
Pedestrian Detection Using Multispectral Images and a Deep Neural Network

Abstract
:1. Introduction
1.1. Pedestrian Safety and Challenges in Pedestrian Detection
1.2. Sensors for Pedestrian Detection
1.3. Computer Vision for Pedestrian Detection
1.4. Pedestrian Detection at Different Lighting Conditions
1.5. Contributions on Pedestrian Detection
2. Pedestrian Detection in Different Lighting Conditions
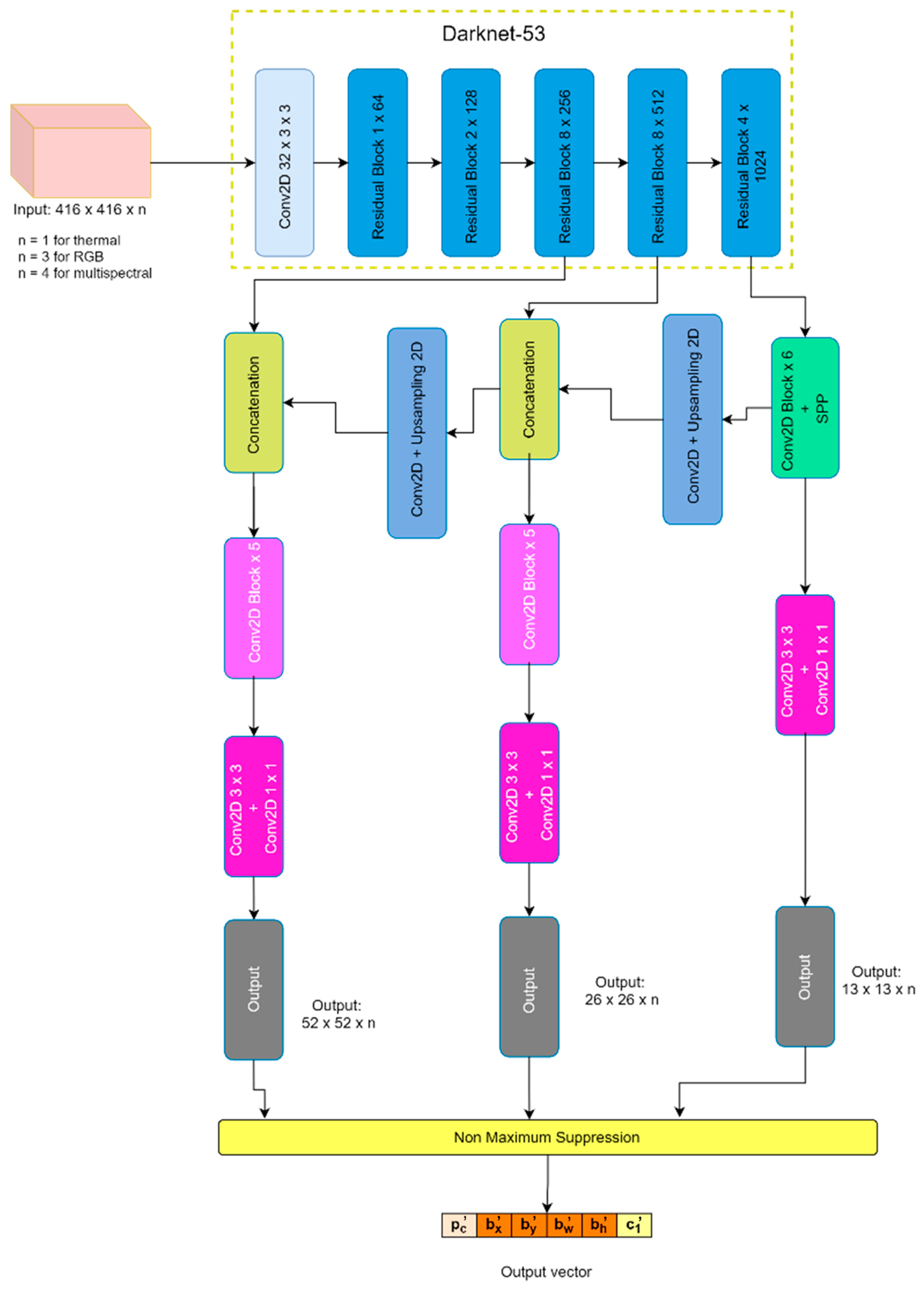
2.1. Multispectral Image Use for YOLO
2.2. Optimization of Deep Neural Network for Improving Detection Accuracy
2.3. Optimization Deep Neural Network for Reducing Processing Time
3. Experimental Results
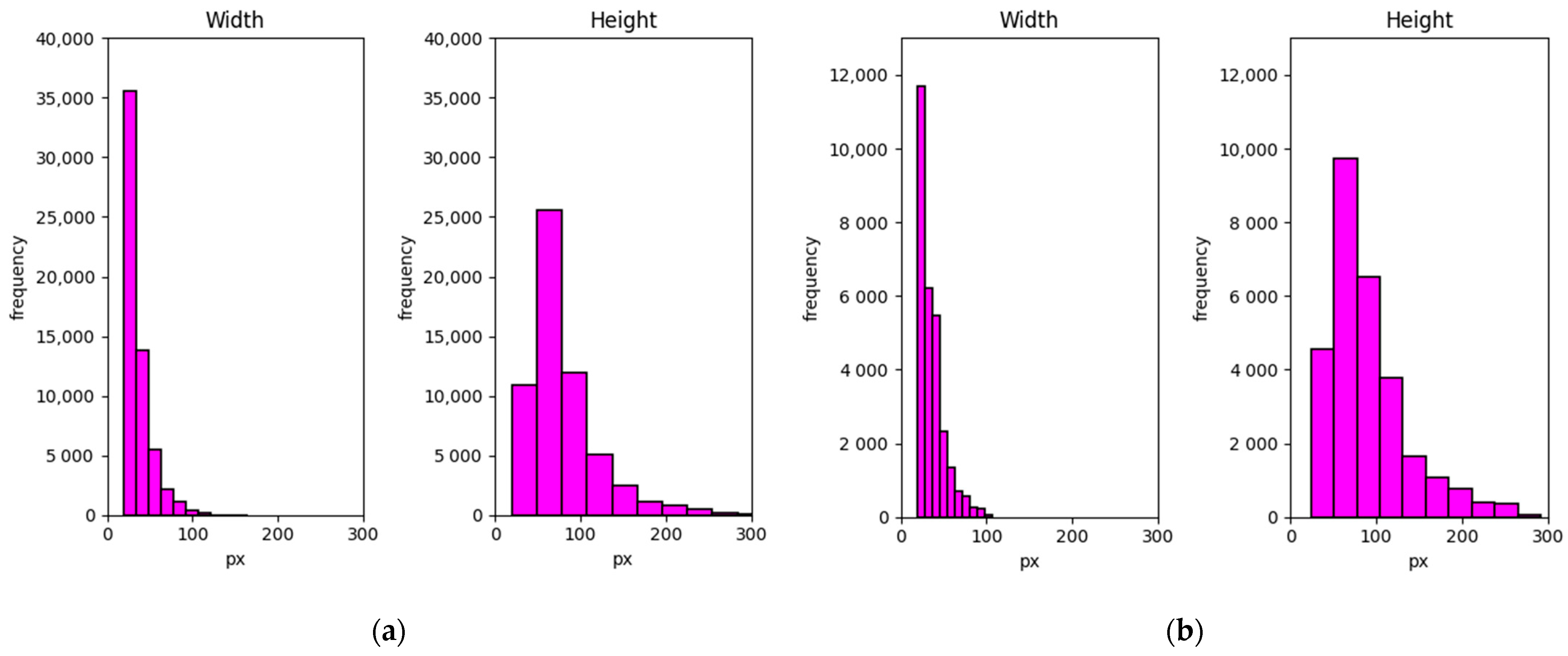
3.1. Dataset and Experiment Setup
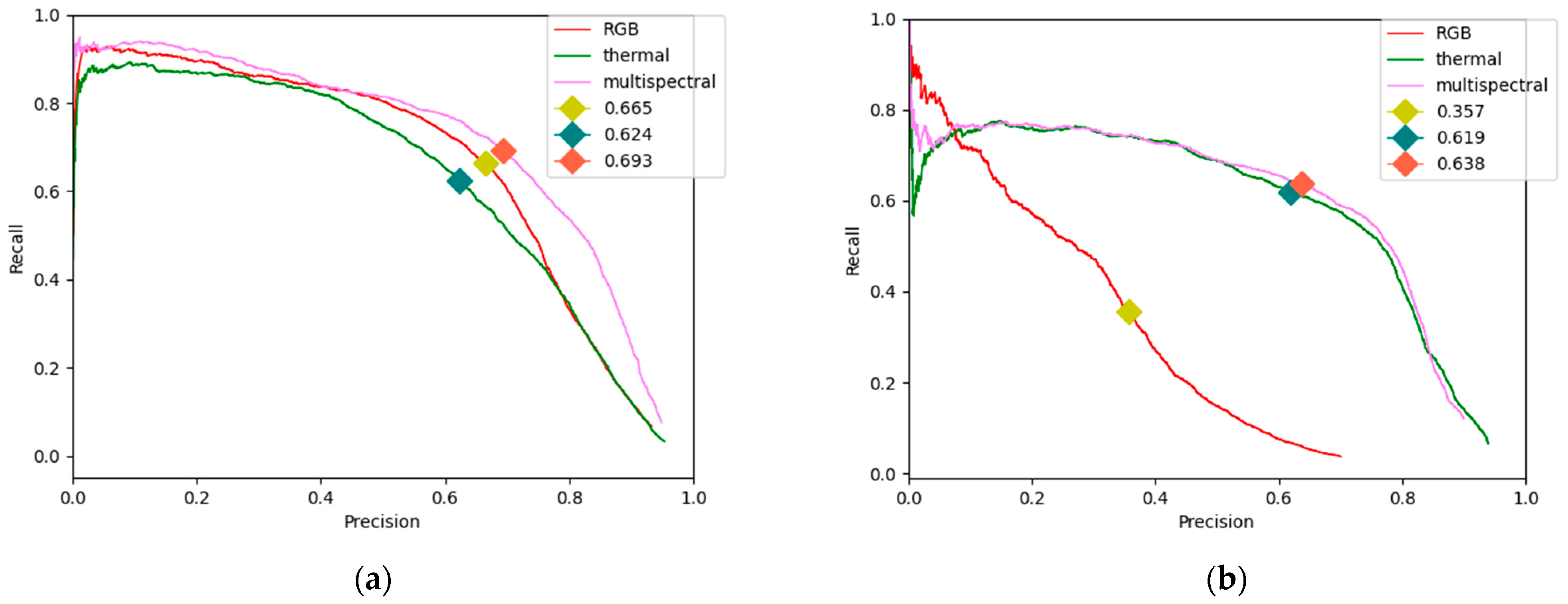
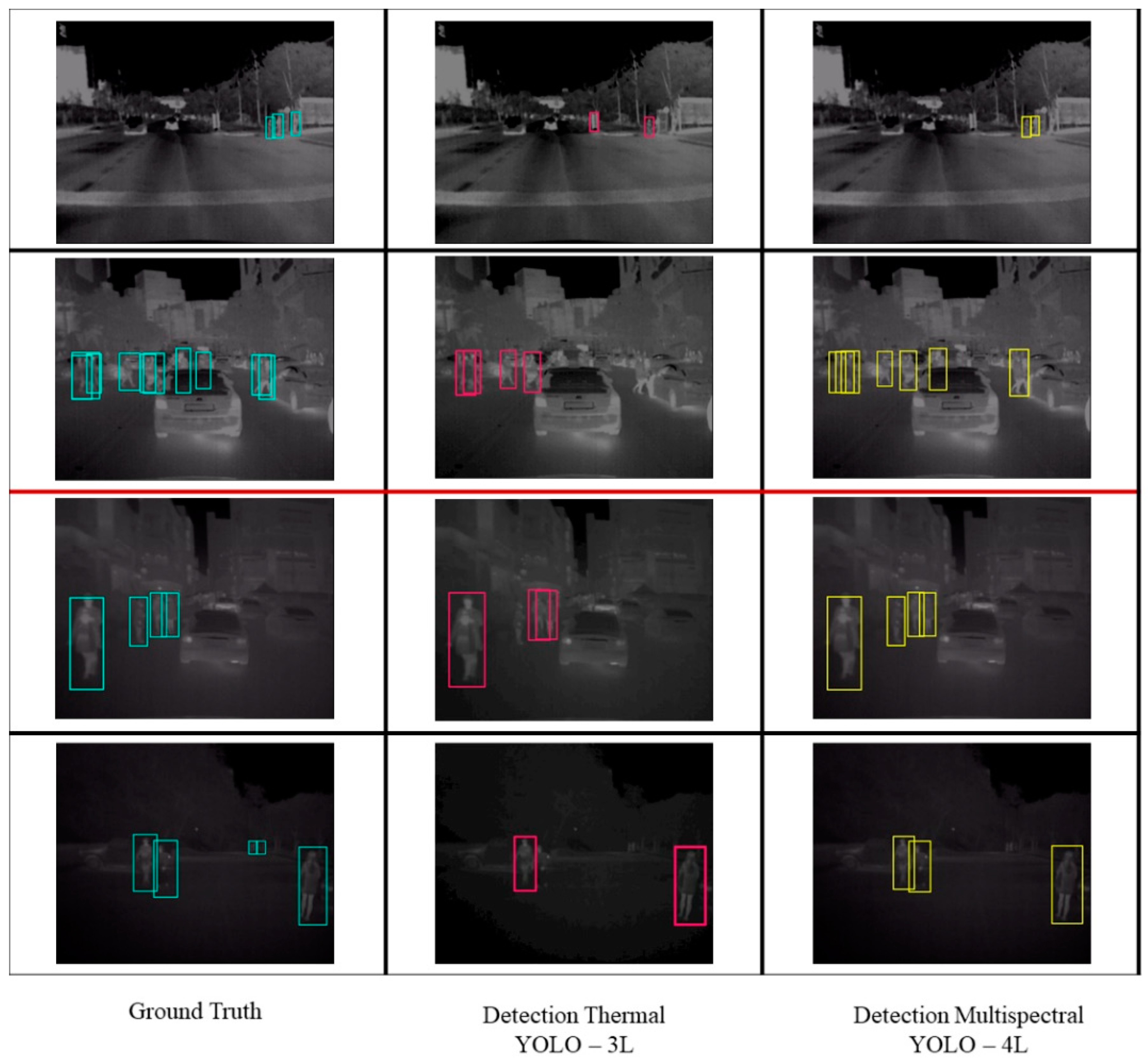
3.2. Pedestrian Detection Performance Using Different Image Sources
3.3. The YOLO Optimization Experimental Results towards the Detection Accuracy
3.4. The YOLO Optimization Experimental Results towards the Processing Time
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Road Safety Report 2019. International Traffic Safety Data and Analysis Group of the International Transportation Forum. Available online: https://www.itf-oecd.org/sites/default/files/docs/irtad-road-safety-annual-report-2019.pdf (accessed on 22 January 2021).
- Wakabayashi, D. Self-Driving Uber Car Kills Pedestrian in Arizona, Where Robots Roam. Available online: https://www.nytimes.com/2018/03/19/technology/uber-driverless-fatality.html (accessed on 8 December 2020).
- Traffic Safety Facts 2017 Data: Pedestrians. National Highway Traffic Safety Administration of the US Department of Transportation. Available online: https://www.nhtsa.gov/technology-innovation/automated-vehicles-safety (accessed on 30 January 2020).
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral Pedestrian Detection: Benchmark Dataset and Baseline. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Automatic Emergency Braking with Pedestrian Detection. American Automobile Association. Available online: https://www.aaa.com/AAA/common/aar/files/Research-Report-Pedestrian-Detection.pdf (accessed on 22 January 2021).
- Yoneda, K.; Suganuma, N.; Yanase, R.; Aldibaja, M. Automated Driving Recognition Technologies for Adverse Weather Conditions. IATSS Res. 2019, 43, 253–262. [Google Scholar] [CrossRef]
- Heuer, M.; Al-Hamadi, A.; Rain, A.; Meinecke, M.M. Detection and Tracking Approach using an Automotive Radar to Increase Active Pedestrian Safety. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium, Dearborn, MI, USA, 8–11 June 2014. [Google Scholar] [CrossRef]
- Premebida, C.; Ludwig, O.; Nunes, U. LIDAR and Vision-based Pedestrian Detection System. J. Field Robot. 2009, 26, 696–711. [Google Scholar] [CrossRef]
- Camara, F.; Bellotto, N.; Cosar, S.; Nathanael, D.; Althoff, M.; Wu, J.; Ruenz, J.; Dietrich, A.; Fox, C. Pedestrian Models for Autonomous Driving Part I: Low-level Models, from Sensing to Tracking. IEEE Trans. Intell. Transp. Syst. 2020, 1–21. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J.; Snow, D. Detecting Pedestrians Using Patterns of Motion and Appearance. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar] [CrossRef] [Green Version]
- Brunetti, A.; Buongiorno, D.; Trotta, G.F.; Bevilacqua, V. Computer Vision and Deep Learning Techniques for Pedestrian Detection and Tracking: A Survey. Neurocomputing 2018, 300, 17–33. [Google Scholar] [CrossRef]
- Zhang, L.; Li, S.Z.; Yuan, X.; Xiang, S. Real-Time Object Classification in Video Surveillance Based on Appearance Learning. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar] [CrossRef]
- Moradi, M.J.; Hariri-Ardebili, M.A. Developing a Library of Shear Walls Database and the Neural Network based Predictive Meta-model. Appl. Sci. 2019, 9, 2562. [Google Scholar] [CrossRef] [Green Version]
- Ganguly, B.; Chaudhuri, S.; Biswas, S.; Dey, D.; Munshi, S.; Chatterjee, B.; Dalai, S.; Chakravorti, S. Wavelet Kernel-Based Convolutional Neural Network for Localization of Partial Discharge Sources Within a Power Apparatus. IEEE Trans. Ind. Inform. 2020, 17, 1831–1841. [Google Scholar] [CrossRef]
- Roshani, M.; Phan, G.T.; Ali, P.J.M.; Roshani, G.H.; Hanus, R.; Duong, T.; Corniani, E.; Nazemi, E.; Kalmoun, E. Evaluation of Flow Pattern Recognition and Void Fraction Measurement in Two Phase Flow Independent of Oil Pipeline’s Scale Layer Thickness. Alex. Eng. J. 2021, 60, 1955–1966. [Google Scholar] [CrossRef]
- Fuqua, D.; Razzaghi, T. A Cost-sensitive Convolution Neural Network Learning for Control Chart Pattern Recognition. Expert Syst. Appl. 2020, 150, 1–17. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J.; Berkeley, U.C.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhao, X.; Li, W.; Zhang, Y.; Gulliver, T.A.; Chang, S.; Feng, Z. A Faster RCNN-based Pedestrian Detection System. In Proceedings of the 2016 IEEE 84th Vehicular Technology Conference (VTC-Fall), Montreal, QC, Canada, 18–21 September 2016. [Google Scholar] [CrossRef]
- Lan, W.; Dang, J.; Wang, Y.; Wang, S. Pedestrian Detection based on YOLO Network Model. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation, Changchun, China, 5–8 August 2018. [Google Scholar] [CrossRef]
- Liu, D.; Gao, S.; Chi, W.; Fan, D. Pedestrian Detection Algorithm based on Improved SSD. Int. J. Comput. Appl. Technol. 2021, 65, 25–35. [Google Scholar] [CrossRef]
- Piniarski, K.; Pawłowski, P.; Dąbrowski, A. Pedestrian Detection by Video Processing in Automotive Night Vision System. In Proceedings of the 2014 Signal Processing: Algorithms, Architectures, Arrangements, and Applications, Poznan, Poland, 22–24 September 2014. [Google Scholar]
- Sun, H.; Wang, C.; Wang, B. Night Vision Pedestrian Detection Using a Forward-Looking Infrared Camera. In Proceedings of the 2011 International Workshop on Multi-Platfor/Multi-Sensor Remote Sensing and Mapping, Xiamen, China, 10–12 January 2011. [Google Scholar] [CrossRef]
- Luo, Y.; Remillard, J.; Hoetzer, D. Pedestrian Detection in Near-Infrared Night Vision System. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010. [Google Scholar] [CrossRef]
- Govardhan, P.; Pati, U.C. NIR Image Based Pedestrian Detection in Night Vision with Cascade Classification and Validation. In Proceedings of the 2014 IEEE International Conference on Advanced Communications, Control and Computing Technologies, Ramanathapuram, India, 8–10 May 2014. [Google Scholar] [CrossRef]
- Han, T.Y.; Song, B.C. Night Vision Pedestrian Detection Based on Adaptive Preprocessing Using near Infrared Camera. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics-Asia, Seoul, Korea, 26–28 October 2016. [Google Scholar] [CrossRef]
- Chebrolu, K.N.R.; Kumar, P.N. Deep Learning Based Pedestrian Detection at All Light Conditions. In Proceedings of the 2019 IEEE International Conference on Communication and Signal Processing, Chennai, India, 4–6 April 2019. [Google Scholar] [CrossRef]
- Hou, Y.L.; Song, Y.; Hao, X.; Shen, Y.; Qian, M.; Chen, H. Multispectral Pedestrian Detection Based on Deep Convolutional Neural Networks. Infrared Phys. Technol. 2018, 94, 69–77. [Google Scholar] [CrossRef]
- Konig, D.; Adam, M.; Jarvers, C.; Layher, G.; Neumann, H.; Teutsch, M. Fully Convolutional Region Proposal Networks for Multispectral Person Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Choi, H.; Kim, S.; Park, K.; Sohn, K. Multi-Spectral Pedestrian Detection Based on Accumulated Object Proposal with Fully Convolutional Networks. In Proceedings of the 2016 International Conference on Pattern Recognition, Cancún, Mexico, 4–8 December 2016. [Google Scholar] [CrossRef]
- Nataprawira, J.; Gu, Y.; Goncharenko, I.; Kamijo, S. Pedestrian Detection on Multispectral Images in Different Lighting Conditions. In Proceedings of the 39th IEEE International Conference on Consumer Electronics, Online Meeting, 10–12 January 2021. [Google Scholar]
- Nataprawira, J. Pedestrian Detection in Different Lighting Conditions Using Deep Neural Network and Multispectral Images. Bachelor’s Thesis, Ritsumeikan University, Kyoto, Japan, 1 February 2021. [Google Scholar]
- Versaci, M.; Morabito, F.C. Image Edge Detection: A New Approach Based on Fuzzy Entropy and Fuzzy Divergence. Int. J. Fuzzy Syst. 2021, 1–19. [Google Scholar] [CrossRef]
- Glenn, J.; Yonghye, K.; guigarfr; Josh, V.M.; perry0418; Ttayu; Marc; Gabriel, B.; Fatih, B.; Daniel, S.; et al. ultralytics/yolov3: [email protected]:0.95 on COCO2014. Available online: https://zenodo.org/record/3785397#.YGlfdT8RXIU (accessed on 23 June 2020). [CrossRef]
- Lu, Y.; Zhang, L.; Xie, W. YOLO-Compact: An Efficient YOLO Network for Single Category Real-Time Object Detection. In Proceedings of the 32nd Chinese Control and Decision Conference, Hefei, China, 22–24 August 2020. [Google Scholar] [CrossRef]
- Chen, K.; Deng, J.D. An Optimized CNN Model for Pedestrian Implement on Development Boards. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics, Osaka, Japan, 15–18 October 2019. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: A Benchmark. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–26 June 2009. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLO-4L | YOLO-4L-C1 | YOLO-4L-C2 | YOLO-4L-C3 | YOLO-4L-C4 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Layer | Filters | Size | Layer | Filters | Size | Layer | Filters | Size | Layer | Filters | Size | Layer | Filters | Size |
| Conv | 32 | 3 × 3 | Conv | 32 | 3 × 3 | Conv | 32 | 3 × 3 | Conv | 32 | 3 × 3 | Conv | 32 | 3 × 3 |
| Conv | 64 | 3 × 3 | Conv | 64 | 3 × 3 | Conv | 64 | 3 × 3 | Conv | 64 | 3 × 3 | Conv | 64 | 3 × 3 |
| Conv | 32 | 1 × 1 | Conv | 32 | 1 × 1 | Conv | 32 | 1 × 1 | Conv | 32 | 1 × 1 | Conv | 32 | 1 × 1 |
| Conv | 64 | 3 × 3 | Conv | 64 | 3 × 3 | Conv | 64 | 3 × 3 | Conv | 64 | 3 × 3 | Conv | 64 | 3 × 3 |
| 1 × Residual Block | 1 × Residual Block | 1 × Residual Block | 1 × Residual Block | 1 × Residual Block | ||||||||||
| Conv | 128 | 3 × 3 | Conv | 128 | 3 × 3 | Conv | 128 | 3 × 3 | Conv | 128 | 3 × 3 | Conv | 128 | 3 × 3 |
| Conv | 64 | 1 × 1 | Conv | 64 | 1 × 1 | Conv | 64 | 1 × 1 | Conv | 64 | 1 × 1 | Conv | 64 | 1 × 1 |
| Conv | 128 | 3 × 3 | Conv | 128 | 3 × 3 | Conv | 128 | 3 × 3 | Conv | 128 | 3 × 3 | Conv | 128 | 3 × 3 |
| 2 × Residual Block | 2 × Residual Block | 2 × Residual Block | 2 × Residual Block | 2 × Residual Block | ||||||||||
| 5 × Feature Output | 1 × Feature Output | 5 × Feature Output | 1 × Feature Output | 1 × Feature Output | ||||||||||
| Conv | 256 | 3 × 3 | Conv | 256 | 3 × 3 | Conv | 256 | 3 × 3 | Conv | 256 | 3 × 3 | Conv | 256 | 3 × 3 |
| Conv | 128 | 1 × 1 | Conv | 128 | 1 × 1 | Conv | 128 | 1 × 1 | Conv | 128 | 1 × 1 | Conv | 128 | 1 × 1 |
| Conv | 256 | 3 × 3 | Conv | 256 | 3 × 3 | Conv | 256 | 3 × 3 | Conv | 256 | 3 × 3 | Conv | 256 | 3 × 3 |
| 8 × Residual Block | 8 × Residual Block | 4 × Residual Block | 4 × Residual Block | 4 × Feature Output | ||||||||||
| 5 × Feature Output | 1 × Feature Output | 5 × Feature Output | 1 × Feature Output | 1 × Feature Output | ||||||||||
| Conv | 512 | 3 × 3 | Conv | 512 | 3 × 3 | Conv | 512 | 3 × 3 | Conv | 512 | 3 × 3 | Conv | 512 | 3 × 3 |
| Conv | 256 | 1 × 1 | Conv | 256 | 1 × 1 | Conv | 256 | 1 × 1 | Conv | 256 | 1 × 1 | Conv | 256 | 1 × 1 |
| Conv | 512 | 3 × 3 | Conv | 512 | 3 × 3 | Conv | 512 | 3 × 3 | Conv | 512 | 3 × 3 | Conv | 512 | 3 × 3 |
| 8 × Residual Block | 8 × Residual Block | 4 × Residual Block | 4 × Residual Block | 2 × Residual Block | ||||||||||
| 5 × Feature Output | 1 × Feature Output | 5 × Feature Output | 1 × Feature Output | 1 × Feature Output | ||||||||||
| Conv | 1024 | 3 × 3 | Conv | 1024 | 3 × 3 | Conv | 1024 | 3 × 3 | Conv | 1024 | 3 × 3 | Conv | 1024 | 3 × 3 |
| Conv | 512 | 1 × 1 | Conv | 512 | 1 × 1 | Conv | 512 | 1 × 1 | Conv | 512 | 1 × 1 | Conv | 512 | 1 × 1 |
| Conv | 1024 | 3 × 3 | Conv | 1024 | 3 × 3 | Conv | 1024 | 3 × 3 | Conv | 1024 | 3 × 3 | Conv | 1024 | 3 × 3 |
| 4 × Residual Block | 4 × Residual Block | 4 × Residual Block | 4 × Residual Block | 2 × Residual Block | ||||||||||
| 6 × Feature Output + SPP | 1 × Feature Output + SPP | 6 × Feature Output + SPP | 1 × Feature Output + SPP | 1 × Feature Output + SPP | ||||||||||
| Model | Daytime | Nighttime |
|---|---|---|
| YOLO-3L | 69.3% | 63.8% |
| YOLO-4L | 72.1% | 64.2% |
| Configuration | Training | Average | |||||
|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | |||
| YOLO-3L | Thermal | 65.4% | 63.9% | 63.9% | 63.8% | 64.9% | 64.5% |
| Multispectral | 69.6% | 70.7% | 69% | 71.2% | 70.7% | 70.13% | |
| YOLO-4L | Multispectral | 71.2% | 71.7% | 71.2% | 72.5% | 71.8% | 71.4% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nataprawira, J.; Gu, Y.; Goncharenko, I.; Kamijo, S. Pedestrian Detection Using Multispectral Images and a Deep Neural Network. Sensors 2021, 21, 2536. https://doi.org/10.3390/s21072536
Nataprawira J, Gu Y, Goncharenko I, Kamijo S. Pedestrian Detection Using Multispectral Images and a Deep Neural Network. Sensors. 2021; 21(7):2536. https://doi.org/10.3390/s21072536
Chicago/Turabian StyleNataprawira, Jason, Yanlei Gu, Igor Goncharenko, and Shunsuke Kamijo. 2021. "Pedestrian Detection Using Multispectral Images and a Deep Neural Network" Sensors 21, no. 7: 2536. https://doi.org/10.3390/s21072536
APA StyleNataprawira, J., Gu, Y., Goncharenko, I., & Kamijo, S. (2021). Pedestrian Detection Using Multispectral Images and a Deep Neural Network. Sensors, 21(7), 2536. https://doi.org/10.3390/s21072536