1. Introduction
Clustering is an important unsupervised method, and the purpose of clustering is to divide a dataset into multiple clusters (or classes) with high intra-cluster similarity and low inter-cluster similarity. There have been many clustering algorithms, such as k-means (KM) and its variants [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16]. Others are based on minimal spanning trees [
17,
18,
19], density analysis [
20,
21,
22,
23,
24,
25], spectral analysis [
26,
27], subspace clustering [
28,
29], etc.
Generally, k-means minimizes the sum of squared Euclidean distances between each sample point and its nearest clustering center [
1]. One variant of k-means is kernel k-means (KKM) [
30,
31,
32,
33], which is able to find nonlinearly separable structures by using the kernel function method. Another variant of k-means is fuzzy c-means (FCM) [
2], which determines partitions by computing the membership degree of each data point to each cluster. The higher the membership degree, the greater the possibility of the data point belonging to the cluster. Although FCM is more flexible in applications [
11,
12,
13,
14,
15,
16], it is primarily suitable for linearly separable datasets. Kernel fuzzy c-means (KFCM) [
34] is a significantly improved version of fuzzy c-means for clustering linearly inseparable datasets. However, the problem of KFCM with fuzzification parameter
cannot be solved by existing methods.
To solve the special case of KFCM for
, a novel model called kernel probabilistic k-means (KPKM) is proposed. In fact, KPKM is a nonlinear programming model constrained on linear equalities and linear inequalities, and it is equivalent to KFCM at
m = 1. In theory, the proposed KPKM can be solved by the active gradient projection (AGP) method [
35,
36]. Since the AGP method may take too much time on large datasets, we further propose a fast AGP (FAGP) algorithm to solve KPKM more efficiently. Moreover, we report experiments demonstrating its effectiveness compared with KFCM, KKM, FCM, and KM.
The paper is organized as follows:
Section 2 reviews previous work. The KPKM algorithm is proposed in
Section 3.
Section 4 proposes a solution for KPKM.
Section 5 presents descriptions and analyses of experiments. Conclusions and future work are mentioned in
Section 6.
2. Background and Related Work
There has been a lot of work related to this paper, mainly including k-means, fuzzy c-means, kernel k-means and kernel fuzzy c-means.
K-means minimizes the sum of squared Euclidean distances between each sample point and its nearest cluster center. K-means first chooses initial clustering centers randomly or manually, and then partitions a dataset into several clusters (a data point belongs to the cluster whose clustering center is nearest to the data point), and computes the mean of a cluster as the clustering center. K-means repeatedly updates clustering centers and clusters until convergence. FCM has the same ideal as k-means. FCM introduces a membership degree and a fuzzy coefficient m into the objective function. The higher is, the greater possibility of the i-th data point belonging to the j-th cluster. K-means and FCM belong to partition-based clustering algorithms, and partition-based clustering algorithms usually are not able to cluster linearly inseparable datasets. Kernel method maps a linearly inseparable dataset into a linearly separable space, so kernel k-means (and FCM) using a kernel function can cluster linearly inseparable datasets.
2.1. K-Means and Fuzzy C-Means
Let
represent a dataset. K-means divides it into k clusters. If
denotes the
j-th cluster, we have
and
. Using
to stand for the number of elements in
with the center of
, k-means can be described as minimizing the following objective function:
where
Let
. By using c instead of k and assigning membership degree
to the
i-th data point in the
j-th cluster for
and
, the fuzzy c-means clustering model can be formulated as follows:
where
,
and
are computed alternately below [
2].
2.2. Kernel K-Means and Kernel Fuzzy C-Means
To improve performance of k-means and fuzzy c-means in linearly inseparable datasets, we may develop their kernel versions by choosing a feature mapping
from data points to kernel Hilbert space [
37]. Though
is usually unknown, it must satisfy
where
is a kernel function. Commonly used kernel functions are presented in
Table 1.
In
Table 1,
denotes the inner product of
and
, and
are parameters of the kernel. The objective function of kernel k-means is defined as
where
Using (
5) and (
7), we have
Let
represent the membership degree of the
i-th point belonging to the
j-th class. Likewise, we can define the kernel FCM clustering model as follows.
where
The membership degree is computed via
3. Kernel Probabilistic K-Means
In this section, the kernel probabilistic k-means (KPKM) are proposed.
We first review the problem. When
, the KFCM model gets into a special case, namely,
where
This special case cannot be solved by Lagrangian optimization for
, because (
12) cannot be computed when
(when
,
cannot be computed).
In this paper, we use the optimization methods to solve this problem, but the partial derivative of (
13) with respect to
is
, and it does not contain
.
In order to solve the problem, we introduce (
14) into (
13), and redefine the member degrees
as probability
for
and
. Finally, we have
where probability vector
(
16) is the proposed kernel probabilistic k-means.
The proposed KPKM is a soft clustering method. The is the probability of the i-th data point belonging to the j-th cluster. The higher is, the greater possibility of the i-th data point belonging to the j-th cluster. In KKM, the membership degree has only two values (0 and 1). In the proposed KPKM, (although final ).
4. A Fast Solution to KPKM
KPKM is a nonlinear programming problem with linear equalities and linear inequalities constraints, and it is able to be solved by active gradient projection [
35,
36] theoretically. In this section, on the basis of AGP, we first calculate the gradient of of the objection function of KPKM, and then design a fast AGP algorithm to solve the KPKM model.
The fast AGP has two advantages: iteratively updating the projection matrix and estimating the maximum step length.
4.1. Gradient Calculation
For convenience, we define
as
Using the chain rule on (
16), we obtain
According to (
17), we can further derive
By substituting (
19) into (
18), we finally get
and the gradient
4.2. Fast AGP
In the constraints of KPKM, there are
L linear equalities and
K×L linear inequalities,
Let
. Let
be the identity matrix of size
. Define two matrices, inequality matrix
and equality matrix
, where
Note that each row of
corresponds to one and only one inequality in (
23), and each row of
corresponds to one and only one equality in (
22). Accordingly, the KPKM’s constraints can be simply expressed as
where
. Let
stand for a randomly initialized probability vector, and
for the probability vector at iteration
k. The rows of inequality matrix
can be broken into two groups: one is active; the other is inactive. The active group is composed of all inequalities that must work exactly as an equality at
, whereas the inactive group is composed of the left inequalities. If
and
respectively denote the active group and the inactive group, we have
At iteration
k, the active matrix
is defined as
When
is not a square matrix, we can construct its projection matrix
and the corresponding orthogonal projection matrix
as follows:
Suppose that
from
is the active row vector at iteration k, satisfying
and
. According to matrix theory [
38], we can more efficiently compute
and
by
Furthermore, we can compute the projected gradient by
Using
, we update the probability vector
as
where
is the step length. Usually,
is chosen as a small number. For fast convergence, we estimate the maximum step length as follows.
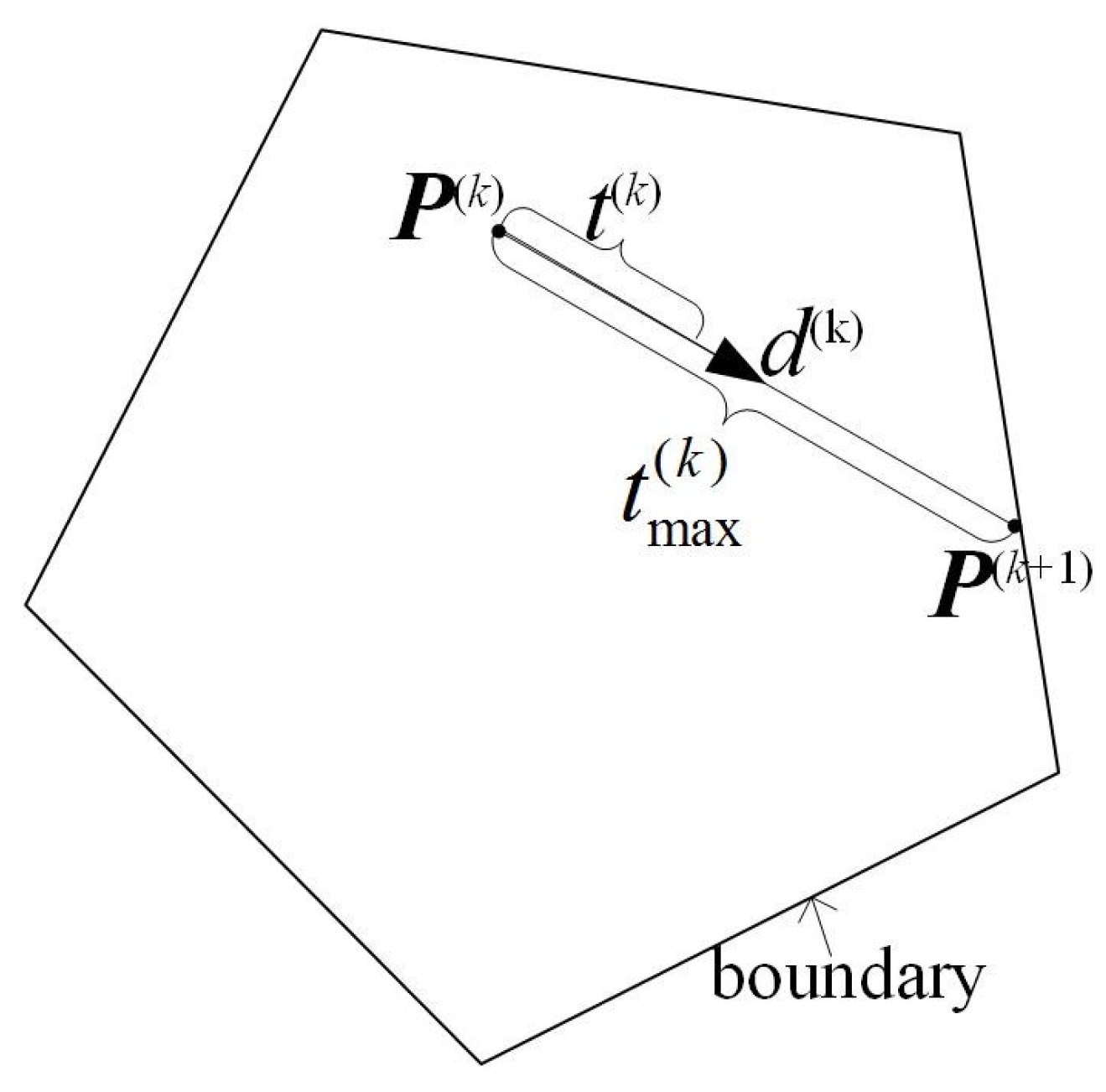
- (1)
Let for ;
- (2)
Compute for and ;
- (3)
.
As shown in
Figure 1, maximum step length is compared with small step length.
When is a square matrix, it must be invertible. In this case, we actually have , and . Thus, is not a feasible descent direction. A new descent direction can be computed as follows:
- (1)
- (2)
Break
into two parts
and
, namely,
where the size of
is the number of rows of
, and that of
is the number of rows of
.
- (3)
If
, stop. Otherwise, choose any element from
that is less than 0 and delete the corresponding row of
; then use (
29)–(
31) and (
33) to compute
.
The above fast AGP solution to KPKM is outlined in Algorithm 1. Compared with the original AGP, the fast AGP has two advantages: iteratively updating the projection matrix (shown in (
32)) and estimating the maximum step length (shown in (
35)).
4.3. Analysis of Complexity
In this section, the computational complexities for the traditional AGP algorithm and the proposed FAGP algorithm are analyzed. Let
represent the iteration number of AGP. Let
represent the iteration number of FAGP. In computations of all matrices, the computational complexity of the projection matrix
is the highest. In the AGP algorithm, computing
via (
30) requires
, so the total computational complexity for AGP algorithm is
. In the FAGP algorithm,
is computed via (
32), and it does not require to compute the inverse of matrices (i.e.,
), and computing
via (
32) requires
, so the total computational complexity for FAGP algorithm (i.e., Algorithm 1) is
.
| Algorithm 1 Fast active gradient projection (FAGP). |
| Input: X and K |
| Do: |
(1) Let , ,,
initialize , go to (4); |
| (2) Find meeting and ; |
| (3) Compute by (32);
|
| (4) Compute by (31), and by (33);
|
| (5) Compute by (35), and by (34);
|
| (6) Let , if , go to (2); |
| (7) Construct by (29), and by (36); |
| (8) Break into and by (37); |
| (9) If all elements of are more than 0, stop; |
(10) Choose any element less than 0 from ,
and delete the corresponding row of ; |
| (11) Reconstruct by (29); |
| (12) Compute by (30), and by (31); |
| (13) Compute by (33), and by (35); |
| (14) Compute by (34); |
| (15) Let , and go to (7). |
| Output: the probability vector |
5. Experimental Results
In order to evaluate performance of the proposed KPKM model (equivalent to KFCM at
m = 1) solved by the FAGP algorithm, we have conducted a lot of experiments on one synthetic dataset, ten UCI datasets (
http://archive.ics.uci.edu/ml (accessed on 8 March 2021)) and the MNIST dataset (
http://yann.lecun.com/exdb/mnist/ (accessed on 8 March 2021)). These datasets are detailed in
Section 5.1,
Section 5.2 and
Section 5.3. In
Section 5.1, we use a synthetic dataset to compare KPKM using a Gaussian kernel with KPKM using a linear kernel. In
Section 5.2 and
Section 5.3, we compare the proposed KPKM with KFCM, KKM, FCM, and KM to evaluate the performance of KPKM solved by the proposed fast AGP. Moreover, the
Section 5.4 and
Section 5.5 evaluate the descent stability and convergence speed of the proposed FAGP, respectively. In the experiments, we implemented our own MATLAB code for KPKM, KFCM, and KKM with two build-in functions,
sparse and
full, employed for matrix optimization. Moreover, we called MATLAB’s build-in functions
fcm and
kmeans for FCM and KM, respectively.
All experiments were carried out on a PC with an Intel(R) Core(TM) i7-4790 CPU at 3.60 GHz, 8.00 G RAM, running Windows 7 and MATLAB 2015a.
5.1. The Experiment on the Synthetic Dataset
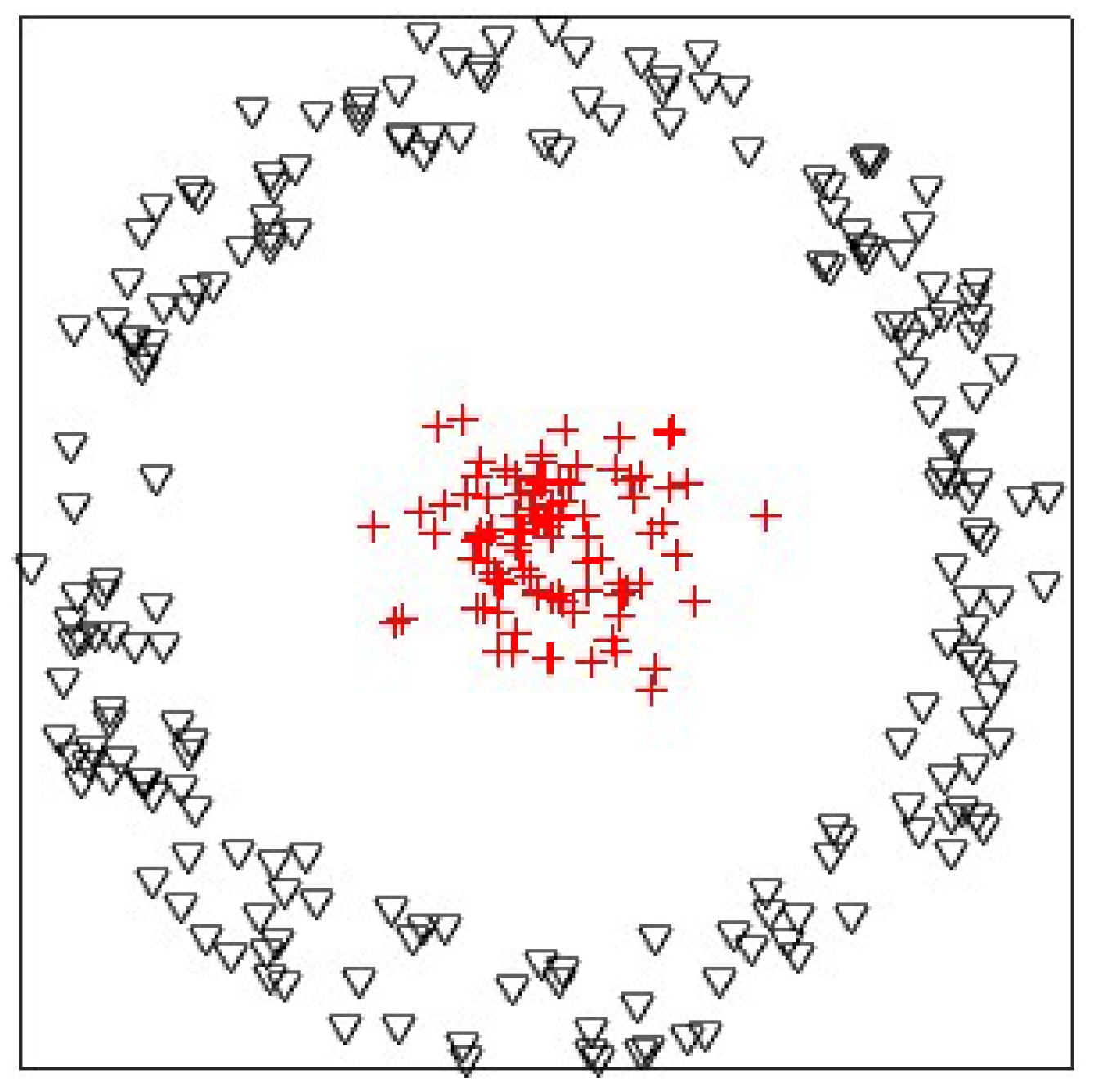
In this experiment, we analyzed the influences of the Gaussian radial basis function kernel and the linear kernel on KPKM when clustering one synthetic dataset, which is shown in
Figure 2. The synthetic dataset contained 300 points, with 100 and 200 being from two linearly inseparable classes, disc and ring, respectively. The result is displayed in
Figure 3. Obviously, Gaussian radial basis function KPKM can cluster perfectly, whereas linear KPKM cannot.
5.2. Experiment on Ten UCI Datasets
In this experiment, we compare the clustering performance of KPKM with the performances of KFCM, KKM, FCM, and KM in terms of three measures: normalized mutual information (NMI), adjusted Rand index (ARI), and v-measure (VM) [
39,
40]. NMI is a normalization of the mutual information score to scale the results between 0 (no mutual information) and 1 (perfect correlation). The NMI is defined as
where
is the entropy of
U; MI is given by
where
is the number of the samples in cluster
. ARI is an adjusted similarity measure between two clusters. The ARI is defined as
where RI is the ratio of data points clustered correctly to all data points, and
E(RI) is the expectation of RI. VM is a harmonic mean between homogeneity and completeness, where homogeneity means that each cluster is a subset of a single class, and completeness means that each class is a subset of a single cluster. The VM is defined as
The higher the NMI, ARI and VM, the better the performance.
We describe the ten UCI datasets represented in
Table 2 by name, code, number of instances, number of classes and number of dimensions. A set of experiential parameters was selected. We set
m = 2 for KFCM, and
m = 1.3 for FCM. With the Gaussian radial basis function kernel, we also selected appropriate
(shown in
Table 3), and report the clustering results in
Table 4. The better results in each case is highlighted in bold. (The performance of many a method depends on parameters [
41]. By experiments we found that for different algorithms with the same kernel function, the most appropriate parameters are usually different, so we used different settings to make the methods have the best clustering performances they could. We also tried to select the most appropriate parameter by using our experience.) We ran every algorithm 10 times, and average results were calculated.
- (1)
For NMI, KPKM had the best clustering results on nine datasets, so the clustering performance of KPKM was the best for NMI.
- (2)
For ARI, KPKM had the best clustering results on six datasets. KFCM, KKM, FCM, and KM performed the best on 2, 1, 0, and 1 datasets, respectively, so KPKM performed the best for ARI.
- (3)
For VM, KPKM, KFCM, KKM, FCM, and KM had the best clustering results on 7, 0, 2, 1, and 0 datasets, respectively. Thus, KPKM had the best clustering performance for VM.
Overall, KPKM is better than the other models.
5.3. Experiment on the MNIST Dataset
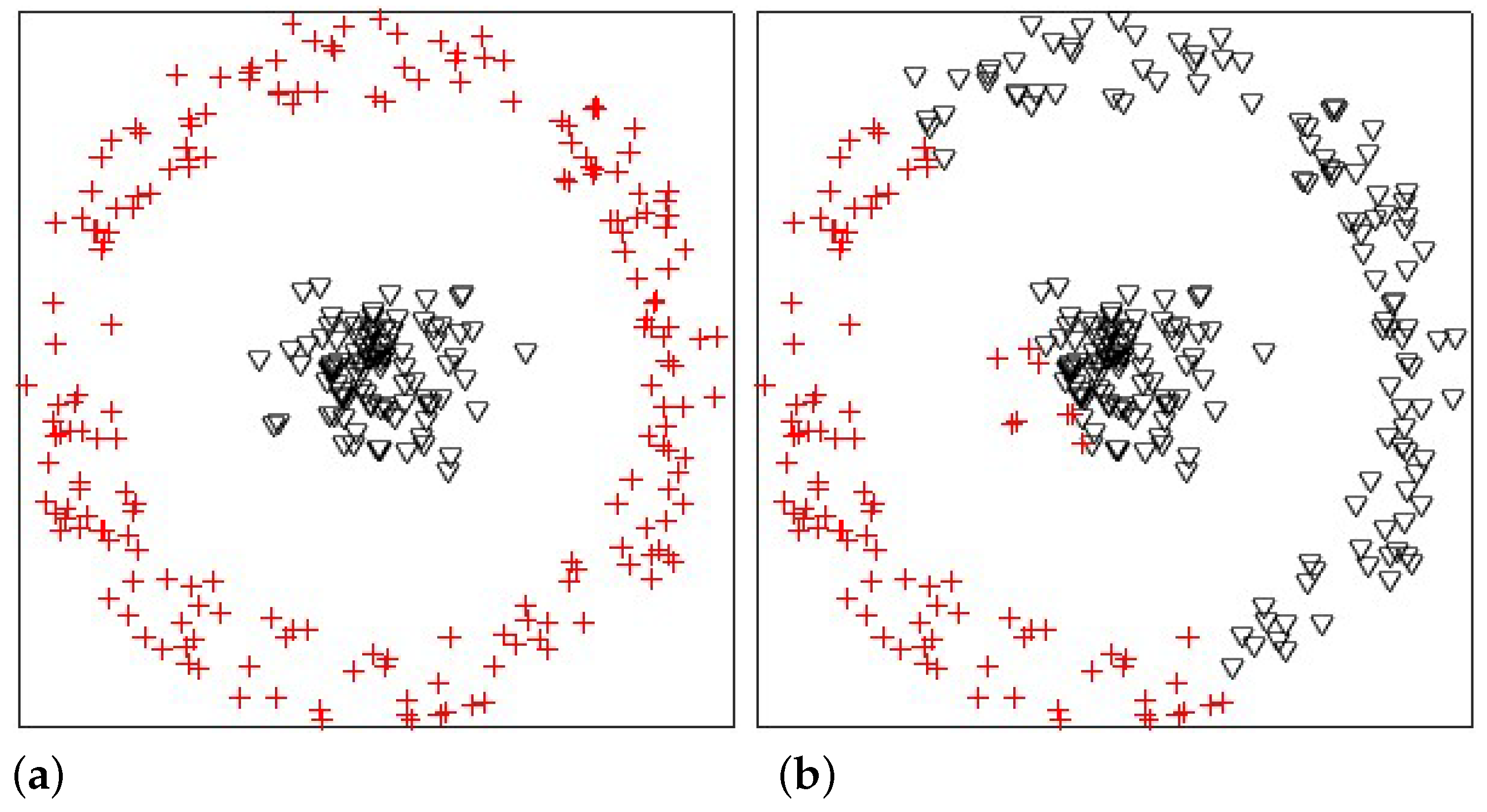
In this experiment, we used the MNIST dataset to compare KPKM with KFCM and KKM when clustering digital images. The MNIST dataset was composed of handwritten digits, with 60,000 examples for training and 10,000 examples for testing. All digits were size-normalized and centered in fixed-size images. To evaluate the clustering performances of KPKM, KFCM, and KKM, we randomly chose 1000 training examples; 100 are shown in
Figure 4.
Moreover, we defined a CWSS kernel based on complex wavelet structural similarity (CWSS) [
42]. CWSS may be regarded as a coefficient that does not change the structural content of an image. By using
to denote the similarity between two images
and
, we can express the CWSS kernel as
where
is set for KFCM, and
for both KPKM and KKM. Additionally,
m = 1.3 is set for KFCM. We present the results in
Table 5, with the examples of
Figure 4 correspondingly being displayed in
Figure 5. From
Table 5, we can see that KPKM outperformed KFCM and KKM in terms of NMI, ARI, and VM. From
Figure 5, we can observe that both KPKM and KKM found ten clusters, whereas KFCM found only seven clusters, although the number of clusters was set to ten.
5.4. Experiment for Descent Stability
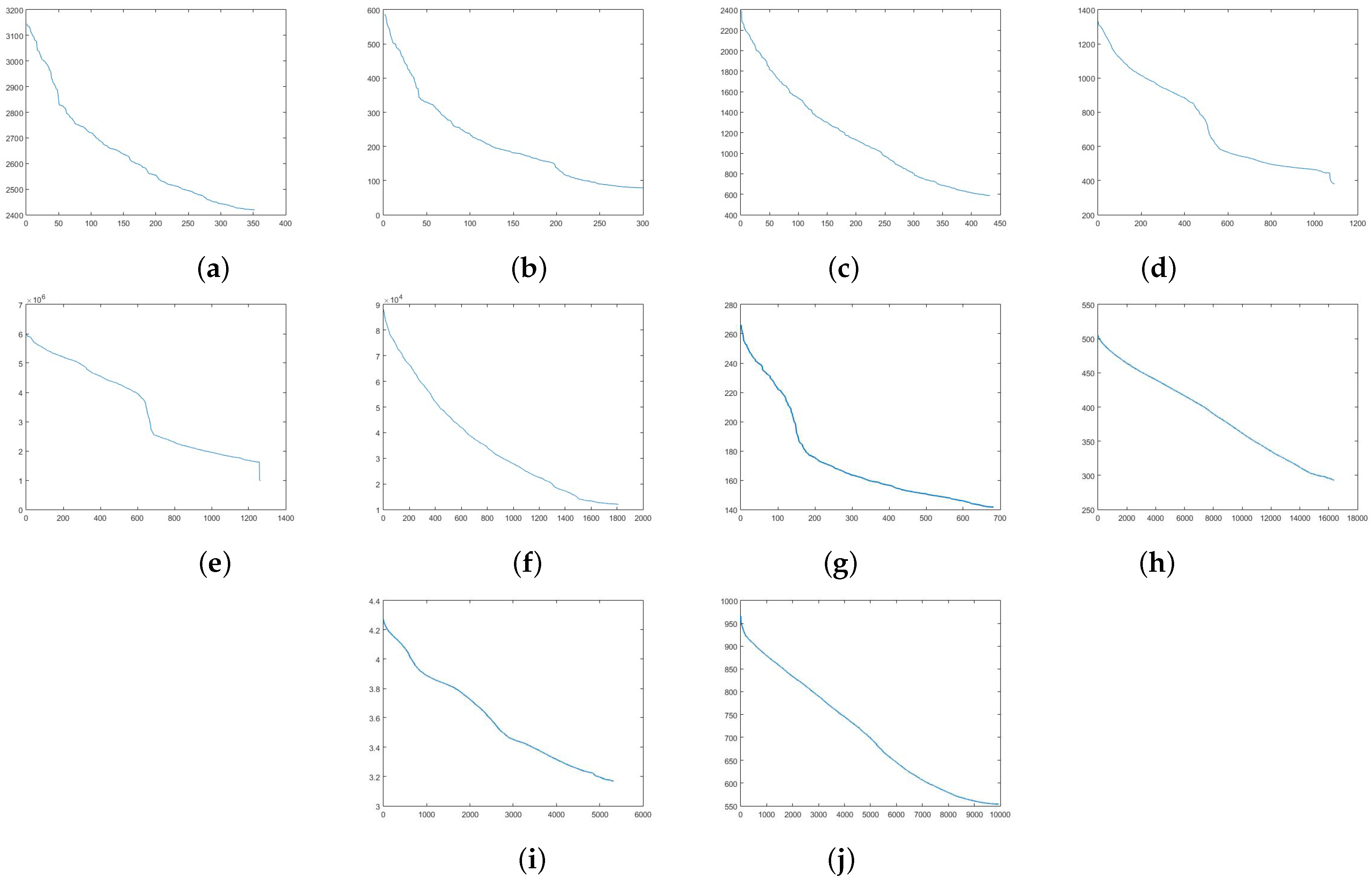
In this experiment, we used 10 UCI datasets to evaluate descent stability of FAGP. AGP selects a small step length to converge. If AGP selects a large step length, the objective function value may descend with oscillation, and even does not converge. FAGP iteratively estimates a maximum step length at each iteration for speeding up its convergence. However, does it have any serious influence on the convergence? we ran the proposed FAGP on 10 UCI datasets to demonstrate the descent stability of FAGP. As shown in
Figure 6, we can see that FAGP descends stably without oscillation at each iteration.
5.5. Convergence Speed Comparison between FAGP and AGP
In this experiment, we compared the convergence speeds of FAGP and AGP by using running time on 10 UCI datasets.
is the ratio of FAGP’s running time to AGP’s. FAGP and AGP used the same initializations in each case. The results are presented in
Table 6 and
Table 7 (“–” means the running time was too long to obtain the final clustering results), and we can observe the proposed FAGP ran faster than AGP on all the 6 datasets. For Iris and Seeds datasets, FAGP used less than 10% of running time of AGP. FAGP also required fewer iterations than AGP. For large datasets, the running time of AGP was too long, but the proposed fast AGP could obtain the final clustering results.
6. Conclusions
In this paper, a novel clustering model (i.e., KPKM) was proposed. The proposed KPKM solves the problem of KFCM for m = 1, and this problem cannot be solved by existing method. The traditional AGP method can solve the proposed KPKM, but the efficiency of AGP is low. A fast AGP was proposed to speed up the AGP. The proposed fast AGP uses a maximum step length strategy to reduce the iteration number and uses an iterative method to update the projection matrix. The experimental results demonstrated that the fast AGP is able to solve the KPKM and the fast AGP requires less running time than AGP (the proposed FAGP requires 4.22–27.90% of the running time of AGP on real UCI datasets). The convergence of the proposed method was also analyzed by experiments. Additionally, in the experiments, the KPKM model could produce overall better clustering results than the other models, including KFCM, KKM, FCM, and KM. The proposed KPKM obtained the best clustering results on at least 6 real UCI datasets (a total of 10 real UCI datasets were used).
As future work, the proposed KPKM using other kernels will be evaluated in a variety of applications. For large datasets, the proposed method still has some disadvantages, so the next project will include speeding up the AGP on large datasets.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}