
Machine Learning Methods of Regression for Plasmonic Nanoantenna Glucose Sensing


Abstract
:1. Introduction
1.1. SEIRA Glucose Sensing
1.2. SEIRA Glucose Sensing—Inverse Problem
1.3. Contribution
2. Regression Methods in Machine Learning
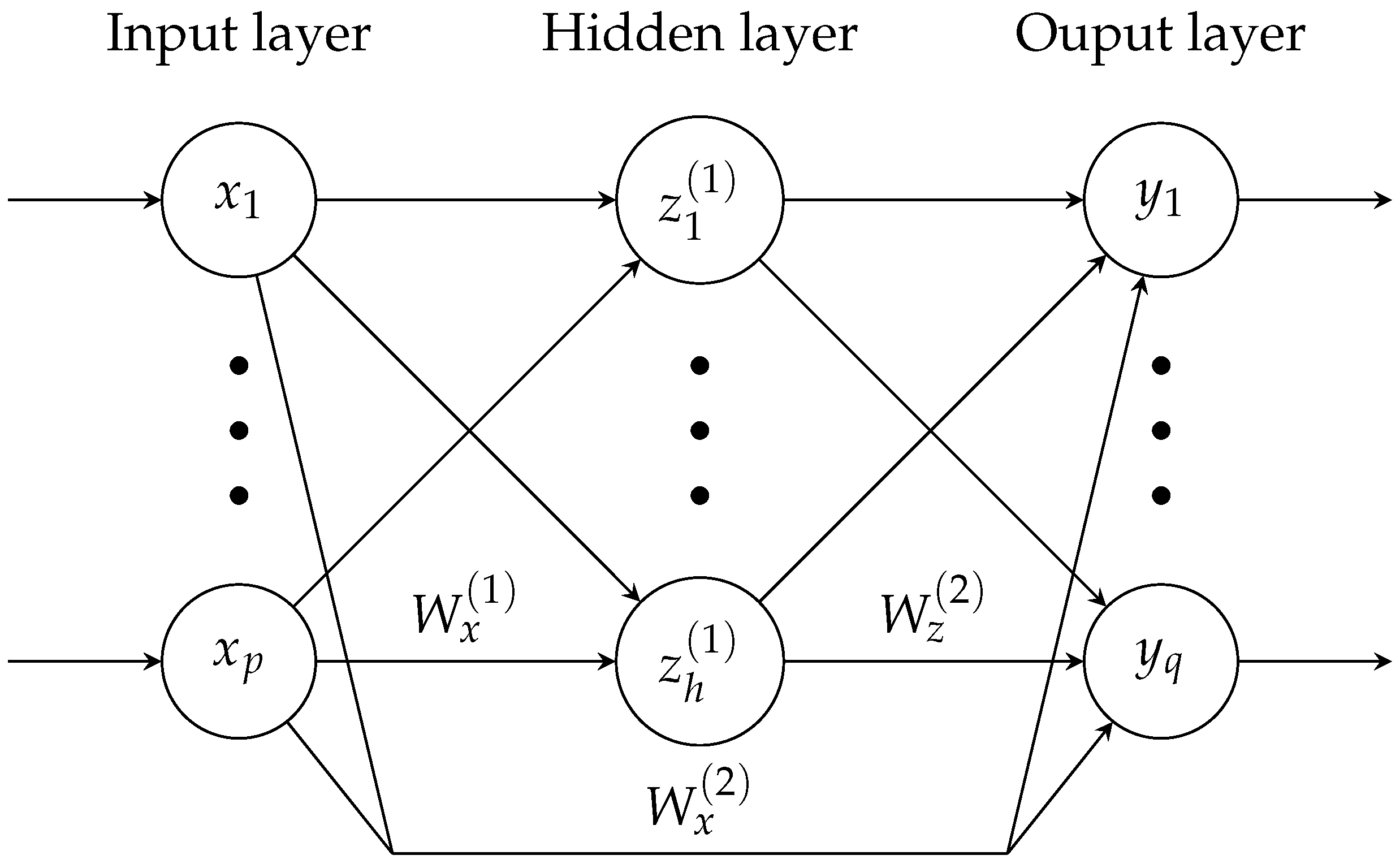
2.1. Cascade-Forward Neural Network
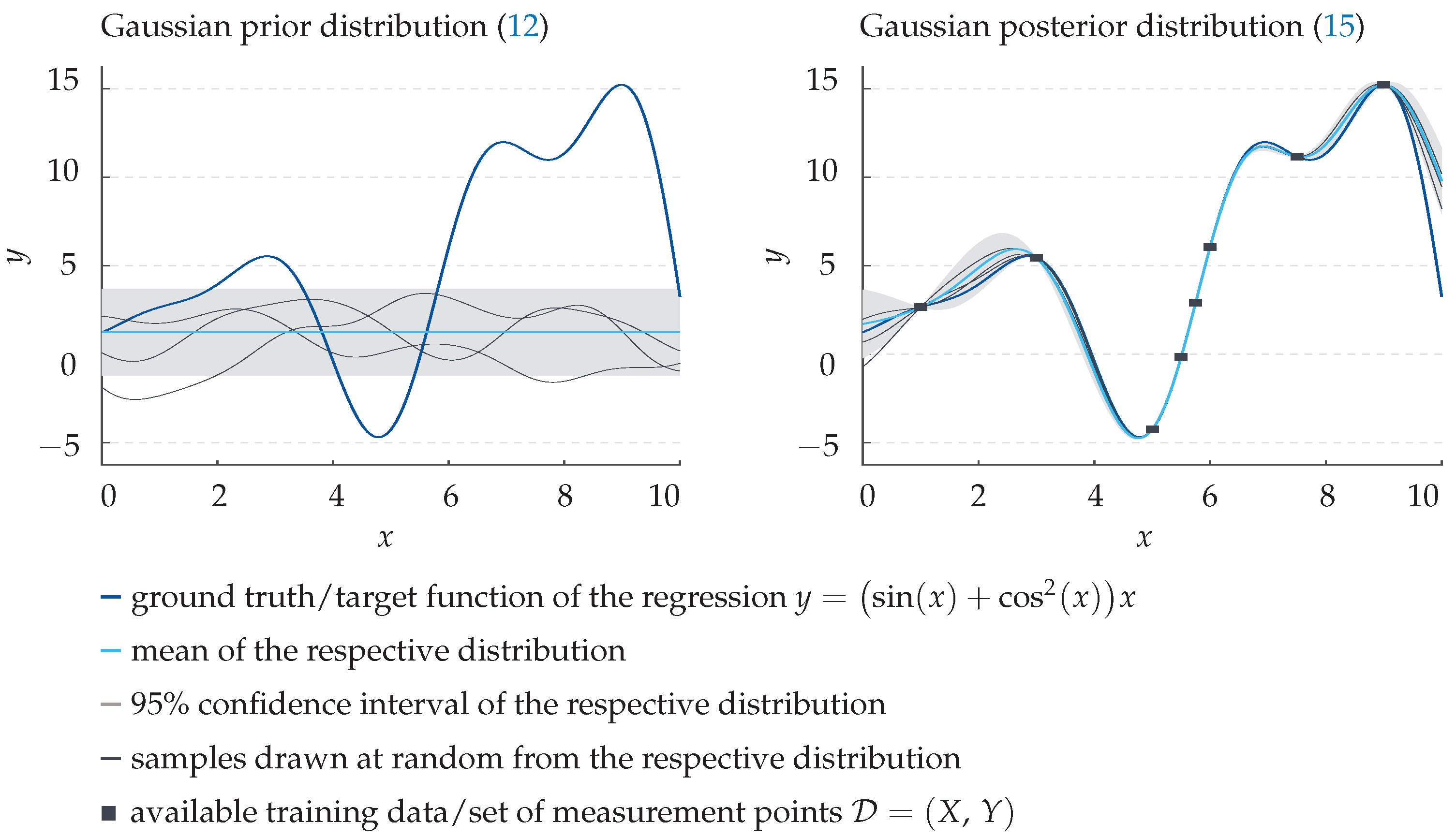
2.2. Gaussian Process Regression
3. Experimental Setup
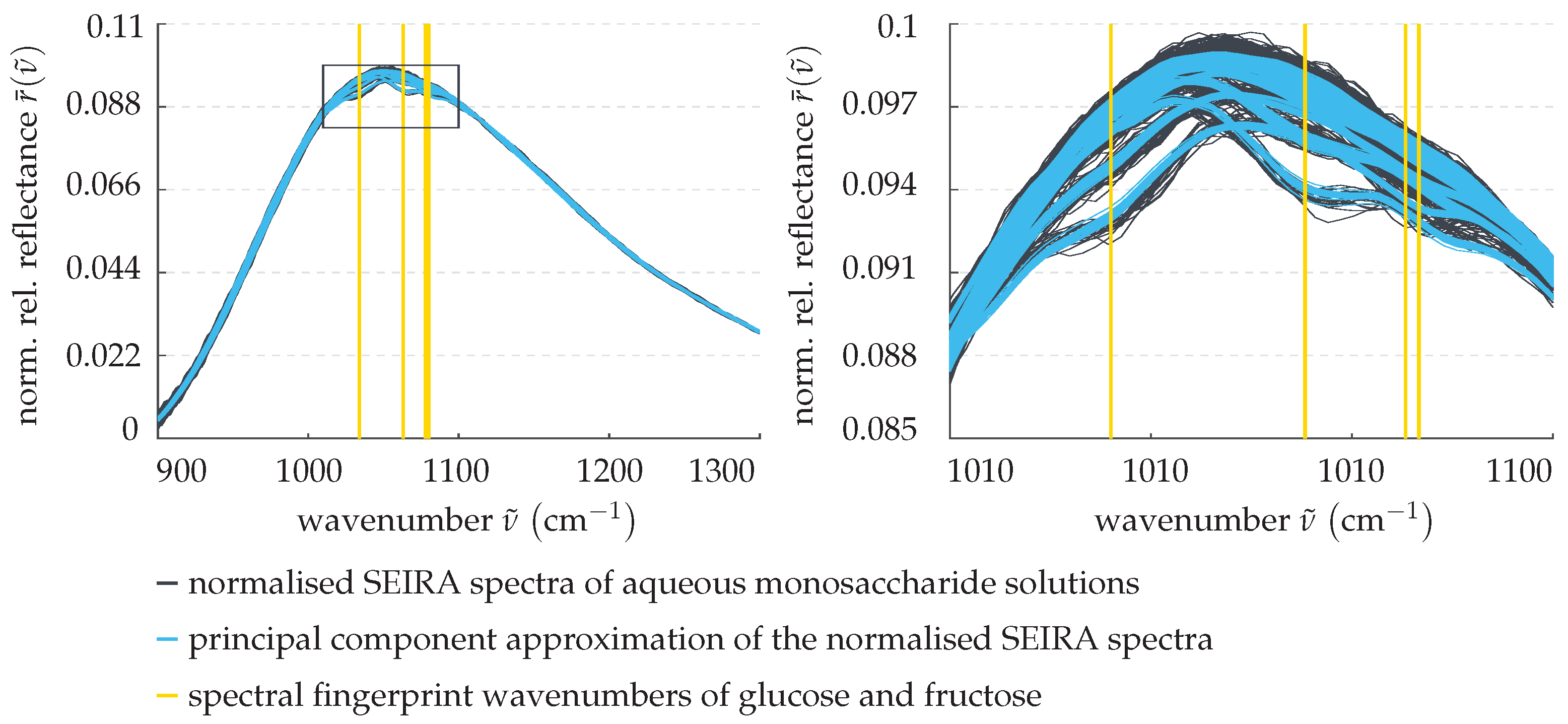
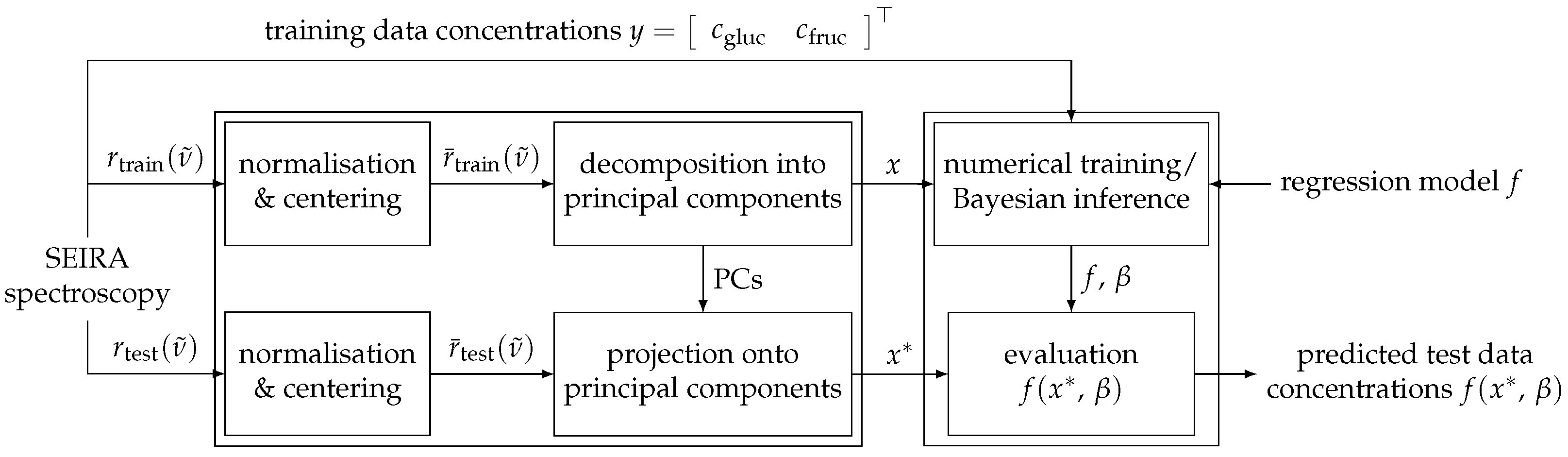
3.1. Data Pre-Processing
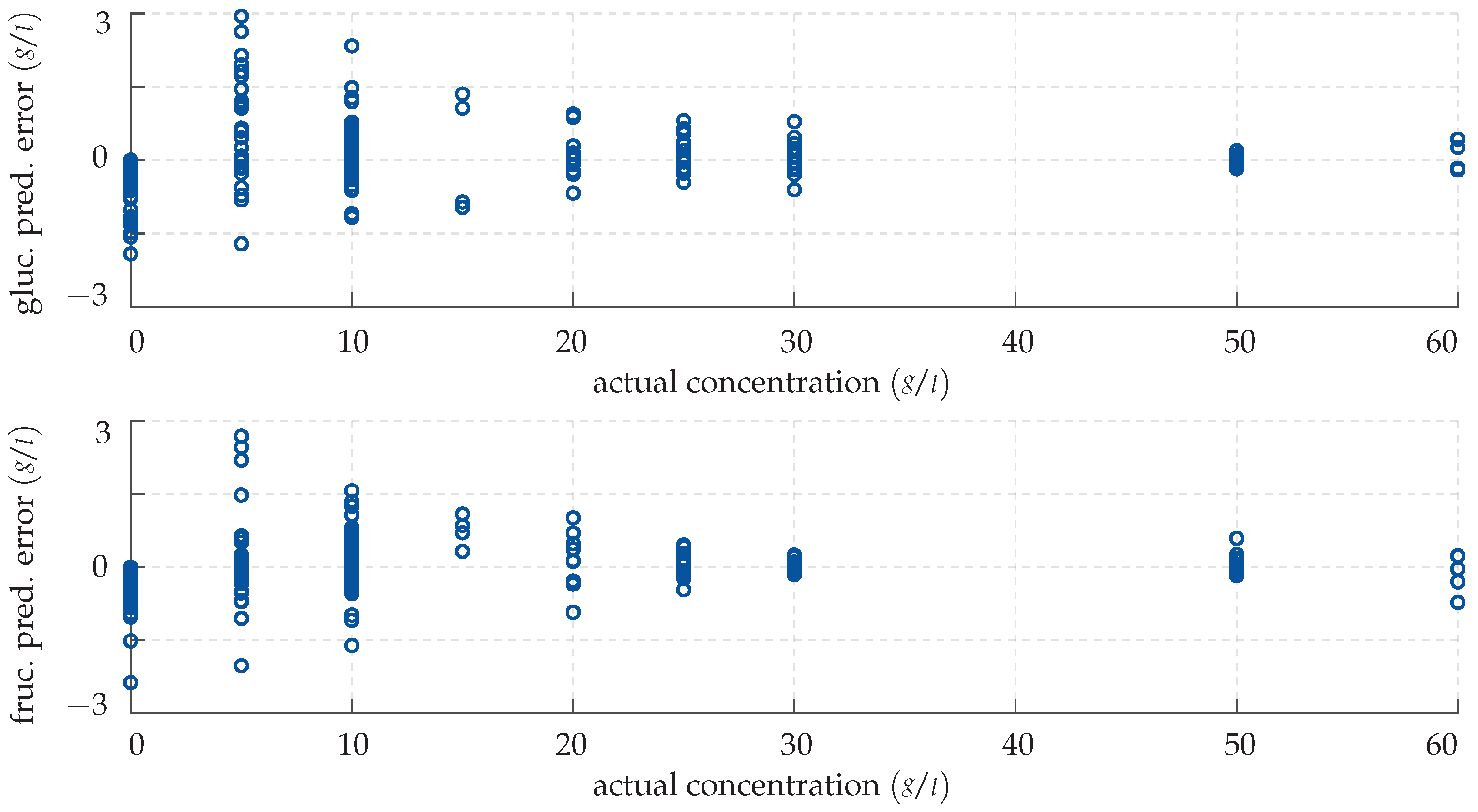
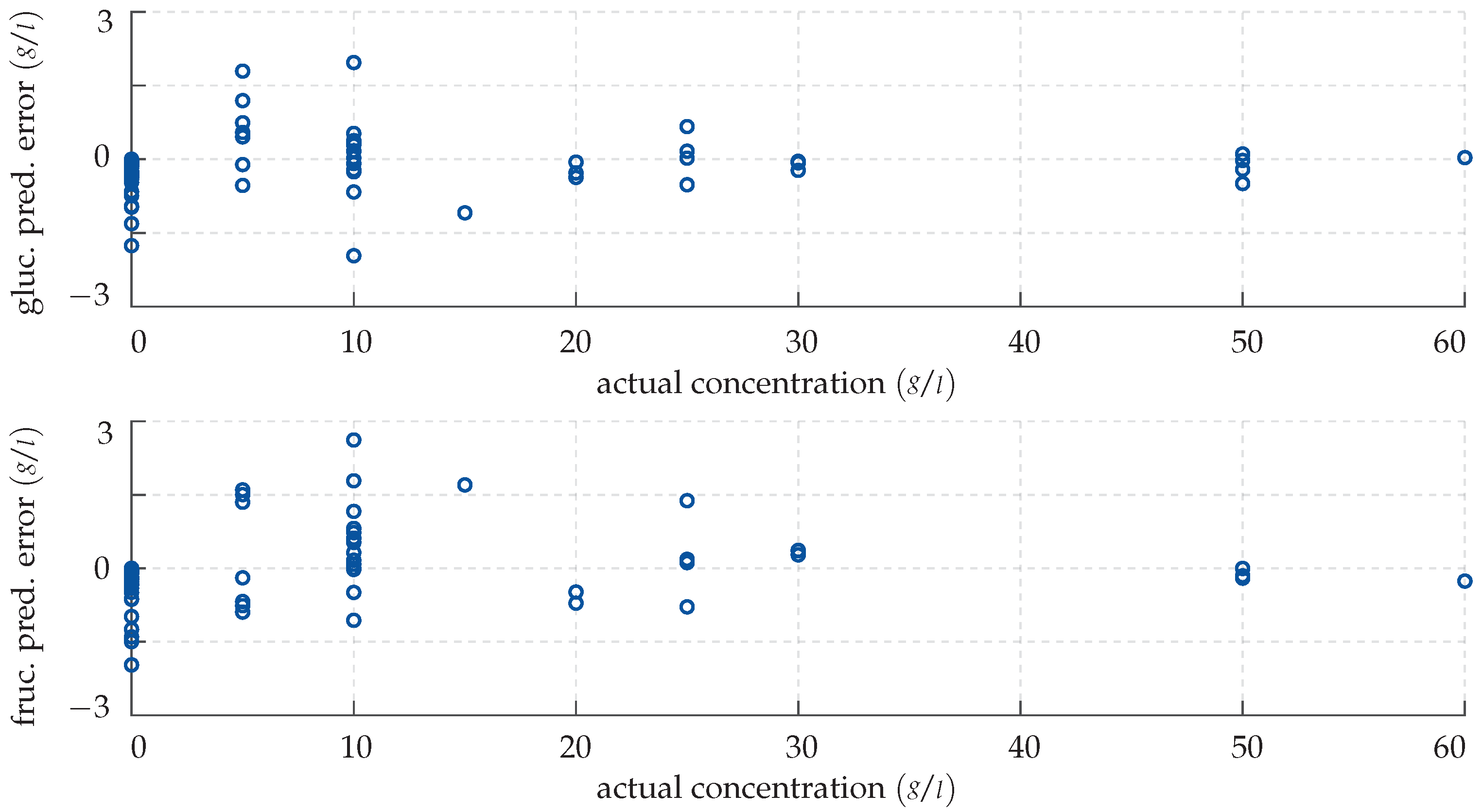
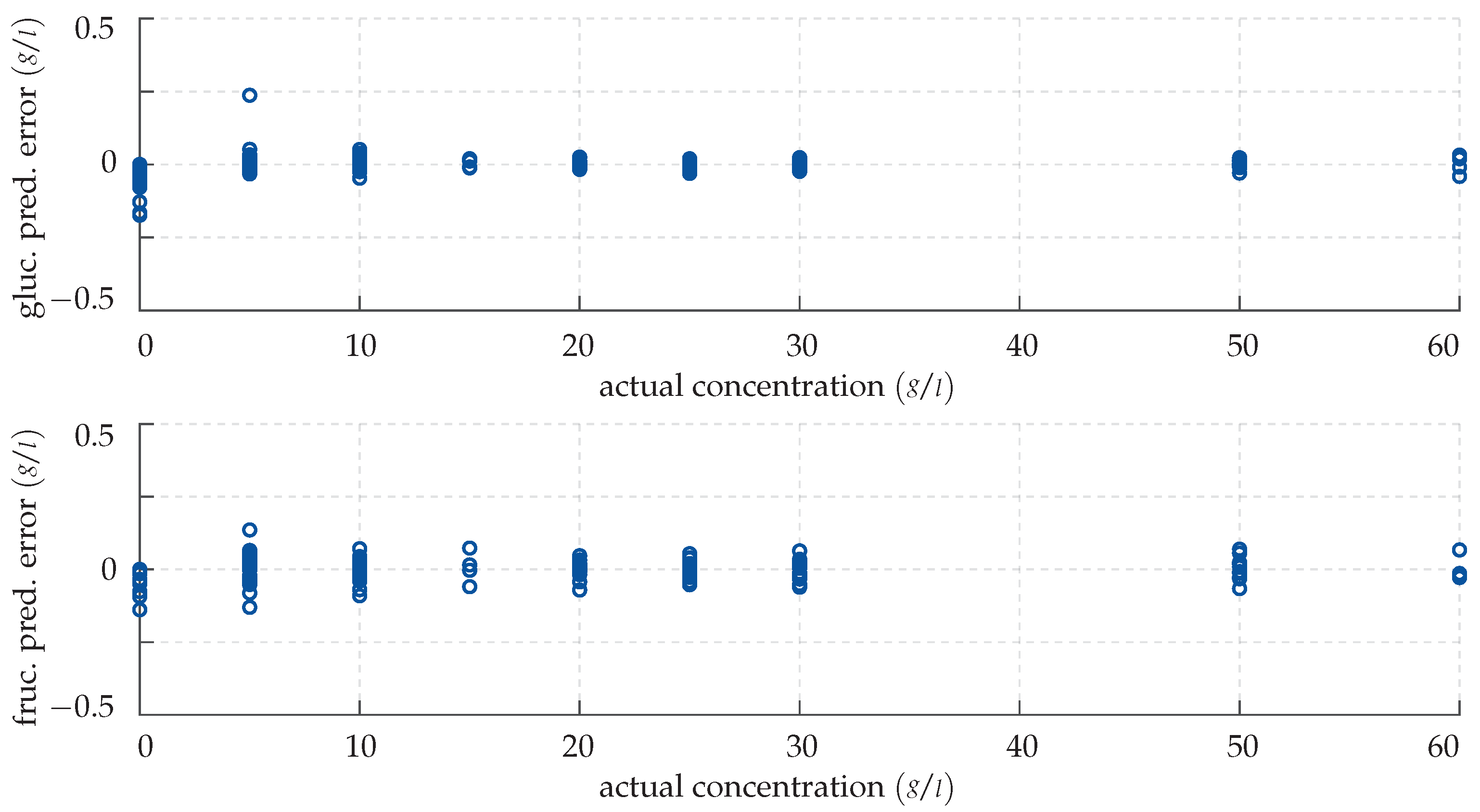
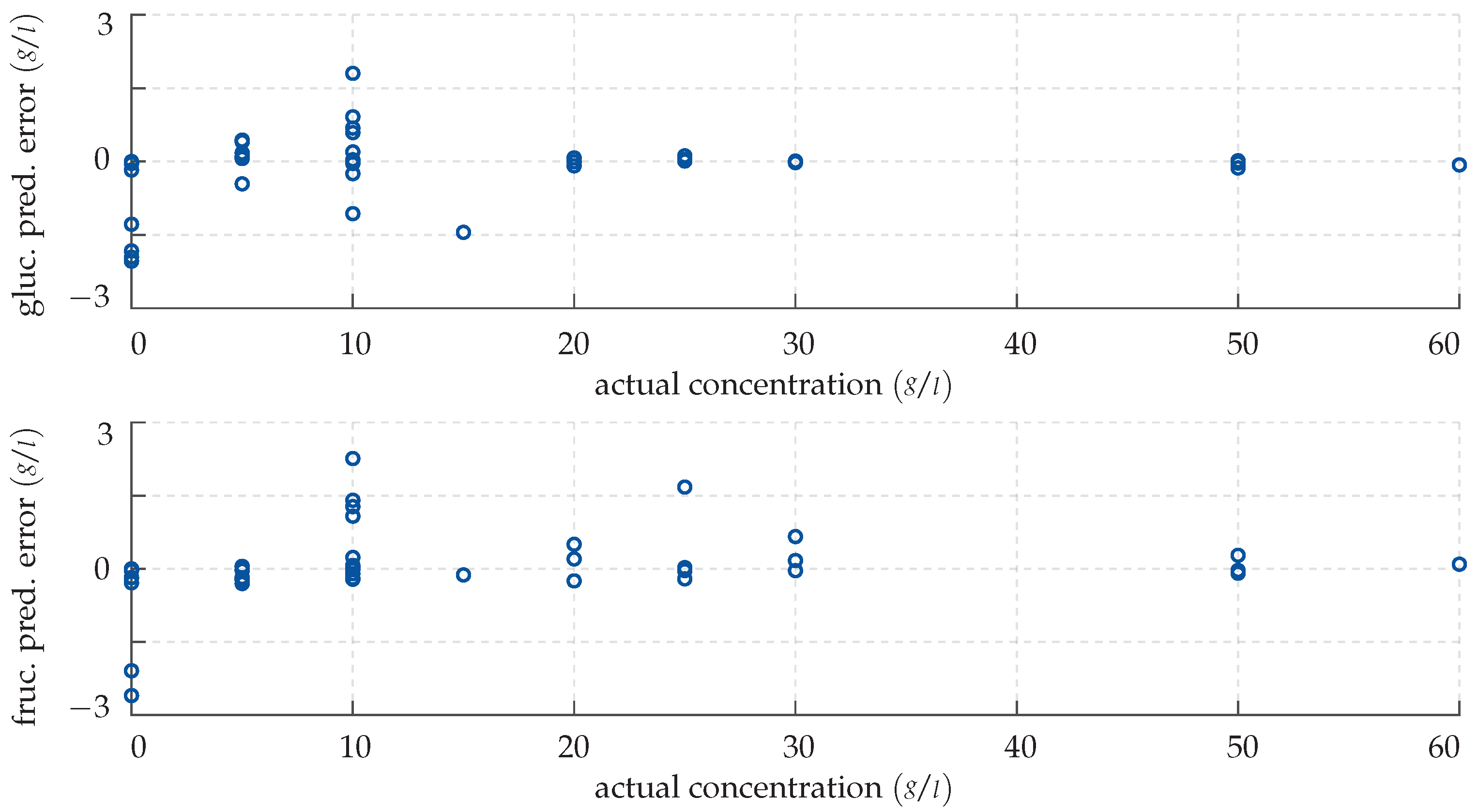
4. Results
4.1. Cascade-Forward Neural Network
4.2. Gaussian Process Regression
5. Discussion and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Technical Specifications and Software

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| gold nanoantennas | length , width, thickness , |
|---|---|
| chromium adhesion layer underneath, | |
| periodicity in x-direction , | |
| periodicity in y-direction , | |
| fabricated via electron beam lithography (EBL) | |
| FTIR spectrometer | Bruker VERTEX 80 |
| Bruker Optik GmbH, 76275 Ettlingen, Germany | |
| Optical microscope | Bruker Hyperion 2000, Schwarzschild objective |
| 15-fold magnification, | |
| Bruker Optik GmbH, 76275 Ettlingen, Germany | |
| detection | nitrogen-cooled mercury cadmium telluride (MCT) |
| detector, measurement spot |
References
- Mehrotra, P. Biosensors and their applications—A review. J. Oral Biol. Craniofac. Res. 2016, 6, 153–159. [Google Scholar] [CrossRef] [Green Version]
- World Health Organization. Definition, Diagnosis and Classification of Diabetes Mellitus and Its Complications: Report of a WHO Consultation. Part 1, Diagnosis and Classification of Diabetes Mellitus; World Health Organization: Geneva, Switzerland, 1999. [Google Scholar]
- American Diabetes Association. Diagnosis and classification of diabetes mellitus. Diabetes Care 2014, 37 (Suppl. 1), 81–90. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Edelman, S.V. Importance of Glucose Control. Med. Clin. N. Am. 1998, 82, 665–687. [Google Scholar] [CrossRef]
- Shokrekhodaei, M.; Quinones, S. Review of Non-invasive Glucose Sensing Techniques: Optical, Electrical and Breath Acetone. Sensors 2020, 20, 1251. [Google Scholar] [CrossRef] [Green Version]
- Lindner, N.; Kuwabara, A.; Holt, T. Non-invasive and minimally invasive glucose monitoring devices: A systematic review and meta-analysis on diagnostic accuracy of hypoglycaemia detection. Syst. Rev. 2021, 10, 145. [Google Scholar] [CrossRef]
- Bruen, D.; Delaney, C.; Florea, L.; Diamond, D. Glucose Sensing for Diabetes Monitoring: Recent Developments. Sensors 2017, 17, 1866. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T. Non-Invasive Glucose Monitoring: A Review of Challenges and Recent Advances. Curr. Trends Biomed. Eng. Biosci. 2017, 6, 1–8. [Google Scholar] [CrossRef]
- Villena Gonzales, W.; Mobashsher, A.T.; Abbosh, A. The Progress of Glucose Monitoring-A Review of Invasive to Minimally and Non-Invasive Techniques, Devices and Sensors. Sensors 2019, 19, 800. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Witkowska Nery, E.; Kundys, M.; Jeleń, P.S.; Jönsson-Niedziółka, M. Electrochemical Glucose Sensing: Is There Still Room for Improvement? Anal. Chem. 2016, 88, 11271–11282. [Google Scholar] [CrossRef]
- Rao, G.; Guy, R.H.; Glikfeld, P.; LaCourse, W.R.; Leung, L.; Tamada, J.; Potts, R.O.; Azimi, N. Reverse iontophoresis: Noninvasive glucose monitoring in vivo in humans. Pharm. Res. 1995, 12, 1869–1873. [Google Scholar] [CrossRef]
- Omer, A.E.; Shaker, G.; Safavi-Naeini, S.; Alquie, G.; Deshours, F.; Kokabi, H.; Shubair, R.M. Non-Invasive Real-Time Monitoring of Glucose Level Using Novel Microwave Biosensor Based on Triple-Pole CSRR. IEEE Trans. Biomed. Circuits Syst. 2020, 14, 1407–1420. [Google Scholar] [CrossRef] [PubMed]
- Omer, A.E.; Shaker, G.; Safavi-Naeini, S.; Kokabi, H.; Alquié, G.; Deshours, F.; Shubair, R.M. Low-cost portable microwave sensor for non-invasive monitoring of blood glucose level: Novel design utilizing a four-cell CSRR hexagonal configuration. Sci. Rep. 2020, 10, 15200. [Google Scholar] [CrossRef]
- Chen, T.; Li, S.; Sun, H. Metamaterials application in sensing. Sensors 2012, 12, 2742–2765. [Google Scholar] [CrossRef] [PubMed]
- Pickup, J.C.; Hussain, F.; Evans, N.D.; Rolinski, O.J.; Birch, D.J.S. Fluorescence-based glucose sensors. Biosens. Bioelectron. 2005, 20, 2555–2565. [Google Scholar] [CrossRef]
- Klonoff, D.C. Overview of fluorescence glucose sensing: A technology with a bright future. J. Diabetes Sci. 2012, 6, 1242–1250. [Google Scholar] [CrossRef] [Green Version]
- Szunerits, S.; Boukherroub, R. Sensing using localised surface plasmon resonance sensors. Chem. Commun. 2012, 48, 8999–9010. [Google Scholar] [CrossRef] [PubMed]
- Maier, S.A. Plasmonics: Fundamentals and Applications; Springer: New York, NY, USA, 2010. [Google Scholar]
- Thompson, J.M. Infrared Spectroscopy, 1st ed.; Pan Stanford Publishing: Milton, GA, USA, 2018. [Google Scholar]
- Yadav, J.; Rani, A.; Singh, V.; Murari, B.M. Prospects and limitations of non-invasive blood glucose monitoring using near-infrared spectroscopy. Biomed. Signal Process Control 2015, 18, 214–227. [Google Scholar] [CrossRef]
- Neubrech, F.; Pucci, A.; Cornelius, T.W.; Karim, S.; García-Etxarri, A.; Aizpurua, J. Resonant plasmonic and vibrational coupling in a tailored nanoantenna for infrared detection. Phys. Rev. Lett. 2008, 101, 157403. [Google Scholar] [CrossRef] [Green Version]
- Neubrech, F.; Huck, C.; Weber, K.; Pucci, A.; Giessen, H. Surface-Enhanced Infrared Spectroscopy Using Resonant Nanoantennas. Chem. Rev. 2017, 117, 5110–5145. [Google Scholar] [CrossRef]
- Kühner, L.; Semenyshyn, R.; Hentschel, M.; Neubrech, F.; Tarín, C.; Giessen, H. Vibrational Sensing Using Infrared Nanoantennas: Toward the Noninvasive Quantitation of Physiological Levels of Glucose and Fructose. ACS Sens. 2019, 4, 1973–1979. [Google Scholar] [CrossRef]
- Adato, R.; Altug, H. In-situ ultra-sensitive infrared absorption spectroscopy of biomolecule interactions in real time with plasmonic nanoantennas. Nat. Commun. 2013, 4, 2154. [Google Scholar] [CrossRef] [PubMed]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2002. [Google Scholar]
- Schuler, B.; Kühner, L.; Hentschel, M.; Giessen, H.; Tarín, C. Adaptive Method for Quantitative Estimation of Glucose and Fructose Concentrations in Aqueous Solutions Based on Infrared Nanoantenna Optics. Sensors 2019, 19, 3053. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eilers, P.H.; Boelens, H.F. Baseline Correction with Asymmetric Least Squares Smoothing; Leiden University Medical Centre Report; Leiden University Medical Centre: Leiden, The Netherlands, 2005. [Google Scholar]
- Galushkin, A.I. Neural Networks Theory; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Warsito, B.; Santoso, R.; Suparti; Yasin, H. Cascade Forward Neural Network for Time Series Prediction. J. Phys. Conf. Ser. 2018, 1025, 012097. [Google Scholar] [CrossRef]
- Khan, S.A.; Shahani, D.T.; Agarwala, A.K. Sensor calibration and compensation using artificial neural network. ISA Trans. 2003, 42, 337–352. [Google Scholar] [CrossRef]
- Oh, H.S.; Kang, G.; Kim, U.; Seo, J.K.; You, W.S.; Choi, H.R. Force/torque sensor calibration method by using deep-learning. In Proceedings of the 14th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Jeju, Korea, 28 June–1 July 2017; pp. 777–782. [Google Scholar] [CrossRef]
- Almassri, A.M.M.; Wan Hasan, W.Z.; Ahmad, S.A.; Shafie, S.; Wada, C.; Horio, K. Self-Calibration Algorithm for a Pressure Sensor with a Real-Time Approach Based on an Artificial Neural Network. Sensors 2018, 18, 2561. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yamamoto, K.; Togami, T.; Yamaguchi, N.; Ninomiya, S. Machine Learning-Based Calibration of Low-Cost Air Temperature Sensors Using Environmental Data. Sensors 2017, 17, 1290. [Google Scholar] [CrossRef] [Green Version]
- Baronas, R.; Ivanauskas, F.; Maslovskis, R.; Vaitkus, P. An Analysis of Mixtures Using Amperometric Biosensors and Artificial Neural Networks. J. Math. Chem. 2004, 36, 281–297. [Google Scholar] [CrossRef]
- Schackart, K.E.; Yoon, J.Y. Machine Learning Enhances the Performance of Bioreceptor-Free Biosensors. Sensors 2021, 21, 5519. [Google Scholar] [CrossRef] [PubMed]
- Ramasahayam, S.; Koppuravuri, S.H.; Arora, L.; Chowdhury, S.R. Noninvasive blood glucose sensing using near infra-red spectroscopy and artificial neural networks based on inverse delayed function model of neuron. J. Med. Syst. 2015, 39, 166. [Google Scholar] [CrossRef] [PubMed]
- Han, G.; Chen, S.; Wang, X.; Wang, J.; Wang, H.; Zhao, Z. Noninvasive blood glucose sensing by near-infrared spectroscopy based on PLSR combines SAE deep neural network approach. Infrared Phys. Technol. 2021, 113, 103620. [Google Scholar] [CrossRef]
- Ghosh, K.; Stuke, A.; Todorović, M.; Jørgensen, P.B.; Schmidt, M.N.; Vehtari, A.; Rinke, P. Deep Learning Spectroscopy: Neural Networks for Molecular Excitation Spectra. Adv. Sci. 2019, 6, 1801367. [Google Scholar] [CrossRef]
- Li, X.; Shu, J.; Gu, W.; Gao, L. Deep neural network for plasmonic sensor modeling. Opt. Mater. Express 2019, 9, 3857. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning, 3rd ed.; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Monroy, J.G.; Lilienthal, A.J.; Blanco, J.L.; Gonzalez-Jimenez, J.; Trincavelli, M. Probabilistic gas quantification with MOX sensors in Open Sampling Systems—A Gaussian Process approach. Sens. Actuators B Chem. 2013, 188, 298–312. [Google Scholar] [CrossRef] [Green Version]
- Urban, S.; Ludersdorfer, M.; van der Smagt, P. Sensor Calibration and Hysteresis Compensation with Heteroscedastic Gaussian Processes. IEEE Sens. J. 2015, 15, 6498–6506. [Google Scholar] [CrossRef]
- Geng, Z.; Yang, F.; Chen, X.; Wu, N. Gaussian process based modeling and experimental design for sensor calibration in drifting environments. Sens. Actuators B Chem. 2015, 216, 321–331. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, W.; Wang, Z.; Chao, X. Gaussian process regression for direct laser absorption spectroscopy in complex combustion environments. Opt. Express 2021, 29, 17926–17939. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Ou, X.; Martin, E. Calibration of Spectroscopic Sensors with Gaussian Process and Variable Selection. IFAC Proc. Vol. 2007, 40, 137–142. [Google Scholar] [CrossRef]
- Chen, T.; Morris, J.; Martin, E. Gaussian process regression for multivariate spectroscopic calibration. Chemometr. Intell. Lab. Syst. 2007, 87, 59–71. [Google Scholar] [CrossRef] [Green Version]
- Valletta, J.J.; Chipperfield, A.J.; Byrne, C.D. Gaussian Process modelling of blood glucose response to free-living physical activity data in people with type 1 diabetes. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; pp. 4913–4916. [Google Scholar] [CrossRef] [Green Version]
- Świątek, J.; Tomczak, J.M. Advances in Systems Science; Springer International Publishing: Cham, Switzerland, 2017; Volume 539. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]











| Monosaccharide Concentration in the Sample in g/L | Number of Samples |
|---|---|
| 5 | 4 |
| 10 | 8 |
| 20 | 2 |
| 25 | 2 |
| 30 | 2 |
| 50 | 3 |
| Concentration of Glucose in the Sample in g/L | Concentration of Fructose in the Sample in g/L | Number of Samples |
|---|---|---|
| 5 | 5 | 2 |
| 5 | 10 | 1 |
| 10 | 5 | 1 |
| 10 | 10 | 3 |
| 10 | 15 | 1 |
| 15 | 10 | 1 |
| 10 | 20 | 2 |
| 20 | 10 | 2 |
| 25 | 25 | 1 |
| 30 | 60 | 1 |
| 60 | 30 | 1 |
| 50 | 50 | 1 |
| Method of Estimation | Maximum Absolute Deviation g/L | Mean Deviation Abs. g/L, Rel. % | RMS Error g/L |
|---|---|---|---|
| Cascade-forward neural network | |||
| Gaussian process regression | |||
| Linear regression | |||
| order polynomial regression | |||
| Support vector regression | |||
| Schuler et al. [26] | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Corcione, E.; Pfezer, D.; Hentschel, M.; Giessen, H.; Tarín, C. Machine Learning Methods of Regression for Plasmonic Nanoantenna Glucose Sensing. Sensors 2022, 22, 7. https://doi.org/10.3390/s22010007
Corcione E, Pfezer D, Hentschel M, Giessen H, Tarín C. Machine Learning Methods of Regression for Plasmonic Nanoantenna Glucose Sensing. Sensors. 2022; 22(1):7. https://doi.org/10.3390/s22010007
Chicago/Turabian StyleCorcione, Emilio, Diana Pfezer, Mario Hentschel, Harald Giessen, and Cristina Tarín. 2022. "Machine Learning Methods of Regression for Plasmonic Nanoantenna Glucose Sensing" Sensors 22, no. 1: 7. https://doi.org/10.3390/s22010007
APA StyleCorcione, E., Pfezer, D., Hentschel, M., Giessen, H., & Tarín, C. (2022). Machine Learning Methods of Regression for Plasmonic Nanoantenna Glucose Sensing. Sensors, 22(1), 7. https://doi.org/10.3390/s22010007