1. Introduction
Heterogeneous multi-sensors play an important role in information perception, the acquired data may contain some ambiguous and conflicting information due to the limitations of multi-sensor devices’ measurement accuracy and the complexity of the working environment, which may result in inaccurate data-fusion decisions [
1]. Consequently, the way to better handle multi-sensor data and improve data-fusion accuracy is a popular research direction in the field of data-fusion technology. Common data-fusion algorithms currently include Kalman filtering [
2], Bayesian estimation [
3], Dempster–Shafer (D-S) evidence theory [
4], and artificial neural networks [
5], etc. Bayesian networks and D-S evidence theory are commonly used to deal with the uncertainty in multi-sensor data, which frequently results in anomalous data. However, the Bayesian estimation fusion method requires access to prior data to generate new probability estimates, which is not always possible [
6]. Dempster–Shafer (D-S) evidence theory is a theory of fuzzy reasoning proposed by Dempster in 1967 [
7] and subsequently refined by Shafer [
8]. It has been widely employed in areas such as target identification [
9], multi-attribute decision analysis [
10], fault diagnostics [
11], and robotics research [
12] due to its capacity to better handle uncertain and unknown situations with unknown prior probabilities. Although the D-S evidence theory has been applied in a number of fields, it has certain problems. One is that there is no unified method for determining the BPA function, and the other is that the evidence theory is prone to produce results that contradict the facts when dealing with highly conflicting evidence, and there is no unified method for solving this problem. Most scholars have done some research on the above two problems.
Determining the BPA function is an important step in evidence theory, which influences the accuracy of fusion results to some extent. Many researchers have proposed various methods for determining BPA functions [
13,
14,
15]. The cloud model [
16] is a concept proposed by Professor Li in 1995, which is a cognitive model based on probability statistics and fuzzy set theory. It can well portray the fuzziness and randomness of information and is applicable to the field of multi-sensor information fusion. Peng et al. [
17] improved the multi-criteria group decision method by using a cloud-model method to deal with uncertain information based on information fusion and information measurement, Liu et al. [
18] used the cloud model to describe the load direction in topology optimization with uncertainty, and Peng et al. [
19] proposed an uncertain pure linguistic information multicriteria group decision-making method based on the cloud model, demonstrating the advantage of the cloud model in dealing with uncertain information. In this paper, the cloud model is used to determine the BPA function to convert measured quantitative data to qualitative concepts.
The directions for improving the accuracy of traditional evidence theory fusion can be divided into two major areas: improvement of combination rules [
20,
21] and improvement of the body of evidence. The former blames the D-S rule for producing results that contradict the facts, achieving certain results but destroying the D-S rule’s own advantages, such as the law of exchange and the law of union. The latter believes that the problem stems from the unreliability of the information source and uses an improved approach to the body of evidence to deal with the conflict, which retains the good characteristics of Dempster’s rule and weakens the influence of conflicting evidence on the fusion result. As Haenni [
22] points out, the improvement of the body of evidence is more reasonable both from an engineering and mathematical standpoint. The calculation and assignment of weights to the body of evidence is critical to improving the body of evidence, and some scholars have conducted a series of studies on how to evaluate the body of evidence’s weights. Murphy [
23] proposed a simple averaging method to assign the same weight to each piece of evidence, but it ignores the relationship between the evidence and is therefore unreasonable. Deng et al. [
24] proposed a more convergent method based on the rules of evidence theory after weighted average processing of evidence based on trust degree, but it does not take into account the characteristics of the evidence itself. There are two methods for determining the weight of the body of evidence: according to the relationship between the evidence and according to the characteristics of the evidence itself. For the former, Wang et al. [
25], Jousselme et al. [
26], and Dong et al. [
27] measure the relationship between evidence by using the Pignistic probability distance, the Jousselme distance, and cosine similarity, respectively; however, using a single measure of evidence relationship to find the weight of evidence does not accurately describe the relationship between evidence in certain cases. For the latter, scholars have proposed various uncertainty measures based on information entropy, such as Yager’s [
28] dissonance measure based on the likelihood function and Deng’s [
29] evidence uncertainty measure based on Shannon entropy, but such methods deal with evidence in a one-sided manner, replacing the entire uncertainty interval with only part of the evidence information. Deng et al. [
30] developed a method for evaluating evidence uncertainty based on the Hellinger distance of the uncertainty interval, which is simple to compute and measures uncertainty well for a better integration effect. The relationship between evidence and the characteristics of the evidence itself do not affect each other and are both valid information available within the evidence, yet some current scholarly approaches to improving evidence theory consider only one of them to deal with the evidence, undermining the integrity of the evidentiary information. Some scholars have proposed ways to improve the evidence theory based on both, but they both have some room for improvement. For example, Tao et al. [
31] proposed a multi-sensor data-fusion method based on the Pearson correlation coefficient and information entropy. Xiao et al. [
32] proposed a multi-sensor data-fusion method based on belief dispersion of evidence and Deng entropy [
29]. Wang et al. [
33] combined the Jaccard coefficient and cosine similarity to calculate evidence similarity, combined with evidence-based precision and entropy of evidence to calculate evidence certainty. Although these methods combine the relationship between evidence and the characteristics of evidence itself, they all have certain disadvantages. The Pearson correlation coefficient is only used to portray the linear correlation between normally distributed attributes, which is more demanding on evidence. The Jaccard coefficient and cosine similarity sometimes cannot measure the relationship between evidence correctly. Using information entropy cannot measure the characteristics of evidence itself comprehensively, etc.
In order to more accurately measure the relationship between evidence and the characteristics of evidence itself, and improve the accuracy of data fusion, this paper proposes an improved evidence-theory method based on multiple relationship measures and focal element interval distance. We combine the Jousselme distance, cosine similarity and the Jaccard coefficient to calculate the similarity between the evidence, and we use the Hellinger distance between the evidence determination intervals to measure the certainty of the evidence. Based on these calculations, the evidence weight coefficients are then jointly improved. Finally, the original evidence is average-weighted and fused by using the Dempster rule to produce the result. In addition, we analyze the results of the arithmetic examples to demonstrate the validity of the proposed improved evidence theory. By using the aforementioned improved evidence theory along with cloud model, we developed a multi-sensor data-fusion method. The BPA functions corresponding to each data source are determined based on the cloud model, which converts the collected quantitative data into stereotypical concepts. The fusion results are obtained by fusing each BPA function by using the improved evidence theory mentioned above.
Multi-sensor data-fusion technology can combine relevant information within multiple sensors, thereby increasing the safety and reliability of the overall system. The proposed multi-sensor data-fusion method can be utilized in multi-sensor systems in various fields, such as fault-determination systems, target identification systems, environmental monitoring systems, and intelligent firefighting systems, among others. Due to external factors or their own aging faults, one or more sensors may acquire incorrect information, causing the fusion results to be contradictory to the facts. The proposed method overcomes the problem, improves the handling of ambiguity in sensor data, increases the reliability of data fusion results, and makes it easier for people to make appropriate decisions. We establish an early indoor fire detection model to test the efficacy of the proposed strategy. The proposed method improves accuracy by 0.7–10.2% and reduces false alarm rate by 0.9–6.4% when compared to the traditional evidence theory and other improved evidence theories. It has better fusion performance, which provides some reference value for multi-sensor data fusion.
3. The Proposed Method
Based on the above theoretical knowledge, this paper proposes a heterogeneous data-fusion method based on a cloud model and improved evidence theory. In order to obtain the BPA function of evidence more accurately, we consider the ambiguity of multi-sensor data when completing data transformation by using the cloud model. To improve the reliability of the fusion results, we propose a new method for measuring the similarity of evidence and improve the evidence by combining the similarity and certainty of evidence together. The specific method for determining the BPA function and calculating the similarity of evidence and the certainty of evidence are described in this section, and finally the overall steps of the method are proposed.
3.1. Determination Method of BPA Function
It is assumed that the multi-sensor system’s data information is pre-processed to extract
n classes of data, forming
n bodies of evidence, i.e.,
, where
is the
ith class of data measured by the system. Based on the knowledge gained from the cloud model, the membership degree
for the values of discrete feature variables is calculated as follows in Equation (7):
where
is the membership of the
ith class of data relative to the
jth evaluation index under the
kth judgment within the same acquisition cycle of the multi-sensor system,
is the expectation value of class
i data relative to the
jth evaluation index obtained in Equation (1), and
is a normal random number generated with
as the expectation and
as the standard deviation obtained in Equation (1).
k is the number of times the multi-sensor acquires data in the same acquisition cycle, when
k is greater than 1, the membership of class
i data with respect to the
jth evaluation index can be determined by the maximum of the
k affiliation values when the feature parameters have multiple values:
The multi-sensor membership matrix can be calculated based on the membership degree
:
The elements in each row in Equation (9) represent the membership of the ith (i = 1, 2, ⋯, n) class of data of the multi-sensor for the jth (j = 1, 2, ⋯, m) evaluation index, and the elements in each column represent the membership of all data information collected by the multi-sensor system at a certain time for the jth (j = 1, 2, ⋯, m) evaluation index.
The obtained membership matrix
basically satisfies the definition of probability assignment but does not satisfy
. Considering that the actual use of the sensor will produce a certain measurement error, the following definition is added to transform the membership of each evaluation index into a BPA function:
where
denotes the uncertainty of the
ith characteristic parameter,
is the basic probability assignment value of the uncertainty of the
ith piece of evidence, and
is the basic probability assignment value of the
jth evaluation index of the
ith piece of evidence.
3.2. Similarity of Evidence
Classical measures for describing the relationship between evidence include: conflict coefficient K, Pignistic probability distance, Jousselme distance and cosine similarity, and so on. The computation of the conflict coefficient K is given in (6), and assuming that the evidence bodies and are BPA functions of the identification framework , the calculation of the Pignistic probability distance, Jousselme distance, and cosine similarity is given below.
Pignistic probability distance [
25]
Pignistic probability distance is a measure of conflicting relationships between evidence. Let the recognition frame
,
m is the BPA function of
, and if
, then
is said to be the Pignistic probability of the focal element
A.
Assuming that
and
are the corresponding Pignistic probability functions, the Pignistic probability distances are calculated as follows:
where
and
are the vector forms of the evidences
and
, and
D is a
positive definite matrix, its mathematical expression is:
, where the element
,
is any focal element in evidence
and
is any focal element in evidence
, which can also be called the Jaccard coefficient and can be used to reveal the relationship between unifocal and multifocal elements of the evidence.
The Jousselme distance is a measure of the conflicting relationships of the evidence, and the higher its value, the greater the conflict between the evidence.
The cosine similarity can be used to calculate the similarity of the evidence. The greater the cosine similarity, the greater the confidence between the evidence.
where
.
The accuracy of the various measurements is examined based on the above computation by calculating the measures under different conditions in conjunction with Example 1.
Example 1. Suppose there are identification frames
with different distributions of evidence bodies under different conditions, as shown in
Table 1.
The body of evidence under Situation 1 is identical, and its conflict coefficient K is calculated by using Equation (6), yielding 0.75, which contradicts the fact, whereas cosine similarity and the Jousselme distance yield 1, which is consistent with the fact. Situation 2’s evidence is radically different, and the Jousselme distance metric produces 0.707, which is inconsistent with the facts, whereas the cosine similarity computation yields 0, which is consistent with the facts. Because it is impossible to determine whether the body of evidence under Situation 3 supports each focal element on average, the body of evidence under Situation 3 is somewhat conflicting, and the results of the Pignistic probability distance and cosine similarity are both 0, which contradict the facts, the result of the Jousselme distance is 0.577, which is more consistent with the facts.
From the above analysis, the cosine similarity measure is more accurate when measuring evidence with only a subset of single focal elements, and less accurate when faced with evidence containing a subset of multiple focal elements. Wang et al. [
33] combined cosine similarity and the Jaccard coefficient to measure the relationship between evidence. But both measures are similarity measures, and the analysis of how the evidence relates to each other is not thorough enough. This can lead to inaccurate measurements in some situations, such as when evidence
and
in Situation 4 point to different correct propositions and there is a big disagreement. However, Wang’s method gives a similarity of 0.80, which is less consistent with the facts. Therefore, this paper proposes to combine conflicting evidence and similarity to jointly measure the relationship between evidence. Because the Jousselme distance can measure the relationship between evidence more accurately in most cases, and it is introduced to jointly measure the relationship between evidence.
Assuming the identification framework
, we define the local similarity of evidence
as:
According to Equation (15), the local similarities of the evidence under different situations in Example 1 are: 1, 0, 0.244, and 0.470, all of which are more consistent with the facts. Based on the local similarity
, the global similarity
can be derived for each piece of evidence, and its normalization can lead to the similarity-based weight coefficient
, which is calculated as follows:
3.3. Certainty of Evidence
The properties of the evidence itself can be measured based on the degree of certainty of the evidence. In probability theory, the Hellinger distance is a complete distance metric defined in the space of probability distributions and can be used to measure the similarity between two probability distributions. It has the advantage of stability and reliability compared to other metrics. Deng et al. [
30] measured the uncertainty of the evidence itself by calculating the uncertainty interval distance of the evidence focal elements. However, finding the weight of the evidence based on uncertainty involves more steps and is more tedious than finding the weight based on certainty, so this paper proposes a method by which to combine the Hellinger distance of the evidence support interval and rejection interval to jointly measure the certainty of the evidence.
Suppose
are two probability distribution vectors of the random variable Z, and the Hellinger distance is
Assuming the identification framework
and defining
as the evidence certainty, the calculation of
is as follows:
where
is the normalization factor. The Hellinger distance reaches its maximum when the evidence determines that the interval is [1,1] or [0,0], which leads to the calculation of the normalization factor:
.
Normalizing the resulting determinacy
obtains the weight of the evidence based on the determinacy:
3.4. Steps of the Proposed Method
Based on the above study, the specific steps of the proposed method in this paper are given as follows, and the flow chart is shown in
Figure 2.
Step 1: After pre-processing the data from sensors, the BPA function of each data source related to the body of evidence is calculated by integrating the cloud model and each data evaluation index.
Step 2: With the obtained BPA function of each evidence, the weight based on the similarity of evidence is calculated by combining Equations (15) and (16), and the weight based on the certainty of evidence is calculated by combining Equations (18) and (19).
Step 3: With the weights
and
, the total weight of the evidence body is calculated and normalized to obtain the final weight
, which is calculated as follows:
Step 4: Based on the weights
, the original evidence is averaged and weighted to obtain the processed body of evidence
m,
Step 5: Use Dempster’s fusion rule to perform n − 1 fusion for evidence body m.
4. Numerical Example and Simulation Results
In this section, the proposed improved D-S evidence theory method based on similarity and certainty, as well as the proposed overall method of heterogeneous data fusion based on cloud model and evidence theory, are evaluated and simulated to demonstrate the feasibility and effectiveness of the proposed method in this paper.
4.1. The method for Improving D-S Evidence Theory
In this section, four common conflicting, normal, and multi-quantity single-focal and multi-focal element evidences are fused based on the proposed improvement method, comparing traditional evidence theory, classical improvement methods, and similar improvement methods, and demonstrating the effectiveness of the proposed methods in this paper through Examples 2–4. We take the methods proposed by Deng Z. [
30] and Wang [
33] as similar improvement methods.
Example 2. In evidence theory, there are four common sorts of conflicts: complete conflict, 0 trust conflict, 1 trust conflict, and severe conflict [
36], and the BPA functions for the four typical conflicts are provided in
Table 2.
The global similarity
and own determination
of each evidence under the four conflict types are shown in
Table 3. The weights
and
of the evidence can be calculated based on the degree of similarity
and the degree of certainty
, and the overall weight
of the evidence can be obtained by combining the weights
and
.
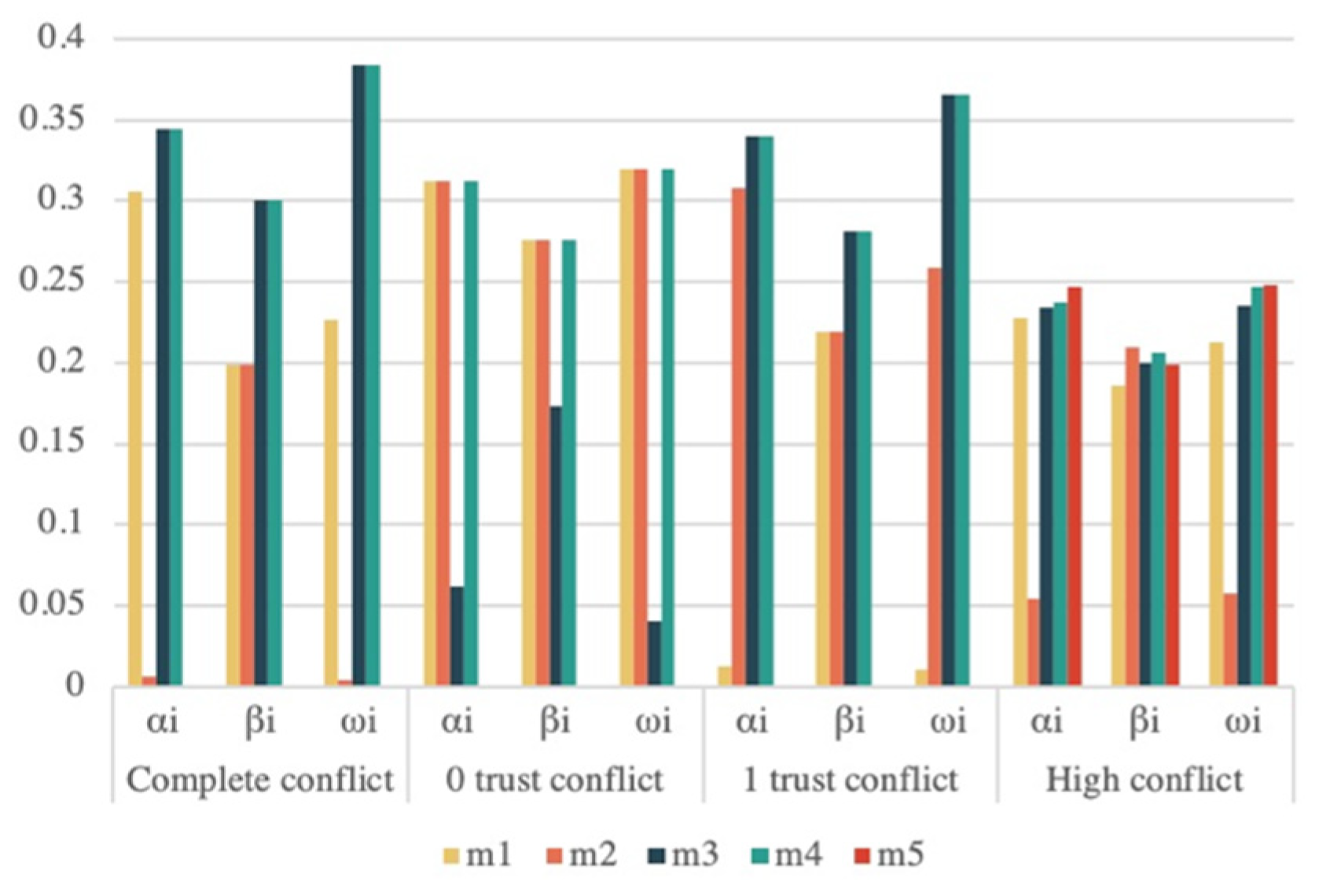
Figure 3 displays the distribution chart for each weight.
Figure 3 shows that the weights of conflicting evidence are lower than those of normal evidence, and the distribution of each weight is consistent with the facts. We combined similarity and certainty to improve the body of evidence in order to improve the science of data fusion, and it should be noted that because the certainty of evidence describes the characteristics of the evidence itself, which includes the interval information of all focal elements within the evidence and is independent of the relationship between the evidence, the weights
and
are not always positively correlated.
Table 4 displays the fusion results of the traditional D-S rule, the methods proposed by Sun [
20], Murphy [
23], Deng Y. [
24], Deng Z. [
30], and Wang [
33], and the improved method proposed in this paper. As seen in
Table 4, when confronted with the four conflicting situations listed above, the D-S fusion rule fails or does not match the genuine situation, and Sun’s method allocates the uncertainty to the entire set, resulting in high BPA values for the entire set that do not fit the true situation. The larger the value of BPA after fusing, the greater the amount of confidence in the proposition. Although the approaches of Murphy, Deng Y., Deng Z., and Wang yield correct answers, the method proposed in this work yields a higher BPA function value and converges faster, demonstrating that the improved method in this research performs better than the other methods in resolving the four conflicts. The fusion BPA results on the reasonable propositions of each algorithm are shown in
Figure 4.
Example 3. Assume the radar identification library contains three radar model data
A,
B, and
C, with identification frame
. Five existing heterogeneous sensors are used separately to identify the radar radiation sources, yielding a total of five conflicting evidences ranging from
m1 to
m5.
Table 5 and
Table 6 show the results of a specific two times, which represent the data distribution of multi-quantity single and multi-focal element conflict evidence, respectively.
The global similarity
and certainty
of each evidence under single and multifocal elements are shown in
Table 7. The weights of evidence
,
and
for a different number of evidence cases are shown in
Figure 5. From
Figure 5, it can be seen that the weight of conflicting evidence is less than the normal weight, the weight occupied by conflicting evidence gradually decreases as the number of evidence increases, and the distribution of each evidence is consistent with the facts, which proves the rationality of the method proposed in this paper.
To verify the effectiveness of the improved method proposed in this paper, the evidences are fused by using Murthy [
23], Deng Y. [
24], Deng Z. [
30], and Wang [
33], and the proposed method are fused respectively.
Table 8 shows the fusion results for each method, and
Figure 6 shows the comparison of BPA values for reasonable propositions. From the fusion results and comparison results, it can be concluded that when facing different numbers of single and multifocal element conflicting evidence bodies, the traditional D-S fusion results all contradict the facts. Although Murthy [
23], Deng Y. [
24], Deng Z. [
30], and Wang [
33] and the proposed method all point to the correct results, the BPA functions of the proposed method are higher than the other two improved methods, and as the number of evidence bodies increases, the improved method converges faster with higher accuracy on the BPA value as the number of evidence bodies increases.
Example 4. With the identification frame
, there are five normal evidence bodies from m
1 to m
5, and the distribution is shown in
Table 9.
The proposed improved method’s fusion of normal evidence is compared to the traditional evidence theory to demonstrate the proposed improved method’s superior performance in dealing with normal data, and the fusion results are shown in
Table 10. Compared to the traditional evidence theory algorithm, the proposed method can also get correct results when dealing with normal body of evidence and has a higher BPA function with higher credibility.
According to the above examples, the similarity and certainty-based evidence theory fusion algorithm proposed in this paper performs better in handling both normal and conflicting evidence bodies, demonstrating the improved method’s rationality and effectiveness.
4.2. The Proposed Holistic Approach
To demonstrate the feasibility and effectiveness of the proposed data-fusion method, the heterogeneous data-fusion method combining cloud model and the proposed improved evidence theory in this paper is used for indoor early fire detection in this subsection.
It has been discovered that the combination of temperature, smoke concentration, and CO concentration has superior detection performance in fires [
37], and the above information is collected as fire characteristic parameters in this paper. The fire discrimination results are divided into three categories: no fire, smoldering fire, and open fire. In the established fire identification framework
,
represent no fire, smoldering fire, and open fire, respectively, and
indicates uncertainty of fire. Lin et al. [
38] proposed a fire-detection method by using the Jousselme distance to improve the evidence corresponding to the fire characteristic parameters and fusing the evidence according to Dempster’s rule to improve the timeliness of detection. However, the method ignored the characteristics of the evidence body itself and did not fully exploit the fire data information. Because the attribute values corresponding to the three fire characteristic parameters of CO concentration, smoke concentration, and temperature have certain stability and the interval distribution obeys normal distribution within a certain value interval [
39], the cloud model of each data source based on the forward cloud generator and the evaluation index of each parameter is built, and the cloud diagram is shown in
Figure 7.
PyroSim fire simulation software provides a visual user interface for fire dynamic simulation (FDS) and can more accurately predict the distribution of characteristic parameters such as fire smoke and temperature [
40], so this paper simulates the occurrence of fire to obtain fire characteristic parameters. We build the indoor scenario as follows:
The length, width and height of the room are 5, 5, 3 m;
The room has a sofa, wooden bed and wooden table, in the upper left corner of the room from the wall 1 m set CO, temperature and smoke sensor group;
Set the vent: room left wall with 1 × 1 m window, room directly opposite the sofa with 1.2 × 2 m door;
The fire burning material is n-Heptane, the center of combustion is the center of the wooden bed, the burning area is 1 m2.
By setting different heat release rate and heat ramp up time to simulate the occurrence of open fire and negative fire in the room, the starting room temperature is 30 °C, the simulation time is 30 s, and the data acquisition frequency is 2 Hz. Based on the proposed data-fusion method, a fire detection model is built. The initial fire detection probability is estimated by combining CO concentration, smoke concentration, and temperature data. The probability of smoldering fire and open flame within the initial fire detection probability is also added, and if it is greater than 0.75, the fire occurred in the room.
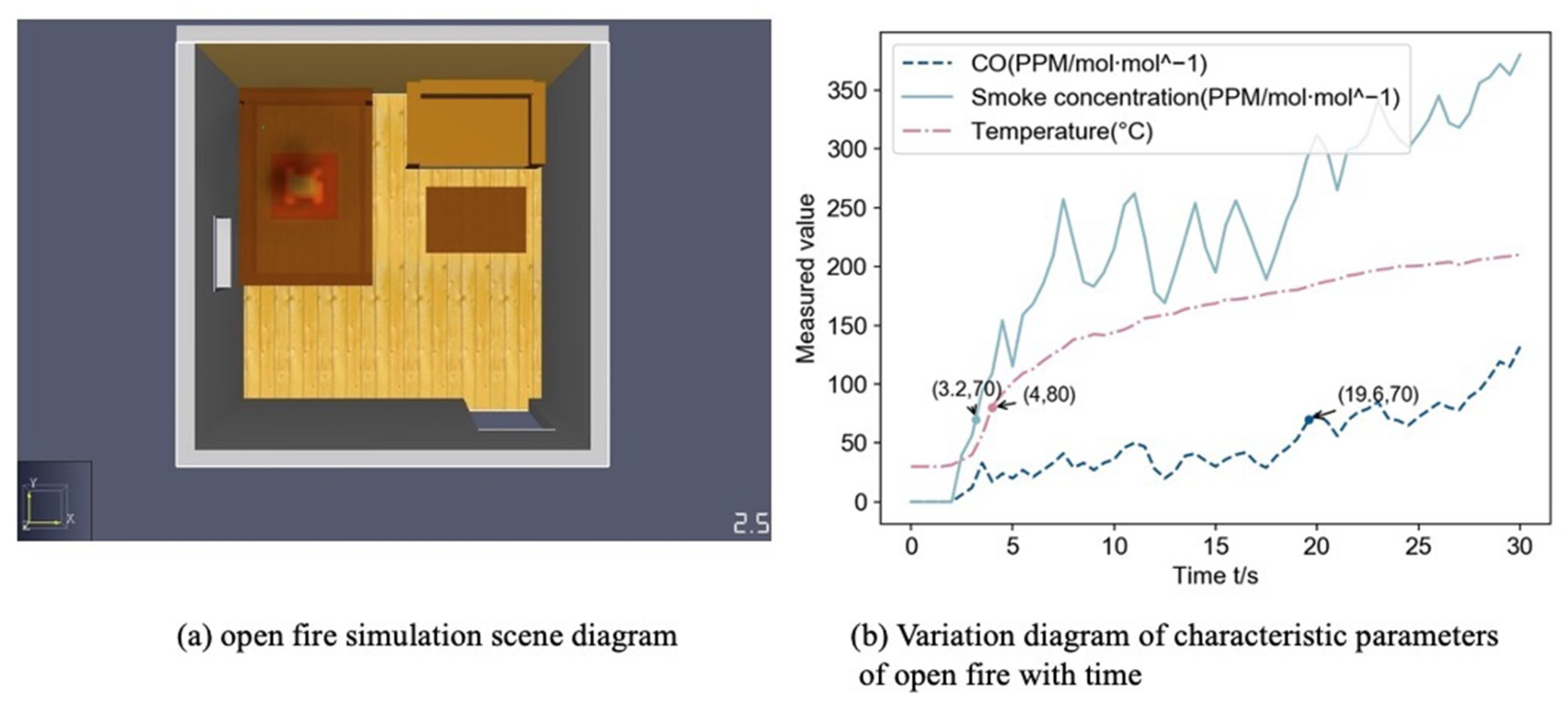
Figure 8a depicts a simulation of an open fire with visible fire and black smoke visible at t = 2.5 s.
Figure 8b shows the change of the measured CO concentration, smoke concentration, and temperature data with time. When the probability of an open fire is 1, the values of CO, smoke, and temperature are the thresholds, and the time when each parameter first reached the threshold is shown in
Figure 8b. The three characteristic parameters of CO, smoke, and temperature had almost no fluctuation in the first 2 s and increased rapidly after 2 s. The temperature and smoke reached the threshold value relatively quickly, and all parameters showed an increasing trend in the first 30 s response time.
To determine whether a fire has occurred, the early open fire data from this simulation are fused using the traditional D-S evidence theory, the methods proposed by Murphy [
23], Deng Y. [
24], Deng. Z. [
30], and Wang [
33] and this paper, respectively. Because the frequency of data acquisition in the simulation is 2 Hz, the period of data fusion is 0.5 s. The traditional evidence theory, Murphy’s Deng Y’s., and Deng. Z’s methods all detect fire at t = 3.5 s, Wang’s method detects fire at t = 3 s, and the proposed method detects fire at t = 2.5 s, proving the method’s effectiveness.
Figure 9 depicts the probability comparison of fire occurrence in this open fire scenario.
A smoldering fire’s combustion features include the emission of a significant amount of black smoke from the combustion point prior to the appearance of the evident fire.
Figure 10a depicts a simulation of a smoldering fire, with a clear fire visible at t = 18 s.
Figure 10b displays a time-plot of the data collected by the multi-sensor group during the first 30 s. As shown in
Figure 10b, the rising trend of each characteristic parameter in the shaded fire scenario is slower than it is in the open fire scenario, and the parameters only continue to grow after 7 s as a result of the early shaded fire’s insufficient combustion.
The determination of whether a fire has occurred is made possible by combining data on smoldering fires based on the traditional D-S evidence theory, the methods proposed by Murphy [
23], Deng Y. [
24], Deng. Z. [
30], and Wang [
33] and this paper, respectively. The method proposed in this paper can detect the occurrence of fire at t = 10 s, which is earlier than the 11.5 s of Wang’s method, 11.5 s of Deng Y.’s method, 12 s of Deng Z’s method, 13.5 s of traditional evidence theory, and 17 s of Murthy’s method, as shown in
Figure 11. As illustrated in
Figure 11, when compared to the traditional evidence theory, classical improvement method, and similar improvement method, the method proposed in this paper not only detects the occurrence of fire in advance, but also has a higher detection accuracy.
To further verify the effectiveness of the proposed fire detection method, we obtained different CO concentration, smoke concentration and temperature data by setting different combustibles, combustion locations, heat release rates, and heat ramp-up times. Then we made our own fire dataset, which included 1000 positive samples and 1000 negative samples. Based on the traditional evidence theory, classical improvement method, similarity improvement method and the proposed method in this paper, the homemade samples are fused to calculate the accuracy rate and false alarm rate of detection. Assuming that TP represents the number of samples correctly judged to be fires, FN represents the number of samples not correctly judged to be fires, FP represents the number of samples misreported to be fires, and TN represents the number of samples correctly judged to be fires that did not occur. The accuracy and false alarm rates (FAR) are calculated as Equation (22):
Table 11 shows the fire detection accuracy and false alarm rate of various methods. According to
Table 11, compared to other methods, the proposed method increased the fire detection rate by 0.7–10.2% and reduces the false alarm rate by 0.9–6.4%, which improves the reliability of fire discrimination obviously.
It is evident that when applied to indoor fire detection, the proposed heterogeneous data-fusion method has better fire detection performance and can simultaneously improve the timeliness and accuracy of detection, proving its feasibility and effectiveness in multi-sensor data fusion.
5. Conclusions
In this paper, a multi-sensor heterogeneous data fusion strategy based on the cloud model and improved evidence theory is presented, which can better cope with the ambiguity and conflict of heterogeneous multi-sensor gathered data. The cloud model is used to estimate the BPA function of each data source’s associated evidence. Evidence similarity is calculated by using multi-relationship measures, evidence certainty is measured by using interval distance, the body of evidence is jointly improved by combining the evidence’s similarity and certainty, and the improved body is fused by using Dempster’s rule. The usefulness of the improved evidence theory technique is validated in this research, and the results show that the proposed method performs better when dealing with both conflicting and normal evidence. The method is used for indoor fire detection in light of the issues of prolonged duration and low accuracy. Compared to traditional evidence theory, classical improvement method, and similar improvement method, the proposed method improves detection speed by 0.5–3 s, accuracy by 0.7–10.2%, and reduces the false alarm rate by 0.9–6.4%, which has better detection performance. It also provides a specific reference value for multi-source information fusion.
In future work, we intend to test the feasibility of the proposed method on other multi-sensor acquisition information systems, as well as investigate how to combine homogeneous and heterogeneous data fusion algorithms to fully exploit effective data information and improve data fusion accuracy.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}