
Aeroengine Working Condition Recognition Based on MsCNN-BiLSTM

Abstract
:1. Introduction
2. Basic Theory
2.1. Aeroengine Working Condition Recognition
2.2. CNN–LSTM
3. The Proposed Model
3.1. Multi-Scale Convolutional Neural Networks
3.1.1. Multi-Scale Feature Extraction Network
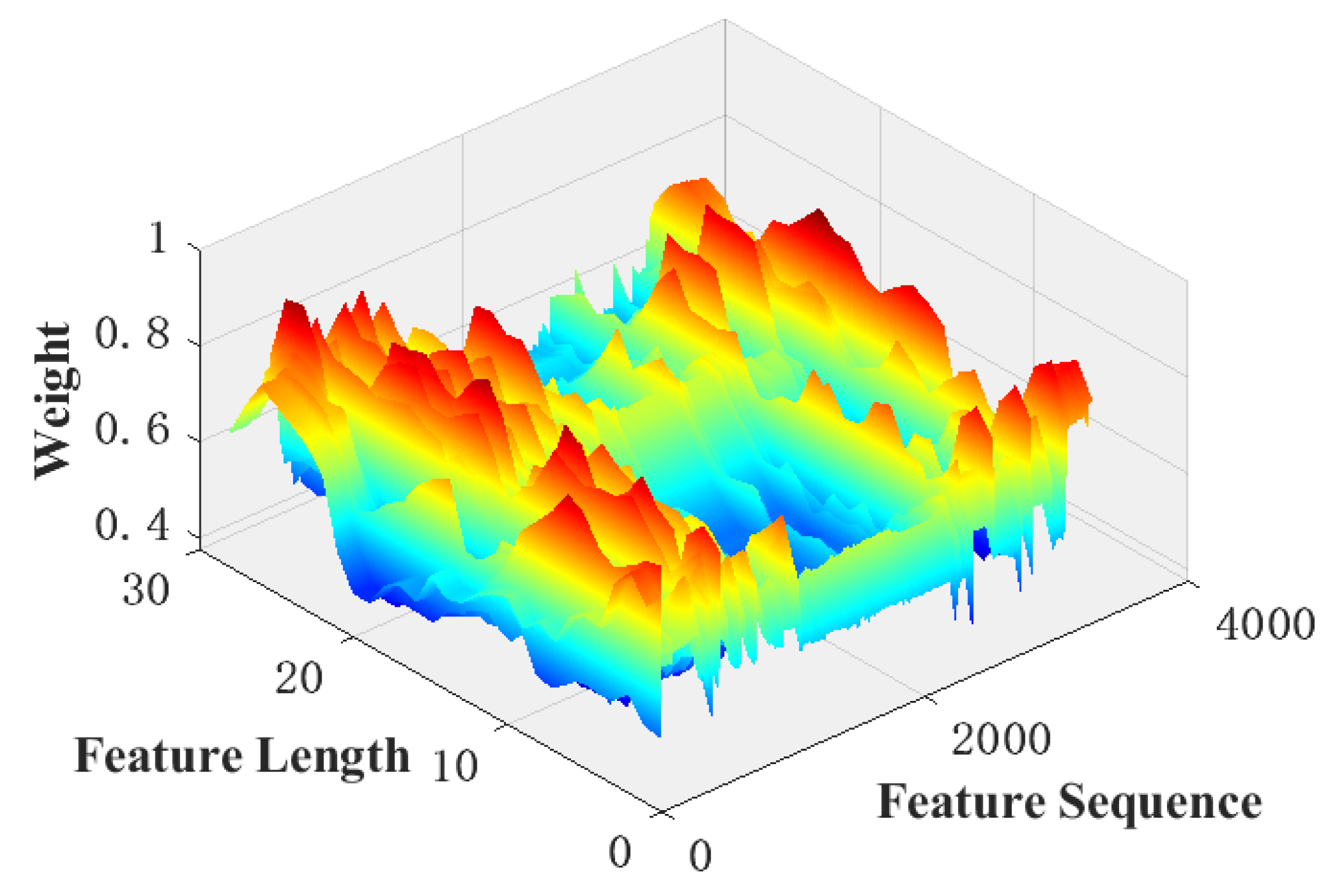
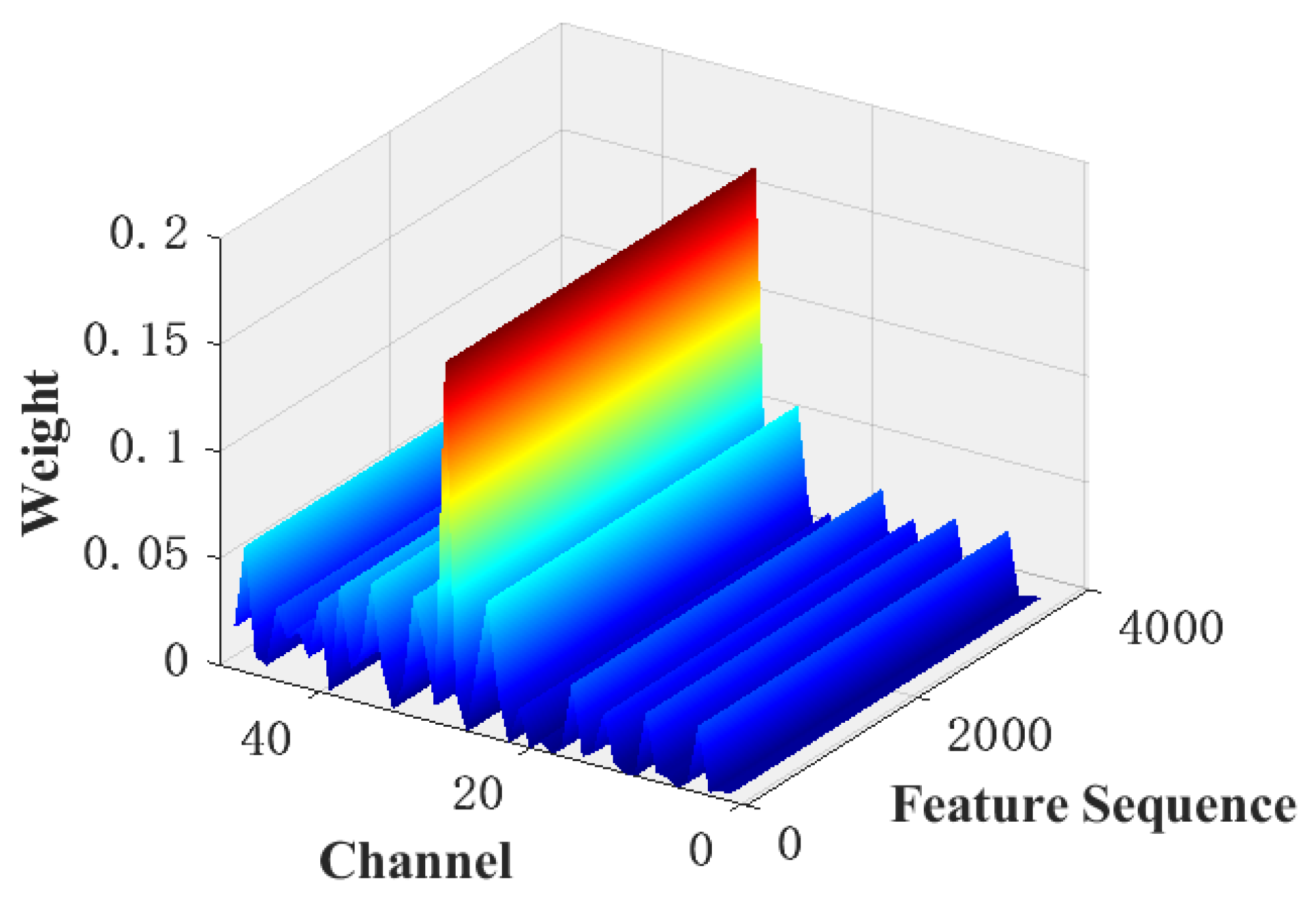
3.1.2. Adaptive Weight Correction Unit
3.2. Overall Structure
3.3. Main Steps
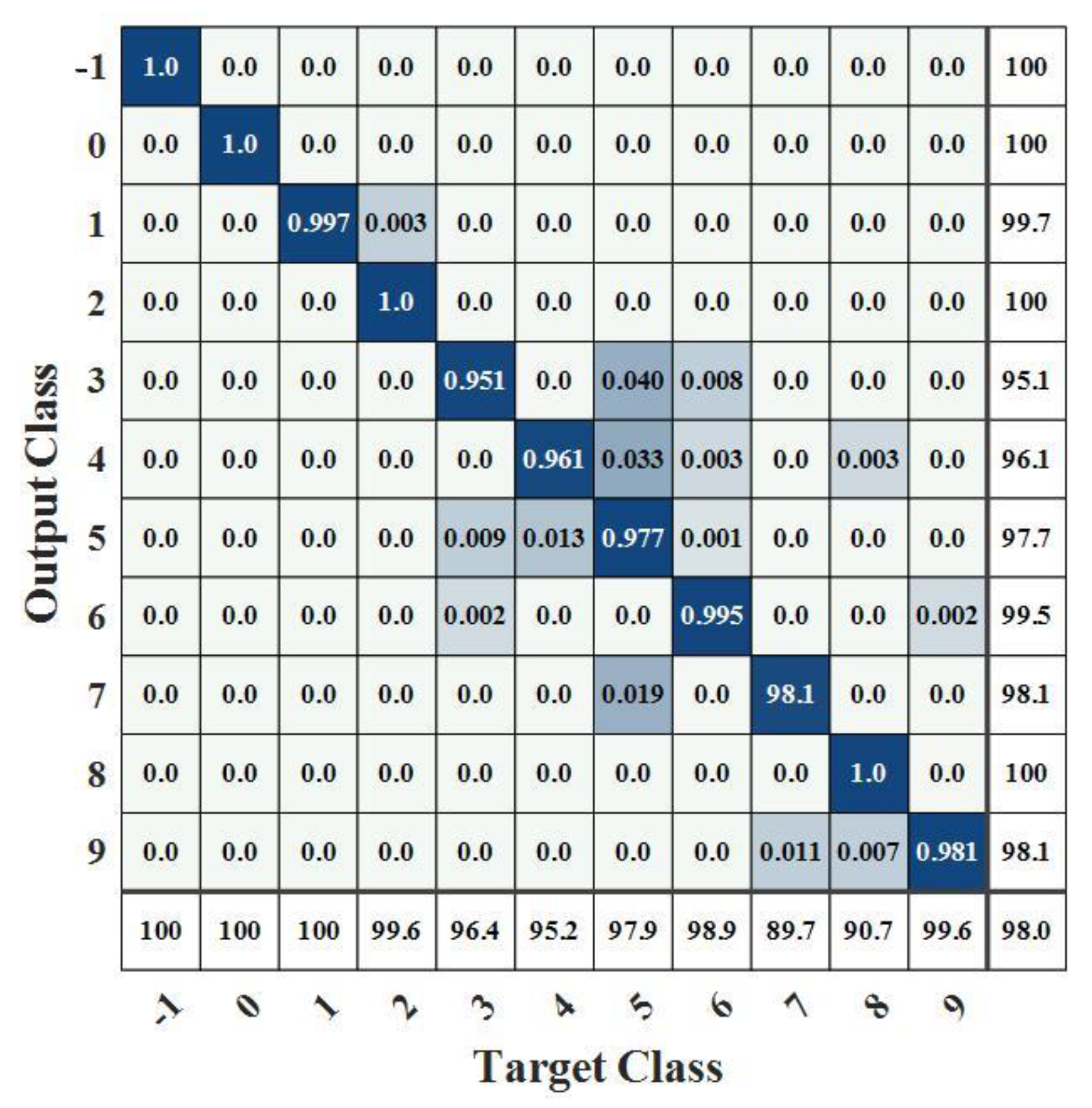
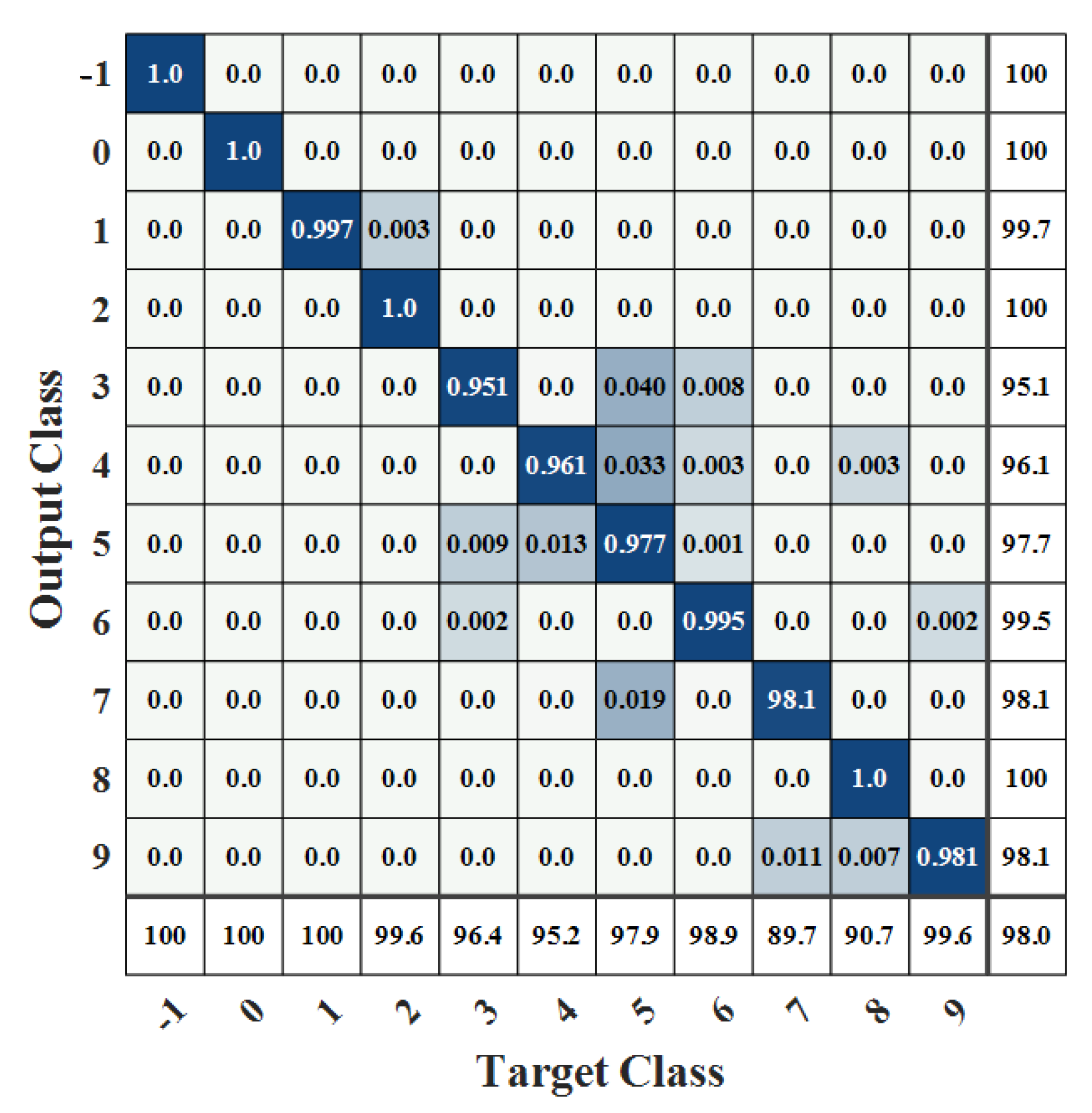
4. Validation and Analysis
4.1. Model Validation
- (1)
- It is obvious that the proposed model has higher recognition accuracy than BP–ANN, CNN, and BiLSTM models, which have lower recognition accuracy, especially for acceleration and maximum condition recognition accuracy and low recall rate for turning off afterburner recognition. BiLSTM has only a 55.8% recall rate for turning off afterburner recognition.
- (2)
- Compared with the single-scale convolution, the recognition accuracy of the proposed model has been improved by using the multi-scale convolution strategy, especially for the transition condition of acceleration and deceleration, which shows that the multi-scale convolution strategy can effectively extract the features of the engine transition conditions.
- (3)
- The combination of CNN and BiLSTM models resulted in higher model accuracy than when one model was used alone.
4.2. Analysis of Attention Modules
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gligorijevic, J.; Gajic, D.; Brkovic, A.; Savic-Gajic, I.; Georgieva, O.; Di Gennaro, S. Online Condition Monitoring of Bearings to Support Total Productive Maintenance in the Packaging Materials Industry. Sensors 2016, 16, 316. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Huang, Z.; Lang, R.; Qin, H.; Zhou, K.; Cao, Y. A Real-Time Interference Monitoring Technique for GNSS Based on a Twin Support Vector Machine Method. Sensors 2016, 16, 329. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y. Research on aero-engine fault diagnosis based on Elman neural network. Master’s Thesis, Civil Aviation University of China (CAUC), Tianjin, China, 2019. [Google Scholar]
- Kuang, D.; Fu, Y.M.; Fang, L.Y. Application of Big Data Mining Analysis in Aircraft Engine Condition Monitoring and Fault Diagnosis. J. Xi′an Aeronaut. Univ. 2017, 35, 42–46. [Google Scholar]
- Zhou, S.M.; Qu, J.L.; Gao, F.; Wang, X.F. Aeroengine working condition recognition based on HE-SVDD. Chin. J. Sci. Instrum. 2016, 37, 308–315. [Google Scholar] [CrossRef]
- He, D.W.; Peng, J.B.; Hu, J.H.; Song, Z.P. Aeroengine working condition recognition based on MKSVDD optimized by improved BA. J. Beijing Univ. Aeronaut. Astronaut. 2018, 44, 2238–2246. [Google Scholar] [CrossRef]
- Li, D.Z.; Peng, J.B.; Zhao, Z.P.; Wang, W.X.; Zhao, B. An aeroengine working condition recognition Based on Random Frest. J. Air Force Eng. Univ. (Nat. Sci. Ed.) 2020, 21, 15–20. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Wei, L.; Yangqing, J.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Chen, K.Q.; Zhu, Z.L.; Deng, X.M.; Ma, C.X.; Wang, H.A. Deep learning for multi-scale object detection: A survey. Ruan Jian Xue Bao J. Softw. 2021, 32, 1201–1227. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 354–370. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Guo, X.; Chen, L.; Shen, C. Hierarchical adaptive deep convolution neural network and its application to bearing fault diagnosis. Measurement 2016, 93, 490–502. [Google Scholar] [CrossRef]
- Tian, Y.; Liu, X. A deep adaptive learning method for rolling bearing fault diagnosis using immunity. Tsinghua Sci. Technol. 2019, 24, 750–762. [Google Scholar] [CrossRef]
- Qian, W.; Li, S.; Wang, J.; An, Z.; Jiang, X. An intelligent fault diagnosis framework for raw vibration signals: Adaptive overlapping convolutional neural network. Meas. Sci. Technol. 2018, 29, 095009. [Google Scholar] [CrossRef]
- Wei, X.L.; Chao, Q.; Tao, J.F.; Liu, C.L.; Wang, L.Y. Cavitation fault diagnosis method for high-speed plunger pump based on LSTM and CNN. Acta Aeronaut. Astronaut. Sin. 2021, 42, 435–445. [Google Scholar]
- Han, S.Y.; Shao, H.D.; Jiang, H.K.; Zhang, X.Y. Intelligent fault diagnosis of aeroengine high-speed bearing using enhanced CNN. Acta Aeronaut. Et Astronaut. Sin. 2021, 42, 1–15. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Implication | The Employed Data (D(i) = D(j)-D(j-i)) |
|---|---|---|
| Power level angle | ||
| Low-pressure rotor rotating speed | ||
| High-pressure rotor rotating speed | ||
| Inlet guide vane angle | ||
| High-pressure guide vane variable angle | ||
| Tailpipe nozzle area | ||
| Exhaust gas temperature | ||
| Oil supply duty cycle signal |
| Model | Typical Working Condition | Overall | |||||
|---|---|---|---|---|---|---|---|
| A | D | T | M | OFF AF | AF | ||
| BP-ANN | 92.1 | 90.2 | 92.9 | 97.9 | 67.4 | 98.1 | 94.7 |
| CNN | 93.4 | 97.3 | 94.5 | 98.4 | 83.7 | 98.5 | 96.4 |
| MSCNN | 94.5 | 92.9 | 96.4 | 98.6 | 83.7 | 97 | 96.7 |
| BiLSTM | 86.3 | 83 | 84.7 | 98.3 | 55.8 | 98.1 | 93.8 |
| MSCNN–BiLSTM | 94.5 | 97.3 | 95.6 | 99.5 | 90.7 | 100 | 97.3 |
| MSCNN–BiLSTM–SE | 95 | 96.6 | 96.5 | 98.7 | 91.5 | 99.8 | 97.6 |
| MSCNN–BiLSTM–MSA | 94.5 | 95.5 | 96.7 | 98.9 | 93 | 99.6 | 97.4 |
| The proposed model | 96 | 96.4 | 97.5 | 99 | 91.9 | 99.6 | 98 |
| Model | Typical Working Condition | Overall | |||||
|---|---|---|---|---|---|---|---|
| A | D | T | M | OFF AF | AF | ||
| BP-ANN | 86.2 | 88.9 | 96.3 | 95.3 | 100 | 92.1 | 94.7 |
| CNN | 89.1 | 89.6 | 98.2 | 98.2 | 94.7 | 96.3 | 96.4 |
| MSCNN | 92.8 | 92.9 | 96.9 | 98 | 87.8 | 95.9 | 96.7 |
| BiLSTM | 87.1 | 93 | 93.5 | 93.5 | 100 | 89.9 | 93.8 |
| MSCNN–BiLSTM | 92.5 | 91.9 | 98.3 | 98.9 | 100 | 97.4 | 97.3 |
| MSCNN–BiLSTM–SE | 92.5 | 93 | 98.1 | 98.5 | 100 | 97.6 | 97.6 |
| MSCNN–BiLSTM–MSA | 94.3 | 92.8 | 97.7 | 98.4 | 100 | 96.7 | 97.4 |
| The proposed model | 95.1 | 94.7 | 98.1 | 99.2 | 100 | 97.8 | 98 |
| label | Aeroengine Working Condition |
|---|---|
| −1 | Placing the throttle off and cutting off the engine |
| 0 | Unstart |
| 1 | Starting |
| 2 | Idling |
| 3 | Acceleration |
| 4 | Deceleration |
| 5 | Throttling |
| 6 | Maximum |
| 7 | Turning on afterburner |
| 8 | Getting the throttle out of afterburner |
| 9 | Afterburner |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, J.; Peng, J.; Wang, W.; Li, S. Aeroengine Working Condition Recognition Based on MsCNN-BiLSTM. Sensors 2022, 22, 7071. https://doi.org/10.3390/s22187071
Zheng J, Peng J, Wang W, Li S. Aeroengine Working Condition Recognition Based on MsCNN-BiLSTM. Sensors. 2022; 22(18):7071. https://doi.org/10.3390/s22187071
Chicago/Turabian StyleZheng, Jinsong, Jingbo Peng, Weixuan Wang, and Shuaiguo Li. 2022. "Aeroengine Working Condition Recognition Based on MsCNN-BiLSTM" Sensors 22, no. 18: 7071. https://doi.org/10.3390/s22187071
APA StyleZheng, J., Peng, J., Wang, W., & Li, S. (2022). Aeroengine Working Condition Recognition Based on MsCNN-BiLSTM. Sensors, 22(18), 7071. https://doi.org/10.3390/s22187071