1. Introduction
In recent years, E2E speech recognition models have been widely used in the field of automatic speech recognition [
1,
2,
3,
4]. The E2E approach achieves performance comparable to traditional systems by using a single E2E model instead of separate components [
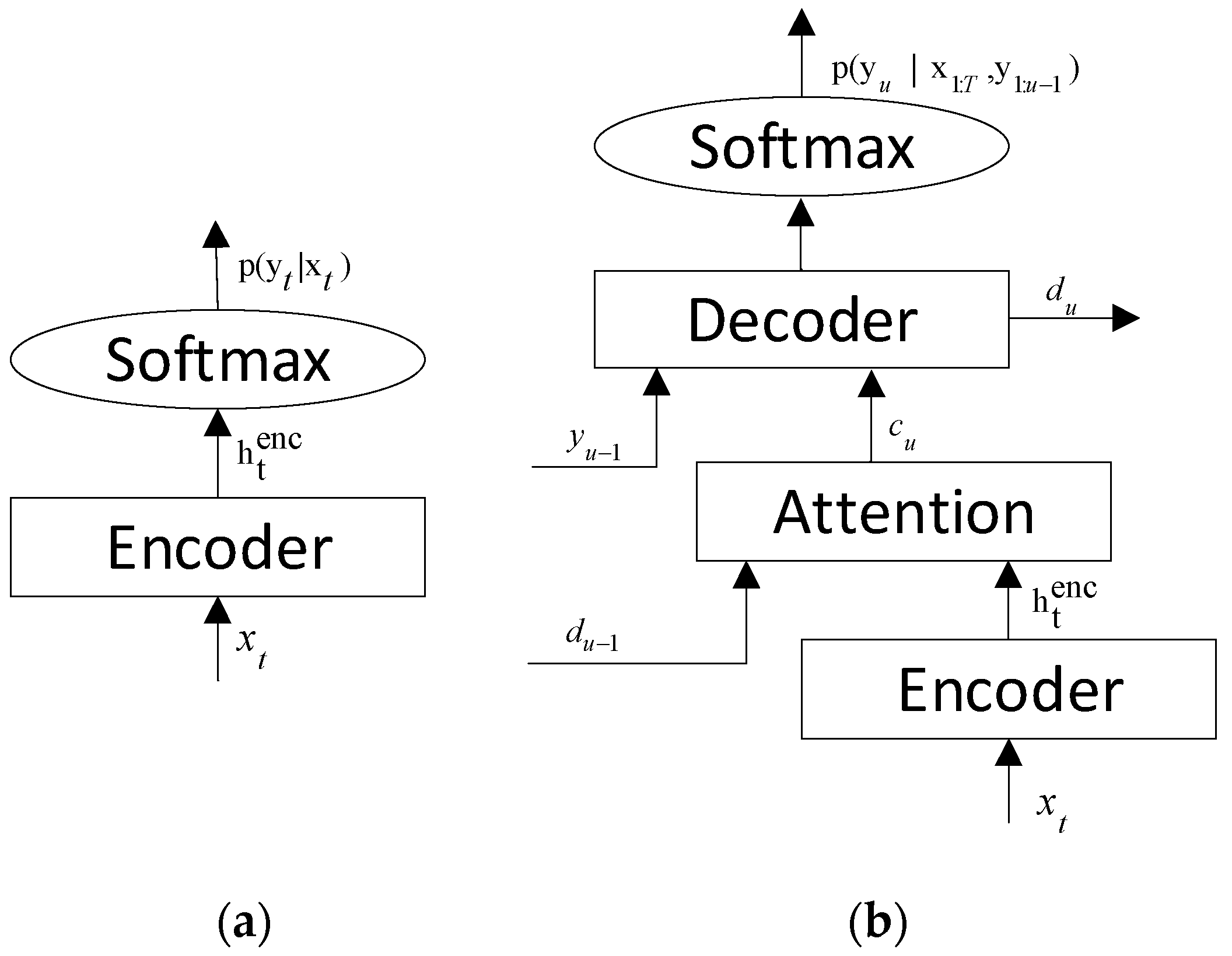
5]. Unlike the traditional speech recognition model, the E2E model has a simpler structure. By constructing a neural network, the same function as that of the traditional model can be achieved, and joint optimization can be achieved. The E2E models mainly include the Listen-Attend-Spell (LAS) model, which is also called the attention-based encoder–decoder (AED) model [
6], connectionist temporal classification (CTC) model or recurrent neural network transducer (RNN-T) model [
7]. CTC uses the method of adding a blank tag, <blank>, to the output sequence in order to align the speech frame sequence and the text sequence so that the training process can be simplified. RNN-T is improved based on CTC, which augments the CTC encoder with a recurrent neural network language model (LM). Compared with CTC, RNN-T is no longer limited in the length of its input and output sequences, but it is more challenging to train. AED, another of the most commonly used structures, includes an encoder module for feature extraction and a decoder module using attention mechanism. This architecture can use various types of neural networks, such as the convolutional neural network (RNN) [
8], Gate Recurrent Unit (GRU) [
9] and transformer [
10]. The attention mechanism in AED pays attention to the complete sequence. Still, it is impossible to achieve strong alignment between audio signals and text labels due to the monotonicity between them. To overcome the above problem, a hybrid CTC/Attention model was proposed by Watanabe [
11]. The key of the CTC/Attention model is to train the shared encoder with both the CTC and attention decoder as objective functions [
12]. This training strategy dramatically improves the convergence of attention-based models and reduces the alignment problem, so it has become the standard training recipe for most AED models [
13,
14]. It effectively combines the advantages of the two frameworks and achieves similar results to the traditional ASR system based on a simple structure.
Low-resource languages comprise a large percentage of world languages, as 94% of languages are spoken by less than one million people [
15]. Although technology giants such as Google, Apple, Facebook, Microsoft, Amazon and IBM have built advanced speech recognition engines for English, European and Asian languages, research on ASR systems for most Central Asian languages such as Uzbek is still in its infancy [
16]. The reason for this status is the lack of standard corpora and the existence of dialect differences [
17]. Although a series of studies have been carried out under the condition of a lack of resources [
18,
19,
20], the challenge of poor generalization ability and high error rate due to the scarcity of resources still exists under the condition of low resources. Most researchers improve the resource scarcity problem through multilingual training and data augmentation. Multilingual learning can alleviate the problem of insufficient resources by acquiring language information from rich languages or similar languages [
21]. At the same time, another simple and effective method is transfer learning, which first trains the network on a resource-rich corpus, and then, only fine-tunes it. E2E speech recognition technology does not rely on linguistic knowledge but only needs speech and its corresponding pronunciation text. The recognition effect depends on the size of the corpus to a certain extent. Other languages such as CSJ [
22], Switchboard [
23], ksponspeech [
24], etc. have thousands of hours of training data. Uzbek and Turkish, belonging to the Galoric and Oguz branches of the Altaic language family, respectively, are agglutinative languages without a large amount of training data. Furthermore, the linguistic studies of these two Central Asian languages are incomplete. Due to the lack of relevant professional knowledge, it is very difficult to organize pronunciation dictionaries and define phoneme sets, and it is impossible to use traditional methods such as HMM/DNN to recognize them.
There are two main challenges in building an ASR system for these two languages: First, these two languages, as low-resource languages, not only have fewer corpus resources but also belong to agglutinative languages. By concatenating different suffix sequences, new word forms can be derived from a single stem, including many words with the same stem but different endings. This leads to its rich vocabulary, which increases the difficulty in speech recognition. Secondly, there are dialect differences in the same language, and there are labeled data with dialect differences in existing datasets. Additionally, since there is a lack of a corresponding pronunciation dictionary, our models operate on character units that are created via sentencepiece [
25]. In addition, adding a CTC model during E2E model training has been proven to improve system performance effectively, but there has not been much research on agglutinative language speech recognition based on hybrid CTC/attention architecture.
To address these issues, we propose an ASR system based on hybrid CTC/attention architecture for Turkish and Uzbek. In our work, we use the speechbrain [
26] speech recognition toolkit to build models. The main contributions of this paper are as follows:
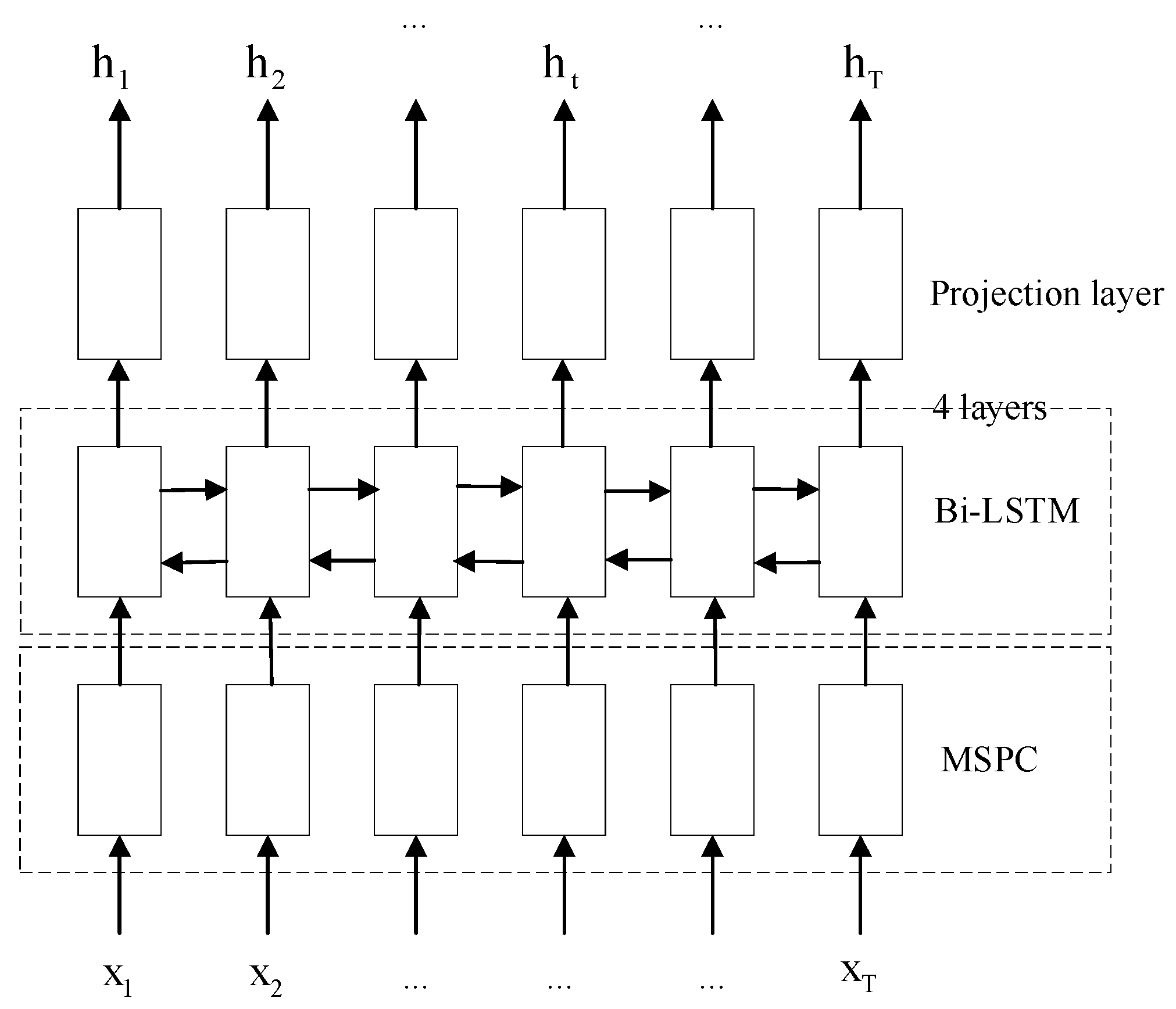
We propose a feature extractor called Multi-Scale Parallel Convolution (MSPC) and combine it with bidirectional long short-term memory (Bi-LSTM) to form an encoder structure to improve the recognition rate and system robustness of the end-to-end model.
The location-aware attention is improved to consider the impact of attention weight history on attention.
By arranging and combining a variety of data augment methods, we achieve the best model training effect.
In the decoding stage, an RNN language model is added and initialized using a fine-tuned pre-trained BERT [
27].
The rest of this paper is organized as follows. In
Section 2, we briefly introduce the related work and particularly describe the development of hybrid CTC/attention systems and their application in low-resource speech recognition. In
Section 3, the proposed method is introduced in detail.
Section 4 presents experiments using our improved attention, MSPC and data augment scheme compared to the state-of-the-art (SOTA) hybrid CTC/attention E2E ASR model [
28]. In
Section 5, we summarize the work we have conducted and put forward the prospects.
2. Related Work
The E2E speech recognition model unifies traditional acoustic, pronunciation, and language models into a single acoustic model. It not only reduces the complexity of speech recognition modeling but also performs better than traditional models [
29].
CTC is the first E2E model structure widely used in ASR [
1,
30,
31]. In [
32], CTC was proposed for the first time and was used for a speech recognition task in 2013. Unlike the HMM structure, it automatically learns and optimizes the correspondence between audio information and annotated text during training, and does not need to achieve frame alignment before network training. The disadvantage is that it assumes that each tag is independent of the others, but in reality, there is context dependency between tags at each moment. To solve this problem, RNN-T introduces a predictive network to learn context information, which is equivalent to the language model [
33]. Another way to alleviate the condition-independent hypothesis is to use the attention mechanism [
34], which is completed by improving the encoder structure without changing the objective function.
In contrast with CTC, AED does not require conditional independence assumptions and is another framework for E2E ASR models [
6]. The structure consists of an encoder, a decoder and an attention module. The encoder and decoder are built using recurrent neural networks and an attention module to achieve soft alignment between labels and audio information. However, the AED model has poor generalization ability for long audio segments [
35]. The inconsistent lengths of input and output sequences increase the difficulty in alignment. For long audio, it is necessary to manually set a window to limit the exploration range of attention. Secondly, the alignment in the attention mechanism can be easily destroyed by noise.
In order to solve the alignment problem in AED, Kim S et al. proposed hybrid CTC/attention architecture [
36]. The attention and CTC models are optimized by sharing encoders within the multi-task learning framework, and the convergence of the model is accelerated while correcting the alignment problem [
13]. The attention-based sequence-to-sequence network is trained using CTC as an auxiliary objective function during training. The forward–backward algorithm of CTC can enforce a monotonic alignment between audio and label sequences. In such structures, attention mechanisms that are often employed are additive attention [
37], location-aware attention [
38], scaled dot-product attention [
39], etc. to perform attention operations on the entire input representation. In [
40], the model is further improved by combining the scores from the AED model and the CTC model in both rescoring and one-pass decoding during the decoding process. Seki H et al. sped up the decoding process of the hybrid CTC/attention model by vectorizing multiple assumptions in beam search [
41]. Then, various hybrid models were proposed to solve the alignment problem [
42,
43].
In addition, LM pre-training has become a common technology in the NLP field, and BERT is one of them, which uses a transformer to build a text encoder. Unlike BERT, GPT2 consists of multiple layers of unidirectional transformers that generate data representations through historical context [
44]. Sanh V et al. proposed a knowledge distillation method to compress BERT into DistilBERT [
45]. This method is also used in GPT2 model compression. Language models are widely used in ASR task [
46]. Combining LM with an end-to-end ASR model is common through shallow fusion [
47] or cold fusion [
48]. Self-supervised pre-training models are widely used in end-to-end speech recognition tasks, but as the decoder is based on acoustic representation, it is impossible to carry out separate pre-training. Recently, some research has been conducted to integrate BERT into the ASR model [
49]. In [
50], K Deng et al. initialize the encoder using wav2vec2.0 [
51], and the decoder through a pre-trained LM DistilGPT2, to take full advantage of the pre-trained acoustic and language models.
The end-to-end models described above have been widely used in various languages, but only a few have been applied to Central Asian languages. Dalmia S et al. first tried to use the CTC framework to build a multilingual ASR system for low-resource languages including Turkish [
20]. Mamyrbayev O et al. used different types of neural networks, a CTC model and attention-based encoder–decoder models for E2E speech recognition in agglutinative languages, achieving good results without integrating language models [
52]. Cheng Yi et al. fusd a pre-trained acoustic encoder (wav2vec2.0) and a pre-trained linguistic encoder (BERT) into an end-to-end ASR model [
53]; the fusion model only needed to be fine-tuned on a limited dataset. Orken Zh et al. proposed a joint model based on CTC and the attention mechanism for recognition of Kazakh speech in noisy conditions [
54]. In addition to the improvement of the model structure, some important technologies are often applied to low-resource speech recognition, which is also the key to improving performance [
55]. The most widespread application for these is data augmentation, a technology for increasing the amount of data needed for training speech recognition systems. Common data augmentation methods include specaugment [
56], speed perturbation [
57] and multilingual processing. There are also some recently adopted data augmentation methods. For example, in [
58], the ASR system receives pre-synthesized speech from Tacotron for out-of-domain data augmentation. Another popular method used on limited datasets is transfer learning [
59], that is, using a small amount of data to retrain the basic acoustic model that is trained from other resource-rich speech databases. Cho J et al. attempted to use data from 10 BABEL languages to build a multilingual seq2seq model as a prior model, and then, port them towards four other BABEL languages using a transfer learning approach [
60]. In addition, the construction of multilingual models has also become a new direction in attempting to solve the problem of the lack of corpus resources. Yi J et al. proposed adversarial multilingual training to train bottleneck (BN) networks for the target language, ensuring that the shared layers can extract language-invariant features [
61]. With the multilingual CTC/attention model proposed by Liang S, Yan W used the optimal solution to complete the model evaluation and achieved similar performance to the traditional model, which provided a research basis for future exploration of speech recognition in different languages [
62].
4. Experiments
We used the speechbrain [
26] toolkit to build the proposed model, using the word error rate (WER) and character error rate (CER) as the primary evaluation metrics. Our studies were conducted on high-performance computing (HPC) nodes equipped with one NVIDIA TITAN RTX GPU with 24 GB of RAM and an i7-7800X CPU.
4.1. Data Preparation
The Common Voice dataset is a multilingual public dataset containing more than 15,000 h of 96 languages. Each dataset entry consists of an individual MP3 audio file and corresponding text file. The Turkish and Uzbek corpuses used in our research were collected and validated via Mozilla’s Common Voice initiative [
66]. Using either the Common Voice website or the iPhone app, contributors record their voices by reading sentences displayed on the screen. In addition, to demonstrate the effectiveness of our proposed model, we also carried out experiments on the LibriSpeech [
67] dataset. All speeches were sampled at 16 kHz.
Table 1 presents the details of the three datasets.
Eighty-dimensional log-Mel filterbank features were extracted for speech frames with a 25 ms length and 10 ms shift. To solve the problem of training over-fitting when the training set is not extensive enough, we used a linear combination of multiple data augmentation methods to achieve the best results.
4.2. Experimental Setup
We first trained and tested our implementation over the LibriSpeech dataset. Specifically, we used train-clean-100 as our training set and dev-clean/dev-other as our validation set. For evaluation, we reported the CER and WER on the subsets test-clean and test-other. Then, we also evaluated the other two sets. All experiments were implemented using speechbrain with the default configurations. The detailed experimental configuration is shown in
Table 2. ‘blstmp’ means that the encoder is the projected bidirectional long short-term memory neural network. “VGG+4blstmp” means that an encoder is composed of a vaccination guidelines group (VGG) [
68] layer followed by four blstmp layers. Location-lstm is the attention mechanism that we modified. Bi-GRU represents a bidirectional gated recurrent unit. We enhanced the training data using MUSAN [
69] and RIRs [
70] as noise sources to double the amount of training data. The experiment details are shown in
Section 4.3 and
Section 4.4.
4.3. The Results of Comparative Experiments
We trained all the models in the train-clean-100 subset and tested the test-clean and test-other subsets. The experimental results are shown in
Table 3. Among them, the semi-supervised method and Ensemble (five models) method were trained with pseudo-labels, using 100 h paired data and 360 h unpaired audio.
From
Table 3, we can see that our model obtains better performance in the CER and WER. We only changed the structure of the model from the baseline. Our model performs worse than the baseline using the content-based method on the test-clean subset. Although the recognition results using context-based attention in the model are more accurate than location-aware attention, the improvement is limited to the test-other dataset. Test-other, as the part of the speech recognition task with a high word error rate, has a higher WER. Our model has a better recognition effect and better robustness. Compared with the baseline, the WER on the two subsets is reduced by 0.35% and 2.66%, respectively. Compared with the other supervised methods, except for the Ensemble method, our model obtains the optimal performance. We guess that this is because the Ensemble method combines multiple models during training to increase label diversity and prevent models from being overconfident about noisy pseudo-labels. The second possible reason is that the method used additional 360 h unpaired audio for model training, which improved the model’s generalization.
Table 4 shows that our method achieves overall performance improvement in all cases. When decoding without RNNLM, our model acquires 0.66% and 4.17% relative CER and WER reductions compared with the baseline in the Turkish dataset. Moreover, we achieve relative CER and WER reductions of 5.82% and 7.07% with pretrained RNNLM.
For Uzbek, our model also improves in the main performance indicators. Because the corpus size is larger than that of Turkish, the convergence speed of the model is obviously faster, and the number of training rounds is less than that of the former. In particular, the relative WER is reduced by 6.53% and 7.08% when decoding with and without the RNNLM.
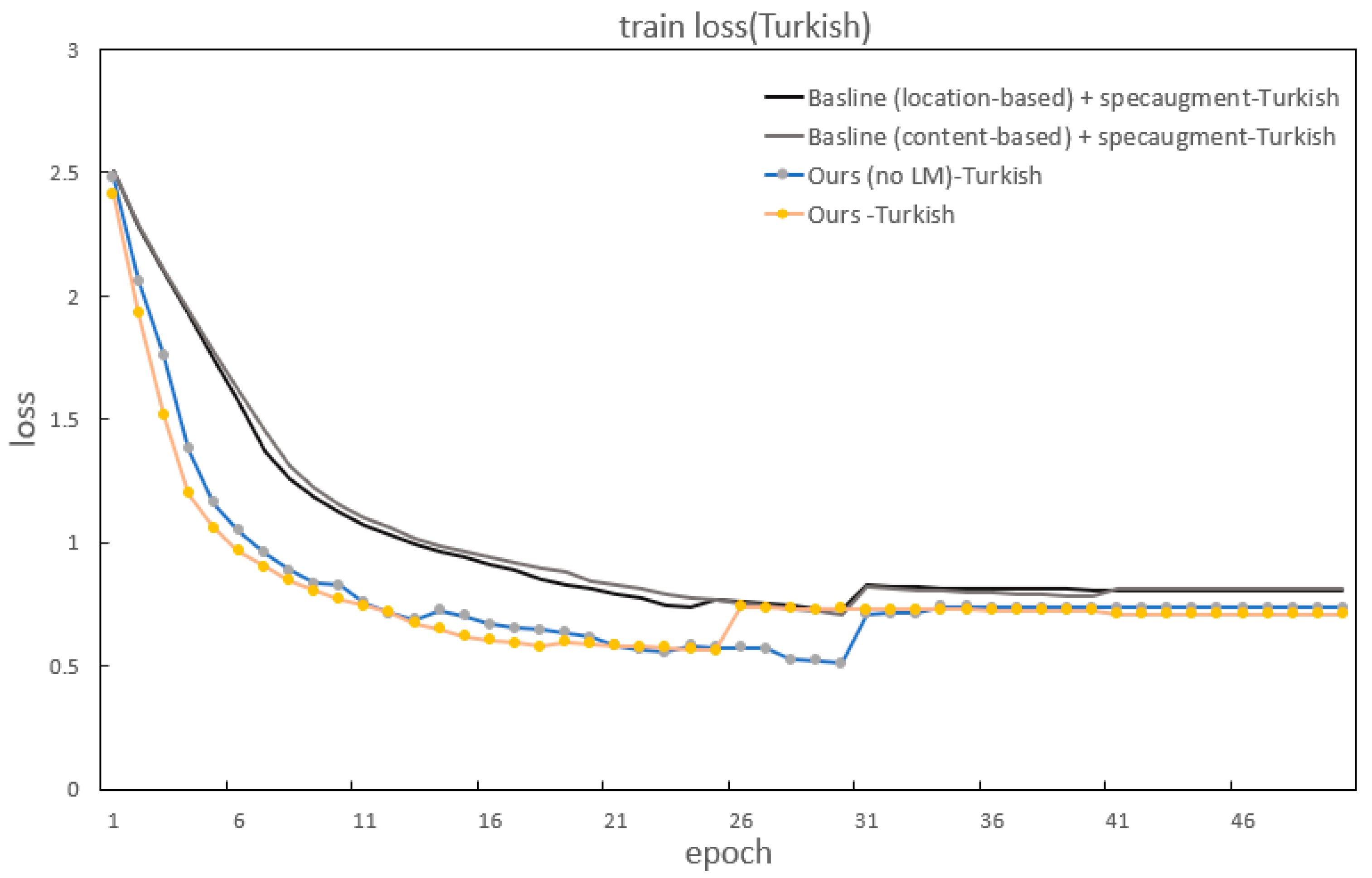
In addition to improvements in the CER and WER, our method also significantly outperforms the baselines in accelerating model convergence.
Figure 7 and
Figure 8 show the specific details of the convergence in model training. It can be seen that our model has the fastest convergence and the shortest loss curve compared to the baseline models using two kinds of attention.
4.4. The Results of Ablation Experiments
In this subsection, we further validate the effectiveness of our proposed MSPC structure and improved location-aware attention module on the Common Voice—Turkish corpus and explore the performance of different data enhancement methods.
To determine the effectiveness of each module, we added the single modules to the experiment separately.
Table 5 shows the performance of location-LSTM attention. From
Table 5, it is not difficult to find that compared with location-aware attention and context-based attention, while the CER of the model after adding location-LSTM attention improves, the WER performance is basically the same. The performance of CER shows that it can effectively capture the local dependencies of speech frames. Although location-LSTM attention improves the performance to a lesser extent, it proves the effectiveness of the improved attention.
According to
Table 6, after we use the proposed MSPC as the feature extractor, the WER is improved by 1.25%. This justifies that using MSPC instead of VGG as the feature extractor is reasonable. When we add two modules to the model simultaneously, our method improves the relative character error rate and relative word error rate by 0.75% and 1.73%, respectively, compared to the baseline. This proves that the network can extract features of different scales and learn the context information of speech signals, thus improving the recognition rate of end-to-end models.
To further explore the effect of combining different data augmentation methods on the experimental results. The noise method uses the noise dataset provided by [
70] to add noise to the original audio. After analyzing the experimental results in
Table 7, we found that using speed perturbation and the noisy method at the same time has advantages in terms of word error rate compared with using specaugment and the noisy method simultaneously. In terms of training speed, the former is also slightly better. Therefore, we take speed perturbation + noise as our final data augmentation scheme.
4.5. Effectiveness of Hyperparameters
In the experiments described in the previous two sections, when using beam search decoding, the beam width is set to 8. In this section, we explore the effect of different beam widths on the final result. As seen in
Table 8, WER gradually decreases with the increase in the set beam width during decoding. When we use different widths, there is a definite improvement in system performance. The reason for this phenomenon is that the larger the width, the more choices we have to consider, and the better the sentence is likely to be. We did not choose a larger width, because it would increase the computational cost of the algorithm and greatly affect the decoding speed.
The RNNLM used in the experiments is initialized using the DistilBERTurk1 model. DistilBERTurk was trained on 7 GB of the original training data that were used for training BERTurk, using the cased version of BERTurk as a teacher model. When the beam width is 8, CER and WER are reduced by about 5% and 3%, respectively, after adding the language model. However, the relative improvement decreases further when the beam width increases to 16. This proves that the beam width has some effect on the results, and the gap is further narrowed when the language model is added.
5. Conclusions and Future Work
In this paper, we studied the application of the hybrid model in agglutinative language speech recognition and proposed a CNN-based feature extractor, MSPC, that uses different convolution kernel sizes to extract features of different sizes. Then, by improving its location-aware attention, the impact of the attention weight history on the results is considered while focusing on the location information. The results of the experiments show that the constructed model performs better after adding the language model, which not only exceeds the baseline model but also shows better performance compared with the mainstream model.
In the future, we will improve the following aspects of the proposed model. The Altaic language family contains many agglutinative languages, which have a small corpus due to their small number of speakers. Thus, we will explore multilingual speech recognition based on this model so that our model can fully use multilingual information and improve the accuracy of low-resource speech recognition. Additionally, streaming speech recognition has gone mainstream. Therefore, we will further improve the model structure to suit the needs of streaming speech recognition.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}