1. Introduction
Research and development in respect of unmanned aerial vehicles (UAVs) have increased dramatically in recent years, particularly in respect of multirotor aerial vehicles, due to their agility, maneuverability, and ability to be deployed in many complex missions. Based on this, the research community has mainly focused on autonomous navigation applications where the environment is static and mapped, and obstacle locations are assumed to be known in advance. Moreover, the accessibility of Global Navigation Satellite System (GNSS) information helps a UAV’s autonomous navigation. However, nowadays, there is an expanding demand for complex outdoor applications, such as rescue, search, and surveillance. In this type of task, the absence of GNSS and environment knowledge due to their dynamics makes it mandatory to use the aerial robot’s exteroceptive sensors for navigation and collision avoidance.
The constraints mentioned above are present in most point-goal autonomous navigation and collision avoidance (PANCA) scenarios. Earlier methods have tackled this issue by dividing it into two modules: a global planning module, which creates trajectories from the robot’s current position to a given target-goal [
1]; and path following module, which keeps the robot close to the planned path [
2]. However, both modules depend on environment characteristics and robot dynamics, making them sensitive and needing them to be re-tuned for each scenario. Nevertheless, these methods suffer from the stochastic dynamic behavior of the obstacles and high computational cost when applied to highly unstructured environments.
More recently, the success of deep learning (DL) in solving artificial intelligence problems [
3] has motivated researchers in the field of autonomous systems to apply recent algorithms to common robotic issues like navigation, decision making, and control [
4]. However, DL algorithms work in a supervised fashion, and use structured datasets to train models that require a lot of data and manual labeling, which is a time-consuming process. Reinforcement learning frameworks have been merged with DL to address these limitations, which has led to a new research area called deep reinforcement learning (DRL) [
5]. DRL automates the process by mapping high-dimensional sensory information to robot motion commands without referencing the ground-truth (unsupervised manner). It requires only a scalar reward function to motivate the learning agent through trial-and-error experiences of interacting with the environment by seeking to find the best action for each given state. Even though significant progress has recently been made in the DRL area and its application to autonomous navigation and collision avoidance problems [
6], existing approaches are still limited mainly to two aspects: (i) some of the algorithms require billions of interactions with the environment, which can be costly. They need very sophisticated computing resources, and the obtained policies are prone to failure in many PANCA scenarios where a GPS signal is not available, which makes them inapplicable in real robotic systems [
7]; (ii) methods suffer from the generalization capability to new unseen environments or target goals. These limitations degrade the performance of the navigation system in complex and unstructured scenes.
This work addresses the above-motioned issues by proposing an onboard actor–critic deep reinforcement learning (DRL) approach that allows safe goal navigation by mapping exteroceptive sensors, robot state, and goal information to continuous velocity control inputs, which allows better generalization and learning efficiency. The proposed method has been evaluated for different tasks: (1) generalization capabilities to new unseen goals, where the mission objective is to navigate toward a target goal that was not seen during training; (2) robustness against localization noise, where a Gaussian noise was added to the robot localization system during the testing phase before moving to the real-world experiments; (3) optimal motion, where the developed approach was compared with a nonlinear model predictive control (NMPC) technique, in terms of path shortness toward the goal; (4) sim-to-real generalization, where the obtained policies were tested in a real aerial robot to demonstrate the navigation efficiency.
In summary, a novel navigation system for a micro aerial vehicle (MAV) has been proposed. To train and test the developed approach, we created a simulation framework based on the Gazebo open-source 3D robotics simulator. The reality gap was closed by simulating the aerial robot and the sensors using the original specifications. A vast set of simulation experiments shows that the proposed approach can achieve point-goal navigation in optimal paths, outperforming the NMPC method. The developed algorithm runs in real-time onboard the UAV using an NVIDIA Jetson board TX2 GPU. The obstacle detection was performed using Hokuyo 2D lidar measurements. The UAV state estimation was achieved by using Intel’s tracking camera RT265. The remainder of this paper is organized as follows.
Section 2 introduces related work.
Section 3 describe the aerial robot platform, and the architecture of the developed algorithm.
Section 4 presents the simulation results.
Section 5 presents the real-time experiments, and we finally conclude in
Section 6.
2. Related Work
Moving from an initial position to another target location is an ordinary task for humans. For a robot, such a job is a significant challenge due to the environment dynamics, especially in respect of aerial robotics. Several works have been proposed for autonomous navigation, and collision avoidance when the obstacles’ location or an environment map are known in advance based on the simultaneous localization and mapping (SLAM) algorithm [
8]. Under this assumption, the collision-free trajectory can be computed offline. In the literature, many different approaches exist that perform the path-planning task, for instance, the road-map approach and its different methods [
9], artificial potential field approach [
10], and other graph-search-based approaches, such as the
(AStar) algorithm and breadth-first search (BFS) [
11].
Those algorithms are highly dependent on the environment map representation method (metric or feature-based). The map’s accuracy and the number of obstacles have a significant influence on the path-finding algorithm. One of our approach’s primary advantages compared to these methods is that it does not require a prior map of the environment or obstacle location. Other classical approaches rely on predefined landmarks that are used on the run time for navigation [
12]. Our method does not make any assumption on the landmarks of the environment. With the recent development in edge computing systems, alternative approaches have been proposed for reactive planning, where the system relies on the immediate perception of its surrounding environment for decision-making. This increases the autonomy of the robotic systems and makes them avoid dynamic obstacles. For instance, in [
13], the authors proposed an approach based on nonlinear model predictive control (NMPC) for dynamic collision avoidance for a multi-rotor unmanned aerial vehicle. The presented technique combines the optimal path planning and optimal control design into a unified optimization problem; it was tested only in simulation, and it does not consider the model uncertainty and external disturbances. Another work applies an adaptive NMPC for quadrotor navigation, while taking into account specific exogenous signals [
14]. This technique seems to be computationally heavy due to the combined online parameter estimation and safe trajectory generation. Ref. [
15] presents an NMPC-based strategy for a quadrotor UAV in a 3D unknown environment. This approach is still limited because it assumes that the obstacle is static, which is not the case in the real world. These MPC-based approaches are prone to failure and are vulnerable to the local minima problem.
Attractive alternative approaches for robot motion planning are based on machine learning techniques. Typical methods are supervised imitation learning [
16] and deep reinforcement learning [
17]. Imitation learning uses expert demonstrations that are saved as datasets for training the navigation policies. The work in [
18] showed that it is possible to navigate an autonomous UAV in a forest-like environment by imitating human control. The work presented in [
19] extends this approach to an indoor environment where a quadrotor learns to cross a corridor. In [
20], the authors explored the application of imitation learning for an unmanned ground vehicle (UGV). However, these algorithms suffer from generalization capabilities to scenarios not included in the training data, which are primarily held for flying robots in 3D environments. Moreover, collecting useful, expert demonstrations for aerial robots is a nontrivial task as these robots can be hard to control, need an expert pilot, and cannot operate for a long time due to the power limitations.
More recently, deep reinforcement learning (DRL) has been used in many robotic applications [
21]. For instance, in [
22], the authors proposed a proximal policy optimization approach for fixed-wing UAV attitude control. Other work has used the same algorithm for quadrotor UAV attitude control [
23]. In [
24], navigation of an autonomous underwater vehicle (AUV) was addressed using the deep deterministic policy gradients (DDPG) algorithm. Other work has used the same technique (DDPG) for landing a quadrotor in a moving object [
25]. Ref. [
26] discusses asynchronous off-policy updates for learning robotic manipulation tasks. Regarding the DRL application for navigation and collision avoidance tasks, there are few works that have addressed these issues. In [
27], the authors reported that deep RL-based navigation could be useful in crowded spaces by modeling human–robot and human–human interactions as a reinforcement learning framework. The learned socially cooperative policies were tested on a real ground robot. A differential drive mobile robot point stabilization problem was addressed in [
28] by adopting the DDPG algorithm for calculating the desired velocities while taking both kinematic and dynamic constraints into account, such as speed and acceleration limits. Ref. [
29] presented a map-based DRL for mobile robot navigation by formulating the obstacle avoidance task as a DRL problem based on a generated local probabilistic cost map, which was treated as an input for the dueling double deep Q-network (DQN) algorithm. This technique is prone to failure in crowded environments where the map is unreliable or unavailable.
However, DRL algorithms’ applications for aerial robotic navigation tasks are still in the early stages of development. In [
30], the authors proposed a learning method called CAD2RL. It takes RGB images as its input and generates velocity commands. The policy was trained using the Monte Carlo policy evaluation algorithm. Memory-based DRL for obstacle avoidance in an unknown environment was presented in [
31], and the work considers a UAV performing a random exploration in an indoor environment, which is relatively easy compared to a point-goal navigation task. In [
32], the authors presented a motion planning technique for a quadrotor UAV. The approach uses a depth image as the input for the DQN algorithm and returns a discrete set of actions to guide the UAV. This approach is still limited; it lacks the generalization capabilities toward new target goals, and the discrete action can create undesirable osculation, which makes the aerial robot drift from the desired trajectory. The work in [
33] addressed this limitation by adopting the DDPG algorithm with continuous action space for UAV navigation in 3D space, yet still in an unrealistic simulated environment. The work in [
34] applies a DQN algorithm for a drone delivery task, where the UAV tries to reach a predefined goal while avoiding obstacles based on depth images. This approach’s main drawback is that it uses a discrete action space for guiding the UAV, and it was tested only in simulation. Other recent works have applied actor–critic architecture to achieve UAV autonomous navigation in large-scale complex environments, and this was tested only in a simulated environment [
35].
3. Robot Platform and System Description
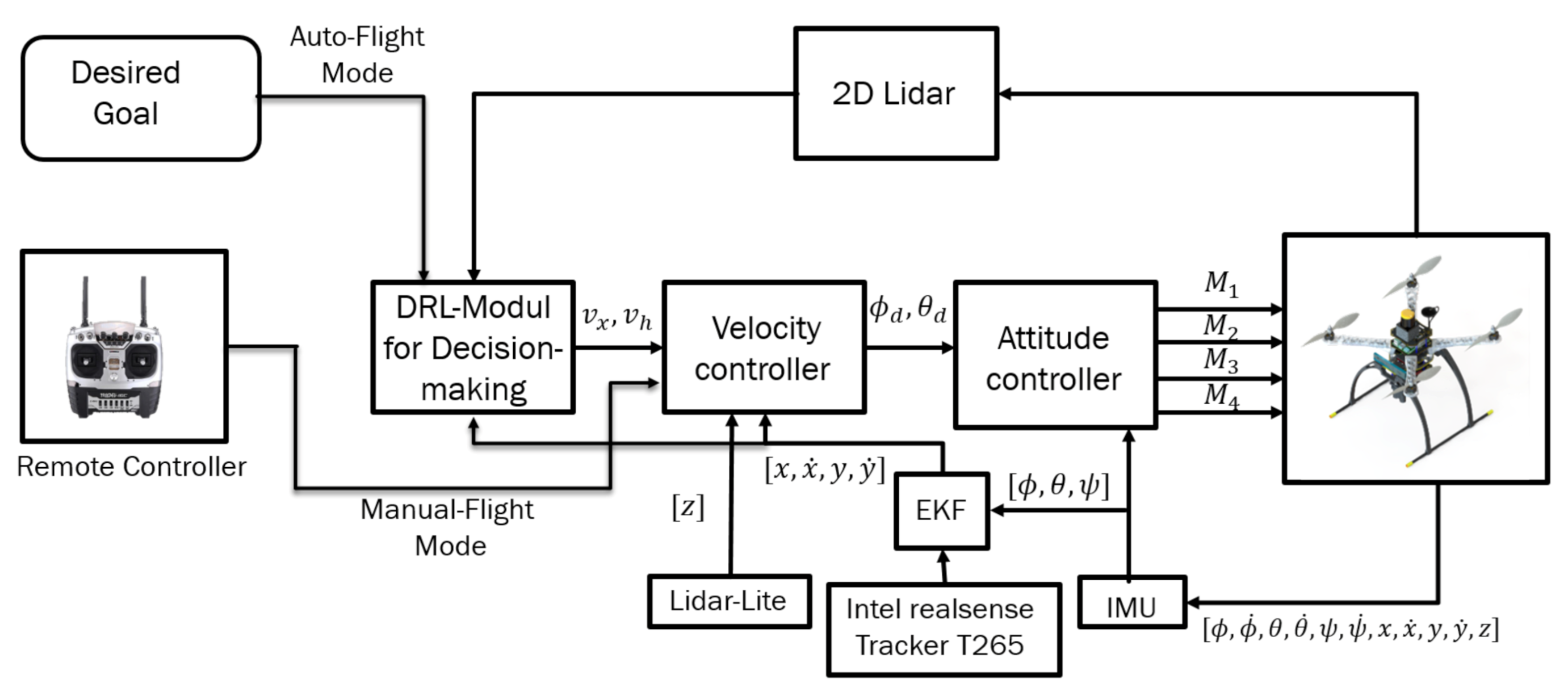
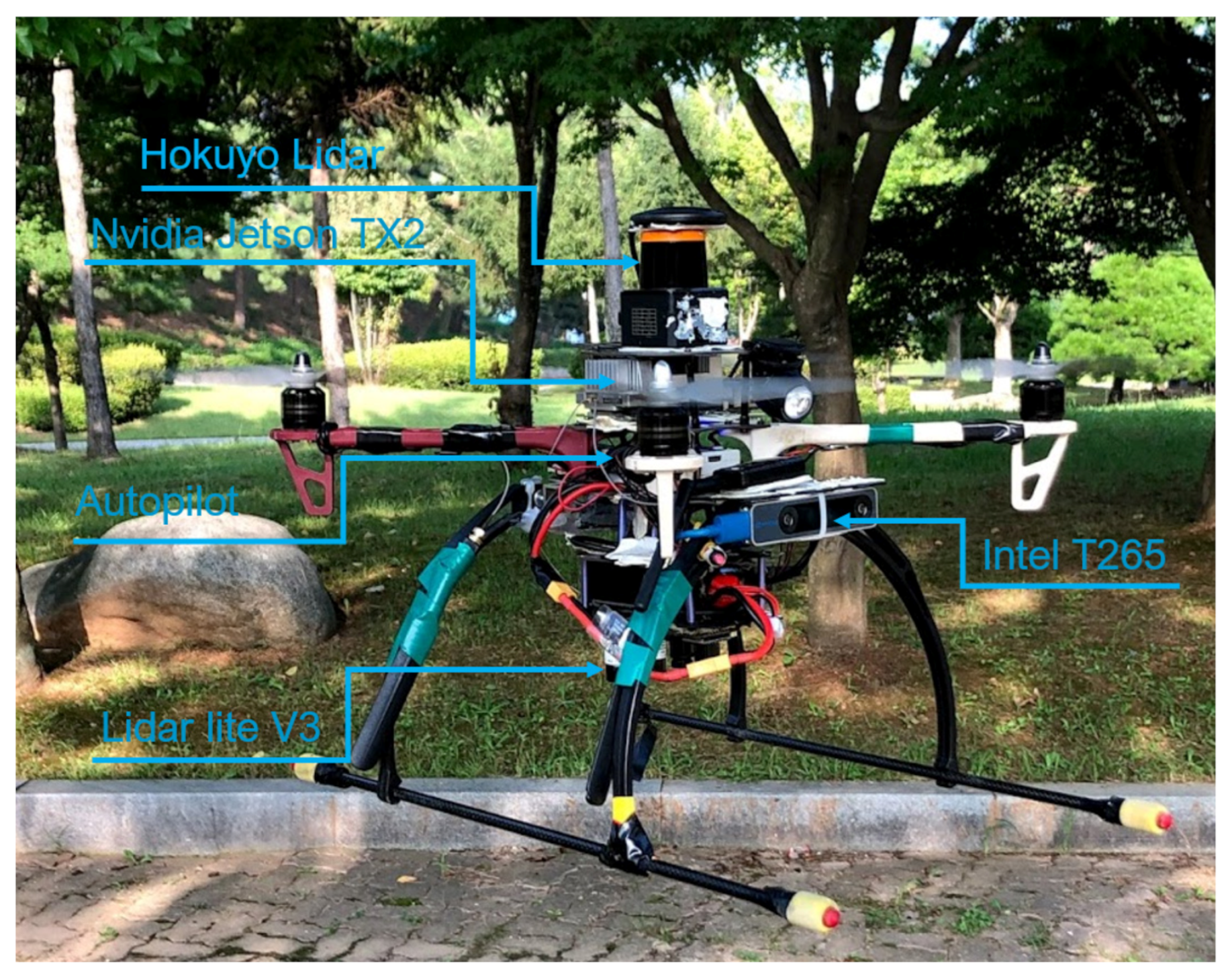
Experiments were performed using a customized quadrotor MAV (
Figure 1). The aerial robot includes an autopilot for flight control and an Nvidia Jetson TX2 onboard computer, mounted on top of the Auvidea J120 carrier board. The developed algorithms use a Hokuyo UST-10LX laser scan measurement within the field of view of 90 degrees and the MAV’s position, ground velocity, and orientation, which was estimated using a forward-facing fish-eye Intel tracking camera T265 module fused with other sensors (e.g., IMU data) using an extended Kalman filter (EKF) running on Pixhawk open-source flight control software [
36]. For accurate altitude feedback, the system uses a Lidar-Lite V3 laser range finder. A software part relay on the JetPack 3.2 (the Jetson SDK) and a robot operating system (ROS kinetic) were also installed for sensor interfacing. The deep reinforcement learning (DRL) module plays an essential role by adjusting the MAV’s linear velocity
and heading rate
towards the goal point while avoiding possible obstacles in the path. The detailed configuration of the aerial robot is shown in
Table 1. The commanded velocities serve as a set-point for the high-level flight velocity controller. The complete architecture of the proposed system is presented in
Figure 2. The human pilot can select between two flight modes, manual or auto, using a radio transmitter. If the auto mode is selected, the DRL module will guide the drone towards the predefined goal-point while avoiding obstacles, and this makes the drone fully autonomous and able to navigate in an unknown outdoor environment. In case of an emergency, the pilot can intervene at any time by switching to manual flight mode.
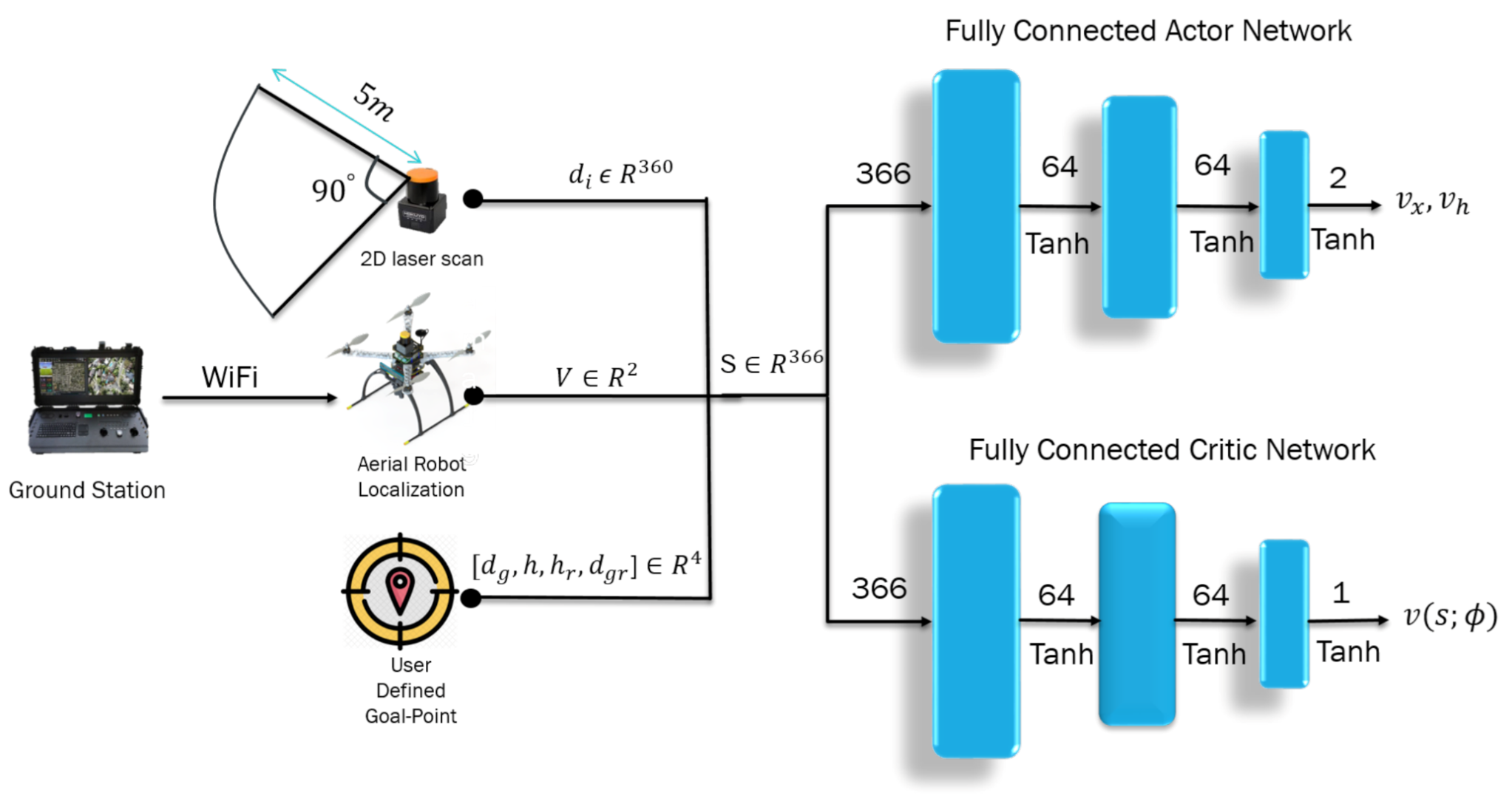
Problem Formulation
Conventional autonomous navigation and collision avoidance methods require prior knowledge of the environment for decision making (e.g., obstacle location assumed to be known, availability of the environment map). In an outdoor scenario, the environment is continuously changing, and building an accurate map representation in such cases becomes difficult and unfeasible. The point-goal autonomous navigation and collision avoidance (PANCA) have been formulated as a Markov decision process (MDP) to overcome these limitations. The MAV seeks to find the goal in a forest-like scenario by interacting with the environment using a lidar range finder. The MAV interacts with the environment by performing a continuous action
, which includes two moving commands (forward velocity and heading rate
), and the environment provides a reward scalar
at time
to show how good or bad the taken action was in a particular state
. These interactions can be represented by a tuple
, where
is the terminal state. In the PANCA task, the MAV reaches the terminal state when it finds the goal-point within 2 m of accuracy, when it crashes into an obstacle, or when the maximum number of steps is reached. To solve this MDP problem, we proposed a learning-based actor–critic architecture that learns the optimal navigation policy
, which is parameterized by the weights of the actor neural network
. The actor-network is designed to map the input states represented by the MAV’s current linear velocities
, current distance, and heading from the goal-point; and their rate of change and the laser scan data to a probability distribution over all possible actions. The critic-network approximates the action-value function, as shown in
Figure 3.
Both neural networks are the same, containing an input layer with a size of 366, followed by a hidden layer with 64 neurons. Finally, the output is forwarded to the last layer to generate the velocity commands
in the body frame of the MAV. The Tanh activation function follows each layer. The proposed algorithm is a model-free, on-policy, actor–critic, policy-gradient method, in which we try to learn a policy
by maximizing the true value-function
directly by calculating the gradient of the objective function
with respect to the neural network’s weights
.
To calculate the gradient, we take a full interaction trajectory
, which can be represented as
The
function below represents the sum of all rewards obtained during the course of a trajectory
within
T step
where
is the discount factor. Then we can calculate the probability
of the trajectory
given policy
as follows
The gradient of the objective function
is
Using the score function gradient estimator, we can estimate the gradients of the expectation
as follows:
where
is the advantage that can be estimated using the n-step
-target generalized advantage estimation (GAE) as follows:
As a result, the estimated advantage
can be expressed with TD-
as
in which if
we can get the one-step advantage estimate
Similarly, if
, the infinite-step advantage estimate will be obtained.
where
is the critic network weight, and
is the discount factor. To reduce the gradient estimate’s high-variance after an optimization step, we clip the gradient update to be in a specific interval
with
, which leads to minimal variance.
To successfully perform the desired PANCA task, a hybrid reward function
(shaped: with respect to flight time; sparse: with respect to laser scan data and the current distance from the goal) was designed for training the learning agent. The shaped function motivates the flying robot to reach the goal-point in minimal time, while the sparse function lets it avoid colliding with obstacles, it provides a negative reward
if the minimum distance from any obstacle is lower than
. If the distance from any obstacle is greater than
and the MAV reaches the goal-point within an accuracy of
, a significant positive reward is assigned
, the training episode finishes, and the MAV is randomly reinitialized to a new position. Hence, if the MAV is still far from the goal, a shaped reward will be given
. By summing the three rewards, we obtain the final reward function
. Algorithm 1 presents the designed reward function in detail. The full workflow for the presented approach is shown in Algorithm 2.
| Algorithm 1 Reward Function Definition |
![Sensors 21 02534 i001]() |
| Algorithm 2 Learning-based control policy for the point-goal autonomous navigation and collision avoidance (PANCA) tasks |
![Sensors 21 02534 i002]() |
Moreover, to verify the learning-based algorithm’s effectiveness, a comparison with a monlinear model predictive (NMPC) technique has been proposed in simulation experiments. To reduce the computational cost of the NMPC, 10 steps ahead was used for prediction, and the direct multiple shooting method was used to convert the optimal control problem (OCP) into a nonlinear programming problem (NLP). The simplified discrete differentially flat prediction plant model that was used for the MAV is presented below.
where
are the commanded linear forward velocity and the heading rate, respectively. The NMPC task formulates an optimal control problem (OCP) with constraints on states, manipulated variables, and obstacles that were detected using 2D laser scan measurements, which were considered as a state inequality constraint of a collision-free area. The complete OCP can be formulated as follows:
where
are the MAV’s current state and the desired goal, respectively; U represents the lumped control inputs
; and
are the diagonal weighting matrices as shown in Equation (
14).
is the MAV’s initial state and is the 2D point cloud reflected from the nearest obstacle from the MAV. is the desired safety distance given by the user.
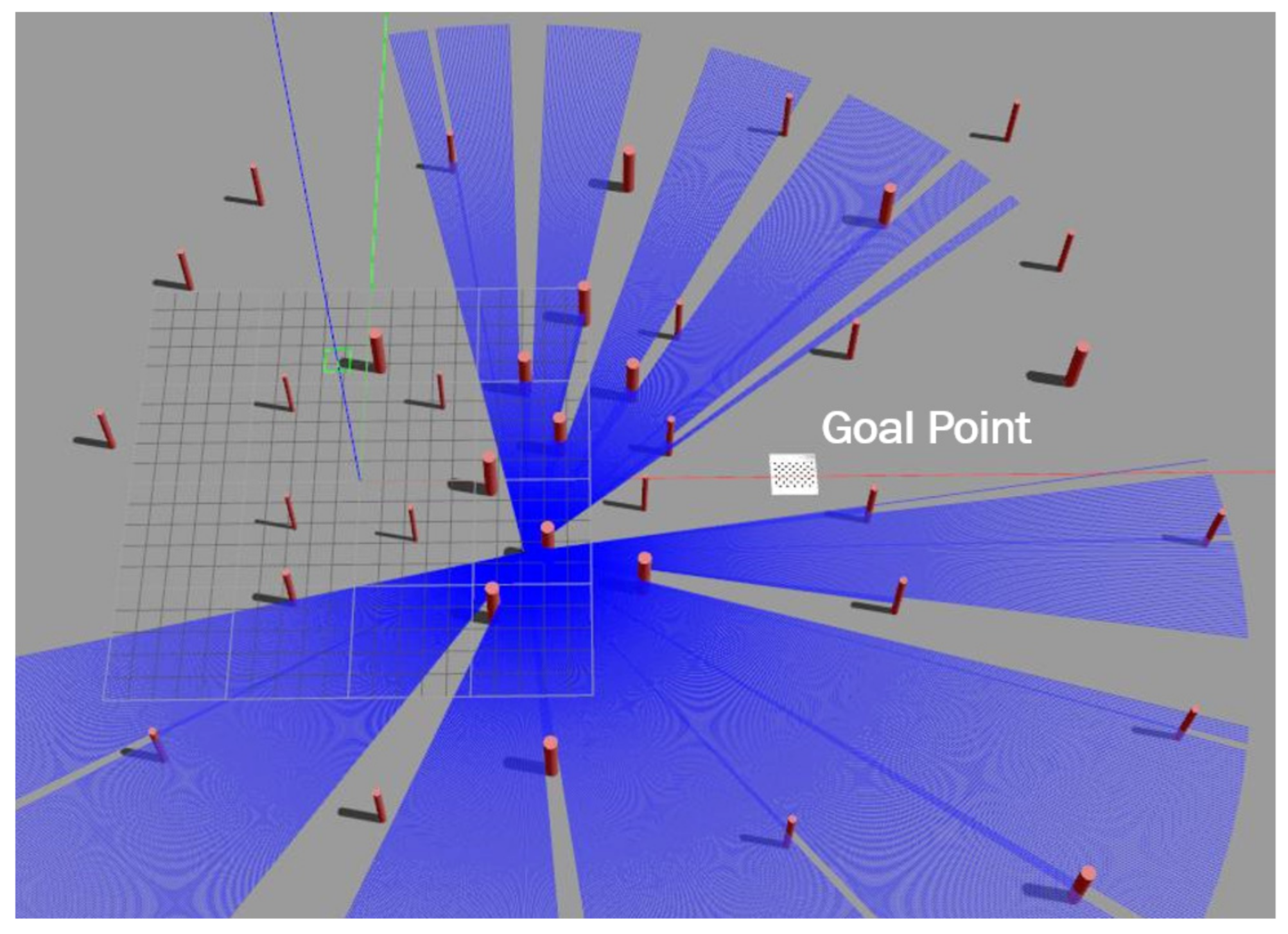
4. Training and Testing the Navigation Policy in Simulation
The main objective of point-goal navigation is to find the shortest path from a random initial position to the target goal location. To train and test the navigation policy, a simulated outdoor environment that contains multiple obstacles placed randomly was built on top of the Gazebo simulator (see
Figure 4). Firstly, training was performed in the environment by generating samples from a single simulated MAV equipped with a localization system and a 2D lidar. The MAV starts from a random initial position and tries to reach the goal. If the MAV arrives at the goal point, it gets a positive reward, both the MAV’s position and the goal position change, and a new episode begins. By doing this, the sample’s correlation will be reduced effectively. The training was performed using an Nvidia GTX 1080Ti GPU, Intel Xeon(R) CPU E5-2650v4 2.20 GHz × 24, and 125 GB of RAM. The MAV’s altitude was 1.2 m and it had a maximum forward speed of 1 m/s and maximum heading rate of 0.8 rad/s. The policy was trained using the Pytorch framework, CUDA
, and CuDNN 7.5. It took approximately 4 days to reach the 8 millionth training step.
Table 2 shows the learning parameters in detail.
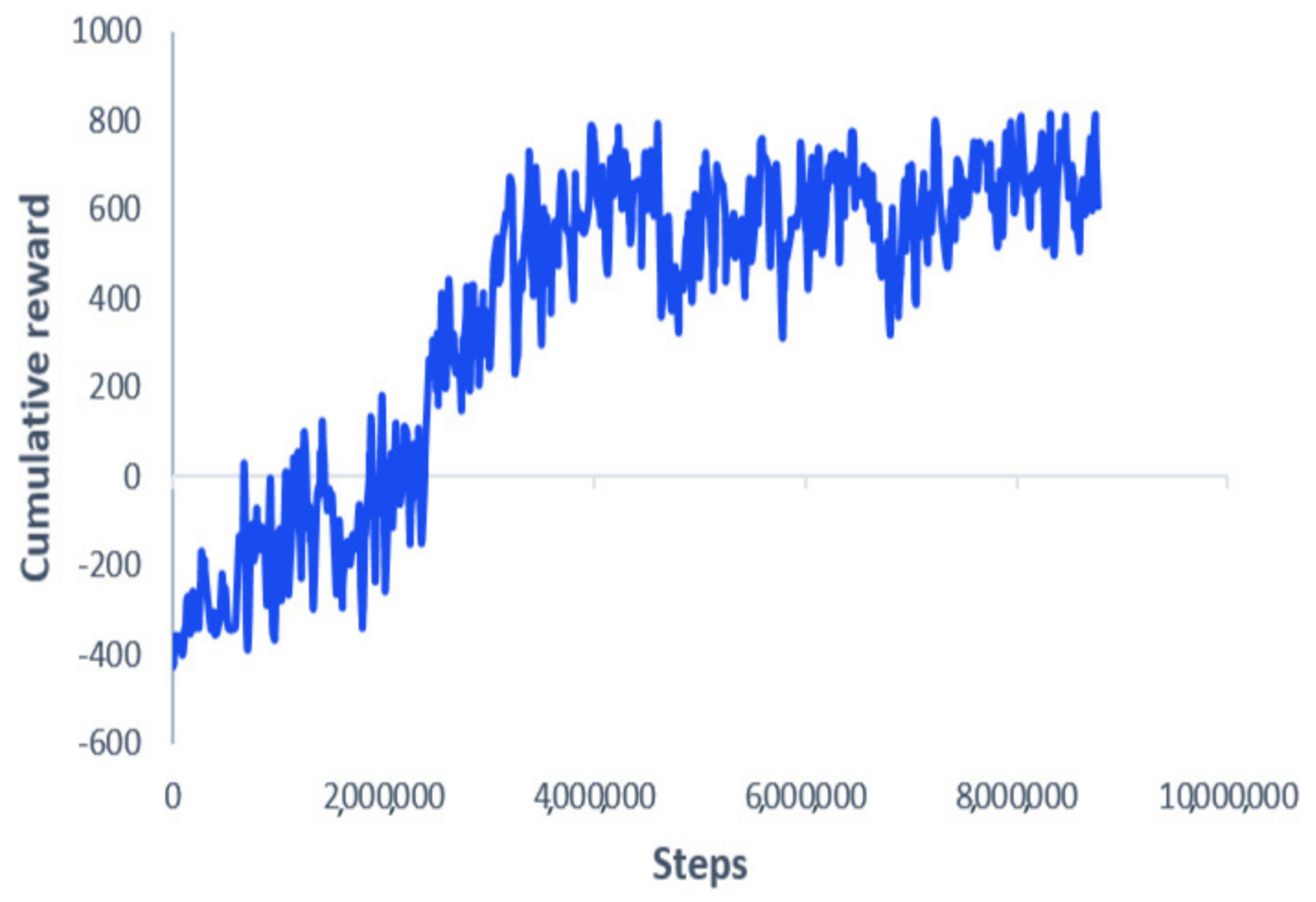
Figure 5 shows the learning curve. Starting from a negative value of
, the curve increases gradually until it converges to a particular positive value, around 500. This indicates that the MAV is learning gradually to avoid obstacles and reach the desired goal, leading to positive cumulative rewards. After the training finished, the obtained models were saved for testing purposes. Several performance metrics have been imposed to verify our algorithm’s effectiveness, such as generalization capabilities to new unseen goals, different initial takeoff positions, robustness against localization noise, and motion optimality. In the first simulation tests, the goal and takeoff positions were changed to new places not seen during the training phase. The developed algorithm was benchmarked with the NMPC technique presented earlier.
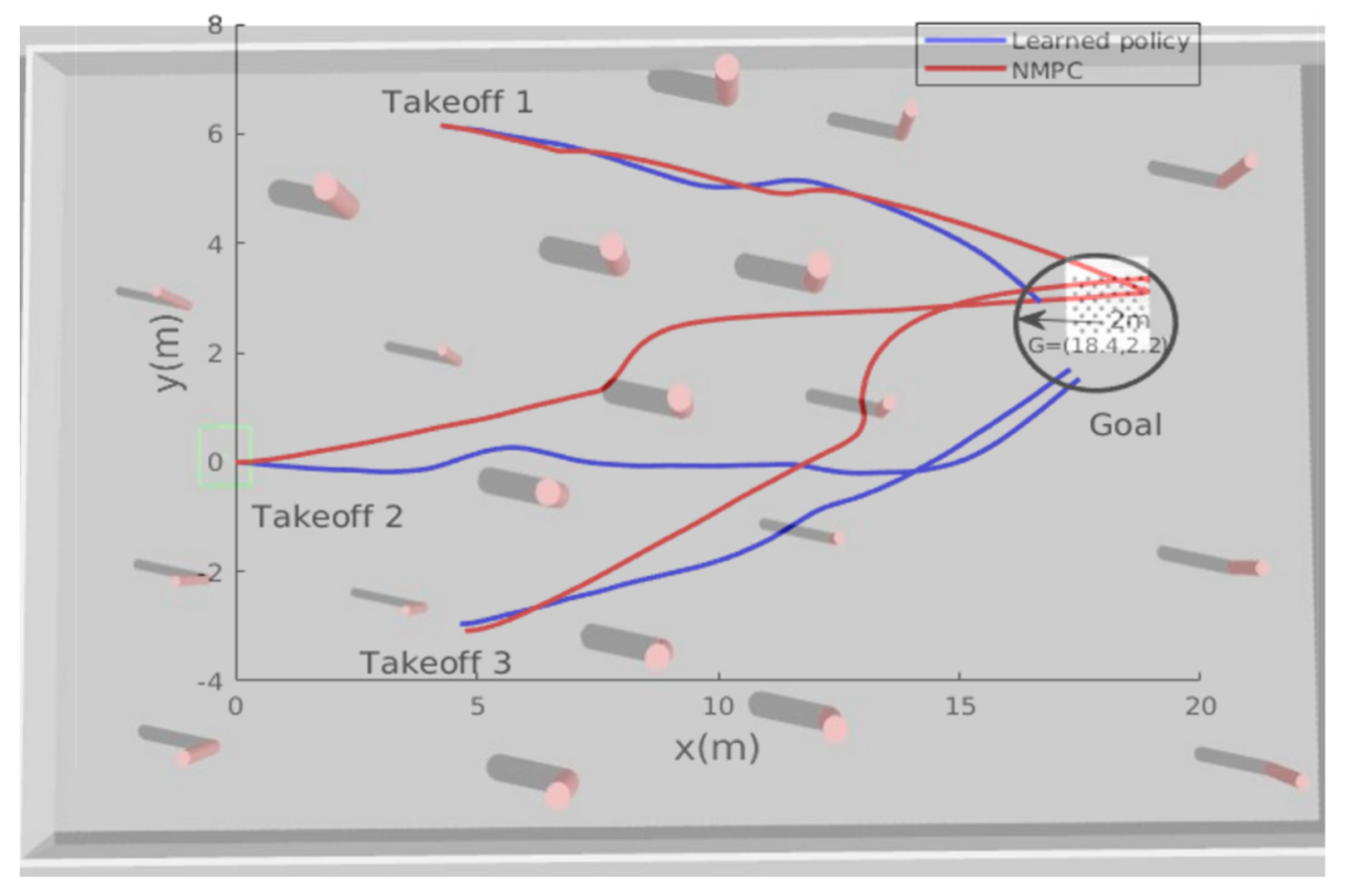
Figure 6 shows the paths taken by the MAV while trying to reach the desired goal location, starting from three different initial positions; both algorithms successfully guided the MAV towards the goal while avoiding the obstacles.
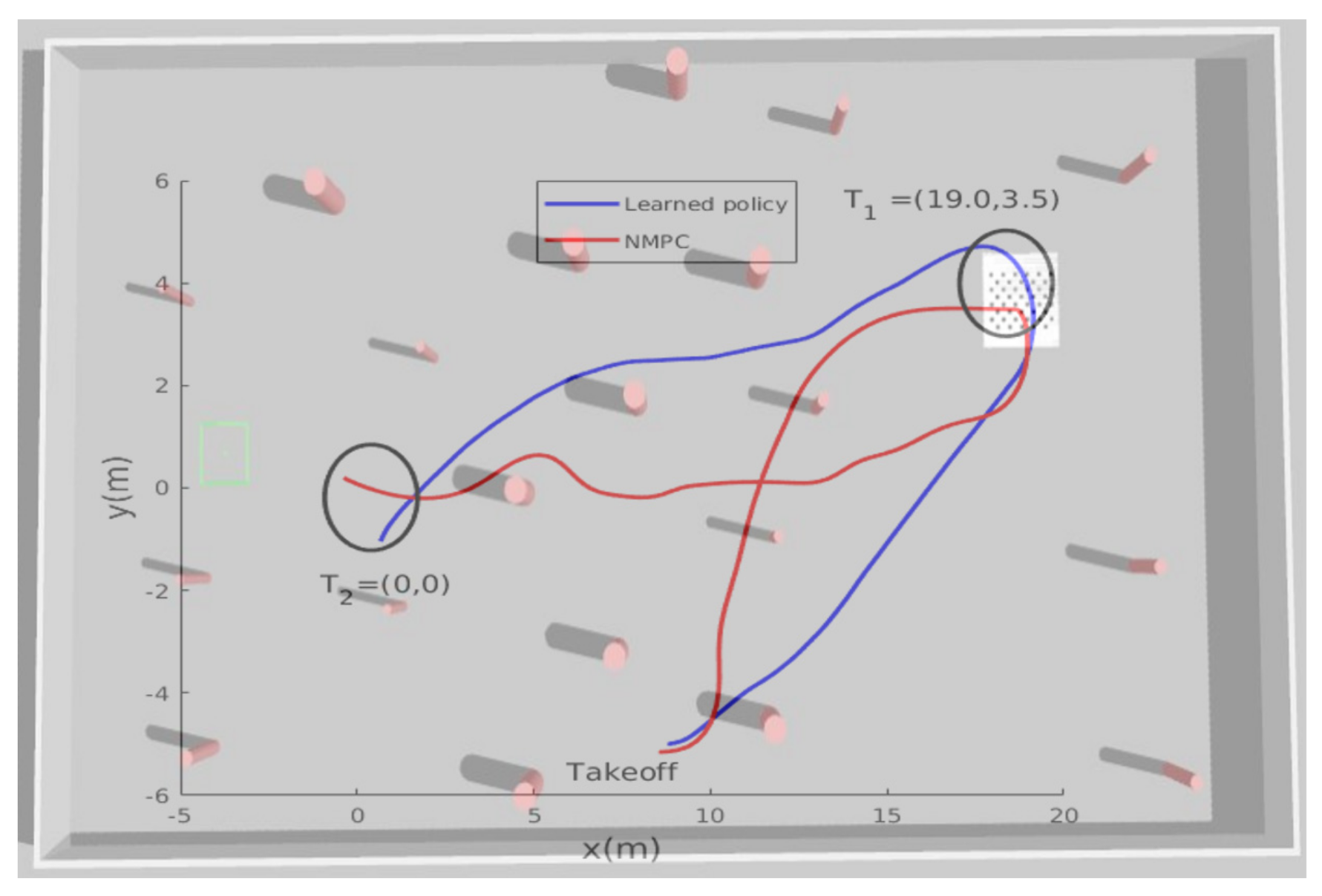
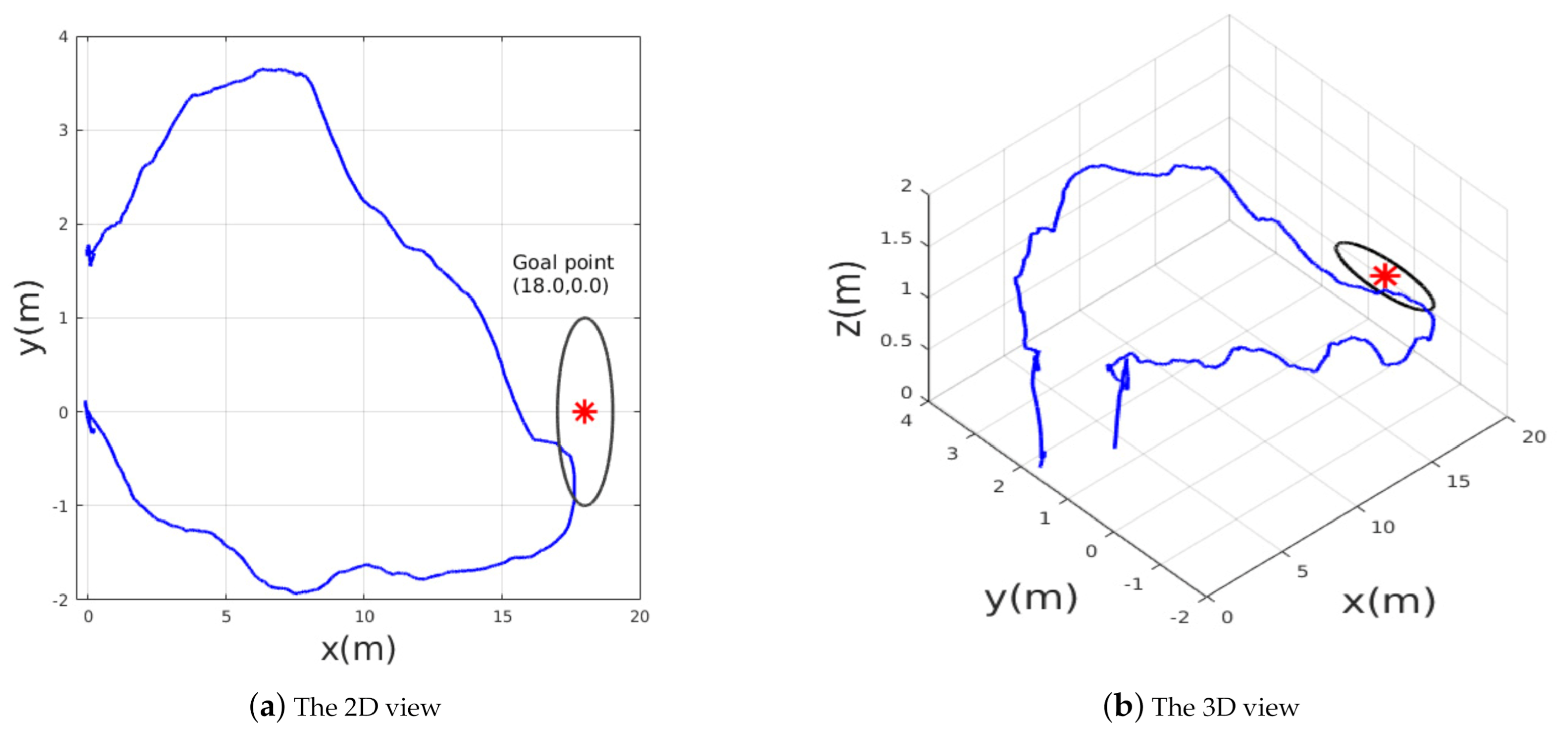
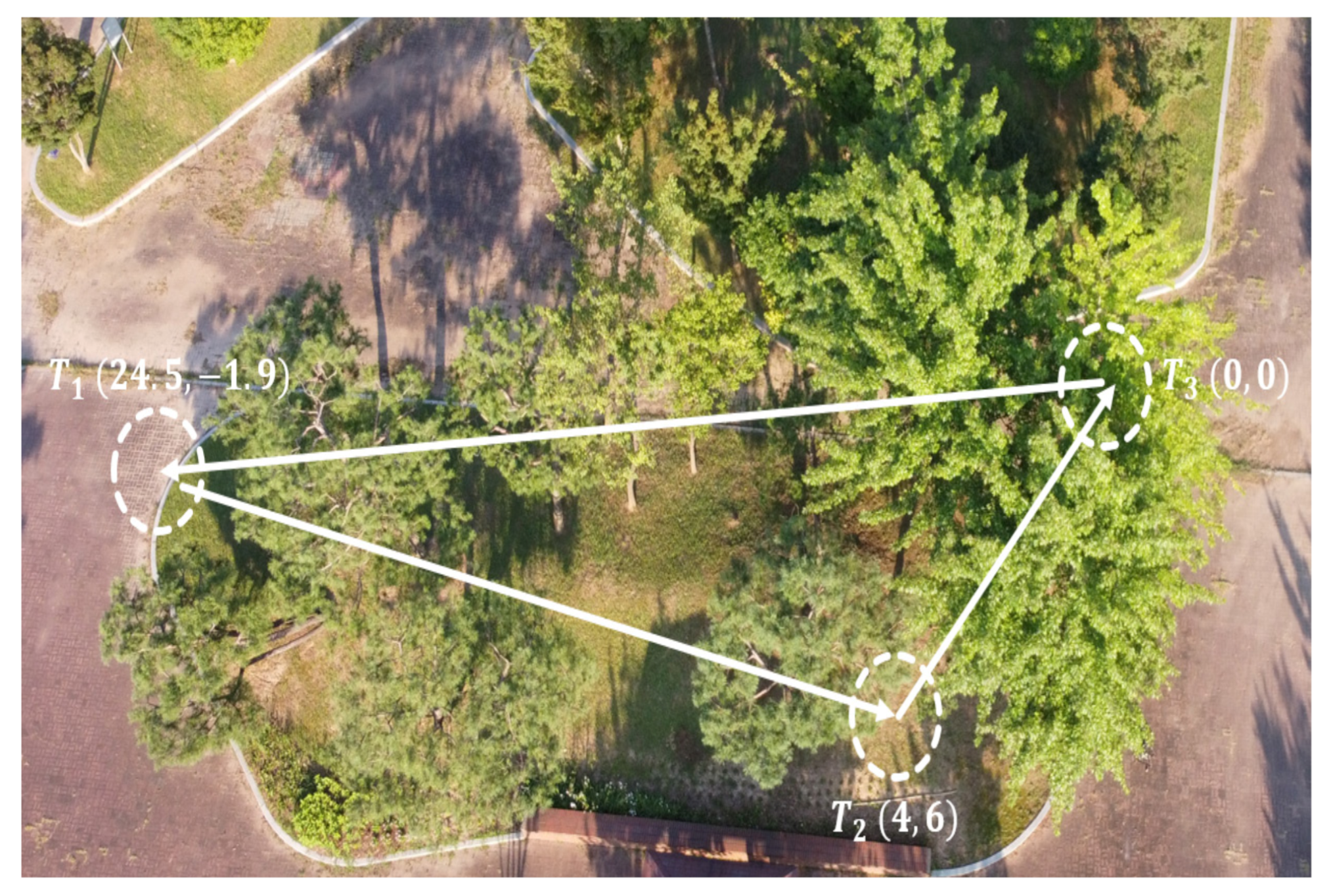
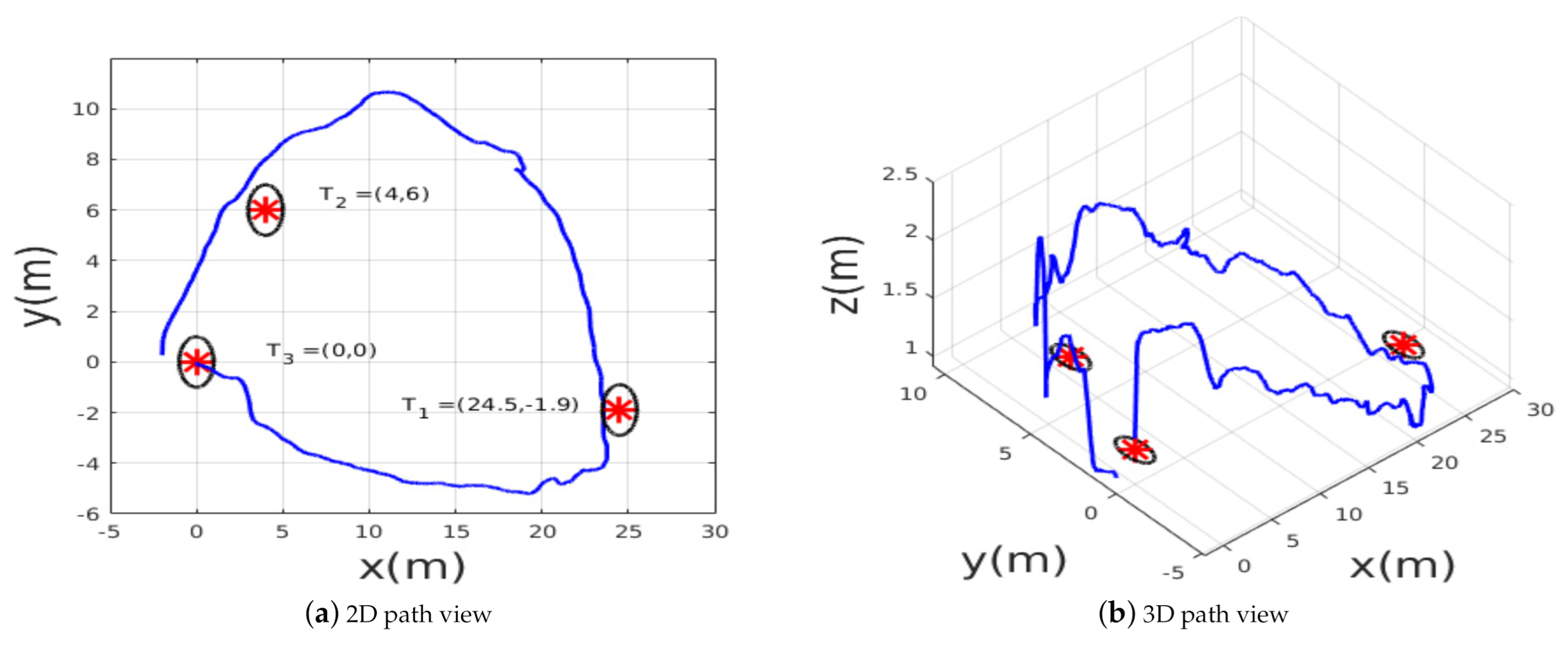
Figure 7 presents the obtained results from the second simulation tests. After takeoff, the MAV was ordered to reach two way-points
within an accuracy of 2 m. In this simulated scenario, the learning-based algorithm showed better performance in terms of trajectory smoothness and shortness compared with the NMPC technique.
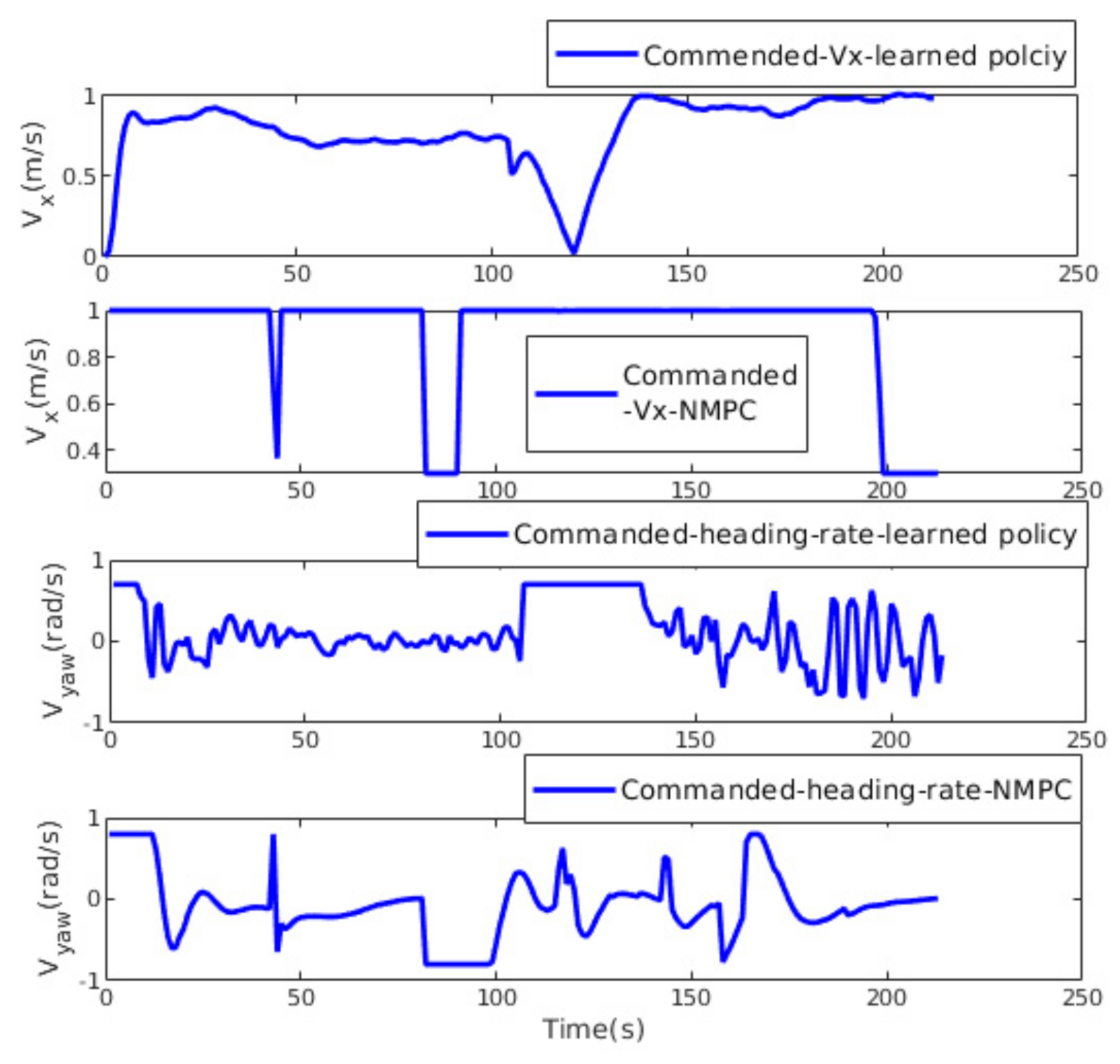
Samples from the commanded linear and angular velocities are shown in
Figure 8. The NMPC control inputs are more oscillating and jerky, which leads to undesirable motion. In contrast, the learned policy shows smooth velocity commands, making it more suitable for the real MAV.
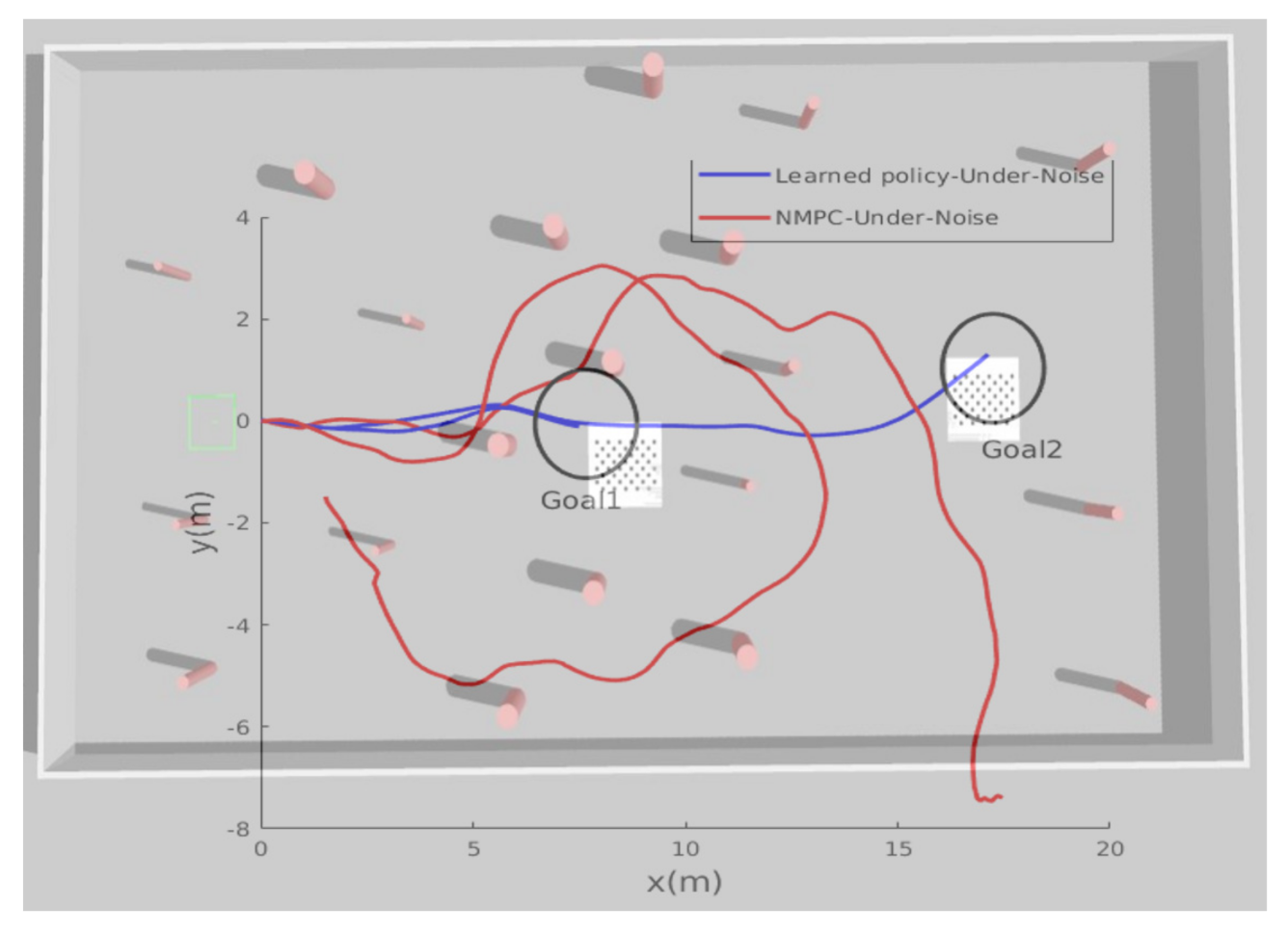
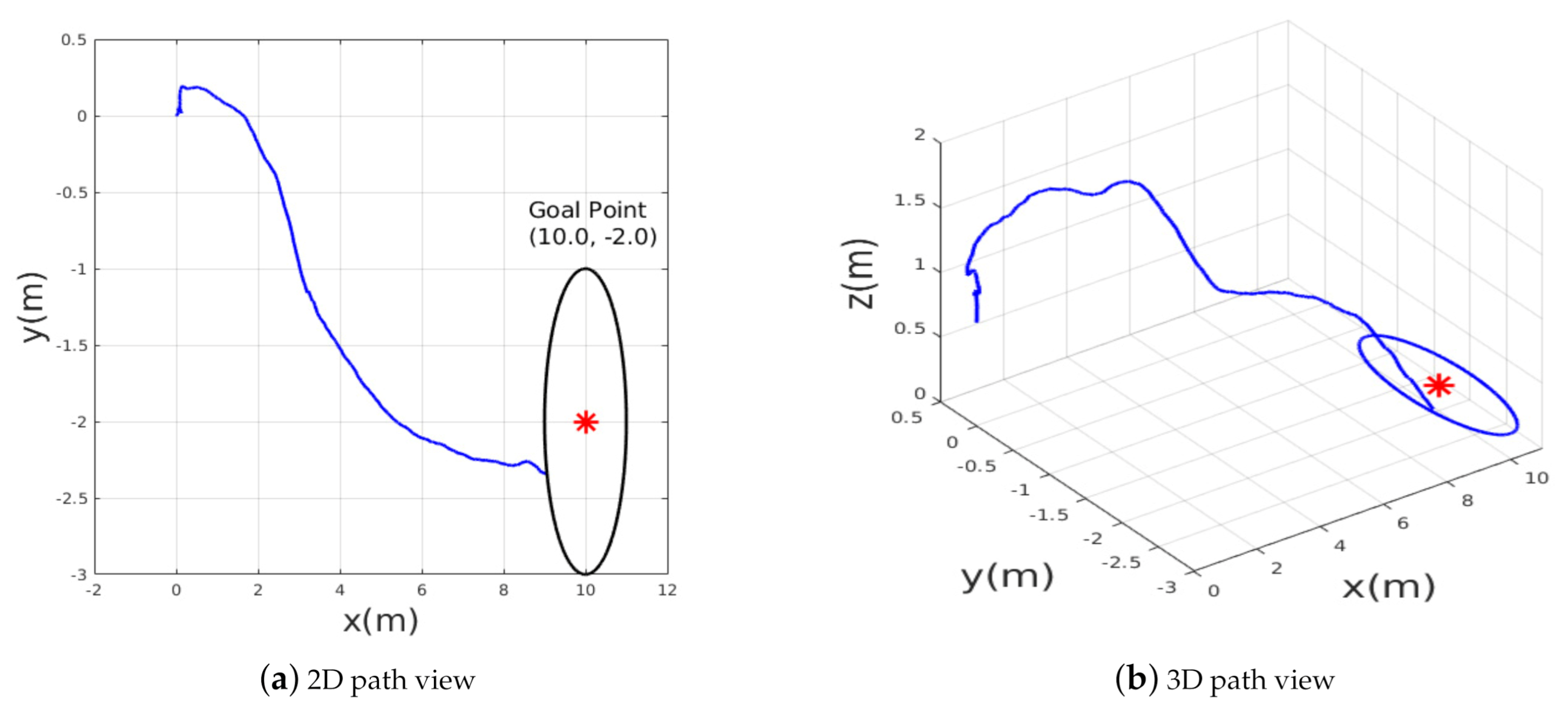
In addition to the generalization capability requirements, robustness against noise also was verified by adding Gaussian noise to the localization system (position and velocity) to mimic the real sensor measurements. In this third test, the MAV took off from an initial position of
under noisy localization input, and was ordered to reach the desired goal
.
Figure 9 shows the current path taken by the aerial robot. The obtained results show that the NMPC could handle the localization noise at all; even with a small variance of
, the MAV failed to find the goal and at the end it crashed. However, the new proposed learning-based algorithm shows better results. Under the same simulated noise, the MAV avoided the obstacles and achieved the goal with an accuracy of 2 m. Another test was carried out in the same environment where the desired goal was closer
and relatively easy to find; the NMPC was still not able to guide the MAV towards it, while the learned policy was able to guide the MAV to reach the goal smoothly and robustly. To understand the simulated scenarios, the reader is encouraged to watch the videos included in the Data Availability Statement.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}