
Augmenting Social Science Research with Multimodal Data Collection: The EZ-MMLA Toolkit


Abstract
:1. Introduction
2. Literature Review
2.1. Why Multimodal Sensing? Examples from Educational Research
2.2. Current Toolkits Used to Conduct Multimodal Research
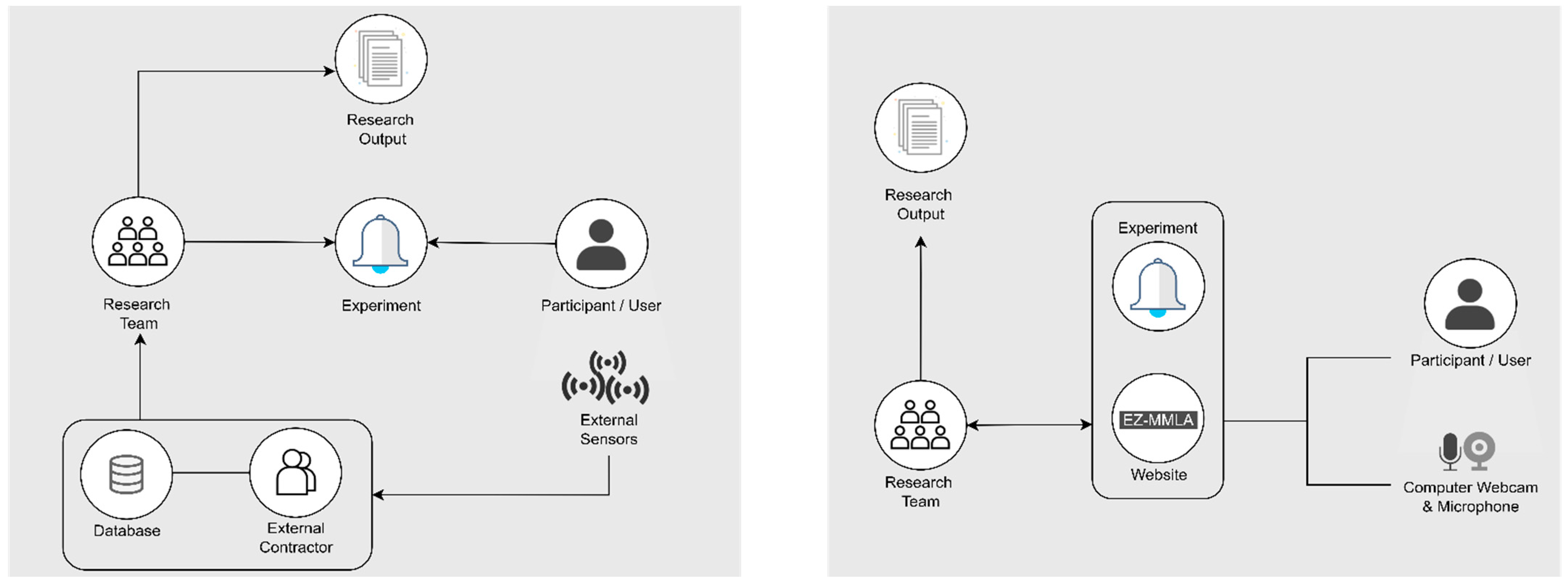
3. Multimodal Data Collection
3.1. Conventional Multimodal Data Collection
- Accessibility: Logistically challenging data collection and data analyses processes can restrict access to users without a strong technical background (c.f., computer scientists, engineers, statisticians).
- Affordability: While sensors are becoming more affordable as a whole, research-grade equipment still tends to be cost inhibitive. This results in multimodal data research being restricted to well-funded teams or to more commercially lucrative research areas.
- Invasiveness: Sensors created for research can still be bulky and invasive for human participants, impacting the state of the participant, their reaction to stimuli, or how aware they are of being observed. This can create noise in the data, or be the cause of Hawthorne effects and similar biases.
3.2. Web-Based Multimodal Data Collection
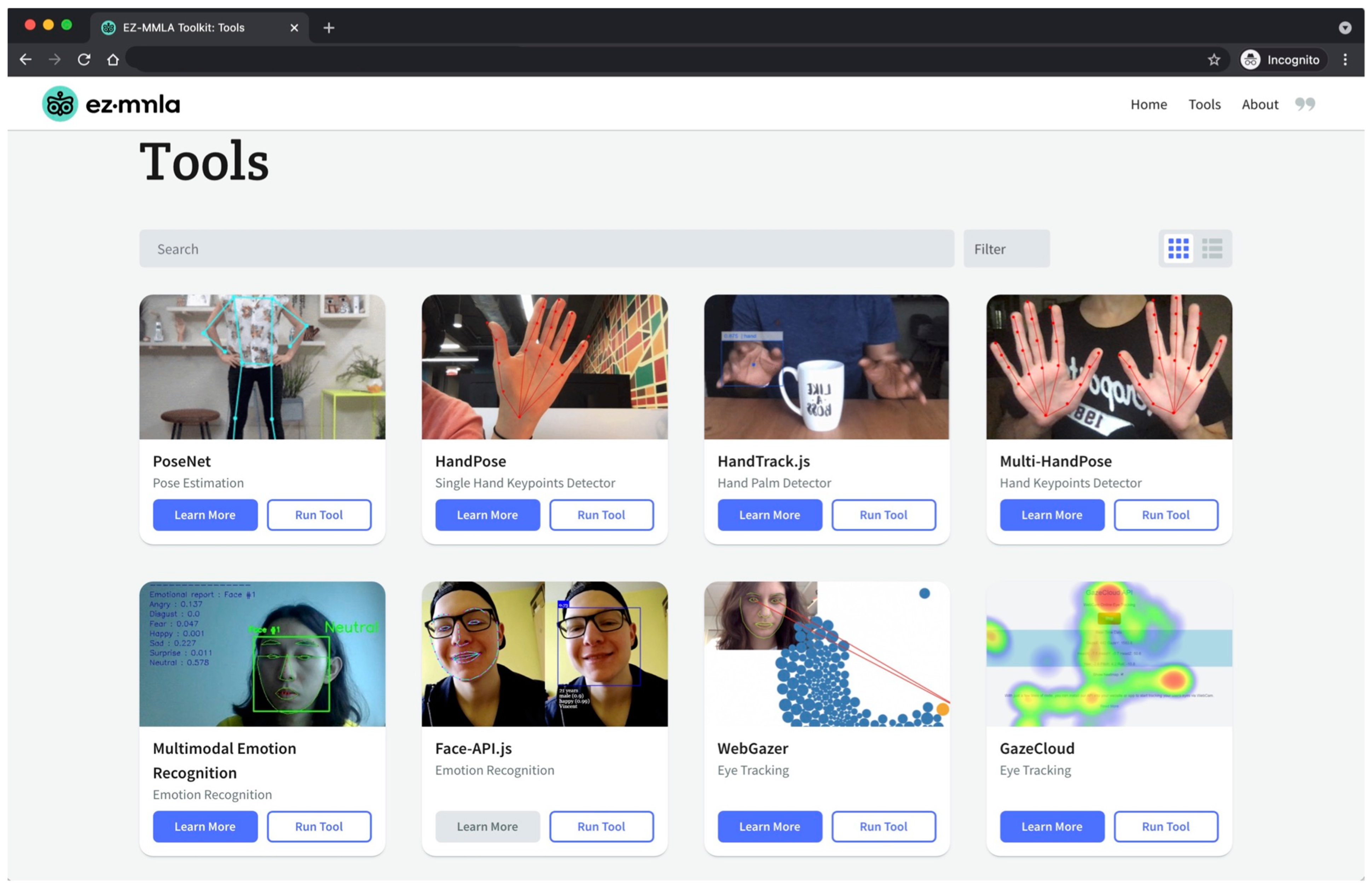
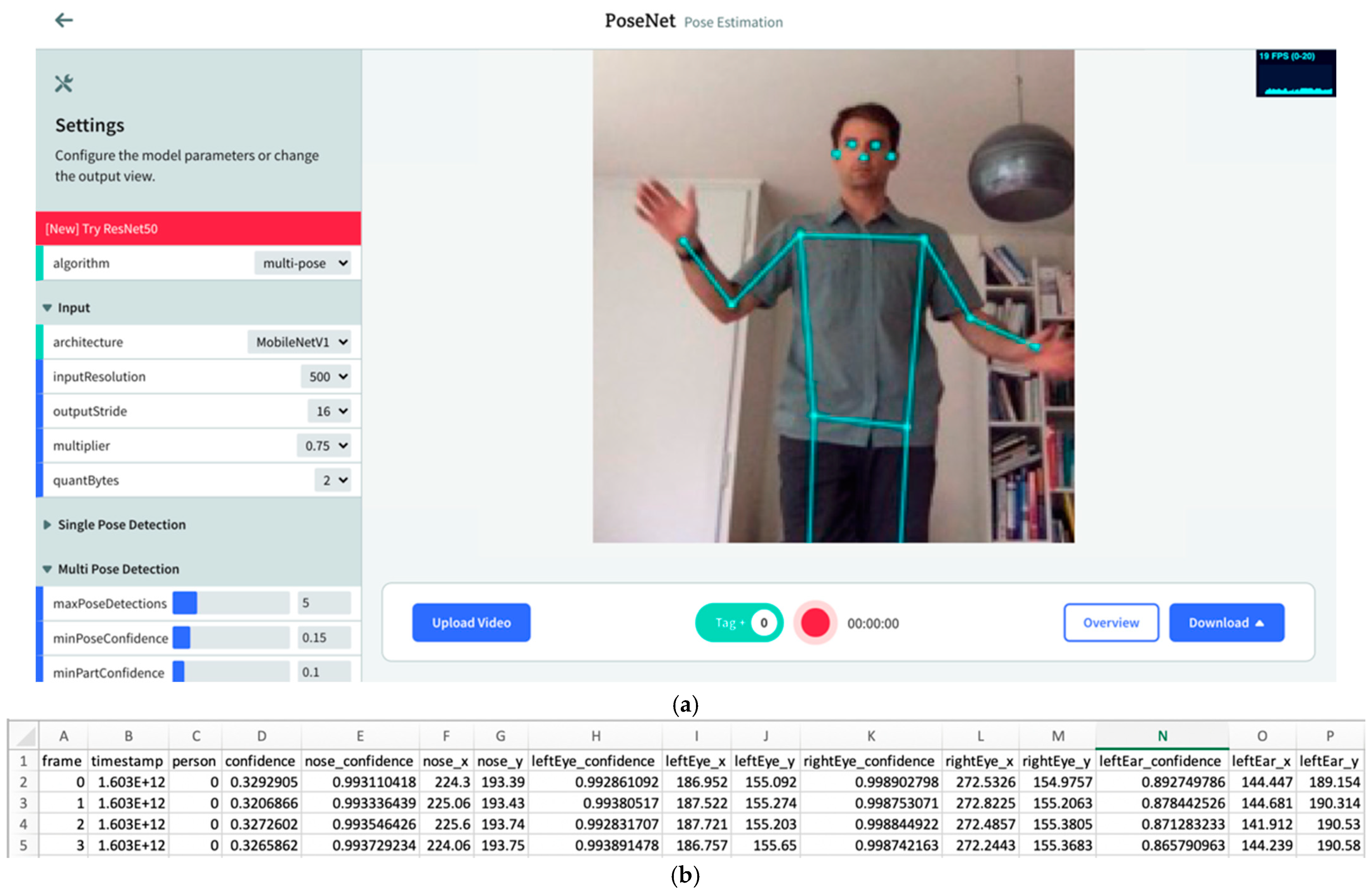
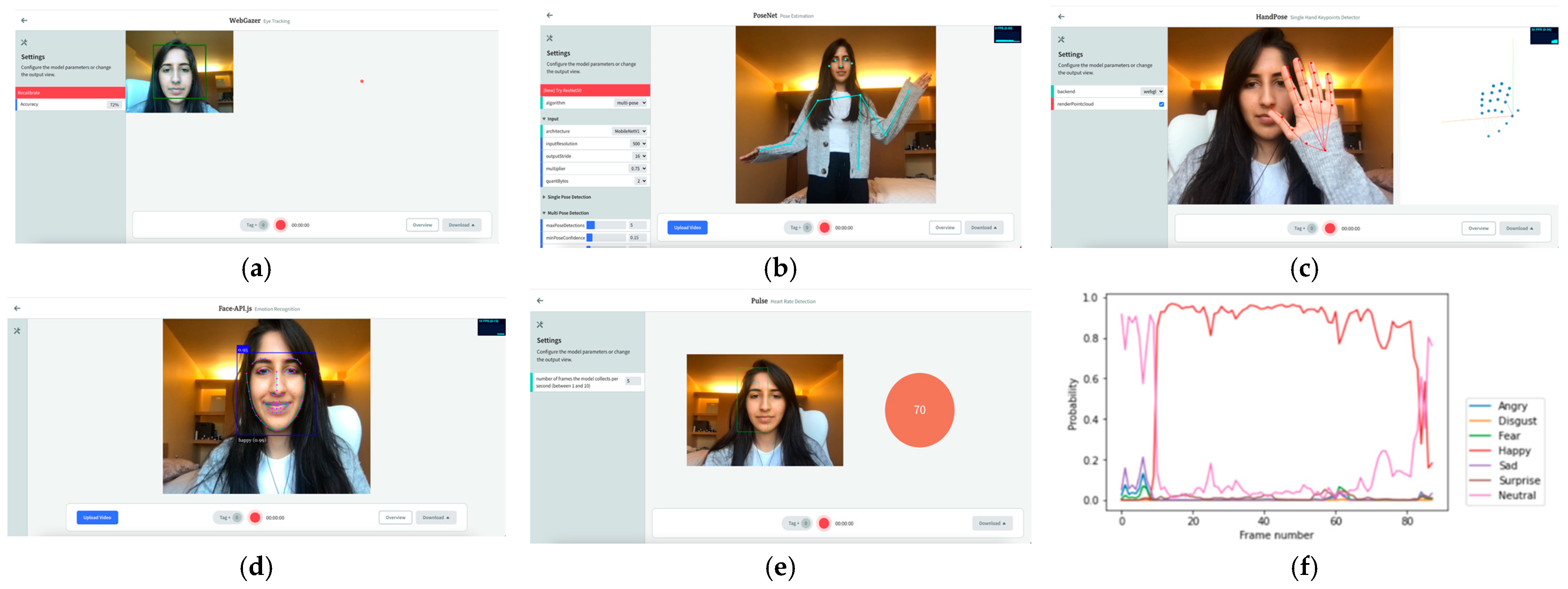
4. System Description
4.1. Comparing the EZ-MMLA Toolkit with Traditional Data Collection Tools
4.2. Possible Applications of the EZ-MMLA Toolkit
4.3. Case Study: A Course on Multimodal Learning Analytics
4.3.1. User Feedback
4.3.2. Preliminary Research Questions
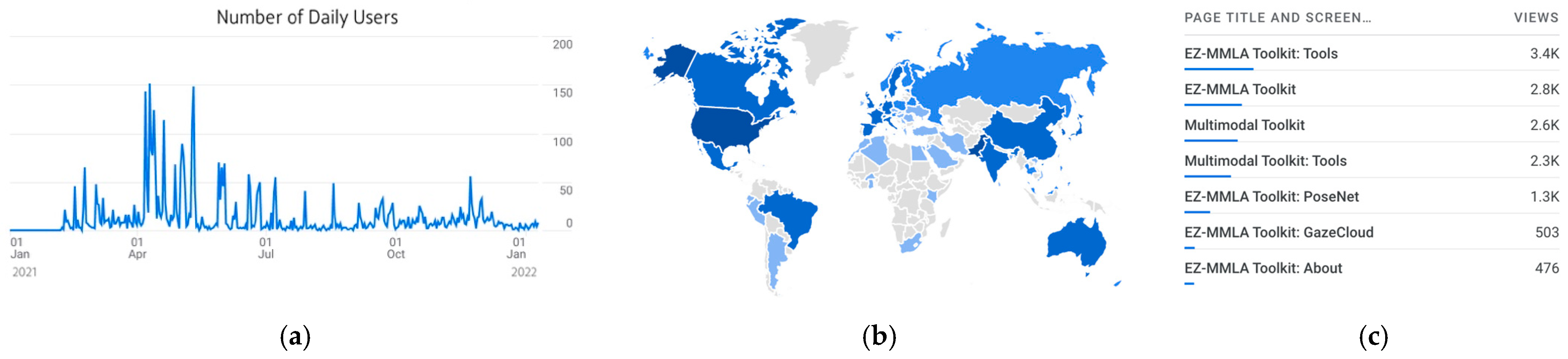
4.3.3. Website Usage
5. Discussion
5.1. Limitations
- (1)
- Usability: The use of web-based applications can still be challenging for some users—especially for certain learner types or when dealing with technical terms and instructions that might be difficult to understand. Additionally, the proposed approach has not been extensively tested across an adequately diverse pool of users. In particular, there is little testing on users with disabilities, where it is likely that we will find usability concerns.
- (2)
- Web-reliance: The proposed approach inevitably is limited by the accessibility of a stable internet connection—which is not possible for some user groups. Additionally, the reliance of our proposed approach on web platforms complicates the implementation of machine learning models because they will need to be re-optimized for use online. During development, we found that most of the most accessible and relevant machine learning libraries and software for multimodal data collection were implemented in languages such as Python and C++ and were not developed with web applications in mind. As such, this limits the range of usable machine learning libraries and poses a significant resource cost if models need to be reimplemented, reformatted, or translated for use in an online toolkit.
- (3)
- Accuracy: The accuracies of several implemented models leave to be desired (mostly because they are open-source projects) and limits the research potential of the toolkit. Furthermore, the accuracy of the data collected has not been extensively tested at the time of writing due to the novelty of our platform. This is also an important limitation because it restricts the overall usability of our tools as researchers will not have a strong understanding of the validity and integrity of the data collected.
5.2. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Brüning, O.; Burkhardt, H.; Myers, S. The Large Hadron Collider. Prog. Part. Nucl. Phys. 2012, 67, 705–734. [Google Scholar] [CrossRef] [Green Version]
- Gardner, J.P.; Mather, J.C.; Clampin, M.; Doyon, R.; Greenhouse, M.A.; Hammel, H.B.; Hutchings, J.B.; Jakobsen, P.; Lilly, S.J.; Long, K.S.; et al. The James Webb Space Telescope. Space Sci. Rev. 2006, 4, 485–606. [Google Scholar] [CrossRef] [Green Version]
- Blikstein, P. Multimodal Learning Analytics. In Proceedings of the Third International Conference on Learning Analytics and Knowledge, New York, NY, USA, 8–13 April 2013; ACM: New York, NY, USA, 2013; pp. 102–106. [Google Scholar]
- Cukurova, M.; Giannakos, M.; Martinez-Maldonado, R. The Promise and Challenges of Multimodal Learning Analytics. Br. J. Educ. Technol. 2020, 51, 1441–1449. [Google Scholar] [CrossRef]
- Schneider, J.; Börner, D.; Van Rosmalen, P.; Specht, M. Augmenting the Senses: A Review on Sensor-Based Learning Support. Sensors 2015, 15, 4097–4133. [Google Scholar] [CrossRef] [Green Version]
- Sharma, K.; Giannakos, M. Multimodal Data Capabilities for Learning: What Can Multimodal Data Tell Us about Learning? Br. J. Educ. Technol. 2020, 51, 1450–1484. [Google Scholar] [CrossRef]
- Schneider, B.; Blikstein, P. Unraveling Students’ Interaction around a Tangible Interface Using Multimodal Learning Analytics. J. Educ. Data Min. 2015, 7, 89–116. [Google Scholar]
- Worsley, M.; Blikstein, P. What’s an Expert? Using Learning Analytics to Identify Emergent Markers of Expertise through Automated Speech, Sentiment and Sketch Analysis. In Proceedings of the 4th International Conference on Educational Data Mining (EDM ’11), Eindhoven, The Netherlands, 6–8 July 2011; pp. 235–240. [Google Scholar]
- Ocumpaugh, J.; Baker, R.S.J.D.; Rodrigo, M.A. Quantitative Field Observation (QFOs) Baker-Rodrigo Observation Method Protocol (BROMP) 1.0 Training Manual Version 1.0 2012. Proc. IEEE 2003, 91, 1370–1390. [Google Scholar]
- Anderson, J.R. Spanning Seven Orders of Magnitude: A Challenge for Cognitive Modeling. Cogn. Sci. 2002, 26, 85–112. [Google Scholar] [CrossRef]
- Schneider, B.; Reilly, J.; Radu, I. Lowering Barriers for Accessing Sensor Data in Education: Lessons Learned from Teaching Multimodal Learning Analytics to Educators. J. STEM Educ. Res. 2020, 3, 91–124. [Google Scholar] [CrossRef]
- Martinez-Maldonado, R.; Mangaroska, K.; Schulte, J.; Elliott, D.; Axisa, C.; Shum, S.B. Teacher Tracking with Integrity: What Indoor Positioning Can Reveal About Instructional Proxemics. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Saquib, N.; Bose, A.; George, D.; Kamvar, S. Sensei: Sensing Educational Interaction. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 1–27. [Google Scholar] [CrossRef]
- Ahuja, K.; Kim, D.; Xhakaj, F.; Varga, V.; Xie, A.; Zhang, S.; Agarwal, Y. EduSense: Practical Classroom Sensing at Scale. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–26. [Google Scholar] [CrossRef]
- iMotions. iMotions Biometric Research Platform. 2015. Available online: https://imotions.com/ (accessed on 21 August 2019).
- Wagner, J.; Lingenfelser, F.; Baur, T.; Damian, I.; Kistler, F.; André, E. The Social Signal Interpretation (SSI) Framework: Multimodal Signal Processing and Recognition in Real-Time. In Proceedings of the 21st ACM international conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 831–834. [Google Scholar]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.-L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Blikstein, P.; Worsley, M. Multimodal Learning Analytics and Education Data Mining: Using Computational Technologies to Measure Complex Learning Tasks. J. Learn. Anal. 2016, 3, 220–238. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Torralba, A.; Freeman, W.T.; Durand, F.; Adelson, E.H. Motion Magnification. ACM Trans. Graph. 2005, 24, 519–526. [Google Scholar] [CrossRef]
- Lee, V. The Quantified Self (QS) Movement and Some Emerging Opportunities for the Educational Technology Field. Educ. Technol. 2013, 53, 39–42. [Google Scholar]
- Mitri, D.D.; Schneider, J.; Specht, M.; Drachsler, H. From Signals to Knowledge: A Conceptual Model for Multimodal Learning Analytics. J. Comput. Assist. Learn. 2018, 34, 338–349. [Google Scholar] [CrossRef] [Green Version]
- Brooke, J. SUS: A “Quick and Dirty” Usability Scale. In Usability Evaluation in Industry; CRC Press: Boca Raton, FL, USA, 1996; ISBN 978-0-429-15701-1. [Google Scholar]
- Braun, V.; Clarke, V. Using Thematic Analysis in Psychology. Qual. Res. Psychol. 2006, 3, 77–101. [Google Scholar] [CrossRef] [Green Version]
- Bangor, A.; Kortum, P.; Miller, J. Determining What Individual SUS Scores Mean: Adding an Adjective Rating Scale. J. Usability Stud. 2009, 4, 114–123. [Google Scholar]
- Newman, F. Authentic Achievement: Restructuring Schools for Intellectual Quality; Jossey-Bass: San Francisco, CA, USA, 1996. [Google Scholar]
- Beier, M.E.; Kim, M.H.; Saterbak, A.; Leautaud, V.; Bishnoi, S.; Gilberto, J.M. The Effect of Authentic Project-Based Learning on Attitudes and Career Aspirations in STEM. J. Res. Sci. Teach. 2019, 56, 3–23. [Google Scholar] [CrossRef]
- Papoutsaki, A.; Sangkloy, P.; Laskey, J.; Daskalova, N.; Huang, J.; Hays, J. WebGazer: Scalable Webcam Eye Tracking Using User Interactions. In Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016; AAAI: New York, NY, USA, 2016; pp. 3839–3845. [Google Scholar]
- Schneider, B.; Sharma, K.; Cuendet, S.; Zufferey, G.; Dillenbourg, P.; Pea, R. Leveraging Mobile Eye-Trackers to Capture Joint Visual Attention in Co-Located Collaborative Learning Groups. Int. J. Comput.-Support. Collab. Learn. 2018, 13, 241–261. [Google Scholar] [CrossRef]
- Chartrand, T.L.; Bargh, J.A. The Chameleon Effect: The Perception–Behavior Link and Social Interaction. J. Pers. Soc. Psychol. 1999, 76, 893–910. [Google Scholar] [CrossRef] [PubMed]
- Hagras, H. Toward Human-Understandable, Explainable AI. Computer 2018, 51, 28–36. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Physical Sensor | Webcam-Based Sensor |
|---|---|---|
| Skeletal tracking | Kinect v2 © Pro: 3D tracking Con: Noisy in case of occlusions; discontinued | PoseNet Con: 2D tracking (no depth) Pro: more accurate in case of occlusions |
| Eye-tracking | Tobii 4C/5 © Pro: accurate Con: cost | Webgazer Pro: can be integrated to any website Con: less accurate |
| Hand tracking | Leap Motion © Pro: easily integrated to any headset | Google AI Hand Tracking Pro: as accurate as physical sensors Con: slow for multiple hands |
| Physiological sensing | Empatica E4 © Pro: electrodermal (EDA) data Pro: accurate heart rate (HR) data Con: cost | Video Magnification [19] Con: no EDA data Con: noisy HR data |
| Applicable to all modalities | Con: cost (requires a dedicated device/license) or the use of an SDK to access the data Pro: data quality is guaranteed | Pro: easy to set up, anyone can collect data Pro: data is processed locally (via JavaScript) Con: data quality can vary |
| Theme | Examples |
|---|---|
| Interest in one’s own data | “I like VERY MUCH using data generated by ourselves” “I like learning and analyzing my own learning process” |
| Authenticity | “a real world scenario” “I liked that it was grounded in something real-world and relevant to the class” |
| Accessibility | “Easy to use, time limit had to be monitored. Great resource.” “The fact that we got to actually use the Emotion Detecting tool and analyze it this week far exceeded my expectations in terms of what is possible to do as a student in our 3rd week of class!” |
| Technical issues | “The eye tracking data collection website tend to make my laptop run slowly.” “[The videos on the data collection website] take forever to load and keep buffering.” |
| Learning curve | “I wished there is a tutorial to the data collection website, there are a lot of functions I knew after I finished collecting my data.” “When I was collecting eye-gaze data from gazecloud, it took me several tries to figure out how I can both read and let gazecloud track my eyes.” |
| Data quality | “I wish I was made more cognizant of how [the] quality [of] the data being collected is as I was being recorded (because I forgot a lot of the time). If there was a camera to show us how the camera is detecting our position, I might change my behaviors so that I have my webcam screen on/not be leaning back out of view” “Using the gaze recorder on Chrome, I had it in another desktop view and it did not record my gaze while I was reading my classmate’s slide. So I had to do it over again, and tried to replicate where my attention was but, clearly, it is already manipulated data.” |
| Privacy | “my camera was on and I had no idea if it was recording or not.” “I’m not sure what is the data collection website, if that refers to having camera on while watching the asynchronous video, it felt weird and I feel my privacy is being violated a little.” |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schneider, B.; Hassan, J.; Sung, G. Augmenting Social Science Research with Multimodal Data Collection: The EZ-MMLA Toolkit. Sensors 2022, 22, 568. https://doi.org/10.3390/s22020568
Schneider B, Hassan J, Sung G. Augmenting Social Science Research with Multimodal Data Collection: The EZ-MMLA Toolkit. Sensors. 2022; 22(2):568. https://doi.org/10.3390/s22020568
Chicago/Turabian StyleSchneider, Bertrand, Javaria Hassan, and Gahyun Sung. 2022. "Augmenting Social Science Research with Multimodal Data Collection: The EZ-MMLA Toolkit" Sensors 22, no. 2: 568. https://doi.org/10.3390/s22020568
APA StyleSchneider, B., Hassan, J., & Sung, G. (2022). Augmenting Social Science Research with Multimodal Data Collection: The EZ-MMLA Toolkit. Sensors, 22(2), 568. https://doi.org/10.3390/s22020568