
Health Monitoring of Large-Scale Civil Structures: An Approach Based on Data Partitioning and Classical Multidimensional Scaling





Abstract
:1. Introduction
2. Classical Multidimensional Scaling
3. Proposed SHM Data-Driven Method via CMDS
4. Experimental Validation
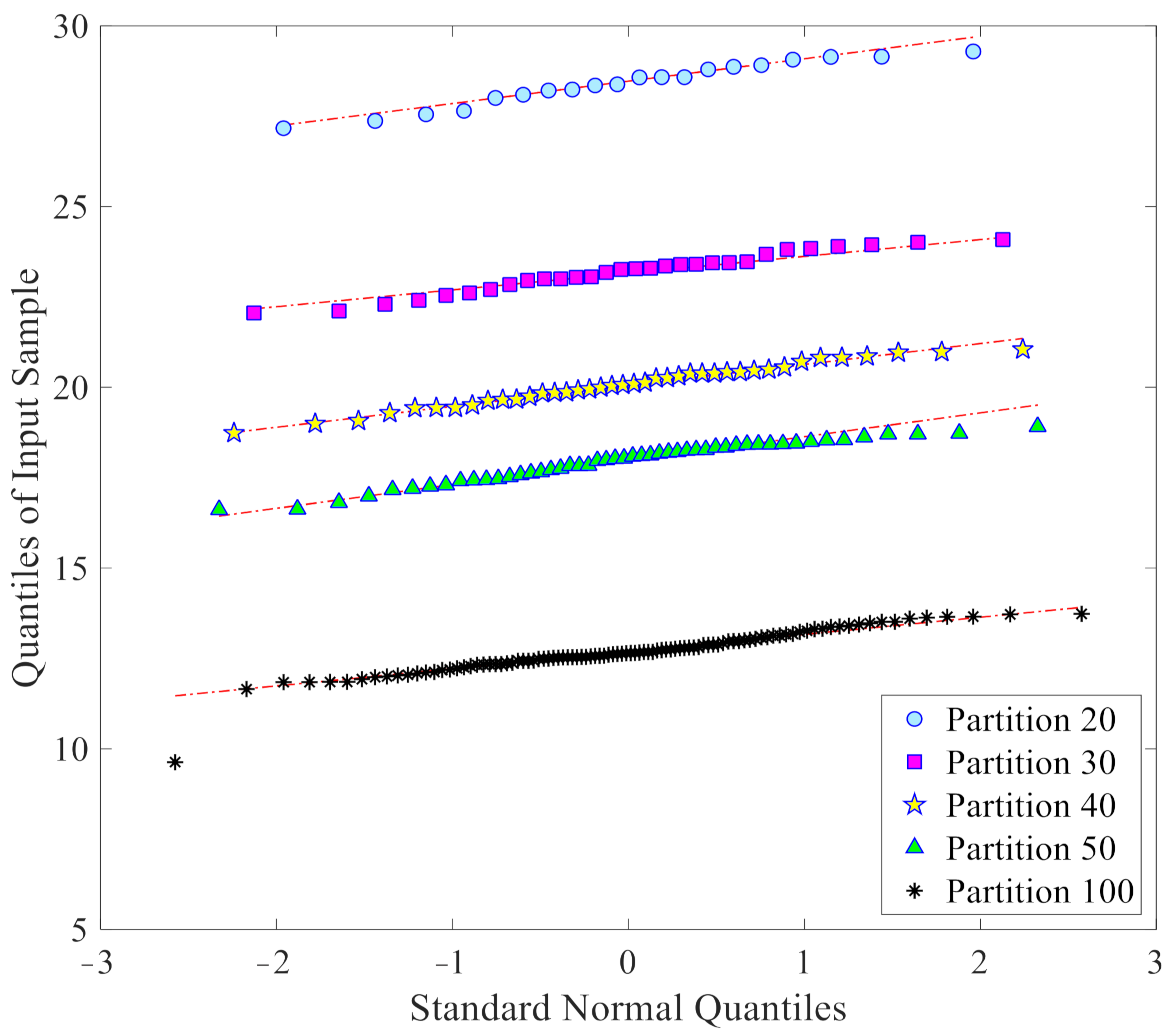
4.1. ASCE Structure—Phase II
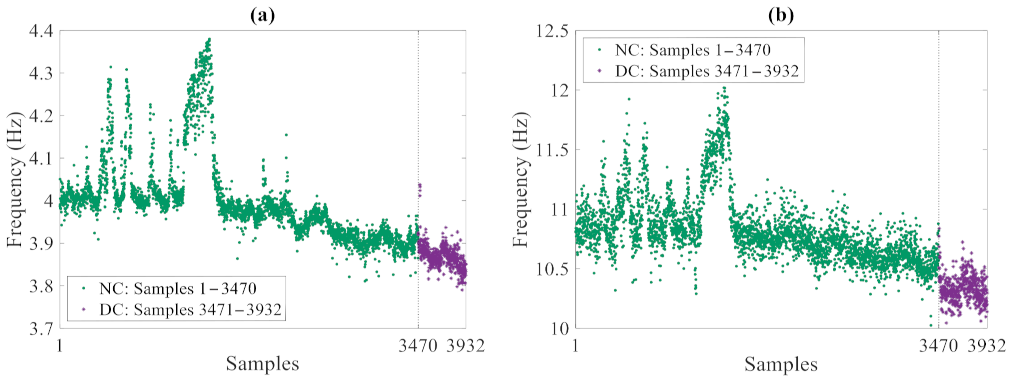
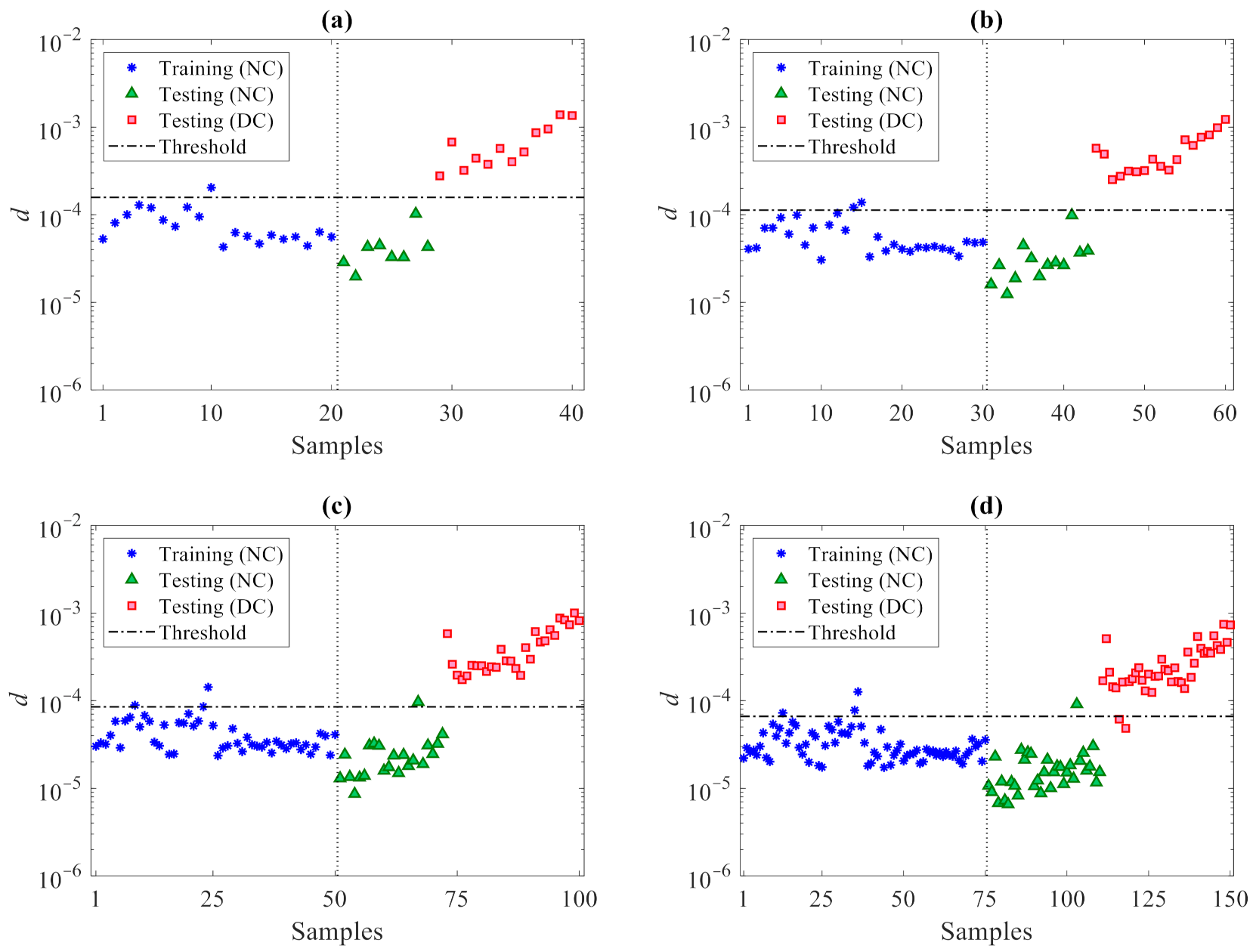
4.2. Z24 Bridge
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Burgos, D.A.T.; Vargas, R.C.G.; Pedraza, C.; Agis, D.; Pozo, F. Damage identification in structural health monitoring: A brief review from its implementation to the use of data-driven applications. Sensors 2020, 20, 733. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahmed, H.; La, H.M.; Gucunski, N. Review of non-destructive civil infrastructure evaluation for bridges: State-of-the-art robotic platforms, sensors and algorithms. Sensors 2020, 20, 3954. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhou, X.; Wang, X.; Dong, L.; Qian, Y. Deployment of a Smart Structural Health Monitoring System for Long-Span Arch Bridges: A Review and a Case Study. Sensors 2017, 17, 2151. [Google Scholar] [CrossRef] [PubMed]
- Eftekhar Azam, S.; Mariani, S. Online damage detection in structural systems via dynamic inverse analysis: A recursive Bayesian approach. Eng. Struct. 2018, 159, 28–45. [Google Scholar] [CrossRef]
- Sarmadi, H.; Entezami, A.; Ghalehnovi, M. On model-based damage detection by an enhanced sensitivity function of modal flexibility and LSMR-Tikhonov method under incomplete noisy modal data. Eng. Comput. 2020. [Google Scholar] [CrossRef]
- Sehgal, S.; Kumar, H. Structural dynamic model updating techniques: A state of the art review. Arch. Comput. Methods Eng. 2016, 23, 515–533. [Google Scholar] [CrossRef]
- Krishnan, M.; Bhowmik, B.; Hazra, B.; Pakrashi, V. Real time damage detection using recursive principal components and time varying auto-regressive modeling. Mech. Syst. Sig. Process. 2018, 101, 549–574. [Google Scholar] [CrossRef] [Green Version]
- Jin, S.-S.; Jung, H.-J. Vibration-based damage detection using online learning algorithm for output-only structural health monitoring. Struct. Health Monit. 2018, 17, 727–746. [Google Scholar] [CrossRef]
- Hu, W.-H.; Tang, D.-H.; Teng, J.; Said, S.; Rohrmann, R.G. Structural Health Monitoring of a Prestressed Concrete Bridge Based on Statistical Pattern Recognition of Continuous Dynamic Measurements over 14 years. Sensors 2018, 18, 4117. [Google Scholar] [CrossRef] [Green Version]
- Entezami, A.; Sarmadi, H.; Behkamal, B.; Mariani, S. Big Data Analytics and Structural Health Monitoring: A Statistical Pattern Recognition-Based Approach. Sensors 2020, 20, 2328. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sarmadi, H.; Yuen, K.-V. Early damage detection by an innovative unsupervised learning method based on kernel null space and peak-over-threshold. Comput. Aided Civ. Infrastruct. Eng. 2021, in press. [Google Scholar]
- Barrias, A.; Casas, J.R.; Villalba, S. A Review of Distributed Optical Fiber Sensors for Civil Engineering Applications. Sensors 2016, 16, 748. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Q.; Okabe, Y.; Yu, F. Ultrasonic Structural Health Monitoring Using Fiber Bragg Grating. Sensors 2018, 18, 3395. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Xue, X. Advances in the Structural Health Monitoring of Bridges Using Piezoelectric Transducers. Sensors 2018, 18, 4312. [Google Scholar] [CrossRef] [Green Version]
- Mirzazadeh, R.; Eftekhar Azam, S.; Mariani, S. Mechanical Characterization of Polysilicon MEMS: A Hybrid TMCMC/POD-Kriging Approach. Sensors 2018, 18, 1243. [Google Scholar] [CrossRef] [Green Version]
- Capellari, G.; Chatzi, E.; Mariani, S.; Eftekhar Azam, S. Optimal design of sensor networks for damage detection. Procedia Eng. 2017, 199, 1864–1869. [Google Scholar] [CrossRef]
- Capellari, G.; Chatzi, E.; Mariani, S. Cost-benefit optimization of sensor networks for SHM applications. Proceedings 2018, 2, 132. [Google Scholar] [CrossRef] [Green Version]
- Moughty, J.J.; Casas, J.R. A State of the Art Review of Modal-Based Damage Detection in Bridges: Development, Challenges, and Solutions. Appl. Sci. 2017, 7, 510. [Google Scholar] [CrossRef] [Green Version]
- Entezami, A.; Shariatmadar, H. An unsupervised learning approach by novel damage indices in structural health monitoring for damage localization and quantification. Struct. Health Monit. 2018, 17, 325–345. [Google Scholar] [CrossRef]
- Datteo, A.; Quattromani, G.; Cigada, A. On the use of AR models for SHM: A global sensitivity and uncertainty analysis frame-work. Reliab. Eng. Syst. Saf. 2018, 170, 99–115. [Google Scholar] [CrossRef]
- Entezami, A.; Shariatmadar, H.; Mariani, S. Fast unsupervised learning methods for structural health monitoring with large vibration data from dense sensor networks. Struct. Health Monit. 2020, 19, 1685–1710. [Google Scholar] [CrossRef]
- Entezami, A.; Mariani, S. Early Damage Detection for Partially Observed Structures with an Autoregressive Spectrum and Distance-Based Methodology. In European Workshop on Structural Health Monitoring; Springer: Cham, Switzerland, 2020; pp. 427–437. [Google Scholar]
- Sarmadi, H.; Karamodin, A. A novel anomaly detection method based on adaptive Mahalanobis-squared distance and one-class kNN rule for structural health monitoring under environmental effects. Mech. Syst. Sig. Process. 2020, 140, 106495. [Google Scholar] [CrossRef]
- Sarmadi, H.; Entezami, A.; Saeedi Razavi, B.; Yuen, K.-V. Ensemble learning-based structural health monitoring by Mahalanobis distance metrics. Struct. Contr. Health Monit. 2021, 28, e2663. [Google Scholar] [CrossRef]
- Entezami, A.; Shariatmadar, H.; Mariani, S. Early damage assessment in large-scale structures by innovative statistical pattern recognition methods based on time series modeling and novelty detection. Adv. Eng. Softw. 2020, 150, 102923. [Google Scholar] [CrossRef]
- Capellari, G.; Chatzi, E.; Mariani, S. Structural Health Monitoring Sensor Network Optimization through Bayesian Experimental Design. ASCE ASME J. Risk Uncertain. Eng. Syst. Part. A Civ. Eng. 2018, 4, 04018016. [Google Scholar] [CrossRef]
- Eftekhar Azam, S.; Mariani, S.; Attari, N.K.A. Online damage detection via a synergy of proper orthogonal decomposition and recursive Bayesian filters. Nonlinear Dyn. 2017, 89, 1489–1511. [Google Scholar] [CrossRef]
- Eftekhar Azam, S.; Rageh, A.; Linzell, D. Damage detection in structural systems utilizing artificial neural networks and proper orthogonal decomposition. Struct. Contr. Health Monit. 2019, 26, e2288. [Google Scholar] [CrossRef]
- Azimi, M.; Eslamlou, A.D.; Pekcan, G. Data-driven structural health monitoring and damage detection through deep learning: State-of-the-art review. Sensors 2020, 20, 2778. [Google Scholar] [CrossRef]
- Vitola, J.; Pozo, F.; Tibaduiza, D.A.; Anaya, M. Distributed Piezoelectric Sensor System for Damage Identification in Structures Subjected to Temperature Changes. Sensors 2017, 17, 1252. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Camacho Navarro, J.; Ruiz, M.; Villamizar, R.; Mujica, L.; Quiroga, J. Features of Cross-Correlation Analysis in a Data-Driven Approach for Structural Damage Assessment. Sensors 2018, 18, 1571. [Google Scholar] [CrossRef] [Green Version]
- Yan, B.; Zou, Q.; Dong, Y.; Shao, X. Application of PZT Technology and Clustering Algorithm for Debonding Detection of Steel-UHPC Composite Slabs. Sensors 2018, 18, 2953. [Google Scholar] [CrossRef] [Green Version]
- Entezami, A.; Sarmadi, H.; Saeedi Razavi, B. An innovative hybrid strategy for structural health monitoring by modal flexibility and clustering methods. J. Civ. Struct. Health Monit. 2020, 10, 845–859. [Google Scholar] [CrossRef]
- Sarmadi, H.; Entezami, A.; Salar, M.; De Michele, C. Bridge health monitoring in environmental variability by new clustering and threshold estimation methods. J. Civ. Struct. Health Monit. 2021. [Google Scholar] [CrossRef]
- Kim, B.; Min, C.; Kim, H.; Cho, S.; Oh, J.; Ha, S.-H.; Yi, J.-h. Structural Health Monitoring with Sensor Data and Cosine Similarity for Multi-Damages. Sensors 2019, 19, 3047. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sarmadi, H.; Entezami, A. Application of supervised learning to validation of damage detection. Arch. Appl. Mech. 2021, 91, 393–410. [Google Scholar] [CrossRef]
- Borg, I.; Groenen, P.J. Modern Multidimensional Scaling: Theory and Applications; Springer: New York, NY, USA, 2005. [Google Scholar]
- Seber, G.A.F. Multivariate Observations; Wiley & Sons: Hoboken, NJ, USA, 1984. [Google Scholar]
- Izenman, A.J. Modern Multivariate Statistical Techniques: Regression, Classification and Manifold Learning; Springer: New York, NY, USA, 2008. [Google Scholar]
- Dyke, S.J.; Bernal, D.; Beck, J.; Ventura, C. Experimental phase II of the structural health monitoring benchmark problem. Proccedings of the 16th ASCE Engineering Mechanics Conference, Seattle, WA, USA, 16–18 July 2003. [Google Scholar]
- Leybourne, S.J.; McCabe, B.P. A consistent test for a unit root. J. Bus. Econ. Statis. 1994, 12, 157–166. [Google Scholar]
- Maeck, J.; De Roeck, G. Description of Z24 Bridge. Mech. Syst. Sig. Process. 2003, 17, 127–131. [Google Scholar] [CrossRef]
- Kramer, M.A. Autoassociative neural networks. Comput. Chem. Eng. 1992, 16, 313–328. [Google Scholar] [CrossRef]
- Entezami, A.; Sarmadi, H.; Mariani, S. An Unsupervised Learning Approach for Early Damage Detection by Time Series Analysis and Deep Neural Network to Deal with Output-Only (Big) Data. Eng. Proc. 2020, 2, 17. [Google Scholar]
- Mujica, L.; Rodellar, J.; Fernandez, A.; Guemes, A. Q-statistic and T2-statistic PCA-based measures for damage assessment in structures. Struct. Health Monit. 2010, 10, 539–553. [Google Scholar] [CrossRef]
- Krishnan, M.; Bhowmik, B.; Tiwari, A.K.; Hazra, B. Online damage detection using recursive principal component analysis and recursive condition indicators. Smart Mater. Struct. 2017, 26, 085017. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Direction | Floor No. | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| West | 4 | 7 | 10 | 13 |
| Center | 5 | 8 | 11 | 14 |
| East | 6 | 9 | 12 | 15 |
| Case No. | Condition | Description |
|---|---|---|
| 1 | Undamaged | Full braced structural system |
| 2 | Damaged | Elimination of braces from the east side at all floors |
| 3 | Damaged | Elimination of braces from the south-east corner at all floors |
| 4 | Damaged | Elimination of braces from the south-east corner at the first and fourth floors |
| 5 | Damaged | Elimination of braces from the south-east corner at the first floor |
| Sensor No. | Case No. | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| 4 | 0.0001 | 0.0004 | 0.0001 | 0.0001 | 0.0001 |
| 5 | 0.0057 | 0.0024 | 0.0012 | 0.0009 | 0.0012 |
| 6 | 0.0019 | 0.0002 | 0.0001 | 0.0001 | 0.0026 |
| 7 | 0.0002 | 0.0008 | 0.0001 | 0.0001 | 0.0002 |
| 8 | 0.0011 | 0.0015 | 0.0005 | 0.0005 | 0.0003 |
| 9 | 0.0145 | 0.0011 | 0.0061 | 0.0042 | 0.0402 |
| 10 | 0.0002 | 0.0003 | 0.0001 | 0.0002 | 0.0002 |
| 11 | 0.0011 | 0.0003 | 0.0009 | 0.0003 | 0.0003 |
| 12 | 0.0002 | 0.0001 | 0.0001 | 0.0002 | 0.0003 |
| 13 | 0.0069 | 0.0025 | 0.0019 | 0.0031 | 0.0198 |
| 14 | 0.0051 | 0.0023 | 0.0007 | 0.0007 | 0.0041 |
| Sensor No. | Order | p-Value |
|---|---|---|
| 4 | 98 | 0.1295 |
| 5 | 81 | 0.1048 |
| 6 | 141 | 0.0799 |
| 7 | 158 | 0.0581 |
| 8 | 109 | 0.2513 |
| 9 | 77 | 0.3833 |
| 10 | 113 | 0.2376 |
| 11 | 96 | 0.1437 |
| 12 | 92 | 0.2812 |
| 13 | 74 | 0.0794 |
| 14 | 77 | 0.1027 |
| 15 | 116 | 0.1778 |
| No. p of Partitions | Case No. | |
|---|---|---|
| 4 | 5 | |
| 10 | 0 (0%) | 0 (0%) |
| 20 | 0 (0%) | 0 (0%) |
| 30 | 0 (0%) | 2 (6.67%) |
| 40 | 0 (0%) | 2 (5%) |
| 50 | 0 (0%) | 4 (8%) |
| 60 | 1 (1.67%) | 8 (13.34%) |
| 70 | 1 (1.42%) | 10 (14.28%) |
| 80 | 1 (1.25%) | 18 (22.50%) |
| 90 | 1 (1.11%) | 18 (20%) |
| 100 | 1 (1%) | 21 (21%) |
| No. p of Partitions | Type I | Type II | Total |
|---|---|---|---|
| 20 | 1 (3.57%) | 0 (0%) | 1 (2.5%) |
| 30 | 2 (4.65%) | 0 (0%) | 2 (3.34%) |
| 50 | 4 (5.55%) | 0 (0%) | 4 (4%) |
| 75 | 4 (3.63%) | 2 (5%) | 6 (4%) |
| 100 | 5 (3.50%) | 2 (3.51%) | 7 (2.5%) |
| 120 | 5 (2.81%) | 2 (3.22%) | 7 (2.92%) |
| 150 | 8 (3.63%) | 4 (5%) | 12 (4%) |
| 200 | 7 (2.43%) | 4 (3.57%) | 11 (2.75%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Entezami, A.; Sarmadi, H.; Behkamal, B.; Mariani, S. Health Monitoring of Large-Scale Civil Structures: An Approach Based on Data Partitioning and Classical Multidimensional Scaling. Sensors 2021, 21, 1646. https://doi.org/10.3390/s21051646
Entezami A, Sarmadi H, Behkamal B, Mariani S. Health Monitoring of Large-Scale Civil Structures: An Approach Based on Data Partitioning and Classical Multidimensional Scaling. Sensors. 2021; 21(5):1646. https://doi.org/10.3390/s21051646
Chicago/Turabian StyleEntezami, Alireza, Hassan Sarmadi, Behshid Behkamal, and Stefano Mariani. 2021. "Health Monitoring of Large-Scale Civil Structures: An Approach Based on Data Partitioning and Classical Multidimensional Scaling" Sensors 21, no. 5: 1646. https://doi.org/10.3390/s21051646
APA StyleEntezami, A., Sarmadi, H., Behkamal, B., & Mariani, S. (2021). Health Monitoring of Large-Scale Civil Structures: An Approach Based on Data Partitioning and Classical Multidimensional Scaling. Sensors, 21(5), 1646. https://doi.org/10.3390/s21051646