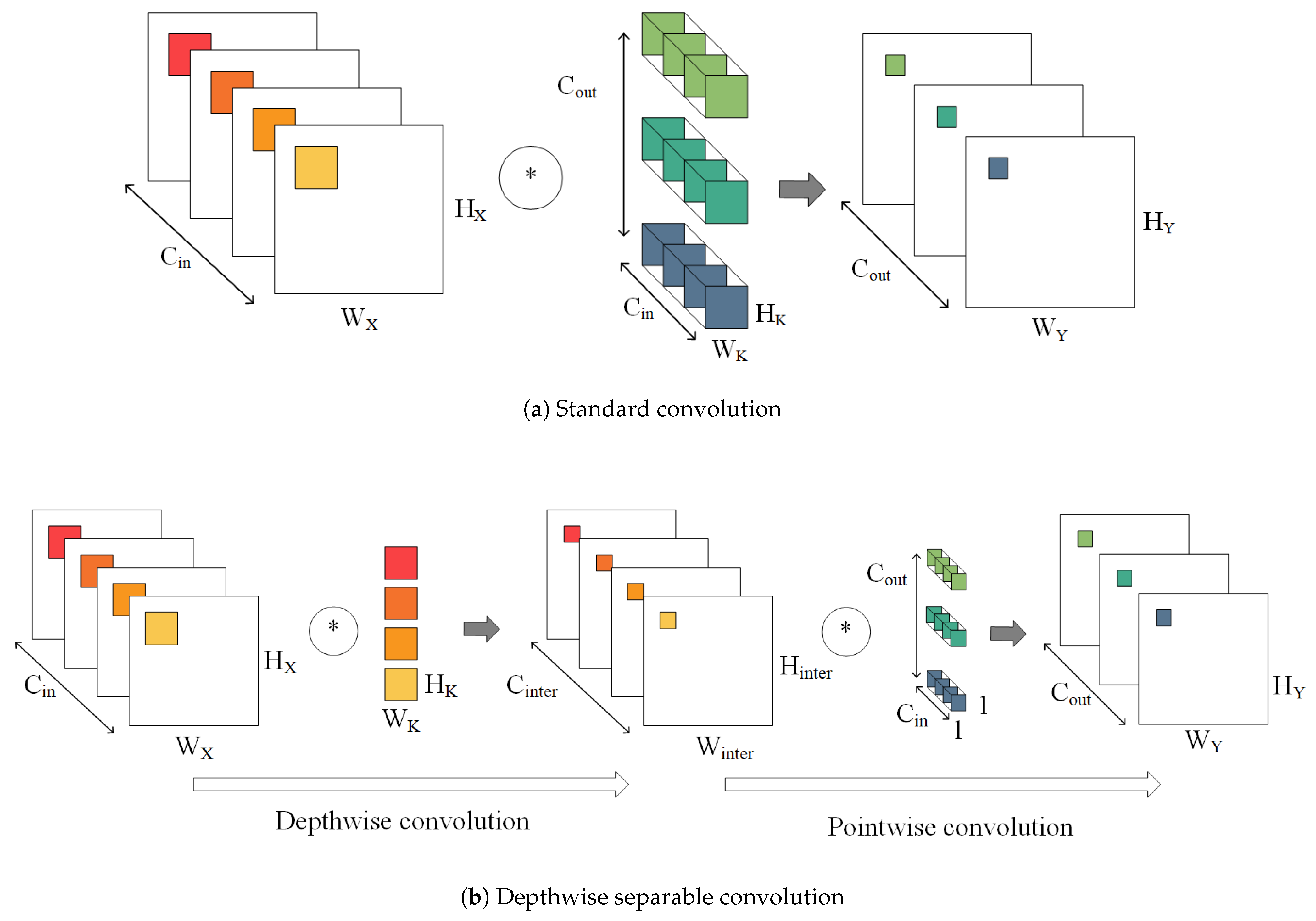
The main contributions of this paper are as follows. (1) Deep separable convolution is applied in odor identification. We propose a lightweight deep learning odor identification model named OI-DSCNN, which balances the speed and accuracy of the odor identification algorithm. (2) Accelerated deep learning algorithm based on Field-Programmable Gate Array (FPGA) is introduced into odor identification, in which the overall architecture and modules of OI-DSCNN are designed and optimized. Therefore, odor identification is accelerated in FPGA. (3) The SF-KL quantization scheme is designed to reduce FPGA resource consumption and maintain the accuracy.
This article is composed as follows. In
Section 2, the OI-DSCNN model is first introduced, and then the design and implementation of SF-KL are introduced in detail. In
Section 3, the architecture of OI-DSCNN in FPGA, and the design and optimization of each module are illustrated. In
Section 4, experiments for the evaluation of the model are demonstrated. In
Section 5, conclusions are drawn and future research is prospected.
3. FPGA Design and Implementation
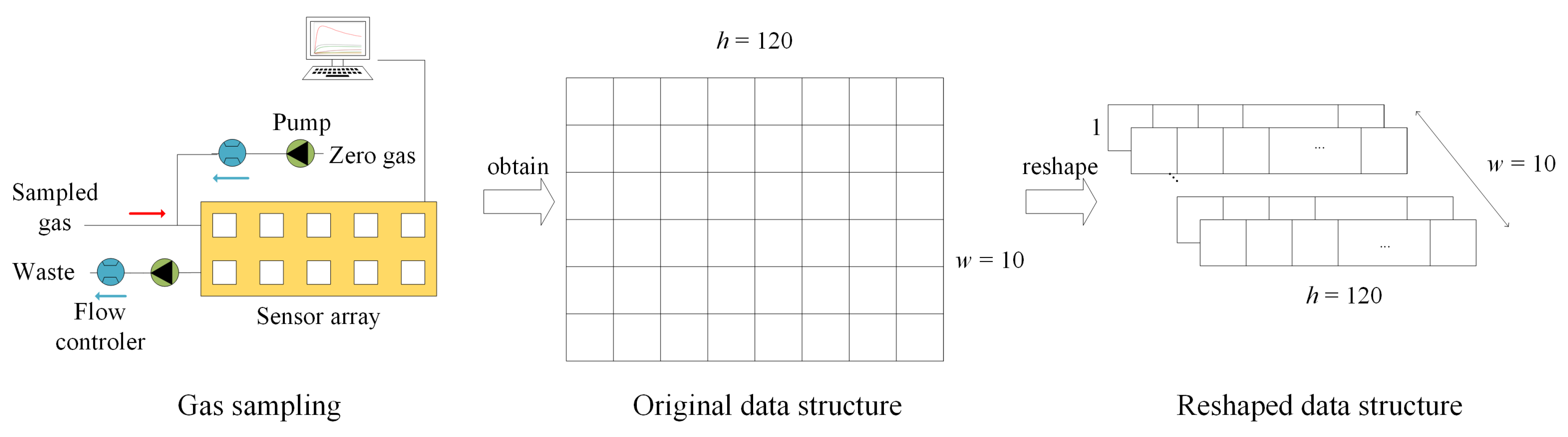
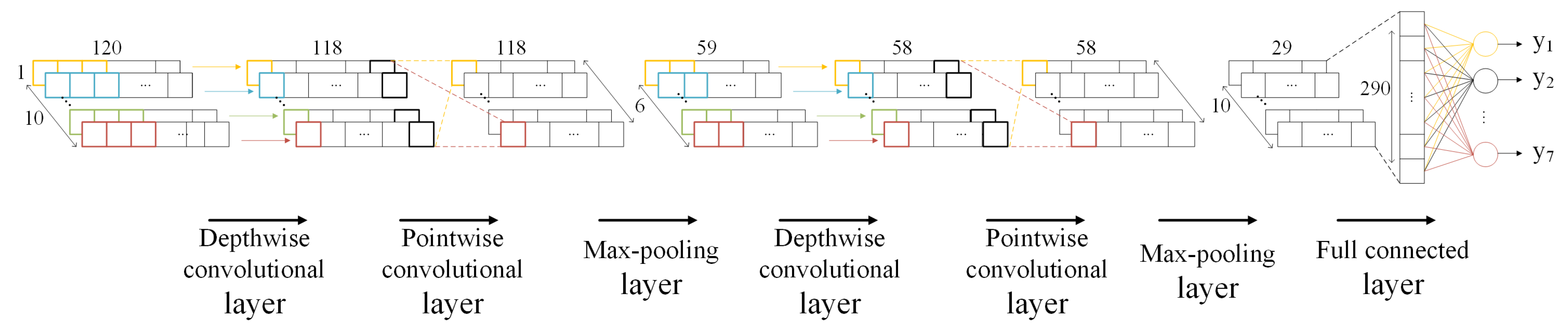
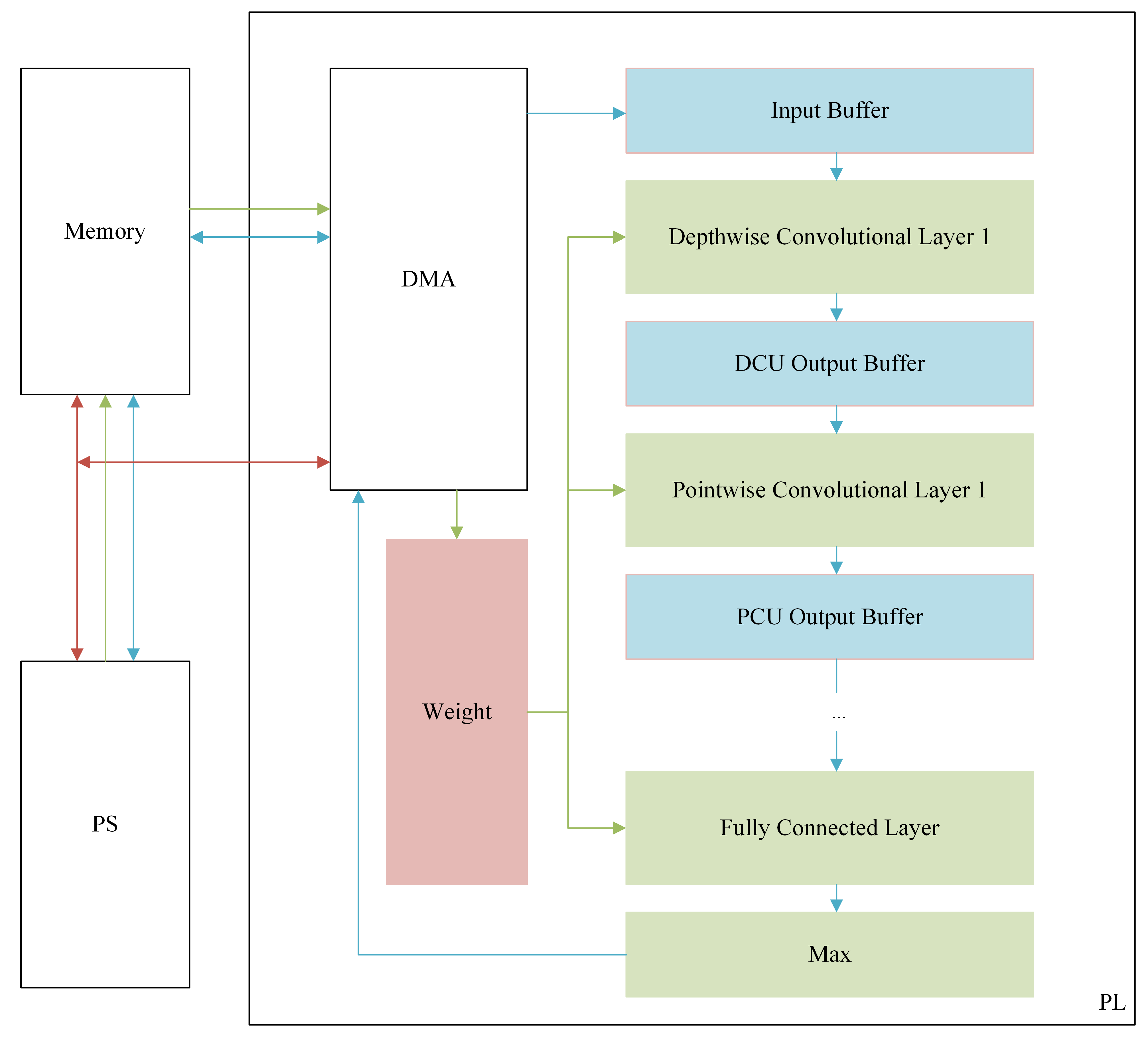
Figure 4 describes the overview of the system architecture. This system was implemented on the Digilent Arty Z7-7020 development board, USA, which is detailed in
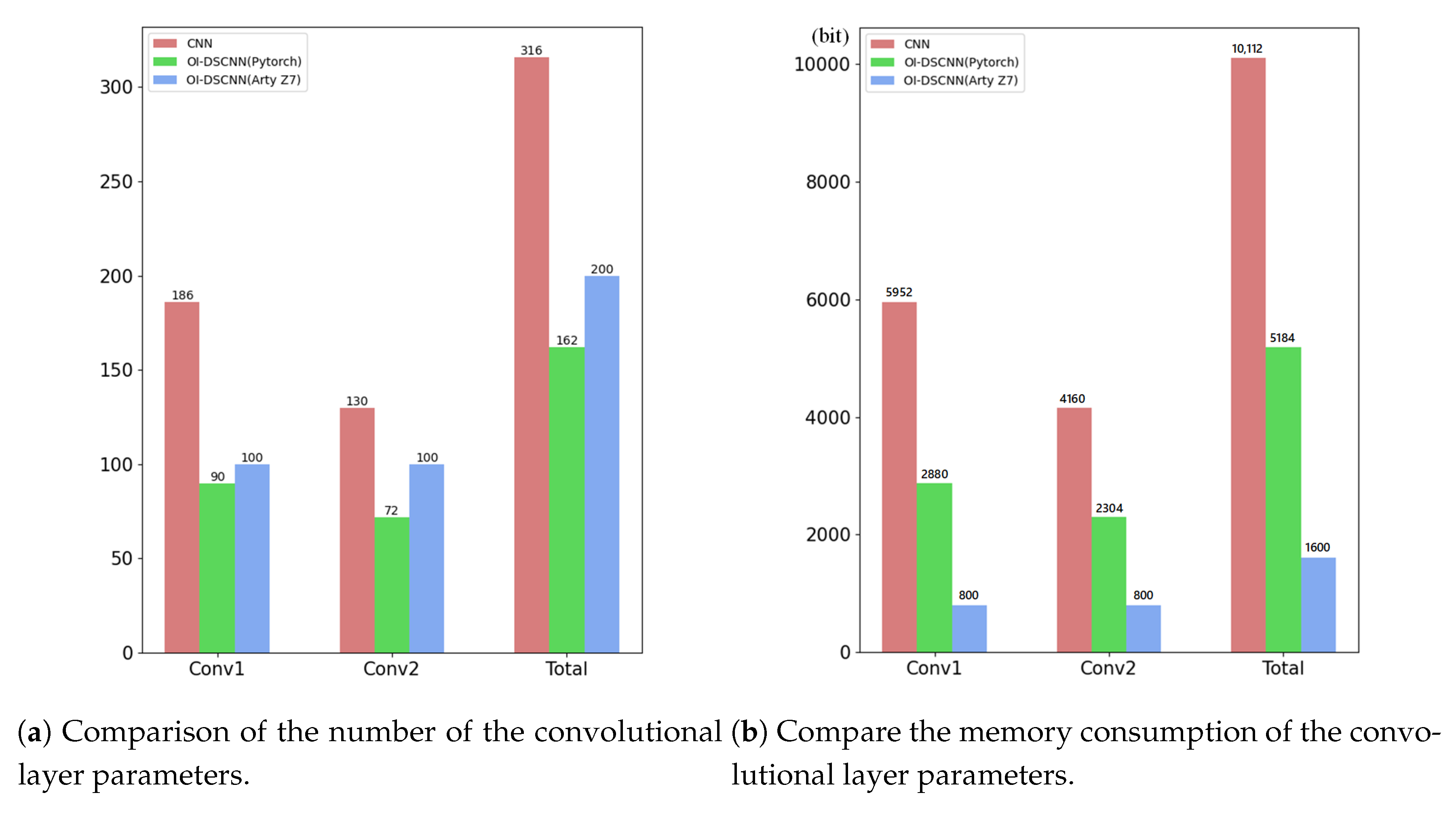
Section 4. In order to take advantage of parallel computation in FPGA, the four convolutional layers and the fully connected layer are operated in a pipeline. In order to reduce the data access time and improve the performance of the system, the output of each layer of the network is stored in on-chip memory. The system is composed of PS block, PL block, and DDR memory. The PL block composes of winograd depthwise convolution unit (WDCU), pointwise convolution unit (PCU), fully connected unit (FCU), on-chip memory, and direct memory access (DMA). WDCU, PCU, and FCU are responsible for calculating each convolutional layer, activation layer, max-pooling layer, and fully connected layer. On-chip memory includes input data buffer, intermediate data buffer, and weight buffer. The input data buffer, intermediate data buffer, and the weight buffer for the fully connected layer were designed by block RAM (BRAM), while the weights of convolutional layers are stored in distributed RAM (DRAM). Thank to some techniques used when modeling OI-DSCNN, the number of parameters and computational complexity saw a significant decrease, which the experimental results will be illustrated in detail in
Section 4. Besides, the BRAM with 630 KB in a Zynq-7020 chip is sufficient to store such a small scale of several input samples when the model is implemented in the pipeline. Moreover, it is also sufficient to store intermediate results, input data, and parameters in the on-chip memory, which reduces the memory access timing and enhances the performance of system.
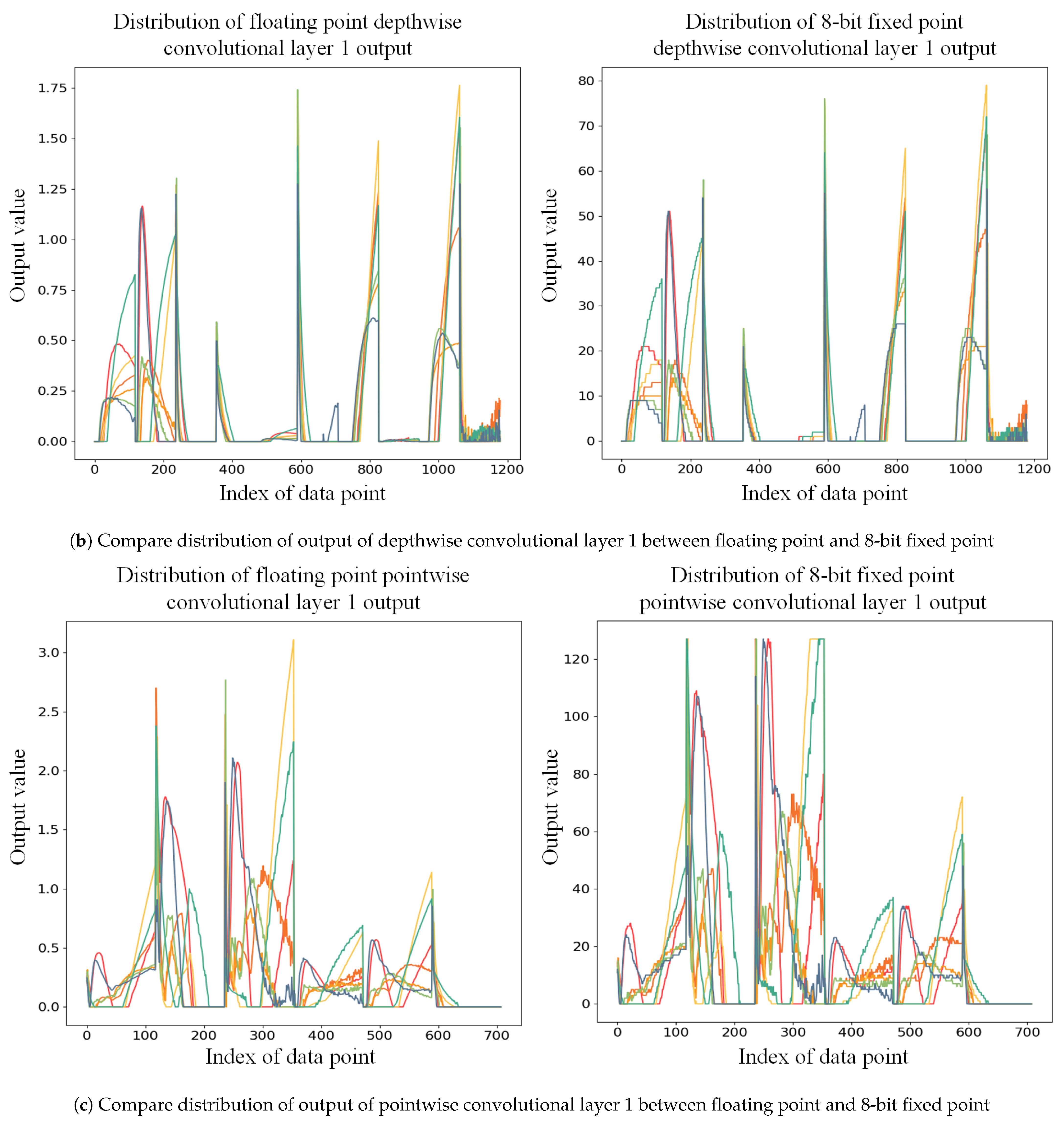
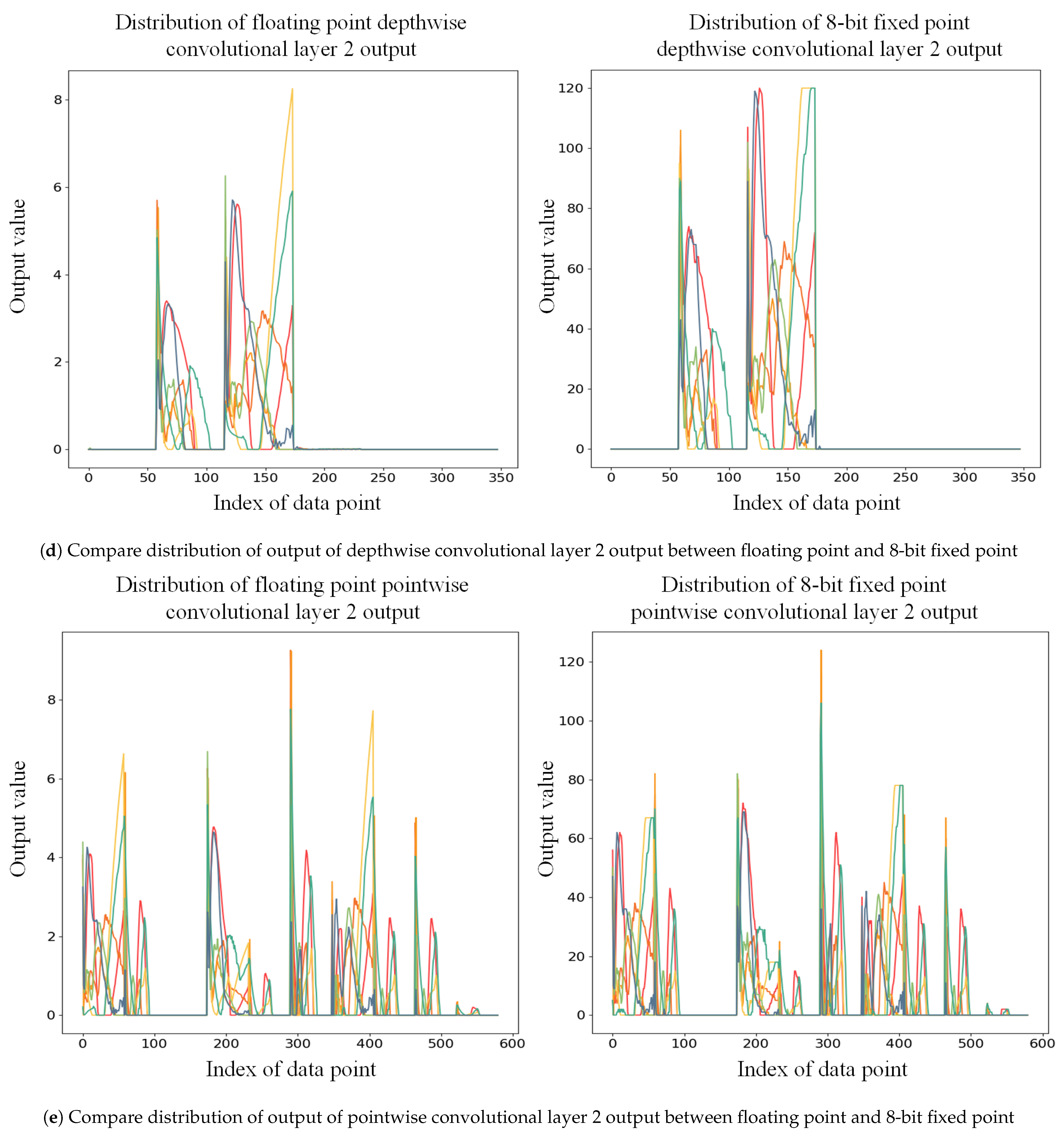
The core of the PL design is the convolution layer, which significantly impacts the computation rate of the entire system. Due to the grouped convolution structure of the depthwise convolution layer, the data within each input channel cannot be reused. The Winograd algorithm for depthwise convolution was introduced [
41], and the structure of the WDCU was presented in
Section S1. WDCU consists of line buffer, input transformation unit, multiplier array unit, configurable output inverse transformation unit, and relu and quantization unit. A line buffer is used to buffer the data transferred to the input transformation unit. The transformed input data are transmitted to the multiplier array unit that multiplies the inputs and the weights from the WDCU weight buffer unit. After the inverse transformation of the Winograd algorithm is completed by the configurable output inverse transformation unit, the 8-bit output of the depthwise convolutional layer is obtained through relu and quantization unit and transmitted to the WDCU output buffer.
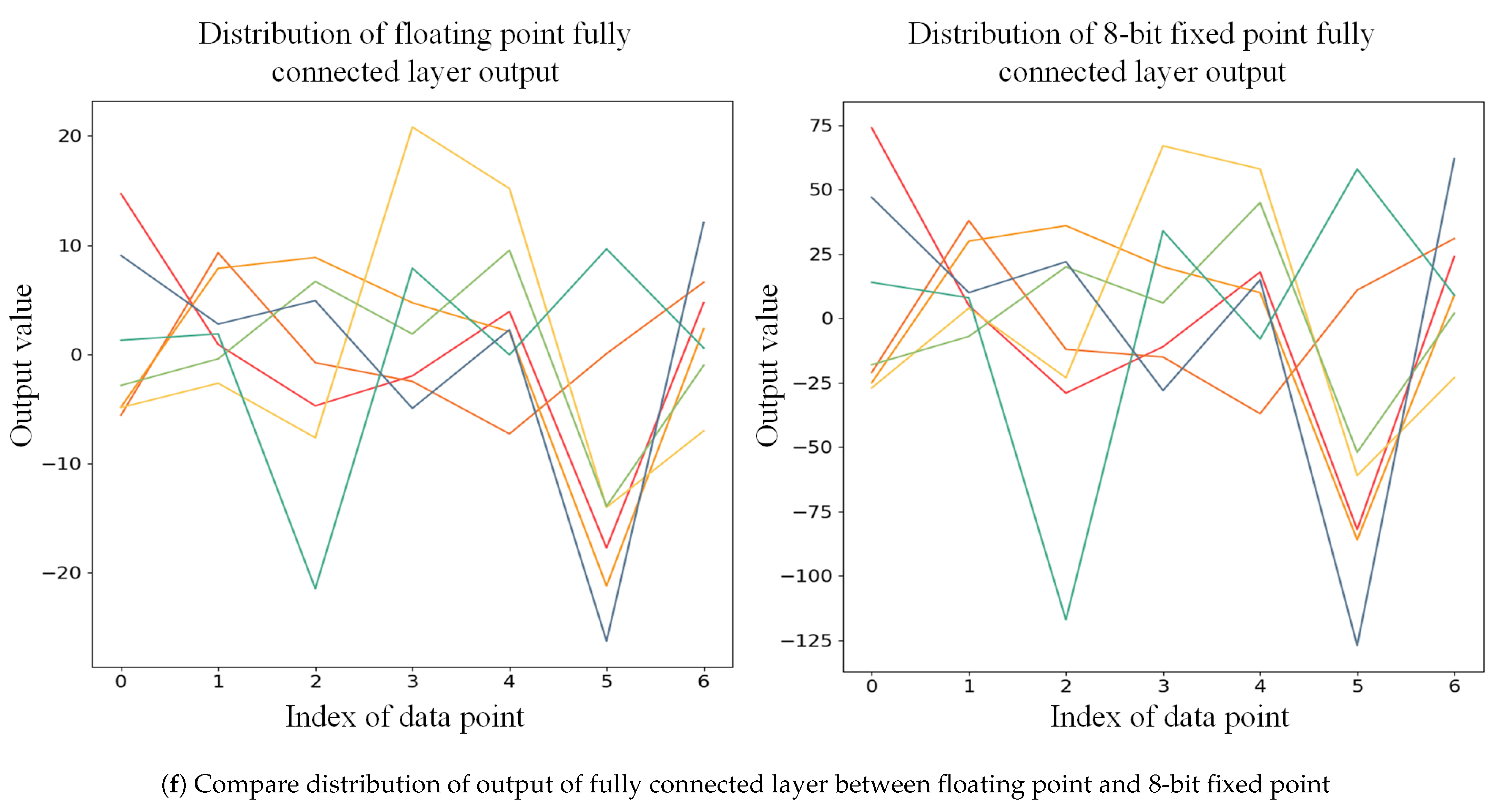
The PCU, which is used for pointwise convolution, comprises line buffer, multiplier array unit, adder tree unit, relu and quantization unit, and maxpooling unit. The output of WDCU is connected to the line buffer of the first PCU, then passed to the line buffer of the next PCU. Details about the design of PCU can be seen in
Section S2. For the fully connected layer, as the weights and data are not reused, a compromise solution is adopted in our design [
42,
43]. The FCU, which is used to calculate the output of fully connected layer, comprises line buffer, multiplier array unit, adder tree unit, and accumulator unit. FCU divides the data from the PCU output buffer into several
small scale vectors and obtains the output through multiplier array unit, adder tree unit, accumulator unit, and quantization unit. Details about the design of FCU can be seen in
Section S3. The final outputs of FCU are compared in the max unit, and then the comparison result is sent to the PS block.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}