
Hybrid Deep Learning Models with Sparse Enhancement Technique for Detection of Newly Grown Tree Leaves


Abstract
:1. Introduction
2. Materials and Methods
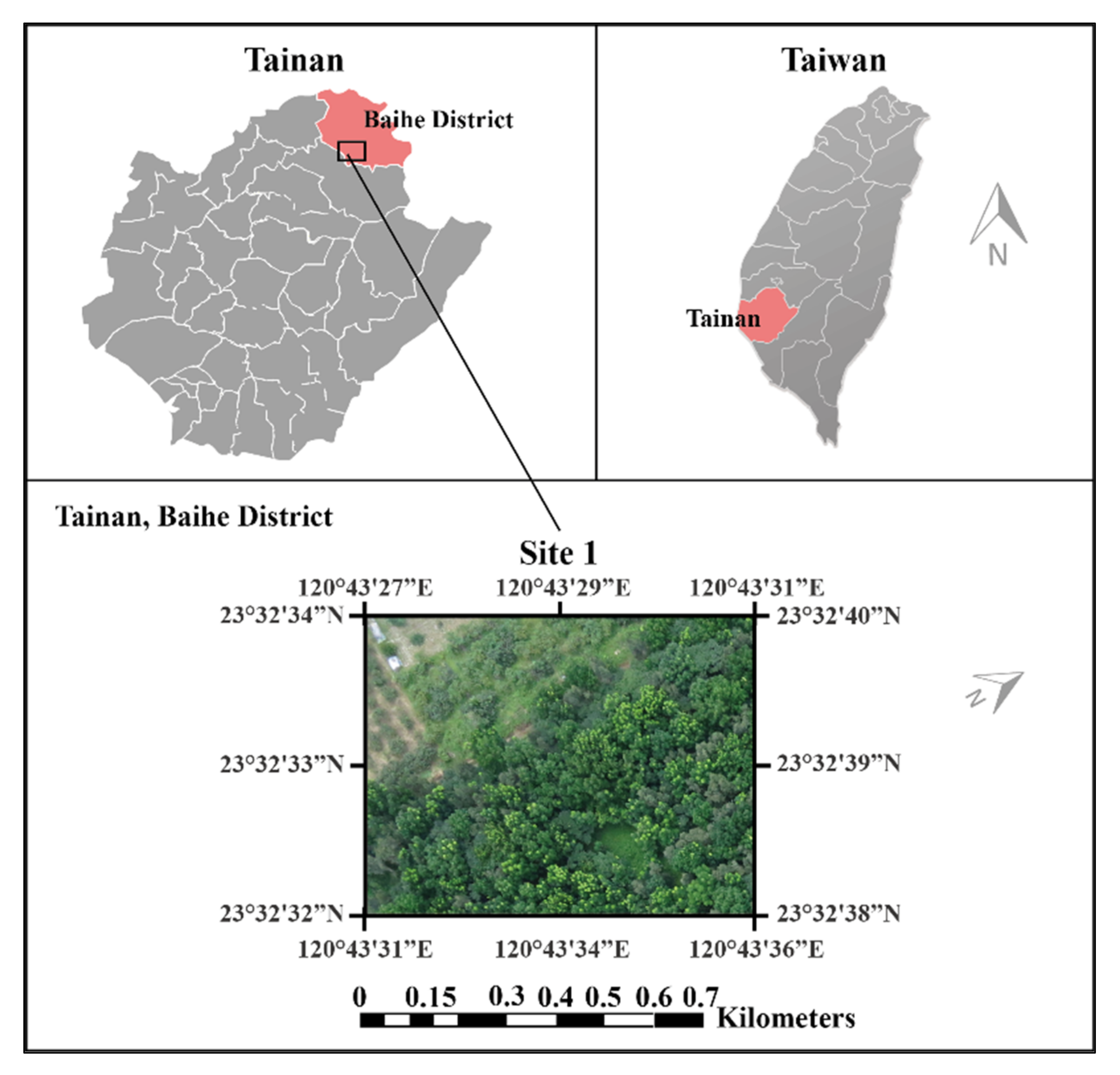
2.1. Description of the Study Site
Ground Truth
2.2. Deep Learning Models
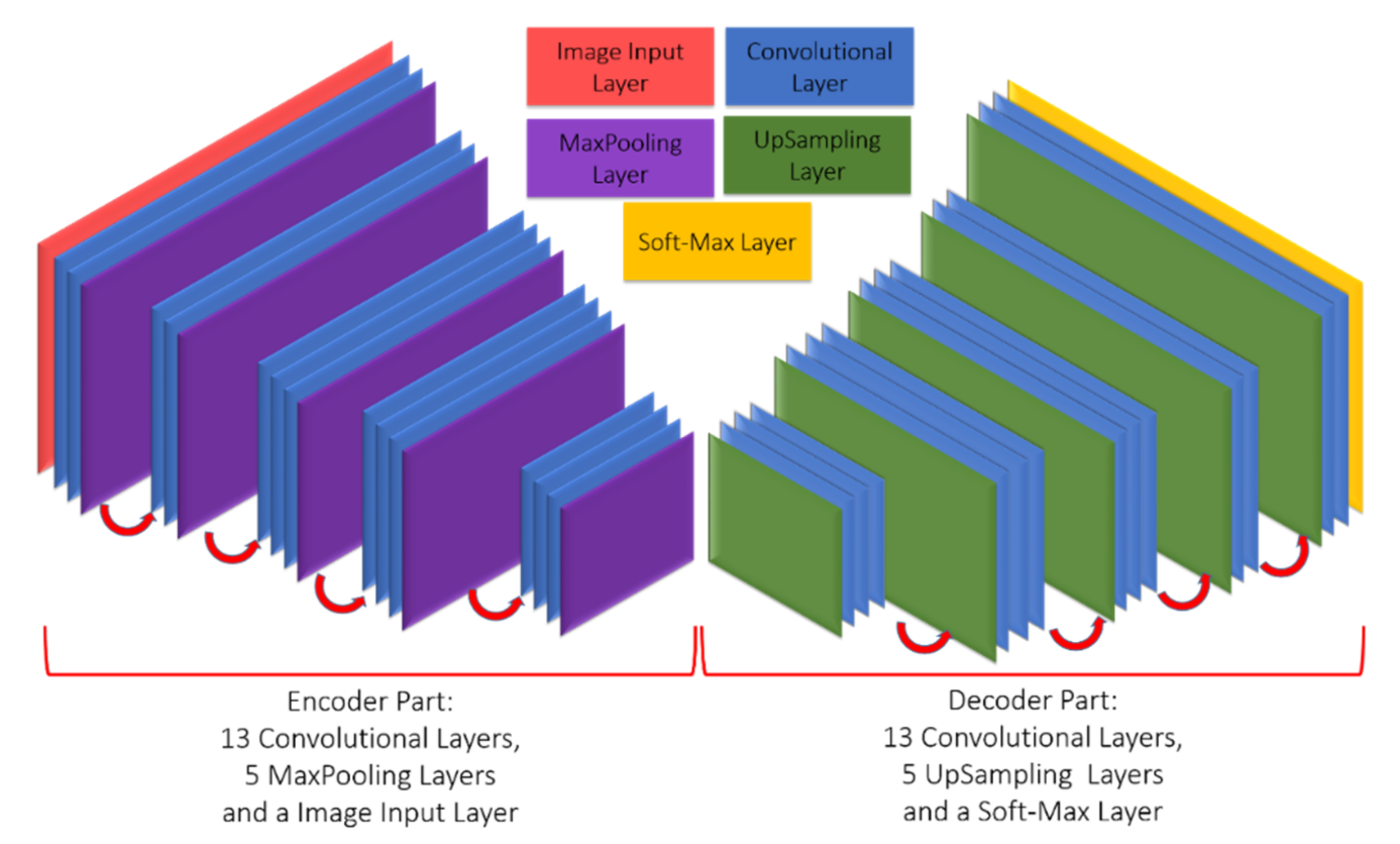
2.2.1. SegNet
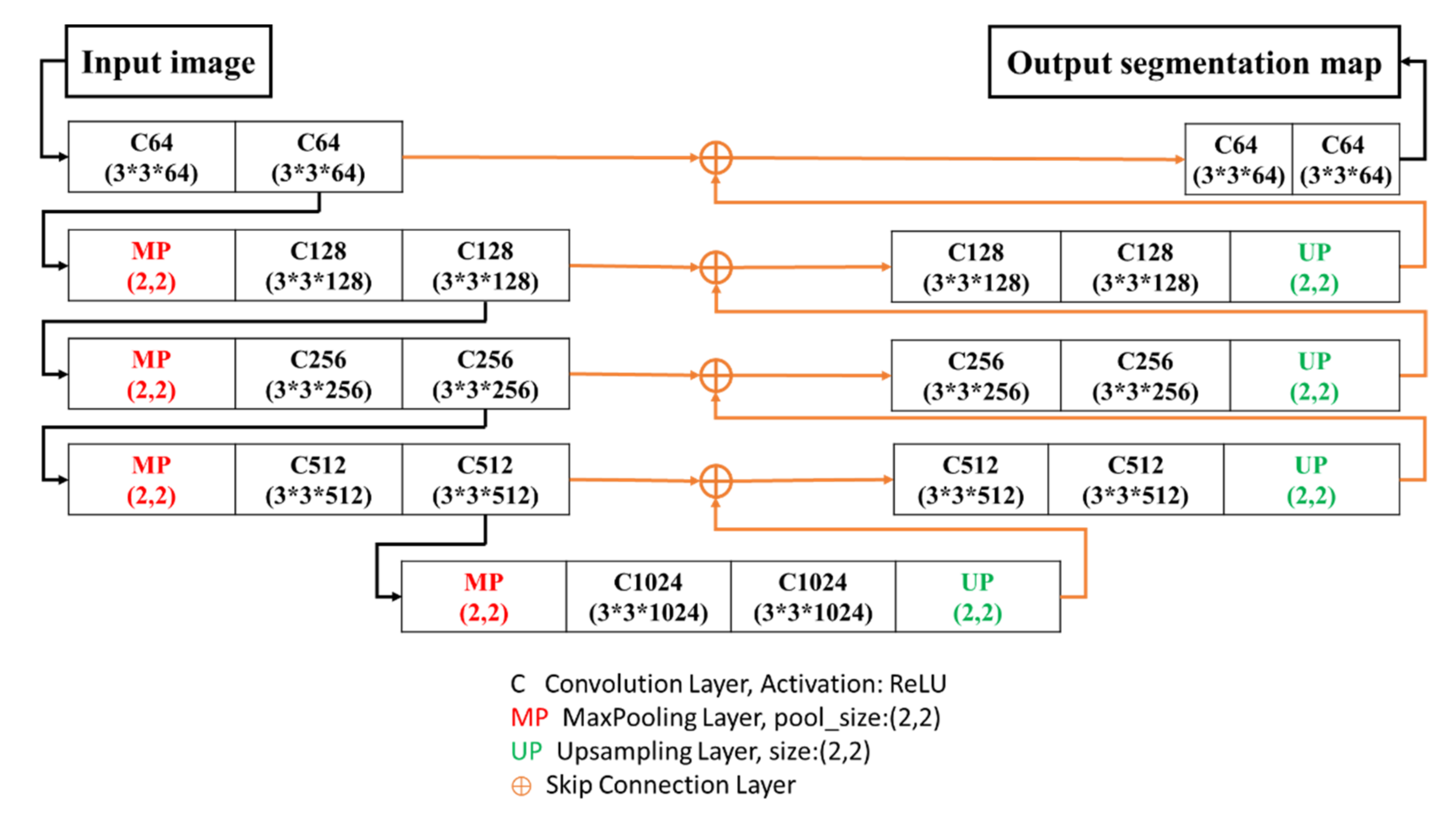
2.2.2. U-Net
2.3. Loss Function of the Convolutional Neural Network
2.3.1. Binary Cross-Entropy (Binary CE or CE)
2.3.2. Weighted Cross-Entropy (WCE)
2.3.3. Balanced Cross-Entropy (BCE)
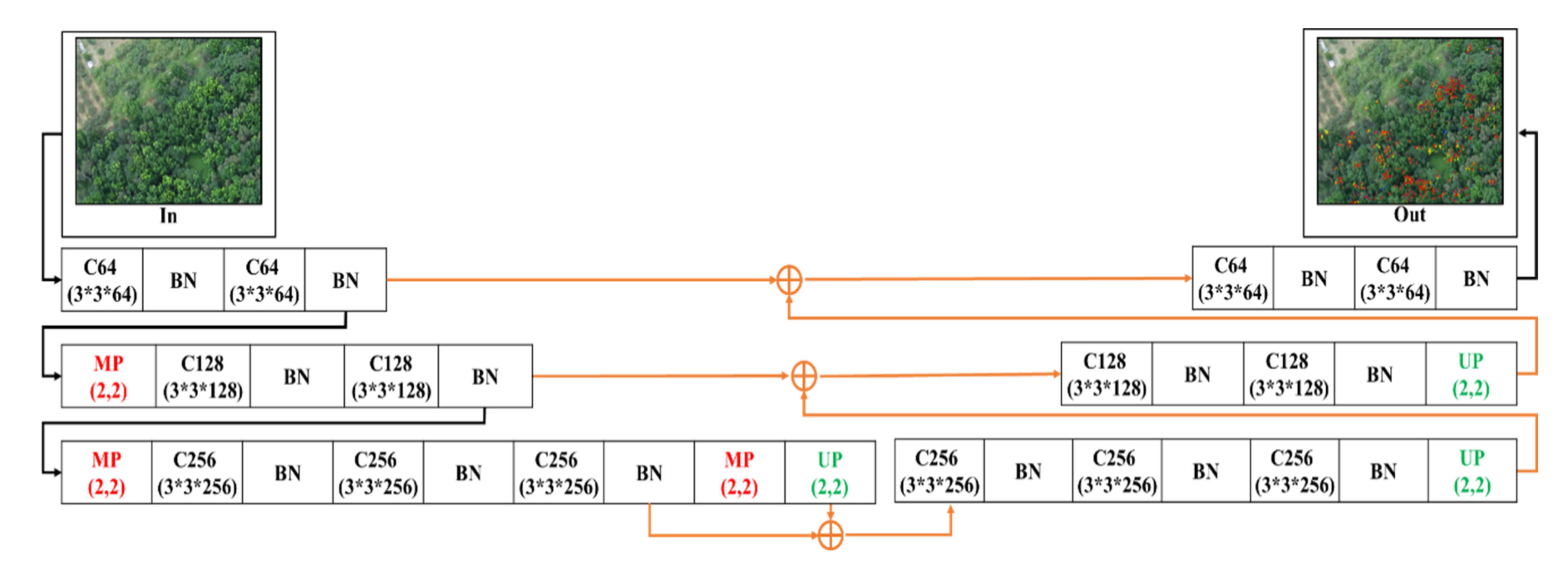
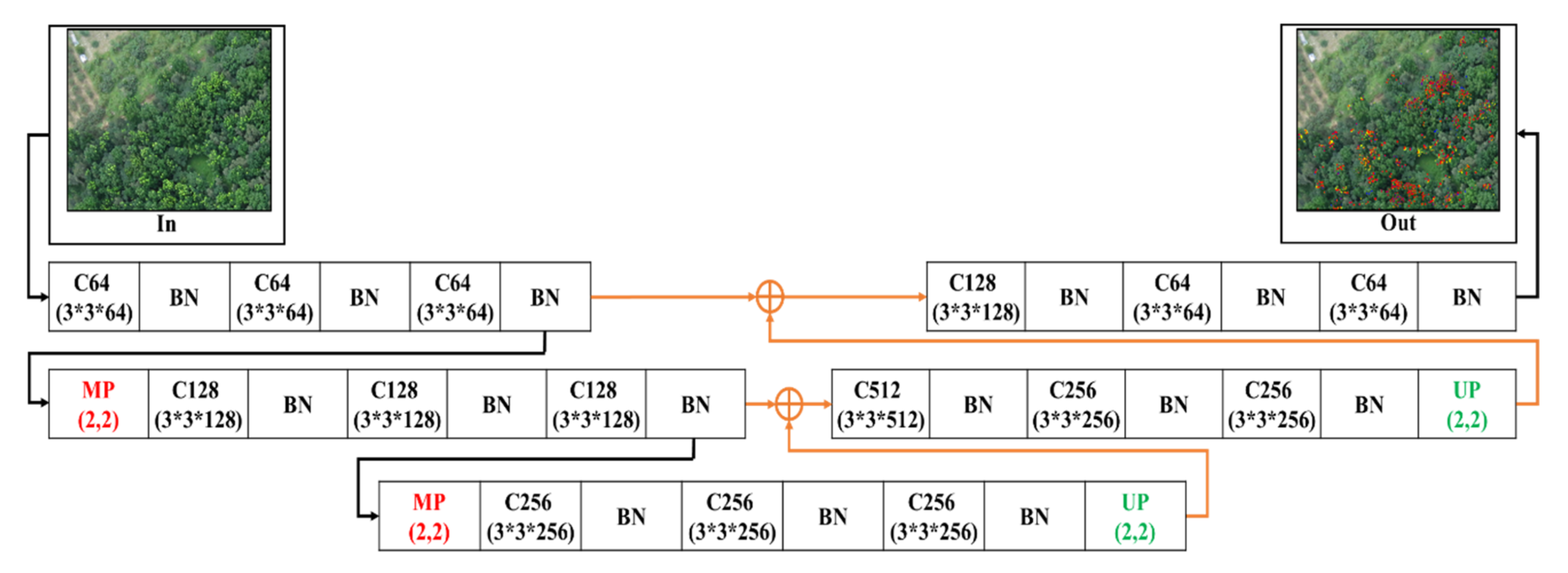
2.4. Hybrid Convolutional Neural Networks
2.4.1. 3-Layer SegNet (3L-SN)
2.4.2. 3-Layer U-SegNet (3L-USN)
2.4.3. 2-Layer U-SegNet (2L-U-SN)
2.4.4. 2-Layer Conv-U-SegNet (2L-Conv-USN)
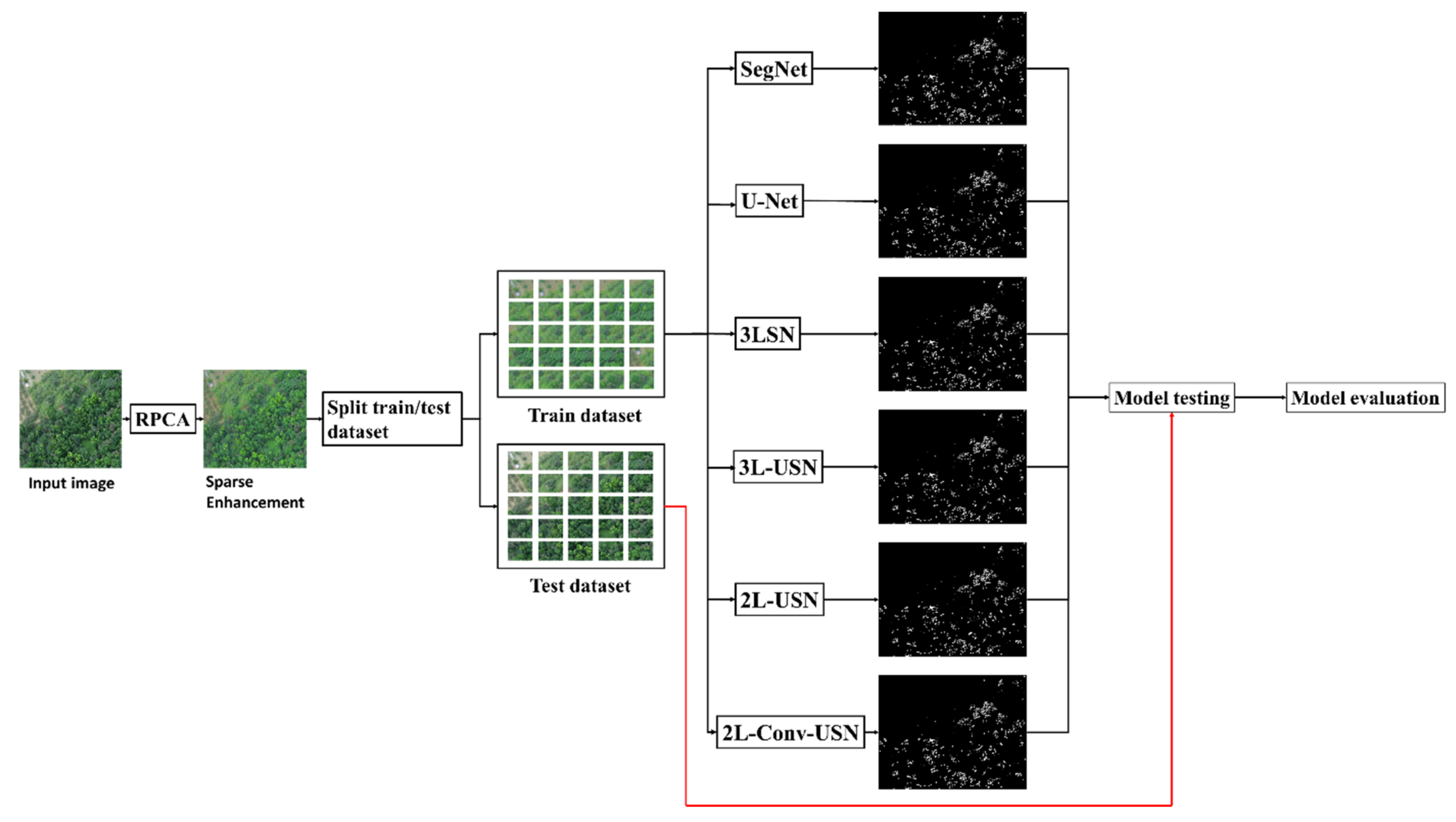
2.5. Robust Principal Component Analysis (RPCA) and Sparse Enhancement (SE)
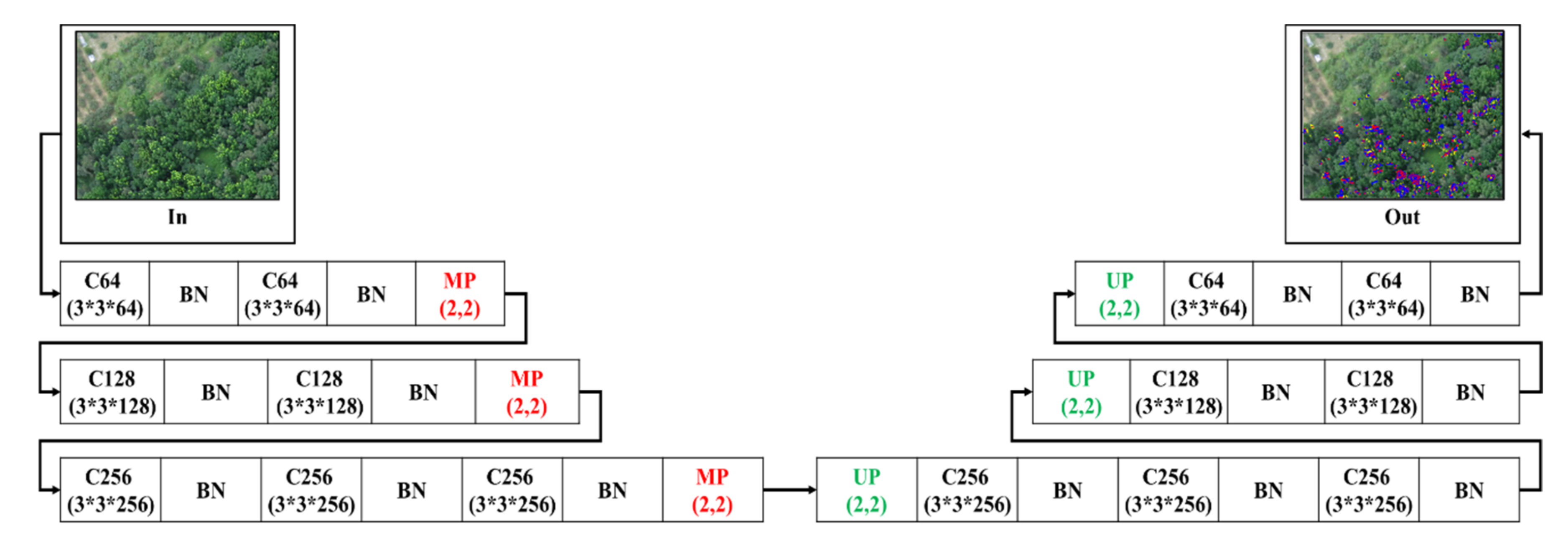
2.6. Hybrid Convolutional Neural Network with Sparse Enhancement
2.6.1. Training Data Set
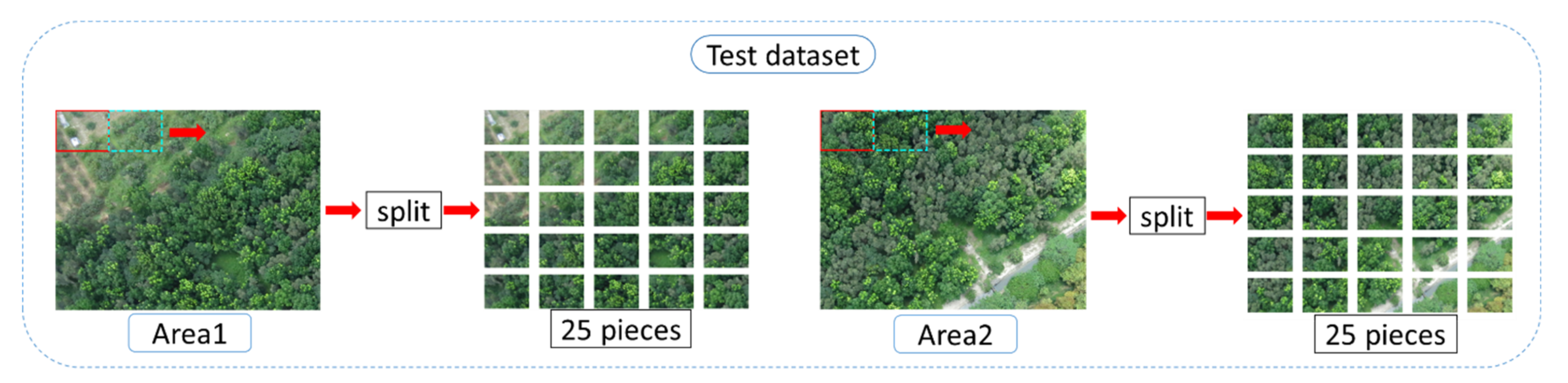
2.6.2. Testing Data Set
2.7. Evaluation of Detection Results
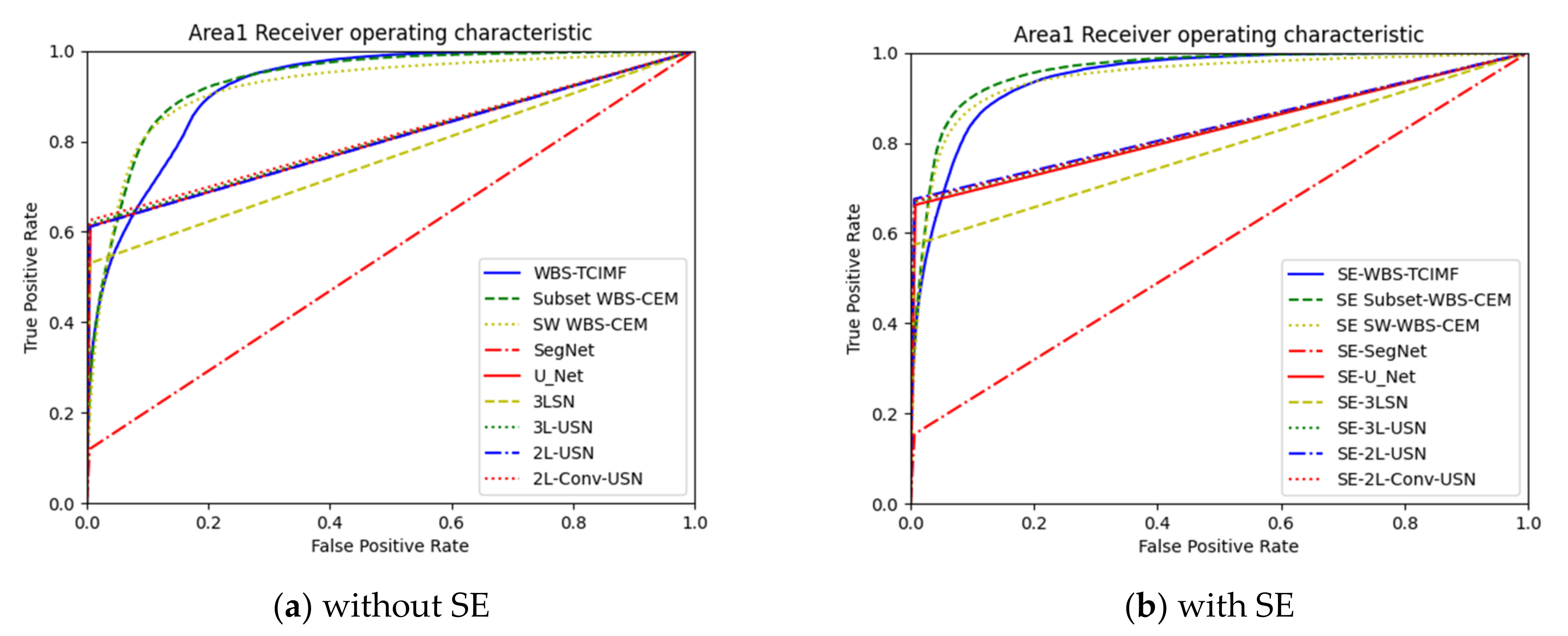
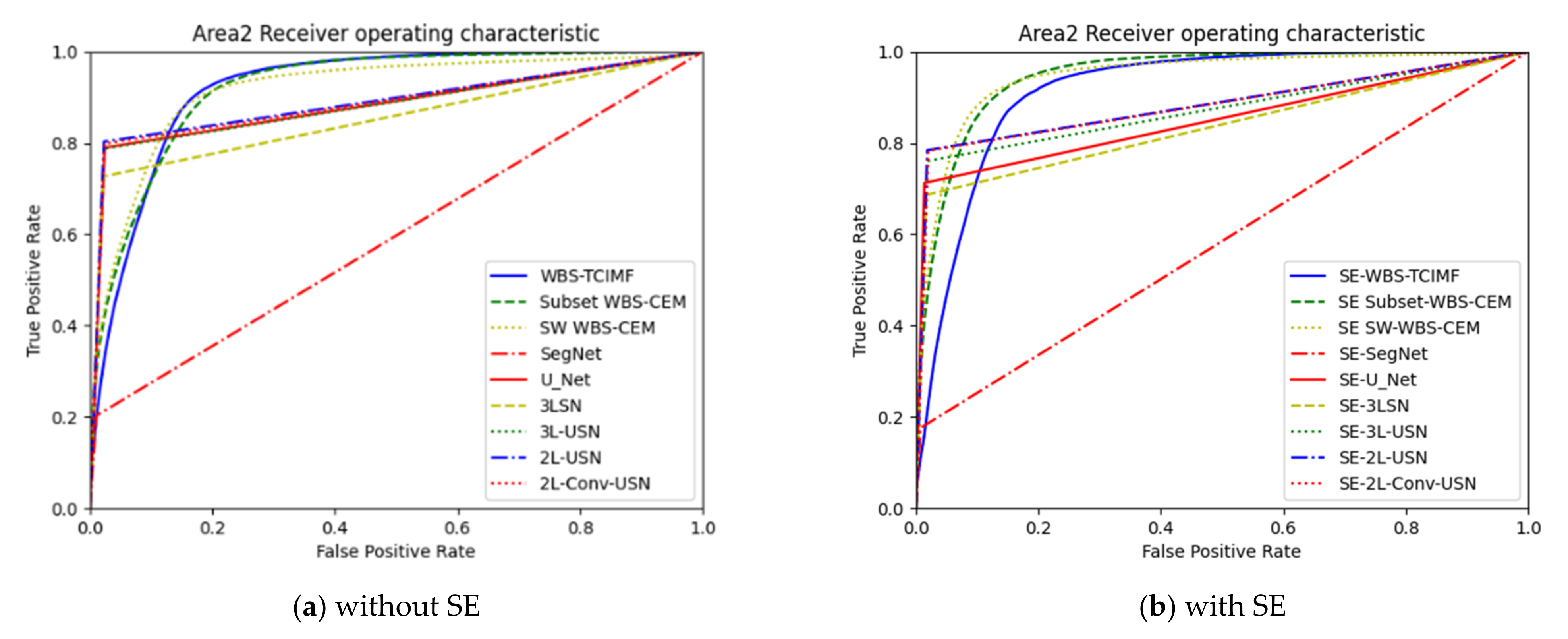
2.7.1. ROC Curve
2.7.2. Cohen’s Kappa
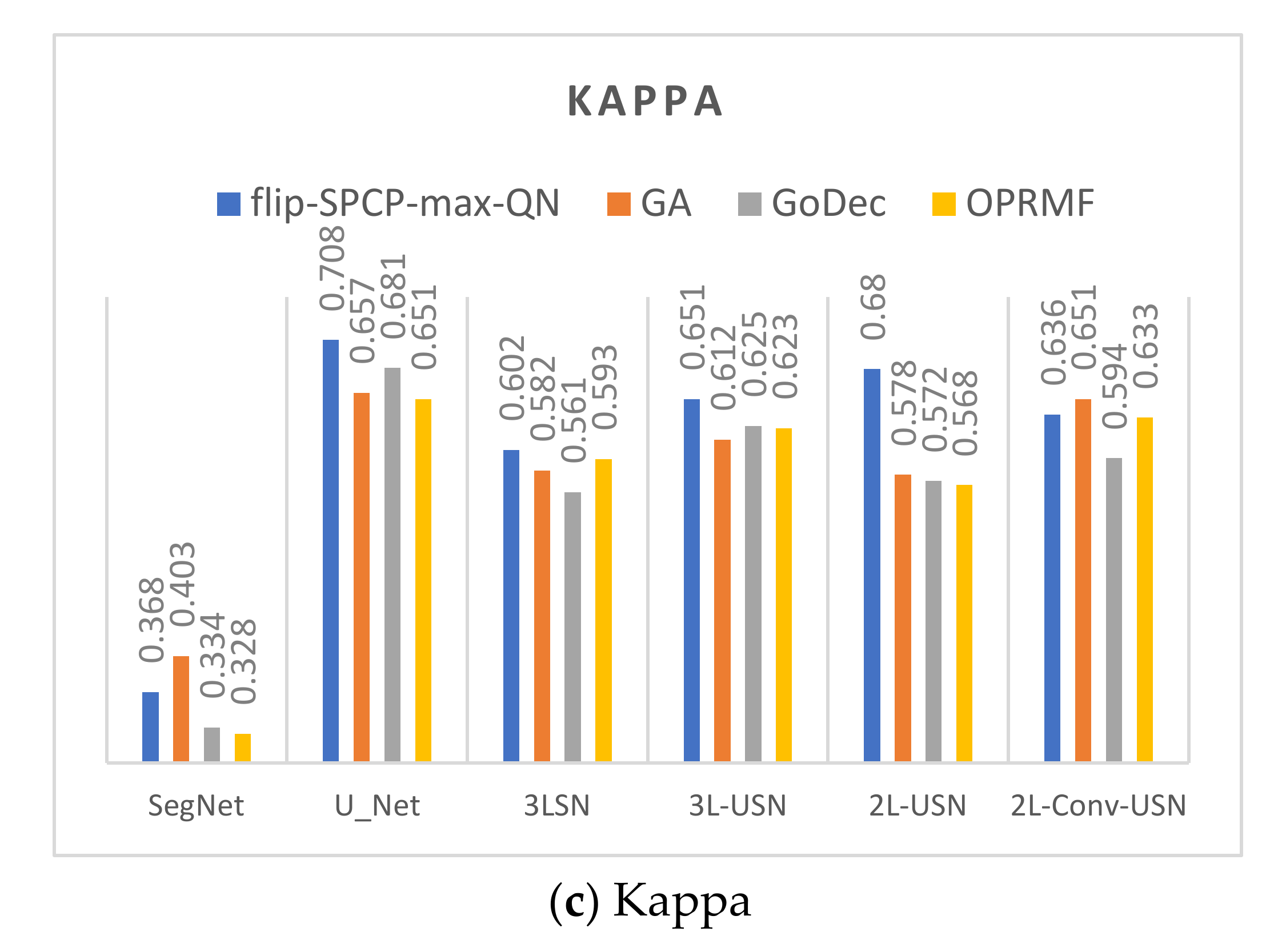
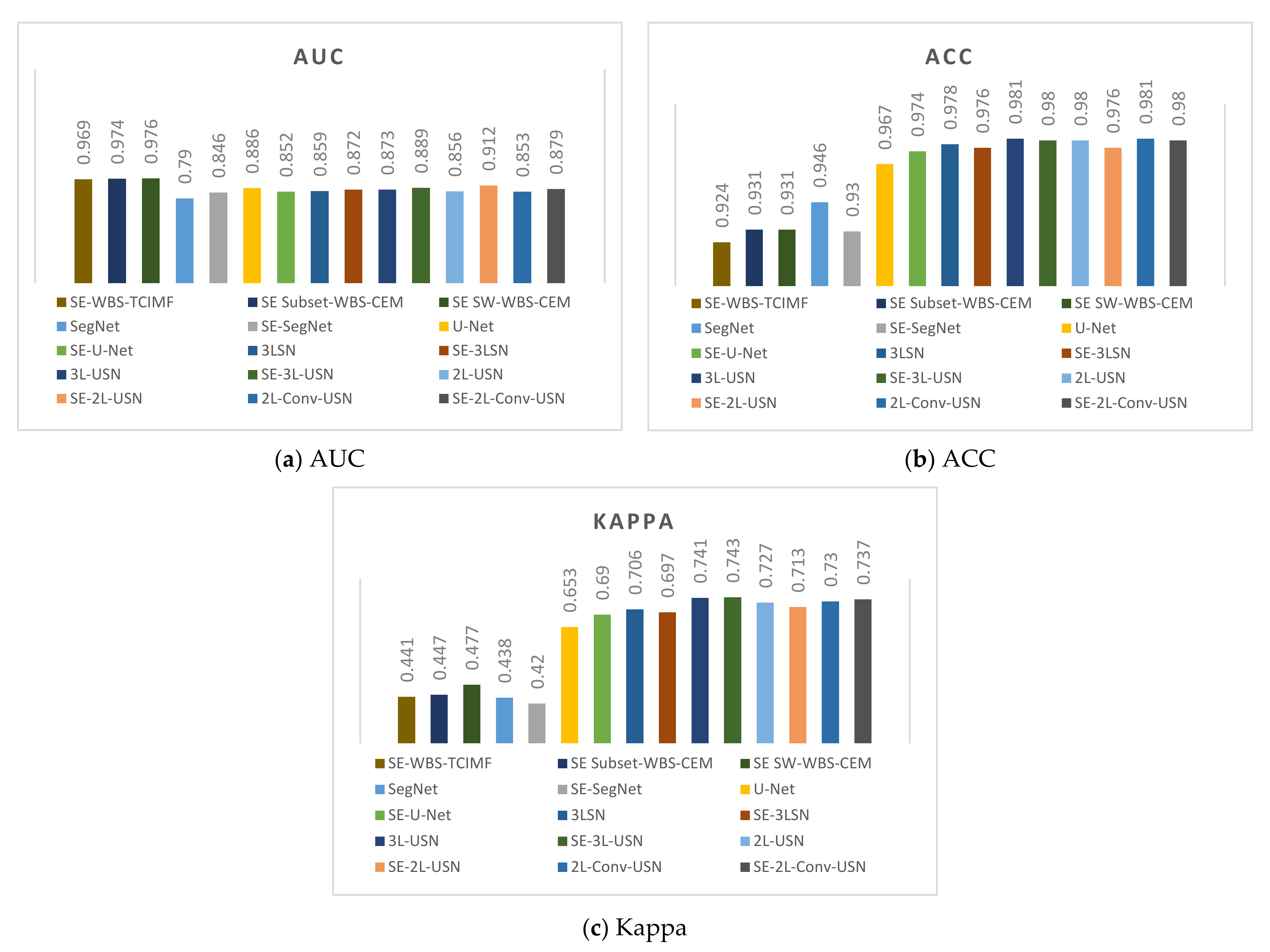
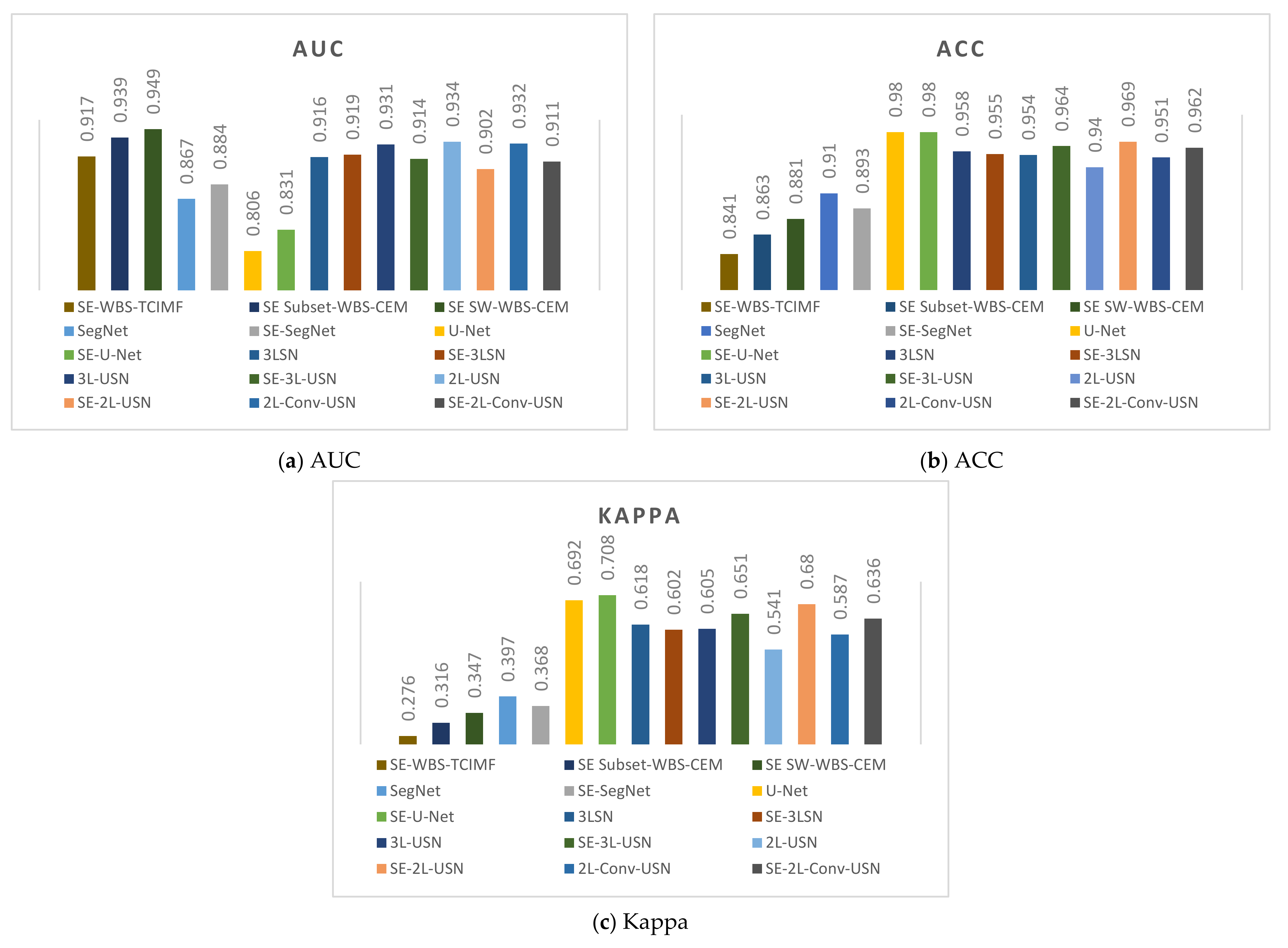
3. Results
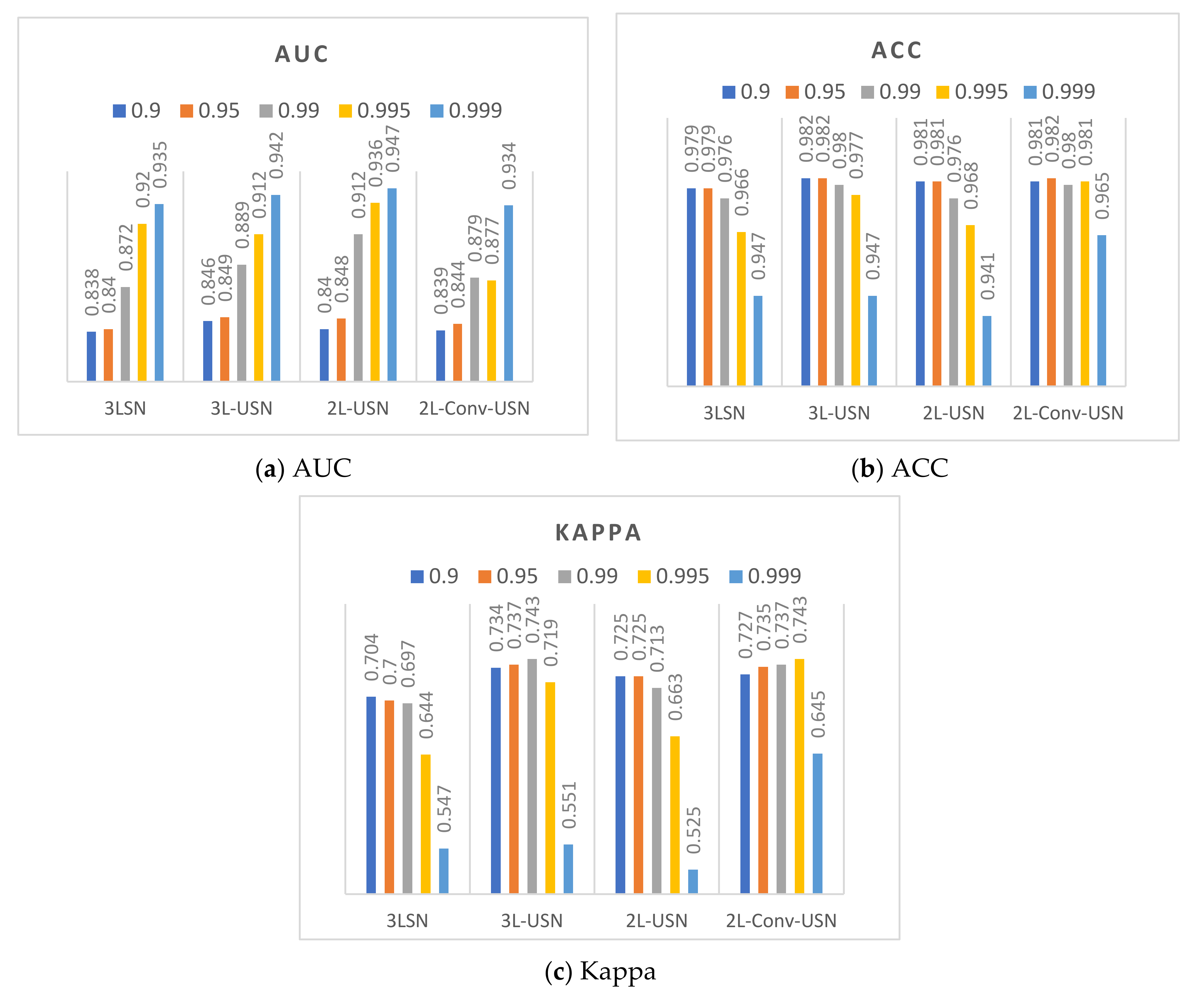
3.1. BCE Parameter
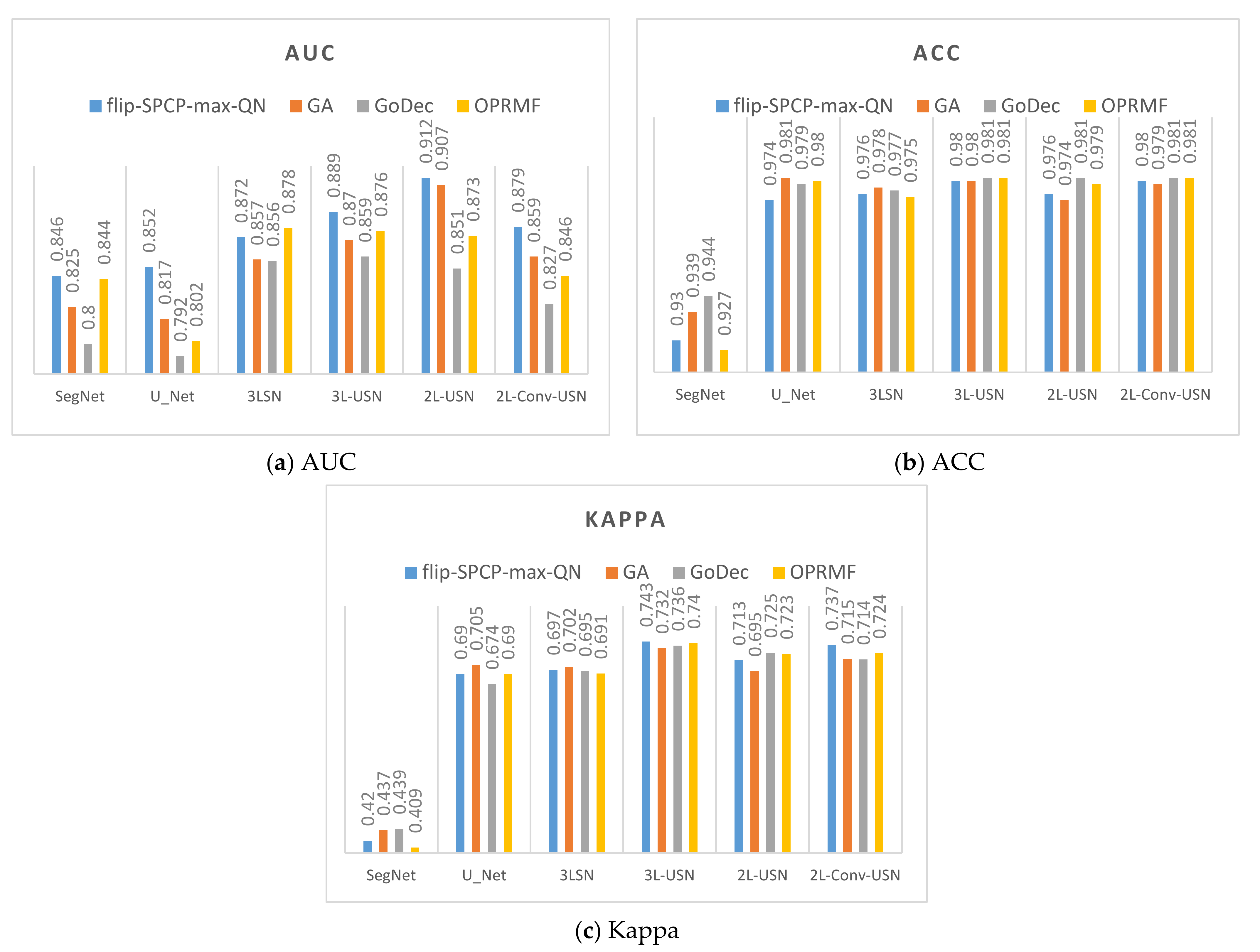
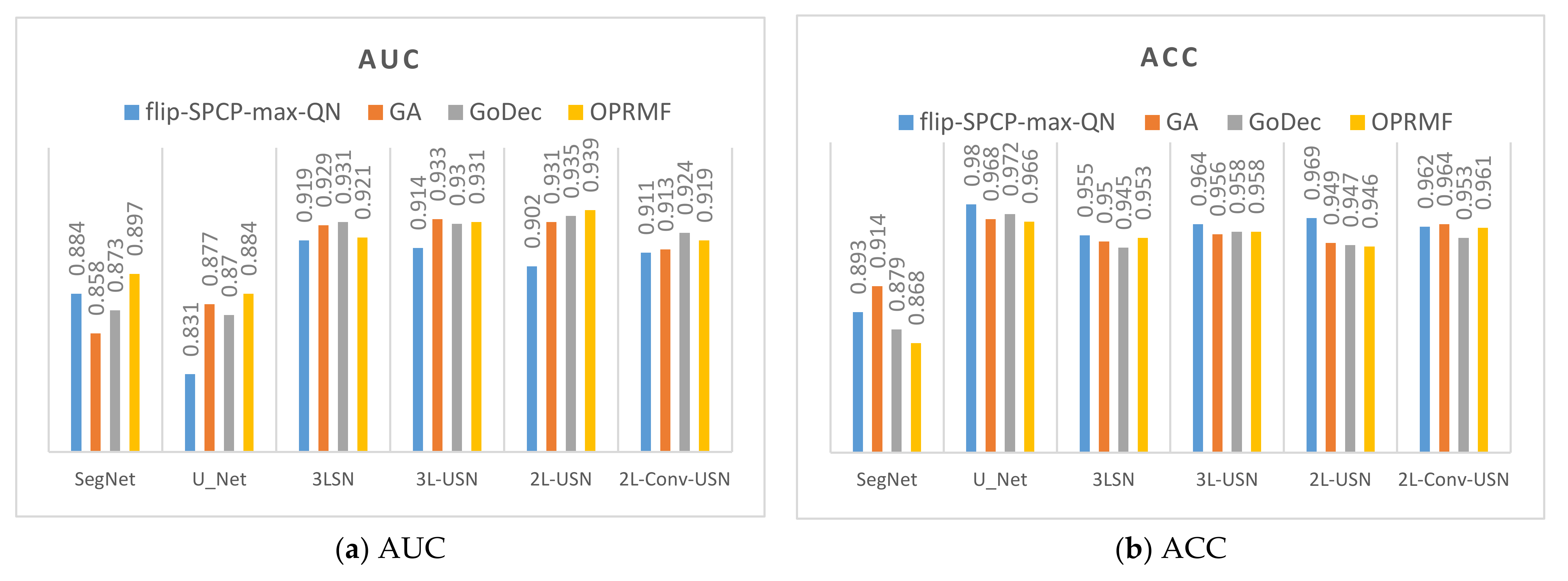
3.2. Results of Different Kernels in SE
3.3. Results of Hybrid CNN Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Food and Agriculture Organization of the United Nations. Global Forest Resources Assessment 2015: How are the world’s Forests Changing? 2nd ed.; Food & Agriculture Org.: Rome, Italy, 2018. [Google Scholar]
- Lin, C.; Dugarsuren, N. Deriving the Spatiotemporal NPP Pattern in Terrestrial Ecosystems of Mongolia Using MODIS Imagery. Photogramm. Eng. Remote Sens. 2015, 81, 587–598. [Google Scholar] [CrossRef]
- Lin, C.; Thomson, G.; Popescu, S.C. An IPCC-compliant technique for forest carbon stock assessment using airborne LiDAR-derived tree metrics and competition index. Remote Sens. 2016, 8, 528. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Chen, S.-Y.; Chen, C.-C.; Tai, C.-H. Detecting newly grown tree leaves from unmanned-aerial-vehicle images using hyperspectral target detection techniques. ISPRS J. Photogramm. Remote Sens. 2018, 142, 174–189. [Google Scholar] [CrossRef]
- Götze, C.; Gerstmann, H.; Gläßer, C.; Jung, A. An approach for the classification of pioneer vegetation based on species-specific phenological patterns using laboratory spectrometric measurements. Phys. Geogr. 2017, 38, 524–540. [Google Scholar] [CrossRef]
- Burai, P.; Deák, B.; Valkó, O.; Tomor, T. Classification of Herbaceous Vegetation Using Airborne Hyperspectral Imagery. Remote Sens. 2015, 7, 2046–2066. [Google Scholar] [CrossRef] [Green Version]
- Mohan, M.; Silva, C.A.; Klauberg, C.; Jat, P.; Catts, G.; Cardil, A.; Hudak, A.T.; Dia, M. Individual Tree Detection from Unmanned Aerial Vehicle (UAV) Derived Canopy Height Model in an Open Canopy Mixed Conifer Forest. Forests 2017, 8, 340. [Google Scholar] [CrossRef] [Green Version]
- Wallace, L.; Lucieer, A.; Watson, C.S. Evaluating Tree Detection and Segmentation Routines on Very High Resolution UAV LiDAR Data. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7619–7628. [Google Scholar] [CrossRef]
- Dugarsuren, N.; Lin, C. Temporal variations in phenological events of forests, grasslands and desert steppe ecosystems in Mongolia: A remote sensing approach. Ann. For. Res. 2016, 59, 175–190. [Google Scholar] [CrossRef] [Green Version]
- Popescu, S.C.; Zhao, K.; Neuenschwander, A.; Lin, C. Satellite lidar vs. small footprint airborne lidar: Comparing the accuracy of aboveground biomass estimates and forest structure metrics at footprint level. Remote Sens. Environ. 2011, 115, 2786–2797. [Google Scholar] [CrossRef]
- Zeng, M.; Li, J.; Peng, Z. The design of Top-Hat morphological filter and application to infrared target detection. Infrared Phys. Technol. 2006, 48, 67–76. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Debes, C.; Zoubir, A.M.; Amin, M.G. Enhanced Detection Using Target Polarization Signatures in Through-the-Wall Radar Imaging. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1968–1979. [Google Scholar] [CrossRef]
- Qi, S.; Ma, J.; Tao, C.; Yang, C.; Tian, J. A Robust Directional Saliency-Based Method for Infrared Small-Target Detection Under Various Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2013, 10, 495–499. [Google Scholar] [CrossRef]
- Lo, C.-S.; Lin, C. Growth-Competition-Based Stem Diameter and Volume Modeling for Tree-Level Forest Inventory Using Airborne LiDAR Data. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2216–2226. [Google Scholar] [CrossRef]
- Lin, C.; Popescu, S.C.; Huang, S.C.; Chang, P.T.; Wen, H.L. A novel reflectance-based model for evaluating chlorophyll concentrations of fresh and water-stressed leaves. Biogeosciences 2015, 12, 49–66. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Tsogt, K.; Zandraabal, T. A decompositional stand structure analysis for exploring stand dynamics of multiple attributes of a mixed-species forest. For. Ecol. Manag. 2016, 378, 111–121. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hasan, M.A.; Lonardi, S. DeeplyEssential: A deep neural network for predicting essential genes in microbes. BMC Bioinform. 2020, 21, 367. [Google Scholar] [CrossRef]
- Le, N.Q.K.; Do, D.T.; Hung, T.N.K.; Lam, L.H.T.; Huynh, T.-T.; Nguyen, N.T.K. A Computational Framework Based on Ensemble Deep Neural Networks for Essential Genes Identification. Int. J. Mol. Sci. 2020, 21, 9070. [Google Scholar] [CrossRef] [PubMed]
- Le, N.Q.K.; Huynh, T.-T. Identifying SNAREs by Incorporating Deep Learning Architecture and Amino Acid Embedding Representation. Front. Physiol. 2019, 10, 1501. [Google Scholar] [CrossRef] [PubMed]
- Song, J.; Liu, G.; Jiang, J.; Zhang, P.; Liang, Y. Prediction of Protein–ATP Binding Residues Based on Ensemble of Deep Convolutional Neural Networks and LightGBM Algorithm. Int. J. Mol. Sci. 2021, 22, 939. [Google Scholar] [CrossRef]
- Le, N.Q.K. Fertility-GRU: Identifying Fertility-Related Proteins by Incorporating Deep-Gated Recurrent Units and Original Position-Specific Scoring Matrix Profiles. J. Proteome Res. 2019, 18, 3503–3511. [Google Scholar] [CrossRef]
- Munir, K.; Elahi, H.; Ayub, A.; Frezza, F.; Rizzi, A. Cancer Diagnosis Using Deep Learning: A Bibliographic Review. Cancers 2019, 11, 1235. [Google Scholar] [CrossRef] [Green Version]
- Chougrad, H.; Zouaki, H.; Alheyane, O. Deep Convolutional Neural Networks for breast cancer screening. Comput. Methods Programs Biomed. 2018, 157, 19–30. [Google Scholar] [CrossRef]
- Lee, J.-H.; Kim, D.-H.; Jeong, S.-N.; Choi, S.-H. Detection and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm. J. Dent. 2018, 77, 106–111. [Google Scholar] [CrossRef]
- Yu, B.; Wang, Y.; Wang, L.; Shen, D.; Zhou, L. Medical Image Synthesis via Deep Learning. Adv. Exp. Med. Biol. 2020, 1213, 23–44. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Zhang, Y.; Li, L. Study of the Application of Deep Convolutional Neural Networks (CNNs) in Processing Sensor Data and Biomedical Images. Sensors 2019, 19, 3584. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Suzuki, K. Overview of deep learning in medical imaging. Radiol. Phys. Technol. 2017, 10, 257–273. [Google Scholar] [CrossRef] [PubMed]
- Harangi, B. Skin lesion classification with ensembles of deep convolutional neural networks. J. Biomed. Inform. 2018, 86, 25–32. [Google Scholar] [CrossRef] [PubMed]
- El-Khatib, H.; Popescu, D.; Ichim, L. Deep Learning–Based Methods for Automatic Diagnosis of Skin Lesions. Sensors 2020, 20, 1753. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Wei, X.; Guo, Y.; Gao, X.; Yan, M.; Sun, X. A new semantic segmentation model for remote sensing images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1776–1779. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Sun, S.; Yang, L.; Liu, W.; Li, R. Feature Fusion Through Multitask CNN for Large-scale Remote Sensing Image Segmentation. arXiv 2018, arXiv:1807.09072v1. [Google Scholar]
- Zheng, C.; Zhang, Y.; Wang, L. Semantic Segmentation of Remote Sensing Imagery Using an Object-Based Markov Random Field Model with Auxiliary Label Fields. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3015–3028. [Google Scholar] [CrossRef]
- Chen, G.; Zhang, X.; Wang, Q.; Dai, F.; Gong, Y.; Zhu, K. Symmetrical Dense-Shortcut Deep Fully Convolutional Networks for Semantic Segmentation of Very-High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1633–1644. [Google Scholar] [CrossRef]
- Lotte, R.G.; Haala, N.; Karpina, M.; Aragão, L.E.O.E.C.D.; Shimabukuro, Y.E. 3D Façade Labeling over Complex Scenarios: A Case Study Using Convolutional Neural Network and Structure-From-Motion. Remote Sens. 2018, 10, 1435. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for robust semanticpixel-wise labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Treml, M.; Arjona-Medina, J.; Unterthiner, T.; Durgesh, R.; Friedmann, F.; Schuberth, P.; Mayr, A.; Heusel, M.; Hofmarcher, M.; Widrich, M.; et al. Speeding up semantic segmentation for autonomous driving. In Proceedings of the Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Jeon, W.-S.; Rhee, S.-Y. Plant Leaf Recognition Using a Convolution Neural Network. Int. J. Fuzzy Lg. Intell. Syst. 2017, 17, 26–34. [Google Scholar] [CrossRef] [Green Version]
- Kaya, A.; Keceli, A.S.; Catal, C.; Yalic, H.Y.; Temucin, H.; Tekinerdogan, B. Analysis of transfer learning for deep neural network based plant classification models. Comput. Electron. Agric. 2019, 158, 20–29. [Google Scholar] [CrossRef]
- Nkemelu, D.K.; Omeiza, D.; Lubalo, N. Deep convolutional neural network for plant seedlings classification. arXiv 2018, arXiv:1811.08404. [Google Scholar]
- Lv, M.; Zhou, G.; He, M.; Chen, A.; Zhang, W.; Hu, Y. Maize Leaf Disease Identification Based on Feature Enhancement and DMS-Robust Alexnet. IEEE Access 2020, 8, 57952–57966. [Google Scholar] [CrossRef]
- Dalal, T.; Singh, M. Review Paper on Leaf Diseases Detection and Classification Using Various CNN Techniques. In Mobile Radio Communications and 5G Networks; Springer International Publishing: Singapore, 2021; pp. 153–162. [Google Scholar]
- Tm, P.; Pranathi, A.; SaiAshritha, K.; Chittaragi, N.B.; Koolagudi, S.G. Tomato Leaf Disease Detection Using Convolutional Neural Networks. In Proceedings of the 2018 Eleventh International Conference on Contemporary Computing (IC3), Noidia, India, 2–4 August 2018; pp. 1–5. [Google Scholar]
- Gandhi, R.; Nimbalkar, S.; Yelamanchili, N.; Ponkshe, S. Plant disease detection using CNNs and GANs as an augmentative approach. In Proceedings of the 2018 IEEE International Conference on Innovative Research and Development (ICIRD), IEEE, Bangkok, Thailand, 11–12 May 2018; pp. 1–5. [Google Scholar]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [Green Version]
- Naik, S.; Shah, H. Classification of Leaves Using Convolutional Neural Network and Logistic Regression. In ICT Systems and Sustainability; Springer: Singapore, 2021; pp. 63–75. [Google Scholar]
- Grinblat, G.L.; Uzal, L.C.; Larese, M.G.; Granitto, P.M. Deep learning for plant identification using vein morphological patterns. Comput. Electron. Agric. 2016, 127, 418–424. [Google Scholar] [CrossRef] [Green Version]
- Dos Santos Ferreira, A.; Freitas, D.M.; da Silva, G.G.; Pistori, H.; Folhes, M.T. Weed detection in soybean crops using ConvNets. Comput. Electron. Agric. 2017, 143, 314–324. [Google Scholar] [CrossRef]
- Barré, P.; Stöver, B.C.; Müller, K.F.; Steinhage, V. LeafNet: A computer vision system for automatic plant species identification. Ecol. Inform. 2017, 40, 50–56. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Pradhan, P.; Meyer, T.; Vieth, M.; Stallmach, A.; Waldner, M.; Schmitt, M.; Popp, J.; Bocklitz, T. Semantic Segmentation of Non-linear Multimodal Images for Disease Grading of Inflammatory Bowel Disease: A SegNet-based Application. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2019), Prague, Czech Republic, 19–21 February 2019; pp. 396–405. [Google Scholar]
- Khagi, B.; Kwon, G.-R. Pixel-Label-Based Segmentation of Cross-Sectional Brain MRI Using Simplified SegNet Architecture-Based CNN. J. Healthc. Eng. 2018, 2018, 3640705. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mittal, A.; Hooda, R.; Sofat, S. LF-SegNet: A fully convolutional encoder–decoder network for segmenting lung fields from chest radiographs. Wirel. Pers. Commun. 2018, 101, 511–529. [Google Scholar] [CrossRef]
- Falk, T.; Mai, D.; Bensch, R.; Çiçek, Ö.; Abdulkadir, A.; Marrakchi, Y.; Böhm, A.; Deubner, J.; Jäckel, Z.; Seiwald, K.; et al. U-Net: Deep learning for cell counting, detection, and morphometry. Nat. Methods 2019, 16, 67–70. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Esser, P.; Sutter, E. A Variational U-Net for Conditional Appearance and Shape Generation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8857–8866. [Google Scholar]
- Von Eicken, T.; Basu, A.; Buch, V.; Vogels, W. U-Net: A user-level network interface for parallel and distributed computing. ACM SIGOPS Oper. Syst. Rev. 1995, 29, 40–53. [Google Scholar] [CrossRef]
- Dong, H.; Yang, G.; Liu, F.; Mo, Y.; Guo, Y. Automatic Brain Tumor Detection and Segmentation Using U-Net Based Fully Convolutional Networks. In Proceedings of the Annual Conference on Medical Image Understanding and Analysis, Edinburgh, UK, 11–13 July 2017; Springer: Cham, Switzerland, 2017; pp. 506–517. [Google Scholar]
- Jansson, A.; Humphrey, E.; Montecchio, N.; Bittner, R.; Kumar, A.; Weyde, T. Singing voice separation with deep u-net convolutional networks. In Proceedings of the International Society for Music Information Retrieval Conference, Suzhou, China, 23–27 October 2017. [Google Scholar]
- Kumar, P.; Nagar, P.; Arora, C.; Gupta, A. U-SegNet: Fully convolutional neural network based automated brain tissue segmentation tool. arXiv 2018, arXiv:1806.04429. [Google Scholar]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 1–37. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Chanussot, J.; Wei, Z. Joint Reconstruction and Anomaly Detection from Compressive Hyperspectral Images Using Mahalanobis Distance-Regularized Tensor RPCA. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2919–2930. [Google Scholar] [CrossRef]
- Tan, C.H.; Chen, J.; Chau, L.P. Edge-preserving rain removal for light field images based on RPCA. In Proceedings of the 22nd International Conference on Digital Signal Processing (DSP), London, UK, 23–25 August 2017; pp. 1–5. [Google Scholar]
- Rezaei, B.; Ostadabbas, S. Background Subtraction via Fast Robust Matrix Completion. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 1871–1879. [Google Scholar]
- Kaloorazi, M.F.; De Lamare, R.C. Low-rank and sparse matrix recovery based on a randomized rank-revealing decomposition. In Proceedings of the 2017 22nd International Conference on Digital Signal Processing (DSP), London, UK, 23–25 August 2017; pp. 1–5. [Google Scholar]
- Dao, M.; Kwan, C.; Ayhan, B.; Tran, T.D. Burn scar detection using cloudy MODIS images via low-rank and sparsity-based models. In Proceedings of the 2016 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Washington, DC, USA, 7–9 December 2016; pp. 177–181. [Google Scholar]
- Lee, P.H.; Chan, C.C.; Huang, S.L.; Chen, A.; Chen, H.H. Blood vessel extraction from OCT data by short-time RPCA. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 394–398. [Google Scholar]
- Chai, Y.; Xu, S.; Yin, H. An Improved ADM algorithm for RPCA optimization problem. In Proceedings of the 32nd Chinese Control Conference, Xi’an, China, 26–28 July 2013; pp. 4476–4480. [Google Scholar]
- Wen, F.; Zhang, Y.; Gao, Z.; Ling, X. Two-Pass Robust Component Analysis for Cloud Removal in Satellite Image Sequence. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1090–1094. [Google Scholar] [CrossRef]
- Lin, Z.; Chen, M.; Ma, Y. The Augmented Lagrange Multiplier Method for Exact Recovery of Corrupted Low-Rank Matrices. arXiv 2010, arXiv:1009.5055. [Google Scholar]
- Chen, S.Y.; Lin, C.; Tai, C.H.; Chuang, S.J. Adaptive Window-Based Constrained Energy Minimization forDetection of Newly Grown Tree Leaves. Remote Sens. 2018, 10, 96. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.-I. Hyperspectral Data Processing: Algorithm Design and Analysis; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Chen, S.-Y.; Lin, C.; Chuang, S.-J.; Kao, Z.-Y. Weighted Background Suppression Target Detection Using Sparse Image Enhancement Technique for Newly Grown Tree Leaves. Remote Sens. 2019, 11, 1081. [Google Scholar] [CrossRef] [Green Version]
- Bar, M.; Ori, N. Leaf development and morphogenesis. Development 2014, 141, 4219–4230. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Lin, C.-H. Comparison of carbon sequestration potential in agricultural and afforestation farming systems. Sci. Agricola 2013, 70, 93–101. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Wang, J.-J. The effect of trees spacing on the growth of trees in afforested broadleaf stands on cultivated farmland. Q. J. Chin. For. 2013, 46, 311–326. [Google Scholar]
- Lin, C. Improved derivation of forest stand canopy height structure using harmonized metrics of full-waveform data. Remote Sens. Environ. 2019, 235, 111436. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Liang, N.T.J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- De Boer, P.-T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A Tutorial on the Cross-Entropy Method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Aurelio, Y.S.; de Almeida, G.M.; de Castro, C.L.; Braga, A.P. Learning from imbalanced data sets with weighted cross-entropy function. Neural Process. Lett. 2019, 50, 1937–1949. [Google Scholar] [CrossRef]
- Pan, S.; Zhang, W.; Zhang, W.; Xu, L.; Fan, G.; Gong, J.; Zhang, B.; Gu, H. Diagnostic Model of Coronary Microvascular Disease Combined with Full Convolution Deep Network with Balanced Cross-Entropy Cost Function. IEEE Access 2019, 7, 177997–178006. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Daimary, D.; Bora, M.B.; Amitab, K.; Kandar, D. Brain TumorSegmentation from MRI Images using Hybrid Convolutional NeuralNetworks. Procedia Comput. Sci. 2020, 167, 2419–2428. [Google Scholar] [CrossRef]
- Wright, J.; Peng, Y.; Ma, Y.; Ganesh, A.; Rao, S. Robust Principal Component Analysis: Exact Recovery of Corrupted Low-Rank Matrices by Convex Optimization. In Proceedings of the Neural Information Processing Systems, NIPS, Vancouver, BC, Canada, 7–10 December 2009. [Google Scholar]
- Bouwmans, T.; Zahza, E. Robust PCA via Principal Component Pursuit: A Review for a Comparative Evaluation in Video Surveillance. Comput. Vis. Image Underst. 2014, 122, 22–34. [Google Scholar] [CrossRef]
- Vaswani, N.; Bouwmans, T.; Javed, S.; Narayanamurthy, P. Robust PCA and Robust Subspace Tracking. IEEE Signal Process. Mag. 2017, 35, 32–55. [Google Scholar] [CrossRef] [Green Version]
- Hauberg, S.; Feragen, A.; Black, M.J. Grassmann Averages for Scalable Robust PCA. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–27 June 2014; pp. 3810–3817. [Google Scholar]
- Wang, N.; Yao, T.; Wang, J.; Yeung, D.Y. A Probabilistic Approach to Robust Matrix Factorization. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; pp. 126–139. [Google Scholar]
- Aravkin, A.; Becker, S.; Cevher, V.; Olsen, P. A variational approach to stable principal component pursuit. arXiv 2014, arXiv:1406.1089. [Google Scholar]
- Zhou, T.; Tao, D. GoDec: Randomized low-rank & sparsity matrix decompositionin noisy case. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Albertella, A.; Sacerdote, F. Spectral analysis of block averaged data in geopotential global model determination. J. Geod. 1995, 70, 166–175. [Google Scholar] [CrossRef]
- Poor, H.V. An Introduction to Detection and Estimation Theory, 2nd ed.; Springer: New York, NY, USA, 1994. [Google Scholar]
- Chen, S.-Y.; Chang, C.-Y.; Ou, C.-S.; Lien, C.-T. Detection of Insect Damage in Green Coffee Beans Using VIS-NIR Hyperspectral Imaging. Remote Sens. 2020, 12, 2348. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Code Description | Parameter Information |
|---|---|---|
| C | Convolution Layer | Kernel Size: (3, 3) Padding: same Activation: ReLU Filter Size -> C64, C128, C256 |
| BN | BatchNormalization Layer | |
| MP | MaxPooling Layer | |
| UP | UpSampling Layer | |
| Out | Convolution Layer | Kernel Size: (1, 1) Padding: same Activation: sigmoid Filter Size: 1 |
| ⊕ | Skip Connection Layer |
| Error Matrix | Ground Truth | Total | ||
|---|---|---|---|---|
| NGL (p) | Non-NGL (n) | |||
| Detection | NGL (p′) | True Positive | False Positive | |
| Non-NGL (n′) | False Negative | True Negative | ||
| Total | . | Total Pixels | ||
| Global Target Detection | |||||
| AUC | PD/TPR | PF/FPR | ACC | Kappa | |
| Traditional ACE | 0.9417 | 0.8827 | 0.1099 | 0.8897 | 0.3389 |
| WBS-ACE (ED) | 0.9375 | 0.8697 | 0.1113 | 0.888 | 0.3313 |
| Traditional TCIMF | 0.95737 | 0.8903 | 0.1076 | 0.8924 | 0.3472 |
| WBS-TCIMF(ED) | 0.9583 | 0.8906 | 0.1082 | 0.8917 | 0.3458 |
| Traditional CEM | 0.9606 | 0.8915 | 0.1022 | 0.8976 | 0.3604 |
| WBS-CEM(ED) | 0.9713 | 0.9029 | 0.0738 | 0.9254 | 0.4483 |
| Sparse WCEM | 0.971 | 0.9067 | 0.08 | 0.9194 | 0.4288 |
| Local Target Detection | |||||
| AUC | PD/TPR | PF/FPR | ACC | Kappa | |
| Subset CEM | 0.9685 | 0.9099 | 0.0874 | 0.9125 | 0.4074 |
| Subset WBS-CEM | 0.9725 | 0.9177 | 0.0827 | 0.9173 | 0.4248 |
| SW CEM | 0.9694 | 0.9151 | 0.0811 | 0.9188 | 0.4289 |
| SW WBS-CEM | 0.9749 | 0.9204 | 0.0729 | 0.9269 | 0.4588 |
| ASW CEM | 0.9704 | 0.9257 | 0.0753 | 0.9248 | 0.4526 |
| ASW WBS-CEM | 0.9781 | 0.9325 | 0.0673 | 0.9327 | 0.4847 |
| Deep Learning Based (Proposed) | |||||
| Model | AUC | TPR | FPR | ACC | Kappa |
| SegNet | 0.79 | 0.621 | 0.042 | 0.946 | 0.438 |
| U-Net | 0.886 | 0.799 | 0.026 | 0.967 | 0.653 |
| 3LSN | 0.859 | 0.73 | 0.012 | 0.978 | 0.706 |
| 3L-USN | 0.773 | 0.757 | 0.01 | 0.981 | 0.741 |
| 2L-USN | 0.856 | 0.821 | 0.009 | 0.98 | 0.727 |
| 2L-Conv-USN | 0.853 | 0.715 | 0.009 | 0.981 | 0.73 |
| Global Target Detection | |||||
| AUC | PD/TPR | PF/FPR | ACC | Kappa | |
| SE-WBS-ACE | 0.9658 | 0.9154 | 0.0887 | 0.9115 | 0.4058 |
| SE-WBS-TCIMF | 0.9691 | 0.8963 | 0.0749 | 0.9241 | 0.4417 |
| SE-WBS-CEM | 0.9713 | 0.9029 | 0.0738 | 0.9254 | 0.4483 |
| Sparse WCEM | 0.971 | 0.9067 | 0.08 | 0.9194 | 0.4288 |
| Local Target Detection | |||||
| AUC | PD/TPR | PF/FPR | ACC | Kappa | |
| SE Subset-WBS-CEM | 0.9749 | 0.9159 | 0.0681 | 0.9313 | 0.4744 |
| SE SW-WBS-CEM | 0.9766 | 0.9241 | 0.0681 | 0.9316 | 0.4778 |
| SE ASW-WBS-CEM | 0.9796 | 0.9324 | 0.0616 | 0.9382 | 0.5076 |
| Deep Learning Based (Proposed) | |||||
| Model | AUC | TPR | FPR | ACC | Kappa |
| SE-SegNet | 0.846 | 0.751 | 0.063 | 0.93 | 0.42 |
| SE-U-Net | 0.852 | 0.719 | 0.014 | 0.974 | 0.69 |
| SE-3L SegNet | 0.872 | 0.76 | 0.015 | 0.976 | 0.697 |
| SE-3L-U-SegNet | 0.889 | 0.789 | 0.012 | 0.98 | 0.743 |
| SE-2L-U-SegNet | 0.912 | 0.844 | 0.019 | 0.976 | 0.713 |
| SE-2L-Conv-U-SegNet | 0.879 | 0.77 | 0.011 | 0.98 | 0.737 |
| Global Target Detection | |||||
| AUC | TPR | FPR | ACC | Kappa | |
| Traditional ACE | 0.943 | 0.899 | 0.131 | 0.871 | 0.325 |
| WBS-ACE | 0.948 | 0.910 | 0.140 | 0.862 | 0.312 |
| Traditional TCIMF | 0.952 | 0.907 | 0.138 | 0.864 | 0.315 |
| WBS-TCIMF | 0.888 | 0.925 | 0.230 | 0.777 | 0.202 |
| Traditional CEM | 0.950 | 0.903 | 0.132 | 0.870 | 0.324 |
| WBS-CEM | 0.893 | 0.925 | 0.220 | 0.787 | 0.212 |
| Local Target Detection | |||||
| AUC | TPR | FPR | ACC | Kappa | |
| Subset CEM | 0.952 | 0.893 | 0.114 | 0.887 | 0.359 |
| Subset WBS-CEM | 0.917 | 0.923 | 0.180 | 0.824 | 0.255 |
| SW CEM | 0.921 | 0.849 | 0.110 | 0.889 | 0.351 |
| SW WBS-CEM | 0.923 | 0.903 | 0.146 | 0.856 | 0.299 |
| ASW CEM | 0.942 | 0.875 | 0.097 | 0.901 | 0.390 |
| ASW WBS-CEM | 0.932 | 0.918 | 0.141 | 0.862 | 0.313 |
| Deep Learning Based (Proposed) | |||||
| AUC | TPR | FPR | ACC | Kappa | |
| SegNet | 0.867 | 0.819 | 0.086 | 0.91 | 0.397 |
| U-Net | 0.806 | 0.617 | 0.006 | 0.98 | 0.692 |
| 3L SegNet | 0.916 | 0.87 | 0.038 | 0.958 | 0.618 |
| 3L-USN | 0.931 | 0.906 | 0.044 | 0.954 | 0.605 |
| 2L-USN | 0.934 | 0.928 | 0.059 | 0.94 | 0.541 |
| 2L-Conv-USN | 0.932 | 0.912 | 0.048 | 0.951 | 0.587 |
| Global Target Detection | |||||
| AUC | TPR | FPR | ACC | Kappa | |
| SE-WBS-ACE | 0.950 | 0.911 | 0.126 | 0.876 | 0.339 |
| SE-WBS-TCIMF | 0.917 | 0.909 | 0.162 | 0.841 | 0.276 |
| SE-WBS-CEM | 0.916 | 0.916 | 0.172 | 0.832 | 0.265 |
| Local Target Detection | |||||
| AUC | TPR | FPR | ACC | Kappa | |
| Subset SE-WBS-CEM | 0.939 | 0.921 | 0.140 | 0.863 | 0.316 |
| SW SE-WBS-CEM | 0.938 | 0.898 | 0.120 | 0.881 | 0.347 |
| ASW SE-WBS-CEM | 0.949 | 0.924 | 0.117 | 0.885 | 0.363 |
| Deep Learning Based (Proposed) | |||||
| Model | AUC | TPR | FPR | ACC | Kappa |
| SegNet | 0.884 | 0.874 | 0.106 | 0.893 | 0.368 |
| U-Net | 0.831 | 0.669 | 0.008 | 0.98 | 0.708 |
| 3LSN | 0.919 | 0.881 | 0.042 | 0.955 | 0.602 |
| 3L-USN | 0.914 | 0.86 | 0.032 | 0.964 | 0.651 |
| 2L-USN | 0.902 | 0.828 | 0.024 | 0.969 | 0.68 |
| 2L-Conv-USN | 0.911 | 0.855 | 0.033 | 0.962 | 0.636 |
| Area | Model | AUC | TPR | FPR | ACC | Kappa |
|---|---|---|---|---|---|---|
| 1 | SegNet | +0.560▲ | +0.130▲ | +0.021▲ | −0.016▼ | −0.018▼ |
| U-Net | −0.034▼ | −0.080▼ | −0.080▼ | +0.008▲ | +0.037▲ | |
| 3LSN | +0.013▲ | +0.030▲ | +0.003▲ | −0.002▼ | −0.009▼ | |
| 3L-USN | +0.114▲ | +0.032▲ | +0.032▲ | −0.001▼ | +0.002▲ | |
| 2L-USN | +0.056▲ | +0.013▲ | +0.010▲ | −0.004▼ | −0.014▼ | |
| 2L-Conv-USN | +0.026▲ | +0.055▲ | +0.002▲ | −0.001▼ | +0.007▲ |
| Area | Model | AUC | TPR | FPR | ACC | Kappa |
|---|---|---|---|---|---|---|
| 2 | SegNet | +0.017▲ | +0.055▲ | +0.020▲ | −0.017▼ | −0.029▼ |
| U-Net | +0.025▲ | +0.052▲ | +0.002▲ | 0.000▲ | +0.016▲ | |
| 3LSN | +0.003▲ | +0.011▲ | +0.004▲ | −0.003▼ | −0.016▼ | |
| 3L-USN | −0.017▼ | −0.046▼ | −0.012▼ | +0.010▲ | +0.001▲ | |
| 2L-USN | −0.032▼ | −0.100▼ | −0.035▼ | +0.029▲ | +0.141▲ | |
| 2L-Conv-USN | −0.021▼ | −0.057▼ | −0.015▼ | +0.011▲ | +0.049▲ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.-Y.; Lin, C.; Li, G.-J.; Hsu, Y.-C.; Liu, K.-H. Hybrid Deep Learning Models with Sparse Enhancement Technique for Detection of Newly Grown Tree Leaves. Sensors 2021, 21, 2077. https://doi.org/10.3390/s21062077
Chen S-Y, Lin C, Li G-J, Hsu Y-C, Liu K-H. Hybrid Deep Learning Models with Sparse Enhancement Technique for Detection of Newly Grown Tree Leaves. Sensors. 2021; 21(6):2077. https://doi.org/10.3390/s21062077
Chicago/Turabian StyleChen, Shih-Yu, Chinsu Lin, Guan-Jie Li, Yu-Chun Hsu, and Keng-Hao Liu. 2021. "Hybrid Deep Learning Models with Sparse Enhancement Technique for Detection of Newly Grown Tree Leaves" Sensors 21, no. 6: 2077. https://doi.org/10.3390/s21062077
APA StyleChen, S. -Y., Lin, C., Li, G. -J., Hsu, Y. -C., & Liu, K. -H. (2021). Hybrid Deep Learning Models with Sparse Enhancement Technique for Detection of Newly Grown Tree Leaves. Sensors, 21(6), 2077. https://doi.org/10.3390/s21062077