1. Introduction
Artificial intelligence (AI) allows us to automate multiple tasks in different areas, such as artificial vision, which makes it possible to perform several jobs that were previously believed only humans would be capable of doing. The tasks are those such as object identification or object location in digital images; processes such as these require previous knowledge of the objects you are looking for, as well as the context in which they are found, requirements that are completely related to the vision and cognitive abilities of humans.
In recent years, deep neural networks (DNN) have made a huge advances in recognition tasks in multiple areas due to the capabilities of feature-extraction layers that DNNs have embedded in their design, which make them very attractive in multiple disciplines. Zhang et al. [
1] created a fruit classification system using a deep neural network to replace handcrafted features, beating state-of-the-art approaches. Horng et al. [
2] used a DNN, feeding it with aerial images to classify tree areas and help in the understanding of land use. Sebti et al. [
3] provided a solution for forecasting and diagnosing of diabetic retinopathy by training a convolutional neural network with retina images, achieving over 96% accuracy.
Previous authors tackled the guitar/instrument classification problem, for example, Rabelo et al. [
4] used a support vector machine to classify the sounds of guitars (in a binary problem) from two brands, obtaining 95% accuracy with a particular approach. Yet, this was done by using the sound (music notes) generated by the instrument, instead of images, to perform the classification tasks. Banerjee et al. [
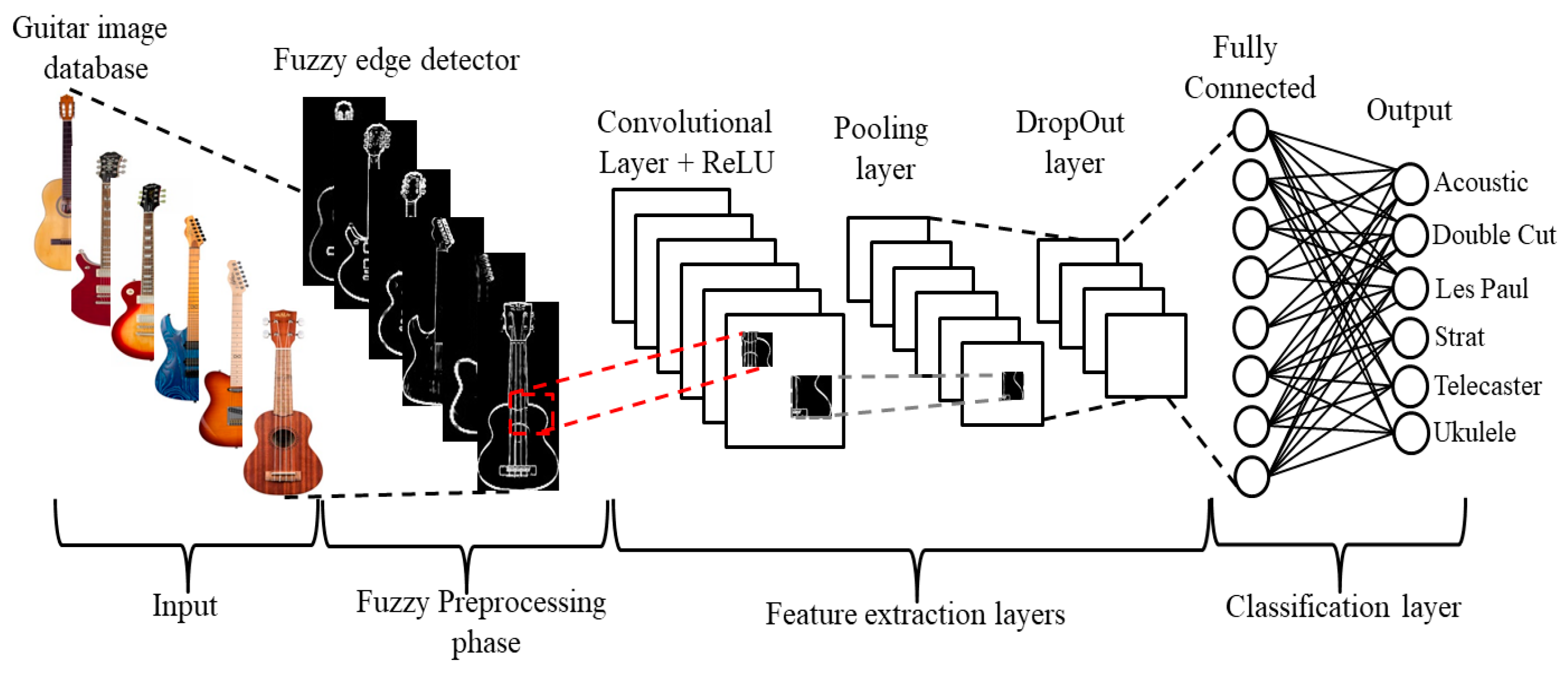
5] used musical notes and support vector machines to classify string instruments (cello, double bass, guitar, and violin), obtaining up to 100% recognition with random forest. This paper proposes an artificial vision system that performs the classification by body types of some of the most popular guitar styles found nowadays. The system operates by exploiting the capabilities of the feature-extraction layers of DNN, feeding them with pictures of the guitars that need to be classified by the user. Given the lack of previous attempts to do so, we created a dataset by scraping images from popular search engines to generate a competent database that contained sufficient images of some of the most popular guitar models. The application of image-based instrument-classification systems could have great relevance in retail stores and warehouses of music instrument franchises, where there is a constant flow of inventory involved, especially of used products. Intelligent systems could be applied for inventory keeping or organization of unlabeled items. Another form of implementation viable for the music industry is a complementary system for off-site quoting services for instrument purchases or store credit requests, making it more compelling for customers to sell used instruments to the store for resale.
The process of detecting edges is an essential part of pattern-recognition systems; it simplifies the analysis by reducing the image to its minimal expression, and by doing so, it reduces the amount of processing needed [
6]. This could be considered a difficult task, especially when the images contain noise or include irrelevant information. To solve this challenge, some fuzzy edge-detectors have been proposed. In Tao et al. [
7], Hu et al. [
8], and Ontiveros-Robles et al. [
9], the authors presented some edge-detection methodologies with their foundation in type-1 fuzzy systems, T1FS. In Mendoza et al. [
10,
11], the authors propose fuzzy edge-detection based on the Sobel operator and interval type-2 fuzzy systems IT2FS. In Biswas et al. [
12] and Melin et al. [
13], the Canny method and the morphological gradient approach were improved using IT2FS, respectively. In the area of pattern-recognition, fuzzy edge-detection methods play an important role in improving the recognition rate when comparing the results with images without processing or when traditional filters are applied. We can mention other research works, where some edge-detection methodologies were based on T1FS, IT2FS, and general type-2 fuzzy sets (GT2FS) used in the preprocessing pipeline for face-recognition based on a monolithic neural network [
14,
15]. Mendoza et al. [
16] applied edge-detectors to two face databases; this detection system was based on T1 and IT2FS. The edges found were used as inputs for a face-recognition system; the authors concluded that the recognition achieved by the system was improved when fuzzy edge-detection methods were applied. Martinez et al. [
17] presented a face-recognition method with its foundation in modular neural networks, with favorable results when the fuzzy Sobel edge-detection was performed.
The success of convolutional neural networks (CNNs) in classification is due to their ability to perform both feature-extraction and classification, and most models perform very well without preprocessing steps. However, sometimes, the dataset images are unbalanced, have lower resolution, poor quality, or acquired some noise or uncertainty during the capture process. Due to these facts, some approaches use additional preprocessing methods, including image resizing, data augmentation, cropping, converting to grayscale to reduce the preprocessing time, and adding filters and equalization to improve the image quality or resolution. In the literature, we can find some works that have shown that the use of preprocessing methods before CNN-based models improves the results. Cordero-Martínez et al. [
18,
19] presented a comparison of four image preprocessing methods to classify diabetic retinopathy using CNN, and the authors evidenced and concluded that the preprocessing steps are important to increase the accuracy of the results. Kato et al. [
20] proposed a preprocessing approach applied before a CNN-based model, and the results were 34.8% higher than the conventional CNN model. In Musallam et al. [
21], three preprocessing steps were proposed to enhance the quality of MRI (magnetic resonance imaging) before these were introduced to a deep convolutional neural network (DCNN), which involved removing confusing objects, using a non-local mean algorithm (NLM), and applying histogram equalization. These were applied for automatic detection of brain tumors in MRI images and experimental results proved the robustness of the proposed architecture, which increased the detection accuracy of a variety of brain diseases in a short time compared to other well-known deep convolutional neural network (DCNN) models such as VGG16 [
22], VGG19 [
22], and hybrid CNN-SVM [
23]. Finally, Lăzărescu et al. [
24] presented an algorithm for fingerprint classification using a combination of edge features and CNN. In this work, some preprocessing steps were applied, including edge-enhancement operations, data resizing, data augmentation, and the images were enhanced using Prewitt and Laplacian of Gaussian. The proposed algorithm achieved a very good performance compared to the traditional hand-crafted features.
The motivation to implement fuzzy edge-detection in this paper as a preprocessing phase was that fuzzy logic is a good technique to model the uncertainty or noise encountered in images where, with an appropriate filtering operator, this will be suppressed. The fuzzy methodologies (Prewitt, Sobel, and morphological gradient fuzzy edge-detectors) presented in this paper consider implementing only T1 fuzzy sets and are referenced from the previous state-of-the-art research [
25,
26]. The implementation and combination of fuzzy preprocessing techniques and convolutional neural networks produce powerful artificial intelligence tools for pattern recognition.
3. Results
To compare the efficiency of the proposed models, we implemented them in Python, using the TensorFlow framework with the Keras API. Summaries of the results of the 30 experiments performed for each preprocessing approach for CNN-I and CNN-II are shown in
Table 6 and
Table 7, respectively, and the results for the VGG16 model are displayed in
Table 8. Fuzzy preprocessing showed an overall performance improvement against the grayscale images and the classic edge-detection methodologies. The experiments were performed on a laptop with the following specifications: CPU Intel core i7-11800H, 32 GB DDR4 RAM at 3200 MHz, and an Nvidia RTX 3080 Laptop GPU with 16 GB of video memory.
To evaluate the performance between the fuzzy preprocessing techniques and the color images, we calculated a ROC curve to have a visual representation of the performance of each class. Curves were calculated for both proposed models, as shown in
Figure 10 for CNN-I and
Figure 11 for CNN-II, each time with the best instance of the models trained.
To expand the results of the ROC graph where the RGB images presented a slightly lower accuracy when compared to some of the fuzzy detectors, we calculated the average training time for each model.
Figure 12 contains the average training time per model in seconds for CNN-I, and
Figure 13 presents the averages for CNN-II.
Statistical Test between Classic and Fuzzy Preprocessing Techniques
To verify the existence of significant evidence of the performance gain obtained with the different fuzzy preprocessing techniques, a Z-test statistical analysis was applied to compare the fuzzy preprocessing approaches (fuzzy MG edge-detection, fuzzy Sobel edge-detection, and fuzzy Prewitt) against the raw images (only resizing the images to fit the model). The tests for each preprocessing methodology were made independent for each model. The Z-test was a right-tailed test; the parameters used for the tests were the following:
Right-tailed test;
(95% confidence level, rejection zone at );
;
: Fuzzy preprocessing approach offers less or equal accuracy than the raw images . : ;
: Fuzzy preprocessing approach offers more accuracy than the raw images . : (affirmation).
The results of the null hypothesis test for CNN-I are shown in
Table 9. The
variables represent the mean and standard deviation, respectively, for the fuzzy preprocessing approach;
represent the mean and standard deviation, respectively, for raw images and grayscale.
The results for the Z-test for the CNN-II model are then shown in
Table 10.
4. Discussion
As demonstrated in the literature review, in addition to the results obtained, implementing fuzzy image preprocessing techniques before feeding the images into a convolutional neural network has proven to be beneficial in most instances for improving the accuracy of the model. As shown in
Table 6 and
Table 7, the maximum accuracy was obtained with fuzzy Sobel and fuzzy Prewitt for CNN-I, with a value of 71.76% in both cases after performing the 30 experiments; in the case of the CNN-II, fuzzy Sobel achieved the best model performance, obtaining the maximum accuracy of 75.18%. These are competitive results against RGB images, where the latter do not require preprocessing but need more computational resources and time to train the model.
When reviewing the classical edge-detection methodologies for CNN-I, we can note that Sobel and MG preprocessing tended to decrease the accuracy, with an average of 53.07% for MG and 64.72% for Sobel. With Prewitt, we obtained the best average for the model with 67.63%, even better than the RGB images, which gave a result of 66.87%. The average for the fuzzy preprocessing offered a slight improvement of almost 1% when compared to the RGB images in all instances. The results obtained with CNN-II also followed a tendency where the classic Sobel and MG offered a decrease in the average of almost 15% for MG and 4% for Sobel. We also noted comparable averages with the fuzzy approaches and with Prewitt preprocessing; all four options were comparable to RGB images with a delta of .
In the case of CNN-II, even though the model had an overall accuracy improvement, when compared to CNN-I, we can note a similar pattern to CNN-I where classical edge-detection methodologies suffered an accuracy loss compared to grayscale images, though applying fuzzy filters allowed us to surpass the grayscale approach. In this case, the performance loss with MG edge-detection was more significant, with a 14.34% lower accuracy. In the case of the Sobel edge-detection, we had a 2.41% accuracy loss on average. Fuzzy Prewitt reported a 1.08% accuracy improvement when compared to the grayscale preprocessing, and a 0.18% accuracy improvement when compared to the color images.
The results obtained with the pre-trained VGG16 model, denoted in
Table 8, were not as impressive as those for the specialized model without preprocessing, especially when compared to CNN-II with fuzzy Sobel, which gave over a 1.9% accuracy improvement with the best models. This alternative could represent a decent out-of-the-box implementation, without taking into consideration the training times needed, because the model utilizes 224 × 224 px RGB images instead of the 150 × 150 px grayscale used for fuzzy Sobel.
The results can be validated with the ROC curves shown in
Figure 10 and
Figure 11, which show the sensitivity and specificity of the models. We can observe that each class in every model has a similar performance, where the models are performing a decent separation of the classes. The models present a similar level of area under the curve (AOC) due to the relatively small differences between them; we found no more than a 2% difference between preprocessing methodologies and no more than a 5% difference between the best CNN-I models compared to the best of CNN-II models.
The ROC curves shown in
Figure 10 and
Figure 11 demonstrate similar behavior in terms of accuracy between the fuzzy preprocessing and the color (RGB) images. To evaluate the effectiveness of the proposed methodologies in both architectures, we performed a time analysis by training 30 independent models, to evaluate the average training time, and we calculated the average preprocessing time for the images (
Figure 12 and
Figure 13). With CNN-I, we noted a reduction by an average of 23% in the training time with the fuzzy preprocessing. In the case of CNN-II, we had a reduction in time of 18.5% with the more complex architecture. In both instances, we managed to achieve similar accuracy rates with a significant reduction in training time. These reductions can be significant in similar applications in which the models need to be trained with more information.
The models trained with a preprocessing step showed a clear advantage in training time when compared to the color images, due to the utilization of a single layer, instead of the three layers used in RGB images. The trade-off between the optimization in training times and doubling the preprocessing step time is directly reflected in GPU usage, which normally represents the highest upfront cost when compared to CPU usage, in the development of these types of systems.
The results of the statistical analysis performed, demonstrated in
Table 9 and
Table 10, show that for CNN-I, the comparison between the utilization of fuzzy preprocessing against RGB images revealed a significant difference with the fuzzy Prewitt application, with a Z-score of 2.3. In the other two instances, the fuzzy filters presented better accuracy, but the threshold was not reached. On the other hand, when comparing the fuzzy filters against the grayscale images, we can note that all the Z-scores surpassed the 1.96 threshold, therefore, providing enough evidence to accept our alternative hypothesis, making the fuzzy preprocessing step a compelling alternative to improve accuracy. The results obtained for CNN-II demonstrated that there is sufficient evidence to validate the usage of a fuzzy filter (Prewitt) when compared to the grayscale model. The main support for this was the lack of margin between the results, where the margins of improvement in precision were not as tangible as for CNN-I, which had less capacity to extract characteristics from which it benefitted on multiple occasions with the use of fuzzy edge-detectors.
5. Conclusions and Future Work
The experimentation and statistical analysis showed that implementing fuzzy edge-detection for images before feeding them into the convolutional layers in a DNN (in some instances) can significantly improve the accuracy of the trained models, while reducing training times, especially in model CNN-I, where less filters are used for feature extraction. On other hand, model CNN-II, with more filters per layer, demonstrated improved accuracy, but no significant evidence was found to validate the usage of preprocessing layers.
When investigating the pre-trained VGG16 model, a 2% reduction in accuracy was found compared to CNN-2 with the RGB images, making it a poor alternative, especially considering the model size and training times.
We believe that the main limiting factors that affected our results were the complexity of our training information, with vast differences between images in the same category of the dataset, as well as similarities between the classes. In the future, we would like to improve the dataset and develop a more curated version that does not include the huge variation in the current version, and we would like to implement the proposed preprocessing methodology and model to benchmark datasets, to compare the efficiency against state-of-the-art models.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









