
Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures

 , , , and
, , , and
Abstract
:1. Introduction
- We proposed a customized CNN architecture for crack detection and localization in concrete structures. The proposed model was compared with various existing models based on various factors, e.g., training data size, heterogeneity among the data samples, computational time, and number of epochs, and the results demonstrate that the customized CNN model achieved a good balance between accuracy, network complexity, and training time. The results also show that a promising level of accuracy can be achieved by reducing data collection efforts and optimizing the model’s computational complexity.
- We investigated the effect of network complexity, data size, and variance among data samples on the performance of the models. The results clearly show that network complexity and variance in the data sample have the greatest influence on the model performance and are more important than the size of the data.
- Based on the experimental results, a discussion was undertaken which provides the significance of the deep learning models for crack detection in a concrete structure. In general, the discussion provides a reference for researchers working in the field of crack detection and localization using deep learning techniques.
2. Overview of the Proposed System
Dataset Preparation
3. Training Models
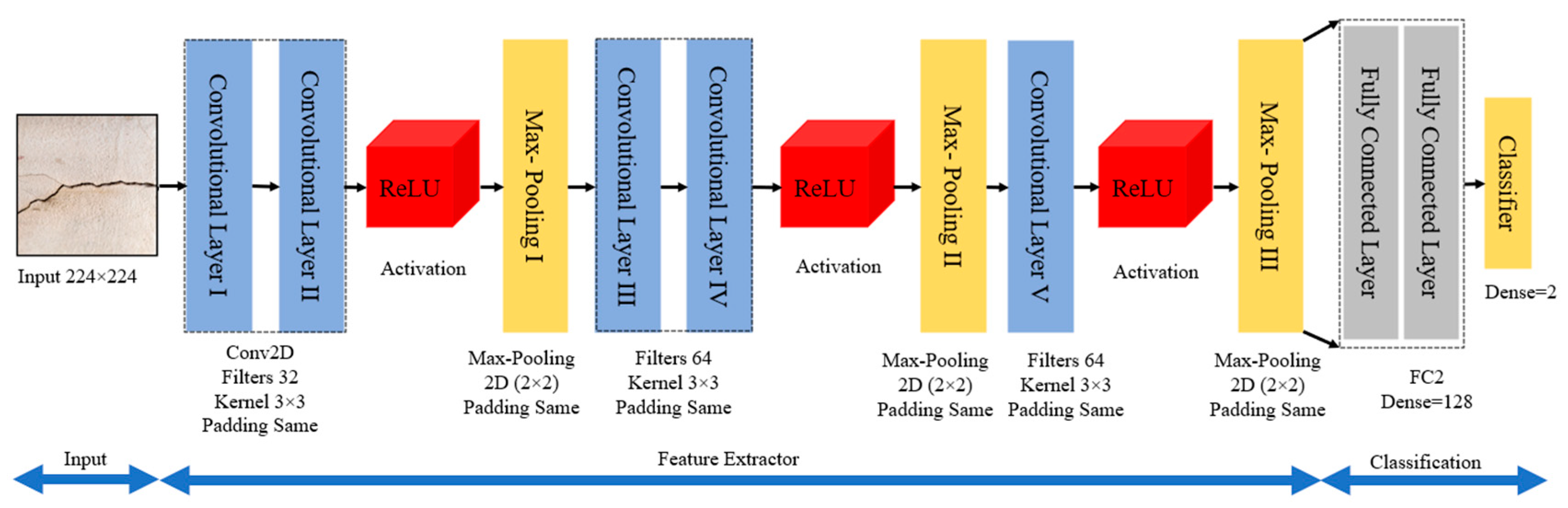
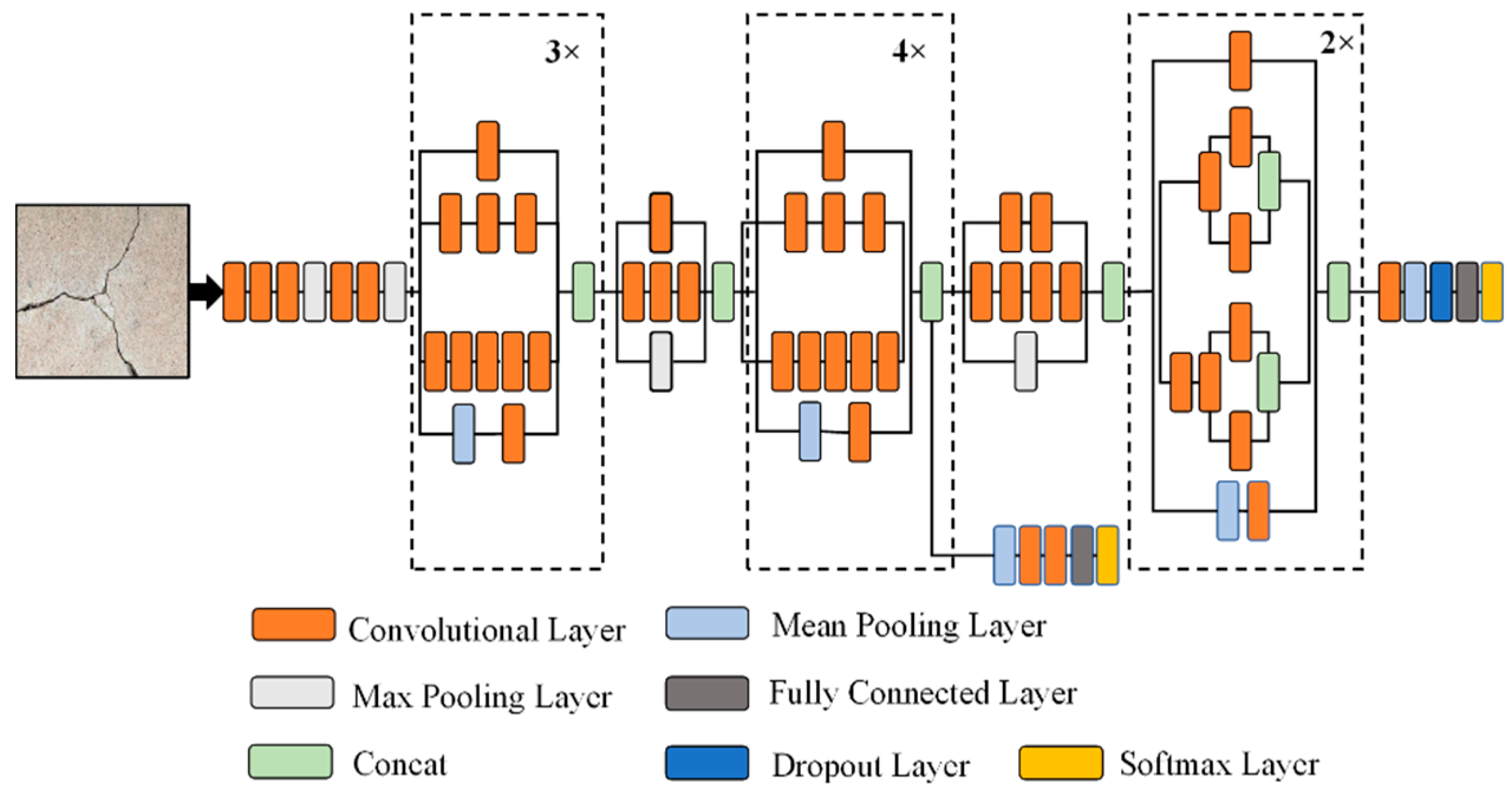
3.1. Customized CNN Model
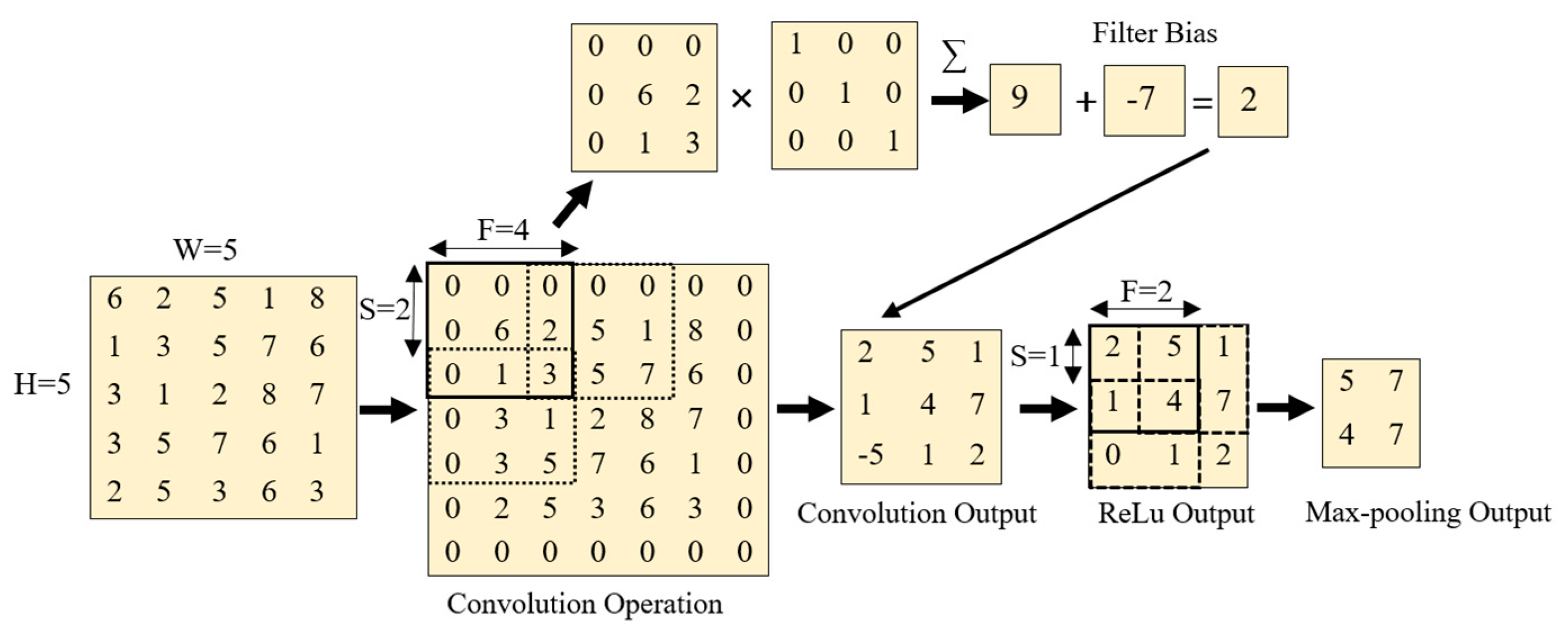
3.1.1. Convolutional Layer
3.1.2. Activation Layer
3.1.3. Max-Pooling Layer
3.1.4. Fully Connected Layer
3.1.5. Softmax Layer
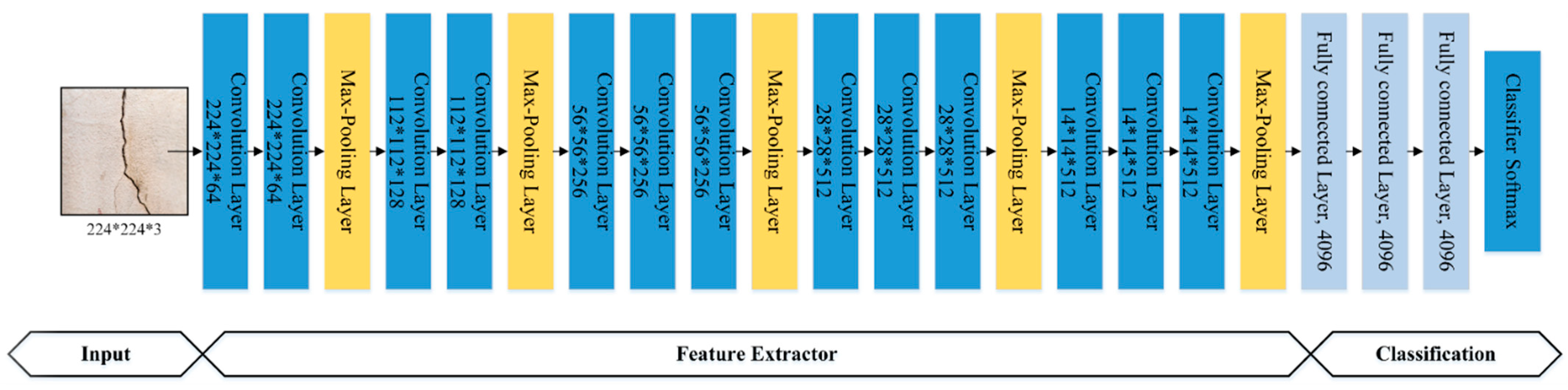
3.2. Pre-Trained VGG-16 Model
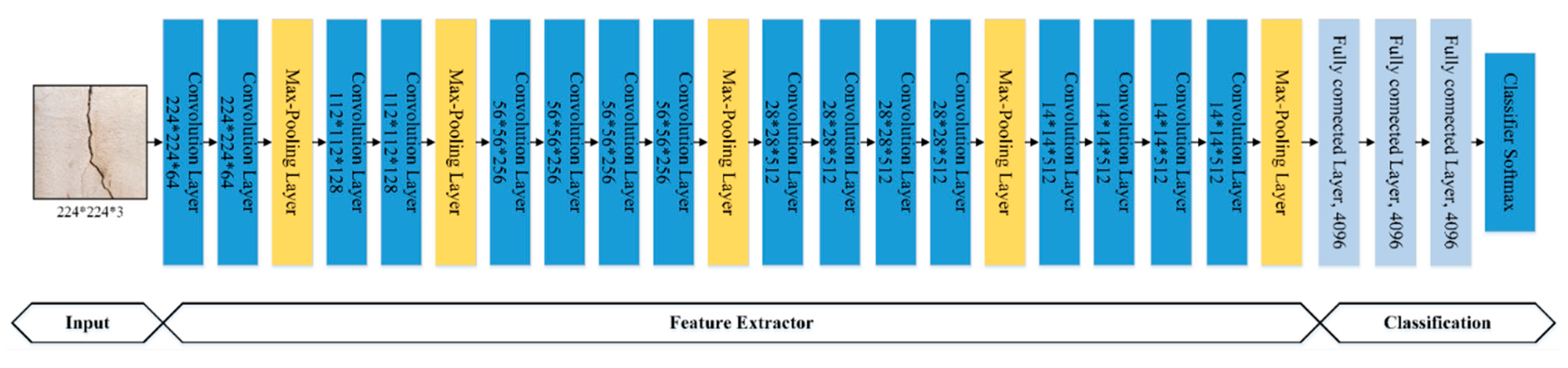
3.3. Pre-Trained VGG-19 Model
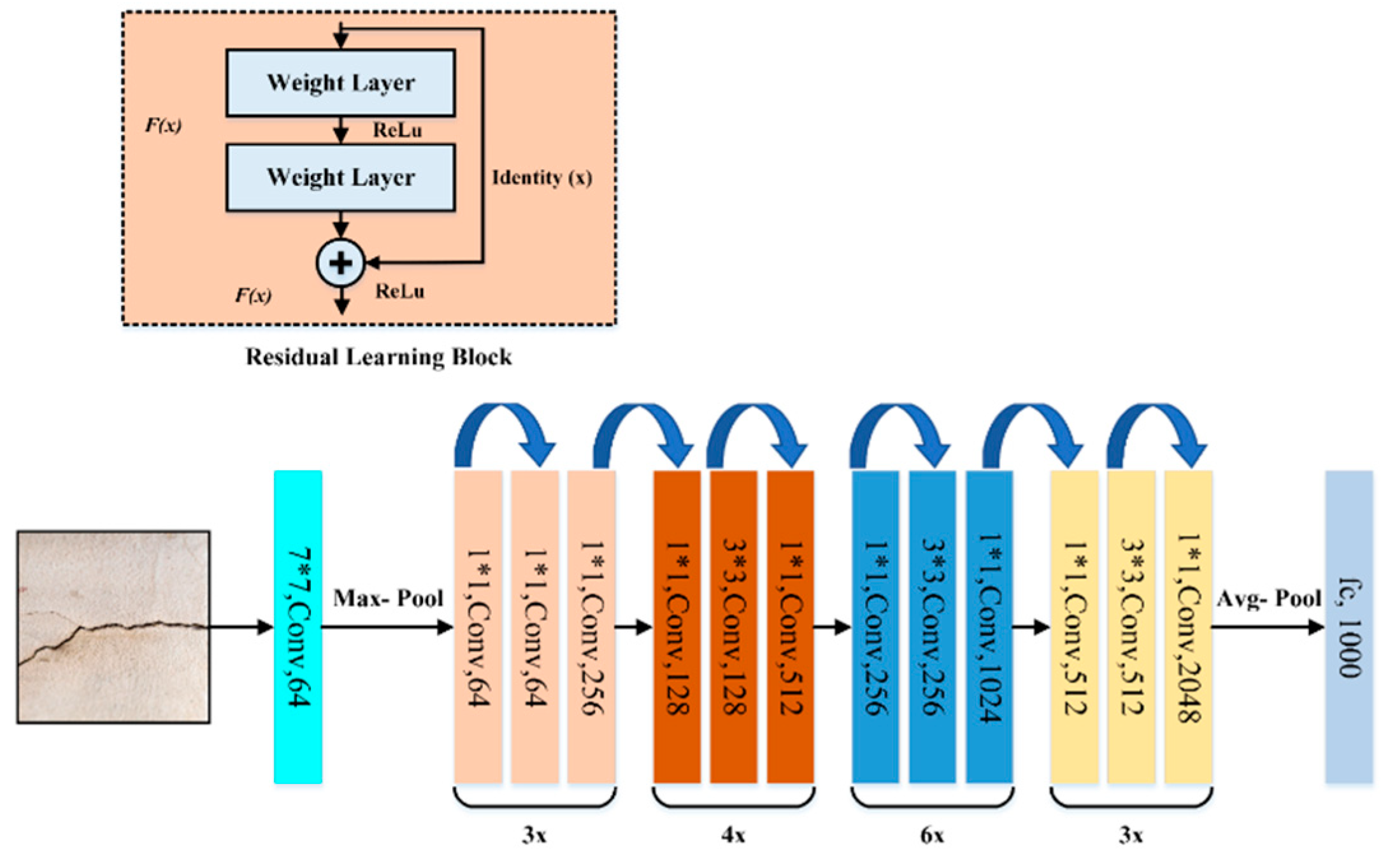
3.4. ResNet-50 Model
3.5. Inception-V3 Model
4. Experiments and Results
4.1. Evaluation Metrics
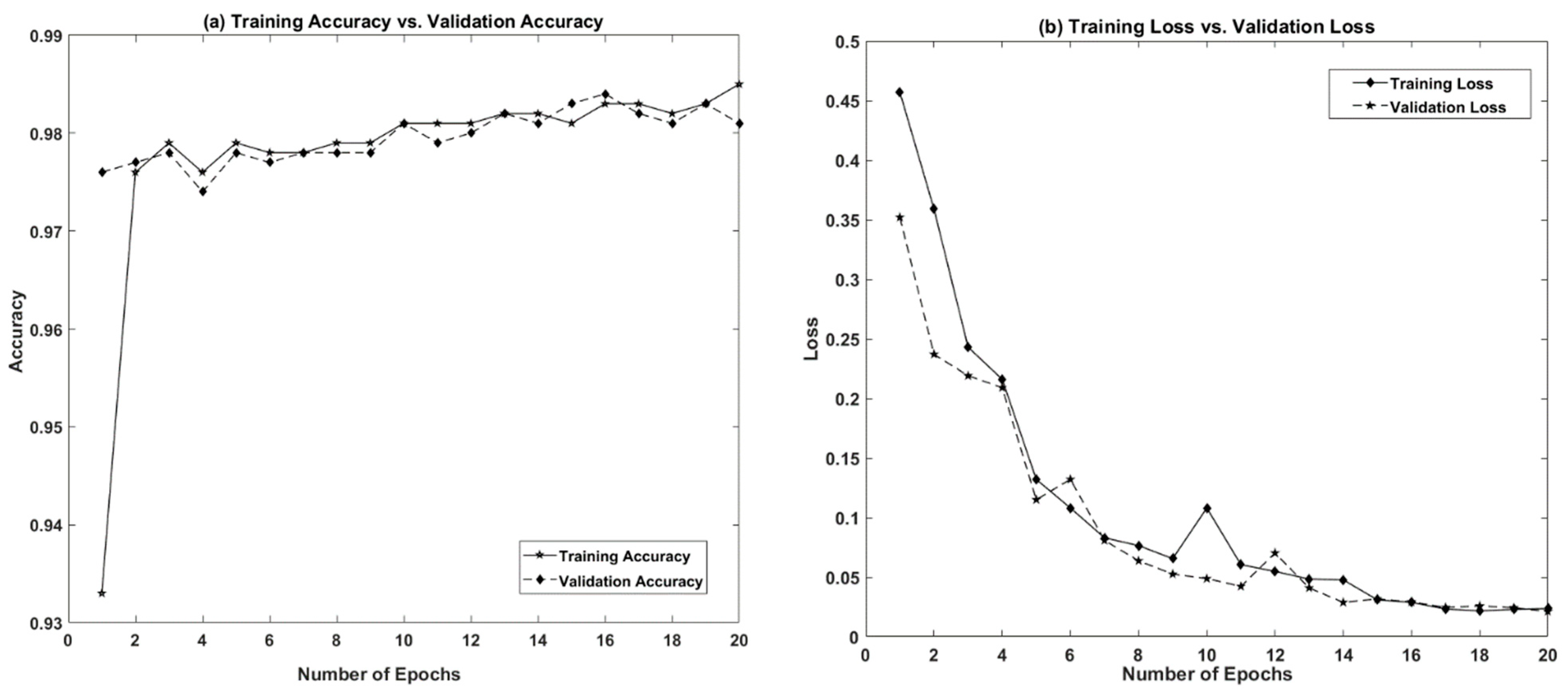
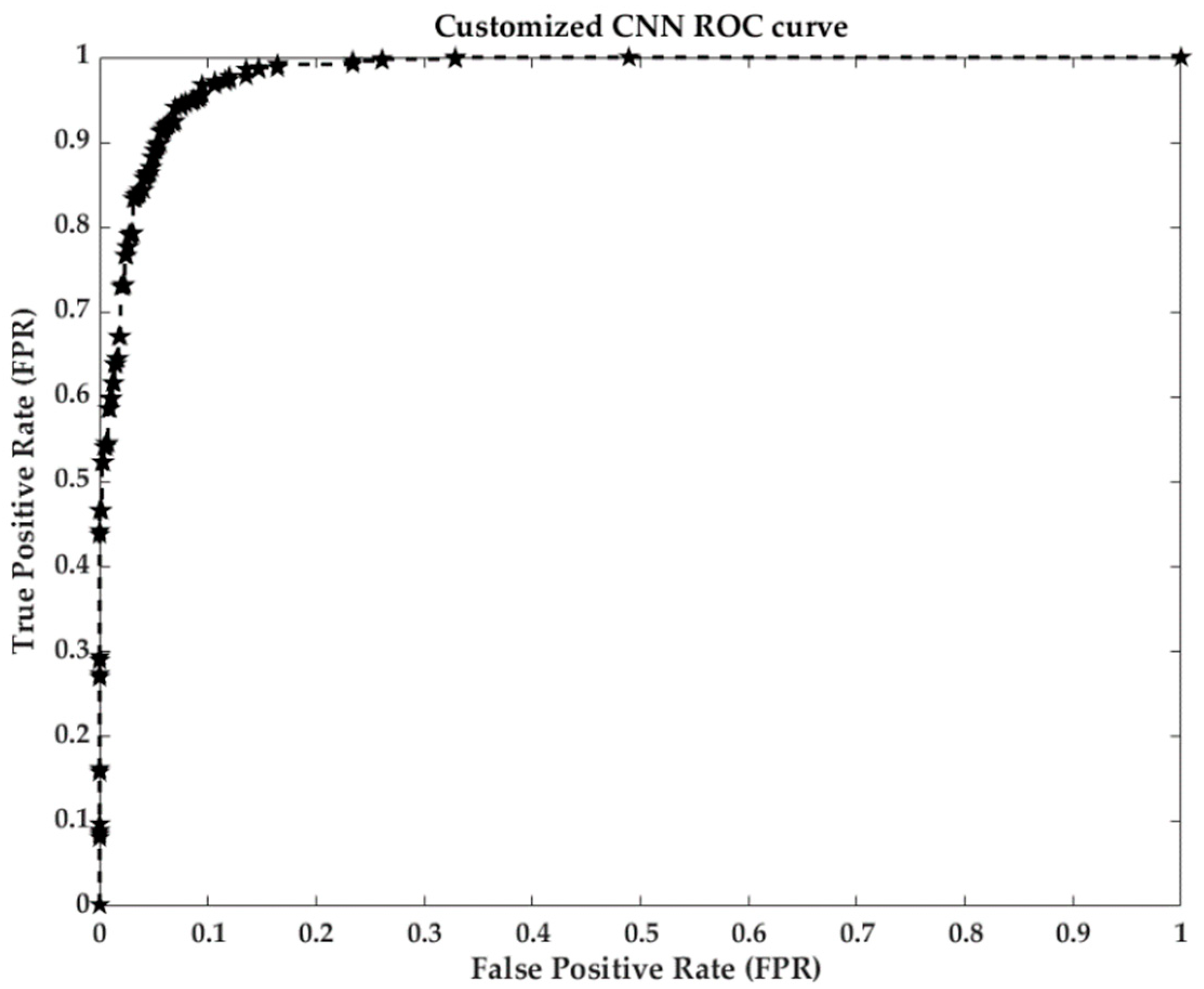
4.2. Classification Results
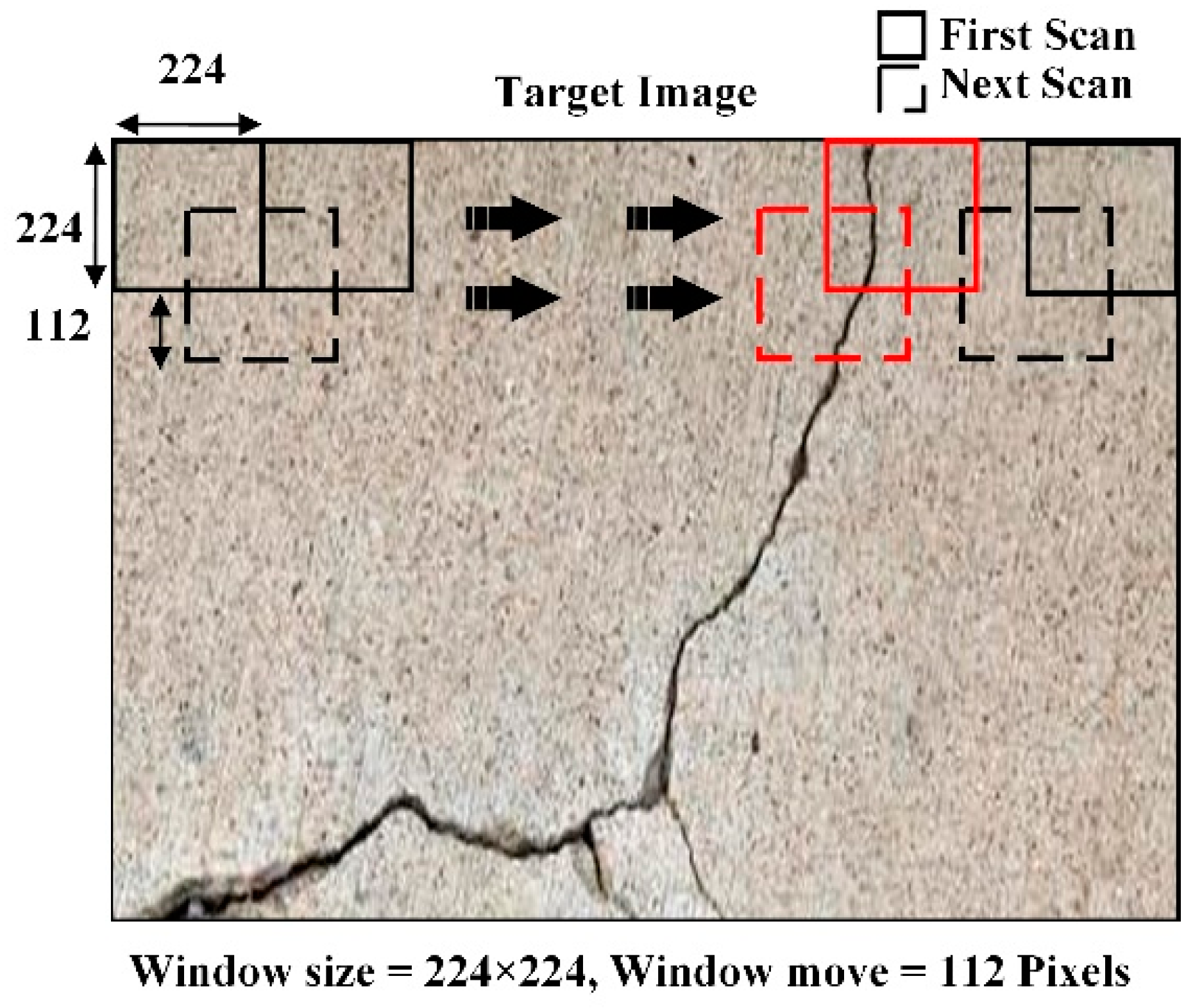
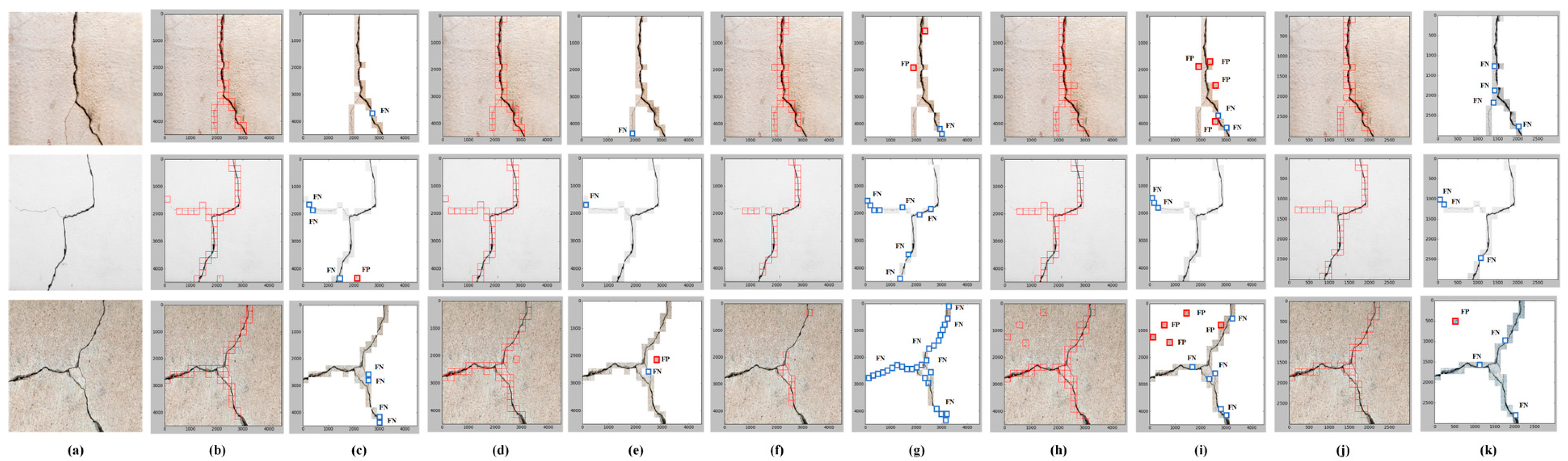
4.3. Localization Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Kamaliardakani, M.; Sun, L.; Ardakani, M.K. Sealed-Crack Detection Algorithm Using Heuristic Thresholding Approach. J. Comput. Civ. Eng. 2016, 30, 04014110. [Google Scholar] [CrossRef]
- Li, Q.; Zou, Q.; Zhang, D.; Mao, Q. FoSA: F* Seed-growing Approach for crack-line detection from pavement images. Image Vis. Comput. 2011, 29, 861–872. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Nakamura, S.; Hashimoto, S. An efficient crack detection method using percolation-based image processing. In Proceedings of the 2008 3rd IEEE Conference on Industrial Electronics and Applications, ICIEA 2008, Singapore, 3–5 June 2008; pp. 1875–1880. [Google Scholar] [CrossRef]
- Sinha, S.K.; Fieguth, P.W. Morphological segmentation and classification of underground pipe images. Mach. Vis. Appl. 2006, 17, 21–31. [Google Scholar] [CrossRef]
- Sinha, S.K.; Fieguth, P.W. Automated detection of cracks in buried concrete pipe images. Autom. Constr. 2006, 15, 58–72. [Google Scholar] [CrossRef]
- Chambon, S.; Subirats, P.; Dumoulin, J. Introduction of a wavelet transform based on 2D matched filter in a Markov random field for fine structure extraction: Application on road crack detection. In Image Processing: Machine Vision Applications II; International Society for Optics and Photonics: Bellingham, WA, USA, 2009; Volume 7251, p. 72510A. [Google Scholar] [CrossRef]
- Fujita, Y.; Hamamoto, Y. A robust automatic crack detection method from noisy concrete surfaces. Mach. Vis. Appl. 2011, 22, 245–254. [Google Scholar] [CrossRef]
- O’Byrne, M.; Ghosh, B.; Schoefs, F.; Pakrashi, V. Regionally enhanced multiphase segmentation technique for damaged surfaces. Comput. Civ. Infrastruct. Eng. 2014, 29, 644–658. [Google Scholar] [CrossRef] [Green Version]
- O’Byrne, M.; Schoefs, F.; Ghosh, B.; Pakrashi, V. Texture Analysis Based Damage Detection of Ageing Infrastructural Elements. Comput. Civ. Infrastruct. Eng. 2013, 28, 162–177. [Google Scholar] [CrossRef] [Green Version]
- Moon, H.G.; Kim, J.H. Inteligent crack detecting algorithm on the concrete crack image using neural network. In Proceedings of the 28th International Symposium on Automation and Robotics in Construction, ISARC 2011, Seoul, Korea, 21 June–2 July 2011; pp. 1461–1467. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.W.; Huang, J.H.; Sung, J.C.; Lee, C.C. Detection of cracks using neural networks and computational mechanics. Comput. Methods Appl. Mech. Eng. 2002, 191, 2831–2845. [Google Scholar] [CrossRef]
- Sinha, S.K.; Fieguth, P.W. Neuro-fuzzy network for the classification of buried pipe defects. Autom. Constr. 2006, 15, 73–83. [Google Scholar] [CrossRef]
- Wu, W.; Liu, Z.; He, Y. Classification of defects with ensemble methods in the automated visual inspection of sewer pipes. Pattern Anal. Appl. 2015, 18, 263–276. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Masri, S.F.; Padgett, C.W.; Sukhatme, G.S. An innovative methodology for detection and quantification of cracks through incorporation of depth perception. Mach. Vis. Appl. 2013, 24, 227–241. [Google Scholar] [CrossRef]
- Müller, J.; Müller, J.; Tetzlaff, R. NEROvideo: A general-purpose CNN-UM video processing system. J. Real-Time Image Process. 2016, 12, 763–774. [Google Scholar] [CrossRef]
- Kalfarisi, R.; Wu, Z.Y.; Soh, K. Crack Detection and Segmentation Using Deep Learning with 3D Reality Mesh Model for Quantitative Assessment and Integrated Visualization. J. Comput. Civ. Eng. 2020, 34, 04020010. [Google Scholar] [CrossRef]
- Chen, F.C.; Jahanshahi, M.R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Yang, X.; Gao, X.; Song, B.; Yang, D. Aurora image search with contextual CNN feature. Neurocomputing 2018, 281, 67–77. [Google Scholar] [CrossRef]
- Han, D.; Liu, Q.; Fan, W. A new image classification method using CNN transfer learning and web data augmentation. Expert Syst. Appl. 2018, 95, 43–56. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T. Lightweight Road Manager: Smartphone-Based Automatic Determination of Road Damage Status by Deep Neural Network. In Proceedings of the 5th ACM SIGSPATIAL International Workshop on Mobile Geographic Information Systems; MobiGIS ’16; Association for Computing Machinery: New York, NY, USA, 2016; pp. 37–45. [Google Scholar] [CrossRef]
- Xia, Y.; Yu, H.; Wang, F.-Y. Accurate and Robust Eye Center Localization via Fully Convolutional Networks. EEE/CAA J. Autom. Sin. 2019, 6, 1127–1138. [Google Scholar] [CrossRef]
- Ali, L.; Valappil, N.K.; Kareem, D.N.A.; John, M.J.; Jassmi, H.A. Pavement Crack Detection and Localization using Convolutional Neural Networks (CNNs). In Proceedings of the 2019 International Conference on Digitization (ICD), Sharjah, UAE 18–19 November 2019; pp. 217–221. [Google Scholar] [CrossRef]
- Ali, L.; Harous, S.; Zaki, N.; Khan, W.; Alnajjar, F.; Jassmi, H.A. Performance Evaluation of Different Algorithms for Crack Detection in Concrete Structures. In Proceedings of the 2021 2nd International Conference on Computation, Automation and Knowledge Management (ICCAKM), Dubai, UAE, 19–21 January 2021; pp. 53–58. [Google Scholar] [CrossRef]
- Fei, Y.; Wang, K.C.; Zhang, A.; Chen, C.; Li, J.Q.; Liu, Y.; Yang, G.; Li, B. Pixel-Level Cracking Detection on 3D Asphalt Pavement Images Through Deep-Learning- Based CrackNet-V. IEEE Trans. Intell. Transp. Syst. 2020, 21, 273–284. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the International Conference on Image Processing, ICIP, Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Wang, K.C.P.; Zhang, A.; Li, J.Q.; Fei, Y.; Chen, C.; Li, B. Deep Learning for Asphalt Pavement Cracking Recognition Using Convolutional Neural Network. In Airfield and Highway Pavements 2017: Design, Construction, Evaluation, and Management of Pavements, Proceedings of the International Conference on Highway Pavements and Airfield Technology, ASCE American Society of Civil Engineers 2017, Philadelphia, PA, USA, 27–30 August 2017; American Society of Civil Engineers: Reston, VA, USA, 2017; pp. 166–177. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic Bridge Crack Detection Using a Convolutional Neural Network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef] [Green Version]
- Pauly, L.; Hogg, D.; Fuentes, R.; Peel, H. Deeper networks for pavement crack detection. In Proceedings of the 34th ISARC, Taipei, Taiwan, 28 June–1 July 2017; pp. 479–485. [Google Scholar]
- Fan, Z.; Li, C.; Chen, Y.; Mascio, P.D.; Chen, X.; Zhu, G.; Loprencipe, G. Ensemble of Deep Convolutional Neural Networks for Automatic Pavement Crack Detection and Measurement. Coatings 2020, 10, 152. [Google Scholar] [CrossRef] [Green Version]
- Tong, Z.; Gao, J.; Zhang, H. Recognition, location, measurement, and 3D reconstruction of concealed cracks using convolutional neural networks. Constr. Build. Mater. 2017, 146, 775–787. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic pixel-level crack detection and measurement using fully convolutional network. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput. Aided Civil Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Fei, Y.; Liu, Y.; Tao, S.; Chen, C.; Li, J.Q.; Li, B. Deep Learning–Based Fully Automated Pavement Crack Detection on 3D Asphalt Surfaces with an Improved CrackNet. J. Comput. Civ. Eng. 2018, 32, 04018041. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Zhang, K.; Cheng, H.D.; Zhang, B. Unified Approach to Pavement Crack and Sealed Crack Detection Using Preclassification Based on Transfer Learning. J. Comput. Civ. Eng. 2018, 32, 04018001. [Google Scholar] [CrossRef]
- Gao, Y.; Mosalam, K.M. Deep Transfer Learning for Image-Based Structural Damage Recognition. Comput. Civ. Infrastruct. Eng. 2018, 33, 748–768. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Yoon, Y.S.; Kim, H. A deep residual network with transfer learning for pixel-level road crack detection. In 35th International Symposium on Automation and Robotics in Construction (ISARC 2018); IAARC Publications: Berlin, Germany, 2018; pp. 753–756. [Google Scholar] [CrossRef] [Green Version]
- da Silva, W.R.L.; de Lucena, D.S. Concrete Cracks Detection Based on Deep Learning Image Classification. Proceedings 2018, 2, 489. [Google Scholar] [CrossRef] [Green Version]
- Gopalakrishnan, K.; Gholami, H.; Vidyadharan, A.; Choudhary, A.; Agrawal, A. Crack damage detection in unmanned aerial vehicle images of civil infrastructure using pre-trained deep learning model. Int. J. Traffic Transp. Eng. 2018, 8, 1–14. [Google Scholar] [CrossRef]
- Feng, C.; Zhang, H.; Wang, S.; Li, Y.; Wang, H.; Yan, F. Structural Damage Detection using Deep Convolutional Neural Network and Transfer Learning. KSCE J. Civ. Eng. 2019, 23, 4493–4502. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. SDNET2018: An annotated image dataset for non-contact concrete crack detection using deep convolutional neural networks. Data Br. 2018, 21, 1664–1668. [Google Scholar] [CrossRef]
- Özgenel, Ç.F. Concrete Crack Images for Classification. Version 2. Mendeley Data 2019. [Google Scholar] [CrossRef]
- Wanderley, M.D.D.S.; e Bueno LD, A.; Zanchettin, C.; Oliveira, A.L. The Impact of Dataset Complexity on Transfer Learning over Convolutional Neural Networks. In Artificial Neural Networks and Machine Learning—ICANN 2017; Springer: Cham, Switzerland, 2017; pp. 582–589. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2014; Volume 8689, pp. 818–833. [Google Scholar] [CrossRef] [Green Version]
- Luo, X.; Zhou, M.; Xia, Y.; Zhu, Q.; Ammari, A.C.; Alabdulwahab, A. Generating Highly Accurate Predictions for Missing QoS Data via Aggregating Nonnegative Latent Factor Models. IEEE Trans. Neural Netw. Learn Syst. 2016, 27, 524–537. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Wu, H.; Yuan, H.; Zhou, M. Temporal Pattern-Aware QoS Prediction via Biased Non-Negative Latent Factorization of Tensors. IEEE Trans. Cybern. 2020, 50, 1798–1809. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve Restricted Boltzmann machines. In Proceedings of the ICML 2010—27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Słoński, M. A comparison of deep convolutional neural networks for image-based detection of concrete surface cracks. Comput. Assist. Methods Eng. Sci. 2019, 26, 2. [Google Scholar]
- Fang, F.; Li, L.; Gu, Y.; Zhu, H.; Lim, J.-H. A novel hybrid approach for crack detection. Pattern Recognit. 2020, 107, 107474. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Construct. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Yan, J.; Downey, A.; Cancelli, A.; Laflamme, S.; Chen, A.; Li, J.; Ubertini, F. Concrete crack detection and monitoring using a capacitive dense sensor array. Sensors 2019, 19, 1843. [Google Scholar] [CrossRef] [Green Version]
- Ying, X. An Overview of Overfitting and its Solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Gochoo, M.; Tan, T.-H.; Huang, S.-C.; Batjargal, T.; Hsieh, J.-W.; Alnajjar, F.S.; Chen, Y.-F. Novel IoT-Based Privacy-Preserving Yoga Posture Recognition System Using Low-Resolution Infrared Sensors and Deep Learning. IEEE Internet Things J. 2019, 6, 7192–7200. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Kei, L.S.; Li, C. Automatic Pixel-Level Pavement Crack Detection Using Information of Multi-Scale Neighborhoods. IEEE Access 2018, 6, 24452–24463. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training Data | Validation Data | Testing Data | |||
|---|---|---|---|---|---|---|
| Crack Patches | Non-Crack Patches | Crack Patches | Non-Crack Patches | Crack Patches | Non-Crack Patches | |
| 2.8 k | 840 | 840 | 280 | 280 | 280 | 280 |
| 5.6 k | 1680 | 1680 | 560 | 560 | 560 | 560 |
| 8.4 k | 2520 | 2520 | 840 | 840 | 840 | 840 |
| 10.4 k | 3120 | 3120 | 1040 | 1040 | 1040 | 1040 |
| 13.4 k | 4020 | 4020 | 1340 | 1340 | 1340 | 1340 |
| 15.6 k | 4680 | 4680 | 1560 | 1560 | 1560 | 1560 |
| 20.8 k | 6240 | 6240 | 2080 | 2080 | 2080 | 2080 |
| 25 k | 7500 | 7500 | 2500 | 2500 | 2500 | 2500 |
| Deep Learning Model | Number of Convolutional Layers | Number of Parameters (Millions) |
|---|---|---|
| Customized CNN | 5 | 2.70 |
| VGG-16 | 16 | 138 |
| VGG-19 | 19 | 143.67 |
| ResNet-50 | 50 | 23.78 |
| Inception V3 | 48 | 21.80 |
| Models | ||||||||
|---|---|---|---|---|---|---|---|---|
| Dataset Size | Customized CNN Model | |||||||
| Confusion Matrices | Validation Accuracy | Testing Accuracy | Precision | Recall | F Score | |||
| 2.8 k | Class | Crack (0) | Non-Crack (1) | 0.991 | 0.985 | 1.000 | 0.973 | 0.986 |
| Crack (0) Non-Crack (1) | 297 | 0 | ||||||
| 8 | 255 | |||||||
| 5.6 k | Crack (0) | 530 | 2 | 0.981 | 0.978 | 0.996 | 0.960 | 0.977 |
| Non-Crack (1) | 22 | 566 | ||||||
| 8.4 k | Crack (0) | 828 | 8 | 0.982 | 0.980 | 0.990 | 0.971 | 0.981 |
| Non-Crack (1) | 24 | 820 | ||||||
| 10.4 k | Crack (0) | 1020 | 17 | 0.964 | 0.952 | 0.983 | 0.925 | 0.953 |
| Non-Crack (1) | 82 | 961 | ||||||
| 13.4 k | Crack (0) | 1309 | 4 | 0.984 | 0.958 | 0.997 | 0.925 | 0.959 |
| Non-Crack (1) | 106 | 1261 | ||||||
| 15.6 k | Crack (0) | 1568 | 3 | 0.975 | 0.890 | 0.998 | 0.822 | 0.901 |
| Non-Crack (1) | 339 | 1210 | ||||||
| 20.8 k | Crack (0) | 2133 | 5 | 0.957 | 0.908 | 0.997 | 0.850 | 0.918 |
| Non-Crack (1) | 374 | 1648 | ||||||
| 25 k | Crack (0) | 2449 | 16 | 0.967 | 0.958 | 0.997 | 0.850 | 0.918 |
| Non-Crack (1) | 192 | 2343 | ||||||
| VGG-16 Model | ||||||||
| 2.8 k | Class | Crack | Non-Crack | 0.997 | 0.998 | 1.000 | 0.996 | 0.998 |
| Crack (0) | 297 | 0 | ||||||
| Non-Crack (1) | 1 | 262 | ||||||
| 5.6 k | Crack (0) | 531 | 1 | 0.999 | 0.999 | 0.998 | 1.000 | 0.999 |
| Non-Crack (1) | 0 | 588 | ||||||
| 8.4 k | Crack (0) | 832 | 4 | 0.999 | 0.997 | 0.995 | 0.998 | 0.997 |
| Non-Crack (1) | 1 | 843 | ||||||
| 10.4 k | Crack (0) | 1030 | 7 | 0.994 | 0.992 | 0.993 | 0.992 | 0.992 |
| Non-Crack (1) | 8 | 1035 | ||||||
| 13.4 k | Crack (0) | 1312 | 1 | 0.998 | 0.998 | 0.999 | 0.997 | 0.998 |
| Non-Crack (1) | 3 | 1364 | ||||||
| 15.6 k | Crack (0) | 1555 | 16 | 0.997 | 0.994 | 0.989 | 0.998 | 0.994 |
| Non-Crack (1) | 2 | 1547 | ||||||
| 20.8 k | Crack (0) | 2117 | 21 | 0.994 | 0.992 | 0.990 | 0.994 | 0.992 |
| Non-Crack (1) | 11 | 2011 | ||||||
| 25 k | Crack (0) | 2450 | 60 | 0.987 | 0.986 | 0.976 | 0.996 | 0.986 |
| Non-Crack (1) | 9 | 2481 | ||||||
| VGG-19 Model | ||||||||
| 2.8 k | Class | Crack | Non-Crack | 0.900 | 0.899 | 0.976 | 0.855 | 0.911 |
| Crack (0) | 290 | 7 | ||||||
| Non-Crack (1) | 49 | 214 | ||||||
| 5.6 k | Crack (0) | 519 | 13 | 0.917 | 0.916 | 0.975 | 0.866 | 0.917 |
| Non-Crack (1) | 80 | 508 | ||||||
| 8.4 k | Crack (0) | 810 | 26 | 0.944 | 0.937 | 0.968 | 0.911 | 0.939 |
| Non-Crack (1) | 79 | 765 | ||||||
| 10.4 k | Crack (0) | 1009 | 28 | 0.929 | 0.929 | 0.973 | 0.894 | 0.932 |
| Non-Crack (1) | 119 | 924 | ||||||
| 13.4 k | Crack (0) | 1278 | 35 | 0.955 | 0.951 | 0.973 | 0.930 | 0.951 |
| Non-Crack (1) | 95 | 1272 | ||||||
| 15.6 k | Crack (0) | 1527 | 44 | 0.954 | 0.951 | 0.972 | 0.934 | 0.952 |
| Non-Crack (1) | 107 | 1442 | ||||||
| 20.8 k | Crack (0) | 2068 | 70 | 0.952 | 0.952 | 0.967 | 0.941 | 0.954 |
| Non-Crack (1) | 129 | 1893 | ||||||
| 25 k | Crack (0) | 2396 | 69 | 0.960 | 0.960 | 0.972 | 0.949 | 0.960 |
| Non-Crack (1) | 128 | 2407 | ||||||
| ResNet-50 Model | ||||||||
| 2.8 k | class | Crack | Non-Crack | 0.994 | 0.994 | 0.988 | 1.000 | 0.994 |
| Crack (0) | 260 | 3 | ||||||
| Non-Crack (1) | 0 | 297 | ||||||
| 5.6 k | Crack (0) | 578 | 10 | 0.992 | 0.983 | 0.983 | 0.991 | 0.987 |
| Non-Crack (1) | 8 | 524 | ||||||
| 8.4 k | Crack (0) | 823 | 20 | 0.994 | 0.987 | 0.976 | 0.998 | 0.987 |
| Non-Crack (1) | 1 | 836 | ||||||
| 10.4 k | Crack (0) | 1027 | 16 | 0.990 | 0.986 | 0.984 | 0.987 | 0.986 |
| Non-Crack (1) | 13 | 1024 | ||||||
| 13.4 k | Crack (0) | 1358 | 9 | 0.995 | 0.995 | 0.993 | 0.998 | 0.996 |
| Non-Crack (1) | 2 | 1311 | ||||||
| 15.6 k | Crack (0) | 1526 | 23 | 0.990 | 0.990 | 0.985 | 0.996 | 0.990 |
| Non-Crack (1) | 6 | 1565 | ||||||
| 20.8 k | Crack (0) | 1985 | 37 | 0.990 | 0.988 | 0.981 | 0.995 | 0.988 |
| Non-Crack (1) | 10 | 2128 | ||||||
| 25 k | Crack (0) | 2433 | 369 | 0.994 | 0.994 | 0.984 | 0.991 | 0.987 |
| Non-Crack (1) | 50 | 2148 | ||||||
| Inception V3 Model | ||||||||
| 2.8 k | class | Crack | Non-Crack | 0.996 | 0.973 | 0.943 | 1.000 | 0.970 |
| Crack (0) | 248 | 15 | ||||||
| Non-Crack (1) | 0 | 297 | ||||||
| 5.6 k | Crack (0) | 588 | 0 | 0.998 | 0.952 | 1.000 | 0.931 | 0.964 |
| Non-Crack (1) | 53 | 479 | ||||||
| 8.4 k | Crack (0) | 838 | 5 | 0.995 | 0.994 | 0.994 | 0.994 | 0.994 |
| Non-Crack (1) | 5 | 832 | ||||||
| 10.4 k | Crack (0) | 1031 | 12 | 0.990 | 0.987 | 0.988 | 0.986 | 0.987 |
| Non-Crack (1) | 14 | 1023 | ||||||
| 13.4 k | Crack (0) | 1288 | 79 | 0.997 | 0.970 | 0.942 | 1.000 | 0.970 |
| Non-Crack (1) | 0 | 1313 | ||||||
| 15.6 k | Crack (0) | 691 | 858 | 0.991 | 0.725 | 0.446 | 1.000 | 0.617 |
| Non-Crack (1) | 0 | 1571 | ||||||
| 20.8 k | Crack (0) | 1622 | 400 | 0.979 | 0.899 | 0.802 | 0.987 | 0.885 |
| Non-Crack (1) | 20 | 2118 | ||||||
| 25 k | Crack (0) | 2463 | 71 | 0.985 | 0.982 | 0.972 | 0.992 | 0.982 |
| Non-Crack (1) | 18 | 2448 | ||||||
| Dataset Size | Models | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CNN Model | VGG-16 | VGG-19 | ResNet-50 | Inception v3 | ||||||
| Accuracy | ||||||||||
| 1st | 20th | 1st | 20th | 1st | 20th | 1st | 20th | 1st | 20th | |
| 2.8 k | 0.976 | 0.983 | 0.980 | 0.998 | 0.894 | 0.900 | 0.673 | 0.954 | 0.976 | 0.973 |
| 5.6 k | 0.958 | 0.970 | 0.965 | 0.996 | 0.867 | 0.917 | 0.475 | 0.983 | 0.975 | 0.952 |
| 8.4 k | 0.963 | 0.977 | 0.969 | 0.994 | 0.944 | 0.937 | 0.498 | 0.987 | 0.972 | 0.994 |
| 10.4 k | 0.935 | 0.933 | 0.968 | 0.990 | 0.857 | 0.929 | 0.550 | 0.986 | 0.957 | 0.987 |
| 13.4 k | 0.977 | 0.980 | 0.992 | 0.989 | 0.898 | 0.951 | 0.935 | 0.995 | 0.957 | 0.970 |
| 15.6 k | 0.962 | 0.899 | 0.984 | 0.995 | 0.952 | 0.951 | 0.980 | 0.990 | 0.936 | 0.725 |
| 20.8 k | 0.942 | 0.937 | 0.975 | 0.993 | 0.926 | 0.952 | 0.984 | 0.988 | 0.970 | 0.899 |
| 25 k | 0.946 | 0.941 | 0.982 | 0.986 | 0.9412 | 0.960 | 0.980 | 0.994 | 0.977 | 0.982 |
| Model | Patch Size | Single Patch Computation Time (Seconds) | Total Image (2240 × 2240) Computation Time (Seconds) | Model Size |
|---|---|---|---|---|
| Customized CNN Model | 224 × 224 | 0.0048 | 0.48 | 10.3 MB |
| VGG-16 Model [36] | 224 × 224 | 0.1995 | 19.95 | 528 MB |
| VGG-19 Model [36] | 224 × 224 | 0.2093 | 20.93 | 549 MB |
| ResNet-50 Model [37] | 224 × 224 | 0.0662 | 6.62 | 98 MB |
| Inception-V3 Model [38] | 229 × 229 | 0.0385 | 3.85 | 92 MB |
| Reference | Dataset | No. of Conv Layers | No. of Fully Connected Layers | No. of Epochs | No. of Images | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|---|---|---|
| Zhang et al. [26] | CCIC [47] | 4 | 2 | <20 | 1000 k | NA | 0.8696 | 0.9251 | 0.8965 |
| Sattar et al. [46] | SDNET [46] | 5 | 3 | B = 32 W = 30 P = 30 | 56 k | B = 0.9045 W = 0.8745 P = 0. 9486 | NA | NA | NA |
| Sattar et al. [56] | SDNET [46] | 5 | 3 | 30 | 18 k | 0.97 | NA | NA | 0.80 |
| Słoński et al. [54] | SDNET [46] | 4 | 3 | 100 | 5.2 k | 0.85 | NA | NA | NA |
| Fang et al. [55] | CCIC [47] +SDNET [46] + Dataset from [56] | 3 | 2 | 20 | 184 k | NA | 0.184 | 0.943 | 0.307 |
| Proposed Method | CCIC [47] +SDNET [46] | 4 | 2 | 20 | 25 k | 0.967 | 0.997 | 0.850 | 0.918 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, L.; Alnajjar, F.; Jassmi, H.A.; Gocho, M.; Khan, W.; Serhani, M.A. Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures. Sensors 2021, 21, 1688. https://doi.org/10.3390/s21051688
Ali L, Alnajjar F, Jassmi HA, Gocho M, Khan W, Serhani MA. Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures. Sensors. 2021; 21(5):1688. https://doi.org/10.3390/s21051688
Chicago/Turabian StyleAli, Luqman, Fady Alnajjar, Hamad Al Jassmi, Munkhjargal Gocho, Wasif Khan, and M. Adel Serhani. 2021. "Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures" Sensors 21, no. 5: 1688. https://doi.org/10.3390/s21051688
APA StyleAli, L., Alnajjar, F., Jassmi, H. A., Gocho, M., Khan, W., & Serhani, M. A. (2021). Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures. Sensors, 21(5), 1688. https://doi.org/10.3390/s21051688