
An Efficient and Privacy-Preserving Scheme for Disease Prediction in Modern Healthcare Systems

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
- We propose a secure scheme for the healthcare data collected from IoT devices in modern healthcare systems.
- A Log of Round value-based Elliptic Curve Cryptography (LR-ECC) is presented for enhanced healthcare data security during the data transfer phase.
- We also propose a disease prediction system using Elephant Herding Genetic Algorithm-based Deep Learning Neural Network (EHGA-DLNN) classification algorithm.
- The proposed approach outperforms existing disease prediction systems in terms of privacy and security, according to the findings of the experiments.
2. Related Work
3. Methodology
3.1. Authentication Phase
- Registration;
- Login;
- Verification.
3.1.1. Registration
Patient Details
Combine Text
Ciphering Combined Text
Key Generation
3.1.2. Login
3.1.3. Verification
3.2. Secure Data Transfer Phase
3.3. Disease Prediction System (DPS)
3.3.1. Data Collection
3.3.2. Preprocessing
Data Deduplication
- Missing value imputation
- MinMax normalization
3.3.3. Matrix Representation
3.3.4. Matrix Reduction
- Step 1: First, take the preprocessed data’s matrix representation as
- Step 2: Next, take and that represents the betwixt-class as well as within-class scatter matrices that are articulated as:
- Step 3: For the reduction accuracy level enhancement, the Gaussians kernel is utilized for computing the distances among the data points, in addition to the Kernel matrix is gauged (with the kernel trick), which is articulated as:
- Step 4: LDA searches for a linear subspace ( components) within which the projections of the disparate classes are best divided, as stated using maximizing the subsequent discriminant criterion.
- Step 5: Order the eigenvectors by means of lessening the eigenvalue. Finally, the reduced feature set can well be attained by,
3.3.5. Classification Using Elephant Herding Genetic Algorithm Based Deep Learning Neural Network (EHGA-DLNN)
- The Input Layer
- The Hidden Layer
- The Output Layer
| Algorithm 1 EHGA-DLNN algorithm |
| Input: Reduced matrix set |
| Output: Classified disease-affected data. |
| , |
| Calculate the number of training samples |
| if |
| Error ( is not an integer) |
| end if |
| for each reduced data do |
| Update the position of the weight value using EHGA |
| Update the new position using, |
| while (v < iter) do |
| Perform activation function by using |
| //calculation of activation function |
| for do |
| Calculate hidden layer output by |
| Compute output layer output by |
| end for |
| end while |
3.4. Monitoring
4. Results and Discussion
4.1. Evaluation Parameters
- (i)
- Encryption time: It is the difference between the encryption starting and ending times and the time taken by the encryption algorithm to construct a ciphertext from plain text.
- (ii)
- Decryption time: The difference between the encryption beginning and finishing times is used to calculate it.
- (iii)
- Accuracy: It might be indicated by the probability that a record is precisely identified that it could be normal or disease affected.
- (iv)
- Sensitivity: The rate of correct differentiation between normal and disease-affected data.
- (v)
- Specificity: It is the rate of accurate classification of disease that affects the total classified results.
- (vi)
- Precision: For a certain class, it is the count of accurately envisaged records over the entire envisaged records.
- (vii)
- Recall: For a specific class, it is the count of accurately envisaged disease-affected outcomes over all the records available in the dataset.
- (viii)
- F-measure: It utilizes precision and recall for the holistic estimation of a model and is described as their harmonic mean.
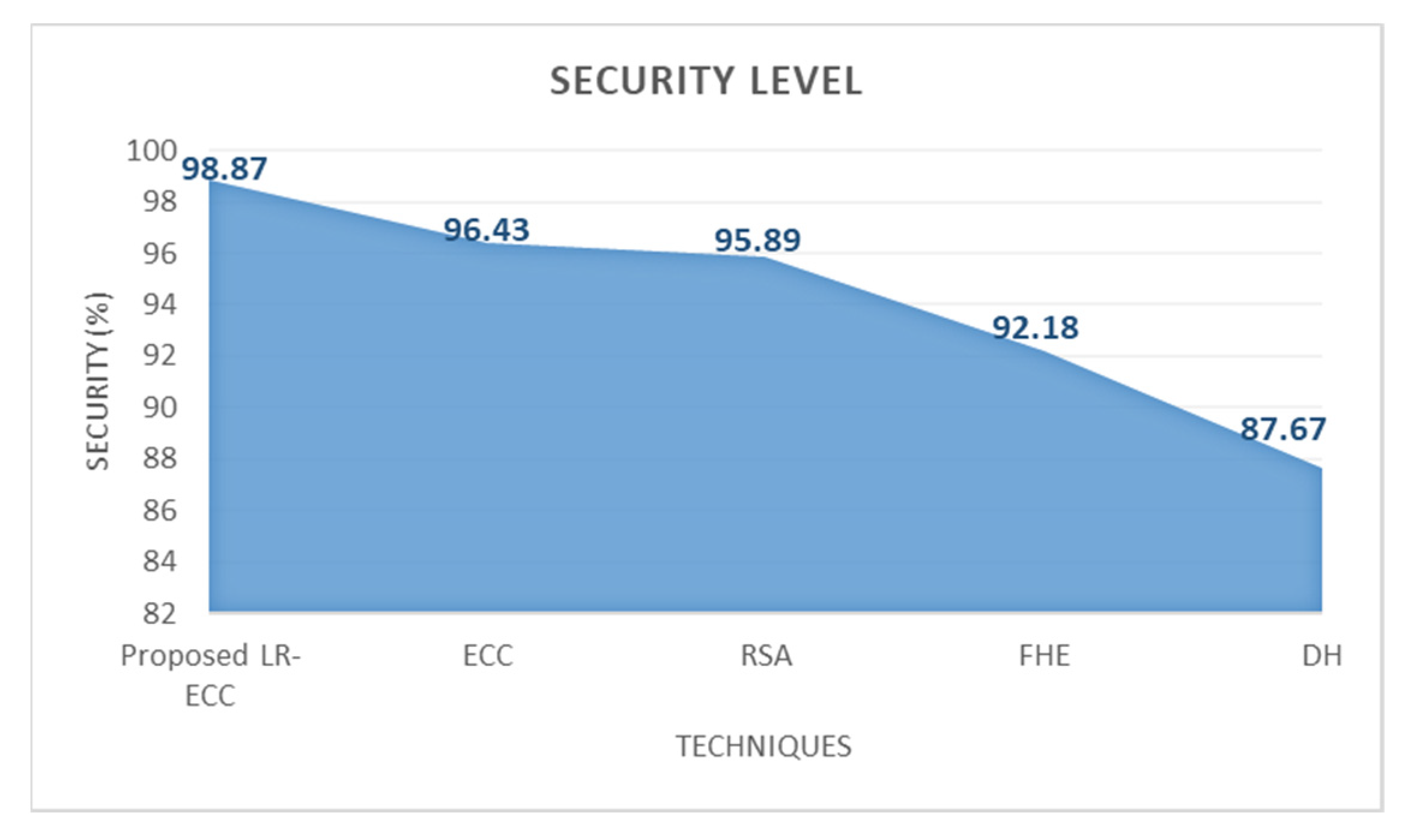
4.2. Analysis of Security Level Performance
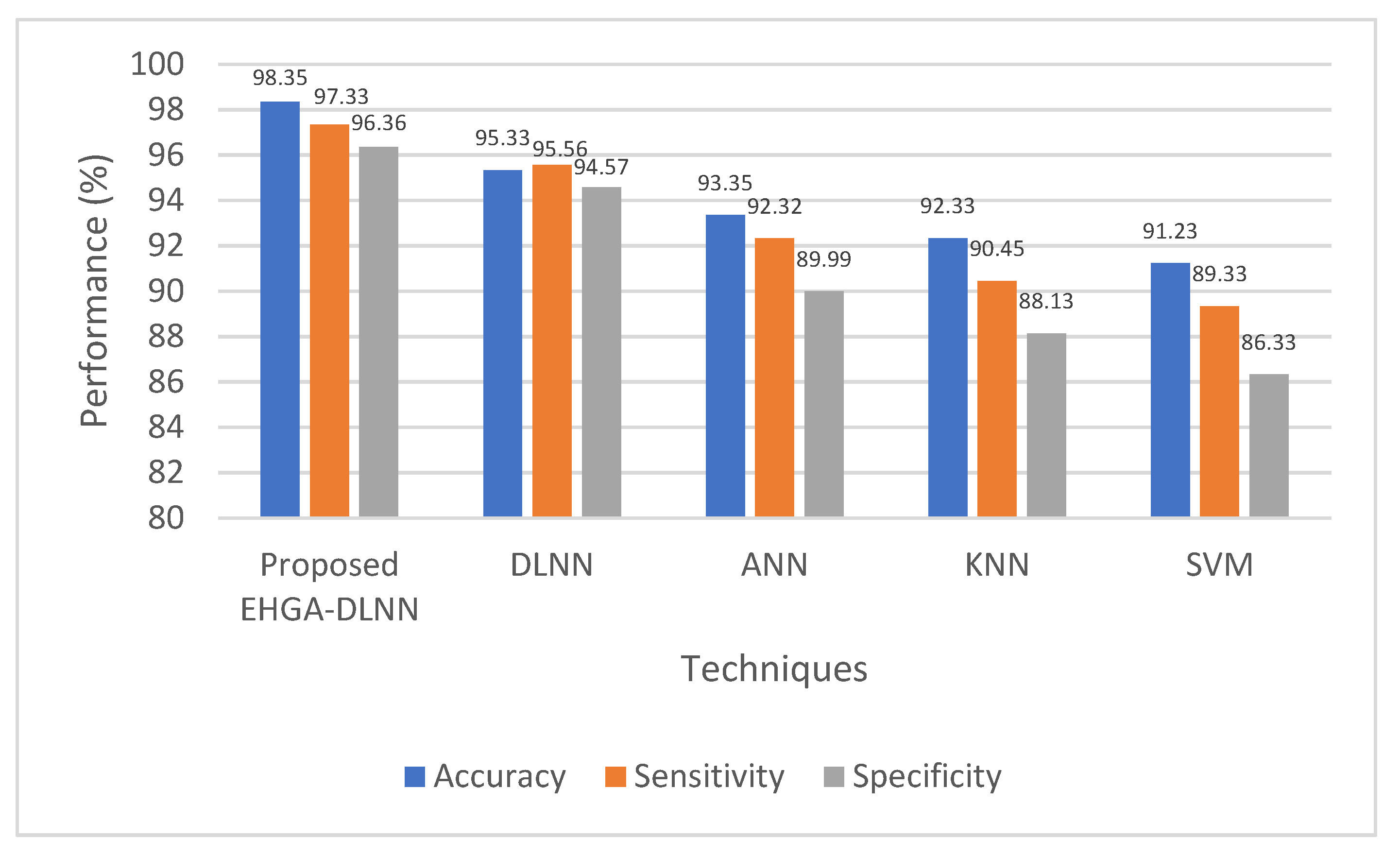
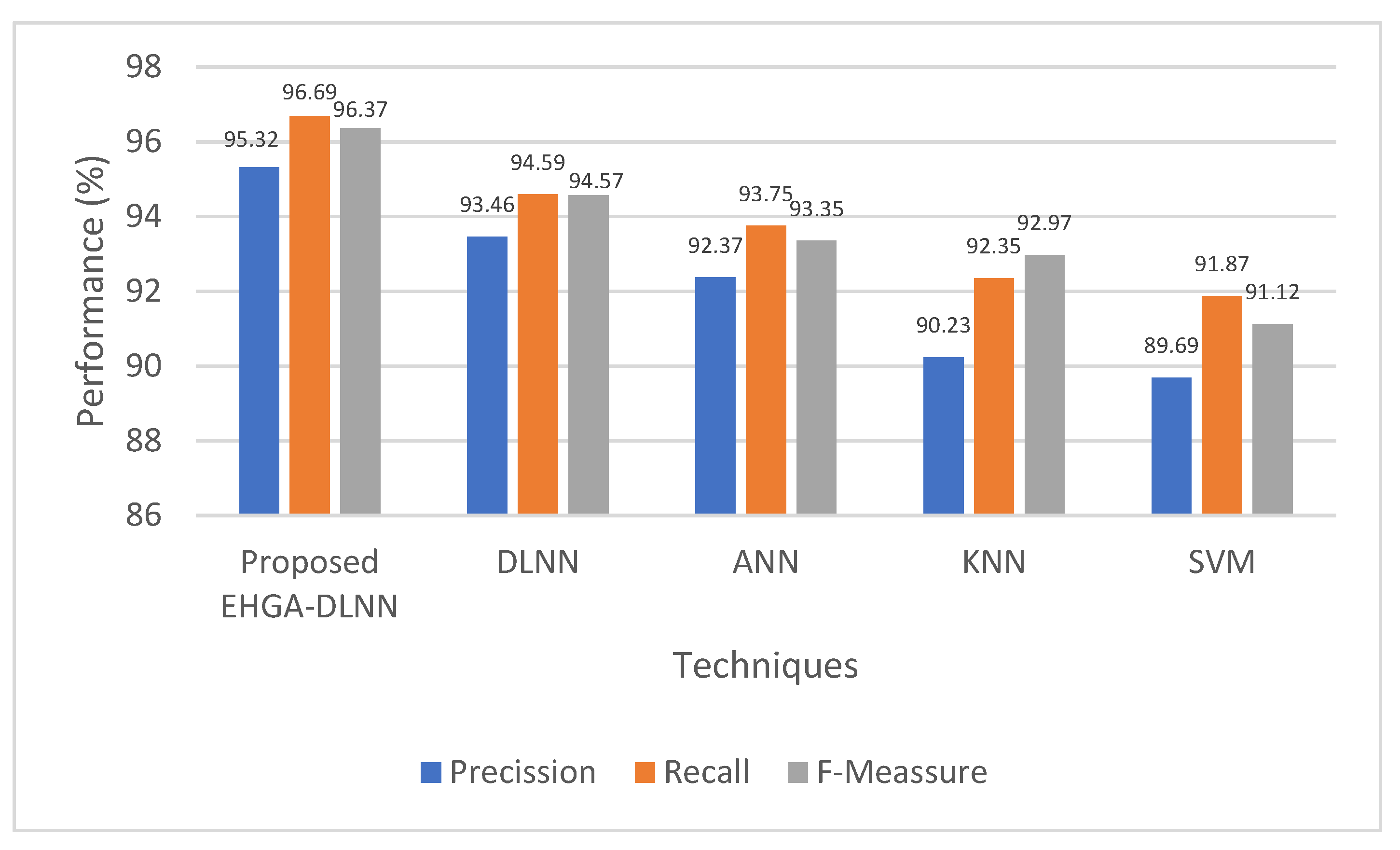
4.3. Performance Analysis of Classification
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sharma, S.; Chen, K.; Sheth, A. Toward practical privacy-preserving analytics for IoT and cloud-based healthcare systems. IEEE Internet Comput. 2018, 22, 42–51. [Google Scholar] [CrossRef] [Green Version]
- Benhlima, L. Big data management for healthcare systems: Architecture, requirements, and implementation. Adv. Bioinform. 2018, 2018, 1–10. [Google Scholar] [CrossRef]
- Baker, S.B.; Xiang, W.; Atkinson, I. Internet of things for smart healthcare: Technologies, challenges, and opportunities. IEEE Access 2017, 5, 26521–26544. [Google Scholar] [CrossRef]
- Khan, M.A. An IoT Framework for Heart Disease Prediction Based on MDCNN Classifier. IEEE Access 2020, 8, 34717–34727. [Google Scholar] [CrossRef]
- Wan, J.; Al-awlaqi, M.A.A.H.; Li, M.; O’Grady, M.; Gu, X.; Wang, J.; Cao, N. Wearable IoT enabled real-time health monitoring system. EURASIP J. Wirel. Commun. Netw. 2018, 1, 298. [Google Scholar] [CrossRef]
- Butpheng, C.; Yeh, K.H.; Xiong, H. Security and Privacy in IoT-Cloud-Based e-Health Systems—A Comprehensive Review. Symmetry 2020, 12, 1191. [Google Scholar] [CrossRef]
- Satpathy, S.; Mohan, P.; Das, S.; Debbarma, S. A new healthcare diagnosis system using an IoT-based fuzzy classifier with FPGA. J. Supercomput. 2019, 76, 5849–5861. [Google Scholar] [CrossRef]
- Guk, K.; Han, G.; Lim, J.; Jeong, K.; Kang, T.; Lim, E.K.; Jung, J. Evolution of wearable devices with real-time disease monitoring for personalized healthcare. Nanomaterials 2019, 9, 813. [Google Scholar] [CrossRef] [Green Version]
- Ganesan, M.; Sivakumar, N. IoT based heart disease prediction and diagnosis model for healthcare using machine learning models. In Proceedings of the IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 29–30 March 2019; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Jagadeeswari, V.; Subramaniyaswamy, V.; Logesh, R.; Vijayakumar, V. A study on medical Internet of Things and Big Data in personalized healthcare system. Health Inf. Sci. Syst. 2018, 6, 14. [Google Scholar] [CrossRef]
- Lahoura, V.; Singh, H.; Aggarwal, A.; Sharma, B.; Mohammed, M.A.; Damaševičius, R.; Kadry, S.; Cengiz, K. Cloud computing-based framework for breast cancer diagnosis using extreme learning machine. Diagnostics 2021, 11, 241. [Google Scholar] [CrossRef]
- Koundal, D.; Sharma, B. Challenges and future directions in neutrosophic set-based medical image analysis. In Neutrosophic Set in Medical Image Analysis; Academic Press: Cambridge, MA, USA, 2019; pp. 313–343. [Google Scholar]
- Shivani, S.; Patel, S.C.; Arora, V.; Sharma, B.; Jolfaei, A.; Srivastava, G. Real-time cheating immune secret sharing for remote sensing images. J. Real-Time Image Process. 2021, 18, 1493–1508. [Google Scholar] [CrossRef]
- Garg, H.; Sharma, B.; Shekhar, S.; Agarwal, R. Spoofing detection system for e-health digital twin using EfficientNet Convolution Neural Network. Multimed. Tools Appl. 2022, 81, 26873–26888. [Google Scholar] [CrossRef]
- Sankar, S.; Somula, R.; Kumar, R.L.; Srinivasan, P.; Jayanthi, M.A. Trust-aware routing framework for internet of things. Int. J. Knowl. Syst. Sci. (IJKSS) 2021, 12, 48–59. [Google Scholar] [CrossRef]
- Kumar, R.L.; Khan, F.; Kadry, S.; Rho, S. A survey on blockchain for industrial internet of things. Alex. Eng. J. 2022, 61, 6001–6022. [Google Scholar] [CrossRef]
- Shabbir, M.; Shabbir, A.; Iwendi, C.; Javed, A.R.; Rizwan, M.; Herencsar, N.; Lin, J.C.W. Enhancing security of health information using modular encryption standard in mobile cloud computing. IEEE Access 2021, 9, 8820–8834. [Google Scholar] [CrossRef]
- Iwendi, C.; Huescas, C.G.Y.; Chakraborty, C.; Mohan, S. COVID-19 health analysis and prediction using machine learning algorithms for Mexico and Brazil patients. J. Exp. Theor. Artif. Intell. 2022, 1–21. [Google Scholar] [CrossRef]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Koppu, S.; Maddikunta, P.K.R.; Srivastava, G. Deep learning disease prediction model for use with intelligent robots. Comput. Electr. Eng. 2020, 87, 106765. [Google Scholar] [CrossRef]
- Kaur, P.; Kumar, R.; Kumar, M. A healthcare monitoring system using random forest and internet of things (IoT). Multimed. Tools Appl. 2019, 78, 19905–19916. [Google Scholar] [CrossRef]
- Köse, T.; Özgür, S.; Coşgun, E.; Keskinoğlu, A.; Keskinoğlu, P. Effect of Missing Data Imputation on Deep Learning Prediction Performance for Vesicoureteral Reflux and Recurrent Urinary Tract Infection Clinical Study. BioMed Res. Int. 2020, 2020, 1–15. [Google Scholar] [CrossRef]
- Denham, B.; Pears, R.; Naeem, M.A. Enhancing random projection with independent and cumulative additive noise for privacy-preserving data stream mining. Expert Syst. Appl. 2020, 152, 113380. [Google Scholar] [CrossRef]
- Boulemtafes, A.; Derhab, A.; Challal, Y. A review of privacy-preserving techniques for deep learning. Neurocomputing 2020, 384, 21–45. [Google Scholar] [CrossRef]
- Eicher, J.; Bild, R.; Spengler, H.; Kuhn, K.A.; Prasser, F. A comprehensive tool for creating and evaluating privacy-preserving biomedical prediction models. BMC Med. Inform. Decis. Mak. 2020, 20, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shanmugapriya, E.; Kavitha, R. Medical big data analysis: Preserving security and privacy with hybrid cloud technology. Soft Comput. 2019, 23, 2585–2596. [Google Scholar] [CrossRef]
- Deebak, B.D.; Al-Turjman, F.; Aloqaily, M.; Alfandi, O. An authentic-based privacy preservation protocol for smart e-healthcare systems in IoT. IEEE Access 2019, 7, 135632–135649. [Google Scholar] [CrossRef]
- Chenthara, S.; Ahmed, K.; Wang, H.; Whittaker, F. Security and privacy-preserving challenges of e-health solutions in cloud computing. IEEE Access 2019, 7, 74361–74382. [Google Scholar] [CrossRef]
- Saha, R.; Kumar, G.; Rai, M.K.; Thomas, R.; Lim, S.-J. Privacy Ensured ${e} $-Healthcare for Fog-Enhanced IoT Based Applications. IEEE Access 2019, 7, 44536–44543. [Google Scholar] [CrossRef]
- al Hamid, H.A.; Rahman, S.M.M.; Hossain, M.S.; Almogren, A.; Alamri, A. A security model for preserving the privacy of medical big data in a healthcare cloud using a fog computing facility with pairing-based cryptography. IEEE Access 2017, 5, 22313–22328. [Google Scholar] [CrossRef]
- Jiang, L.; Xu, C.; Wang, X.; Lin, C. Statistical learning based fully homomorphic encryption on encrypted data. Soft Comput. 2017, 21, 7473–7483. [Google Scholar] [CrossRef]
- Ma, Z.; Ma, J.; Miao, Y.; Liu, X. Privacy-preserving and high-accurate outsourced disease predictor on random forest. Inf. Sci. 2019, 496, 225–241. [Google Scholar] [CrossRef]
- Alabdulkarim, A.; Al-Rodhaan, M.; Ma, T.; Tian, Y. PPSDT: A novel privacy-preserving single decision tree algorithm for clinical decision-support systems using IoT devices. Sensors 2019, 19, 142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Malathi, D.; Logesh, R.; Subramaniyaswamy, V.; Vijayakumar, V.; Sangaiah, A.K. Hybrid reasoning-based privacy-aware disease prediction support system. Comput. Electr. Eng. 2019, 73, 114–127. [Google Scholar] [CrossRef]
- Zhu, D.; Zhu, H.; Liu, X.; Li, H.; Wang, F.; Li, H.; Feng, D. CREDO: Efficient and privacy-preserving multi-level medical pre-diagnosis based on ML-kNN. Inf. Sci. 2020, 514, 244–262. [Google Scholar] [CrossRef]
- Yang, X.; Lu, R.; Shao, J.; Tang, X.; Yang, H. An efficient and privacy-preserving disease risk prediction scheme for e-healthcare. IEEE Internet Things J. 2018, 6, 3284–3297. [Google Scholar] [CrossRef]
- Kumar, P.M.; Lokesh, S.; Varatharajan, R.; Babu, G.C.; Parthasarathy, P. Cloud and IoT based disease prediction and diagnosis system for healthcare using Fuzzy neural classifier. Future Gener. Comput. Syst. 2018, 86, 527–534. [Google Scholar] [CrossRef]
- Zhang, C.; Zhu, L.; Xu, C.; Lu, R. PPDP: An efficient and privacy-preserving disease prediction scheme in cloud-based e-Healthcare system. Future Gener. Comput. Syst. 2018, 79, 16–25. [Google Scholar] [CrossRef]
- Thilakarathne, N.N.; Muneeswari, G.; Parthasarathy, V.; Alassery, F.; Hamam, H.; Mahendran, R.K.; Shafiq, M. Federated Learning for Privacy-Preserved Medical Internet of Things. Intell. Autom. Soft Comput. 2022, 33, 157–172. [Google Scholar] [CrossRef]
- Verma, A.; Agarwal, G.; Gupta, A.K. A novel generalized fuzzy intelligence-based ant lion optimization for internet of things based disease prediction and diagnosis. Clust. Comput. 2022, 1–16. [Google Scholar] [CrossRef]
- Kathamuthu, N.D.; Chinnamuthu, A.; Iruthayanathan, N.; Ramachandran, M.; Gandomi, A.H. Deep Q-Learning-Based Neural Network with Privacy Preservation Method for Secure Data Transmission in Internet of Things (IoT) Healthcare Application. Electronics 2022, 11, 157. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Proposed EHGA-DLNN | DLNN | ANN | KNN | SVM |
|---|---|---|---|---|---|
| Accuracy | 98.35 | 95.33 | 93.35 | 92.33 | 91.23 |
| Sensitivity | 97.33 | 95.56 | 92.32 | 90.45 | 89.33 |
| Specificity | 96.36 | 94.57 | 89.99 | 88.13 | 86.33 |
| Precision | 95.32 | 93.46 | 92.37 | 90.23 | 89.69 |
| Recall | 96.69 | 94.59 | 93.75 | 92.35 | 91.87 |
| F-measure | 96.37 | 94.57 | 93.35 | 92.97 | 91.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Padinjappurathu Gopalan, S.; Chowdhary, C.L.; Iwendi, C.; Farid, M.A.; Ramasamy, L.K. An Efficient and Privacy-Preserving Scheme for Disease Prediction in Modern Healthcare Systems. Sensors 2022, 22, 5574. https://doi.org/10.3390/s22155574
Padinjappurathu Gopalan S, Chowdhary CL, Iwendi C, Farid MA, Ramasamy LK. An Efficient and Privacy-Preserving Scheme for Disease Prediction in Modern Healthcare Systems. Sensors. 2022; 22(15):5574. https://doi.org/10.3390/s22155574
Chicago/Turabian StylePadinjappurathu Gopalan, Shynu, Chiranji Lal Chowdhary, Celestine Iwendi, Muhammad Awais Farid, and Lakshmana Kumar Ramasamy. 2022. "An Efficient and Privacy-Preserving Scheme for Disease Prediction in Modern Healthcare Systems" Sensors 22, no. 15: 5574. https://doi.org/10.3390/s22155574
APA StylePadinjappurathu Gopalan, S., Chowdhary, C. L., Iwendi, C., Farid, M. A., & Ramasamy, L. K. (2022). An Efficient and Privacy-Preserving Scheme for Disease Prediction in Modern Healthcare Systems. Sensors, 22(15), 5574. https://doi.org/10.3390/s22155574