
Non-Negative Matrix Factorization Based on Smoothing and Sparse Constraints for Hyperspectral Unmixing

Abstract
:1. Introduction
2. Linear Spectral Mixture Model
3. Sparse and Smooth Constrained NMF Method
3.1. The Sparseness of the Abundance
3.2. The Smoothness of the Abundance
3.3. The Smoothness of the End member
3.4. Smoothing and Sparse Constraints-NMF(SSC-NMF) HU Model
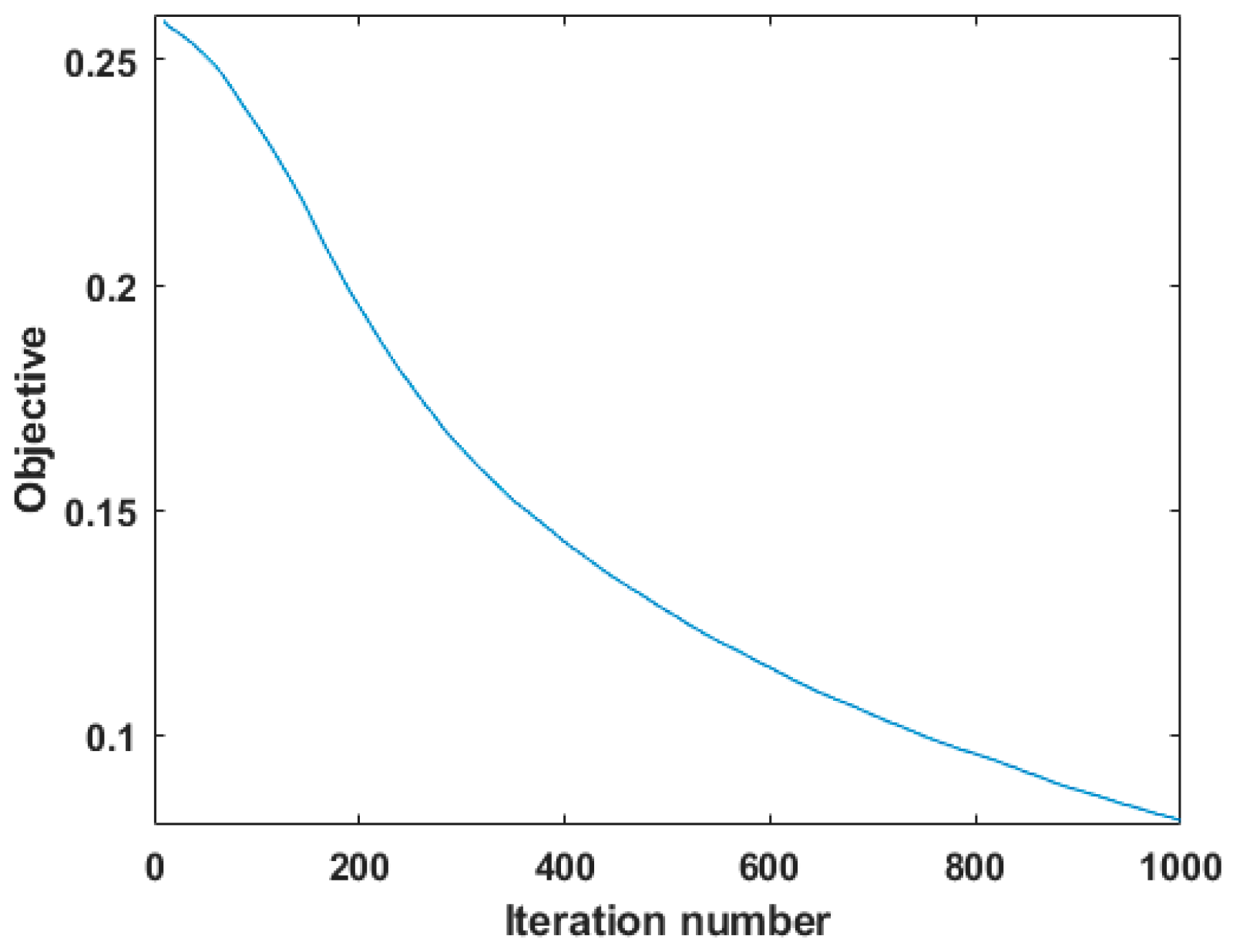
3.5. Model Optimization
3.6. Update Rules
3.6.1. End-Members Estimation
3.6.2. Abundance Estimation
3.6.3. Abundance Denoising
| Algorithm 1 Smoothing and Sparse Constraints NMF for HU |
| 1. Input: The observed mixture data , the number of end-members , the maximum number of iterations , the parameters . 2. Output: End-member signature matrix and abundance matrix . 3. Initialize , and weighted matrix . 4. Repeat until convergence: 5. Update the weight matrix with Equation (6); 6. Using Equation (19) to update ; 7. Obtain the augmentation matrix of and respectively using Equation (23) 8. Update by Equation (24); 9. Update with Equation (27). |
4. Experimental Results and Discussion
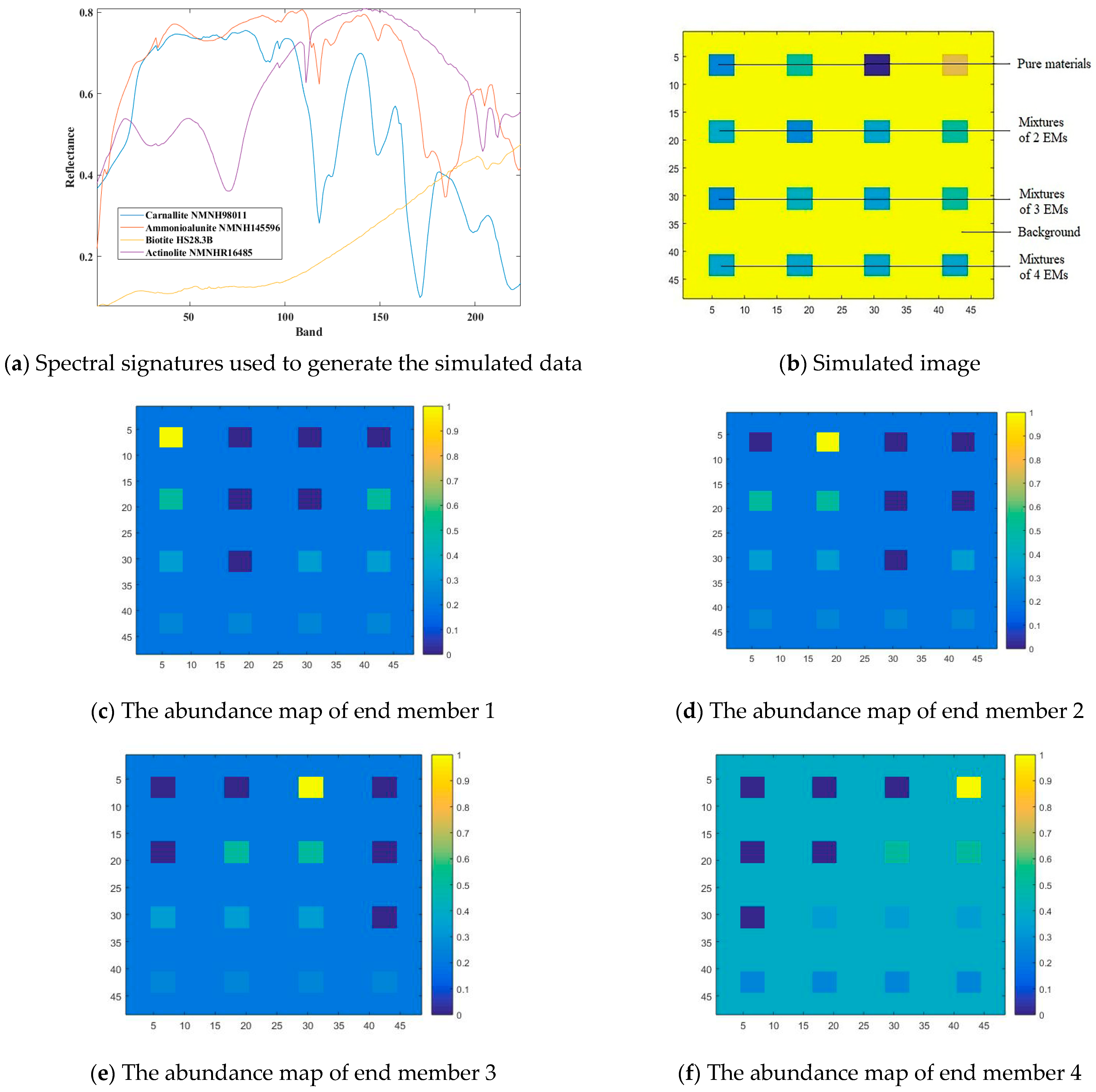
4.1. Simulated Data Experiments
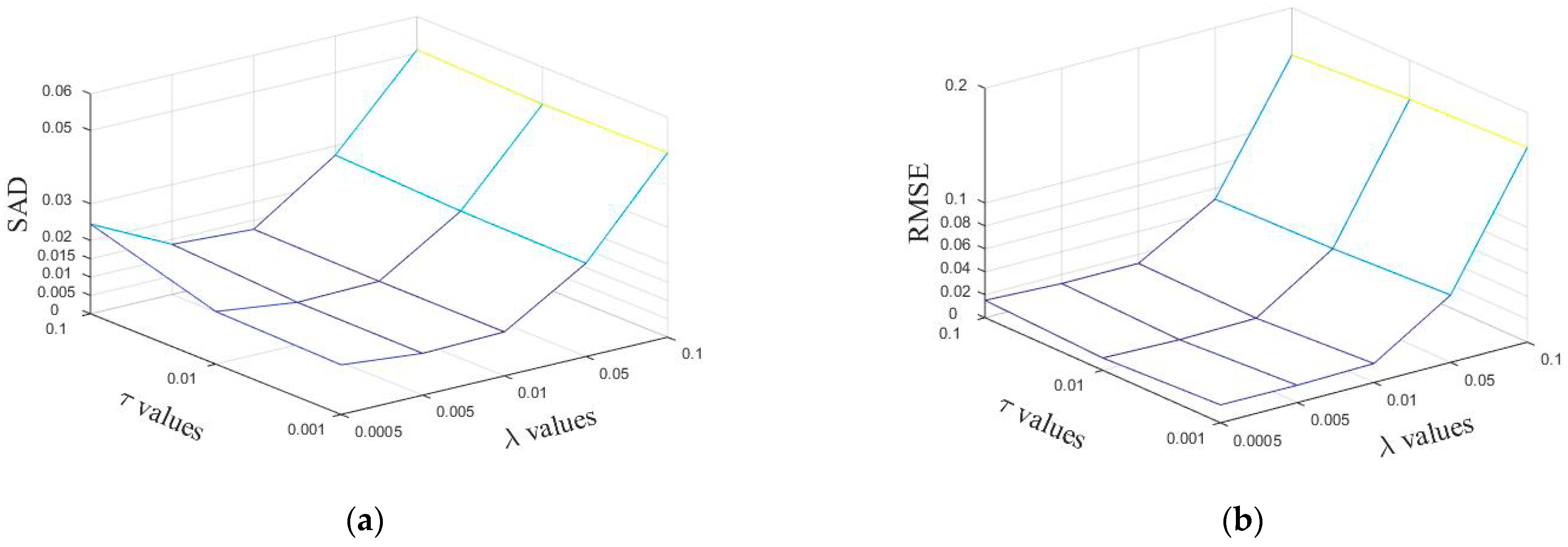
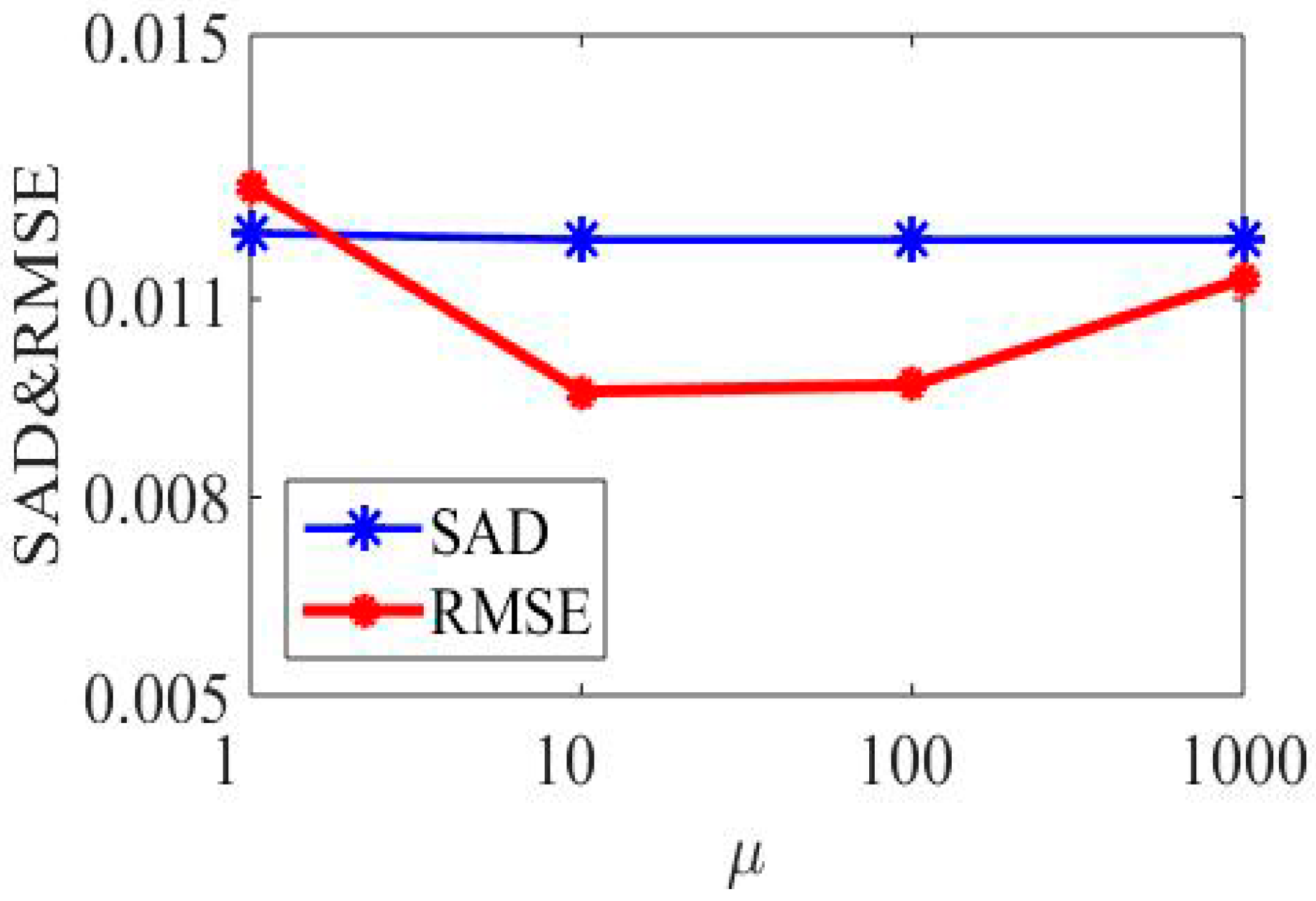
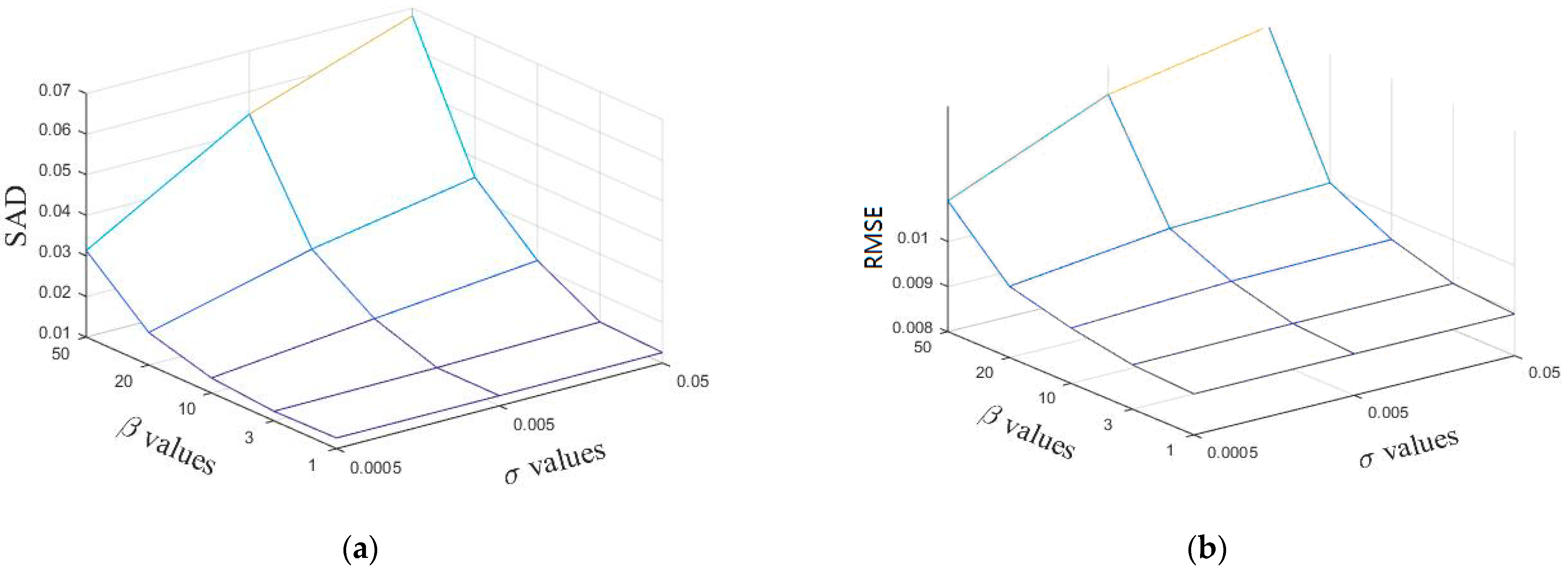
4.1.1. Parameter Selection
4.1.2. Robustness Analysis
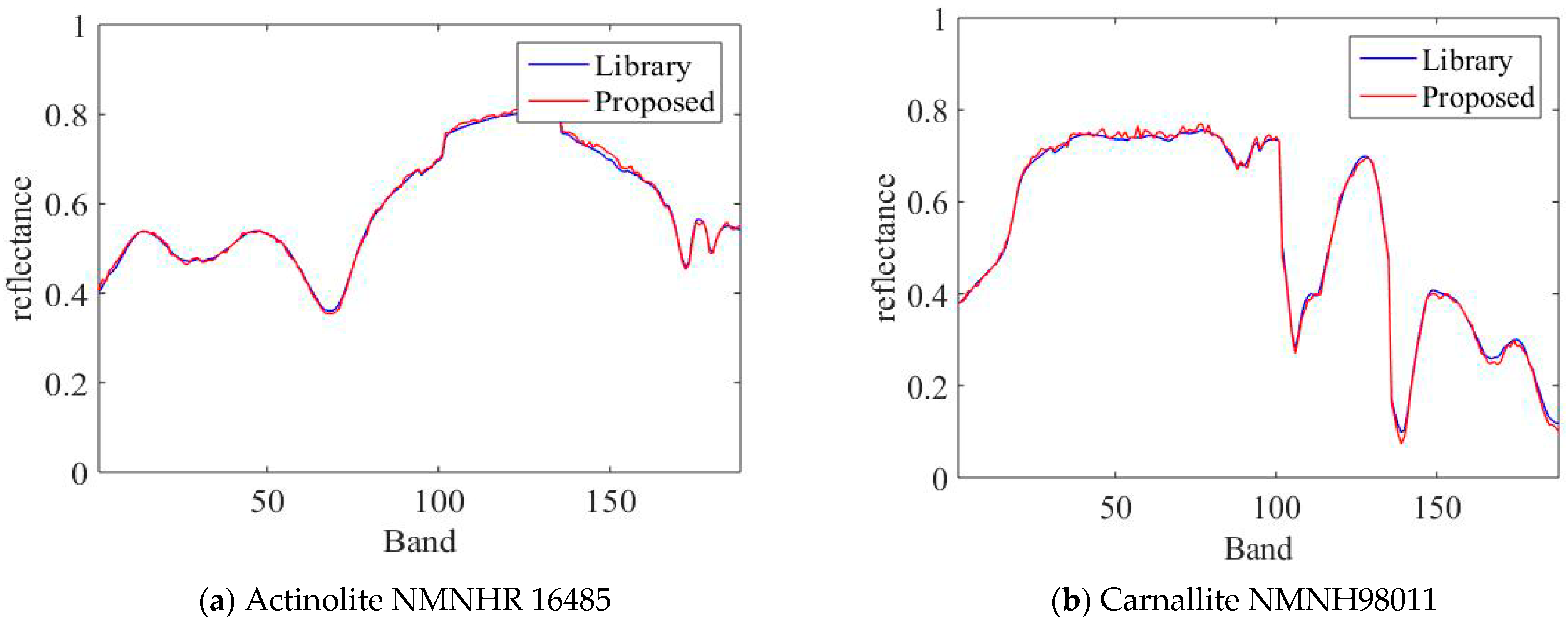
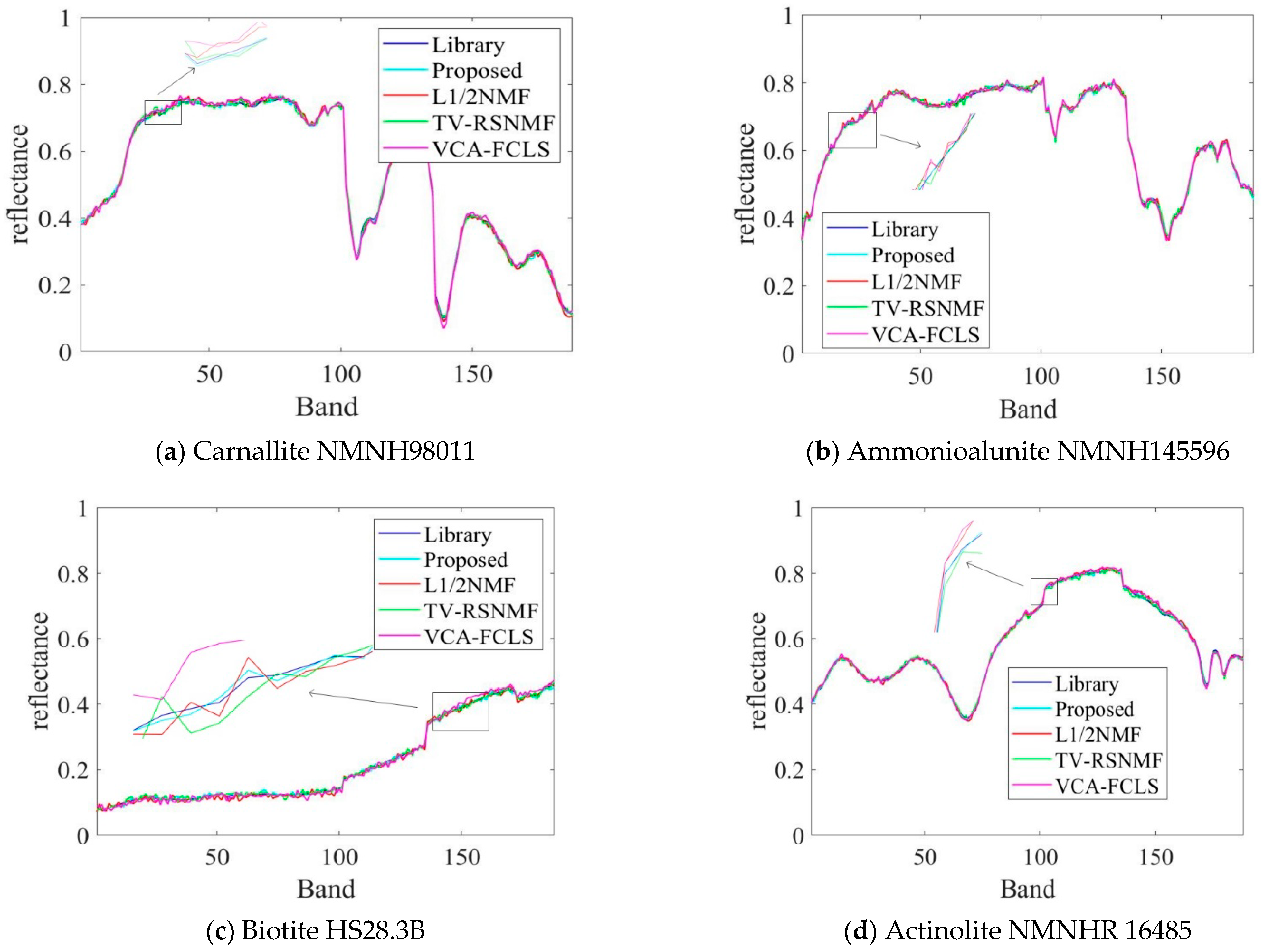
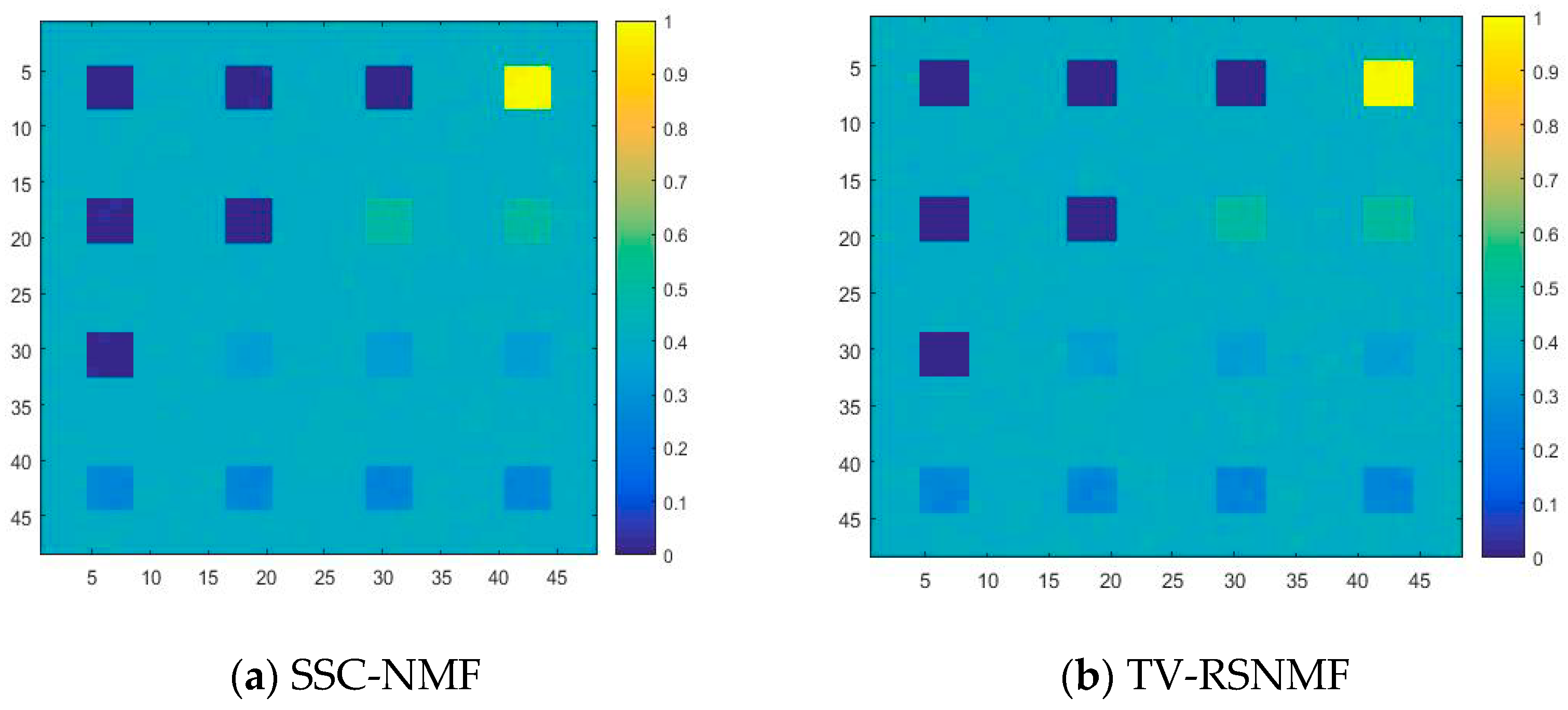
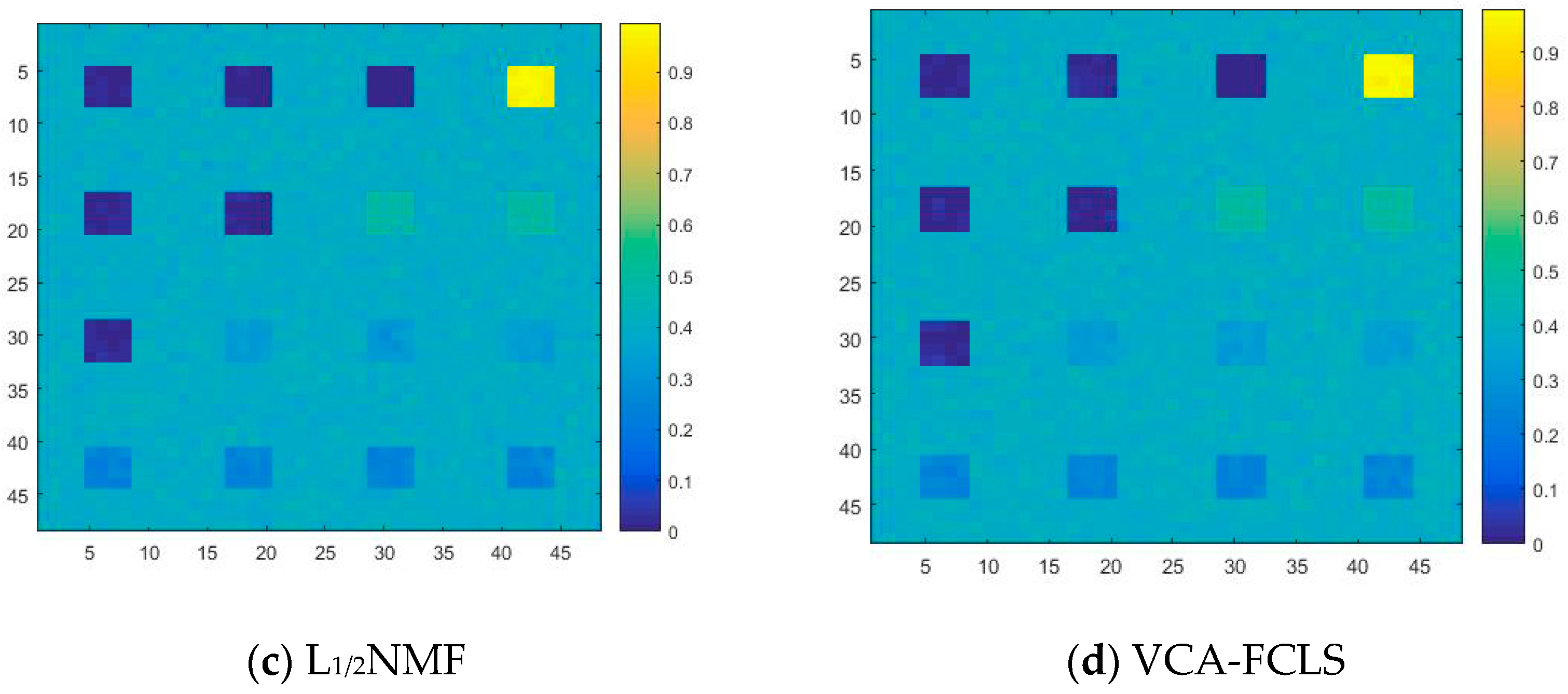
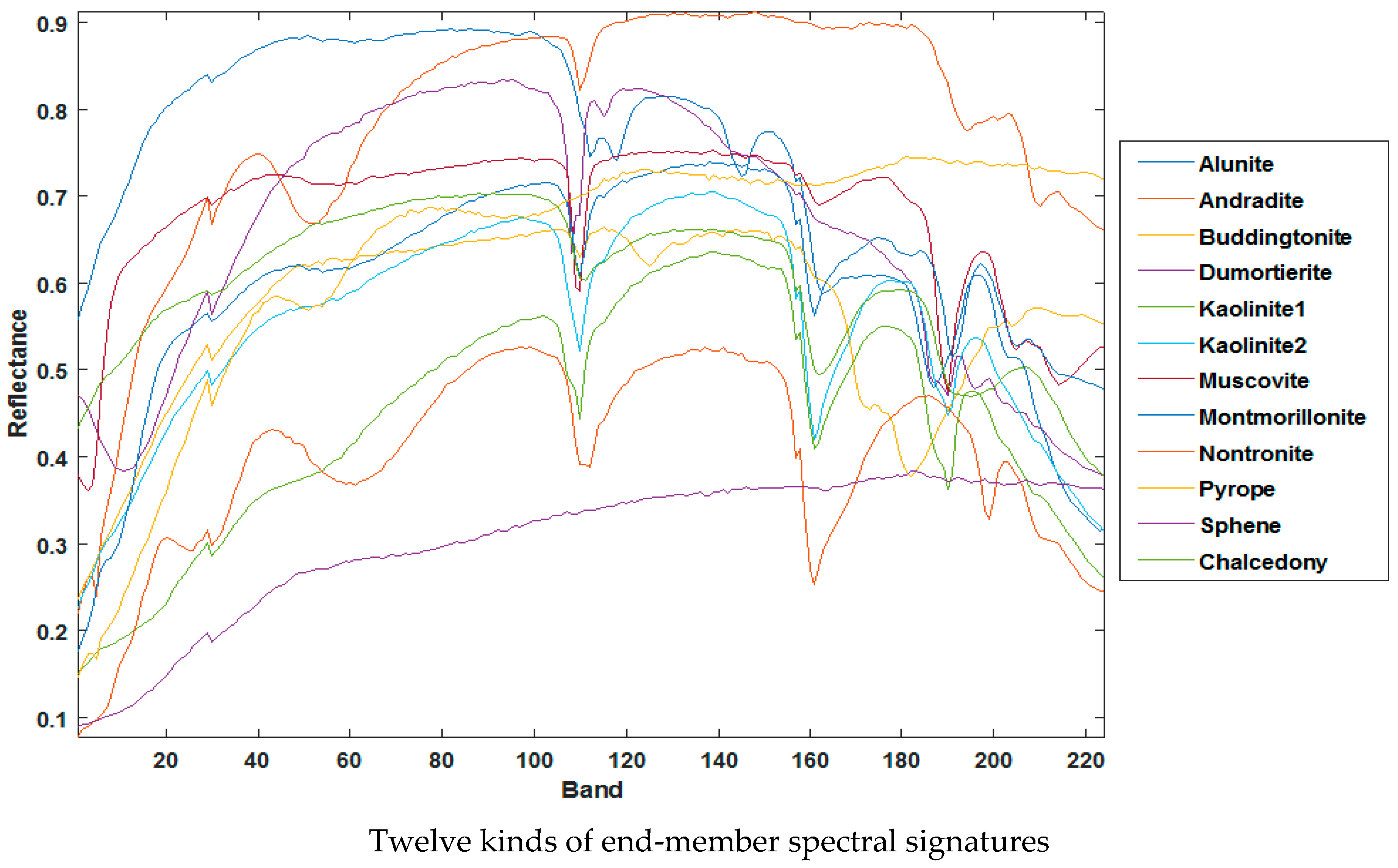
4.2. Real Data Experiments
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring Models and Data for Remote Sensing Image Caption Generation. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2183–2195. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-dias, J.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef] [Green Version]
- Dobigeon, N.; Tourneret, J.-Y.; Richard, C.; Bermudez, J.C.M.; McLaughlin, S.; Hero, A.O. Nonlinear Unmixing of Hyperspectral Images: Models and Algorithms. IEEE Signal Process. Mag. 2013, 31, 82–94. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Cai, G. Endmember Extraction by Pure Pixel Index Algorithm from Hyperspectral Image. In Proceedings of the 2008 International Conference on Optical Instruments and Technology: Advanced Sensor Technologies and Applications, Beijing, China, 16 November 2008; p. 7157. [Google Scholar] [CrossRef]
- Winter, M.E. N-FINDR: An Algorithm for Fast Autonomous Spectral End_Member Determination in Hyperspectral Data. In Imaging Spectrom V; International Society for Optics and Photonics: Bellingham, WA, USA, 1999; Volume 3753, pp. 266–275. [Google Scholar] [CrossRef]
- Nascimento, J.; Dias, J. Vertex Component Analysis: A Fast Algorithm to Unmix Hyperspectral Data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef] [Green Version]
- Miao, L.; Qi, H. Endmember Extraction from Highly Mixed Data Using Minimum Volume Constrained Nonnegative Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2007, 45, 765–777. [Google Scholar] [CrossRef]
- Heinz, D.; Chang, C.I. Fully constrained least squares linear spectral mixture analysis method for material quantification in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 529–545. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Jiang, Y.; Wu, F.; Wu, F. Quantitative Interpretation of Mineral Hyperspectral Images Based on Principal Component Analysis and Independent Component Analysis Methods. Appl. Spectrosc. 2014, 68, 502–509. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2001; pp. 556–562. [Google Scholar]
- Zare, A.; Gader, P. Hyperspectral Band Selection and Endmember Detection Using Sparsity Promoting Priors. IEEE Geosci. Remote Sens. Lett. 2008, 5, 256–260. [Google Scholar] [CrossRef]
- Qian, Y.; Jia, S.; Zhou, J.; Robleskelly, A. Hyperspectral Unmixing Via L1/2 Sparsity-Constrained Nonnegative Matrix Factorization. IEEE Trans Geosci. Remote Sens. 2011, 49, 4282–4297. [Google Scholar] [CrossRef] [Green Version]
- Hua, Z.; Li, X.; Qiu, Q.; Zhao, L. Autoencoder Network for Hyperspectral Unmixing with Adaptive Abundance Smoothing. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1640–1644. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L. Total Variation Regularized Reweighted Sparse Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3909–3921. [Google Scholar] [CrossRef]
- Gu, Y.; Zhang, Y.; Zhang, J. Integration of Spatial–Spectral Information for Resolution Enhancement in Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1347–1358. [Google Scholar] [CrossRef]
- Jia, S.; Qian, Y.-T.; Ji, Z. Nonnegative Matrix Factorization with Piecewise Smoothness Constraint for Hyperspectral Unmixing. In Proceedings of the International Conference on Wavelet Analysis & Pattern Recognition, Hong Kong, China, 30–31 August 2008. [Google Scholar] [CrossRef]
- Casalino, G.; Gillis, N. Sequential Dimensionality Reduction for Extracting Localized Features. Pattern Recognit. 2017, 63, 15–29. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Dong, L.; Li, X. Hyperspectral Unmixing Using Nonlocal Similarity-Regularized Low-Rank Tensor Factorization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5507614. [Google Scholar] [CrossRef]
- Imbiriba, T.; Borsoi, R.A.; Bermudez, J.C.M. Low-Rank Tensor Modeling for Hyperspectral Unmixing Accounting for Spectral Variability. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1833–1842. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Feng, R.; Wang, L.; Zhong, Y.; Zhang, L. Superpixel-Based Reweighted Low-Rank and Total Variation Sparse Unmixing for Hyperspectral Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 629–647. [Google Scholar] [CrossRef]
- Huang, R.; Li, X.; Zhao, L. Nonnegative Matrix Factorization with Data-Guided Constraints for Hyperspectral Unmixing. Remote Sens. 2017, 9, 1074. [Google Scholar] [CrossRef] [Green Version]
- Candes, E.; Wakin, M.; Boyd, S. Enhancing sparsity by reweighted ℓ1 minimization. J. Fourier Anal. Appl. 2008, 14, 877–905. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total Variation Based Noise Removal Algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Kimura, T.; Takahashi, N. Gauss-Seidel HALS Algorithm for Nonnegative Matrix Factorization with Sparseness and Smoothness Constraints. IEICE Trans. Fundam. Electron. 2017, E100-A, 2925–2935. [Google Scholar] [CrossRef] [Green Version]
- Beck, A.; Teboulle, M. Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Trans. Image Process. 2009, 18, 2419–2434. [Google Scholar] [CrossRef] [PubMed] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mixture Proportion (%) | End Member 1 (Carnallite) | End Member 2 (Ammonioalunite) | End Member 3 (Biotite) | End Member 4 (Actinolite) |
|---|---|---|---|---|
| Case 1 | 20 | 20 | 20 | 40 |
| Case 2 | 33 | 33 | 33 | 0 |
| Case 3 | 0 | 33 | 33 | 33 |
| Case 4 | 25 | 25 | 25 | 25 |
| SNR/dB | SSC-NMF | TV-RSNMF | L1/2NMF | VCA-FCLS |
|---|---|---|---|---|
| 15 | 0.0389 | 0.0397 | 0.0440 | 0.0564 |
| 25 | 0.0116 | 0.0125 | 0.0149 | 0.0167 |
| 35 | 0.0046 | 0.0047 | 0.0046 | 0.0049 |
| SNR/dB | SSC-NMF | TV-RSNMF | L1/2NMF | VCA-FCLS |
|---|---|---|---|---|
| 15 | 0.0378 | 0.0418 | 0.0492 | 0.0473 |
| 25 | 0.0092 | 0.0104 | 0.0158 | 0.0171 |
| 35 | 0.0057 | 0.0058 | 0.0059 | 0.0074 |
| Method | SSC-NMF | TV-RSNMF | L1/2NMF | VCA-FCLS | ULTRA-V |
|---|---|---|---|---|---|
| Alunite | 0.1049 | 0.1064 | 0.0921 | 0.0859 | 0.0842 |
| Andradite | 0.0872 | 0.0878 | 0.0652 | 0.0582 | 0.0511 |
| Buddingtonite | 0.0972 | 0.0964 | 0.0648 | 0.0724 | 0.0571 |
| Dumortierite | 0.1086 | 0.1112 | 0.0972 | 0.0978 | 0.0991 |
| Kaolinite1 | 0.1316 | 0.1316 | 0.1268 | 0.1222 | 0.1778 |
| Kaolinite2 | 0.0450 | 0.0449 | 0.0440 | 0.0458 | 0.0481 |
| Muscovite | 0.1278 | 0.1279 | 1.1667 | 1.1522 | 0.8819 |
| Montmorillonite | 0.0696 | 0.0698 | 0.0720 | 0.0717 | 0.0919 |
| Nontronite | 0.0902 | 0.0904 | 0.1173 | 0.1070 | 0.1379 |
| Pyrope | 0.0879 | 0.0881 | 0.1897 | 0.1783 | 0.1421 |
| Sphene | 1.0130 | 1.0130 | 0.0826 | 0.0876 | 0.0897 |
| Chalcedony | 0.0695 | 0.0761 | 0.1919 | 0.1675 | 0.1771 |
| Mean | 0.1694 | 0.1703 | 0.1925 | 0.1872 | 0.1698 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, X.; Guo, B. Non-Negative Matrix Factorization Based on Smoothing and Sparse Constraints for Hyperspectral Unmixing. Sensors 2022, 22, 5417. https://doi.org/10.3390/s22145417
Jia X, Guo B. Non-Negative Matrix Factorization Based on Smoothing and Sparse Constraints for Hyperspectral Unmixing. Sensors. 2022; 22(14):5417. https://doi.org/10.3390/s22145417
Chicago/Turabian StyleJia, Xiangxiang, and Baofeng Guo. 2022. "Non-Negative Matrix Factorization Based on Smoothing and Sparse Constraints for Hyperspectral Unmixing" Sensors 22, no. 14: 5417. https://doi.org/10.3390/s22145417
APA StyleJia, X., & Guo, B. (2022). Non-Negative Matrix Factorization Based on Smoothing and Sparse Constraints for Hyperspectral Unmixing. Sensors, 22(14), 5417. https://doi.org/10.3390/s22145417