1. Introduction
Effectively monitoring and controlling air quality has become an important issue of concern to the public today. Air pollution significantly impacts human health, ranging from mild chronic respiratory symptoms to acute respiratory infections, exacerbating pre-existing heart and lung diseases [
1,
2]. Even if people only expose themself to mild air pollution, it will shorten their lives [
3]. Thus, people living in urban areas or nearby industrial areas demand information on atmospheric air quality because they have a higher risk of exposure to elevated air pollution [
4].
To acquire the air quality information, government and environmental protection agencies have started to set up fixed-site air quality monitoring stations in various regions. These monitoring stations have accurate instruments to regularly monitor air quality in the environment, analyze the concentration of pollutants, and provide information to the public for reference [
5,
6]. However, building more fixed-site air quality monitoring stations is difficult due to terrain limitations and the high cost of setting up and maintaining the stations. The monitoring data provided by the stations are relatively sparse and therefore cannot meet the increasing demand for air quality information. Therefore, various techniques have been proposed to improve the spatial density of air quality information, such as the detection of short-term air quality campaigns by the mobile laboratory [
7], interpolation by mathematical models [
8], and detection by various new low-cost sensors [
9,
10]. With more air quality information, more services, such as forecasts and real-time alarms, can be provided to the public. The low-cost sensors are popular with people today, because the components are available and affordable in the market. People who care about air pollution can obtain a direct onsite measurement themselves, and, furthermore, environmental protection agencies have also started to adopt low-cost sensors in areas without a monitoring station to obtain supplementary air quality information [
11].
Although low-cost sensors are economical and easy to set up, some performances still stand to be improved, including their accuracy, cross-sensitivity, reproducibility, and reliability [
12]. To enhance the detection of sensors, many researchers have focused on developing new sensing materials. Chemically modified SnO
2 nanosurfaces using metals or other metal oxides showed highly selective sensing materials for CO, NH
3, H
2S, and NO
2 gas molecules [
13]. PbS quantum dots/TiO
2 nanotube arrays possess a good response towards NH
3 gas at room temperature [
14]. Furthermore, gas sensor arrays based on MEMS gas sensor platforms, consisting of different nano-sized and metal oxide semiconductor (MOS) particles, were developed to detect CO, NOx, and NH
3; their gas-sensing characteristics in the binary mixed-gas system were investigated [
15]. The new sensing materials can make gas sensing more accurate, but these low-cost sensors have not fully met all the practical needs.
On the other hand, artificial intelligence (AI) technology has rapidly developed in recent years and has been successfully applied in many fields. Thus, especially in terms of machine learning, AI technology was also combined with gas sensors for more accurate detection. An artificial neural network (ANN) model was used with a sensing array that had four quartz crystal microbalance (QCM) devices to distinguish the type of organic vapors [
16]. An array that contained six ZnO-based sensors was combined with an ANN model to recognize concentrations of H
2, CH₄, and CO gases [
17]. A surface acoustic wave (SAW) sensor coated with a functionalized polymer detected harmful vapors, and an ANN pattern-recognition model was implemented to recognize vapor types [
18]. The research mentioned above show that combining a gas sensor array with an ANN model can identify mixed gases’ compositions and concentrations in a well-controlled laboratory. This result is consistent with the report that sensors’ performance was concluded to be satisfactory under a range of specific conditions [
11]. ANN models were further applied with sensors in the field with consideration of temperature, humidity, wind speed, and pressure. Field calibration of low-cost commercial sensors in detecting NO, CO, and CO
2 gases was studied. The result showed that ANN is the most effective method among linear regression, multiple linear regression, and ANN [
19]. Another CO electrochemical sensor was also calibrated with an ANN model by considering temperature and humidity [
20]. Thus ANN has good results in in-field gas classification and concentration identification.
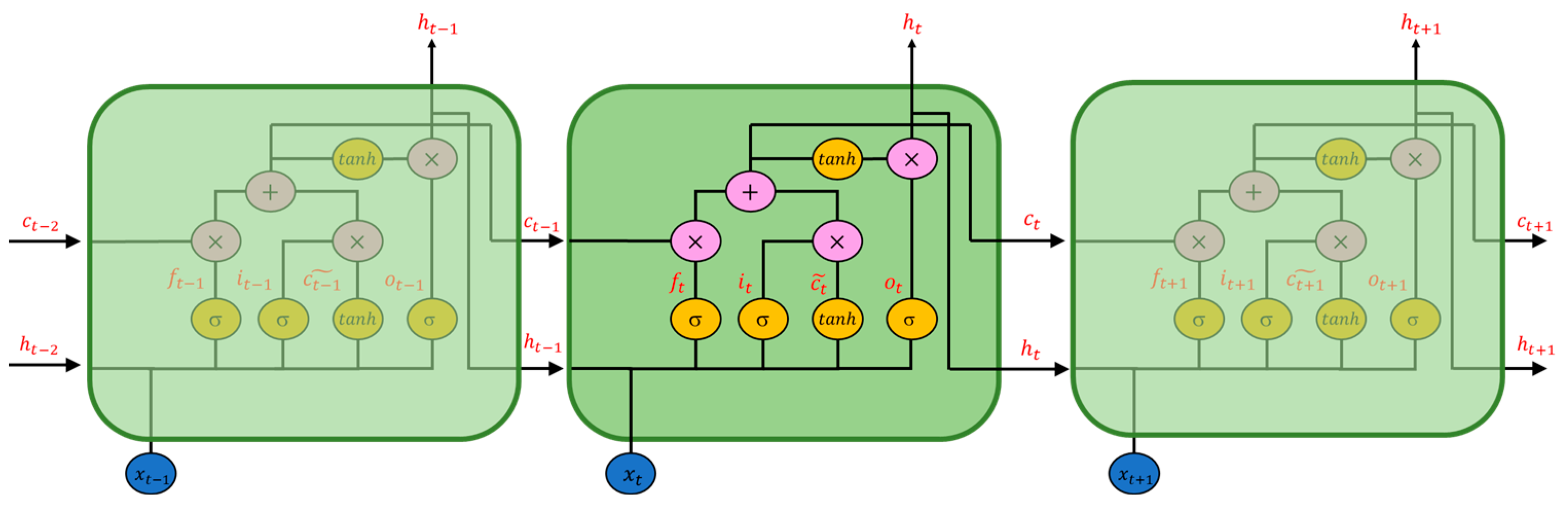
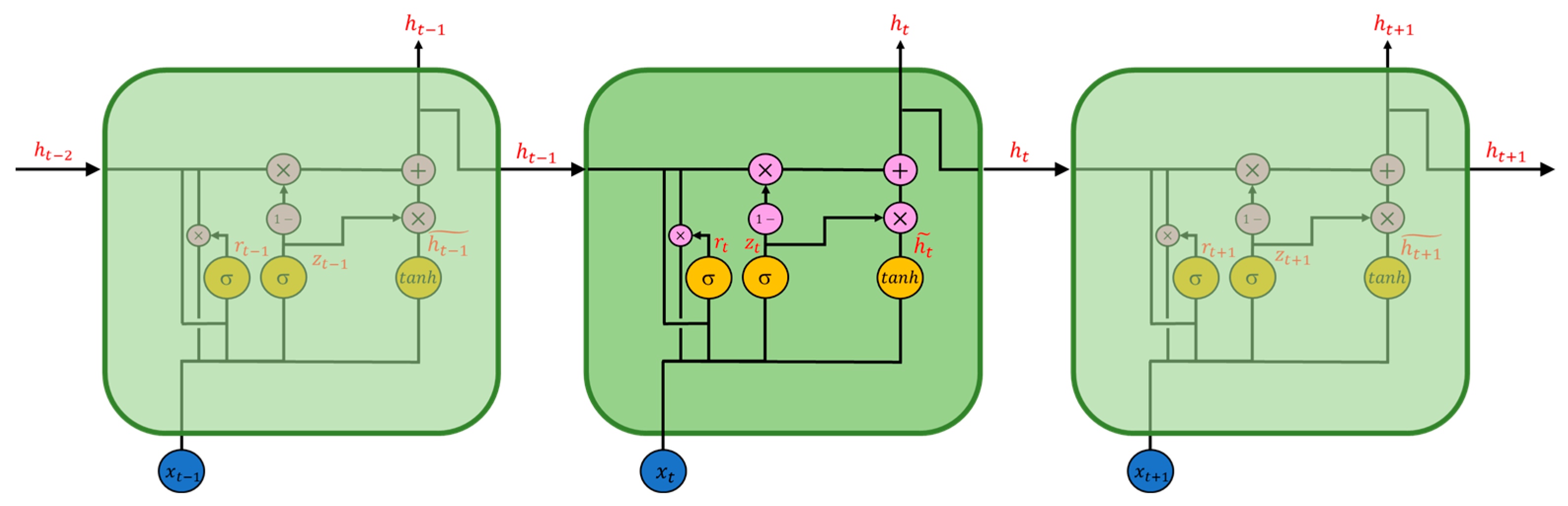
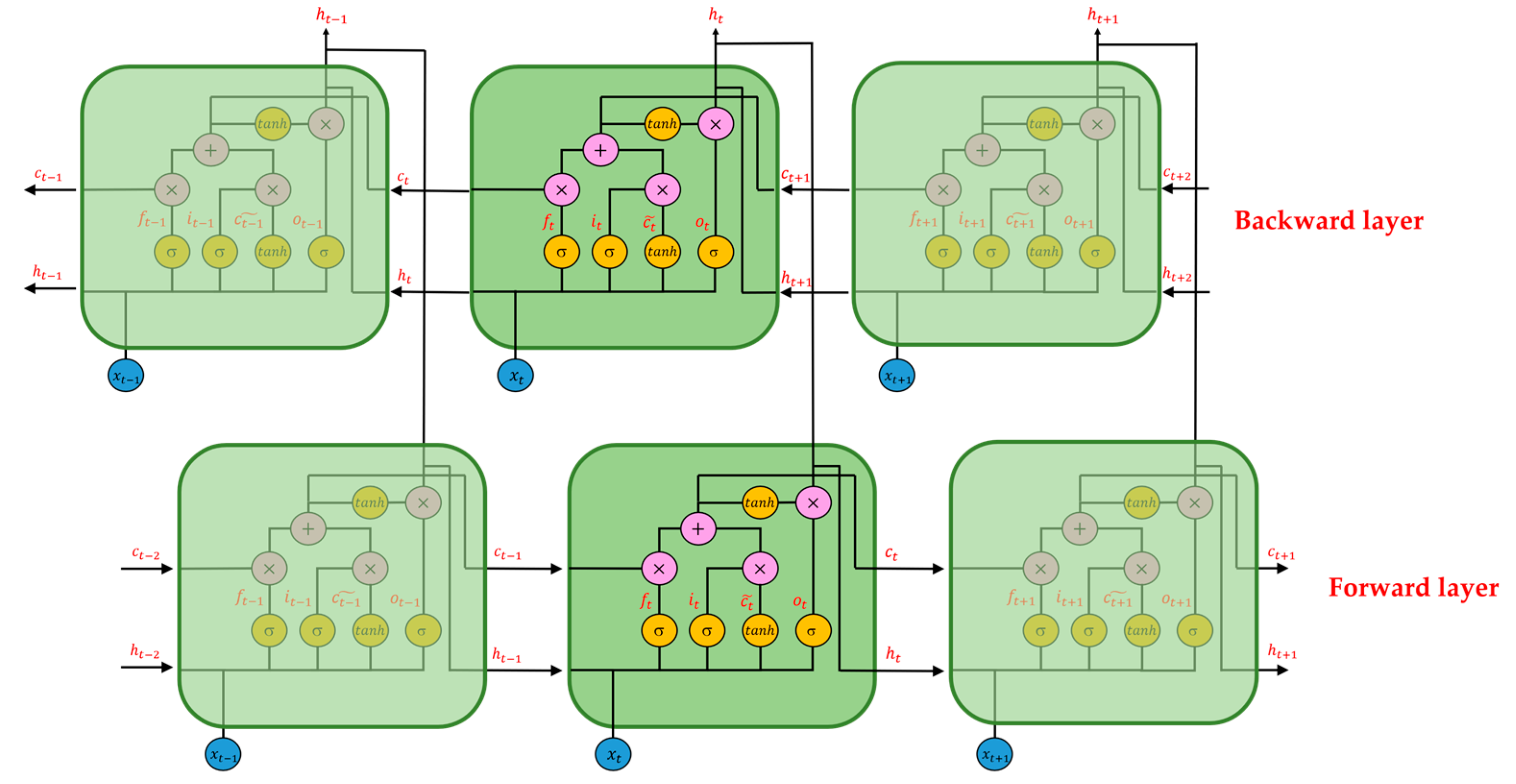
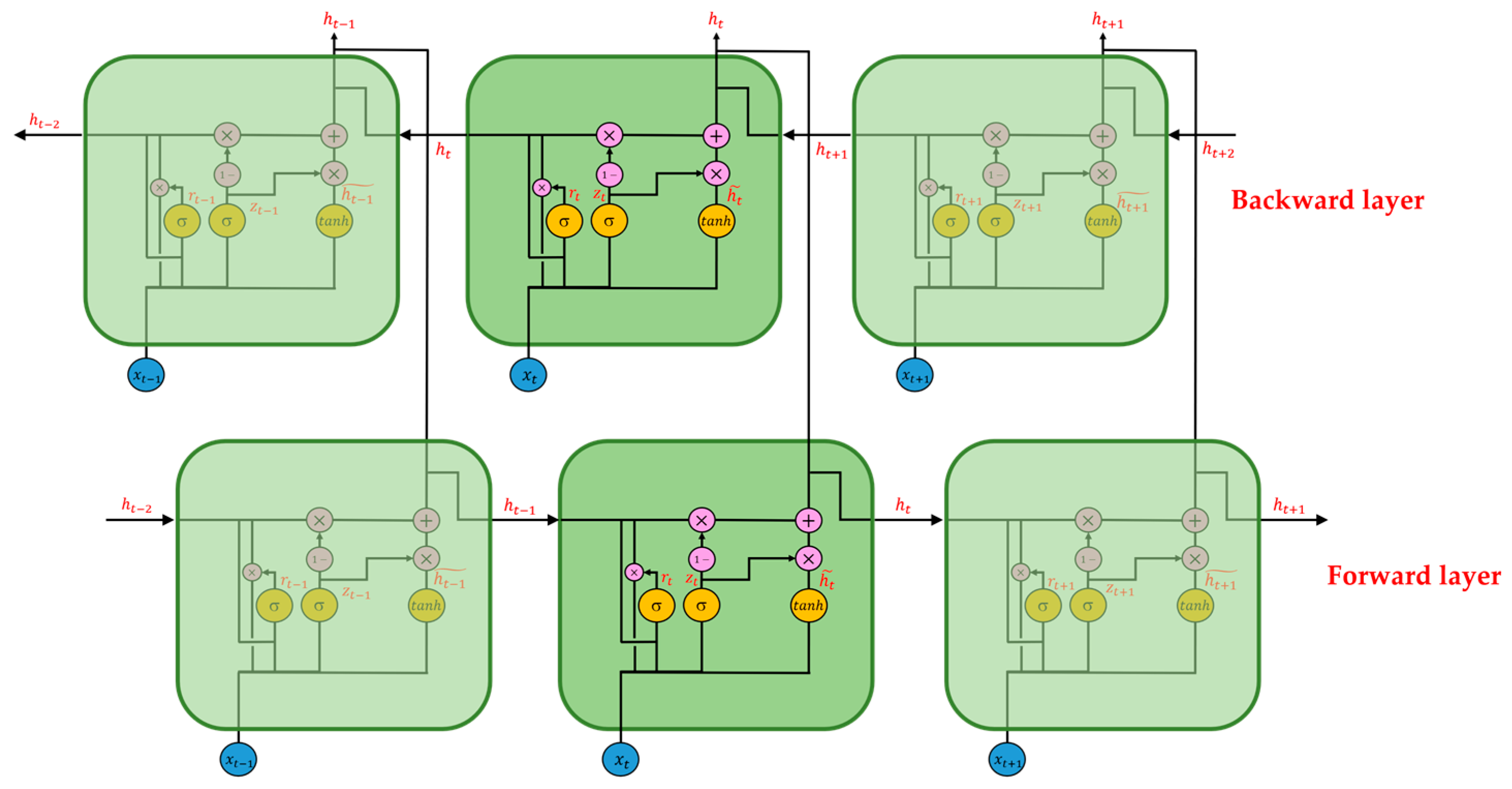
Recurrent neural network (RNN) is another deep learning method often used to solve sequence problems due to its gated unit design [
21,
22]. RNN models contain different types of model, Long Short-Term Memory (LSTM) [
23], Gated Recurrent Unit (GRU) [
24], Bi-directional Long Short-Time Memory (Bi-LSTM) [
25], and Bi-directional Gated Recurrent Unit (Bi-GRU). Since time characteristics accompany gas-sensing data, RNNs are expected to deal with time-dependent gas concentrations and other interfering factors. The LSTM model was used to predict air pollution concentrations with MOS gas sensors in Amravati and Bengaluru, India [
26]. Different RNNs also estimated the gas concentrations considering temperature, flow rate, and negative pressure, and the LSTM model has higher prediction accuracy [
27]. In another measurement conducted using MOS gas sensor arrays, considering temperature, relative humidity, and absolute humidity, the LSTM model had higher accuracy than the ANN model in the concentration recognition of a gas mixture [
28]. The results show that the RNN model can effectively analyze the gas concentration data when it has interference factors; with a better model performance, improving the accuracy of low-cost sensors is feasible.
In fact, both the ANN and the RNN have made good progress in in-field gas sensing. ANN first made feasibility in gas classification and concentration detection; RNN further processed the sequence measured concentration data and interference factors to improve accuracy. Moreover, it is noticeable that sensors may have inconsistent performance in different measurement scenarios. For example, performance can vary significantly in different areas due to different environmental conditions [
10,
26,
29]. In practical applications, the long-term correlation between low-cost gas sensors and reference instruments is not stable, mainly due to the change in field temperature and humidity [
10]. Thus, the gas-sensing calibration technology still has the problem of generalizability.
The ensemble model is a recent solution to the bottleneck of deep learning, which improves the prediction performance of a single model by training multiple single models and combining their prediction results [
30,
31]. Ensemble machine learning has been used widely in various fields, such as face recognition, target tracking, and bioinformatics [
32,
33,
34,
35]. On the other hand, the current research on gas sensing with machine learning are all based on a single individual model, and thus an ensemble model has the potential to improve gas-sensing performance.
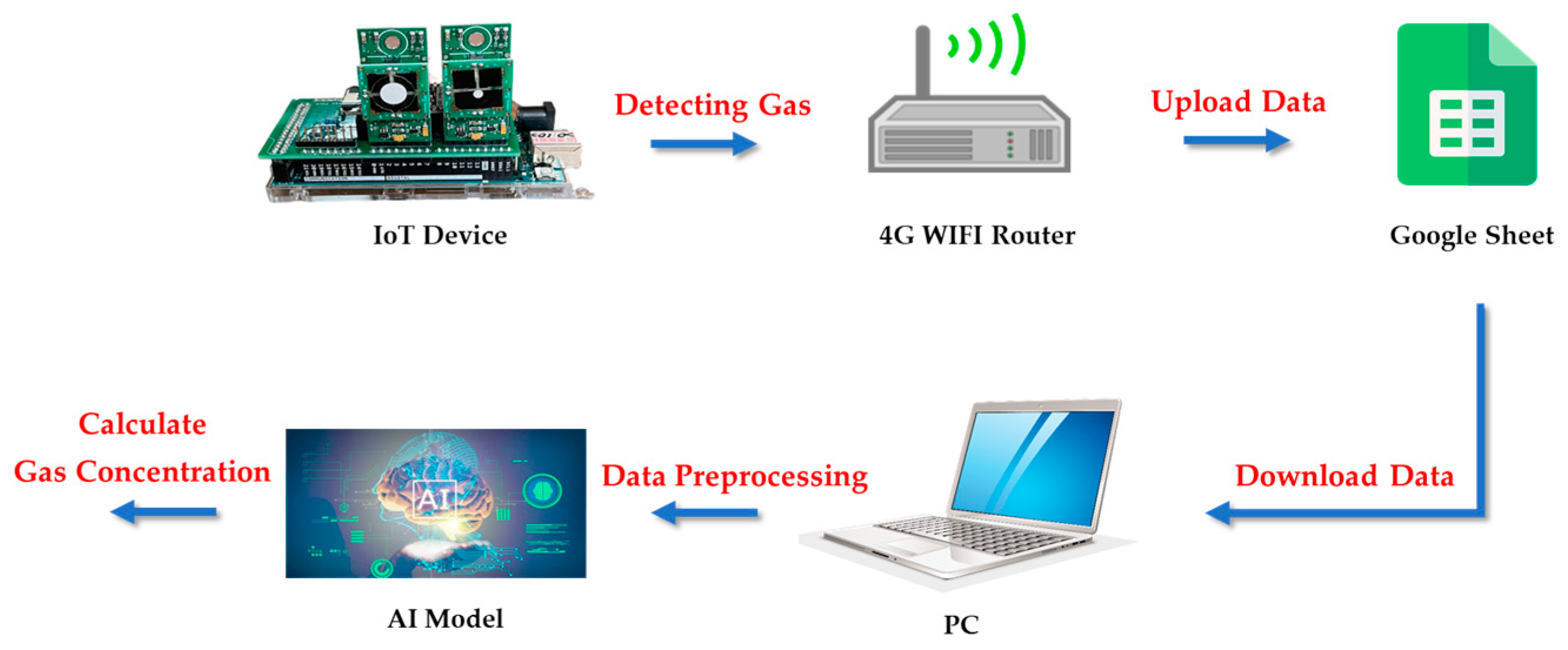
Therefore, this paper aims to study the development of ensemble models to monitor in-field gas concentrations with low-cost commercial gas sensors. The generalizability of the trained model to be used with sensors in different environmental conditions was also tested. First, we collected the concentrations of CO, O3, and NO2 gases and the atmospheric conditions with homemade IoT devices for the following model training. The preprocessing of data included outlier detection and normalization. Second, four types of RNN model, LSTM, GRU, Bi-LSTM, and Bi-GRU, were introduced; a loss function and an evaluation function were also defined for training and optimizing a single RNN model. In the third part, the four types of optimized RNN single model were presented. Then, an ensemble model containing static models, i.e., the optimized RNN single models and a dynamic model, was composed and trained. For better generalizability of the model, a retraining procedure for the ensemble model was processed to make the model more flexible to adapt to various environmental conditions and improve the long-term sensing performance. Finally, the discussion and conclusion were presented.
4. Development of Ensemble Models
Ensemble models consisting of different RNNs were developed to detect target gas concentrations in this study. Traditionally, developers use the validation dataset and take the evaluated index to obtain the best machine learning model. The steps include: 1. a series of hyperparameter tests by the training data; 2. evaluating the performance by the validation data; and 3. selecting the model hyperparameter which shows the best evaluation in the last step. The optimal model selected by the above procedures can achieve the best performance in the validation set, but some disadvantages exist. First, the procedure is time- and labor-consuming, but only one, the optimal hyperparameter configuration, is selected. The other models that result from the hyperparameter optimization are abandoned. Next, the features of the validation dataset can not guarantee consistency with those of the future new data. The model with the best performance of the validation-run set may not have the best performance while applied to the new data in the future. Thus, improvement by using an ensemble model was proposed to enable the modification of the model and learn the generalizability of future data.
Developing ensemble models includes optimizing hyperparameters, comparing memory cells, and ensembling and retraining the best model. The machine learning programs were based on Python3.8, Tensorflow-gpu 2.4.0, and execution on graphics cards of NVIDIA Titan XP and NVIDIA RTX 3080. Details are in the following subsections.
4.1. Optimization of Hyperparameters
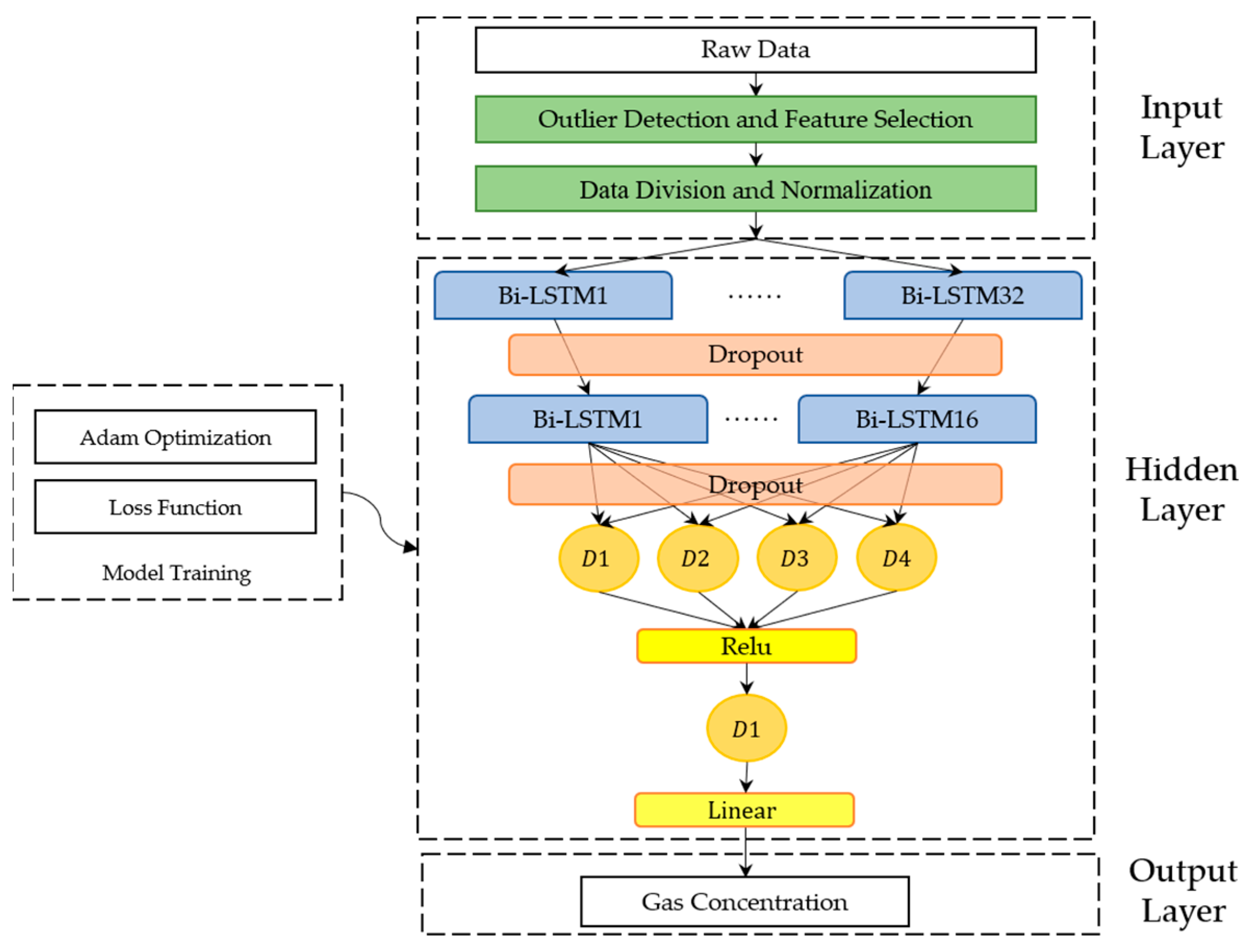
In machine learning, hyperparameters include the model hyperparameters and the algorithm hyperparameters. Model hyperparameters, such as the number of layers, neurons, and input features, affect the model’s best performance. Algorithm hyperparameters include the selection of the optimizer, learning rate, batch size, etc., which significantly affect the convergence and training time of the model. A series of hyperparameter optimizations was processed in the study. We first optimized the model hyperparameter to determine the basic architecture of each gas model. Then, the algorithm hyperparameters were optimized so that each gas model could shorten the training time and converge to a better local minimum.
The model hyperparameters of a single weak model for detecting a specific gas were determined firstly. Configurations of the model for a single-gas detection (CO, O
3, and NO
2) are shown in
Table 4. We compare the influence of the number of BiL layers on the performance of each gas model, which is one to three layers, respectively. Each layer has a specific number of neurons, which is a power of 2, as shown in the brackets. Finally, the number of BiL layers of the CO model was set to two, and the number of BiL layers of the O
3 model and the NO
2 model was set to three.
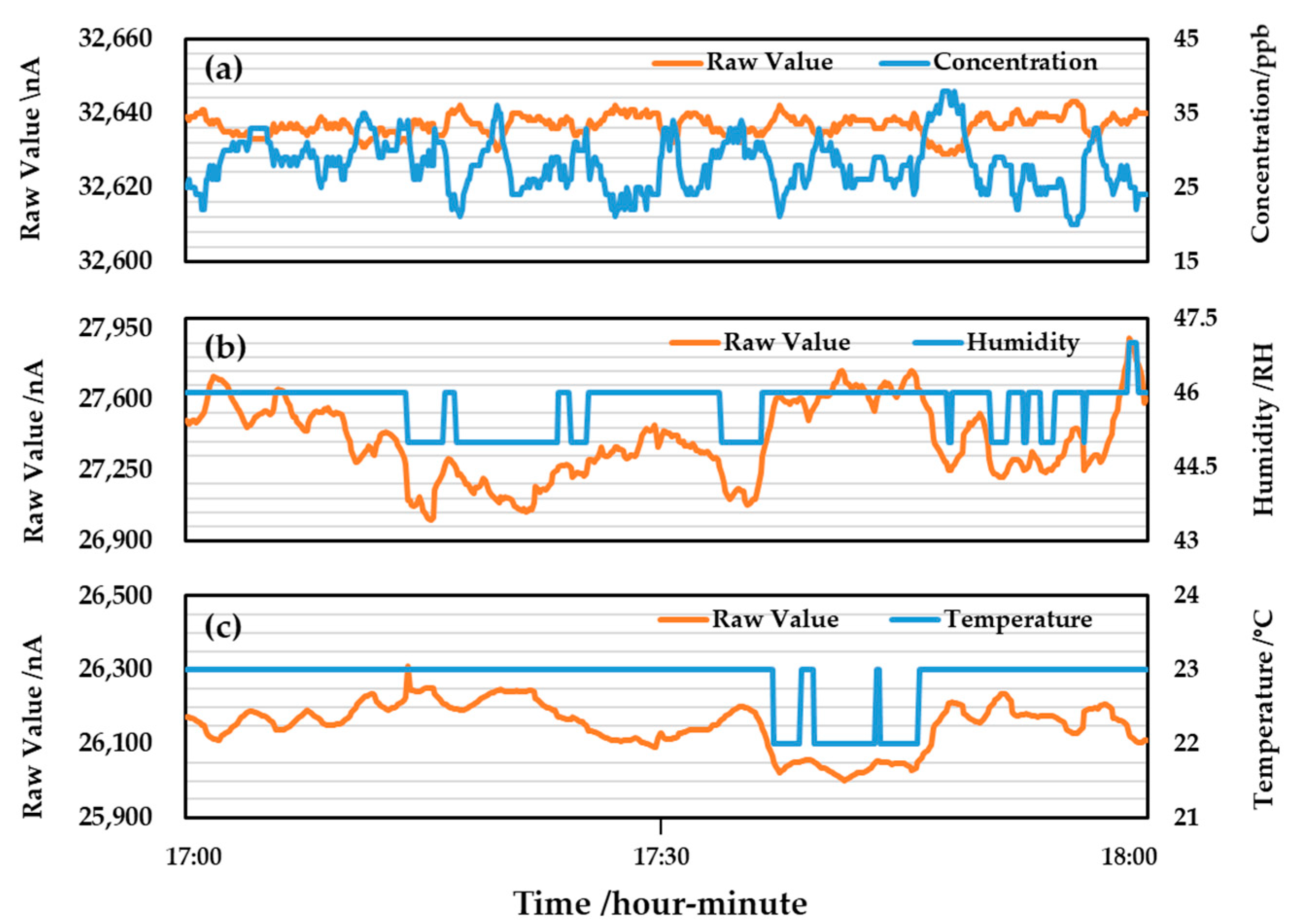
Next, we compared the performance of the model validation set with the number of input features to determine the number of input features for each gas model. The input feature contains the raw values from the gas sensors (gas concentration, humidity, and temperature). The MAPE of the CO gas model is 16.31% when it is trained with the dual gas features of CO and O
3 and 17.35% when trained with the single-gas feature of CO. The performance of the dual-gas features is improved by 1.04%. The MAPE of the O
3 gas model was 36.98% after training with O
3 and NO
2 dual gas features and 41.67% after training with O
3 single gas features. The performance using the dual-gas feature is 4.7% higher than that of the single-gas feature; the reason is that the O
3 gas sensor is disturbed by NO
2 gas (as mentioned in
Section 2.1). Therefore, adding the O
3 gas feature can significantly improve the performance of the validation set of the O
3 gas model. The MAPE of the NO
2 gas model was 86.27% after training with O
3 and NO
2 dual gas features and 68.05% after training with NO
2 single gas features. The performance of the single-gas feature is 18.22% higher than that of the dual-gas feature; the reason is that the NO
2 gas sensor is less disturbed by O
3 gas similarly. Therefore, adding the O
3 gas feature will reduce the validation set performance of the NO
2 gas model. Through the above experiments, we determined the model hyperparameters of the gas model, including the basement architecture and input features. Next, the algorithm hyperparameter for each gas model will be optimized.
The algorithm hyperparameters, e.g., the batch size and the dropout layer coefficient, are optimized to reduce the model’s training time and improve the model’s convergence. The batch size is the number of samples used for training once. A larger batch size can shorten the training time of the model, but the variance between batches is slight when calculating the gradient of each batch in reverse. Therefore, the gradient obtained from each batch varies little, and the lack of gradient randomness tends to fall into a poor local minimum. Smaller batches require a longer calculation time for each iteration, which prolongs the training time of the model and increases the time cost of model tuning. However, compared with the large batch, the small batch has the advantage of gradient randomness, resulting in it converging better to the local minimum. In summary, choosing an appropriate batch size is necessary to balance the training time and convergence of the model.
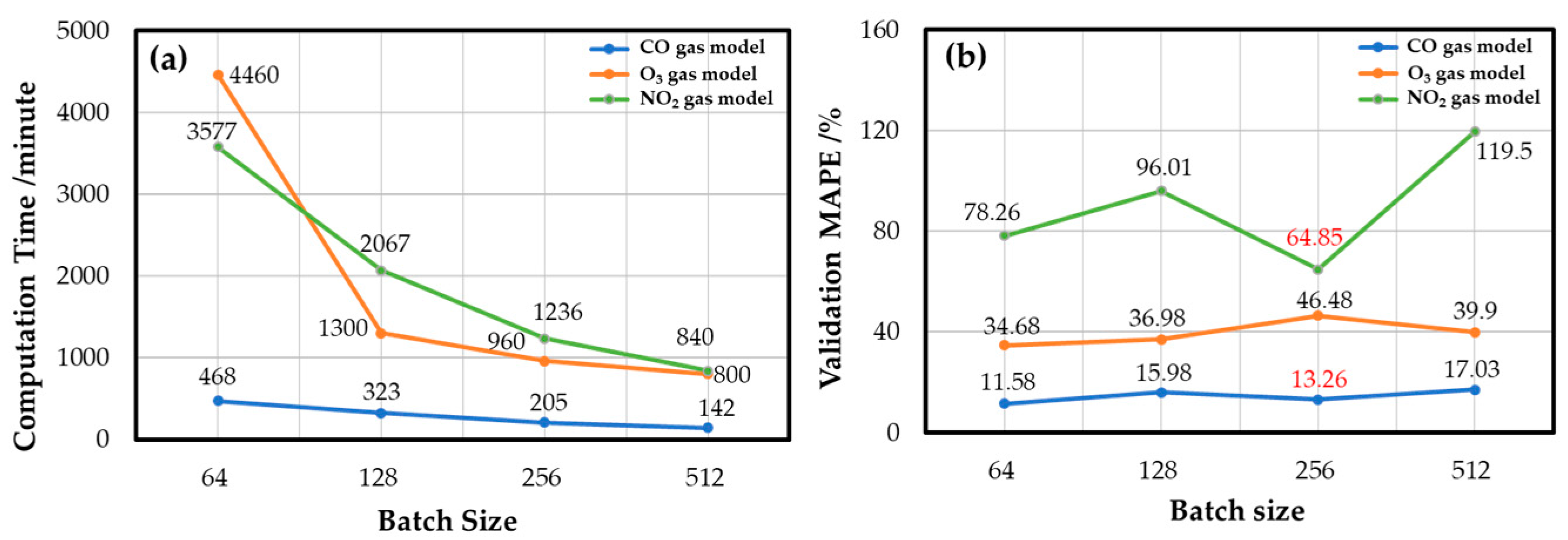
Figure 10 shows the experimental results of the effects of the batch size in developing the gas models. Although the batch size of 64 achieved the best convergence, it took twice the computation time as long as the batch size of 256, and the performance difference between the two was only 1.68%. Finally, the batch size of 256 was selected as the best batch size configuration for the CO gas model. The decision of O
3 gas and NO
2 gas models also considered the time cost, and the final batch sizes were 128 and 256, respectively.
After this, the dropout layer coefficients of each gas model were determined. The dropout layer is a method used to improve model overfitting by shielding a certain percentage of neurons in each epoch, so that model training does not rely too much on specific neurons for training and prevents model overfitting [
41]. By adjusting the coefficient of the dropout layer appropriately, the overfitting phenomenon of each target gas model on the training set can be effectively alleviated, and the performance of the verification set of each target gas model can be effectively improved.
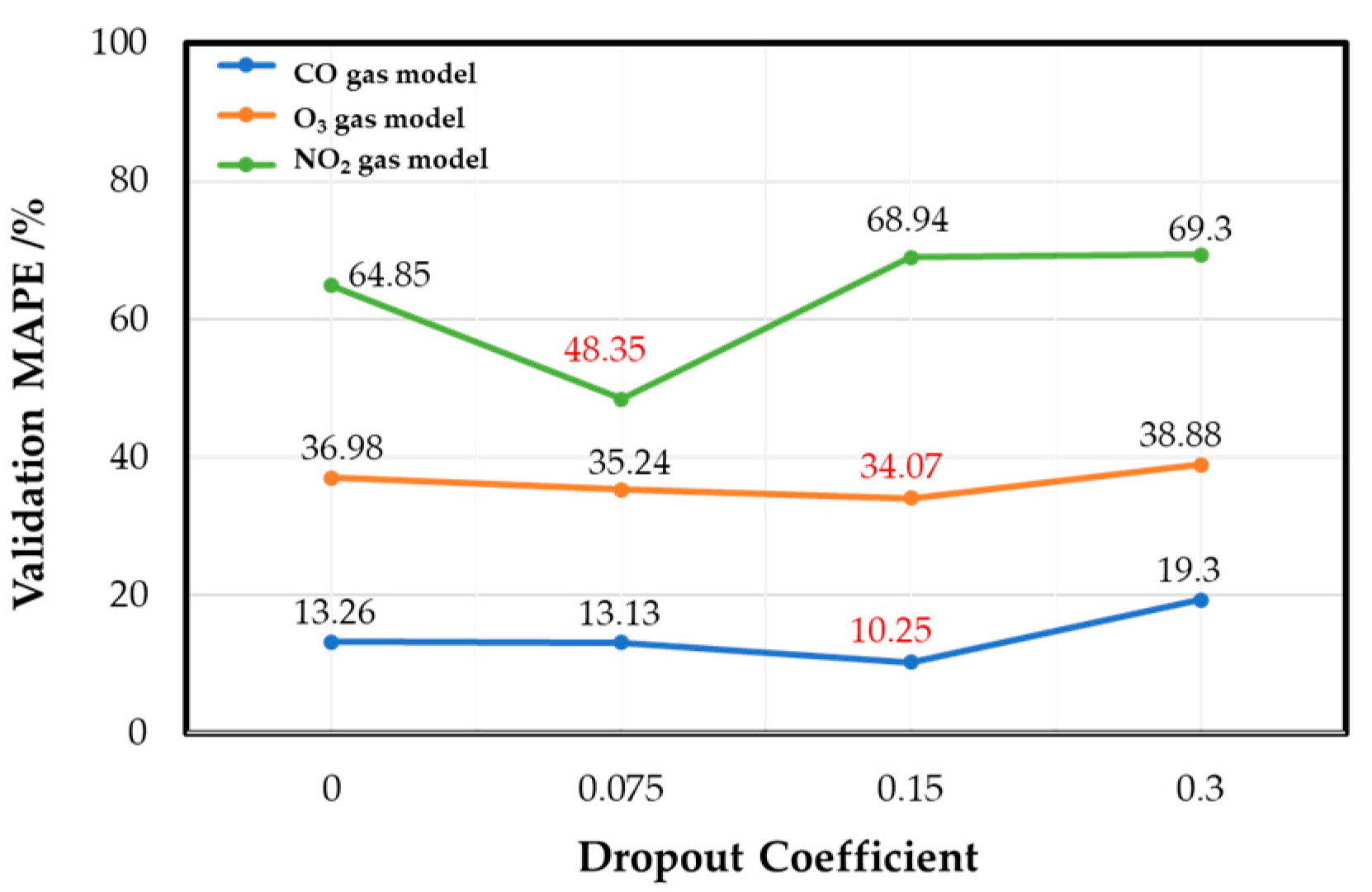
Figure 11 shows that, when the dropout coefficient is 0.15, the CO gas and the O
3 gas models have the best validation set performance, with 10.25% and 34.07% MAPE, respectively. The NO
2 gas model has the best validation performance when the dropout coefficient is 0.075, with 48.35% MAPE.
By optimizing the model hyperparameters and algorithm hyperparameters, the single weak model of each gas was trained. Subsequently, multiple single weak models were created for the ensembles by replacing the memory cell units of different types to improve the poor generalization of the single weak model on the new data.
4.2. Comparison of Memory Cells
The memory cell used in the model is a vital model hyperparameter to be discussed. The recurrent neural layer uses the Bi-LSTM memory cell unit in the last section. More types of different memory cell units, including Bi-GRU, LSTM, and GRU, are compared based on their performance in the validation set testing.
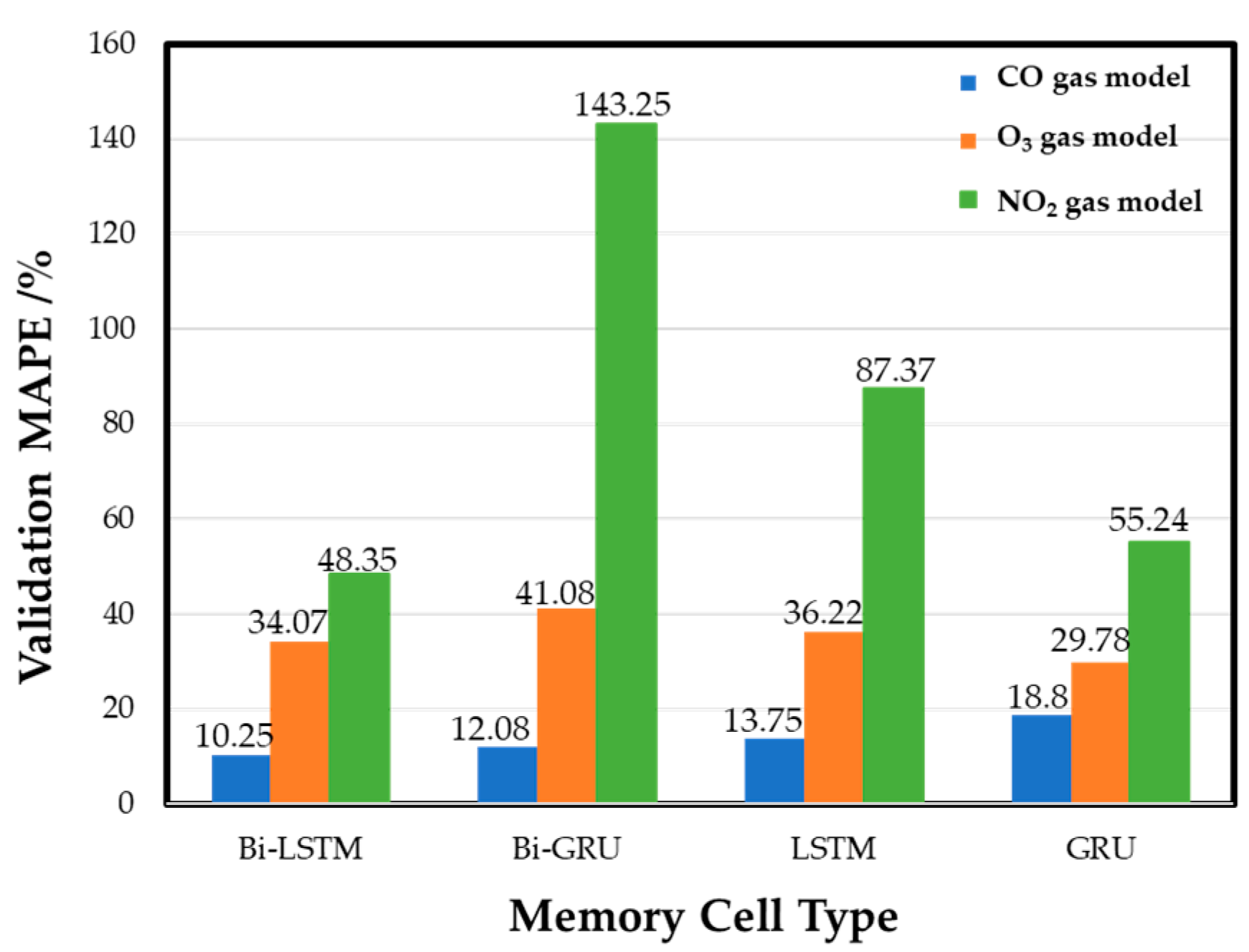
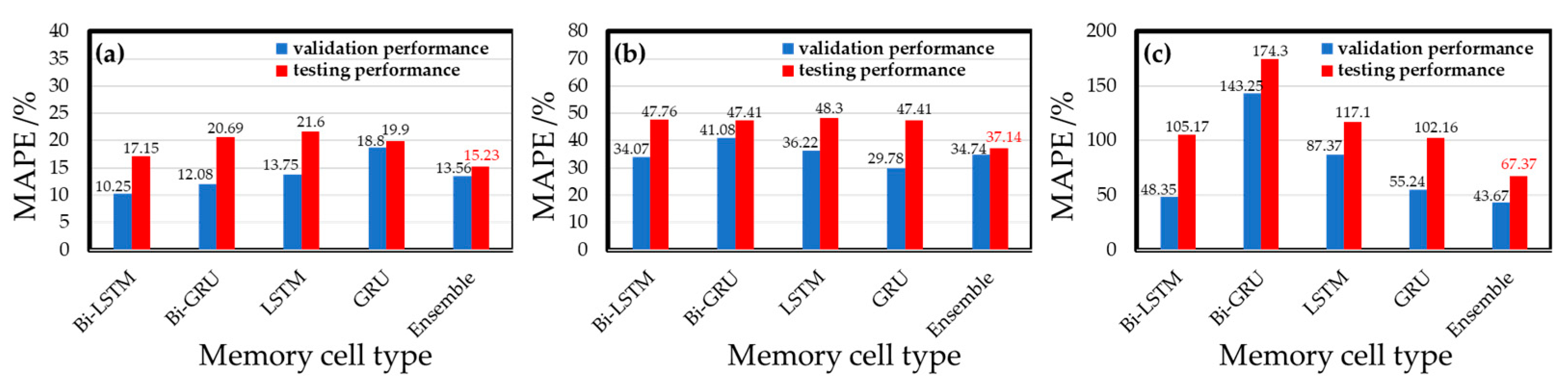
Figure 12 shows the experimental training results of different memory cells in each gas model. The results show that Bi-LSTM is the best cell for the CO gas model, with a MAPE of 10.25%. The other MAPE values are 12.08% for Bi-GRU memory cells, 13.75% (LSTM), and 18.8% (GRU). The performance of the O
3 gas model is best (29.78% MAPE) when GRU is used, and the MAPE values are 34.07%, 41.08%, and 36.22% for the Bi-LSTM, Bi-GRU, and LSTM cells, respectively. In the NO
2 gas model, Bi-LSTM shows the best performance in the validation set, and the MAPE is 48.35%. The MAPE values obtained by other memory cell training models are 143.25% (Bi-GRU), 87.37% (LSTM), and 55.24% (GRU), respectively. The results show that the gas models trained by different memory cells have various performances in the validation set. Basically, the commercial sensor’s native resolution limits the performance. The NO
2 sensor has the lowest ratio of the average annual concentration to resolution, and thus the MAPE of the NO
2 sensor model is always higher than the models of the other two gases. Compared with the CO gas model and the O
3 gas model, the NO
2 gas models have the most considerable performance variation while different memory cells are used. Subsequently, by integrating each gas model trained by four different memory cells, an ensemble model can be retrained to be the best model for gas concentration detecting.
4.3. Ensemble Models to Obtain the Best Model
Ensemble models are proposed in this study to reuse all the single weak models trained in the last steps.
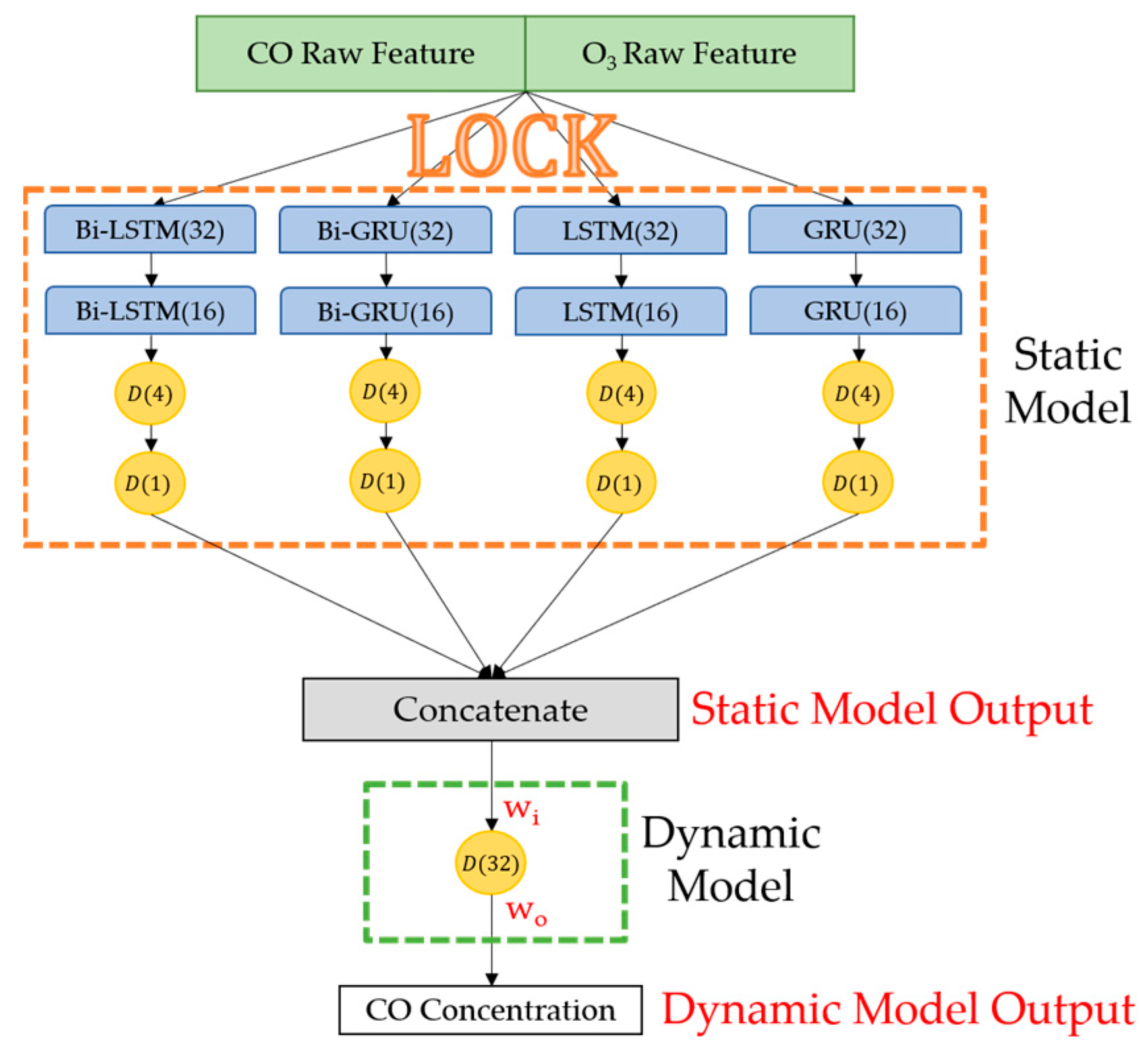
Figure 13 shows schematic diagrams of the ensemble models for CO gas; models for detecting O
3 and NO
2 gas are constructed in the same way. The orange dashed line in
Figure 13 indicates the four types of recurrent neural models trained in
Section 4.2. These recurrent neural models are integrated, and their parameters inherited from the last step are frozen in the ensemble model; thus, it is named a static model. The green dashed line in
Figure 13 highlights a fully connected neural network responsible for receiving output values and training data from the static model and then determining their parameters through backpropagation. Since the weight coefficients (w
i and w
o in
Figure 13) will change in the further retraining procedure, this NN is named the dynamic model. The dynamic model learns the deviation relation of different RNN models through retraining, summarizes the target gas concentration calculated by the static model, and outputs the final summarized target gas concentration value.
The performance values of the ensemble model and every single weak model for three target gases are shown in
Figure 14. Considering the CO gas models, in the training phase, the validation set testing of the ensemble model is not optimal, with a MAPE of 13.56%. The single models using Bi-LSTM and Bi-GRU memory cells have better MAPE values of 10.25% and 12.08%. However, in the testing phase, where the new data (i.e., testing dataset) were used, the 15.23% MAPE of the ensemble model is the best one in all models. The results show that all the CO single weak models have significantly lower performance values in the testing set than in the validation set. The Bi-LSTM single model, which has the best performance in the validation set, is not globally optimal for the test set, indicating that the single weak model has poor applicability to the new data. The ensemble model maintains a certain model performance on the new data and effectively improves the model’s generalizability to the new data.
A similar result was obtained from the experiments using O3 gas models. The ensemble model’s validation performance (34.74% MAPE) for O3 gas is not the best one compared to the other four single weak models, while the performances of the single-memory-cell model using GRU and Bi-LSTM were MAPEs of 29.78% and 34.07%, respectively. However, in the testing phase, all models examined new data (i.e., test dataset) for testing, and the integrated model had the best MAPE (37.14%) again. The O3 gas ensemble model is more applicable and keeps the model’s generalizability to new data.
In the tests of the NO2 gas models, the ensemble model has the best performance in both the validation and testing sets, and the MAPE values were 43.67% and 67.37%, respectively. The performance of the NO2 ensemble model decreases less than that of the single weak model in the test set compared with that of the single weak model in the validation set, indicating that the NO2 ensemble model is better than that of the single weak model in the application of new data. However, there is still room for improvement compared with the CO gas and O3 gas ensemble models.
It can be summarized that the static model part of the ensemble models contains the fundamental properties of the gas sensors found by the optimized single weak models. Further, the dynamic model part is a combination of the calibrated models and thus can achieve better performance by tuning weight coefficients. According to these experimental results of different gas ensemble models, the model deviation of a single-memory-cell model was effectively offset by integrating more types of recurrent neural models. Thus, ensemble models can have a better generalizability for handling individual differences in the commercial sensors of the same module; therefore, the ensemble model was chosen as the best model for gas concentration detection.
4.4. Ensemble Model Retraining
In the previous section, the ensemble model had the best performance for each gas, but further tests observed a decayed performance while more new data were input. The reason is that the data used to train the ensemble RNN models were collected from January 5 to March 23, containing only a partial property in a whole year. Thus when the new data collected from March 23 to April 14 was input into the model, the performance became unstable, because the atmospheric conditions changed across different seasons. Therefore, we propose a periodical retraining procedure. The periodic retraining procedure regularly updates the dynamic model’s weights to conform to the deviation of the characteristic distribution of the new dataset collected in the atmospheric environment in each period. It extends the life cycle of the integrated gas models.
The flow chart of an optimal gas model is set out in
Figure 15. Data engineering is the first step in dealing with a new dataset, including preprocessing, outlier cleaning, and normalization, as mentioned in
Section 2. The second step, model engineering, contains a recursive work—model online, performance monitoring, and model retraining. We obtained the best ensemble model through a training series, as shown in
Section 4.1,
Section 4.2 and
Section 4.3. Then, the model was activated to calculate gas concentrations; this model was named
model online. Under regular monitoring, the model’s performance declined with time; therefore, the program counts on the amount of data that the model has calculated and decides whether to retrain the dynamic model. While the amount of data calculated by the model reached two hundred, model retraining was triggered in the study. The testing dataset became a new training dataset in the retraining procedure. The upper and lower limits of the scaling scale of the new training dataset were consistent with the original training dataset to ensure the consistency of the new and old datasets. We used the new training dataset to train the dynamic model again and then updated the weight coefficients (as shown in
Section 4.3). By periodically updating the dynamic model’s weight coefficients, the gas model’s performance at each stage is stabilized and extends the gas model’s life cycle.
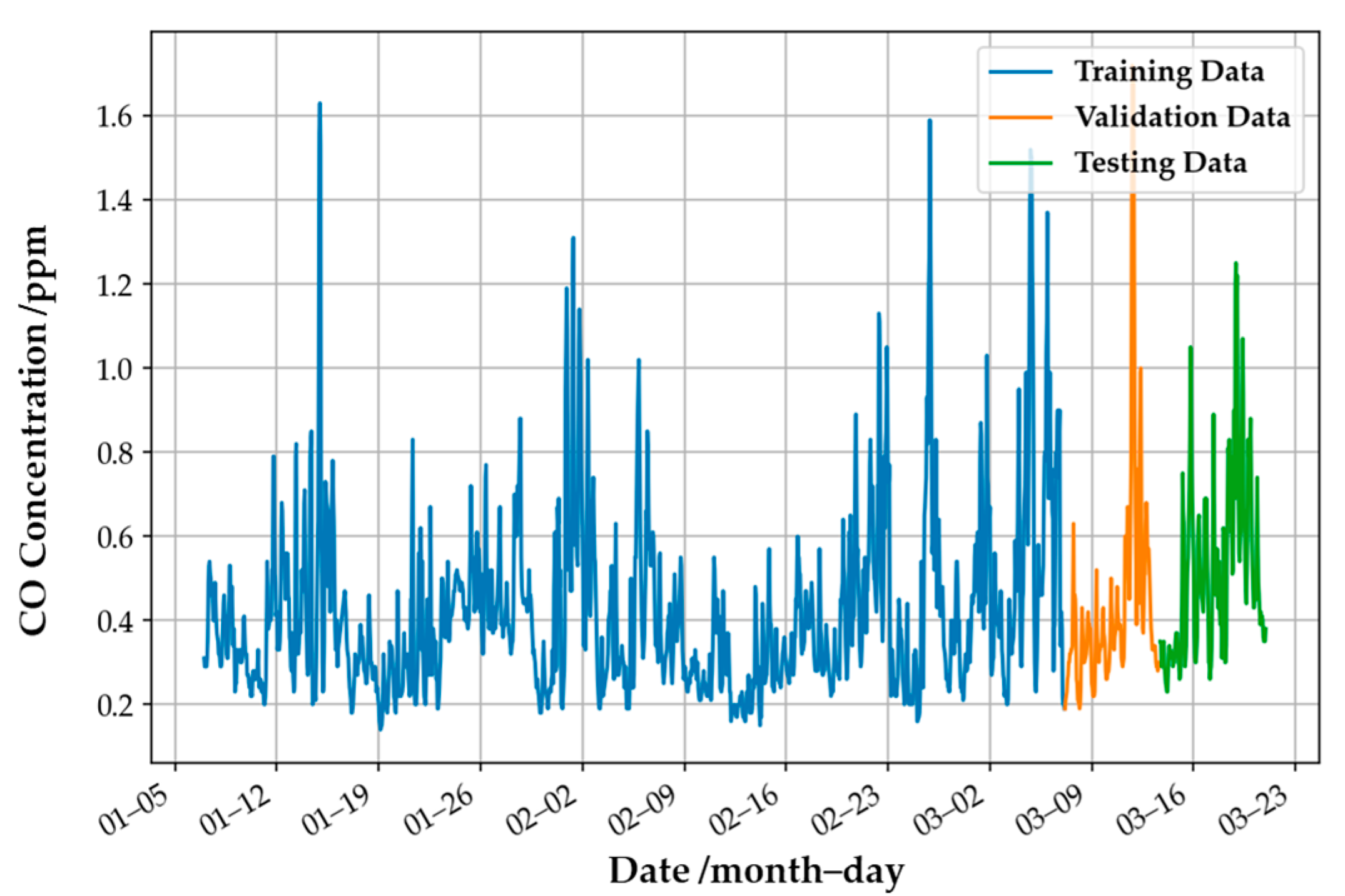
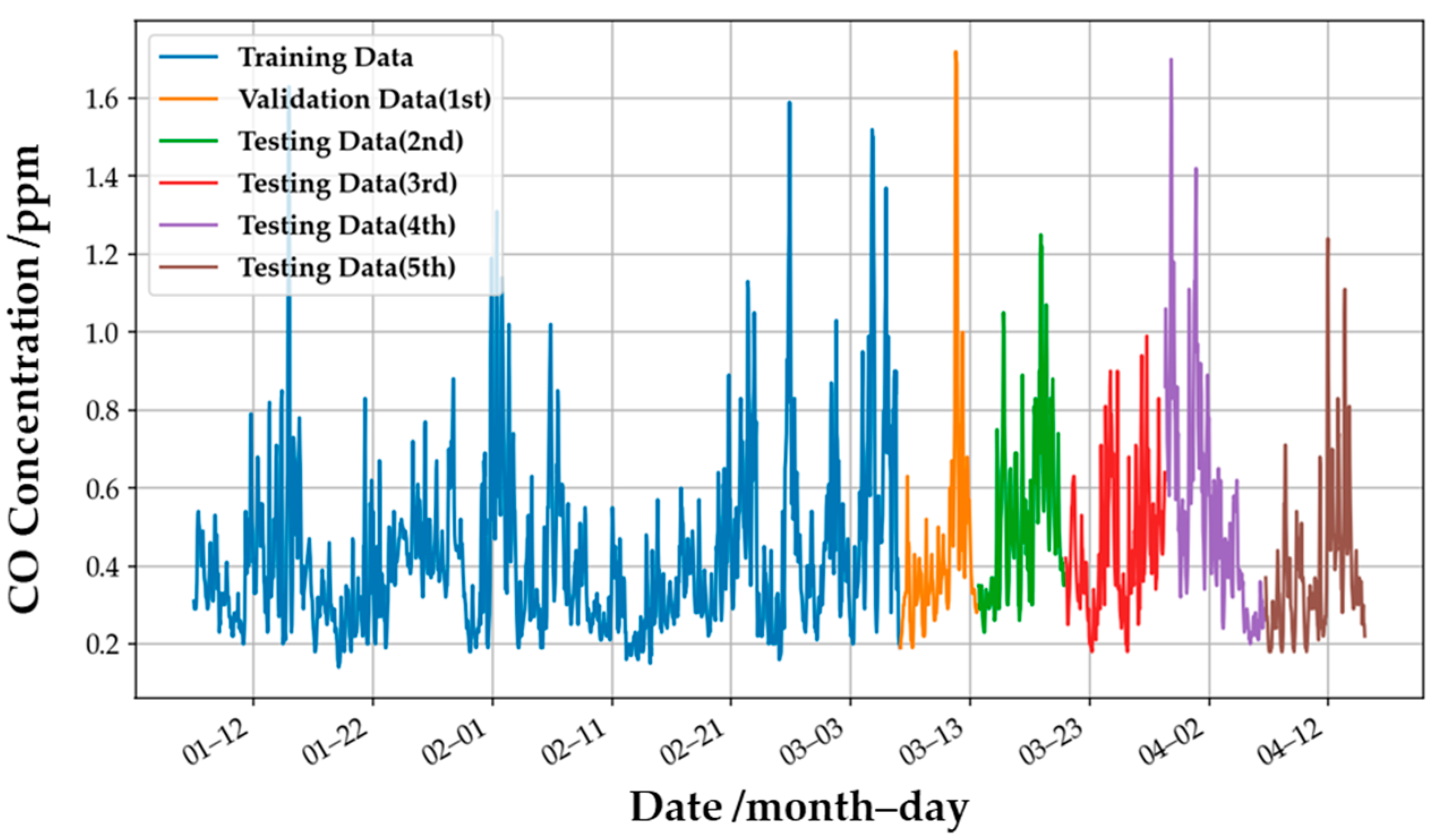
The ensemble model for CO gas was used to demonstrate the performance of the retrained model.
Figure 16 shows the actual CO concentration values provided by the EPA, and the lines in different colors present the definition of the dataset. The initial single weak models were trained by the training dataset (the blue line, which contains 1500 pieces of data), and the ensemble model for CO was defined. Then the weights of the dynamic model are defined by updating the weights of the original model according to the newly added data in each period (i.e., the orange, green, red, purple, and brown lines). The amount of data for each period is 200, and the initial learning rate of the model is 0.1 times that of the original static model. The retraining method of the O
3 and NO
2 gas models is the same as that of the CO gas model: use the previous period’s data as new training data, and retrain the model through the new data of the previous period to improve the generalization ability of the retrained model in the next period.
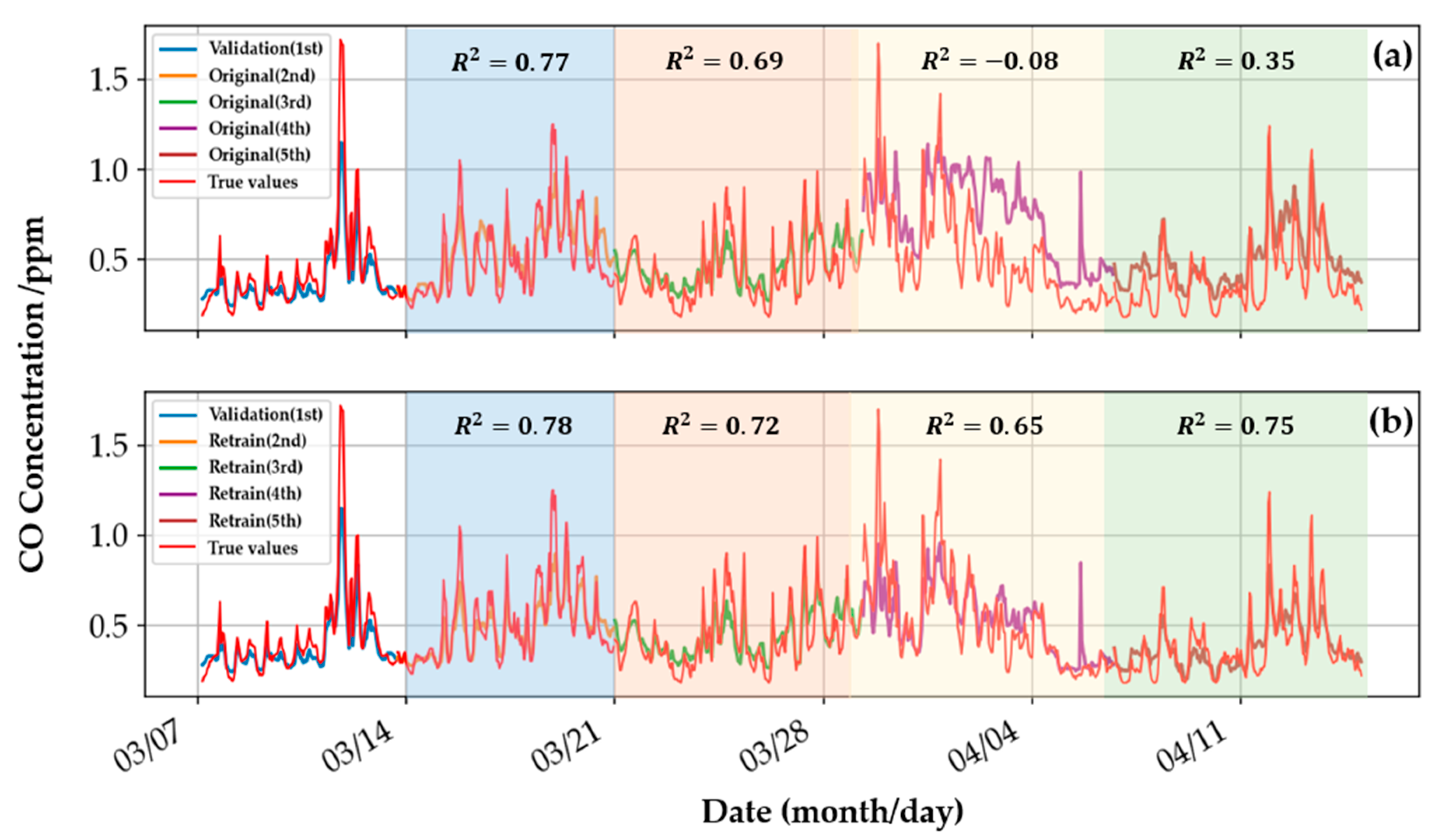
Figure 17 shows the actual CO concentration, the original model’s output values, and the retrained model’s outputs. The weight coefficients in the original ensemble model are unchanged after being defined in the training phase.
Figure 17a shows the significant differences between the output concentrations and the actual values. The performance was estimated using the residual sum of squares of the linear regression model, i.e., the R
2 value. In the fourth interval, the R
2 value of the original CO gas model is negative, hinting at the failure of the linear regression model, and the model’s overall performance is not stable enough to handle changes in new data. The results of the O
3 and NO
2 gas models are similar, and the results are summarized in
Table 5. The retrained model updated the gas model through the last period’s data and dynamically corrected the concentration interpretation of the static model in each period. Thus
Figure 17b shows a smaller difference in each period. The retrained model has an average R
2 of 0.73 over the four intervals. As shown in
Table 5, the long-term average R
2 of the four intervals of the retrained O
3 and NO
2 gas ensemble model are 0.51 and 0.37, respectively, which are better than the results of the original ensemble models.
Compared with the original model without retraining, the sensor performance of the retrained model is much more stable in the different periods. The retraining procedure can update the parameters of the dynamic model in the ensemble model, meaning that the machine learning model with regular retraining is a potential solution to calibrate sensors deployed in different environments (area or season). Thus, the model’s life cycle is effectively prolonged.
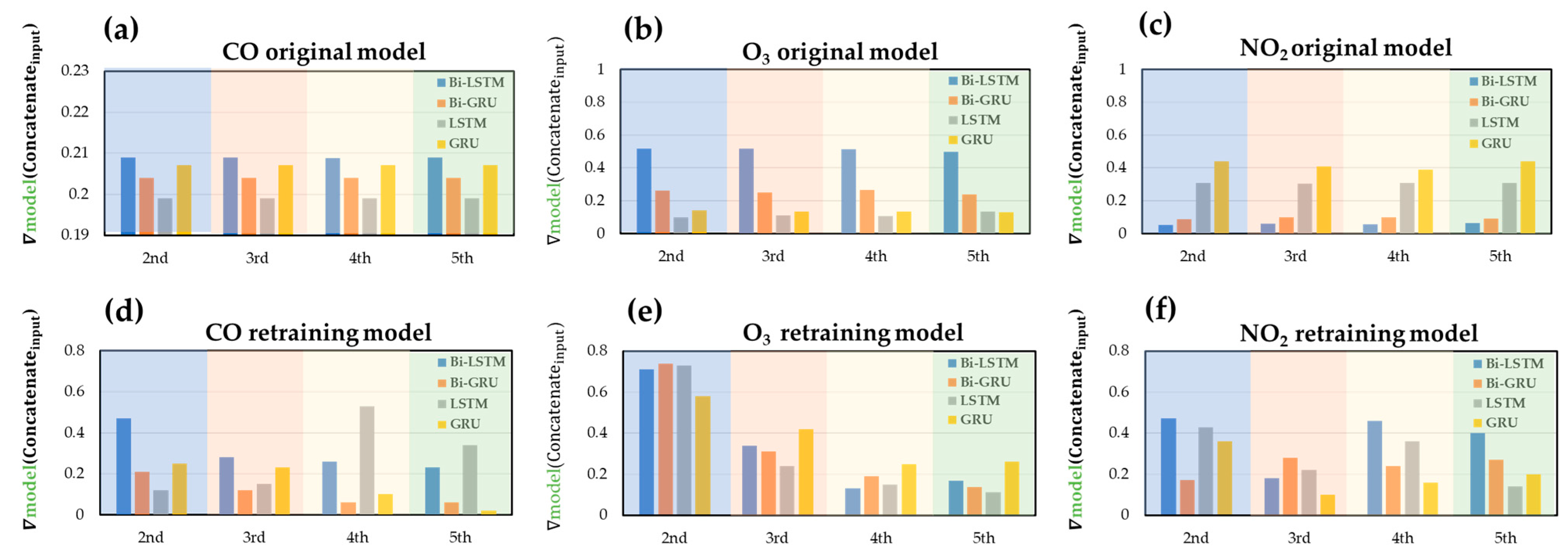
Furthermore, the contribution of each static model to the final output value of the ensemble model was estimated. The degree of the gradient contribution was used, which was obtained by differentiating the output of the dynamic model with respect to that of the static model as follows:
The gradient contribution of every data point in each interval was calculated, summed, and averaged, and the results are shown in
Figure 18. In the original gas models, the gradient contribution of each static model to the dynamic model is unchanged in all periods. The original gas model interprets gas concentration on the new data with the same gradient contribution in each period; the model cannot be dynamically adjusted with time, resulting in poor model performance and generalizability on the new dataset. Compared with the original gas model, the retrained gas model uses the new data of the previous period to update the weight coefficients of the dynamic model. Thus, the retrained gas model adjusts the gradient contribution of the static model and corrects the static model output in each period; the improved concentration estimations were observed in
Figure 17 and
Table 5. The retraining procedure provides the ensemble models better generalizability on new data.
4.5. Feasibility of Onsite Gas Sensing
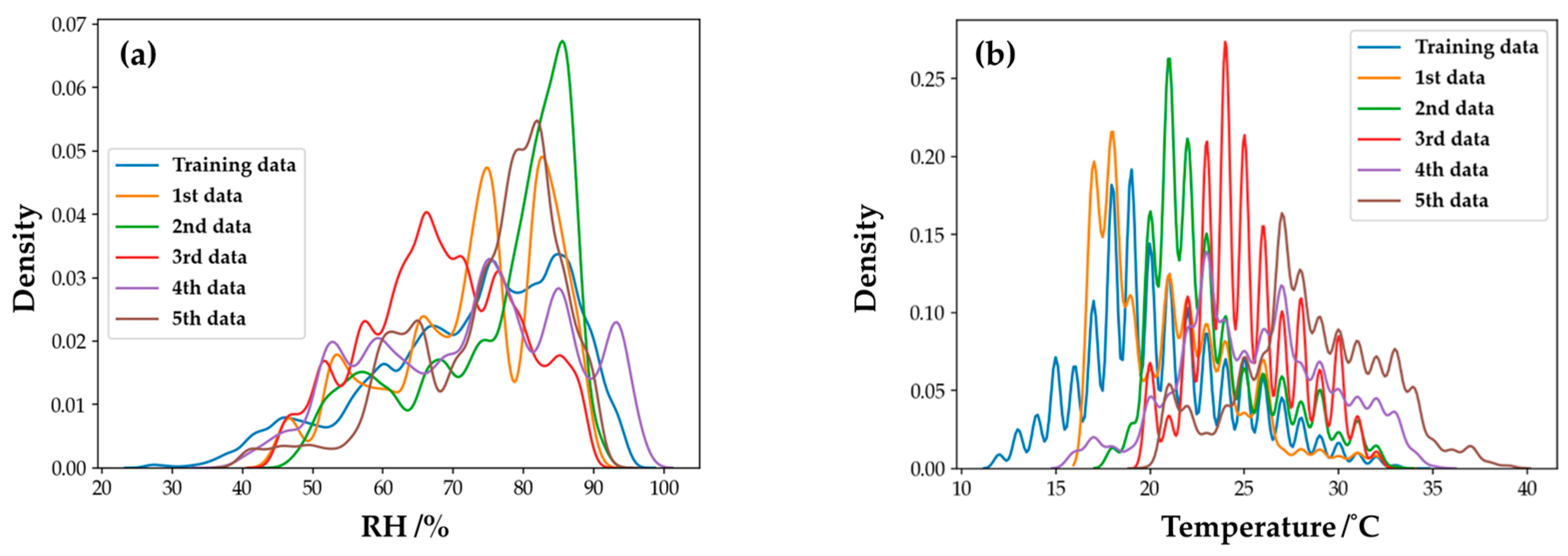
This study discussed the feasibility of using IoT gas sensors in a natural atmospheric environment. According to the Kernel Density Estimation (KDE) [
42] of humidity and temperature, as shown in
Figure 19, our sensors were in a rapid-change humidity and temperature environment instead of a constant temperature/humidity chamber in a laboratory. Under these varying conditions, our ensemble model can still maintain a relatively stable performance. The ensemble machine learning model can apply IoT sensors to achieve accurate air pollution detection.
A comparison of the sensing performance and equipment cost of the gas sensing equipment of other manufacturers is shown in
Table 6 (reference source: AQ-SPEC [
43]). The R
2 performance of our low-cost IoT device with AI assistance in all target gases is slightly lower than that of other gas-sensing devices, but the gap is not significant. Considering the cost of a large number of deployed gas detection equipment, the low-cost IoT device in this study is far less expensive than other brands of gas detection equipment. Based on cost performance advantages, more low-cost IoT devices such as the one developed in this study can be deployed to improve the spatial density information of CO, O
3, and NO
2 gases.
5. Conclusions
This paper studied ensemble models of RNN for onsite gas concentration detection using low-cost commercial sensors. IoT sensing devices for CO, O3, and NO2 were designed, fabricated, and then deployed in the field to monitor atmospheric air conditions. The time-sequence data of concentration, temperature, and humidity were collected for three months. Single weak RNN models for the three target gases were developed first, and then the ensemble models combining four types of RNN models were defined and studied. Results showed that the ensemble models improved the sensing performance for all gases. The results show that integrating four types of RNN models can significantly improve the performance in the testing set, showing a better result than any single RNN model. The static model part of the ensemble models contains the fundamental properties of the gas sensors, and the dynamic model part is a combination to achieve better performance. Thus, the ensemble model has a better generalizability for the commercial sensors for gas concentration detection.
Furthermore, a retraining procedure was designed as the optimal model to maintain stable model performance and prolong the life cycle. The performance of the original model without retraining is volatile in different periods, while the retraining model can solve this problem well. The periodic retraining procedure can update the parameters of the dynamic model in the ensemble model, meaning that the trained machine learning models can be easily applied while the sensors are deployed in a different environment (area, season). The results showed that the long-term average determination coefficient (R2) of the CO gas model reaches 0.73, it reached 0.51 for the O3 gas model and 0.37 for the NO2 gas model. The performance is still limited by the native sensitivity and the target selectivity. However, with the help of our ensemble models, these sensors have a specific correlation with the actual concentration announced by the EPA. The results promise accurate air pollution detection feasibility using commercial gas sensors in natural changing temperatures and humidity environments.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



