
ENERDGE: Distributed Energy-Aware Resource Allocation at the Edge

 , ,
, ,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
1.1. Motivation & Challenges
1.2. Contributions & Outline
- We propose a performance modeling approach based on Switching Systems Theory, to define virtual hardware profiles, i.e., flavors, for the edge infrastructure, providing application QoS guarantees under various operating conditions. The specific QoS metric investigated in the proposed approach is the application’s response time, but other relevant metrics could have been used as well. This modeling allows for dynamic selection and allocation of the appropriate amount of resources for each application (i.e., switching between the different hardware profiles), based on the anticipated workload demands. Leveraging the capabilities provided by this switching, we design a two-stage distributed, energy aware, proactive resource allocation mechanism.
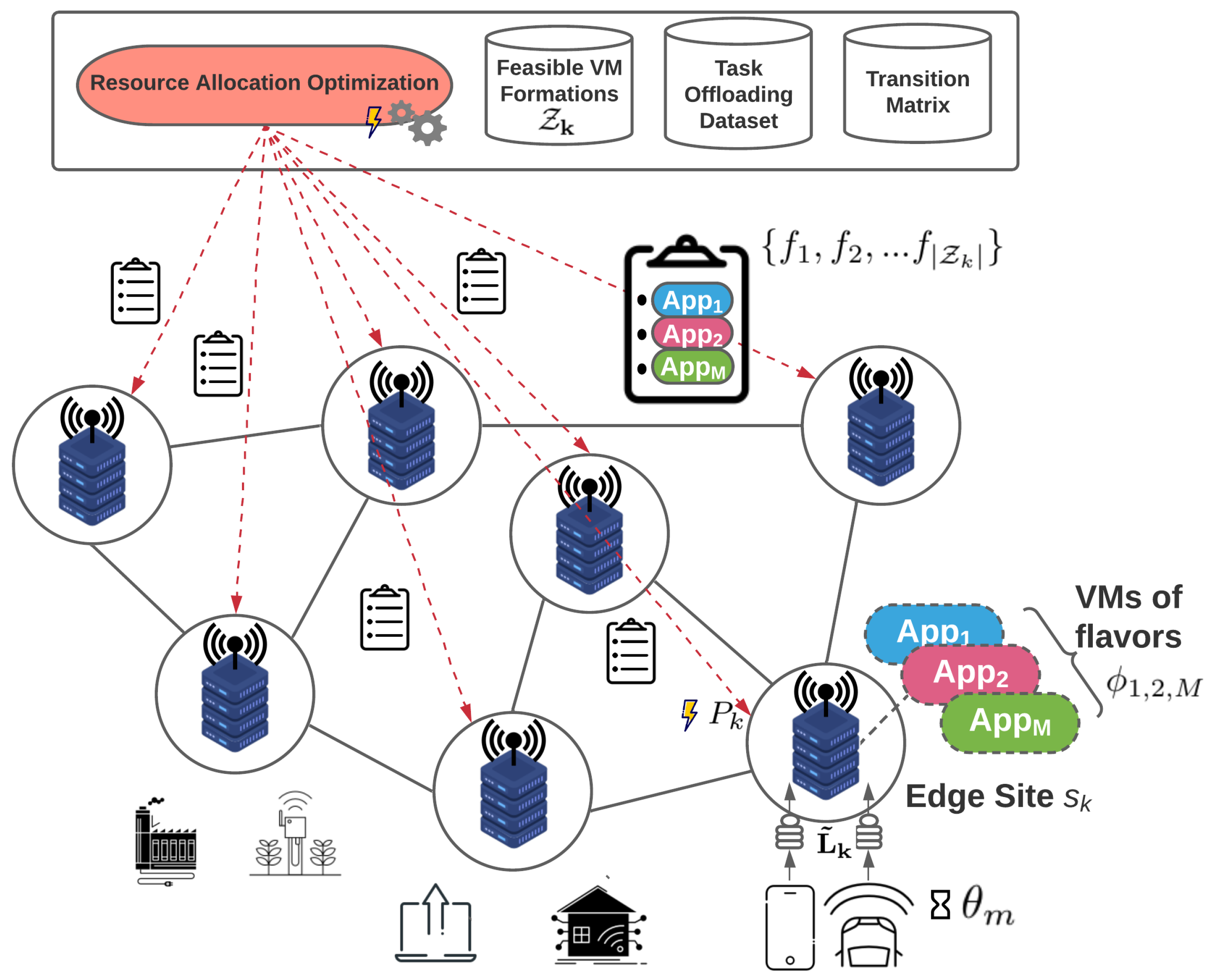
- During the first stage, we extend current literature works that jointly address task offloading and resource allocation on a single edge site (i.e., [9]), to simultaneously minimize the total energy consumption of each edge site and provide guaranteed satisfaction of the QoS requirements of each deployed application. In order to accommodate the workload prediction demands at this stage, we utilise an existing user mobility prediction mechanism, based on the concept of the n-Mobility Markov Chain location prediction [10], to estimate the movement of the mobile devices between different sites within the edge infrastructure and subsequently the density of the users on each point of interest.
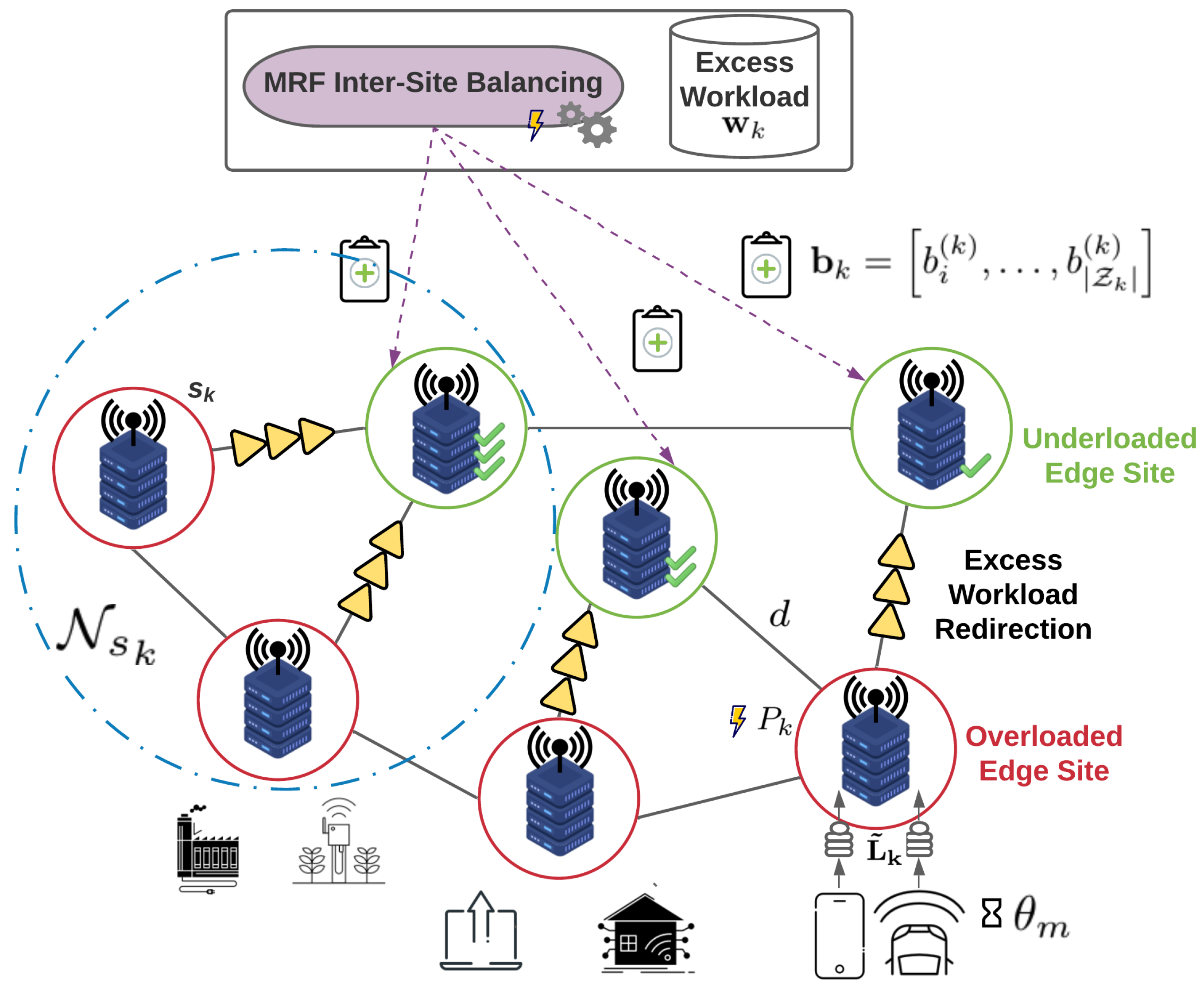
- During the second stage, we combine this approach with a novel Markov Random Field (MRF) mechanism that incorporates in its objective function all optimization criteria; this mechanism aims at redirecting tasks that cannot be executed locally under the given energy and QoS requirements of the first step, balancing resource utilization throughout the whole infrastructure. Thus, it achieves a better total energy management optimization through an efficient state space search in a distributed fashion, while taking into consideration any additional network delays incurred. This is the first approach of such a combination, and it could potentially pave the way for other similar MRF designs as optimizers in relevant problems. The integration of the above modeling and resource allocation approaches composes a task offloading and energy-aware resource allocation mechanism for accommodating dynamic spatiotemporal workload demands.
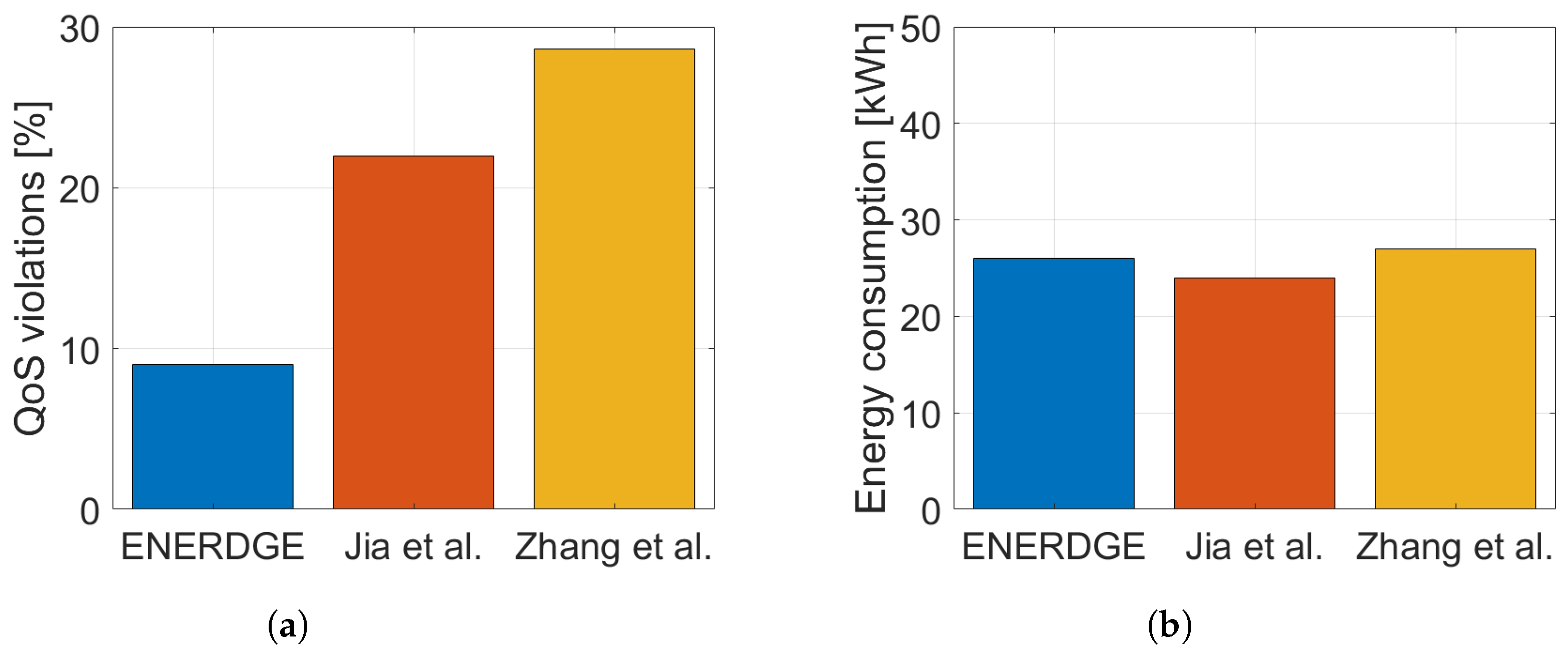
- Finally, we provide a detailed evaluation of our approach in terms of energy consumption minimization and QoS satisfaction for both stages of the mechanism. Then, we compare it with a well-established study [11] and a more recent one [12]. Based on a realistic application simulation, our solution outperforms both approaches in terms of adaptation efficiency. In other words, our approach yields less energy consumption for achieving the same QoS guarantees, or equivalently, it achieves higher QoS guarantees for the same energy consumption.
2. Related Work
2.1. Mobility Prediction for Task Offloading
2.2. Single-Site Offloading & Resource Allocation
2.3. Multi-Site Offloading & Resource Allocation
3. System Model
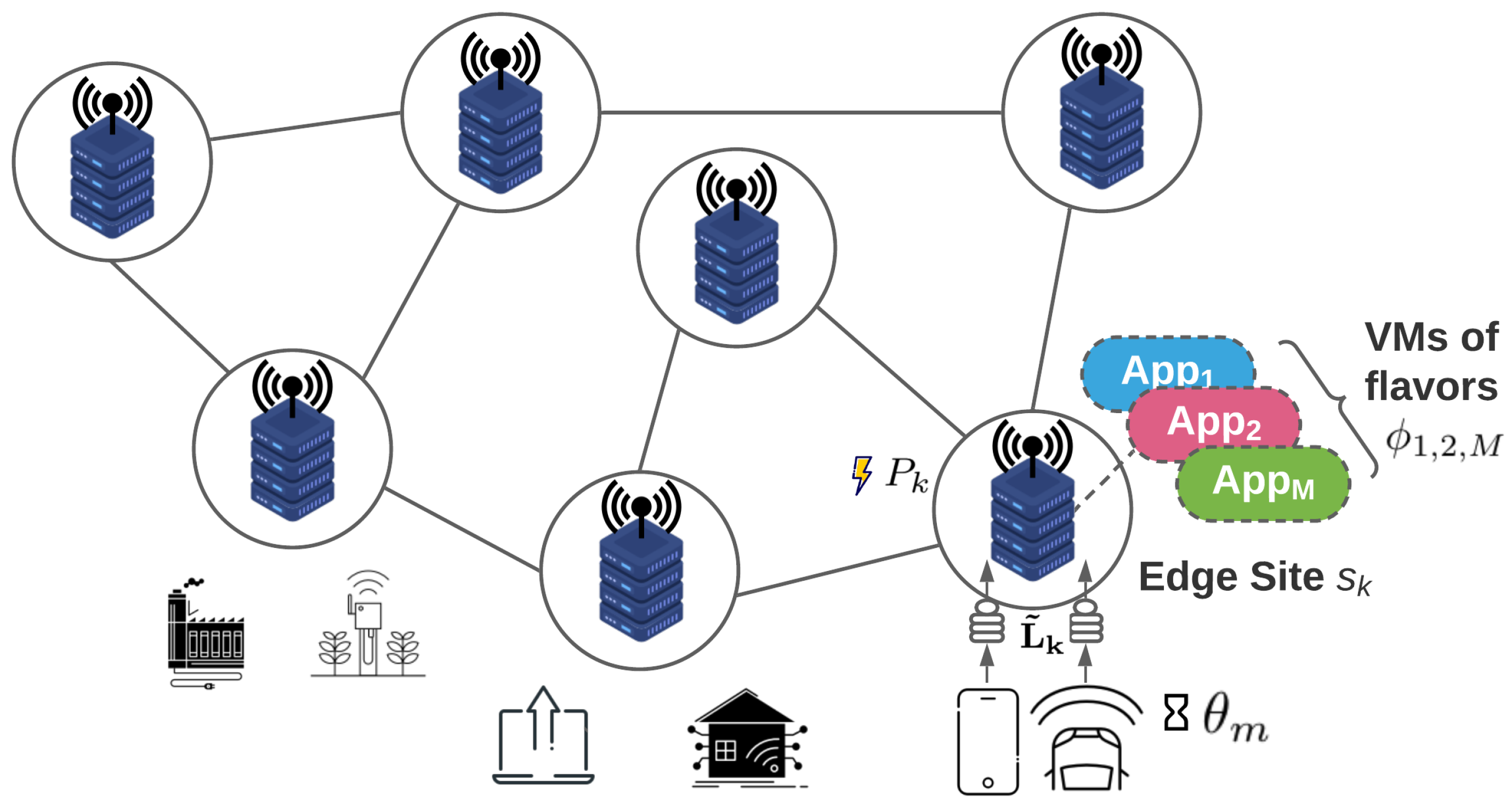
3.1. Edge Infrastructure & Applications
3.2. Task Offloading
3.3. VM Flavor Design
3.4. Power Modeling
3.5. User Density and Workload Prediction
4. Resource Allocation & Workload Redistribution
4.1. Stage 1—Resource Allocation Optimization
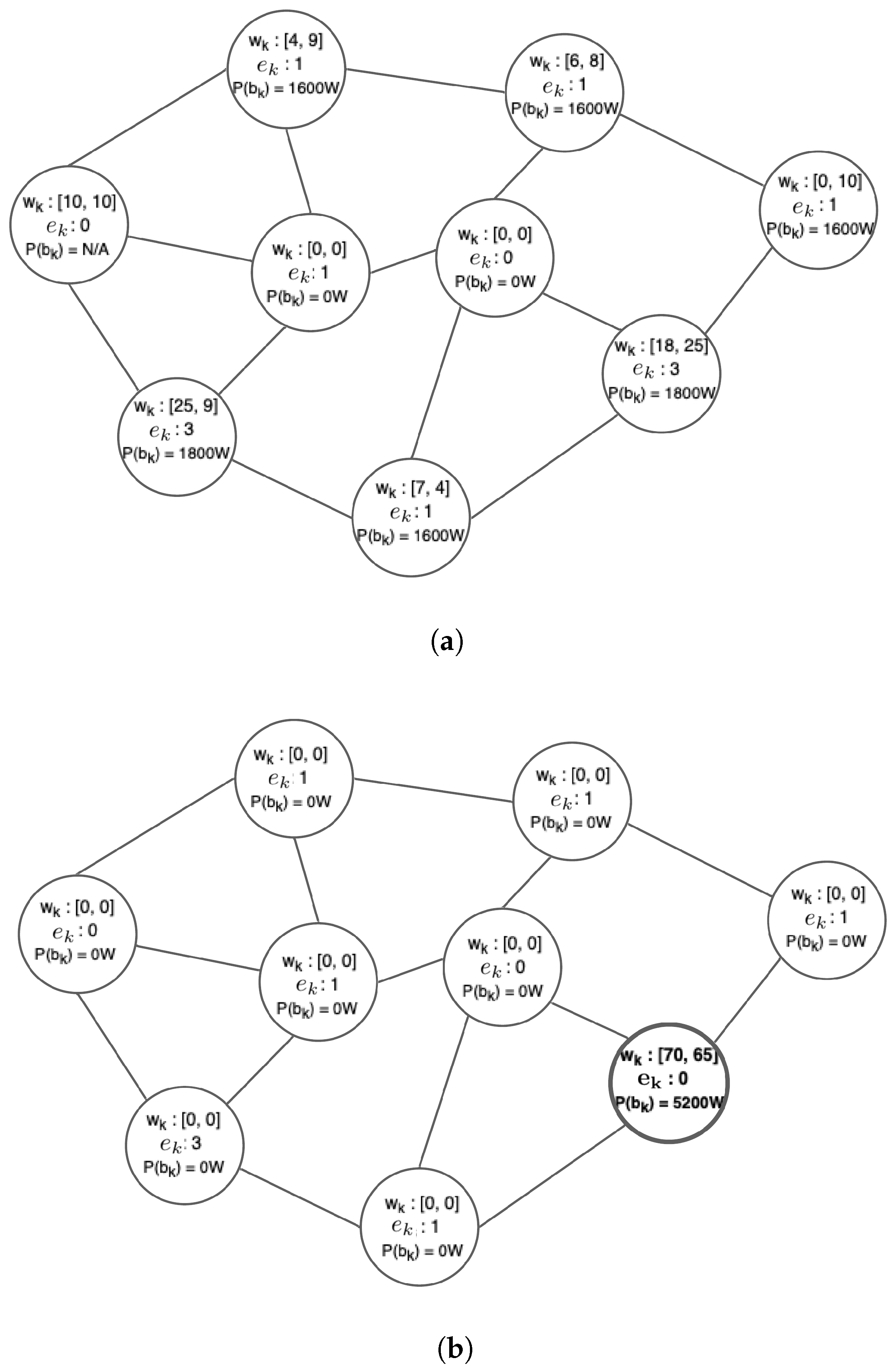
4.2. Stage 2—Inter-Site Redistribution of Excess Workload
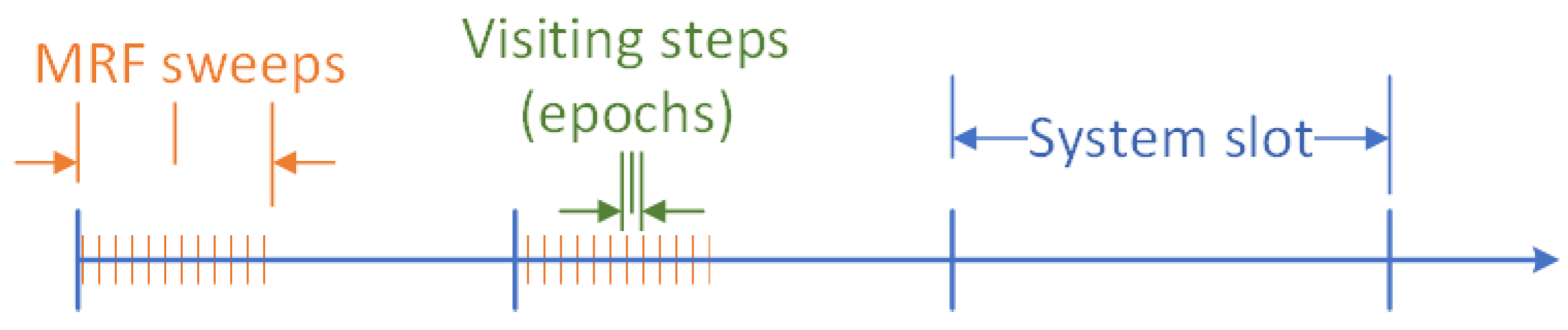
4.3. ENERDGE Core Algorithm
| Algorithm 1: ENERDGE core algorithm. |
 |
5. Performance Evaluation
5.1. Smart Museum Experiment Setting
5.2. Resource Allocation Evaluation
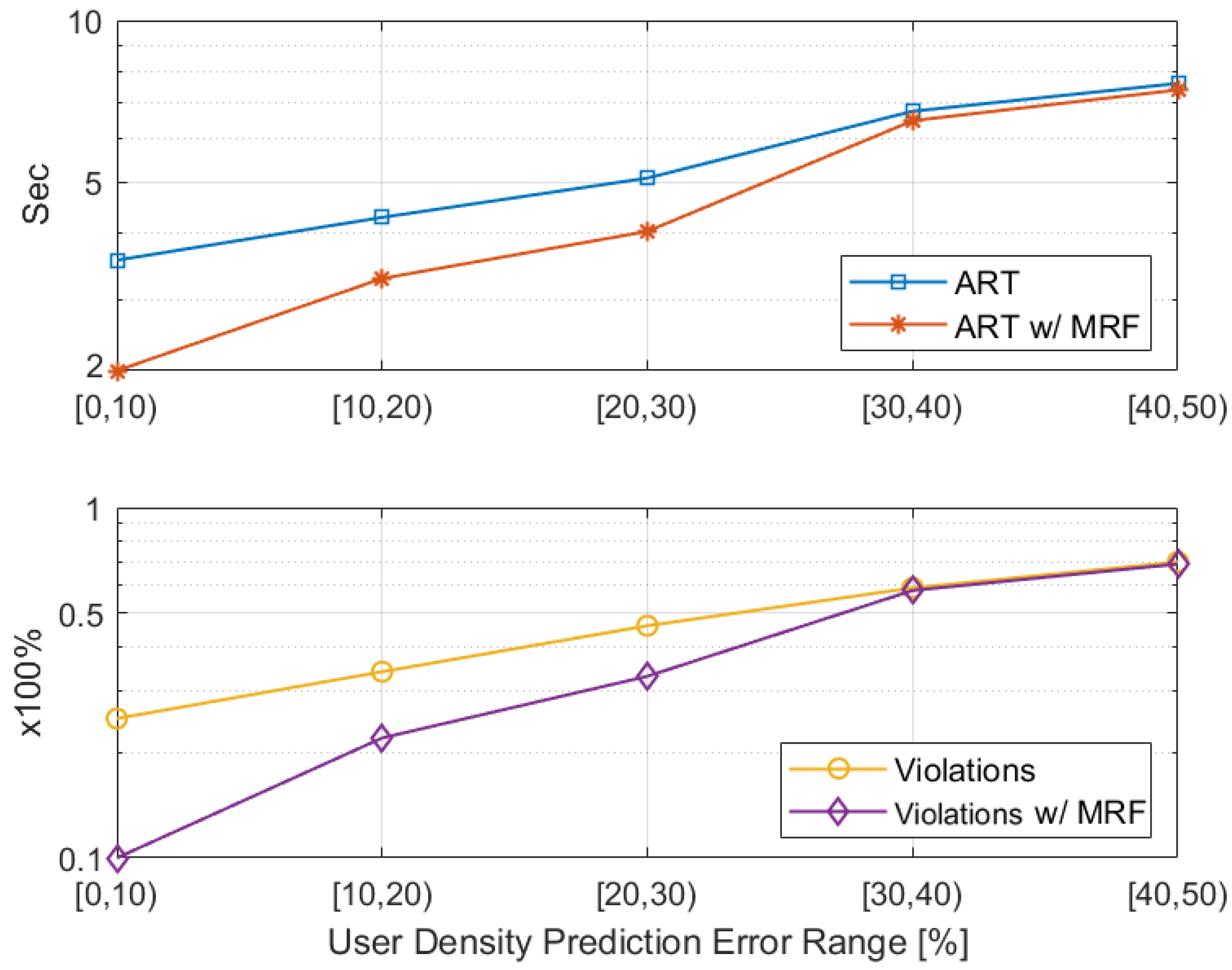
5.2.1. User Density Prediction Impact
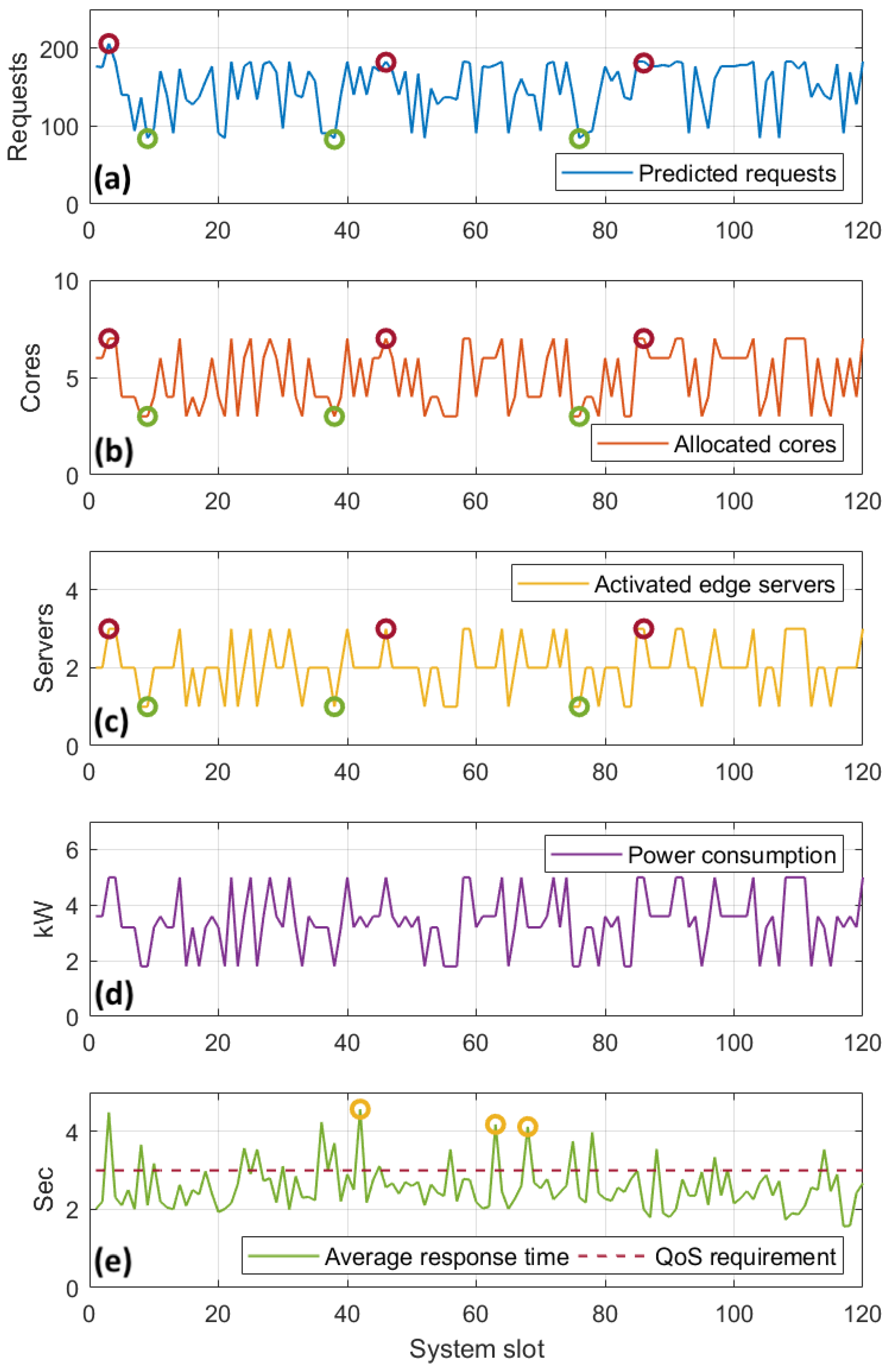
5.2.2. Stage 1 Evaluation—Response to Dynamic Network Conditions
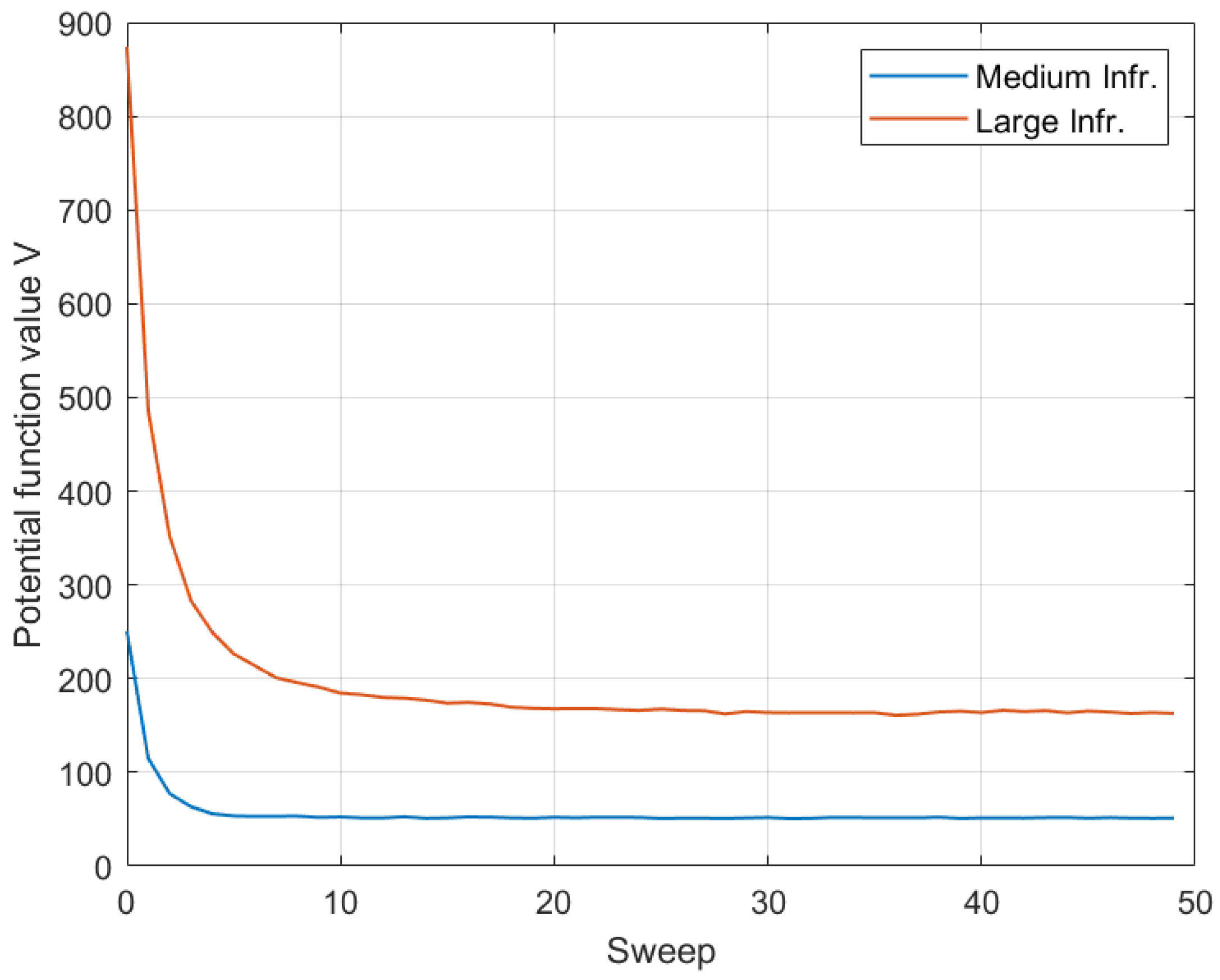
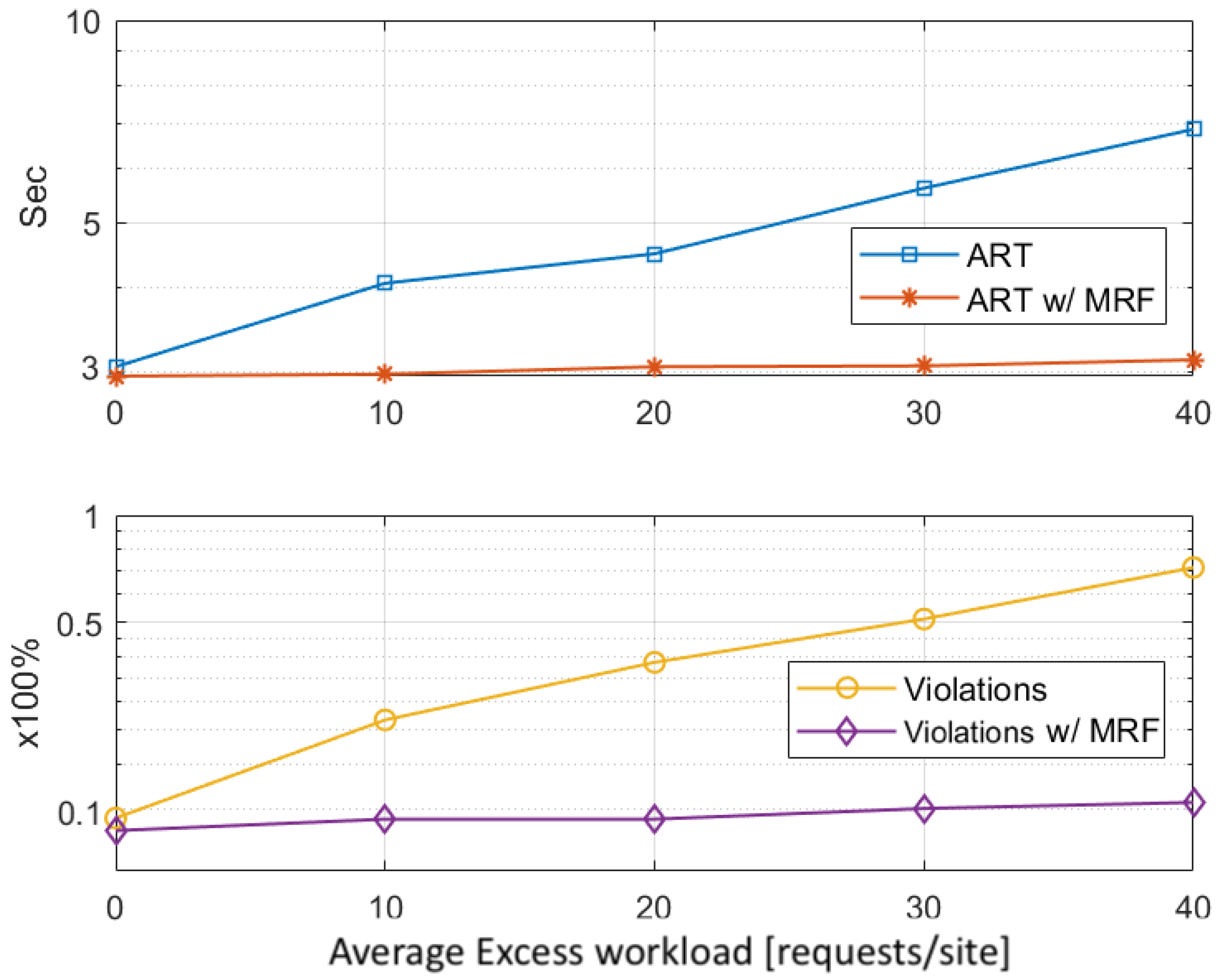
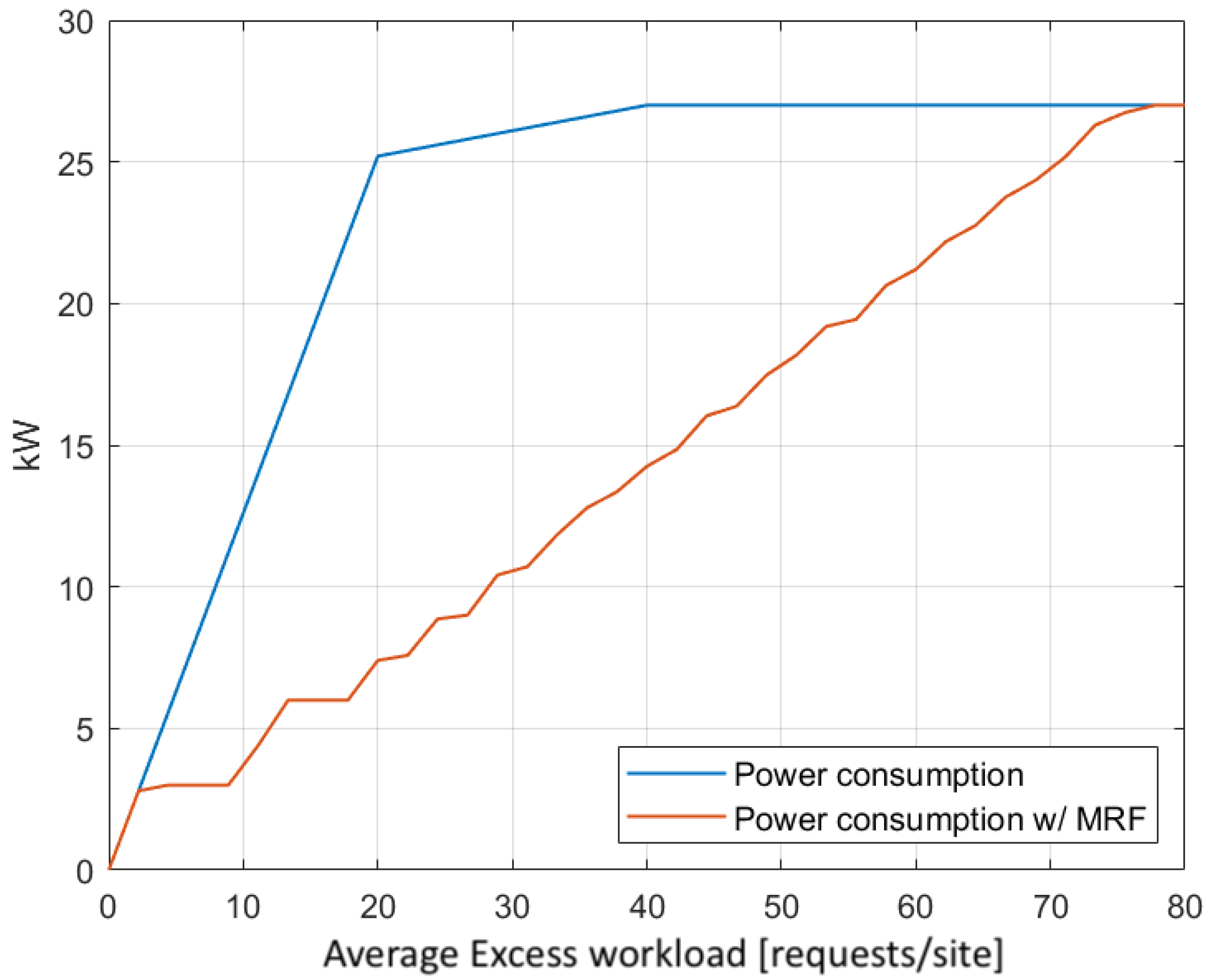
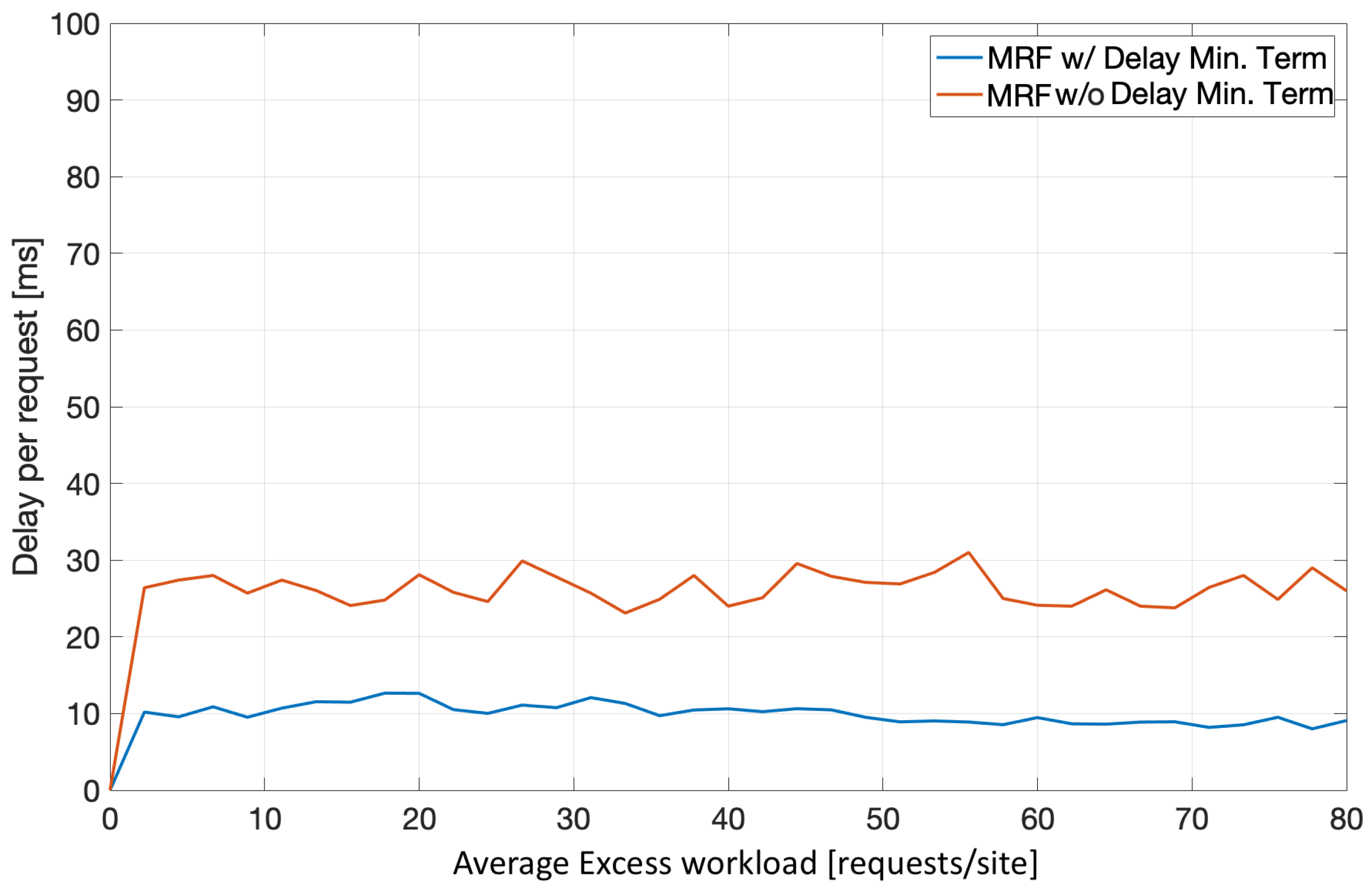
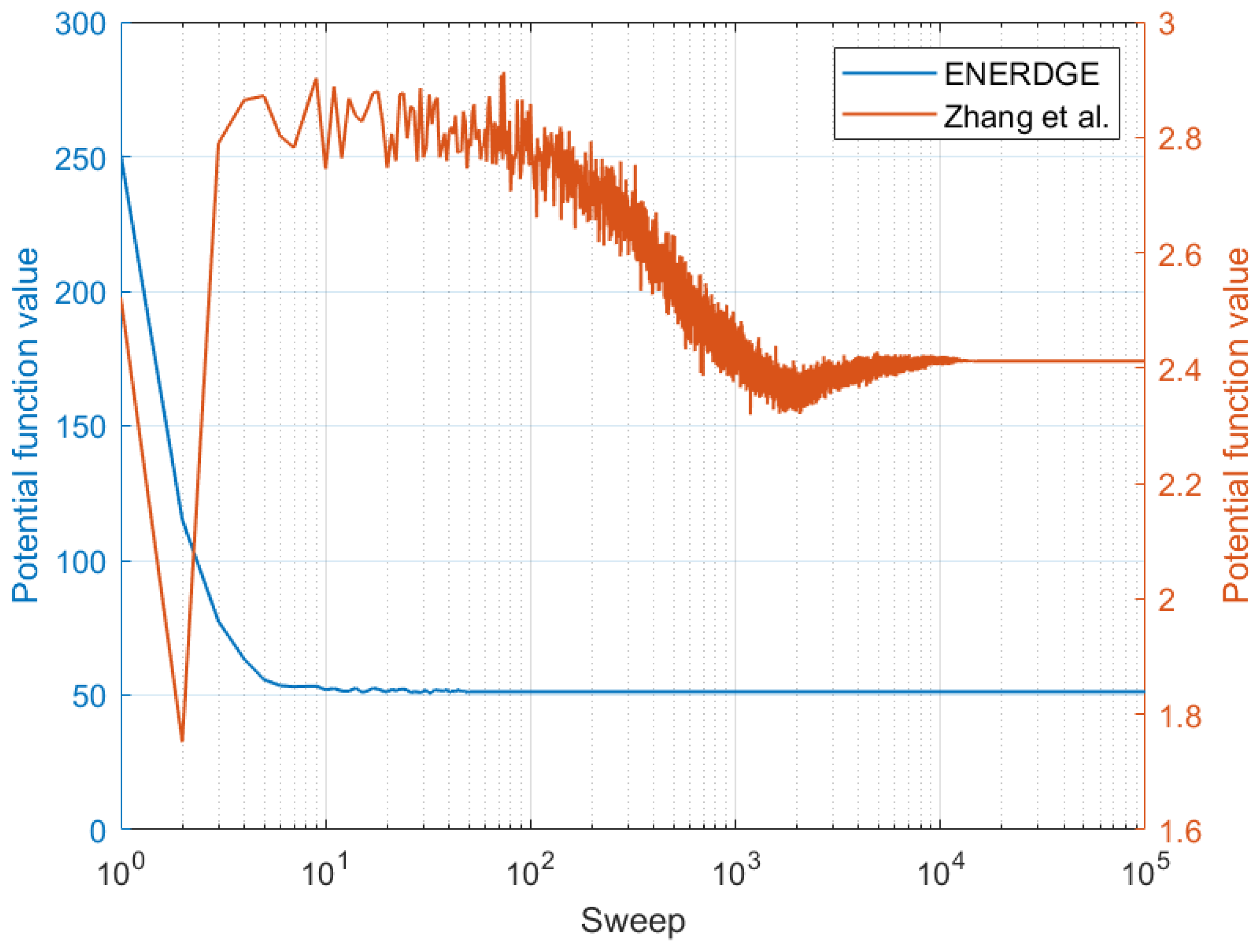
5.2.3. Stage 2 Evaluation—MRF-Based Excess Workload Redistribution Analysis
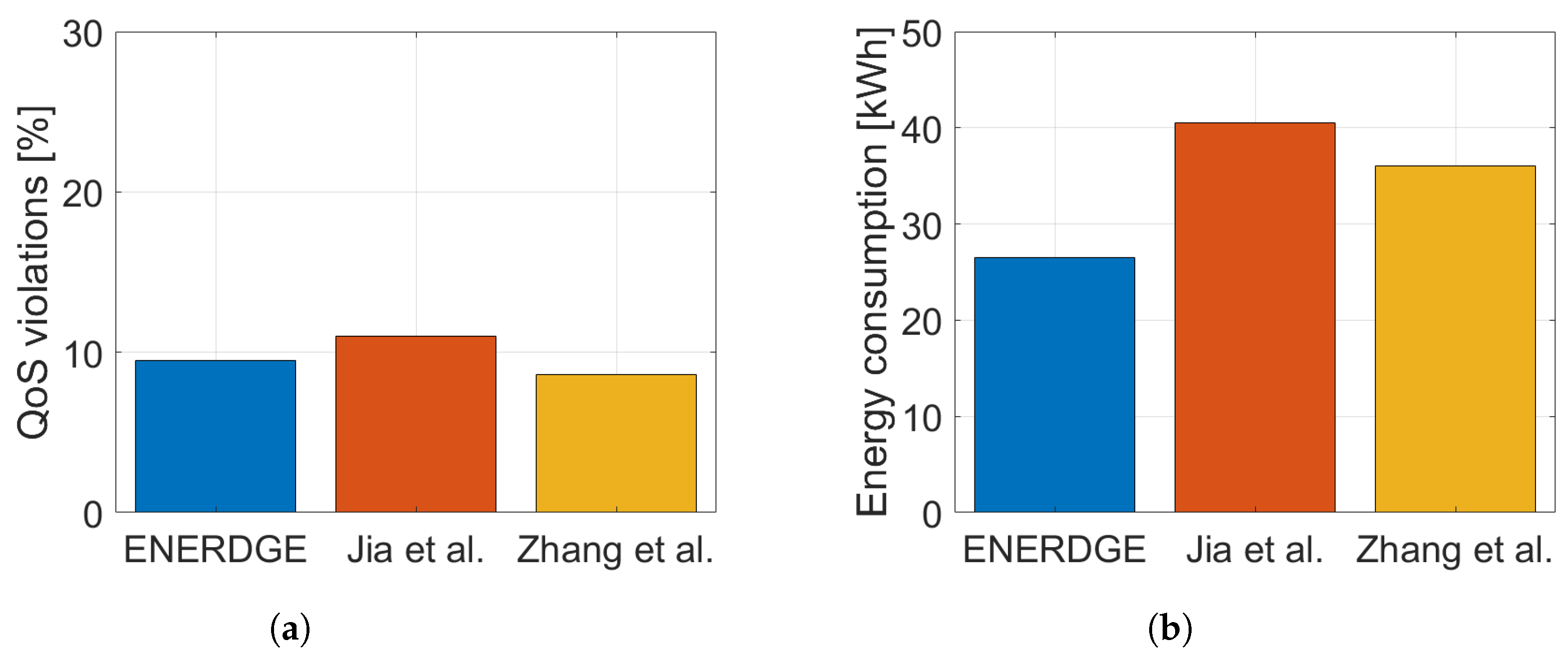
5.3. Two-Stage Approach Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Jeon, Y.; Baek, H.; Pack, S. Mobility-aware optimal task offloading in distributed edge computing. In Proceedings of the 2021 International Conference on Information Networking (ICOIN), Jeju Island, Korea, 13–16 January 2021; pp. 65–68. [Google Scholar]
- Bebortta, S.; Senapati, D.; Panigrahi, C.R.; Pati, B. An adaptive performance modeling framework for QoS-aware offloading in MEC-based IIoT systems. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Sahni, Y.; Cao, J.; Zhang, S.; Yang, L. Edge mesh: A new paradigm to enable distributed intelligence in internet of things. IEEE Access 2017, 5, 16441–16458. [Google Scholar] [CrossRef]
- Li, S.; Zhang, N.; Lin, S.; Kong, L.; Katangur, A.; Khan, M.K.; Ni, M.; Zhu, G. Joint admission control and resource allocation in edge computing for internet of things. IEEE Netw. 2018, 32, 72–79. [Google Scholar] [CrossRef]
- Thai, M.T.; Lin, Y.D.; Lai, Y.C.; Chien, H.T. Workload and capacity optimization for cloud-edge computing systems with vertical and horizontal offloading. IEEE Trans. Netw. Serv. Manag. 2019, 17, 227–238. [Google Scholar] [CrossRef]
- Xia, X.; Chen, F.; He, Q.; Grundy, J.; Abdelrazek, M.; Jin, H. Online collaborative data caching in edge computing. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 281–294. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S. An energy-aware edge server placement algorithm in mobile edge computing. In Proceedings of the 2018 IEEE International Conference on Edge Computing (EDGE), San Francisco, CA, USA, 2–7 July 2018; pp. 66–73. [Google Scholar]
- Daraghmeh, M.; Al Ridhawi, I.; Aloqaily, M.; Jararweh, Y.; Agarwal, A. A power management approach to reduce energy consumption for edge computing servers. In Proceedings of the 2019 Fourth International Conference on Fog and Mobile Edge Computing (FMEC), Rome, Italy, 10–13 June 2019; pp. 259–264. [Google Scholar]
- Avgeris, M.; Spatharakis, D.; Dechouniotis, D.; Kalatzis, N.; Roussaki, I.; Papavassiliou, S. Where there is fire there is smoke: A scalable edge computing framework for early fire detection. Sensors 2019, 19, 639. [Google Scholar] [CrossRef] [Green Version]
- Gambs, S.; Killijian, M.O.; del Prado Cortez, M.N. Next, place prediction using mobility markov chains. In Proceedings of the MPM ’12-First Workshop on Measurement, Privacy, and Mobility, Bern, Switzerland, 10 April 2012; pp. 1–6. [Google Scholar]
- Jia, M.; Liang, W.; Xu, Z.; Huang, M. Cloudlet load balancing in wireless metropolitan area networks. In Proceedings of the IEEE INFOCOM 2016-The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Zhang, F.; Deng, R.; Zhao, X.; Wang, M.M. Load Balancing for Distributed Intelligent Edge Computing: A State-based Game Approach. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 1066–1077. [Google Scholar] [CrossRef]
- Guo, J.; Song, Z.; Cui, Y.; Liu, Z.; Ji, Y. Energy-efficient resource allocation for multi-user mobile edge computing. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–7. [Google Scholar]
- Saeik, F.; Avgeris, M.; Spatharakis, D.; Santi, N.; Dechouniotis, D.; Violos, J.; Leivadeas, A.; Athanasopoulos, N.; Mitton, N.; Papavassiliou, S. Task offloading in Edge and Cloud Computing: A survey on mathematical, artificial intelligence and control theory solutions. Comput. Netw. 2021, 195, 108177. [Google Scholar] [CrossRef]
- Dechouniotis, D.; Athanasopoulos, N.; Leivadeas, A.; Mitton, N.; Jungers, R.M.; Papavassiliou, S. Edge Computing Resource Allocation for Dynamic Networks: The DRUID-NET Vision and Perspective. Sensors 2020, 20, 2191. [Google Scholar] [CrossRef]
- Wang, L.; Jiao, L.; Li, J.; Mühlhäuser, M. Online resource allocation for arbitrary user mobility in distributed edge clouds. In Proceedings of the ICDCS 2017—The 37th IEEE International Conference on Distributed Computing Systems, Atlanta, GA, USA, 5–8 June 2017; pp. 1281–1290. [Google Scholar]
- Puliafito, C.; Mingozzi, E.; Vallati, C.; Longo, F.; Merlino, G. Companion fog computing: Supporting things mobility through container migration at the edge. In Proceedings of the IEEE SMARTCOMP 2018—The 4th IEEE International Conference on Smart Computing, Taormina, Italy, 18–20 June 2018; pp. 97–105. [Google Scholar]
- Labriji, I.; Meneghello, F.; Cecchinato, D.; Sesia, S.; Perraud, E.; Strinati, E.C.; Rossi, M. Mobility aware and dynamic migration of MEC services for the Internet of Vehicles. IEEE Trans. Netw. Serv. Manag. 2021, 18, 570–584. [Google Scholar] [CrossRef]
- Plachy, J.; Becvar, Z.; Strinati, E.C. Dynamic resource allocation exploiting mobility prediction in mobile edge computing. In Proceedings of the IEEE PIMRC 2016—27th IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, Valencia, Spain, 4–8 September 2016; pp. 1–6. [Google Scholar]
- Sun, X.; Ansari, N. Adaptive avatar handoff in the cloudlet network. IEEE Trans. Cloud Comput. 2017, 7, 664–676. [Google Scholar] [CrossRef]
- Shi, Y.; Chen, S.; Xu, X. MAGA: A mobility-aware computation offloading decision for distributed mobile cloud computing. IEEE Internet Things J. 2017, 5, 164–174. [Google Scholar] [CrossRef]
- Al-Shuwaili, A.; Simeone, O. Energy-efficient resource allocation for mobile edge computing-based augmented reality applications. IEEE Wirel. Commun. Lett. 2017, 6, 398–401. [Google Scholar] [CrossRef]
- Elgendy, I.A.; Zhang, W.Z.; Zeng, Y.; He, H.; Tian, Y.C.; Yang, Y. Efficient and secure multi-user multi-task computation offloading for mobile-edge computing in mobile IoT networks. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2410–2422. [Google Scholar] [CrossRef]
- Ren, J.; Yu, G.; Cai, Y.; He, Y. Latency optimization for resource allocation in mobile-edge computation offloading. IEEE Trans. Wirel. Commun. 2018, 17, 5506–5519. [Google Scholar] [CrossRef] [Green Version]
- Farris, I.; Militano, L.; Nitti, M.; Atzori, L.; Iera, A. MIFaaS: A mobile-IoT-federation-as-a-service model for dynamic cooperation of IoT cloud providers. Future Gener. Comput. Syst. 2017, 70, 126–137. [Google Scholar] [CrossRef] [Green Version]
- Sonmez, C.; Ozgovde, A.; Ersoy, C. Fuzzy workload orchestration for edge computing. IEEE Trans. Netw. Serv. Manag. 2019, 16, 769–782. [Google Scholar] [CrossRef]
- Jia, M.; Liang, W.; Xu, Z.; Huang, M.; Ma, Y. Qos-aware cloudlet load balancing in wireless metropolitan area networks. IEEE Trans. Cloud Comput. 2018, 8, 623–634. [Google Scholar] [CrossRef] [Green Version]
- Leivadeas, A.; Nilsson Y., T.; Elahi, A.; Keyhanian, A.; Lambadaris, I. Link Adaptation for Fair Coexistence of Wi-Fi and LAA-LTE. In Proceedings of the ACM MobiWac 2018—The 16th ACM International Symposium on Mobility Management and Wireless Access, Montreal, QC, Canada, 28 October–2 November 2018; pp. 43–50. [Google Scholar]
- Erceg, V. IEEE 802.11-03/940r4; IEEE P802.11 Wireless LANs TGn Channel Models; IEEE: Piscataway, NJ, USA, 2004. [Google Scholar]
- Madwifi Project—Minstrel Algorithm. Available online: https://sourceforge.net/p/madwifi/svn/HEAD/tree/madwifi/trunk/ath_rate/minstrel/minstrel.txt (accessed on 8 May 2021).
- Tran, T.X.; Pompili, D. Joint task offloading and resource allocation for multi-server mobile-edge computing networks. IEEE Trans. Veh. Technol. 2018, 68, 856–868. [Google Scholar] [CrossRef] [Green Version]
- Leivadeas, A.; Papagianni, C.; Papavassiliou, S. Going Green with the Networked Cloud: Methodologies and Assessment. In Wiley Quantitative Assessments of Distributed Systems: Methodologies and Techniques; John Wiley & Sons: New York, NY, USA, 2015; pp. 351–374. [Google Scholar]
- Cuervo, E.; Balasubramanian, A.; Cho, D.k.; Wolman, A.; Saroiu, S.; Chandra, R.; Bahl, P. MAUI: Making smartphones last longer with code offload. In Proceedings of the ACM MobiSys 2010—The 8th Annual International Conference on Mobile Systems, Applications, and Services, San Francisco, CA, USA, 15–18 June 2010; pp. 49–62. [Google Scholar]
- Kosta, S.; Aucinas, A.; Hui, P.; Mortier, R.; Zhang, X. Thinkair: Dynamic resource allocation and parallel execution in the cloud for mobile code offloading. In Proceedings of the IEEE INFOCOM 2012—The 31st Annual IEEE International Conference on Computer Communications, Orlando, FL, USA, 25–30 March 2012; pp. 945–953. [Google Scholar]
- Ljung, L. System Identification: Theory for the User; Prentice-Hall: Englewood Cliffs, NJ, USA, 1987. [Google Scholar]
- GLPK (GNU Linear Programming Kit). Available online: https://www.gnu.org/software/glpk/ (accessed on 30 November 2021).
- Beloglazov, A.; Buyya, R.; Lee, Y.C.; Zomaya, A. A taxonomy and survey of energy-efficient data centers and cloud computing systems. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2011; Volume 82, pp. 47–111. [Google Scholar]
- Falkner, M.; Leivadeas, A.; Lambadaris, I.; Kesidis, G. Performance analysis of virtualized network functions on virtualized systems architectures. In Proceedings of the IEEE CAMAD 2016-21st IEEE International Workshop on Computer Aided Modelling and Design of Communication Links and Networks, Toronto, ON, Canada, 23–25 October 2016; pp. 71–76. [Google Scholar]
- Bohnert, F.; Zukerman, I. Personalised viewing-time prediction in museums. User Model.-User-Adapt. Interact. 2014, 24, 263–314. [Google Scholar] [CrossRef]
- Dash, S. Exponential lower bounds on the lengths of some classes of branch-and-cut proofs. Math. Oper. Res. 2005, 30, 678–700. [Google Scholar] [CrossRef] [Green Version]
- Kindermann, R.; Snell, J.L. Markov random fields and their applications. Am. Math. Soc. 1980, 1. [Google Scholar]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, PAMI-6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Silva Filho, M.C.; Oliveira, R.L.; Monteiro, C.C.; Inácio, P.R.; Freire, M.M. CloudSim plus: A cloud computing simulation framework pursuing software engineering principles for improved modularity, extensibility and correctness. In Proceedings of the IFIP/IEEE IM 2017—The 15th IFIP/IEEE International Symposium on Integrated Network Management, Lisbon, Portugal, 8–12 May 2017; pp. 400–406. [Google Scholar]
- Cao, J.; Zhao, Y.; Lai, X.; Ong, M.E.H.; Yin, C.; Koh, Z.X.; Liu, N. Landmark recognition with sparse representation classification and extreme learning machine. J. Frankl. Inst. 2015, 352, 4528–4545. [Google Scholar] [CrossRef]
- Chen, Z.; Hu, W.; Wang, J.; Zhao, S.; Amos, B.; Wu, G.; Ha, K.; Elgazzar, K.; Pillai, P.; Klatzky, R.; et al. An empirical study of latency in an emerging class of edge computing applications for wearable cognitive assistance. In Proceedings of the SEC ’17—The Second ACM/IEEE Symposium on Edge Computing, San Jose, CA, USA, 12–14 October 2017; pp. 1–14. [Google Scholar]
- Le Tan, C.N.; Klein, C.; Elmroth, E. Location-aware load prediction in edge data centers. In Proceedings of the IEEE FMEC 2017-The 2nd International Conference on Fog and Mobile Edge Computing, Valencia, Spain, 8–11 May 2017; pp. 25–31. [Google Scholar]
- Jin, C.; Bai, X.; Yang, C.; Mao, W.; Xu, X. A review of power consumption models of servers in data centers. Appl. Energy 2020, 265, 114806. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Interpretation |
|---|---|
| Site k | |
| S | Set of sites, sites in total |
| M | Number of applications |
| Acceptable response time for App. m | |
| VM flavor of application m | |
| Cores requested by VM flavor | |
| Throughput guaranteed by VM flavor | |
| Server’s CPU capacity | |
| Server’s power consumption | |
| Server’s max. power consumption | |
| Power consumption of VM flavor | |
| A feasible VM formation | |
| Set of feasible VM formations at site | |
| N | Size of VM formation |
| Servers’ CPU cores threshold at site | |
| Edge infrastructure’s power consumption | |
| Power consumption of site | |
| Number of servers with VM formation | |
| Number of available servers in site | |
| Power consumption of VM formation | |
| Max. workload served by VM formation | |
| Predicted workload for site | |
| Neighborhood of site | |
| Excess workload for App. m at site | |
| Number of servers of type i at site | |
| Power consumption of | |
| Random field | |
| MRF potential function | |
| Properly selected MRF constants | |
| L, K, | Parameters of reflected sigmoid function |
| t | Visiting epoch of MRF |
| w | MRF sweep index |
| MRF temperature at sweep w |
| Server () | App1 VMs | App2 VMs |
|---|---|---|
| 1 | 1 × medium | 1 × small |
| 2 | 1 × medium | 1 × small |
| 3 | 1 × medium | - |
| Site Workload Capacity | 81 | 82 |
| Flavor | Small | Medium | Large | |||
|---|---|---|---|---|---|---|
| App1 | App2 | App1 | App2 | App1 | App2 | |
| Cores | 1 | 1 | 2 | 2 | 4 | 4 |
| QoS (s) | 3 | 3 | 3 | 3 | 3 | 3 |
| Maximum Requests/Slot | 11 | 38 | 27 | 82 | 59 | 173 |
| Server | App1 VMs | App2 VMs | Allocated Cores |
|---|---|---|---|
| 1 | 1 × small | 1 × medium | 3 |
| 2 | 1 × small | 1 × medium | 3 |
| 3 | - | 1 × small | 1 |
| Site Workload Capacity | 22 | 202 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Avgeris, M.; Spatharakis, D.; Dechouniotis, D.; Leivadeas, A.; Karyotis, V.; Papavassiliou, S. ENERDGE: Distributed Energy-Aware Resource Allocation at the Edge. Sensors 2022, 22, 660. https://doi.org/10.3390/s22020660
Avgeris M, Spatharakis D, Dechouniotis D, Leivadeas A, Karyotis V, Papavassiliou S. ENERDGE: Distributed Energy-Aware Resource Allocation at the Edge. Sensors. 2022; 22(2):660. https://doi.org/10.3390/s22020660
Chicago/Turabian StyleAvgeris, Marios, Dimitrios Spatharakis, Dimitrios Dechouniotis, Aris Leivadeas, Vasileios Karyotis, and Symeon Papavassiliou. 2022. "ENERDGE: Distributed Energy-Aware Resource Allocation at the Edge" Sensors 22, no. 2: 660. https://doi.org/10.3390/s22020660
APA StyleAvgeris, M., Spatharakis, D., Dechouniotis, D., Leivadeas, A., Karyotis, V., & Papavassiliou, S. (2022). ENERDGE: Distributed Energy-Aware Resource Allocation at the Edge. Sensors, 22(2), 660. https://doi.org/10.3390/s22020660