Non-Communication Decentralized Multi-Robot Collision Avoidance in Grid Map Workspace with Double Deep Q-Network


Abstract
:1. Introduction
2. Related Work
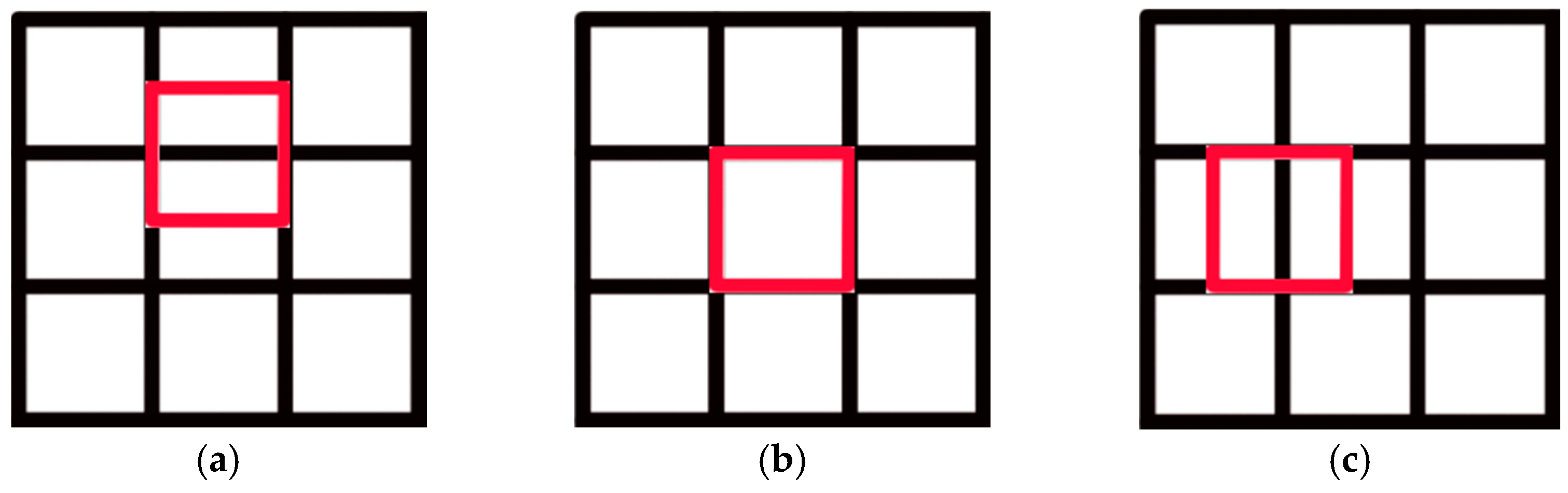
3. Problem Formulation
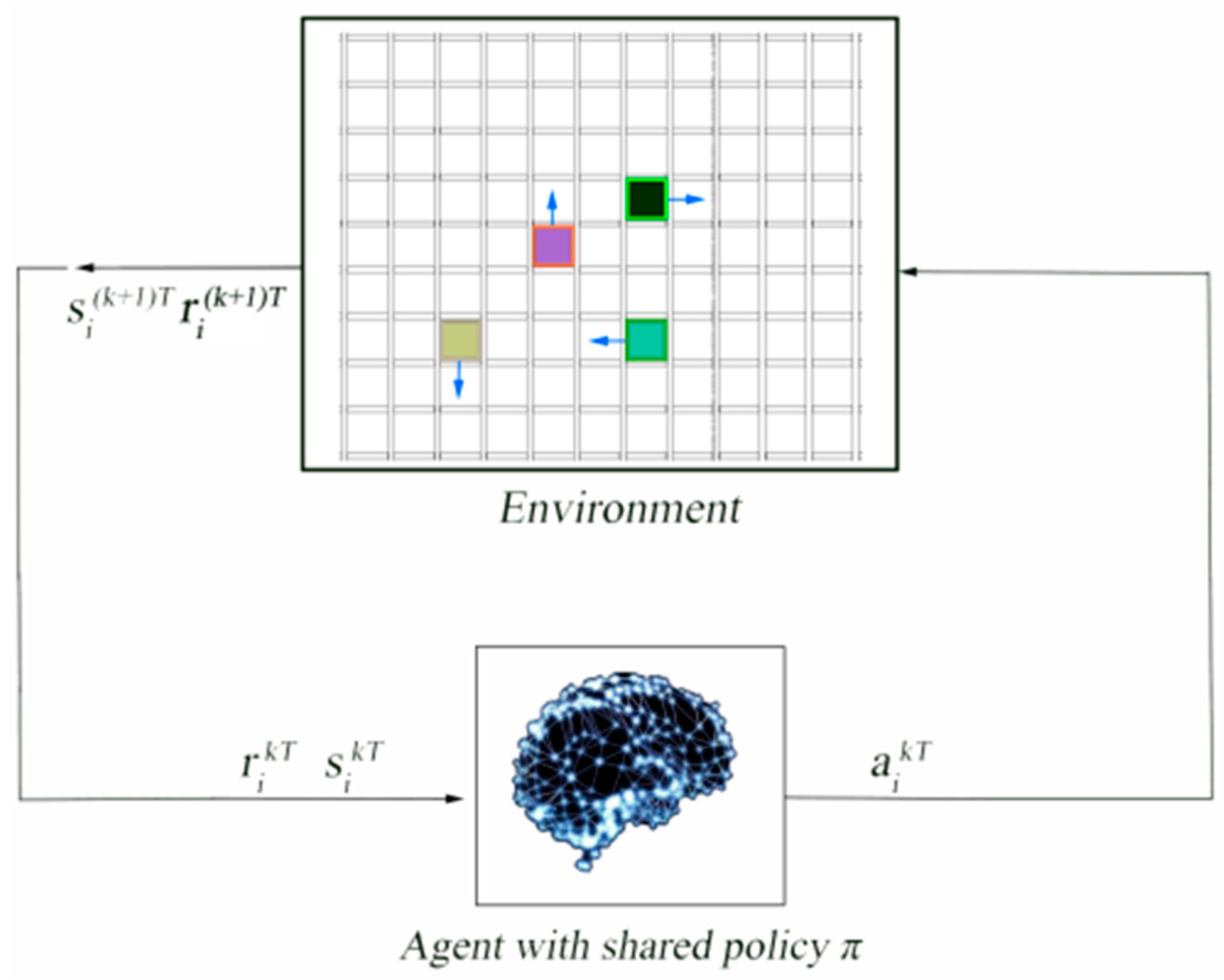
4. Algorithm Framework and Training
4.1. Reward Design
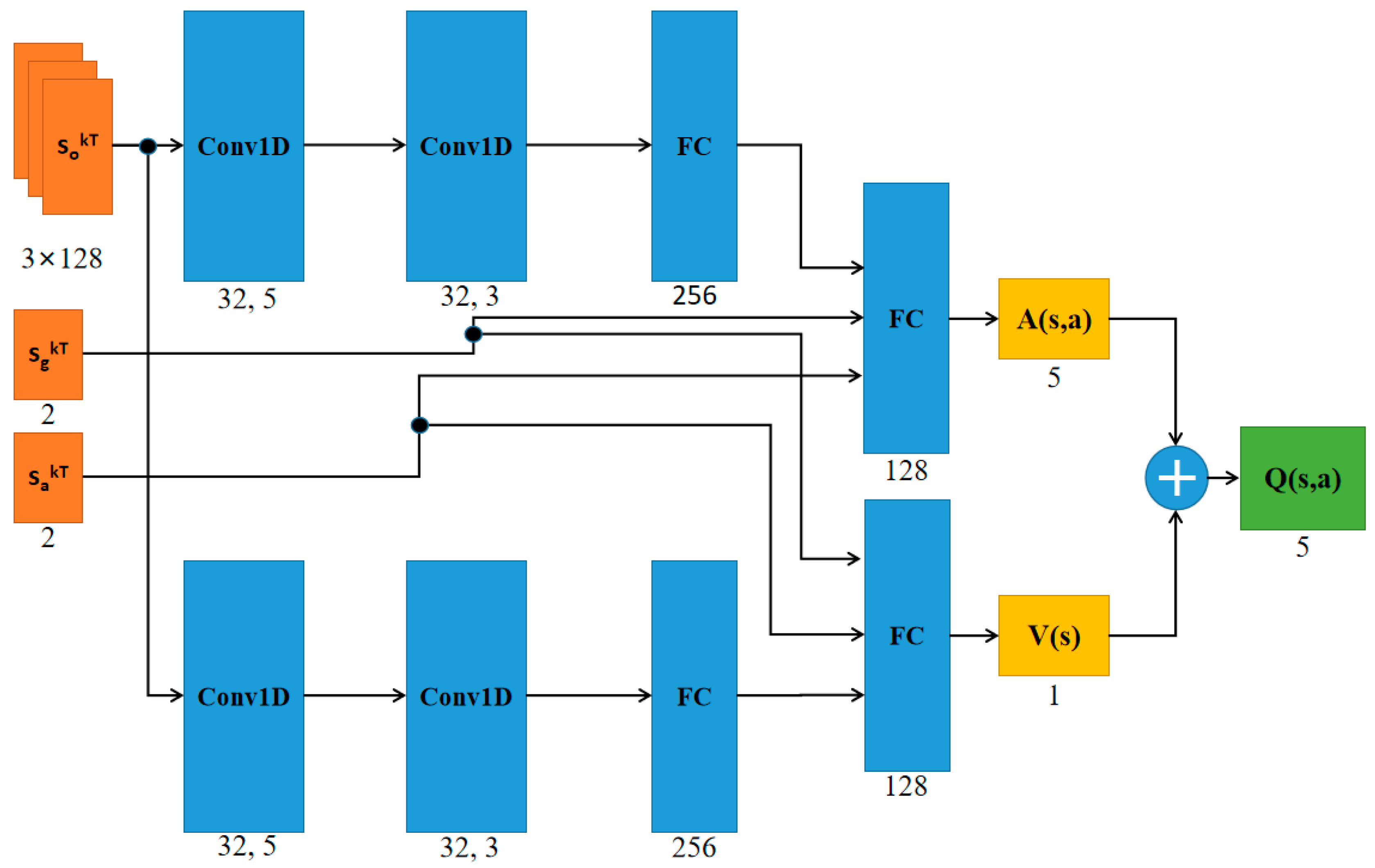
4.2. Network Architecture and Training Procedure
| Algorithm 1: DQN with Multiple Robots in Grid Map | |
| 1 | Initialize replay memory D to capacity Ca; |
| 2 | Initialize action-value function Q with random weights θ; |
| 3 | Initialize target action-value function Q with weights θ_ = θ; |
| 4 | For episode = 1, 2,... do |
| 5 | // Collect data in parallel |
| 6 | For robot i = 1, 2,..., N do |
| 7 | Run Ti timesteps |
| 8 | With probability ε select a random action at |
| 9 | otherwise select at = argmaxa Q(ϕ(st), a; θ), where t∈[0, Ti] |
| 10 | Execute action at emulator and observe reward rt and st+1 |
| 11 | Preprocess ϕt+1 = ϕ(st+1) |
| 12 | Store transition (ϕt, at, rt, ϕt+1) in D |
| 13 | break, if |
| 14 | End For |
| 15 | //Updata policy |
| 16 | if the state in step j+1 is terminnated then |
| 17 | yj = ri |
| 18 | else |
| 19 | yj = ri + γmaxa’ Q(ϕj+1, a’; θ_) |
| 20 | end |
| 21 | Perform a gradient descent step on (yj−Q(ϕj, aj; θ))2 with respect to the network parameters θ |
| 22 | Every C steps reset Q = Q |
| 23 | End For |
5. Experiment
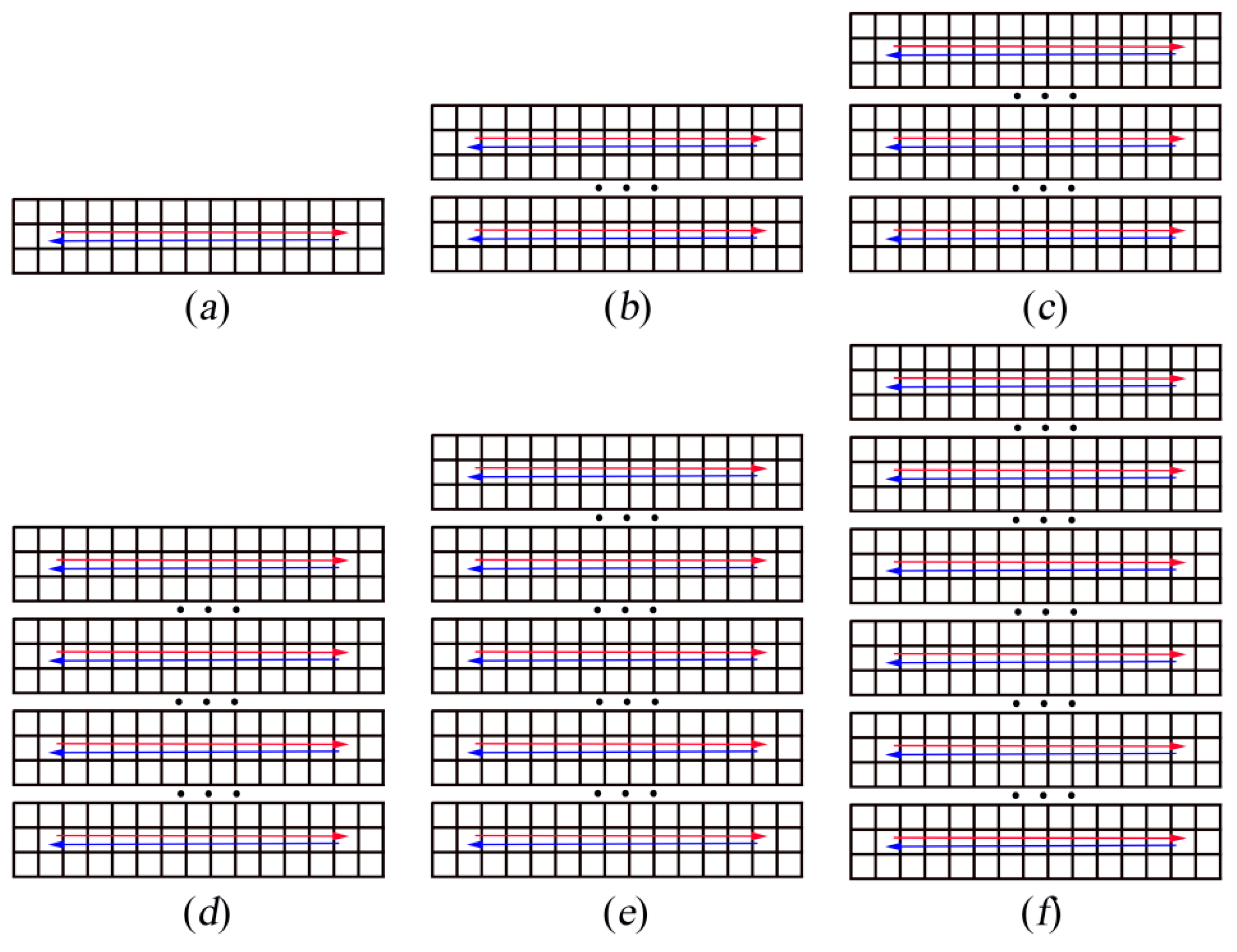
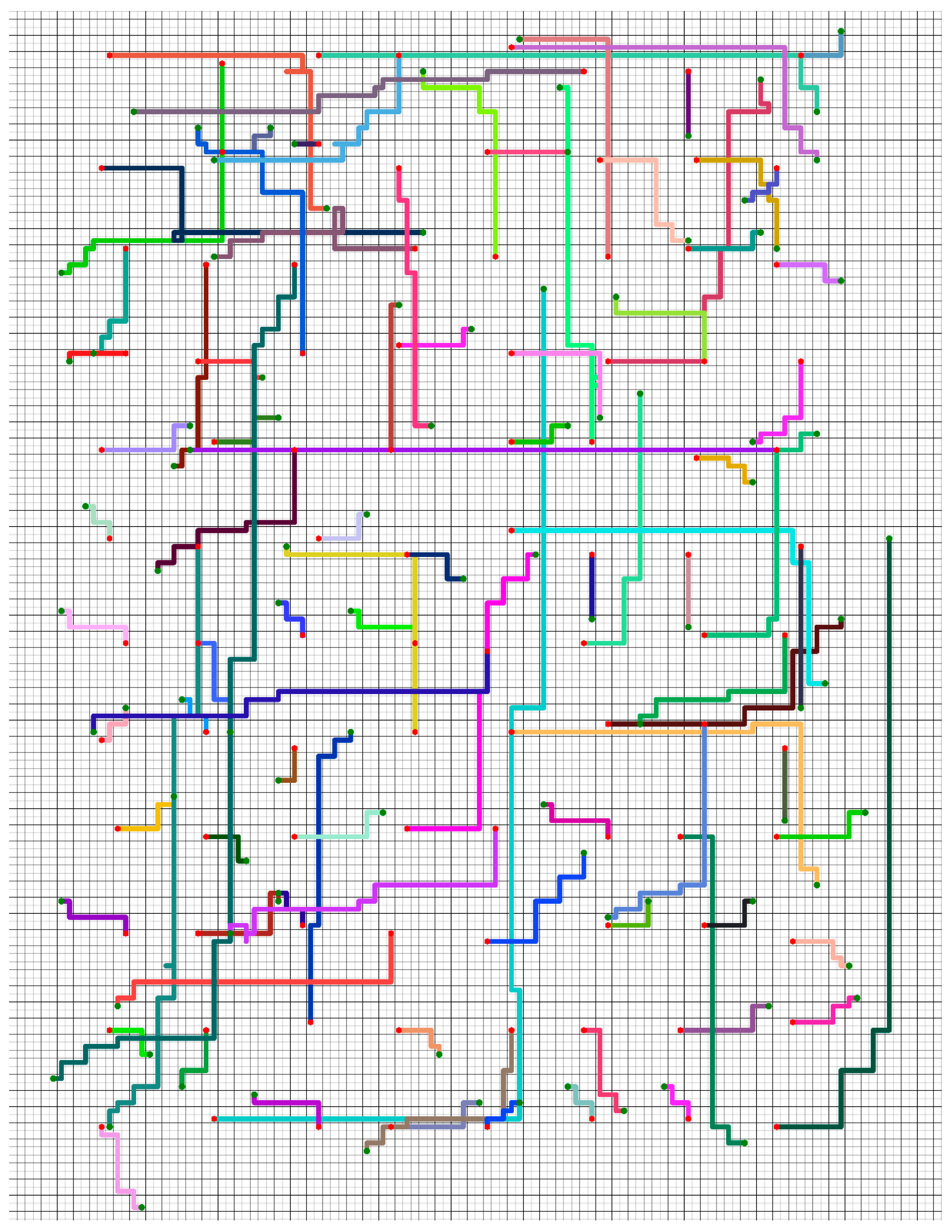
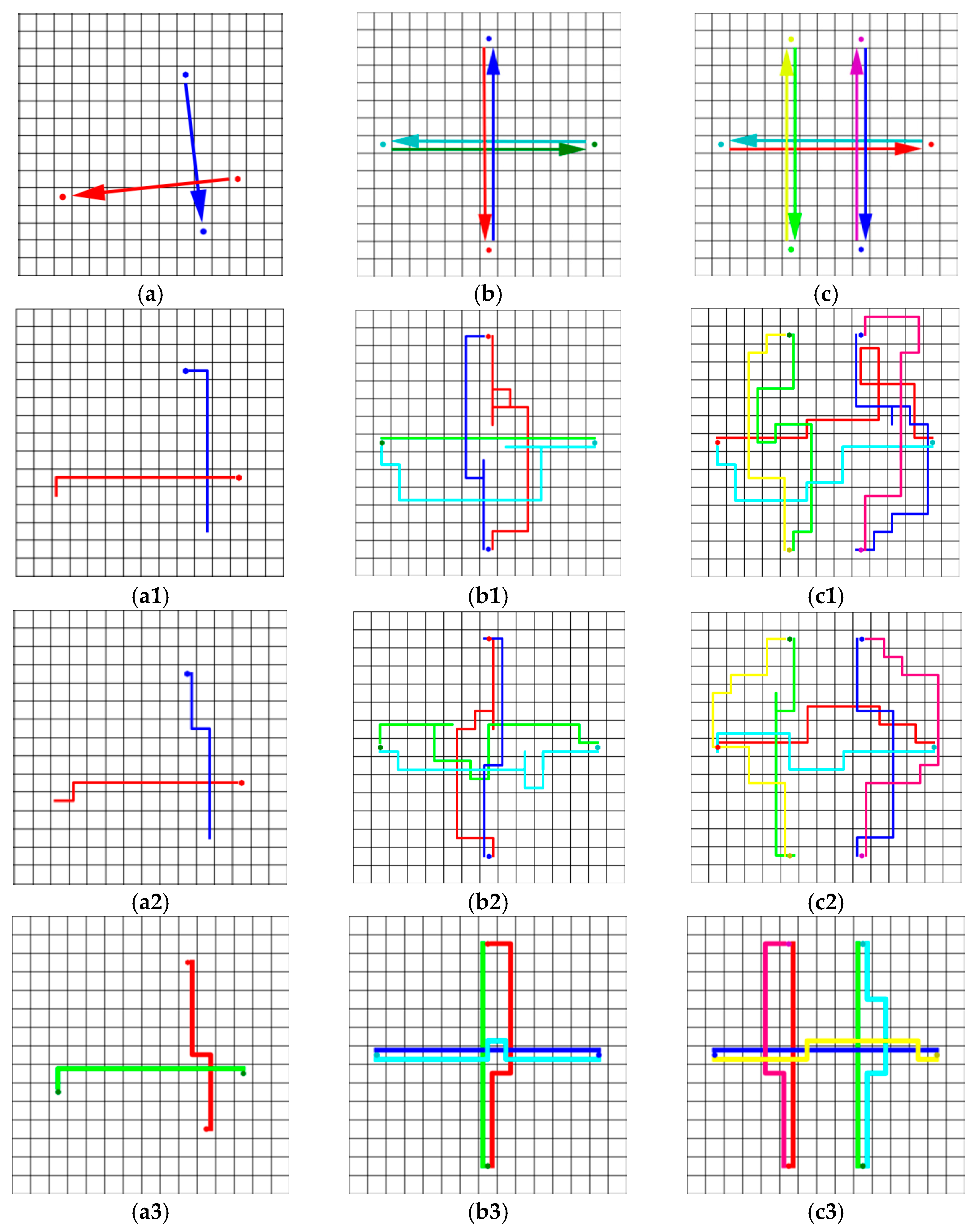
5.1. Training Scenarios
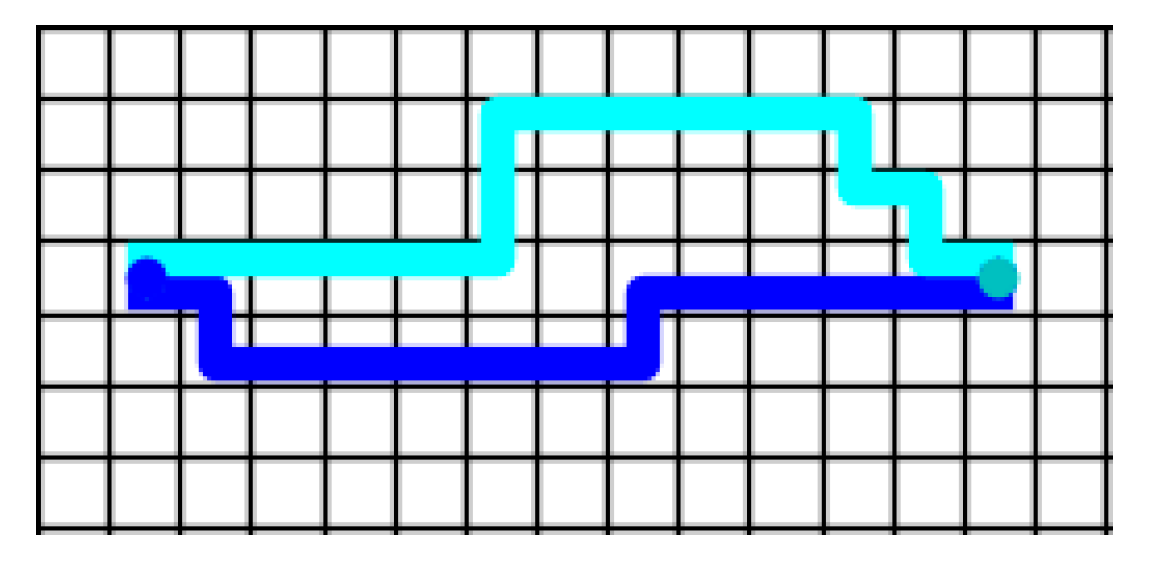
5.2. Simulation Results
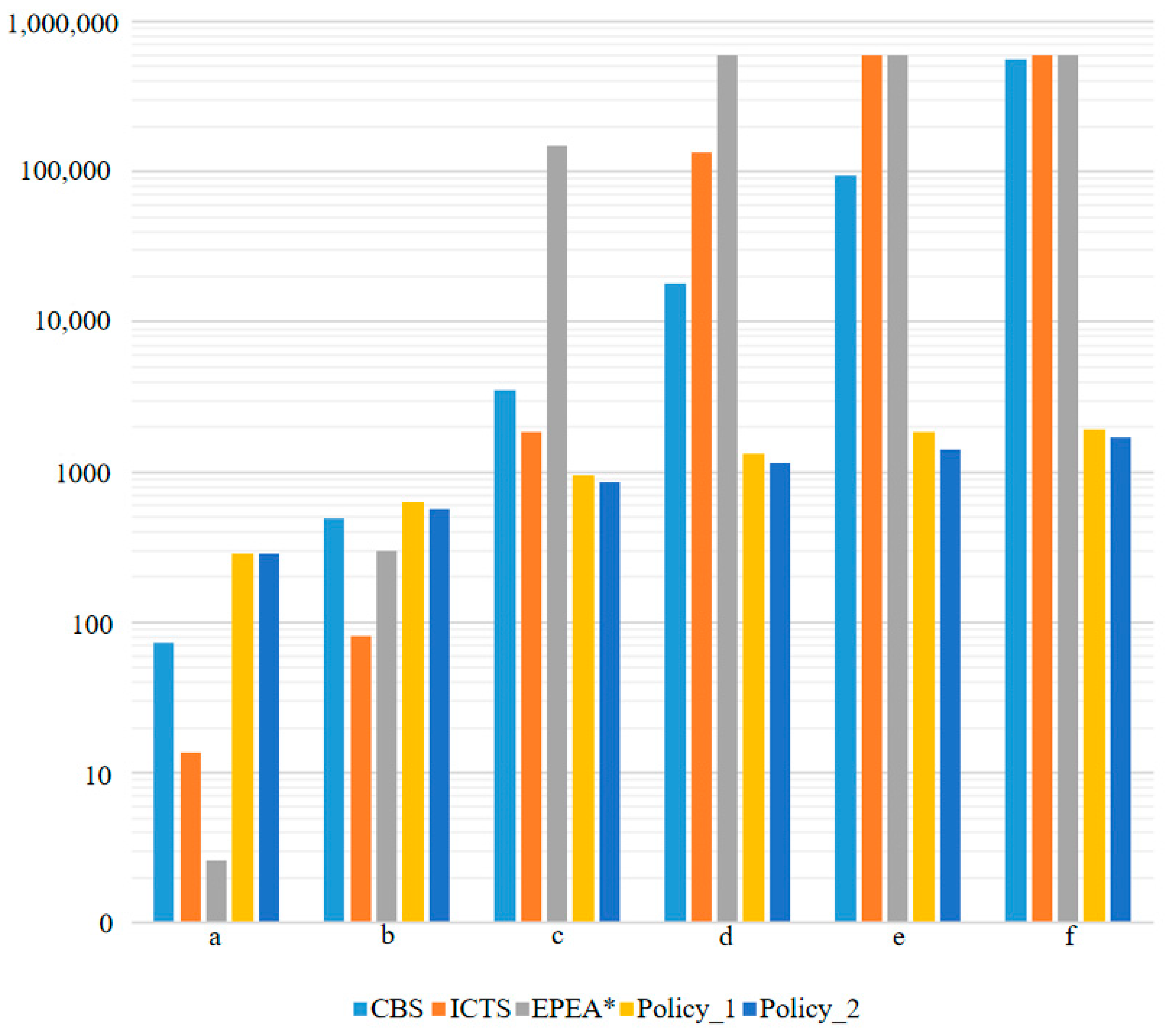
5.3. Compared with Centralized Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DDQN | Double Deep Q-Network |
| Adam | Adaptive moment estimation |
| Conv1D | convolutional neural network |
| FC | fully connected neural network |
| EPEA* | Enhanced Partial Expansion A* |
| ICTS | Increasing Cost Tree Search |
| CBS | Conflict-Based Search |
| CADRL | collision avoidance with deep reinforcement learning |
| RVO | reciprocal velocity obstacle |
| ORCA | optimal reciprocal collision avoidance |
| GA3C-CADRL | GPU/CPU Asynchronous Advantage Actor-Critic for Collision Avoidance with Deep reinforcement learning |
| SA-CADRL | socially aware CADRL |
References
- Chen, Y.F.; Liu, M.; Everett, M.; How, J.P. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In Proceedings of the International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 285–292. [Google Scholar]
- Chen, Y.F.; Everett, M.; Liu, M.; How, J.P. Socially aware motion planning with deep reinforcement learning. arXiv 2017, arXiv:1703.08862. [Google Scholar]
- Semnani, S.H.; Liu, H.; Everett, M.; de Ruiter, A.; How, J.P. Multi-Agent Motion Planning for Dense and Dynamic Environments via Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2020, 5, 3221–3226. [Google Scholar] [CrossRef] [Green Version]
- Long, P.; Fan, T.; Liao, X.; Liu, W.; Zhang, H.; Pan, J. Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6252–6259. [Google Scholar]
- Van den Berg, J.; Lin, M.; Manocha, D. Reciprocal velocity obstacles for real-time multi-agent navigation. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation (ICRA), Pasadena, CA, USA, 19–23 May 2008; pp. 1928–1935. [Google Scholar]
- Alonso-Mora, J.; Breitenmoser, A.; Rufli, M.; Beardsley, P.; Siegwart, R. Optimal reciprocal collision avoidance for multiple non-holonomic robots. In Distributed Autonomous Robotic Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 203–216. [Google Scholar]
- Chen, G.; Yao, S.; Ma, J.; Pan, L.; Chen, Y.; Xu, P.; Ji, J.; Chen, X. Distributed Non-Communicating Multi-Robot Collision Avoidance via Map-Based Deep Reinforcement Learning. Sensors 2020, 20, 4836. [Google Scholar] [CrossRef] [PubMed]
- Everett, M.; Chen, Y.F.; How, J.P. Motion Planning Among Dynamic, Decision-Making Agents with Deep Reinforcement Learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3052–3059. [Google Scholar]
- Yu, J.; LaValle, S.M. Optimal Multirobot Path Planning on Graphs: Complete Algorithms and Effective Heuristics. IEEE Trans. Robot. 2016, 32, 1163–1177. [Google Scholar] [CrossRef]
- Semnani, S.H.; de Ruiter, A.; Liu, H. Force-based algorithm for motion planning of large agent teams. arXiv 2019, arXiv:1909.05415. [Google Scholar]
- Kiril, S.; Kleinbort, M. The Critical Radius in Sampling-Based Motion Planning. Int. J. Robot. Res. 2020, 39, 266–285. [Google Scholar] [CrossRef]
- Luna, R.J.; Bekris, K.E. Push and swap: Fast cooperative path-finding with completeness guarantees. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Solovey, K.; Halperin, D. On the hardness of unlabeled multi-robot motion planning. Int. J. Robot. Res. 2016, 35, 1750–1759. [Google Scholar] [CrossRef]
- Mellinger, D.; Kushleyev, A.; Kumar, V. Mixed-integer quadratic program trajectory generation for heterogeneous quadrotor teams. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 477–483. [Google Scholar]
- Hoy, M.; Matveev, A.S.; Savkin, A.V. Algorithms for collision-free navigation of mobile robots in complex cluttered environments: A survey. Robotica 2015. [Google Scholar] [CrossRef] [Green Version]
- Patle, B.; Babu, L.G.; Pandey, A.; Parhi, D.; Jagadeesh, A. A review: On path planning strategies for navigation of mobile robot. Def. Technol. 2019, 15, 582–606. [Google Scholar] [CrossRef]
- Tang, S.; Thomas, J.; Kumar, V. Hold or take optimal plan (hoop): A quadratic programming approach to multi-robot trajectory generation. Int. J. Robot. Res. 2018, 37, 1062–1084. [Google Scholar] [CrossRef]
- Augugliaro, F.; Schoellig, A.P.; D’Andrea, R. Generation of collision-free trajectories for a quadrocopter fleet: A sequential convex programming approach. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 1917–1922. [Google Scholar] [CrossRef]
- Preiss, J.A.; Hönig, W.; Ayanian, N.; Sukhatme, G.S. Downwash-aware trajectory planning for large quadrotor teams. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 250–257. [Google Scholar] [CrossRef] [Green Version]
- Van den Berg, J.; Guy, S.J.; Lin, M.; Manocha, D. Reciprocal n-body collision avoidance. In Robotics Research; Springer: Berlin/Heidelberg, Germany, 2011; pp. 3–19. [Google Scholar]
- Van den Berg, J.; Snape, J.; Guy, S.J.; Manocha, D. Reciprocal collision avoidance with acceleration-velocity obstacles. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 13 May 2011; pp. 3475–3482. [Google Scholar] [CrossRef]
- Rezaee, H.; Abdollahi, F. A Decentralized Cooperative Control Scheme with Obstacle Avoidance for a Team of Mobile Robots. IEEE Trans. Ind. Electron. 2014, 61, 347–354. [Google Scholar] [CrossRef]
- Zhou, D.; Wang, Z.; Bandyopadhyay, S.; Schwager, M. Fast, On-line Collision Avoidance for Dynamic Vehicles Using Buffered Voronoi Cells. IEEE Robot. Autom. Lett. 2017, 2, 1047–1054. [Google Scholar] [CrossRef]
- Standley, T. Finding Optimal Solutions to Cooperative Pathfinding Problems. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2010, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Goldenberg, M.; Felner, A.; Stern, R.; Sturtevant, N.; Holte, R.C.; Schaeffer, J. Enhanced Partial Expansion A*. J. Artif. Intell. Res. 2014, 50, 141–187. [Google Scholar] [CrossRef]
- Sharon, G.; Stern, R.; Goldenberg, M.; Felner, A. The increasing cost tree search for optimal multi-agent pathfinding. Artif. Intell. 2013, 195, 470–495. Available online: http://www.sciencedirect.com/science/article/pii/S0004370212001543 (accessed on 14 November 2012). [CrossRef] [Green Version]
- Barer, M.; Sharon, G.; Stern, R.; Felner, A. Suboptimal variants of the conflict-based search algorithm for the multi-agent pathfinding problem. In Proceedings of the ECAI 201—21st European Conference on Artificial Intelligence, Prague, Czech Republic, 18–22 August 2014. [Google Scholar]
- Boyarski, E.; Felner, A.; Stern, R.; Sharon, G.; Betzalel, O.; Tolpin, D.; Shimony, E. ICBS: Improved Conflict-Based Search Algorithm for Multi-Agent Pathfinding. In Proceedings of the Eighth Annual Symposium on Combinatorial Search, Ein Gedi, Israel, 11–13 June 2015. [Google Scholar]
- Snape, J.; van den Berg, J.; Guy, S.J.; Manocha, D. Independent Navigation of Multiple Mobile Robots with Hybrid Reciprocal Velocity Obstacles. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 11–15 October 2009; pp. 5917–5922. [Google Scholar]
- Snape, J.; van den Berg, J.; Guy, S.J.; Manocha, D. The hybrid reciprocal velocity obstacle. IEEE Trans. Robot. 2011, 27, 696–706. [Google Scholar] [CrossRef] [Green Version]
- Van den Berg, J.; Overmars, M. Planning time-minimal safe paths amidst unpredictably moving obstacles. Int. J. Robot. Res. 2008, 27, 1274–1294. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-learning. arXiv 2015, arXiv:1509.06461. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Fan, T.; Long, P.; Liu, W.; Pan, J. Distributed multi-robot collision avoidance via deep reinforcement learning for navigation in complex scenarios. Int. J. Robot. Res. 2020. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Last Action | Forward | Backward | Left | Right | Stop |
|---|---|---|---|---|---|
| sakT | (0,1) | (0,−1) | (−1,0) | (1,0) | (0,0) |
| akT (gr)ikT sakT | (0,1) | (0,−1) | (1,0) | (−1,0) |
|---|---|---|---|---|
| (0,v) | w2 × mykT | w2 × mykT | w1 × mykT | w1 × mykT |
| (0,−v) | w2 × mykT | w2 × mykT | w1 × mykT | w1 × mykT |
| (v,0) | w1 × mxkT | w1 × mxkT | w2 × mxkT | w2 × mxkT |
| (−v,0) | w1 × mxkT | w1 × mxkT | w2 × mxkT | w2 × mxkT |
| Num | Policy_1 | Policy_2 | ||
|---|---|---|---|---|
| 2 | 500/500 (9910) | 100% | 500/500 (9385) | 100% |
| 3 | 500/500 (16,605) | 100% | 500/500 (15,460) | 100% |
| 4 | 493/500 (22,505) | 98.60% | 500/500 (21,895) | 100% |
| 5 | 487/500 (29,420) | 97.40% | 500/500 (27,250) | 100% |
| 6 | 486/500 (37,845) | 97.20% | 495/500 (36,580) | 99.00% |
| 7 | 483/500 (48,985) | 96.60% | 493/500 (42,145) | 98.60% |
| 8 | 483/500 (65,555) | 96.60% | 492/500 (52,000) | 98.40% |
| 9 | 479/500 (82,100) | 95.80% | 490/500 (64,725) | 98.00% |
| Policy | a | b | c | d | e | f |
|---|---|---|---|---|---|---|
| CBS | 73.2 | 493.1 | 3545.8 | 18,168.3 | 94,618.5 | 564,439.2 |
| ICTS | 13.58 | 81.75 | 1860 | 135,365 | >600,000 | >600,000 |
| EPEA* | 2.61 | 299.3 | 148,224.7 | >600,000 | >600,000 | >600,000 |
| Policy_1 | 285 | 627 | 959.5 | 1339.5 | 1862 | 1947.5 |
| Policy_2 | 285 | 570 | 855 | 1140 | 1425 | 1710 |
| Cases | CBS | Policy_1 | Policy_2 |
|---|---|---|---|
| a | 1.0 | 1.000 | 1.000 |
| b | 1.104 | 1.917 | 1.479 |
| c | 1.084 | 1.986 | 1.514 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Zhao, Y.; Zhao, H.; Zheng, B. Non-Communication Decentralized Multi-Robot Collision Avoidance in Grid Map Workspace with Double Deep Q-Network. Sensors 2021, 21, 841. https://doi.org/10.3390/s21030841
Chen L, Zhao Y, Zhao H, Zheng B. Non-Communication Decentralized Multi-Robot Collision Avoidance in Grid Map Workspace with Double Deep Q-Network. Sensors. 2021; 21(3):841. https://doi.org/10.3390/s21030841
Chicago/Turabian StyleChen, Lin, Yongting Zhao, Huanjun Zhao, and Bin Zheng. 2021. "Non-Communication Decentralized Multi-Robot Collision Avoidance in Grid Map Workspace with Double Deep Q-Network" Sensors 21, no. 3: 841. https://doi.org/10.3390/s21030841
APA StyleChen, L., Zhao, Y., Zhao, H., & Zheng, B. (2021). Non-Communication Decentralized Multi-Robot Collision Avoidance in Grid Map Workspace with Double Deep Q-Network. Sensors, 21(3), 841. https://doi.org/10.3390/s21030841