
Behavioral Data Analysis of Robot-Assisted Autism Spectrum Disorder (ASD) Interventions Based on Lattice Computing Techniques

 ,
,  ,
,  ,
,  ,
,  , , and
, , and
Abstract
:1. Introduction
2. Data Representation and the Mathematical Instruments
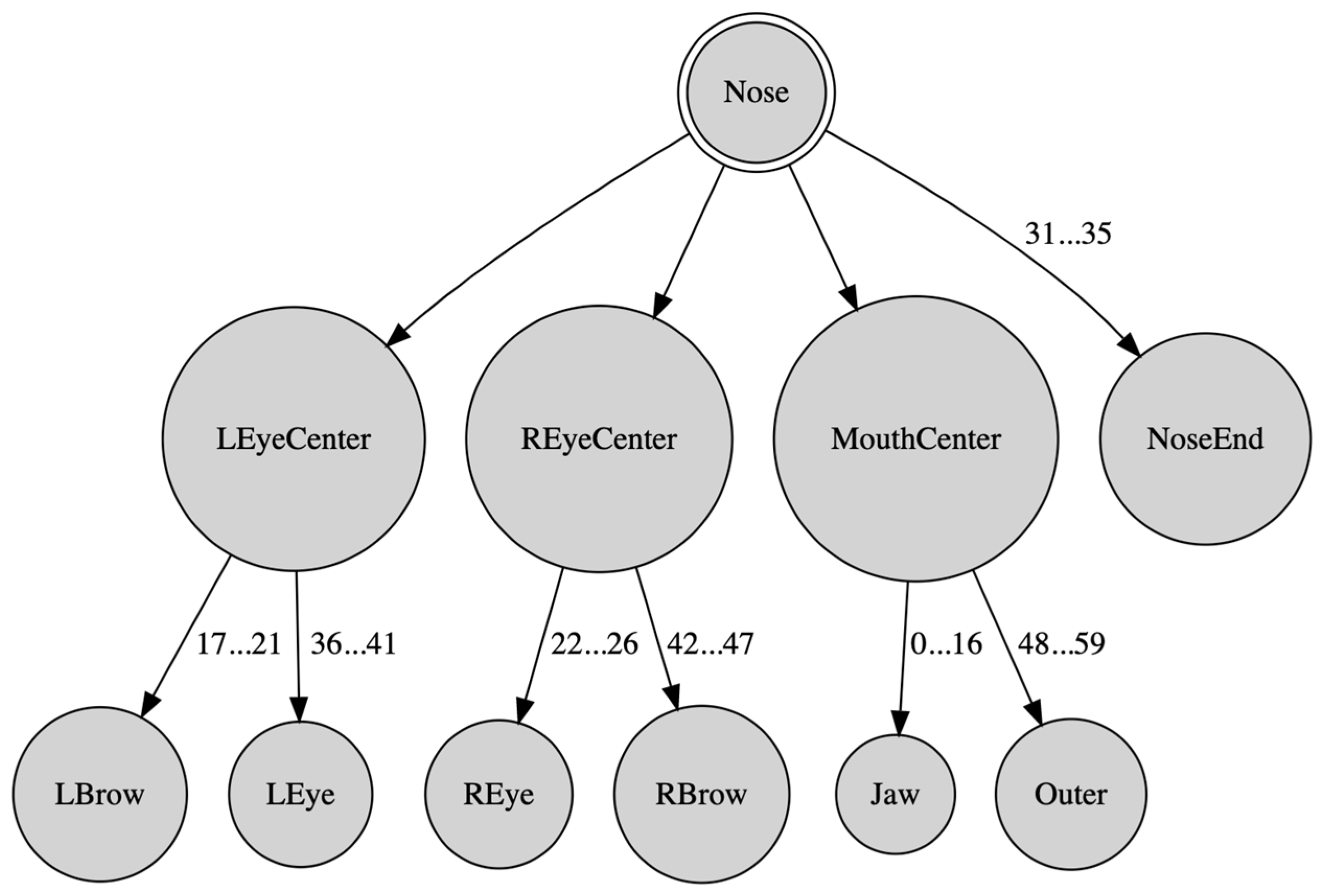
2.1. Face Representation
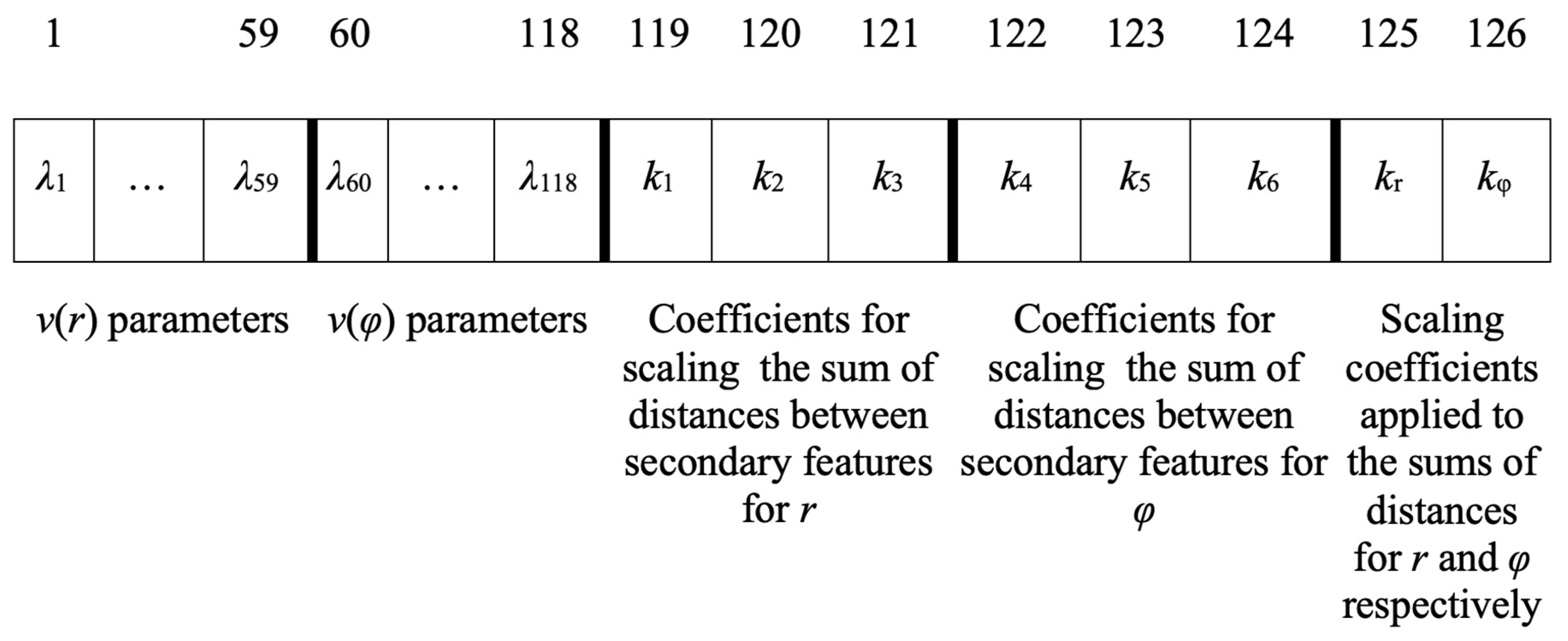
2.2. Distance Metrics between Trees Data Structures
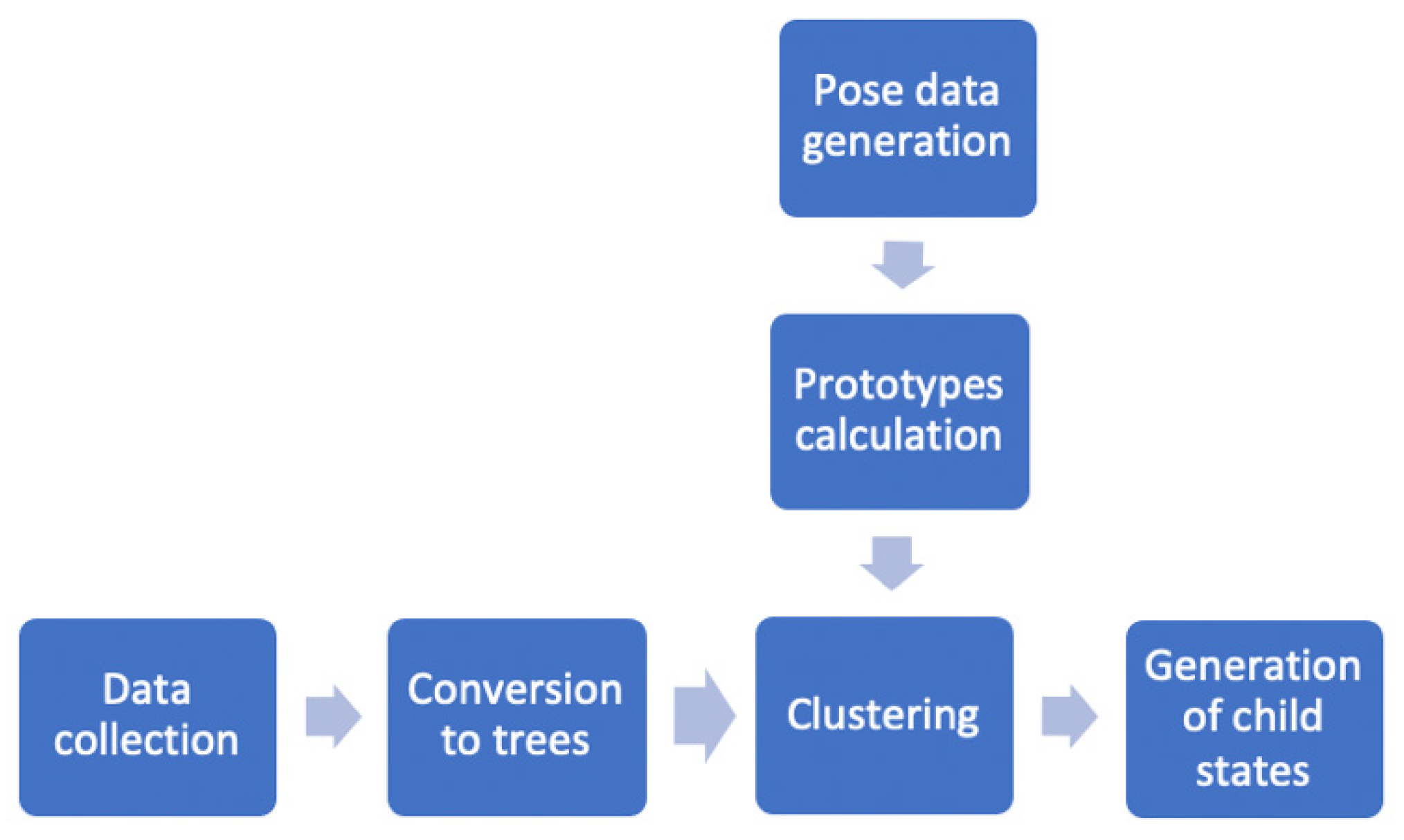
3. Data Acquisition and Pre-Processing
3.1. Data Acquisition
3.2. Structured Head Pose Recognition
3.3. States Induction by Clustering
4. Tools for Behavioral Data Analysis
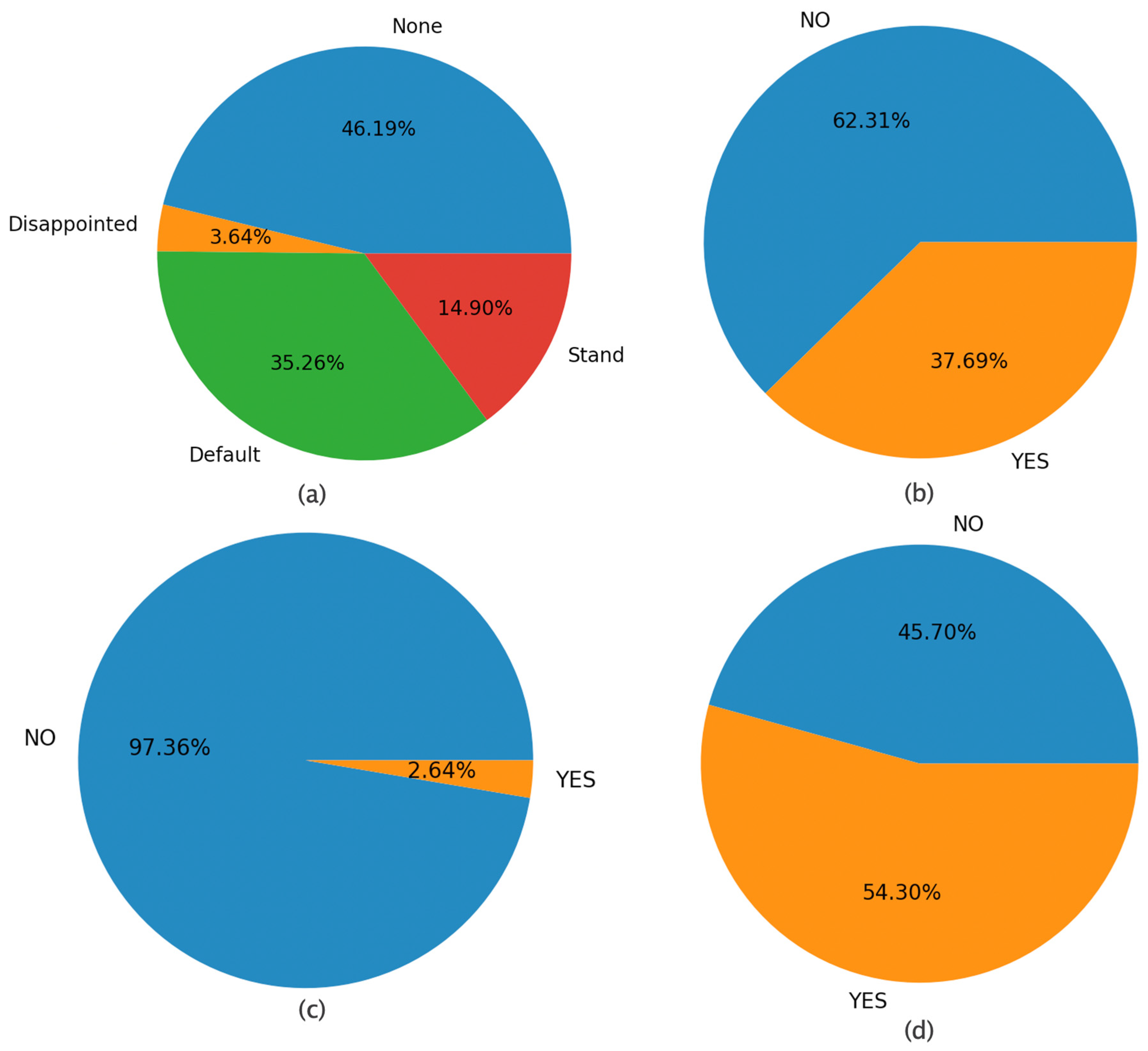
4.1. Relationship between Robot Actions and Child States
4.2. Events and Child’s State Transitions
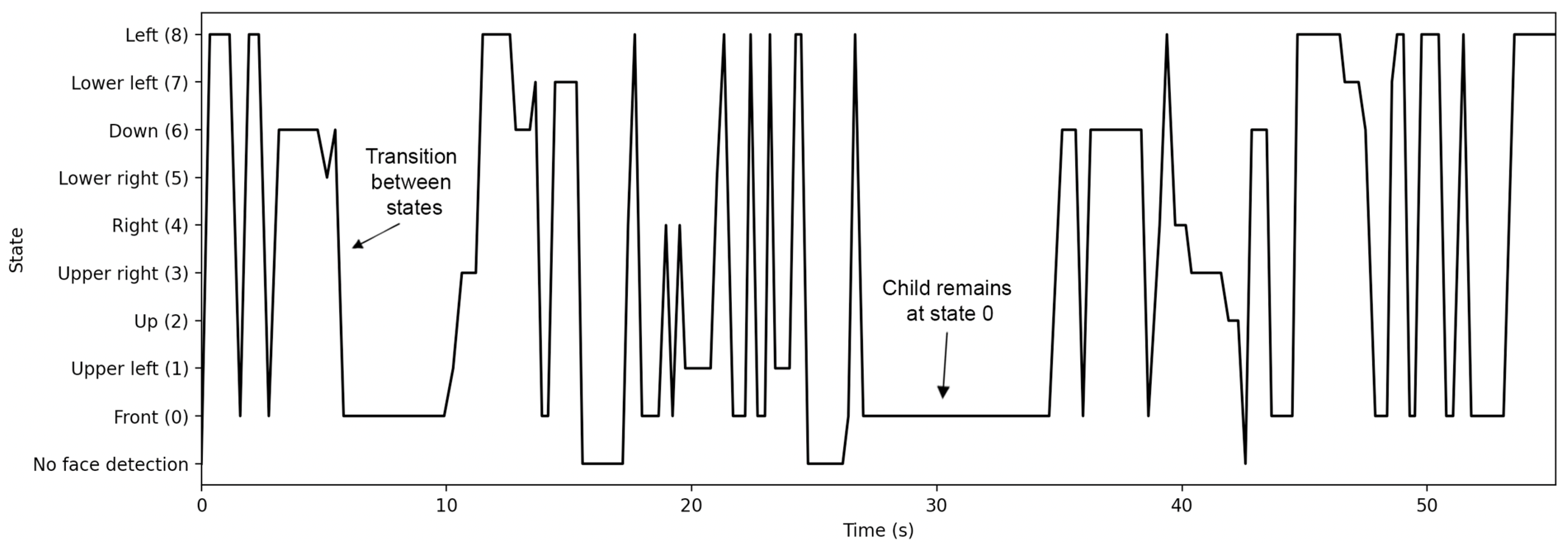
4.3. Visualization of States
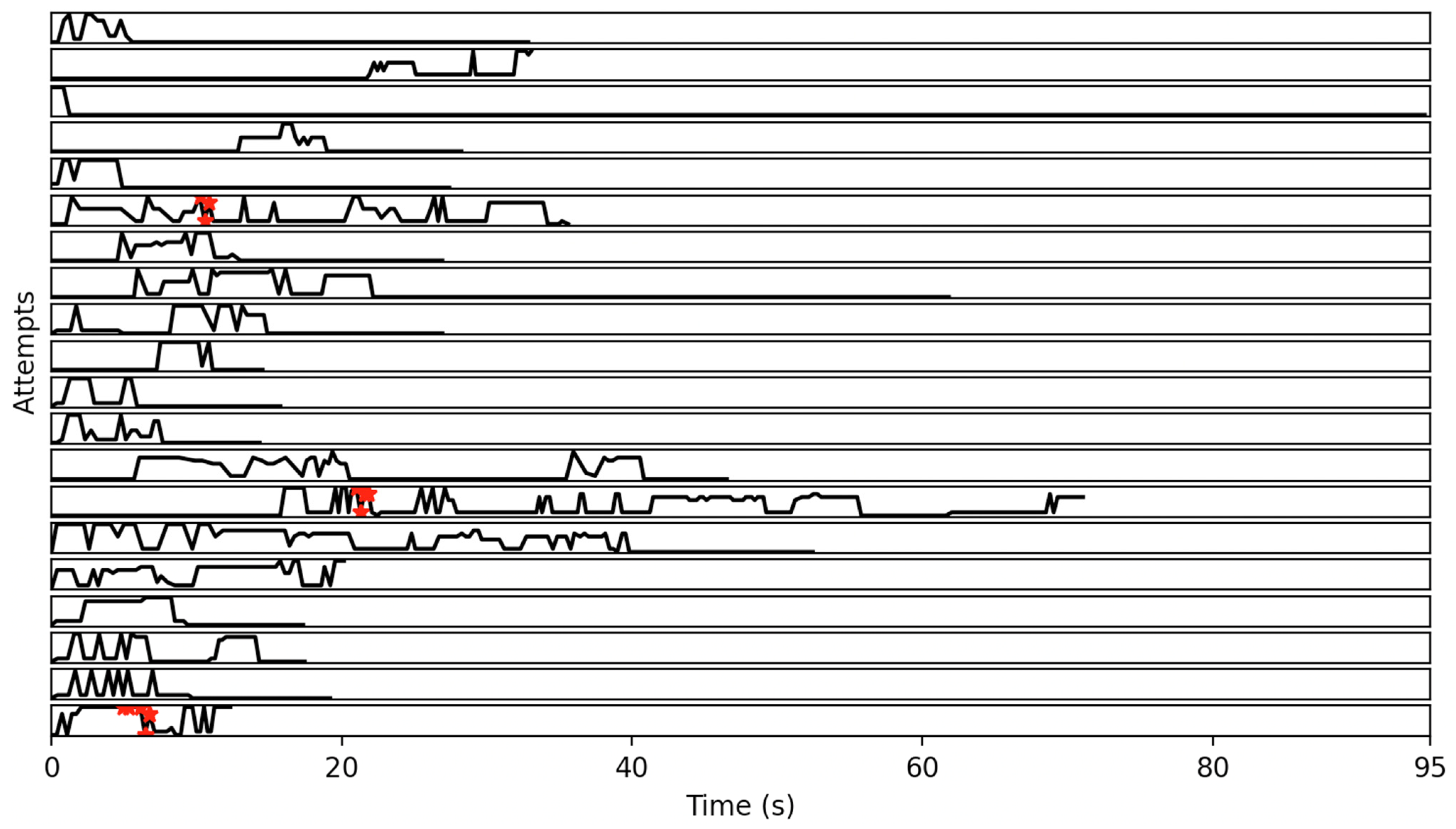
4.4. Patterns of States
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Free Play | The robot welcomes the child and invites him/her to start playing in the provided area. During the play the robot motivates the child. |
| Role Playing—Symbolic Games | The robot asks the child a series of questions, involving storytelling, role playing and creation of stories The robot describes and demonstrates using gestures appropriate behaviors in various everyday scenarios such as how to approach friends, in a birthday party or a restaurant |
| Theory of Mind | Mimics: the children perform gross motor imitation tasks managed by the robot exclusively, with different levels of difficulty |
| Targeted Behavior or Emotion | (a) Shared attention scenario: The robot asks the child to identify objects in the room (b) Memory game with cards. The robot gives instructions of how the game is played (c) “I spy” game, guided by the robot |
| Relaxation | 1. Robot: “Now I want to show you the relaxation corner; there, we will listen to music and learn various tricks you can do when you are not feeling well. Help me find the relaxation corner. Find the green circle on the wall. When you find it, tell me: green circle”. 2. Expected child response: “green circle or circle”. 2a. If yes, then the robot says: “Very nice. Let’s go to the relaxation corner now.” (Accompanied by the therapist and continues the robot to 3). 2b. If not: After 1st failure of child to answer, the robot says: “I’m not sure I understood well. Find the green circle and tell me a green circle”. After 2nd failure of child to answer, the robot says “We have not yet found the relaxation corner. Let’s try again. Look for the green circle and say “green circle”. If there is success, then go to 2a. After 3rd child failure to answer, the robot says “It is not easy to find the relaxation corner. Let’s try next time.” (therapist intervenes) 3. Robot: “Slow breaths help us to be calm. Listen to the sound we make when we take breaths, something like this:” (robot plays back a normal breathing sound). “We can take quick breaths like this:” (robot plays back a fast-breathing sound) “and very slow breaths like this:” (robot plays back a slow-breathing sound). “But only slow breaths help us to calm down. To start the game with the breaths, say: “now”. 4. Expected child response: “now”. 4a. If yes, then the robot says: “Very nice. Let’s start the game with the breaths.” 4b. If not:
|
| The therapist gives the child a pinwheel, and the robot explains the exercise, which is that, at the instruction of the robot, the child must blow on the pinwheel in order to make it spin. | |
| Muscle relaxation scenario where the robot instructs the child in various exercises involving breathing and muscle relaxation. |
References
- Matarić, M.J.; Scassellati, B. Socially Assistive Robotics. In Springer Handbook of Robotics; Springer International Publishing: Cham, Switzerland, 2016; Volume 6, pp. 1973–1994. [Google Scholar]
- Sophokleous, A.; Christodoulou, P.; Doitsidis, L.; Chatzichristofis, S.A. Computer Vision Meets Educational Robotics. Electronics 2021, 10, 730. [Google Scholar] [CrossRef]
- Saleh, M.A.; Hanapiah, F.A.; Hashim, H. Robot applications for autism: A comprehensive review. Disabil. Rehabil. Assist. Technol. 2021, 16, 580–602. [Google Scholar] [CrossRef] [PubMed]
- Kajopoulos, J.; Wong, A.H.Y.; Yuen, A.W.C.; Dung, T.A.; Kee, T.Y.; Wykowska, A. Robot-Assisted Training of Joint Attention Skills in Children Diagnosed with Autism. In International Conference on Social Robotics; Tapus, A., André, E., Martin, J.-C., Ferland, F., Ammi, M., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Volume 4, pp. 296–305. [Google Scholar]
- Mehmood, F.; Ayaz, Y.; Ali, S.; De Cassia Amadeu, R.; Sadia, H. Dominance in Visual Space of ASD Children Using Multi-Robot Joint Attention Integrated Distributed Imitation System. IEEE Access 2019, 7, 168815–168827. [Google Scholar] [CrossRef]
- Zheng, Z.; Nie, G.; Swanson, A.; Weitlauf, A.; Warren, Z.; Sarkar, N. A Randomized Controlled Trial of an Intelligent Robotic Response to Joint Attention Intervention System. J. Autism Dev. Disord. 2020, 50, 2819–2831. [Google Scholar] [CrossRef] [PubMed]
- Katsanis, I.A.; Moulianitis, V.C. An Architecture for Safe Child–Robot Interactions in Autism Interventions. Robotics 2021, 10, 20. [Google Scholar] [CrossRef]
- Schadenberg, B.R.; Reidsma, D.; Heylen, D.K.J.; Evers, V. Differences in Spontaneous Interactions of Autistic Children in an Interaction with an Adult and Humanoid Robot. Front. Robot. AI 2020, 7, 28. [Google Scholar] [CrossRef] [Green Version]
- Lytridis, C.; Bazinas, C.; Papakostas, G.A.; Kaburlasos, V. On Measuring Engagement Level During Child-Robot Interaction in Education. In Advances in Intelligent Systems and Computing; Merdan, M., Lepuschitz, W., Koppensteiner, G., Balogh, R., Obdržálek, D., Eds.; Springer: Cham, Switzerland, 2020; Volume 1023, pp. 3–13. ISBN 9783030269449. [Google Scholar]
- Sidiropoulos, G.K.; Papakostas, G.A.; Lytridis, C.; Bazinas, C.; Kaburlasos, V.G.; Kourampa, E.; Karageorgiou, E. Measuring Engagement Level in Child-Robot Interaction Using Machine Learning Based Data Analysis. In Proceedings of the 2020 International Conference on Data Analytics for Business and Industry: Way Towards a Sustainable Economy (ICDABI), Sakheer, Bahrain, 26–27 October 2020; pp. 1–5. [Google Scholar]
- Werry, I.; Dautenhahn, K.; Harwin, W. Evaluating the Response of Children with Autism to a Robot. In Proceedings of the Rehabilitation Engineering and Assistive Technology Society of North America (RESNA 2001), Reno, NV, USA, 22–24 July 2001. [Google Scholar]
- Senft, E.; Baxter, P.; Belpaeme, T. Human-Guided Learning of Social Action Selection for Robot-Assisted Therapy. In Proceedings of the 4th Workshop on Machine Learning for Interactive Systems, Lille, France, 11 July 2015; pp. 15–20. [Google Scholar]
- Salam, H.; Chetouani, M. Engagement detection based on mutli-party cues for human robot interaction. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 341–347. [Google Scholar]
- Ismail, L.I.; Hanapiah, F.A.; Belpaeme, T.; Dambre, J.; Wyffels, F. Analysis of Attention in Child–Robot Interaction Among Children Diagnosed with Cognitive Impairment. Int. J. Soc. Robot. 2021, 13, 141–152. [Google Scholar] [CrossRef]
- Ali, S.; Mehmood, F.; Ayaz, Y.; Khan, M.J.; Asgher, U. Effect of Paired Stimuli on Joint Attention of Children with ASD. In International Conference on Applied Human Factors and Ergonomics; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2021; Volume 1201, pp. 362–368. ISBN 9783030510404. [Google Scholar]
- Javed, H.; Burns, R.; Jeon, M.; Howard, A.M.; Park, C.H. A Robotic Framework to Facilitate Sensory Experiences for Children with Autism Spectrum Disorder. ACM Trans. Human-Robot Interact. 2020, 9, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Cao, W.; Song, W.; Li, X.; Zheng, S.; Zhang, G.; Wu, Y.; He, S.; Zhu, H.; Chen, J. Interaction with Social Robots: Improving Gaze Toward Face but Not Necessarily Joint Attention in Children with Autism Spectrum Disorder. Front. Psychol. 2019, 10, 1503. [Google Scholar] [CrossRef] [Green Version]
- Cao, H.-L.; Esteban, P.G.; Bartlett, M.; Baxter, P.; Belpaeme, T.; Billing, E.; Cai, H.; Coeckelbergh, M.; Costescu, C.; David, D.; et al. Robot-Enhanced Therapy: Development and Validation of Supervised Autonomous Robotic System for Autism Spectrum Disorders Therapy. IEEE Robot. Autom. Mag. 2019, 26, 49–58. [Google Scholar] [CrossRef]
- Schwarz, J.; Marais, C.C.; Leyvand, T.; Hudson, S.E.; Mankoff, J. Combining body pose, gaze, and gesture to determine intention to interact in vision-based interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 26 April–1 May 2014; pp. 3443–3452. [Google Scholar]
- Greczek, J.; Kaszubski, E.; Atrash, A.; Matarić, M. Graded cueing feedback in robot-mediated imitation practice for children with autism spectrum disorders. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014; Volume 32, pp. 561–566. [Google Scholar]
- Hadfield, J.; Chalvatzaki, G.; Koutras, P.; Khamassi, M.; Tzafestas, C.S.; Maragos, P. A Deep Learning Approach for Multi-View Engagement Estimation of Children in a Child-Robot Joint Attention Task. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1251–1256. [Google Scholar]
- Ali, S.; Mehmood, F.; Ayaz, Y.; Asgher, U.; Khan, M.J. Effect of Different Visual Stimuli on Joint Attention of ASD Children Using NAO Robot. In International Conference on Applied Human Factors and Ergonomics; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2020; Volume 953, pp. 490–499. ISBN 9783030204723. [Google Scholar]
- Nasir, J.; Bruno, B.; Chetouani, M.; Dillenbourg, P. What if Social Robots Look for Productive Engagement? Int. J. Soc. Robot. 2021. [Google Scholar] [CrossRef]
- Papakostas, G.A.; Sidiropoulos, G.K.; Lytridis, C.; Bazinas, C.; Kaburlasos, V.G.; Kourampa, E.; Karageorgiou, E.; Kechayas, P.; Papadopoulou, M.T. Estimating Children Engagement Interacting with Robots in Special Education Using Machine Learning. Math. Probl. Eng. 2021, 2021, 9955212. [Google Scholar] [CrossRef]
- Anagnostopoulou, D.; Efthymiou, N.; Papailiou, C.; Maragos, P. Engagement Estimation During Child Robot Interaction Using Deep Convolutional Networks Focusing on ASD Children. In Proceedings of the IEEE International Conference on Robotics & Automation (ICRA2021), Xi’an, China, 30 May–5 June 2021; pp. 3641–3647. [Google Scholar]
- Lei, X.; Rau, P.-L.P. Effect of Robot Tutor’s Feedback Valence and Attributional Style on Learners. Int. J. Soc. Robot. 2021, 13, 1579–1597. [Google Scholar] [CrossRef]
- Mehmood, F.; Mahzoon, H.; Yoshikawa, Y.; Ishiguro, H.; Sadia, H.; Ali, S.; Ayaz, Y. Attentional Behavior of Children with ASD in Response to Robotic Agents. IEEE Access 2021, 9, 31946–31955. [Google Scholar] [CrossRef]
- Alnajjar, F.; Cappuccio, M.; Renawi, A.; Mubin, O.; Loo, C.K. Personalized Robot Interventions for Autistic Children: An Automated Methodology for Attention Assessment. Int. J. Soc. Robot. 2021, 13, 67–82. [Google Scholar] [CrossRef]
- Ali, S.; Mehmood, F.; Ayaz, Y.; Khan, M.J.; Sadia, H.; Nawaz, R. Comparing the Effectiveness of Different Reinforcement Stimuli in a Robotic Therapy for Children With ASD. IEEE Access 2020, 8, 13128–13137. [Google Scholar] [CrossRef]
- Blackburn, S. Structuralism. In The Oxford Dictionary of Philosophy; Blackburn, S., Ed.; Oxford University Press: Oxford, UK, 2008; p. 353. ISBN 978-0-19-954143-0. [Google Scholar]
- Freedheim, D.K.; Weiner, I.B. Handbook of Psychology, Volume 1: History of Psychology; John Wiley and Sons: Hoboken, NJ, USA, 2003; ISBN 0471176699. [Google Scholar]
- Oosterwijk, S.; Lindquist, K.A.; Anderson, E.; Dautoff, R.; Moriguchi, Y.; Barrett, L.F. States of mind: Emotions, body feelings, and thoughts share distributed neural networks. Neuroimage 2012, 62, 2110–2128. [Google Scholar] [CrossRef] [Green Version]
- Pandini, A.; Fornili, A.; Kleinjung, J. Structural alphabets derived from attractors in conformational space. BMC Bioinform. 2010, 11, 97. [Google Scholar] [CrossRef] [Green Version]
- Kaburlasos, V.G. The lattice computing (LC) paradigm. In Proceedings of the Fifteenth International Conference on Concept Lattices and Their Applications (CLA 2020), Tallinn, Estonia, 29 June–1 July 2020; Volume 2668, pp. 1–7. [Google Scholar]
- Papadakis, S.E.; Kaburlasos, V.G.; Papakostas, G.A. Two Fuzzy Lattice Reasoning (FLR) Classifiers and their Application for Human Facial Expression Recognition. J. Mult.-Valued Log. Soft Comput. 2014, 22, 561–579. [Google Scholar]
- Meng, X.; Liu, M.; Zhou, H.; Wu, J.; Xu, F.; Wu, Q. Fuzzy C-Means on Metric Lattice. Autom. Control Comput. Sci. 2020, 54, 30–38. [Google Scholar] [CrossRef]
- Lytridis, C.; Lekova, A.; Bazinas, C.; Manios, M.; Kaburlasos, V.G. WINkNN: Windowed Intervals’ Number kNN Classifier for Efficient Time-Series Applications. Mathematics 2020, 8, 413. [Google Scholar] [CrossRef] [Green Version]
- Amos, B.; Ludwiczuk, B.; Satyanarayanan, M. OpenFace: A General-Purpose Face Recognition Library with Mobile Applications; Technical Report CMU-CS; CMU School of Computer Science: Pittsburgh, PA, USA, 2016. [Google Scholar]
- Kaburlasos, V.G.; Lytridis, C.; Bazinas, C.; Chatzistamatis, S.; Sotiropoulou, K.; Najoua, A.; Youssfi, M.; Bouattane, O. Head Pose Estimation Using Lattice Computing Techniques. In Proceedings of the 2020 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 17–19 September 2020; pp. 1–5. [Google Scholar]
- Kaburlasos, V.G.; Lytridis, C.; Vrochidou, E.; Bazinas, C.; Papakostas, G.A.; Lekova, A.; Bouattane, O.; Youssfi, M.; Hashimoto, T. Granule-Based-Classifier (GbC): A Lattice Computing Scheme Applied on Tree Data Structures. Mathematics 2021, 9, 2889. [Google Scholar] [CrossRef]
- American Psychiatric Association. DSM-5 Diagnostic Classification. In Diagnostic and Statistical Manual of Mental Disorders; American Psychiatric Association: Washington, DC, USA, 2013. [Google Scholar]
- Holeva, V.; Nikopoulou, V.-A.; Papadopoulou, M.; Vrochidou, E.; Papakostas, G.A.; Kaburlasos, V.G. Toward Robot-Assisted Psychosocial Intervention for Children with Autism Spectrum Disorder (ASD). In Social Robotics; Salichs, M.A., Ge, S.S., Barakova, E.I., Cabibihan, J.-J., Wagner, A.R., Castro-González, Á., He, H., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 484–493. ISBN 9783030358877. [Google Scholar]
- Nikopoulou, V.A.; Holeva, V.; Kerasidou, M.D.; Kechayas, P.; Papadopoulou, M.; Vrochidou, E.; Papakostas, G.A.; Kaburlasos, V.G. Identifying Linguistic Cues; Towards Developing Robots with Empathy in Autism Interventions. J. Clin. Med. Kazakhstan 2020, 2, 27–33. [Google Scholar] [CrossRef]
- Kaburlasos, V.G.; Tsoukalas, V.; Moussiades, L. FCknn: A granular knn classifier based on formal concepts. In Proceedings of the 2014 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Beijing, China, 6–11 July 2014; pp. 61–68. [Google Scholar]












| Robot Actions per Modality | Child State |
|---|---|
| Points in child’s face (68 facial landmarks) |
| |
| |
| |
| Frame sampling time: Date and time | |
| Distance/Lighting Condition | Classification Results (%) | |
|---|---|---|
| Tree | Vector | |
| 40 cm/Normal | 97.8 | 86.8 |
| 40 cm/Dim | 78.4 | 66.7 |
| 1 m/Normal | 97.0 | 84.2 |
| 1 m/Dim | 74.6 | 46.7 |
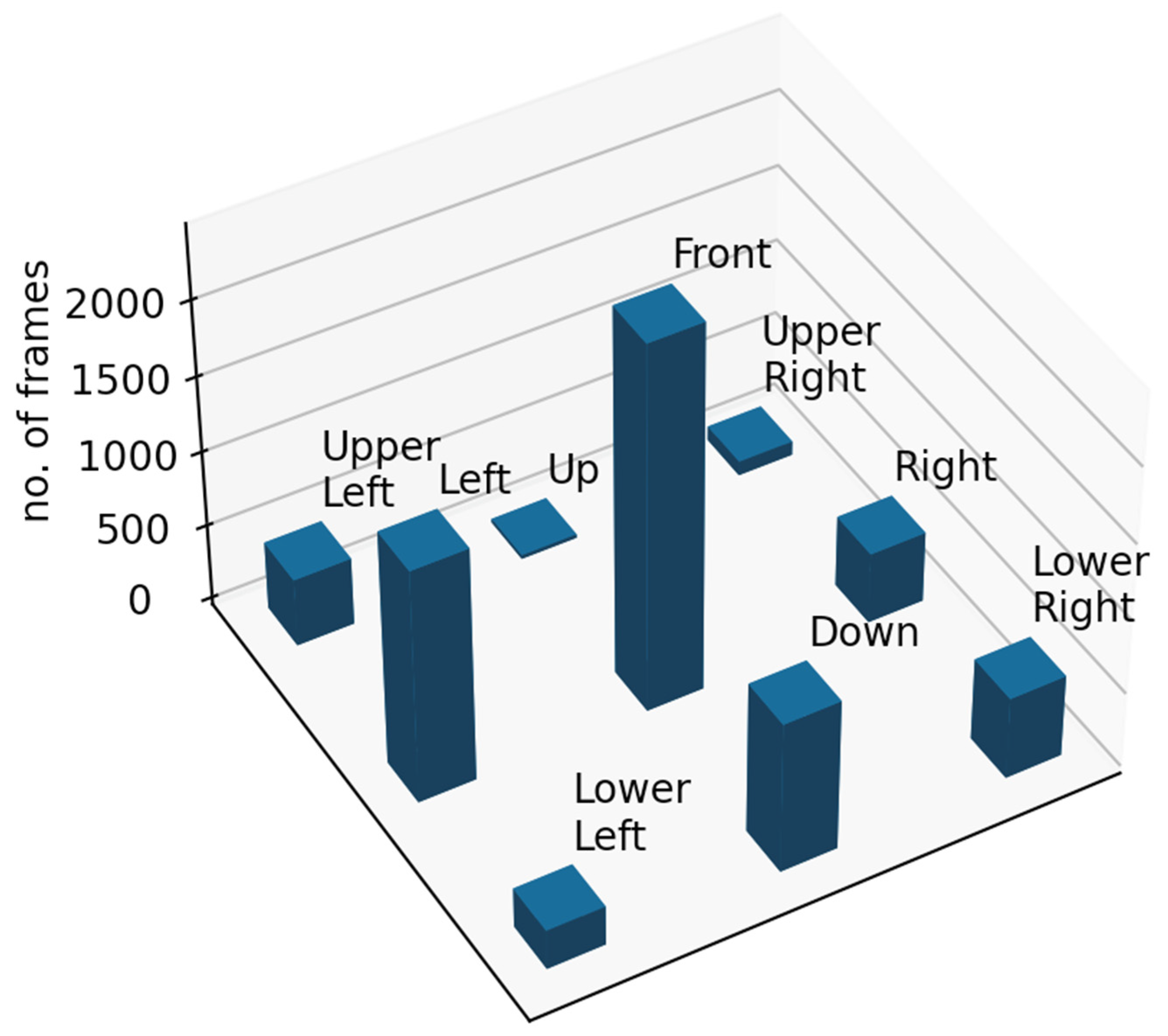
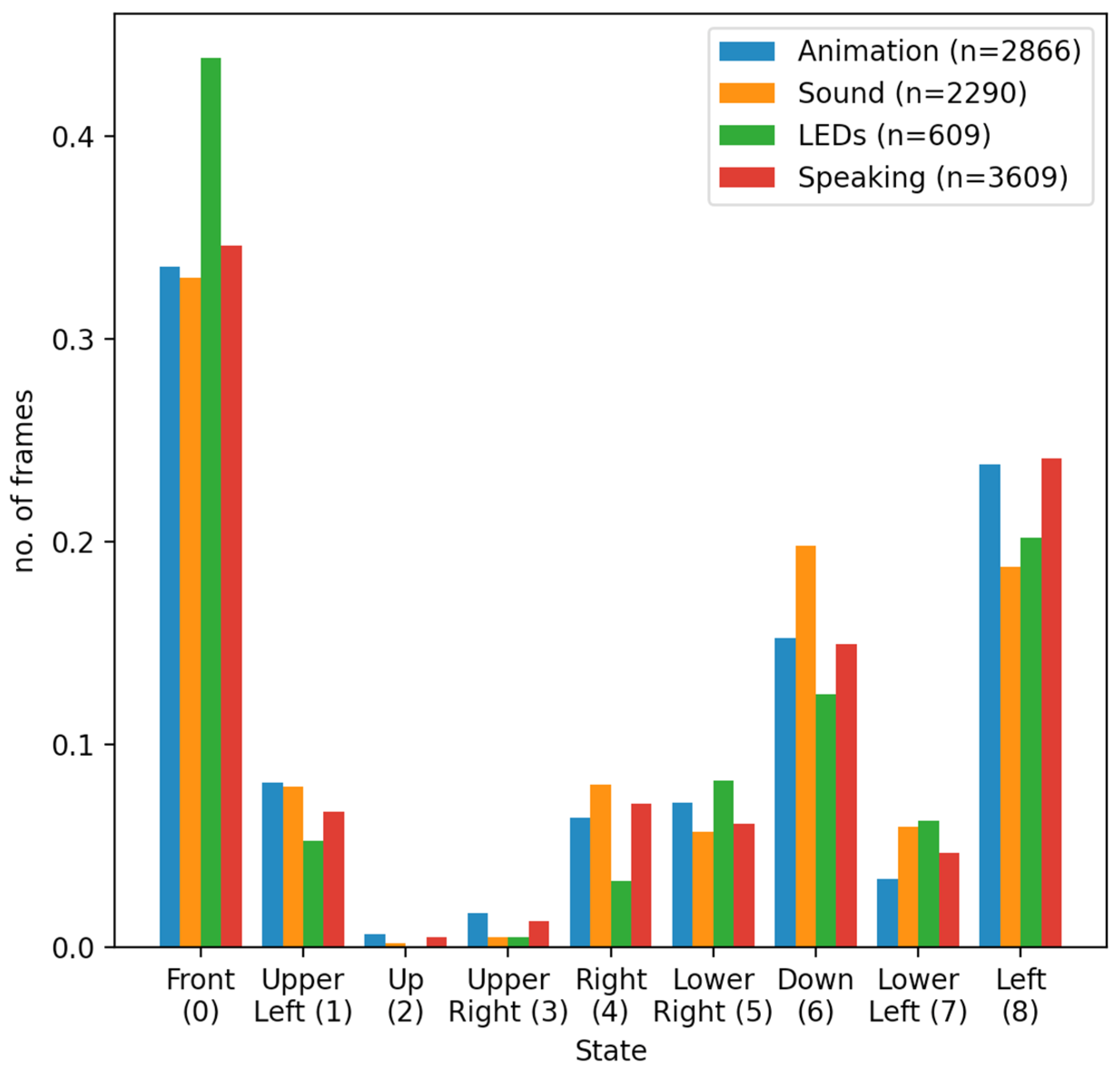
| Robot Modalities | Front (0) | Upper Left (1) | Up (2) | Upper Right (3) | Right (4) | Lower Right (5) | Down (6) | Lower Left (7) | Left (8) |
|---|---|---|---|---|---|---|---|---|---|
| Animation | 0.335 | 0.081 | 0.007 | 0.017 | 0.064 | 0.071 | 0.152 | 0.034 | 0.239 |
| Sound | 0.330 | 0.079 | 0.003 | 0.005 | 0.080 | 0.057 | 0.198 | 0.059 | 0.189 |
| LEDs | 0.438 | 0.052 | 0 | 0.005 | 0.032 | 0.082 | 0.125 | 0.062 | 0.204 |
| Speaking | 0.346 | 0.067 | 0.005 | 0.013 | 0.071 | 0.061 | 0.149 | 0.046 | 0.242 |
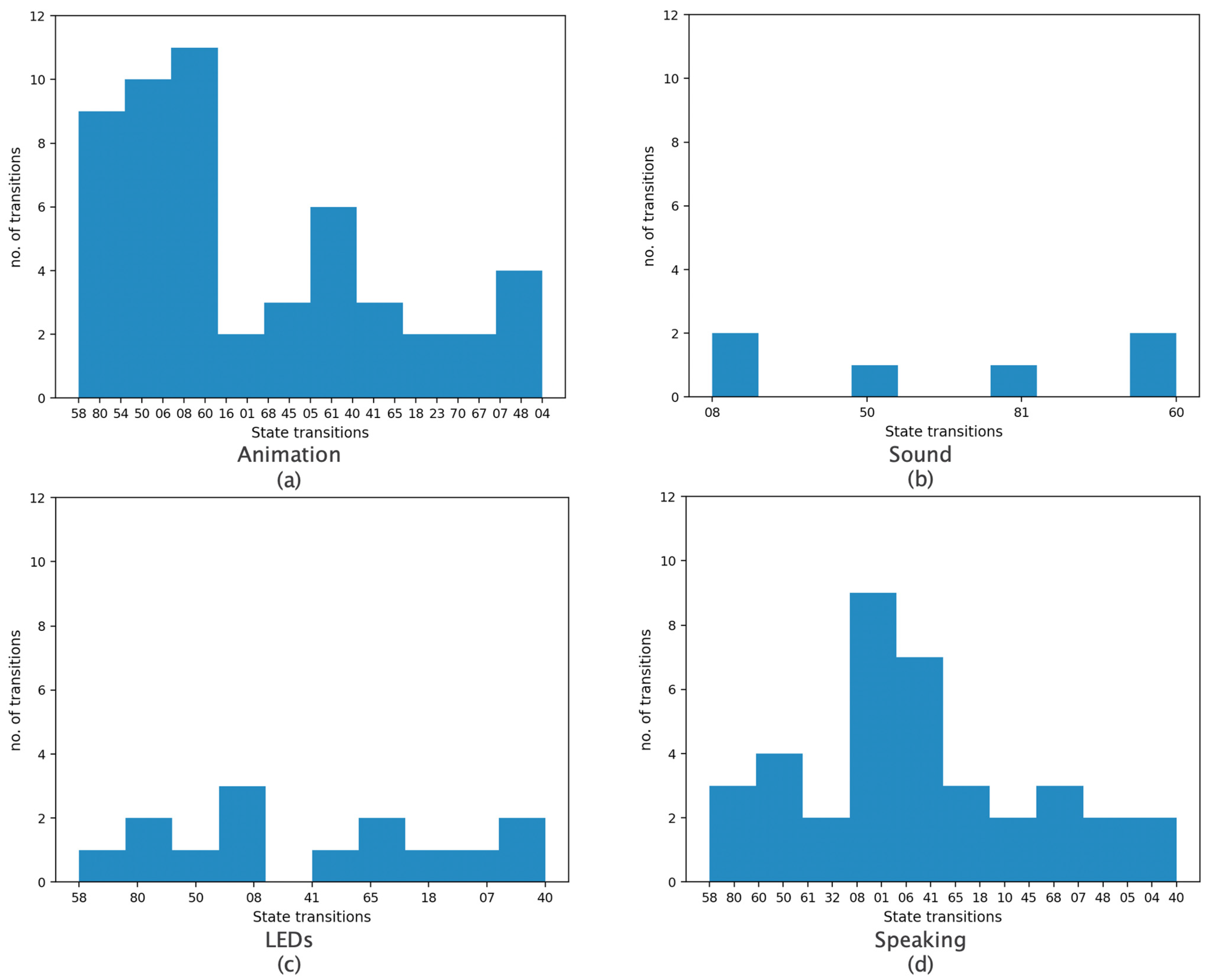
| No. of State Transitions at | ||||||
|---|---|---|---|---|---|---|
| Robot | sk+1 | sk+2 | sk+3 | |||
| Actions | Yes | No | Yes | No | Yes | No |
| Animation | 52 | 109 | 64 | 93 | 73 | 83 |
| Sound | 6 | 5 | 3 | 7 | 4 | 5 |
| LEDs | 14 | 19 | 10 | 22 | 12 | 21 |
| Speaking | 37 | 87 | 44 | 78 | 51 | 71 |
| TOTAL | 109 | 220 | 121 | 200 | 140 | 180 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lytridis, C.; Kaburlasos, V.G.; Bazinas, C.; Papakostas, G.A.; Sidiropoulos, G.; Nikopoulou, V.-A.; Holeva, V.; Papadopoulou, M.; Evangeliou, A. Behavioral Data Analysis of Robot-Assisted Autism Spectrum Disorder (ASD) Interventions Based on Lattice Computing Techniques. Sensors 2022, 22, 621. https://doi.org/10.3390/s22020621
Lytridis C, Kaburlasos VG, Bazinas C, Papakostas GA, Sidiropoulos G, Nikopoulou V-A, Holeva V, Papadopoulou M, Evangeliou A. Behavioral Data Analysis of Robot-Assisted Autism Spectrum Disorder (ASD) Interventions Based on Lattice Computing Techniques. Sensors. 2022; 22(2):621. https://doi.org/10.3390/s22020621
Chicago/Turabian StyleLytridis, Chris, Vassilis G. Kaburlasos, Christos Bazinas, George A. Papakostas, George Sidiropoulos, Vasiliki-Aliki Nikopoulou, Vasiliki Holeva, Maria Papadopoulou, and Athanasios Evangeliou. 2022. "Behavioral Data Analysis of Robot-Assisted Autism Spectrum Disorder (ASD) Interventions Based on Lattice Computing Techniques" Sensors 22, no. 2: 621. https://doi.org/10.3390/s22020621
APA StyleLytridis, C., Kaburlasos, V. G., Bazinas, C., Papakostas, G. A., Sidiropoulos, G., Nikopoulou, V. -A., Holeva, V., Papadopoulou, M., & Evangeliou, A. (2022). Behavioral Data Analysis of Robot-Assisted Autism Spectrum Disorder (ASD) Interventions Based on Lattice Computing Techniques. Sensors, 22(2), 621. https://doi.org/10.3390/s22020621