
The TinyV3RSE Hardware-in-the-Loop Vision-Based Navigation Facility



Abstract
:1. Introduction
2. Notation
- Two- and three-dimensional vectors are denoted, respectively, with lower- and upper-case bold text, such as and .
- Matrices are in plain text in brackets, such as .
- Vector initialization is performed with parentheses, such as .
- is the 3D reference frame centered in the 3D point a with axes , , and . All the reference frames are right-handed and orthonormal.
- The rotation matrix from to is . All rotations have a passive function.
- The 3D vector from s to c is labeled and, when expressed in the reference frame, is denoted .
- is the a 2D reference frame centered in the 2D point A with axes and which are orthonormal.
- The homography matrix from to is .
- The 2D vector from S to C is labeled and, when expressed in the reference frame, is denoted .
- The 3D vector in homogeneous form is labeled and the 2D vector in homogeneous form is labeled .
- Projection of the 3D vector on the 2D image is labeled .
- The identity matrix of dimension n is labeled . The zero matrix is labeled while the zero n-dimensional vector is labeled .
3. Hardware-in-the-Loop Facilities for Space Navigation
3.1. Generalities on Hardware-in-the-Loop Facilities
3.2. Past Work on Optical Facilities
4. Facility Design and Performances
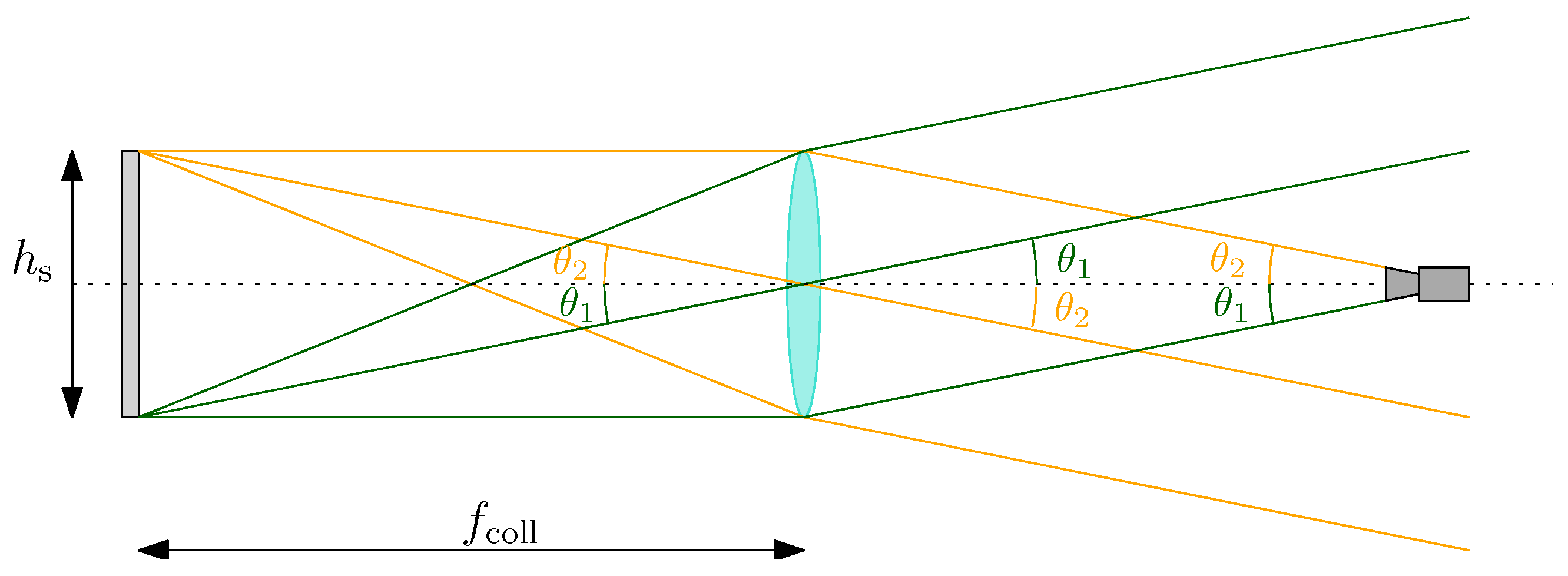
4.1. Design Drivers
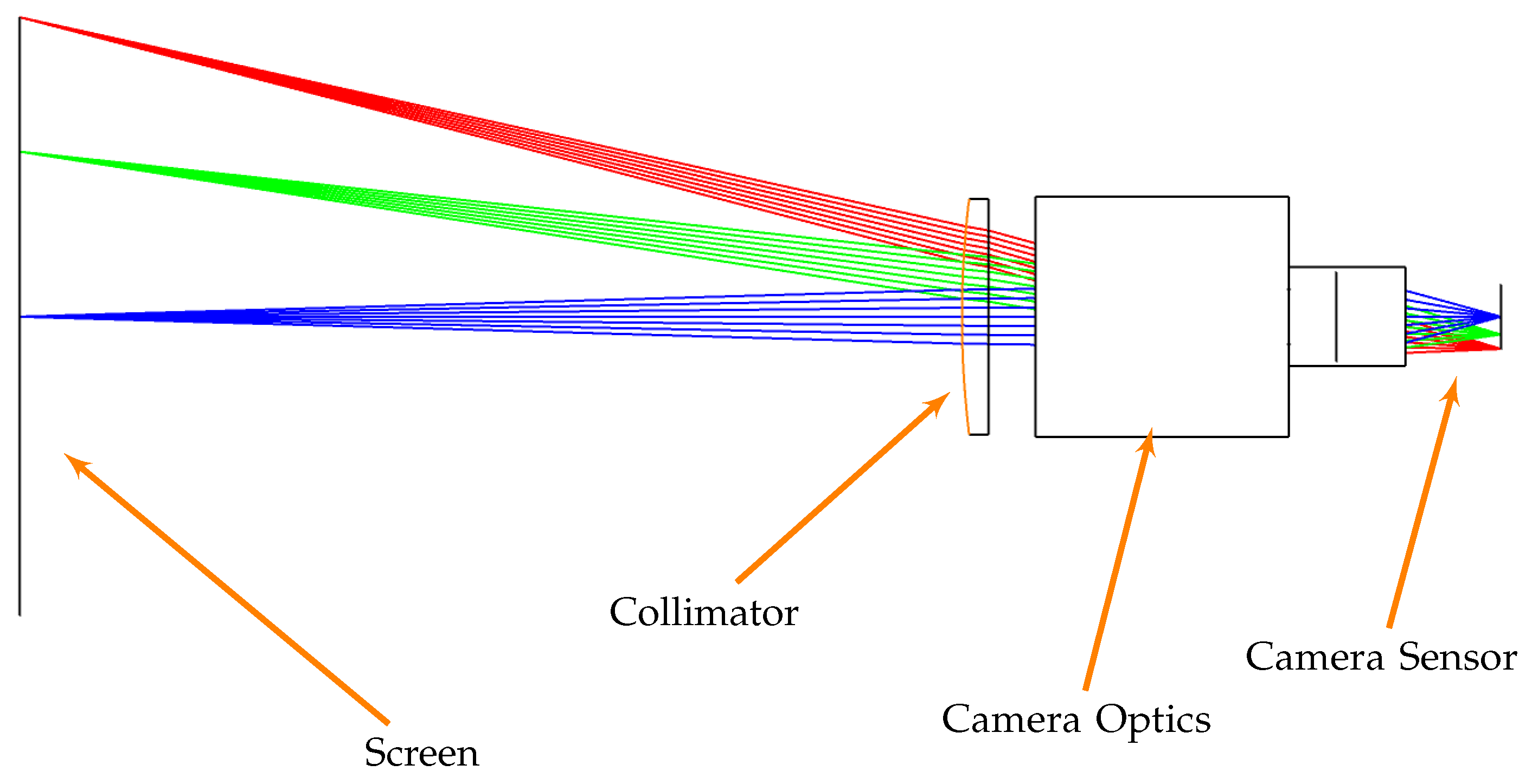
4.2. Components Selection
- The camera assembly composed of the camera interface and its mechanical support that enables vertical translation, pitch, and yaw mechanical adjustments;
- The high-resolution screen assembly composed of the screen and its support, whose orientation is set to ensure that the screen and the optical plane of the camera are parallel;
- The collimator assembly composed of the collimating lens and its support. The collimator support comprises an optical holder that can rotate, change the height, and can be finely adjusted laterally and transversely.
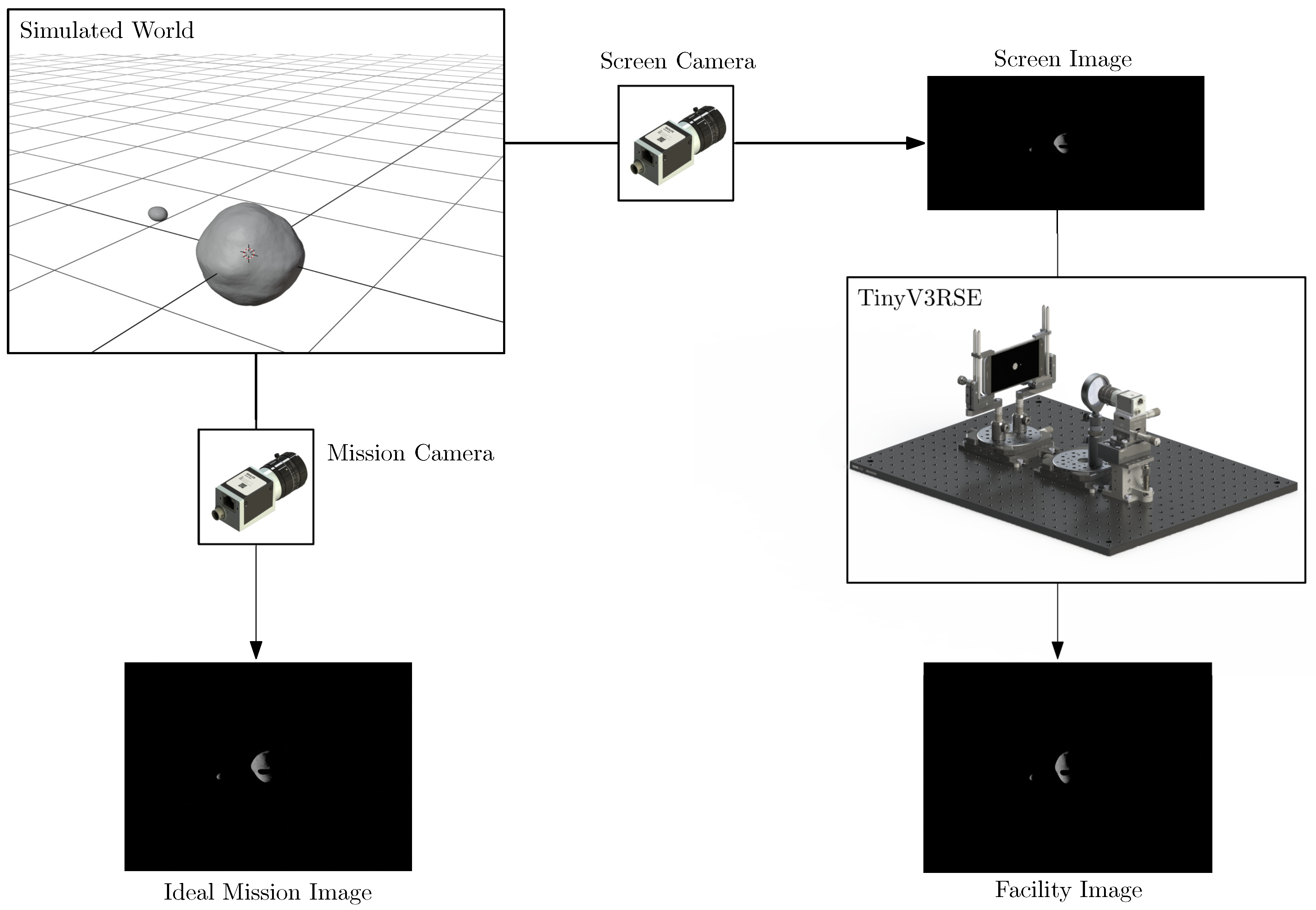
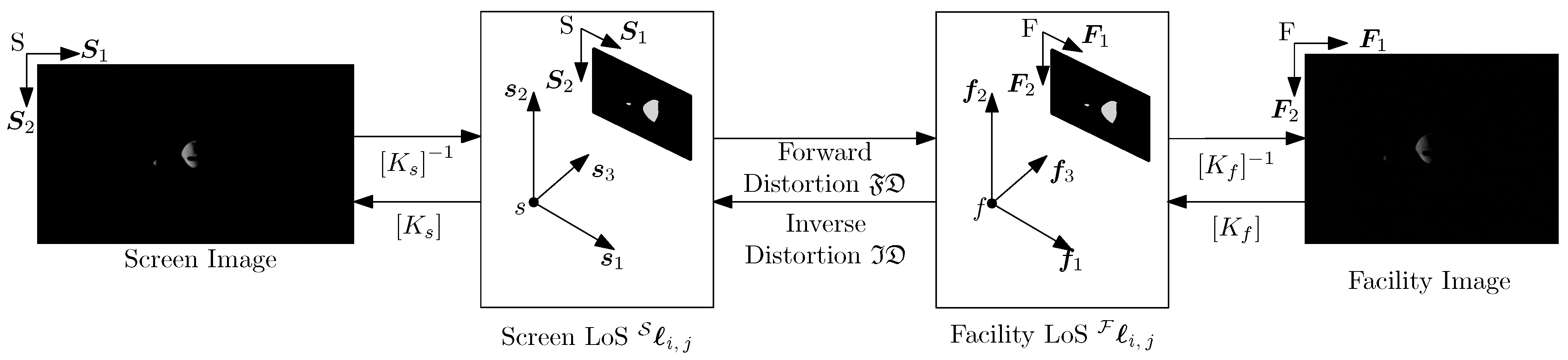
4.3. Functional Workflow
- The ideal mission image, which is the image that would be acquired by the modeled camera, labeled mission camera, in the virtual world.
- The screen image, which is acquired from the virtual world to be displayed on the screen. The camera rendering this image is labeled screen camera and is defined to match the screen resolution by keeping the FoV equal to the mission camera.
- The facility image, which is the image acquired in the facility by stimulating the facility camera.
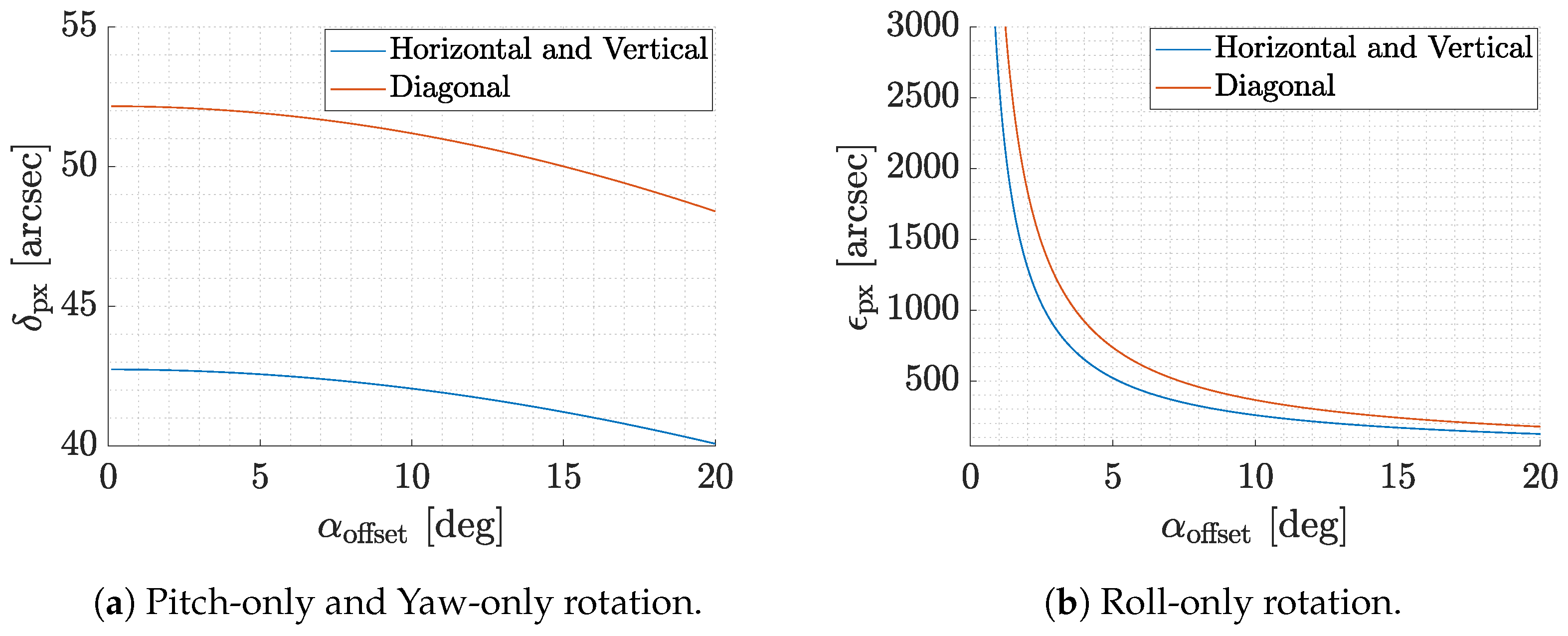
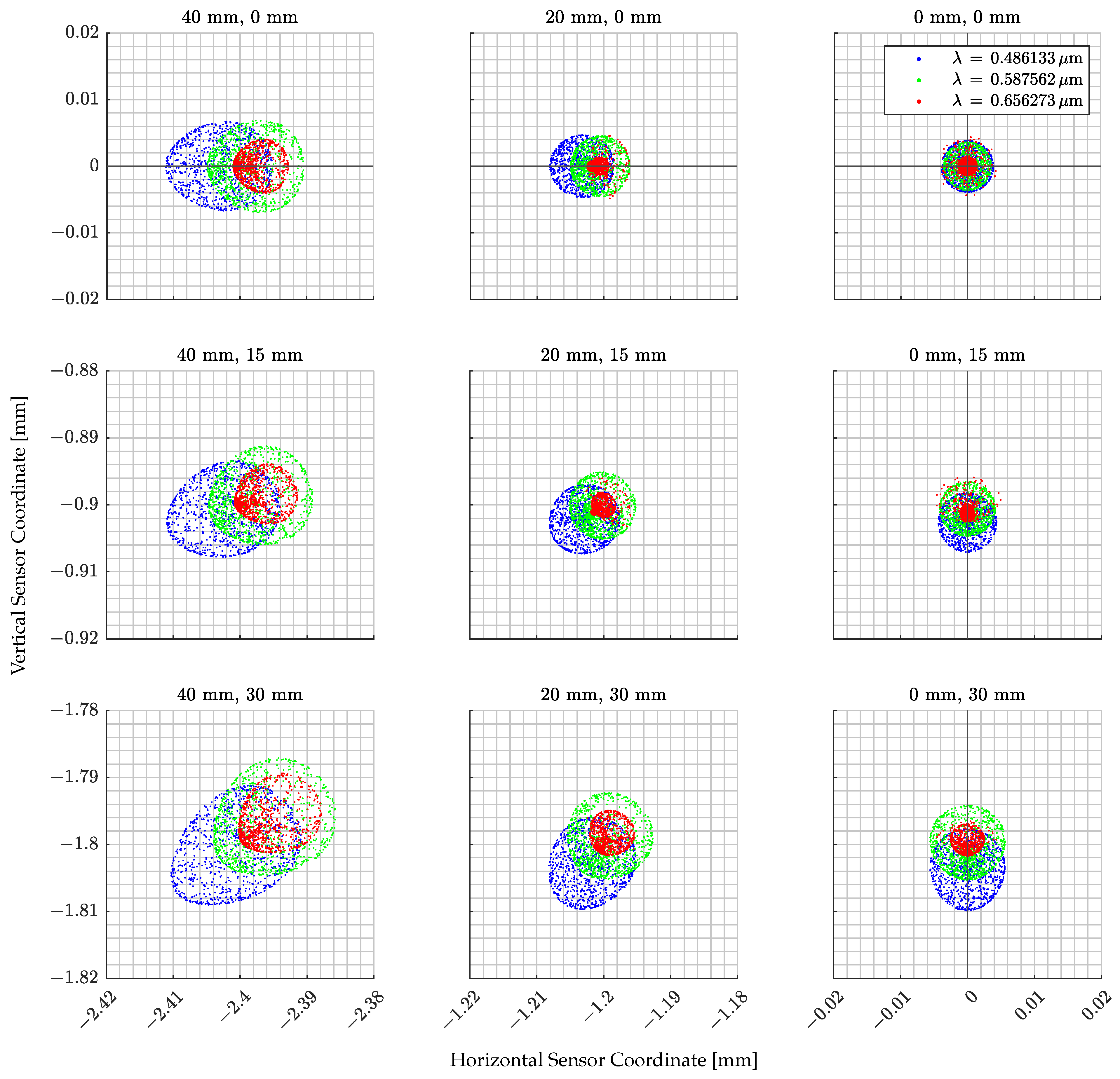
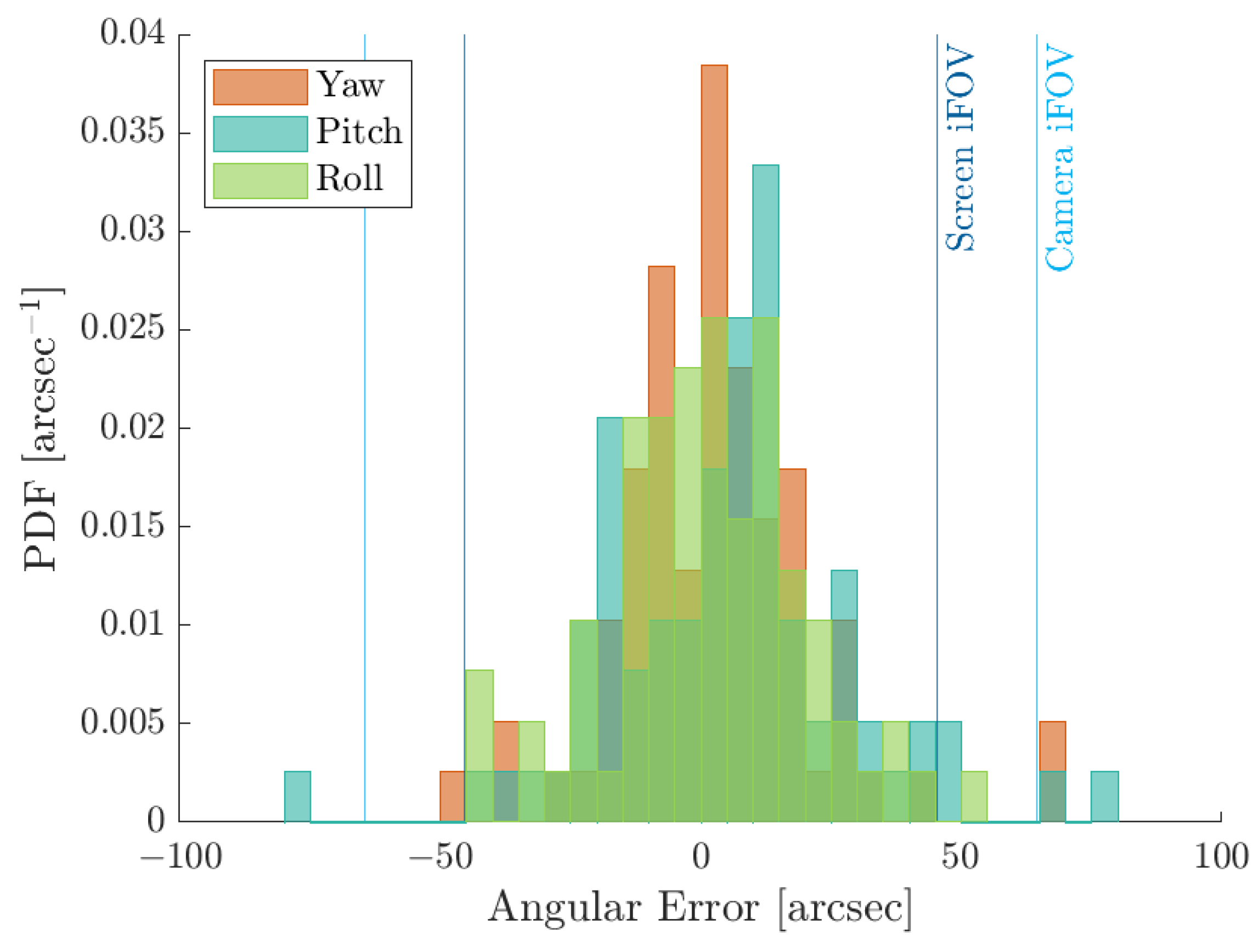
4.4. Achievable Performances with Selected Hardware
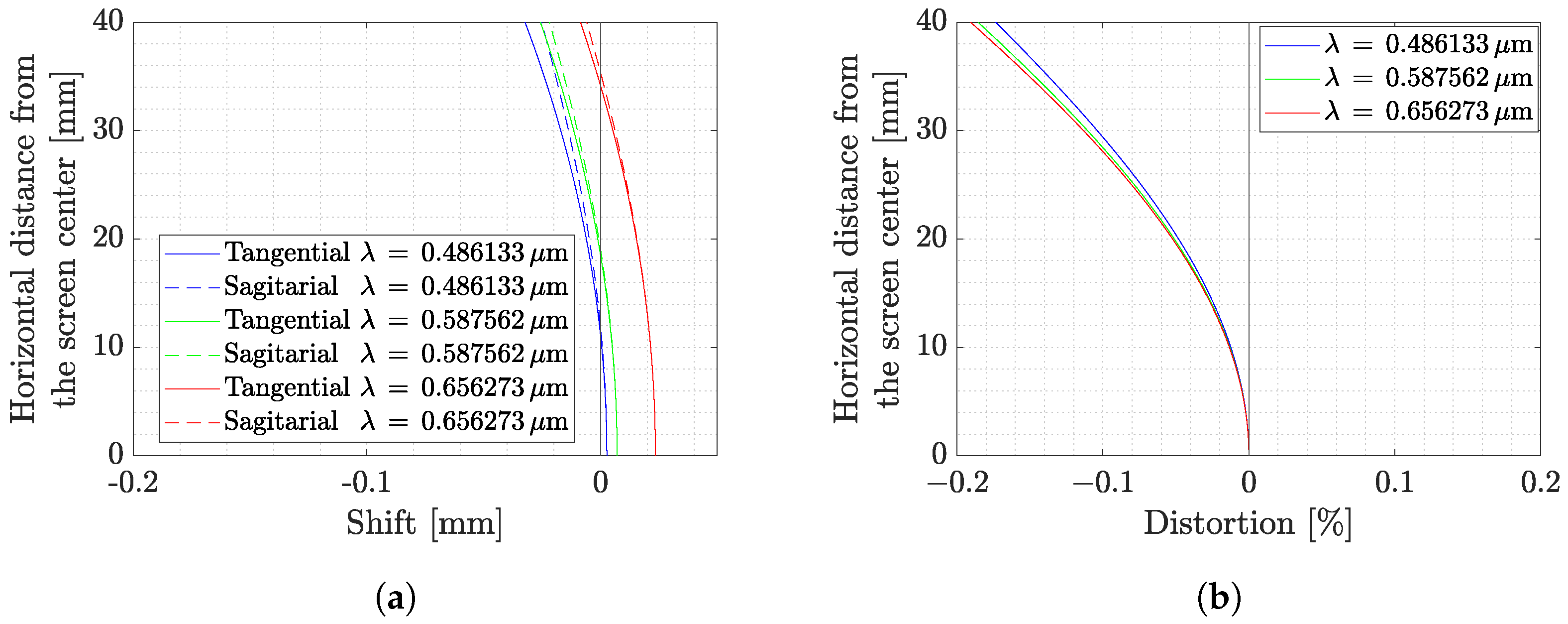
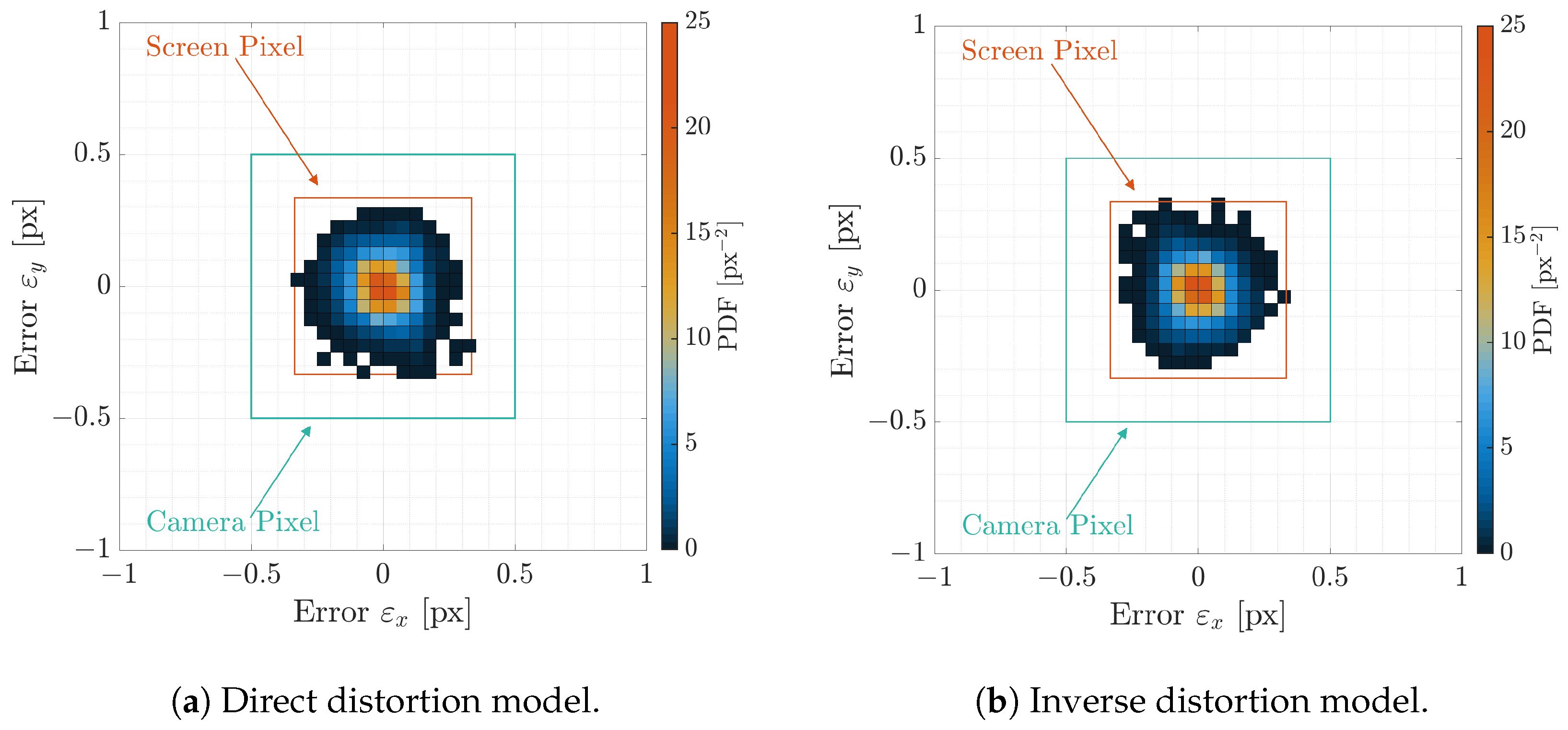
4.5. Distortion Analysis
5. Geometrical Calibration and Compensation
- Calibration is defined as the process of estimating and quantifying the effect of the artifacts. This step is generally put in place by operators before facility use.
- Compensation is defined as the process of modifying the TinyV3RSE data to counteract the artifacts’ effect.
5.1. Geometrical Calibration
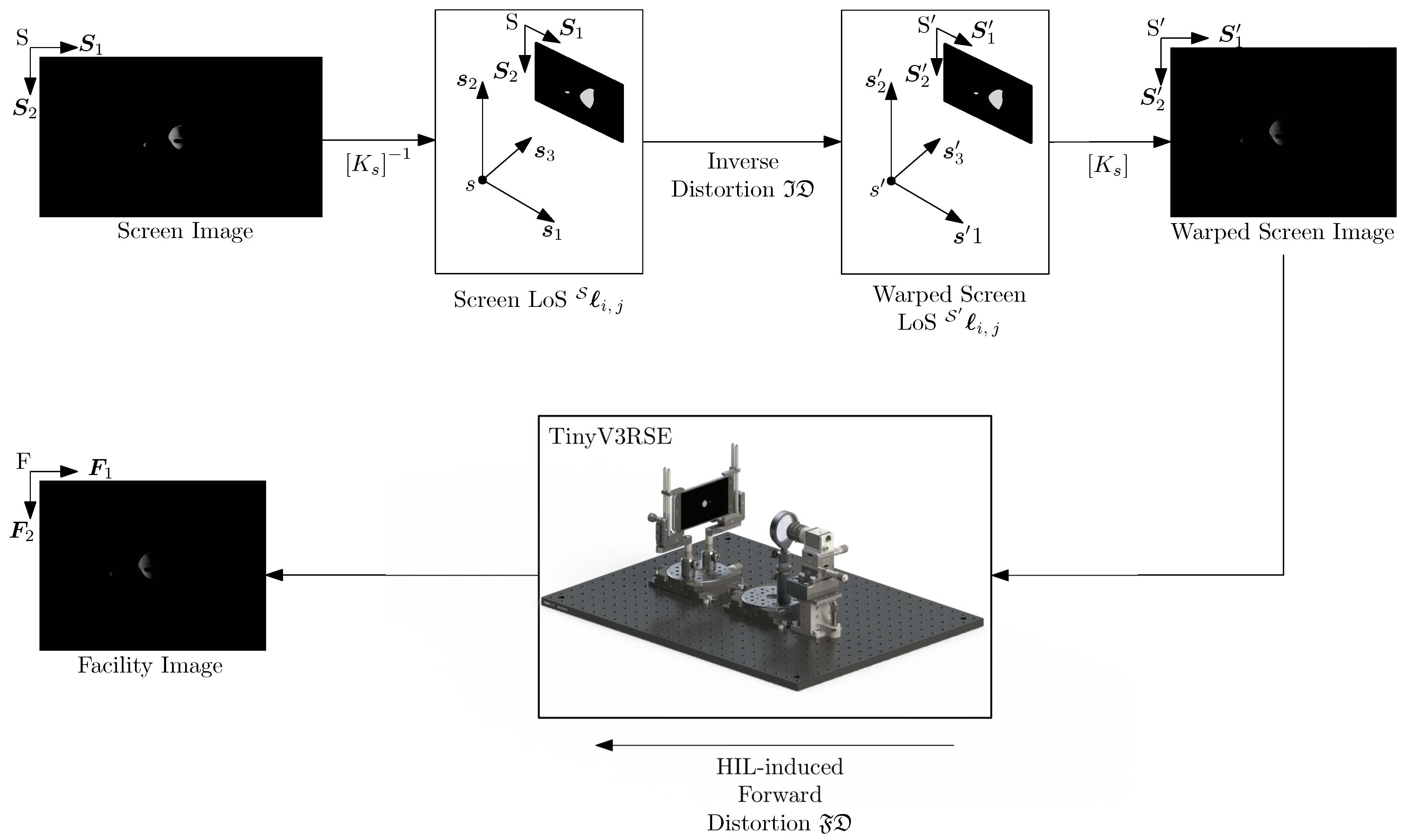
5.2. Upstream Compensation
5.3. Downstream Compensation
5.4. Discussion on Compensations
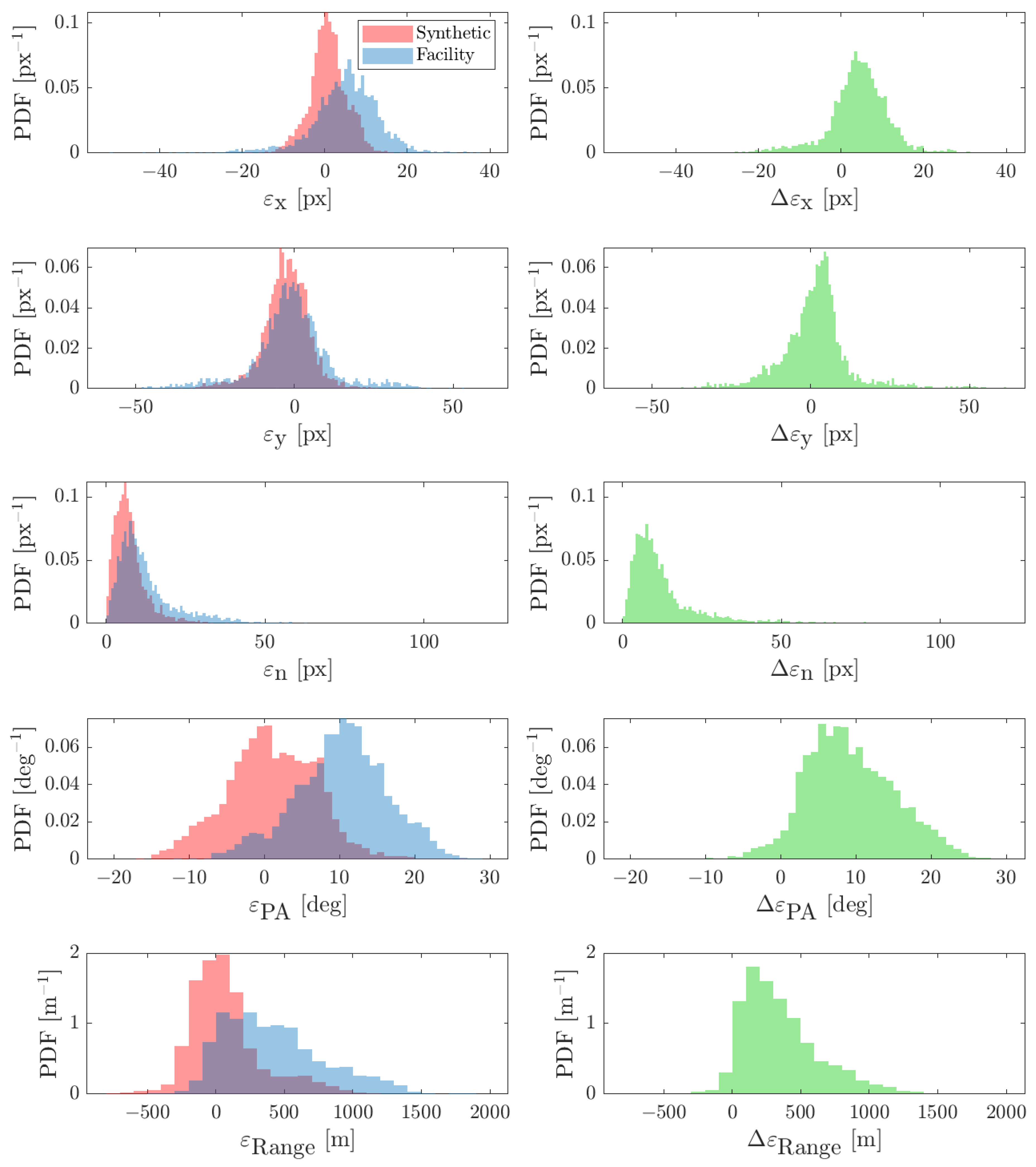
6. Calibration and Compensation Performance
6.1. Calibration
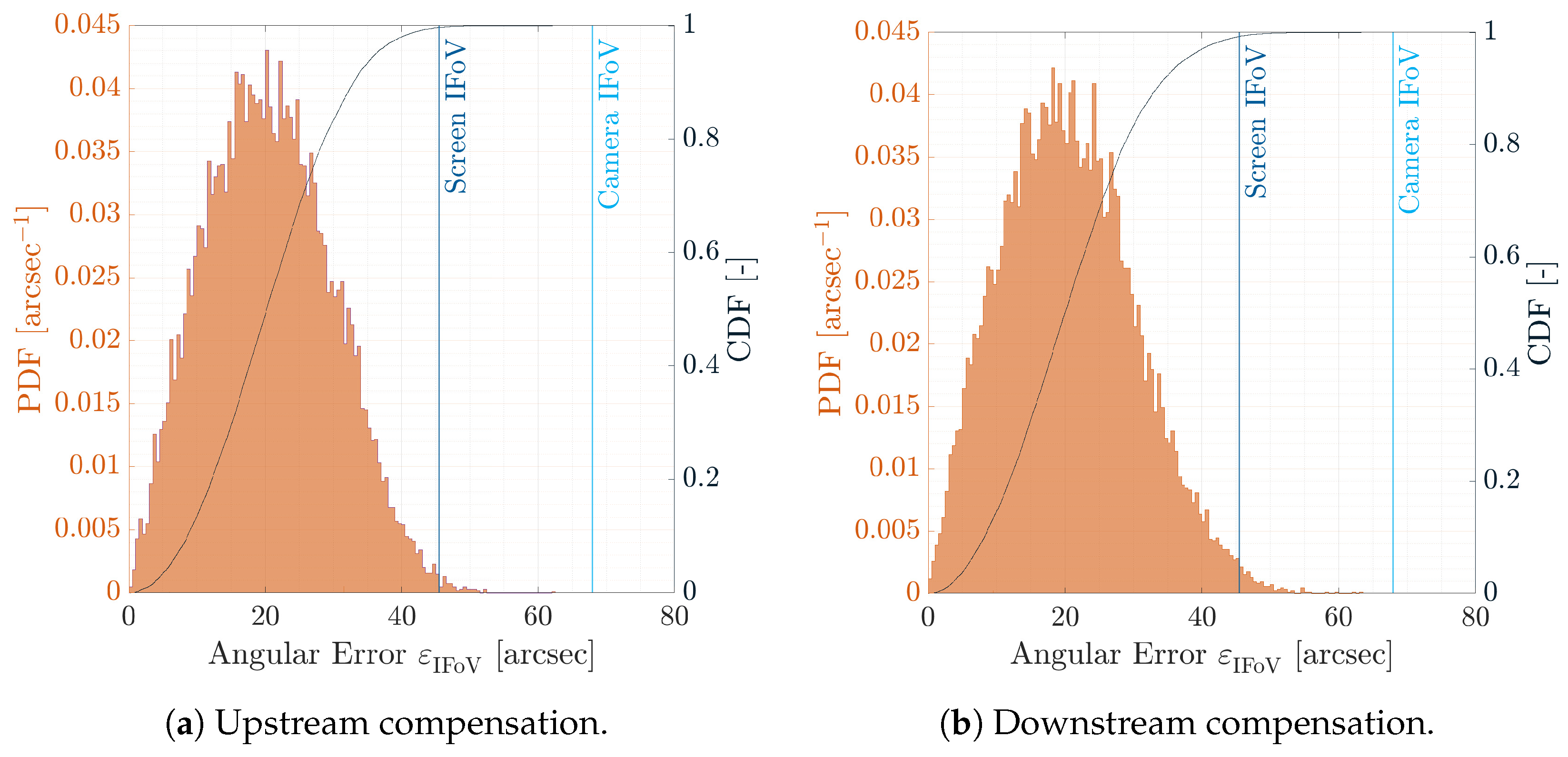
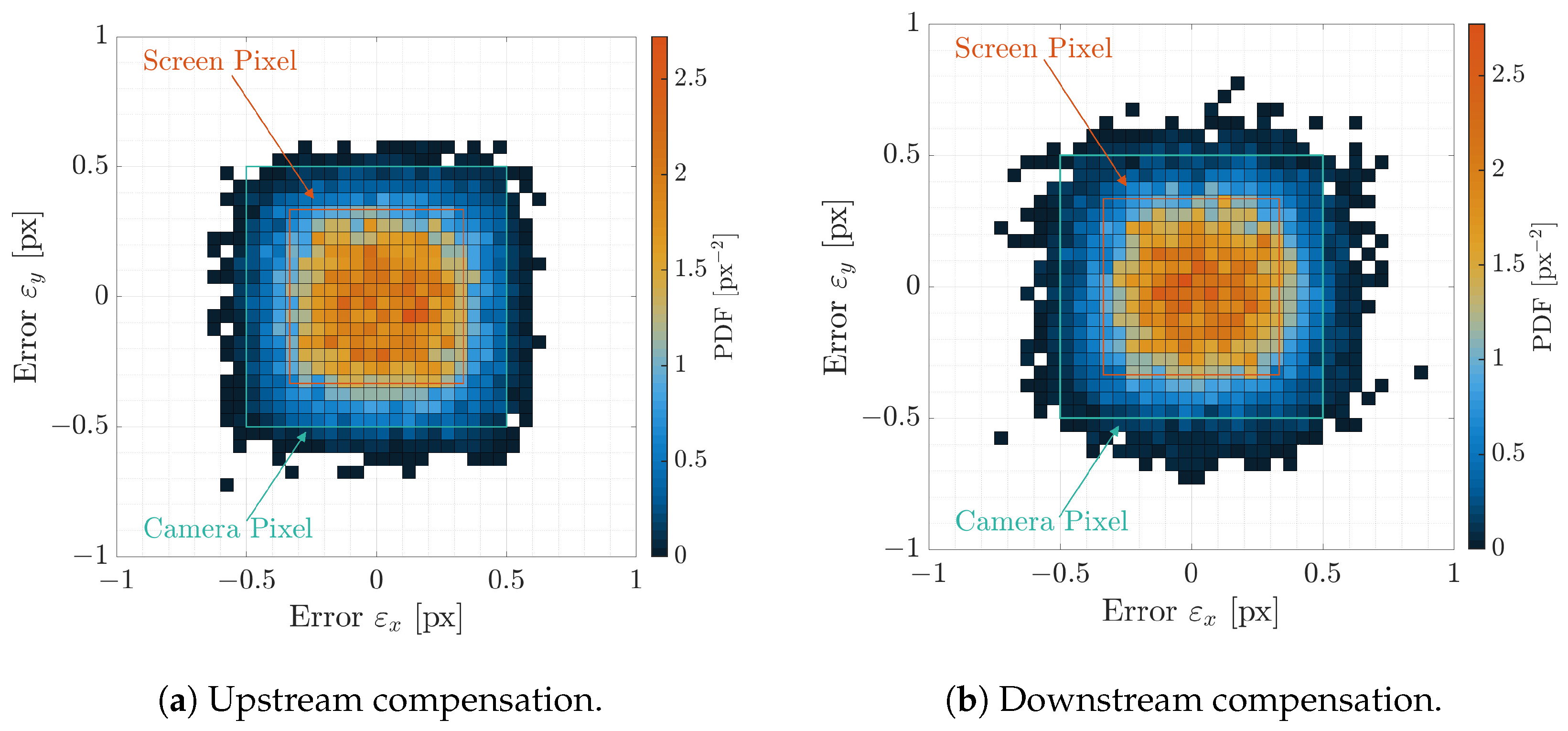
6.2. Upstream and Downstream Compensation
7. Applications
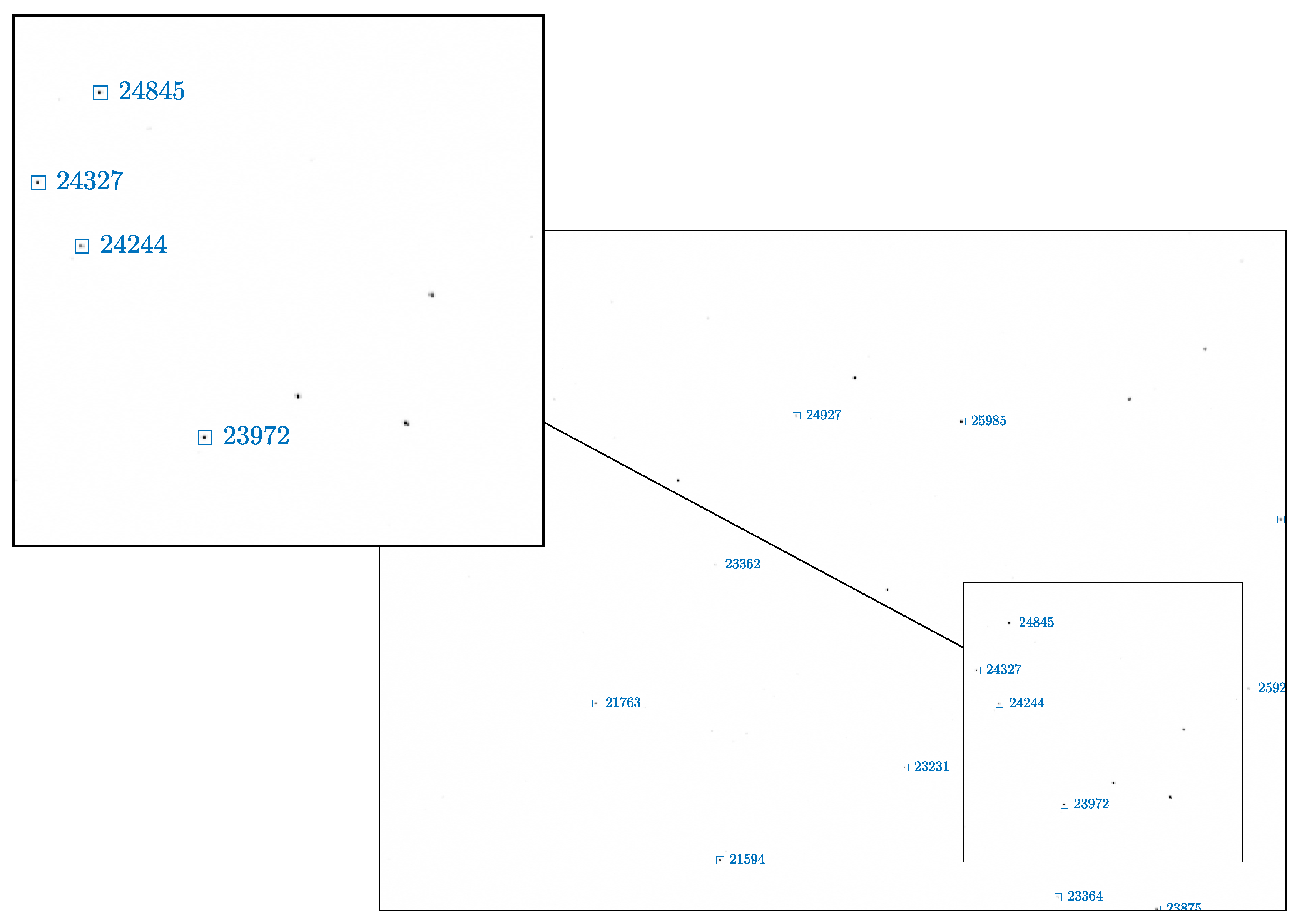
7.1. Image Processing for Attitude Determination
- Centroid extraction which provides the center of brightness of bright spots in the image.
- Star asterism identification which performs matching between the bright spots and the on-board star catalog.
- Attitude determination which solves the Wabha’s problem [36] by finding the probe orientation given a series of LoSes in the spacecraft-fixed reference frame and the inertial reference frame.
- Planet identification which performs matching between the inertial positions of the planets and their counterparts observed in the image.
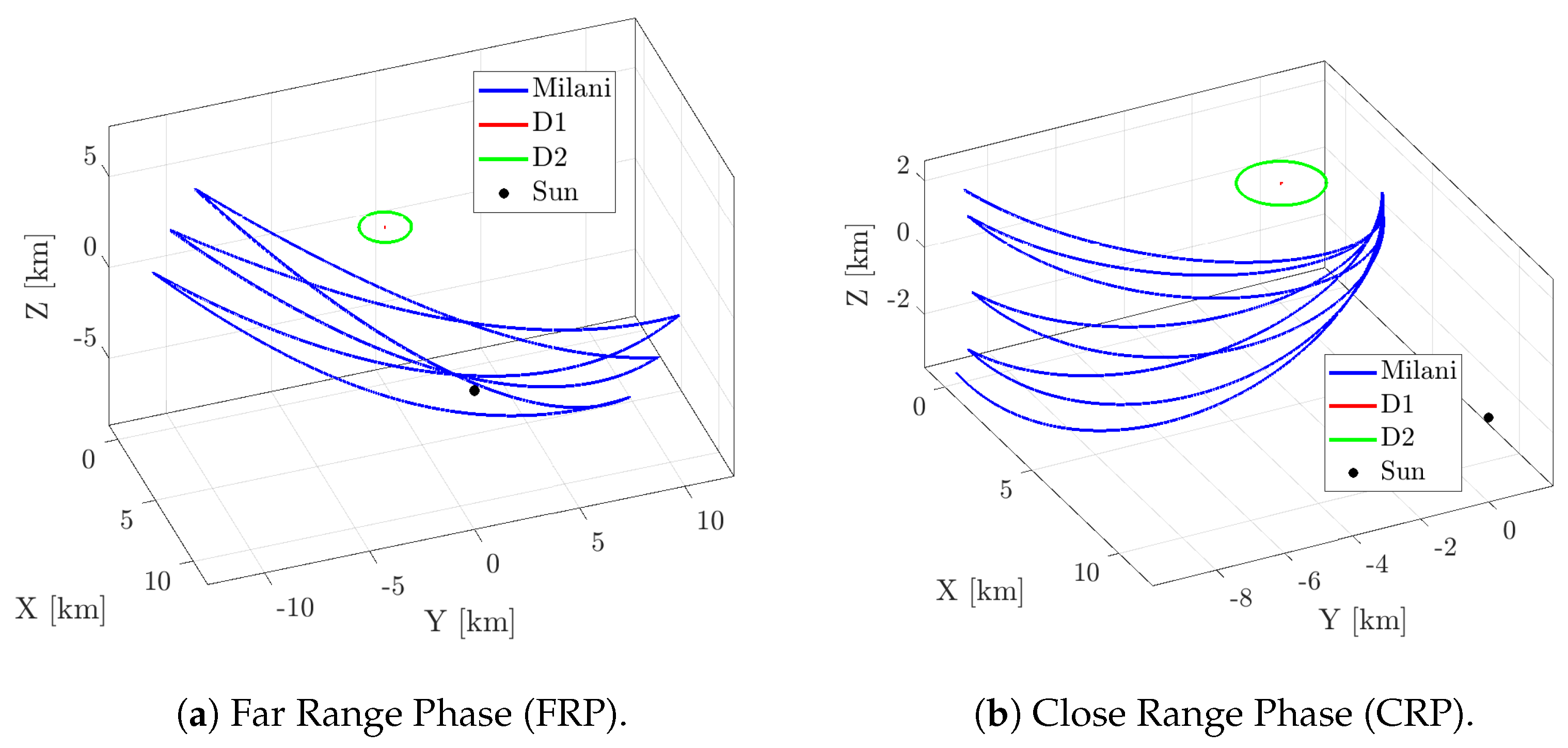
7.2. Image Processing for Small Body Navigation
- The raw image is analyzed to identify the primary and the secondary. From this step, a set of geometrical characteristics of the corresponding pixel blobs, such as the centroid and the best-ellipse-fitting parameters, are computed.
- The so-called WCOB (Weighted Center Of Brightness) is applied to determine a data-driven weighted correction on the Center of Figure (CoF) to approximate the primary Center of Brightness (CoB). During this phase, the phase angle (PA) is also computed with data-driven functions.
- Finally, the range to the primary is estimated from an apparent diameter formula.
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Quadrelli, M.B.; Wood, L.J.; Riedel, J.E.; McHenry, M.C.; Aung, M.; Cangahuala, L.A.; Volpe, R.A.; Beauchamp, P.M.; Cutts, J.A. Guidance, Navigation, and Control Technology Assessment for Future Planetary Science Missions. J. Guid. Control Dyn. 2015, 38, 1165–1186. [Google Scholar] [CrossRef] [Green Version]
- Belgacem, I.; Jonniaux, G.; Schmidt, F. Image processing for precise geometry determination. Planet. Space Sci. 2020, 193, 105081. [Google Scholar] [CrossRef]
- Jonniaux, G.; Gherardi, D. Development, tests and results of onboard image processing for JUICE. In Proceedings of the 11th International ESA Conference on Guidance, Navigation & Control Systems, Virtual, 22–25 June 2021. [Google Scholar]
- Rowell, N.; Parkes, S.; Dunstan, M.; Dubois-Matra, O. PANGU: Virtual spacecraft image generation. In Proceedings of the 5th International Conference on Astrodynamics Tools and Techniques, ICATT, Noordwijk, The Netherlands, 29 May–1 June 2012. [Google Scholar]
- Lebreton, J.; Brochard, R.; Baudry, M.; Jonniaux, G.; Salah, A.H.; Kanani, K.; Le Goff, M.; Masson, A.; Ollagnier, N.; Panicucci, P.; et al. Image Simulation for Space Applications with the SurRender Software. In Proceedings of the 11th International ESA Conference on Guidance, Navigation & Control Systems, Virtual, 22–25 June 2021. [Google Scholar]
- Blender Online Community. Blender—A 3D Modelling and Rendering Package; Blender Foundation-Stichting Blender Foundation: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Panicucci, P.; Pugliatti, M.; Franzese, V.; Topputo, F. Improvements and applications of the DART vision-based navigation test-bench TinyV3RSE. In Proceedings of the AAS GN&C Conference, Breckenridge, CO, USA, 3–9 February 2022. [Google Scholar]
- Pugliatti, M.; Panicucci, P.; Franzese, V.; Topputo, F. TINYV3RSE: The DART Vision-Based Navigation Test-bench. In Proceedings of the AIAA Scitech 2022 Forum, San Diego, CA, USA, 3–7 January 2022; p. 1193. [Google Scholar]
- Volpe, R.; Sabatini, M.; Palmerini, G.B.; Mora, D. Testing and Validation of an Image-Based, Pose and Shape Reconstruction Algorithm for Didymos Mission. Aerotec. Missili Spaz. 2020, 99, 17–32. [Google Scholar] [CrossRef]
- Petit, A.; Marchand, E.; Kanani, K. Vision-based space autonomous rendezvous: A case study. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 619–624. [Google Scholar]
- Zwick, M.; Huertas, I.; Gerdes, L.; Ortega, G. ORGL–ESA’S test facility for approach and contact operations in orbital and planetary environments. In Proceedings of the International Symposium on Artificial Intelligence, Robotics and Automation in Space (i-SAIRAS), Madrid, Spain, 6 June 2018. [Google Scholar]
- Brannan, J.; Scott, N.; Carignan, C. Robot Servicer Interaction with a Satellite During Capture. In Proceedings of the International Symposium on Artificial Intelligence, Robotics and Automation in Space (iSAIRAS), Madrid, Spain, 6 June 2018. [Google Scholar]
- Rufino, G.; Moccia, A. Laboratory test system for performance evaluation of advanced star sensors. J. Guid. Control Dyn. 2002, 25, 200–208. [Google Scholar] [CrossRef] [Green Version]
- Samaan, M.A.; Steffes, S.R.; Theil, S. Star tracker real-time hardware in the loop testing using optical star simulator. Spacefl. Mech. 2011, 140, 2233–2245. [Google Scholar]
- Nardino, V.; Guzzi, D.; Burresi, M.; Cecchi, M.; Cecchi, T.; Corti, F.; Corti, M.; Franci, E.; Guidotti, G.; Pippi, I.; et al. MINISTAR: A miniaturized device for the test of star trackers. In Proceedings of the International Conference on Space Optics—ICSO, Crete, Greece, 9–12 October 2018; Volume 11180, pp. 2821–2827. [Google Scholar]
- Rufino, G.; Accardo, D.; Grassi, M.; Fasano, G.; Renga, A.; Tancredi, U. Real-time hardware-in-the-loop tests of star tracker algorithms. Int. J. Aerosp. Eng. 2013, 2013, 505720. [Google Scholar] [CrossRef] [Green Version]
- Filipe, N.; Jones-Wilson, L.; Mohan, S.; Lo, K.; Jones-Wilson, W. Miniaturized star tracker stimulator for closed-loop testing of cubesats. J. Guid. Control Dyn. 2017, 40, 3239–3246. [Google Scholar] [CrossRef]
- Rufino, G.; Moccia, A. Stellar scene simulation for indoor calibration of modern star trackers. Space Technol. 2001, 21, 41–51. [Google Scholar]
- Roessler, D.; Pedersen, D.A.K.; Benn, M.; Jørgensen, J.L. Optical stimulator for vision-based sensors. Adv. Opt. Technol. 2014, 3, 199–207. [Google Scholar] [CrossRef]
- Beierle, C.; Sullivan, J.; D’Amico, S. Design and Utilization of the Stanford Vision-Based Navigation Testbed for Spacecraft Rendezvous. In Proceedings of the 9th International Workshop on Satellite Constellations and Formation Flying, University of Colorado, Boulder, Boulder, CO, USA, 19–21 June 2017. [Google Scholar]
- Beierle, C.; Sullivan, J.; D’amico, S. High-fidelity verification of vision-based sensors for inertial and far-range spaceborne navigation. In Proceedings of the 26th International Symposium on Space Flight Dynamics (ISSFD), Matsuyama, Japan, 3–9 June 2017. [Google Scholar]
- Bradski, G. The openCV library. Dr. Dobb’s J. Softw. Tools Prof. Program. 2000, 25, 120–123. [Google Scholar]
- Beierle, C.; D’Amico, S. Variable-magnification optical stimulator for training and validation of spaceborne vision-based navigation. J. Spacecr. Rocket. 2019, 56, 1060–1072. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Nature Switzerland AG: Cham, Switzerland, 2022. [Google Scholar]
- Pellacani, A.; Graziano, M.; Fittock, M.; Gil, J.; Carnelli, I. HERA vision based GNC and autonomy. In Proceedings of the 8th European Conference for Aeronautics and Space Sciences, Madrid, Spain, 1–4 July 2019. [Google Scholar] [CrossRef]
- Holt, G.N.; D’Souza, C.N.; Saley, D.W. Orion optical navigation progress toward exploration mission 1. In Proceedings of the 2018 Space Flight Mechanics Meeting, Kissimmee, FL, USA, 8–12 January 2018; p. 1978. [Google Scholar]
- Samaan, M.A.; Mortari, D.; Junkins, J.L. Nondimensional star identification for uncalibrated star cameras. J. Astronaut. Sci. 2006, 54, 95–111. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Tang, Z.; von Gioi, R.G.; Monasse, P.; Morel, J.M. A precision analysis of camera distortion models. IEEE Trans. Image Process. 2017, 26, 2694–2704. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Piccolo, F.; Pugliatti, M.; Panicucci, P.; Topputo, F. Toward verification and validation of the Milani Image Processing pipeline in the hardware-in-the-loop testbench TinyV3RSE. In Proceedings of the 44th AAS Guidance, Navigation and Control Conference, Breckenridge, CO, USA, 4–9 February 2022; pp. 1–21. [Google Scholar]
- Di Domenico, G.; Andreis, E.; Morelli, A.C.; Merisio, G.; Franzese, V.; Giordano, C.; Morselli, A.; Panicucci, P.; Ferrari, F.; Topputo, F. Toward Self-Driving Interplanetary CubeSats: The ERC-Funded Project EXTREMA. In Proceedings of the 72nd International Astronautical Congress (IAC 2021), Dubai, United Arab Emirates, 25–29 October 2021; pp. 1–11. [Google Scholar]
- Ferrari, F.; Franzese, V.; Pugliatti, M.; Giordano, C.; Topputo, F. Preliminary mission profile of Hera’s Milani CubeSat. Adv. Space Res. 2021, 67, 2010–2029. [Google Scholar] [CrossRef]
- Andreis, E.; Franzese, V.; Topputo, F. Onboard Orbit Determination for Deep-Space CubeSats. J. Guid. Control Dyn. 2022, 45, 1–14. [Google Scholar] [CrossRef]
- Andreis, E.; Panicucci, P.; Franzese, V.; Topputo, F. A Robust Image Processing Pipeline for Planets Line-Of-sign Extraction for Deep-Space Autonomous Cubesats Navigation. In Proceedings of the 44th AAS Guidance, Navigation and Control Conference, Breckenridge, CO, USA, 4–9 February 2022; pp. 1–19. [Google Scholar]
- Markley, F.L.; Crassidis, J.L. Fundamentals of Spacecraft Attitude Determination and Control; Springer: New York, NY, USA; Heidelberg, Germany; Dordrecht, The Netherlands; London, UK, 2014; Volume 1286. [Google Scholar]
- Mortari, D. Search-less algorithm for star pattern recognition. J. Astronaut. Sci. 1997, 45, 179–194. [Google Scholar] [CrossRef]
- Bella, S.; Andreis, E.; Franzese, V.; Panicucci, P.; Topputo, F. Line-of-Sight Extraction Algorithm for Deep-Space Autonomous Navigation. In Proceedings of the 2021 AAS/AIAA Astrodynamics Specialist Conference, Virtual, 9–11 August 2021; pp. 1–18. [Google Scholar]
- Buonagura, C.; Pugliatti, M.; Topputo, F. Procedural Minor Body Generator Tool for Data-Driven Optical Navigation Methods. In Proceedings of the 6th CEAS Specialist Conference on Guidance, Navigation and Control-EuroGNC, Berlin, Germany, 3–5 May 2022; pp. 1–15. [Google Scholar]
- Michel, P.; Küppers, M.; Carnelli, I. The Hera mission: European component of the ESA-NASA AIDA mission to a binary asteroid. In Proceedings of the 42nd COSPAR Scientific Assembly, Pasadena, CA, USA, 4–22 July 2018; Volume 42. [Google Scholar]
- Pugliatti, M.; Franzese, V.; Rizza, A.; Piccolo, F.; Bottiglieri, C.; Giordano, C.; Ferrari, F.; Topputo, F. Design of the on-board image processing of the Milani mission. In Proceedings of the AAS GN&C conference, Breckenridge, CO, USA, 3–9 February 2022. [Google Scholar]
- Pugliatti, M.; Franzese, V.; Topputo, F. Data-driven Image Processing for Onboard Optical Navigation Around a Binary Asteroid. J. Spacecr. Rocket. 2022, 59, 943–959. [Google Scholar] [CrossRef]
- Pugliatti, M.; Rizza, A.; Piccolo, F.; Franzese, V.; Bottiglieri, C.; Giordano, C.; Ferrari, F.; Topputo, F. The Milani mission: Overview and architecture of the optical-based GNC system. In Proceedings of the AIAA Scitech 2022 Forum, San Diego, CA, USA, 3–7 January 2022; p. 2381. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Direct Distortion | Inverse Distortion | |
|---|---|---|
| Model | Model | |
| Upstream | Downstream | Uniform Bivariate | |
|---|---|---|---|
| Compensation | Compensation | Distribution | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panicucci, P.; Topputo, F. The TinyV3RSE Hardware-in-the-Loop Vision-Based Navigation Facility. Sensors 2022, 22, 9333. https://doi.org/10.3390/s22239333
Panicucci P, Topputo F. The TinyV3RSE Hardware-in-the-Loop Vision-Based Navigation Facility. Sensors. 2022; 22(23):9333. https://doi.org/10.3390/s22239333
Chicago/Turabian StylePanicucci, Paolo, and Francesco Topputo. 2022. "The TinyV3RSE Hardware-in-the-Loop Vision-Based Navigation Facility" Sensors 22, no. 23: 9333. https://doi.org/10.3390/s22239333
APA StylePanicucci, P., & Topputo, F. (2022). The TinyV3RSE Hardware-in-the-Loop Vision-Based Navigation Facility. Sensors, 22(23), 9333. https://doi.org/10.3390/s22239333