3.1. Cooperative Perception and Scenario Description
Once a route destination is decided, automated vehicles calculate a suitable route according to context information, e.g., traffic congestion and toll fees. Information-enriched maps, called dynamic maps, are considered as a promising tool to provide such information to automated vehicles. Dynamic maps consist of static information and dynamic information. In detail, the dynamic information includes information about surrounding moving obstacles such as vehicles and pedestrians, and static information includes HD 3D geographic information, e.g., 3D object distribution and lane information.
Automated vehicles need such dynamic information in order to detect and avoid obstacles. Since dynamic maps must provide various information to perform detection and avoidance, automated vehicles are equipped with various sensors such as radar sensors, stereo cameras, and LiDAR sensors. These sensors provide specific data and information about the vehicle environment and update the dynamic map continuously. LiDAR/radar sensors measure the time it takes for an optical/electrical pulse to return to the LiDAR/radar sensor and provide the distance to the object. Cameras can capture objects’ shapes and movements and even estimate distance by parallax angles with stereoscopic setups. The detailed characteristics of the three sensors are the following:
LiDAR sensors provide the distance to an object, and the accuracy is significantly higher than from a radar sensor. Therefore, it can generate a precise 3D map of the surroundings, but it is hard to provide high accuracy data in bad weather, and LiDAR sensors generate a large amount of data.
Radar sensors estimate the velocity, distance, and angle of an object and can work in bad weather, but have difficulty providing high-accuracy data.
Cameras are good at the classification of objects because they can see color, but the operation is degraded in bad weather or when there is dust in the optical path.
In this paper, we focused on LiDAR sensors in more detail, because these sensors contribute to creating HD dynamic maps, and their output data rate is dominant among automotive sensors, which has a great effect on cooperative perception. According to the measurement principle of LiDAR sensors, when an obstacle is in the FOV (Field-Of-View) of a LiDAR sensor, it can provide the location of the obstacle. On the other hand, it cannot provide any information about an obstacle in a blind spot. Furthermore, as an obstacle that partially blocks a LiDAR sensor’s FOV approaches the LiDAR sensor, the visible area of the LiDAR sensor becomes narrower. As a result, the ability to recognize all obstacles by using only onboard sensors becomes extremely low. To obtain information about blind spots, sharing other sensor data through V2V and V2I (Vehicle-to-Infrastructure) communication is proposed. Sharing sensor data between vehicles is often called cooperative perception. The main advantage of cooperative perception is that it can provide an extended sensing area without substantial additional costs. This additional sensing area contributes to improving traffic efficiency, as well as traffic safety. In [
17], it was shown that cooperative perception effectively helped to trigger the early lane changing in the experiment, which contributed to comfortable and safe driving.
The resolution of onboard sensors is an important factor in cooperative perception or recognition. Furthermore, the performance of communication is also an important factor in cooperative perception. Since automated vehicles are equipped with many sensors to recognize their surrounding obstacles, the amount of the generated data is very large, and these data need to be transmitted and processed within the given latency requirements. So far, there are two types of standardized V2V communication systems. One is IEEE (Institute of Electrical and Electronics Engineers) 802.11p, which is one of the dedicated short-range communications. IEEE 802.11p is designed to reduce the latency in V2V communications and consists of two main features. Firstly, it does not require the establishment of a basic service set. Secondly, CSMA/CA (Carrier Sense Multiple Access/Collision Avoidance) is adopted to avoid collision due to simultaneous access. However, the usage of the CSMA/CA mechanism degrades the performance in high traffic density areas mainly due to frequent simultaneous access and many hidden nodes [
18]. The other option is LTE (Long-Term Evolution) V2V services. From Release 14, LTE has started to support V2V communications. It has a PC5interface for direct communications and a Uuinterface for long-range cellular network communications. The main advantage of LTE V2V is that it can reuse the same technology for cellular communications. Therefore, we can directly use the already deployed hardware such as base stations. Furthermore, the provided capacity is higher than IEEE 802.11p. However, as the performance of DSRC (Dedicated Short-Range Communication) degrades in high traffic density, the performance of C-V2X also degrades.
Currently, not only conventional V2V communications, but also millimeter-wave communications are expected to be used for cooperative perception. In [
19], the authors experimented with cooperative perception without using millimeter-wave communications. Although a 2D LiDAR sensor, which generates fewer data points than a 3D LiDAR sensor, was used in the experiment, position estimation errors were still caused, especially for a high vehicle velocity. This suggests that conventional V2V communications are not sufficient to share HD 3D sensor data. Furthermore, applications for automated driving such as machine learning prefer raw sensor data to compressed sensor data, which leads to requiring a very high data rate [
20]. These problems can be solved by using millimeter-wave communications, which provide a high data rate. For example, IEEE 802.11ad has a more than 8 GHz continuous band in four channels, which provides a large channel capacity to transmit sensor data. In [
8], as shown in the related works, the requirement for the transmission of raw sensor data rate was estimated as 1 Gb/s. Therefore, we compared the realized safety between conventional and millimeter-wave communications.
Using V2V communications and high-speed information processing technology, automated vehicles are expected to improve traffic efficiency and safety in various driving scenarios. Since considering all driving scenarios makes the analysis complicated, we focused on a driving scenario on a two-lane road where head-on collisions often occur. One of the driving maneuvers on a two-lane road is overtaking. In [
21], an overtaking maneuver was included in tactical and operational maneuvers of ADS (Automated Driving Systems), and many Level 4 automated vehicles have the feature of an overtaking maneuver. This fact indicates that, although an overtaking maneuver is riskier than following the leading vehicle, it is necessary to improve traffic flow and shorten the trip time. In human driving, overtaking at a high velocity is very dangerous especially on a road without a lane separator for the oncoming traffic like on a highway.
A human driver is trained to slow down to make space behind the leading vehicle and then try to obtain a clear view of traffic to observe the curvature of the road and closer to the center of the neighbor lane. Once the road ahead is considered safe for overtaking, the driver accelerates and starts the maneuver. With traffic information beyond the limitations of a human FOV from a driver seat, automated vehicles with V2V communication are expected to overtake with less acceleration and deceleration at a high velocity.
To realize safe overtaking, we assumed an overtaking scenario on a two-lane road, as illustrated in
Figure 2, and estimated the amount of generated sensor data. This scenario focused on a transition period in which both automated vehicles and human-driven vehicles drive on the road, which limits cooperating vehicles. The driving scenario was that the ego vehicle tries to overtake the blue leading vehicle. Since frequent acceleration and deceleration do not occur on a straight road, the ego and the oncoming vehicles run with the same velocity
V for simplicity. When the ego vehicle tries to overtake, the blue vehicle drives slow enough for simplicity. Moreover, considering that many Level 4 automated vehicles are equipped with the feature of lane centering, we assumed that all vehicles ran on the center of the road [
21]. Using this lane centering function, we also assumed that beam alignment for the V2V communication was ideally performed. When the ego vehicle recognizes the oncoming vehicle by a 3D LiDAR sensor on a roof and safety is not ensured, the ego vehicle does not execute overtaking. The problem is that many beams from the LiDAR sensor are blocked by the leading vehicle. From this point, we call the leading vehicle the blocking vehicle. In this analysis, the blocking vehicle was assumed as an automated vehicle, and the oncoming vehicle was assumed as a human-driven vehicle. Therefore, the ego vehicle can communicate with the blocking vehicle and compensate for the blocked area by cooperative perception. The following sections explain the details of the scenario factors.
3.2. Vehicle Movement
In this section, a condition for safe overtaking is discussed from the viewpoint of vehicle movement. In [
22], it was said that preventable accidents that can be predicted rationally must not be caused in the ODD (Operational Design Domain) of automated vehicles. From this rule, collision with the oncoming vehicle that can be predicted by automotive sensors should be prevented in the assumed overtaking scenario. To achieve this goal from the viewpoint of vehicle movement, we focused on overtaking movement and braking. The braking movement was considered for an emergency case where the ego vehicle and the oncoming vehicle have to brake during the overtaking. This movement ensures no collision after the braking of both vehicles. The overtaking movement was considered for safe overtaking. This movement ensures no collision with the blocking and oncoming vehicles during the overtaking. The following paragraphs explain the details.
To ensure no collision in an emergency case, we defined the required braking distance. Braking types are classified into the emergency type and comfortable type. When a driver notices an unexpected object on a road, emergency braking occurs with a deceleration of more than 4.5
. Usually, almost all drivers brake with a deceleration of more than 3.4
. This deceleration enables a driver to keep the vehicle in a lane without losing control when braking on a wet roadway. Furthermore, 3.4
is regarded as being a comfortable rate of deceleration. Comfortable braking is desirable to provide comfortable driving in automated vehicles. The comfortable braking distance is given as follows [
23,
24].
where
V is the velocity (km/h) of a vehicle and
is the braking distance (m). Considering the reaction time of drivers, the minimum brake reaction times can be 0.64 s for alerted drivers and 1.64 s for an unexpected event [
23]. In automated vehicles, electronic control units can perform control in milliseconds. Therefore, the brake reaction time was regarded as negligible. Since both the ego vehicle and the oncoming vehicle have to avoid the collision in this scenario, the required braking distance became
.
To ensure overtaking movement, firstly, we defined a driving path for overtaking. The driving path is shown in
Figure 3 as a black arrow. This driving path was designed to avoid the collision with the blocking vehicle so that the ego vehicle had to turn two times. For example, if we wanted to describe this driving path very simply, it could be described by four quadrants. However, this curve design did not consider vehicle dynamics.
The clothoid described as Equation (
2) is one of the curves that considers the vehicle dynamics, where
A is the clothoid parameter. The clothoid is defined as a trajectory that meets
, where
R is the radius of curvature and
L is the length of the curve. Curvature
of the clothoid can be calculated as
. Curvature and vehicle dynamics relate in terms of vehicle handling. In general, when a vehicle enters a curve, a driver has to turn the steering wheel along the curve. If we make the driving path with four quadrants, a vehicle entering this driving path has to turn the steering wheel quickly. This quick turning is caused by a curvature gap between a straight line and a quadrant. On the other hand, if we use a part of the clothoid from
, as shown in
Figure 3, the driver does not have to turn the steering wheel quickly, and since
increases linearly from
, it is enough to turn at a constant velocity.
As explained, the clothoid is suitable to design the driving path in terms of linearly increasing curvature, so it is hard to handle analytically. Therefore, we used the sigmoid curve in our simulation. The characteristics of the sigmoid curve are that it is easier to configure and compute than the clothoid [
25].
The function of the sigmoid curve and its parameters
are shown in Equation (
3). The way to construct the driving path with the sigmoid curve is shown in
Figure 3. In other words, half of the driving path consists of two sigmoid curves that have a mirror symmetry.
In order to configure the sigmoid curve, we needed to determine the
parameters. The parameter
B depends on the road width. In this driving path, the ego vehicle was assumed to move from the center of the lane to the center of the neighbor lane, then return to the first lane. From this assumption,
B is equal to the width of a single lane. The parameter
a determines the curvature of the sigmoid curve. In order to determine
a, we considered a slip and constructed a sigmoid curve that does not cause slip at a minimum curvature radius shown in
Figure 4. The judgment of the slip is performed by the following formula.
where
m is the mass of the vehicle,
v is the velocity of the vehicle,
R is the curvature radius at the point where the vehicle places,
is the coefficient of static friction, and
g is gravity acceleration. Since we assumed that the ego vehicle drives along the path at a constant velocity, the minimum curvature radius without slip is
from Equation (
4). Finally, the parameter
determines the length of the sigmoid curve. The length is determined by the duration to complete the overtaking, which was set in advance.
Figure 5 shows the examples of the driving path at 20 km/h and 50 km/h. From the figure, it is shown that when the vehicle velocity becomes low, the slope of the driving path becomes steep. This can be explained by the definition of
. In other words, a vehicle driving at a low velocity can turn sharply without slipping.
To compare with the distance required by the braking, firstly, we derived the distance for the overtaking driving path. Since the oncoming vehicle drives on the neighboring lane, the ego vehicle has to finish overtaking by the time the oncoming vehicle arrives at the collision point.
Figure 6 shows both driving paths from the start point to the collision point, where
v is the velocity of the vehicle,
is the duration to complete the overtaking, and
is shown in
Figure 4. The collision occurs when the ego vehicle moves to the center of the neighboring lane to overtake the blocking vehicle. Since the driving path is a mirror symmetry curve, when the ego vehicle arrives at the center of the neighbor lane, the oncoming vehicle moves for
. Therefore, the distance required for the overtaking driving path becomes
.
From the above discussion, we combined the distance required for the driving path and the comfortable braking.
Figure 7 shows the distance required for comfortable braking and for the three driving path cases. It is shown that the driving path required a larger distance than the comfortable braking distance at a low velocity, and this was reversed at a high velocity. Therefore, considering the driving path is important especially at a low velocity. Namely, the required distance
can be formulated as follows.
3.3. Derivation of the Required Data Rate
In this section, the details of the recognition process are introduced. In general, object recognition can be classified into two cases. One is specific object recognition. This recognition tries to classify an object as a specific object. The other is general object recognition. In contrast to the former recognition, this recognition tries to classify an object as a generic object. Since we focused on the recognition of a vehicle, specific object recognition was adopted, and we refer to the recognition target as the target vehicle. In this case, the ego vehicle wants to prevent a collision with the oncoming vehicle so that the oncoming vehicle becomes the target vehicle. The recognition part consists of three phases. The first phase is the simulation of LiDAR sensor data in the virtual environment and clustering point cloud about the target vehicle. The second phase is the extraction of feature points from the clustered points. The final phase is the decision about recognition. The following paragraphs explain the details of each phase.
In the first phase, regarding lasers from a LiDAR sensor as geometric optics, ray-tracing simulation of LiDAR sensor data was adopted. In order to implement ray tracing easily, objects such as vehicles, buildings, and roads consist of triangle meshes. From this setting, a point
on a triangle mesh can be described with three position vectors
,
, and
and two parameters
as the following formula.
Furthermore, the point
can be also described by a normalized direction vector
departing from the laser source
to
.
Since the laser propagates in three-dimensional space, the departure angle can be described by azimuth angle
and elevation angle
. When a point is on the mesh, parameters
u and
v have to meet
and
. On the other hand, parameter
t has to meet
. In order to confirm whether these conditions are met or not, we solved these parameters by combining Equations (
6) and (
7) and adopting Cramer’s rule.
As mentioned above, before extracting the feature points only from the target vehicle points for recognition, clustering is needed to remove irrelevant points. In this simple ray tracing algorithm, the function of linking the hit object to the laser is implemented. As a result, the LiDAR sensor in our simulation knows which object the laser is reflected from so that we can only select the points of the target vehicle and perform clustering easily.
In the second phase, we extracted feature points from the clustered points. When we want to describe features of point cloud data, or LiDAR sensor data, a feature descriptor is often used. SHOT (Signature of Histogram of OrienTation) and PFH (Point Feature Histogram) are the typical feature descriptors. These descriptors use a histogram to describe features around a point [
26,
27]. In general, the calculation time of a feature descriptor depends on the dimension of the descriptor. In order to avoid this complicated discussion, we used edge points, which are basic features. Extracting edges was performed by PCA (Principal Component Analysis) [
28]. This PCA method is faster and more robust to noise than using a Gauss map. The key point of this process is that edge points are extracted by the eigenvalues of a covariance matrix. The quantity made of the eigenvalues is called the surface curvature, and it is calculated for each point. When the surface curvature exceeds a threshold, the point is regarded as an edge point. The threshold is tuned by observing the distribution of the surface curvature.
The final phase is the decision about recognition. In this simulation, we adopted model-based recognition. This recognition method is a matching problem between scene and model points. Scene points are obtained from the output of the LiDAR sensor. On the other hand, model points are prepared in advance and have enough points to extract the feature points of the target vehicle. The process of this recognition consists of calculating the feature points of the model and scene points and searching for the correspondence of the feature points between the model and scene points. If there are corresponding points, clustering with regard to the corresponding points is performed.
We simplified two points about this model-based recognition process. The first point is using not the entire scene points, but the points clustered from the scene points. This extraction is performed in the first phase of ray tracing. The second point is the decision way of recognition. We defined a recognition score
S as the ratio of the number of edge points shown in Equation (
8).
and
are the number of edge points calculated from the two configurations, as shown in
Figure 8.
The difference of these configurations is that the right configuration includes all objects, but the left configuration only includes the target vehicle, as shown in
Figure 8. In the
Figure 8a case, the sensing range of the LiDAR sensor for the ego vehicle is described by the green range. This environment enables the ego vehicle to sense the target vehicle with an LoS (Line-of-Sight). In the
Figure 8b case, there are two LiDAR sensors. One is on the ego vehicle, but contrary to the former case, the blue vehicle blocks the sensing, as shown by the yellow range. The other is on the blue blocking vehicle, which senses with an LoS the same as the former case. The edge points obtained in the
Figure 8a case are regarded as the maximum number of edge points of the target vehicle that the ego vehicle can obtain. On the other hand, the edge points in
Figure 8b can be obtained in two ways, that is using cooperative perception or not. Using cooperative perception, the edge points calculation is based on the yellow and blue sensing range, while without cooperative perception, it is only based on the yellow sensing range.
Figure 9a shows the entire edge points in the model points.
Figure 9b shows two points. One is the white edge points obtained under the
Figure 8a configuration, and the other is the red points obtained under the
Figure 8b configuration using cooperative perception. Since the red points are also obtained from an LoS place, the red and white points’ distribution is similar.
Counting the number of edge points is different between the two configurations.
in Equation (
8) is the number of LoS edge points obtained in the
Figure 8a case. In detail, firstly, the LoS edge points of the model points are calculated by PCA edge extraction and voxelized. The resolution of the voxelization is based on the error range of a LiDAR sensor. Secondly, the edge points are moved and aligned with the target vehicle. Finally, the voxelized edge points that are in the LoS from the ego vehicle are extracted. On the other hand, the first process for
is the simulation of the LiDAR sensor data under the
Figure 8b configuration. Since we focused on whether the scene points are on edges or not, we defined that the scene points have information about one feature point when a scene point is near the voxelized edge points of the model points. As a result,
is the total number of voxelized edge points obtained from the scene points. After the calculation of
and
, the ratio and threshold were compared, and when the ratio was more than the threshold, we defined that the ego vehicle recognized the target vehicle.
In the vehicle movement part, we derived the required distance
to avoid a collision. Furthermore, from the recognition process, we can judge that the ego vehicle recognizes the target vehicle at a given distance. Therefore, the combination of the required distance
in Equation (
5) and the recognition process derives the required sensor data rate
to avoid a collision as follows.
where
S is the recognition score in Equation (
8),
and
are the scanning range in the azimuth and elevation angle,
is scan frequency (Hz) of the LiDAR sensor, and
is the amount of information per one laser point (bit). Note that the required sensor data rate depends on the velocity
v of the ego vehicle and the distance
. Finally, we can derive the realized maximum overtaking velocity by obtaining the minimum outage capacity that exceeds the required sensor data rate, which will be introduced in the simulation section.
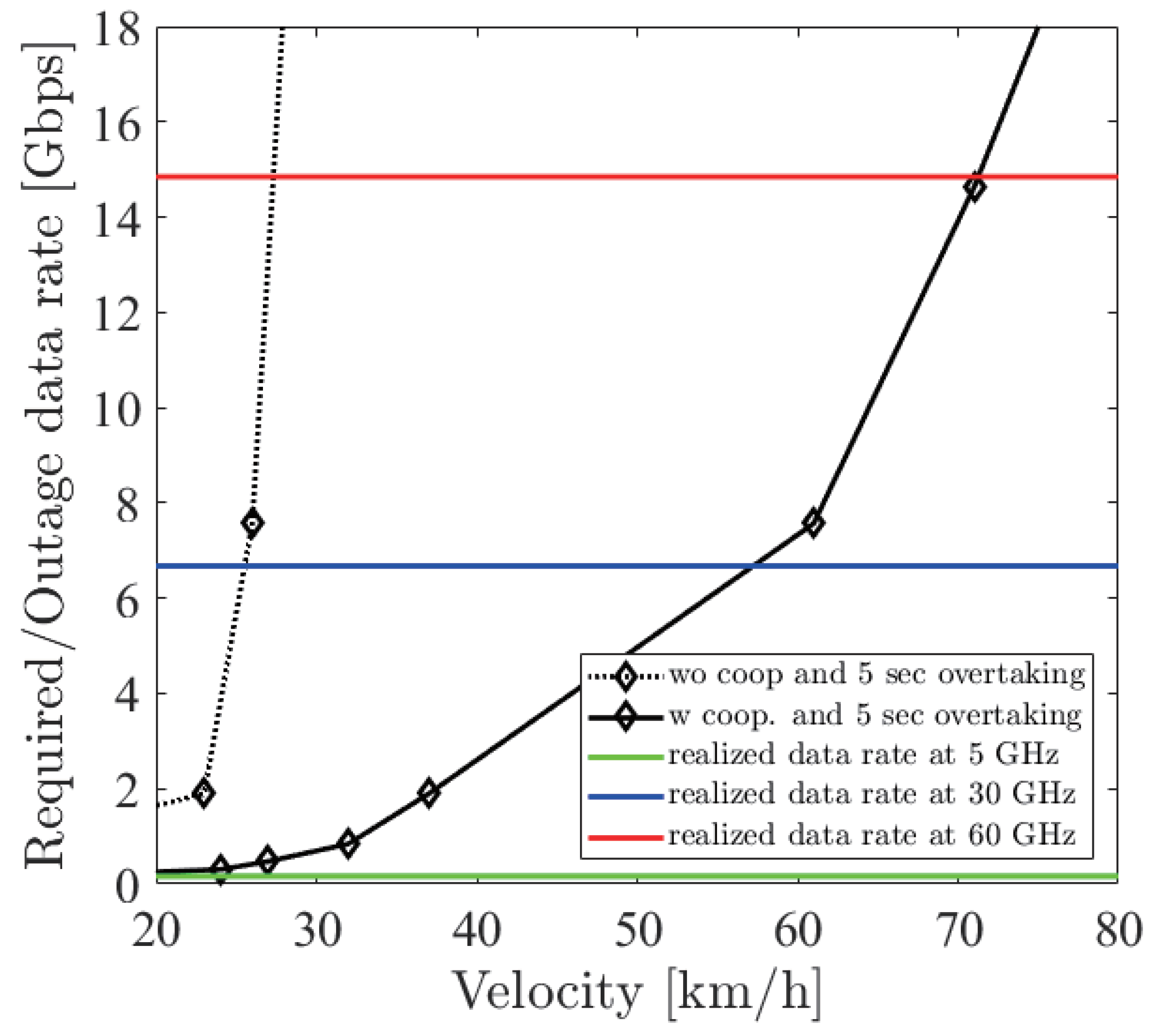
Figure 10 shows the required sensor data rate with the two options such as cooperative perception and driving path. The solid (dotted) line with square markers shows the minimum required sensor data rate to overtake with (not) using cooperative perception and not considering the driving path. The solid (dotted) line with circle markers considers the driving path with (without) cooperative perception. From the figure, firstly, we can see that all required sensor data rates rapidly increased. This rapid increase was due to the laser density, or the resolution of the LiDAR sensor, which became rapidly sparse at a far place. In the case of no cooperative perception, since the blocking vehicle interrupted the sensing, a much higher resolution was required so that the required sensor data rate increased rapidly. Secondly, there was a difference between considering the driving path or not. This reflects the result of the 5 s driving overtaking shown in
Figure 7 so that no difference was seen at more than 60 km/h.
Figure 11 shows the required sensor data rate with
m and 5 s overtaking. In the case of using cooperative perception, as
becomes larger, the required sensor data rate becomes smaller. When
is large, the blocking vehicle gets near to the oncoming vehicle. This allows the blocking vehicle to recognize the oncoming vehicle with a low-resolution LiDAR sensor. On the other hand, the required sensor data rate in no cooperative perception depends on two factors, which leads to a complicated result. One is the distance
. When
is large with the presence of the blocking vehicle, it is easy for a high-resolution LiDAR sensor on the ego vehicle to see the shape of the whole oncoming vehicle in a small sensing range, which obviously has a limit for the recognition. The other is distance
. As the blocking vehicle gets near to the ego vehicle, the blocking vehicle blocks a large part of the range that sees the oncoming vehicle except for a very near location. Since the LiDAR sensor is on the roof, a large part of the blocking vehicle does not block the sensing in the case of a very near location. From
Figure 11, the required sensor data rate becomes high from
m to
m, but it becomes low from
m to
m. This result tells us that sensing with no cooperative perception on a two-lane road heavily depends on many factors such as the size and the location of vehicles, which will make the requirements complicated. On the other hand, sensing with cooperative perception simply depends on
.
Figure 12 shows the required sensor data rate using two different LiDAR sensors. One is a linear spacing LiDAR sensor, and the other is a non-linear spacing LiDAR sensor. In the case of linear spacing, the LiDAR sensor has an equally spaced elevation angle resolution such as Velodyne VLP-16. On the other hand, a non-linear spacing LiDAR sensor such as Velodyne VLP-32 has a dense and sparse spacing part. In this analysis, we fixed the number of lasers between the two LiDAR sensors. The details of non-linear spacing are shown in
Table 1. From the figure, we can see that a non-linear spacing LiDAR sensor has a better ability to recognize a far object. However, notice that non-linear spacing provides sparse information about a near object.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}