
Novel Perspectives for the Management of Multilingual and Multialphabetic Heritages through Automatic Knowledge Extraction: The DigitalMaktaba Approach †

 ,
,  ,
,  and
and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
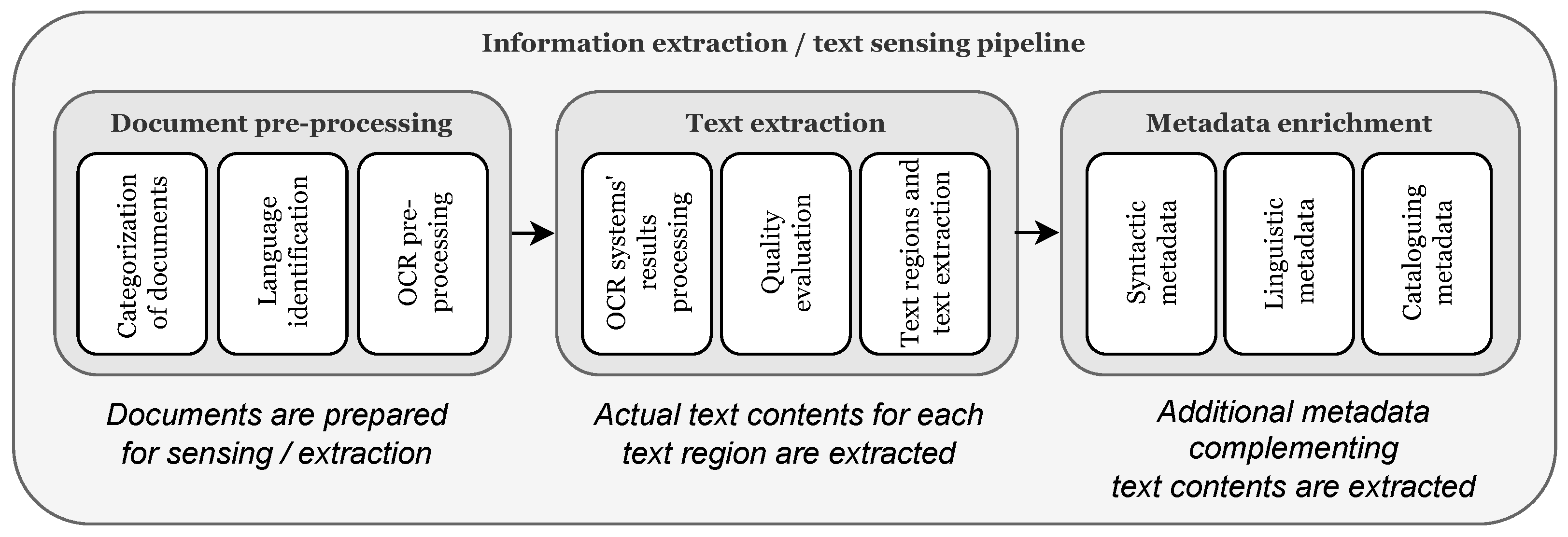
- Text extraction, leveraging and combining the output of the best-performing OCR libraries in order to extract text information in a more accurate and uniform way than current proposals;
- Metadata enrichment, enabling to automatically capture useful metadata: (a) syntactic metadata, including text-regions information (improved w.r.t. the state of the art approaches by means of a newly proposed text-region numbering and merging approach), identified language(s) and character(s), text size and position on page, and the self-assessed quality of extraction through an ad-hoc metric; (b) linguistic metadata, including links to external linguistic resources providing useful information such as word definitions for further (semantic) processing; and (c) cataloguing metadata, through a novel approach for automatic title and author identification in a frontispiece.
2. Related Works
2.1. Projects and Proposals for the Curation of Digital Libraries in Arabic-Script Languages
2.2. Text Sensing/Extraction/OCR in Arabic-Script Languages
2.3. Comparison and Discussion of Innovative Aspects of DigitalMaktaba w.r.t. State of the Art Techniques
- Multiple languages: the presented innovative workflow and tool works in the Arabic, Persian and Azerbaijani languages, which have not been considered together in other works;
- A larger size: the project is aimed at the creation of a very large digital library (300,000+ books, much more than other projects, which are aimed at thousands of books at most), thanks also to the innovative automation features which are not present in the discussed other projects (see below);
- Non-Latin alphabet metadata: the automatically extracted metadata, besides being very rich (see points below), contribute to the creation of a digital library integrated with SBN without relying on transliteration (in contrast to the cited state of the art projects).
- Better effectiveness: thanks to the proposed text and text-regions extraction approaches, the achieved effectiveness is better than the state of the art techniques (see tests in Section 4);
- Across all considered languages: in contrast to the discussed OCR libraries, all the considered languages are automatically identified without manual work and supported without uneven performance issues.
- Rich metadata: syntactic, linguistic and cataloguing metadata are extracted and stored for each new processed document;
- Automated extraction: the metadata extraction is a fully automated process, including the identification of title and authors, which in state of the art projects (Section 2.1) is performed as a time-consuming manual activity.
- Flexible data management: the system can, at any time, access the data stored in a standard DBMS and convert the bibliographic information toward most desired outputs;
- Less manual work: the extraction pipeline and associated UI features help users in performing less manual work, fully automating batch text and metadata extraction (for instance, the discussed OCR libraries do not support this when working with multiple languages).
3. Materials and Methods
3.1. Text-Sensing Aspects: Information Extraction
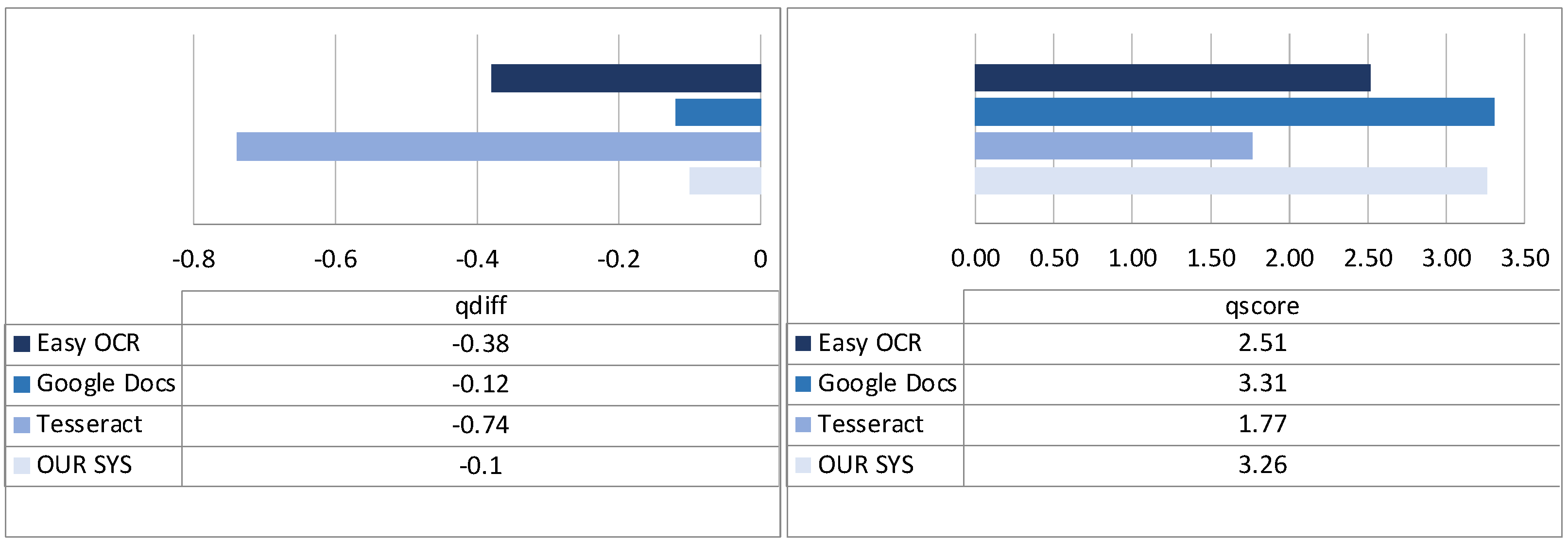
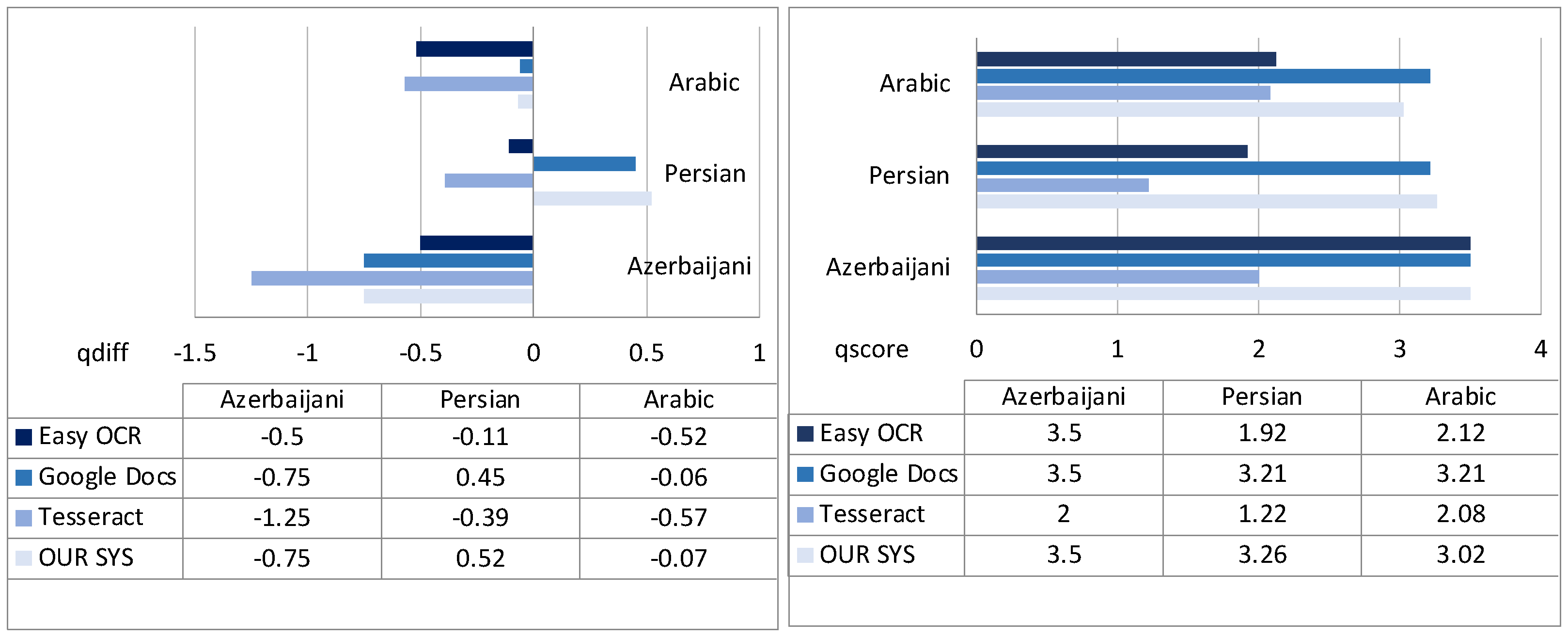
- qdiff (range [−2, 2]), expressing whether the output is in line (0), superior (positive values) or inferior (negative values) to the input quality;
- qscore (range [1, 5]), expressing the quality of the result of the OCR system given the input quality.
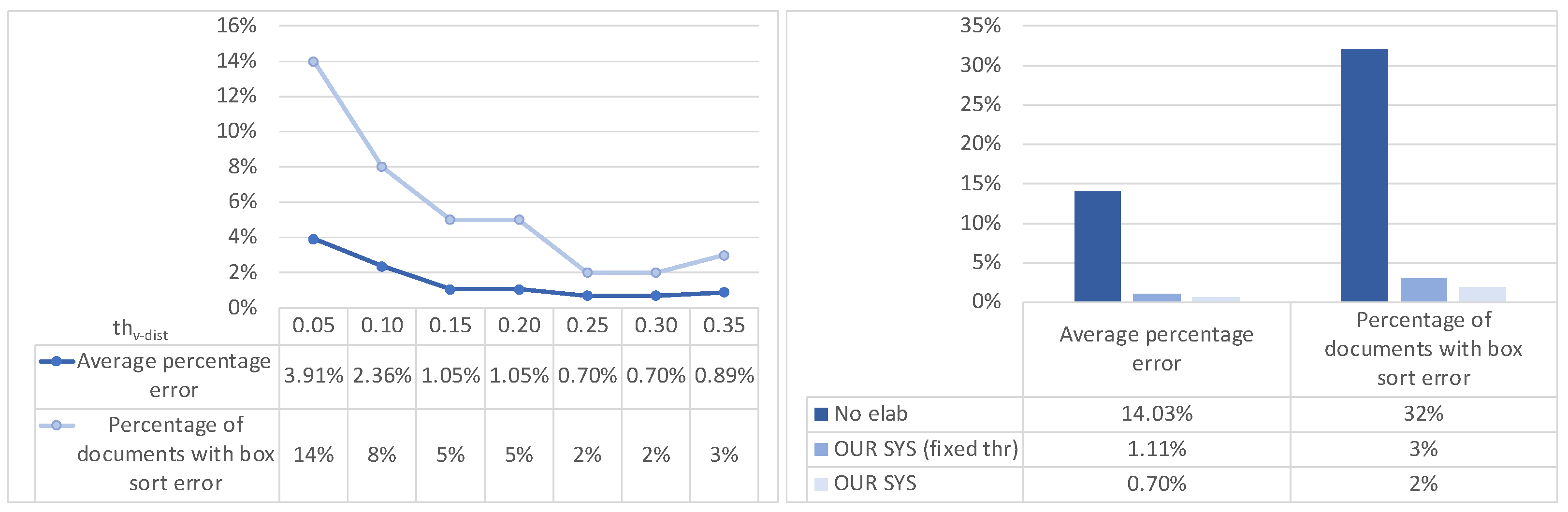
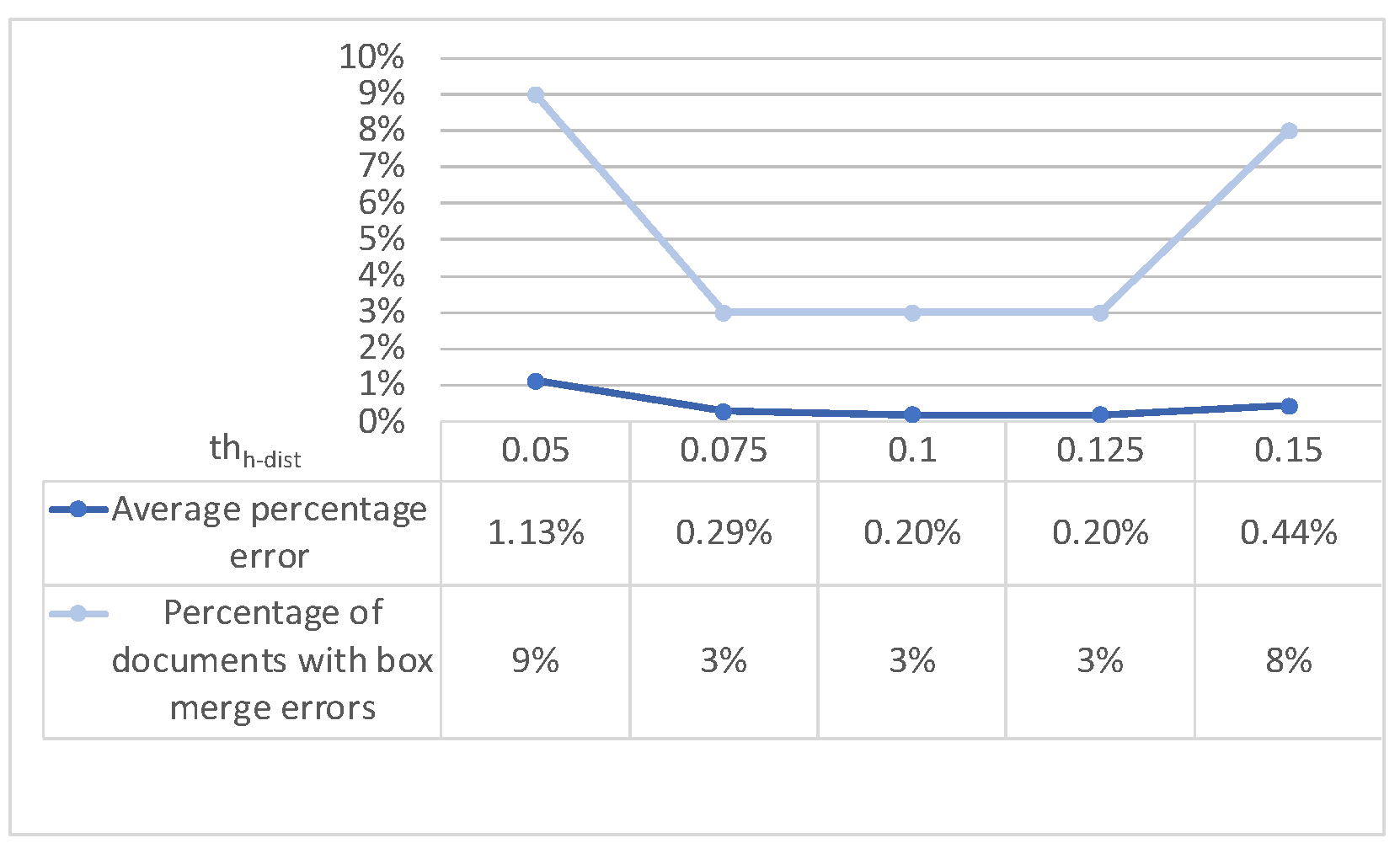
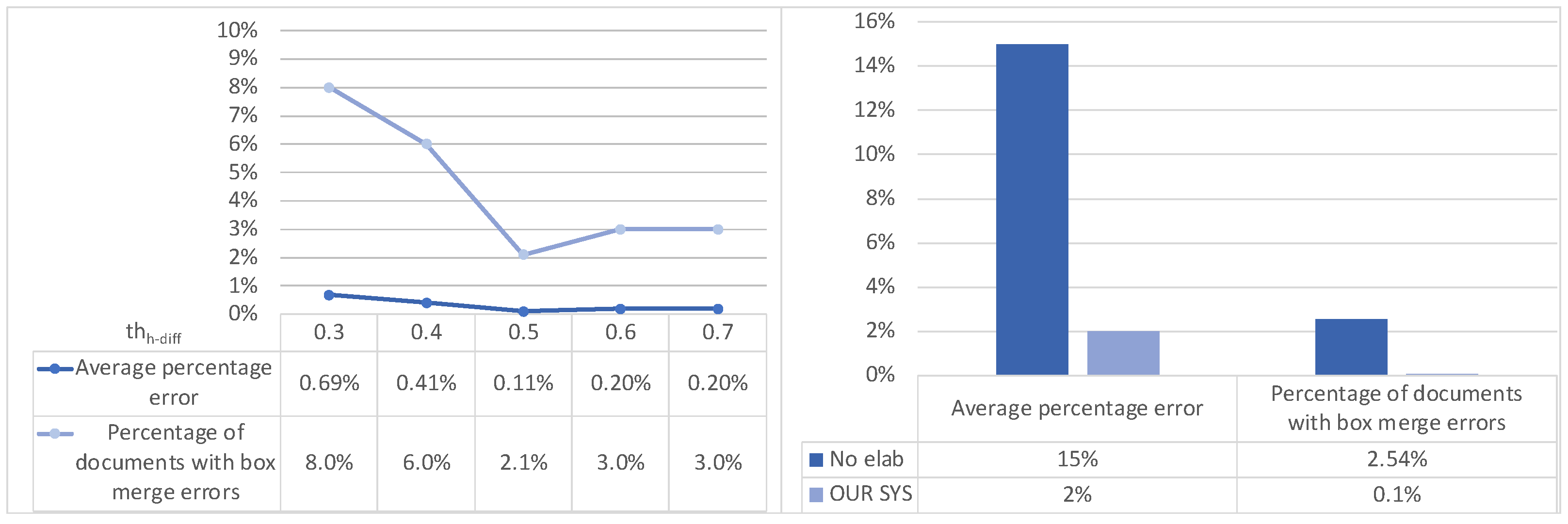
- Horizontal grouping: first of all, the boxes of a page are grouped into horizontal groups following a horizontal grouping criterion (see Figure 3): two boxes will belong to the same group if the vertical distance v-dist between their medians w.r.t. the height of the tallest box does not exceed a given threshold thv-dist;
- Merging: inside each group of boxes are boxes satisfying the merging criteria (i.e., relative height difference below a given threshold thh-diff and horizontal distance relative to page width below a given threshold thh-dist, as depicted in Figure 3);
- (Re)numbering: the resulting boxes are renumbered from top to bottom (different groups) and from right to left (inside each group): Figure 3 shows the resulting numbers on the top right corner of each box.
- Open Multilingual WordNet (http://compling.hss.ntu.edu.sg/omw/(accessed on 10 March 2022)) providing word lookup for the three different languages (only unvocalized words, in the case of Arabic) and access to extended semantic information (including word definitions). Arabic and Persian/Azerbaijani Wordnet contain 17,785 and 17,560 synsets, respectively;
- Arramooz (https://github.com/linuxscout/arramooz (accessed on 10 March 2022)) an open-source Arabic dictionary for morphological analysis providing unvocalized word lookup and definitions for the Arabic language. It contains 50,000 words;
- Tashaphyne (https://pypi.org/project/Tashaphyne (accessed on 10 March 2022)), a light stemmer that is used as a devocalizer in order to extend the Arabic coverage of the two previously described resources.
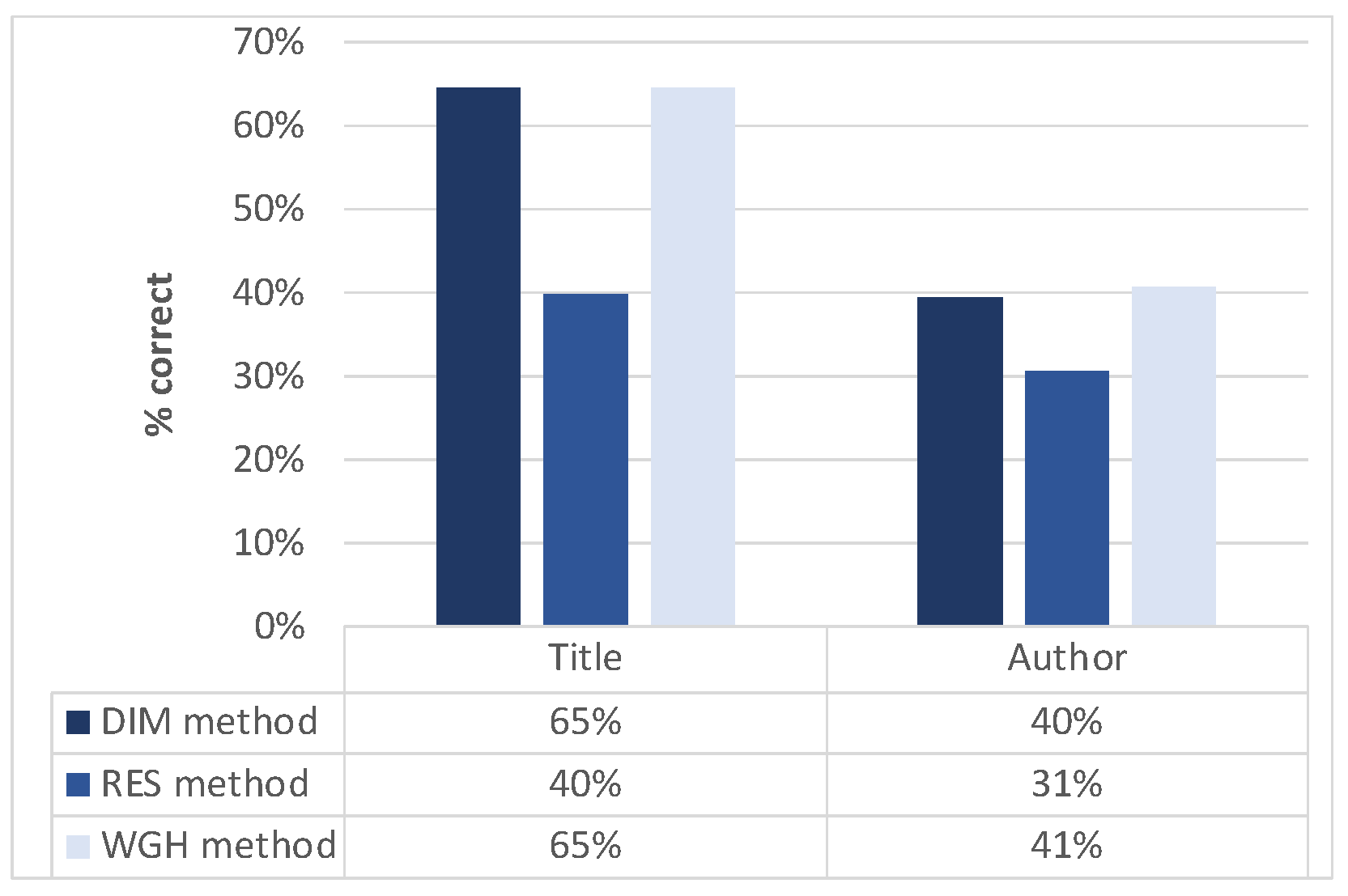
- DIM method: boxes are sorted on vertical dimension, then the first box in the ranking is suggested as title, the second one as author(s) (following the intuition that the largest texts on a frontispiece are typically the title and the authors’ names, in this order);
- RES method: external linguistic resources (including a list of names and surnames in the different languages) are searched and boxes are sorted on the basis of the percentage of found words and names (for identifying title and author, respectively);
- WGH method: method combining the contributions of the previous methods (a linear combination ranking fusion technique [31] is exploited in order to produce final rankings for both title and authors).
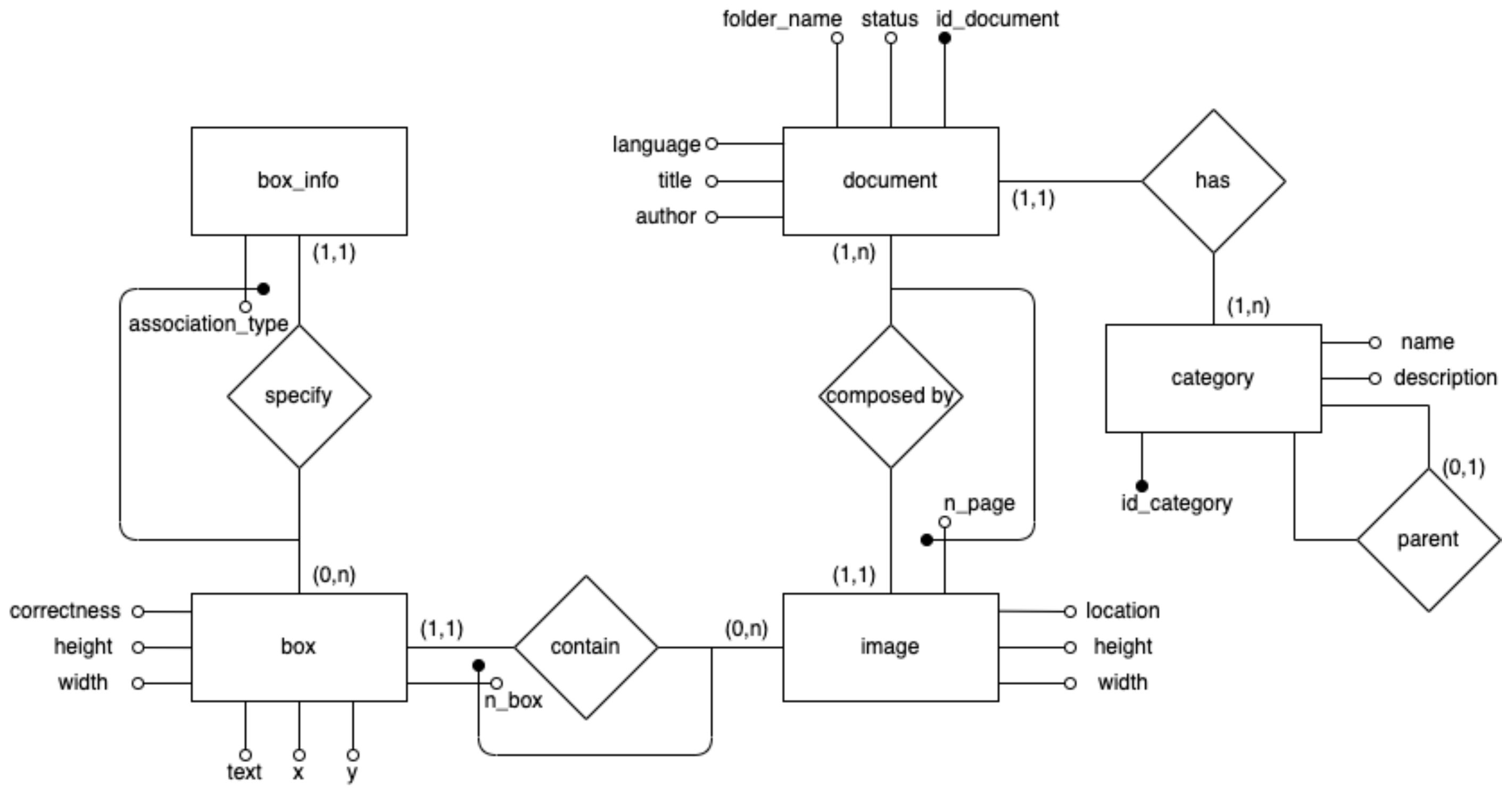
3.2. Data Management
- The document entity is at the heart of the schema and stores the catalogued documents data/metadata, including title, author, language and the path of the folder containing the actual document file(s);
- The details about the scanned images of a document are stored in the Image entity (each image corresponds to a specific document page), including file location and image dimensions;
- The category entity stores information about the specific category (name and description) to which each document belongs. Categories are currently manually selected by the user from a 3-level hierarchy (modelled through a self-association) containing more than 560 entries; however, in the future we plan to provide “smart” techniques based on AI to assist the process by means of relevant suggestions;
- The entities on the left part of the image store useful metadata about both the OCR results and the feedback coming from system use: for each image, the Box entity stores the text regions associated to an image (position, dimensions, text, and automatic quality evaluation as described in previous section), while Box_info stores the semantic information about the box content (i.e., the fact that the box contains author, title, and other information is stored in the association_type property).
4. Results and Discussion
4.1. Prototype: User Interface and Functionalities
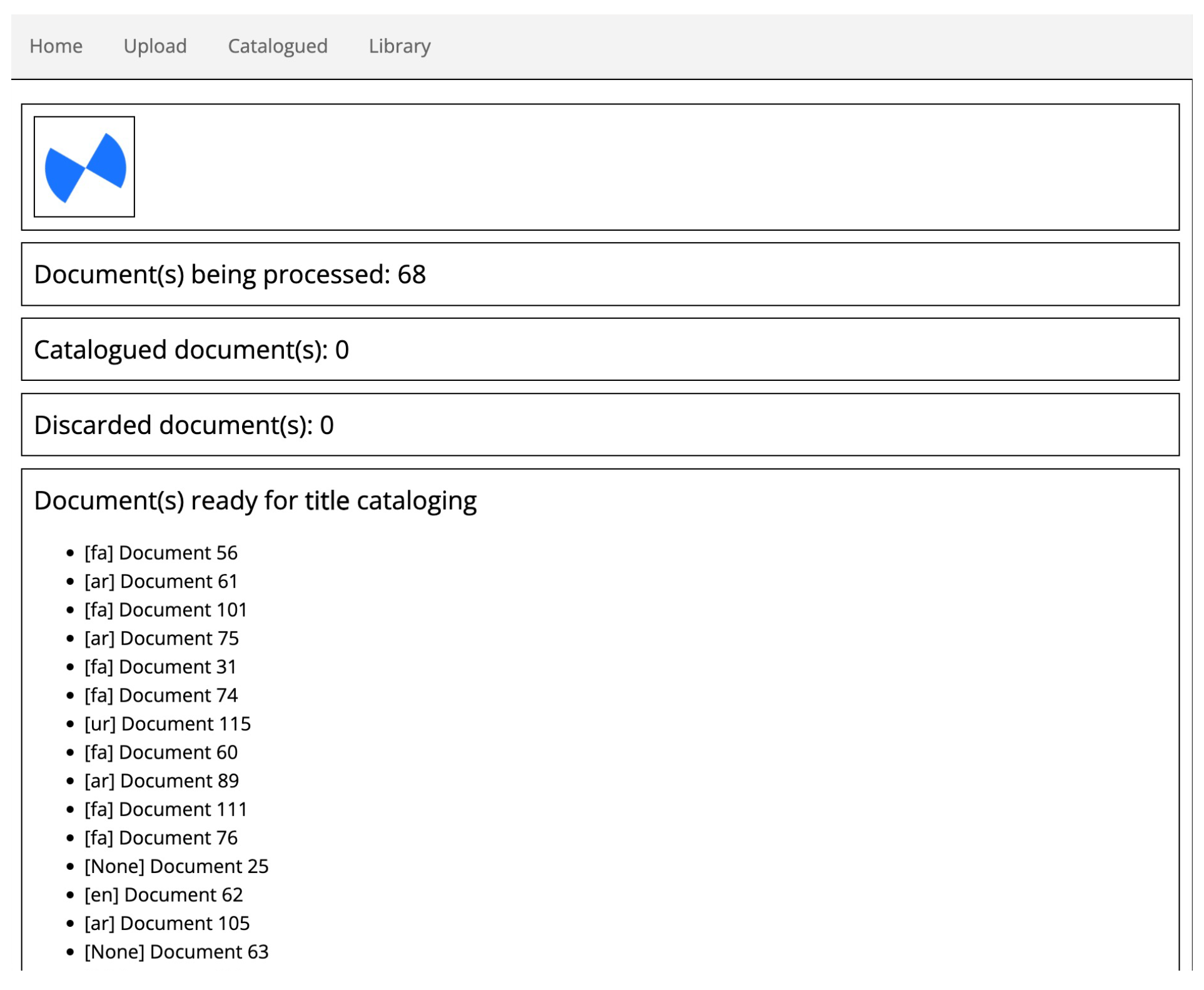
- Batch document preprocessing: this allows to preprocess an entire folder of PDF documents. The current implementation exploits multithreading for faster processing, using one OCR thread per page. The UI informs users on the documents being processed and allows them to proceed to document cataloguing for the ones that are ready (see Figure 5);
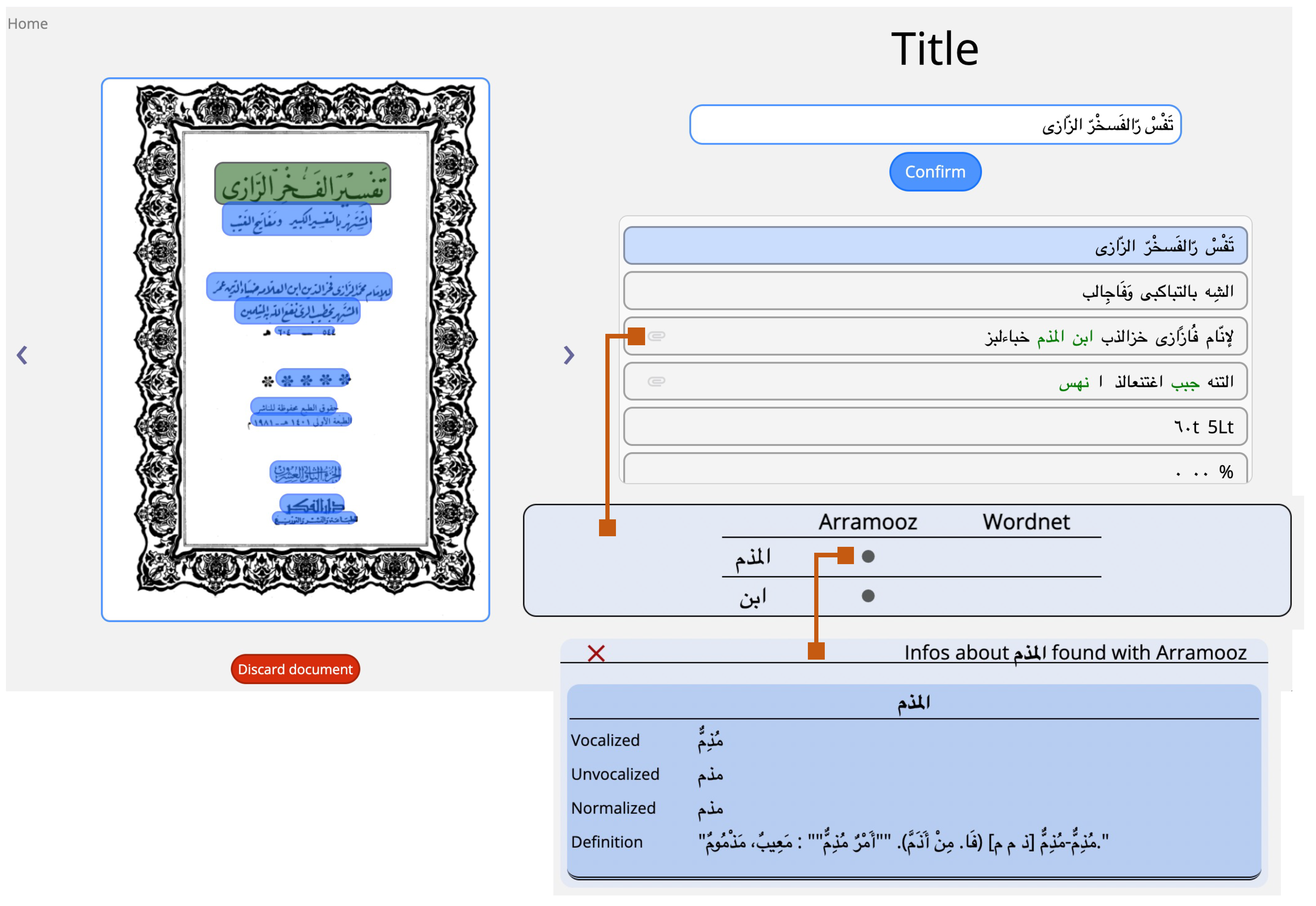
- Catalogue an already processed document: this guides the user on a series of steps where (s)he is provided with a graphical user interface in order to finalize document properties input (title, author, category, etc.). For instance, the UI for title selection (Figure 6) shows the document frontispiece (on the left) and automatically selects the text region(s) (whose extracted text content is shown on the right) that are most likely to contain the title. The user is able to select different text regions to modify/merge their text (text is concatenated from right to left based on the order in which they are clicked). The tool also visually helps users by showing at a glance the automatically discovered links to the available linguistic resources: the found words are shown in green color and, when the “clip” icon is clicked, a popup displays which words are found in which linguistic resource and, for each of them, related information such as vocalized versions and definitions (lower part of Figure 6). See Section 3.1 for a description of the involved extraction process for text, text regions (including automatic region merge and sorting), and linguistic and cataloguing metadata (including automatic author and title identification);
- Various search functions on the catalogue database, including author and title full-text search and category search (see Section 3.2);
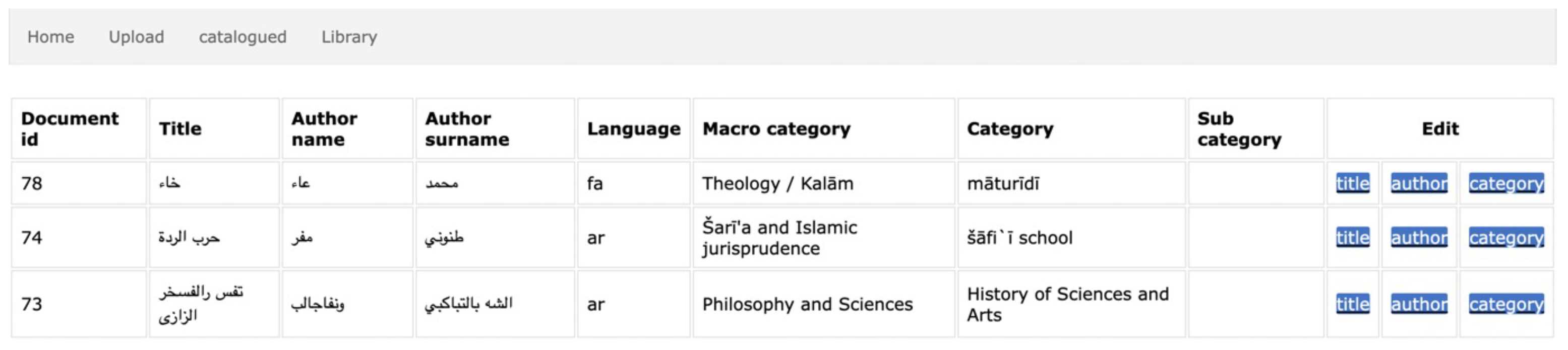
- see a summary of the currently catalogued documents data (Figure 7);
- Other miscellaneous functions: modify already entered data, delete documents from database, restore deleted documents, view catalogued documents.
4.2. Experimental Evaluation
4.3. Future Work
- From a data-management perspective, special focus will be given to the data interchange and long-term preservation aspects, in order to allow data interchange with catalogue data from other libraries and make the managed data readable and usable also on a long-term basis [36];
- Intelligent and AI-based techniques will also have a prominent role: intelligent assistance features will be designed and implemented in order to bring new levels of assistance to the cataloguing process. Data entering will be supported by suggestions derived from user feedback and previously entered data, thus integrating and extending the author-/title-identification techniques we described in this paper; supervised machine-learning models will enable automatic publication-type recognition and provide a systematisation and classification of data according to the topographic design of the La Pira library;
- The design of incremental ML algorithms will ensure that the tool can “learn” and become more and more automated and effective with use. Both classic and deep-learning algorithms will be considered, deployed on parallel architectures for faster execution. Special attention will be given to interpretable machine-learning algorithms, following the recent interpretable machine-learning trend in different fields [37], with the aim of going beyond the black-box nature of ML suggestions and explaining them, also in the library cataloguing/cultural heritage context, where this has seldom been performed;
- Ee plan to extend the scope of the experimental tests by considering incrementally larger portions of the use case library.
5. Conclusions
- Overcoming the limitations of current text-extraction tools: non-uniform OCR with different characters, backwardness of OCR for Arabic, poor automation and extraction of additional metadata;
- Faster pipeline: To date, the cataloguing of documents has been performed manually, document by document, opening them one at a time, searching inside the information to be catalogued and then moving to the next one. By employing the tool being developed, we can drastically reduce the time spent cataloguing simpler documents (since the suggested output will need fewer modifications from the user), while for the most complex ones, the system can still provide useful suggestions. In both cases, this system will speed-up the entire procedure;
- Greater consistency and fewer errors: In fact, with the automatic suggestions supplied to the user, it will become easier to avoid mistakes while inserting the document’s information, making the extracted data less error-prone. Moreover, the system will constantly perform checks on previously catalogued data in order to avoid inconsistencies, which can be very common in manual cataloguing (e.g., an author surname inserted with/without name, abbreviated name, etc.);
- Consistently better system output through time: by means of the machine-learning/intelligent features, the system will provide an output that will be better and better as the system is used, exploiting its “training” on previously catalogued, similar documents;
- Flexibility of data output/exchange: being a system based on a complete data-management system on which all the user and system output is stored, the system can at any time access the stored data and convert the bibliographic information toward most desired outputs, thus facilitating data exchange;
- Efficiency and Explainability: advanced data-management and machine-learning techniques will enable high efficiency levels for significant data-cataloguing needs, while the explainability of the models will make the intelligent assistance tools more usable.
- Advancement of studies on cataloguing in multi-literate environments without leaning exclusively on confusing transliteration systems;
- Exchange of IT, humanist and library personnel, enhancement of professional skills, training activities extended to realities with similar needs;
- Strengthening of library services thanks to shared international standards, expanding library heritage, databases integration, maximum access to the heritage, possibility of using the language of the document without the mediation of other languages.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| oq | manually assessed OCR output quality |
| iq | manually assessed OCR input quality |
| qdiff | resulting quality difference from oq-iq |
| qscore | overall quality of the OCR system result, given the input quality |
| v-dist | vertical distance |
| h-dist | horizontal distance |
| h-diff | text boxes height difference |
| thv-dist | Threshold on vertical distance |
| thh-diff | Threshold on height difference |
| thh-dist | Threshold oh horizontal distance |
| h | boxes height |
| g | box(es) group |
References
- Nasir, I.M.; Khan, M.A.; Yasmin, M.; Shah, J.H.; Gabryel, M.; Scherer, R.; Damaševičius, R. Pearson Correlation-Based Feature Selection for Document Classification Using Balanced Training. Sensors 2020, 20, 6793. [Google Scholar] [CrossRef] [PubMed]
- Kyamakya, K.; Haj Mosa, A.; Machot, F.A.; Chedjou, J.C. Document-Image Related Visual Sensors and Machine Learning Techniques. Sensors 2021, 21, 5849. [Google Scholar] [CrossRef] [PubMed]
- Miller, M.T.; Romanov, M.G.; Savant, S.B. Digitizing the Textual Heritage of the Premodern Islamicate World: Principles and Plans. Int. J. Middle East Stud. 2018, 50, 103–109. [Google Scholar] [CrossRef]
- Kitab Project. Available online: https://kitab-project.org/about/ (accessed on 10 March 2022).
- Persian Digital Library, Roshan Institute for Persian Studies, University of Maryland. Available online: https://persdigumd.github.io/PDL/ (accessed on 10 March 2022).
- Bergamaschi, S.; Martoglia, R.; Ruozzi, F.; Vigliermo, R.A.; De Nardis, S.; Sala, L.; Vanzini, M. Preserving and Conserving Culture: First Steps towards a Knowledge Extractor and Cataloguer for Multilingual and Multi-Alphabetic Heritages. In Proceedings of the Conference on Information Technology for Social Good, GoodIT ’21, Rome, Italy, 9–11 September 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 301–304. [Google Scholar] [CrossRef]
- DAR Project. Available online: http://dar.bibalex.org/webpages/aboutdar.jsf (accessed on 10 March 2022).
- Perseus Project. Available online: http://www.perseus.tufts.edu/hopper/research (accessed on 10 March 2022).
- Shamela Library. Available online: http://shamela.ws/ (accessed on 10 March 2022).
- Shiaonline Library. Available online: http://shiaonlinelibrary.com (accessed on 10 March 2022).
- Ganjoor. Available online: https://ganjoor.net/ (accessed on 10 March 2022).
- Hazm, Baray-e Pardazesh-e Zaban-e Farsi. Available online: https://www.sobhe.ir/hazm/ (accessed on 10 March 2022).
- Steingass, F.J. A Comprehensive Persian-English Dictionary, Including the Arabic Words and Phrases to be Met with in Persian Literature; Routledge & K.Paul: London, UK, 1892. [Google Scholar]
- ACO—Arabic Collections Online. Available online: https://dlib.nyu.edu/aco/ (accessed on 10 March 2022).
- The British Library Projects: Arabic collection. Available online: https://www.bl.uk/collection-guides/arabic-manuscripts (accessed on 16 February 2022).
- The British Library Projects: Persian collection. Available online: https://www.bl.uk/projects/digital-access-to-persian-manuscripts (accessed on 16 February 2022).
- QDL—Qatar Digital Library. Available online: https://www.qdl.qa/en/about (accessed on 16 February 2022).
- Iran Heritage. Available online: https://www.iranheritage.org/ (accessed on 16 February 2022).
- Al-Muhtaseb, H.A. Arabic Text Recognition of Printed Manuscripts: Efficient Recognition of Off-Line Printed Arabic Text Using Hidden Markov Models, Bigram Statistical Language Model, and Post-processing. Ph.D. Thesis, University of Bradford, Bradford, UK, 2010. [Google Scholar]
- Obaid, A.M. A New Pattern Matching Approach to the Recognition of Printed Arabic. In Proceedings of the Computational Approaches to Semitic Languages, SEMITIC@COLING 1998, Montreal, Canada, 16 August 1998; Université de Montréal: Montréal, QC, Canada, 1998. [Google Scholar]
- Amin, A. Recognition of printed Arabic text using machine learning. In Proceedings of the Document Recognition V, San Jose, CA, USA, 24 January 1998; Lopresti, D.P., Zhou, J., Eds.; SPIE: Bellingham, WA, USA, 1998; Volume 3305, pp. 62–71. [Google Scholar]
- Mohammad, K.; Qaroush, A.; Ayyesh, M.; Washha, M.; Alsadeh, A.; Agaian, S. Contour-based character segmentation for printed Arabic text with diacritics. J. Electron. Imaging 2019, 28, 043030. [Google Scholar] [CrossRef]
- Mohamad, R.A.; Mokbel, C.; Likforman-Sulem, L. Combination of HMM-Based Classifiers for the Recognition of Arabic Handwritten Words. In Proceedings of the 9th International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Paraná, Brazil, 23–26 September; IEEE: Piscataway, NJ, USA, 2007; pp. 959–963. [Google Scholar]
- Aghbari, Z.A.; Brook, S. HAH manuscripts: A holistic paradigm for classifying and retrieving historical Arabic handwritten documents. Expert Syst. Appl. 2009, 36, 10942–10951. [Google Scholar] [CrossRef]
- Hamdani, M.; Doetsch, P.; Kozielski, M.; Mousa, A.E.; Ney, H. The RWTH Large Vocabulary Arabic Handwriting Recognition System. In Proceedings of the 11th IAPR International Workshop on Document Analysis Systems, Tours, France, 7–10 April 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 111–115. [Google Scholar] [CrossRef] [Green Version]
- Dehghan, M.; Faez, K. Farsi Handwritten Character Recognition with Moment Invariants. In Proceedings of the 13th International Conference on Digital Signal Processing, Santorini, Greece, 2–4 July 1997; Volume 2, pp. 507–510. [Google Scholar] [CrossRef]
- Mowlaei, A.; Faez, K.; Haghighat, A.T. Feature extraction with wavelet transform for recognition of isolated handwritten Farsi/Arabic characters and numerals. In Proceedings of the 14th International Conference on Digital Signal Processing, DSP 2002, Santorini, Greece, 1–3 July 2002; IEEE: Piscataway, NJ, USA, 2002; pp. 923–926. [Google Scholar] [CrossRef]
- Soleymani-Baghshah, M.; Shouraki, S.B.; Kasaei, S. A Novel Fuzzy Approach to Recognition of Online Persian Handwriting. In Proceedings of the Fifth Int. Conference on Intelligent Systems Design and Applications (ISDA 2005), Wroclaw, Poland, 8–10 September 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 268–273. [Google Scholar] [CrossRef]
- Ghadikolaie, M.F.Y.; Kabir, E.; Razzazi, F. Sub-Word Based Offline Handwritten Farsi Word Recognition Using Recurrent Neural Network. ETRI J. 2016, 38, 703–713. Available online: http://xxx.lanl.gov/abs/https://onlinelibrary.wiley.com/doi/pdf/10.4218/etrij.16.0115.0542 (accessed on 10 March 2022). [CrossRef]
- Bonyani, M.; Jahangard, S. Persian Handwritten Digit, Character, and Words Recognition by Using Deep Learning Methods. CoRR 2020. Available online: http://xxx.lanl.gov/abs/2010.12880 (accessed on 10 March 2022).
- Zhang, K.; Li, H. Fusion-based recommender system. In Proceedings of the 2010 13th International Conference on Information Fusion, Edinburgh, UK, 26–29 July 2010; pp. 1–7. [Google Scholar] [CrossRef]
- Martoglia, R. Facilitate IT-Providing SMEs in Software Development: A Semantic Helper for Filtering and Searching Knowledge. In Proceedings of the SEKE, Miami Beach, FL, USA, 7–9 July 2011; pp. 130–136. [Google Scholar]
- Furini, M.; Mandreoli, F.; Martoglia, R.; Montangero, M. A Predictive Method to Improve the Effectiveness of Twitter Communication in a Cultural Heritage Scenario. ACM J. Comput. Cult. Herit. 2022, 15, 21. [Google Scholar] [CrossRef]
- Martoglia, R. Invited speech: Data Analytics and (Interpretable) Machine Learning for Social Good. In Proceedings of the IEEE International Conference on Data, Information, Knowledge and Wisdom (DIKW), Haikou, China, 17–19 December 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Martoglia, R.; Pontiroli, M. Let the Games Speak by Themselves: Towards Game Features Discovery Through Data-Driven Analysis and Explainable AI. In Proceedings of the IEEE International Conference on Data, Information, Knowledge and Wisdom (DIKW), Haikou, China, 17–19 December 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Borghoff, U.M.; Rödig, P.; Scheffczyk, J.; Schmitz, L. Long-Term Preservation of Digital Documents: Principles and Practices; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Ahmad, M.A.; Eckert, C.; Teredesai, A.; McKelvey, G. Interpretable Machine Learning in Healthcare. IEEE Intell. Inform. Bull. 2018, 19, 1–7. [Google Scholar]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bergamaschi, S.; De Nardis, S.; Martoglia, R.; Ruozzi, F.; Sala, L.; Vanzini, M.; Vigliermo, R.A. Novel Perspectives for the Management of Multilingual and Multialphabetic Heritages through Automatic Knowledge Extraction: The DigitalMaktaba Approach. Sensors 2022, 22, 3995. https://doi.org/10.3390/s22113995
Bergamaschi S, De Nardis S, Martoglia R, Ruozzi F, Sala L, Vanzini M, Vigliermo RA. Novel Perspectives for the Management of Multilingual and Multialphabetic Heritages through Automatic Knowledge Extraction: The DigitalMaktaba Approach. Sensors. 2022; 22(11):3995. https://doi.org/10.3390/s22113995
Chicago/Turabian StyleBergamaschi, Sonia, Stefania De Nardis, Riccardo Martoglia, Federico Ruozzi, Luca Sala, Matteo Vanzini, and Riccardo Amerigo Vigliermo. 2022. "Novel Perspectives for the Management of Multilingual and Multialphabetic Heritages through Automatic Knowledge Extraction: The DigitalMaktaba Approach" Sensors 22, no. 11: 3995. https://doi.org/10.3390/s22113995
APA StyleBergamaschi, S., De Nardis, S., Martoglia, R., Ruozzi, F., Sala, L., Vanzini, M., & Vigliermo, R. A. (2022). Novel Perspectives for the Management of Multilingual and Multialphabetic Heritages through Automatic Knowledge Extraction: The DigitalMaktaba Approach. Sensors, 22(11), 3995. https://doi.org/10.3390/s22113995