1. Introduction
Structural health monitoring (SHM) allows identifying the states of structures to prevent damage that can occur because of operational and/or environmental conditions. It is possible to detect the beginning of a possible damage/failure in a structure and its components using methods associated with SHM systems [
1]. Damage identification includes several levels including damage detection [
2,
3]. However, disturbances for robust damage identification need to be considered using algorithms for data-driven strategies [
4]. Damage detection under changing environmental and operational conditions (EOC)—as in reality—is very complicated because the damage effects on the measured signals are masked by the EOC effects on the signals. The environmental conditions to which the structure is subjected has a stochastic nature; hence, the aim is to develop reliable methods for monitoring structures [
5].
Wind power plants are a good example of systems exposed to environmental influences. Offshore wind power is clean energy that exploits high and uniform wind speed conditions with even larger offshore wind turbines [
6]. However, it is necessary to lower the operations and maintenance (O&M) costs by anticipating potential wind-turbine damage. Therefore, SHM systems are a helpful tool in the wind power industry that help provide early damage alerts and reduce maintenance costs [
7].
Recently, sensors and signal processing techniques have been successfully applied for the analysis and evaluation of structures for obtaining significant and reliable results when the state of structures is evaluated [
8]. The EOC effects on signals can be filtered or considered using pattern-recognition techniques. These data-based methods rely on pattern recognition and artificial intelligence techniques to differentiate a healthy structure from a damaged one.
Damage diagnosis for offshore wind-turbine foundations remains an open field of research. Common SHM approaches are based on guided waves with a known input excitation; however, in this type of structure, the applicability of guided waves is not functional because external perturbation effects caused by wind and marine waves are ignored. An approach based only on vibration-response accelerometer signals needs to be considered to address the challenge of online and in-service SHM for wind turbines. Some variants of the vibration-response-only SHM strategy for wind-turbine foundations have been reported. Vidal et al. [
7] developed a data-driven approach with the following four stages: the wind is simulated as Gaussian white noise [
9] and the data from accelerometers are collected; the data are pre-processed via group-reshape and column-scaling; a feature extraction approach based on principal component analysis (PCA) is used; and finally,
k nearest neighbors (
kNN) and quadratic-kernel support vector machine (SVM) [
10] are tested as classifiers. The best classification accuracy is obtained using the SVM algorithm, and it reaches
.
In contrast to the conventional data-driven SHM techniques, the deep learning approach has been demonstrated its successfully application to solve SHM problems [
11,
12]. An approach based on a deep learning strategy via convolutional neural networks (CNNs) was presented in [
13]. The deep learning approach is based on the signal-to-image conversion of the accelerometer data to gray-scale multichannel images with as many channels as the number of sensors in the condition monitoring system. Furthermore, it is based on a data augmentation strategy to diminish the test set error of the deep CNN used to classify the images. The CNN comprises seven convolutional layers performing feature extraction, followed by three fully connected layers and a SoftMax block for classification; an overall accuracy of
is obtained. Hoxha et al. [
14] solved the identification and classification damage problem in an experimental laboratory wind-turbine offshore jacket-type foundation through a fractal dimension methodology that performs feature extraction in a machine learning (ML) setting.
kNN, quadratic SVM, and Gaussian SVM were used as classifiers. The best algorithm was found to be the Gaussian SVM, which achieved a classification accuracy of
.
This research seeks to solve the damage classification problem of in situ real structures exposed to strong changes in EOCs (e.g., offshore wind power plants) using ML algorithms that use signals from sensor networks as inputs. The main goal of data-driven algorithms is to analyze large or complex sensor networks that provide multivariate information using ML approaches. These complex sensor networks can be found in some SHM solutions [
15,
16], classification of gases by means of electronic noses [
17,
18], and classification of liquids by means of electronic tongues [
19], among others. A common problem for data-driven algorithms is that data captured by the network of sensors have a high dimensionality [
20], and therefore, algorithms are employed to handle and process this large amount of information. Within the pattern-recognition process, the extraction of both linear and nonlinear characteristics reduces the dimensionality of the original data by eliminating redundant characteristics and noise from the sensor signals [
21]. Linear and nonlinear manifold learning algorithms [
22] can be used in the feature extraction stage and as subspace learning algorithms [
23] to minimize intraclass distances and maximize distances between classes in a clustering or cluster problem. This facilitates the classification of the ML algorithm, which can be unsupervised, semi-supervised, or supervised.
Different strategies have been used to solve structural damage-detection problems. There are traditional, machine learning methods with their parametric and non-parametric variants and deep learning methods [
24]. In 2020, Gardner et al. presents the power of machine learning with methods such as compressive sensing and transfer learning to solve different structural analysis [
25]. In Chandrasekhar et al., a machine learning approach is used to solve SHM in operational wind-turbine blades. This work uses Gaussian processes (GPs) to predict the edge frequencies of one blade given that of another to identify the healthy state of the blade [
26]. A systematic review of machine learning algorithms in structural health monitoring is presented in [
27]. That work highlights the importance of data manipulation in machine learning tasks, including topics as data cleaning and feature engineering.
Previous studies focused on structural damage classification using multisensor systems; they used several ML algorithms and data reduction for pattern recognition. For instance, PCA [
28], self-organizing maps (SOM) [
29],
kNN [
30], artificial immune systems (AIS) [
31], SVMs [
32], and
t-distributed stochastic neighbor embedding (t-SNE) [
33,
34]. This study presents a structural damage classification methodology for pattern recognition and signal processing in sensor networks that achieves good classification performance and advantages in calculation time to continue the improvement and development of damage classification methodologies. This methodology is composed of different stages: normalization of the signal considering the differences in magnitudes obtained by the sensors; linear feature extraction; and dimensionality reduction via the PCA method to form a feature vector that will serve as input to an extreme gradient boosting ML classifier algorithm. This methodology was validated using a small-scale wind-turbine jacket foundation. In addition, a 5-fold cross-validation procedure was performed to determine the average classification performance measures of an unbalanced classification problem showing excellent results.
The remainder of this paper is organized as follows.
Section 2 describes the main problem considered in the current work. Then, in
Section 3 and
Section 4, the proposed SHM strategy is described in detail.
Section 3 lists the steps performed in the training data preparation.
Section 3 describes the small-scale wind-turbine foundation with all its parts, the excitation system, sensors, and data acquisition process. Then,
Section 4 describes the XGBoost classifier as an ensemble method (
Section 4.1).
Section 5 summarizes the flow of the real-time classification of a new observation from a wind turbine (WT) that must be diagnosed. In
Section 6, the obtained results are compiled, and they indicate exceptional performance for all considered metrics. Finally, the main conclusions are presented in
Section 7, in addition to the future research directions.
2. Problem Statement
This study aims to provide an accurate structural damage classification methodology that can specify whether a wind-turbine foundation is damaged; if it is damaged, the methodology can detect the nature of the damage. The classification methodology is derived by first obtaining a training set of data from both damaged and non-damaged structures (data acquisition). These data are properly pre-processed (data normalization and unfolding), and data transformation and dimensionality reduction techniques are applied to discard features that are not relevant to the classification problem (linear feature extraction). These new small-dimensional data are used as inputs to train the supervised machine learning classifier. Once the classification methodology is employed, given a new experimental sample of the wind-turbine foundation, the classification algorithm can predict the structural state of the foundation.
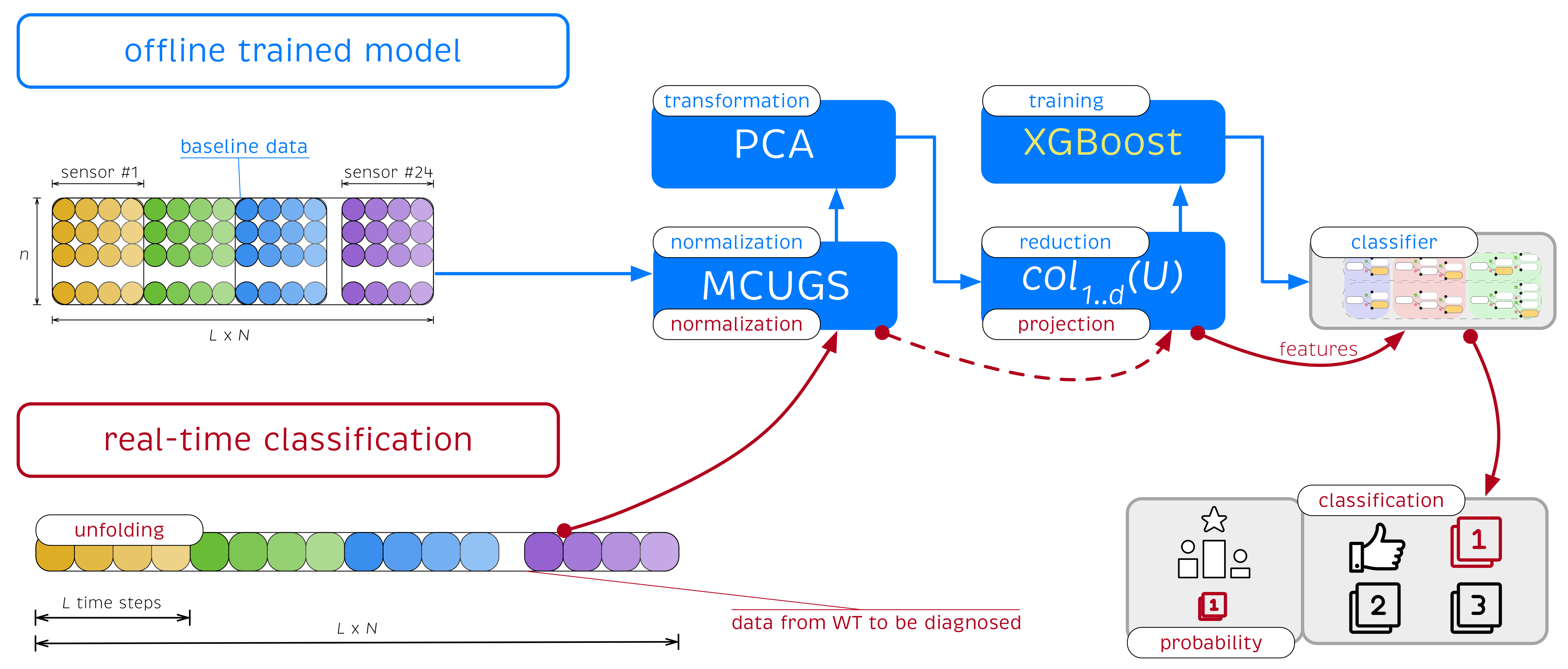
Figure 1 illustrates the process used to obtain the damage classifier.
Before using the classification algorithm to classify new data, it is crucial to evaluate the performance of the algorithm. This evaluation is a challenging problem because the available data samples must be used to define the classifier and estimate its performance when making predictions of new samples. The training dataset and test set must be sufficiently large and representative of the underlying problem so that the resulting performance of the classifier is not too optimistic or pessimistic. In fact, if the collected dataset is very large and representative, one can split the dataset into two parts and use the first part to train the model and the second part to test it. However, this is rarely the case, and it is standard to use a k-fold cross-validation error estimation method.
The basic idea of this procedure is to split the full dataset into
k folds (or subsets). This allows the generation of
k models, each of which takes the data from
folds to train the algorithm and use the remaining data to set its performance. The overall performance of the model is calculated from the mean of the estimates of these runs (see
Figure 2).
4. Damage Detection and Classification Procedure: Extreme Gradient Boosting
This section explains the main characteristics of the XGBoost classifier. First, a detailed explanation of the XGBoost classifier as an ensemble method (providing a forest of regression trees) is provided, followed by a description of the main XGBoost parameters (see
Section 4.2). Finally,
Section 4.3 presents the validation procedure for evaluating the performance of the classifier.
4.1. XGBoost as an Ensemble Method
Currently, one of the most popular and accurate machine learning classifiers is the extreme gradient boosting technique (XGBoost) [
41]. The gradient boosting method [
42] can improve speed and performance. This section briefly describes the main characteristics of the XGBoost method. Readers are referred to [
41,
43] for fully detailed explanations.
The XGBoost method is an ensemble method that involves sequentially creating and adding regression trees. New trees are created to correct the errors in the predictions from the existing set of trees, which boosts the attributes that lead to the misclassification from the previous tree. Thus, multiple trees are built on top of each other to correct the errors in the previous tree. The XGBoost classifier thus provides a forest of regression trees, where the prediction of the forest is a weighted average of the predictions of its trees.
XGBoost exploits the limit of computational resources in the gradient boosting decision tree algorithm [
42]. The boosting approach employs random sampling to train several classifiers, and then, the classifiers are assembled to synthesize a higher-performance classifier [
44]. Boosting assigns a weight to each observation and modifies the weight after training a classifier. Observations with modified weights are employed to train the next classifier. In addition, the gradient boosting method focuses on the gradient reduction of the loss function in the previous tree-trained models. XGBoost is a scalable tree boosting system that exploits a weighted quantile sketch for approximate tree learning [
41].
Some important characteristics that make the XGBoost classifier one of the best classifier algorithms are the use of inbuilt cross-validation, which handles missing values; the use of regularization to avoid overfitting in the model; a novel tree learning algorithm for handling sparse data; save resources and time with a cache access pattern mechanism; and incorporate sharding and data compression.
The use of the XGBoost technique for multiclass classification purposes is shown here for a particular example of a sample composed of 3 classes,
; four features
(continuous real values); and a forest obtained using an ensemble of two boosting rounds (see
Figure 6). In the first round of the XGBoost method, one regression tree per class is trained
. Unlike in decision trees, each regression tree produces a continuous score on the
ith leaf.
Given a new sample to be classified, the decision rules in each tree are used to produce a set of three raw scores (one per class)
, which are then transformed into probability values
using the SoftMax function. This in turn yields a (first-round) class prediction
as
Predictions obtained in this first round are used to train the second round of trees in the forest, thereby obtaining a new regression tree per class
. After applying the decision rules in each tree, it produces a set of three raw scores
. The computation of the probability per class based on the two-round forest is computed by first adding the raw score values per class, i.e.,
. Then, the SoftMax function is used to obtain the probability of class membership and a new (second-round and final) class prediction
as
The same technique applies if more boosting rounds are added. If the XGBoost technique provides a forest
where
R denotes the number of boosting rounds and
l denotes the total number of classes, given a sample, the row scores per class/tree are computed
and added to obtain a final score per class
. The final score is then transformed to the probability of class membership
to obtain a final class prediction
as [
45]:
Consider the specific example given in
Figure 6, and a specific sample with features
, and
. In this case, the decision rules of the forest predict that this sample is associated with the leaves
of the first round and to the leaves
of the second round. Therefore, the class prediction of the sample is
based on the computations listed in
Table 3.
In addition to the great classification power of the XGboost method, the final classifier provides two relevant additional benefits. The first benefit is that for a given sample, the XGBoost classifier not only provides a prediction for the class of the sample, but also provides a probability-like measure of the sample belonging to each class category. From Equation (
6), given a sample, the XGBoost classifier returns
Class prediction ;
Probability associated with the predicted class ;
Probability associated with each class .
This additional information can be used to assess the reliability of the prediction (values of close to 1 provide very reliable predictions) and to show the behavior of the classifier when discriminating between classes (for values of not close to 1, the probabilities associated with each class serve as additional information on possible alternative class predictions).
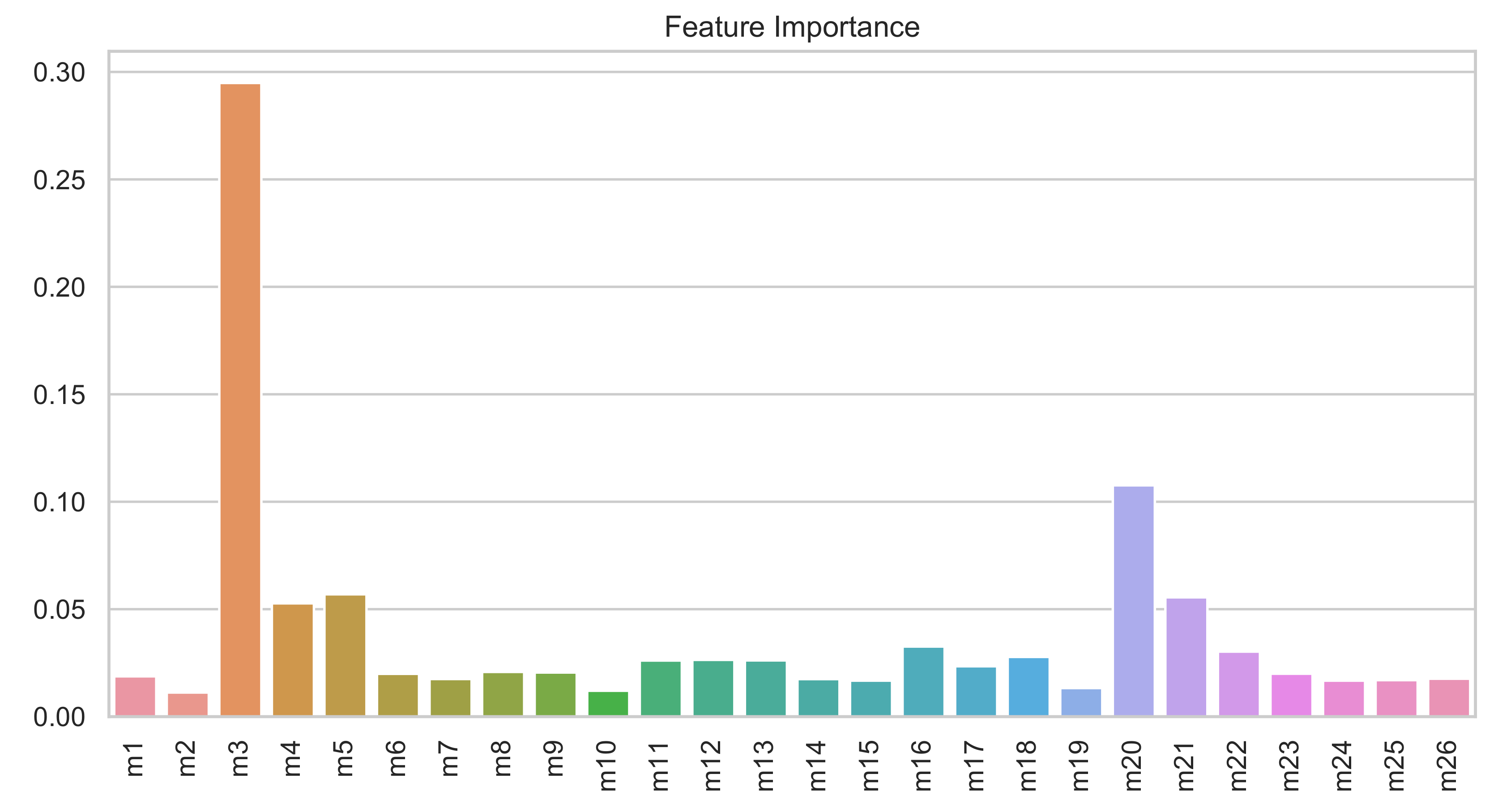
The second extra benefit is that the random forest provides estimates of the feature importance automatically. The more an attribute is used to make key decisions with decision trees, the higher is its relative importance. More details can be found in ([
45], Section 10.13.1).
4.2. XGBoost Parameters
The performance, complexity, and overfitting properties of the XGBoost method depend on the proper tuning of the hyperparameters. The best model should balance the model complexity with its predictive power. This tuning can be performed via experimentation or by using specific routines (Python scikit-learn gridsearchCV, for instance).
A brief description of the main XGBoost parameters used in this study is provided here. The parameters can be set into categories as shown in
Table 4; it is important to highlight that in this work, any non-described parameter is set to its default value.
The first category of general parameters guides the overall function of the classifier. The most important parameter in this category is the booster parameter that defines the type of model (tree-based or linear model).
In the second category,
learning task parameters, we find the parameters that specify the learning task and corresponding learning objective. In particular, we set the value of
objective to be
multi:softmax to predict the class of each data sample or
multi:softprob to predict the probabilities of each data sample belonging to each class category, and the number of classes is defined by the parameter
num_class. Once the probabilities are computed, the results of
multi:softmax can be directly obtained by selecting the class with a higher probability, as shown in
Section 4.1. Two relevant parameters in this category are the
seed and
random_state parameters. The output of the XGBoost method is a random forest, and as the name indicates, randomness is introduced in the process to avoid overfitting (for instance, when growing the trees, randomness on the selected training samples, and feature selection is introduced). Setting specific values for random seeds allow for reproducibility of the results. However, picking a convenient seed may result in over-optimistic results. Therefore, the seed should only be fixed for reproducibility and not to increase performance.
The final category corresponds to the
booster parameters that guide the individual booster trees at each step. The three main parameters controlling the complexity of the final random forest are
n_estimators,
max_depth, and
learning_rate. The
n_estimators parameter determines the number of trees to grow per class (number of rounds); therefore, the final number of trees in the forest is
times the number of classes. The
max_depth parameter controls the maximum depth of each decision tree. The maximum number of nodes in the forest is
. Increasing this value increases the complexity of the model and makes it more likely to overfit because it allows the model to learn very specific relations for certain samples. Finally, the
learning_rate parameter or shrinkage parameter is analogous to the learning rate in gradient-boosted models. The learning rate corresponds to how quickly the error is corrected from each tree to the next, and it is a simple constant
. The raw scores obtained in each boosting round
are weighted by
learning_rate to add smaller corrections in each round; therefore, small learning rates slows down the learning and makes the boosting process more conservative. Another set of interesting parameters in this category is
reg_alpha and
reg_lambda, which introduce
and
regularization terms in the convex loss function to avoid overfitting (see [
41]). Increasing these values makes the model more conservative. Finally, the parameters
subsample and
colsample_bytree control the fraction of items to be subsampled to train a particular tree. Every time a new tree in the random forest is trained, the algorithm selects a random sample from the complete training dataset and a random subset of the features to train the tree. The
subsample parameter is the ratio of training instances to be selected; that is, if
subsample at each boosting iteration, the classifier randomly selects
of the training samples to train the trees in this round. Furthermore, the
colsample_bytree parameter is the fraction of features to be sampled randomly for each tree. The default value of 1 indicates no subsampling. Lower values make the algorithm more conservative and prevent overfitting.
4.3. k-Fold Cross-Validation and Unbalanced Classification Performance Measures
It is crucial to evaluate the performance of the machine learning model on unseen data. A test dataset with new instances must be available to check the correctness of the predicted classes for evaluating the performance of a model. In multiclass classification problems (problems where each input sample must be classified into one, and only one, non-overlapping class), each sample from the test dataset has a class label that is compared to the predicted class label. A measure of correctly or incorrectly recognized classes must be defined.
Therefore, model validation has two key points:
- (1)
how to define the test and training datasets so that no overfitting occurs (i.e., that no too-optimistic estimates are obtained); and,
- (2)
how to define the performance/accuracy measure from the correctness/incorrectness of the predicted classes.
k-fold cross-validation is one of the most used techniques to determine the training and test data sets when a limited amount of data is available. This is because it avoids overfitting and results in a less biased or less optimistic estimate of the model skill compared to a simple train/test split [
46]. In this study, a 5-fold cross-validation is used as the resampling procedure to evaluate the XGBoost model (see
Figure 2).
Each fold of the cross-validation procedure provides a measure of the performance of the classification algorithms, i.e.,
; the total predicted performance is given by its mean
The standard deviation of these performance measures can also be computed as
A large standard deviation indicates that the performance measures are far from its mean . This suggests that samples were not selected appropriately or that the method was too subsample-dependent.
In general, the classification performance for a given fold is defined by specific measures of the confusion matrices (see details below). Although this is not the approach used in this work, it is common practice to obtain the total performance by first adding the five confusion matrices associated with each fold directly and then computing the performance of the total matrix, despite the performance measures being nonlinear.
Specific performance measures used in the present work are described as follows: Given the classification results associated with a fold, the correctness of the classification method associated with this fold is evaluated by first computing the number of correctly recognized class samples (true positives, TP), the number of correctly recognized samples that do not belong to the class (true negatives, TN), and samples that either were incorrectly assigned to a class (false positives, FP) or that were not recognized as class samples (false negatives, FN). This information is summarized in a multiclass confusion matrix [
7,
47]. Indeed, let
denote the five class labels associated with the experiment (undamaged, damage 1, damage 2, damage 3, and damage 4, respectively), and
denote the number of samples belonging to class
, which have been classified as belonging to class
. This information can be stored in the confusion matrix listed in
Table 5.
Then, for a given class
, we denote by
,
,
, and
, the number of samples that, with respect to class
, are TPs, TNs, FNs, and FPs, respectively; these are computed from the confusion matrix as
where
l denotes the total number of classes or labels, i.e.,
in the present work. In addition, following [
47], we introduce the performance measures associated with class
as
and
where
coincides with the total number of tested samples (
for a specific fold or
if the global added confusion matrix is considered).
The quality of the classification strategy for the fold is assessed in this case because of data imbalance, which uses macro-averaging global performance measures that treat all classes equally instead of favoring the larger ones. Global measures are computed by averaging the measures obtained in each class, namely
the global F
-score measure is not computed by averaging the per-class F
-score measures but by using the global precision and recall measures.
The final overall performance measure of the classifier is obtained by computing the average and standard deviation of the five-fold performance measures.
5. Proposed Methodology: Real-Time Structural Damage Diagnose
Section 3 and
Section 4 describe the training and validation of the XGBoost classifier using the samples obtained from the experiments under different white noise signals and different structural states. However, the described strategy can be used for real-time damage detection. Given a new sample associated with a specific wind turbine, a fast real-time prediction of the structural state of the structure can be performed.
In this context, an offline strategy is adopted. In the offline stage, the
baseline data (set of initial samples used to generate the XGBoost classifier) was used to determine the pre-trained XGBoost classifier. The offline stage stores the MCUGS normalization parameters, the PCA projection matrix selects the relevant features, and the classifier is given in the form of a forest regression tree. This information is then used in the online stage for real-time classification of a new observation. A flowchart of the proposed approach to illustrate how the SHM strategy is applied when a new wind turbine (WT) should be classified is depicted in
Figure 7.
Given a new single observation of the wind turbine to be diagnosed that contains signals measured by the
sensors during the
time instants, we construct a new data row vector
unfolded as any of the rows of matrix
in Equation (
4), i.e.,
The collected data were first normalized using the pre-stored MCUGS parameters (the mean
and the standard deviation
given in Equations (
1) and (
2), respectively), which produced the normalized raw vector
defined as
The normalized data were then projected using the pre-stored PCA projection matrix to select the relevant features to be used in the XGBoost classifier.
is projected onto the vector space spanned by the first
d principal components stored in the matrix
using the vector-to-matrix product
is a
d-dimensional vector that is the projection of
into the PCA model. The components of this vector are the
d features
, which are the inputs of the XGBoost classifier; see Equation (
5).
As shown in
Section 4.1 and in
Table 3, features
associated with the wind turbine to be diagnosed are directly inserted into the
forest classifier, which returns a set of probabilities
, where
l denotes the total number of different structural states and
denotes the probability that the sample belongs to the structural state
i. Thus, the real-time classification strategy provides the following: (1) the structural state/class prediction
; (2) the related probability of class membership
used for reliability (we can associate a higher or lower level of confidence in our decision based on the value of
); and (3) probability associated with each of the other structural states.
The problem considered in the present work is related to real-time structural damage diagnosis and classification. A closely related problem is the early detection of incipient damage (prognosis). Prognosis methodologies contribute a predictive maintenance option that provide the decision-maker the flexibility to determine whether and when to act before the structure is severely damaged [
48]. To this goal, instead of a structural damage classification problem, anomaly detection can be considered. In the case of anomaly detection, a similar approach can be used to classify the structure as healthy or not healthy.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}