
ConTra Preference Language: Privacy Preference Unification via Privacy Interfaces


Abstract
:1. Introduction
2. Background
2.1. Negotiation Automation Levels
- Level 1—Manual fine-grained consent: This is the very basic case where only the privacy policy is given. Users need to inform themselves about the policy content and can personalize the policy by either accepting or rejecting optional content manually, i.e., give consent. Finally, the user can agree to the policy. In this case, no tools support the process.
- Level 2—Manual consent profile selection: As on level 1, the privacy policy is given and users have to inform themselves about its content. Policy negotiation support is offered by providing predefined privacy profiles, e.g., predefined by the Controller, which users can select and possibly personalize. Based on the selected profile, users agree to the policy.
- Level 3—Preference-based consent negotiation: Level 3 introduces user preferences which are defined in an initial setup process. During policy negotiation, the predefined preferences are compared against the policy, which results in either a match or mismatch. If a mismatch happens, users usually receive hints about what parts of the policy did not match the preferences. Based on this information, users can personalize the privacy policy and make their decision if they agree to it.
- Level 4—Preference-based consent recommendation: Similar to level 3, user preferences are defined in a setup process beforehand. Privacy policies are then analyzed during policy negotiation and compared against the predefined preferences. As a result, recommendations are given to users regarding how to personalize the policy. Users can then decide whether to apply the suggested options or not and agree to the policy by themselves.
- Level 5—Preference-based automated consent: As with level 4, predefined preferences are compared to the privacy policy during negotiation. Then, the policy is automatically personalized based on the comparison, and consent is given automatically. In this case, there is no user interaction at policy negotiation at all.
2.2. Preference Language Requirements
2.3. Related Work
3. ConTra Preference Language
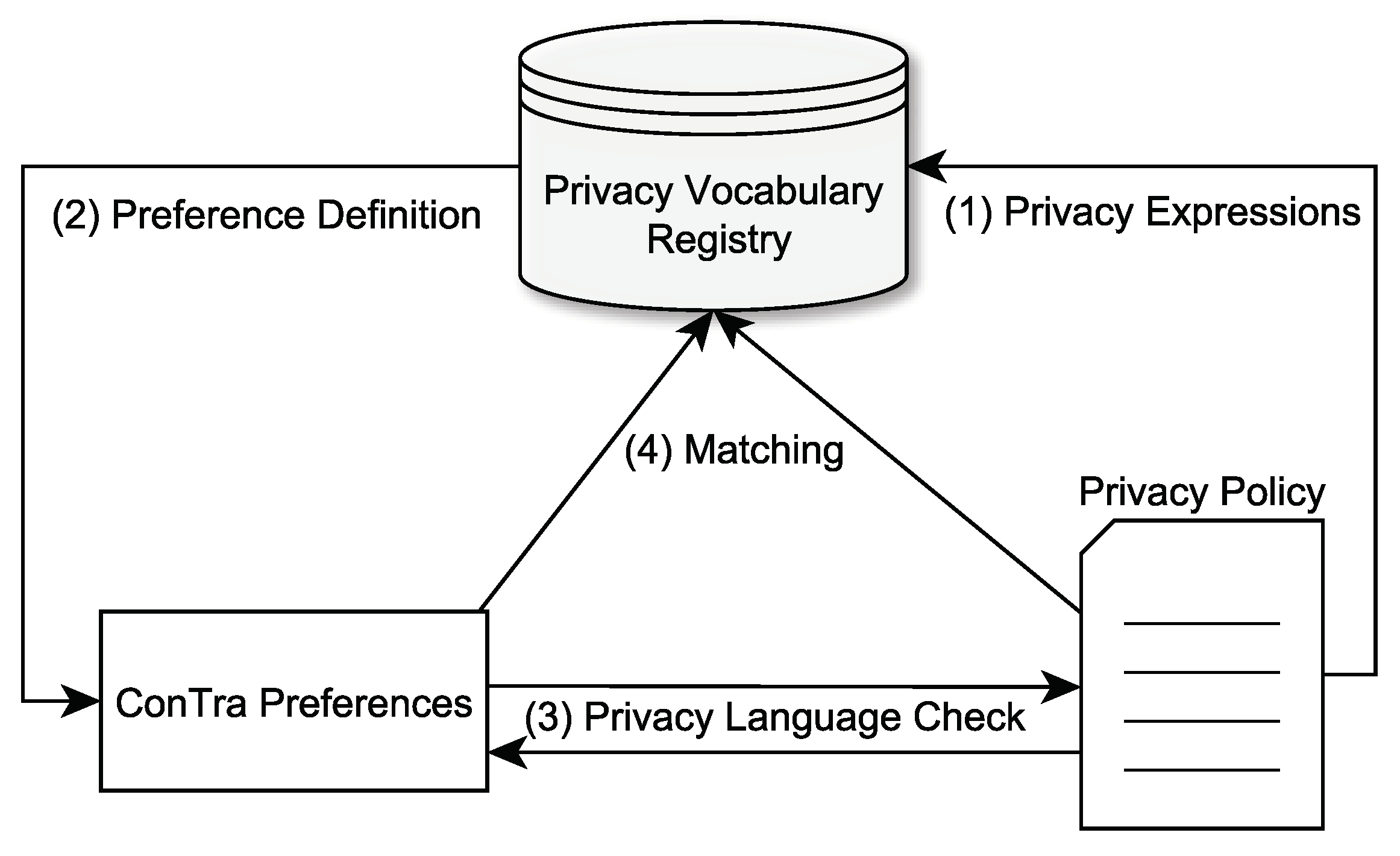
3.1. Concept
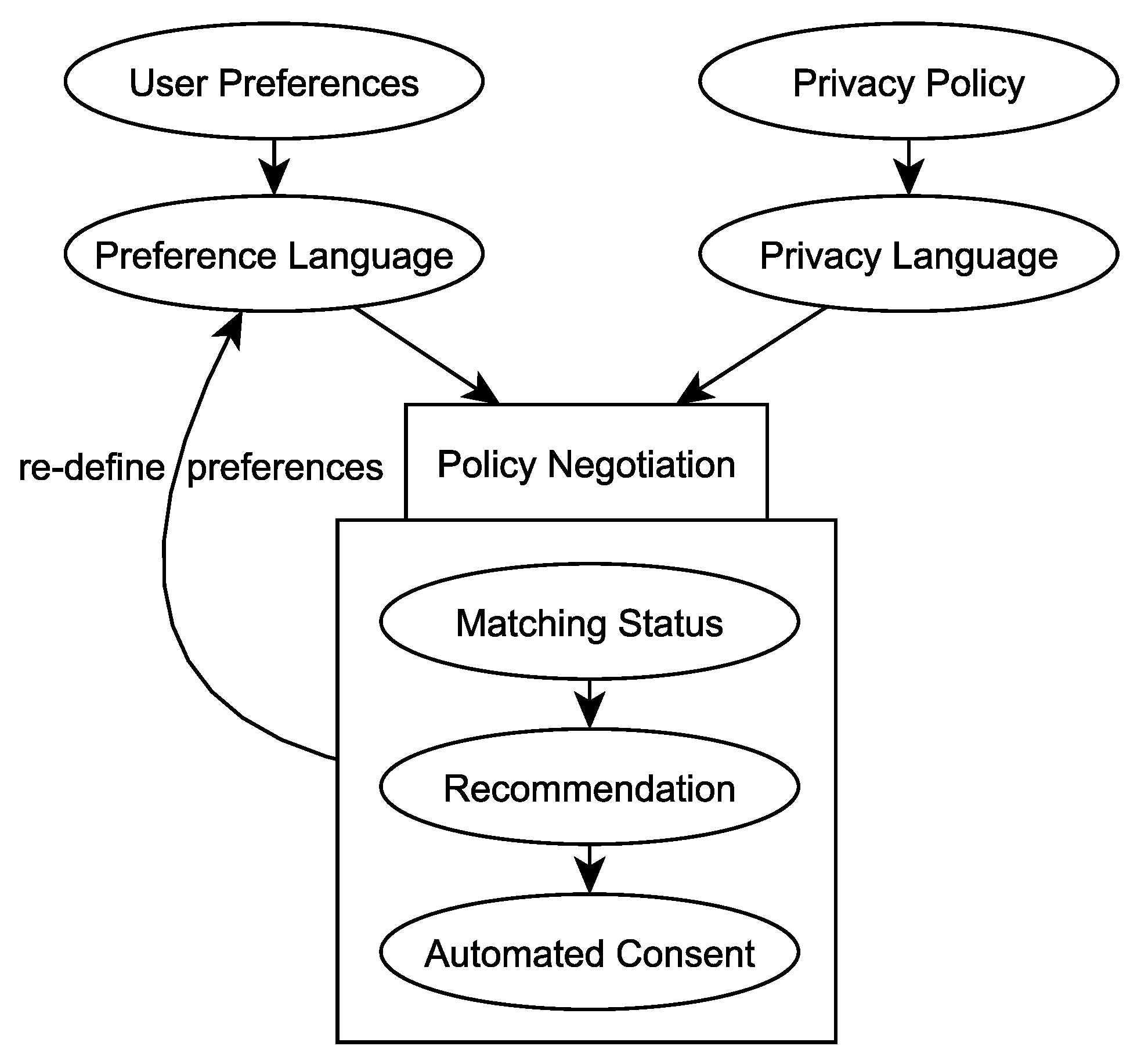
3.1.1. Preference Setup
3.1.2. Policy Negotiation
3.1.3. Deontic Logic
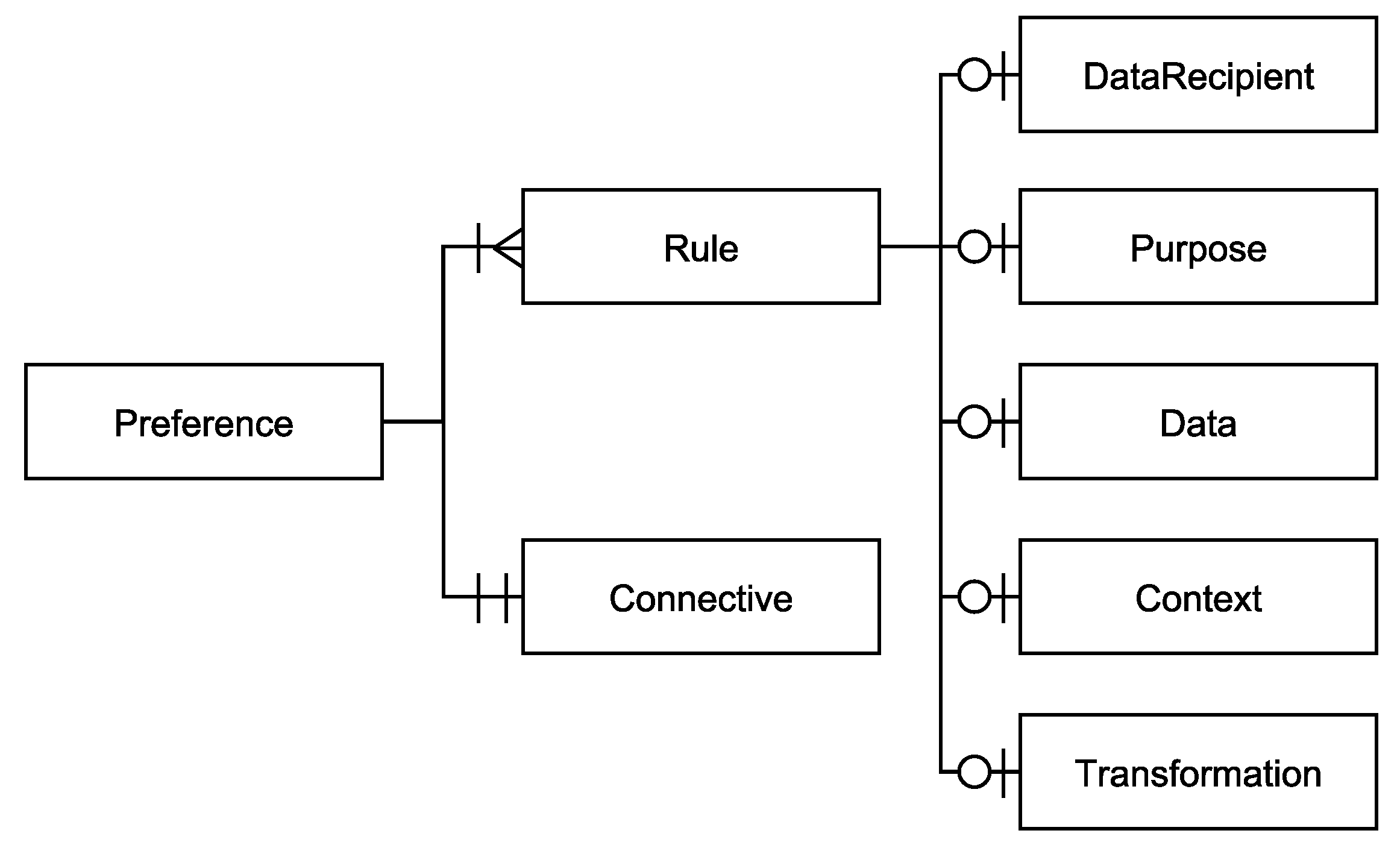
3.2. Structure and Elements
3.3. Use Cases
- 1
- "preference" : {
- 2
- "connective" : AND,
- 3
- "rule" : {
- 4
- "purpose" : {
- 5
- "permitted" : ["E-Commerce"],
- 6
- "excluded" : [*]
- 7
- },
- 8
- "data" : {
- 9
- "permitted" : ["Address", "Financial Data"],
- 10
- "excluded" : [ ]
- 11
- }
- 12
- }
- 13
- }
- 1
- "preference" : {
- 2
- "connective" : AND,
- 3
- "rule" : {
- 4
- "purpose" : {
- 5
- "permitted" : ["E-Commerce"],
- 6
- "excluded" : [*]
- 7
- },
- 8
- "data" : {
- 9
- "permitted" : ["Address", "Financial Data"],
- 10
- "excluded" : [ ]
- 11
- }
- 12
- },
- 13
- "rule" : {
- 14
- "dataRecipient" : {
- 15
- "thirdPartySharing" : "false"
- 16
- },
- 17
- "purpose" : {
- 18
- "permitted" : ["Product Recommendation"],
- 19
- "excluded" : [ ]
- 20
- },
- 21
- "data" : {
- 22
- "permitted" : [*],
- 23
- "excluded" : [ ]
- 24
- },
- 25
- "context" : {
- 26
- "region" : "European Union"
- 27
- }
- 28
- }
- 29
- }
- 1
- "preference" : {
- 2
- "connective" : AND,
- 3
- "rule" : {
- 4
- "purpose" : {
- 5
- "permitted" : ["E-Commerce"],
- 6
- "excluded" : [*]
- 7
- },
- 8
- "data" : {
- 9
- "permitted" : ["Address", "Financial Data"],
- 10
- "excluded" : [ ]
- 11
- },
- 12
- "data" : {
- 13
- "permitted" : ["GPS-Coordinates", "Sensor Data"],
- 14
- "excluded" : [ ]
- 15
- },
- 16
- "context" : {
- 17
- "startWeekday" : "Monday",
- 18
- "endWeekday" : "Friday",
- 19
- "startTime" : "07:00:00",
- 20
- "endTime" : "16:00:00"
- 21
- },
- 22
- "transformation" : "no_method"
- 23
- }
- 24
- }
4. Privacy Interfaces
4.1. Concept
4.2. Vocabulary
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Linden, T.; Khandelwal, R.; Harkous, H.; Fawaz, K. The Privacy Policy Landscape After the GDPR. Proc. Priv. Enhancing Technol. 2020, 2020, 47–64. [Google Scholar] [CrossRef] [Green Version]
- McDonald, A.M.; Cranor, L.F. The cost of reading privacy policies. I/S J. Law Policy Inf. Soc. 2008, 4, 1–22. [Google Scholar]
- Ulbricht, M.R.; Pallas, F. YaPPL—A Lightweight Privacy Preference Language for Legally Sufficient and Automated Consent Provision in IoT Scenarios. In Proceedings of the DPM/CBT@ESORICS, Barcelona, Spain, 6–7 September 2018; pp. 329–344. [Google Scholar] [CrossRef]
- Lorrie, C.; Giles, H.; Marc, L.; Massimo, M.; Martin, P.-M.; Joseph, R.; Matthias, S. The Platform for Privacy Preferences 1.1 (P3P1.1) Specification; Technical Report; W3C: Cambridge, MA, USA, 2006. [Google Scholar]
- Ardagna, C.; Bussard, L.; De Capitani Di Vimercati, S.; Neven, G.; Pedrini, E.; Paraboschi, S.; Preiss, F.; Samarati, P.; Trabelsi, S.; Verdicchio, M.; et al. Primelife policy language. In Proceedings of the W3C Workshop on Access Control Application Scenarios, W3C, Luxembourg, 17–18 November 2009. [Google Scholar]
- Gerl, A.; Bennani, N.; Kosch, H.; Brunie, L. LPL, Towards a GDPR-Compliant Privacy Language: Formal Definition and Usage. In Transactions on Large-Scale Data- and Knowledge-Centered Systems XXXVII; Part of Springer Nature 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 41–80. [Google Scholar] [CrossRef]
- SPECIAL. Scalable Policy-Aware Linked Data Architecture for Privacy, Transparency and Compliance. 2017–2019. Available online: https://specialprivacy.ercim.eu/ (accessed on 20 June 2022).
- Lorrie, C.; Marc, L.; Massimo, M. A P3P Preference Exchange Language 1.0 (APPEL1.0); Technical Report; W3C: Cambridge, MA, USA, 2002. [Google Scholar]
- Agrawal, R.; Kiernan, J.; Srikant, R.; Xu, Y. XPref: A preference language for P3P. Comput. Netw. 2005, 48, 809–827. [Google Scholar] [CrossRef]
- Kokolakis, S. Privacy attitudes and privacy behaviour: A review of current research on the privacy paradox phenomenon. Comput. Secur. 2015, 64, 122–134. [Google Scholar] [CrossRef]
- Kapitsaki, G.M.; Dini Kounoudes, A.; Achilleos, A.P. An overview of user privacy preferences modeling and adoption. In Proceedings of the 2020 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Portoroz, Slovenia, 26–28 August 2020; pp. 569–576. [Google Scholar] [CrossRef]
- European-Parliament. General Data Protection Regulation, 2016. Regulation (EU) 2016 of the European Parliament and of the Council of on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of Such Data, and Repealing Directive 95/46/EC. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32016R0679 (accessed on 27 June 2022).
- Pereira, F.; Crocker, P.; Leithardt, V.R. PADRES: Tool for PrivAcy, Data REgulation and Security. SoftwareX 2022, 17, 100895. [Google Scholar] [CrossRef]
- Gjermundrød, H.; Dionysiou, I.; Costa, K. privacyTracker: A Privacy-by-Design GDPR-Compliant Framework with Verifiable Data Traceability Controls. In Proceedings of the Current Trends in Web Engineering, Lugano, Switzerland, 6–9 June 2016; Casteleyn, S., Dolog, P., Pautasso, C., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 3–15. [Google Scholar]
- Ashley, P.; Hada, S.; Karjoth, G.; Schunter, M. E-P3P Privacy Policies and Privacy Authorization. In Proceedings of the 2002 ACM Workshop on Privacy in the Electronic Society, WPES ’02, Washington, DC, USA, 21 November 2002; ACM: New York, NY, USA, 2002; pp. 103–109. [Google Scholar] [CrossRef]
- Iyilade, J.; Vassileva, J. P2U: A Privacy Policy Specification Language for Secondary Data Sharing and Usage. In Proceedings of the IEEE Security and Privacy Workshops, San Jose, CA, USA, 17–18 May 2014. Technical Report. [Google Scholar]
- Ashley, P.; Hada, S.; Karjoth, G.; Powers, C.; Schunter, M. Enterprice Privacy Authorization Language (EPAL 1.2); Technical Report; IBM: Armonk, NY, USA, 2003; Available online: https://www.zurich.ibm.com/security/enterprise-privacy/epal/Specification/ (accessed on 20 June 2022).
- Gerl, A.; Meier, B. The Layered Privacy Language Art. 12–14 GDPR Extension–Privacy Enhancing User Interfaces. Datenschutz Datensicherheit-DuD 2019, 43, 747–752. [Google Scholar] [CrossRef]
- Li, N.; Yu, T.; Antón, A. A semantics-base approach to privacy languages. Comput. Syst. Sci. Eng. CSSE 2006, 21, 1–22. [Google Scholar]
- Becker, M.Y.; Malkis, A.; Bussard, L. A Framework for Privacy Preferences and Data-Handling Policies; Technical Report MSR-TR-2009-128; Microsoft Research: Redmond, WA, USA, 2009. [Google Scholar]
- Kapitsaki, G.M. Reflecting User Privacy Preferences in Context-Aware Web Services. In Proceedings of the 2013 IEEE 20th International Conference on Web Services, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 123–130. [Google Scholar] [CrossRef]
- Cranor, L.F.; Arjula, M.; Guduru, P. Use of a P3P User Agent by Early Adopters. In Proceedings of the 2002 ACM Workshop on Privacy in the Electronic Society, WPES ’02, Washington, DC, USA, 21 November 2002; ACM: New York, NY, USA, 2002; pp. 1–10. [Google Scholar] [CrossRef] [Green Version]
- Azraoui, M.; Elkhiyaoui, K.; Önen, M.; Bernsmed, K.; De Oliveira, A.S.; Sendor, J. A-PPL: An Accountability Policy Language. In Data Privacy Management, Autonomous Spontaneous Security, and Security Assurance: 9th International Workshop, DPM 2014, 7th International Workshop, SETOP 2014, and 3rd International Workshop, QASA 2014, Wroclaw, Poland, 10–11 September 2014; Revised Selected Papers; Springer International Publishing: Cham, Switzerland, 2015; pp. 319–326. [Google Scholar] [CrossRef]
- Sanchez, O.R.; Torre, I.; He, Y.; Knijnenburg, B.P. A recommendation approach for user privacy preferences in the fitness domain. User Model. User Adapt. Interact. 2019, 30, 513–565. [Google Scholar] [CrossRef]
- Angulo, J.; Fischer-Hübner, S.; Pulls, T.; Wästlund, E. Towards Usable Privacy Policy Display & Management—The PrimeLife Approach. In Proceedings of the HAISA, London, UK, 7–8 July 2011; pp. 108–118. [Google Scholar]
- Harkous, H.; Fawaz, K.; Lebret, R.; Schaub, F.; Shin, K.G.; Aberer, K. Polisis: Automated Analysis and Presentation of Privacy Policies Using Deep Learning. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; USENIX Association: Baltimore, MD, USA, 2018; pp. 531–548. [Google Scholar]
- Fitch, F.B. GH von Wright. Deontic logic. Mind, n. s. vol. 60 (1951), pp. 1–15. J. Symb. Log. 1952, 17, 140. [Google Scholar] [CrossRef]
- Ligatti, J.; Rickey, B.; Saigal, N. LoPSiL: A Location-Based Policy-Specification Language. In Proceedings of the Security and Privacy in Mobile Information and Communication Systems, Turin, Italy, 3–5 June 2009; Volume 17, pp. 265–277. [Google Scholar] [CrossRef] [Green Version]
- PrimeLife. PrimeLife—Bringing Sustainable Privacy and Identity Management to Future Networks and Services. 2008–2011. Available online: http://primelife.ercim.eu/ (accessed on 20 June 2022).
- Pandit, H.J.; Polleres, A.; Bos, B.; Brennan, R.; Bruegger, B.; Ekaputra, F.J.; Fernández, J.D.; Hamed, R.G.; Kiesling, E.; Lizar, M.; et al. Creating a Vocabulary for Data Privacy. In Proceedings of the On the Move to Meaningful Internet Systems: OTM 2019 Conferences, Rhodes, Greece, 21–25 October 2019; Panetto, H., Debruyne, C., Hepp, M., Lewis, D., Ardagna, C.A., Meersman, R., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 714–730. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Pl Comp | GDPR | Transparency | Readable | Expressiveness | Context | Extensibility | |
|---|---|---|---|---|---|---|---|
| APPEL | ✓ | ||||||
| XPref | ✓ | ||||||
| SemPref | ✓ | ✓ | |||||
| SecPAL4P | ✓ | ✓ | ✓ | ||||
| PPL | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| CPL | ✓ | ✓ | |||||
| YaPPL | ✓ | ✓ | ✓ | ✓ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Becher, S.; Gerl, A. ConTra Preference Language: Privacy Preference Unification via Privacy Interfaces. Sensors 2022, 22, 5428. https://doi.org/10.3390/s22145428
Becher S, Gerl A. ConTra Preference Language: Privacy Preference Unification via Privacy Interfaces. Sensors. 2022; 22(14):5428. https://doi.org/10.3390/s22145428
Chicago/Turabian StyleBecher, Stefan, and Armin Gerl. 2022. "ConTra Preference Language: Privacy Preference Unification via Privacy Interfaces" Sensors 22, no. 14: 5428. https://doi.org/10.3390/s22145428
APA StyleBecher, S., & Gerl, A. (2022). ConTra Preference Language: Privacy Preference Unification via Privacy Interfaces. Sensors, 22(14), 5428. https://doi.org/10.3390/s22145428