
A Novel Upsampling and Context Convolution for Image Semantic Segmentation


Abstract
:1. Introduction
- (1)
- We propose a novel upsampling convolution method to preserve the spatial information of the image in the network. The DUC is able to propagate fine-grained structure details from the input high-resolution image into the low-resolution feature map in an end-to-end trainable fashion.
- (2)
- To incorporate the object’s local contextual information into the network we develop a novel dense local context convolution method based on dilated convolution. The proposed method extracts dense contextual information using dilated convolutions in parallel and cascade with different dilation rates.
- (3)
- The proposed methods boost the performance of baseline networks for semantic segmentation in terms of pixel accuracy and mean intersection over union and outperform the state-of-the-art methods.
2. Related Works
3. Proposed Method
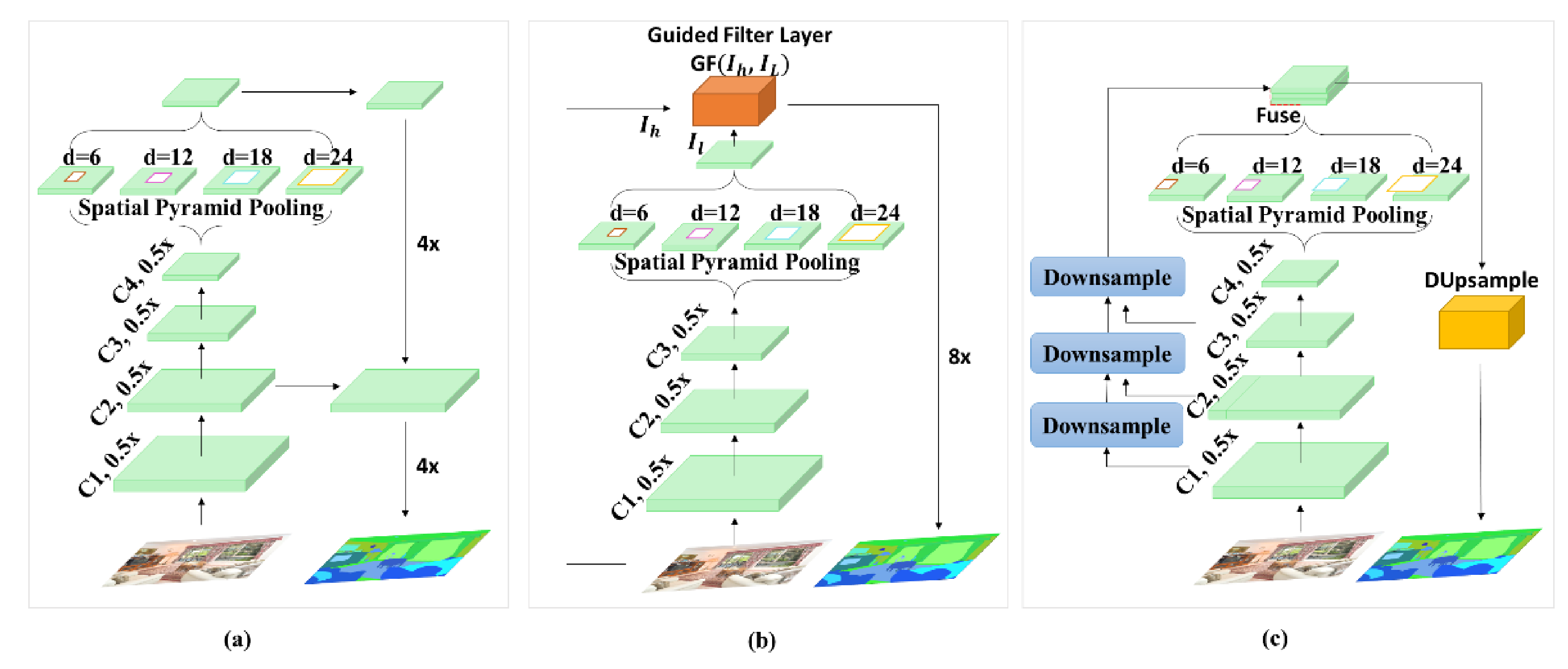
3.1. Joint Upsampling
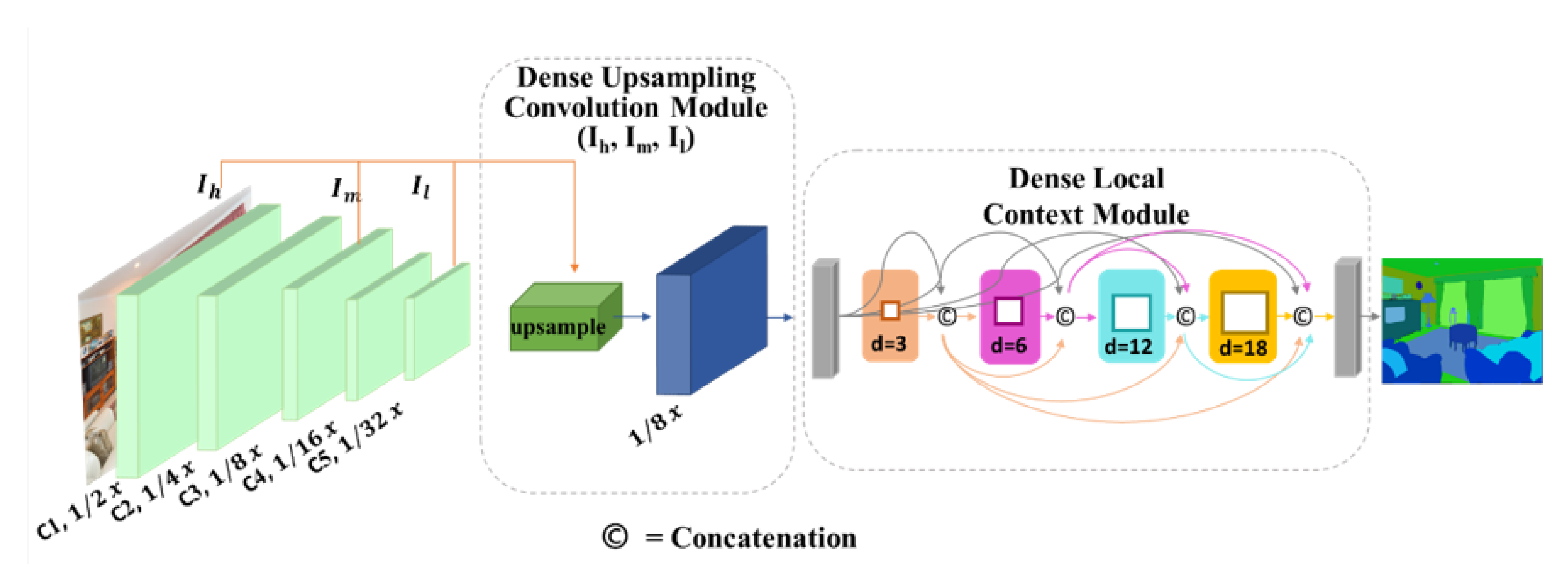
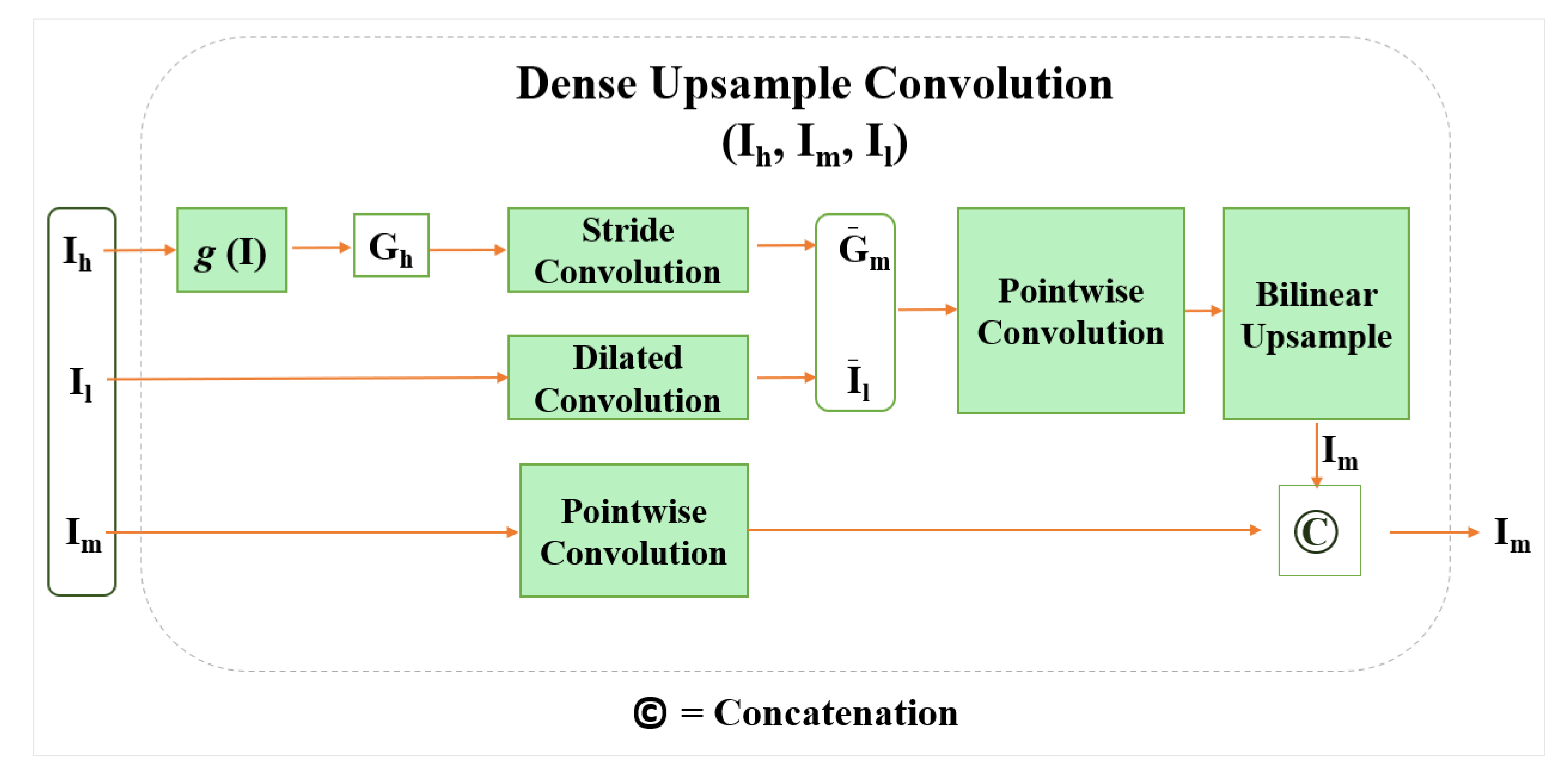
3.2. Dense Upsampling Convolution (DUC)
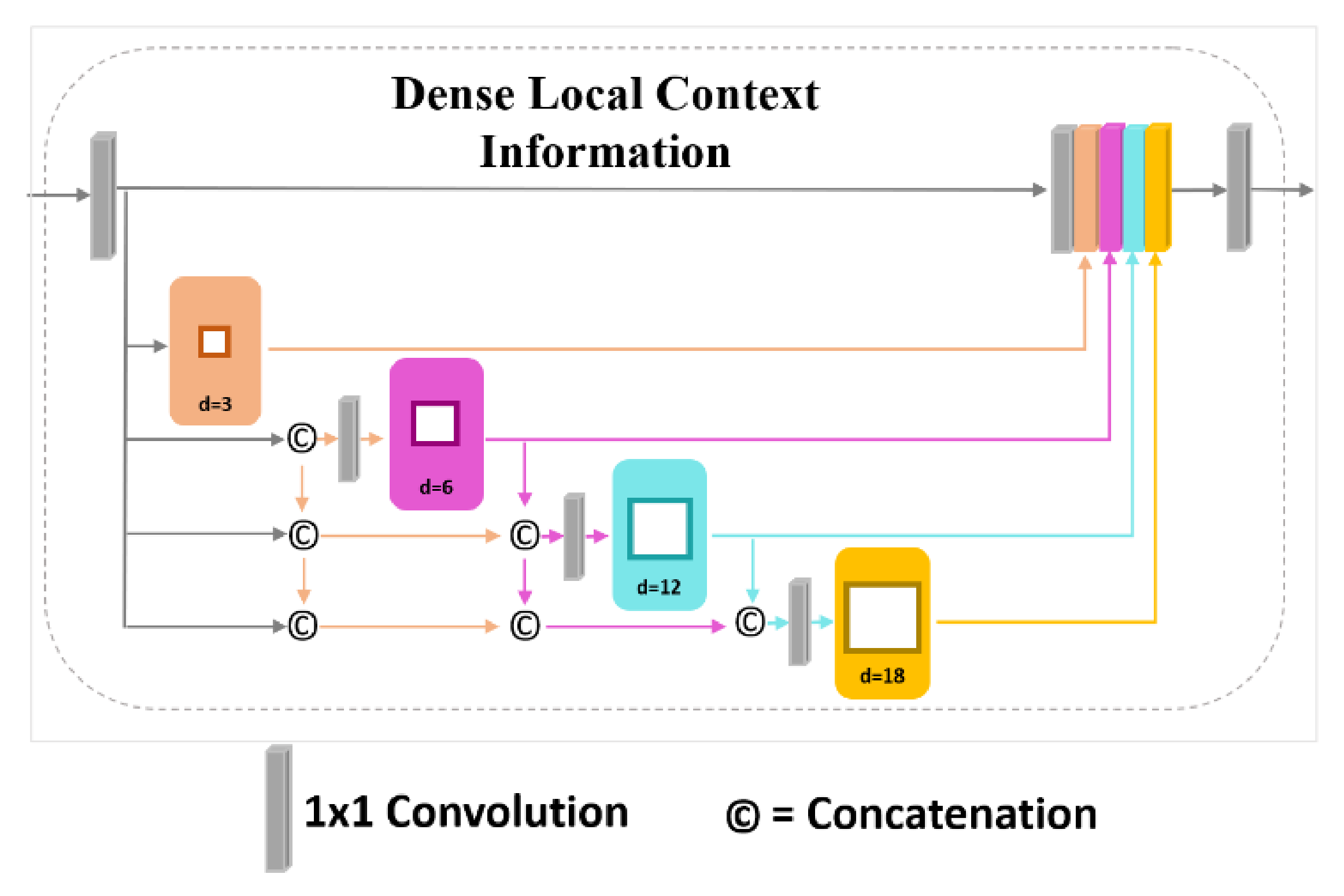
3.3. Dense Local Context (DLC) Convolution
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Loss Function
4.4. Performance Evaluation
5. Results
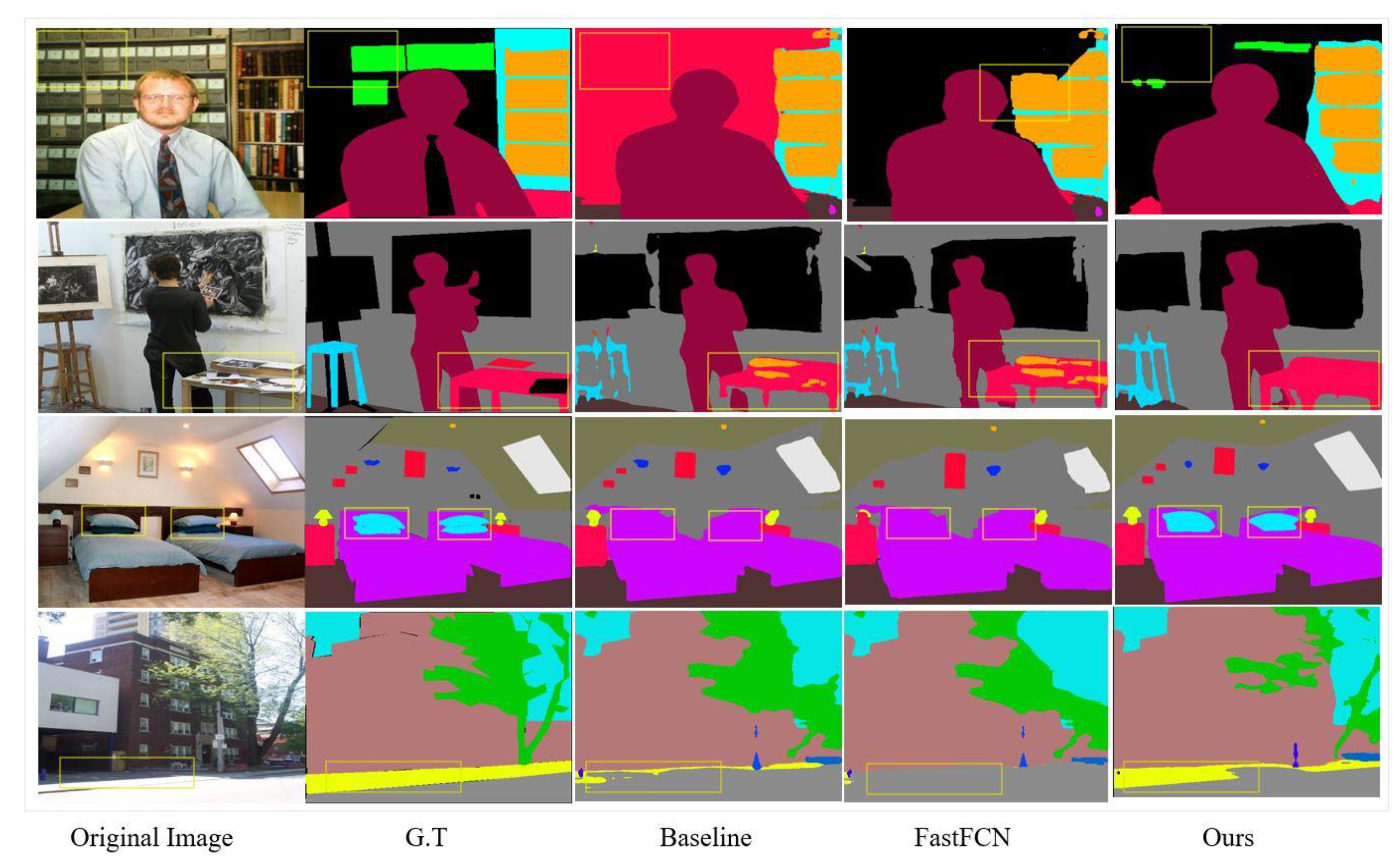
5.1. Qualitative Results
5.2. Quantitative Results
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical ikmage database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2553–2561. [Google Scholar]
- Mottaghi, R.; Chen, X.; Liu, X.; Cho, N.-G.; Lee, S.-W.; Fidler, S.; Urtasun, R.; Yuille, A. The role of context for object detection and semantic segmentation in the wild. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 891–898. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural net-works. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks For Large-Scale Image Recognition. In Proceedings of ICLR, San Diego, CA, USA, 7–9 May 2015; pp. 10–18. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.L.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convo-lution for semantic image segmentation. Lect. Notes Comput. Sci. 2018, 11211, 833–851. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 5122–5130. [Google Scholar]
- Wei, Y.-M.; Kang, L.; Yang, B.; Wu, L.-D. Applications of structure from motion: A survey. J. Zhejiang Univ. Sci. 2013, 14, 486–494. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Zhu, Y.; Meng, X. Image segmentation based on support vector machine. In Proceedings of the 2012 2nd International Conference on Computer Science and Network Technology, Changchun, China, 29–31 December 2012; pp. 202–206. [Google Scholar]
- Schroff, F.; Criminisi, A.; Zisserman, A. Object class segmentation using random forests. In Proceedings of the British Machine Vision Conference 2008, Leeds, UK, 1–4 September 2008. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected CRFs with gaussian edge potentials. In Proceedings of the NIPS, Granada, Spain, 12–17 December 2011; pp. 109–117. [Google Scholar]
- He, X.; Zemel, R.S.; Carreira-Perpiñán, M.Á. Multiscale conditional random fields for image labeling. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Pont-Tuset, J.; Arbelaez, P.A.; Barron, J.T.; Marques, F.; Malik, J. Multiscale combinatorial grouping for image segmentation and object proposal generation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 128–140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van De Sande, K.E.A.; Uijlings, J.R.R.; Gevers, T.; Smeulders, A.W.M. Segmentation as selective search for object recognition. In Proceedings of the 2011 International Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1879–1886. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 297–312. [Google Scholar] [CrossRef] [Green Version]
- Mostajabi, M.; Yadollahpour, P.; Shakhnarovich, G. Feedforward semantic segmentation with zoom-out features. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3376–3385. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; Lecun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Caesar, H.; Uijlings, J.; Ferrari, V. Region-based semantic segmentation with end-to-end training. In Constructive Side-Channel Analysis and Secure Design; Mangard, S., Poschmann, A.Y., Eds.; Springer International Publishing: Berlin, Germany, 2016; Volume 9905, pp. 381–397. [Google Scholar]
- Zhang, Y.; Qiu, Z.; Yao, T.; Liu, D.; Mei, T. Fully convolutional adaptation networks for semantic segmentation. In Proceedings of the 2018 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6810–6818. [Google Scholar]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Fast end-to-end trainable guided filter. In Proceedings of the 2018 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1838–1847. [Google Scholar]
- Tian, Z.; He, T.; Shen, C.; Yan, Y. Decoders matter for semantic segmentation: Data-dependent decoding enables flexible feature aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 3121–3130. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef]
- Xu, L.; Ren, J.; Yan, Q.; Liao, R.; Jia, J. Deep edge-aware filters. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1669–1678. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Ding, H.; Jiang, X.; Shuai, B.; Liu, A.Q.; Wang, G. Semantic segmentation with context encoding and multi-path decoding. IEEE Trans. Image Process. 2020, 29, 3520–3533. [Google Scholar] [CrossRef] [PubMed]
- Ding, H.; Jiang, X.; Shuai, B.; Liu, A.Q.; Wang, G. Context contrasted feature and gated multi-scale aggregation for scene segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2393–2402. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in Pytorch. In Proceedings of the NIPS 2017 Autodiff Workshop, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking Wider to See Better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Versaci, M.; Morabito, F.C.; Angiulli, G. Adaptive image contrast enhancement by computing distances into a 4-dimensional fuzzy unit hypercube. IEEE Access 2017, 5, 26922–26931. [Google Scholar] [CrossRef]
- Jeon, G.; Anisetti, M.; Damiani, E.; Monga, O. Real-time image processing systems using fuzzy and rough sets techniques. Soft Comput. 2018, 22, 1381–1384. [Google Scholar] [CrossRef] [Green Version]
- Rahim, S.S.; Jayne, C.; Palade, V.; Shuttleworth, J. Automatic detection of microaneurysms in colour fundus images for diabetic retinopathy screening. Neural Comput. Appl. 2016, 27, 1149–1164. [Google Scholar] [CrossRef]
- Orujov, F.; Maskeliūnas, R.; Damaševičius, R.; Wei, W. Fuzzy based image edge detection algorithm for blood vessel detection in retinal images. Appl. Soft Comput. 2020, 94, 106452. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of International Conference on Learning Representation (ICLR), San Diego, CA, USA, 7–9 May 2016. [Google Scholar]
- Lin, D.; Chen, G.; Cohen-Or, D.; Heng, P.-A.; Huang, H. Cascaded feature network for semantic segmentation of RGB-D images. In Proceedings of the 2017 IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1320–1328. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path refinement networks for high-resolution se-mantic segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1063–6919. [Google Scholar]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. FastFCN: Rethinking dilated convolution in the backbone for semantic segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Yu, C.; Wang, J.; Gao, C.; Yu, G.; Shen, C.; Sang, N. Context prior for scene segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12413–12422. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; Hr, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-attention networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June; pp. 3141–3149.
- Fu, J.; Liu, J.; Jiang, J.; Li, Y.; Bao, Y.; Lu, H. Scene segmentation with dual relation-aware attention net-work. IEEE Trans. Neural Netw. Learn. Syst. 2020, 1–14. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Mean IoU (%) | Pixel Acc. (%) | Final Score |
|---|---|---|---|
| Ours (50) + SS | 43.82 | 81.23 | 62.53 |
| Ours (101) + SS | 44.21 | 82.71 | 63.46 |
| Ours (152) + SS | 44.86 | 82.91 | 63.89 |
| Ours (269) + SS | 46.26 | 83.11 | 64.69 |
| Ours (50) + MS | 44.16 | 81.70 | 62.93 |
| Ours (101) + MS | 46.41 | 82.86 | 64.64 |
| Ours (152) + MS | 46.88 | 83.66 | 65.27 |
| Ours (269) + MS | 47.16 | 83.82 | 65.49 |
| Method | Mean IoU (%) | Pixel Acc. (%) | Final Score |
|---|---|---|---|
| SegNet [10] | 21.64 | 71.00 | 46.32 |
| DilatedNet [47] | 32.31 | 73.55 | 52.93 |
| CascadeNet [48] | 34.90 | 74.52 | 54.71 |
| RefineNet [49] | 40.70 | - | - |
| PSPNet [50] | 43.29 | 81.39 | 62.34 |
| FastFCN [51] | 44.34 | 80.99 | 62.67 |
| EncNet [22] | 44.65 | 81.69 | 63.17 |
| CPNet [52] | 45.39 | 81.04 | 63.21 |
| CGBNet [37] | 44.90 | 82.10 | 63.50 |
| ResNeSt [53] | 46.91 | 82.07 | 64.49 |
| Ours | 46.41 | 82.86 | 64.64 |
| Method | Mean IoU (%) | Pixel Acc. (%) | Final Score |
|---|---|---|---|
| DeepLabV2 [12] | 45.70 | - | - |
| RefineNet [49] | 47.30 | - | - |
| PSPNet [50] | 47.80 | - | - |
| EncNet [22] | 51.70 | - | - |
| Dupsampling [34] | 52.50 | - | - |
| DANet [54] | 52.60 | - | - |
| FastFCN [51] | 53.10 | 79.12 | 66.11 |
| CPNet [52] | 53.90 | ||
| CGBNet [37] | 53.40 | 79.60 | 66.50 |
| DRAN [55] | 55.40 | 79.60 | 67.50 |
| Ours | 56.10 | 81.62 | 68.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sediqi, K.M.; Lee, H.J. A Novel Upsampling and Context Convolution for Image Semantic Segmentation. Sensors 2021, 21, 2170. https://doi.org/10.3390/s21062170
Sediqi KM, Lee HJ. A Novel Upsampling and Context Convolution for Image Semantic Segmentation. Sensors. 2021; 21(6):2170. https://doi.org/10.3390/s21062170
Chicago/Turabian StyleSediqi, Khwaja Monib, and Hyo Jong Lee. 2021. "A Novel Upsampling and Context Convolution for Image Semantic Segmentation" Sensors 21, no. 6: 2170. https://doi.org/10.3390/s21062170
APA StyleSediqi, K. M., & Lee, H. J. (2021). A Novel Upsampling and Context Convolution for Image Semantic Segmentation. Sensors, 21(6), 2170. https://doi.org/10.3390/s21062170