






Camera Motion Agnostic Method for Estimating 3D Human Poses


Abstract
:1. Introduction
- We propose a deep learning-based framework for predicting a pure human pose independent of camera motion. We demonstrate that it is possible to estimate the human pose sequence in the world coordinate system without camera calibration from a video including camera motion.
- We propose a model based on gated recurrent units (GRUs) [22] that transforms the local human pose sequence into the global motion sequence invariant to the selection of the reference coordinate system. The proposed model can be combined with any human pose estimation method that predicts local human poses.
- We propose new metrics for the evaluation of the proposed method. Moreover, we train the proposed model for various input/output rotation representations and rotation loss functions and quantitatively compare them using the proposed evaluation metrics to determine the optimal rotation representation and loss function.
2. Related Works
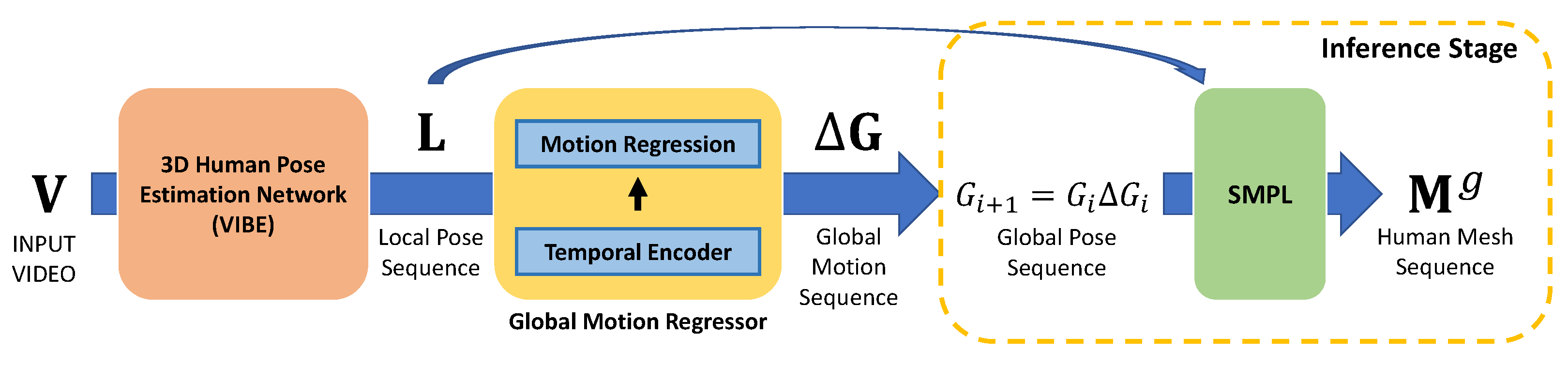
3. Proposed Method
3.1. Overall Approach
3.2. SMPL Representation
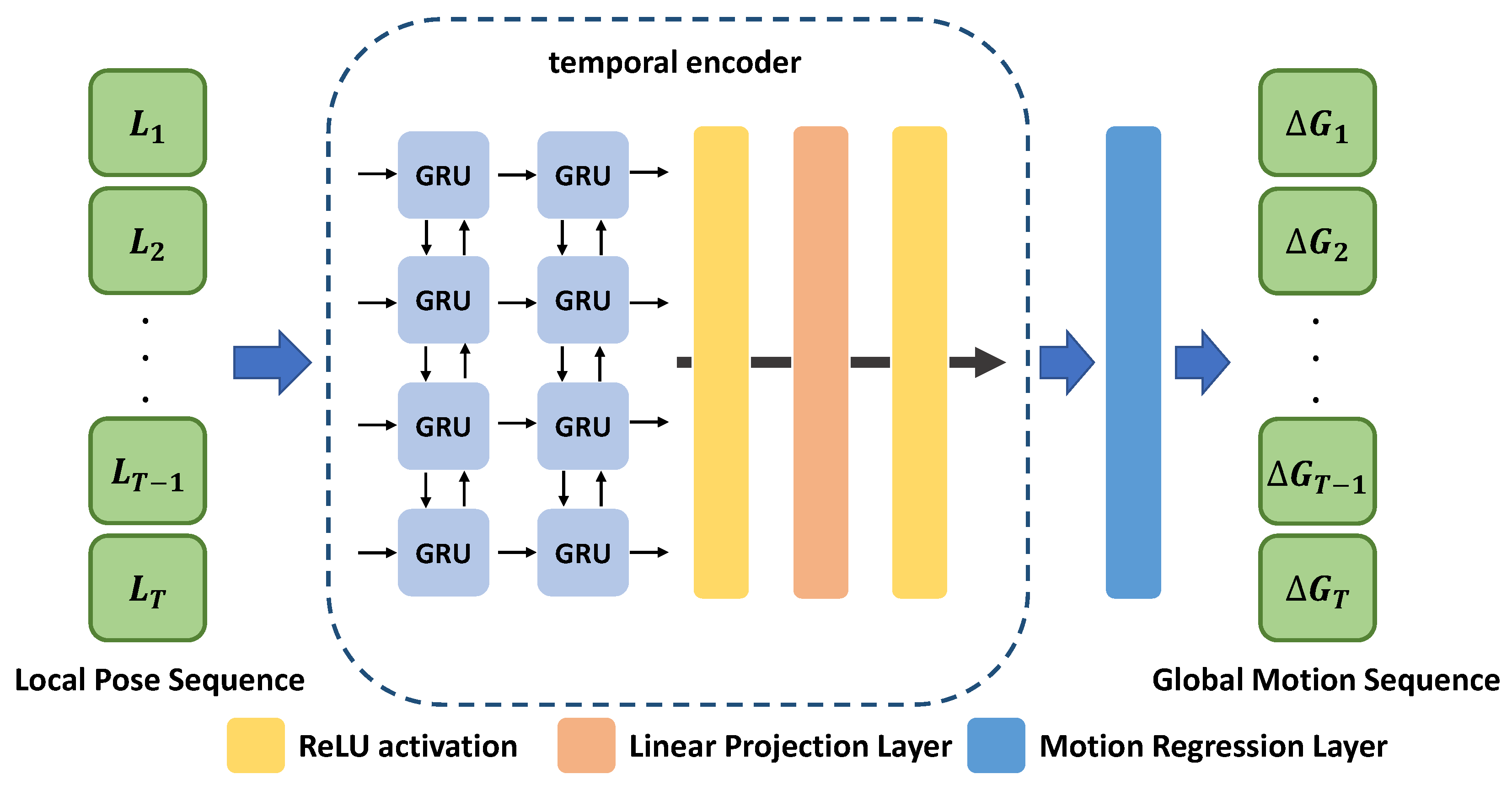
3.3. Global Motion Regressor (GMR)
3.4. Loss Function
3.5. Flip Augmentation
3.6. Inference
4. Experimental Results
4.1. Implementation Details
4.2. Datasets
4.3. Evaluation Metrics
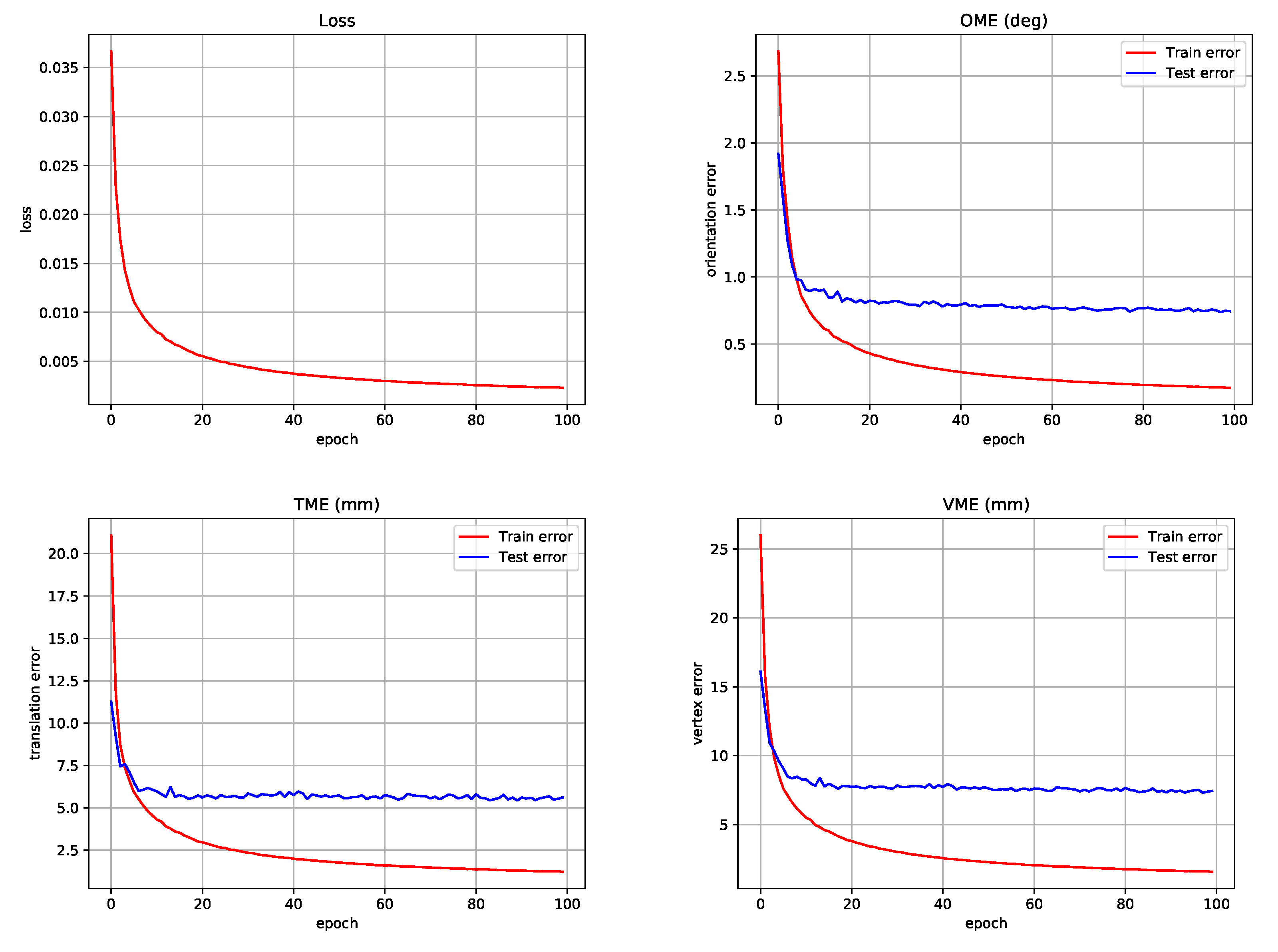
4.4. Ablation Experiments
4.5. Comparison with Existing Method
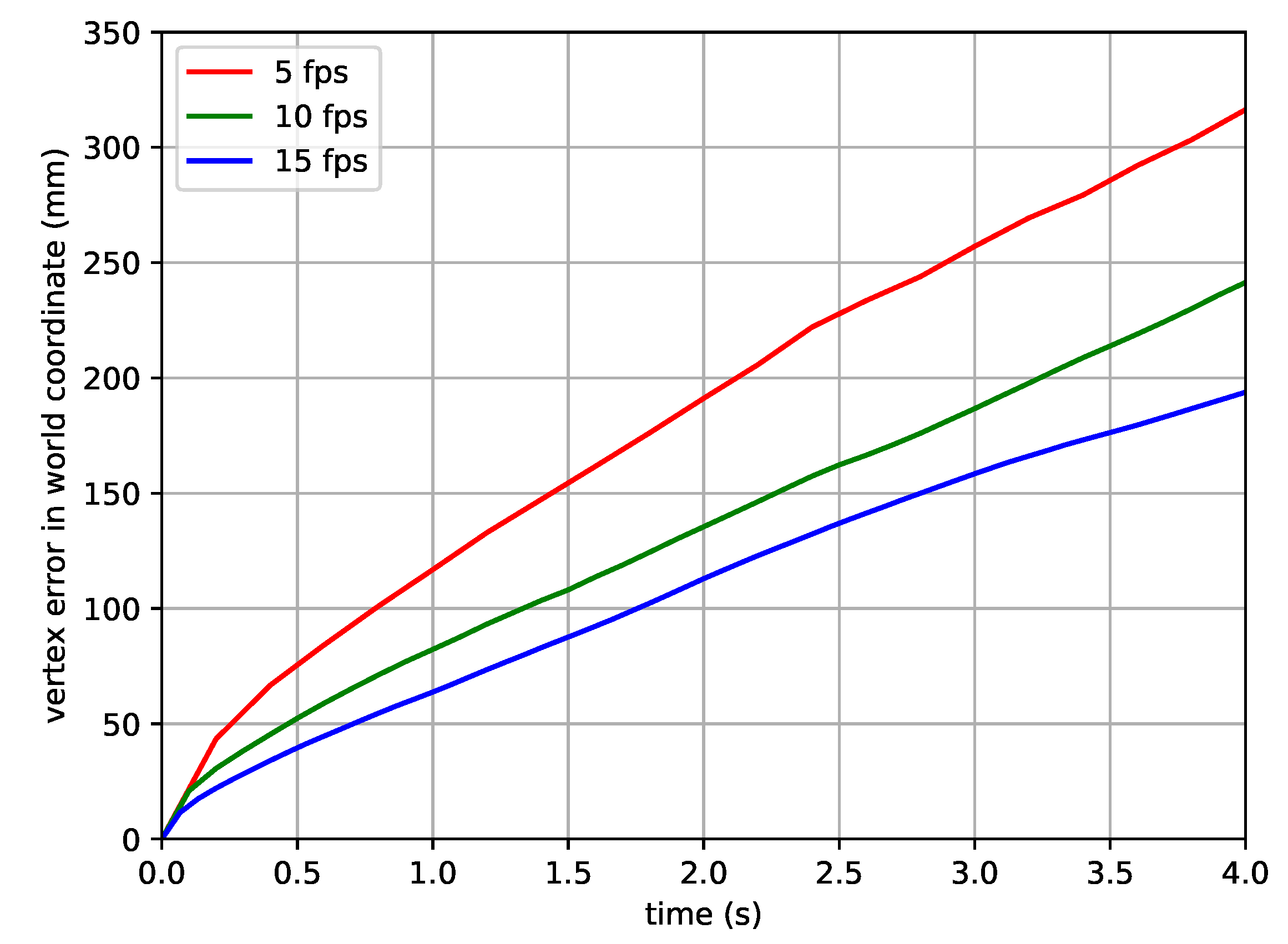
4.6. Limitation of Proposed Method
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, Y.; Bogo, F.; Lassner, C.; Kanazawa, A.; Gehler, P.V.; Romero, J.; Akhter, I.; Black, M.J. Towards accurate marker-less human shape and pose estimation over time. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-fine volumetric prediction for single-image 3D human pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3d human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-end recovery of human shape and pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kolotouros, N.; Pavlakos, G.; Black, M.J.; Daniilidis, K. Learning to reconstruct 3D human pose and shape via model-fitting in the loop. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Kocabas, M.; Karagoz, S.; Akbas, E. Self-supervised learning of 3d human pose using multi-view geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Guler, R.A.; Kokkinos, I. Holopose: Holistic 3D human reconstruction in-the-wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Kolotouros, N.; Pavlakos, G.; Daniilidis, K. Convolutional mesh regression for single-image human shape reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Moon, G.; Lee, K.M. I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Kocabas, M.; Athanasiou, N.; Black, M.J. Vibe: Video inference for human body pose and shape estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Loper, M.; Mahmood, N.; Black, M.J. MoSh: Motion and shape capture from sparse markers. ACM TOG 2014, 33, 220. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Liu, B.; Wang, R.; Ye, Y.; Twigg, C.D.; Kin, K. Online optical marker-based hand tracking with deep labels. ACM TOG 2018, 37, 166. [Google Scholar] [CrossRef] [Green Version]
- Haque, A.; Peng, B.; Luo, Z.; Alahi, A.; Yeung, S.; Fei-Fei, L. Towards viewpoint invariant 3D human pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 160–177. [Google Scholar]
- von Marcard, T.; Henschel, R.; Black, M.J.; Rosenhahn, B.; Pons-Moll, G. Recovering accurate 3D human pose in the wild using imus and a moving camera. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Habermann, M.; Xu, W.; Zollhofer, M.; Pons-Moll, G.; Theobalt, C. Deepcap: Monocular human performance capture using weak supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Raaj, Y.; Idrees, H.; Hidalgo, G.; Sheikh, Y. Efficient online multi-person 2D pose tracking with recurrent spatio-temporal affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM TOG 2015, 34, 248. [Google Scholar] [CrossRef]
- Pavlakos, G.; Zhu, L.; Zhou, X.; Daniilidis, K. Learning to estimate 3D human pose and shape from a single color image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Luo, Z.; Golestaneh, S.A.; Kitani, K.M. 3D Human motion estimation via motion compression and refinement. In Proceedings of the Asian Conference on Computer Vision (ACCV), Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Mahmood, N.; Ghorbani, N.; Troje, N.F.; Pons-Moll, G.; Black, M.J. AMASS: Archive of motion capture as surface shapes. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef]
- Omran, M.; Lassner, C.; Pons-Moll, G.; Gehler, P.; Schiele, B. Neural body fitting: Unifying deep learning and model based human pose and shape estimation. In Proceedings of the International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018. [Google Scholar]
- Kocabas, M.; Huang, C.H.P.; Hilliges, O.; Black, M.J. PARE: Part attention regressor for 3D human body estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Bogo, F.; Kanazawa, A.; Lassner, C.; Gehler, P.; Romero, J.; Black, M.J. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Varol, G.; Ceylan, D.; Russell, B.; Yang, J.; Yumer, E.; Laptev, I.; Schmid, C. Bodynet: Volumetric inference of 3D human body shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, K.; Wang, L.; Liu, Z. End-to-end human pose and mesh reconstruction with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Lin, K.; Wang, L.; Liu, Z. Mesh graphormer. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Kanazawa, A.; Zhang, J.Y.; Felsen, P.; Malik, J. Learning 3D human dynamics from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Arnab, A.; Doersch, C.; Zisserman, A. Exploiting temporal context for 3D human pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sun, Y.; Ye, Y.; Liu, W.; Gao, W.; Fu, Y.; Mei, T. Human mesh recovery from monocular images via a skeleton-disentangled representation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Choi, H.; Moon, G.; Chang, J.Y.; Lee, K.M. Beyond static features for temporally consistent 3D human pose and shape from a video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Wan, Z.; Li, Z.; Tian, M.; Liu, J.; Yi, S.; Li, H. Encoder-decoder with multi-level attention for 3D human shape and pose estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Gallego, G.; Yezzi, A. A compact formula for the derivative of a 3-D rotation in exponential coordinates. J. Math. Imaging Vis. 2015, 51, 378–384. [Google Scholar] [CrossRef] [Green Version]
- Hartley, R.; Trumpf, J.; Dai, Y.; Li, H. Rotation averaging. Int. J. Comput. Vis. 2013, 103, 267–305. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- De la Torre, F.; Hodgins, J.; Bargteil, A.; Martin, X.; Macey, J.; Collado, A.; Beltran, P. Guide to the Carnegie Mellon University Multimodal Activity (CMU-MMAC) Database; Robotics Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 2008. [Google Scholar]
- Trumble, M.; Gilbert, A.; Malleson, C.; Hilton, A.; Collomosse, J.P. Total capture: 3D human pose estimation fusing video and inertial sensors. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6m: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Barnes, C.; Lu, J.; Yang, J.; Li, H. On the continuity of rotation representations in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Mehta, D.; Rhodin, H.; Casas, D.; Fua, P.; Sotnychenko, O.; Xu, W.; Theobalt, C. Monocular 3D human pose estimation in the wild using improved cnn supervision. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.; Tzionas, D.; Black, M.J. Expressive body capture: 3D hands, face, and body from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Strasdat, H.; Davison, A.J.; Montiel, J.M.; Konolige, K. Double window optimisation for constant time visual SLAM. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Li, Z.; Dekel, T.; Cole, F.; Tucker, R.; Snavely, N.; Liu, C.; Freeman, W.T. Learning the depths of moving people by watching frozen people. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence Name | Frame Range | Camera Motion Type |
|---|---|---|
| courtyard_basketball_00 | 00000.jpg–00467.jpg | Small |
| courtyard_basketball_01 | 00000.jpg–00957.jpg | Small |
| courtyard_bodyScannerMotions_00 | 00000.jpg–01256.jpg | Small |
| courtyard_box_00 | 00000.jpg–01040.jpg | Small |
| courtyard_captureSelfies_00 | 00300.jpg–00696.jpg | Small |
| courtyard_golf_00 | 00000.jpg–00603.jpg | Small |
| courtyard_rangeOfMotions_00 | 00000.jpg–00600.jpg | Small |
| courtyard_rangeOfMotions_01 | 00000.jpg–00586.jpg | Small |
| downtown_arguing_00 | 00000.jpg–00897.jpg | Small |
| downtown_crossStreets_00 | 00000.jpg–00587.jpg | Panning |
| downtown_runForBus_00 | 00000.jpg–00207.jpg | Linear |
| downtown_sitOnStairs_00 | 00000.jpg–00477.jpg | Linear & Panning |
| downtown_walkBridge_01 | 00042.jpg–00234.jpg | Panning |
| downtown_walkDownhill_00 | 00132.jpg–00435.jpg | Panning |
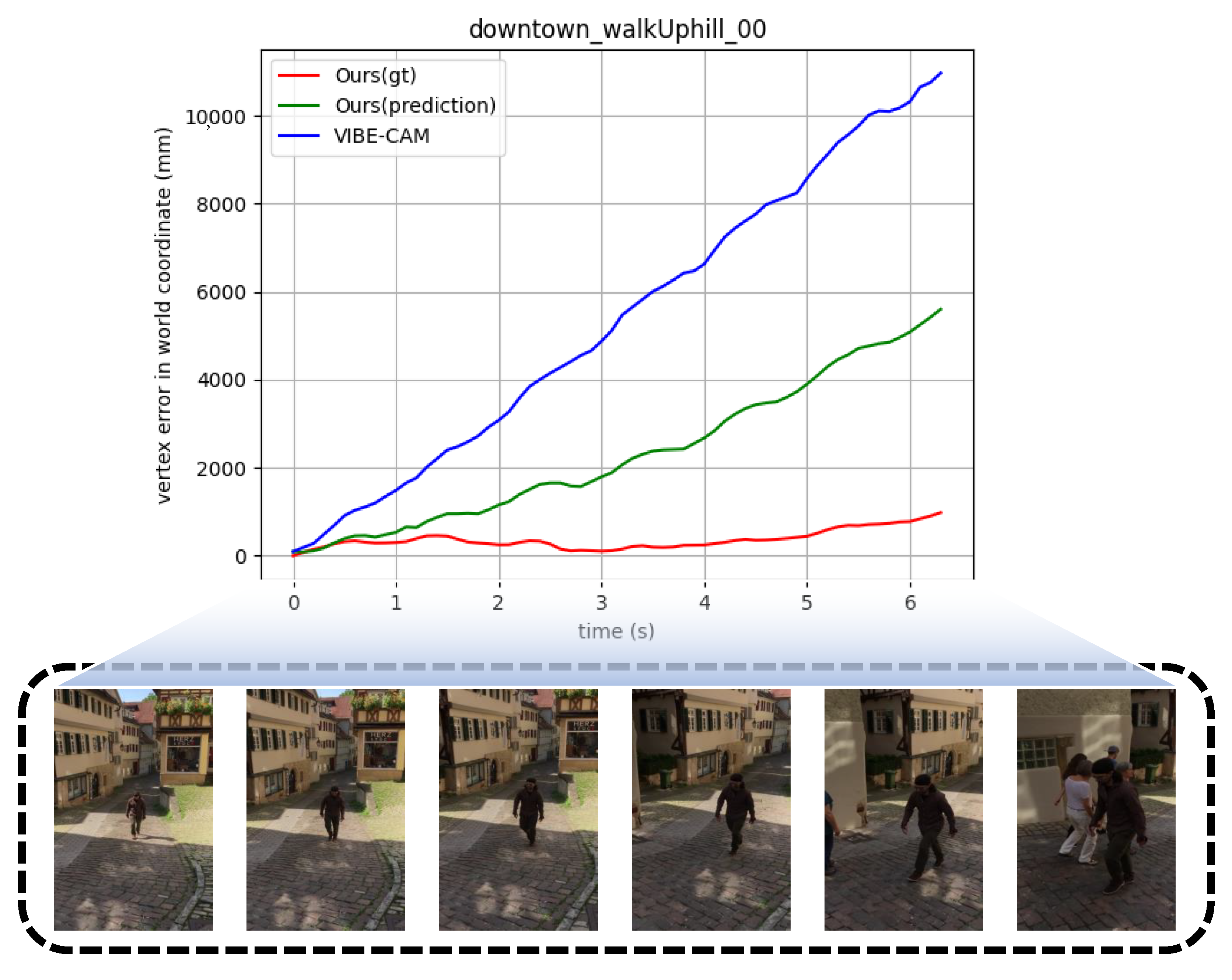
| downtown_walkUphill_00 | 00000.jpg–00285.jpg | Panning |
| downtown_windowShopping_00 | 00048.jpg–00327.jpg | Panning |
| downtown_windowShopping_00 | 00972.jpg–01542.jpg | Linear |
| In/Out | Axis-Angle | 6D | Quaternion |
|---|---|---|---|
| Axis-angle | 10.48 | 10.83 | 11.15 |
| 6D | 9.83 | 10.07 | 10.14 |
| Quaternion | 9.46 | 9.48 | 9.91 |
| Loss Type | OME | TME | VME |
|---|---|---|---|
| Axis-angle | 1.05 | 6.98 | 9.51 |
| Angular | 1.06 | 7.03 | 9.46 |
| Chordal | 1.01 | 6.82 | 9.28 |
| Losses | OME | TME | VME |
|---|---|---|---|
| V | 1.02 | 7.01 | 9.46 |
| V+O | 0.99 | 7.05 | 9.34 |
| V+O+S | 1.03 | 6.88 | 9.31 |
| V+O+S+T | 1.01 | 6.82 | 9.28 |
| Layers/Hidden Units | 512 | 1024 | 2048 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| OME | TME | VME | OME | TME | VME | OME | TME | VME | |
| 2 | 1.01 | 6.82 | 9.28 | 0.93 | 6.33 | 8.56 | 0.85 | 5.92 | 7.92 |
| 3 | 0.92 | 6.28 | 8.58 | 0.86 | 5.91 | 7.96 | 0.79 | 5.56 | 7.47 |
| 4 | 0.85 | 5.70 | 7.74 | 0.80 | 5.48 | 7.37 | 0.76 | 5.14 | 7.01 |
| OME | TME | VME | |
|---|---|---|---|
| w/o flip augmentation | 0.76 | 5.14 | 7.01 |
| w/ flip augmentation | 0.70 | 4.78 | 6.47 |
| Method | OME | TME | VME |
|---|---|---|---|
| Non-sequential | 3.90 | 45.48 | 126.83 |
| Ours | 3.67 | 38.55 | 120.37 |
| Method | OME | TME | VME |
|---|---|---|---|
| VIBE-CAM | 3.88 | 49.83 | 127.07 |
| Ours | 3.67 | 38.55 | 120.37 |
| Ours(GT input) | 1.60 | 27.55 | 29.39 |
| Camera-Motion-Off | Camera-Motion-On | |||||
|---|---|---|---|---|---|---|
| Method | OME | TME | VME | OME | TME | VME |
| VIBE-CAM | 3.77 | 58.01 | 117.28 | 4.66 | 81.70 | 132.63 |
| Ours | 3.80 | 36.37 | 105.11 | 4.01 | 39.27 | 108.08 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.H.; Jeong, S.; Park, S.; Chang, J.Y. Camera Motion Agnostic Method for Estimating 3D Human Poses. Sensors 2022, 22, 7975. https://doi.org/10.3390/s22207975
Kim SH, Jeong S, Park S, Chang JY. Camera Motion Agnostic Method for Estimating 3D Human Poses. Sensors. 2022; 22(20):7975. https://doi.org/10.3390/s22207975
Chicago/Turabian StyleKim, Seong Hyun, Sunwon Jeong, Sungbum Park, and Ju Yong Chang. 2022. "Camera Motion Agnostic Method for Estimating 3D Human Poses" Sensors 22, no. 20: 7975. https://doi.org/10.3390/s22207975
APA StyleKim, S. H., Jeong, S., Park, S., & Chang, J. Y. (2022). Camera Motion Agnostic Method for Estimating 3D Human Poses. Sensors, 22(20), 7975. https://doi.org/10.3390/s22207975