
Supernovae Detection with Fully Convolutional One-Stage Framework



Abstract
:1. Introduction
- We made a labeled dataset, which consists of 12,447 images from the Pan-STARRS with all supernovae labeled.
- We made a labeled dataset, which consists of 716 images from the PSP with all supernovae labeled. Considering the amount of samples in the PSP dataset is too small, we also used the data augmentation technique on this dataset.
- We compared several detection algorithms on both datasets. The FCOS method with better performance is used as the baseline method. In addition, the FCOS algorithm is improved with different techniques, such as data augmentation, attention mechanism, and increasing input size. To verify the challenge mentioned in the [9], we have tested the performance of model training for the hybrid datasets with different blending ratios.
2. Related Works
2.1. Supernovae Classification
2.2. Object Detection
2.3. Attention Mechanism
3. Datasets
3.1. PS1-SN Dataset
3.2. PSP-SN Dataset
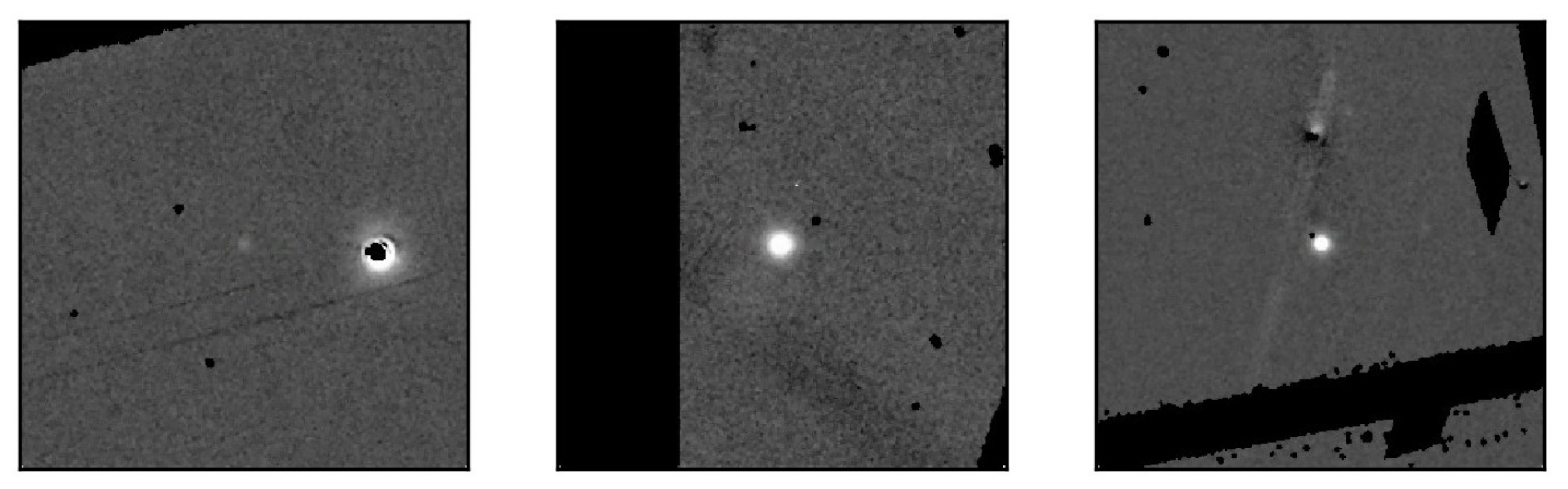
- Most of the images have defects. Typical defects in this dataset are shown in Figure 2, which are caused by low SNR rate, artifacts, equatorial mounts failure, unaligned, different brightness, bad weather, and so on. While these defects increase the variety of data, they also bring about complexity to achieve high detection accuracy.
- The number of samples provided by the PSP project is insufficient. Deep learning methods usually require a large number of samples to train models with high accuracy.
- The images from the PSP are cropped into different sizes. The image sizes of the PSP range from to .
4. Methods
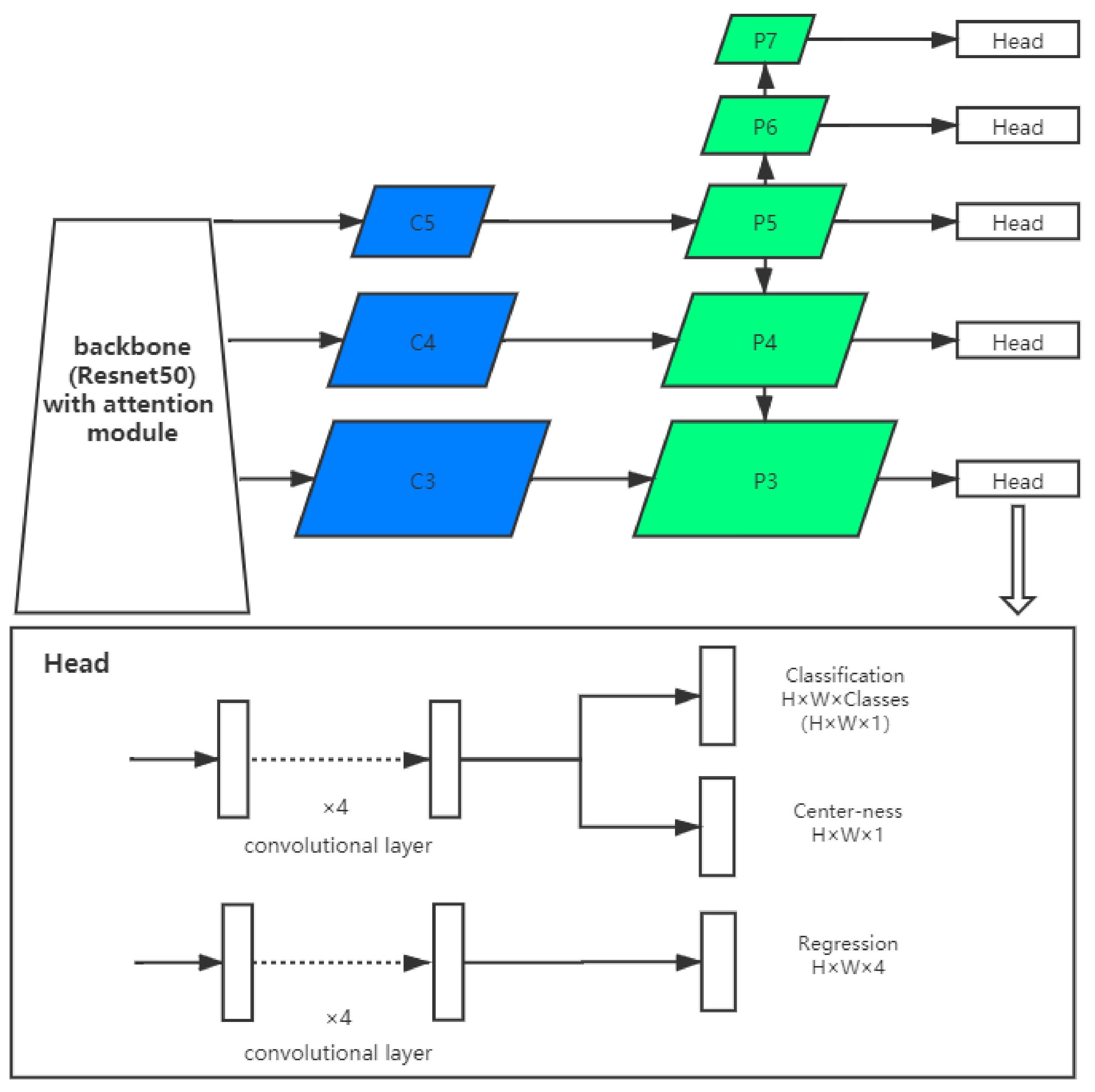
4.1. The FCOS Framework
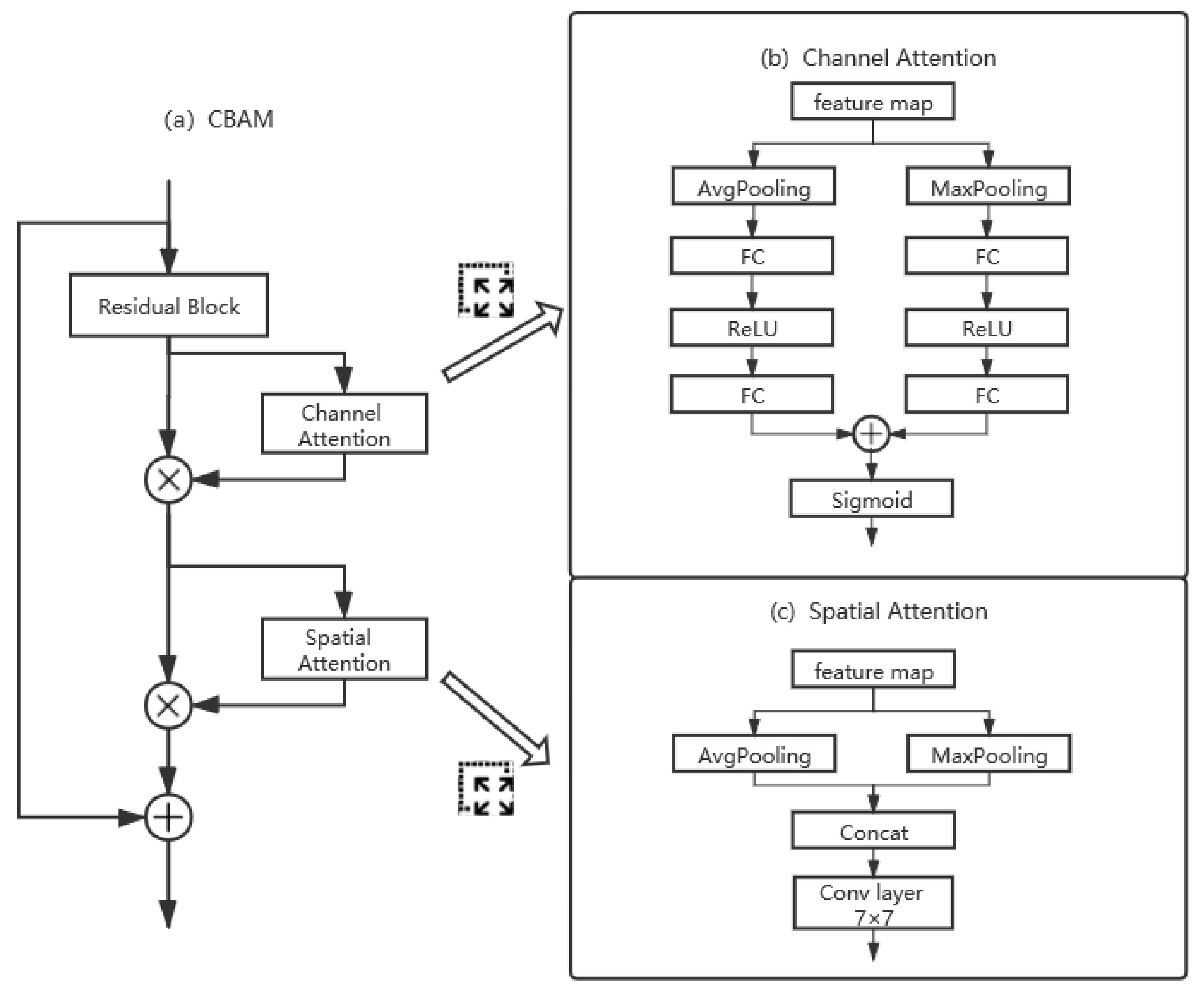
4.2. The Attention Module
4.3. Increase Input Size
5. Experiment
5.1. Model Selection
5.2. Performance Enhancement
6. Discussion
- Upsampling: As described in Section 3, supernovae detection suffers from feature loss in deep convolutional neural networks. We tried upsampling for the feature map with a ratio of 1.2 at the output of each feature pyramid stage and reduced the size shrinkage of the feature map to some extent. However, such a method did not improve much performance.
- Hybrid dataset: This idea is inspired by the article [9]. The author argues that training data for the relevant research lacks statistical representation. To figure out whether the practical representative samples can enhance the performance or not, we blend the two datasets of PSP-Aug and PS1-SN as a hybrid dataset. We test the performance of FCOS with two blending ratios of PSP-Aug to PS1-SN, which are 1:20 and 1:1. The models trained with the hybrid dataset are also fine-tuned to achieve the best performance and the results are listed in Table 5. When the blending ratio is increased, the performance with the PSP-Aug decreases severely while the performance with the PS1-SN does not change too much. This result shows that the detection architecture tends to have good performance on the data with low complexity, while causes performance degradation on the complex data.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abbott, T.; Abdalla, F.B.; Aleksić, J.; Allam, S.; Amara, A.; Bacon, D.; Balbinot, E.; Banerji, M.; Bechtol, K.; Benoit-Lévy, A.; et al. The Dark Energy Survey: More than dark energy—An overview. Mon. Not. R. Astron. Soc. 2016, 460, 1270–1299. [Google Scholar]
- Kaiser, N.; Aussel, H.; Burke, B.E.; Boesgaard, H.; Chambers, K.; Chun, M.R.; Heasley, J.N.; Hodapp, K.W.; Hunt, B.; Jedicke, R.; et al. Pan-STARRS: A large synoptic survey telescope array. In Proceedings of the Survey and Other Telescope Technologies and Discoveries, International Society for Optics and Photonics, Shanghai, China, 14–17 October 2002; Volume 4836, pp. 154–164. [Google Scholar]
- Tyson, J.A. Large synoptic survey telescope: Overview. In Proceedings of the Survey and Other Telescope Technologies and Discoveries, International Society for Optics and Photonics, Shanghai, China, 14–17 October 2002; Volume 4836, pp. 10–20. [Google Scholar]
- Du Buisson, L.; Sivanandam, N.; Bassett, B.A.; Smith, M.R. Machine learning classification of SDSS transient survey images. Mon. Not. R. Astron. Soc. 2015, 454, 2026–2038. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cabrera-Vives, G.; Reyes, I.; Förster, F.; Estévez, P.A.; Maureira, J.C. Deep-HiTS: Rotation invariant convolutional neural network for transient detection. arXiv 2017, arXiv:1701.00458. [Google Scholar] [CrossRef] [Green Version]
- Muthukrishna, D.; Narayan, G.; Mandel, K.S.; Biswas, R.; Hložek, R. RAPID: Early classification of explosive transients using deep learning. Publ. Astron. Soc. Pac. 2019, 131, 118002. [Google Scholar] [CrossRef] [Green Version]
- Burke, C.J.; Aleo, P.D.; Chen, Y.C.; Liu, X.; Peterson, J.R.; Sembroski, G.H.; Lin, J.Y.Y. Deblending and classifying astronomical sources with Mask R-CNN deep learning. Mon. Not. R. Astron. Soc. 2019, 490, 3952–3965. [Google Scholar] [CrossRef] [Green Version]
- Ishida, E.E.O. Machine Learning and the future of Supernova Cosmology. Nat. Astron. 2019, 3, 680–682. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Cabrera-Vives, G.; Reyes, I.; Förster, F.; Estévez, P.A.; Maureira, J.C. Supernovae detection by using convolutional neural networks. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 251–258. [Google Scholar]
- Kimura, A.; Takahashi, I.; Tanaka, M.; Yasuda, N.; Ueda, N.; Yoshida, N. Single-epoch supernova classification with deep convolutional neural networks. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems Workshops (ICDCSW), Atlanta, GA, USA, 5–8 June 2017; pp. 354–359. [Google Scholar]
- Reyes, E.; Estévez, P.A.; Reyes, I.; Cabrera-Vives, G.; Huijse, P.; Carrasco, R.; Forster, F. Enhanced rotational invariant convolutional neural network for supernovae detection. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Charnock, T.; Moss, A. Deep recurrent neural networks for supernovae classification. Astrophys. J. Lett. 2017, 837, L28. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Moller, A.; De Boissiere, T. SuperNNova: An open-source framework for Bayesian, Neural Network based supernova classification. Mon. Notices Royal Astron. Soc. 2019, 491, 4277–4293. [Google Scholar] [CrossRef]
- Saunders, C.; Stitson, M.O.; Weston, J.; Holloway, R.; Bottou, L.; Scholkopf, B.; Smola, A. Support Vector Machine. Comput. Sci. 2002, 1, 1–28. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar]
- Wang, H.; Fan, Y.; Wang, Z.; Jiao, L.; Schiele, B. Parameter-free spatial attention network for person re-identification. arXiv 2018, arXiv:1811.12150. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, S.; Liu, X.; Huang, Y.; Zhou, C.; Miao, H. Video Synopsis Based on Attention Mechanism and Local Transparent Processing. IEEE Access 2020, 8, 92603–92614. [Google Scholar] [CrossRef]
- Lee, Y.; Park, J. CenterMask: Real-Time Anchor-Free Instance Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 13903–13912. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Framework | Dataset | Precision | Recall | F1 |
|---|---|---|---|---|
| DH [12] | PS1-SN | 0.981 | 0.984 | 0.982 |
| CAP [14] | PS1-SN | 0.996 | 0.980 | 0.987 |
| YOLOv3 [27] | PS1-SN | 0.994 | 0.988 | 0.991 |
| FCOS [10] | PS1-SN | 0.996 | 0.986 | 0.994 |
| YOLOv3 | PSP-Ori | 0.618 | 0.764 | 0.683 |
| FCOS | PSP-Ori | 0.879 | 0.579 | 0.713 |
| Parameter | YOLOv3 | FCOS |
|---|---|---|
| learning rate | ||
| momentum | - | |
| decay | ||
| batch size | 16 | 16 |
| epoch | 30 | 16 |
| image size | 416 | 416 |
| Augmented | Max Size | Channel Attention | Spatial Attention | CBAM | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| - | 416 | - | - | - | 0.866 | 0.536 | 0.662 |
| ✓ | 416 | - | - | - | 0.923 | 0.638 | 0.754 |
| ✓ | 416 | ✓ | - | - | 0.912 | 0.623 | 0.740 |
| ✓ | 416 | - | ✓ | - | 0.904 | 0.609 | 0.728 |
| ✓ | 416 | - | - | ✓ | 0.879 | 0.579 | 0.698 |
| ✓ | 800 | - | - | - | 0.926 | 0.645 | 0.760 |
| ✓ | 960 | - | - | - | 0.957 | 0.642 | 0.768 |
| ✓ | 960 | ✓ | - | - | 0.962 | 0.643 | 0.771 |
| ✓ | 960 | - | ✓ | - | 0.960 | 0.645 | 0.772 |
| ✓ | 960 | - | - | ✓ | 0.954 | 0.608 | 0.743 |
| Augmented | Input Size | Channel Attention | Spatial Attention | CBAM | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| - | 416 | - | - | - | 0.618 | 0.764 | 0.683 |
| ✓ | 416 | - | - | - | 0.554 | 0.800 | 0.654 |
| ✓ | 416 | ✓ | - | - | 0.585 | 0.820 | 0.683 |
| ✓ | 416 | - | ✓ | - | 0.569 | 0.774 | 0.656 |
| ✓ | 416 | - | - | ✓ | 0.480 | 0.636 | 0.547 |
| ✓ | 800 | - | - | - | 0.780 | 0.759 | 0.769 |
| ✓ | 960 | - | - | - | 0.742 | 0.794 | 0.767 |
| Test Set | Training Set | Precision | Recall | Cls F-Score | |
|---|---|---|---|---|---|
| PS1-SN | PSP-Aug | ||||
| PS1-SN | 100% | - | 0.996 | 0.995 | 0.994 |
| PS1-SN | 100% | 5% | 0.997 | 0.984 | 0.994 |
| PS1-SN | 100% | 100% | 0.997 | 0.981 | 0.995 |
| PSP-Aug | - | 100% | 0.866 | 0.536 | 0.837 |
| PSP-Aug | 10% | 100% | 0.840 | 0.511 | 0.828 |
| PSP-Aug | 100% | 5% | 0.704 | 0.389 | 0.748 |
| PSP-Aug | 100% | 100% | 0.800 | 0.472 | 0.786 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, K.; Jia, J.; Gao, X.; Sun, T.; Zhou, Z. Supernovae Detection with Fully Convolutional One-Stage Framework. Sensors 2021, 21, 1926. https://doi.org/10.3390/s21051926
Yin K, Jia J, Gao X, Sun T, Zhou Z. Supernovae Detection with Fully Convolutional One-Stage Framework. Sensors. 2021; 21(5):1926. https://doi.org/10.3390/s21051926
Chicago/Turabian StyleYin, Kai, Juncheng Jia, Xing Gao, Tianrui Sun, and Zhengyin Zhou. 2021. "Supernovae Detection with Fully Convolutional One-Stage Framework" Sensors 21, no. 5: 1926. https://doi.org/10.3390/s21051926
APA StyleYin, K., Jia, J., Gao, X., Sun, T., & Zhou, Z. (2021). Supernovae Detection with Fully Convolutional One-Stage Framework. Sensors, 21(5), 1926. https://doi.org/10.3390/s21051926