
Clustering and Smoothing Pipeline for Management Zone Delineation Using Proximal and Remote Sensing



Abstract
:1. Introduction
2. Materials and Methods
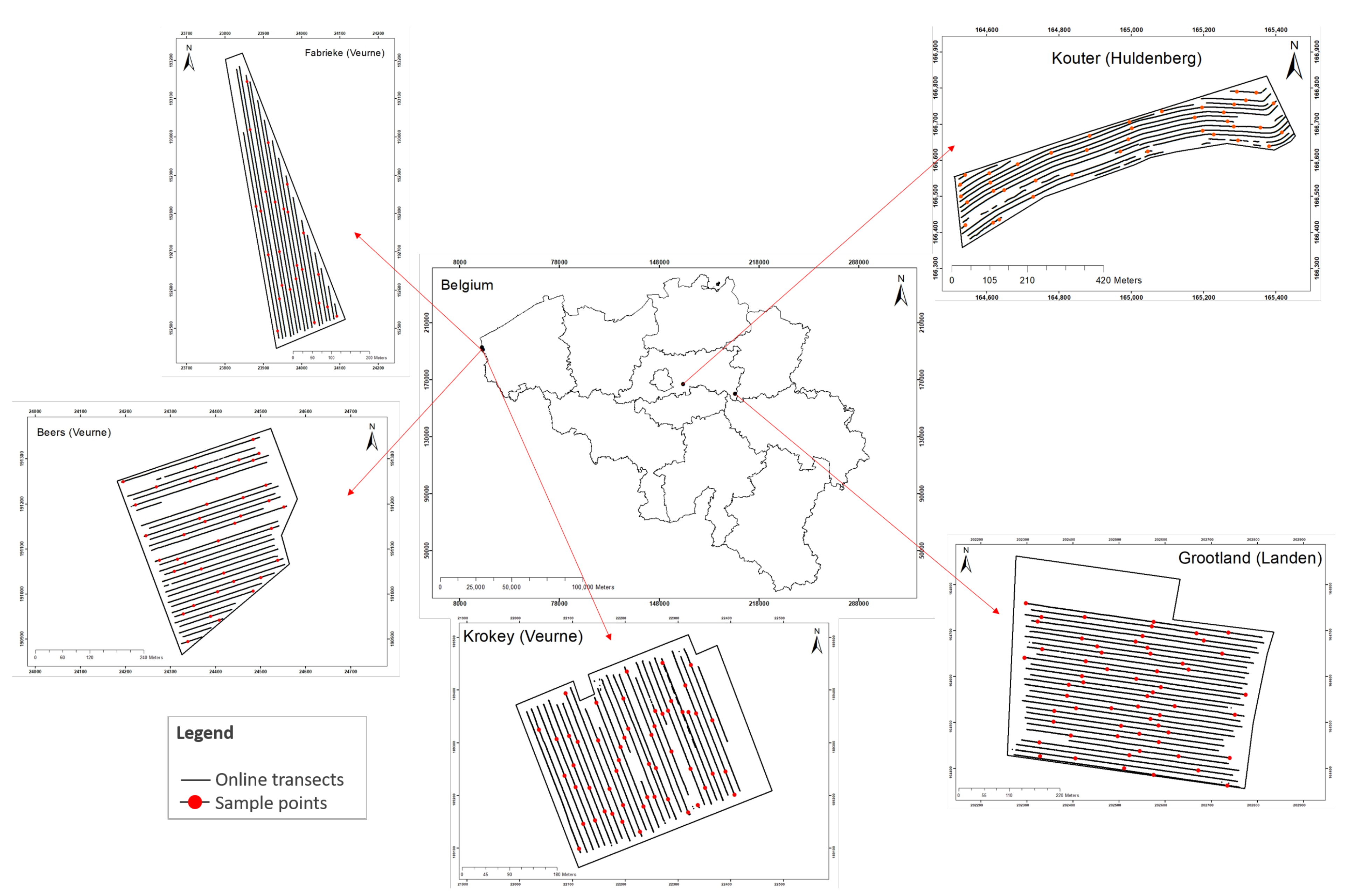
2.1. Experimental Sites
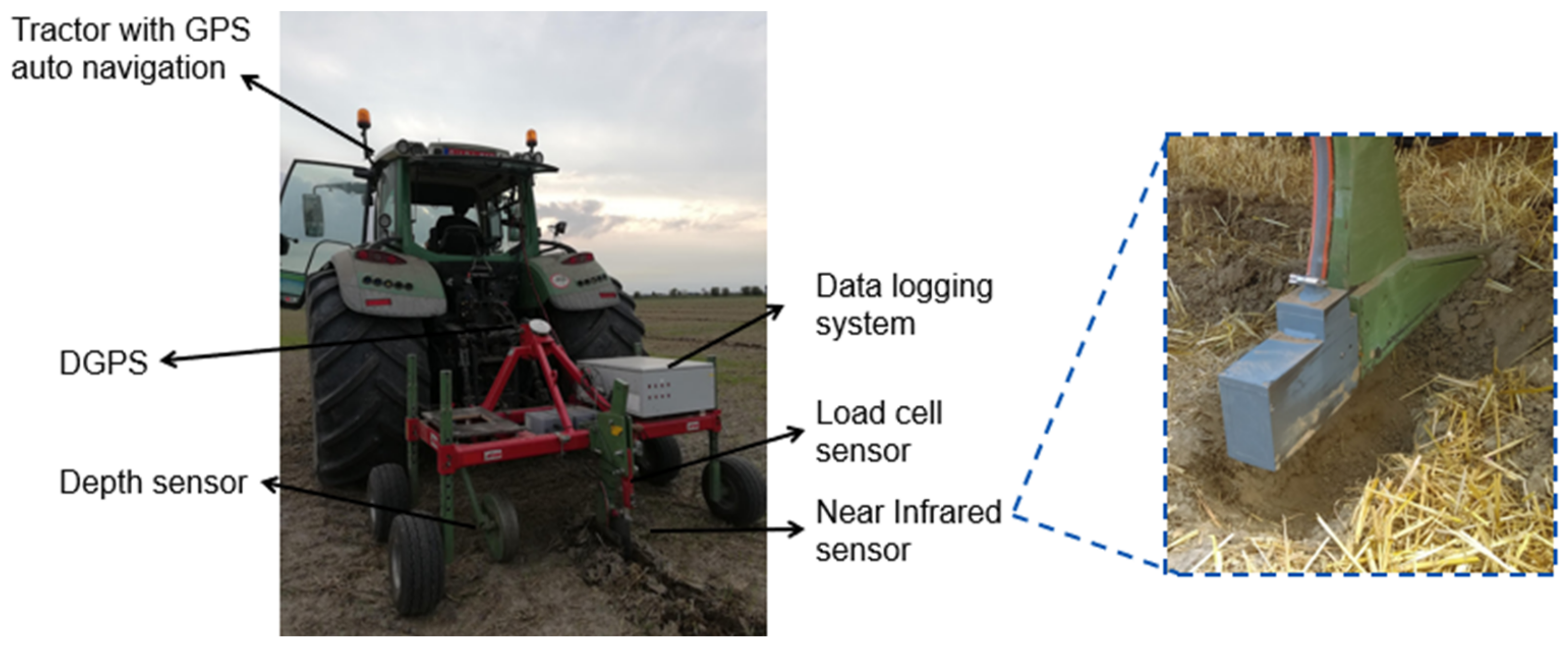
2.2. Data Acquisition
2.3. Modeling of Visible and Near-Infrared Spectra
2.4. Mapping of Online Measured Soil Properties
2.5. Overview of Clustering Algorithms
2.5.1. k-Means
- Randomly initialize k cluster centroids .
- For , update:
- For , update centroid of the data of cluster j.
- Repeat steps 2 and 3 for a specified number of iterations (or until convergence).
2.5.2. Fuzzy C-Means (FCM)
- Randomly initialize k cluster centroids .
- For and , update:
- For , update:
- Repeat steps 2 and 3 for a specified number of iteration (or until convergence).
- After the algorithm stops, each point i joins the cluster with the highest value.
2.5.3. Mean Shift
- Initialize seeds set for calculating the densitywhere is a kernel function.
- For each seed , calculate the mean shift:where denotes the neighborhood of .
- For each seed , update .
- Repeat steps 2 and 3 for a specified number of iterations (or until convergence).
- After the algorithm stops, the modes are considered as the centroids of the clusters, and each point joins to the closest mode.
2.5.4. Hierarchical Clustering
- Assign all points an individual cluster number.
- Merge points with the smallest distance. In other words, points with smallest distance join the same cluster.
- Repeat step 2 until k clusters are obtained.
2.5.5. Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
- Select a random data point.
- If the number of the neighbors is less than , the point is marked as an outlier with label .
- If the number of the neighbors is more than or equal to , the point and its neighbors establish a cluster.
- Repeat step 3 for all points within the established cluster. In other words, for all joined points, check their neighbor points and join their neighbors to the established cluster.
- From the remaining points that have not yet been met, select a random data point. Repeat steps 2 to 5 until all data points are met.
2.6. Feature Selection (Data Decrease)
2.7. Clustering Scenarios
2.8. Evaluation of Clustering Algorithms
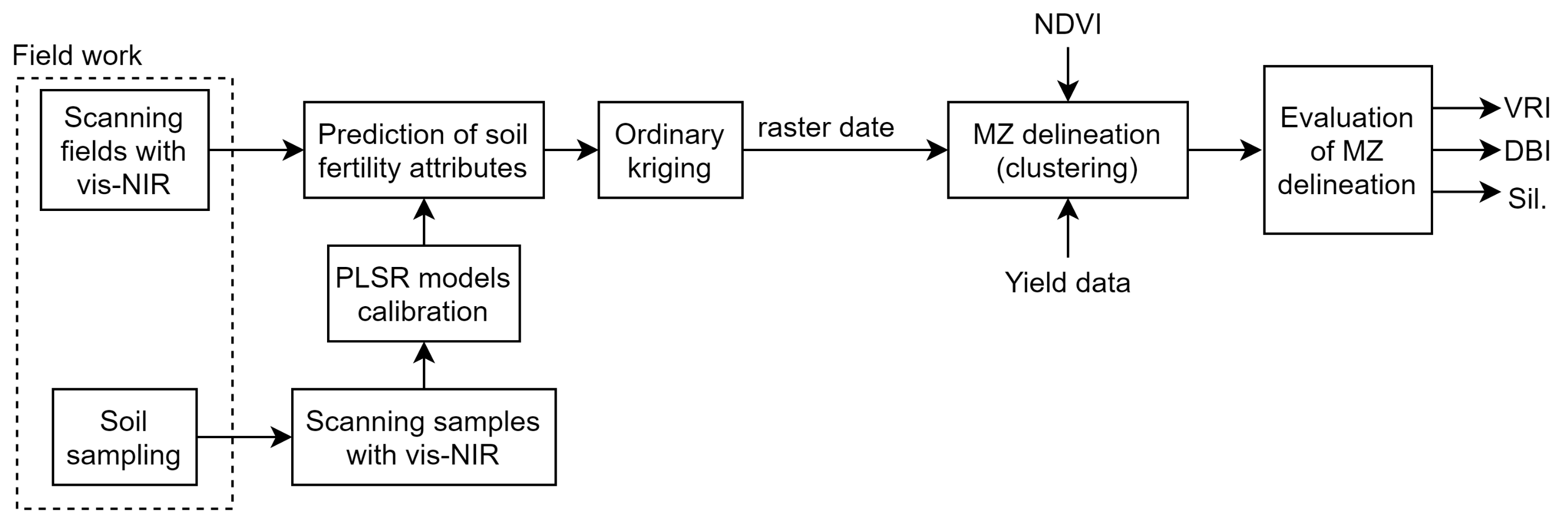
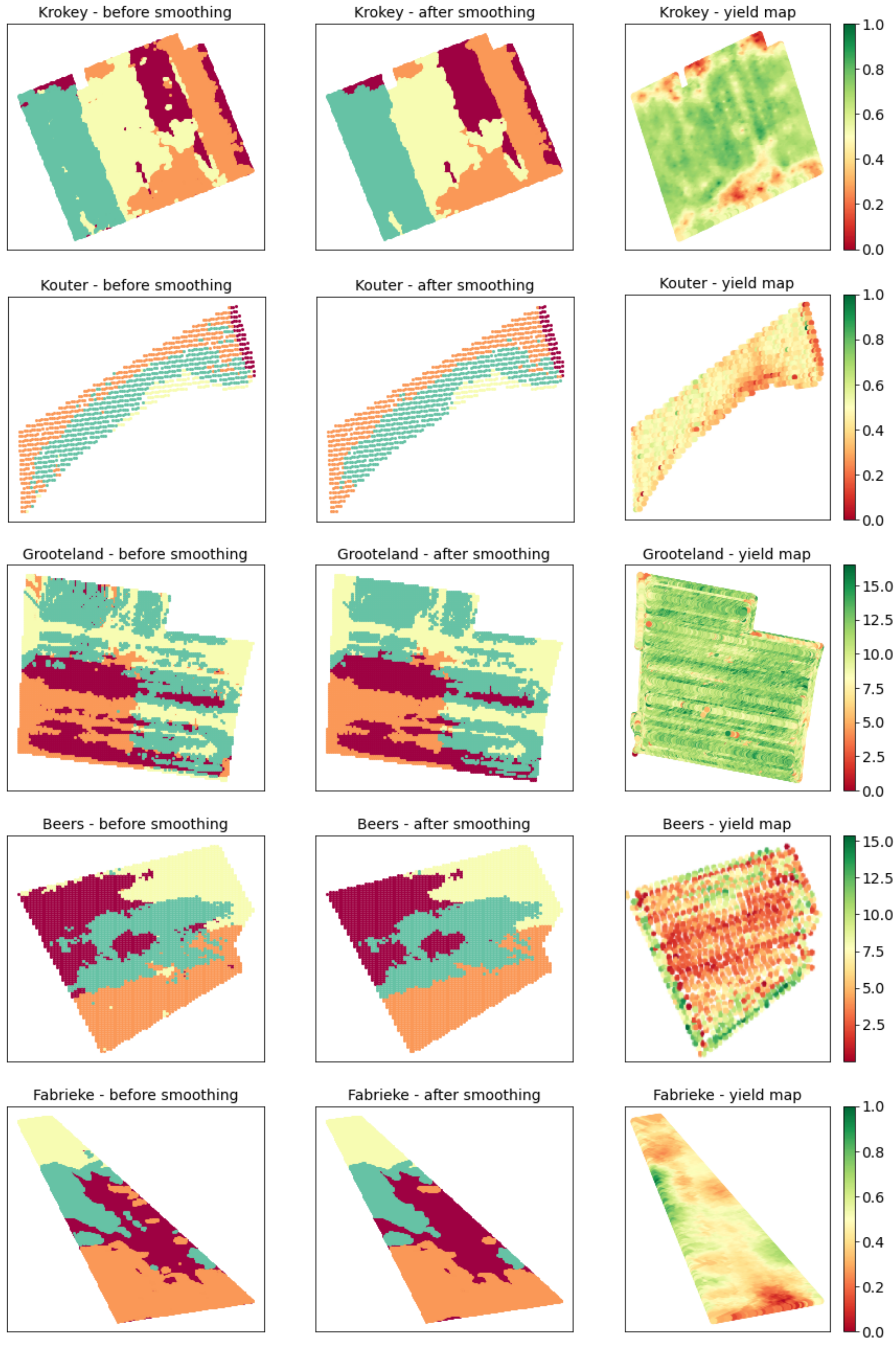
2.9. Clustering and Smoothing Pipeline (CaSP) for Management Zone Delineation
| Algorithm 1: Smoothing algorithm |
 |
3. Results and Discussion
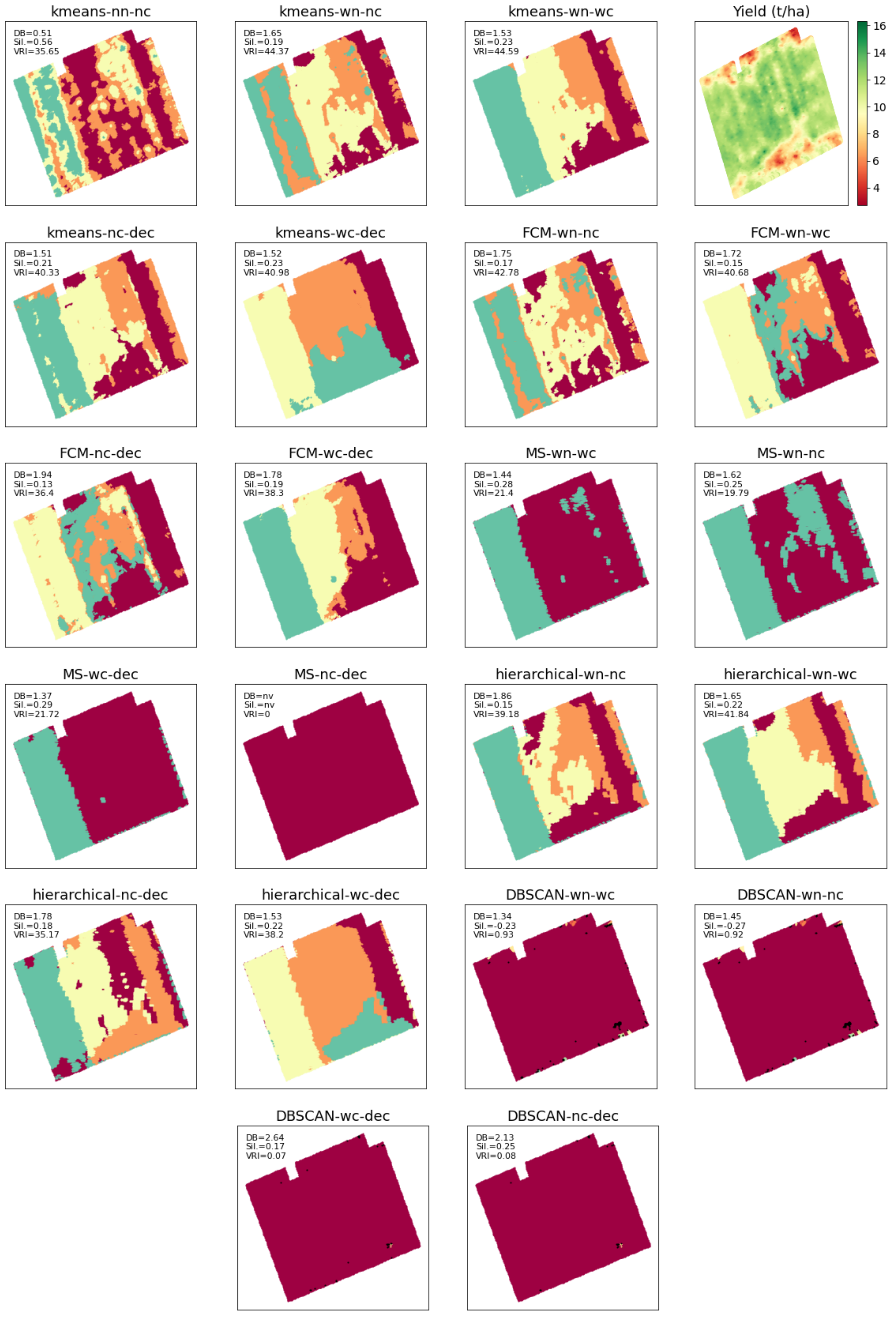
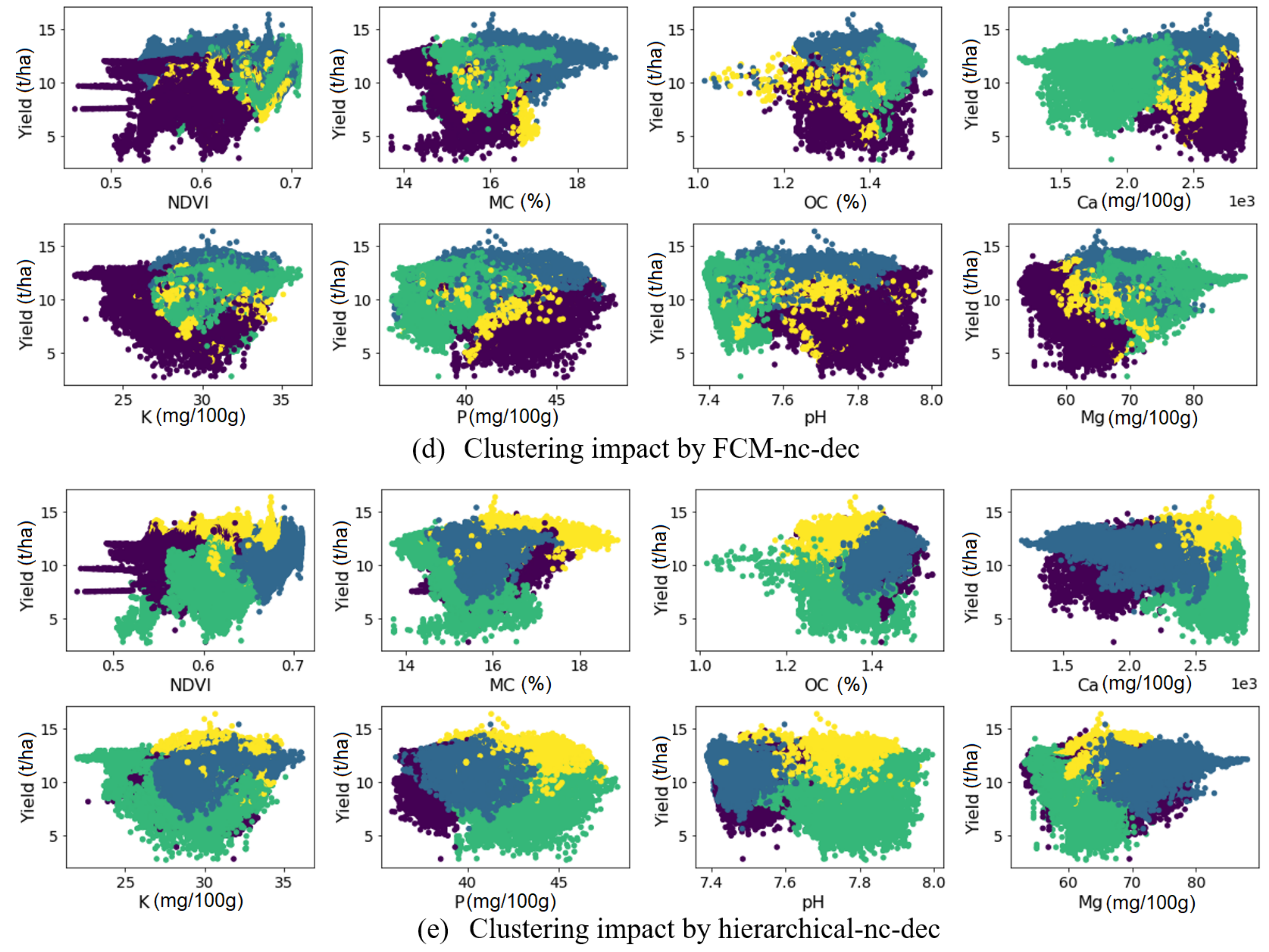
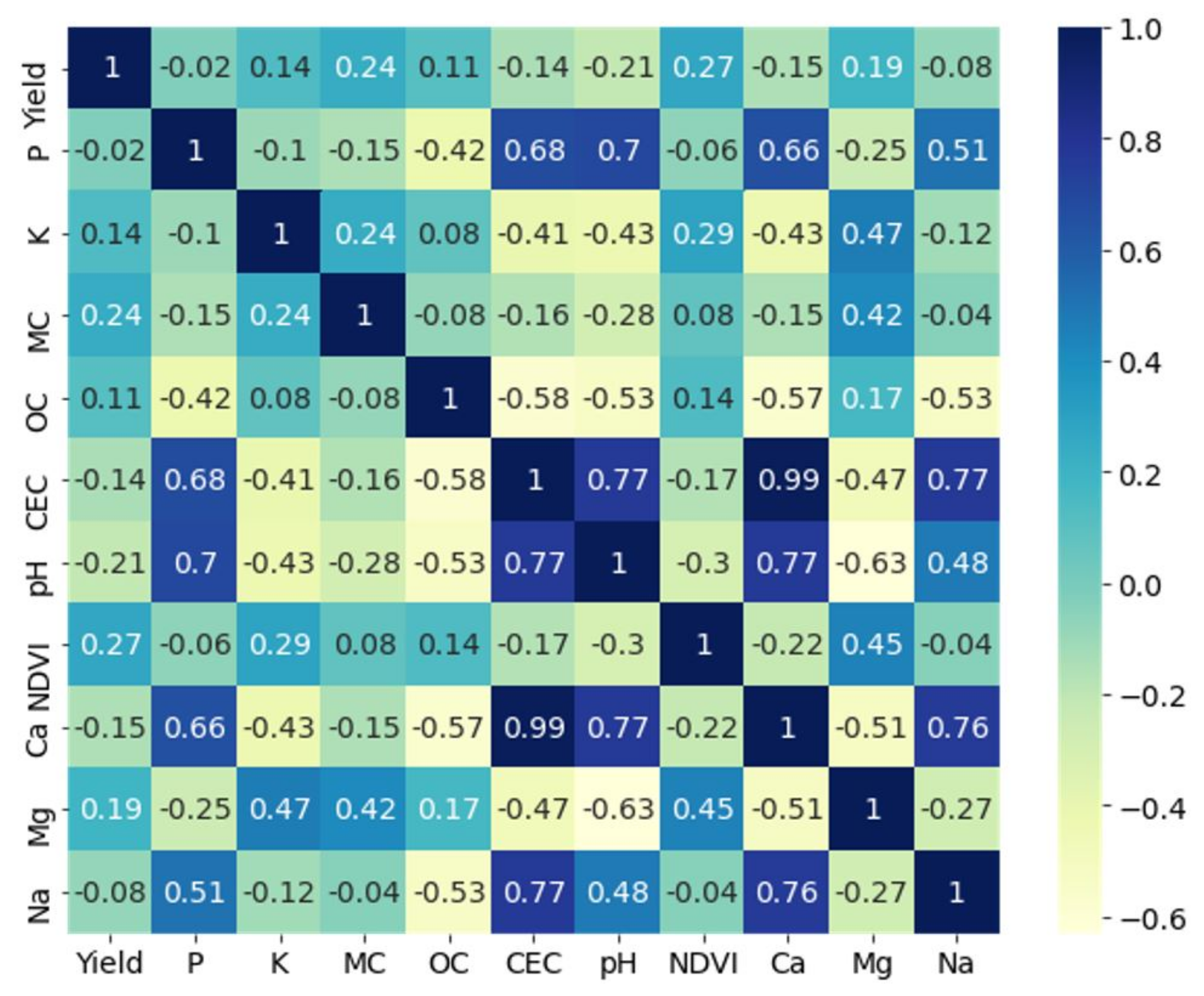
3.1. Evaluation of Clustering Algorithms
3.2. Evaluation of MZ Delineation by CaSP
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| Ca | Calcium |
| CaSP | Clustering and smoothing platform |
| CEC | Cation exchange capacity |
| DBI | Davies–Bouldin index |
| DBSCAN | Density-based spatial clustering of applications with noise |
| DGPS | Differential global positioning system |
| FCM | Fuzzy C-means |
| K | Exchangeable potassium |
| MC | Moisture content |
| Mg | Magnesium |
| MS | Mean-shift |
| MZ | Management zone |
| Na | Sodium |
| NDVI | Normalized difference vegetation index |
| OC | Organic carbon |
| P | Exchangeable phosphorous |
| PA | Precision agriculture |
| Sil. | Silhouette |
| vis-NIR | Visible-near-infrared |
| VRI | Variance reduction index |
References
- Shanahan, J.F.; Kitchen, N.R.; Raun, W.R.; Schepers, J.S. Responsive in-season nitrogen management for cereals. Comput. Electron. Agric. 2008, 61, 51–62. [Google Scholar] [CrossRef] [Green Version]
- Nawar, S.; Corstanje, R.; Halcro, G.; Mulla, D.; Mouazen, A.M. Chapter Four-Delineation of Soil Management Zones for Variable-Rate Fertilization: A Review; Advances in Agronomy; Academic Press: Cambridge, MA, USA, 2017; Volume 143, pp. 175–245. [Google Scholar] [CrossRef]
- Guerrero, A.; De Neve, S.; Mouazen, A.M. Current Sensor Technologies for In Situ and On-Line Measurement of Soil Nitrogen for Variable Rate Fertilization: A Review; Academic Press: Cambridge, MA, USA, 2021. [Google Scholar] [CrossRef]
- Pantazi, X.; Moshou, D.; Mouazen, A.; Alexandridis, T.; Kuang, B. Data fusion of proximal soil sensing and remote crop sensing for the delineation of management zones in arable crop precision farming. In Proceedings of the CEUR Workshop, Kavala, Greece, 17–20 September 2015; pp. 765–776. [Google Scholar]
- Haghverdi, A.; Leib, B.G.; Washington-Allen, R.A.; Ayers, P.D.; Buschermohle, M.J. Perspectives on delineating management zones for variable rate irrigation. Comput. Electron. Agric. 2015, 117, 154–167. [Google Scholar] [CrossRef]
- Vrindts, E.; Mouazen, A.M.; Reyniers, M.; Maertens, K.; Maleki, M.R.; Ramon, H.; De Baerdemaeker, J. Management Zones based on Correlation between Soil Compaction, Yield and Crop Data. Biosyst. Eng. 2005, 92, 419–428. [Google Scholar] [CrossRef]
- Doerge, T. Management Zone Concepts; Potash and Phosphate Institute: Norcross, GA, USA, 2000. [Google Scholar]
- Guerrero, A.; De Neve, S.; Mouazen, A.M. Data fusion approach for map-based variable-rate nitrogen fertilization in barley and wheat. Soil Tillage Res. 2021, 205, 104789. [Google Scholar] [CrossRef]
- De Benedetto, D.; Castrignanò, A.; Rinaldi, M.; Ruggieri, S.; Santoro, F.; Figorito, B.; Gualano, S.; Diacono, M.; Tamborrino, R. An approach for delineating homogeneous zones by using multi-sensor data. Geoderma 2013, 199, 117–127. [Google Scholar] [CrossRef]
- Fleming, K.; Westfall, D.; Wiens, D.; Brondahl, M.C. Evaluating Farmer Defined Management Zone Maps for Variable Rate Fertilizer Application. Precis. Agric. 2000, 2, 201–215. [Google Scholar] [CrossRef]
- Mouazen, A.M. Soil Survey Device; International Publication Published under the Patent Cooperation Treaty (PCT); World Intellectual Property Organization, International Bureau: Brussels, Belgium, 2006; International Publication Number: WO2006/015463; PCT/BE2005/000129; IPC: G01N21/00; G01N21/00. [Google Scholar]
- Nawar, S.; Cipullo, S.; Douglas, R.K.; Coulon, F.; Mouazen, A.M. The applicability of spectroscopy methods for estimating potentially toxic elements in soils: State-of-the-art and future trends. Appl. Spectrosc. Rev. 2019, 55, 1–33. [Google Scholar] [CrossRef]
- Javadi, S.H.; Mouazen, A.M. Data Fusion of XRF and Vis-NIR Using Outer Product Analysis, Granger–Ramanathan, and Least Squares for Prediction of Key Soil Attributes. Remote Sens. 2021, 13, 2023. [Google Scholar] [CrossRef]
- Javadi, S.; Mohammadi, A. Plackett fusion of correlated decisions. AEU-Int. J. Electron. Commun. 2019, 99, 341–346. [Google Scholar] [CrossRef]
- Javadi, S.; Mohammadi, A. Fire detection by fusing correlated measurements. J. Ambient. Intell. Humaniz. Comput. 2017. [Google Scholar] [CrossRef]
- Schenatto, K.; de Souza, E.G.; Bazzi, C.L.; Gavioli, A.; Betzek, N.M.; Beneduzzi, H.M. Normalization of data for delineating management zones. Comput. Electron. Agric. 2017, 143, 238–248. [Google Scholar] [CrossRef]
- Song, X.; Wang, J.; Huang, W.; Liu, L.; Yan, G.; Pu, R. The delineation of agricultural management zones with high resolution remotely sensed data. Precis. Agric. 2009, 10, 471–487. [Google Scholar] [CrossRef]
- Kodaira, M.; Shibusawa, S. Mobile Proximal Sensing with Visible and Near Infrared Spectroscopy for Digital Soil Mapping. Soil Syst. 2020, 4, 40. [Google Scholar] [CrossRef]
- Mouazen, A.M.; Baerdemaeker, J.D.; Ramon, H. Effect of Wavelength Range on the Measurement Accuracy of Some Selected Soil Constituents Using Visual-Near Infrared Spectroscopy. J. Near Infrared Spectrosc. 2006, 14, 189–199. [Google Scholar] [CrossRef]
- Janrao, P.; Palivela, H. Management zone delineation in Precision agriculture using data mining: A review. In Proceedings of the 2015 International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Coimbatore, India, 19–20 March 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Fu, Q.; Wang, Z.; Jiang, Q. Delineating soil nutrient management zones based on fuzzy clustering optimized by PSO. Math. Comput. Model. 2010, 51, 1299–1305. [Google Scholar] [CrossRef]
- Janrao, P.; Mishra, D.; Bharadi, V. Clustering Approaches for Management Zone Delineation in Precision Agriculture for Small Farms. In Proceedings of the International Conference on Sustainable Computing in Science, Technology and Management (SUSCOM), Jaipur, India, 26–28 February 2019. [Google Scholar]
- Karkra, R.; Kaur, S.; Kaur, M.; Sharma, R.; Upadhyay, R.R. Management zone delineation in precision agriculture using machine learning algorithms. J. Nat. Remedies 2020, 21, 22–29. [Google Scholar]
- Javadi, S.H.; Guerrero, A.; Mouazen, A.M. Source localization in resource-constrained sensor networks based on deep learning. Neural Comput. Appl. 2020, 33, 4217–4228. [Google Scholar] [CrossRef]
- Aggelopooulou, K.; Castrignanò, A.; Gemtos, T.; Benedetto, D.D. Delineation of management zones in an apple orchard in Greece using a multivariate approach. Comput. Electron. Agric. 2013, 90, 119–130. [Google Scholar] [CrossRef]
- Landrum, C.; Castrignanò, A.; Mueller, T.; Zourarakis, D.; Zhu, J.; De Benedetto, D. An approach for delineating homogeneous within-field zones using proximal sensing and multivariate geostatistics. Agric. Water Manag. 2015, 147, 144–153. [Google Scholar] [CrossRef]
- Cordero, E.; Longchamps, L.; Khosla, R.; Sacco, D. Joint measurements of NDVI and crop production data-set related to combination of management zones delineation and nitrogen fertilisation levels. Data Brief 2020, 28, 104968. [Google Scholar] [CrossRef]
- Gavioli, A.; de Souza, E.G.; Bazzi, C.L.; Schenatto, K.; Betzek, N.M. Identification of management zones in precision agriculture: An evaluation of alternative cluster analysis methods. Biosyst. Eng. 2019, 181, 86–102. [Google Scholar] [CrossRef]
- Paccioretti, P.; Córdoba, M.; Balzarini, M. FastMapping: Software to create field maps and identify management zones in precision agriculture. Comput. Electron. Agric. 2020, 175, 105556. [Google Scholar] [CrossRef]
- Li, X.; Pan, Y.-C.; Zhong, Q.; Zhao, C.-J. Delineation and Scale Effect of Precision Agriculture Management Zones Using Yield Monitor Data over Four Years. Agric. Sci. China 2007, 6, 180–188. [Google Scholar] [CrossRef]
- Nawar, S.; Abdul Munnaf, M.; Mouazen, A.M. Machine Learning Based On-Line Prediction of Soil Organic Carbon after Removal of Soil Moisture Effect. Remote Sens. 2020, 12, 1308. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Grunwald, S.; Rivero, R.G. Soil Phosphorus and Nitrogen Predictions Across Spatial Escalating Scales in an Aquatic Ecosystem Using Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6724–6737. [Google Scholar] [CrossRef]
- Ji, F.; Meng, J.; Cheng, Z.; Fang, H.; Wang, Y. Crop Yield Estimation at Field Scales by Assimilating Time Series of Sentinel-2 Data Into a Modified CASA-WOFOST Coupled Model. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4400914. [Google Scholar] [CrossRef]
- Javadi, S.H.; Munnaf, M.A.; Mouazen, A.M. Fusion of Vis-NIR and XRF spectra for estimation of key soil attributes. Geoderma 2021, 385, 114851. [Google Scholar] [CrossRef]
- Tavares, T.R.; Molin, J.P.; Javadi, S.H.; Carvalho, H.W.; Mouazen, A.M. Combined Use of Vis-NIR and XRF Sensors for Tropical Soil Fertility Analysis: Assessing Different Data Fusion Approaches. Sensors 2021, 21, 148. [Google Scholar] [CrossRef]
- Mouazen, A.M.; Maleki, M.R.; Cockx, L.; Van Meirvenne, M.; Van Holm, L.H.J.; Merckx, R.; De Baerdemaeker, J.; Ramon, H. Optimum three-point linkage set up for improving the quality of soil spectra and the accuracy of soil phosphorus measured using an on-line visible and near infrared sensor. Soil Tillage Res. 2009, 103, 144–152. [Google Scholar] [CrossRef] [Green Version]
- Barnes, R.J.; Dhanoa, M.S.; Lister, S.J. Standard Normal Variate Transformation and De-Trending of Near-Infrared Diffuse Reflectance Spectra. Appl. Spectrosc. 1989, 43, 772–777. [Google Scholar] [CrossRef]
- Stevens, A.; Ramirez-Lopez, L. An Introduction to the Prospectr Package; R Package Vignette; 2020; Available online: https://cran.r-project.org/web/packages/prospectr/vignettes/prospectr.html (accessed on 25 November 2021).
- Usowicz, B.; Lipiec, J. Spatial variability of soil properties and cereal yield in a cultivated field on sandy soil. Soil Tillage Res. 2017, 174, 241–250. [Google Scholar] [CrossRef]
- Webster, R.; Oliver, M. Spatial Variability and Affecting Factors of Soil Nutrients in Croplands of Northeast China; John Wiley & Sons Ltd.: The Atrium, UK, 2007. [Google Scholar]
- Bhattacharjee, S.; Mitra, P.; Ghosh, S.K. Spatial Interpolation to Predict Missing Attributes in GIS Using Semantic Kriging. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4771–4780. [Google Scholar] [CrossRef]
- Bazzi, C.L.; Souza, E.G.; Uribe-Opazo, M.A.; Nóbrega, L.H.P.; Rocha, D.M. Management Zones Definition Using Soil Chemical and Physical Attributes in a Soybean Area. Eng. Agríc. 2013, 33, 952–964. [Google Scholar] [CrossRef] [Green Version]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Dobermann, A.; Ping, J.L.; Adamchuk, V.I.; Simbahan, G.C.; Ferguson, R.B. Classification of Crop Yield Variability in Irrigated Production Fields. Agron. J. 2003, 95, 1105–1120. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Guerrero, A.; Mouazen, A.M. Map-based variable-rate manure application in wheat using a data fusion approach. Soil Tillage Res. 2021, 207, 104846. [Google Scholar] [CrossRef]
- Munnaf, M.A.; Haesaert, G.; Van Meirvenne, M.; Mouazen, A.M. Map-based site-specific seeding of consumption potato production using high-resolution soil and crop data fusion. Comput. Electron. Agric. 2020, 178, 105752. [Google Scholar] [CrossRef]
- Lang, H.; Xi, Y.; Zhang, X. Ship Detection in High-Resolution SAR Images by Clustering Spatially Enhanced Pixel Descriptor. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5407–5423. [Google Scholar] [CrossRef]
- Pal, N.R.; Bezdek, J.C. On cluster validity for the fuzzy c-means model. IEEE Trans. Fuzzy Syst. 1995, 3, 370–379. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hazelton, P.; Murphy, B. Interpreting Soil Test Results: What Do All the Numbers Mean; CSIRO Publishing: Melbourne, Australia, 2007. [Google Scholar]
- Sharma, A.; Weindorf, D.C.; Wang, D.; Chakraborty, S. Characterizing soils via portable X-ray fluorescence spectrometer: 4. Cation exchange capacity (CEC). Geoderma 2015, 239–240, 130–134. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Field Name | % Clay | % Sand | % Silt | Soil Texture (USDA) | No. Samples | Total Samples |
|---|---|---|---|---|---|---|---|
| Huldenberg | Kouter (Target field) | 12.6 | 11.6 | 75.8 | Silt Loam | 40 | 155 |
| Duidelbergen | 10.2 | 10.3 | 79.4 | Silt Loam | 24 | ||
| Voor de Heeves | 12.0 | 9.5 | 78.5 | Silt Loam | 43 | ||
| Lange Weid | 10.3 | 10.3 | 79.4 | Silt Loam | 48 | ||
| Landen | Grootland (Target field) | 13.3 | 6.3 | 80.4 | Silt Loam | 60 | 179 |
| Gimgelomse | 13.2 | 32.7 | 54.2 | Silt Loam | 38 | ||
| Kattestraat | – | – | – | – | 20 | ||
| Dal | – | – | – | – | 23 | ||
| Bottelare 1 | – | – | – | – | 25 | ||
| Thierry 1 | – | – | – | – | 13 | ||
| Veurne | Beers (Target field) | 16.5 | 54.0 | 29.5 | Sandy Loam | 39 | 122 |
| Fabrieke (Target field) | 16.2 | 37.8 | 46.0 | Loam | 25 | ||
| Krokey (Target field) 2 | 54 | ||||||
| Watermachine | 14.5 | 51.6 | 33.9 | Loam | 20 | ||
| Bottelare 1 | – | – | – | – | 25 | ||
| Thierry 1 | – | – | – | – | 13 |
| Clustering Scenario | Clustering Method and the Conditions of Its Input Data |
|---|---|
| kmeans-nn-nc 1 | k-means, no data normalization, xy coordinate data not considered |
| kmeans-wn-nc | k-means, with data normalization, xy coordinate data not considered |
| kmeans-wn-wc | k-means, with data normalization, with xy coordinate data |
| kmeans-nc-dec | k-means, xy coordinate data not considered, data decreased |
| kmeans -wc-dec | k-means, with xy coordinate data, data decreased |
| FCM-wn-nc | FCM, with data normalization, xy coordinate data not considered |
| FCM-wn-wc | FCM, with data normalization, with xy coordinate data |
| FCM-nc-dec | FCM, xy coordinate data not considered, data decreased |
| FCM-wc-dec | FCM, with xy coordinate data, data decreased |
| MS-wn-nc | Mean shift, with data normalization, xy coordinate data not considered |
| MS-wn-wc | Mean shift, with data normalization, with xy coordinate data |
| MS-wc-dec | Mean shift, with xy coordinate data, data decreased |
| MS-nc-dec | Mean shift, xy coordinate data not considered, data decreased |
| hier-wn-nc | Hierarchical, with data normalization, xy coordinate data not considered |
| hierarchical-wn-wc | Hierarchical, with data normalization, with xy coordinate data |
| hierarchical-nc-dec | Hierarchical, xy coordinate data not considered, data decreased |
| hierarchical-wc-dec | Hierarchical, with xy coordinate data, data decreased |
| DBSCAN-wn-nc | DBSCAN, with data normalization, xy coordinate data not considered |
| DBSCAN-wn-wc | DBSCAN, with data normalization, with xy coordinate data |
| DBSCAN-wc-dec | DBSCAN, with xy coordinate data, data decreased |
| DBSCAN-nc-dec | DBSCAN, xy coordinate data not considered, data decreased |
| Field Name | Krokey | Kouter | Grooteland | Beers | Fabrieke | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Score | DBI | Sil. | VRI | DBI | Sil. | VRI | DBI | Sil. | VRI | DBI | Sil. | VRI | DBI | Sil. | VRI |
| km. 1-nn-nc | 0.51 | 0.56 | 35.65 | 0.55 | 0.53 | 12.25 | 0.67 | 0.45 | 33.81 | 0.56 | 0.52 | 28.27 | 0.75 | 0.31 | 3.56 |
| km.-wn-nc | 1.65 | 0.19 | 44.37 | 1.55 | 0.25 | 33.42 | 1.40 | 0.21 | 47.82 | 1.33 | 0.25 | 45.35 | 1.43 | 0.20 | 23.56 |
| km.-wn-wc | 1.53 | 0.23 | 44.59 | 1.53 | 0.21 | 27.47 | 1.40 | 0.24 | 43.24 | 1.32 | 0.26 | 46.92 | 1.57 | 0.24 | 30.32 |
| km.-nc-dec | 1.51 | 0.21 | 40.33 | 1.33 | 0.27 | 33.31 | 1.45 | 0.20 | 45.86 | 1.36 | 0.24 | 45.19 | 1.21 | 0.31 | 48.50 |
| km.-wc-dec | 1.52 | 0.23 | 40.98 | 1.61 | 0.21 | 26.55 | 1.38 | 0.24 | 41.57 | 1.29 | 0.27 | 47.37 | 1.59 | 0.22 | 28.40 |
| FCM-wn-nc | 1.72 | 0.15 | 40.68 | 2.27 | 0.16 | 24.79 | 2.01 | 0.15 | 42.93 | 1.47 | 0.22 | 44.13 | 1.55 | 0.19 | 55.89 |
| FCM-wn-wc | 1.75 | 0.17 | 42.78 | 1.54 | 0.20 | 26.87 | 1.46 | 0.24 | 42.73 | 1.37 | 0.24 | 45.58 | 1.40 | 0.23 | 57.98 |
| FCM-nc-dec | 1.94 | 0.13 | 36.40 | 2.28 | 0.17 | 21.46 | 1.77 | 0.16 | 42.32 | 1.40 | 0.23 | 45.00 | 1.99 | 0.19 | 19.97 |
| FCM-wc-dec | 1.78 | 0.19 | 38.30 | 1.63 | 0.19 | 25.29 | 1.42 | 0.23 | 41.18 | 1.31 | 0.26 | 46.80 | 1.67 | 0.17 | 10.56 |
| MS-wn-nc | 1.44 | 0.28 | 21.40 | 1.63 | 0.20 | 25.29 | 1.42 | 0.23 | 41.18 | 1.31 | 0.25 | 46.80 | 1.40 | 0.23 | 58.28 |
| MS-wn-wc | 1.62 | 0.25 | 19.79 | 3.45 | 0.07 | 24.89 | 1.43 | 0.26 | 30.28 | 1.41 | 0.23 | 39.73 | 1.00 | 0.32 | 38.30 |
| MS-wc-dec | 1.37 | 0.29 | 21.72 | 1.47 | 0.02 | 20.75 | 1.69 | 0.22 | 21.45 | 1.32 | 0.28 | 37.78 | 1.43 | 0.10 | 24.67 |
| MS-nc-dec | n.v. | n.v. | 0 | 1.05 | 0.15 | 9.56 | 1.43 | 0.23 | 27.16 | 1.67 | 0.23 | 21.92 | 0.93 | 0.16 | 34.23 |
| hier. 2-wn-nc | 1.86 | 0.15 | 39.18 | 2.42 | 0.24 | 16.88 | 2.06 | 0.16 | 36.90 | 1.70 | 0.22 | 37.86 | 1.25 | 0.25 | 55.18 |
| hier.-wn-wc | 1.65 | 0.22 | 41.84 | 2.17 | 0.18 | 18.18 | 1.65 | 0.23 | 36.65 | 1.51 | 0.22 | 40.16 | 1.30 | 0.27 | 55.58 |
| hier.-nc-dec | 1.78 | 0.18 | 35.17 | 1.37 | 0.25 | 31.02 | 1.67 | 0.17 | 41.65 | 1.44 | 0.21 | 41.58 | 1.43 | 0.23 | 29.04 |
| hier.-wc-dec | 1.53 | 0.22 | 38.20 | 1.52 | 0.23 | 29.67 | 1.38 | 0.22 | 38.91 | 1.38 | 0.25 | 45.43 | 1.49 | 0.21 | 28.58 |
| DBS. 3-wn-nc | 1.34 | -0.23 | 0.93 | 2.34 | 0.13 | 10.30 | n.v. | n.v. | 0 | n.v. | n.v. | 0 | 2.76 | 0.16 | 5.77 |
| DBS.-wn-wc | 1.45 | -0.27 | 0.92 | 2.76 | 0.01 | 7.54 | 4.27 | 0.08 | 1.84 | 3.05 | 0.07 | 7.90 | 2.70 | 0.12 | 5.59 |
| DBS.-wc-dec | 2.64 | 0.17 | 0.07 | 1.99 | 0.20 | 10.88 | 1.28 | 0.20 | 0.47 | 0.85 | 0.06 | 1.10 | 2.21 | 0.18 | 14.29 |
| DBS.-nc-dec | 2.13 | 0.25 | 0.08 | 1.82 | 0.26 | 11.84 | 1.72 | 0.00 | 1.94 | 2.42 | -0.1 | 4.43 | 2.03 | 0.23 | 14.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Javadi, S.H.; Guerrero, A.; Mouazen, A.M. Clustering and Smoothing Pipeline for Management Zone Delineation Using Proximal and Remote Sensing. Sensors 2022, 22, 645. https://doi.org/10.3390/s22020645
Javadi SH, Guerrero A, Mouazen AM. Clustering and Smoothing Pipeline for Management Zone Delineation Using Proximal and Remote Sensing. Sensors. 2022; 22(2):645. https://doi.org/10.3390/s22020645
Chicago/Turabian StyleJavadi, S. Hamed, Angela Guerrero, and Abdul M. Mouazen. 2022. "Clustering and Smoothing Pipeline for Management Zone Delineation Using Proximal and Remote Sensing" Sensors 22, no. 2: 645. https://doi.org/10.3390/s22020645
APA StyleJavadi, S. H., Guerrero, A., & Mouazen, A. M. (2022). Clustering and Smoothing Pipeline for Management Zone Delineation Using Proximal and Remote Sensing. Sensors, 22(2), 645. https://doi.org/10.3390/s22020645