
Fault Prediction and Early-Detection in Large PV Power Plants Based on Self-Organizing Maps


 , and
, and
Abstract
:1. Introduction
1.1. Motivation
1.2. Paper Contribution
2. Case Studies and Methods
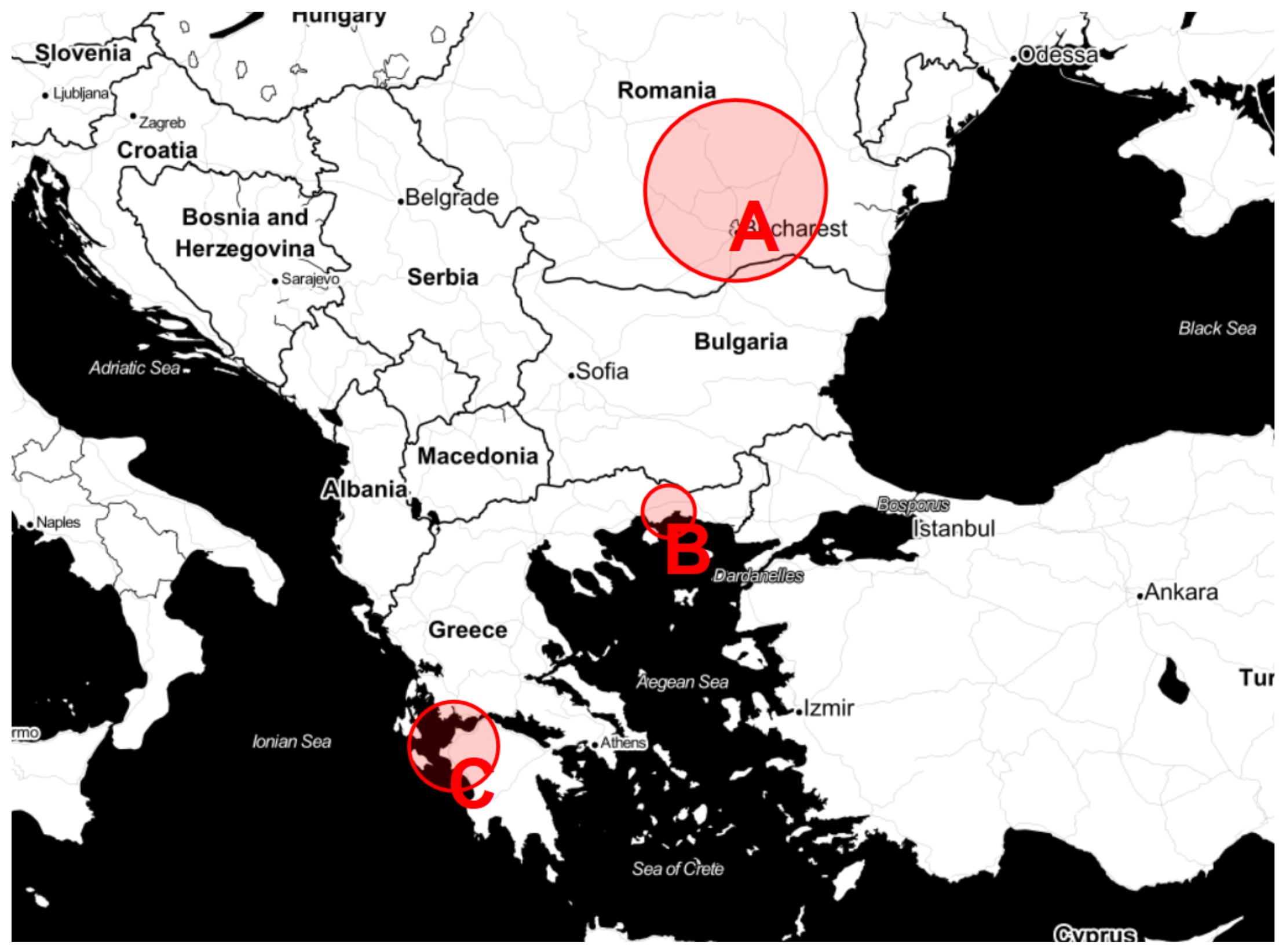
2.1. PV Plants Details
2.2. SCADA Data and Alarm Logbooks
2.3. Data Pre-Processing
2.4. SCADA Imputation
2.5. Data Detrending and Scaling
3. Methodology
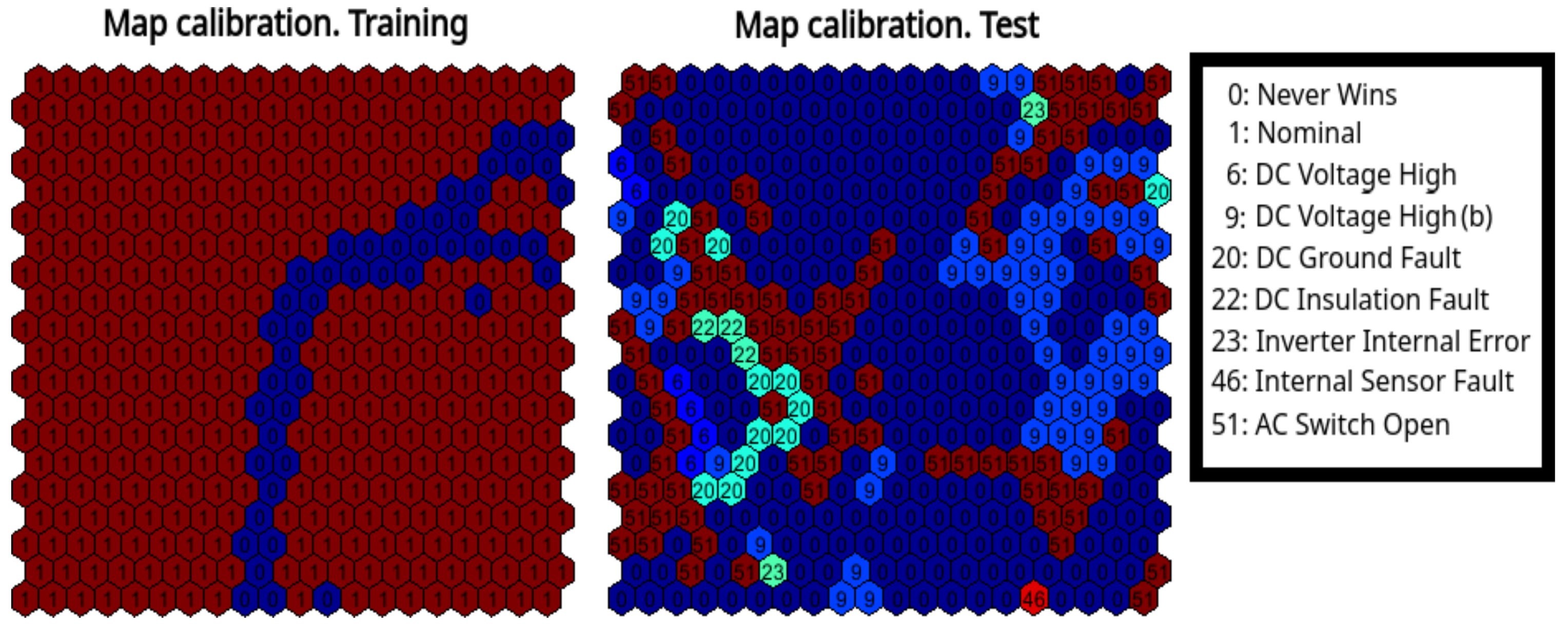
Self-Organizing Map Neural Network Based Key Performance Indicator: Monitoring of Cell Occupancy
4. Results and Discussion
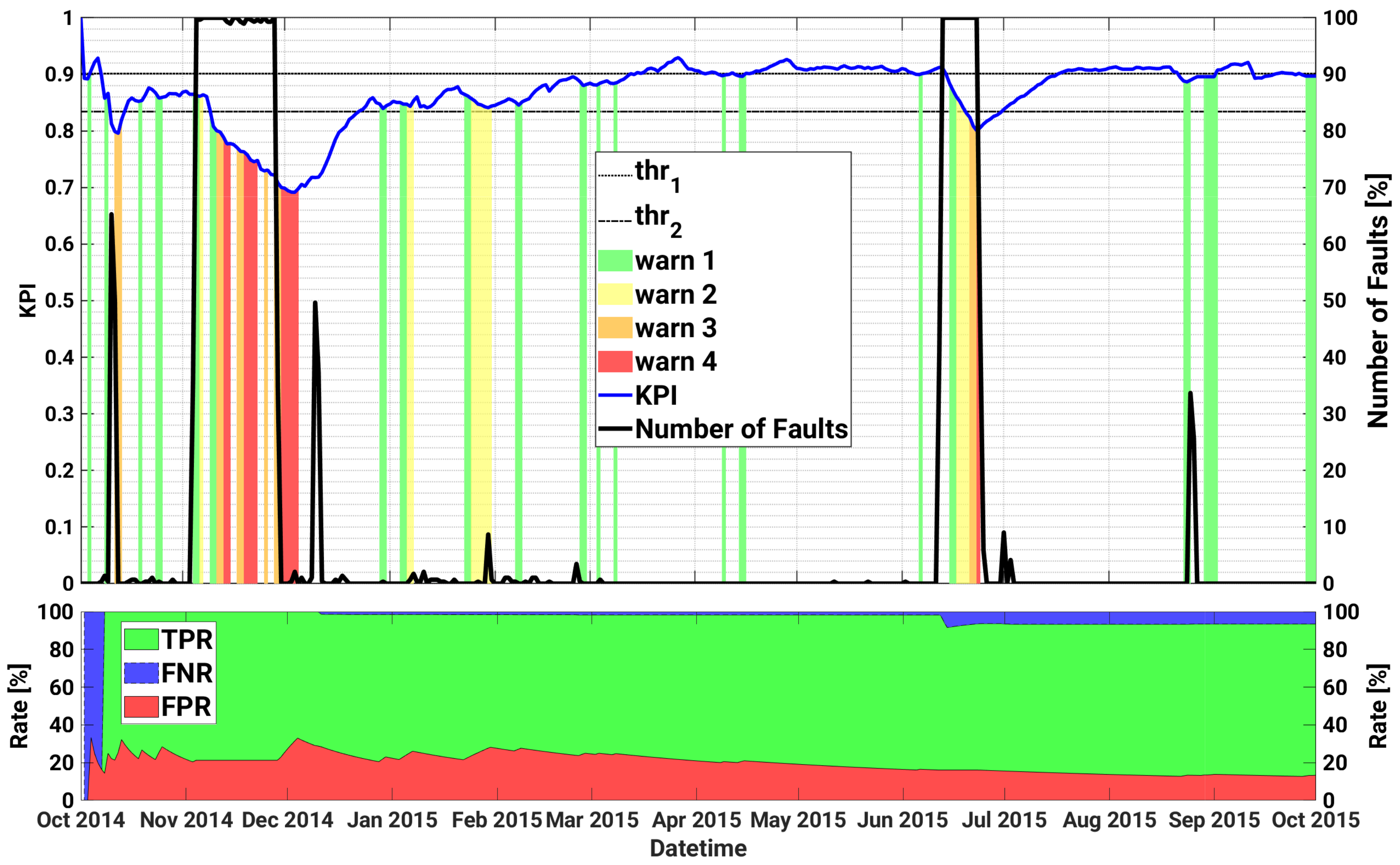
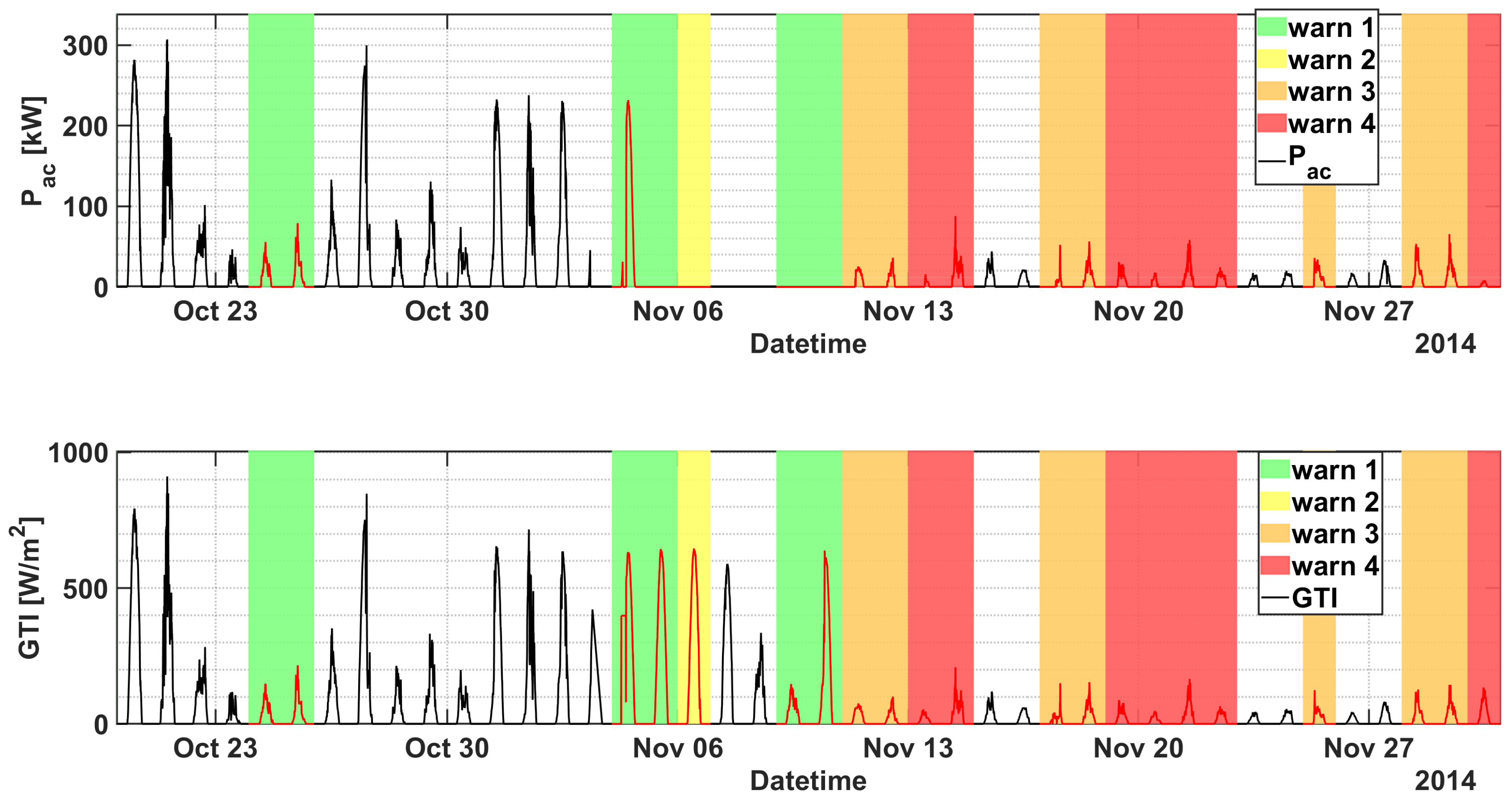
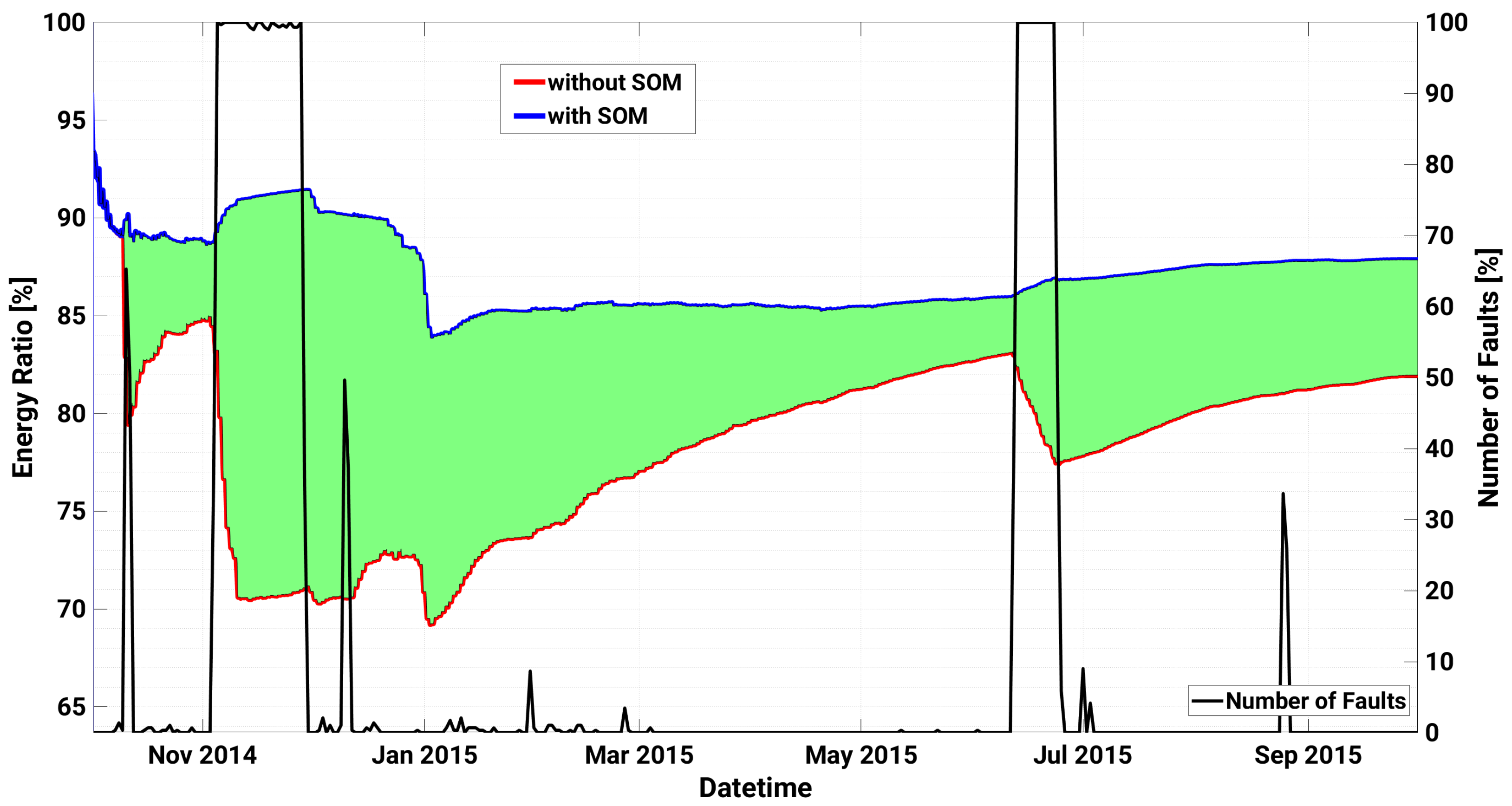
4.1. Plant A
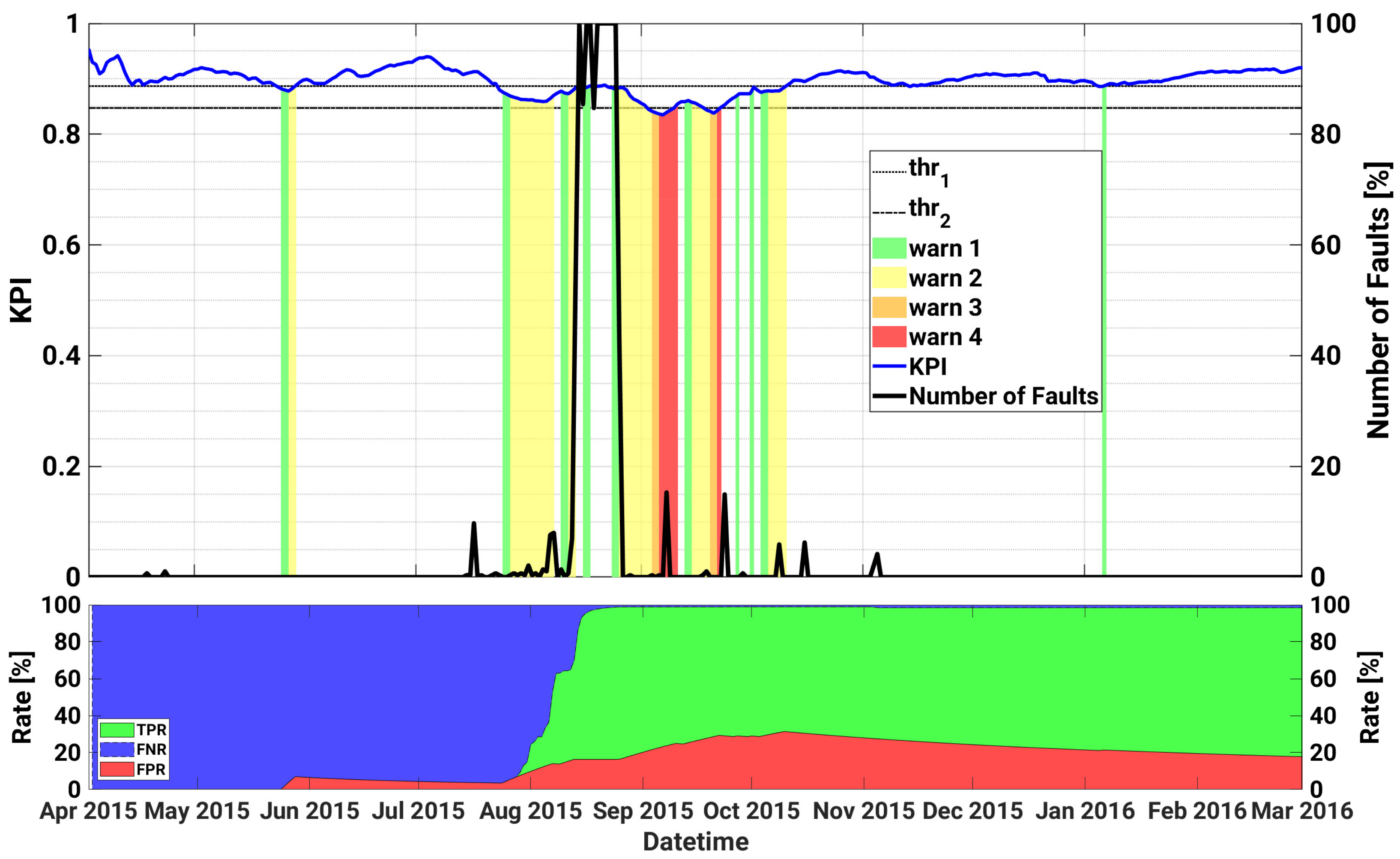
4.2. Plant B
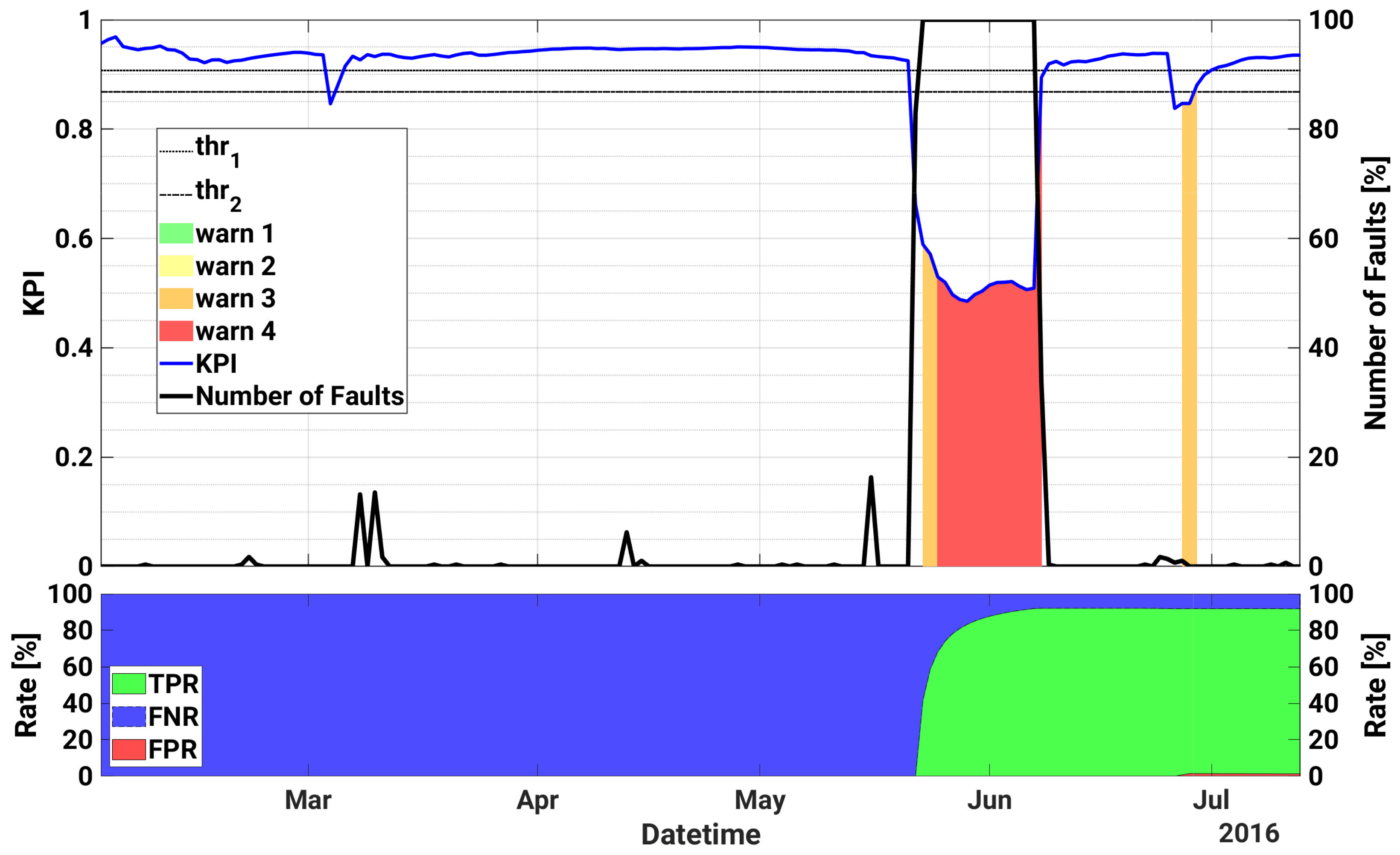
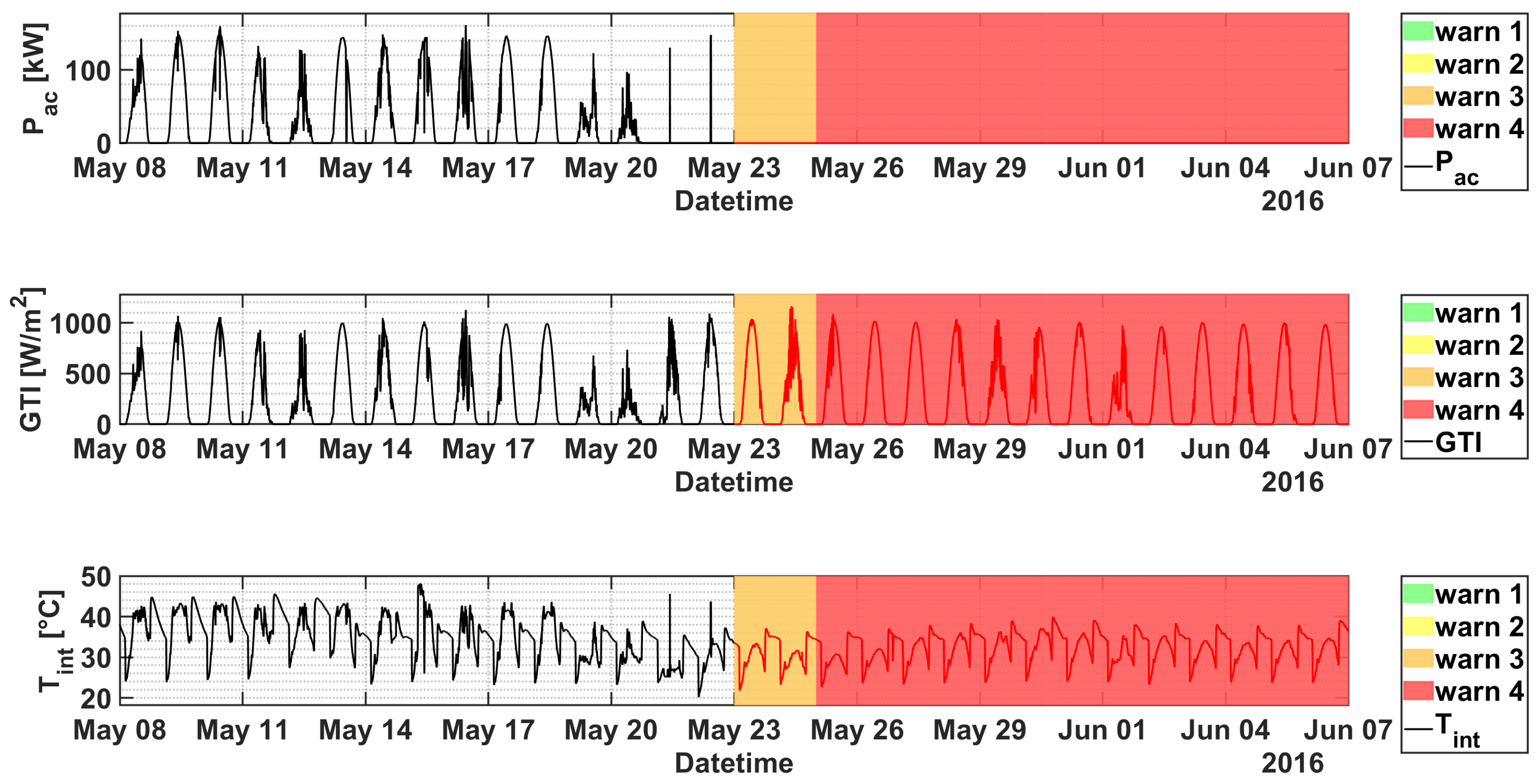
4.3. Plant C
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Moser, D.; Del Buono, M.; Jahn, U.; Herz, M.; Richter, M.; De Brabandere, K. Identification of technical risks in the photovoltaic value chain and quantification of the economic impact. Prog. Photovolt. Res. Appl. 2017, 25, 592–604. [Google Scholar] [CrossRef]
- Lindig, S.; Louwen, A.; Moser, D. Outdoor PV System Monitoring—Input Data Quality, Data Imputation and Filtering Approaches. Energies 2020, 13, 5099. [Google Scholar] [CrossRef]
- Beránek, V.; Olšan, T.; Libra, M.; Poulek, V.; Sedláček, J.; Dang, M.Q.; Tyukhov, I.I. New monitoring system for photovoltaic power plants’ management. Energies 2018, 11, 2495. [Google Scholar] [CrossRef] [Green Version]
- Woyte, A.; Richter, M.; Moser, D.; Mau, S.; Reich, N.; Jahn, U. Monitoring of photovoltaic systems: Good practices and systematic analysis. In Proceedings of the 28th European Photovoltaic Solar Energy Conference, Villepinte, France, 30 September–4 October 2013; pp. 3686–3694. [Google Scholar]
- Moreno-Garcia, I.M.; Palacios-Garcia, E.J.; Pallares-Lopez, V.; Santiago, I.; Gonzalez-Redondo, M.J.; Varo-Martinez, M.; Real-Calvo, R.J. Real-time monitoring system for a utility-scale photovoltaic power plant. Sensors 2016, 16, 770. [Google Scholar] [CrossRef] [Green Version]
- Lazzaretti, A.E.; Costa, C.H.D.; Rodrigues, M.P.; Yamada, G.D.; Lexinoski, G.; Moritz, G.L.; Santos, R.B.D. A monitoring system for online fault detection and classification in photovoltaic plants. Sensors 2020, 20, 4688. [Google Scholar] [CrossRef]
- Okere, A.; Iqbal, M.T. A Review of Conventional Fault Detection Techniques in Solar PV Systems and a Proposal of Long Range (LoRa) Wireless Sensor Network for Module Level Monitoring and Fault Diagnosis in Large Solar PV Farms. Eur. J. Electr. Eng. Comput. Sci. 2020, 4. [Google Scholar] [CrossRef]
- Gimeno-Sales, F.J.; Orts-Grau, S.; Escribá-Aparisi, A.; González-Altozano, P.; Balbastre-Peralta, I.; Martínez-Márquez, C.I.; Seguí-Chilet, S. PV Monitoring System for a Water Pumping Scheme with a Lithium-Ion Battery Using Free Open-Source Software and IoT Technologies. Sustainability 2020, 12, 10651. [Google Scholar] [CrossRef]
- Betti, A.; Lo Trovato, M.; Leonardi, F.S.; Leotta, G.; Ruffini, F.; Lanzetta, C. Predictive Maintenance in Photovoltaic Plants with a Big Data Approach. In Proceedings of the 33rd European Photovoltaic Solar Energy Conference, Amsterdam, The Netherlands, 25–29 September 2017; pp. 1895–2000. [Google Scholar]
- Chine, W.; Mellit, A.; Pavan, A.M.; Kalogirou, S.A. Fault detection method for grid-connected photovoltaic plants. Renew. Energy 2014, 66, 99–110. [Google Scholar] [CrossRef]
- Dhimish, M.; Holmes, V. Fault detection algorithm for grid-connected photovoltaic plants. Sol. Energy 2016, 137, 236–245. [Google Scholar] [CrossRef]
- Pei, T.; Hao, X. A fault detection method for photovoltaic systems based on voltage and current observation and evaluation. Energies 2019, 12, 1712. [Google Scholar] [CrossRef] [Green Version]
- Navid, Q.; Hassan, A.; Fardoun, A.A.; Ramzan, R. An Online Novel Two-Layered Photovoltaic Fault Monitoring Technique Based Upon the Thermal Signatures. Sustainability 2020, 12, 9607. [Google Scholar] [CrossRef]
- Zhao, Q.; Shao, S.; Lu, L.; Liu, X.; Zhu, H. A new PV array fault diagnosis method using fuzzy C-mean clustering and fuzzy membership algorithm. Energies 2018, 11, 238. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Han, F.; Wu, L.; Yu, J.; Cheng, S.; Lin, P.; Chen, H. Random forest based intelligent fault diagnosis for PV arrays using array voltage and string currents. Energy Convers. Manag. 2018, 178, 250–264. [Google Scholar] [CrossRef]
- Zhu, H.; Lu, L.; Yao, J.; Dai, S.; Hu, Y. Fault diagnosis approach for photovoltaic arrays based on unsupervised sample clustering and probabilistic neural network model. Sol. Energy 2018, 176, 395–405. [Google Scholar] [CrossRef]
- Lu, X.; Lin, P.; Cheng, S.; Lin, Y.; Chen, Z.; Wu, L.; Zheng, Q. Fault diagnosis for photovoltaic array based on convolutional neural network and electrical time series graph. Energy Convers. Manag. 2019, 196, 950–965. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, Y.; Wu, L.; Cheng, S.; Lin, P. Deep residual network based fault detection and diagnosis of photovoltaic arrays using current-voltage curves and ambient conditions. Energy Convers. Manag. 2019, 198, 111793. [Google Scholar] [CrossRef]
- Taghezouit, B.; Harrou, F.; Sun, Y.; Arab, A.H.; Larbes, C. Multivariate statistical monitoring of photovoltaic plant operation. Energy Convers. Manag. 2020, 205, 112317. [Google Scholar] [CrossRef]
- Kusiak, A.; Li, W. The prediction and diagnosis of wind turbine faults. Renew. Energy 2011, 36, 16–23. [Google Scholar] [CrossRef]
- Zaher, A.S.A.E.; McArthur, S.D.J.; Infield, D.G.; Patel, Y. Online wind turbine fault detection through automated SCADA data analysis. Wind Energy 2009, 12, 574–593. [Google Scholar] [CrossRef]
- Polo, F.A.O.; Bermejo, J.F.; Fernández, J.F.G.; Marquez, A.C. Assistance to Dynamic Maintenance Tasks by Ann-Based Models. In Advanced Maintenance Modelling for Asset Management; Crespo Márquez, A., González-Prida Díaz, V., Gómez Fernández, J., Eds.; Springer: Cham, Switzerland, 2018; pp. 387–411. [Google Scholar]
- Malarvizhi, M.R.; Thanamani, A.S. K-nearest neighbor in missing data imputation. Int. J. Eng. Res. Dev. 2012, 5, 5–7. [Google Scholar]
- Zhang, S. Nearest neighbor selection for iteratively kNN imputation. J. Syst. Softw. 2012, 85, 2541–2552. [Google Scholar] [CrossRef]
- Arianos, S.; Carbone, A. Detrending moving average algorithm: A closed-form approximation of the scaling law. Phys. A Stat. Mech. Appl. 2007, 382, 9–15. [Google Scholar] [CrossRef] [Green Version]
- Cowan, G. Statistical Data Analysis; Oxford University Press: Oxford, CA, USA, 1998. [Google Scholar]
- Kohonen, T. Self-Organizing Maps, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Tucci, M.; Raugi, M. Adaptive FIR neural model for centroid learning in self-organizing maps. IEEE Trans. Neural Netw. 2010, 21, 948–960. [Google Scholar] [CrossRef] [PubMed]
- Jämsä-Jounela, S.L.; Vermasvuori, M.; Endén, P.; Haavisto, S. A process monitoring system based on the Kohonen self-organizing maps. Control. Eng. Pract. 2003, 11, 83–92. [Google Scholar] [CrossRef] [Green Version]
- Silva, R.G.; Wilcox, S.J. Feature evaluation and selection for condition monitoring using a self-organizing map and spatial statistics. Artif. Intell. Eng. Des. Anal. Manuf. 2019, 33, 1–10. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plant Name | Number of Inverter Modules | Inverter Manufacturer Number | Max Active Power [kW] | Plant Nominal Power [MW] |
|---|---|---|---|---|
| A | 35 | 1 | 385 | 9.8 |
| B | 7 | 1 | 385 | 2.8 |
| C | 25 | 2 | 183.4 | 4.9 |
| Signal Number | Signal Type | Signal Name | Variable Name | Unit |
|---|---|---|---|---|
| 1 | Electrical | DC Current | [A] | |
| 2 | Electrical | DC Voltage | [V] | |
| 3 | Electrical | DC Power | [W] | |
| 4 | Electrical | AC Current | [A] | |
| 5 | Electrical | AC Voltage | [V] | |
| 6 | Electrical | AC Power | [W] | |
| 7 | Environmental | Internal Inverter Temperature | [°C] | |
| 8 | Environmental | Panel Temperature | [°C] | |
| 9 | Environmental | Ambient Temperature | [°C] | |
| 10 | Environmental | Global Tilted Irradiance | GTI | [W/m] |
| 11 | Environmental | Global Horizontal Irradiance | GHI | [W/m] |
| Plant Name | Training Period (dd/mm/yyyy) | Test Period (dd/mm/yyyy) |
|---|---|---|
| A | from 20/03/2014 to 30/09/2014 n° of patterns: 55,872 | from 01/10/2014 to 30/09/2015 n° of patterns: 104,832 |
| B | from 27/10/2014 to 31/03/2015 n° of patterns: 44,640 | from 01/04/2015 to 29/02/2016 n° of patterns: 96,192 |
| C | from 01/02/2015 to 31/01/2016 n° of patterns: 104,832 | from 01/02/2016 to 27/07/2016 n° of patterns: 50,976 |
| Warning Level | Thresholds | Derivative | Persistence |
|---|---|---|---|
| 1 | <0 | 1 day | |
| 2 | <0 | ≥2 days | |
| 3 | <0 | 1 day | |
| 4 | <0 | ≥2 days |
| Fault Name | Severity (1 to 5) | Start Date (dd/mm/yyyy) | End Date (dd/mm/yyyy) |
|---|---|---|---|
| AC Switch Open | 2 | 10/10/2014 | 11/10/2014 |
| AC Switch Open | 2 | 03/11/2014 | 28/11/2014 |
| DC Insulation Fault | 2 | 09/12/2014 | 10/12/2014 |
| DC Voltage High | 2 | 11/06/2015 | 23/06/2015 |
| AC Switch Open | 2 | 24/08/2015 | 25/08/2015 |
| Fault Name | Severity (1 to 5) | Start Date (dd/mm/yyyy) | End Date (dd/mm/yyyy) | Notes |
|---|---|---|---|---|
| Communication Error | 2 | 16/07/2015 | 16/07/2015 | None |
| Internal sensor fault | 2 | 06/08/2015 | 07/08/2015 | Fault Log downloading |
| DC Voltage High | 2 | 13/08/2015 | 25/08/2015 | Device B.1 replaced |
| Internal sensor fault | 2 | 07/09/2015 | 07/09/2015 | Cooling fan replaced |
| Internal sensor fault | 2 | 23/09/2015 | 23/09/2015 | Cooling pump replaced |
| Fault Name | Severity (1 to 5) | Start Date (dd/mm/yyyy) | End Date (dd/mm/yyyy) | Notes |
|---|---|---|---|---|
| AC Voltage out of range | 3 | 07/03/2016 | 07/03/2016 | Grid fault |
| AC Voltage out of range | 3 | 09/03/2016 | 09/03/2016 | Grid fault |
| AC Voltage out of range | 3 | 12/04/2016 | 12/04/2016 | Grid fault |
| AC Voltage out of range | 3 | 15/05/2016 | 15/05/2016 | Scheduled maintenance |
| AC Switch Open | 2 | 21/05/2016 | 07/06/2016 | Inverter 3.5 replaced |
| Test Case | TPR | FNR | FPR |
|---|---|---|---|
| Plant A, inv. A.2 | 93% | 7% | 13% |
| Plant B, inv. B.1 | 98% | 2% | 18% |
| Plant C, inv. 3.5 | 92% | 8% | 1% |
| Test Case | Date of Fault Occurrence (dd/mm/yyyy) | Date of Fault Prediction (dd/mm/yyyy) | Time in Advance of Prediction |
|---|---|---|---|
| Plant A, inv. A.2 | 10/10/2014 | 4/10/2014 | 6 days |
| Plant A, inv. A.2 | 3/11/2014 | 24/10/2014 | 10 days |
| Plant A, inv. A.2 | 09/12/2014 | last warning on 04/12/2014 | (5 days) fault occurs during plant maintenance |
| Plant A, inv. A.2 | 11/06/2015 | 06/06/2015 | 5 days |
| Plant A, inv. A.2 | 24/08/2015 | 23/08/2015 | 1 day |
| Plant B, inv. B.1 | 16/07/2015 | not detected | - minor fault |
| Plant B, inv. B.1 | 06/08/2015 | 26/07/2015 | 10 days |
| Plant B, inv. B.1 | 13/08/2015 | 10/08/2015 | 3 days |
| Plant B, inv. B.1 | 07/09/2015 | 24/08/2015 | 14 days |
| Plant B, inv. B.1 | 23/09/2015 | 14/09/2015 | 9 days |
| Plant C, inv. 3.5 | 21/05/2016 | 21/05/2016 | 0 days |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Betti, A.; Tucci, M.; Crisostomi, E.; Piazzi, A.; Barmada, S.; Thomopulos, D. Fault Prediction and Early-Detection in Large PV Power Plants Based on Self-Organizing Maps. Sensors 2021, 21, 1687. https://doi.org/10.3390/s21051687
Betti A, Tucci M, Crisostomi E, Piazzi A, Barmada S, Thomopulos D. Fault Prediction and Early-Detection in Large PV Power Plants Based on Self-Organizing Maps. Sensors. 2021; 21(5):1687. https://doi.org/10.3390/s21051687
Chicago/Turabian StyleBetti, Alessandro, Mauro Tucci, Emanuele Crisostomi, Antonio Piazzi, Sami Barmada, and Dimitri Thomopulos. 2021. "Fault Prediction and Early-Detection in Large PV Power Plants Based on Self-Organizing Maps" Sensors 21, no. 5: 1687. https://doi.org/10.3390/s21051687
APA StyleBetti, A., Tucci, M., Crisostomi, E., Piazzi, A., Barmada, S., & Thomopulos, D. (2021). Fault Prediction and Early-Detection in Large PV Power Plants Based on Self-Organizing Maps. Sensors, 21(5), 1687. https://doi.org/10.3390/s21051687