
A Robust Dual-Microphone Generalized Sidelobe Canceller Using a Bone-Conduction Sensor for Speech Enhancement

Abstract
:1. Introduction
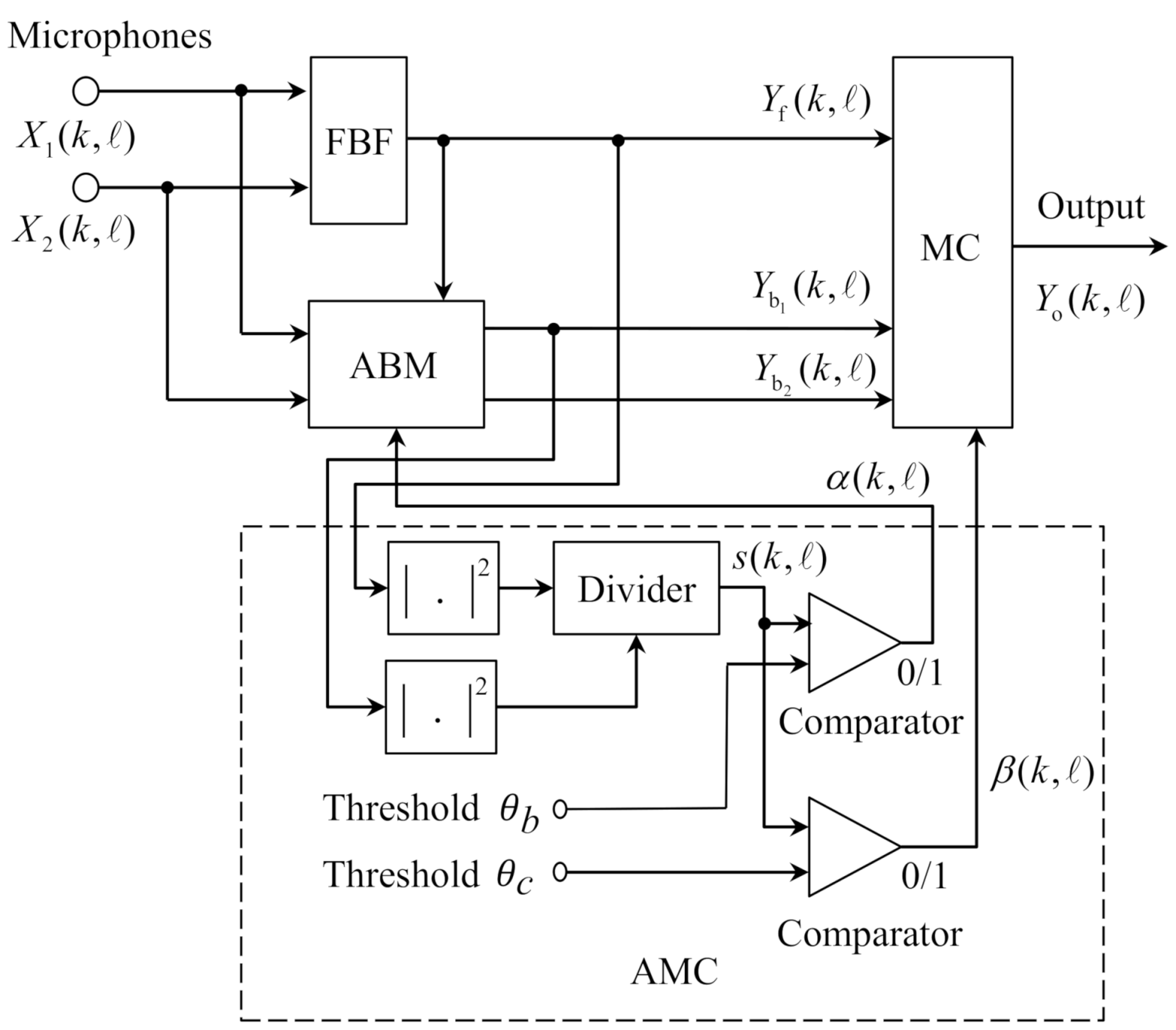
2. Previous Work
3. Proposed Robust GSC
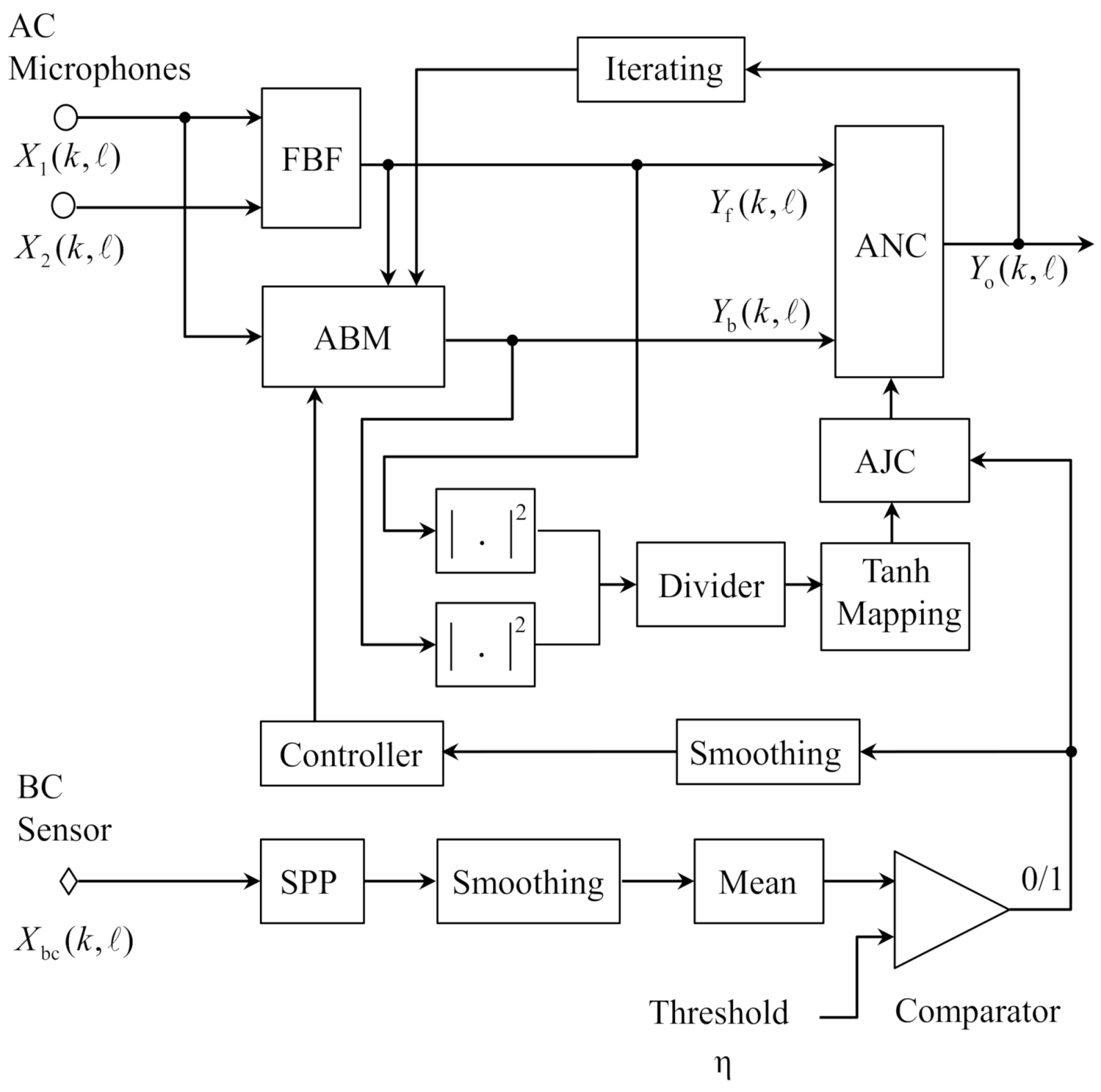
3.1. System Overview
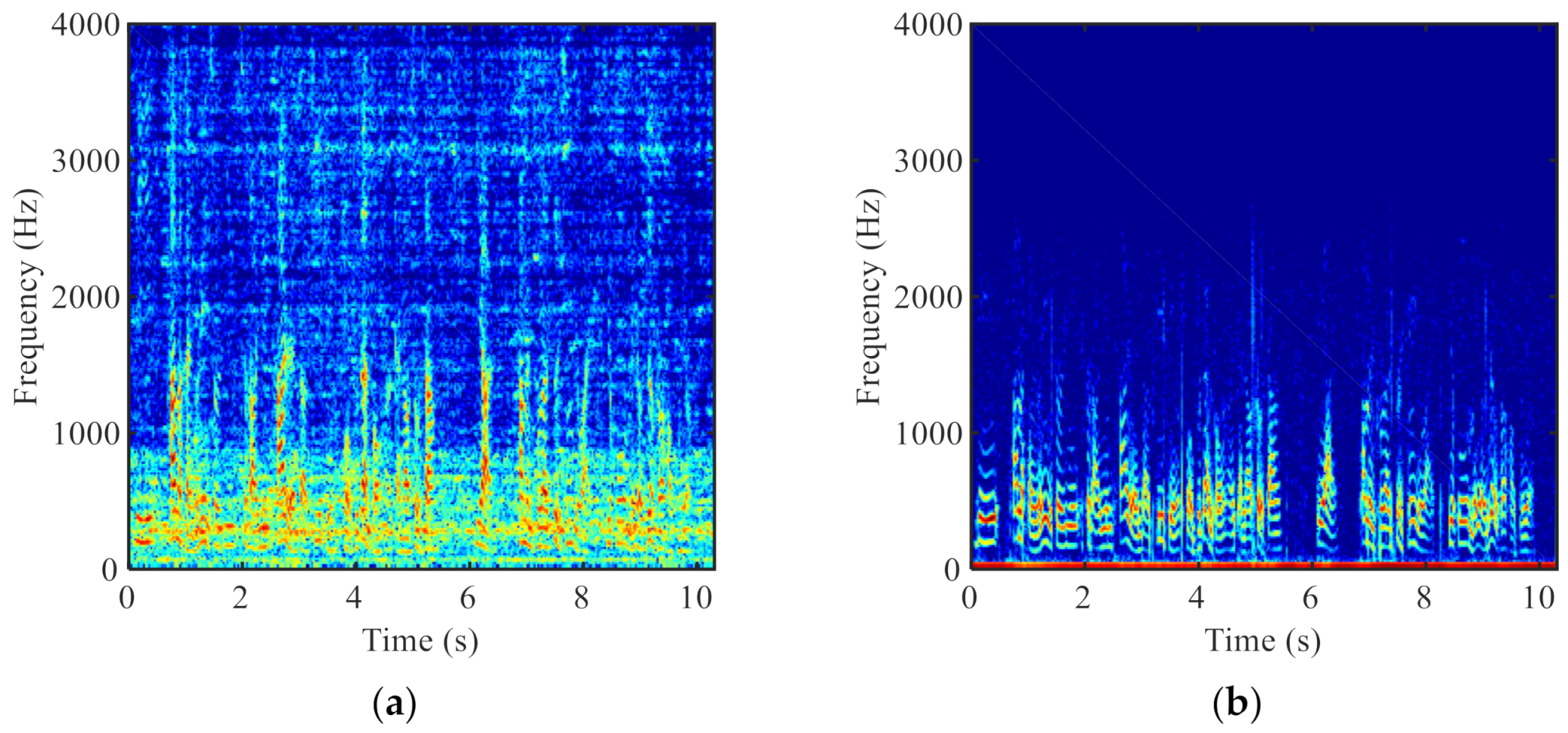
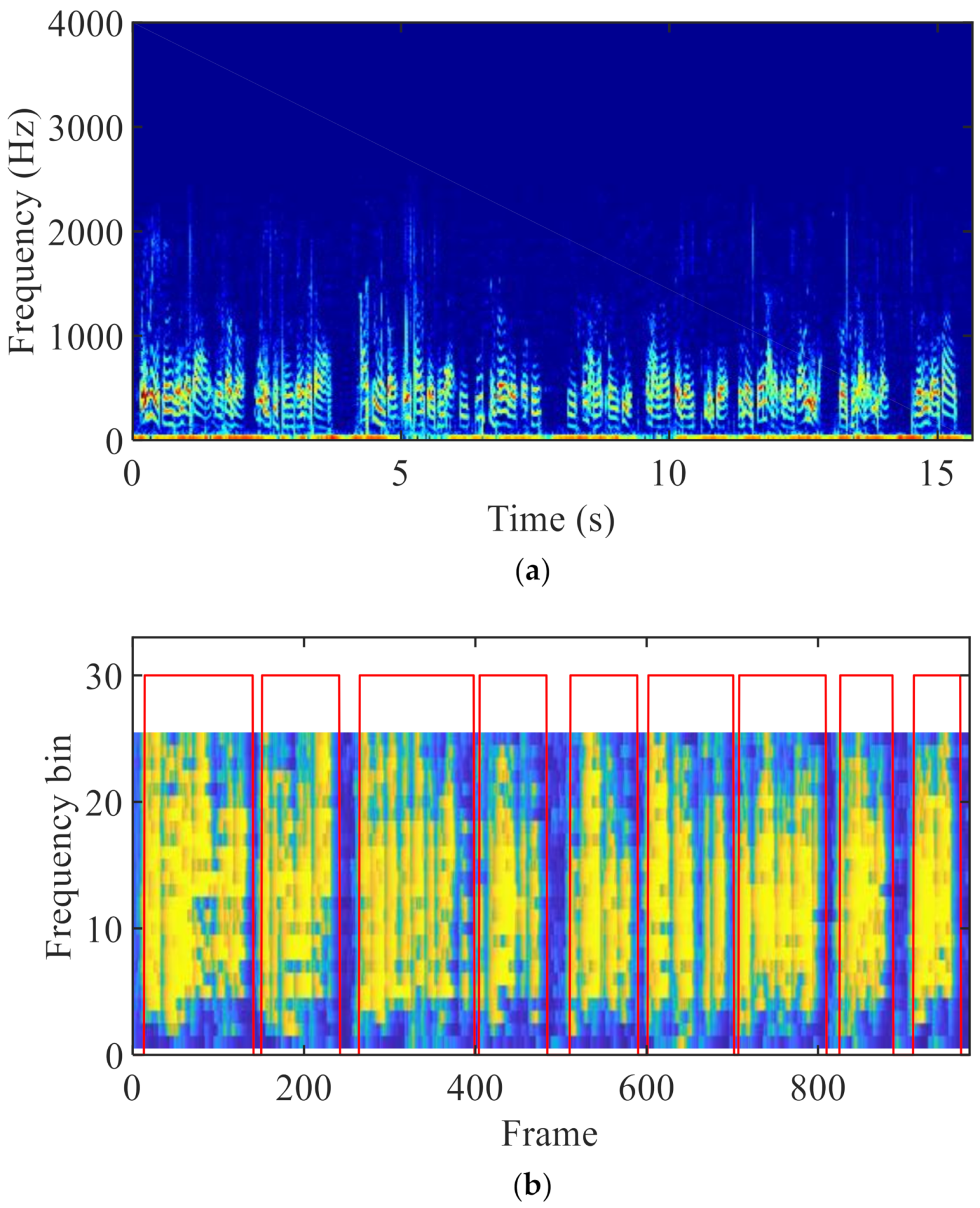
3.2. VAD Based on BC Sensor
3.3. Improved ABM
3.4. Improved ANC
3.5. Iteration
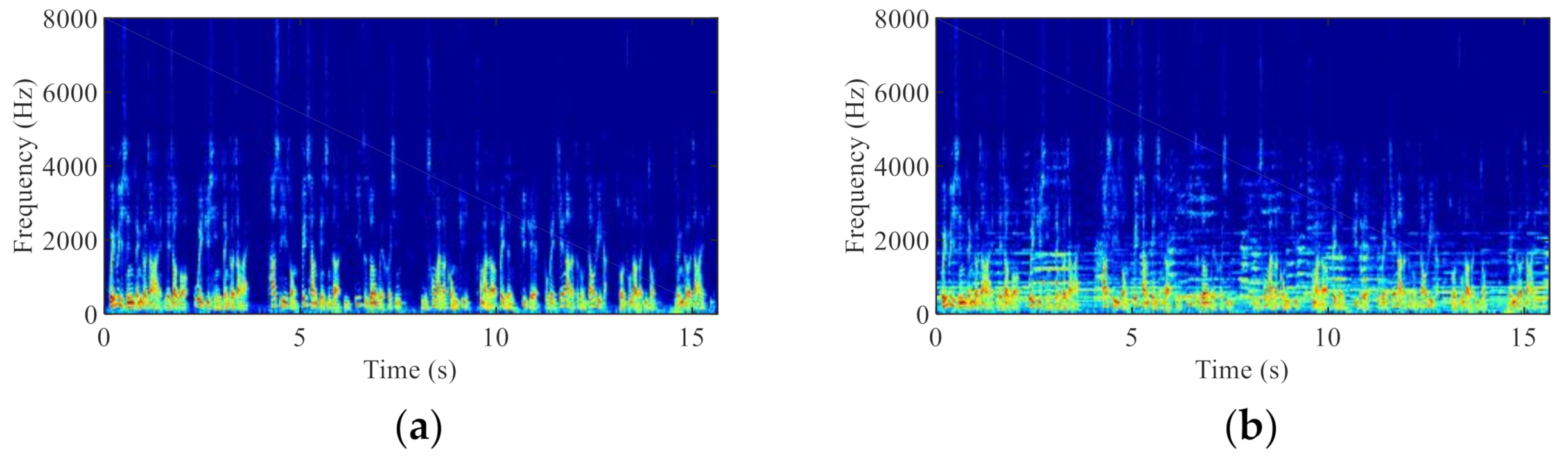
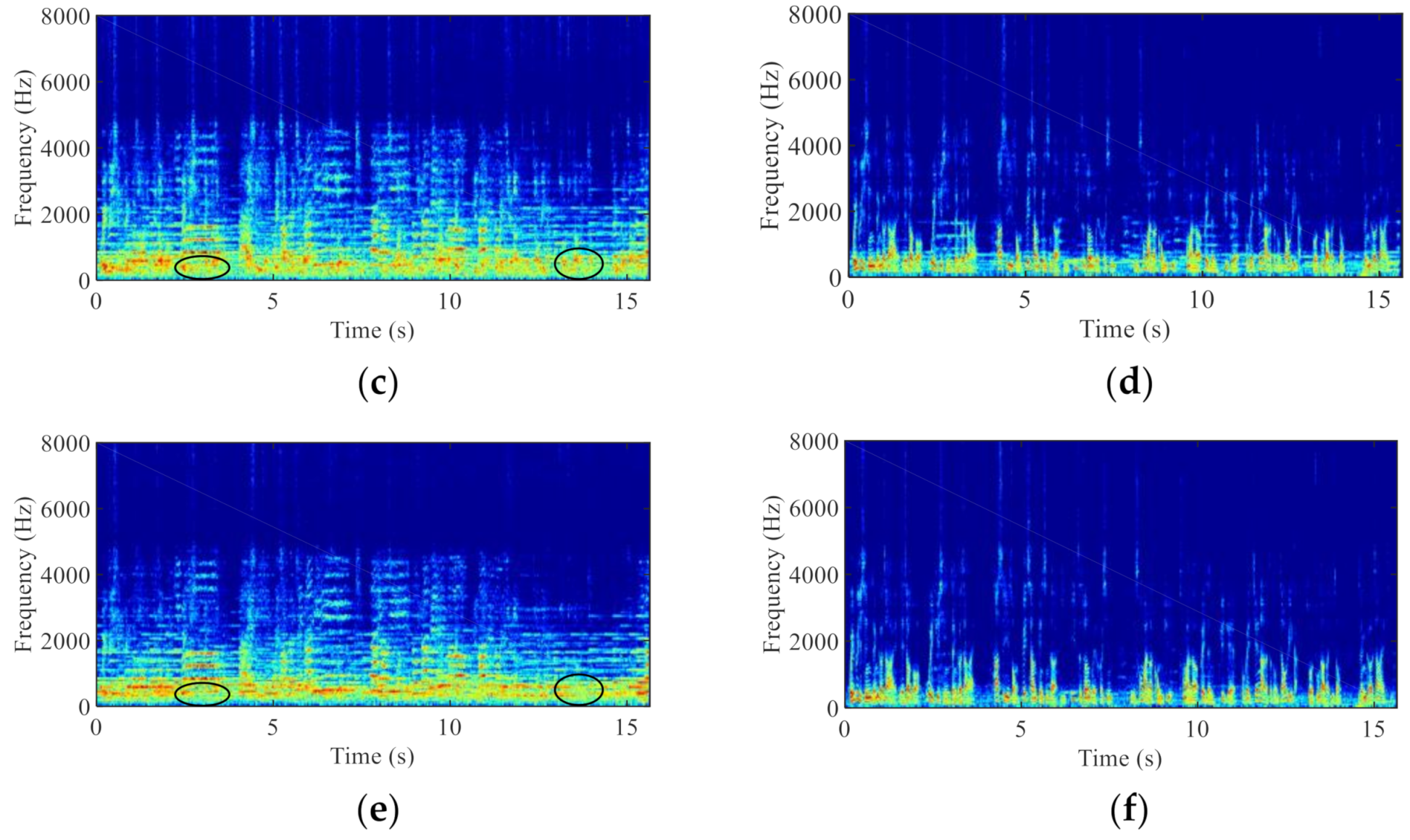
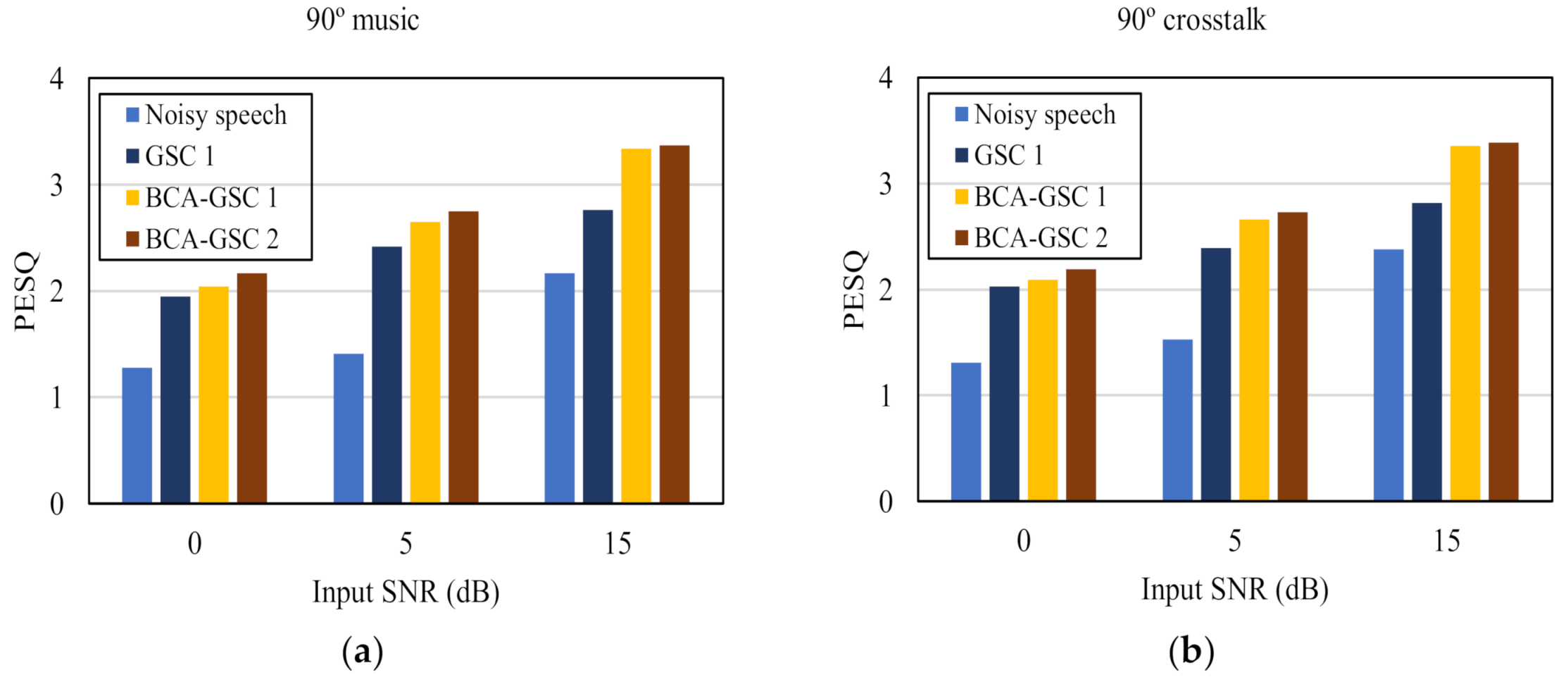
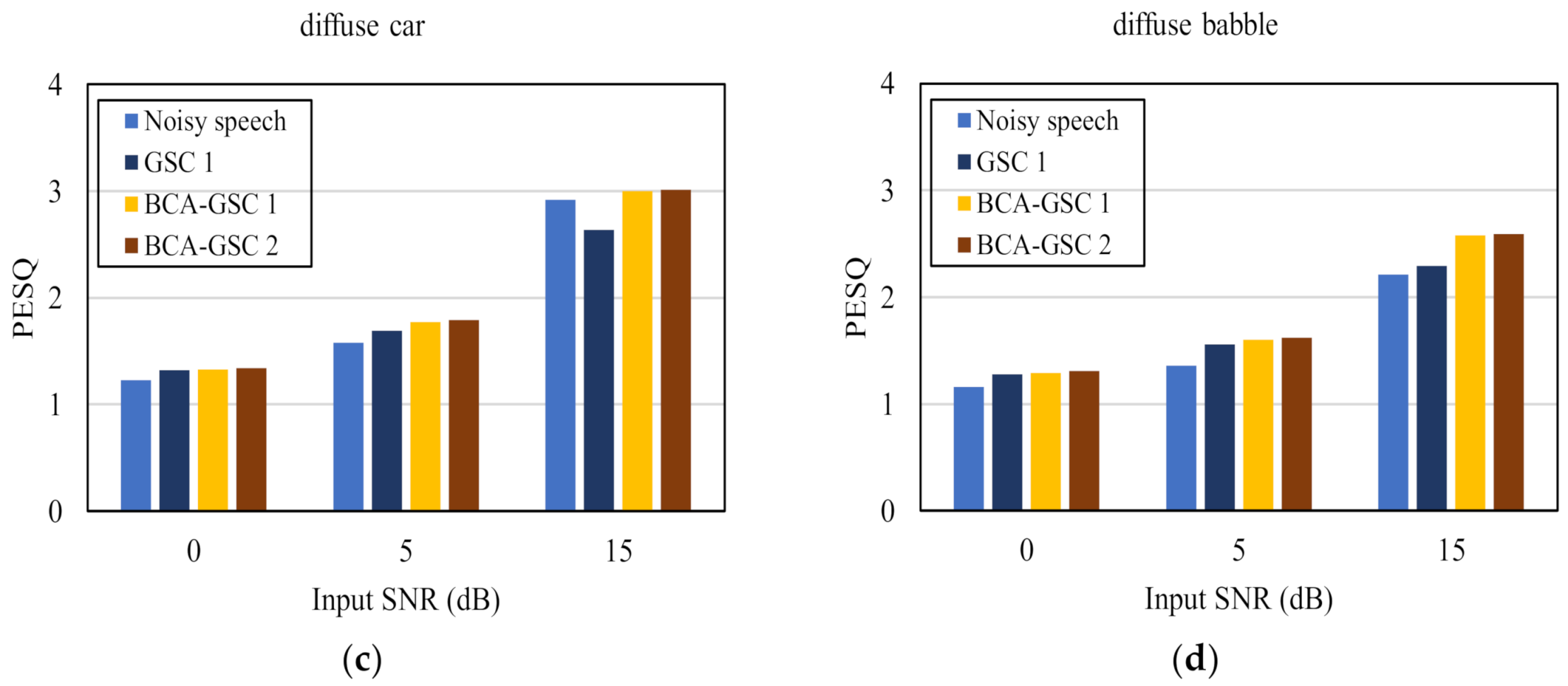
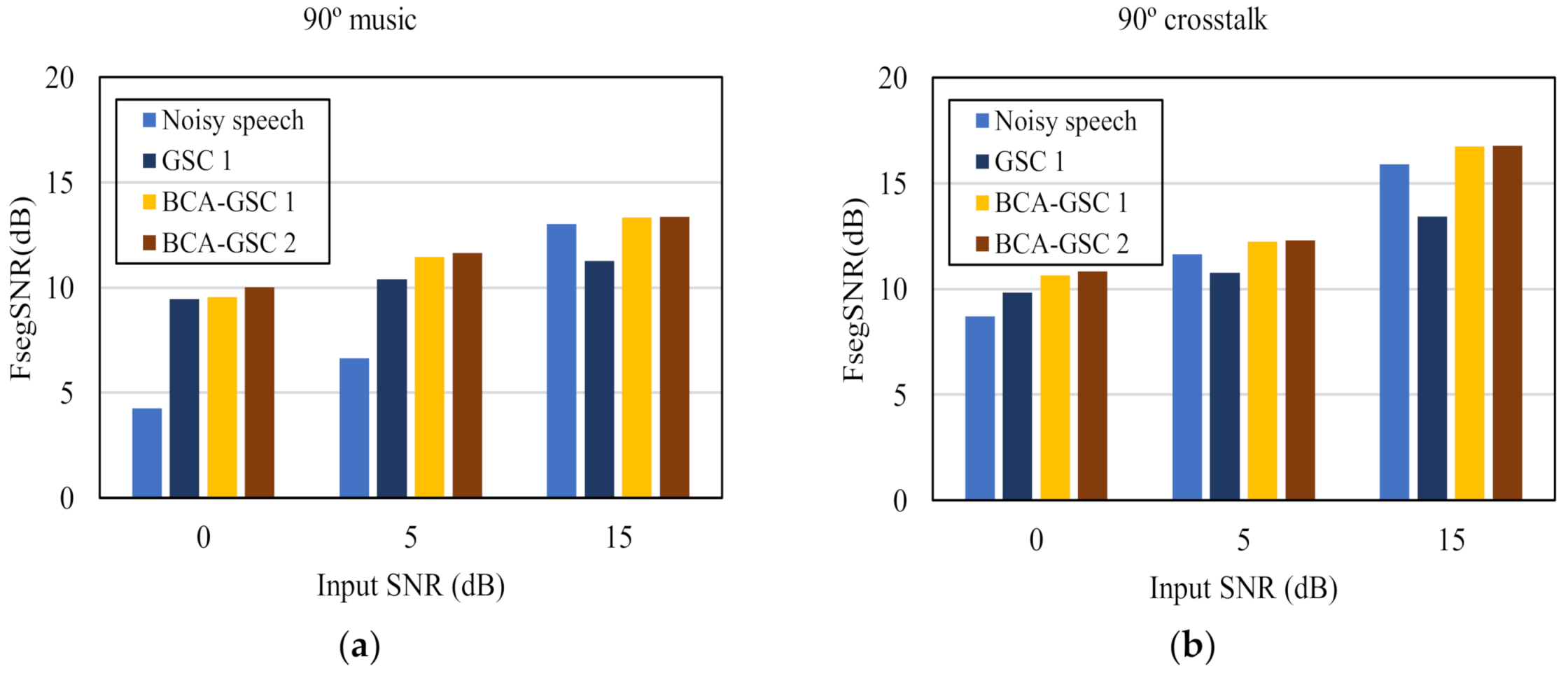
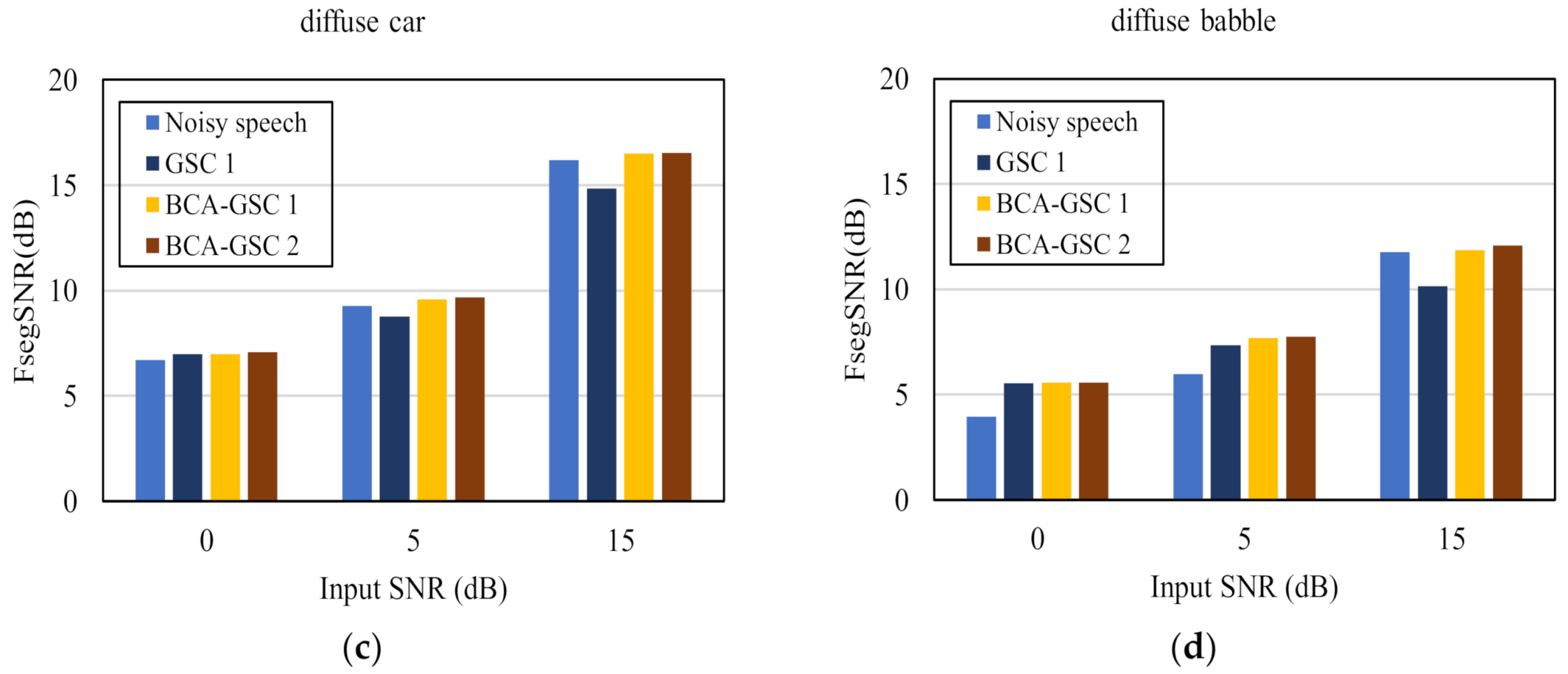
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brandstein, M.; Ward, D. Microphone Arrays; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Merino-Martinez, R.; Sijtsma, P.; Snellen, M.; Ahlefeldt, T.; Spehr, C. A review of acoustic imaging methods using phased microphone arrays. Ceas Aeronaut. J. 2019, 10, 197–230. [Google Scholar] [CrossRef] [Green Version]
- Zhou, M.; Wang, Y.; Liu, Y.; Tian, Z. An information-theoretic view of WLAN localization error bound in GPS-denied environment. IEEE Trans. Veh. Technol. 2019, 68, 4089–4093. [Google Scholar] [CrossRef]
- Zhou, M.; Li, X.; Wang, Y.; Li, S.; Ding, Y.; Nie, W. 6G multi-source information fusion based indoor positioning via Gaussian kernel density estimation. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Hoshuyama, O.; Begasse, B.; Sugiyama, A.; Hirano, A. A Realtime Robust Adaptive Microphone Array Controlled by an SNR Estimation. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98, Seattle, WA, USA, 15 May 1998; pp. 3605–3608. [Google Scholar]
- Hoshuyama, O.; Sugiyama, A.; Hirano, A. A robust adaptive beamformer for microphone arrays with a blocking matrix using constrained adaptive filters. IEEE Trans. Signal Process. 1999, 47, 2677–2684. [Google Scholar] [CrossRef]
- Herbordt, W.; Kellermann, W. Computationally efficient frequency-domain robust generalized sidelobe canceller. In Proceedings of the 7th International Workshop on Acoustic Echo and Noise Control (IWAENC), Darmstadt, Germany, 10–13 September 2001. [Google Scholar]
- Yoon, B.-J.; Tashev, I.; Malvar, H. Robust adaptive beamforming algorithm using instantaneous direction of arrival with enhanced noise suppression capability. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 15–20 April 2007; pp. 133–136. [Google Scholar]
- Khayeri, P.; Abutalebi, H.R.; Abootalebi, V. A nested superdirective generalized sidelobe canceller for speech enhancement. In Proceedings of the 2011 8th International Conference on Information, Communications & Signal Processing, Singapore, 13–16 December 2011; pp. 1–5. [Google Scholar]
- Li, B.; Zhang, L.H. An improved speech enhancement algorithm based on generalized sidelobe canceller. In Proceedings of the 2016 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 11–12 July 2016; pp. 463–468. [Google Scholar]
- Su, J.; Chen, Y.; Sheng, Z.; Huang, Z.; Liu, A.X. From M-ary query to bit query: A new strategy for efficient large-scale RFID identification. IEEE Trans. Commun. 2020, 68, 2381–2393. [Google Scholar] [CrossRef]
- Zhang, B.; Ji, D.; Fang, D.; Liang, S.; Fan, Y.; Chen, X. A novel 220-GHz GaN diode on-chip tripler with high driven power. IEEE Electron Device Lett. 2019, 40, 780–783. [Google Scholar] [CrossRef]
- Lee, C.H.; Rao, B.D.; Garudadri, H. Bone-Conduction sensor assisted noise estimation for improved speech enhancement. Interspeech 2018, 1180–1184. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.; Liu, Z.; Zhang, Z.; Sinclair, M.; Droppo, J.; Deng, L.; Acero, A.; Huang, X. Air- and bone-conductive integrated microphones for robust speech detection and enhancement. In Proceedings of the 2003 IEEE Workshop on Automatic Speech Recognition and Understanding, St Thomas, VI, USA, 30 November–4 December 2003; pp. 249–254. [Google Scholar]
- Tamiya, T.; Shimamura, T. Reconstruction filter design for bone-conducted speech. In Proceedings of the 8th International Conference on Spoken Language Processing, Jeju Island, Korea, 4–8 October 2004. [Google Scholar]
- Kechichian, P.; Srinivasan, S. Model-based speech enhancement using a bone-conducted signal. J. Acoust. Soc. Am. 2012, 131, EL262–EL267. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Cohen, I.; Mousazadeh, S. Multisensory speech enhancement in noisy environments using bone-conducted and air-conducted microphones. In Proceedings of the 2014 IEEE China Summit & International Conference on Signal and Information Processing (ChinaSIP), Xi’an, China, 9–13 July 2014; pp. 1–5. [Google Scholar]
- Huang, B.; Gong, Y.; Sun, J.; Shen, Y. A wearable bone-conducted speech enhancement system for strong background noises. In Proceedings of the 2017 18th International Conference on Electronic Packaging Technology (ICEPT), Harbin, China, 16–19 August 2017; pp. 1682–1684. [Google Scholar]
- Liu, H.P.; Yu, T.; Chiou-Shann, F. Bone-conducted speech enhancement using deep denoising autoencoder. Speech Commun. 2018, 104, 106–112. [Google Scholar] [CrossRef]
- Zhu, M.; Ji, H.; Luo, F.; Chen, W. A Robust Speech Enhancement Scheme on The Basis of Bone-conductive Microphones. In Proceedings of the 3rd International Workshop on Signal Design and Its Applications in Communications (IWSDA), Chengdu, China, 23–27 September 2007; pp. 353–355. [Google Scholar]
- Rahman, M.S.; Saha, A.; Shimamura, T. Low-frequency band noise suppression using bone conducted speech. In Proceedings of the 2011 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, Victoria, BC, Canada, 23–26 August 2011; pp. 520–525. [Google Scholar]
- Shin, H.S.; Fingscheidt, T.; Kang, H.G. A priori SNR estimation using air- and bone-conduction microphones. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2015–2025. [Google Scholar] [CrossRef]
- Cox, H.; Zeskind, R.M.; Owen, M.M. Robust adaptive beamforming. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 1365–1376. [Google Scholar] [CrossRef] [Green Version]
- Gerkmann, T.; Hendriks, R.C. Unbiased MMSE-based noise power estimation with low complexity and low tracking delay. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 1383–1393. [Google Scholar] [CrossRef]
- Chu, Y.; Chan, S.C.; Zhou, Y.; Wu, M. A new diffusion variable spatial regularized QRRLS algorithm. IEEE Signal Process. Lett. 2020, 27, 995–999. [Google Scholar] [CrossRef]
- Chu, Y.J.; Mak, C.M. A new parametric adaptive nonstationarity detector and application. IEEE Trans. Signal Process. 2017, 56, 5203–5214. [Google Scholar] [CrossRef]
- Su, J.; Xu, R.; Yu, S.; Wang, B.; Wang, J. Idle slots skipped mechanism based tag identification algorithm with enhanced collision detection. Ksii Trans. Internet Inf. Syst. 2020, 14, 2294–2309. [Google Scholar]
- Su, J.; Xu, R.; Yu, S.; Wang, B.; Wang, J. Redundant rule detection for software-defined networking. Ksii Trans. Internet Inf. Syst. 2020, 14, 2735–2751. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Tribolet, J.M.; Noll, P.; McDermott, B.; Crochiere, R. A study of complexity and quality of speech waveform coders. In Proceedings of the ICASSP ‘78. IEEE International Conference on Acoustics, Speech, and Signal Processing, Tulsa, OK, USA, 10–12 April 1978; pp. 586–590. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initialization for node k: |
|---|
| , with a small positive constant; and are null vectors. |
| Update: |
| Given , , , the input and the desired signal , we compute when the control factor is positive: |
| (i). The first update: The second update for m = (n mod L) +1: |
| where and are calculated by Givens rotation to obtain the left hand side of each equation above, zm is the m-th row of the identity matrix I. |
| (ii). (back-substitution). |
| Noise Type | SNR (dB) | Noisy | GSC 1 | BCA-GSC 1 | BCA-GSC 2 |
|---|---|---|---|---|---|
| 90o music | 0 | 72.05 | 90.58 | 91.13 | 92.11 |
| 5 | 83.34 | 92.86 | 95.43 | 95.80 | |
| 15 | 95.19 | 94.12 | 97.66 | 97.68 | |
| 90o crosstalk | 0 | 73.75 | 89.79 | 91.69 | 92.32 |
| 5 | 83.69 | 92.35 | 95.44 | 95.61 | |
| 15 | 95.16 | 93.89 | 97.56 | 97.61 | |
| diffuse car | 0 | 79.18 | 80.58 | 82.42 | 82.52 |
| 5 | 87.80 | 87.05 | 89.72 | 89.75 | |
| 15 | 96.64 | 93.43 | 96.87 | 96.93 | |
| diffuse babble | 0 | 62.19 | 71.61 | 71.81 | 72.02 |
| 5 | 75.65 | 82.21 | 83.67 | 83.96 | |
| 15 | 93.70 | 92.14 | 95.47 | 95.51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Wang, H.; Chu, Y.; Liu, H. A Robust Dual-Microphone Generalized Sidelobe Canceller Using a Bone-Conduction Sensor for Speech Enhancement. Sensors 2021, 21, 1878. https://doi.org/10.3390/s21051878
Zhou Y, Wang H, Chu Y, Liu H. A Robust Dual-Microphone Generalized Sidelobe Canceller Using a Bone-Conduction Sensor for Speech Enhancement. Sensors. 2021; 21(5):1878. https://doi.org/10.3390/s21051878
Chicago/Turabian StyleZhou, Yi, Haiping Wang, Yijing Chu, and Hongqing Liu. 2021. "A Robust Dual-Microphone Generalized Sidelobe Canceller Using a Bone-Conduction Sensor for Speech Enhancement" Sensors 21, no. 5: 1878. https://doi.org/10.3390/s21051878
APA StyleZhou, Y., Wang, H., Chu, Y., & Liu, H. (2021). A Robust Dual-Microphone Generalized Sidelobe Canceller Using a Bone-Conduction Sensor for Speech Enhancement. Sensors, 21(5), 1878. https://doi.org/10.3390/s21051878