1. Introduction
According to YouTube, there were approximately 5.5 billion daily video views in the first quarter of 2022. The massive amount of video information available causes people to spend significant time browsing and understanding redundant videos. Therefore, it is important to determine how to find relevant videos quickly among the endless video supply. Video retrieval techniques can help people find videos related to keywords, whereas video summarization techniques can extract representative information directly from a video. Video summarization techniques can generate concise summaries for videos that convey the important components of a complete video. Generating video summaries typically involves using a limited number of images or video clips to represent the main content of an original video sequence, which preserves the authenticity of the video information and saves a significant amount of space.
Research on video summarization techniques has been conducted for decades and good results have been achieved by traditional methods based on sparse modeling representative selection (SMRS) [
1], DC programming [
2], etc. With the development of deep learning, many researchers have used deep learning methods to extract features from videos and have achieved good results. M. Fei et al. [
3] further introduced image entropy in deep learning to maintain the diversity of summaries. T. Hussain et al. [
4] introduced aesthetic and entropic features to keep the summaries interesting and diverse. T. Hussain et al. [
5] applied deep video summarization technology to real life. They proposed a video summarization method using depth features of the lens segmentation method and applied it to resource-constrained devices. In addition, T. Hussain et al. [
6] proposed a deep learning-based video summarization strategy for industrial surveillance scenes to achieve coarse and refined video data, which provides a great contribution to the application of video summarization technology. Additional layers are meaningful in these methods [
4,
5,
6], but they will consume more computation time and increase the complexity of the system. Therefore, an efficient learning mechanism to train DL models remains a challenge. Furthermore, it is difficult to handle the long-term dependency relationship due to the long timeline when processing the long-term monitoring data in the existing methods.
However, deep-learning-based methods rely on labels, whereas reinforcement learning does not rely on labels and allows models to explore and select features in an unsupervised manner. Reinforcement learning updates model parameters using reward functions and gradient descent techniques. In recent years, various researchers have combined deep learning with reinforcement learning to apply deep reinforcement learning (DRL) methods to the task of video summarization. Zhou et al. [
7] proposed a deep learning framework that combines a bidirectional long short-term memory (LSTM) network (BiLSTM) with DRL and called their framework the diversity-representativeness deep summarization network (DR-DSN). The deep summarization network (DSN) predicts a probability for each video frame that indicates the likelihood of selecting that video frame and then takes action to select frames based on the predicted probability distribution to perform video summarization. DSN achieves good results and is competitive in the field of unsupervised video summarization. In addition, most deep-learning-based methods generate video summaries based on supervised learning, where they learn the importance of frames by modeling the temporal dependency between frames or the spatiotemporal structure of the video. The cost of producing video summarization datasets with labels is very expensive, so we focus on an unsupervised video summarization model based on deep reinforcement learning.
However, the performance of a deep reinforcement learning model degrades as video length increases because of the long-term dependency problem. In video summarization tasks, connections between adjacent frames are often established using recursive neural networks, but for tens of thousands of frames of video information, it is difficult to retain information from distant frames, which may lead to the degradation of model performance. This problem is called the long-term dependency problem. This problem limits the performance of existing approaches that focus on semantic objects, actions, emotions, and diversity. Even BiLSTM-based methods are not immune to the problems caused by long-term dependency. Large kernel sizes and deep networks give convolutional neural networks (CNNs) the ability to alleviate the long-term dependency problem. However, RNNs have a completely different structure compared to CNNs and we cannot directly employ the CNN structure in an RNN. To solve this problem, Trinh et al. [
8] introduced auxiliary loss into the main supervised loss function to reconstruct or predict sequence information, which allows RNNs to capture long-term dependencies.
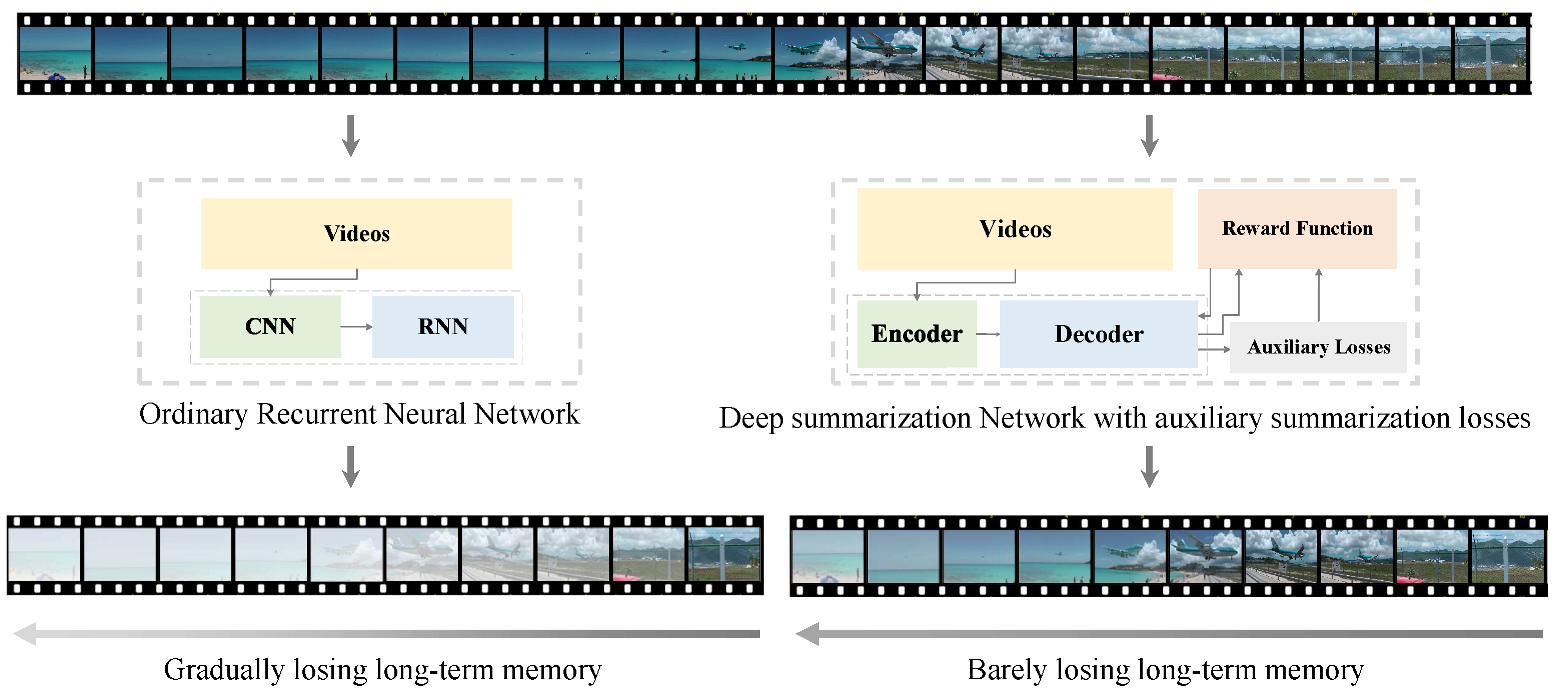
In this paper, to address the long-term dependency problem in the video summarization task, we equate video summarization to a sequential decision process based on inspiration from Trinh et al. [
8]. We propose a summarization selection network with unsupervised summarization loss based on an infinite norm. Similar to existing DSNs [
7], this network also utilizes an encoder–decoder architecture, where the encoder is a CNN that extracts high-dimensional features from videos and the decoder is a one-way LSTM network utilizing unsupervised summary loss to capture the long-term dependencies between video frames. The value of video frames can be calculated from video frame features. The higher the value, the greater the probability of being selected as a key frame. We trained the proposed network using an end-to-end reinforcement learning framework to solve the video summarization problem by updating the model parameters using a reward function that does not rely on any labels or user interactions. Finally, we propose a discrete degree reward function
and compare it to other reward functions to demonstrate its practical value. An overview of the proposed model is presented in
Figure 1. Compared to a traditional RNN, the proposed network is much better at maintaining long-term memory.
An unsupervised auxiliary summarization loss module is proposed to reconstruct random segments of a video by connecting to the LSTM network in parallel at randomly determined anchor points during model training. This loss is used to adjust the parameters of the model by calculating the degree of video feature loss during training. Experimental results demonstrate that the proposed unsupervised auxiliary summary loss can accurately capture the long-term dependencies in videos, significantly improving the performance and generalization ability of the LSTM network.
Furthermore, we explored several reward functions in reinforcement learning for the video summary model. The diversity-representation reward was proposed by Zhou et al. [
7]. The diversity reward evaluates the degree of diversity of generated summaries by computing the differences between selected frames. The representation reward is used to measure the degree to which generated summaries can represent an original video. Although this reward can identify diversity-representative video frames, the cluttered distribution of excessive non-key frames disrupts summarized videos. To address this issue, we propose dispersion rewards, which allow the proposed method to cluster key frames together and reduce the probability of selecting non-key frames. As a result, our model preserves segment integrity and generates high-quality summaries. Additionally, our proposed method is generic and can be easily integrated into existing unsupervised video summarization models.
In summary, the main contributions of this paper are threefold.
We propose a DRL framework with an unsupervised summary loss for video summarization called AuDSN, which solves the long-term dependency problem of reinforcement-learning-based key frame extraction algorithms. Compared to RNN/ LSTM-based video summarization methods, our proposed video summarization framework can capture the long-term dependencies between video frames more effectively;
We employ an unsupervised auxiliary summarization loss for video summarization, which assists in tuning network parameters by calculating the percentage differences between original and selected features. Additionally, the unsupervised auxiliary summarization loss does not increase the parameters of the model and can be easily integrated into other video summarization models;
We propose a novel reward function called dispersion reward () and employ it as a final reward function. Experimental results demonstrate the effectiveness of this reward function for video summarization.
The remainder of this paper is organized as follows. The related work is discussed in detail in
Section 2.
Section 3 describes the proposed pipeline-based AuDSN model. We present the experimental results in
Section 4. Finally,
Section 5 summarizes the key contributions of our work and concludes this paper.
3. Methodology
This paper proposes a deep summarization network with auxiliary summarization losses to improve the performance of video summarization. Specifically, the auxiliary summarization losses are used as auxiliary training in the proposed AuDSN model. A brief overview of the AuDSN model is detailed as follows.
We consider video summarization as the task of making decisions for each frame in a video. We implement DRL models to predict the value of the information contained in each frame and determine the probability of each frame being a key frame based on these values. We then select the final key frames based on a probability distribution. Inspired by Zhou et al. [
7], we developed an end-to-end reinforcement-learning-based summarization network. The pipeline of this network is presented in
Figure 2. We train AuDSN using reinforcement learning. AuDSN receives observations (video frames) at each time step and performs various actions on the observations. Additionally, AuDSN generates auxiliary summary loss values. The environment receives the actions and auxiliary summary loss values and generates a reward and observation for the next time step. The data (
) generated during this process are recorded in a sample database and when the sample data are sufficient, loss values are calculated and the model parameters are updated.
The proposed AuDSN is an encoder–decoder architecture, where the encoder uses a CNN (typically GoogLeNet [
41]) to extract visual features
from an input video frame sequence of length t
. The decoder uses an LSTM network that can capture temporal features. It randomly inserts anchor points in the LSTM network and introduces unsupervised auxiliary summarization loss. A fully connected layer serves as the final layer of the network. The LSTM network takes the high-dimensional features
generated by the encoder as inputs and generates the corresponding hidden states
, some of which will be passed to the unsupervised auxiliary summarization loss function to help the summary network reconstruct historical information as a method of establishing long-term dependencies. The hidden state
is loaded with past information. The value of each frame is obtained through a fully connected layer using the swish activation function [
42] and the fully connected layer using the sigmoid activation function. The value of each frame is used to determine the action
a as follows:
where
is the rectified linear unit (ReLU) activation function,
is the sigmoid activation function,
,
are the weights of the fully connected layer, and
,
are the biases of the fully connected layer.
denotes the probability distributions over all possible action sequences.
are binary samples drawn from the Bernoulli distribution indicating whether the
frame is selected. The Bernoulli distribution is parameterized by
. We obtain a video summary composed of the selected key frames
, where
is the selected key frame with
. We only update the decoder during the training process.
3.1. Auxiliary Summarization Loss
To enhance the ability of LSTM to capture long-term dependencies, we propose a form of unsupervised auxiliary summarization loss that applies to video summarization. This loss not only enhances the memory capabilities of LSTM but can also be easily migrated to other models. It is experimentally demonstrated that this auxiliary summarization loss can help the summarization network establish longer-lasting dependencies and improve the performance of video summarization. During the training progress, we randomly sample multiple anchor locations in the LSTM and insert an unsupervised auxiliary summarization loss function at each location.
An unsupervised auxiliary summarization loss function first reconstructs memories from the past by sampling the subsequence after its anchor point, copying the hidden state of a subsequence of length n after its anchor point, and inserting the first input of this subsequence into the decoder network. The rest of the subsequence features are reconstructed using the decoder network, as shown in
Figure 3. By using this training method, anchor points can be used as temporary memory points for the decoder network to store memories in a sequence. When we insert enough anchor points, the decoder network remembers the entire sequence and reconstructs memories. Therefore, when we reach the end of the sequence, the decoder network remembers a sufficient number of sequences and can generate a high-quality video summary.
The introduction of unsupervised auxiliary summarization loss in the decoder network results in the need for some additional hyperparameters, namely the sampling interval
and subsequence length
. The sampling interval is defined as the samples per unit length that are extracted from the decoder network and composed into subsequences. The subsequence length represents the number of original features contained in each subsequence. We define the auxiliary summarization loss as follows:
where
denotes the sampling interval,
denotes the loss evaluated on the
i-th sampling segment, and the overall auxiliary summarization loss is calculated by summing all subsequence auxiliary summarization losses for a segment. We define the subsequence auxiliary summarization loss as follows:
where
denotes the subsequence length,
l denotes the feature dimension (based on the CNN encoder, the feature dimension we obtain is typically 1024),
Y denotes the original features of the subsequence, and
C denotes the key summary features of the subsequence after decoder selection. The auxiliary summarization loss of each subsequence is obtained by computing the infinite norm error between the vectorized
Y and
C features. This auxiliary summarization loss represents the percentage of the variance between the original features
Y and key summary features
C of the subsequence selected by the decoder.
Tuning hyperparameters is a very expensive process, so we set the lengths of all selected subsequences to be equal. Because the addition of unsupervised auxiliary summarization loss does not change the structure of the decoder module, and high-quality embeddings of input sequences can be learned based on the unsupervised auxiliary summarization loss, the weights of the LSTM network can be fine-tuned using the back-propagation step only.
3.2. Reward Function
In reinforcement learning, the goal of an agent is represented as a special signal called a reward, which is transmitted to the agent through the environment. At each moment, the reward is a single scalar value. Informally, the goal of an agent is to maximize the total reward it receives. This means that what needs to be maximized is not the current reward, but the long-term cumulative reward.
An agent always learns how to maximize its gain and the amount of gain is determined by the reward function. If we want an agent to perform a particular task, then we must provide rewards in such a manner that the agent maximizes its gain while completing the task. Therefore, it is critical that we design the reward function in a way that truly achieves our goal. In video summarization, the key frames are selected from the video, and the selected frames should be diverse, representative, and uniform. Gygli et al. [
10] mentioned that there is no standard answer for a correct summary, but we must guarantee the generation of a high-quality summary.
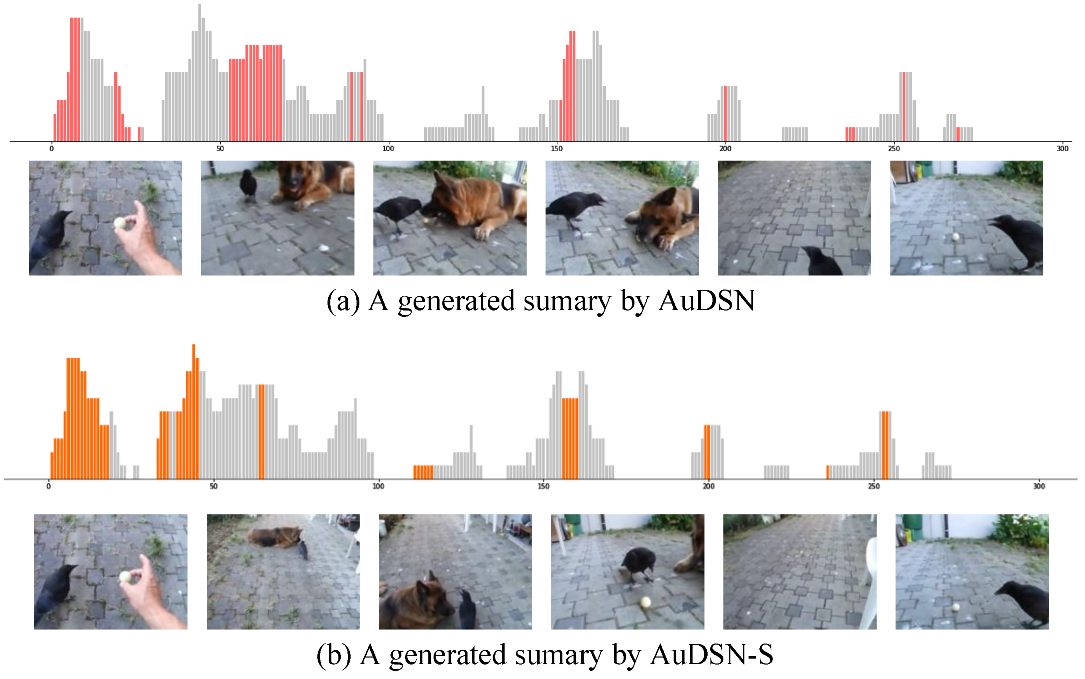
Figure 4 presents the results of the label visualization of three sample videos (Cooking, Fire Domino, and Jumps) from the SumMe dataset. Each video was labeled by 15 to 18 people and each line in the video visualization represents one person’s selection result. As shown in
Figure 4, we should select key frames from labels such as those in
Figure 4a,b for video summarization. In our proposed model, we demonstrate that combining dispersion rewards with two rewards for diversity and representativeness can produce enhanced summaries.
3.2.1. Diversity Reward
The diversity reward function calculates the degree of diversity of a video summary by evaluating the dissimilarity between selected key frames. Specifically, it calculates the variability between selected video frames in the computational feature space to evaluate the diversity of a video summary quantitatively. The diversity reward function is defined as follows:
where
is the set of selected video frames,
is the feature sequence corresponding to the video frames and
represents the dissimilarity function to calculate the dissimilarity between two frames, which is defined as follows:
Therefore, the reward obtained by the agent is higher when the selected frames are more diverse (i.e., larger differences between selected video frames are favored). To ignore the similarity between two temporally distant frames, we set
if
, where
controls the degree of temporal distance consideration [
7].
3.2.2. Representativeness Reward
The representativeness reward is used to measure how well selected key frames represent an original video [
7]. Evaluating the representativeness of a video summary can be formulated as the k-medoids problem [
43], where the representativeness reward is defined as follows:
where
is the feature of the
frame and
y is the set of selected frames, as described above.
3.2.3. Dispersion Reward
When using representativeness rewards, the degree of representativeness is defined as a k-medoids problem. To ensure that the selected video frames are uniform, we propose a dispersion reward function to complement the representativeness reward function to achieve better selection results. The dispersion reward function uses more intuitive criteria. As shown in
Figure 5, the distribution of (a), which has a higher dispersion reward, exhibits significantly better clustering than that of (b), which has a lower dispersion reward. We want clustering results to have small intra-class distances and large inter-class distances (i.e., classification results should have high discrimination). To this end, a criteria function reflecting both intra- and inter-class distances can be constructed.
The intra-class departure matrix is generated by calculating the distance from each sample point to the cluster center. The intra-class distance criteria function, which produces an intra-class departure matrix
, is defined as follows:
where
is the sample mean vector of class
w,
denotes the number of samples in class
w, and
c denotes the number of categories classified.
denotes the
data sample in the
class.
The inter-class distance criterion function, which produces an inter-class deviation matrix
, is defined as follows:
where
c denotes the number of classes to be classified,
m is the mean vector of all samples to be classified,
denotes the number of samples in class
w,
denotes the total number of samples, and
denotes the class center of each class.
The dispersion reward based on the intra-class distance criteria function and inter-class distance criteria function is defined as follows:
where
is the matrix trace.
,
, and
complement each other and work jointly to guide the learning of AuDSN. The determination of optimal weights for the different reward types is discussed later in this paper. The basic reward function is expressed as follows:
3.3. Deep Summarization Network with Auxiliary–Summarization Loss-Based Video Summarization
We train the summary network using a DRL framework. The goal of the proposed summarization method [
7] is to learn a policy function
with parameters
by maximizing the expected rewards
where
is computed using Equation (
2) and
R is computed using Equation (
12).
represents the expected value for calculating the reward.
is defined by our AuDSN.
The agent selects key frames based on the policy function
. This selection is defined as an action
. The agent combines the current observation state
and feature space of the selected video frames to predict a new observation state
. The next action
is determined based on the
n-th reward
. The derivative of
is computed using the REINFORCE algorithm proposed by [
44]. Only the encoder of the network is updated during training.
To reduce the computational load, the final gradient is calculated as the average gradient after executing
N iterations on the same video. A constant baseline
b is subtracted from the
reward
to avoid the type of high variance that leads to divergence. This baseline
b is calculated based on the moving average of the rewards from the previous time steps. The gradient formula is defined as follows:
Additionally, we introduce a regularization term into the probability distributions to constrain the percentage of frames selected for the summary and add the
regularization term to the weight parameters
to avoid overfitting [
7]. The parameters of the optimal policy function are optimized using the stochastic gradient algorithm by combining all conditions. We use Adam [
45] as an optimization algorithm.
5. Conclusions
In this paper, we proposed AuDSN, which is a deep reinforcement network model with unsupervised auxiliary summarization loss. We introduced unsupervised auxiliary summarization loss in the decoder and explored a novel reward function with a dispersion reward. Experimental results on two datasets (SumMe and TVSum) demonstrated that introducing unsupervised auxiliary summarization loss can improve the long-term dependency-capturing ability for a deep summarization network. Additionally, the swish activation function and dispersion reward function can help a deep summarization network construct more coherent, diverse, and representative video summaries. Furthermore, AuDSN is a very lightweight model with a size of only 2.7 MB, presenting the opportunity of deploying it on low-computing-power edge devices. In future work, we will also try to incorporate multi-information, such as sound features, into the model and explore multi-information versions of the deep summarization network framework. Furthermore, we will try to incorporate the proposed video summarization approach into modern media tools to make practical use of the proposed summarization algorithms.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}