1. Introduction
Accurate and up-to-date road maps are critical for location-based services, such as vehicle navigation and geo-enabled social networks. Because road entities change continuously over time, especially in the urban areas of developing countries, existing road maps need to be updated regularly to remain consistent with the real world. However, national mapping agencies usually update road maps by surveying with specialized devices or by digitizing road features from high-resolution satellite imagery. These methods require extensive time and labor, making it difficult to maintain up-to-date maps. In recent years, the widespread use of GPS-enabled devices has driven an explosion of trajectory data from road users, such as vehicle drivers. This new type of geospatial resource contains not only geometrical and topological information for underlying road networks but also semantic information, such as traffic rules and patterns. Moreover, short-term changes in moving paths and rules can be sensed from the continuous tracking data, enabling them to be updated in real-time. For these reasons, extracting road information from trajectory data is becoming an attractive method for road map production and updating [
1,
2].
A number of approaches have been developed to generate road networks from trajectories, including approaches based on spatial clustering [
2,
3,
4], incremental track integration [
5,
6], and intersection linking [
7,
8,
9,
10]. Most of these approaches focus on the extraction of road centerlines, while intersections, defined as areas where two or more roads either meet or cross, are simply recognized as graph nodes where centerlines are connected. In the representation of a road network, intersections can be simple crossroads or various complicated structures, such as roundabouts. Obtaining well-structured intersections is not only essential for building the topology of road networks, but it is also beneficial for obtaining a geometric representation of the roadways. Particularly for urban areas, automatic intersection detection and delineation approaches are highly necessary for various applications, such as traffic management [
11], analyses of transportation routes [
12], and analyses of urban sprawl [
13]. Therefore, intersections must be adequately considered in the generation of road networks.
However, obtaining accurate and well-structured intersections from raw trajectories continues to be a challenging task. From the perspective of traffic engineering, an intersection is designed to allow vehicles to change from one road to another. This means that complex geometrical structures and traffic rules may exist within a small area of an intersection. In one of the earliest attempts to detect intersections, a shape descriptor was designed to represent the heading changes of tracking points around a given location and trained a classifier to discriminate the intersections from non-intersections [
7]. Turning points were detected in literature [
8] by examining changes in the speed and heading of vehicles. The turning points were then grouped to generate intersections by hierarchical clustering. A spatial analysis was performed of the conflict points among the trajectories that intersect with a large angle to compute the layouts of intersections [
14]. To enable the effective detection of turns, literature [
15] proposed a distance-weighted average heading filter to eliminate the serious motor-vehicle trajectory fluctuations, and literature [
16] employed the Douglas–Peucker compression algorithm to remove noise. Intersections were detected in the literature by [
17] using a hierarchical feature extraction strategy. The turning change point pairs were extracted from trajectories by setting the heading and time interval thresholds and were then clustered to obtain the coverage of the intersections. Literature [
18] identified candidate intersection points by applying a hotspot analysis of the local G statistic to the turning angles of tracking points. A large positive G* value represents a hotspot cluster in which the points with large angles are closer together. Subsequently, an adaptive clustering algorithm grouped the candidate points to obtain the intersections. In this approach, the detection result is closely related to the threshold G* value. A novel method for constructing a lane-level motorway network was presented using low-precision GPS data [
19]. In this study, an intersection was defined where two bundles of trajectories merge or diverge. Based on this definition, the QuickBundles clustering method was used to obtain the trajectory bundles [
20]. Then, road intersections were detected though analyzing the intersections of trajectory paths belonging to different bundles. Literature [
21] uses Mask-RCNN to extract macroscopic information on road intersections. In addition to the coverage of intersections, this approach attempts to classify the detected intersections into different patterns.
In general, an essential step prior to intersection generation is the recognition of turns (i.e., the curved parts of vehicle trajectories). Turning points are commonly defined as heading changes exceeding a predefined threshold. Then, spatial analysis is applied to cluster the turning points into intersection units and compute each intersection’s properties. However, these approaches face usability problems. Owing to the diversity of intersection patterns and sizes, it is difficult to determine an appropriate turning angle threshold [
16,
22,
23]. A low or high threshold inevitably leads to incorrect turn detection. Furthermore, quality issues in raw trajectory data, such as fluctuating positional precision and inconsistent sampling rates, increase the difficulty of characterizing the turns occurring at intersections. Other indicators, such as the speed change in the vehicle and the curvature of the segment formed by connecting consecutive tracking points, should be integrated with the change in direction to improve the performance of turn detection.
To address the aforementioned issues, this study introduces a deep learning technique to detect the turns at intersections from raw trajectories, aiming to alleviate the difficulty of parameter setting in turn detection and to develop a more robust method that can benefit from the movement pattern information hidden in each trajectory. Through continuous training, deep neural networks can capture high-level features and identify hidden patterns [
24]. Among various neural networks, the long short-term memory (LSTM) neural network is an effective model for handling time-series data. As an improved version of the traditional recurrent neural network, the LSTM neural network has the ability to capture long-term dependencies in sequencing data [
25,
26]. Previous studies have shown the successful application of LSTM in the fields of natural language processing [
27], machine translation [
28], and speech recognition [
29]. Recent studies have also applied LSTM-based models for trajectory analysis tasks, including trajectory clustering [
30], transportation mode classification [
31], and location prediction [
32,
33]. In this study, we explore the potential of LSTM to detect intersections from trajectories. Specifically, we convert each trajectory into a feature sequence that stores the motion attributes of the vehicle along the trajectory. Subsequently, an LSTM-based model is trained to identify the turning trajectory segments (TTSs), each of which represents a turn occurring at an intersection, by capturing a deep representation of the input feature sequence. Finally, the detected TTSs are clustered to generate the coverage and structure of the intersections.
The remainder of this paper is organized as follows. The proposed approach is explained in
Section 2.
Section 3 presents the experimental datasets, intersection detection results, and detailed analyses. A general discussion is presented in
Section 4, and key areas for future work are described in
Section 5.
2. Methods
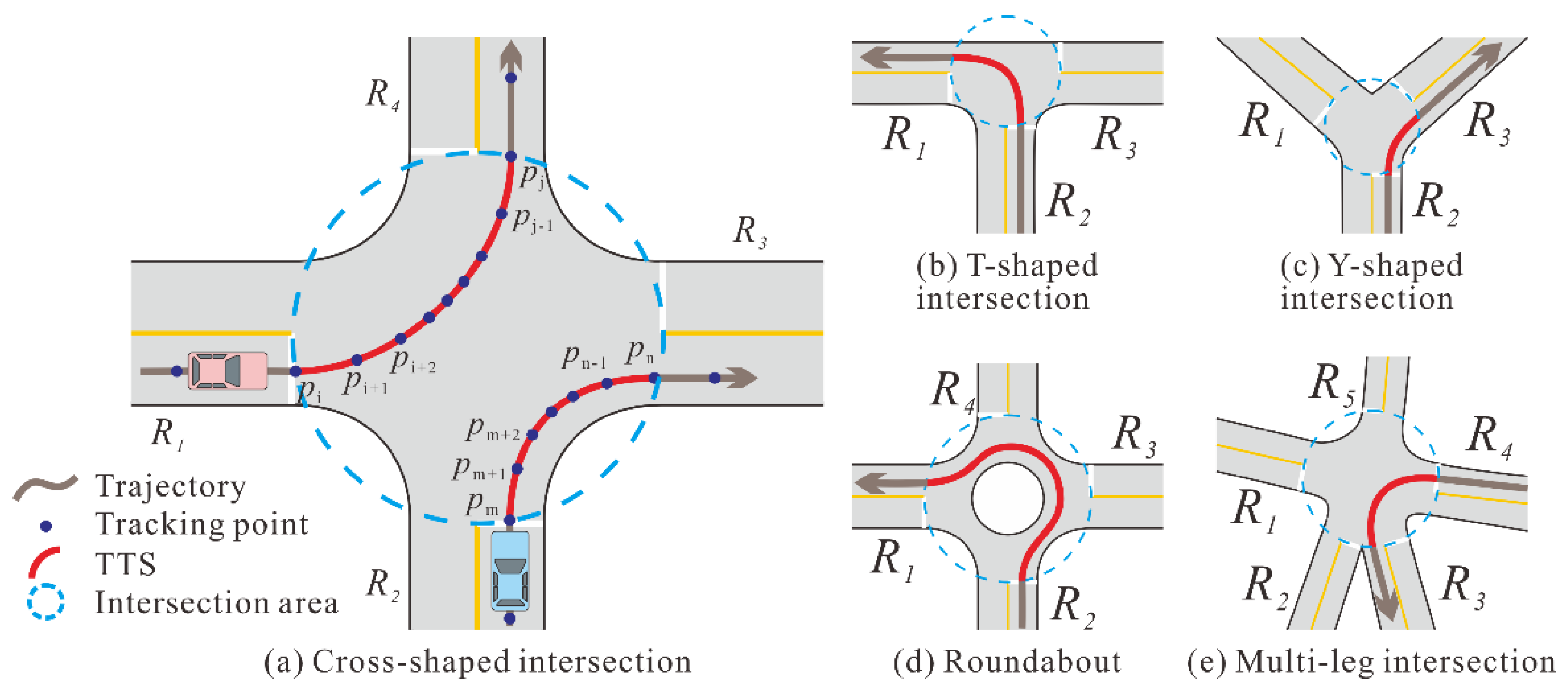
We represent the structure of an intersection as a network graph with a simple circular area. When a vehicle turns within an intersection, the TTS starts from the first tracking point entering the boundary circle and ends with the last point leaving it. As illustrated in
Figure 1a, the trajectory segment from
to
, denoted as
, and the trajectory segment from
to
, denoted as
, are two TTSs that record the left and right turns at a cross-shaped intersection, respectively. Moreover,
and
indicate the entry points, while
and
are located near the exits of the intersection.
Figure 1 shows the TTS samples for the various intersection types.
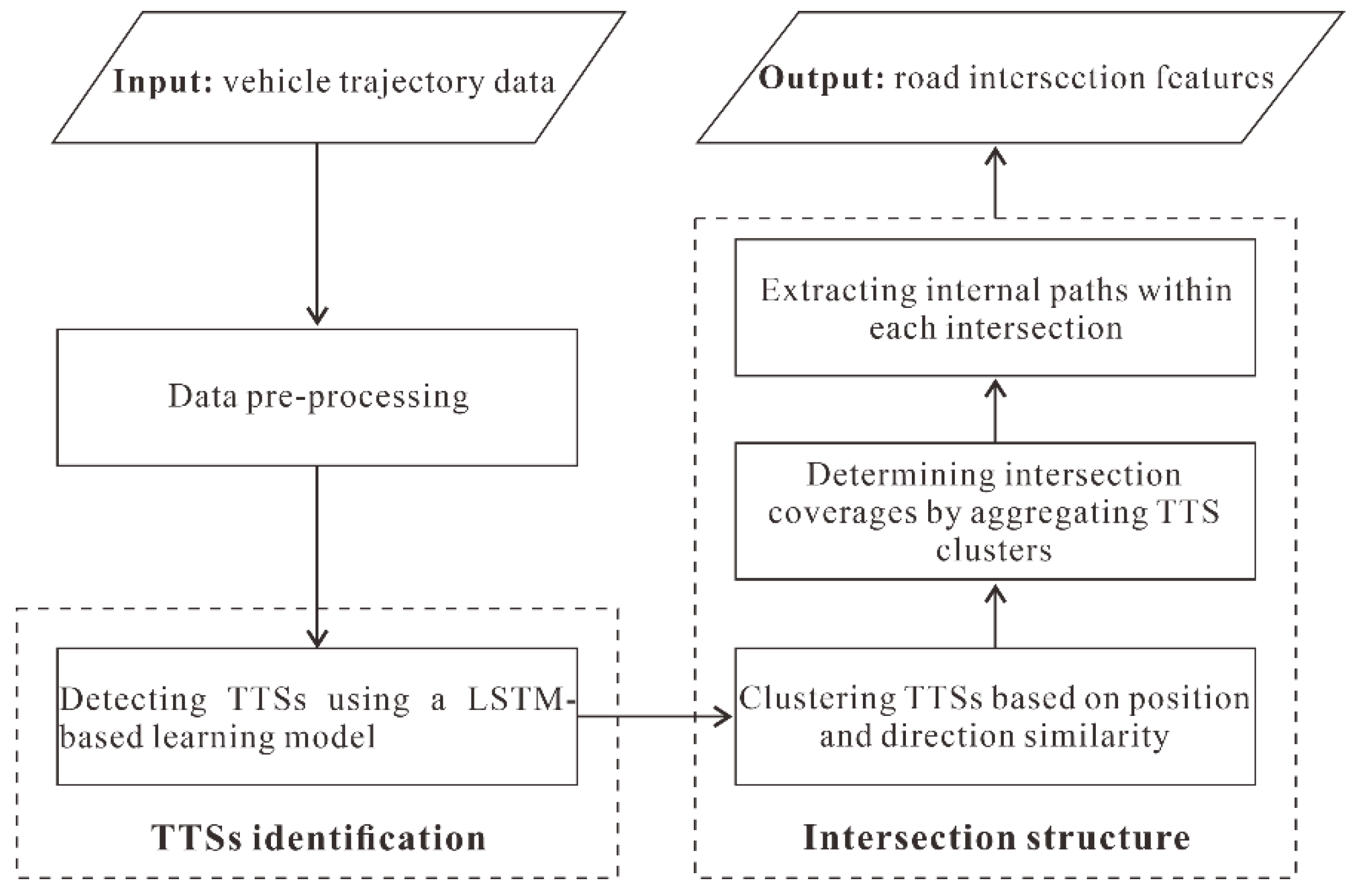
The overall framework of the proposed approach consists of two parts, as illustrated in
Figure 2. Specifically, the two components are:
- (1)
TTS detection: this component identifies the TTSs contained in each trajectory using an LSTM-based model that integrates the various motion attributes implied in the tracking points.
- (2)
Intersection generation: this component calculates the TTS clusters based on the similarity of the position and direction measures and then determines the coverage of the intersections by aggregating the TTS clusters and extracting the internal paths of each intersection.
2.1. Data Pre-Processing
Owing to various uncertain factors, the raw trajectories must be cleaned by reducing the outliers and random errors. Initially, the tracking points for each vehicle are ordered chronologically as a trajectory. When the time interval between two consecutive points exceeds a predefined threshold, , the trajectory is split into two sub-trajectories. Moreover, the tracking points with speeds exceeding the maximum valid speed threshold are labeled invalid. After removing the invalid tracking points, the trajectories whose lengths are smaller than the threshold are also discarded.
An interpolation operation with a distance threshold,
, is performed for each trajectory to ensure that the distances between the pairs of adjacent points are close. Then, the Savitzky–Golay filter is applied to reduce random errors [
34]. As a widely used approach for smoothing a time series, the Savitzky–Golay filter can reduce random positional errors in the input trajectories without causing significant distortion of their original shapes and motion features [
35]. It replaces each tracking point with a new point obtained from a polynomial fit to data within a window centered at the subject point. Note that the parameter settings during the pre-processing are closely related to the characteristics of the trajectory data.
2.2. Detecting TTSs Using an LSTM-Based Model
Let T denote a trajectory that contains a sequence of tracking points
with timestamps
and
denotes the line segment between the two consecutive tracking points
and
. Detecting TTSs contained in T can be viewed as a classification task, which aims to determine whether each line segment belongs to a TTS or not. For this task, an LSTM-based sequence-to-sequence model is proposed to learn and predict the class of each line segment in a trajectory.
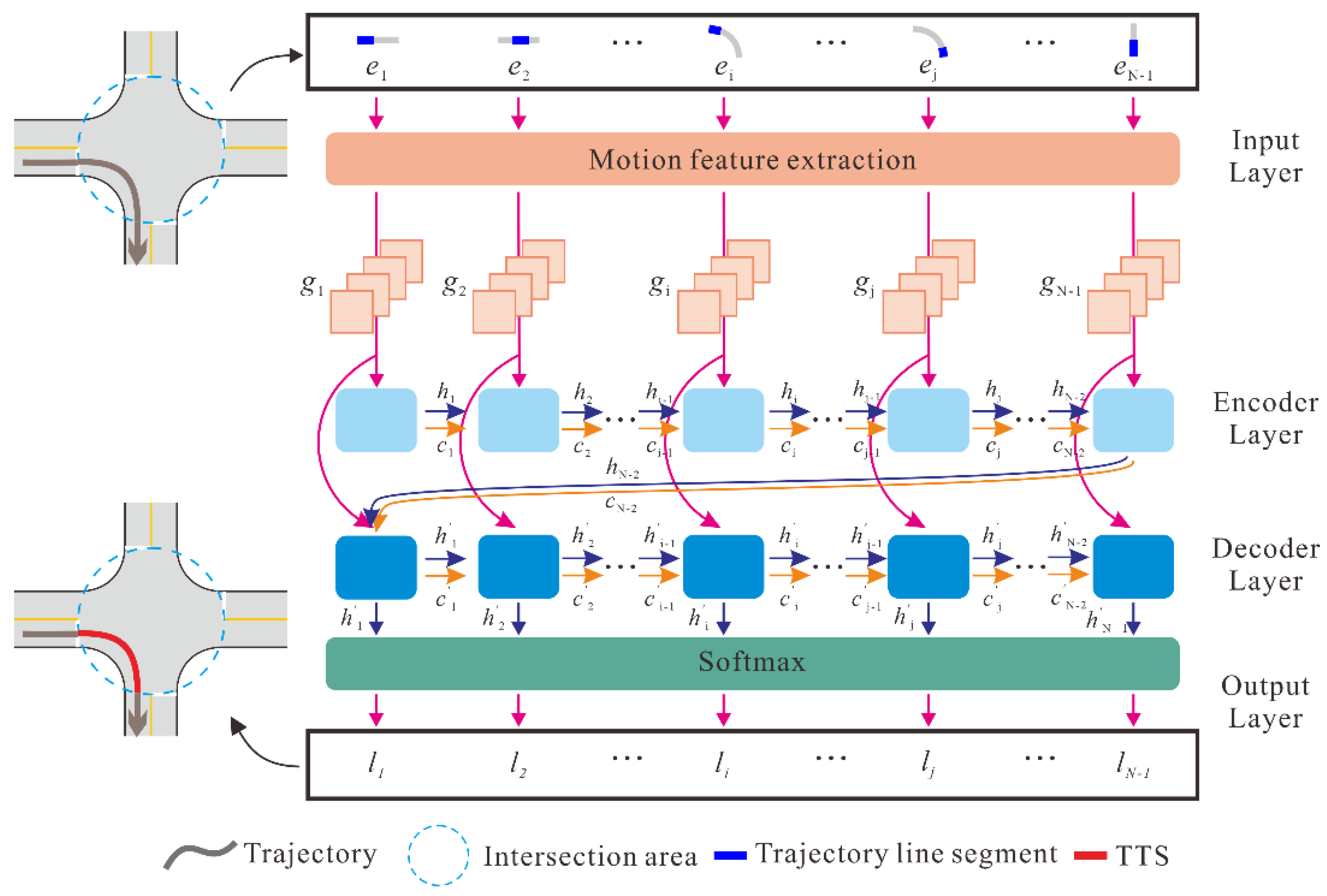
Figure 3 presents the architecture of the proposed model, including the input layer, encoder and decoder layers, and output layer.
2.2.1. Input Layer
The input layer converts the representation of T into a sequence of vectors {g1, g2, …, gN−1}, where gi stores the attributes that describe the motion characteristics of the vehicle at line segment . We traverse a sliding window with constant size , defined by the number of line segments inside the window, along each trajectory to obtain its motion attribute sequence. When the sliding window is centered at line segment , four motion attributes, including tortuosity, turning angle, speed and acceleration, are computed according to the tracking points inside the window.
Distinct from traveling on roadways, a vehicle changes its heading substantially when turning at an intersection. Accordingly, we introduce the tortuosity and turning angle as the first two motion attributes. Let
denote the tracking points inside the sliding window. The tortuosity and turning angle are computed using Equations (1) and (2), respectively.
where
dis(
) is a function that returns the Euclidean distance from
to
and
and
represent the moving headings of tracking points
and
, respectively. The heading of point
is defined as the clockwise angle between due north and the vector
.
Vehicles usually change their speed at intersections, which provides another indicator to detect turning behavior. In this study, speed and acceleration are adopted as the other two motion attributes and are measured using Equations (3) and (4), respectively.
After calculating the four motion attributes of each line segment, a motion attribute sequence with a four-channel structure is constructed for the input trajectory. Note that the sequence length varies among the input trajectories owing to variation in the number of tracking points. To ensure that each instance input to the model has the same size, which is critical for uniformly applying the model weights and biases to the entire batch, a fixed-length processing approach is implemented. Using MaxLen (denoting the constant length of a sequence within a batch) as a threshold, longer sequences are sub-divided, and zero values are appended to the end of the shorter sequences.
2.2.2. Encoder and Decoder Layers
As shown in
Figure 3, the encoder and decoder layers employ two LSTM neural networks. As a recurrent neural network variant, the LSTM effectively overcomes the vanishing and exploding gradient problem by introducing a trainable forget gate [
25].
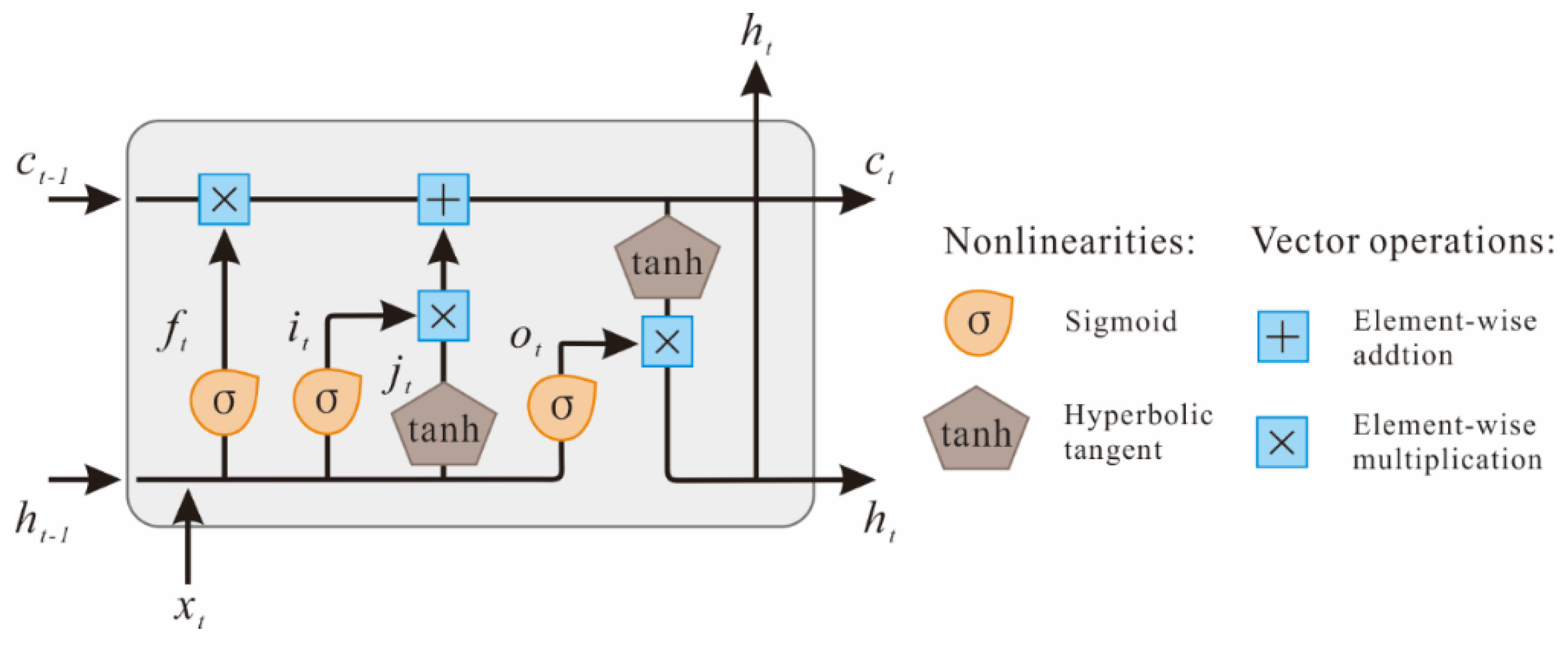
Figure 4 illustrates the structure of an LSTM unit, where
and
are the input and output of the LSTM unit at time
, respectively, and
denotes the cell state of the LSTM unit. In addition,
denotes the vectors of the forget gate,
and
denote the vectors of the input gate, and
denotes the vectors of the output gate. The LSTM unit works based on the following mechanism.
where
represents the element-wise product,
and
denote the weight matrices and bias vectors, which are adjusted through training. The activation functions sigmoid
and hyperbolic tangent
are used for nonlinear scaling.
The encoder sequentially processes the motion attribute sequence {g1, g2, …, gN−1}. Once a new vector gi is added to the encoder, the hidden state and the cell state of the current LSTM unit are calculated based on the input gi, hidden states , and the cell state of the previous LSTM unit. After the last vector, gN−1, is processed, the encoder summarizes the entire input sequence into the final states and . Then, using and as the initial states, the decoder recursively generates the output sequence . The output vector for the ith decoder LSTM unit is derived by combing vector gi and the states and that were obtained from the previous decoder LSTM unit.
2.2.3. Output Layer and Training Process
The output layer generates the classification decision for each line segment of the input trajectory T. By applying the Softmax function to the output vector, , the predicted probability vector is derived for each line segment , where represents the probability of not being a part of a TTS and represents the probability of being a part of a TTS. and are both in the interval of (0, 1). If , is predicted as a part of a TTS; otherwise, is predicted as a part of a non-TTS. The contained TTSs can then be obtained by connecting the consecutive line segments with positive predictions.
The proposed model was trained using a supervised method. The goal of the training process is to learn the optimal parameters that minimize the loss function. In this study, the loss function was calculated using categorical cross-entropy.
2.3. Generating Intersection Structures from TTSs
At this stage, the intersections are generated by estimating the spatial distribution of the detected TTSs. First, the detected TTSs are clustered based on the similarity of the position and direction measures. Then, the coverages of the intersections are determined by aggregating the TTS clusters. Finally, the internal road paths for each intersection are constructed.
2.3.1. Clustering TTSs Based on Position and Direction Similarity
This step aims to obtain clusters of TTSs, with each cluster indicating a turning path. Based on previous studies [
17], the similarity between two TTSs was measured by estimating the differences in position and direction at their critical points. Suppose
and
are the two detected TTSs, and
and
are the middle points of these two TTSs. The position and direction differences between
and
are calculated using equations (11) and (12), respectively.
where
is a function that returns the angle between the vectors of
and
, and a constant
d is utilized to normalize the distance measure during the similarity computation. The overall similarity between the two given TTSs is computed as follows:
where
and
are the weights related to the distance and direction measures, respectively.
Based on the aforementioned similarity model, a seed-based approach was implemented to cluster the detected TTSs. Let
denote the set of TTSs. The clustering process is as follows. (1) Randomly select an element
from
as a cluster seed and search for the elements in
satisfying the condition
, where
is a predefined similarity threshold. (2) Merge the seed TTS as well as the searched TTSs to form a new cluster, which is removed from
. (3) Steps (1) and (2) are repeated until the set
is empty. Finally, the TTSs are organized as a set of clusters,
, where
denotes a TTS cluster. A sample TTS clustering result is shown in
Figure 5, where adjacent TTSs marked with the same color belong to one cluster.
2.3.2. Determining the Coverages of Intersections by Aggregating TTS Clusters
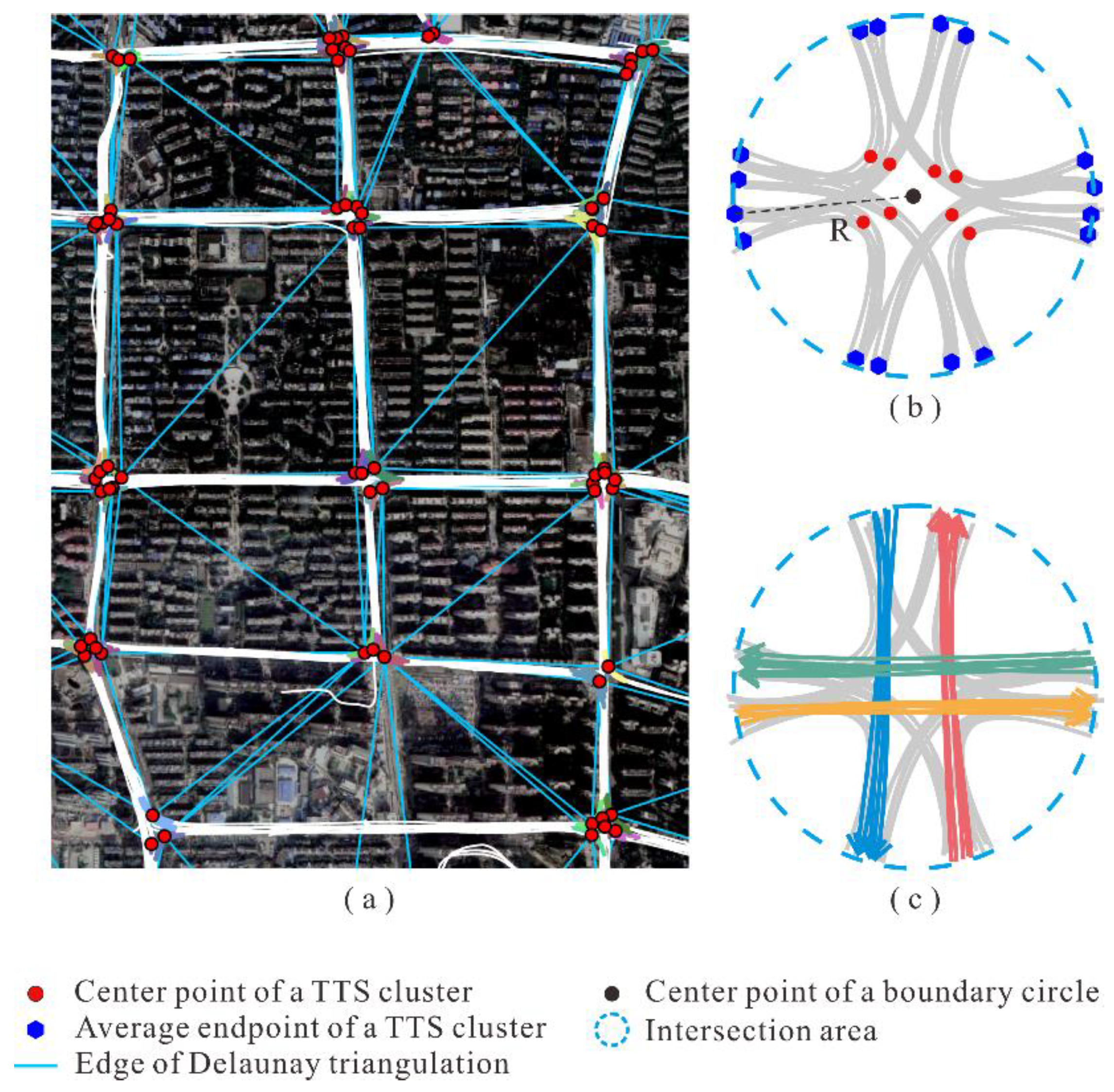
Next, the TTS clusters are aggregated to obtain the spatial coverage of the intersections. The procedure is illustrated in
Figure 6. Each TTS cluster is represented by its center point, which is the average middle point of all the TTSs in the cluster. As depicted in
Figure 6a, a Delaunay triangulation model was built for all the center points to describe the adjacent relationships of the TTS clusters. The triangle edges with lengths exceeding the predefined threshold,
, are removed. Subsequently, the TTS clusters whose center points are connected by the remaining triangle edges are merged into a group.
For each TTS cluster group, a circular area is created as the coverage of the intersection. As shown in
Figure 6b, the center of the circle is defined as the average coordinates of all center points of the TTS clusters, and the radius is determined as the longest distance between the circle center and all endpoints of the TTS clusters. The endpoints of each TTS cluster are computed by averaging the endpoints of all the TTSs in the cluster. Finally, as shown in
Figure 6c, the non-TTSs within the intersection area are extracted by clipping the trajectories with the boundary circle. Note that the obtained non-TTSs are also clustered using the clustering method mentioned earlier.
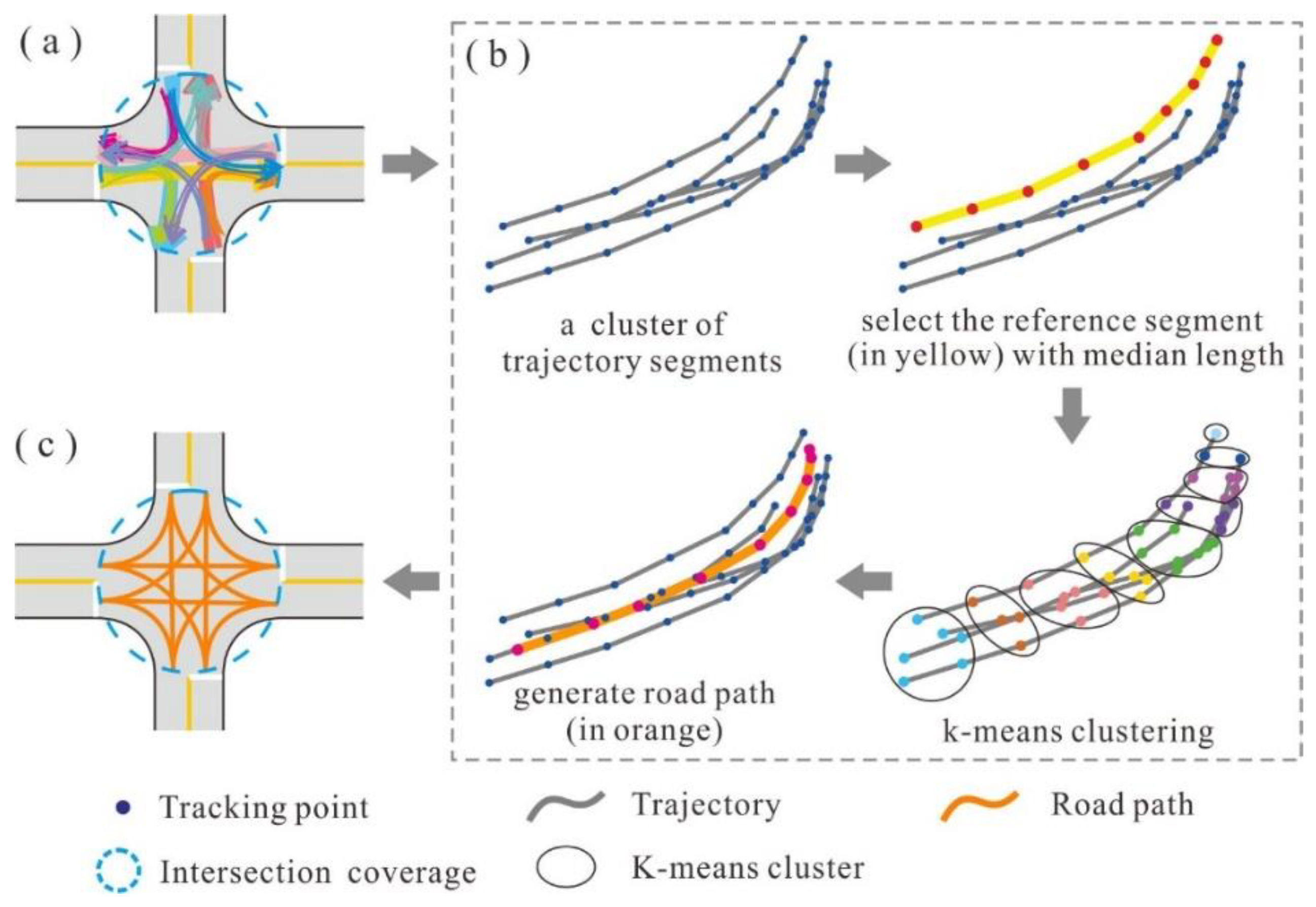
2.3.3. Generating the Structural Model for Each Intersection
The structural model of an intersection can be delineated by extracting the central paths of the associated TTS and non-TTS clusters. The path extraction process is illustrated in
Figure 7. For each TTS or non-TTS cluster, the element with the median length is selected as the reference segment. Next, the tracking points of the reference segment are regarded as the initial centers, and the K-means clustering approach is applied to group all tracking points [
36,
37]. The value of K is set to the number of tracking points in the reference segment. Finally, a path is constructed by connecting the centers of the point groups in chronological order.
4. Discussion
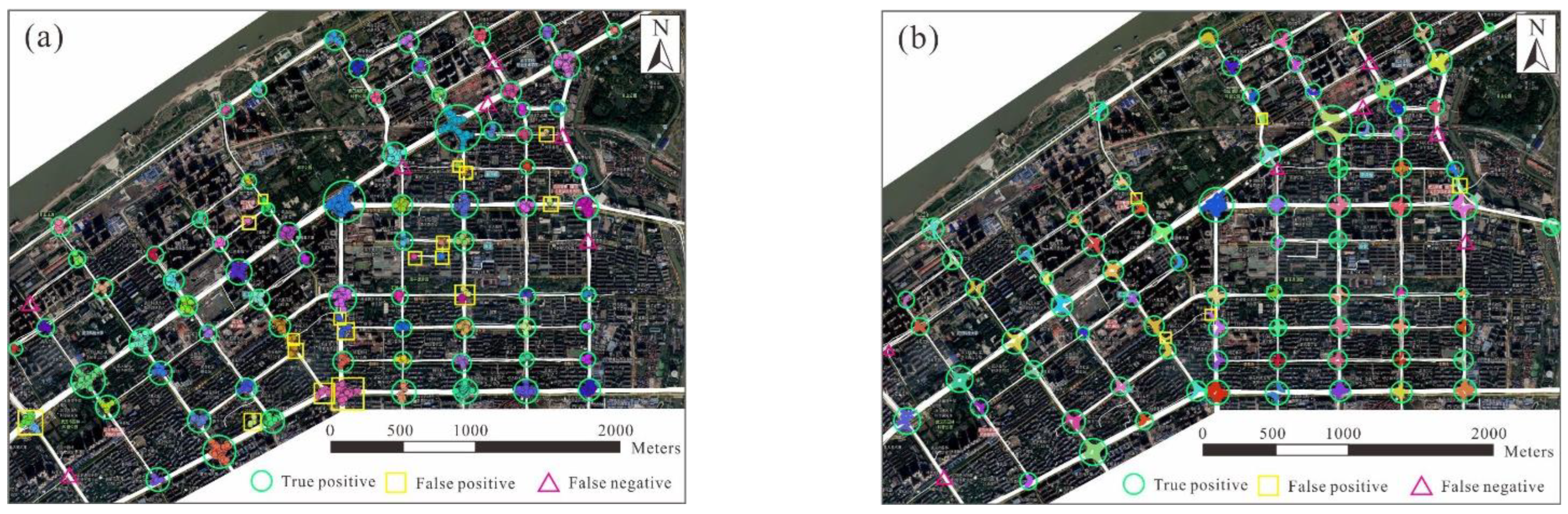
The experimental results show that the proposed approach outperforms the local G* statistic-based approach in terms of precision. This improvement benefited from the introduction of the LSTM neural network, which enabled the extraction of high-level moving patterns based on the implicit direction and speed changes in the trajectories. Thus, it helped our approach to better detect the turns (i.e., TTSs) occurring at intersections. Moreover, the difficulty of the parameter settings during the turn detection was alleviated. Existing approaches require the manual determination of appropriate thresholds on heading changes, which can easily lead to incorrect detection due to the diverse structures and sizes of intersections. In contrast, the proposed approach employs the LSTM neural network to learn knowledge to identify the turns from samples, which does not require a manual setting of relevant parameters or rules.
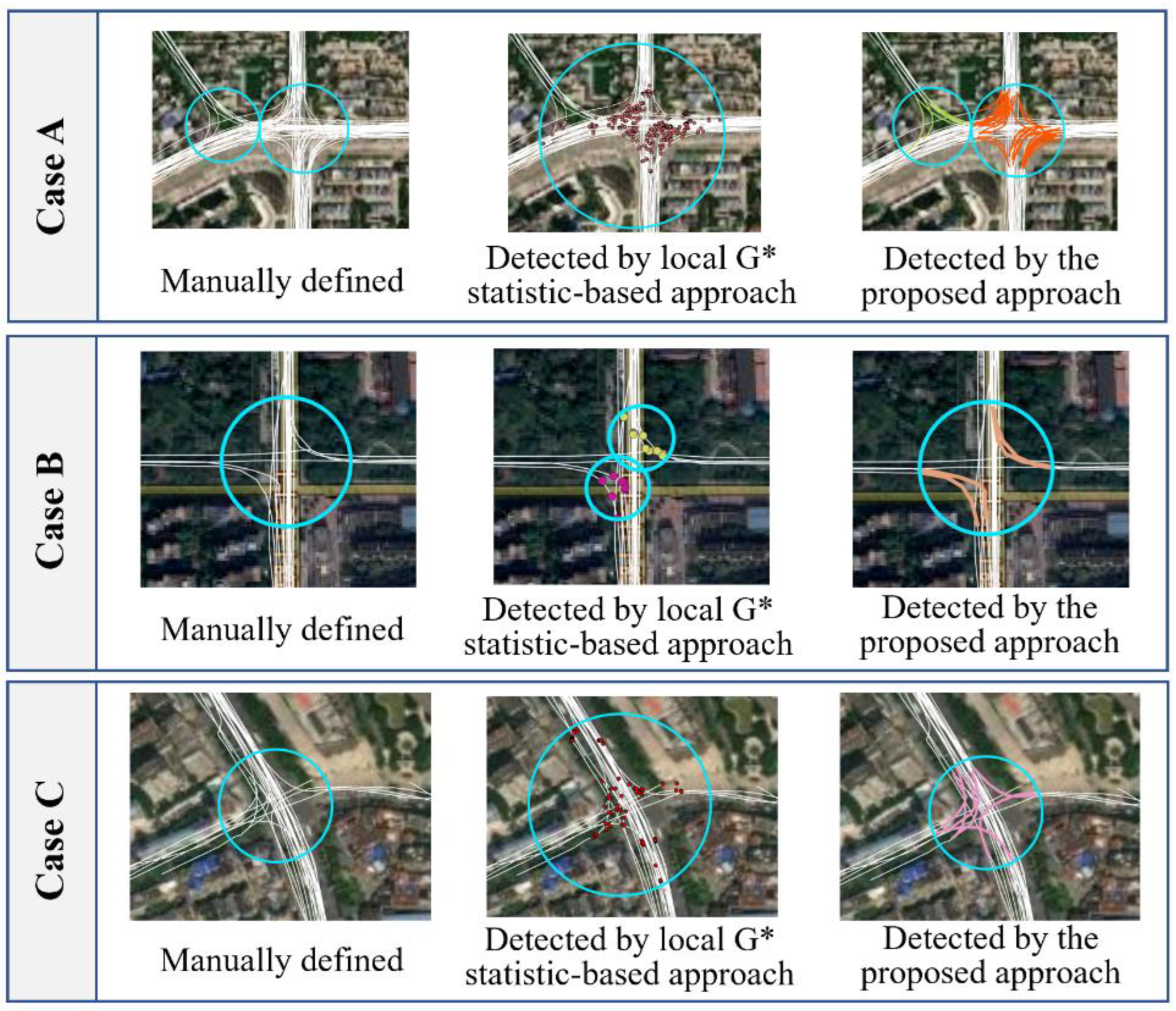
Despite the relatively good performance of the proposed approach, a small number of intersections were not accurately detected. First, the detection of the y- and Y-shaped intersections needs to be improved. Unlike the T-shaped and cross-shaped intersections, the y- and Y-shaped intersections involve turns with slight heading changes. This makes it difficult to identify the associated TTSs from the trajectories, leading to the missing detection of intersections. Second, it is still challenging to obtain the complete structure of complex intersections.
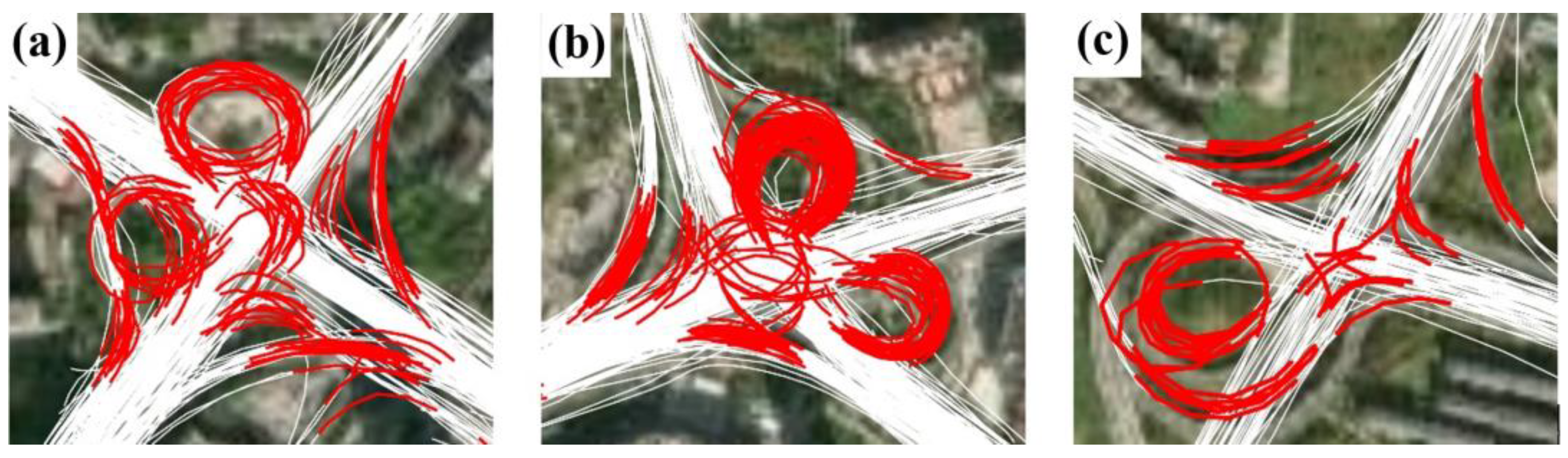
Figure 14 presents a close view of the detected TTSs around several complex intersections. In these examples, many TTSs across intersection areas were missing or not accurately detected, resulting in failures in coverage and internal path generation. The complex intersections, such as interchanges and overpasses, show diverse external shapes and complex internal structures, making their turns much more difficult to characterize. Future work needs to collect more trajectory samples that cover these complex intersections of various sizes and structures and further investigate how those complex intersections can be better tackled.
Moreover, as a supervised learning method, the proposed LSTM-based model depends heavily on high-quality training samples. Labeling sample trajectories requires a certain amount of work and support from professionals. In addition, further investigation is required before using the trained LSTM-based model on other trajectory datasets. For example, applying the model trained on the trajectory samples of Wuhan to detect TTSs in Beijing’s trajectories might see a certain decrease in model performance because of the differences in intersection patterns and local traffic regulations. In such situations, the LSTM-based model may need to be restructured (e.g., the setting of the hidden state in the encode and decode layers) and retrained.
The LSTM-based model alleviates the difficulty of parameter setting and, in turn, detection. However, other steps of the proposed approach, i.e., data pre-processing and intersection structure generation, are still susceptible to the setting of parameters, such as the similarity threshold in TTS clustering and the distance threshold in intersection coverage determination. To solve this problem, an end-to-end approach that generates road intersections from raw trajectories directly using a single neural network or a combination of neural networks needs to be investigated.
5. Conclusions
The widespread use of vehicle trajectory data has provided new opportunities for monitoring transportation infrastructures and updating road maps. However, there is still a lack of effective tools for realizing automatic transformation from raw trajectory data to road features. This paper presents a new approach for detecting turns and generating intersections from trajectories. An LSTM-based model was developed to analyze the motion characteristics of the vehicle along each trajectory and to detect TTSs, each of which indicates a turn at an intersection. The detected TTSs were then clustered to obtain the coverage and internal structure of the intersections. The proposed approach was validated using a trajectory dataset obtained from Wuhan. In a central urban region, the intersection detection achieved a precision of 94.0% and a recall of 91.9%. In a semi-urban region, the intersection detection precision and recall were 94.1% and 86.7%, respectively. These results were better than those obtained using the local G* statistic-based approach.
Future work can focus on three aspects to improve the robustness of our approach. First, it is necessary to establish a high-quality sample dataset that contains trajectories covering intersections with various patterns and sizes. Second, other deep learning networks, such as the one-dimension convolutional or graph neural networks, can be considered when searching for more robust models for turn detection. Third, the quality of the generated intersection features, including position accuracy and structural integrity, needs to be fully assessed against official, authoritative road data. Beyond the specific topic of generating road intersections, the proposed approach can potentially be extended to mine the movement behaviors from spatiotemporal trajectory data. This field provides promise for studies of implicit patterns and interpreting human mobility behaviors by spatiotemporal data analytics.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}