
An Efficient and Uncertainty-Aware Decision Support System for Disaster Response Using Aerial Imagery
 ,
,  and
and 
Abstract
:1. Introduction
1.1. Application Background
1.2. Related Work
1.3. Problem Statement
- Assessment Efficiency for Deployment. Disaster responses are always demanded to take action as soon as possible in order to save victims. However, recent methods pay over-attention to assessment accuracy without concerning the inference time consumption, which makes them difficult to deploy.
- Uncertainty Quantification for Decision Support. It is noticeable that computational models are still an emerging topic without perfect performance in disaster response. The predictive failure may cause more casualties in a fully automatic manner without experts’ intervention. Thus, the BDA should also deliver the uncertainty of assessments as supplementary information other than assertive damage assessment masks for final decisions from experts.
1.4. System Overview and Contribution
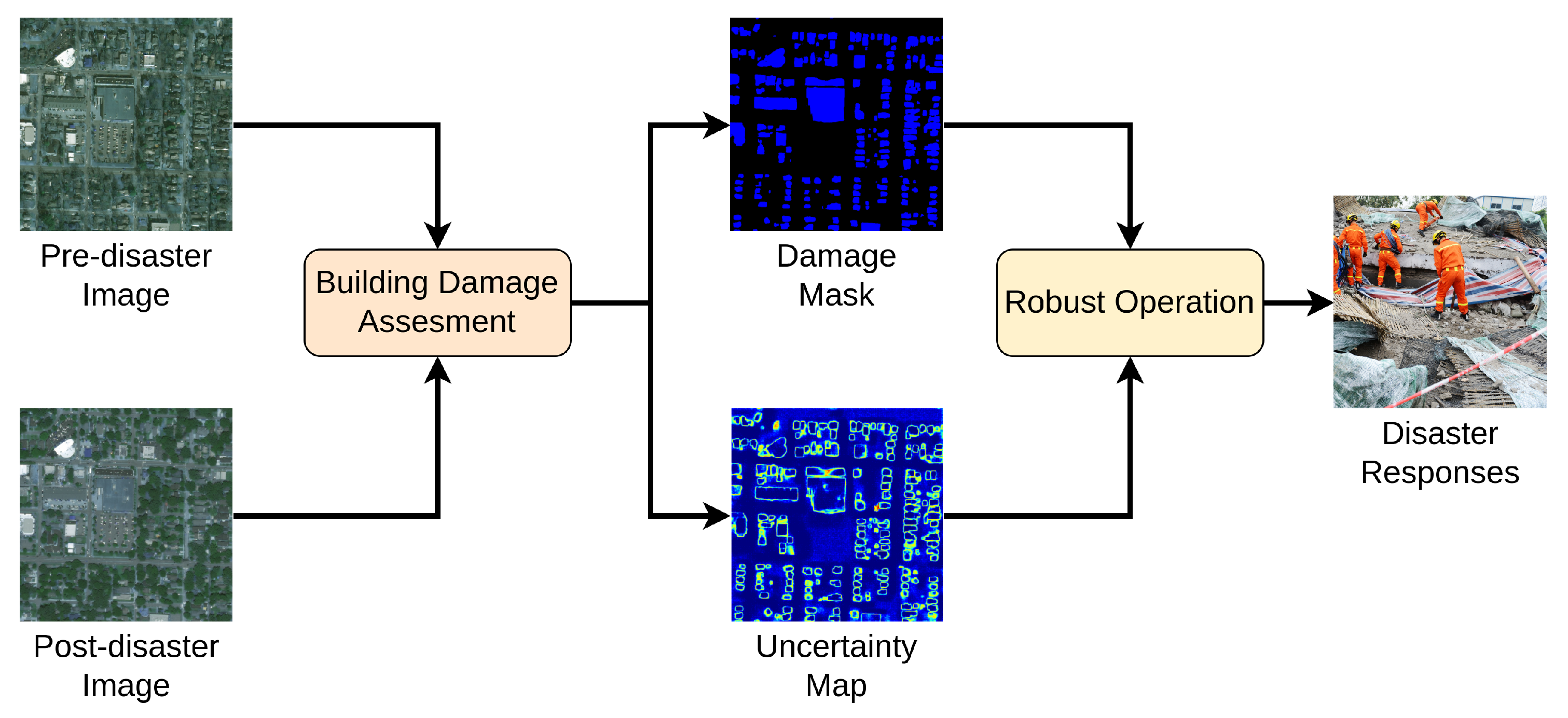
- In this study, an automatic two-stage decision system, i.e., EUDSS, is proposed to enable building damage assessment (BDA) to efficiently support decision-making during disaster response.
- In the first BDA stage, a computational model is proposed, i.e., efficient and uncertainty-aware BDA (EUBDA). The EUBDA first includes an innovative FA module to fuse pre- and post-disaster information. Then, the EUBDA employs MC Dropout to estimate the uncertainty maps with the damage assessment results. Both modules are new to the application domain of disaster response.
- The RO stage introduces a web application to support experts’ decisions regarding rescue plans with additional uncertainty maps. The case studies demonstrate the feasibility of RO in real-world scenarios (https://engineering.ok.ubc.ca/tag/overhead-imagery-hackathon/, accessed on 7 September 2022).
2. Efficient and Uncertainty-Aware Decision Support System
2.1. Building Damage Assessment for Initial Evaluation
2.1.1. Backbones for Multi-Scale Feature Extraction
2.1.2. Fourier Attention for Feature Fusion
2.1.3. Building Localization and Damage Assessment Head
2.1.4. MC Dropout for Uncertainty Estimation
2.1.5. Objective Function
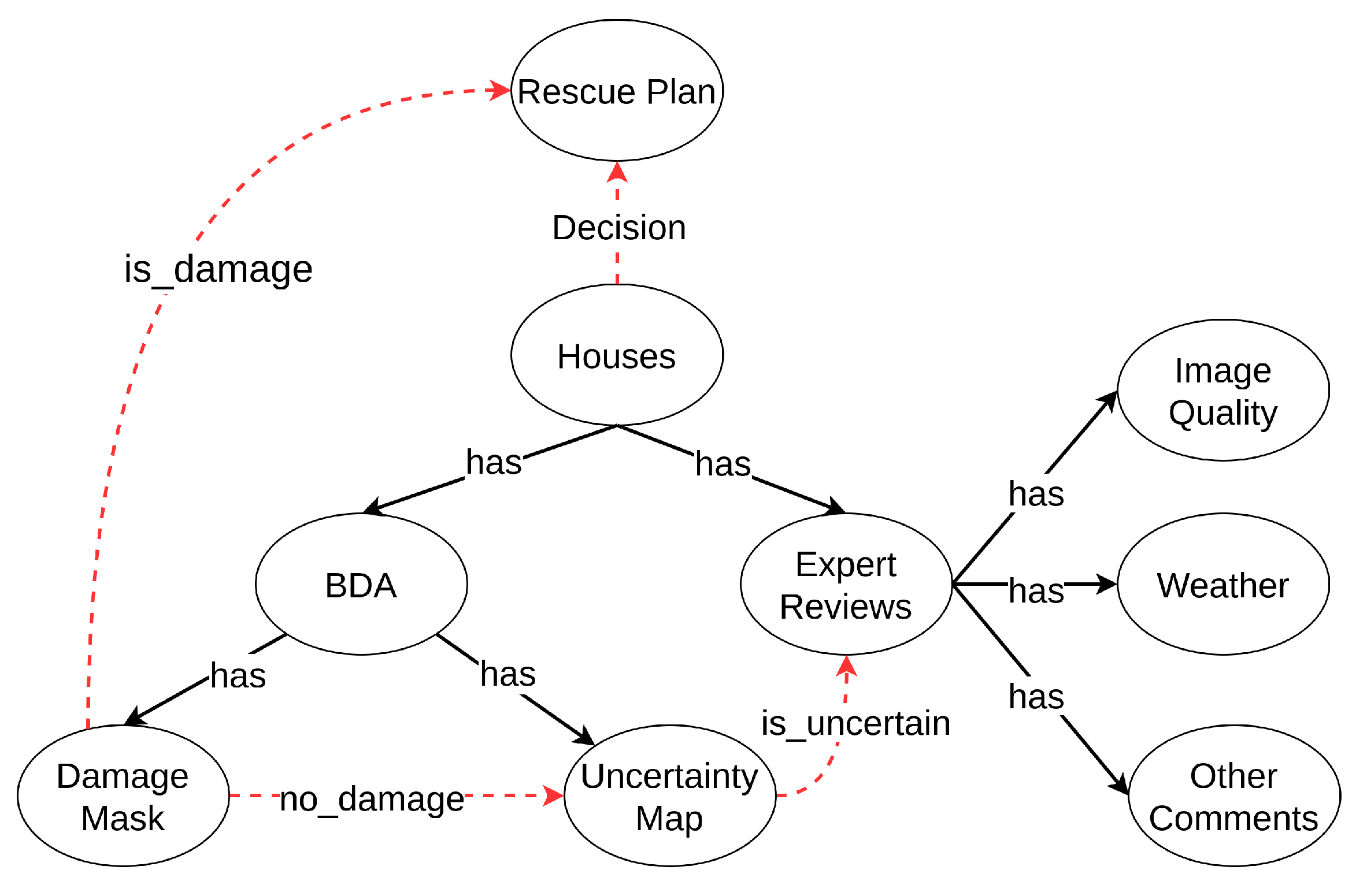
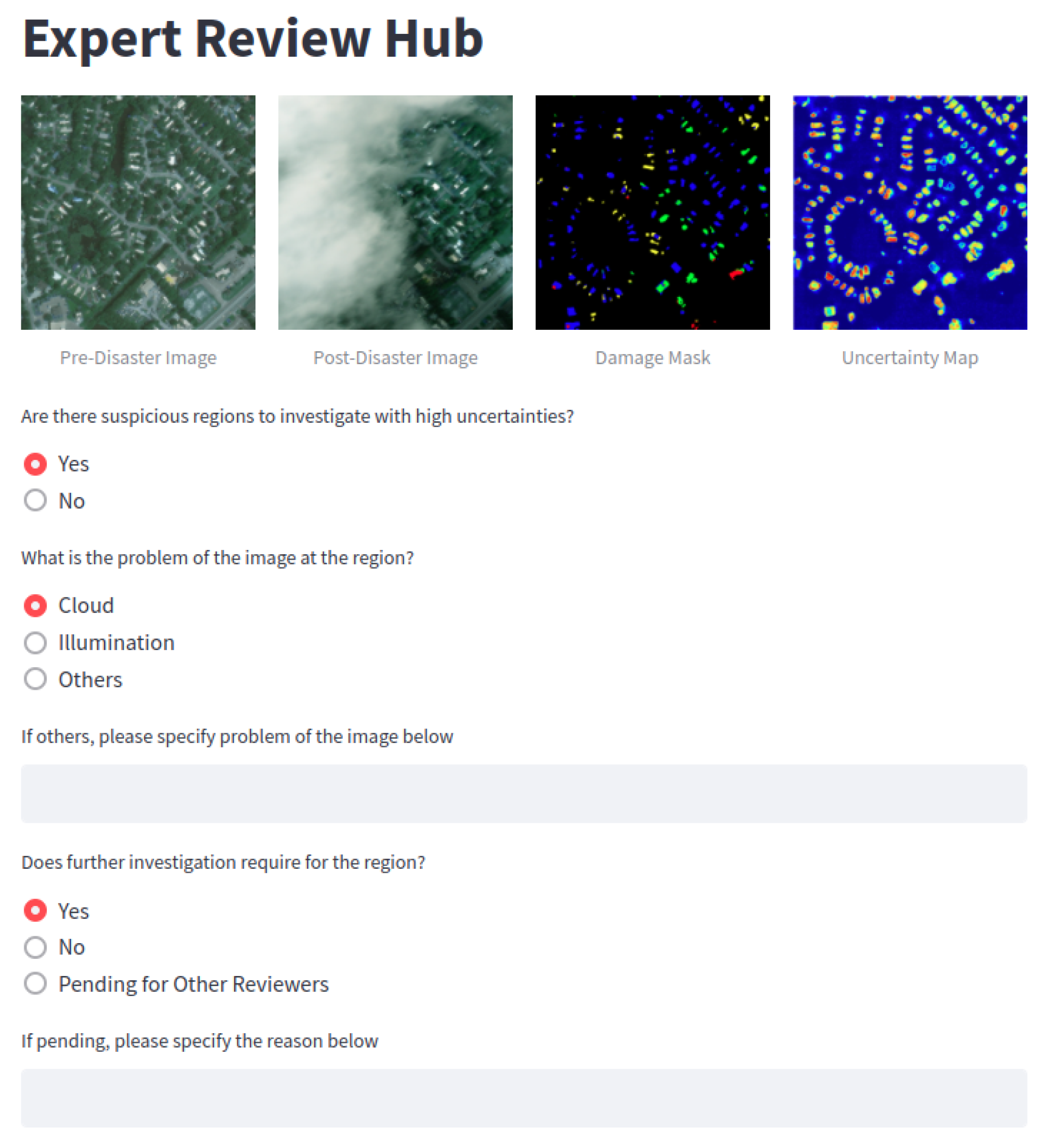
2.2. Robust Operation for Supporting Final Disaster Responses
2.3. Evaluation Metrics
3. Experimental Results
3.1. Experimental Setup
3.2. Results in Building Damage Assessment
3.2.1. Comparison with Light-Weighted Backbones
3.2.2. Comparison with Fusion Operators
3.2.3. Results with Additional MC Dropout
3.2.4. Ablation Studies of Proposed EUBDA
3.2.5. Comparative Studies with Advanced BDA Frameworks
- It is noticeable that all the frameworks are not capable of reaching full confidence in either building localization nor building damage assessment. This indicates that recent computational models still have the chance to miss buildings, which is intolerant for such a life-critical application. The proposed EUBDA offers the mode of MC Dropout (EUBDA-MC) to quantify uncertainty measurement to support decisions post-analysis, which is new to the application domain.
- Even with MC Dropout, the EUBDA-MC can still achieve faster speed than contemporary BDA frameworks.
3.3. Case Studies in Robust Operation with Decision Support Strategy
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shen, Y.; Zhu, S.; Yang, T.; Chen, C.; Pan, D.; Chen, J.; Xiao, L.; Du, Q. BDANet: Multiscale Convolutional Neural Network with Cross-Directional Attention for Building Damage Assessment From Satellite Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5402114. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021. early access. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14449–14458. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Weber, E.; Kané, H. Building Disaster Damage Assessment in Satellite Imagery with Multi-Temporal Fusion. arXiv 2020, arXiv:2004.05525. [Google Scholar]
- Gupta, R.; Shah, M. RescueNet: Joint Building Segmentation and Damage Assessment from Satellite Imagery. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4405–4411. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic Feature Pyramid Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6392–6401. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 833–851. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual, 3–12 November 2021. [Google Scholar]
- Lee-Thorp, J.; Ainslie, J.; Eckstein, I.; Ontanon, S. FNet: Mixing Tokens with Fourier Transforms. arXiv 2021, arXiv:2105.03824. [Google Scholar]
- Gupta, R.; Goodman, B.; Patel, N.N.; Hosfelt, R.; Sajeev, S.; Heim, E.T.; Doshi, J.; Lucas, K.; Choset, H.; Gaston, M.E. Creating xBD: A Dataset for Assessing Building Damage from Satellite Imagery. arXiv 2019, arXiv:1911.09296. [Google Scholar]
- Su, J.; Bai, Y.; Wang, X.; Lu, D.; Zhao, B.; Yang, H.; Mas, E.; Koshimura, S. Technical Solution Discussion for Key Challenges of Operational Convolutional Neural Network-Based Building-Damage Assessment from Satellite Imagery: Perspective from Benchmark xBD Dataset. Remote Sens. 2020, 12, 3808. [Google Scholar] [CrossRef]
- Xview2. The Impact of Code Verification. 2021. Available online: https://xview2.org/challenge (accessed on 10 October 2021).
- Czolbe, S.; Arnavaz, K.; Krause, O.; Feragen, A. Is Segmentation Uncertainty Useful? In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 715–726. [Google Scholar] [CrossRef]
- Jungo, A.; Reyes, M. Assessing Reliability and Challenges of Uncertainty Estimations for Medical Image Segmentation. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 48–56. [Google Scholar] [CrossRef]
- Zhao, Y.; Tian, W.; Cheng, H. Pyramid Bayesian Method for Model Uncertainty Evaluation of Semantic Segmentation in Autonomous Driving. Automot. Innov. 2022, 5, 70–78. [Google Scholar] [CrossRef]
- Besnier, V.; Picard, D.; Briot, A. Learning Uncertainty for Safety-Oriented Semantic Segmentation in Autonomous Driving. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 2016, ICM’16, New York, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Hu, R.; Huang, Q.; Chang, S.; Wang, H.; He, J. The MBPEP: A deep ensemble pruning algorithm providing high quality uncertainty prediction. Appl. Intell. 2019, 49, 2942–2955. [Google Scholar] [CrossRef] [Green Version]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Mobiny, A.; Yuan, P.; Moulik, S.K.; Garg, N.; Wu, C.C.; Nguyen, H.V. DropConnect is effective in modeling uncertainty of Bayesian deep networks. Sci. Rep. 2021, 11, 5458. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Prakash, A.; Chitta, K.; Geiger, A. Multi-Modal Fusion Transformer for End-to-End Autonomous Driving. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 240–248. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Liu, Z.; Zhang, W.; Zhao, P. A cross-modal adaptive gated fusion generative adversarial network for RGB-D salient object detection. Neurocomputing 2020, 387, 210–220. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvtv2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Image Size | Memory | Complexity |
|---|---|---|---|
| MHA | OOM (above 16 GB) | ||
| FA | 2.8 GB |
| Backbone | Loc ↑ | Dmg ↑ | Overall ↑ | No Damage ↑ | Minor ↑ | Major ↑ | Destroyed ↑ | Inference Time ↓ |
|---|---|---|---|---|---|---|---|---|
| V19 [23] | 0.823 | 0.557 | 0.636 | 0.818 | 0.332 | 0.645 | 0.714 | 0.013 |
| R18 [7] | 0.790 | 0.363 | 0.491 | 0.742 | 0.168 | 0.479 | 0.617 | 0.012 |
| MV2 [30] | 0.812 | 0.458 | 0.564 | 0.798 | 0.231 | 0.594 | 0.683 | 0.010 |
| EB0 [31] | 0.831 | 0.089 | 0.312 | 0.748 | 0.025 | 0.535 | 0.623 | 0.025 |
| V39 [23] | 0.836 | 0.574 | 0.646 | 0.835 | 0.431 | 0.668 | 0.732 | 0.016 |
| Backbone | Fusion | Loc ↑ | Dmg ↑ | Overall ↑ | No Damage ↑ | Minor ↑ | Major ↑ | Destroyed ↑ | Inference Time ↓ |
|---|---|---|---|---|---|---|---|---|---|
| R18 | Addition | 0.790 | 0.363 | 0.491 | 0.742 | 0.168 | 0.479 | 0.617 | 0.013 |
| R18 | Gating [32] | 0.791 | 0.070 | 0.286 | 0.752 | 0.055 | 0.029 | 0.301 | 0.014 |
| R18 | CBAM [33] | 0.791 | 0.023 | 0.261 | 0.609 | 0.008 | 0.232 | 0.029 | 0.014 |
| R18 | Involution [34] | 0.794 | 0.002 | 0.244 | 0.100 | 0.001 | 0.001 | 0.035 | 0.013 |
| R18 | SRA [35] | 0.798 | 0.541 | 0.620 | 0.832 | 0.343 | 0.532 | 0.712 | 0.023 |
| R18 | FA (ours) | 0.802 | 0.605 | 0.664 | 0.790 | 0.425 | 0.628 | 0.719 | 0.013 |
| V19 | FA (ours) | 0.851 | 0.621 | 0.690 | 0.820 | 0.434 | 0.646 | 0.740 | 0.014 |
| V39 | FA (ours) | 0.860 | 0.678 | 0.733 | 0.855 | 0.503 | 0.696 | 0.767 | 0.016 |
| Sampling Rate | Loc ↑ | Dmg ↑ | Overall ↑ | No Damage ↑ | Minor ↑ | Major ↑ | Destroyed ↑ | Inference Time ↓ |
|---|---|---|---|---|---|---|---|---|
| - | 0.860 | 0.678 | 0.733 | 0.855 | 0.503 | 0.696 | 0.767 | 0.016 |
| 10 | 0.862 | 0.687 | 0.740 | 0.869 | 0.506 | 0.705 | 0.784 | 0.032 |
| 20 | 0.853 | 0.692 | 0.740 | 0.869 | 0.515 | 0.706 | 0.786 | 0.080 |
| V19 | V39 | FA | MC | Loc ↑ | Dmg ↑ | Overall ↑ | No Damage ↑ | Minor ↑ | Major ↑ | Destroyed ↑ | Inference Time ↓ | Uncertainty |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | - | - | - | 0.823 | 0.557 | 0.636 | 0.818 | 0.332 | 0.645 | 0.714 | 0.013 | - |
| - | ✓ | - | - | 0.836 | 0.574 | 0.646 | 0.835 | 0.431 | 0.668 | 0.732 | 0.016 | - |
| - | ✓ | ✓ | - | 0.860 | 0.678 | 0.733 | 0.855 | 0.503 | 0.696 | 0.767 | 0.016 | - |
| - | ✓ | ✓ | ✓ | 0.862 | 0.687 | 0.740 | 0.869 | 0.515 | 0.706 | 0.786 | 0.080 | ✓ |
| Methods | Loc ↑ | Dmg ↑ | Overall ↑ | No Damage ↑ | Minor ↑ | Major ↑ | Destroyed ↑ | Inference Time ↓ |
|---|---|---|---|---|---|---|---|---|
| Official Baseline [12] | 0.790 | 0.030 | 0.260 | 0.663 | 0.143 | 0.009 | 0.467 | - |
| Top-10 Method [14] | 0.852 | 0.680 | 0.732 | 0.880 | 0.475 | 0.713 | 0.807 | - |
| Top-1 Method [14] | 0.863 | 0.788 | 0.811 | 0.923 | 0.644 | 0.785 | 0.859 | 0.384 |
| Shen et al. [1] | 0.864 | 0.752 | 0.789 | 0.923 | 0.578 | 0.76 | 0.869 | 0.174 |
| Weber et al. [5] | 0.835 | 0.697 | 0.738 | 0.906 | 0.493 | 0.722 | 0.837 | 0.054 |
| EUBDA (ours) | 0.860 | 0.678 | 0.733 | 0.855 | 0.503 | 0.696 | 0.767 | 0.016 |
| EUBDA-MC (ours) | 0.862 | 0.687 | 0.740 | 0.869 | 0.506 | 0.705 | 0.784 | 0.032 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bin, J.; Zhang, R.; Wang, R.; Cao, Y.; Zheng, Y.; Blasch, E.; Liu, Z. An Efficient and Uncertainty-Aware Decision Support System for Disaster Response Using Aerial Imagery. Sensors 2022, 22, 7167. https://doi.org/10.3390/s22197167
Bin J, Zhang R, Wang R, Cao Y, Zheng Y, Blasch E, Liu Z. An Efficient and Uncertainty-Aware Decision Support System for Disaster Response Using Aerial Imagery. Sensors. 2022; 22(19):7167. https://doi.org/10.3390/s22197167
Chicago/Turabian StyleBin, Junchi, Ran Zhang, Rui Wang, Yue Cao, Yufeng Zheng, Erik Blasch, and Zheng Liu. 2022. "An Efficient and Uncertainty-Aware Decision Support System for Disaster Response Using Aerial Imagery" Sensors 22, no. 19: 7167. https://doi.org/10.3390/s22197167
APA StyleBin, J., Zhang, R., Wang, R., Cao, Y., Zheng, Y., Blasch, E., & Liu, Z. (2022). An Efficient and Uncertainty-Aware Decision Support System for Disaster Response Using Aerial Imagery. Sensors, 22(19), 7167. https://doi.org/10.3390/s22197167