
Disentangling Noise from Images: A Flow-Based Image Denoising Neural Network


Abstract
:1. Introduction
- We rethink the image denoising task and present a distribution-learning-based denoising framework.
- We propose a Flow-Based Image Denoising Neural Network (FDN). Unlike the widely used feature-learning-based CNNs in this area, FDN learns the distribution of noisy images instead of low-level features.
- We present a disentanglement method to obtain the distribution of clean ground truth from the noisy distribution, without making any assumptions on noise or employing the priors of images.
- We achieve competitive performance in removing synthetic noise from category-specific images and remote sensing images. For real noise, we also verify our denoising capacity by achieving a new state-of-the-art result on the real-world SIDD dataset.
2. Related Work
2.1. Recent Trends of Image Denoising
2.2. Flow-Based Invertible Networks
3. Our Method
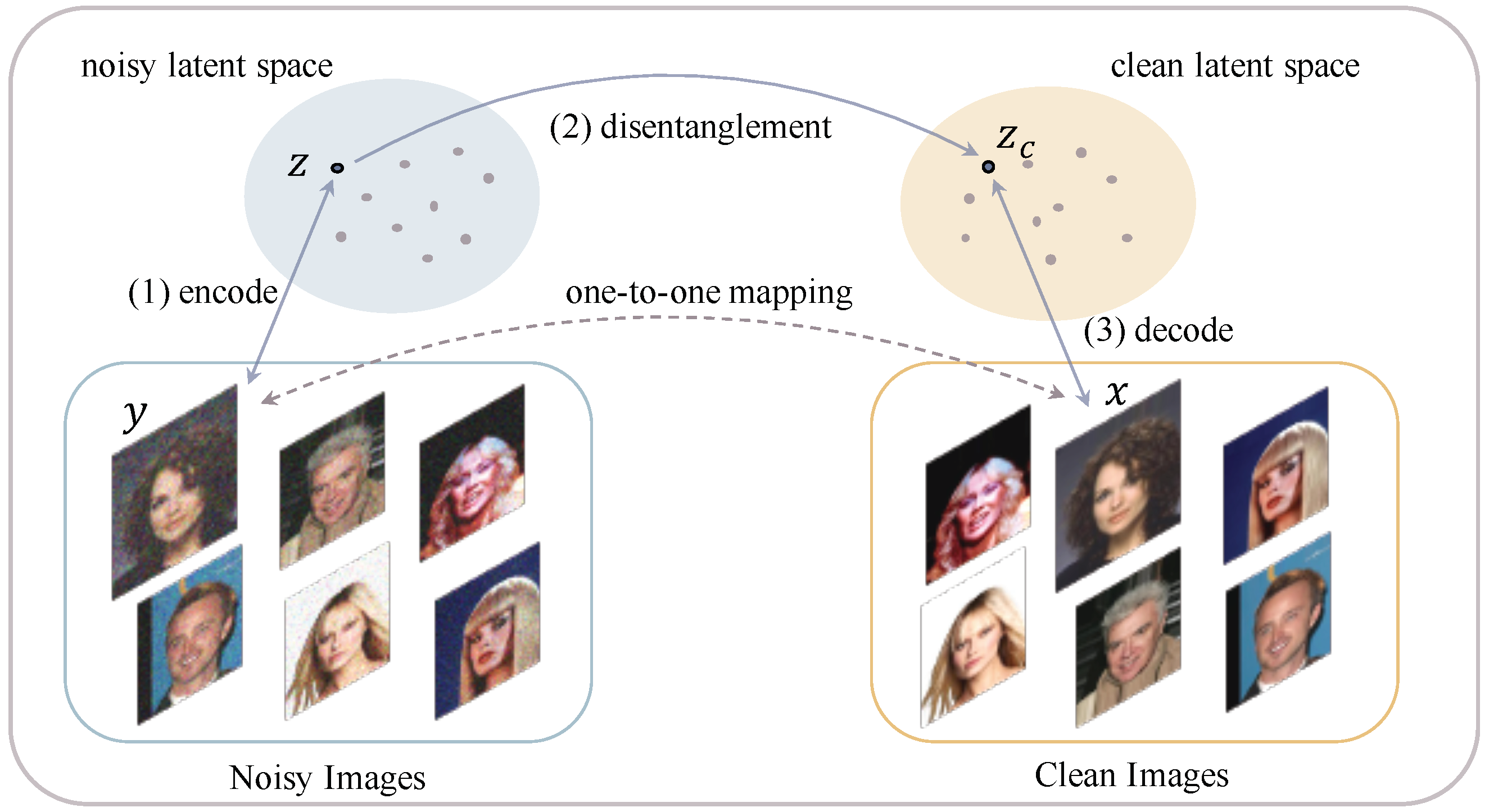
3.1. Concept of Design
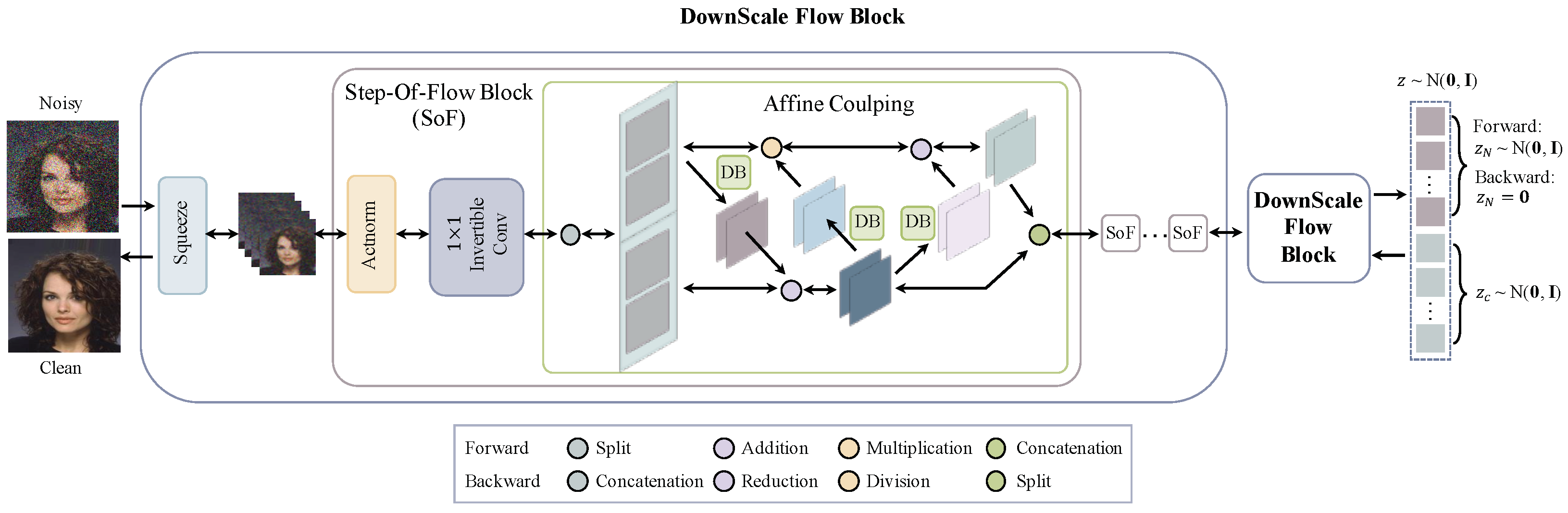
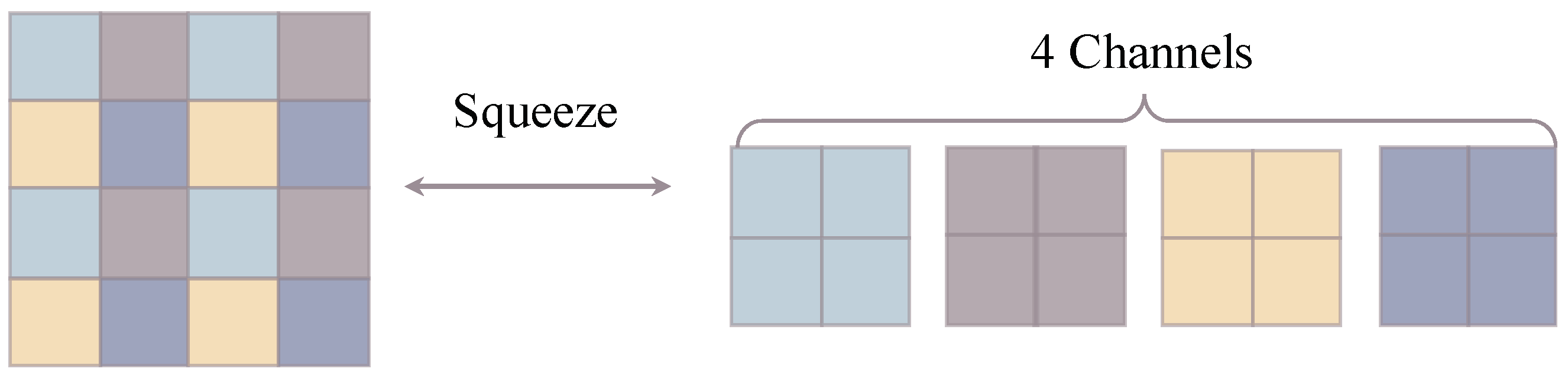
3.2. Network Architecture
3.3. Objective Function
3.4. Data Preprocessing
4. Experiment
4.1. Experimental Settings
4.1.1. Training Details
4.1.2. Datasets
- CelebA [33] is a large human face dataset containing 202,599 face images. We use the 162,770 training images for training and 19,867 validation images for testing. The training images are cropped into patches randomly as the network’s input at the training stage. Since the training set is large enough, we do not apply any data augmentation during training.
- The Flower Dataset [35] contains 102 categories of flowers, including 1020 training images, 1020 validation images, and 6149 test images. To better learn the distribution of flowers, we change the dataset’s partition and use the 6149 images as the training set and the remaining 2040 images as the test set. The training images are randomly cropped into patches with a size of . Flipping and rotation are employed as data augmentation.
- The CUB-200 Dataset [16] includes 11,788 bird images, covering 200 categories of birds. We use 5989 images as the training set and 5790 images as the test set. The training images are cropped into patches with random flipping as data augmentation during training.
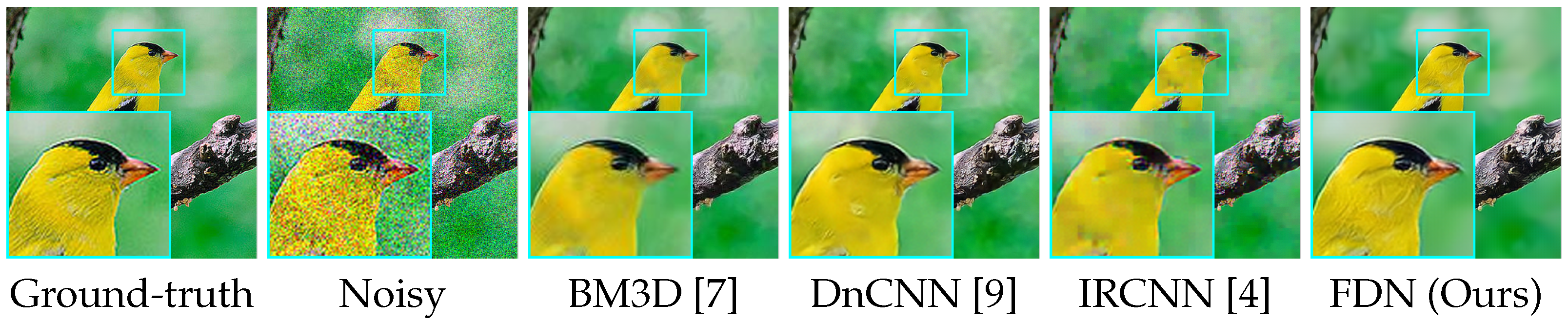
4.2. Category-Specific Image Denoising
4.3. Remote Sensing Image Denoising
4.4. Real Image Denoising
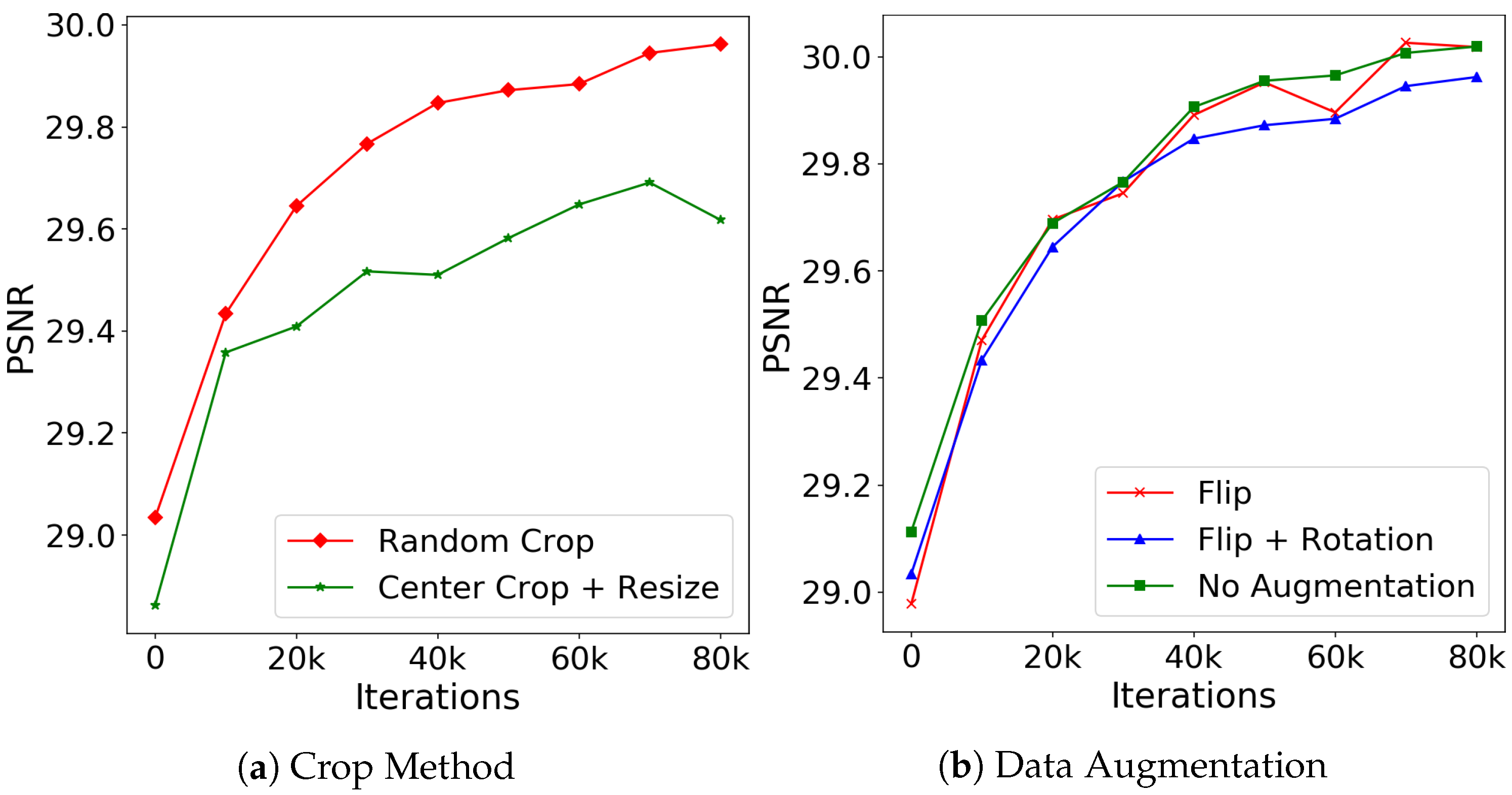
4.5. Ablation Study and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Anwar, S.; Barnes, N. Real Image Denoising with Feature Attention. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, Y.; Anwar, S.; Zheng, L.; Tian, Q. GradNet Image Denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 508–509. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:cs.CV/2001.05566. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Meng, D.; De la Torre, F. Robust Matrix Factorization with Unknown Noise. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1337–1344. [Google Scholar] [CrossRef]
- Zhu, F.; Chen, G.; Hao, J.; Heng, P. Blind Image Denoising via Dependent Dirichlet Process Tree. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1518–1531. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Ganesh, A.; Wright, J.; Xu, W.; Ma, Y. RASL: Robust Alignment by Sparse and Low-Rank Decomposition for Linearly Correlated Images. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2233–2246. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a Fast and Flexible Solution for CNN based Image Denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:stat.ML/1312.6114. [Google Scholar]
- Ma, F.; Ayaz, U.; Karaman, S. Invertibility of convolutional generative networks from partial measurements. Adv. Neural Inf. Process. Syst. 2018, 31, 9628–9637. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using Real NVP. arXiv 2016, arXiv:cs.LG/1605.08803. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative Flow with Invertible 1 × 1 Convolutions. In Advances in Neural Information Processing Systems 31; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 10215–10224. [Google Scholar]
- Liu, Y.; Qin, Z.; Anwar, S.; Caldwell, S.; Gedeon, T. Are Deep Neural Architectures Losing Information? Invertibility Is Indispensable. arXiv 2020, arXiv:cs.CV/2009.03173. [Google Scholar]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. Caltech-UCSD Birds 200; Technical Report CNS-TR-2010-001; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-local sparse models for image restoration. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2272–2279. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Nawaz, M. Variational Regularization for Multi-Channel Image Denoising. Pak. J. Eng. Technol. 2019, 2, 51–58. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 2, pp. 60–65. [Google Scholar] [CrossRef]
- Foi, A.; Katkovnik, V.; Egiazarian, K. Pointwise Shape-Adaptive DCT for High-Quality Denoising and Deblocking of Grayscale and Color Images. IEEE Trans. Image Process. 2007, 16, 1395–1411. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, L.; Zuo, W.; Zhang, D.; Feng, X. Patch Group Based Nonlocal Self-Similarity Prior Learning for Image Denoising. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Las Condes, Chile, 11–18 December 2015; pp. 244–252. [Google Scholar] [CrossRef]
- Zoran, D.; Weiss, Y. From learning models of natural image patches to whole image restoration. In Proceedings of the 2011 International Conference on Computer Vision, Tokyo, Japan, 25–27 May 2011; pp. 479–486. [Google Scholar] [CrossRef] [Green Version]
- Anwar, S.; Porikli, F.; Huynh, C.P. Category-Specific Object Image Denoising. IEEE Trans. Image Process. 2017, 26, 5506–5518. [Google Scholar] [CrossRef] [PubMed]
- Yue, Z.; Yong, H.; Zhao, Q.; Meng, D.; Zhang, L. Variational Denoising Network: Toward Blind Noise Modeling and Removal. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 1690–1701. [Google Scholar]
- Remez, T.; Litany, O.; Giryes, R.; Bronstein, A.M. Class-Aware Fully Convolutional Gaussian and Poisson Denoising. IEEE Trans. Image Process. 2018, 27, 5707–5722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Dinh, L.; Krueger, D.; Bengio, Y. NICE: Non-linear Independent Components Estimation. arXiv 2014, arXiv:cs.LG/1410.8516. [Google Scholar]
- Abdelhamed, A.; Brubaker, M.A.; Brown, M.S. Noise Flow: Noise Modeling With Conditional Normalizing Flows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Ardizzone, L.; Lüth, C.; Kruse, J.; Rother, C.; Köthe, U. Guided Image Generation with Conditional Invertible Neural Networks. arXiv 2019, arXiv:cs.CV/1907.02392. [Google Scholar]
- Xiao, M.; Zheng, S.; Liu, C.; Wang, Y.; He, D.; Ke, G.; Bian, J.; Lin, Z.; Liu, T.Y. Invertible Image Rescaling. In Proceedings of the 16th European Conference Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Las Condes, Chile, 11–18 December 2015. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated Flower Classification over a Large Number of Classes. In Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing, Bhubaneswar, India, 16–19 December 2008. [Google Scholar]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A Remote Sensing Image Dataset for Cloud Removal. arXiv 2019, arXiv:cs.CV/1901.00600. [Google Scholar]
- Xu, J.; Li, H.; Liang, Z.; Zhang, D.; Zhang, L. Real-world Noisy Image Denoising: A New Benchmark. arXiv 2018, arXiv:1804.02603. [Google Scholar]
- Abdelhamed, A.; Lin, S.; Brown, M.S. A High-Quality Denoising Dataset for Smartphone Cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hurault, S.; Ehret, T.; Arias, P. EPLL: An Image Denoising Method Using a Gaussian Mixture Model Learned on a Large Set of Patches. Image Process. Line 2018, 8, 465–489. [Google Scholar] [CrossRef] [Green Version]
- Mao, X.; Shen, C.; Yang, Y. Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A Persistent Memory Network for Image Restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kim, Y.; Soh, J.; Park, G.; Cho, N. Transfer Learning From Synthetic to Real-Noise Denoising With Adaptive Instance Normalization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, Seattle, WA, USA, 13–19 June 2020; pp. 3479–3489. [Google Scholar] [CrossRef]
- Chen, Y.; Pock, T. Trainable Nonlinear Reaction Diffusion: A Flexible Framework for Fast and Effective Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1256–1272. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. CVPR 2019, 2019, 1712–1722. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | BM3D [7] | EPLL [39] | IRCNN [4] | REDNet [40] | DnCNN [9] | FFDNet [10] | FDN (Ours) | |
|---|---|---|---|---|---|---|---|---|
| CelebA [33] | 15 | 35.46 | 33.29 | 35.20 | 35.23 | 35.04 | 35.14 | 35.74 |
| 25 | 32.80 | 30.81 | 32.62 | 32.68 | 32.63 | 32.40 | 32.95 | |
| 50 | 29.46 | 27.65 | 29.24 | 29.56 | 29.57 | 29.44 | 30.29 | |
| Blind | – | – | 31.92 | 33.16 | 32.17 | 32.20 | 33.52 | |
| Flower [35] | 15 | 37.20 | 35.41 | 36.83 | 36.93 | 36.73 | 36.49 | 37.38 |
| 25 | 34.73 | 32.92 | 34.47 | 34.75 | 34.17 | 33.89 | 34.82 | |
| 50 | 31.38 | 29.58 | 30.8 | 31.34 | 30.38 | 30.74 | 31.71 | |
| Blind | – | – | 34.91 | 34.57 | 34.55 | 34.61 | 35.18 | |
| CUB-200 [16] | 15 | 35.08 | 33.31 | 35.14 | 35.16 | 35.21 | 34.86 | 35.30 |
| 25 | 32.59 | 30.83 | 32.71 | 32.80 | 32.45 | 32.33 | 32.94 | |
| 50 | 29.32 | 27.61 | 29.28 | 29.72 | 28.87 | 28.61 | 29.79 | |
| Blind | – | – | 32.49 | 33.18 | 32.89 | 33.07 | 33.20 |
| Dataset | EPLL [39] | MemNet [41] | IRCNN [4] | REDNet [40] | DnCNN [9] | FFDNet [10] | FDN (Ours) | |
|---|---|---|---|---|---|---|---|---|
| RICE1 [36] | 30 | 31.95 | 31.82 | 31.12 | 29.98 | 30.69 | 22.68 | 33.08 |
| 50 | 29.65 | 27.71 | 27.50 | 28.82 | 26.99 | 24.17 | 31.14 | |
| 70 | 28.29 | 27.12 | 26.53 | 26.56 | 25.04 | 23.51 | 30.03 | |
| RICE2 [36] | 30 | 36.05 | 36.49 | 35.83 | 33.12 | 34.68 | 34.02 | 35.93 |
| 50 | 33.22 | 33.62 | 33.74 | 30.40 | 29.57 | 30.26 | 34.71 | |
| 70 | 31.63 | 31.73 | 32.43 | 27.55 | 30.81 | 28.51 | 33.98 |
| Method | DnCNN [9] | TNRD [43] | BM3D [7] | CBDNet [44] | GradNet [2] | AINDNet [42] | VDN [25] | FDN (Ours) |
|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | 23.66 | 24.73 | 25.65 | 33.28 | 38.34 | 39.08 | 39.26 | 39.31 |
| SSIM | 0.583 | 0.643 | 0.685 | 0.868 | 0.953 | 0.955 | 0.955 | 0.955 |
| Param (M) | 0.56 | – | – | 4.34 | 1.60 | 13.76 | 7.81 | 4.38 |
| Inference time (GFlops) | 73.32 | – | – | 80.76 | 213.06 | – | 99.00 | 76.80 |
| PSNR | SoF Blocks | ||
|---|---|---|---|
| Num = 4 | Num = 8 | ||
| Flow Blocks | num = 1 | 29.59 | 29.86 |
| num = 2 | 29.87 | 30.00 | |
| num = 3 | 29.89 | 29.90 | |
| dim() | 1/8 | 1/4 | 1/2 | 3/4 | 7/8 |
|---|---|---|---|---|---|
| PSNR | 29.81 | 30.00 | 30.00 | 30.19 | 30.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Anwar, S.; Qin, Z.; Ji, P.; Caldwell, S.; Gedeon, T. Disentangling Noise from Images: A Flow-Based Image Denoising Neural Network. Sensors 2022, 22, 9844. https://doi.org/10.3390/s22249844
Liu Y, Anwar S, Qin Z, Ji P, Caldwell S, Gedeon T. Disentangling Noise from Images: A Flow-Based Image Denoising Neural Network. Sensors. 2022; 22(24):9844. https://doi.org/10.3390/s22249844
Chicago/Turabian StyleLiu, Yang, Saeed Anwar, Zhenyue Qin, Pan Ji, Sabrina Caldwell, and Tom Gedeon. 2022. "Disentangling Noise from Images: A Flow-Based Image Denoising Neural Network" Sensors 22, no. 24: 9844. https://doi.org/10.3390/s22249844
APA StyleLiu, Y., Anwar, S., Qin, Z., Ji, P., Caldwell, S., & Gedeon, T. (2022). Disentangling Noise from Images: A Flow-Based Image Denoising Neural Network. Sensors, 22(24), 9844. https://doi.org/10.3390/s22249844