
On the Problem of Restoring and Classifying a 3D Object in Creating a Simulator of a Realistic Urban Environment


Abstract
:1. Introduction
2. Materials and Methods
2.1. General Concept and Classification of Neural Networks
- Solving the problem of unknown patterns.
- 2.
- There is no guarantee of repetition and unambiguity of the final results.
- Formalization of knowledge is not necessary; it can be replaced by learning by examples;
- Naturalness of processing and presentation of fuzzy knowledge, similar to the implementation in the brain;
- Parallel processing with proper hardware support creates conditions for real-time operation;
- Hardware implementation is able to provide fault tolerance;
- Processing of multidimensional data (more than three) without increasing labor intensity, as well as knowledge [19].
2.2. The Task of Recognizing 3D Objects in an Image
2.3. Existing Technologies
- Our cloud consists of a chaotic order of points;
- The relationship of points is a certain distance by which it becomes necessary to contact the network;
- Data loss.
- To solve these problems, you can use the following methods:
- Sorting. The method is not the most effective;
- Using a symmetric function to aggregate information. That is, a function whose value does not change depending on the order of the elements.
2.4. Problem Statement
3. Results
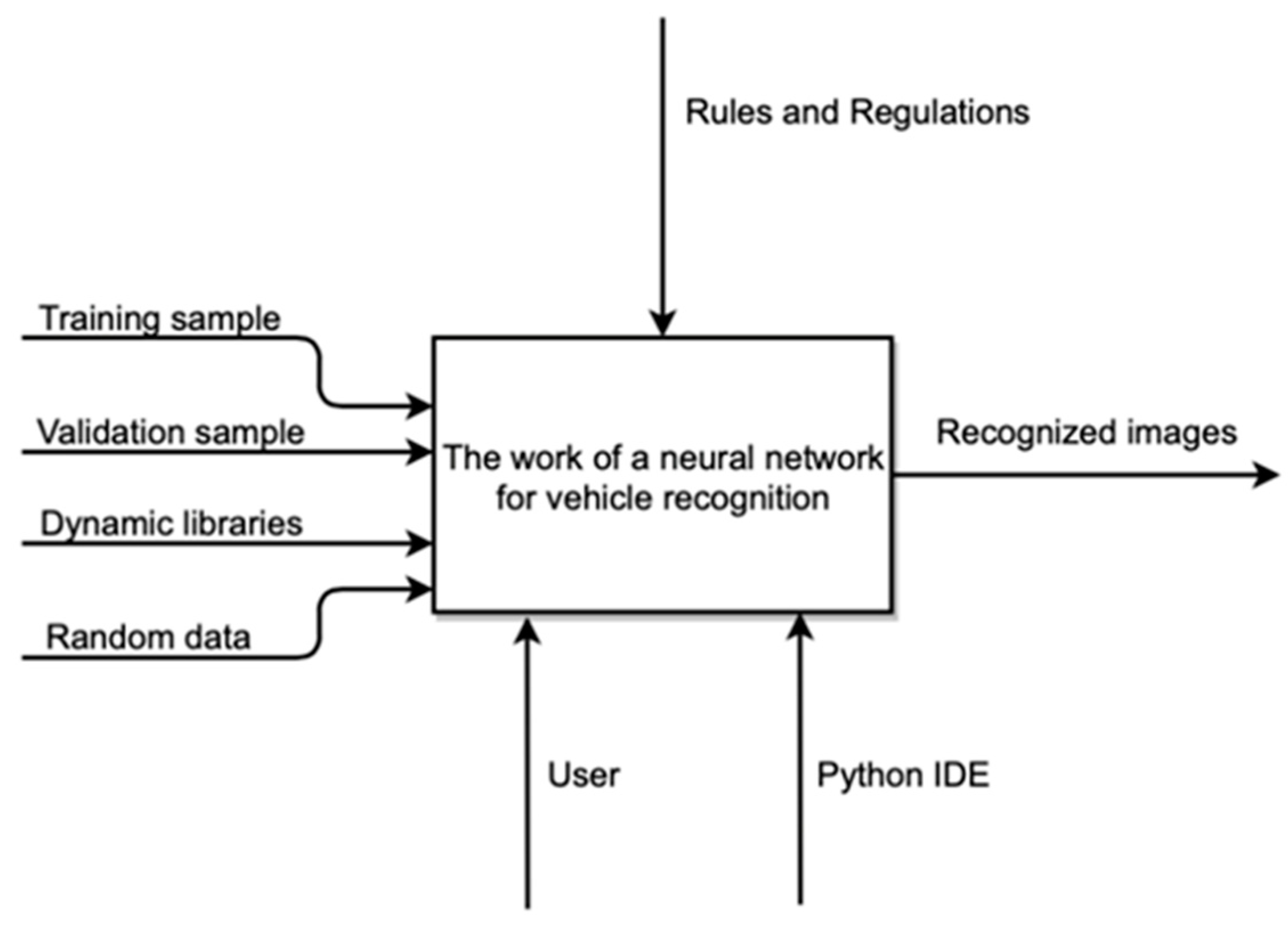
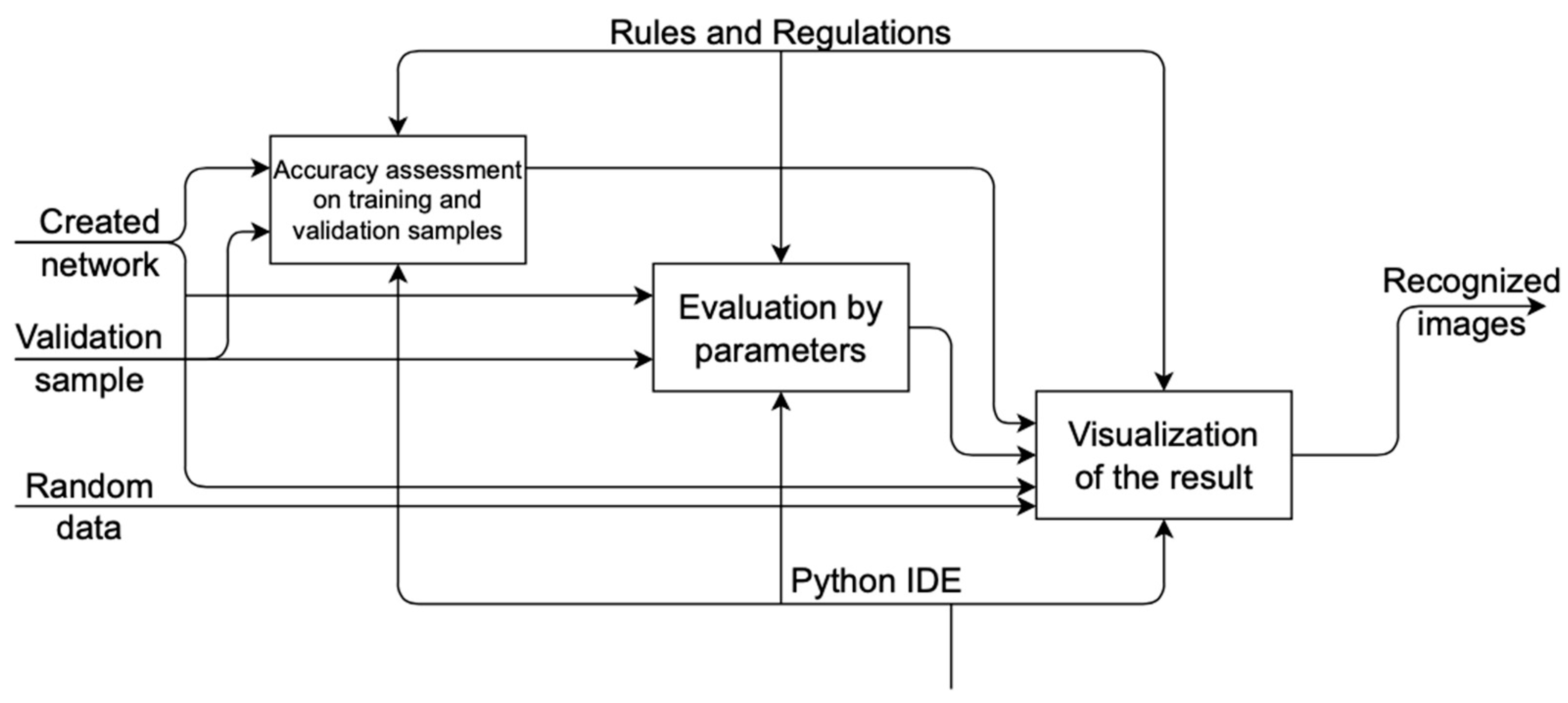
3.1. System Operation Design
- At the output of the system, we get a recognized image;
- The mechanisms are the Python user and environment;
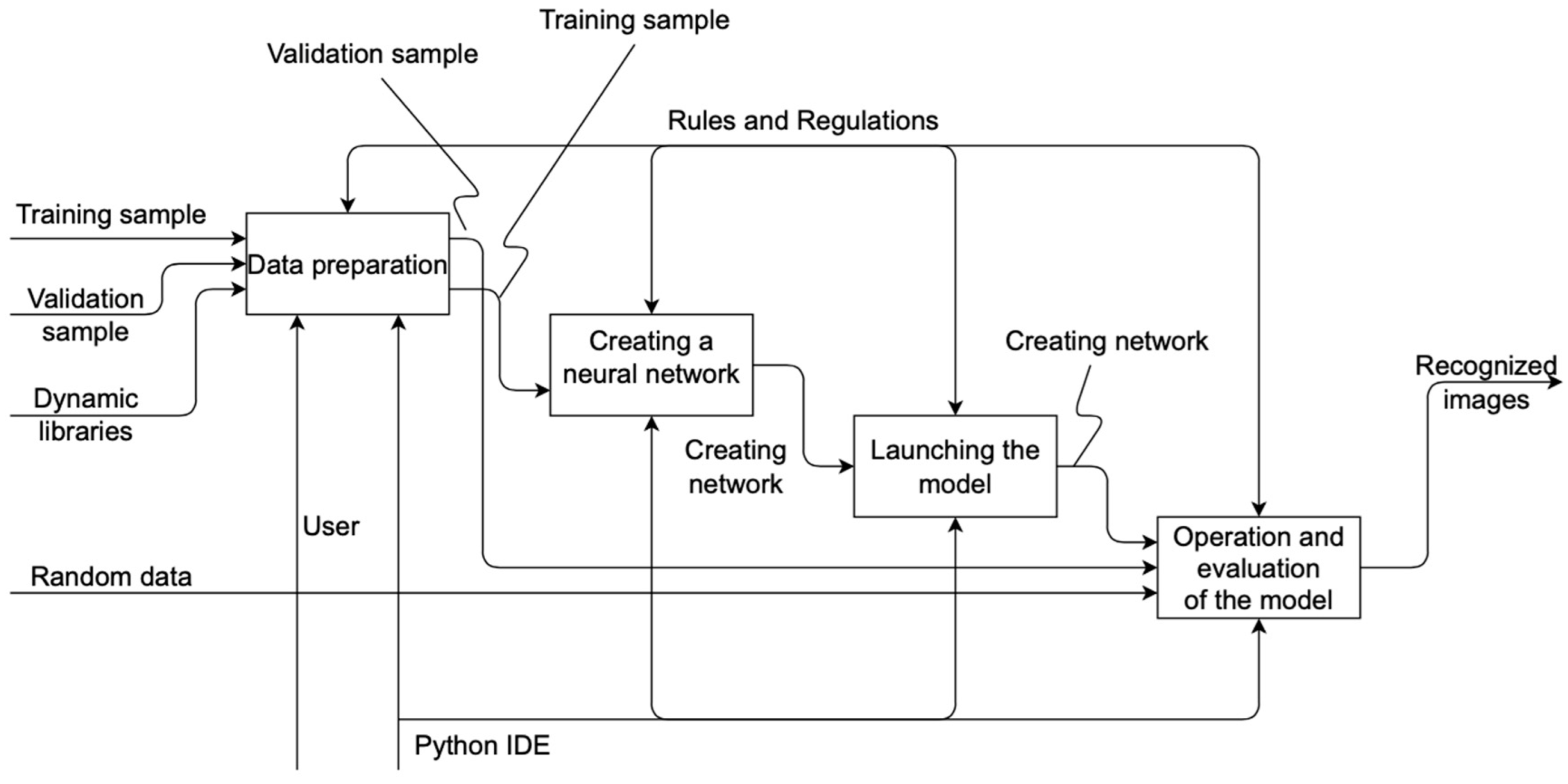
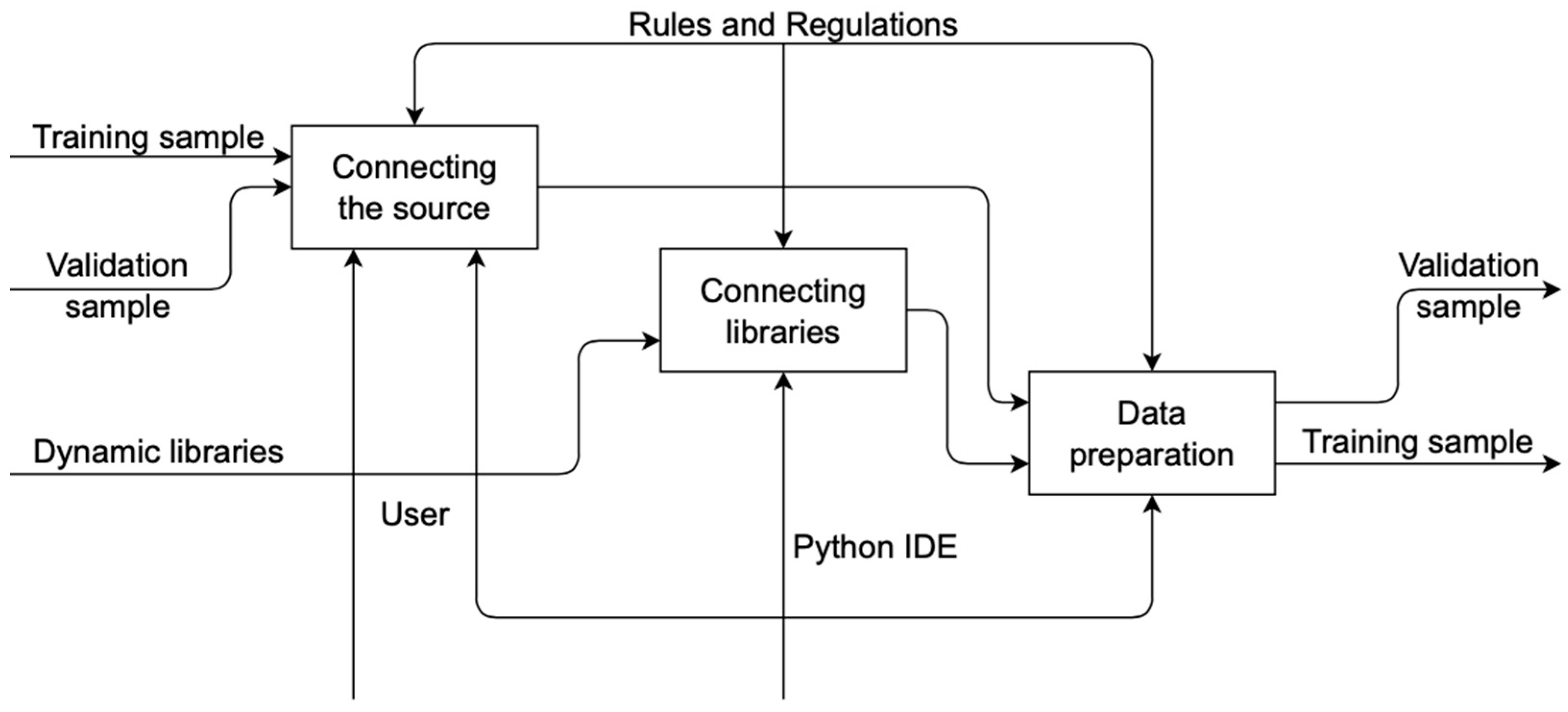
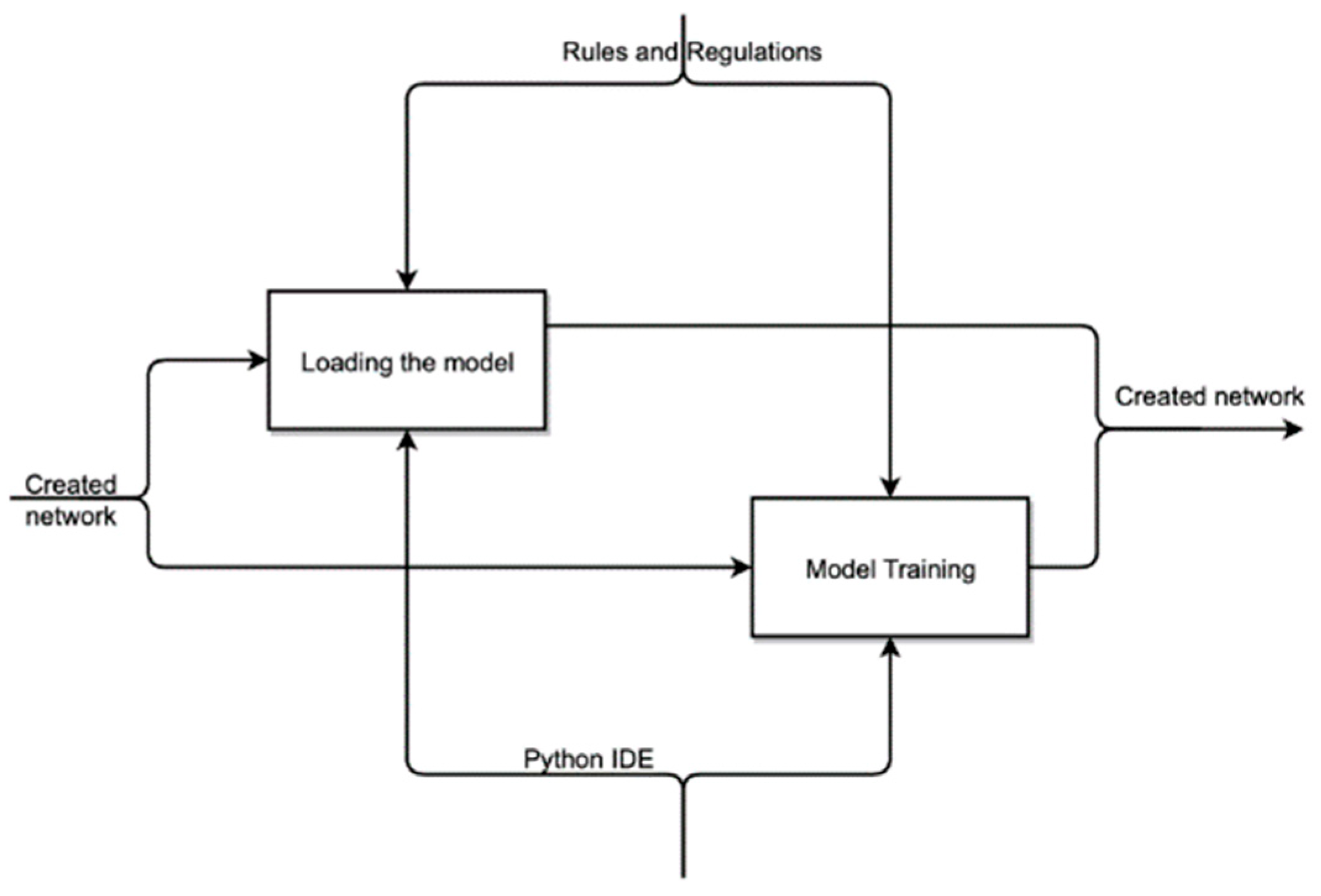
- The decomposition of the context diagram is shown in Figure 2.
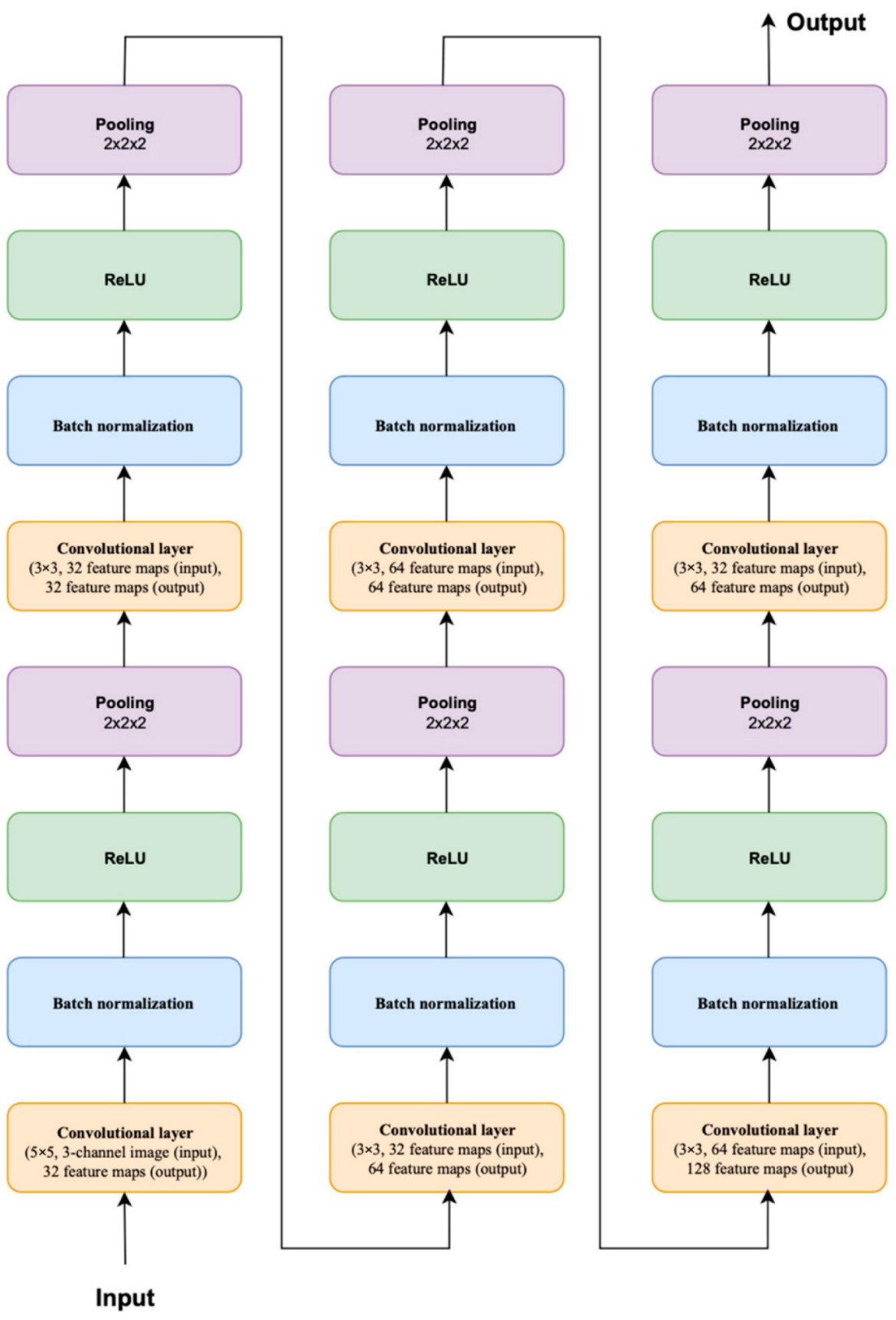
3.2. System Architecture
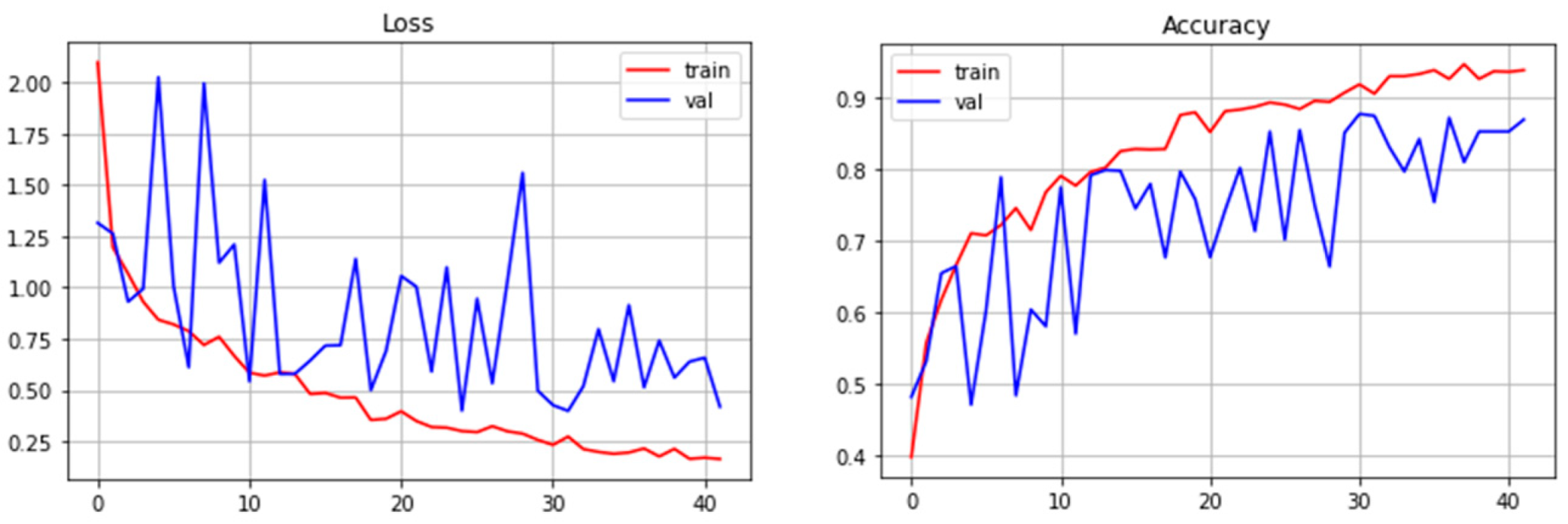
3.3. Description of the Algorithm
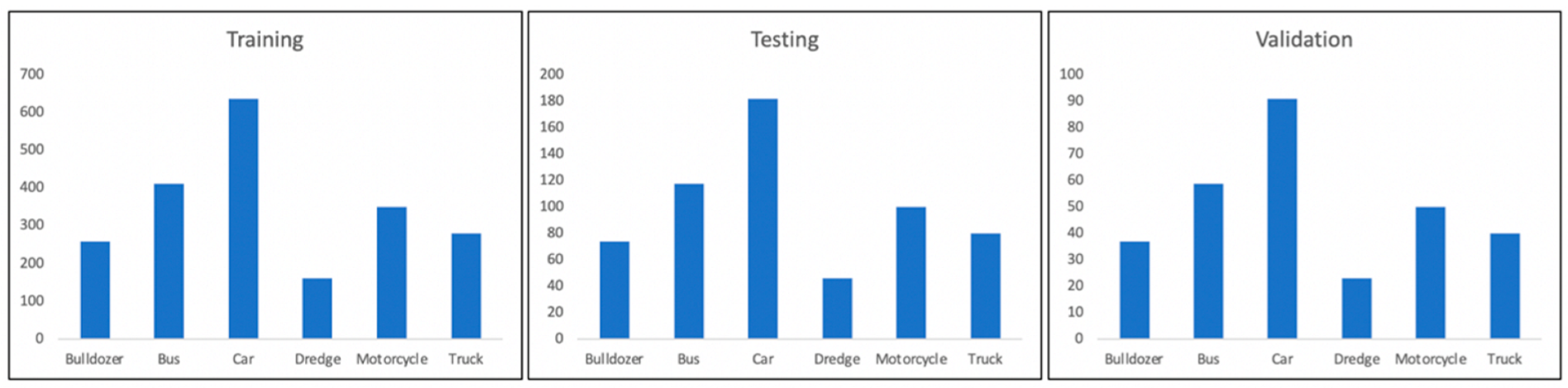
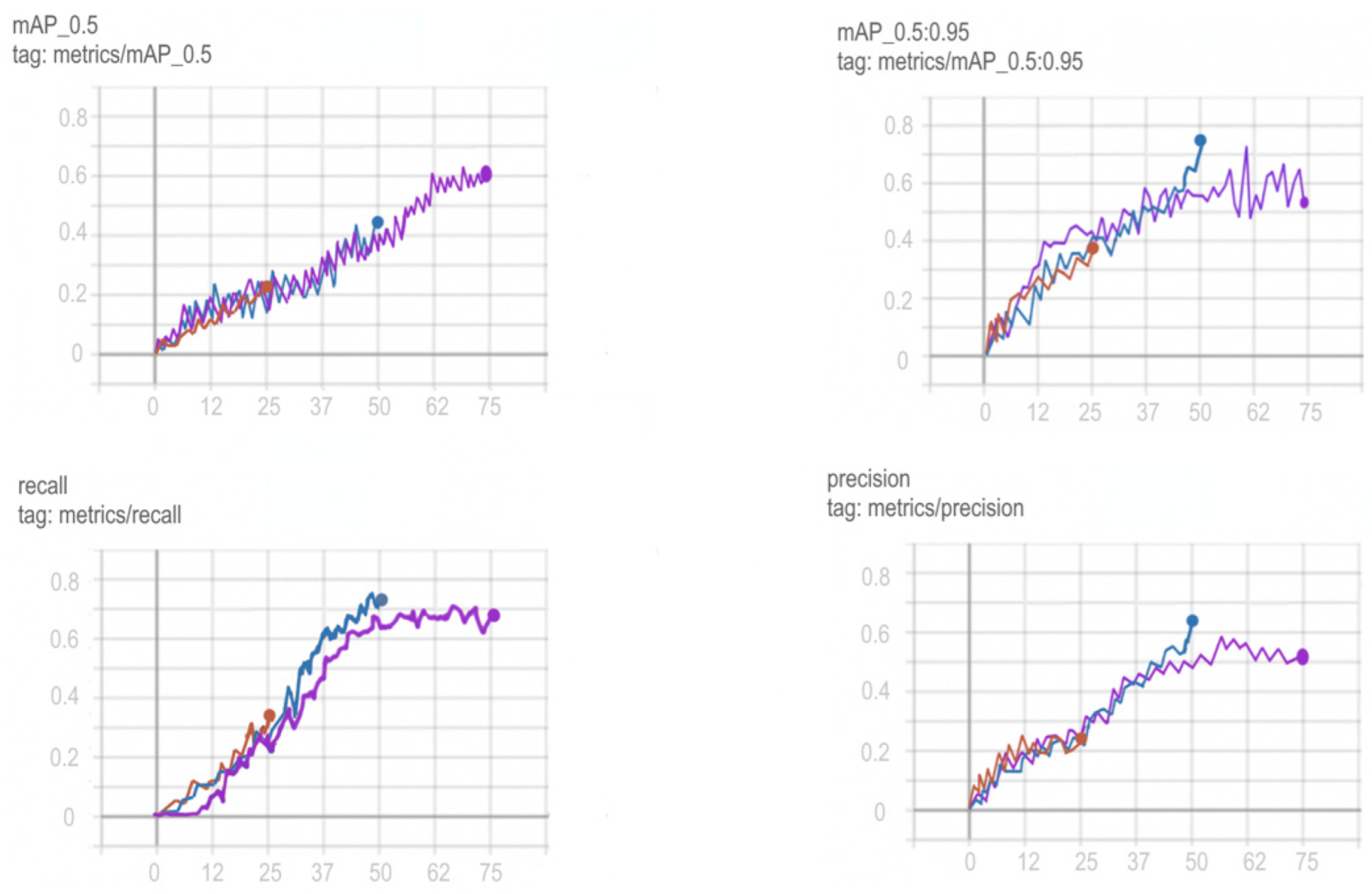
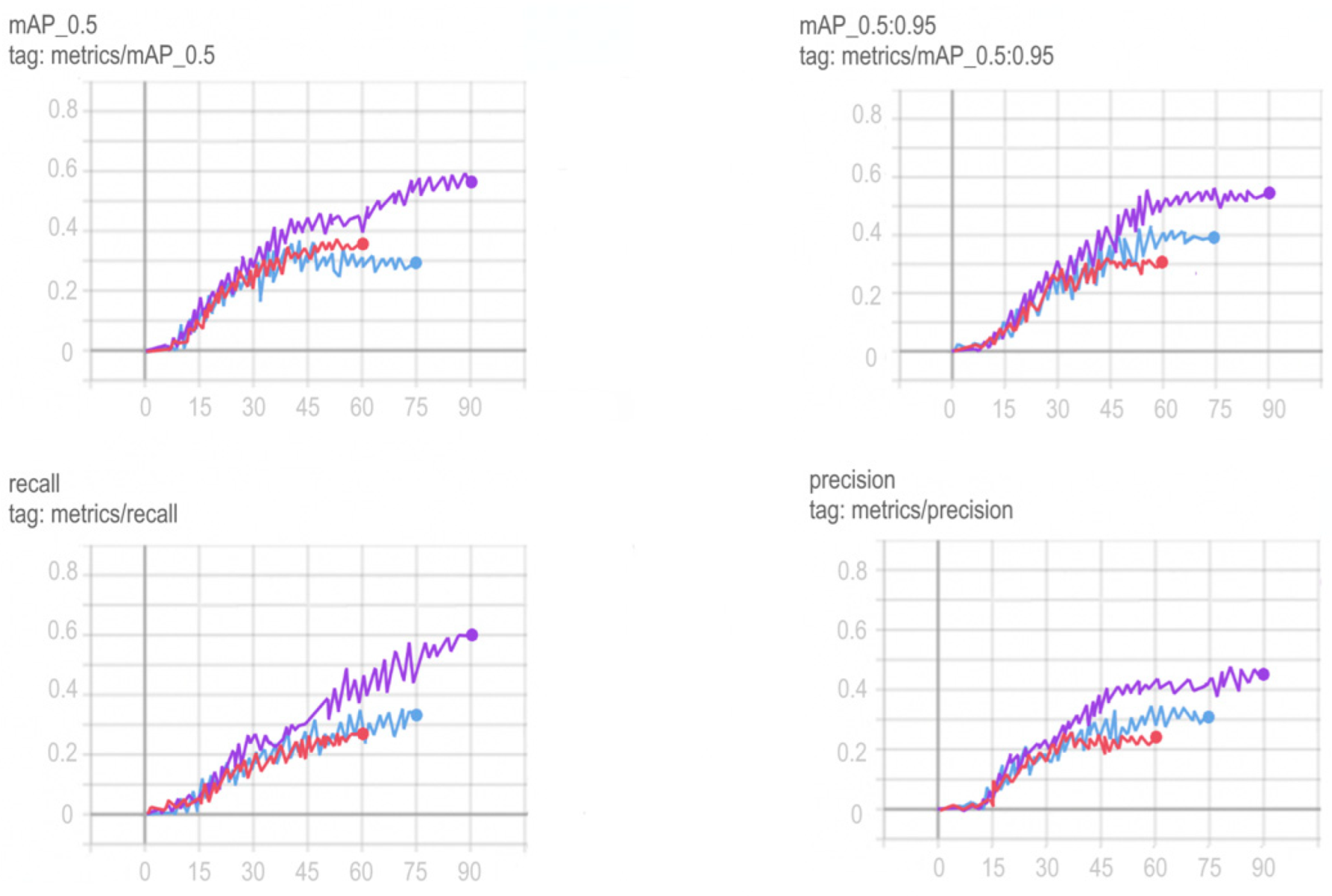
3.4. Formation of a Training Sample
- «Is it a Train or Bus» [29], from here images with buses were used;
- «UK Truck Brands Dataset» [30], which was used to create a sample with trucks;
- «Vehicle Dataset» [31], from which images of motorcycles and cars were taken;
- «Open Images Dataset» [32]. Images with buses and trucks were used from this dataset.
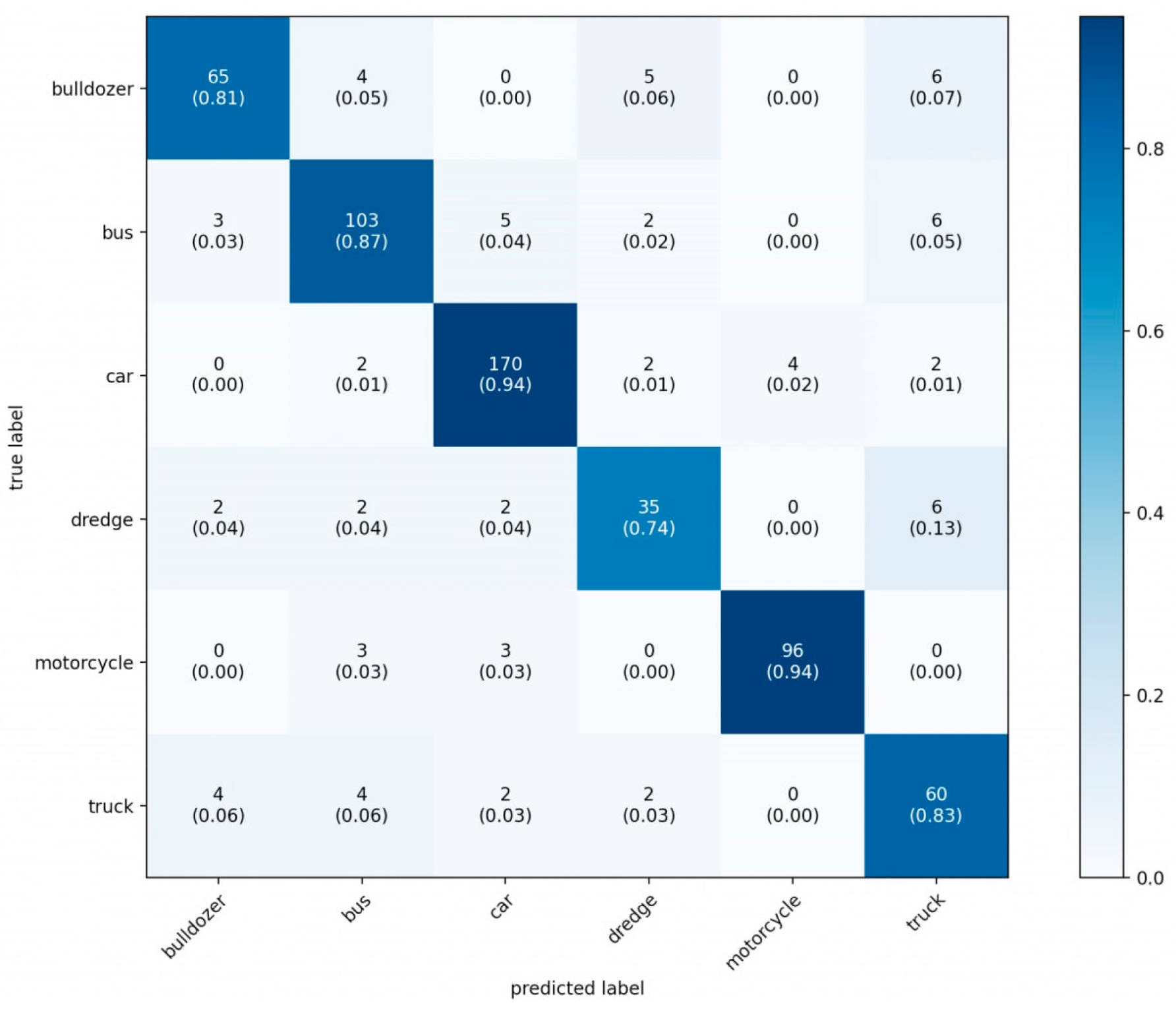
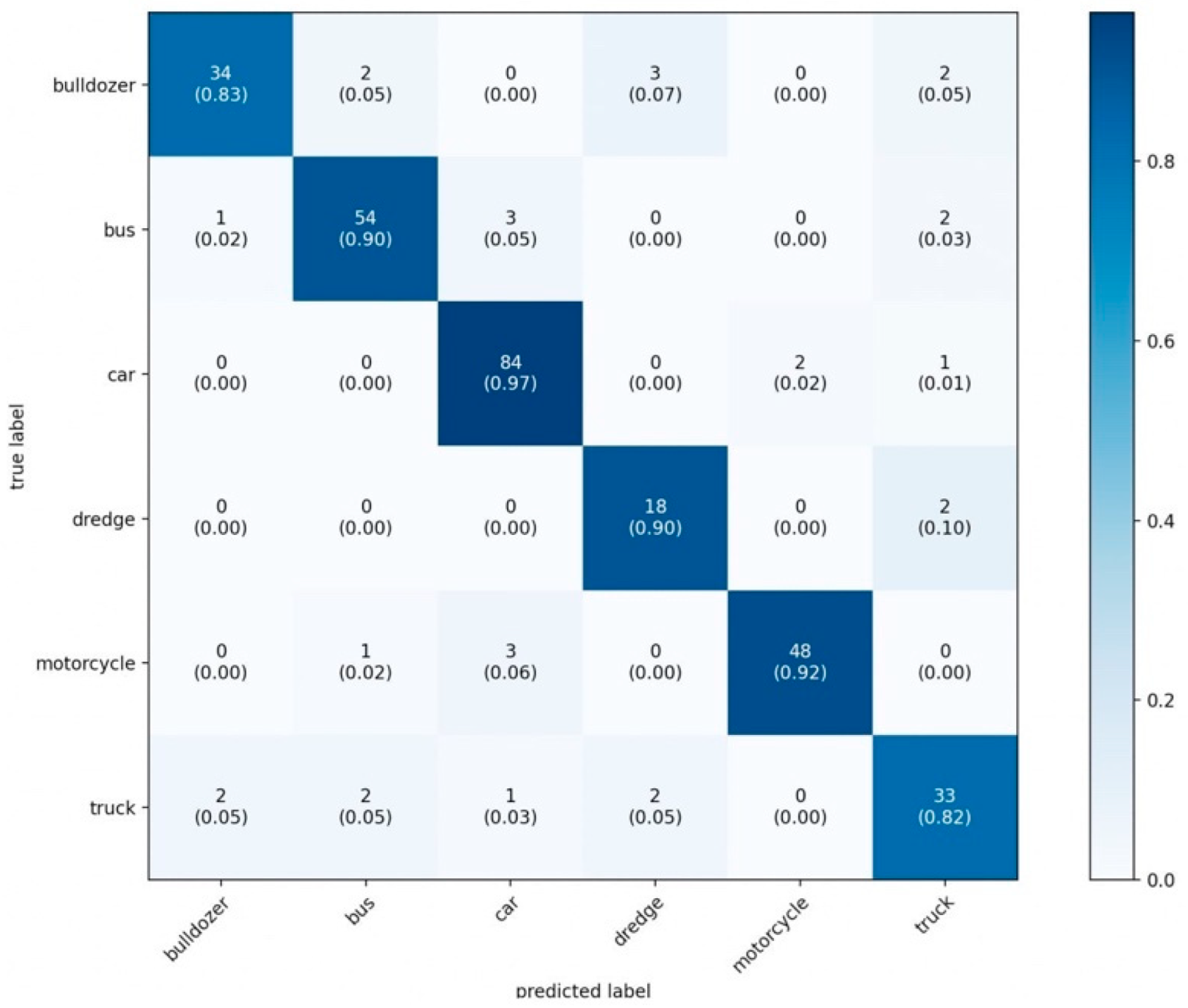
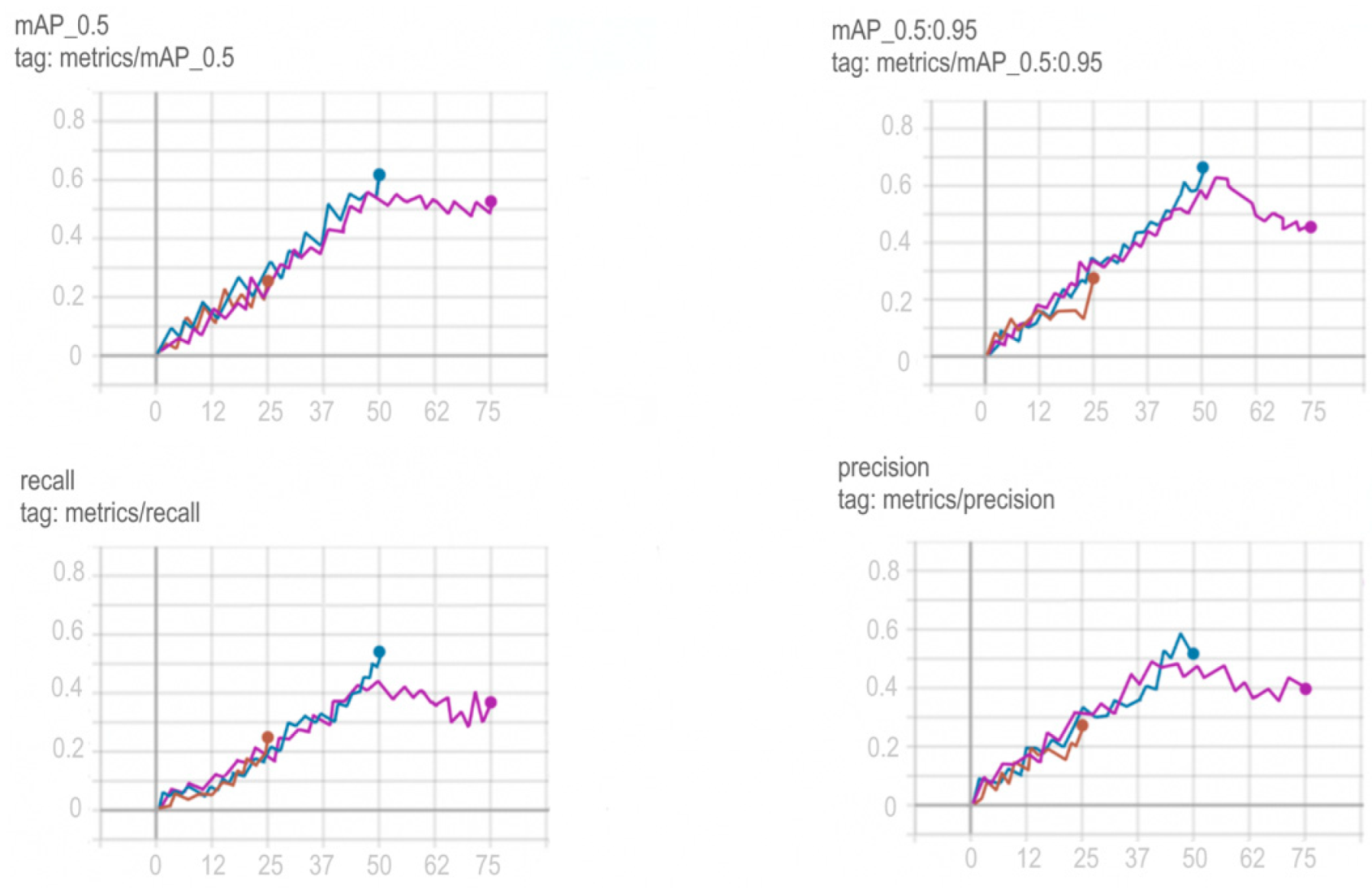
- The network developed by us has the best classification time (5.01442 ms) among the considered models. The closest result was shown by YOLOv5 (5.48544 ms).
- The network developed by us has the best classification accuracy (88.2%) among the models considered. The closest result was shown by the Mask R-CNN model (88.19%).
4. Conclusions
- The system was designed using the standard methodology of business process modeling IDEF0.
- The system architecture has been developed.
- A data set has been formed, consisting of data from open sources (data collected from the site “auto.ru “, datasets: “It is Train or Bus”, “UK Truck Brands Dataset”, “Vehicle Dataset”, “Open Image Dataset”), as well as data collected through the installation, fixed on a car that drove through the streets of Moscow.
- The study and comparison of existing popular neural network models that are used for similar tasks, namely—YOLOv5, Mask R-CNN, ResNeXt, VGG16; these models were trained on the same data as the model being developed.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chmiel, W.; Skalna, I.; Jędrusik, S. Intelligent route planning system based on interval computing. Multimed. Tools Appl. Vol. 2019, 78, 4693–4721. [Google Scholar] [CrossRef] [Green Version]
- Nohel, J.; Stodola, P.; Flasar, Z. Model of the Optimal Maneuver route. In Path Planning for Autonomous Vehicles-Ensuring Reliable Driverless Navigation and Control Maneuver; IntechOpen: London, UK, 2019. [Google Scholar]
- Aguiar, A.P.; Bayer, F.A.; Hauser, J.; Häusler, A.J.; Notarstefano, G.; Pascoal, A.M.; Rucco, A.; Saccon, A. Constrained optimal motion planning for autonomous vehicles using PRONTO. In Sensing and Control for Autonomous Vehicles; Springer: Cham, Switzerland, 2017; pp. 207–226. [Google Scholar]
- Penco, D.; Davins-Valldaura, J.; Godoy, E.; Kvieska, P.; Valmorbida, G. Control for autonomous vehicles in high dynamics maneuvers: LPV modeling and static feedback controller. In Proceedings of the 2021 IEEE Conference on Control Technology and Applications (CCTA), San Diego, CA, USA, 9–11 August 2021; pp. 283–288. [Google Scholar]
- Penco, D.; Davins-Valldaura, J.; Godoy, E.; Kvieska, P.; Valmorbida, G. Self-scheduled H∞ control of autonomous vehicle in collision avoidance maneuvers. IFAC-PapersOnLine 2021, 54, 148–153. [Google Scholar] [CrossRef]
- Peng, Z.; Wang, D.; Li, T.; Han, M. Output-feedback cooperative formation maneuvering of autonomous surface vehicles with connectivity preservation and collision avoidance. IEEE Trans. Cybern. 2019, 50, 2527–2535. [Google Scholar] [CrossRef]
- Nie, L.; Lin, C.; Liao, K.; Liu, S.; Zhao, Y. Unsupervised deep image stitching: Reconstructing stitched features to images. IEEE Trans. Image Process. 2021, 30, 6184–6197. [Google Scholar] [CrossRef]
- Gu, X.; Song, P.; Rao, Y.; Soo, Y.G.; Yeong, C.F.; Tan, J.T.C.; Asama, H.; Duan, F. Dynamic image stitching for moving object. In Proceedings of the 2016 IEEE International Conference on Robotics and Biomimetics (ROBIO), Qingdao, China, 3–7 December 2016; pp. 1770–1775. [Google Scholar]
- Kubanek, M.; Bobulski, J.; Kulawik, J. A method of speech coding for speech recognition using a convolutional neural network. Symmetry 2019, 11, 1185. [Google Scholar] [CrossRef] [Green Version]
- Kulawik, J.; Kubanek, M. Detection of False Synchronization of Stereo Image Transmission Using a Convolutional Neural Network. Symmetry 2021, 13, 78. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, M.; Jiang, L.; Yue, P. An interactive 4D spatio-temporal visualization system for hydrometeorological data in natural disasters. Int. J. Digit. Earth 2020, 13, 1258–1278. [Google Scholar] [CrossRef]
- Cao, W.; Wang, X.; Ming, Z.; Gao, J. A review on neural networks with random weights. Neurocomputing 2018, 275, 278–287. [Google Scholar] [CrossRef]
- Zhang, X.; Zhong, M.; Liu, S.; Zheng, L.; Chen, Y. Template-Based 3D Road Modeling for Generating Large-Scale Virtual Road Network Environment. ISPRS Int. J. Geo-Inf. 2019, 8, 364. [Google Scholar] [CrossRef] [Green Version]
- Malayjerdi, M.; Kuts, V.; Sell, R.; Otto, T.; Baykara, B.C. Virtual simulations environment development for autonomous vehicles interaction. In Proceedings of the ASME International Mechanical Engineering Congress and Exposition, Virtual, Online, 16–19 November 2020; American Society of Mechanical Engineers: New York, NY, USA, 2020; Volume 84492, p. V02BT02A009. [Google Scholar]
- Jia, Q.; Chang, L.; Qiang, B.; Zhang, S.; Xie, W.; Yang, X.; Sun, Y.; Yang, M. Real-Time 3D Reconstruction Method Based on Monocular Vision. Sensors 2021, 21, 5909. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Xie, Y.; Chen, L.; Zhou, X.; Bao, H. NeuralRecon: Real-time coherent 3D reconstruction from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15598–15607. [Google Scholar]
- Jeong, J.; Yoon, T.S.; Park, J.B. Multimodal sensor-based semantic 3D mapping for a large-scale environment. Expert Syst. Appl. 2018, 105, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Kar, A.; Prakash, A.; Liu, M.Y.; Cameracci, E.; Yuan, J.; Rusiniak, M.; Acuna, D.; Torralba, A.; Fidler, S. Meta-sim: Learning to generate synthetic datasets. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 4551–4560. [Google Scholar]
- Linnenberger, A.; McLeod, R.R.; Basta, T.; Stowell, M.H. Three dimensional living neural networks. In Proceedings of the SPIE 9548, Optical Trapping and Optical Micromanipulation XII, San Diego, CA, USA, 28 August 2015; Volume 9548. [Google Scholar] [CrossRef]
- GeÌron, A. Hands-on Machine Learning with Scikit-Learn, Keras and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd ed.; O’Reilly: Sebastopol, CA, USA, 2019. [Google Scholar]
- Wang, J.; Fu, P.; Gao, R.X. Machine vision intelligence for product defect inspection based on deep learning and Hough transform. J. Manuf. Syst. 2019, 51, 52–60. [Google Scholar] [CrossRef]
- Yan, B.; Xu, N.; Zhao, W.B.; Xu, L.P. A three-dimensional Hough transform-based track-before-detect technique for detecting extended targets in strong clutter backgrounds. Sensors 2019, 19, 881. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benning, M.; Celledoni, E.; Ehrhardt, M.J.; Owren, B.; Schönlieb, C.-B. Deep learning as optimal control problems: Models and numerical methods. J. Comput. Dyn. 2019, 6, 171–198. [Google Scholar] [CrossRef] [Green Version]
- Miller, D.; Sünderhauf, N.; Milford, M.; Dayoub, F. Uncertainty for identifying open-set errors in visual object detection. IEEE Robot. Autom. Lett. 2021, 7, 215–222. [Google Scholar] [CrossRef]
- Chen, J.; Jia, K.; Chen, W.; Lv, Z.; Zhang, R. A real-time and high-precision method for small traffic-signs recognition. Neural Comput. Appl. 2022, 34, 2233–2245. [Google Scholar] [CrossRef]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the International Conference on Machine Learning PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Cong, Y.; Tian, D.; Feng, Y.; Fan, B.; Yu, H. Speedup 3-D texture-less object recognition against self-occlusion for intelligent manufacturing. IEEE Trans. Cybern. 2018, 49, 3887–3897. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Auto [Electronic Resource]—Access Mode. Available online: https://auto.ru (accessed on 3 February 2022).
- Dataset «Is it a Train or Bus». Available online: https://www.kaggle.com/notjeremy0w0/is-it-a-train-or-bus (accessed on 3 February 2022).
- Dataset «UK Truck Brands Dataset». Available online: https://www.kaggle.com/bignosethethird/uk-truck-brands-dataset (accessed on 3 February 2022).
- Dataset «Vehicle Dataset». Available online: https://www.kaggle.com/krishrana/vehicle-dataset (accessed on 3 February 2022).
- Dataset «Open Images Dataset». Available online: https://storage.googleapis.com/openimages/web/index.html (accessed on 3 February 2022).
- Gorodnichev, M.G.; Dzhabrailov, K.A.; Polyantseva, K.A.; Gematudinov, R.A. On Automated Safety Distance Monitoring Methods by Stereo Cameras. In Proceedings of the 2020 Systems of Signals Generating and Processing in the Field of on Board Communications, Moscow, Russia, 19–20 March 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Polyantseva, K.; Gorodnichev, M. Neural network approaches in the problems of detecting and classifying roadway defects. In Proceedings of the 2022 Wave Electronics and its Application in Information and Telecommunication Systems, St. Petersburg, Russia, 30 May –3 June 2022; pp. 1–7. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic ReLU. In Computer Vision—ECCV 2020. Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; Volume 12364. [Google Scholar] [CrossRef]
- Medium. Wide Residual Networks with Interactive Code [Electronic resource]. Access Mode. Available online: https://medium.com/@SeoJaeDuk/wide-residual-networks-with-interactive-code-5e190f8f25ec (accessed on 1 February 2022).
- Kim, J.H.; Kim, N.; Park, Y.W.; Won, C.S. Object Detection and Classification Based on YOLO-V5 with Improved Maritime Dataset. J. Mar. Sci. Eng. 2022, 10, 377. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Pant, G.; Yadav, D.P.; Gaur, A. ResNeXt convolution neural network topology-based deep learning model for identification and classification of Pediastrum. Algal Res. 2020, 48, 101932. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint 2014, arXiv:1409.1556. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle | Our Net | YOLOv5 | Mask R-CNN | ResNeXt | VGG16 |
|---|---|---|---|---|---|
| Bulldozer | 0.87 | 0.71 | 0.87 | 0.71 | 0.71 |
| Bus | 0.83 | 0.63 | 0.86 | 0.65 | 0.67 |
| Car | 0.89 | 0.63 | 0.86 | 0.69 | 0.67 |
| Dredge | 1.00 | 0.77 | 0.92 | 0.79 | 0.77 |
| Motorcycle | 0.92 | 0.67 | 1.00 | 0.77 | 0.91 |
| Truck | 0.84 | 0.83 | 0.86 | 0.83 | 0.91 |
| Vehicle | Our Net | YOLOv5 | Mask R-CNN | ResNeXt | VGG16 |
|---|---|---|---|---|---|
| Bulldozer | 1.00 | 0.67 | 0.93 | 0.71 | 0.77 |
| Bus | 0.89 | 0.71 | 0.86 | 0.79 | 0.77 |
| Car | 0.91 | 0.91 | 0.92 | 0.92 | 0.91 |
| Dredge | 0.29 | 0.63 | 0.92 | 0.69 | 0.77 |
| Motorcycle | 0.92 | 0.67 | 0.75 | 0.67 | 0.67 |
| Truck | 0.85 | 0.67 | 1.00 | 0.67 | 0.71 |
| Vehicle | Our Net | YOLOv5 | Mask R-CNN | ResNeXt | VGG16 |
|---|---|---|---|---|---|
| Bulldozer | 0.93 | 0.69 | 0.9 | 0.71 | 0.74 |
| Bus | 0.86 | 0.67 | 0.86 | 0.71 | 0.71 |
| Car | 0.90 | 0.74 | 0.89 | 0.79 | 0.77 |
| Dredge | 0.44 | 0.69 | 0.92 | 0.73 | 0.77 |
| Motorcycle | 0.92 | 0.67 | 0.86 | 0.71 | 0.77 |
| Truck | 0.85 | 0.74 | 0.92 | 0.74 | 0.80 |
| Net Name | Accuracy | Time |
|---|---|---|
| Our net | 88.20% | 5.01442 ms |
| YOLOv5 | 69.37% | 5.48544 ms |
| Mask R-CNN | 88.19% | 6.76321 ms |
| ResNeXt | 73.49% | 6.97524 ms |
| VGG16 | 75.82% | 5.60733 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gorodnichev, M.; Erokhin, S.; Polyantseva, K.; Moseva, M. On the Problem of Restoring and Classifying a 3D Object in Creating a Simulator of a Realistic Urban Environment. Sensors 2022, 22, 5199. https://doi.org/10.3390/s22145199
Gorodnichev M, Erokhin S, Polyantseva K, Moseva M. On the Problem of Restoring and Classifying a 3D Object in Creating a Simulator of a Realistic Urban Environment. Sensors. 2022; 22(14):5199. https://doi.org/10.3390/s22145199
Chicago/Turabian StyleGorodnichev, Mikhail, Sergey Erokhin, Ksenia Polyantseva, and Marina Moseva. 2022. "On the Problem of Restoring and Classifying a 3D Object in Creating a Simulator of a Realistic Urban Environment" Sensors 22, no. 14: 5199. https://doi.org/10.3390/s22145199
APA StyleGorodnichev, M., Erokhin, S., Polyantseva, K., & Moseva, M. (2022). On the Problem of Restoring and Classifying a 3D Object in Creating a Simulator of a Realistic Urban Environment. Sensors, 22(14), 5199. https://doi.org/10.3390/s22145199