1. Introduction
With the optimization of global energy structure, hydropower has been vigorously developed [
1]. As critical equipment of hydropower utilization, it is important to ensure the safe and stable operation of Francis turbine units (FTUs) [
2]. In order to transform the service mode of the FTUs from traditional schedule-based maintenance to state-based maintenance, the prognostic of FTUs has received more and more attention [
3]. There are two main parts in the prognostic of FTUs, including performance state evaluation and degradation trend prediction [
4]. Based on this, the current and future states of FTUs can be determined so as to formulate a targeted maintenance strategy. However, in practical engineering environments, there are three significant difficulties, including low data quality, complex variable operation conditions, and prediction model parameter optimization.
The state monitoring systems of FTUs work in the harsh environment of high humidity, high vibration, and strong electromagnetic. Due to sensor failure, electromagnetic interference, and missing communication packets, the data quality of the actual measured signal is usually low, which is mainly manifested as data anomaly and data loss [
5,
6]. Most signal denoising methods, including spectrum analysis and signal reconstruction, are effective for signals with a high sampling rate and consistent sampling frequency [
7,
8,
9]. However, data loss has a great influence on their practical application. Suppression of abnormal data in practical low-quality data sets of FTUs is rarely discussed in existing studies. As an unsupervised learning algorithm, clustering can adaptively detect potential patterns among multi-dimensional data [
10]. The density-based spatial clustering of applications with noise (DBSCAN) has the ability to identify the isolated noise from data sets with arbitrary shapes, and the DBSCAN is confirmed to be efficient and robust for low-quality data sets [
11,
12]. Therefore the DBSCAN is adopted to clean the actual monitoring data set of the FTU in this study.
Generally, FTUs need to participate in the load and frequency regulation of the power grid, and the incoming water levels fluctuate significantly with seasonal variation. Therefore, the operating condition parameters of FTU change frequently [
13]. Since the monitoring vibration signals are highly correlated to operation condition parameters, the traditional performance evaluation method with a fixed threshold is difficult to reflect the actual state of FTUs accurately [
14]. Machine learning has been widely used in equipment fault diagnosis and performance evaluation due to its good pattern recognition capability [
15]. To establish the performance state evaluation model under variable operation conditions, An et al. and Shan et al. adopted the radial basis function and backpropagation neural network (BPNN), respectively, to fit the mapping relationship between water head, active power, and vibration amplitude, as the healthy state model (HSM) of the FTU [
4,
16]. These studies established the definite functional relation between operation condition parameters and monitoring signal, but the randomness of the signal may still affect the accuracy and stability of these value-to-value mapping models. To deal with it, Rai et al. adopted the Gaussian mixture model (GMM) to fit the probability density distribution (PDD) of vibration features as the HSM of a rolling bearing. The results showed the HSM based on GMM was more accurate and monotonous [
17]. However, in this work, the operation condition parameters were constant. Thus, the variable operation condition parameters and the signal randomness are sufficiently considered in this paper, and the GMM is adopted to fit the probability distribution of the running data set as the HSM of the FTU under complex operating conditions.
After constructing the proposed HSM, the real-time state of the FTU can be quantified as performance degradation indicator (PDI) values. Thus, time-series prediction methods can be used to solve the degradation trend prediction problems. For example, Li et al. combined the convolutional filters and the gated recurrent unit to construct a degradation trend prediction model for a turbofan based on data [
18]. Jin et al. presented a novel adaptive residual long short-term memory network to predict cutter head torque across domains. The prediction performance is effectively improved by using the knowledge of the source domain dataset [
19]. However, most deep learning models only output point prediction values, and it is difficult to quantify the uncertainty of results directly [
20]. As a probability prediction model, the Gaussian process regression (GPR) has been widely proven to perform well in uncertain prediction problems [
21,
22,
23]. However, its property is greatly affected by model parameters. Manual parameter tuning is inefficient and relies on prior knowledge. Therefore, some research adopted intelligent optimization algorithms to optimize prediction model parameters automatically [
24,
25,
26]. However, the accuracy of the prediction model was taken as the only optimization objective in these researches. The confidence interval (CI) width represents the certainty of probability prediction, which is also an important objective to consider. As one of the most popular multiobjective optimization algorithms, the non-dominated sorting genetic algorithm (NSGA-II) reduces the complexity of genetic algorithms with fast calculation and good convergence [
27,
28,
29]. Thus the NSGA-II is adopted to optimize the GPR on the two objectives of accuracy and certainty to construct the multiobjective GPR (MOGPR) for degradation trend prediction of FTUs.
According to the above discussion, in the relative field of the prognostic of FTUs, there are few targeted processing methods for low-quality data obtained in practical engineering environments. Meanwhile, existing evaluation methods of FTU under complex conditions rarely consider the randomness of monitoring data. Moreover, in the interval prediction of PDIs, it is still difficult to optimize model parameters automatically while considering both the accuracy and certainty of results.
In this paper, an ensemble prognostic method of FTUs using low-quality data under variable operation conditions is proposed. The major contributions are outlined as follows:
- (1)
A monitoring data set cleaning approach of FTUs based on DBSCAN is proposed to identify both the singulars and outliers, which enhances the stability and smoothness of the obtained PDI curve.
- (2)
The running data set of the FTU is constructed by fusing the operation condition parameters and the monitoring data. The HSM is established based on the GMM to realize accurate performance evaluation of the FTU under complex operating conditions to improve the robustness of the performance evaluation model against data missing and data randomness.
- (3)
Coupling NSGA-II and GPR, the MOGPR is constructed to automatically tune model parameters, avoiding the dependence on prior knowledge, and the accuracy and certainty of probability prediction are improved synchronously.
The remainder of this paper is organized as follows: In
Section 2, the proposed approach framework and related theories are expounded. In
Section 3, an engineering application of the proposed method is presented. In
Section 4, different data cleaning methods, HSM construction, and trend prediction are compared and discussed. Finally, a summary is presented in
Section 5.
2. Proposed Approach
To evaluate and predict the performance state of FTUs more accurately under the circumstance of low-quality data and variable operation conditions, an ensemble prognostic method of FTUs using low-quality data under variable operation conditions is proposed in this paper, which mainly includes four steps: data acquisition, data cleaning, performance state evaluation, and degradation trend prediction. The proposed framework flow chart is shown in
Figure 1. First, the monitoring data of the water head, active power, and vibration amplitude of the top cover are integrated to construct the running data set of the FTU. Second, aiming at data loss and data anomaly, the data cleaning operation based on DBSCAN is implemented. Third, to solve the problem of monitoring data fluctuating with operation conditions, the HSM is established based on GMM. Then the negative log-likelihood probability (NLLP) is calculated as the PDI of the FTU. The relative trend of PDIs over time reflects the process of performance degradation. Fourth, the MOGPR model is constructed to predict the performance degradation trend of the FTU and takes both prediction accuracy and confidence interval into consideration. Finally, the validity of the performance evaluation model and degradation trend prediction model is evaluated by multi-criterions.
2.1. Data Acquisition
Due to their task of regulating the power grid, the operation condition parameters of FTUs change more frequently than other kinds of rotating machines. Therefore, unlike most traditional methods, operation condition parameters are taken into full consideration in the performance state evaluation in this study. The major operation condition parameters of FTUs include rotation speed (
n), water head (
H), active power (
P), flow rate (
Q), guide vanes opening degree (
α), etc. Since the duration of transient operation conditions is particularly short compared with the total working time of FTUs, only steady operation conditions are considered in this research. So n can be considered equal to the rated value of the FTU. For a specific FTU, there is a certain relationship between
H,
P,
Q, and
α. If two of them are identified, others can be inquired from the comprehensive operation curve of the FTU [
30]. Thus H and P are chosen as the studied operation condition parameters. As a critical component of the FTU, the top cover is used to seal the runner and support the main shaft. Its vibration amplitude (
V) can reflect the performance state of the FTU. In conclusion, the running sample set of the FTU is formed by (
H,
P,
V), including both operation condition parameters and monitoring data.
2.2. Data Cleaning Based on DBSCAN
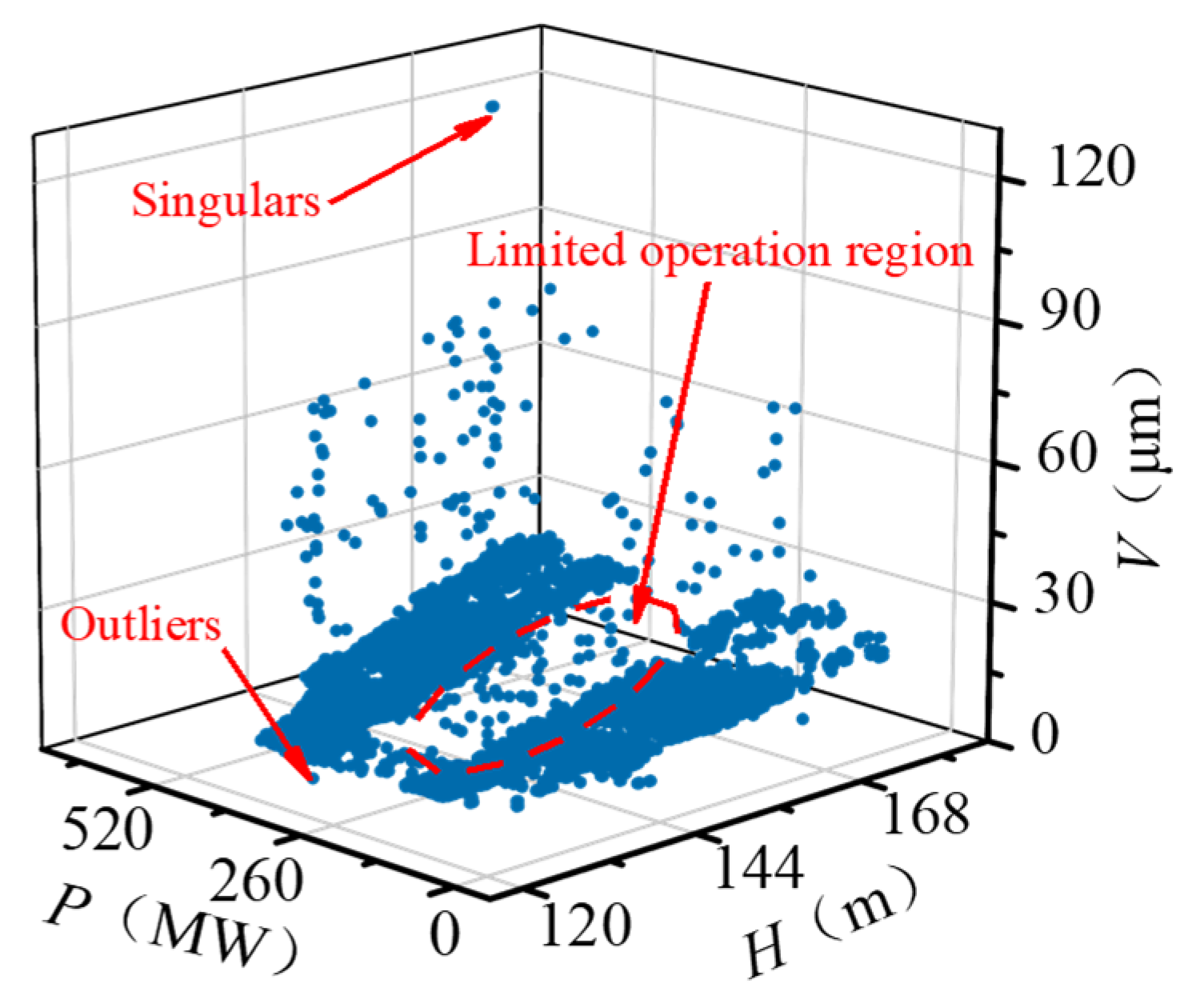
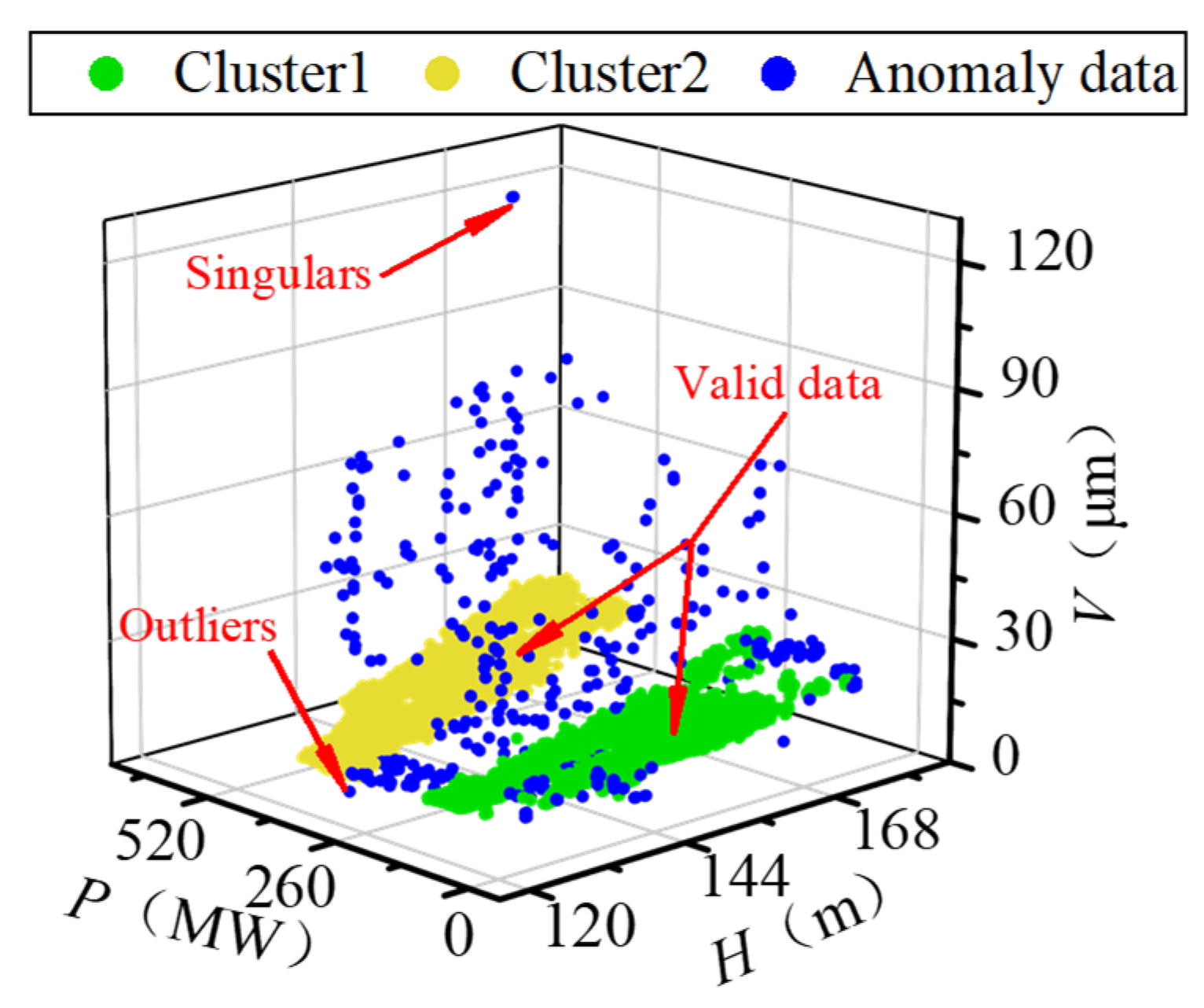
To solve the data anomaly in the raw running sample set, a data cleaning approach based on DBSCAN is proposed. Traditional statistics-based methods such as the 3-sigma principle are effective in detecting singular points, but they can hardly identify outliers whose value is within the normal range [
31]. DBSCAN clustering algorithm has the advantages of high adaptability, extensible dimension, and applicability to arbitrary data shape [
32]. It can automatically identify the singularities and outliers in the multi-dimensional data set. Its schematic diagram is shown in
Figure 2, and the main steps are as follows [
33]:
Step 1: For the sample set , the region whose Euclidean distance from the sample point is less than is defined as the neighborhood of . If the sample number in the neighborhood of is greater than the threshold M, is defined as the core point. Samples that are not core points but are in the neighborhood of a core point are defined as boundary points. Samples that are not core points and are not boundary points are defined as noise points. The neighborhood of a core point is defined as a temporary cluster .
Step 2: Traversal the sample set , if the sample point in the temporary cluster is also a core point in another temporary cluster , the union set is defined as a new temporary cluster.
Step 3: Repeat Step 2 until the sample points in each temporary cluster are all core points or boundary points, then each temporary cluster is determined as a cluster .
2.3. Performance State Evaluation Based on GMM
The performance degradation process of the FTU is reflected in the PDD variation of the running sample set (
H,
P,
V). Thus the GMM is adopted to fit the three-dimensional PDD function of the healthy data as the HSM. In GMM, the population distribution of the sample set is assumed to be a combination of a series of Gaussian distributions:
where
represents the healthy data set,
represents the weight coefficient.
.
is the distribution parameters.
is the PDD function of the
kth Gaussian component given by:
The expectation-maximization algorithm is used to estimate
, and
of the GMM [
34]:
where
is the maximum likelihood estimate value of
.
The NLLP represents the probability that current data is observed based on the prior given by the GMM. It represents the difference between the PDD of running data
and the constructed HSM. So the NLLP is calculated as the PDI of the FTU.
2.4. Degradation Trend Prediction Based on MOGPR
Through the above procedures, the performance state of the FTU is quantified as PDIs. The performance degradation prediction of the FTU is transformed to a time series prediction task. In this section, the GPR and NSGA-II are combined to construct the MOGPR model for the degradation trend prediction.
2.4.1. GPR Algorithm
As a nonparametric Bayesian inference model, GPR is widely used in probability interval prediction [
35,
36]. In GPR, the distribution of possible values at each time point is assumed to obey the Gaussian distribution, which can be expressed in terms of the expectation function
and the covariance function
as:
where
is the independent variables,
is also called the kernel function,
.
The joint distribution of the actual observed values
and
also follows the Gaussian distribution.
where
,
.
Finally, the GPR model can be expressed as:
The kernel functions
are used to enhance the representation of relationships between input samples. Various kernel functions have different properties and characteristics. The commonly used kernel functions include radial basis function (RBF), matern (MA), rational quadratic (RQ). The kernel function adopted in this study is composed of them.
These kernel functions all contain a length scale
. To improve the performance of the model, the common approach is to adjust
manually, which is less efficient. Aiming at this problem, the NSGA-II algorithm is introduced to automatically optimize the GPR model. Since GPR outputs the PDD of predicted values, quantiles and confidence intervals (CIs) can be calculated directly. Interval prediction results are usually evaluated by multiple criteria, including the root-mean-square error (RMSE), which reflects the accuracy, and the prediction interval normalized average (PINAW), which reflects certainty, defined as:
where
is the number of series data,
and
represents the prediction value and the actual value, respectively.
is the difference between the maximum and minimum values of the actual series,
and
represents the upper and lower boundary of 95% CI. Lower RMSEs and PINAWs indicate better accuracy and certainty of the prediction model.
2.4.2. NSGA-II Algorithm
NSGA-II makes excellent improvements on NSGA, and it has faster computational efficiency and population diversity [
37]. There are two basic concepts in NSGA-II: non-dominated sorting and crowding distance. The procedure of non-dominated sorting begins with the identification of non-dominated solutions. As shown in
Figure 3, for two members
and
, if all the objectives of
are better than
,
is defined to dominate
. Then, the members which are not dominated by others constitute the current front. Next, the members of the current front are removed, and the sorting is performed on the remained population. The procedure is repeated until all the members are distributed to different fronts.
The crowding distance is used to measure the density of members. It is defined as the sum of the side length of the cuboid shown in
Figure 3.
where
K is the dimension number of the objectives. Selecting members with a high crowding distance can improve the diversity of the population.
The brief schematic of NSGA-II is illustrated in
Figure 4, and the main steps are as follows:
Step 1: The population is initialized. Then, the offspring population Qt is generated from the parental population Pt through crossover and mutation operations. The population sizes of Pt and Qt are both N.
Step 2: The Pt and Qt are merged to form the Rt. The non-dominated sorting is performed on Rt, and a series of fronts Fi are obtained.
Step 3: The fronts are selected in sort order to form the Pt+1 until the population size of Pt+1 exceeds N. The members of the last front Fl are sorted by the crowding distance. The members are selected in order until the population size of Pt+1 equals N.
Step 4: The above steps are repeated until the maximum number of evolution is reached. Then the first front is selected as the Pareto front.
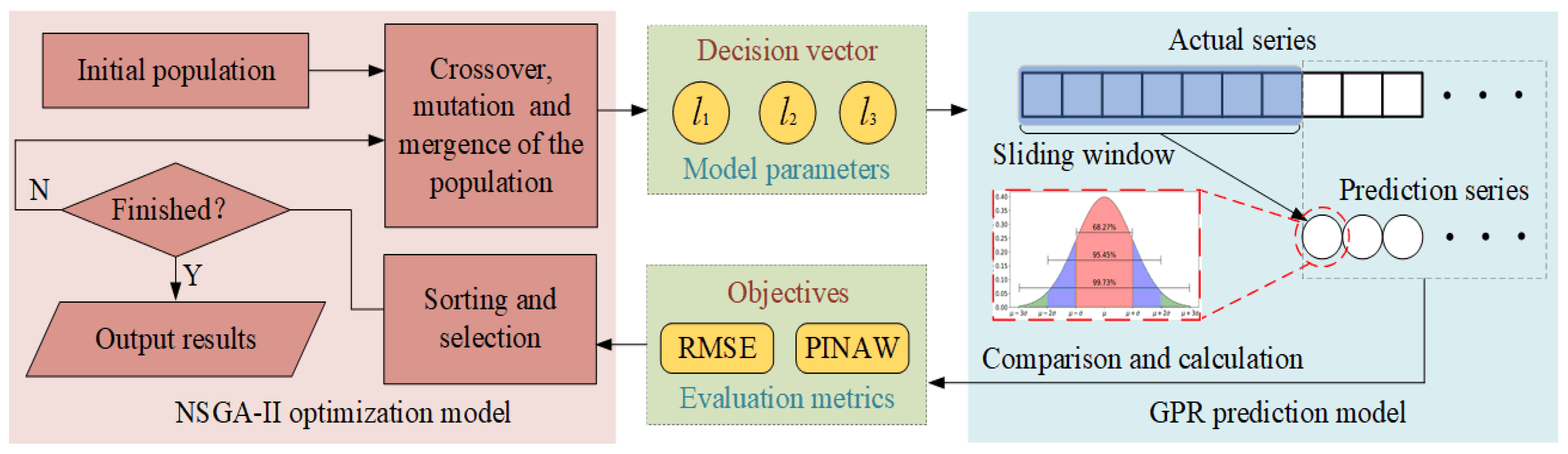
2.4.3. MOGPR Model
The GPR and the NSGA-II are coupled to construct the MOGPR model. The three-dimensional decision vector is formed by the length scales of RBF, MA, and RQ in the GPR model. The multiple objectives include both RMSE and PINAW. The schematic diagram of the MOGPR is illustrated in
Figure 5. The GPR model sets parameter values according to the decision vector generated by NSGA-II and calculates the prediction results. Then the results are compared with the actual values to obtain multi objectives. NSGA-II updates population location according to the multi objectives. Through several epochs of evolution, the Pareto front of the optimal result is finally output.
5. Conclusions
In this study, aiming at the three major practical engineering difficulties of low data quality, complex variable operation conditions, and prediction model parameter optimization, an ensemble prognostic method of FTUs using low-quality data under variable operation conditions is proposed. Firstly, to comprehensively reflect the performance of the FTU under complex operation conditions, the running data set is constructed by combining operation condition parameters and monitoring data. Secondly, to reduce the impact of anomaly data, the DBSCAN is adopted to clean both outliers and singulars in the raw running data set. Thirdly, based on the GMM and the probability theory, the HSM is established, which improves the robustness of the evaluation model against data missing and data randomness. Fourthly, the MOGPR is proposed to predict the performance degradation trend with a confidence interval and to automatically optimize model parameters on both accuracy and certainty. Finally, a series of comparison experiments were implemented on practical data set from an actual large FTU.
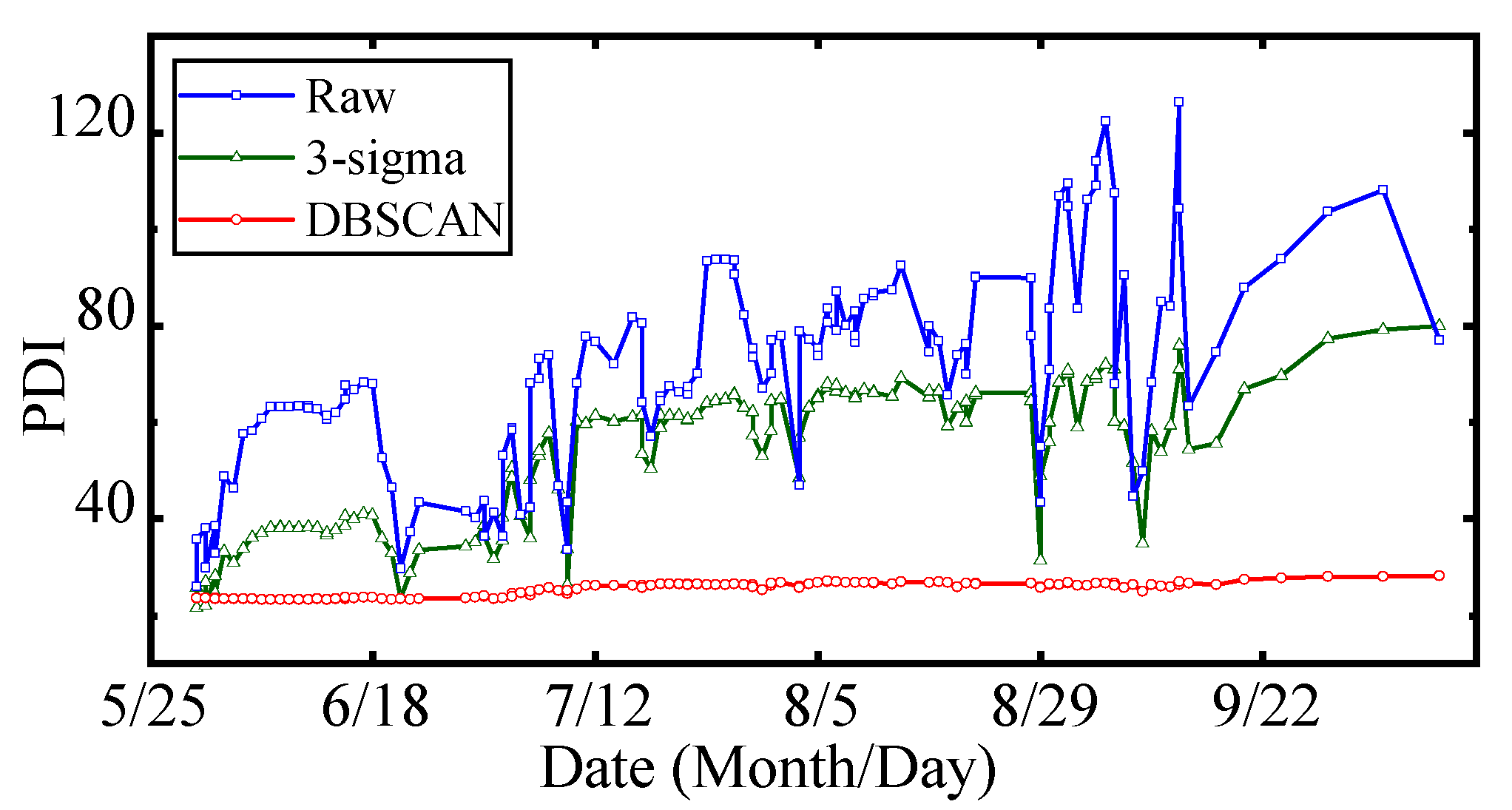
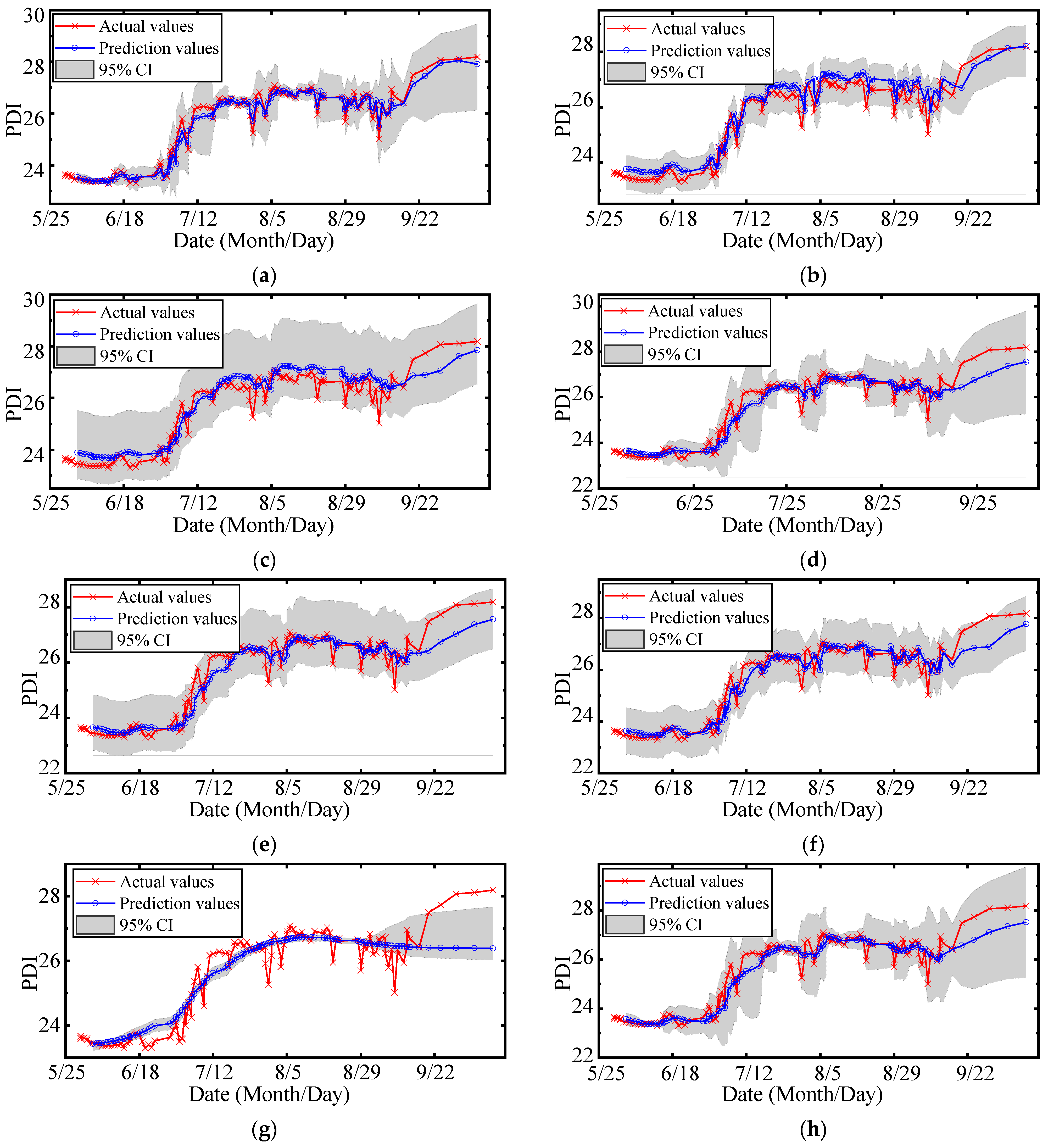
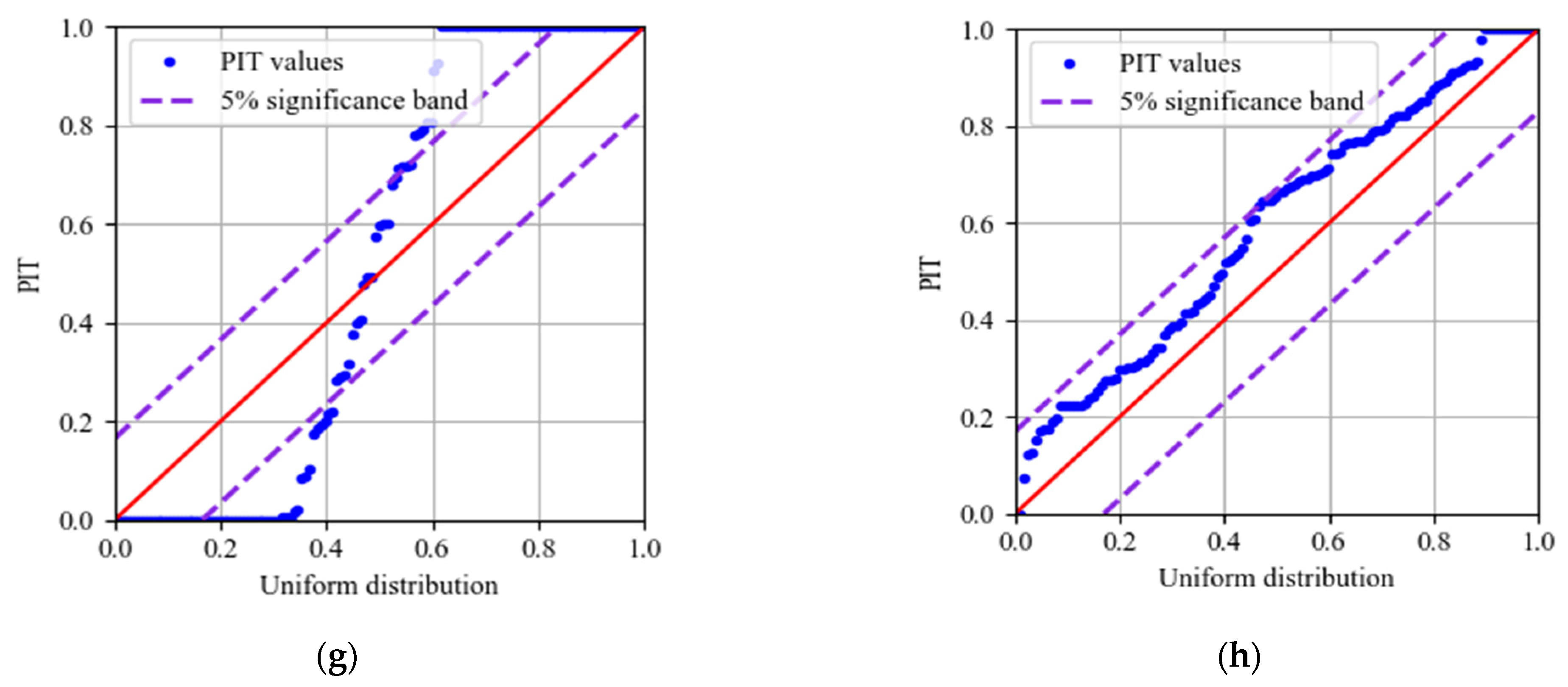
The experimental results demonstrate that: (1) The data cleaning approach based on DBSCAN performs better in identifying both outliers and singularities. The stability and smoothness of PDI curves are improved by 3.2 times and 1.9 times, respectively, by DBSCAN compared with 3-sigma. (2) Compared with SVM and BPNN, the HSM based on GMM has better robustness against data loss. (3) The proposed MOGPR has better accuracy, certainty, and reliability of probability prediction. The root-mean-squared error, the prediction interval normalized average, the prediction interval coverage probability, the mean absolute percentage error, and the R2 score of the proposed method achieved 0.223, 0.289, 1.000, 0.641%, and 0.974, respectively.
Thus, the proposed method can be applied to the performance evaluation and degradation trend prediction of FTUs in a practical engineering environment. In further research, if the running data across multiple maintenance periods are available, the corresponding relationship between PDI values and actual state can be established according to maintenance records. On this basis, the multi-level degradation state of the FTU can be divided, and corresponding maintenance strategies can be formulated to provide technical support for state-based maintenance.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}