


Joint Cross-Consistency Learning and Multi-Feature Fusion for Person Re-Identification
Abstract
:1. Introduction
- (1)
- (2)
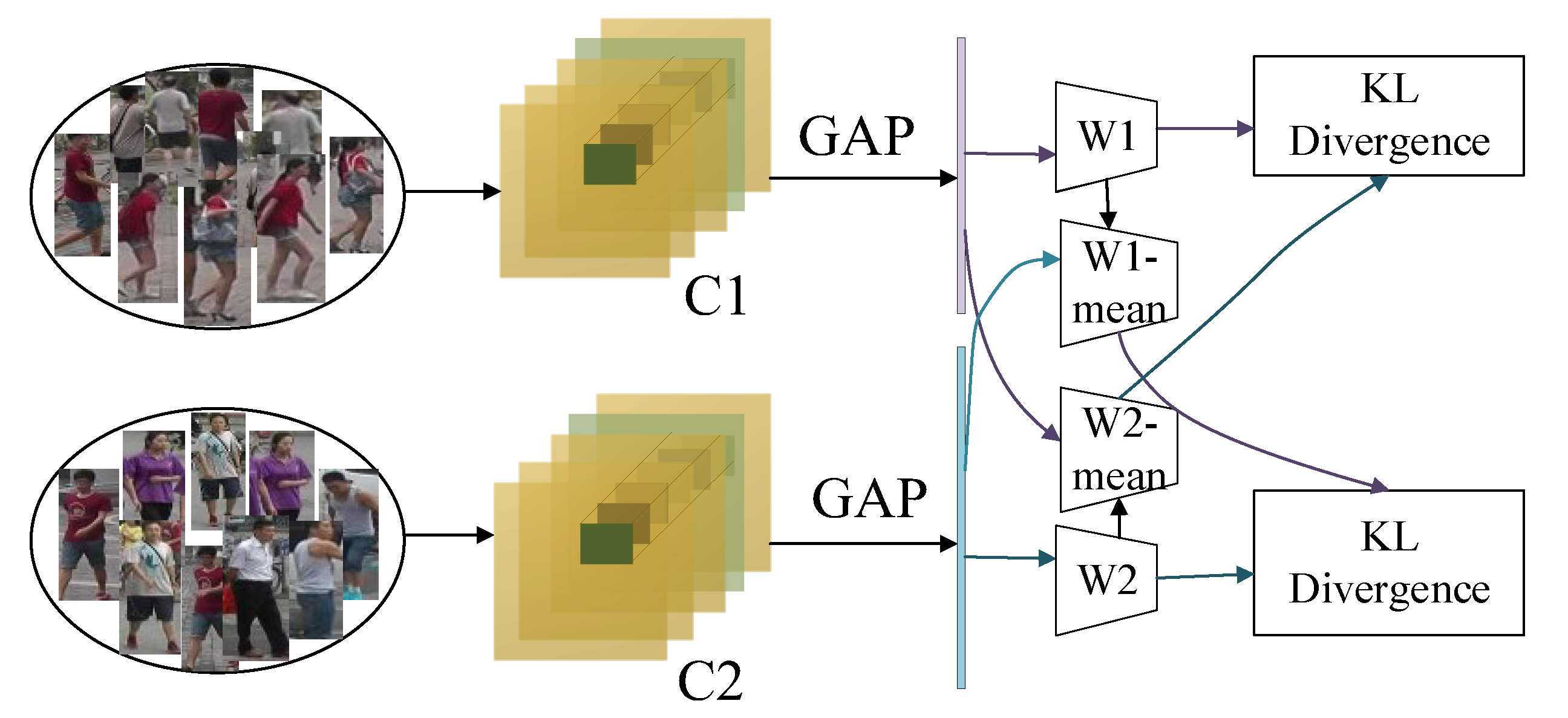
- In the cross-consistency learning module of the model, the model was pre-trained to design image classifiers specific to different viewpoints to extract features from different viewpoints and reduce the impact of viewpoint transformation on the extraction of image information.
- (3)
- The model was fine-tuned in the multi-feature fusion module, and the fused multi-level features were used to match the similarity with images from the image library to enhance the feature representation capability of the model.
- (4)
- In the process of model optimization, for the difference of multiple losses in the optimization space, Cosine Softmax loss [20] was introduced to eliminate the spatial inconsistency of cross-entropy loss and triplet loss, and Cluster Center Loss (CCL) was proposed to make the model focus on intra-class distance as well as inter-class distance in the optimization process.
2. Algorithm Flow
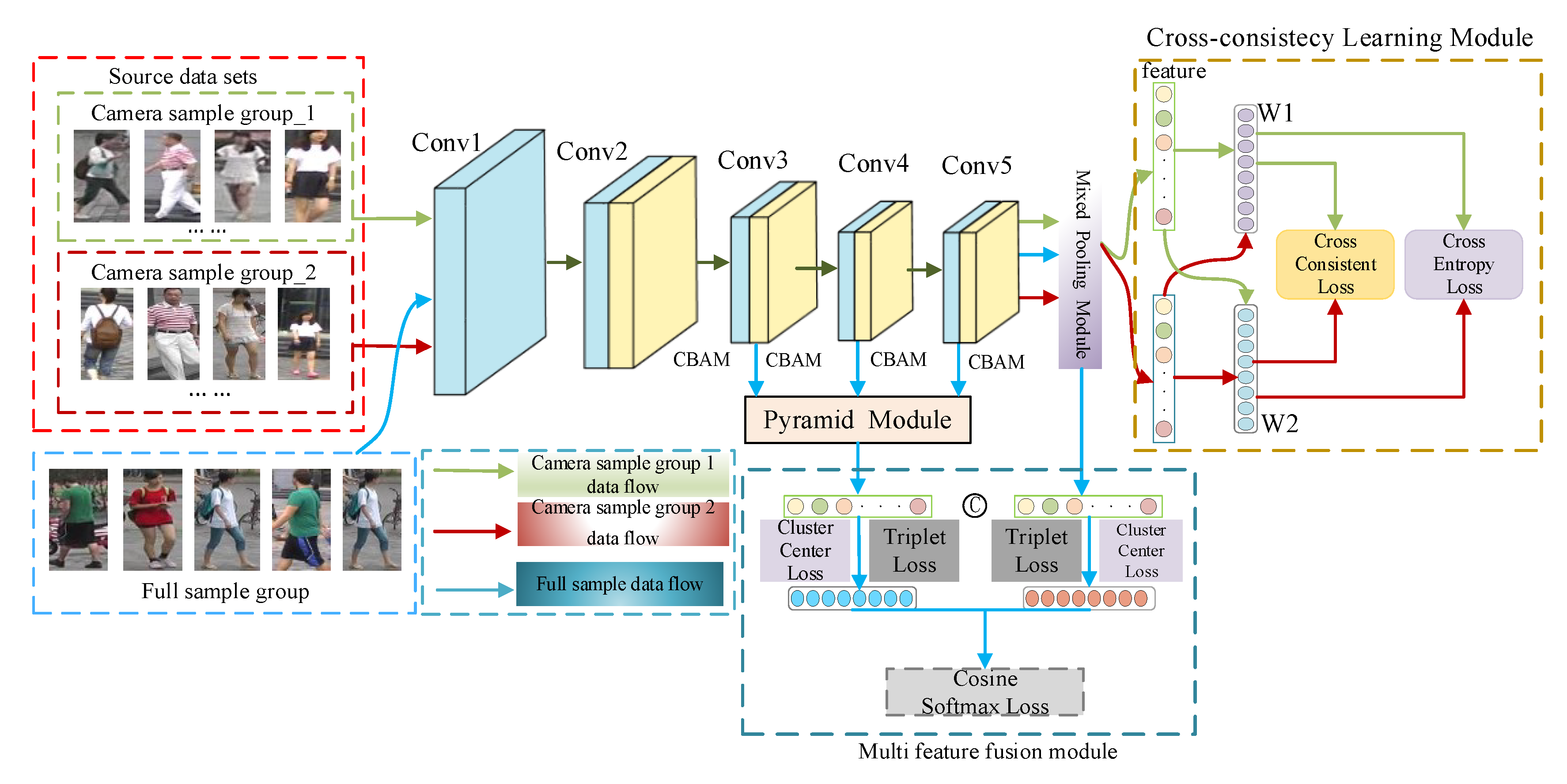
2.1. Network Structure
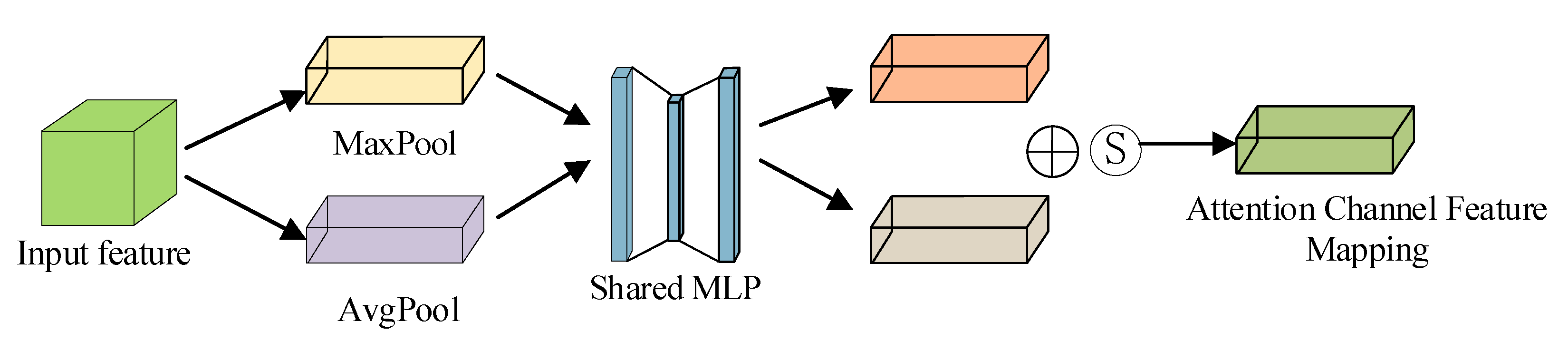
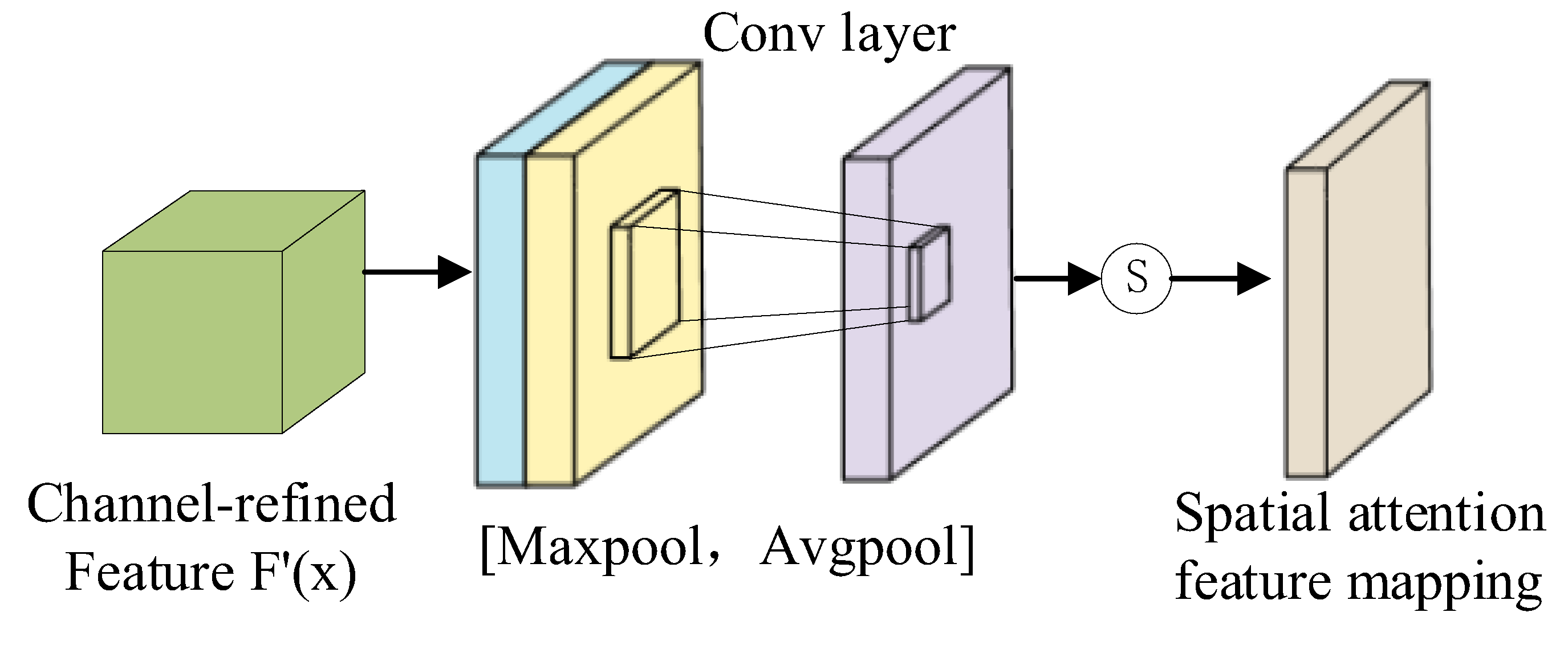
2.2. Attention Mechanism Module
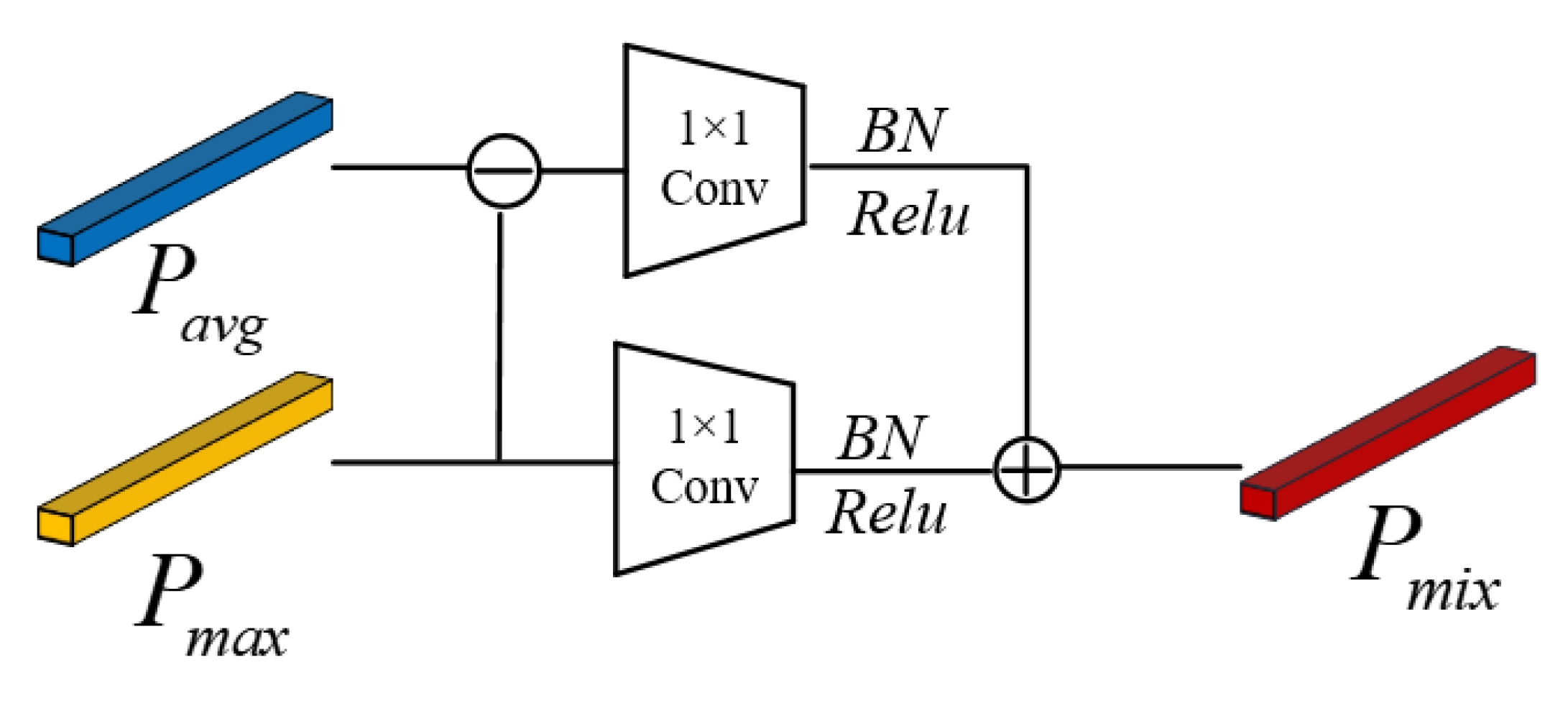
2.3. Mixed Pooling Module
2.4. Cross-Consistent Learning Module
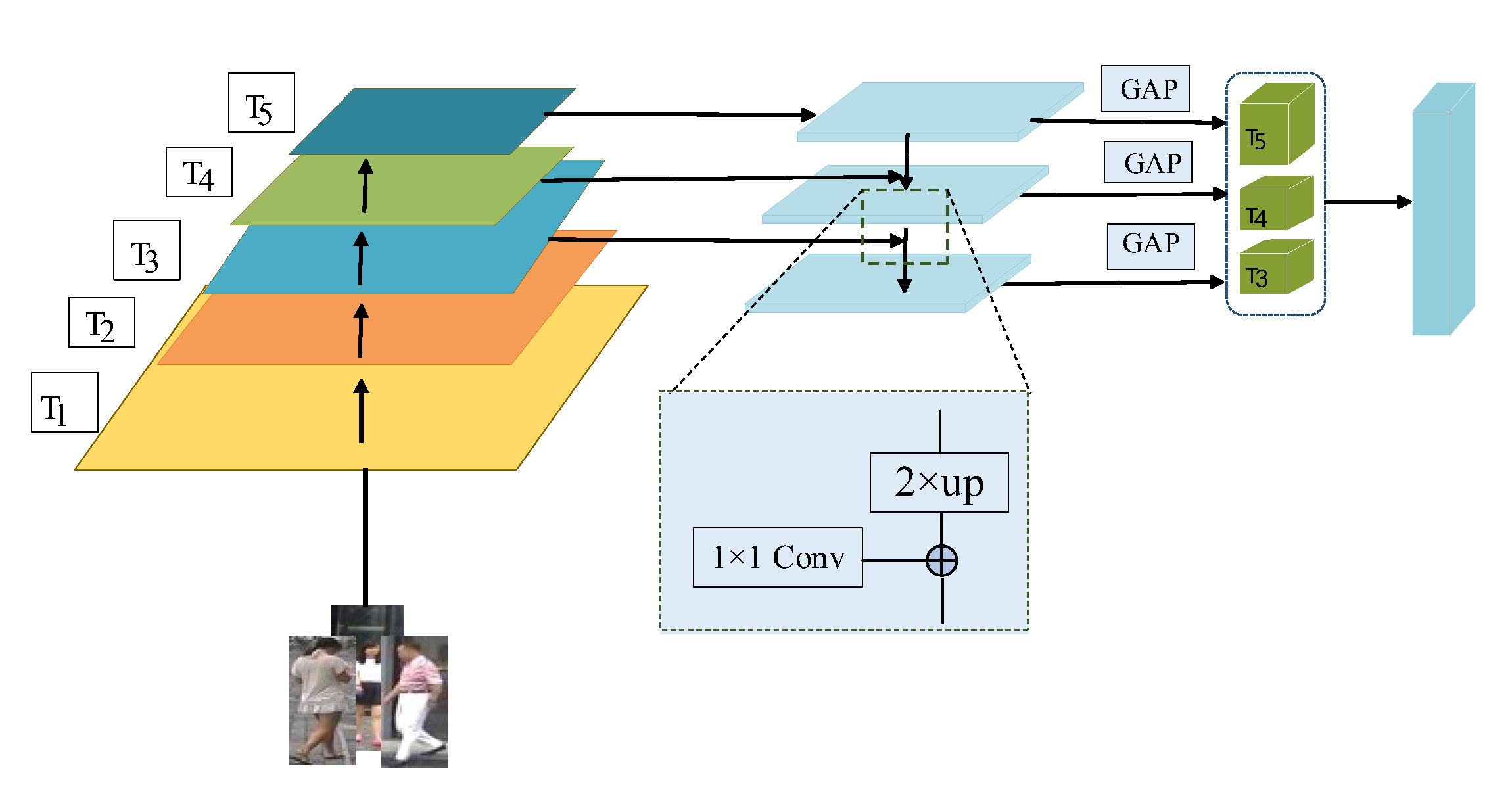
2.5. Feature Pyramid Module
3. Loss Function
3.1. Cross-Entropy Loss and Triplet Loss
3.2. Cosine Softmax Loss
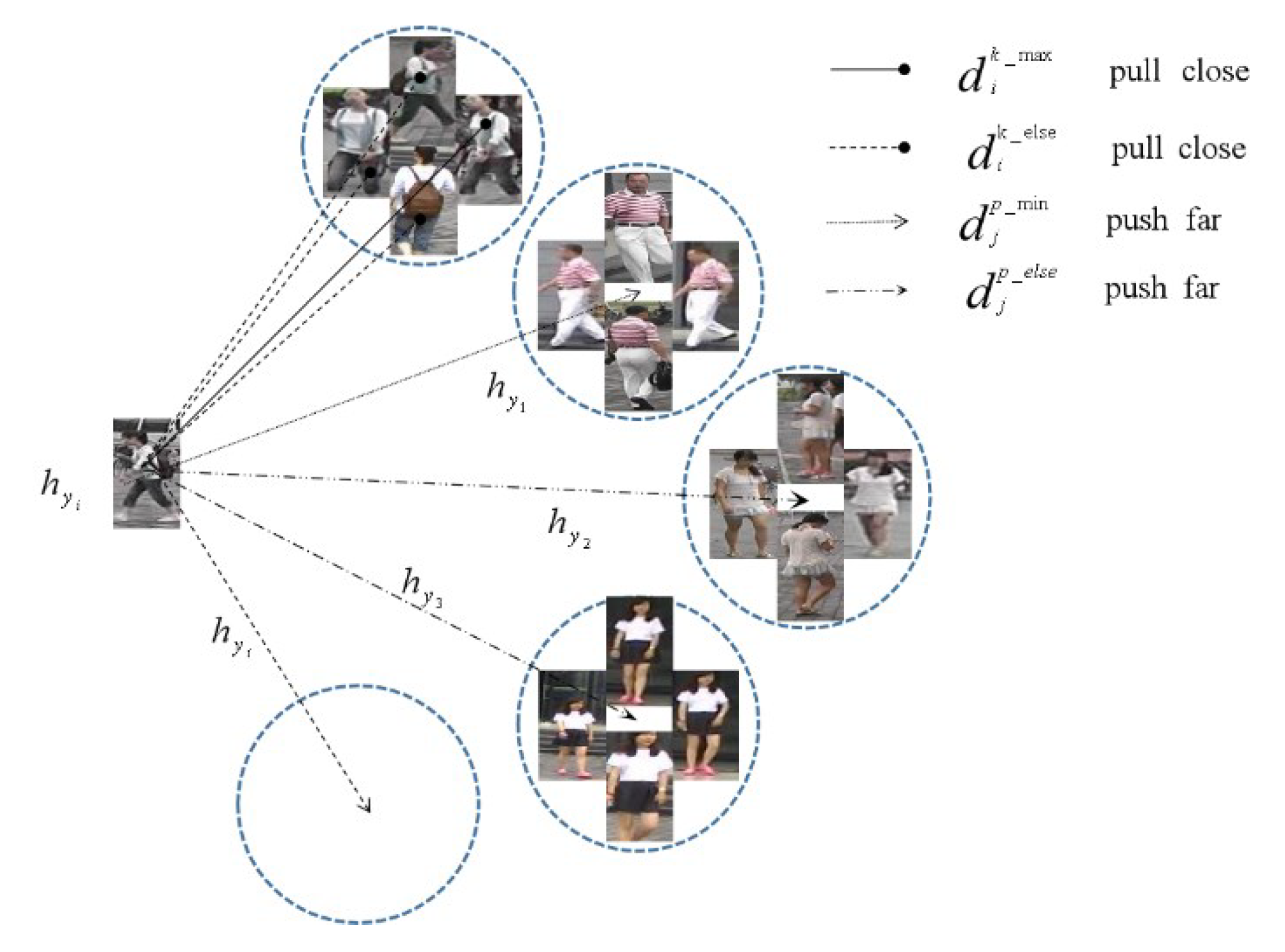
3.3. Loss of Cluster Center
4. Experiments and Analysis
4.1. Experimental Data Set
4.2. Comparison with Existing Methods
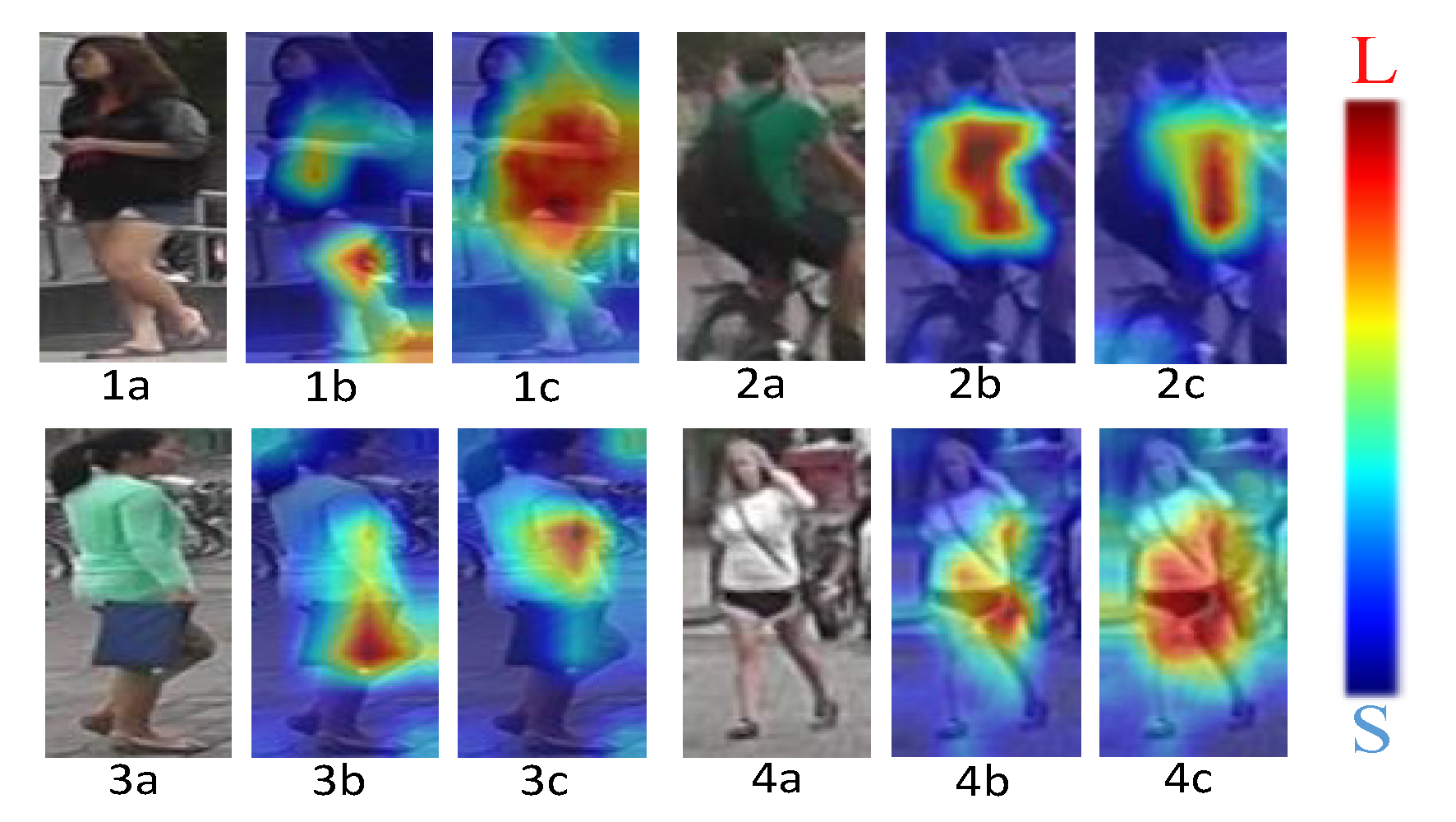
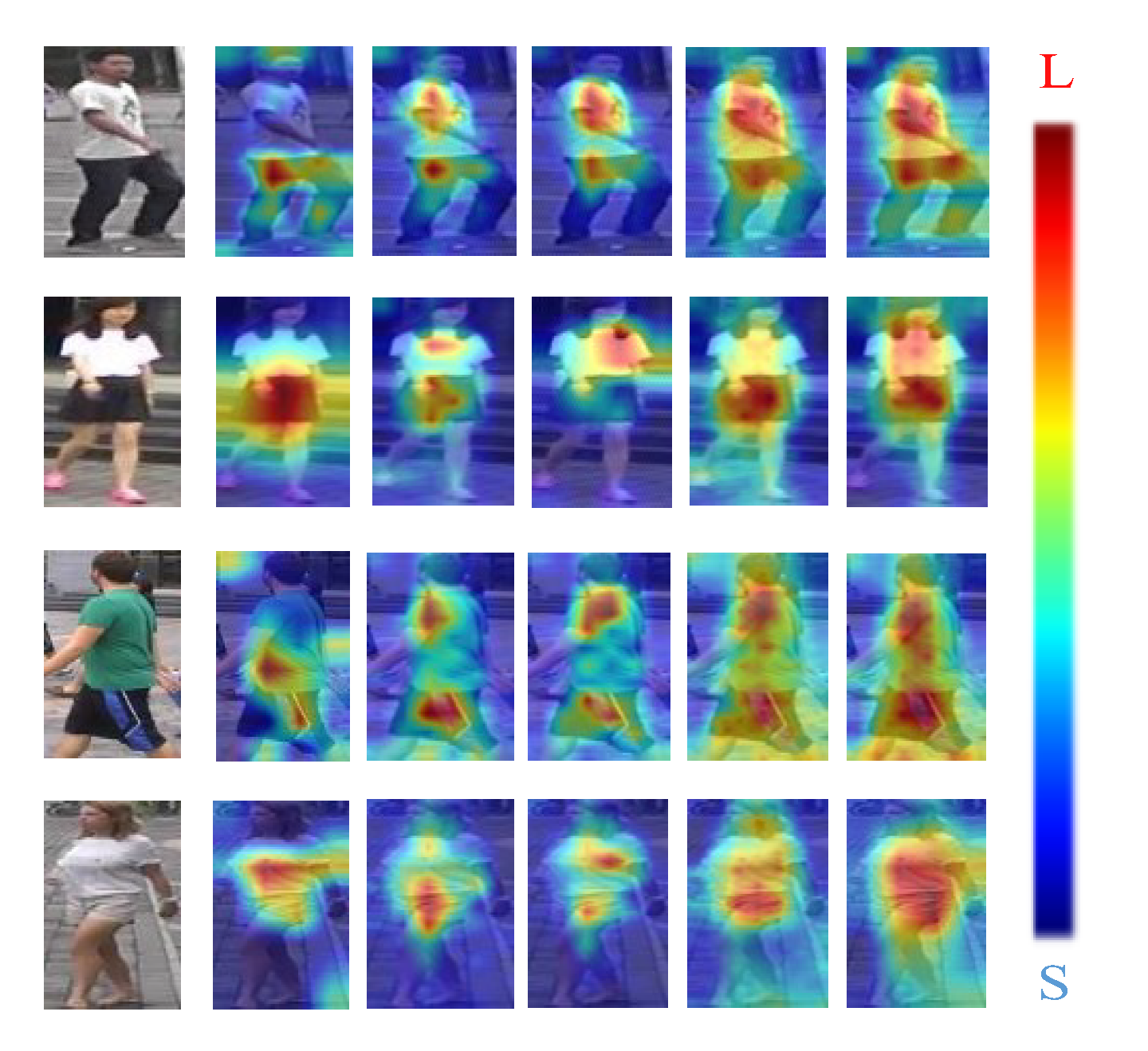
4.3. Analysis of Visualization Results
4.4. Ablation Experiments
4.4.1. Impact of Different Modules
4.4.2. Effect of Different Loss Functions
4.4.3. The Impact of the REA Module
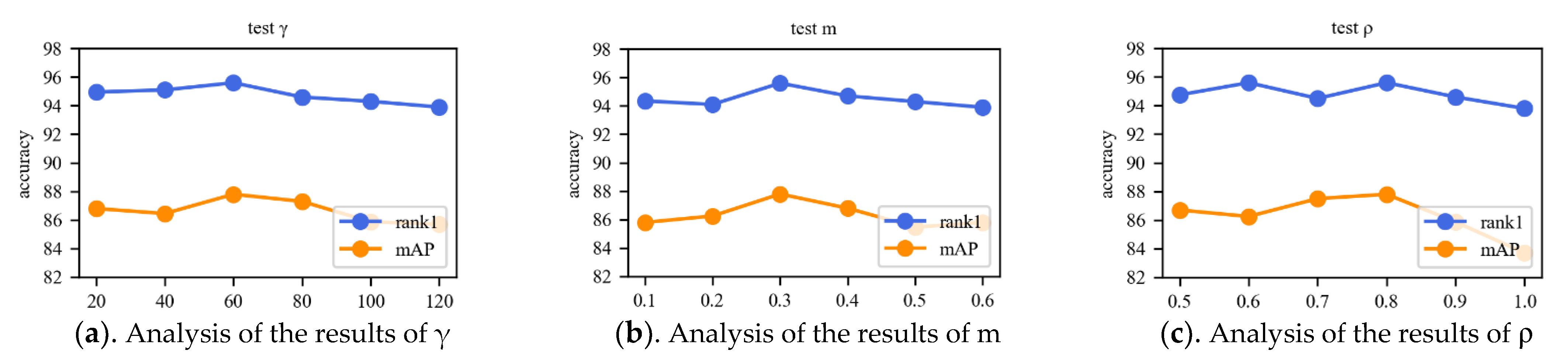
4.4.4. Selection of Parameters
4.5. Results of the Actual Scenario
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, H.; Jiang, W.; Fan, X.; Zhang, S. A survey on deep learning based person re-identification. Acta Autom. Sin. 2019, 45, 2032–2049. [Google Scholar]
- Song, W.R.; Zhao, Q.Q.; Chen, C.H.; Gan, Z.; Liu, F. Survey on pedestrian re-identification research. CAAI Trans. Intell. Syst. 2017, 12, 770–780. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Li, Y.; Liu, C.; Ma, Z. Person Re-identification Based on Improved Cross-view Quadratic Discriminant Analysis. J. Ludong Univ. Nat. Sci. Ed. 2018, 34, 120–127. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Liu, J.; Zha, Z.J.; Wu, W.; Zheng, K.; Sun, Q. Spatial-temporal correlation and topology learning for person re-identification in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4370–4379. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Zheng, F.; Deng, C.; Sun, X.; Jiang, X.; Guo, X.; Yu, Z.; Ji, R. Pyramidal person re-identification via multi-loss dynamic training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8514–8522. [Google Scholar]
- Luo, H.; Jiang, W.; Zhang, X.; Fan, X.; Qian, J.; Zhang, C. AlignedReID++: Dynamically matching local information for person re-identification. Pattern Recognit. 2019, 94, 53–61. [Google Scholar] [CrossRef]
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose-invariant embedding for deep person re-identification. IEEE Trans. Image Process. 2019, 28, 4500–4509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Fu, J.W.; Fan, Z.Z.; Shi, L.R. Person Re-Identification Method Based on Multi-Scale and Multi-Granularity Fusion. Comput. Eng. 2022, 48, 271–279. [Google Scholar]
- Chen, T.; Ding, S.; Xie, J.; Yuan, Y.; Chen, W.; Yang, Y.; Wang, Z. Abd-net: Attentive but diverse person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 8351–8361. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.V.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2016–1 July 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–24 September 2018; pp. 3–19. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5265–5274. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Sønderby, S.K.; Sønderby, C.K.; Maaløe, L.; Winther, O. Recurrent spatial transformer networks. arXiv 2015, arXiv:1509.05329. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. Svdnet for pedestrian retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3800–3808. [Google Scholar]
- Hao, A.X.; Jia, G.J. Person Re-identification Model Combining Attention and Batch Feature Erasure. Comput. Eng. 2022, 48, 270–276. [Google Scholar]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Wang, X. Hydraplus-net: Attentive deep features for pedestrian analysis. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 350–359. [Google Scholar]
- Sun, Y.; Zheng, L.; Li, Y.; Yang, Y.; Tian, Q.; Wang, S. Learning part-based convolutional features for person re-identification. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 902–917. [Google Scholar] [CrossRef] [PubMed]
- Zheng, G.M.; Karanam, S.; Wu., Z. Re-identification with consistent attentive siamese networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5735–5744.
- Wang, G.A.; Yang, S.; Liu, H.; Wang, Z.; Yang, Y.; Wang, S.; Sun, J. High-order information matters: Learning relation and topology for occluded person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6449–6458. [Google Scholar]
- Jin, X.; Lan, C.; Zeng, W.; Chen, Z.; Zhang, L. Style normalization and restitution for generalizable person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3143–3152. [Google Scholar]
- Xiaoyan, Z.; Baohua, Z.; Xiaoqi, L.; Yu, G.; Yueming, W.; Xin, L.; Jianjun, L. The joint discriminative and generative learning for person re-identification of deep dual attention. Opto-Electron. Eng. 2021, 48, 200388. [Google Scholar]
- Dai, Z.; Chen, M.; Gu, X.; Zhu, S.; Tan, P. Batch dropblock network for person re-identification and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 3691–3701. [Google Scholar]
- Chen, G.; Lin, C.; Ren, L.; Lu, J.; Zhou, J. Self-critical attention learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 9637–9646. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-aware global attention for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3186–3195. [Google Scholar]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 15013–15022. [Google Scholar]
- Yang, Z.; Jin, X.; Zheng, K.; Zhao, F. Unleashing Potential of Unsupervised Pre-Training with Intra-Identity Regularization for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 14298–14307. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Market-1501 | DukeMTMC-ReID |
|---|---|---|
| ID | 1501 | 1404 |
| Camera | 6 | 8 |
| Image | 32,668 | 36,411 |
| Train ID | 750 | 702 |
| Test ID | 751 | 702 |
| Retrieved Image | 3368 | 2228 |
| Candidate Set Image | 19,732 | 17,661 |
| Method | Market-1501 | DukeMTMC-ReID | ||
|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | |
| XQDA [6] (Natural Science Edition 2018) | 43.0 | 21.7 | 31.2 | 17.2 |
| IDE [8] (ArxiV 2016) | 72.5 | 46.0 | 65.2 | 44.9 |
| PCB [11] (ECCV 2018) | 92.4 | 77.3 | 81.9 | 65.3 |
| PIE [13] (IEEE 2019) | 78.7 | 53.9 | — | — |
| AlignedReID [13] (2019) | 90.6 | 77.7 | 81.2 | 67.4 |
| ABD-Net [17] (IEEE 2019) | 95.6 | 88.2 | 89.0 | 78.5 |
| SVDNet [24] (IEEE 2017) | 82.3 | 62.1 | 76.7 | 56.8 |
| ABFE-Net [25] (2022) | 94.4 | 85.9 | 88.3 | 75.1 |
| HA-CNN [26] (IEEE 2017) | 91.2 | 75.7 | 80.5 | 63.8 |
| PCB-U+RPP [27] (IEEE 2019) | 93.8 | 81.6 | 84.5 | 71.5 |
| CASN(PCB) [28] (IEEE 2019) | 94.4 | 82.8 | 87.7 | 73.7 |
| HOReID [29] (IEEE 2020) | 94.2 | 84.9 | 86.9 | 75.6 |
| SNR [30] (IEEE 2020) | 94.4 | 84.7 | 84.4 | 72.9 |
| TSNet [31] (2021) | 94.7 | 86.3 | 86.0 | 75.0 |
| BDB [32] (IEEE 2019) | 95.3 | 86.7 | 89.0 | 76.0 |
| SCAL(spatial) [33] (ICCV 2019) | 95.4 | 88.9 | 89.0 | 79.6 |
| SCAL (channel) [33] (ICCV 2019) | 95.8 | 89.3 | 88.9 | 79.1 |
| RGA-SC [34] (CVPR 2020) | 96.1 | 88.4 | — | — |
| TransReID [35] (ICCV 2021) | 95.2 | 89.5 | 90.7 | 82.6 |
| MGN+UP-ReID [36] (CVPR 2022) | 97.1 | 91.1 | — | — |
| CCLM (Ours) | 95.9 | 88.1 | 89.7 | 79.3 |
| Network Structure | Market-1501 | DukeMTMC-ReID | ||
|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | |
| Baseline | 89.3 | 74.5 | 75.2 | 62.5 |
| Baseline + CBAM | 92.2 | 76.4 | 81.5 | 65.4 |
| Baseline + CBAM + MPM | 92.4 | 78.9 | 82.3 | 69.2 |
| Baseline + CBAM + MPM + FPN | 94.4 | 85.5 | 86.4 | 73.4 |
| Baseline + CBAM + MPM + FPN + CCL | 95.9 | 88.1 | 89.7 | 79.3 |
| Loss Function | Market-1501 | DukeMTMC-ReID | ||
|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | |
| Cos | 93.4 | 84.7 | 86.3 | 76.5 |
| Cos + Triplet | 94.2 | 85.6 | 88.4 | 77.9 |
| Cos + Triplet + Center | 95.9 | 88.1 | 89.7 | 79.3 |
| Network Structure | Market-1501 | DukeMTMC-ReID | ||
|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | |
| CCLM | 93.5 | 86.2 | 87.3 | 74.6 |
| CCLM + REA | 95.9 | 88.1 | 89.1 | 79.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, D.; He, T.; Dong, H. Joint Cross-Consistency Learning and Multi-Feature Fusion for Person Re-Identification. Sensors 2022, 22, 9387. https://doi.org/10.3390/s22239387
Ren D, He T, Dong H. Joint Cross-Consistency Learning and Multi-Feature Fusion for Person Re-Identification. Sensors. 2022; 22(23):9387. https://doi.org/10.3390/s22239387
Chicago/Turabian StyleRen, Danping, Tingting He, and Huisheng Dong. 2022. "Joint Cross-Consistency Learning and Multi-Feature Fusion for Person Re-Identification" Sensors 22, no. 23: 9387. https://doi.org/10.3390/s22239387
APA StyleRen, D., He, T., & Dong, H. (2022). Joint Cross-Consistency Learning and Multi-Feature Fusion for Person Re-Identification. Sensors, 22(23), 9387. https://doi.org/10.3390/s22239387