
Performance Evaluation of Machine Learning Frameworks for Aphasia Assessment


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Dataset
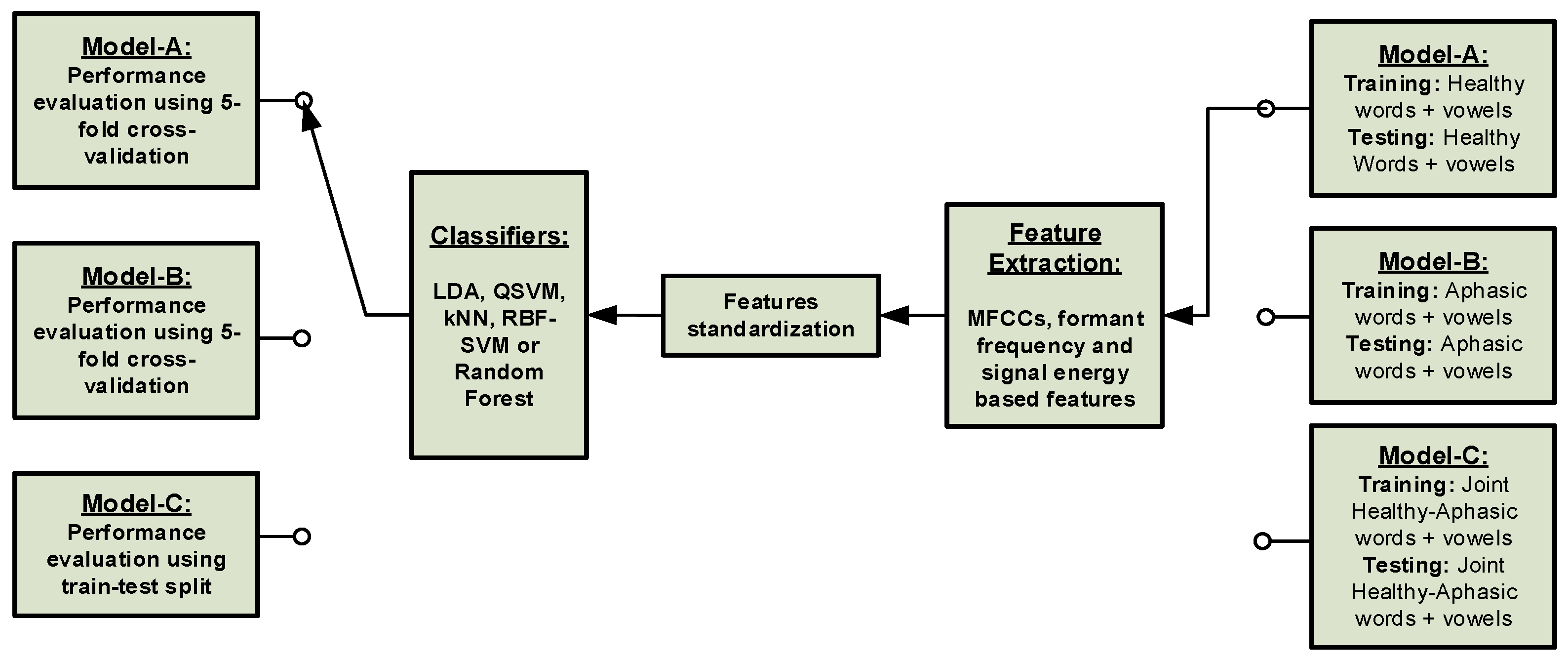
3.2. Machine Learning Frameworks
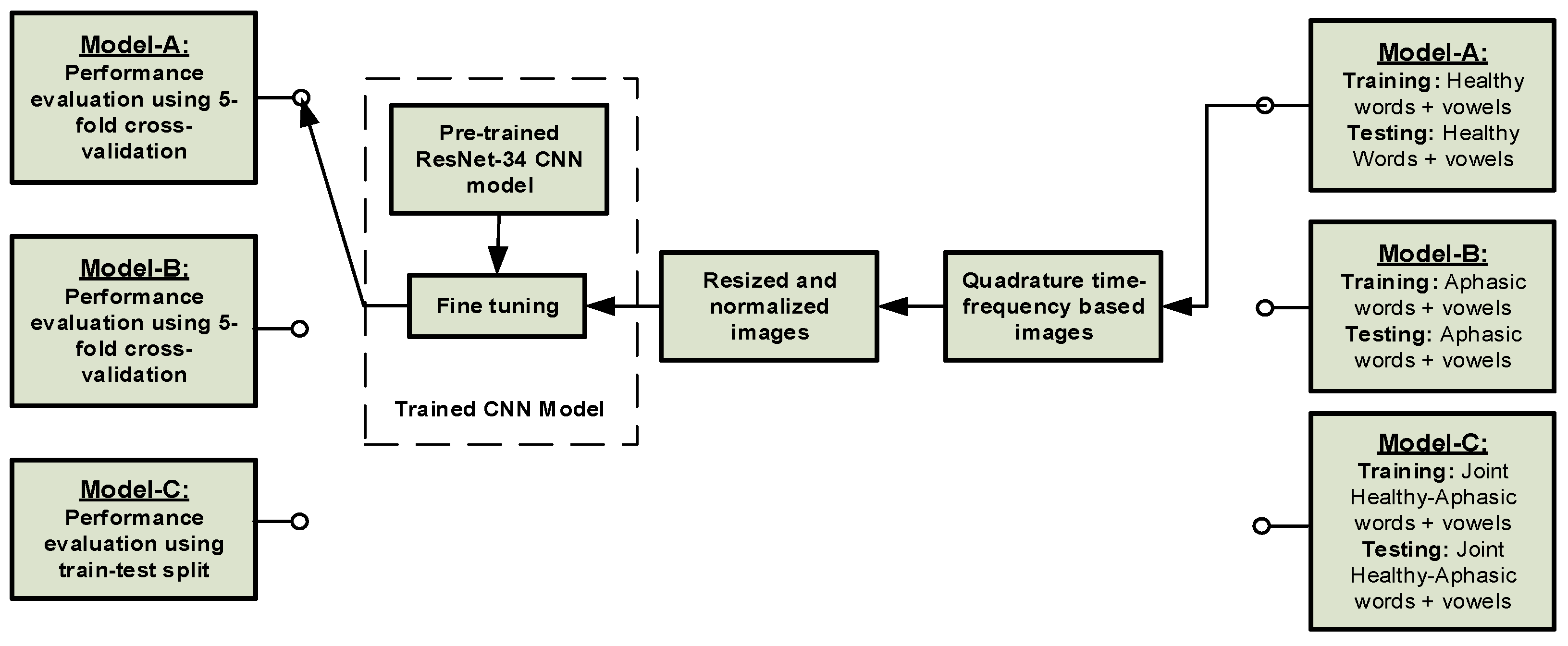
- Model-A: training and testing of the ML frameworks with healthy datasets using a 5-fold cross-validation method.
- Model-B: training and testing of the ML frameworks with aphasic patients’ datasets using a 5-fold cross-validation method.
- Model-C: training of the ML framework with healthy datasets and testing with the aphasic patients’ datasets.
3.2.1. Classical Machine Learning Framework
- Quadratic support vector machine (QSVM)
- A radial basis function (RBF) kernel SVM
- Linear discriminant analysis (LDA)
- Random forest
- K-nearest neighbours (kNN).
3.2.2. Deep Neural Network Framework
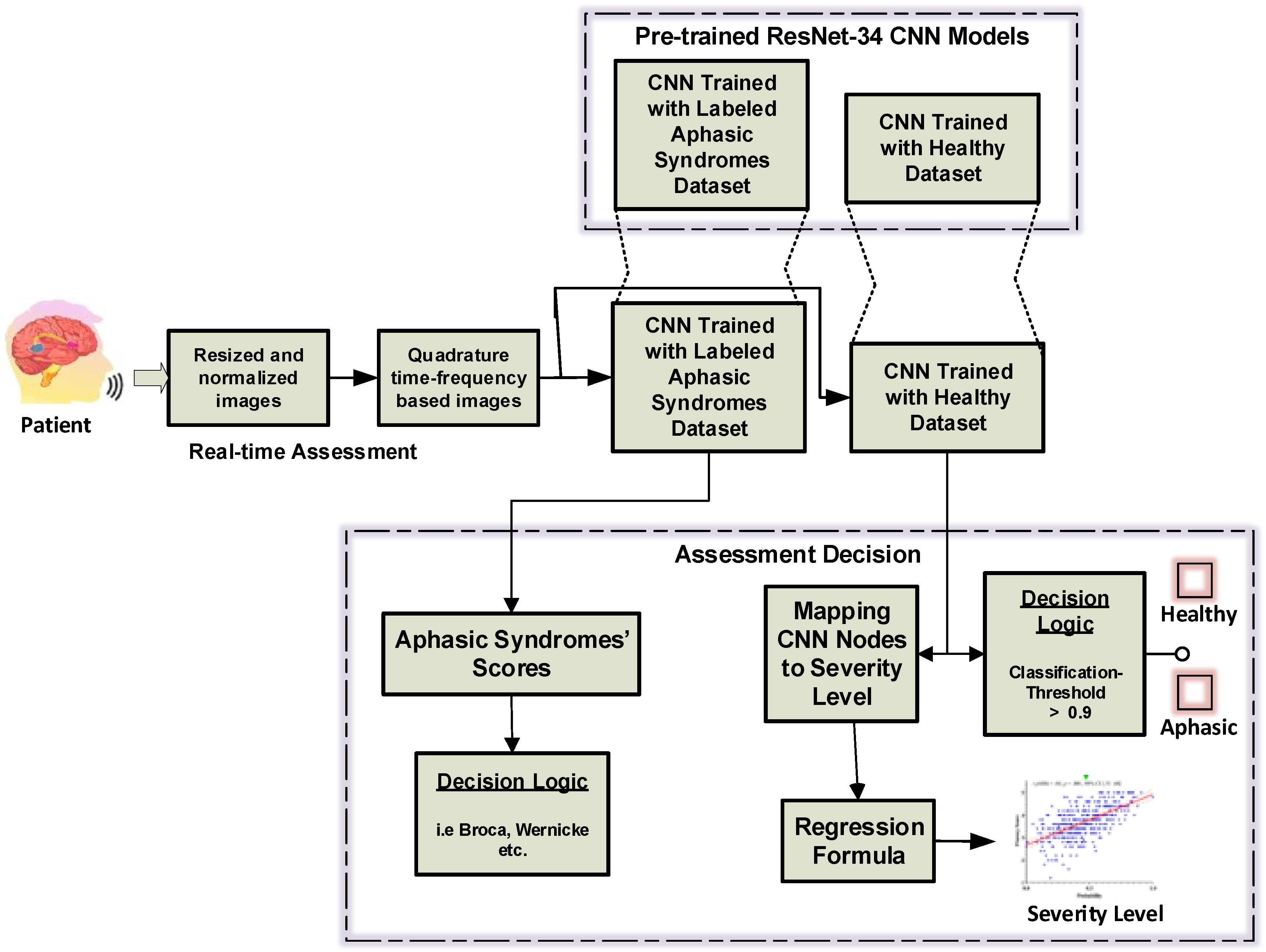
3.2.3. Decision on Classifiers’ Output
| Algorithm 1. Decision Logic for Binary Classification |
| //This process below usually uses the classifier’s output //Binary Classifier has Single Output Node 1: Start 2: κ ⃪ Classification Threshold (cut-off) 3: C1 ⃪ Normal Class 4: C2 ⃪ Aphasia Class 5: Q ⃪ Classifier output//normalized between 0 and 1 6: if Q > κ then C1 //the tested speech is normal else C2 //the tested speech is aphasic 7: End |
3.2.4. Performance Evaluation Metrics
4. Results
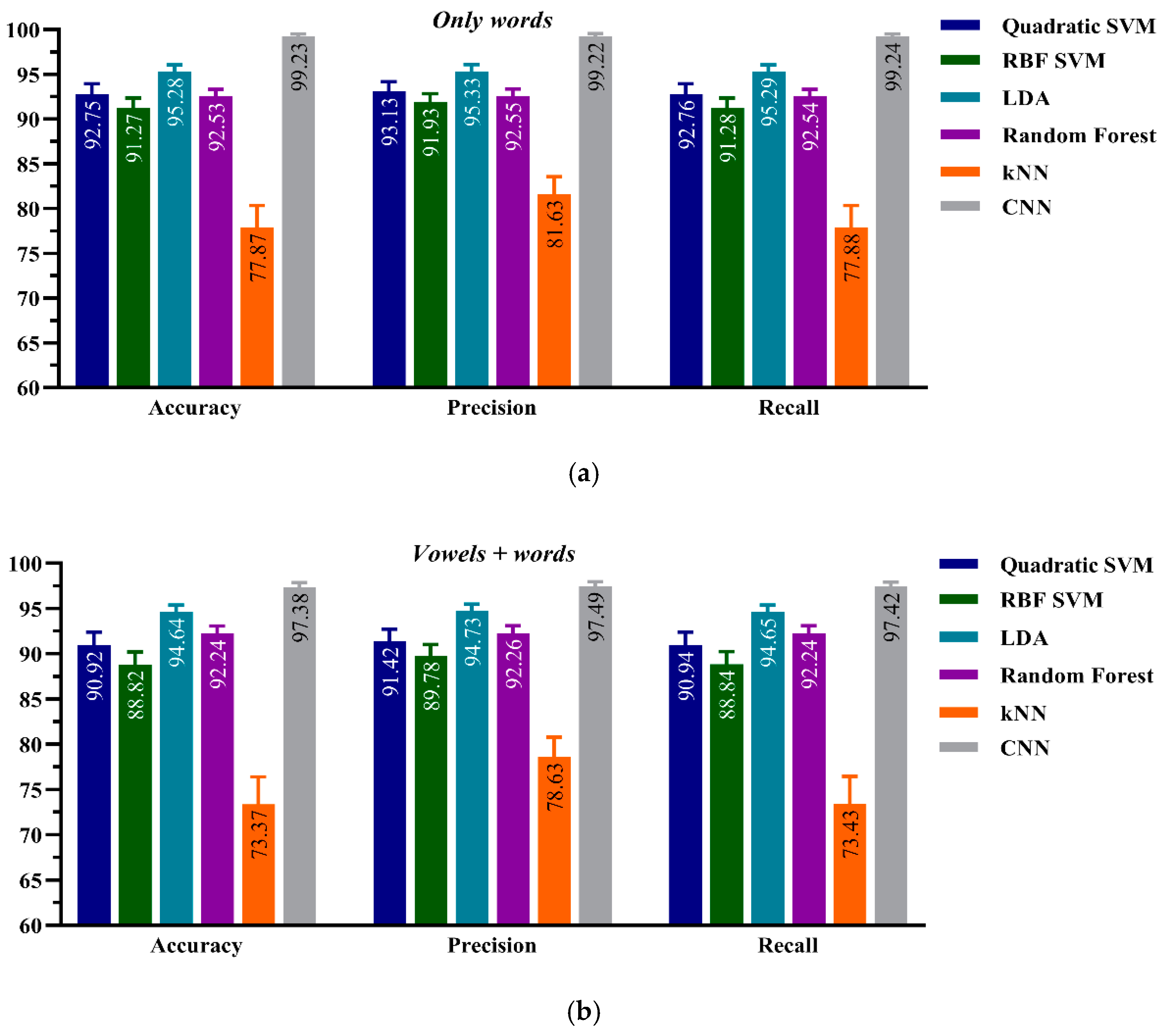
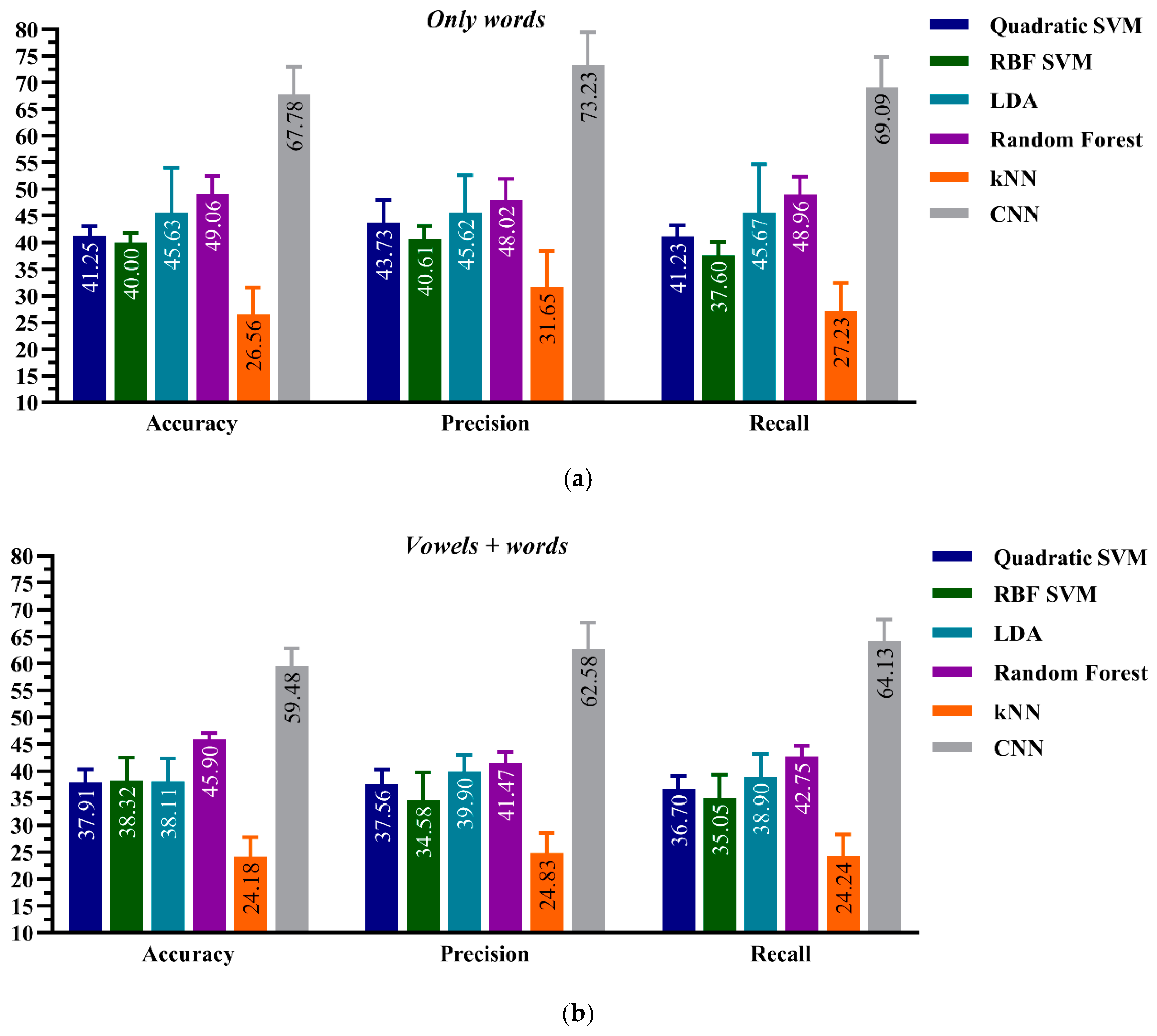
4.1. ML Performance on Healthy Dataset: Model-A
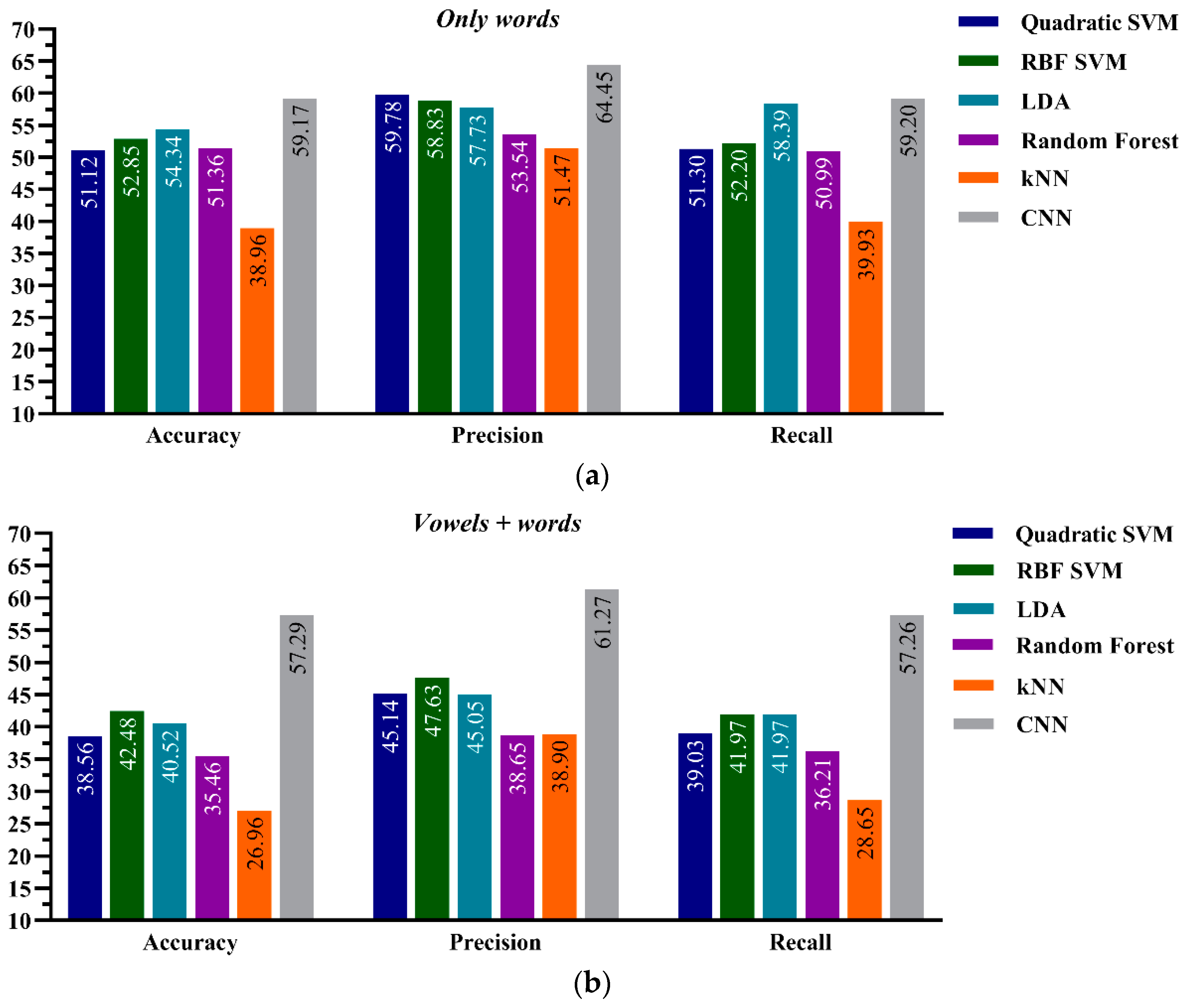
4.2. ML Performance on Aphasic Dataset: Model-B
4.3. ML Performance onr Joint Healthy-Aphasic Datasets: Model-C
5. Discussion
5.1. Healthy Dataset: Model-A
5.2. Aphasic Dataset: Model-B
5.3. Joint Healthy-Aphasic Dataset: Model-C
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Le, D.; Licata, K.; Provost, E.M. Automatic quantitative analysis of spontaneous aphasic speech. Speech Commun. 2018, 100, 1–12. [Google Scholar] [CrossRef]
- Qin, Y.; Lee, T.; Feng, S.; Kong, A.P.H. Automatic Speech Assessment for People with Aphasia Using TDNN-BLSTM with Multi-Task Learning. Interspeech 2018 2018, 3418–3422. [Google Scholar] [CrossRef] [Green Version]
- Le, D. Towards Automatic Speech-Language Assessment for Aphasia Rehabilitation. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 2017. [Google Scholar]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Spielman, J.; Ramig, L.O. Novel Speech Signal Processing Algorithms for High-Accuracy Classification of Parkinson’s Disease. IEEE Trans. Biomed. Eng. 2012, 59, 1264–1271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shahin, M.A.; Ahmed, B.; McKechnie, J.; Ballard, K.J.; Gutierrez-Osuna, R. A comparison of GMM-HMM and DNN-HMM based pronunciation verification techniques for use in the assessment of childhood apraxia of speech. Interspeech 2014, 1, 1583–1587. [Google Scholar]
- Amami, R.; Smiti, A. An incremental method combining density clustering and support vector machines for voice pathology detection. Comput. Electr. Eng. 2017, 57, 257–265. [Google Scholar] [CrossRef]
- Verde, L.; De Pietro, G.; Sannino, G. Voice Disorder Identification by Using Machine Learning Techniques. IEEE Access 2018, 6, 16246–16255. [Google Scholar] [CrossRef]
- Avuçlu, E.; Elen, A. Evaluation of train and test performance of machine learning algorithms and Parkinson diagnosis with statistical measurements. Med. Biol. Eng. Comput. 2020, 58, 2775–2788. [Google Scholar] [CrossRef]
- Qin, Y.; Wu, Y.; Lee, T.; Kong, A.P.H. An End-to-End Approach to Automatic Speech Assessment for Cantonese-speaking People with Aphasia. J. Signal Process. Syst. 2020, 92, 819–830. [Google Scholar] [CrossRef] [Green Version]
- Mahmoud, S.S.; Kumar, A.; Tang, Y.; Li, Y.; Gu, X.; Fu, J.; Fang, Q. An efficient deep learning based method for speech as-sessment of Mandarin-speaking aphasic patients. IEEE J. Biomed. Health Inform. 2020, 24, 3191–3202. [Google Scholar] [CrossRef] [PubMed]
- Mahmoud, S.S.; Fang, Q.; Tang, Y.; Alsulami, M.; Alotaibi, M. Automatic Mandarin Vowels Recognition Framework for Aphasic Patients Rehabilitation. In Proceedings of the 13th IEEE-EMBS International Summer School and Symposium on Medical Devices and Biosensors (MDBS2019), Chengdu, China, 28–29 September 2019. [Google Scholar]
- Le, D.; Licata, K.; Persad, C.; Provost, E.M. Automatic Assessment of Speech Intelligibility for Individuals with Aphasia. IEEE ACM Trans. Audio Speech Lang. Process. 2016, 24, 2187–2199. [Google Scholar] [CrossRef]
- Kohlschein, C.; Schmitt, M.; Schuller, B.; Jeschke, S.; Werner, C.J. A machine learning based system for the automatic evaluation of aphasia speech. In Proceedings of the 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom), Dalian, China, 12–15 October 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Fraser, K.C.; Meltzer, J.A.; Graham, N.L.; Leonard, C.; Hirst, G.; Black, S.E.; Rochon, E. Automated classification of primary progressive aphasia subtypes from narrative speech transcripts. Cortex 2014, 55, 43–60. [Google Scholar] [CrossRef] [PubMed]
- Li, S. Speech Therapy; Huaxia Press: Beijing, China, 2014; pp. 21–34. [Google Scholar]
- Huber, W.; Poeck, K.; Weniger, D. The Aachen aphasia test. In Advances in Neurology. Progress in Aphasiology; Rose, F.C., Ed.; Raven Press: New York, NY, USA, 1984; Volume 42, pp. 291–303. [Google Scholar]
- Goodglass, H.; Kaplan, E. The Assessment of Aphasia and Related Disorders; Williams & Wilkins: Baltimore, MD, USA, 1983. [Google Scholar]
- Järvelin, A.; Juhola, M. Comparison of machine learning methods for classifying aphasic and non-aphasic speakers. Comput. Methods Programs Biomed. 2011, 104, 349–357. [Google Scholar] [CrossRef] [PubMed]
- Gu, Y.; Bahrani, M.; Billot, A.; Lai, S.; Braun, E.J.; Varkanitsa, M.; Bighetto, J.; Rapp, B.; Parrish, T.B.; Caplan, D.; et al. A machine learning approach for predicting post-stroke aphasia recovery: A pilot study. In Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 30 June–3 July 2020; pp. 161–169. [Google Scholar]
- Kristinsson, S.; Zhang, W.; Rorden, C.; Newman-Norlund, R.; Basilakos, A.; Bonilha, L.; Yourganov, G.; Xiao, F.; Hillis, A.; Fridriksson, J. Machine learning-based multimodal prediction of language outcomes in chronic aphasia. Hum. Brain Mapp. 2021, 42, 1682–1698. [Google Scholar] [CrossRef]
- Matias-Guiu, J.A.; Díaz-Álvarez, J.; Cuetos, F.; Cabrera-Martín, M.N.; Segovia-Ríos, I.; Pytel, V.; Moreno-Ramos, T.; Carreras, J.L.; Matías-Guiu, J.; Ayala, J.L.; et al. Machine learning in the clinical and language characterization of primary progressive aphasia variants. Cortex 2019, 119, 312–323. [Google Scholar] [CrossRef] [PubMed]
- Rabiner, L.R.; Schafer, R.W. Theory and Application of Digital Speech Processing; Pearson: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Slaney, M. Auditory toolbox. In Interval Research Corporation; Technical Report No. 10; Interval Research Corporation: Palo Alto, CA, USA, 1998. [Google Scholar]
- Ryant, N.; Slaney, M.; Liberman, M.; Shriberg, E.; Yuan, J. Highly Accurate Mandarin Tone Classification in the Absence of Pitch Information. In Proceedings of the 7th International Conference on Speech Prosody 2014, Dublin, Ireland, 20–23 May 2014; ISCA: Singapore, 2014. [Google Scholar]
- Wainer, J. Comparison of 14 different families of classification algorithms on 115 binary datasets. arXiv 2016, arXiv:1606.00930. [Google Scholar]
- Zhou, J.; Lai, Z.; Miao, D.; Gao, C.; Yue, X. Multi- granulation Rough-Fuzzy Clustering Based on Shadowed Sets. Inf. Sci. 2020, 507, 553–573. [Google Scholar] [CrossRef]
- Yang, H.; Yao, Q.; Yu, A.; Lee, Y.; Zhang, J. Resource Assignment Based on Dynamic Fuzzy Clustering in Elastic Optical Networks with Multi-Core Fibers. IEEE Trans. Commun. 2019, 67, 3457–3469. [Google Scholar] [CrossRef]
- Postorino, M.N.; Versaci, M. A Geometric Fuzzy-Based Approach for Airport Clustering. Adv. Fuzzy Syst. 2014, 2014, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Hussain, Z.; Boashash, B. Adaptive instantaneous frequency estimation of multicomponent FM signals using quadratic time-frequency distributions. IEEE Trans. Signal Process. 2002, 50, 1866–1876. [Google Scholar] [CrossRef]
- Mahmoud, S.S.; Hussain, Z.M.; Cosic, I.; Fang, Q. Time-frequency analysis of normal and abnormal biological signals. Biomed. Signal Process. Control. 2006, 1, 33–43. [Google Scholar] [CrossRef] [Green Version]
- Dodge, S.; Karam, L. Understanding how image quality affects deep neural networks. In Proceedings of the 2016 Eighth International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Suresh, G.J. Prasad Kannojia, Effects of Varying Resolution on Performance of CNN based Image Classification: An Experi-mental Study. Int. J. Comput. Sci. Eng. 2018, 6, 451–456. [Google Scholar]
- Wang, W.; Yang, Y.; Wang, X.; Wang, W.; Li, J. Development of convolutional neural network and its application in image classification: A survey. Opt. Eng. 2019, 58, 040901. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision, WACV 2017, Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference Learning Representation (ICLR), San Diego, CA, USA, 5–8 May 2015. [Google Scholar]
- Krogh, A.; Hertz, J.A. A simple weight decay can improve generalization. In Proceedings of the 4th International Conference on Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1991. [Google Scholar]
- Howard, J. fastai. GitHub Publisher. 2018. Available online: https://github.com/fastai/fastai (accessed on 7 June 2020).
- Christensen, H.; Cunningham, S.; Fox, C.; Green, P.; Hain, T. A comparative study of adaptive, automatic recognition of disordered speech. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Mengistu, K.T.; Rudzicz, F. Comparing Humans and Automatic Speech Recognition Systems in Recognizing Dysarthric Speech. In Proceedings of the Advances in Artificial Intelligence, Perth, Australia, 5–8 December 2011; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Mustafa, M.B.; Rosdi, F.; Salim, S.S.; Mughal, M.U. Exploring the influence of general and specific factors on the recognition accuracy of an ASR system for dysarthric speaker. Expert Syst. Appl. 2015, 42, 3924–3932. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Patients | Gender Male/Female | Age, Yrs. (Mean ± SD) | Cardinal Symptom (#) | Native Dialect (#) |
|---|---|---|---|---|
| 12 | 7/5 | 61.8 ± 14.4 | Broca (6) | Mandarin (6) |
| Dysarthria (3) | ||||
| Anomic (1) | Teochew (2) | |||
| Combined (1) | ||||
| Transcortical motor (1) | Jiaxing (4) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmoud, S.S.; Kumar, A.; Li, Y.; Tang, Y.; Fang, Q. Performance Evaluation of Machine Learning Frameworks for Aphasia Assessment. Sensors 2021, 21, 2582. https://doi.org/10.3390/s21082582
Mahmoud SS, Kumar A, Li Y, Tang Y, Fang Q. Performance Evaluation of Machine Learning Frameworks for Aphasia Assessment. Sensors. 2021; 21(8):2582. https://doi.org/10.3390/s21082582
Chicago/Turabian StyleMahmoud, Seedahmed S., Akshay Kumar, Youcun Li, Yiting Tang, and Qiang Fang. 2021. "Performance Evaluation of Machine Learning Frameworks for Aphasia Assessment" Sensors 21, no. 8: 2582. https://doi.org/10.3390/s21082582
APA StyleMahmoud, S. S., Kumar, A., Li, Y., Tang, Y., & Fang, Q. (2021). Performance Evaluation of Machine Learning Frameworks for Aphasia Assessment. Sensors, 21(8), 2582. https://doi.org/10.3390/s21082582