
MiniDeep: A Standalone AI-Edge Platform with a Deep Learning-Based MINI-PC and AI-QSR System




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We have proposed and built a new AI-Edge platform called “MiniDeep”.
- The proposed MiniDeep can provide developers with a whole deep learning development environment to set up their deep learning life cycle processes, such as model training, model evaluation, model deployment, model inference, ground truth collecting, data pre-processing, and training data management. To the best of our knowledge, such a whole deep learning development environment has not been built before.
- The proposed MiniDeep can use a stand-alone mini-size PC as the edge device. Hence, it can be deployed on the nearby local machine easily, and it has the ability to provide a plug and play feature.
- In the proposed platform, a cloud-edge based deep learning software system can use the edge device to perform inference and use the cloud service to train the neural network model.
- A recommendation system for AI-QSR (Quick Service Restaurant) KIOSK (interactive kiosk) application has been implemented on the proposed platform. The experiment results have demonstrated the effectiveness of this recommendation system.
2. Related Work
2.1. Literature Review
2.2. Motivations
3. Preliminaries
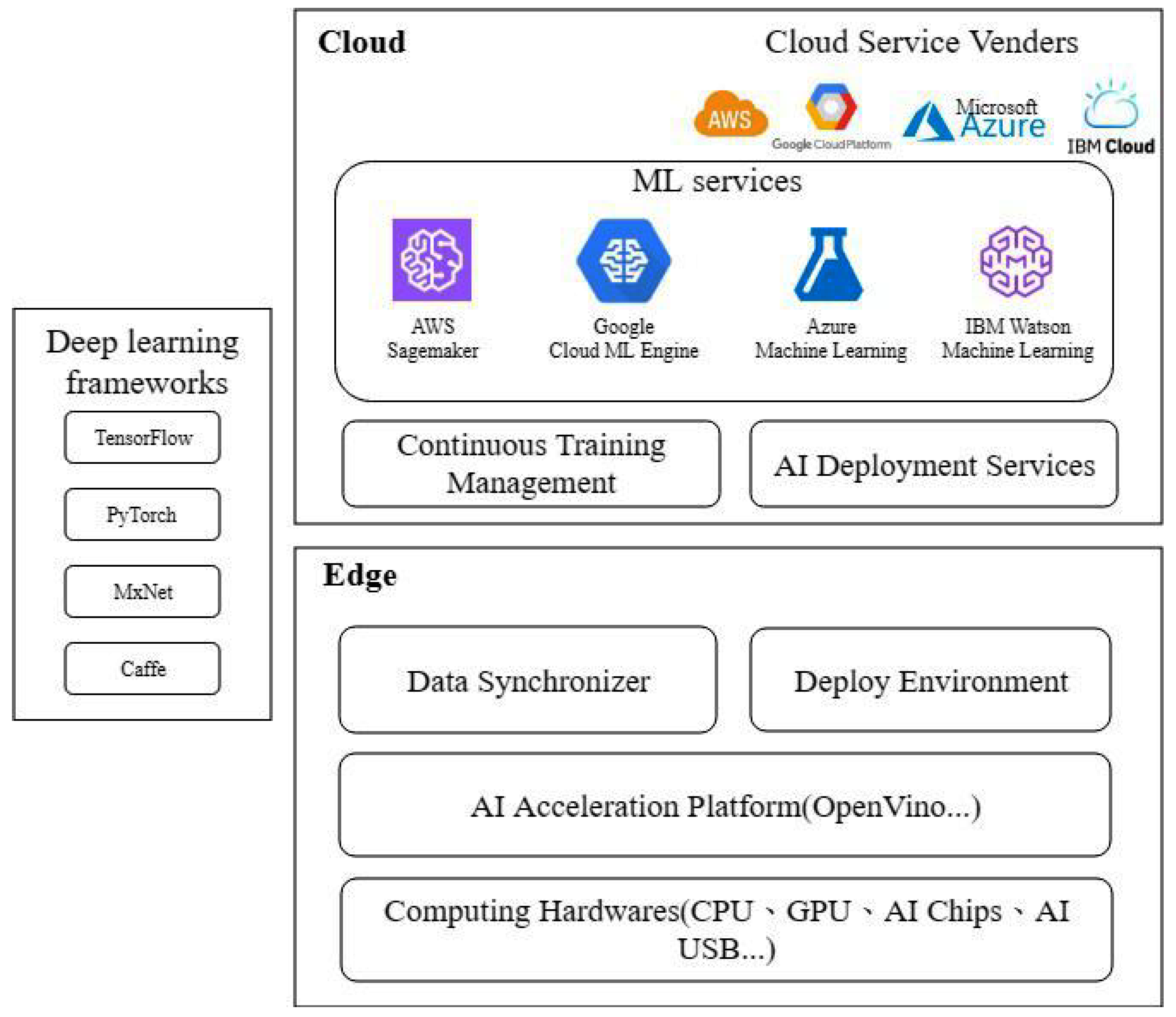
3.1. Edge-Cloud Architecture for Deep Learning
3.2. Deep Learning Cloud Service Overview
3.3. Deep Learning Edge Environment Overview
3.4. Problem Definition
3.5. Problem Formulation
4. MiniDeep Edge-Cloud Platform
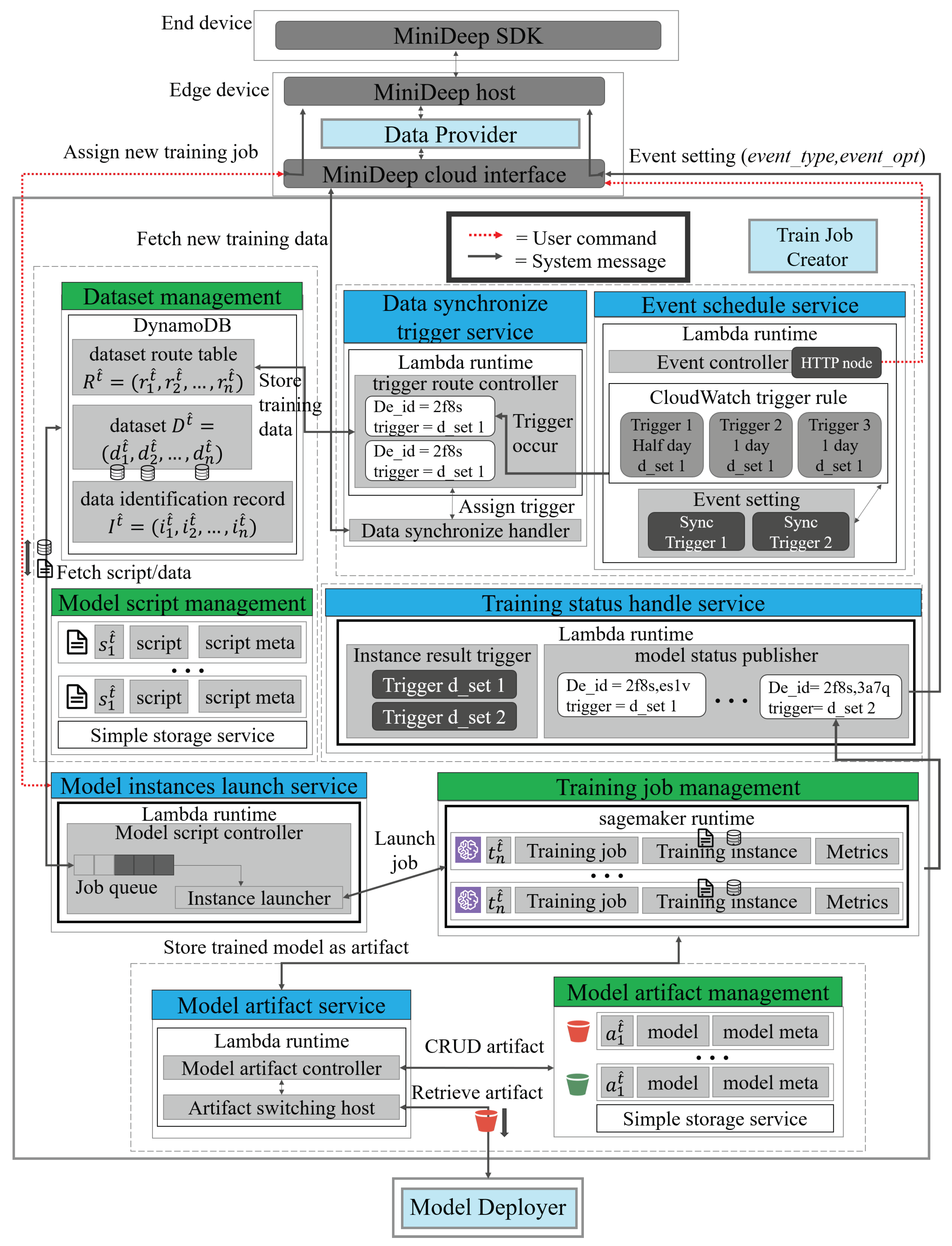
4.1. Minideep System Architecture
4.2. Minideep Platform Usage Design
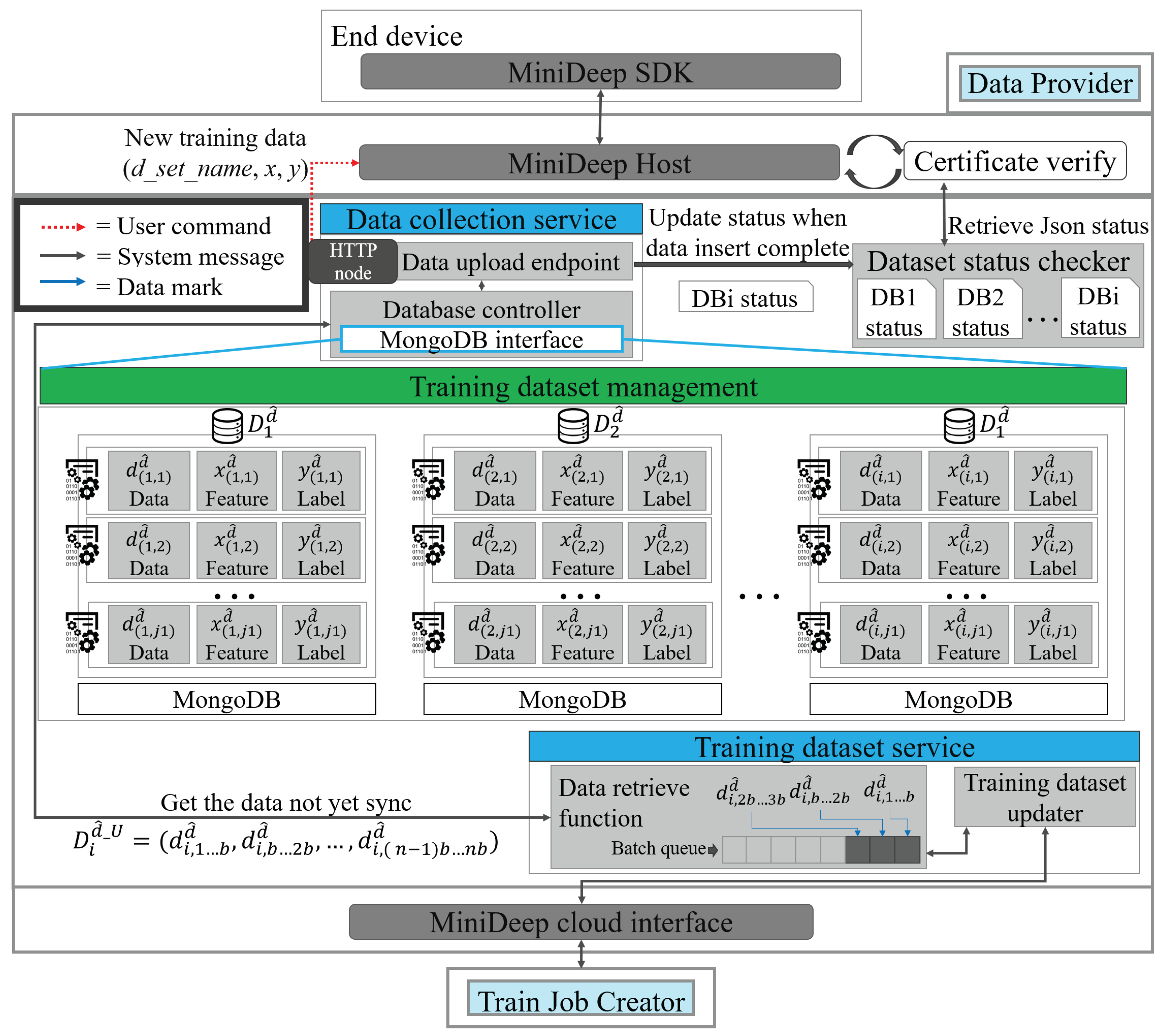
4.2.1. Data Provider
4.2.2. Train Job Creator (TJC)
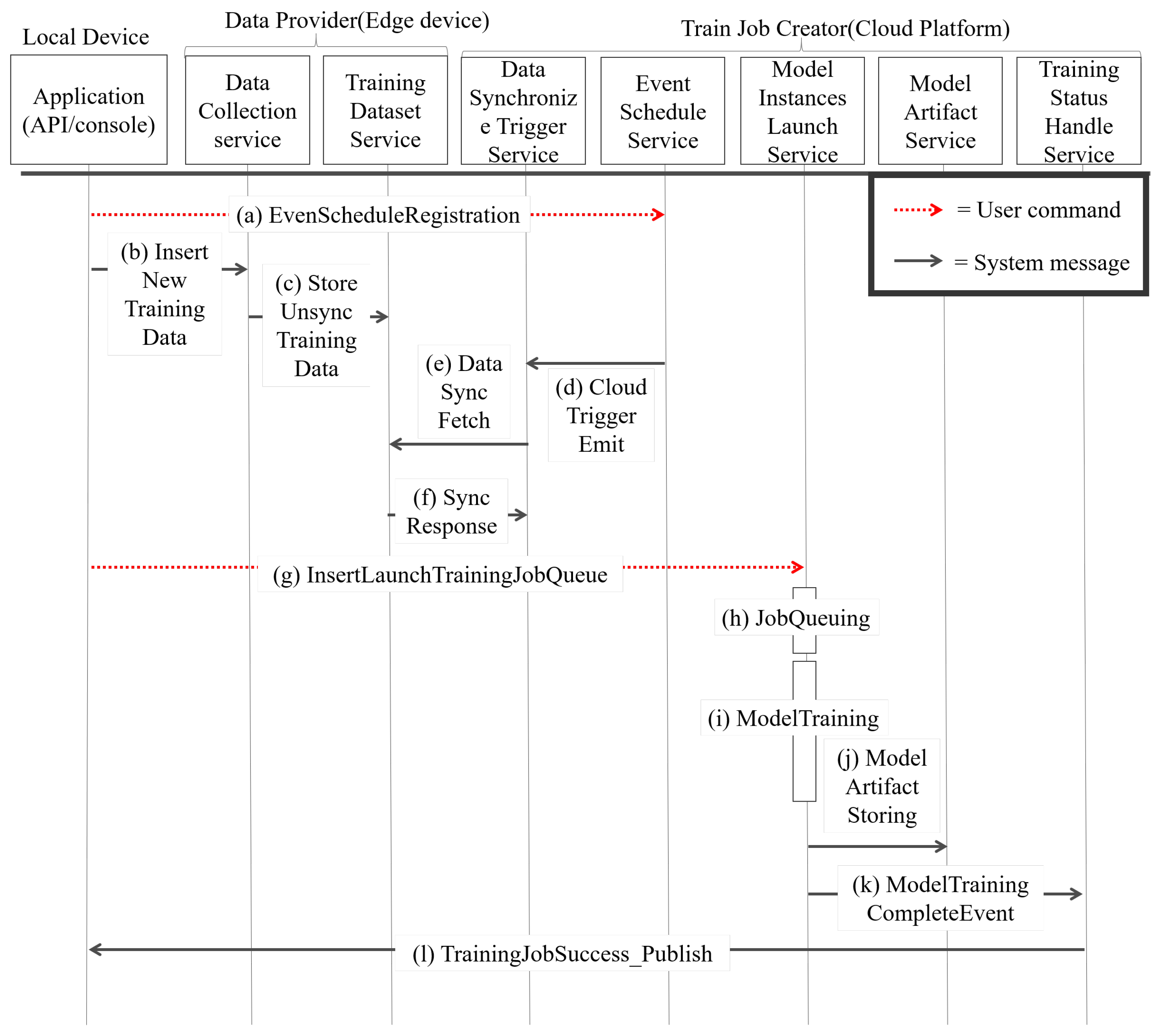
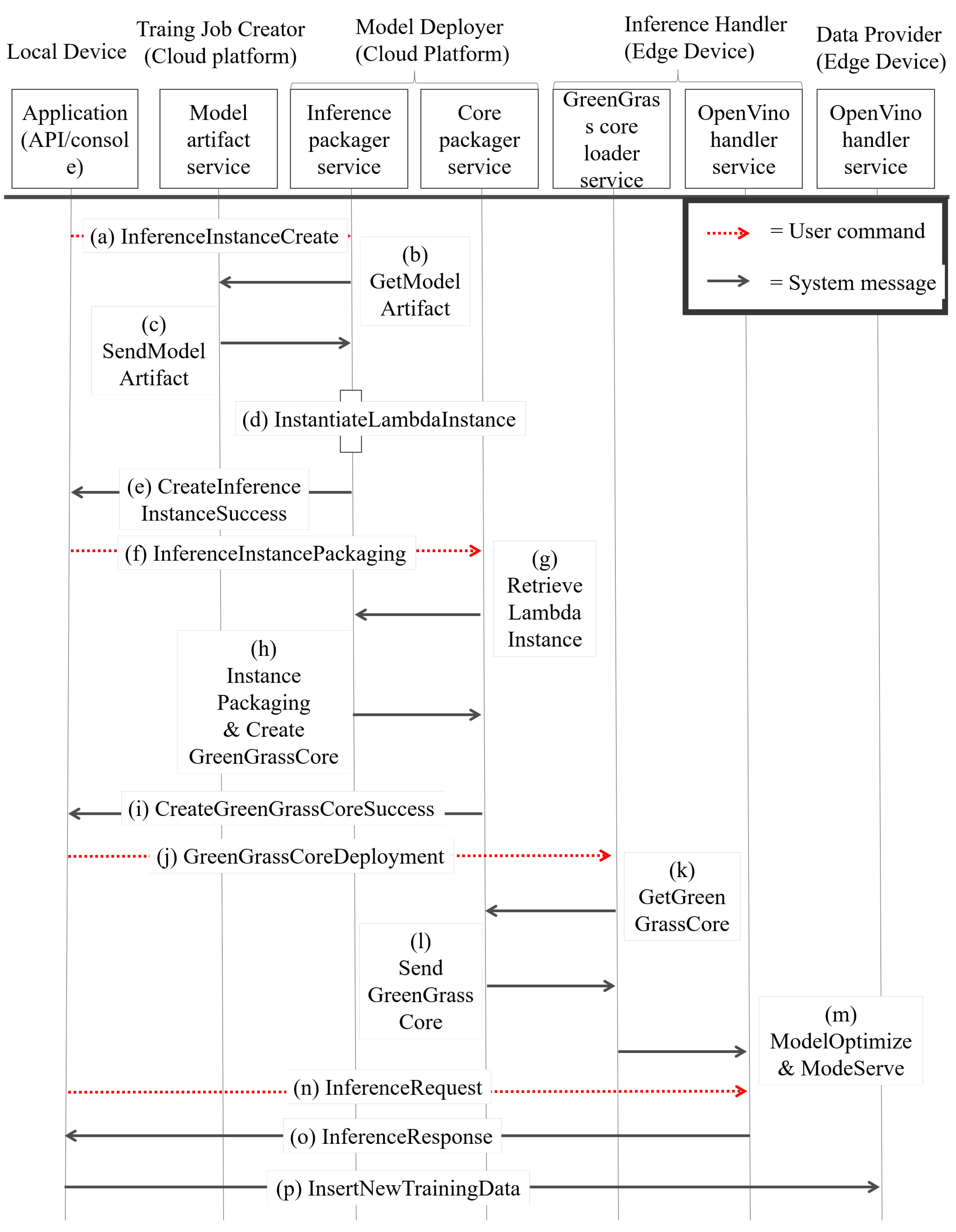
4.3. Training Procedure Details
- S1.
- In the beginning, the user sends an ESR_message (De_id, event_type, event_opt, d_set_name) to the event_schedule_service and creates an f_event on the cloud. The event_schedule_service sets the event by event_type and event_opt. After setting the event, if the APP has the new training data, the APP will send the training data to the new training cycle. The APP sends a message which is called DP_ins () to the data_collection_service for training data insertion. After receiving DP_ins, the data_collection_service indicates the , performing StoreUnsync () to store data in the edge database on the training_dataset_service.
- S2.
- After the edge data are stored in S1, the cloud will fetch data when a fetch event occurred, and the fetch event is named f_event. When f_event occurred, the event_schedule_service calls CloudWatchTriggerEmit (d_set_name, event_id) to control the data_synchronize_trigger_service and the data_synchronize_trigger_service to send a DS_fetch_message ( fetch_id, d_set_name) so as to fetch the new training data. The training_dataset_service receives the DS_fetch_message and issues an SD_response () with the new training data.
- S3.
- When the APP starts a new training job, the user sends ILTJ_message(), determining the training script, to the model_instance_launch_service. After the model_instance_launch_ service receives the ITLJ_message, the model_instance_launch_service will obtain dataset from in the cloud database and obtain the training script from the cloud database. After obtaining all elements, the model_instance_launch_service makes a T_JOB object which records training job information and pushes training job information into JOB_QUEUE. The JOB_QUEUE can adjust resource usage to prevent resource usage overloading by setting. When the T_JOB object is popped out, the model_instance_launch_service launches training job by T_JOB_Launching( , , ) and then performs model training on the cloud service provided by AWS.
- S4.
- When the model training is finished, the model_instance_launch_service calls MS_artifact (, , ) on the model_artifact_service to store the model artifact in the cloud database. The model_instance_launch_service also calls MTC_event (, ) to the training_status_ handle_service. The training_status_handle_service obtains MTC_event and knows which APP device needs to be noticed. The training_status_handle_service sends the TJS_publish (, ) message as successful training job information to the APP.
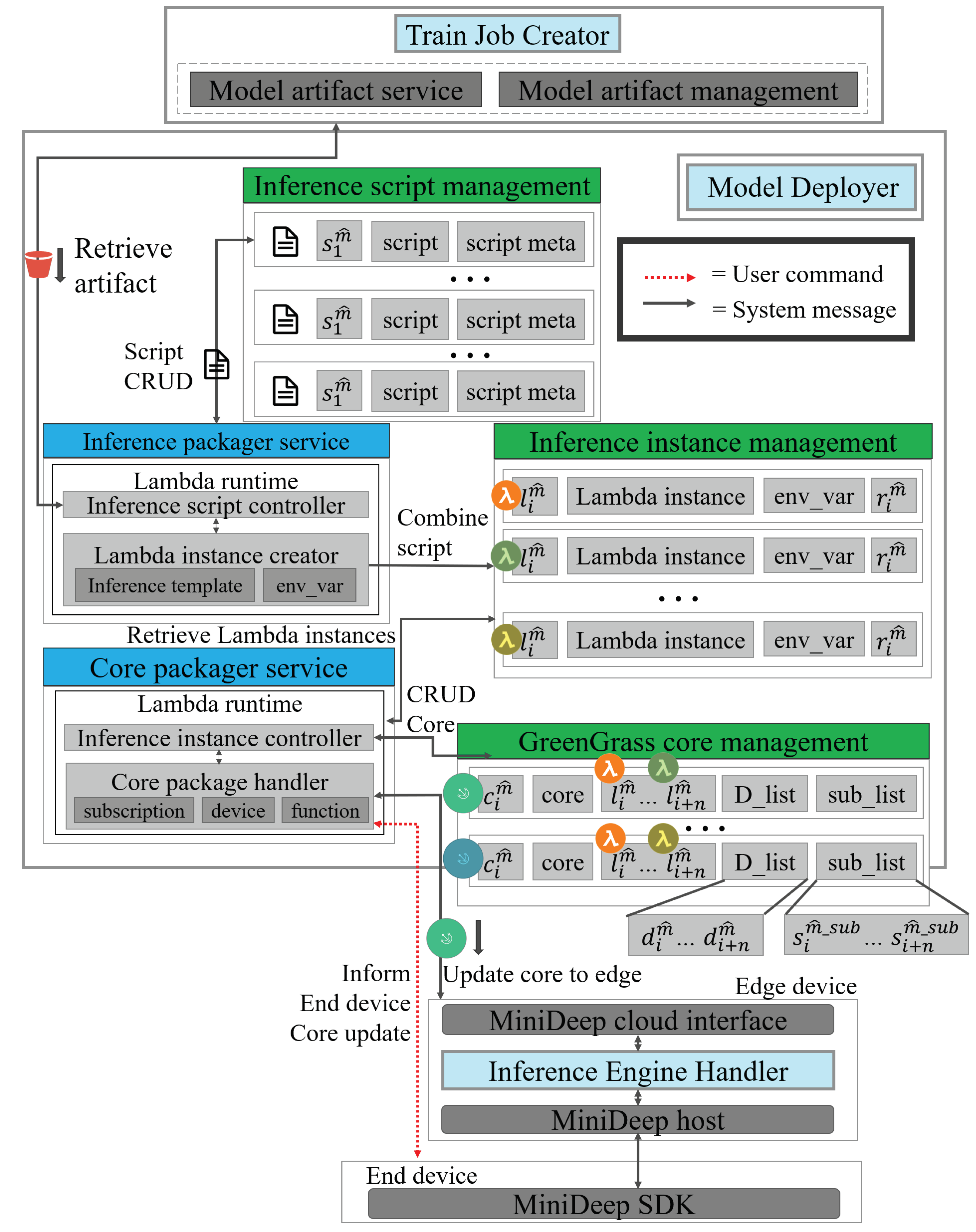
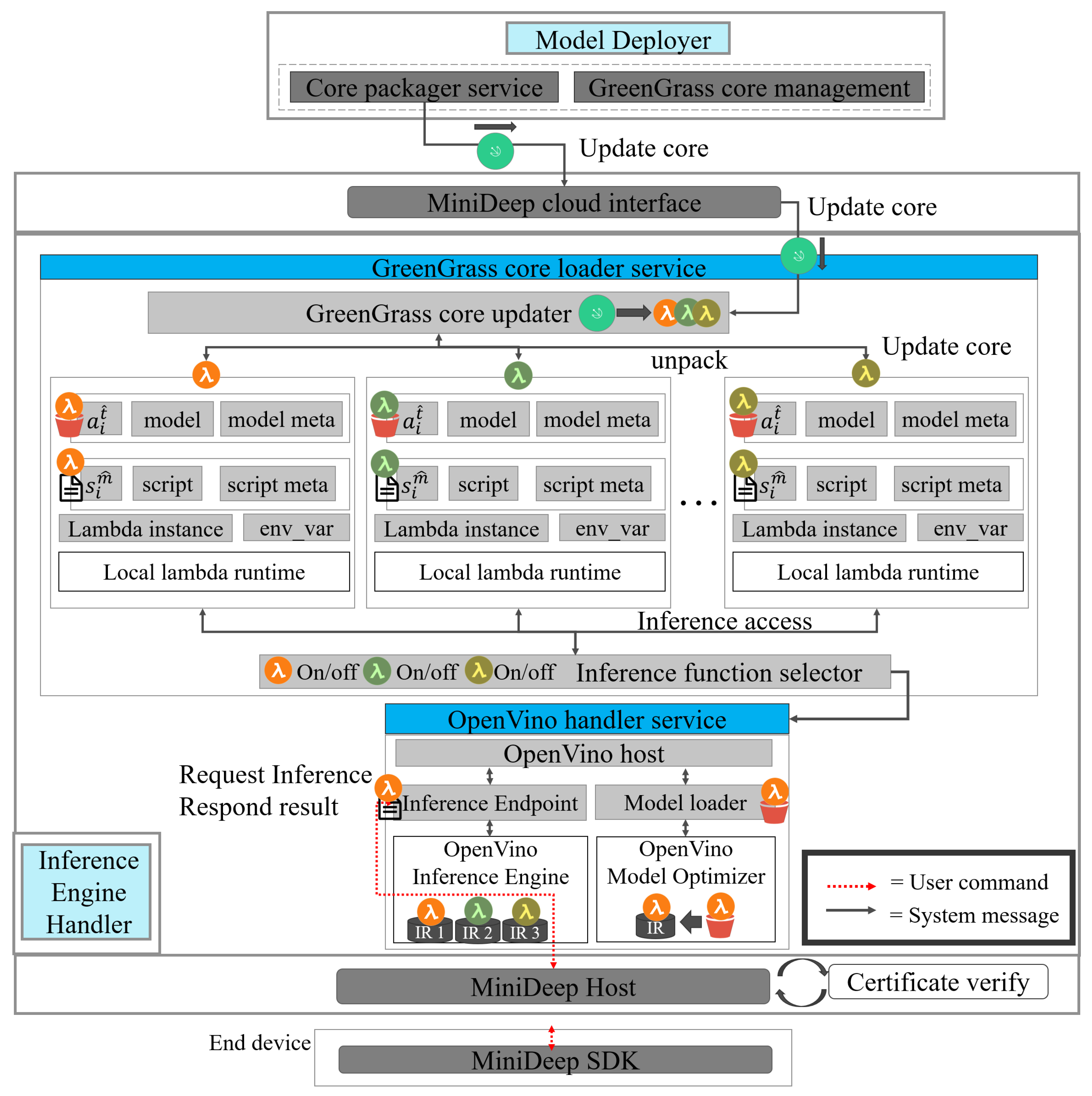
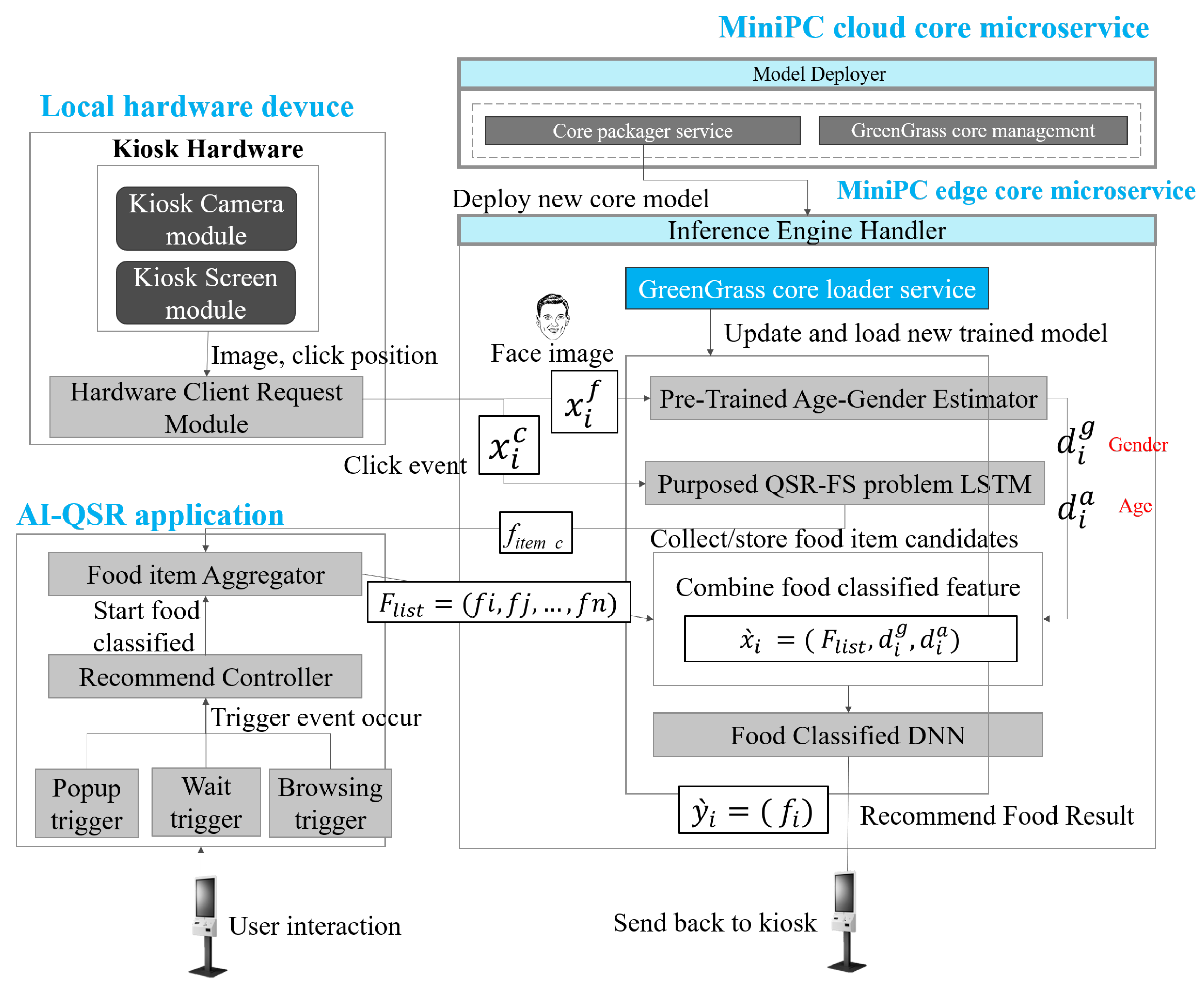
4.4. Model Deployer
4.5. Inference Engine Handler
4.6. Inference Procedure Details
- S1.
- The user sends an IIC_message (, , ) to the inference_packager_service to instantiate the lambda instance . The inference_packager_service receives the IIC_message and tries to obtain data by sending the MA_get_message () to the model_artifact_service. The model_artifact_service receives the MA_get_message and responds with an MA_res_message () which contains the designated model artifact . After the inference_packager_service obtains the model artifact , the inference_packager_service starts LII_start (, ). After finishing LII_start, the inference_packager_ service produces an , sends an IIC_ok_message () and then finishes the setup of the inference instance.
- S2.
- The user creates a package with multiple . The APP sends a message IIP_message (, [ ], ) to the core_packager_service. The core_packager_service receives an IIP_message and starts the packaging process. The core_packager_service first retrieves many from the inference_packager_service by performing the II_retrieve ([]), and the inference_packager_service provides many to the core_packager_service by performing II_retrieve_res ([]). The core_packager_service obtains the list of , packages as a and creates a GGCore instance. After that, the core_packager_service sends back a message which is called IIP_ok_message () with the green grass core ID.
- S3.
- The user deploys the inference-able model to the edge device. The APP sends a GGC_deploy_ message (, ) to the greengrass_core_loader_service to request a deployment. The greengrass_core_loader_service receives a request message called GGC_deploy_message and sends a GGC_get_message () to the core_packager_service. Then, the core_packager_ service responds with a GGC_get_res () which contains the instance. The greengrass_core_loader_service loads the and then passes into Model Optimizer to obtain the file. The file is passed to the openvino_handler_service by performing GGC_serve () to host an inference serving endpoint.
- S4.
- In this step, the user wants to send an inference response and train new data if the data are the new ground true data. The APP sends an Infer_req (, , , ) to the openvino_handler_service. The openvino_handler_service handles an inference request and passes into the in the and then obtains an inference result . After producing inference results in , the openvino_handler_service sends back a Infer_res () to the APP. The APP can realize that the result is accurate or not by human selection. If the human selection is not good, the APP can choose to send a to send new data.
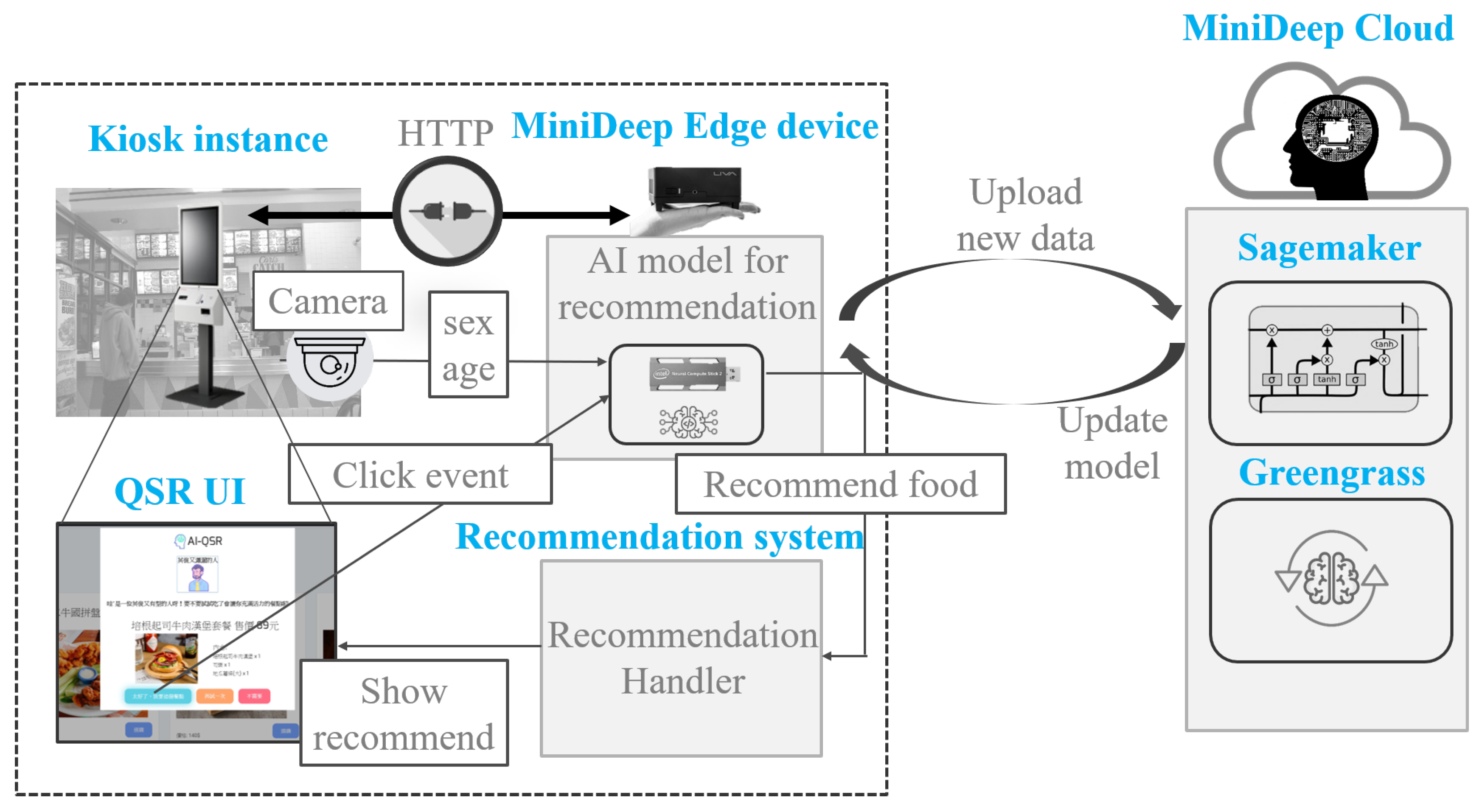
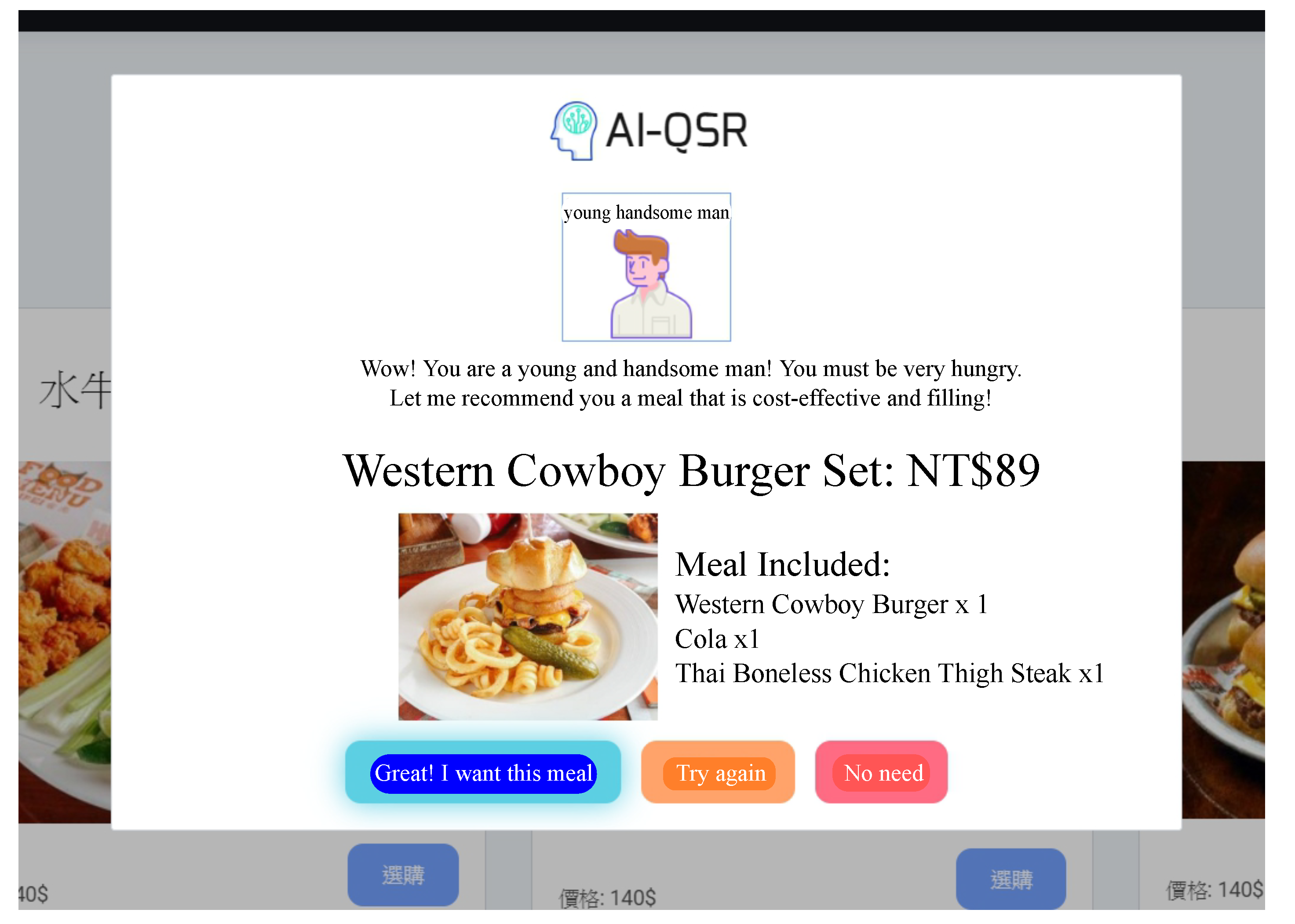
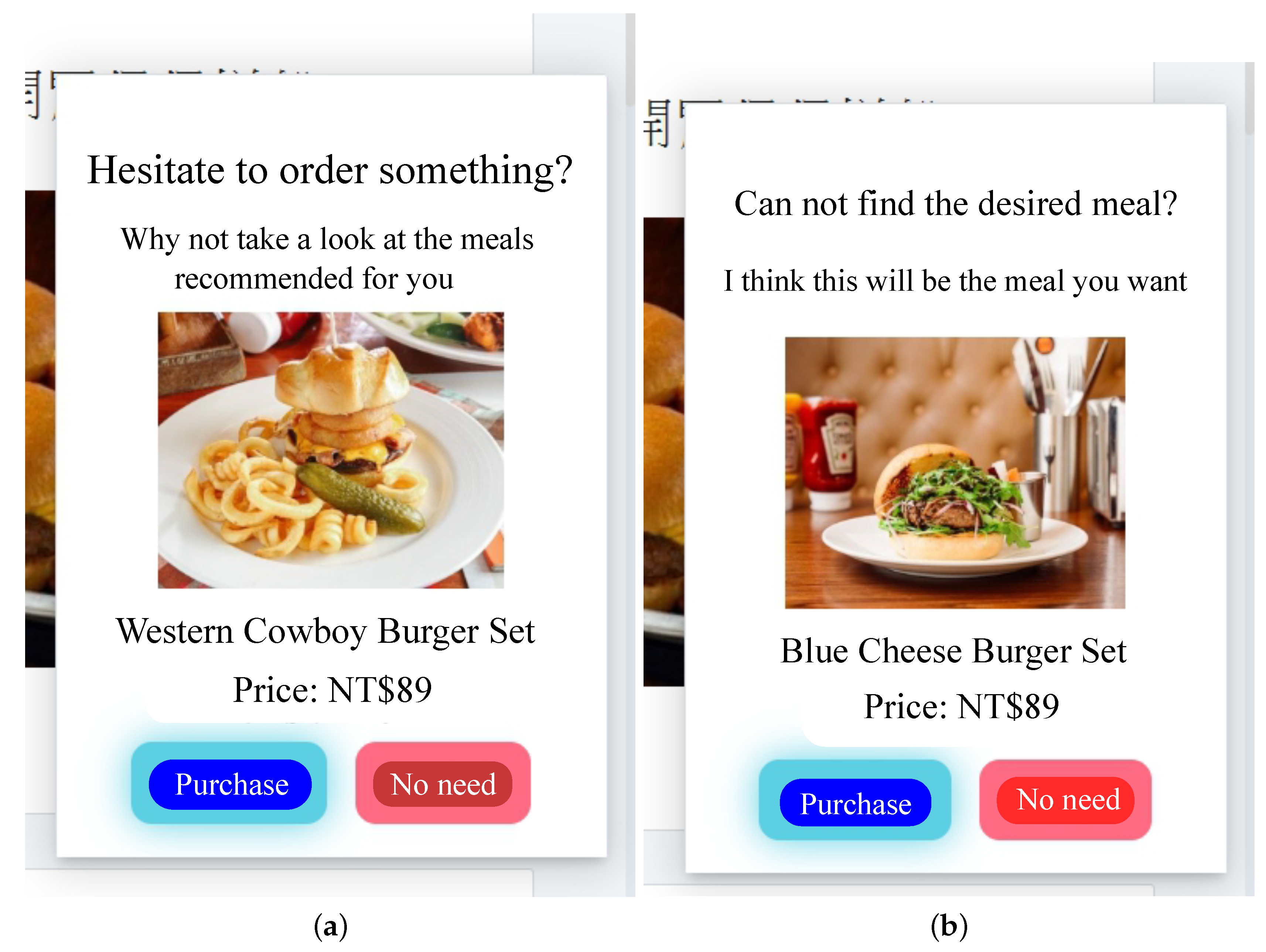
5. AI-QSR KIOSK Application Software Architecture
5.1. AI-QSR System Architecture
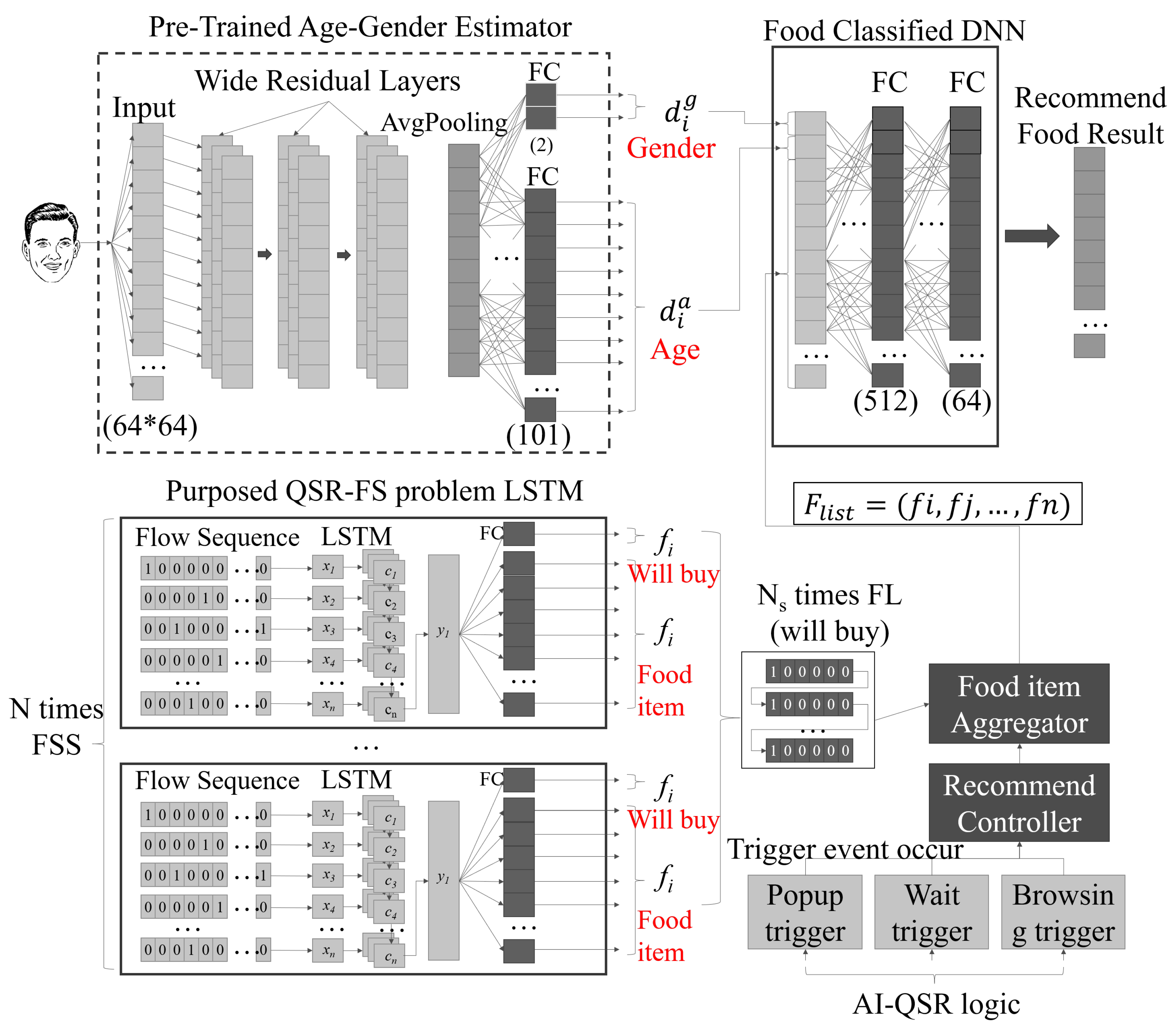
5.2. LSTM-Based Recommendation System Design for AI-QSR
- S1.
- The LSTM of the QSR-FS problem can compute the and by feeding the flow sequence . In our problem, the AI-QSR needs to collect different Flow Sequences to find many food item candidates , so that the AI-QSR computes N flow sequences () as a Flow Sequence Set () and collects at the FI_aggregator (food item aggregator).
- S2.
- The FI_aggregator collects the food item candidates from which the user may buy the food item by checking . The candidate that the user may buy can be combined as (Food List). The is combined and flattened to the high dimension vector. The recommendation system continually collects the user Flow Sequence and maintains the to hit the recommendation result.
- S3.
- When the user hits the T_condition (trigger condition) defined on the AI-QSR application, the AI-QSR application sends an (recommendation launch message) to (recommend controller), and the manages the FI_aggregator and pops out the result.
- S4.
- The camera takes a picture of the user and passes the user’s face image to the pre-trained age–gender estimator to obtain and . The sends an and combines with and to a high dimension vector for a food-classified DNN. The food-classified DNN parses the high-dimension vector and passes the vectors with shape 512 and shape 64 to two fully connective layers.
- S5.
- At the end of the fully connective layer, the output result is called (recommend food result). The is a one-hot-encoding vector in which only the suggested food will be 1 and the other output will be 0.
5.3. AI-QSR Recommendation System Implemented by MiniDeep Platform
6. Experimental Result
6.1. Experimental Environment
6.2. Performance Analysis
- Purchase hit accuracy: The matching possibility of the food recommending by the scheme and users’ purchases.
- Categorical cross-entropy: By calculating the size of the loss function, categorical cross-entropy is the main basis in the learning process and an important criterion for judging the merits of the algorithm after learning.
- Precision: Precision is the ratio of all “correctly retrieved results (True Positive)” to all “actually retrieved (True Positive + False Positive)”.
- Recall: Recall is the ratio of all “correctly retrieved results (True Positive)” to all “results that should be retrieved (True Positive + False Negative)”.
- F1 score: F1 score is the weighted harmonic average of Precision and Recall. When the F1 score is high, it can be proved that the test scheme is effective.
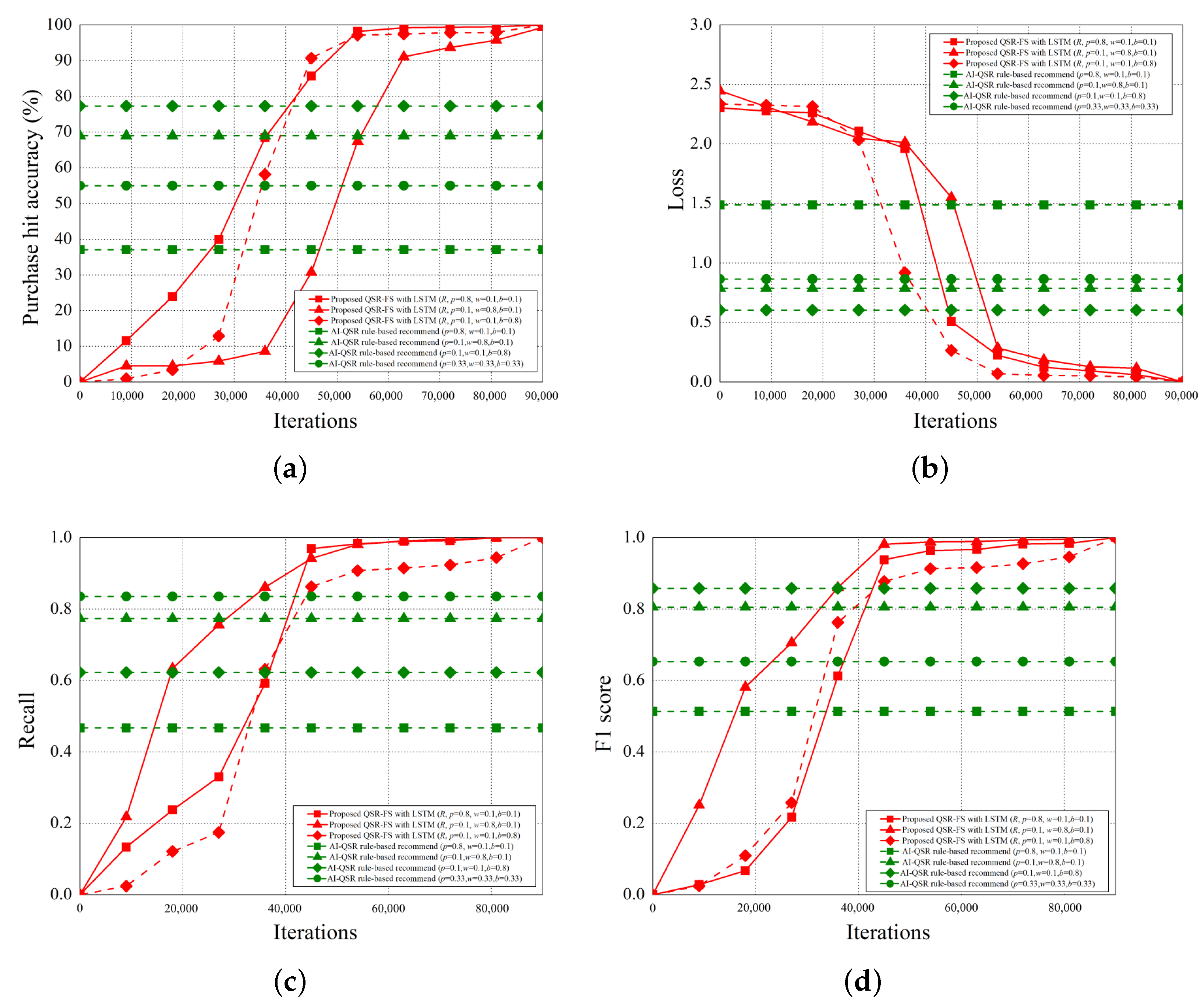
6.2.1. Purchase Hit Accuracy
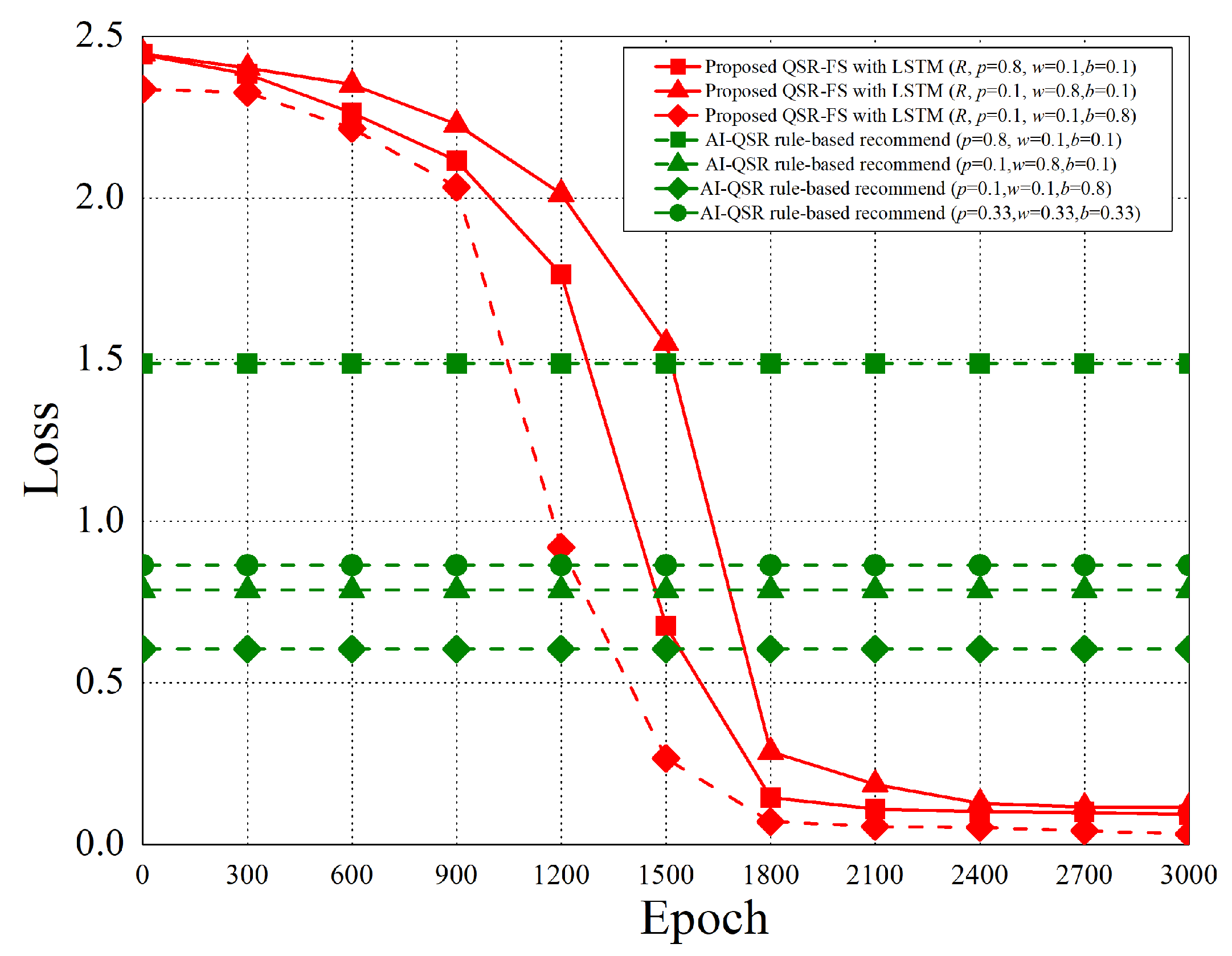
6.2.2. Categorical Cross-Entropy
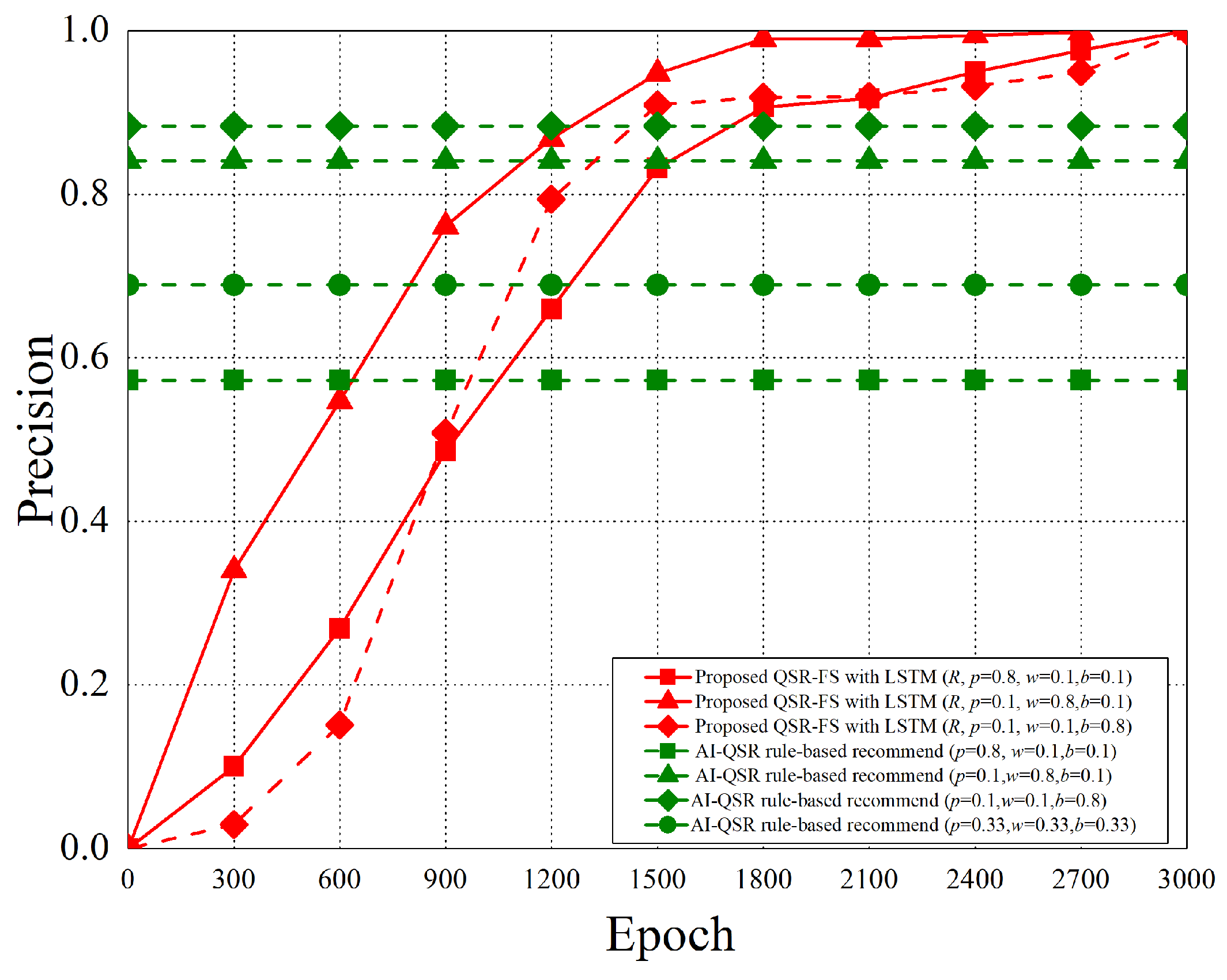
6.2.3. Precision
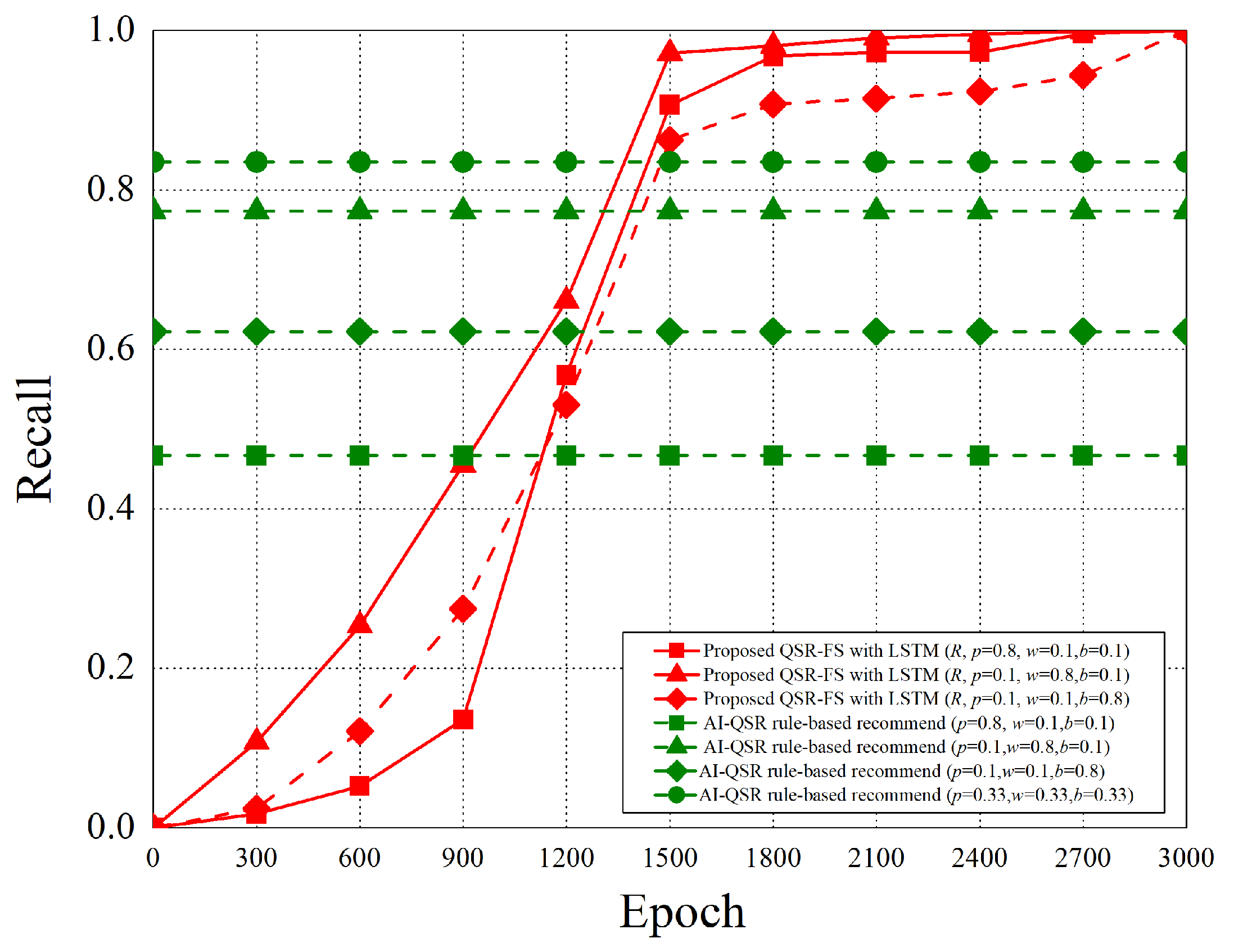
6.2.4. Recall
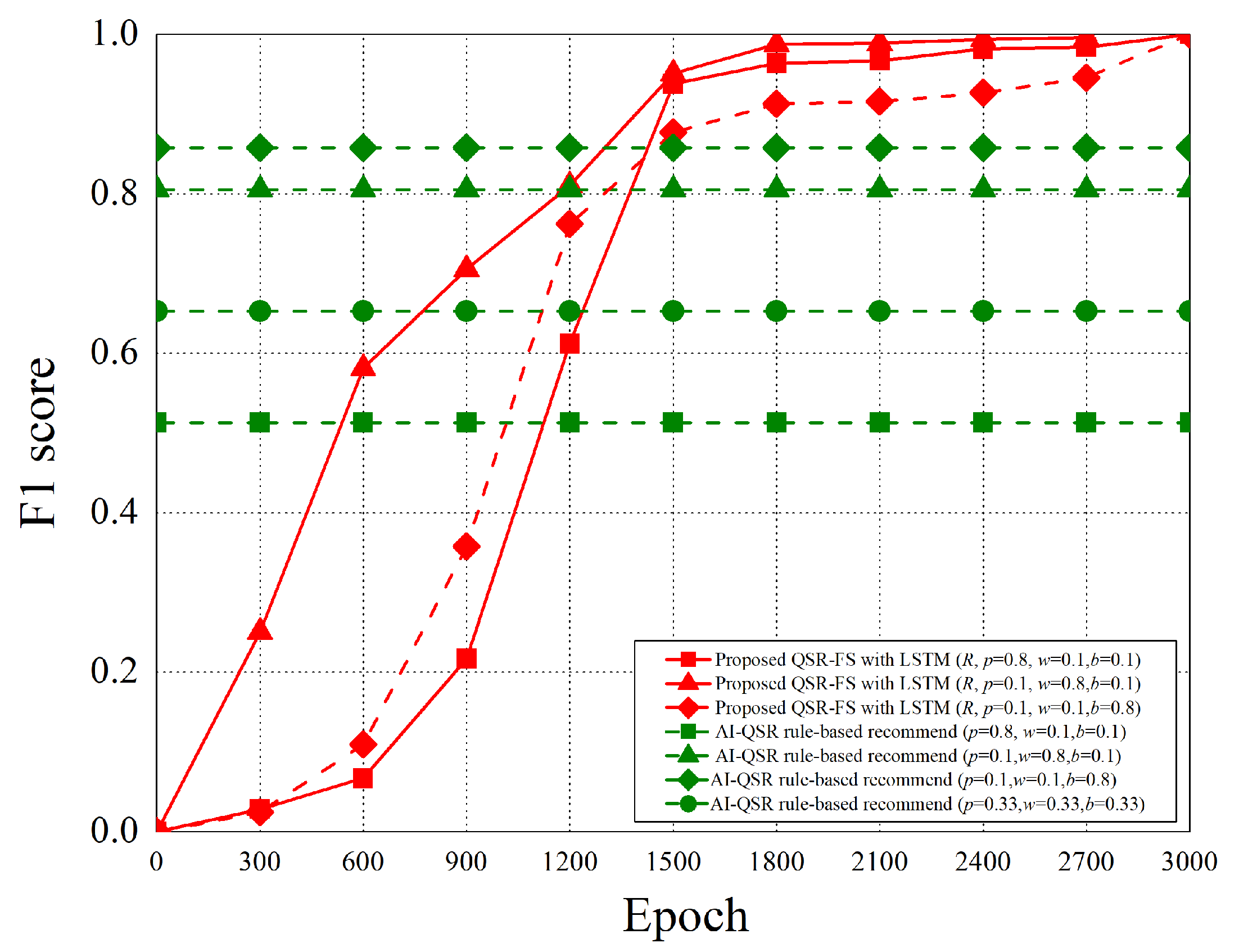
6.2.5. F1 Score
6.2.6. Iterations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Giang, N.; Lea, R.; Blackstock, M.; Leung, V. Fog at the Edge: Experiences Building an Edge Computing Platform. In Proceedings of the IEEE International Conference on Edge Computing (EDGE), San Francisco, CA, USA, 2–7 July 2018; pp. 9–16. [Google Scholar] [CrossRef] [Green Version]
- Ngoko, Y.; Cérin, C. An Edge Computing Platform for the Detection of Acoustic Events. In Proceedings of the IEEE International Conference on Edge Computing (EDGE), Honolulu, HI, USA, 25–30 June 2017; pp. 240–243. [Google Scholar]
- Choi, M.; Jung, H. Development of Fast Refinement Detectors on AI Edge Platforms. In Pattern Recognition, Proceedings of the ICPR International Workshops and Challenges, Virtual, 10–15 January 2021; Springer: Cham, Switzerland, 2021; pp. 592–606. [Google Scholar]
- Riggio, R.; Coronado, E.; Linder, N.; Jovanka, A.; Mastinu, G.; Goratti, L.; Rosa, M.; Schotten, H.; Pistore, M. AI@EDGE: A Secure and Reusable Artificial Intelligence Platform for Edge Computing. In Proceedings of the Joint European Conference on Networks and Communications & 6G Summit (EuCNC/6G Summit), Porto, Portugal, 8–11 June 2021; pp. 1–6. [Google Scholar]
- Hochstetler, J.; Padidela, R.; Chen, Q.; Yang, Q.; Fu, S. Embedded Deep Learning for Vehicular Edge Computing. In Proceedings of the IEEE/ACM Symposium on Edge Computing (SEC 2018), Seattle, WA, USA, 25–27 October 2018; pp. 341–343. [Google Scholar] [CrossRef]
- Moon, J.; Cho, S.; Kum, S.; Lee, S. Cloud-Edge Collaboration Framework for IoT Data Analytics. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 17–19 October 2018; pp. 1414–1416. [Google Scholar] [CrossRef]
- Li, H.; Shou, G.; Hu, Y.; Guo, Z. Mobile Edge Computing: Progress and Challenges. In Proceedings of the 4th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (MobileCloud), Oxford, UK, 29 March–1 April 2016; pp. 83–84. [Google Scholar] [CrossRef]
- Preethi, G.; Krishna, P.; Obaidat, M.; Saritha, V.; Yenduri, S. Application of Deep Learning to Sentiment Analysis for Recommender System on Cloud. In Proceedings of the International Conference on Computer, Information and Telecommunication Systems (CITS), Dalian, China, 21–23 July 2017; pp. 93–97. [Google Scholar] [CrossRef]
- Wu, S.; Wang, Y.; Zhou, A.; Mao, R.; Shao, Z.; Li, T. Towards Cross-Platform Inference on Edge Devices with Emerging Neuromorphic Architecture. In Proceedings of the Design, Automation Test in Europe Conference Exhibition (DATE), Florence, Italy, 25–29 March 2019; pp. 806–811. [Google Scholar] [CrossRef]
- Velasco-Montero, D.; Fernández-Berni, J.; Carmona-Galán, R.; Rodríguez-Vázquez, A. Optimum Selection of DNN Model and Framework for Edge Inference. IEEE Access 2018, 6, 51680–51692. [Google Scholar] [CrossRef]
- Ko, J.; Na, T.; Amir, M.; Mukhopadhyay, S. Edge-Host Partitioning of Deep Neural Networks with Feature Space Encoding for Resource-Constrained Internet-of-Things Platforms. In Proceedings of the 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Xia, C.; Zhao, J.; Cui, H.; Feng, X. Characterizing DNN Models for Edge-Cloud Computing. In Proceedings of the IEEE International Symposium on Workload Characterization (IISWC), Raleigh, NC, USA, 30 September–2 October 2018; pp. 82–83. [Google Scholar] [CrossRef]
- Rothe, R.; Timofte, R.; Van Gool, L. Deep Expectation of Real and Apparent Age from a Single Image Without Facial Landmarks. Int. J. Comput. Vis. 2018, 126, 144–157. [Google Scholar] [CrossRef] [Green Version]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Tang, J.; Wang, K. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. arXiv 2018, arXiv:1809.07426. [Google Scholar]
- Cheng, C.; Yang, H.; Lyu, M.R.; King, I. Where You Like to Go Next: Successive Point-of-interest Recommendation. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2605–2611. [Google Scholar]
- He, R.; Kang, W.; McAuley, J. Translation-based Recommendation. arXiv 2017, arXiv:1707.02410. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based Recommendations with Recurrent Neural Networks. arXiv 2016, arXiv:1511.06939. [Google Scholar]
- Hidasi, B.; Quadrana, M.; Karatzoglou, A.; Tikk, D. Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; ACM: New York, NY, USA, 2016; pp. 241–248. [Google Scholar] [CrossRef]
- Quadrana, M.; Karatzoglou, A.; Hidasi, B.; Cremonesi, P. Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks. arXiv 2017, arXiv:1706.04148. [Google Scholar]
- Jannach, D.; Ludewig, M. When Recurrent Neural Networks Meet the Neighborhood for Session-Based Recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems (RecSys 2017), Como, Italy, 27–31 August 2017; pp. 306–310. [Google Scholar] [CrossRef]
- Mokdara, T.; Pusawiro, P.; Harnsomburana, J. Personalized Food Recommendation Using Deep Neural Network. In Proceedings of the Seventh ICT International Student Project Conference (ICT-ISPC), Nakhonpathom, Thailand, 11–13 July 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Leong, P.; Goh, O.; Kumar, Y. MedKiosk: An Embodied Conversational Intelligence via Deep Learning. In Proceedings of the 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Guilin, China, 29–31 July 2017; pp. 394–399. [Google Scholar] [CrossRef]
- Wang, C.; Yang, G.; Papanastasiou, G.; Zhang, H.; Rodrigues, J.J.P.C.; de Albuquerque, V.H.C. Industrial Cyber-Physical Systems-Based Cloud IoT Edge for Federated Heterogeneous Distillation. IEEE Trans. Ind. Inform. 2021, 17, 5511–5521. [Google Scholar] [CrossRef]
- Kasi, S.K.; Kasi, M.K.; Ali, K.; Raza, M.; Afzal, H.; Lasebae, A.; Naeem, B.; ul Islam, S.; Rodrigues, J.J.P.C. Heuristic Edge Server Placement in Industrial Internet of Things and Cellular Networks. IEEE Internet Things J. 2021, 8, 10308–10317. [Google Scholar] [CrossRef]
- OpenVino. Available online: https://software.intel.com/en-us/openvino-toolkit (accessed on 10 July 2022).
- yu4u/age-gender-estimation. Available online: https://github.com/yu4u/age-gender-estimation (accessed on 10 July 2022).





















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-S.; Cheng, K.-H.; Hsu, C.-S.; Zhang, H.-L. MiniDeep: A Standalone AI-Edge Platform with a Deep Learning-Based MINI-PC and AI-QSR System. Sensors 2022, 22, 5975. https://doi.org/10.3390/s22165975
Chen Y-S, Cheng K-H, Hsu C-S, Zhang H-L. MiniDeep: A Standalone AI-Edge Platform with a Deep Learning-Based MINI-PC and AI-QSR System. Sensors. 2022; 22(16):5975. https://doi.org/10.3390/s22165975
Chicago/Turabian StyleChen, Yuh-Shyan, Kuang-Hung Cheng, Chih-Shun Hsu, and Hong-Lun Zhang. 2022. "MiniDeep: A Standalone AI-Edge Platform with a Deep Learning-Based MINI-PC and AI-QSR System" Sensors 22, no. 16: 5975. https://doi.org/10.3390/s22165975
APA StyleChen, Y. -S., Cheng, K. -H., Hsu, C. -S., & Zhang, H. -L. (2022). MiniDeep: A Standalone AI-Edge Platform with a Deep Learning-Based MINI-PC and AI-QSR System. Sensors, 22(16), 5975. https://doi.org/10.3390/s22165975